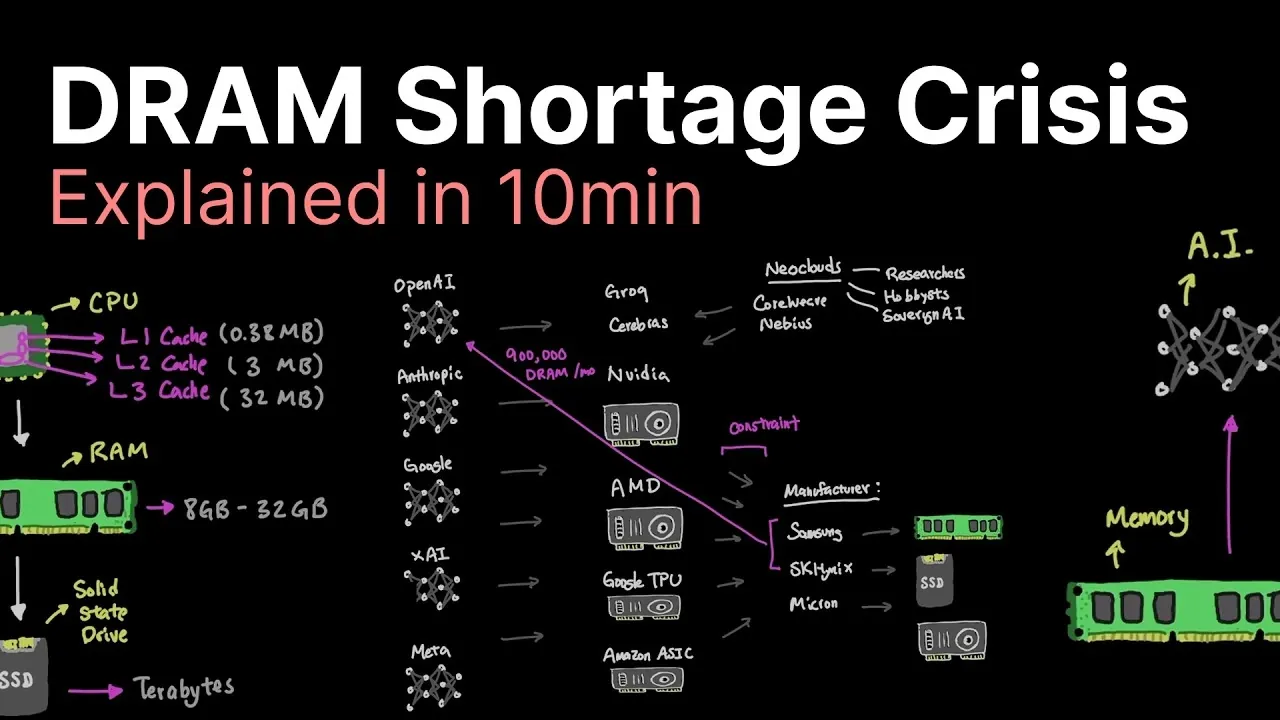
![AI Memory Crisis: Why DRAM is the New GPU Bottleneck [2025]](https://tryrunable.com/blog/ai-memory-crisis-why-dram-is-the-new-gpu-bottleneck-2025/image-1-1771348073858.jpg)
Introduction: The Invisible Cost Multiplier
When you hear "AI infrastructure is expensive," your brain probably conjures up one image: a warehouse full of Nvidia GPUs, each one costing tens of thousands of dollars. That's the narrative that dominates tech coverage. But here's the uncomfortable truth nobody talks about at dinner parties: GPU costs are only half the story.
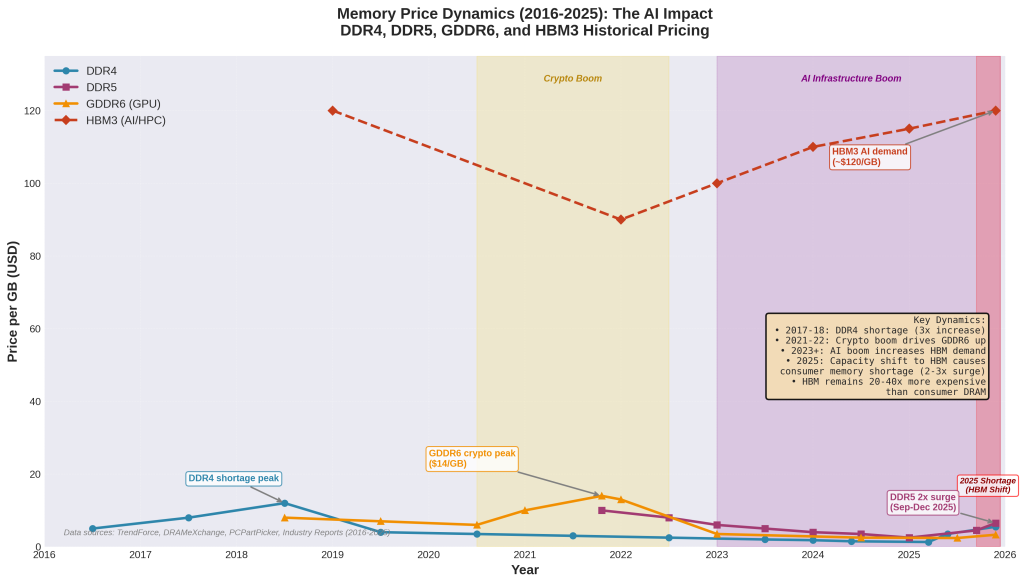
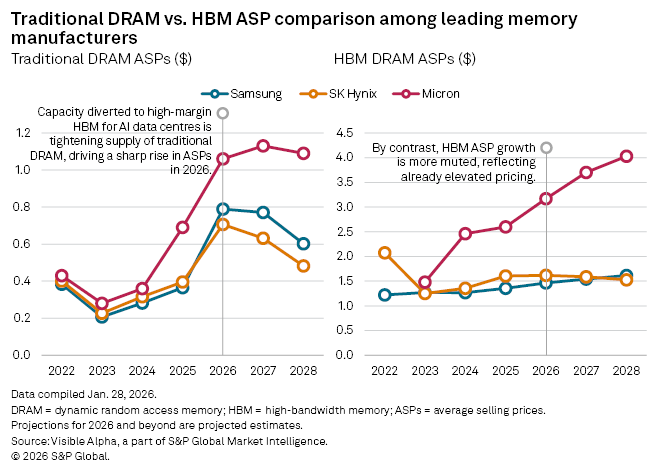
Memory—specifically DRAM chips—has become the hidden crisis in AI infrastructure. In just twelve months, DRAM prices jumped roughly 7x. Not 7 percent. Seven times. While the industry races to build out billions of dollars in new data centers to handle AI workloads, memory constraints are creating a completely different set of problems. This isn't theoretical. Companies are hitting memory walls right now, and it's forcing them to rethink how they architect everything from data centers down to the code that runs inference.
The irony? Most people still think GPUs are the bottleneck. But as hyperscalers scale, memory orchestration is becoming the differentiator between companies that can run AI profitably and companies that can't.
This matters because the cost of memory directly affects how much you can process, how fast you can process it, and whether your AI application makes money or bleeds it. When you're running language models at scale, you're not just paying for compute—you're paying for every byte that needs to stay accessible in fast memory while your inference happens. Get memory management wrong, and you're paying 7-10x more than a company that gets it right.
What's emerging is an entirely new discipline: memory orchestration. It's a weird hybrid between infrastructure engineering, hardware design, and software optimization. The companies mastering it—like Anthropic with prompt caching, or internal teams at hyperscalers optimizing their memory stacks—are finding ways to do the same computational work with fewer tokens, shorter cache windows, and smarter data placement. These aren't marginal improvements. These are the difference between a viable business model and one that folds.
Let's dig into why this matters, how it's actually implemented, and what's coming next.
Understanding the DRAM Price Spike: Why It Happened
The DRAM shortage didn't appear out of nowhere. It's the result of several converging pressures that all hit at once.
First, there's the obvious one: demand exploded. When Chat GPT launched, nobody knew what "inference" even meant. Now, billions of people are running language models multiple times per day. Each query needs memory. Lots of it. A single inference might require 50GB of model weights plus another 20-30GB of working memory for tokens, activations, and intermediate results. When you're running millions of simultaneous queries, that multiplies fast.
