![Edge AI Models on Feature Phones, Cars & Smart Glasses [2025]](https://tryrunable.com/blog/edge-ai-models-on-feature-phones-cars-smart-glasses-2025/image-1-1771422018369.jpg)
Edge AI is Finally Becoming Real, and It's Starting in India
For years, we've heard about AI coming to "the edge." The phrase got thrown around so much at conferences that it became almost meaningless. Cloud processing this, edge computing that. Nobody was actually building it for the billions of people still using decade-old phones.
Then this happened. An Indian startup called Sarvam walked into a summit in New Delhi with something genuinely different: AI models so small they fit in megabytes. Not gigabytes. Megabytes. Models that run on Nokia feature phones with zero internet connection. Models that work in cars. Models embedded in homemade smart glasses.
This isn't theoretical anymore. This is deployment.
What makes this moment significant isn't just the technical achievement, though that's remarkable. It's the market realization it represents. There are still over 1 billion feature phone users globally. Another 1.5 billion people on slower networks where cloud latency kills user experience. The automotive industry is desperate for AI that doesn't require constant connectivity. Wearables manufacturers want intelligence without the battery drain of cloud calls.
Sarvam figured out how to build for all of them simultaneously. And they did it by asking a different question than everyone else: instead of "how do we shrink cloud models," they asked "how do we build models that were never meant to be large?"
The answer is reshaping what edge AI actually means.
TL; DR
- Models in Megabytes: Sarvam developed AI models under 100MB that run offline on feature phones, cars, and wearables without cloud connectivity
- Partnerships Announce Mass Deployment: Collaborations with HMD, Qualcomm, and Bosch indicate imminent rollout across millions of devices globally
- Offline-First Architecture: Models work completely offline in local languages, handling government schemes, market information, and voice assistance
- Smart Glasses Entry: Sarvam Kaze glasses launching May 2025 as India-manufactured consumer hardware with edge AI
- Market Shift: Company pivoting from enterprise voice models to consumer-focused deployments across three device categories simultaneously

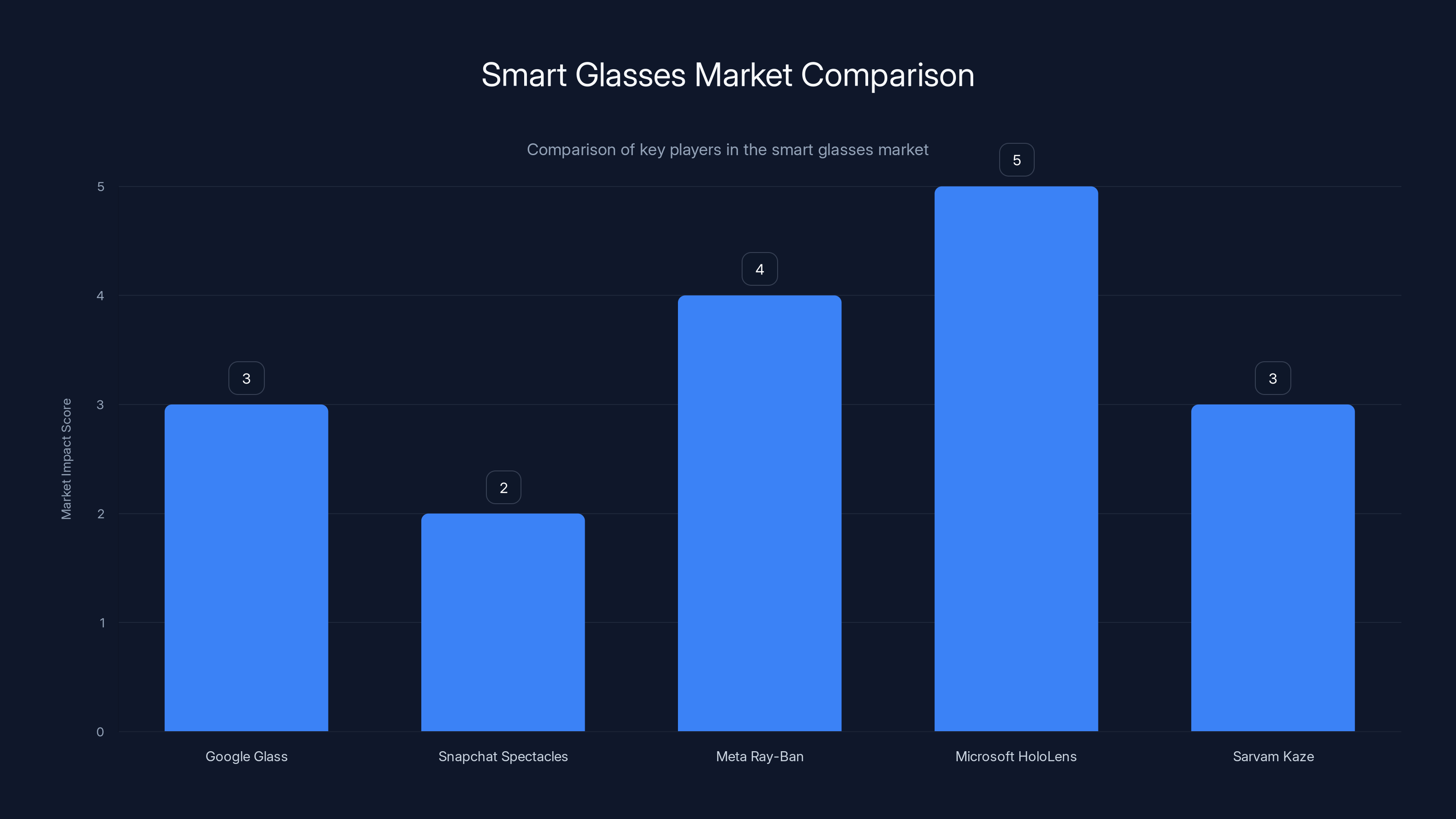
Sarvam Kaze is positioned as a developer-focused smart glasses option, with a unique edge AI approach. Estimated data shows it has a moderate market impact compared to established players.
The Feature Phone Problem Nobody Was Solving
Let's start with the obvious: the world's largest phone market isn't using smartphones.
India has roughly 1.2 billion mobile phone users. More than 400 million of them still use feature phones. Not by choice in most cases, but because a $20 Nokia still works perfectly fine for calling, texting, and the occasional browser experience that takes 30 seconds to load.
For AI companies, these devices were invisible. The business case didn't exist. Why build for a feature phone user when you could target the premium smartphone market? Feature phone users didn't have the income to justify development costs. They didn't have reliable internet. They barely had color screens on some models.
But Sarvam looked at this differently. They saw 400 million potential users who had zero access to AI. They saw use cases that made sense: a farmer checking crop prices at a local market. A small business owner understanding government subsidy schemes. Someone in a rural area getting health guidance in their local language. None of these required cloud connectivity. None of them needed a premium experience. They just needed intelligence delivered in a way that worked.
So they built for constraint instead of abundance.
