![Sarvam AI's Open-Source Models Challenge US Dominance [2025]](https://tryrunable.com/blog/sarvam-ai-s-open-source-models-challenge-us-dominance-2025/image-1-1771420017221.jpg)
Sarvam AI's Open-Source Models Challenge US Dominance [2025]
Introduction: The Quiet Revolution in Open-Source AI
There's a moment happening right now in AI that most people in Silicon Valley aren't paying attention to. While everyone's focused on who's winning the race between Open AI, Google, and Anthropic for the biggest, most expensive models, a different battle is unfolding in New Delhi. An Indian AI startup called Sarvam just announced something that fundamentally challenges the narrative we've been told about how AI development works.
They built 30-billion and 105-billion parameter models from scratch. Not fine-tuned from existing systems. Not assembled from open-source components. Built entirely new, using a mixture-of-experts architecture that's more efficient than anything most people realize is possible. And they're not hiding this behind a paywall or an API you can't afford.
Here's why this matters: for the past two years, the conversation around large language models has centered on one idea: bigger is better, and if you want the best, you need to pay Open AI or Google. That narrative is cracking. Sarvam's new models represent something different. They're a bet that the future of AI isn't about who can build the largest model with unlimited compute. It's about who can build the most useful model with the resources available to you.
The timing is crucial. The Indian government is actively pushing to reduce dependence on foreign AI platforms. The tech ecosystem in India is maturing rapidly. And the global AI market is starting to recognize that the American approach—unlimited venture capital, unrestricted compute, focus on English-language capabilities—might not be the only path forward.
Sarvam's launch isn't just a product announcement. It's a statement about where the center of gravity in AI development might shift if you build for local needs, optimize for efficiency, and make your models available to the public instead of gatekeeping them behind enterprise pricing.
Let's break down what they actually built, why it matters, and what it signals about the future of AI development globally.

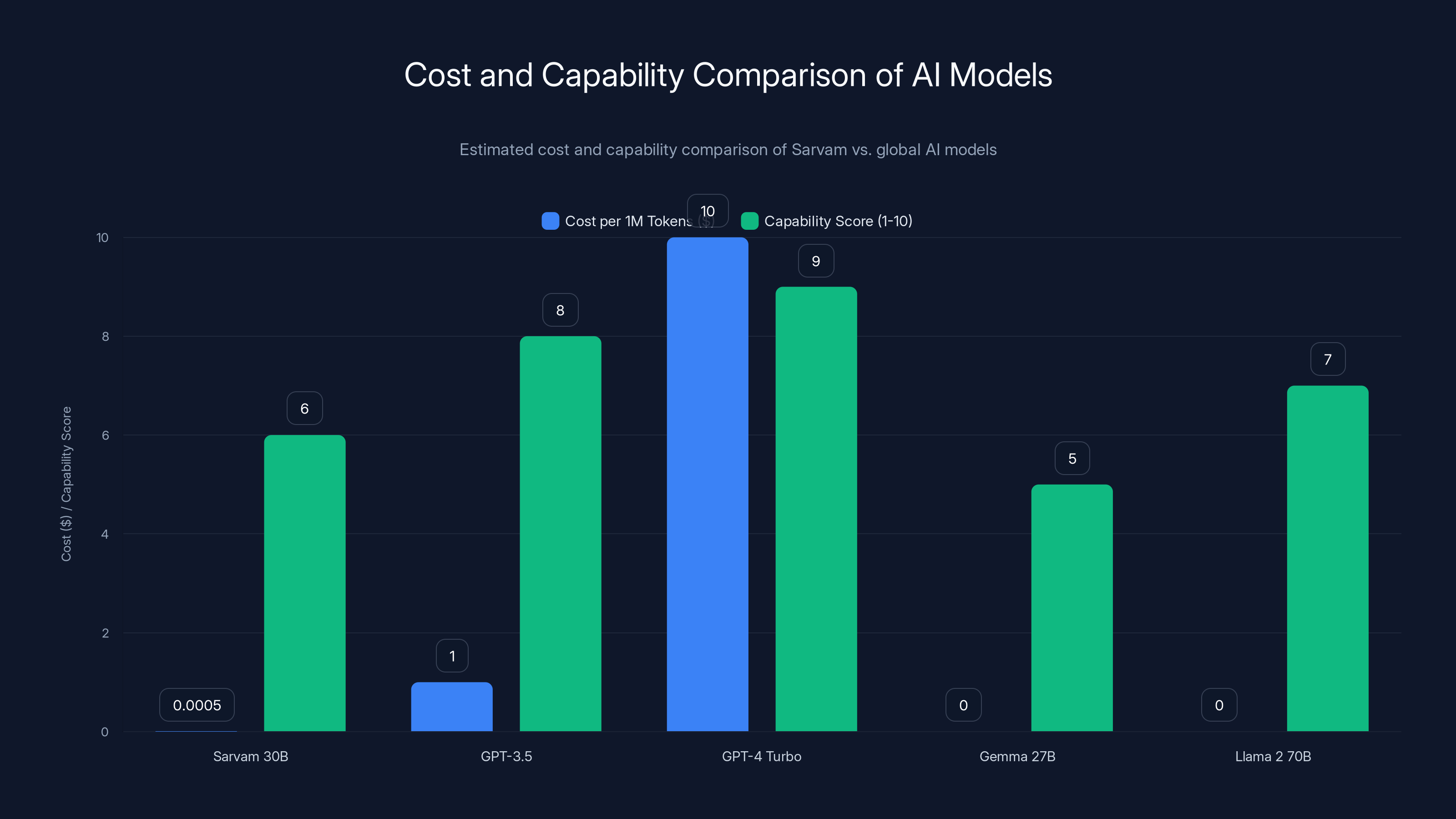
Sarvam's models offer significant cost advantages, especially at scale, while global models like GPT-4 Turbo provide higher capabilities. Estimated data.