Second, the chip industry wasn't prepared. DRAM fabrication is incredibly capital-intensive. Turning on new production capacity takes years and billions of dollars. When the AI boom hit, fabs were already running near capacity from cryptocurrency mining, consumer electronics, and data center expansion. They couldn't flip a switch and double output. Instead, prices went up, which is how markets signal scarcity.
Third, there's hoarding. When prices are rising and everyone knows prices are rising, companies buy more than they need right now. It's rational behavior that makes the shortage worse. Every hyperscaler wants memory in reserve, which tightens supply even more.
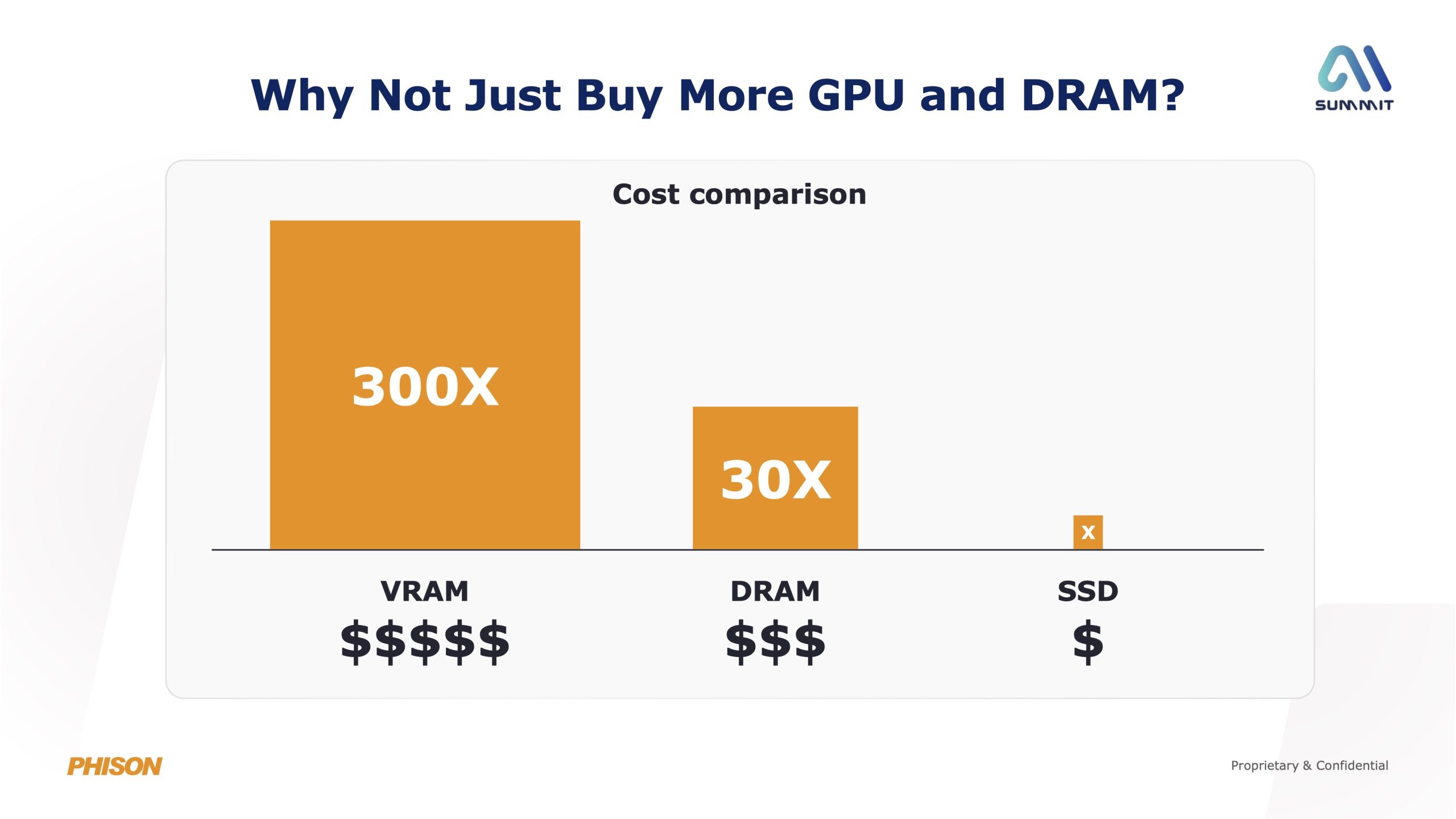
Here's the math on what this means: A typical GPU-heavy AI training rig might need 512GB of HBM (high-bandwidth memory) for the GPU itself, plus another 2TB of DRAM for the system. At 2023 prices, that DRAM cost maybe
And here's the thing: prices are starting to moderate, but they're not going back to 2023 levels. The new normal is probably 2-3x higher than where we started. Which means companies either find ways to use less memory, or they exit the business.
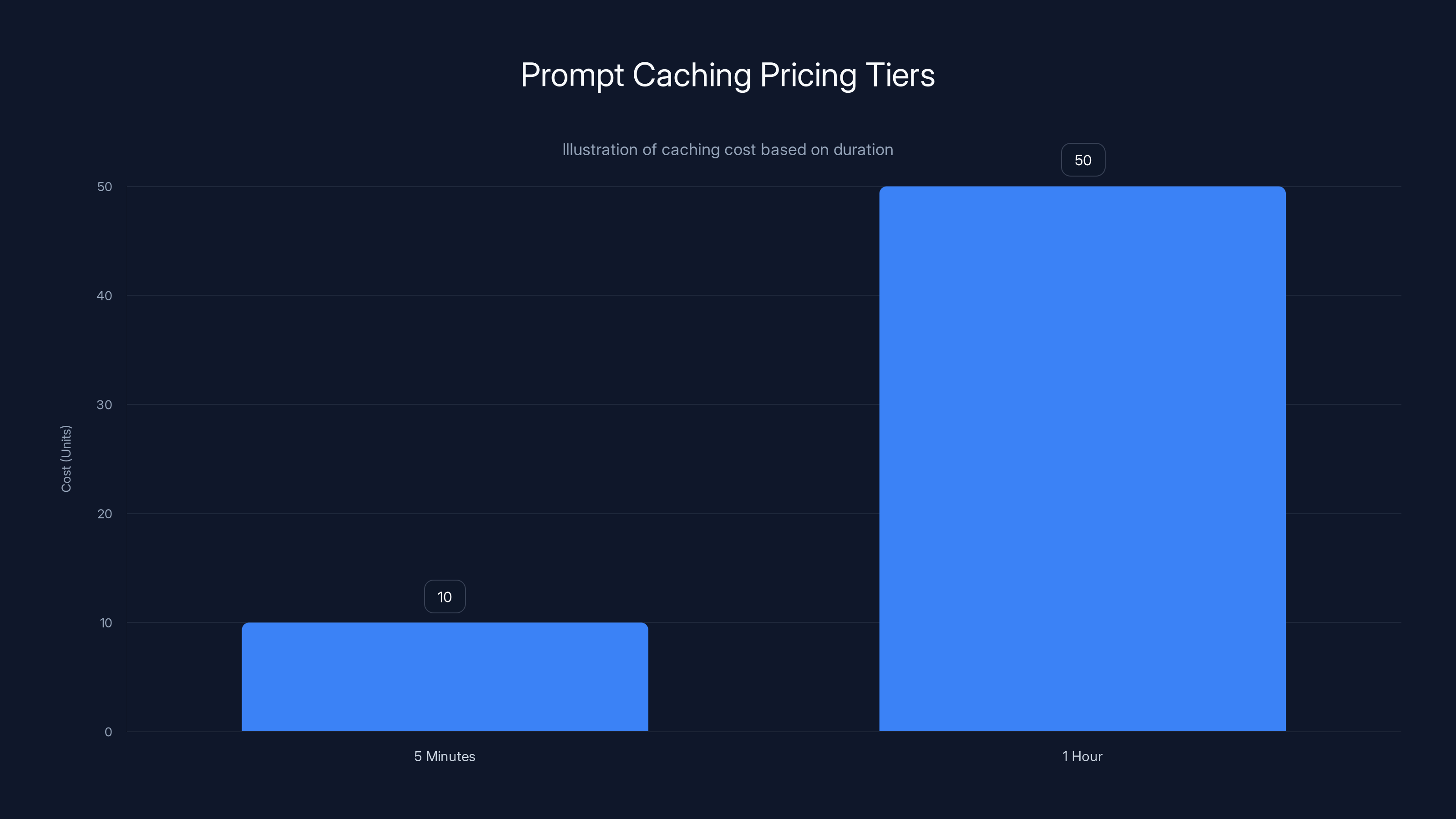
Caching costs increase with duration, incentivizing users to choose shorter cache windows. Estimated data based on typical pricing structures.