Traditional AI companies approach edge computing by taking their cloud models and compressing them. They use quantization (reducing numerical precision), pruning (removing less-important connections), knowledge distillation (training smaller models to mimic larger ones). It works, sort of. You can fit a model into maybe 500MB. Maybe 200MB if you're aggressive.
But you can't fit it into 50MB while maintaining meaningful capability. And you definitely can't build a conversational AI that handles multiple languages, understands context, and works offline in that footprint.
Sarvam's approach was different. Instead of shrinking existing models, they built models from scratch with size as the primary constraint. This meant making tradeoffs from day one: this model won't handle every edge case, but it will handle the 80% of queries that actually matter in a feature phone context. It will prioritize local language support from the ground up. It will be designed for intermittent connectivity, not cloud fallback.
The result? Models that actually work on devices that have been considered "AI-proof" by the entire industry.
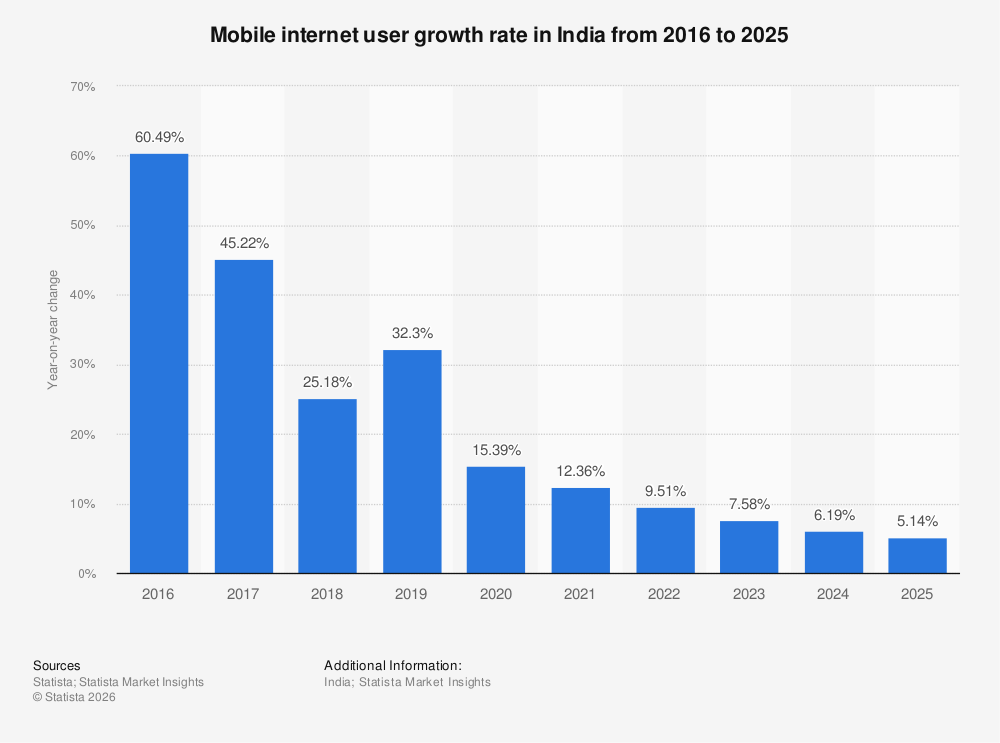
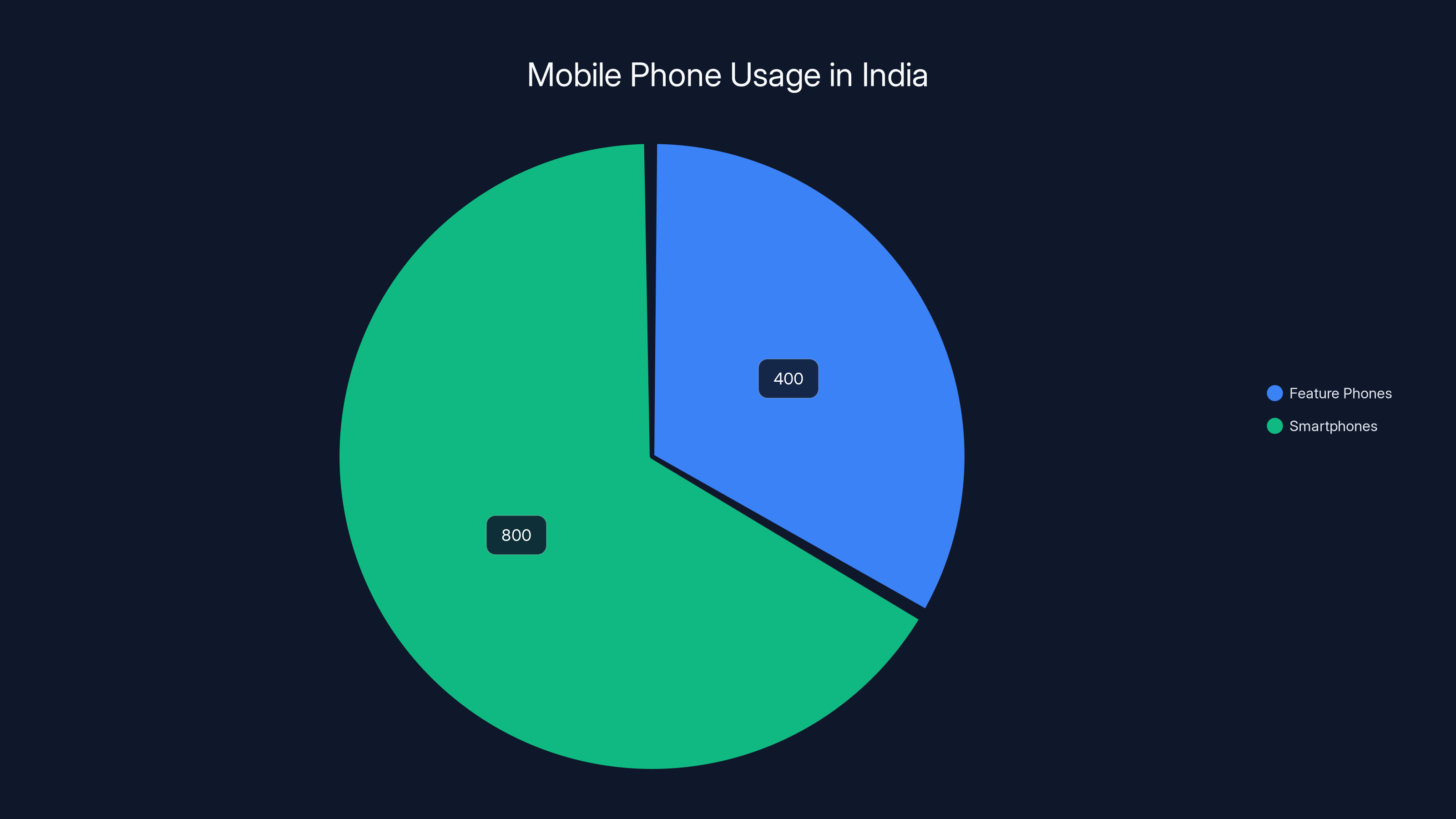
Estimated data shows that approximately 33% of India's mobile users still rely on feature phones, highlighting a significant market for AI solutions tailored to these devices.