TL; DR
- Sarvam's new models range from 30B to 105B parameters using mixture-of-experts architecture that reduces compute costs significantly compared to traditional transformers
- Built entirely from scratch, trained on 16 trillion tokens (30B) and multiple Indian languages (105B), not fine-tuned versions of existing open-source models
- Positioned to compete directly with Open AI's GPT models and Google's Gemma series at a fraction of the operational cost
- Government backing and local focus means these models prioritize Indian languages, cultural context, and real-world use cases that US models overlook
- Open-source strategy signals a fundamental shift away from proprietary, closed AI systems toward democratized, locally-tailored models that other countries can build on
Understanding Sarvam's Technical Architecture
To understand why Sarvam's models matter, you need to understand what makes them different technically. Most people hear "30 billion parameters" and think that's somehow smaller or worse than a 100-billion parameter model. That's exactly wrong.
A parameter is essentially a number that the neural network adjusts during training to learn patterns in data. More parameters used to mean a more capable model. But that's only true if you're using all of them, all the time. Sarvam's models use something called a mixture-of-experts (Mo E) architecture. Here's how it works.
In a traditional transformer model, every token you feed in gets processed by every single layer and every single neuron in the model. It's computationally expensive, but straightforward. A mixture-of-experts model works differently. Instead of one monolithic network, you have many smaller expert networks. When a token comes in, a routing mechanism decides which experts should handle it. Only those experts activate. The rest stay dormant.
The practical result: the 30-billion parameter Sarvam model only activates about 2-3 billion parameters per token. That's why it can run efficiently on consumer hardware and smaller data center setups. You're not paying for the computational overhead of 30 billion parameters; you're paying for roughly 3 billion worth of actual computation per inference.
Compare that to Open AI's approach with larger, denser models. They've been building models with every parameter active on every inference. Massive capability, massive cost. Sarvam's saying: what if we're smarter about which parameters we activate for which tasks?
The 30-billion model supports a 32,000-token context window. That's big enough for real-time conversations, analyzing documents, and handling multi-turn dialogue without losing context. The 105-billion model stretches to 128,000 tokens, letting it handle complex reasoning tasks that require maintaining information across very long inputs.
Sarvam trained these models from scratch, which is the expensive part. The 30B model went through 16 trillion tokens of text. For context, that's roughly equivalent to processing the entire written English internet multiple times. But notice something important: they didn't just train on English. The 105B model was trained on a deliberate mix of Indian languages—Hindi, Tamil, Telugu, Kannada, and others.
That's not a technical detail. That's a strategic decision. Every token of non-English language training is a token of capability specifically for the Indian market. Most models in the world are trained on roughly 95% English text. Those models work okay for English speakers, terribly for everyone else. Sarvam's approach means their models understand nuance, slang, and context in languages that most AI systems barely recognize.