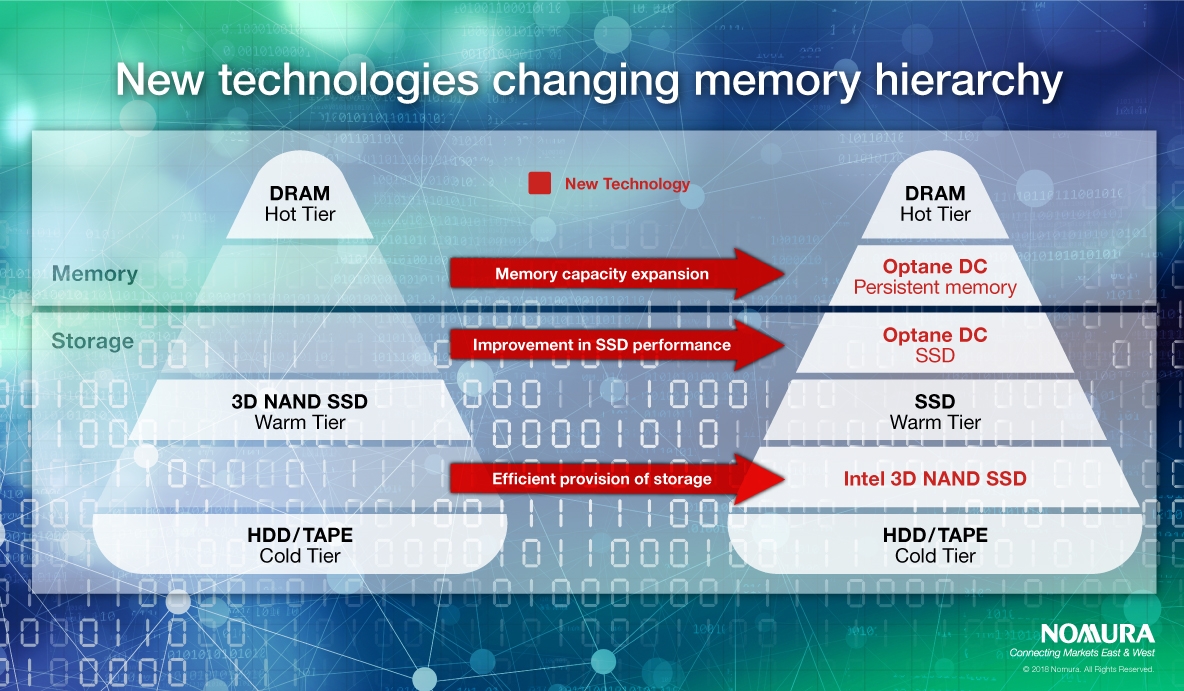
The Memory Hierarchy: DRAM vs. HBM vs. Storage
When people say "memory," they're actually talking about three completely different things. Understanding the differences is critical because they're dramatically different in cost, speed, and how they're used.
DRAM (Dynamic Random-Access Memory) is the workhorse. It's the main memory system in data centers. It's relatively slow compared to the other options—latency in the 50-100 nanosecond range—but it's massive in capacity and cost-effective. A single server might have 512GB or more. When you're doing inference, DRAM holds model weights, caches, and intermediate data that the GPU or CPU needs to access thousands of times per second.
HBM (High-Bandwidth Memory) is a completely different beast. It sits directly on the GPU die or next to it, connected by super-fast buses. A modern Nvidia H100 GPU has about 80GB of HBM. The bandwidth is roughly 15x higher than DRAM—we're talking 4-5 terabytes per second versus 200-300 gigabytes per second. That speed advantage matters enormously when you're doing heavy compute. But here's the catch: it's incredibly expensive, and there's only so much you can fit on a chip. You can't just add more HBM like you can add more DRAM.
Storage is everything else: SSDs, NVMe drives, network storage. It's massive (petabytes available), but slower. Accessing data from storage is 1,000x slower than accessing DRAM, and 100,000x slower than HBM. You only reach into storage when you have no choice.
When you're running inference, the goal is obvious: keep everything in HBM if you can. If you can't, move it to DRAM. And avoid storage at all costs, because the latency will kill your query speed.
The optimization challenge: You have a fixed amount of HBM (limited and expensive), a large but finite amount of DRAM (expensive and getting more so), and essentially unlimited storage (cheap but slow). How do you decide what lives where, and how do you manage moving data between them without destroying performance?
This is where memory orchestration enters the picture.
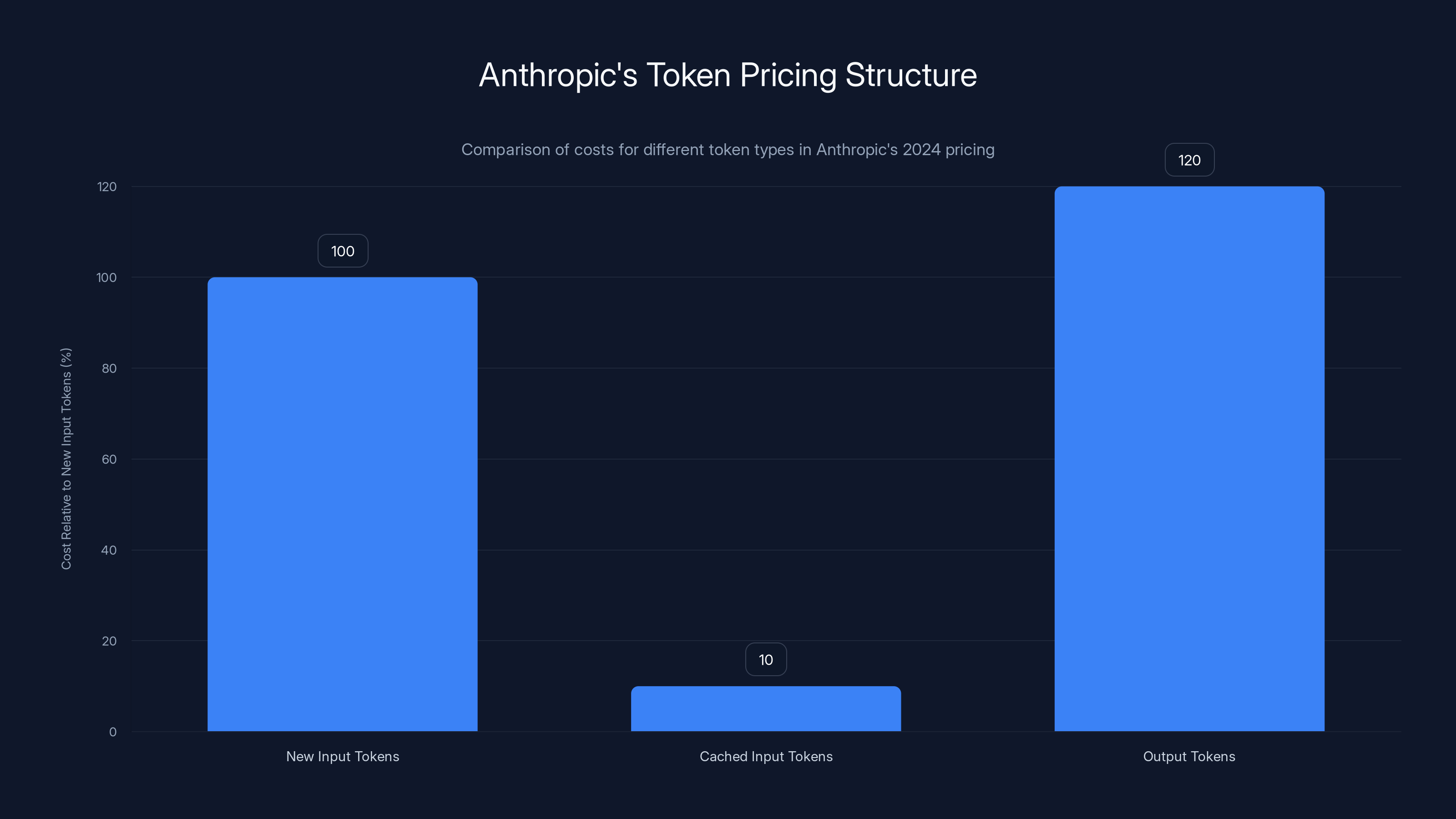
Output tokens are the most expensive due to memory allocation needs, while cached tokens are 90% cheaper than new input tokens. Estimated data.