How Models Actually Fit in Megabytes
Here's where the technical magic actually happens.
When Sarvam says their models are "only megabytes," people assume this means terrible performance. They're imagining something that can barely process text. But that's a misunderstanding of what's possible when you optimize differently.
Consider a standard language model. GPT-3 has 175 billion parameters. Even after aggressive quantization, that's still multiple gigabytes. But GPT-3 was trained on the entire internet to be generally useful at anything. It needed that capacity because it could be asked about literally any topic.
Now consider a feature phone model trained on:
- 50,000 government schemes (specific country)
- 10,000 common crop varieties with prices and seasons
- 100 common health conditions and home remedies
- 500 local language variations and dialects
That's not less capable. That's more focused. A model trained on just these domains can outperform a giant general model because every parameter has been optimized for the actual use case.
Sarvam's architecture uses several techniques working together:
Sparse Attention Patterns mean the model doesn't process entire sequences all at once. It focuses on relevant parts. If you're asking about crop prices, the attention mechanism prioritizes agricultural vocabulary. This reduces computation and memory requirements dramatically.
Quantized Weights and Activations store numbers with lower precision. Instead of 32-bit floating point (4 bytes per number), you might use 8-bit (1 byte). For millions of parameters, this is a 4x size reduction immediately. Modern quantization methods (like INT8 or INT4) lose surprisingly little accuracy because neural networks are robust to this kind of precision loss.
Knowledge Distillation from larger models compresses understanding into smaller architectures. Sarvam likely trained smaller models using outputs from larger ones, so the tiny model learns to produce similar results without needing the same capacity.
Local Language Tokenization is custom-built. Instead of generic Unicode handling, models use language-specific tokenization that represents common words and phrases more efficiently. A Hindi tokenizer might have specific tokens for common phrases that would require multiple tokens in a general tokenizer.
The result: a 40MB model that understands conversational Hindi about government schemes, can identify what a user is actually asking for (despite grammar variations and dialect differences), and can retrieve the right information without needing external APIs.
There's another critical insight here: offline operation removes an entire class of requirements. Cloud-connected models need to handle authentication, API rate limiting, network timeouts, and fallback mechanisms. An offline model just... runs. It doesn't need to validate tokens or check quotas. This simplifies the engineering significantly.
The HMD Partnership: Bringing Conversational AI to Millions
HMD Global manufactures Nokia phones. They're everywhere in developing markets. When Sarvam announced a partnership with HMD, they weren't just getting theoretical deployment capability. They got access to tens of millions of actual devices in the field.
The demo at the India AI Impact Summit showed exactly what this looks like: a user taps a dedicated AI button on a Nokia feature phone. They ask, in Hindi, about a specific government scheme they might qualify for. The phone processes locally. It returns an answer about eligibility, documentation needed, and where to apply. All offline. All in under two seconds.
This is remarkable because it's simple. It's not trying to be Chat GPT. It's trying to be useful.
There are roughly 100-150 major government schemes active in India at any time. Eligibility rules are complex and often depend on specific conditions: income level, land ownership, age, disability status, social category. A farmer might qualify for three schemes but not know it. The documentation is often in English. The application process exists in multiple departments with different portals.
A localized AI assistant that understands these schemes and can guide someone through eligibility is genuinely valuable. And it needs to work offline because rural connectivity is intermittent at best.
HMD's distribution gives Sarvam immediate access to users who have zero other options for this kind of service. It's not incremental deployment—it's potentially 50-100 million feature phones getting AI capability within 18-24 months.
The feature phone market moves slowly, but when it moves, it moves massively. Unlike the smartphone market where you're competing for upgrades, feature phone deployments are often carrier or distributor decisions made once and deployed to entire regions.
One unclear aspect: the demo showed what looked like offline capability, but Sarvam didn't specify whether all features work without connectivity. Some models might download updates over Wi-Fi at night, or refresh data periodically when internet is available. The feature phone market is also shifting—older phones get replaced gradually with slightly newer ones that have better specs. The ecosystem is more fluid than static.
But the core promise holds: a working AI assistant on a device that costs $25 and has been in production for five years.
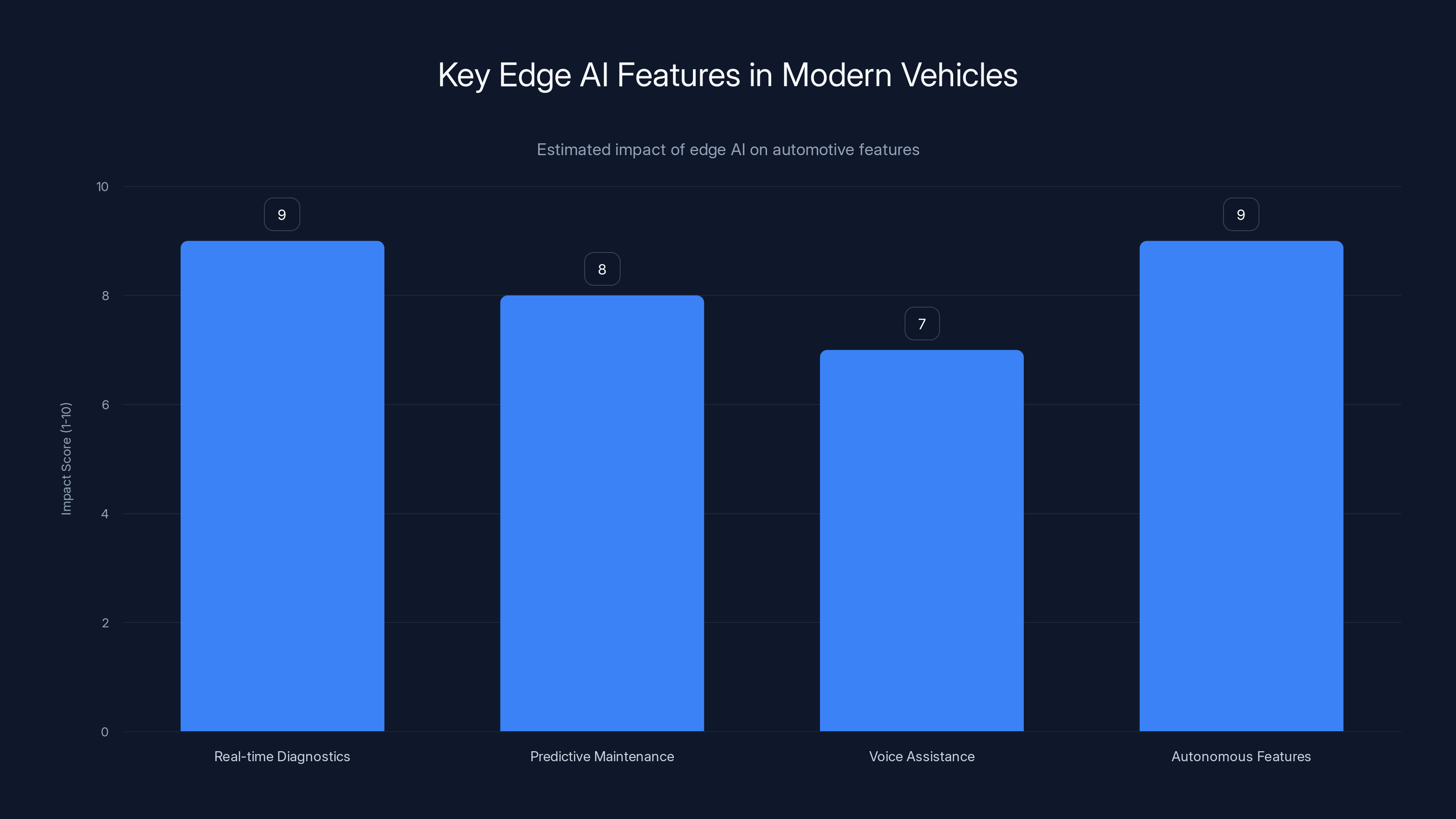
Edge AI significantly enhances real-time diagnostics and autonomous features in vehicles, with high impact scores. Estimated data.
Qualcomm Optimization: Purpose-Built Chipsets for Edge Models
Here's something most people miss: optimizing AI models for specific hardware is completely different from just making them smaller.
Qualcomm didn't just say "yeah, we'll support your models." They worked with Sarvam to tune models specifically for Snapdragon chipsets in feature phones. This is similar to how Apple optimizes iOS apps for A-series chips, but for AI.
Feature phone processors (like the Snapdragon 215, 216, or 410 series) are ancient by smartphone standards. Launched 5+ years ago. But they have specific capabilities. They have fixed-point arithmetic units. They have memory hierarchies optimized for certain access patterns. They don't have specialized AI accelerators like modern Snapdragon 8 Gen 3 chips.
Sarvam's models were likely rewritten at the assembly level to take advantage of these specific capabilities. Instead of using floating-point operations, they use fixed-point math where possible (faster on old chips). Memory access patterns were optimized to fit processor cache better. Operations were sequenced to avoid pipeline stalls.
This is the difference between "the model runs" and "the model runs fast enough to feel responsive." A poorly optimized model on old hardware might take 5 seconds per query. Optimized for the chipset, you get 500ms. That's the difference between something users will use and something they'll abandon.
Qualcomm's "Sovereign AI Experience Suite" announcement suggests they're building this into their platform layer. Future Snapdragon releases will likely include optimizations for running edge models natively. This benefits Sarvam directly—newer phones mean better performance without Sarvam changing their models.
It also signals something larger: the semiconductor industry is pivoting toward edge AI. Qualcomm, MediaTek, and others are adding specialized support for efficient inference. This doesn't require massive investments in specialized AI accelerators. It requires better support for the techniques edge models actually use: quantized inference, sparse operations, efficient memory patterns.
Within 18-24 months, running small language models on feature phones won't be a novelty. It'll be expected.
The Automotive Play: Cars That Think Without Calling Home
The feature phone partnership gets headlines. The Bosch partnership changes the industry.
Cars are becoming data centers on wheels. Modern vehicles generate gigabytes of telemetry: engine performance, fuel efficiency, tire pressure, brake wear, acceleration patterns, location history. They're connected to the internet, they call home with diagnostics. They increasingly make decisions about performance, diagnostics, and user interface based on cloud computing.
But there's a massive problem: latency. When you're driving, you can't have a 200ms round trip to a server and back while deciding how to adjust throttle response. You can't depend on network connectivity for safety-critical decisions. You can't send location data to a server if you want privacy.
Edge AI in cars means:
Real-time Diagnostics: The car monitors thousands of signals. An edge model running locally can detect anomalies immediately. Engine knock detection, transmission issues, suspension problems. It identifies patterns that don't require cloud computation, reducing false alarms and improving response time.
Predictive Maintenance: A model running locally can forecast failures weeks in advance by analyzing sensor data. Oil viscosity changes, bearing temperature patterns, hydraulic pressure signatures. These don't need cloud computation—they need continuous, local analysis.
Voice Assistance Without Data Harvesting: Cars can have conversational interfaces that work without sending audio to a cloud provider. Your conversations with the car's assistant stay private. Navigation commands, climate controls, entertainment selections all processed locally.
Autonomous Features: Level 2-3 autonomous driving requires real-time decision making. While major compute might happen in the car itself, edge models can handle scenario evaluation and edge case detection faster than cloud-based systems.
Bosch equips roughly 50 million vehicles annually. If they integrate Sarvam's models into their telematics and diagnostics platform, you're looking at tens of millions of vehicles with embedded edge AI within a few years.
The Bosch announcement was sparse on details, but the implications are staggering. Every future Bosch-equipped vehicle becomes a deployment platform for edge AI. Every diagnostic performed locally instead of cloud-bound is one more use case proving the concept.
The automotive market is also where licensing and deployment agreements are cleaner. A car manufacturer makes one decision to integrate a technology, and it reaches millions of units. Unlike the consumer market where adoption is fragmented, automotive is highly consolidated. Five major OEMs account for the vast majority of global production. One integration agreement could mean instant deployment at scale.
Bosch's relationship with these OEMs, combined with Sarvam's model efficiency, creates a path that didn't exist before: AI that works in every car, improves with manufacturer updates, and never requires external connectivity for core features.