Prompt Caching: The First Major Solution
Prompt caching is the simplest and most obvious memory optimization, but it's also surprisingly complex to implement well.
The idea is straightforward: if you're going to ask an AI model multiple questions about the same document, or run multiple inferences with the same system prompt, you don't want to reprocess the same tokens every time. So you cache them. The first query processes the full prompt and stores the results. The second query reuses the cache.
This sounds simple, right? Run it once, reuse it. But here's where it gets complicated.
When you cache a prompt, you're storing the full set of activations (intermediate outputs from every layer of the model) from processing those tokens. For a 100K token prompt run through a 70-billion parameter model, that's a lot of data. Gigabytes, easily. And here's the problem: that cache is only useful if you reuse it quickly. If you wait too long before the next query, or if you add new tokens to your prompt, the cache becomes stale or partially invalid.
Anthropic recognized this and built their prompt caching into Claude's pricing. But they didn't make it simple. They made it configurable. You can pay to cache for 5 minutes, or for 1 hour. The longer you want the cache to stick around, the more you pay. Why? Because holding data in memory costs the provider money. They need to incentivize users to pick the right cache window for their use case.
What started as a simple pricing page—"use caching, save 90% on cache reads"—has evolved into what one semiconductor analyst called "an encyclopedia of advice." There are 5-minute tiers, 1-hour tiers, and nothing beyond. Why nothing beyond? Because at some point, it's cheaper to just reprocess the tokens than to pay for indefinite caching.
Here's the unintuitive part: every new token you add to your prompt might bump something else out of the cache. So if you're trying to maintain a cache of a 50K token context, and you add another 1K tokens, you might lose the cache entirely and have to reprocess everything. It's like a very weird memory game where you're constantly deciding what to keep and what to throw away.
The practical impact: Companies using prompt caching intelligently can reduce their token costs by 80-90% on repeat queries. That's not marginal. That's the difference between a
But here's the catch: you need to design your application around it. If you're writing ad-hoc queries, you don't get the benefit. If you're building a document analysis system where multiple users ask questions about the same document, you win big. It's an architectural decision that forces you to think about how data flows through your system.
Cache Optimization and Memory Orchestration
Prompt caching is the user-facing feature. Behind the scenes, there's a much bigger problem: how do you manage all of that cache across multiple GPUs, multiple servers, and multiple data centers?
This is where companies like Tensor Mesh come in. They're building tools to optimize how cache is allocated, evicted, and reused across the infrastructure layer. It's foundational stuff that most end users never see, but it's critical.
Think of it this way: you've got 100 servers, each with 2TB of DRAM. When a query comes in, it needs to be routed to a server that has the necessary cache. If the cache isn't there, you have to move it (expensive and slow) or recompute it (computationally expensive). As queries stack up, you've got dozens of different cache states across the cluster, and you need to make real-time decisions about where to put new data.
This is a scheduling problem, a memory allocation problem, and a performance optimization problem all rolled into one. And it's nowhere near solved.
Current approaches typically:
- Route queries to the server that already has the relevant cache
- Evict the oldest or least-used cache entries when memory runs out
- Replicate hot cache across multiple servers for redundancy
- Move cache between DRAM and storage when memory is tight
- Preload anticipated cache before queries arrive
None of these are perfect. Routing adds latency. Eviction can break other queries. Replication wastes space. Moving data between DRAM and storage is incredibly slow. Preloading requires predicting which queries are coming, which is basically fortune-telling.
The companies getting this right are experimenting with AI-driven cache prediction. If you can predict which documents or contexts are likely to be queried next, you can keep their cache warm and ready. But prediction is hard, and being wrong is expensive.
What's emerging is a new class of infrastructure tools specifically designed to solve this. They sit between the application layer and the hardware layer, making constant micro-decisions about memory allocation. It's unglamorous work, but it's becoming foundational to AI infrastructure economics.
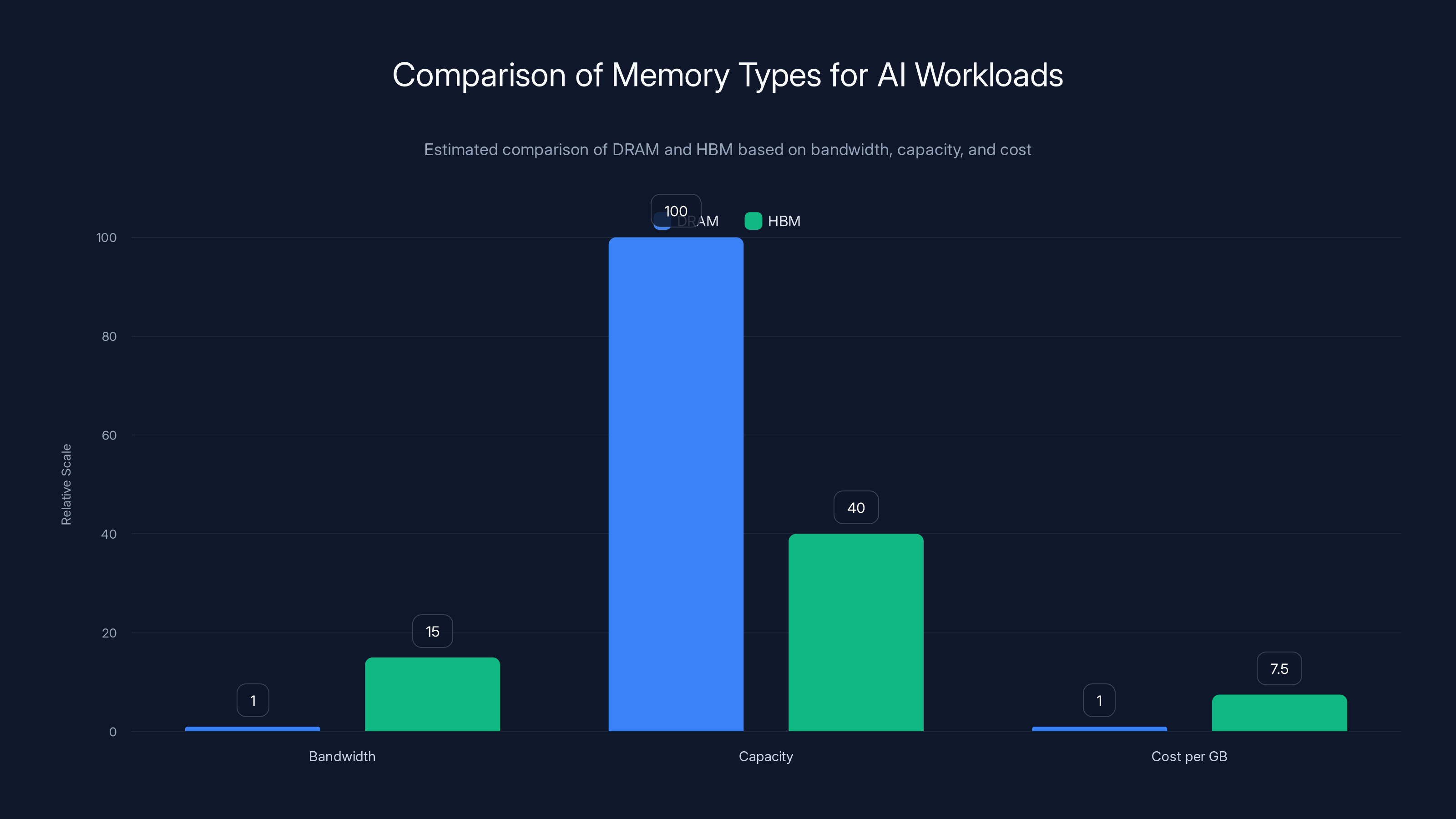
HBM offers 15x higher bandwidth than DRAM but at a higher cost and lower capacity. Estimated data highlights the trade-offs between DRAM and HBM for AI workloads.