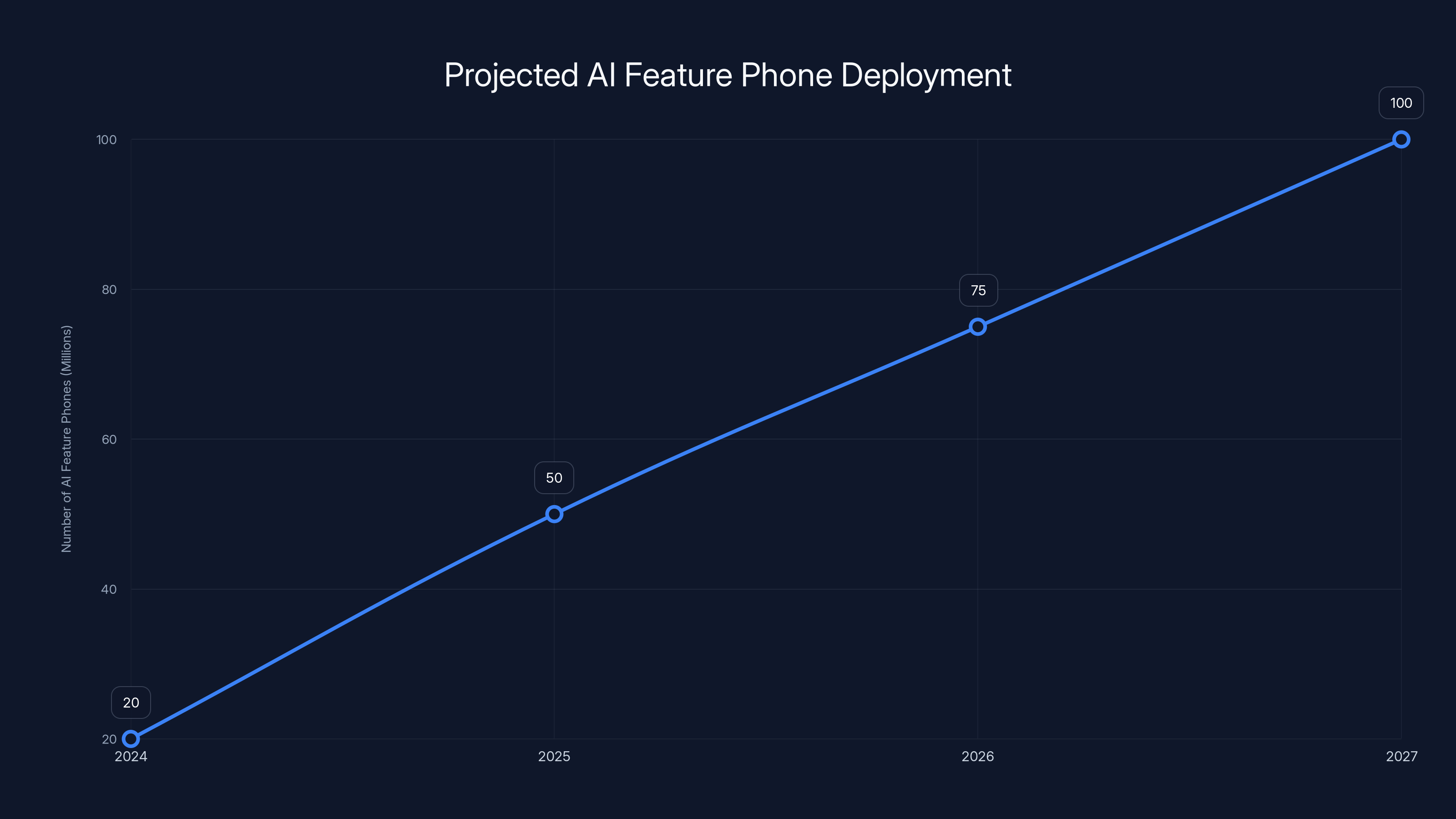
Estimated data shows a rapid deployment of AI-enabled feature phones, potentially reaching 100 million units by 2027. This expansion is crucial for providing offline AI services in regions with limited connectivity.
Smart Glasses: The Consumer Hardware Bet
Then there's Sarvam Kaze.
When a startup enters the smart glasses market, you have to ask: why? The category is littered with failures. Google Glass looked terrible and felt creepy. Snapchat's Spectacles never scaled. Meta's Ray-Ban collaboration is... something, but it's not dominant. Microsoft's HoloLens owns the enterprise space but costs $3,500.
Sarvam's positioning is different. They're not trying to be a general computing platform. They're not competing with smartphones. Kaze is explicitly a "builder's device"—meaning developers, early adopters, and technical users.
But here's what's important: it's India-designed and manufactured. This matters. India has been largely absent from consumer hardware manufacturing for consumer electronics. Phones? Manufactured in India but designed overseas. Watches? Same story. This is one of the first meaningful consumer electronics devices designed and built in India.
The smart glasses market needs a player that understands edge AI from the ground up. Most AR glasses companies start with cloud-heavy AI because that's what they know. Sarvam starts with local edge models because that's their foundation.
A pair of AR glasses with local edge AI can:
- Recognize objects and text in real-time without cloud calls
- Understand what the user is looking at and provide contextual information
- Translate signs and documents on the fly
- Assist with navigation without constantly streaming camera feed to a server
- Run for days on battery because processing happens locally
The May 2025 launch means Sarvam is targeting the wave of developer interest in spatial computing that'll follow Meta's next-generation releases and Apple's Vision Pro maturation. They're not trying to be a mass-market product immediately. They're establishing presence in a category that's about to explode.
India's hardware manufacturing ecosystem has been improving dramatically. Electronics manufacturing clusters in Tamil Nadu, Karnataka, and Uttar Pradesh have been expanding. Labor costs are lower but quality has been improving. Supply chains for components are established. Shipping and logistics work. What's been missing is high-volume consumer electronics design that's not just assembly of overseas designs.
Sarvam Kaze could be the first in a wave of India-designed consumer hardware. If it works, if developers adopt it, it opens possibilities for follow-on devices.

The Enterprise-to-Consumer Shift
Sarvam started in enterprise. They built voice models for customer support centers. Banks use their tech to handle customer inquiries. Insurance companies use them to process claims. It's boring, profitable work.
But the company realized something: voice models in customer support are always cloud-based because they run in data centers. The entire business model depends on hardware the company owns, not hardware in users' hands.
The shift to feature phones, cars, and glasses means deploying models on hardware the company doesn't own. This changes everything about business models, updates cycles, monetization, and support.
For feature phones and automotive, Sarvam is likely taking licensing fees or revenue shares. HMD pays per device or per activation. Bosch pays per vehicle or per diagnostic performed. Qualcomm might take a cut in their SDK, but that's indirect.
For smart glasses, they're selling hardware directly and need the margins to support manufacturing, supply chain, customer support, and future development.
This is a major pivot, and pivots are risky. But it's also necessary. The enterprise voice AI market is growing, but it's also becoming commoditized. Google, Amazon, and others can outspend Sarvam on general-purpose voice AI. Sarvam's advantage is specialization in on-device, edge-first models. That advantage is most defensible when they own the hardware or are deeply integrated into it.

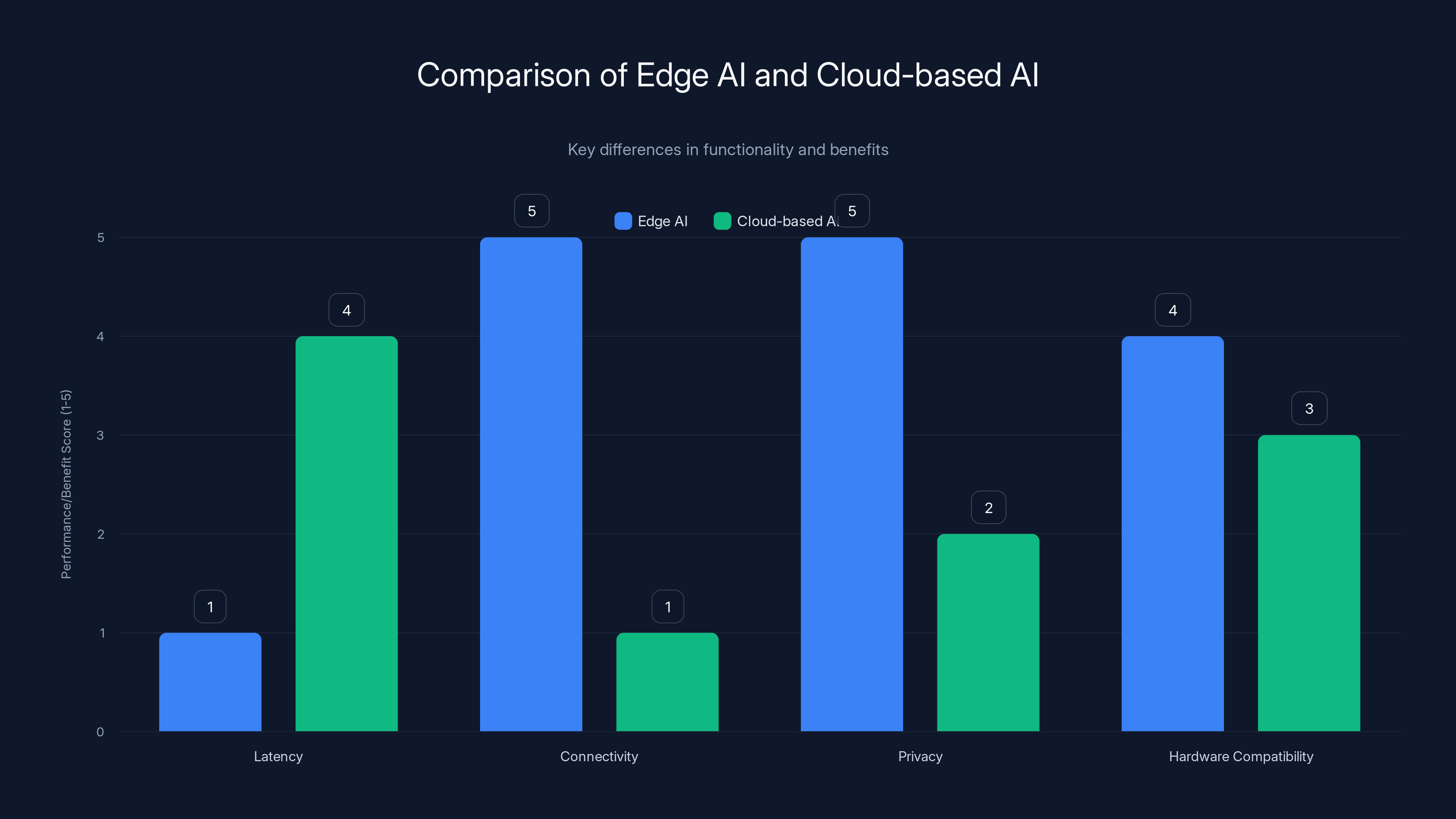
Edge AI models excel in low latency, offline operation, and privacy, making them suitable for devices with limited connectivity and older hardware. Estimated data based on general characteristics.
The Data Privacy Angle
There's something Sarvam keeps mentioning that most companies downplay: data stays on device.
When you ask a cloud-based AI about which government schemes you might qualify for, that query gets transmitted, processed on someone's servers, and logged. Same with health questions. Or financial information. Or location-based requests.
For users in markets where privacy concerns are high (basically everywhere now), local processing is a feature, not a limitation. Your government scheme queries stay on your phone. Your car's health diagnostics don't get uploaded. Your glasses don't send vision data to a server.
This has become increasingly important as privacy regulations tighten. GDPR in Europe, Personal Data Protection Act in India (DPDPA), various state laws in the US. Cloud-based AI processing creates compliance obligations. Local processing mostly doesn't.
For companies deploying AI to hundreds of millions of users in developing markets, the legal and regulatory advantages of edge processing are enormous. It's not just privacy theater. It's actual legal risk reduction.
Bosch's automotive diagnostics staying local means vehicle owners don't have to worry about their driving patterns being transmitted and analyzed. HMD users getting government scheme advice locally means no transmission of potentially sensitive information. Meta could theoretically see everything you're looking at with smart glasses; Sarvam's glasses process locally so they can't.
This positioning is becoming more valuable, not less, as regulatory pressure increases.

Market Size and Timeline
Let's ground this in actual numbers.
Feature phone market: 350-400 million units globally, about 250 million in developing markets. If Sarvam captures even 5% through HMD and carrier partnerships, that's 12-20 million deployments. At any reasonable revenue model (licensing fees, revenue share, or ad support), that's hundreds of millions in potential revenue.
Automotive market: 80 million vehicles annually, of which Bosch supplies maybe 30-40 million. Not all will get AI-enabled diagnostics immediately. But even 20% penetration in five years means 40-60 million vehicles with Sarvam models built in.
Smart glasses: Harder to estimate. The category doesn't exist yet at scale. But if AR glasses reach 100 million annual units (plausible by 2028-2030), and Sarvam captures 3-5% for India-market and developer-focused sales, that's 3-5 million units annually.
The timeline matters. Feature phones get deployment this year (HMD commitment seemed immediate). Automotive integration takes 18-36 months from partnership to production vehicles (automotive development cycles are slow). Smart glasses launch May 2025.
Sarvam is looking at potentially 50-100 million devices with their models within three years. That's scale comparable to major tech platforms.

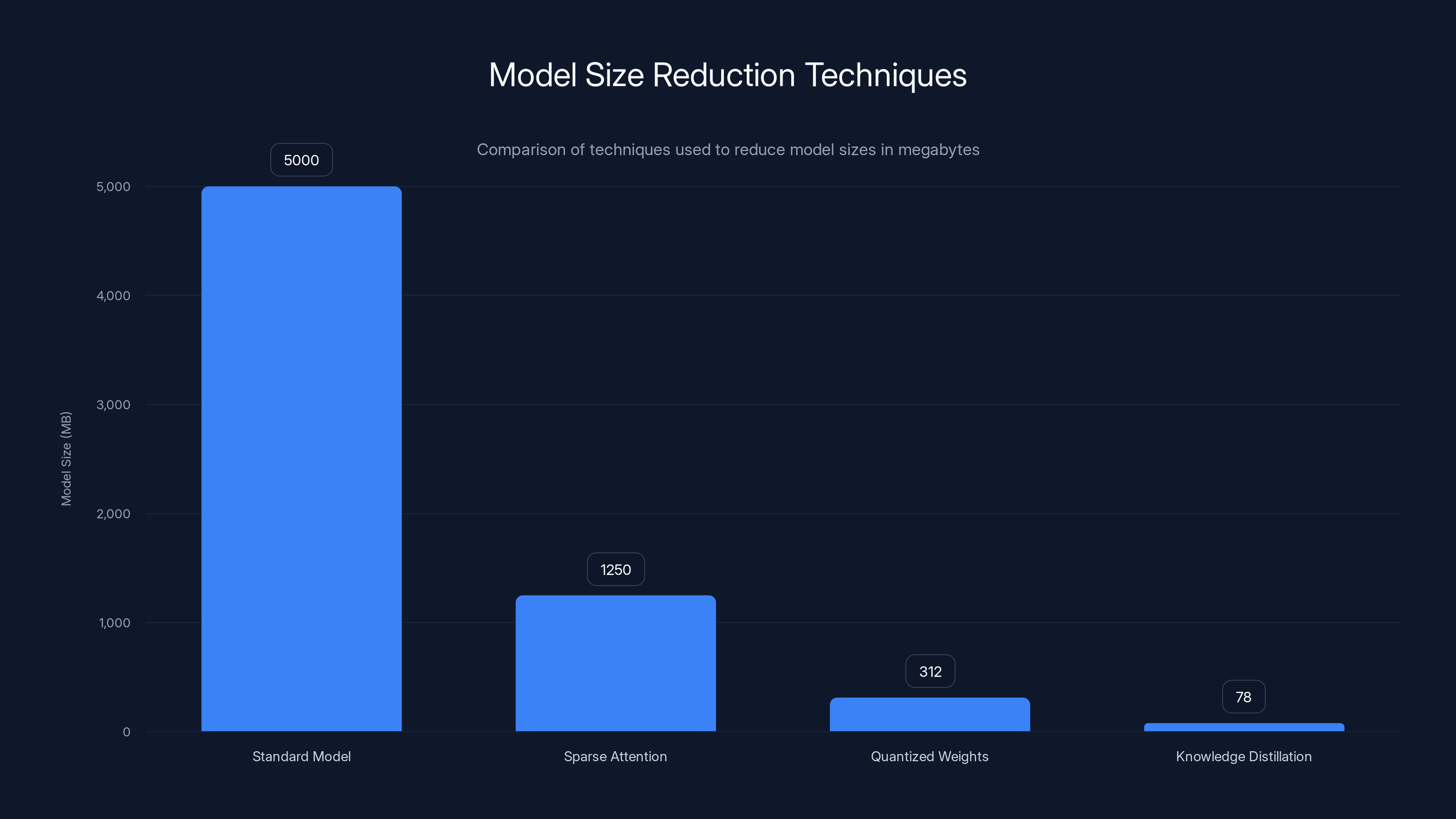
Techniques like Sparse Attention, Quantized Weights, and Knowledge Distillation significantly reduce model sizes from gigabytes to megabytes, enabling efficient performance in specific domains. Estimated data.