HBM vs. DRAM: The Hardware Decision
Data center operators face a critical hardware decision: should we buy more HBM-equipped GPUs, or fill out our systems with additional DRAM?
The trade-offs are brutal.
HBM advantages:
- Massively higher bandwidth (4+ TB/s vs. 300 GB/s)
- Latency measured in nanoseconds
- Sits right on the GPU, no bottlenecks
- Enables much faster model execution
HBM disadvantages:
- Costs 5-10x more per gigabyte than DRAM
- Limited capacity (typically 24-80GB per GPU)
- Can't easily upgrade or add more
- Requires specific GPU models that support it
DRAM advantages:
- Much cheaper per gigabyte
- Can add more easily (just add more modules)
- Available in massive quantities (terabytes possible)
- Works with any system
DRAM disadvantages:
- Much lower bandwidth
- Higher latency
- Gets expensive when you need a lot
For training, the math usually favors HBM. You're moving massive amounts of data constantly, and bandwidth is king. But for inference, DRAM can make sense if you're smart about cache management.
Here's a concrete example: Running inference on a 70B parameter model on an H100 with 80GB HBM costs you almost nothing to load the model weights. The 80GB fits perfectly. But if you're running the same model on a CPU-only system, you need 140GB of DRAM just for the model. At current prices, that's a $5K+ difference in memory alone.
But here's where it gets weird: if you're doing batched inference where you process multiple queries simultaneously, you might need more total memory for KV cache (key-value pairs that accumulate as the model generates tokens) than the model weights themselves. In that case, all the HBM in the world doesn't help you. You need DRAM.
The optimal configuration depends entirely on your workload. And that's why this has become such an active area of research and optimization.

Token Efficiency: The Real Optimization
Here's something that most people miss: the ultimate solution to the memory problem isn't better hardware. It's writing software that needs fewer tokens.
Why? Because tokens directly translate to memory usage. More tokens means more KV cache, which means more memory, which means slower inference or more hardware.
Here's the math:
When a language model generates a response, it does token-by-token. For each new token, it needs to attend to every previous token (in most architectures). That attention mechanism requires storing the key and value vectors for every token processed so far. For a 100K context with a 70B parameter model, that KV cache is roughly 400GB.
If you can structure your system to never need more than 50K tokens of context, you cut the memory requirement by half. If you can get down to 20K tokens, you cut it by 5x.
So how do you reduce tokens?
Prompt compression: Remove unnecessary information from your prompts. Instead of including the full document, include a summary. Instead of full function signatures, include a skeleton. The model still understands what to do, but with less context.
Retrieval optimization: Instead of putting everything in context, retrieve only the relevant pieces. Search for what you need instead of keeping everything available.
Structured outputs: Instead of asking the model to generate arbitrary text, constrain it to specific formats. "Output JSON with these fields" uses fewer tokens than "write whatever you want."
Batching: Process multiple queries together instead of one at a time. This amortizes the prompt overhead across queries.
Token prediction: Use smaller, faster models to predict which tokens the big model will generate, then skip the expensive inference. This is speculative decoding, and it's becoming increasingly important.
Companies that get good at token efficiency will run cheaper inference than competitors. Period. It's that simple.
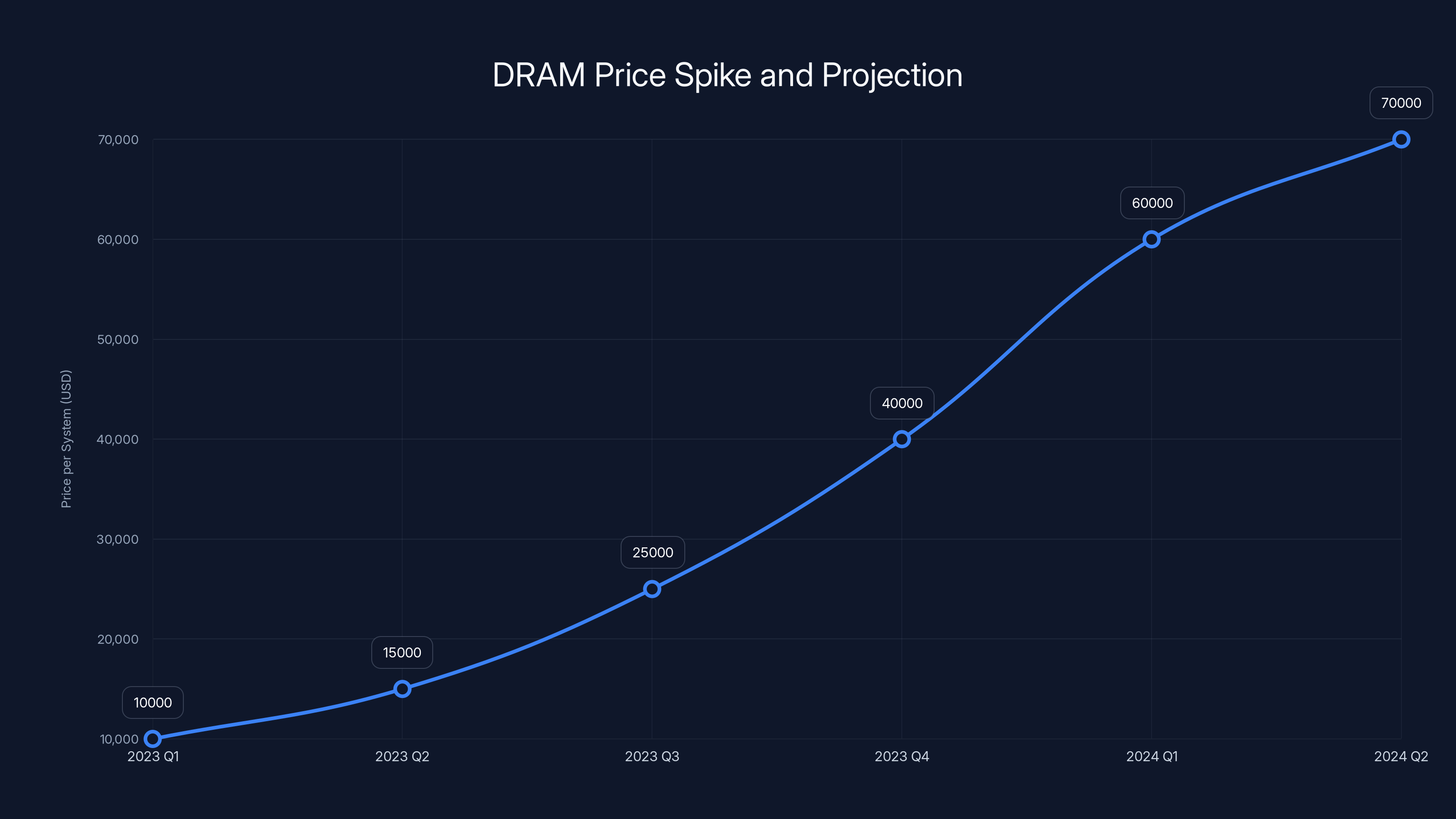
DRAM prices surged from
Model Swarms and Distributed Inference
As memory becomes the constraint, a new architectural pattern is emerging: splitting inference across multiple smaller models instead of running one huge model.
Instead of a single 70B parameter model, you might run five 14B models in parallel, each handling a different part of the computation. Or you might use a smaller model for triage (deciding which specialized model to route to) and larger models for specialized tasks.
This seems wasteful at first. Doesn't one big model do everything better? Sometimes yes. But here's the thing: multiple smaller models can fit in memory together, which means lower latency, easier parallelization, and more graceful degradation if one model fails.
The key insight is that different queries need different amounts of computation. A simple question that could be answered by a 7B model shouldn't go through a 70B model. But how do you route traffic to the right model?
This is where smaller triage models come in. Anthropic has been exploring this. You can use a tiny model (a few billion parameters) to decide: "Is this a simple question?" If yes, route to a small model. If it's complex, route to a larger one. The latency and cost savings are enormous.
But it gets more complex when you think about shared cache. If you're running five 14B models on the same server, they're competing for the same DRAM. Their KV caches might interfere with each other. The scheduler needs to understand that query A is using model 1, and query B is using model 3, and they have different memory requirements.
This is why memory orchestration at the infrastructure level becomes critical. You need a scheduler that understands not just the queries, but the models they're using, the cache they require, and how to prioritize them.
Quantization: The Hidden Memory Saver
Here's a trick that doesn't get enough attention: quantization can dramatically reduce memory requirements while keeping model quality surprisingly high.
Quantization means representing model weights with fewer bits. Instead of 32-bit floating point (which is standard), use 8-bit integers. Or 4-bit. Or even 2-bit in extreme cases.
The memory savings are linear. 4-bit quantization uses 1/8 the memory of 32-bit. For a 70B parameter model, that's the difference between 140GB and 17.5GB. That's transformative.
The catch? The model might be slightly less accurate. In many cases, barely noticeably. For some tasks, the difference is substantial.
Here's what companies are doing:
- Quantize to 8-bit for production. Minimal quality loss, 4x memory savings.
- Quantize to 4-bit for less critical tasks or when speed matters more than accuracy.
- Quantize weights but keep activations in higher precision for better performance.
- Use different precision for different layers (lower layers get more compression).
- Apply dynamic quantization where you adjust precision based on the input.
The space is moving quickly. Techniques like GPTQ, AWQ, and newer approaches like layer-wise quantization are making it possible to quantize aggressively without destroying model quality.
For memory-constrained environments, quantization is one of the highest-ROI optimizations you can do. It's also relatively straightforward to implement, which is why you're seeing it used everywhere now.
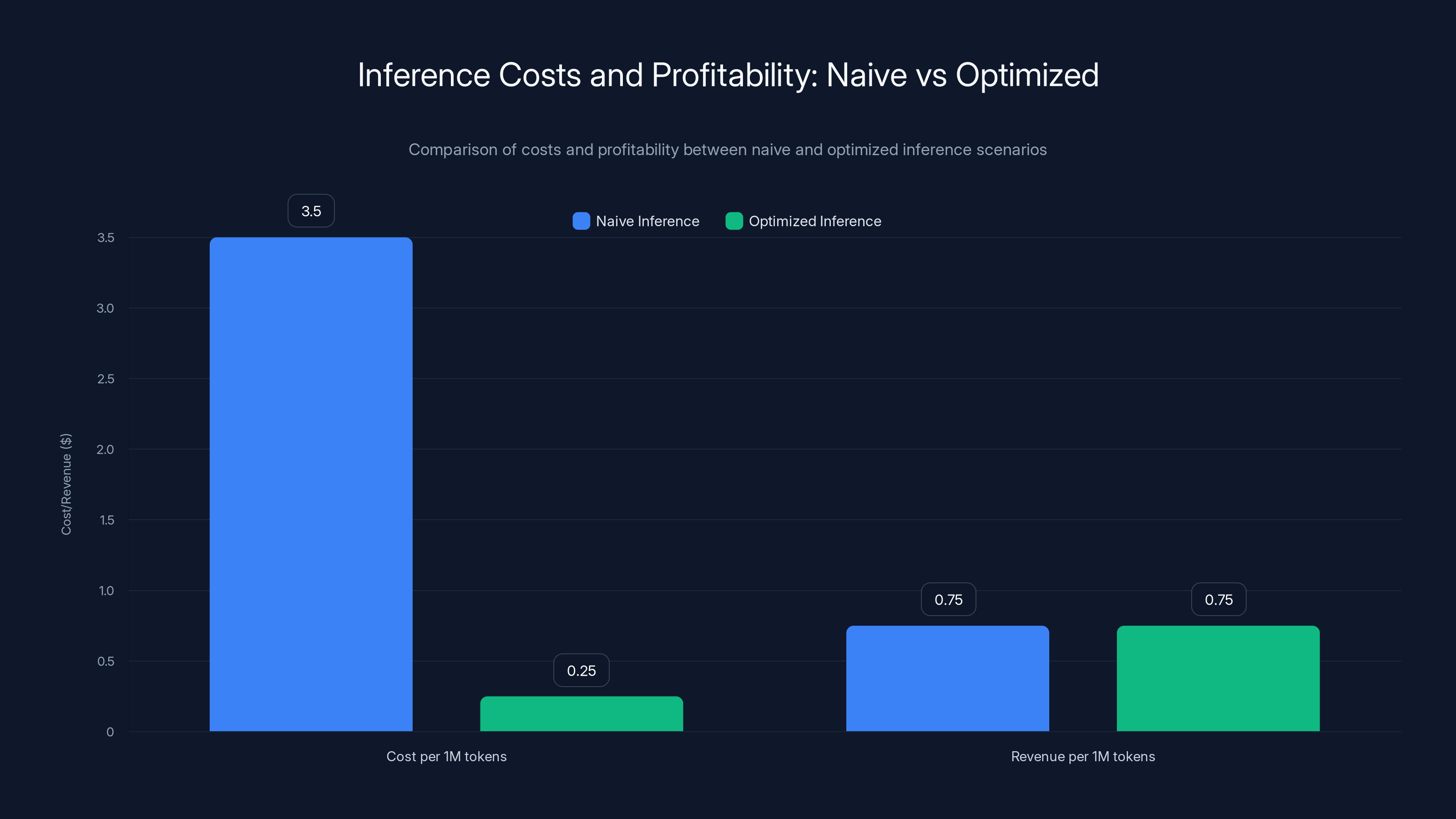
Optimized inference significantly reduces costs from
The Economics: How Memory Constraints Affect Pricing
When you understand memory constraints, you understand why AI API pricing is what it is.
Consider Anthropic's pricing structure. They charge different rates for cached input tokens versus new input tokens. The reason? Cached tokens don't require additional memory, inference, or computation. They're free (or nearly free) to the provider. New tokens require memory allocation, GPU compute, and DRAM bandwidth. These are expensive.
Anthropic's 2024 pricing (for reference):
- New input tokens: expensive
- Cached input tokens: 90% cheaper
- Output tokens: most expensive
Why are output tokens expensive? Because they require KV cache allocation. Every token generated needs to add to the cache for future tokens in the same conversation. As conversations get longer, KV cache grows, memory pressure increases, and the cost compounds.
This pricing structure creates incentives for users to structure their applications around caching. Which is exactly what Anthropic wants. It's an alignment of incentives: the company saves money, and the user saves money. Win-win.
But it gets more complex with volume commitments. If you're a customer spending $1M/month, you can negotiate different rates. What's the negotiation really about? Memory provisioning. Can we commit to caching windows that let us guarantee memory allocation patterns? Can we batch your traffic in ways that let us fill our servers more efficiently?
For startups and small companies using these APIs, understanding these constraints can be the difference between a viable business model and one that doesn't pencil out. If your application needs 100K token contexts, and you're using Claude at the standard rates, your costs are devastating. But if you can compress those contexts to 20K tokens through smart retrieval and summarization, suddenly the economics work.

Data Center Architecture: The Hardware Layer
The memory crisis is forcing data center operators to completely rethink infrastructure.
Traditional data center design treated compute and memory as separate concerns. You had GPU racks, and you had memory racks, connected by interconnects. The bandwidth between them was the bottleneck.
But when bandwidth is the constraint, this doesn't work. You need memory right next to compute. Which is driving new design patterns:
Disaggregated inference: Separate models run on specialized hardware in different locations. The orchestrator routes queries to the right hardware. This lets you scale memory and compute independently.
In-memory caching clusters: Dedicated systems that do nothing but hold cache in DRAM, serving cache hits to GPU clusters. Think of them as cache-as-a-service within your data center.
Heterogeneous compute: Mix of CPUs, GPUs, TPUs, and specialized inference chips, each optimized for different memory/compute trade-offs.
Tiered memory design: L1 cache on GPU (ultra-fast, tiny), L2 cache in HBM or local DRAM (fast, medium), L3 cache in distributed DRAM (slower, huge), L4 cache in NVMe (massive, slow).
Hyperscalers are investing billions in building infrastructure designed around these patterns. It's not just about buying more hardware—it's about buying different hardware and connecting it differently.