The Competitive Implications
Most AI companies have ignored edge deployment because it requires different expertise. Building compression techniques for edge models isn't as sexy as building larger models. Optimizing for old hardware isn't as impressive as announcing new capabilities. There's no GitHub buzz for efficient quantization.
But this creates opportunity. The companies dominating edge AI (which devices represent 95% of deployed computing) won't necessarily be the ones dominating cloud AI.
Qualcomm, ARM, MediaTek—the semiconductor companies—suddenly matter more. They can optimize their chipsets for edge models and become the enabling layer that everything else builds on.
Small, focused startups (like Sarvam) can out-maneuver giants because they're not carrying the overhead of being generally useful. They can be specifically excellent at one thing: running conversational AI on feature phones, or diagnostics on cars, or translation on glasses.
Google, OpenAI, Anthropic: they're focused on cloud models for good reasons (that's where the revenue is, for now). They're not ignoring edge, but they're not prioritizing it either. This gap is where Sarvam operates.
The next 18-24 months will determine whether edge AI becomes a first-class citizen of the AI industry or remains a boutique concern. Sarvam's deployment trajectory might be the inflection point.

Technical Challenges Ahead
None of this is simple. Deploying models to feature phones sounds straightforward until you consider:
Update Management: How do you push model updates to 50 million feature phones? You can't rely on automatic updates like smartphones. Feature phones don't check for updates. Some users might not have internet for months. Updates need to be pushed through carrier channels or included in carrier-distributed OS updates.
Linguistic Diversity: Sarvam's models handle Hindi. But India has 22 official languages. The feature phone market includes speakers of Marathi, Bengali, Tamil, Telugu, Kannada, Malayalam, Gujarati, and many more. Building separate models for each is expensive. Multilingual models are possible but require careful training.
Hallucination and Safety: When models are wrong, how wrong can they be? A government scheme model giving incorrect eligibility information is a liability issue. Medical information models are even more critical. Edge models can't easily call home to a fact-checking service. Safety needs to be built in from the start.
Hardware Heterogeneity: Feature phones aren't a single target. A phone from 2013 has different capabilities than one from 2018. Some have 64MB RAM, others 256MB. Some have fast processors, others are slow. Sarvam's models need to work across a range, which means testing on dozens of devices and accepting that some will be slow.
Network Intermittency: Cars in rural areas might lose connectivity for hours. Phones in regions with poor coverage might be offline for days. Models need to function completely disconnected, and when connectivity returns, they need to sync state gracefully.
Battery Life: On a phone with a 1000mAh battery and a 400MHz processor, running inference constantly drains battery fast. Models need to be efficient not just computationally but in terms of power consumption. This might mean limiting model execution, throttling inference, or accepting longer response times.
These are solvable problems, but they require different engineering than cloud-native deployments. Sarvam clearly has the expertise, but as scale increases, these challenges multiply.

The Sovereign AI Angle
There's a geopolitical dimension Sarvam hasn't emphasized but that matters: sovereign AI.
AI models developed outside India, trained on non-Indian data, running on infrastructure the Indian government doesn't control—these create dependency and potential surveillance vectors. When the Indian government talks about "Sovereign AI," they mean models trained by Indian companies, using Indian data, with infrastructure and control domestic.
Sarvam's partnerships with Qualcomm and Bosch show openness to international collaboration, but the core models, training, and business are Indian-founded and based. The smart glasses are manufactured in India. The models are trained for Indian use cases.
Governments globally are interested in this model. China obviously (Baidu, Alibaba). Europe (with various AI initiatives). And India, where there's explicit interest in not being purely dependent on US-based AI companies.
This creates a tailwind for Sarvam. Indian government contracts, subsidies for domestic AI adoption, preference in tenders—these could accelerate deployment. The Indian government wants AI companies that can claim they're sovereign alternatives to Google and OpenAI.
The smart glasses manufacturing in India signals this positioning. It's not just about cost. It's about being able to say "this is made in India" and meaning it end-to-end.

What Sarvam Gets Right
Amidst all the technical complexity, Sarvam's core insight is simple: the most useful AI isn't the most capable AI.
GPT-4 can discuss philosophy. But a feature phone user needs to know if they qualify for a scholarship. GPT-4 is useless. A small model trained on scholarship eligibility rules is perfect.
This applies everywhere. A car doesn't need general intelligence. It needs to know if the engine is failing. A pair of glasses doesn't need to understand the entire internet. It needs to identify plants or translate signs.
By focusing on specific use cases and building for constraint, Sarvam makes AI useful in contexts that seemed closed off. They're not trying to build AGI or compete on capabilities. They're trying to solve specific problems efficiently.
This is fundamentally different from how most AI companies think. It's also where the next decade of AI growth probably is: not in making bigger models, but in finding the right problem for different-sized models and different deployment contexts.

The Next Frontier: IoT and Industrial Deployment
Feature phones, cars, and glasses are just the beginning.
IoT devices—smart home sensors, industrial equipment, agricultural monitoring systems—represent hundreds of billions of potential deployments. Every sensor, every camera, every piece of connected hardware could have embedded AI. But currently, most IoT is cloud-dependent, which creates latency, privacy, and cost problems.
Sarvam has barely touched industrial IoT. But their technology scales there directly. A manufacturing facility monitoring equipment health could use Sarvam's models for local anomaly detection. Agricultural sensors could identify crop diseases locally. Smart city infrastructure could process data at the edge.