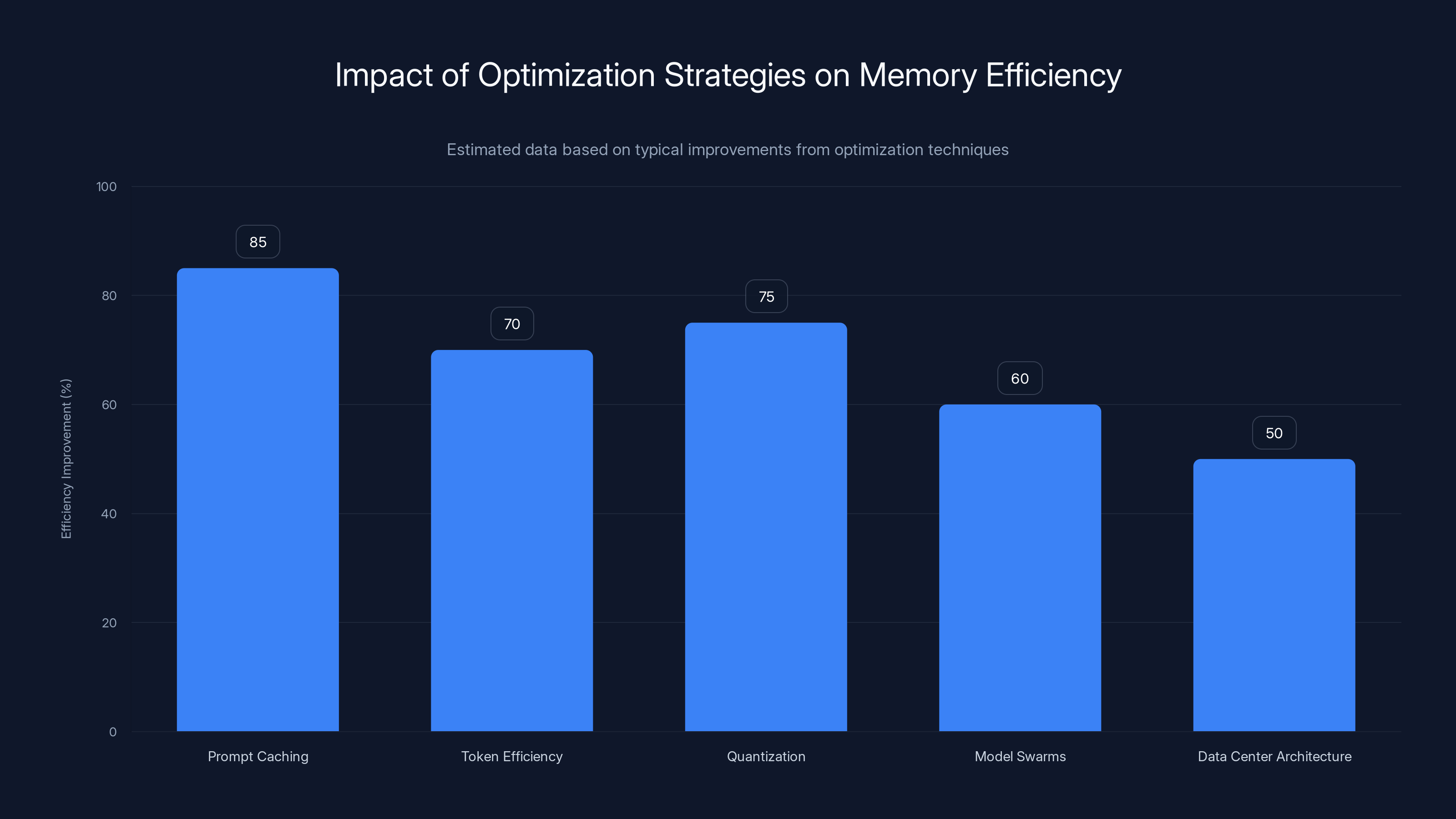
Quantization and prompt caching are leading strategies, offering up to 85% and 75% memory efficiency improvements respectively. Estimated data based on typical outcomes.
Open-Source and Self-Hosted Solutions
While the hyperscalers are building proprietary infrastructure, there's a parallel movement in open-source focusing on memory efficiency.
Projects like Hugging Face's transformers library have added extensive memory optimization features. Libraries like v LLM focus specifically on inference optimization with advanced KV cache management.
What's interesting is that the community innovations often end up being adopted by commercial providers. Techniques that start as open-source projects become industry standard.
Common optimizations in open-source:
- KV cache quantization (store the cache in 8-bit instead of 32-bit)
- Memory-efficient attention mechanisms (like Flash Attention)
- Paged KV cache (treat cache like OS memory pages, can spill to disk)
- Token pruning (remove unimportant tokens from the KV cache to free memory)
The advantage of self-hosted solutions is that you're not constrained by a provider's pricing decisions. You can use whatever optimization works best for your workload. The disadvantage is that you have to manage everything: hardware, software updates, monitoring, reliability.
For companies processing specialized data or with specific latency requirements, this can make sense. For most others, using someone else's optimized infrastructure is cheaper than doing it yourself.
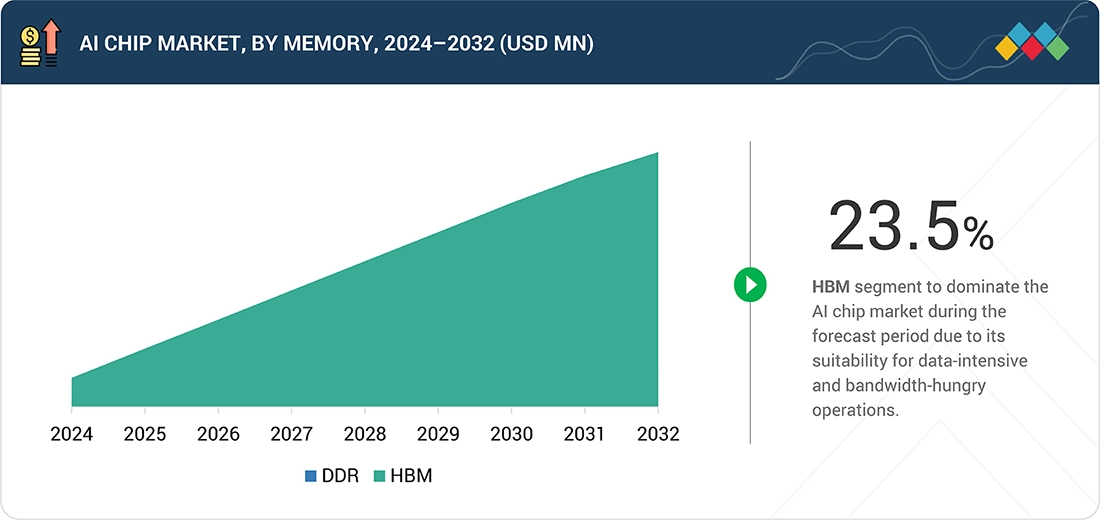
Emerging Tools and Technologies
The memory orchestration problem is new enough that tools are still being invented.
We're seeing emergence of dedicated orchestration layers: software that sits between applications and infrastructure, making real-time decisions about memory allocation, cache management, and query routing.
These tools handle things like:
- Predicting which data will be needed and preloading it
- Deciding what to evict when memory gets full
- Routing queries to servers with the best cache locality
- Managing KV cache lifecycle
- Optimizing prompt compression
- Handling cache coherency across distributed systems
Some of this is happening inside companies like Anthropic or Open AI. Some is happening in tools that companies are building for themselves. And increasingly, this is becoming a market where startups and open-source projects are building general-purpose solutions.
We're probably 2-3 years away from having standardized, battle-tested tools for this. Right now, most companies are solving these problems by hand, which is expensive and error-prone.

Inference Costs and Profitability
All of this infrastructure complexity exists for one reason: inference is expensive, and companies need to make it cheaper.