This is where edge AI becomes transformational. Not in consumer devices, but in the infrastructure and industrial deployments that haven't been touched by AI yet because cloud connectivity is impractical or uneconomical.
Sarvam's models have proven they work on constrained devices. The next step is proving they work in harsh environments, at 99.9% uptime requirements, with no human intervention for months at a time.
The Bottom Line
Sarvam's announcement isn't just about feature phones and cars and glasses. It's a signal that edge AI is becoming production-ready.
For the past several years, edge AI was the always-coming-soon frontier. Everyone said it was important. Nobody was deploying at real scale. Sarvam is breaking that pattern by committing to specific deployment timelines with major partners and showing working demos.
If they execute on the HMD partnership, if Bosch integrates their models into production vehicles, if the Kaze glasses gain developer adoption, we'll look back at 2025 as the year edge AI stopped being theoretical.
This matters because it means AI becomes useful to the billions of people currently left out of the AI revolution. Not in the future, not theoretically, but in the actual devices they use, the cars they ride in, the glasses on their faces.
That's not a small thing. That's the real democratization of AI.

FAQ
What exactly are edge AI models, and how do they differ from cloud-based AI?
Edge AI models run locally on devices like phones, cars, and glasses rather than sending data to cloud servers for processing. Cloud-based AI sends requests to distant servers, processes them there, and returns results, which creates latency and requires constant connectivity. Edge models eliminate this latency, work without internet, and keep your data private because nothing leaves your device. Sarvam's models prove this works even on old hardware from feature phones to decade-old car computers.
How does Sarvam fit their AI models into just megabytes of space?
Sarvam doesn't compress general-purpose models. Instead, they build models from scratch designed specifically for one task—like identifying government scheme eligibility or diagnosing engine problems. This focused approach eliminates unnecessary capacity. They also use quantization (storing numbers with less precision), sparse attention (focusing on relevant parts of input), and language-specific tokenization. The result is models under 100MB that perform well for their specific purpose without needing to be generally intelligent.
Why is offline-first design important for Sarvam's models?
Offline-first design means models work completely without internet connectivity, which is essential for feature phone users in developing markets where connections are intermittent. It also provides privacy because data never leaves the device, eliminating transmission, logging, and potential surveillance. For automotive applications, offline models enable safety-critical decisions to happen instantly without waiting for cloud responses. Offline operation also simplifies the engineering significantly because you don't need to handle authentication, API rate limiting, or network timeouts.
What does the HMD partnership actually mean for feature phone users?
HMD manufactures Nokia phones and has tens of millions of devices globally. The partnership commits to bringing Sarvam's conversational AI assistant to these phones, starting with support for government schemes and local information in Indian languages. Users will tap an AI button and ask questions conversationally—in Hindi or other local languages—and get answers offline. This represents potential deployment to 50-100 million devices within 2-3 years, making AI accessible to people who've never had it before.
How does Bosch's collaboration change the automotive market?
Bosch equips roughly 50 million vehicles annually and works with all major automakers. Their integration of Sarvam's edge AI for diagnostics means every future Bosch-equipped vehicle could have local AI analyzing engine health, predicting maintenance needs, and identifying problems in real-time. This eliminates dependency on cloud connectivity for diagnostics, improves response speed, and keeps vehicle data private rather than transmitted to manufacturers. The automotive industry's slow but decisive decision-making means one integration at Bosch could result in millions of deployments within 5-7 years.
Why is manufacturing smart glasses in India significant?
Most consumer electronics designed in India are actually designed overseas. Sarvam Kaze is rare as a consumer device designed and manufactured in India. This signals India's emerging capability in consumer hardware manufacturing and demonstrates that world-class electronics can be built domestically. It also positions India as a potential hub for hardware innovation, not just software, and creates a foundation for future consumer device companies building on India-based design and manufacturing.
What's the difference between Sarvam's approach and how other companies handle edge AI?
Most AI companies start with large cloud models and compress them for edge deployment. This approach has limits—you can only compress so much before losing meaningful capability. Sarvam starts by asking what problem needs solving and building the smallest possible model that solves it well. A model trained specifically for crop price information or government scheme eligibility from the ground up works better and smaller than a general-purpose model compressed down. This "build-for-edge-first" approach is less common but increasingly valuable.
Could these edge models handle more complex tasks like medical diagnosis?
Sarvam could build specialized medical models for specific conditions or symptoms, but accurate medical diagnosis is more complex than scheme eligibility or crop information. Edge models would likely handle triage (initial screening) or basic recommendations but would need to be carefully validated and come with liability considerations. For medical use cases, edge AI would probably work alongside cloud systems—screening locally, then connecting to specialists when needed. This is more promising than cloud-only approaches because it reduces unnecessary specialist referrals.
What happens if edge AI models make mistakes or give wrong information?
This is a genuine concern, especially for government scheme guidance or medical information. Sarvam would need careful training, continuous testing, and likely human-in-the-loop validation for critical use cases. Unlike cloud systems that can be updated globally instantly, feature phones and cars update slowly, so models need to be right before deployment. For some categories (medical, financial), edge models might include disclaimers or guardrails limiting what they claim to know. Safety-critical systems would probably use edge models for initial filtering or information retrieval, with human verification for final decisions.
How does Sarvam compete with tech giants like Google and Amazon in AI?
Sarvam doesn't compete head-to-head. Google and Amazon dominate cloud AI because that's where profit margins are highest and they have unlimited data and compute resources. Sarvam's advantage is in building AI for constraint—specifically for devices without good cloud connectivity, in markets where users need local privacy, and for specific use cases where smaller models actually work better. This is a different category. Microsoft and Qualcomm might be more direct competitors in edge AI, but most major cloud companies haven't prioritized it aggressively because profit models aren't clear. Sarvam's focus gives them an advantage in this specific lane.

Key Takeaways
Sarvam's announcements represent a real inflection point in AI deployment. The company isn't building the most sophisticated models or competing on general intelligence. They're solving a different problem: making AI work on the billion devices already in people's hands, in cars they already drive, in new glasses entering the market.
The feature phone partnership with HMD means 50+ million people could get meaningful AI assistance within two years. The Bosch collaboration signals that automotive AI is moving from cloud-dependent systems to local intelligence. The smart glasses establish a hardware play that could expand into future devices.
What makes this significant isn't just the technology. It's the business clarity. Sarvam identified a market nobody else was taking seriously (feature phone users), built technology specifically for that market's constraints, and secured deployment partnerships that make scale plausible. That's rare in AI companies.
The next 18 months will determine whether edge AI becomes mainstream or remains a boutique concern. Sarvam's execution against these timelines is a key signal to watch.

Related Articles
- Sarvam AI's Open-Source Models Challenge US Dominance [2025]
- Meta, NVIDIA Confidential Computing & WhatsApp AI [2025]
- Why VR's Golden Age is Over (And What Comes Next) [2025]
- How Deep AI Integration Transforms Customer Service ROI [2025]
- Meta's Facial Recognition Smart Glasses: Privacy, Tech, and What's Coming [2025]
- How AI Transforms Startup Economics: Enterprise Agents & Cost Reduction [2025]