Here's the brutal math:
Scenario 1: Naive inference
- 70B parameter model: 140GB memory
- Running on 8x GPU setup: $3M hardware
- Utility costs: $50K/month
- Amortization: 50K/month operating = $350K/month
- Throughput: 100 queries/second, average tokens: 1,000
- Cost per 1M tokens: roughly $3.50
- Revenue (at competitive pricing): 1.00 per 1M tokens
- Result: Losing money on every query
Scenario 2: Optimized inference
- Same hardware
- But with: caching, quantization, model routing, prompt compression
- Actual throughput: 400 queries/second (4x improvement from batching and routing)
- Actual tokens per query: 500 (2x reduction from compression)
- Effective cost per 1M tokens: $0.25
- Revenue: 1.00 per 1M tokens
- Result: Actually profitable
That's the difference between company survival and bankruptcy. And that's why memory optimization is taken so seriously. It's not a nice-to-have. It's existential.
The spread between companies that get this right and companies that don't is enormous. If company A can do inference at 4x lower cost than company B, they can undercut on price while maintaining margins, win market share, and eventually drive B out of business.

The Software Layer: How Applications Adapt
As infrastructure constraints become clearer, application developers are adapting their designs.
Instead of building applications that assume unlimited inference capacity, they're building applications that actively manage memory:
Prompt engineering for efficiency: Prompts are written to convey maximum information in minimum tokens. This is an art form.
Retrieval-augmented generation (RAG): Instead of including full documents in context, retrieve only relevant sections. This dramatically reduces token requirements.
Multi-turn conversation design: Structure conversations to avoid requiring full history. Summarize and archive old turns.
Request batching: Process multiple user requests together when possible. Reduces per-request overhead.
Fallback models: Use small models for easy queries, large models for hard ones. Route appropriately.
Applications that adapt to memory constraints become cheaper to run and faster for users. This creates competitive advantage.
Future Trends: What's Coming
Where is this heading?
Memory density improvements: As process nodes shrink and techniques like 3D stacking improve, DRAM capacity and bandwidth will increase. Prices will eventually come down from current peaks.
New memory technologies: NAND-based and other emerging technologies might eventually replace some DRAM use cases, offering different cost/performance trade-offs.
Smarter models: Models that naturally require less memory (through efficient architectures) will have massive advantages.
Standardized orchestration: What's custom today will become standard infrastructure within 3-5 years.
Decentralized inference: As costs come down, more inference moves to edge devices instead of centralized data centers.
Neuromorphic computing: Entirely different architectures that don't have the memory constraints of traditional neural networks.
The memory crisis is real today, but it's not forever. However, the companies that learn memory optimization now will have skills that apply to whatever comes next.
Key Takeaways: What This Means for Your Business
Let's get practical. What should you actually do about this?
If you're an infrastructure company: The memory optimization tools market is wide open. Build tools that help others manage their memory constraints. This is valuable, defensible, and has long product-market fit.
If you're building AI applications: Design your system around memory constraints from day one. Use caching, retrieval, and prompt compression. This directly impacts your unit economics.
If you're running your own inference: Invest in quantization, KV cache optimization, and request batching. These give you 2-4x cost reductions with modest engineering effort.
If you're using AI APIs: Understand caching, use it aggressively, design prompts for compression, and batch requests when possible. Your API bills depend on it.
If you're investing in infrastructure: Memory is just as important as compute. Companies that have solved the memory puzzle will dominate. The hardware economics are shifting.
The companies that master memory orchestration will win. Not because they have better marketing or funding, but because they'll be able to run the same workloads at lower cost. And that compounds over time.

Conclusion: Why This Matters More Than You Think
We started with a simple observation: DRAM prices went up 7x in one year. That sounds like a hardware problem. But it's actually a fundamental constraint on AI economics.
When infrastructure gets expensive, software has to get smarter. When the constraint becomes memory, everything from application architecture to data center design has to adapt. This is exactly where we are.
The good news? There's massive opportunity here. Companies haven't figured out optimal memory orchestration yet. There are 5-10x cost improvements waiting to be captured. Entire categories of tools need to be built. New architectural patterns are emerging.
The bad news? This is hard. Memory optimization isn't flashy. It doesn't make headlines. But it's the difference between an AI application that makes money and one that hemorrhages it.
The companies winning today aren't the ones with the biggest GPUs. They're the ones that have solved the invisible problem: how to move the right data to the right place at the right time, and how to do it cheaply enough that inference remains profitable.
If you're building in AI infrastructure, memory orchestration is the frontier. If you're building AI applications, understanding these constraints is how you stay profitable. And if you're just paying attention? Remember that the next bottleneck isn't compute. It's memory.
FAQ
What is DRAM and why does it matter for AI inference?
DRAM (Dynamic Random-Access Memory) is the main memory system used in data centers to store model weights, caches, and intermediate data during inference. It matters for AI because every query requires memory to hold the model, process tokens, and store the key-value cache. With DRAM costs up 7x in the last year, memory has become a critical cost component alongside GPUs.
How does prompt caching reduce inference costs?
Prompt caching stores the processed activations from your initial prompt, so subsequent queries can reuse that cached data instead of reprocessing the same tokens. For repeated queries about the same document or context, this can reduce costs by 80-90% because cached tokens incur minimal compute or memory overhead. Services like Anthropic's Claude offer tiered pricing for different cache windows (5 minutes to 1 hour) based on how long you want data retained.
What is the difference between HBM and DRAM for AI workloads?
HBM (High-Bandwidth Memory) offers 15x higher bandwidth than DRAM but is limited in capacity (typically 24-80GB per GPU) and costs 5-10x more per gigabyte. DRAM is slower but available in much larger quantities and is significantly cheaper. For training, HBM's bandwidth advantage is critical. For inference, DRAM often makes more economic sense if you're clever about cache management, though the choice depends entirely on your specific workload patterns.
How can token efficiency improve AI infrastructure economics?
Every token processed requires memory for KV cache and compute resources. By reducing the number of tokens needed—through prompt compression, retrieval-augmented generation, or structured outputs—you proportionally reduce memory requirements and inference costs. A company that can do the same work with half the tokens runs at half the cost, creating significant competitive advantage in unit economics.
What is memory orchestration and why do companies need it?
Memory orchestration is the practice of intelligently managing where data lives in a system hierarchy (HBM, DRAM, NVMe) and how it moves between them. As companies run distributed inference across multiple GPUs and servers, they need systems that decide which cache to keep warm, what to evict when memory fills up, and how to route queries to servers with the best cache locality. Without orchestration, you're making expensive memory movement decisions reactively instead of proactively.
Can quantization significantly reduce memory requirements without hurting model quality?
Yes. Quantizing a 70B parameter model from 32-bit to 8-bit reduces memory usage by 4x with minimal quality loss, while 4-bit quantization achieves 8x reduction with slightly more accuracy degradation. Modern quantization techniques like GPTQ and AWQ are mature enough that they're being used in production systems. For many applications, the quality loss is imperceptible while the memory savings are transformative.
What happens when you run out of memory during inference?
When memory is exhausted, systems typically spill to slower storage (NVMe or network storage), which causes dramatic latency increases. A query that should complete in 100ms might take 5+ seconds. Alternatively, the system might reject the request or offload it to another server. This is why proper memory management and prediction of future memory needs is critical for maintaining reliable inference performance.
How do cloud AI providers price based on memory constraints?
Providers like Anthropic build memory constraints into their pricing directly: new input tokens cost more than cached tokens (which don't require new memory), and output tokens cost the most because they grow the KV cache. Some providers offer volume discounts that explicitly correlate to guaranteed memory provisioning patterns. Understanding these pricing structures and designing applications around them can reduce costs by 2-5x.

Quick Navigation for Optimization Strategies
For those looking to immediately improve memory efficiency:
- Prompt Caching for reducing repeated query costs by 80-90%
- Token Efficiency for architectural redesigns that need fewer tokens
- Quantization for quick wins in memory reduction
- Model Swarms for distributing workloads across smaller models
- Data Center Architecture for infrastructure-level optimization
Related Articles
- SurrealDB 3.0: One Database to Replace Your Entire RAG Stack [2025]
- Adani's $100B AI Data Center Bet: India's Infrastructure Play [2025]
- PlayStation 6 Release Delayed, Switch 2 Pricing Hike: AI Memory Crisis [2025]
- India AI Impact Summit 2025: Key News, Investments, and Industry Shifts [2025]
- OpenAI Hires OpenClaw Developer Peter Steinberger: The Future of Personal AI Agents [2025]
- Blackstone's $1.2B Bet on Neysa: India's AI Infrastructure Revolution [2025]