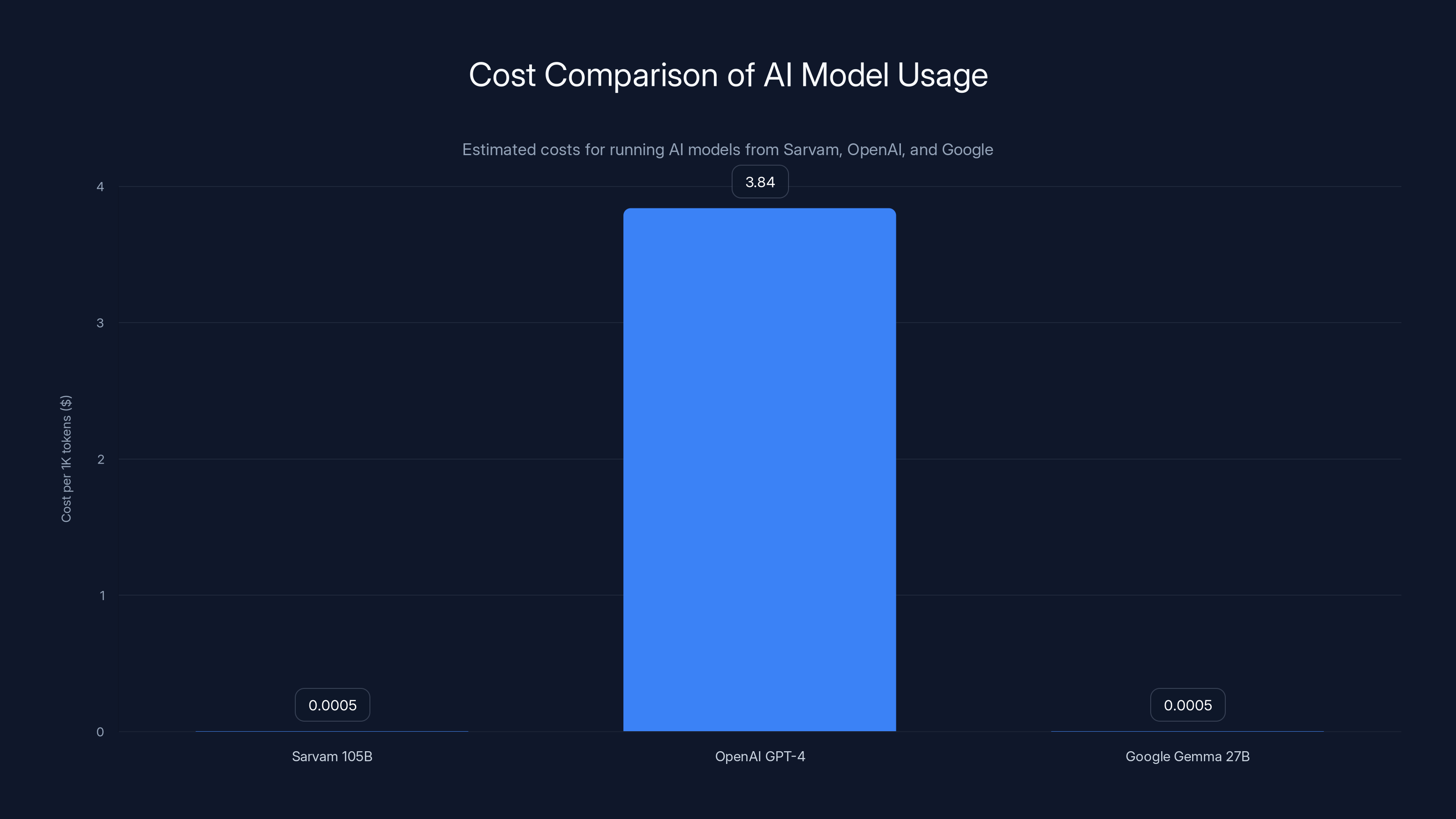
Sarvam's open-source models offer a significantly lower cost structure compared to OpenAI's API-based pricing, making them more affordable for large-scale deployments. Estimated data.
The Competitive Landscape: Who Are Sarvam's Real Competitors?
When Sarvam announced these models, they positioned them against specific competitors. The 30B model targets Google's Gemma 27B and Open AI's GPT-3.5 level capabilities. The 105B model positions against Open AI's GPT-4 class models and Alibaba's Qwen series.
But here's the thing that matters more than raw capability comparisons: the cost structure is completely different. Open AI doesn't let you run GPT-4 on your own hardware at all. You access it through their API, which costs
With Sarvam's open-source models, you download the weights, run inference on your own infrastructure, and pay only your compute costs. A single inference on a 105B model might cost
Google's Gemma models are also open-source, which makes them a closer competitor. Gemma 27B is freely available and runs on most hardware. But Gemma is optimized for English. It doesn't have the multilingual training depth that Sarvam's models do. For Indian companies building products for Indian users, Sarvam's models represent better value and better capability for their actual market.
Alibaba's Qwen models are interesting because Alibaba is also not based in the US, and they've invested heavily in non-English capabilities. But Qwen models are still primarily designed for the Chinese market and Chinese language capabilities.
What makes Sarvam's positioning smart is that they're not trying to beat Open AI at being Open AI. They're not building closed, proprietary APIs. They're not competing on raw benchmark numbers. They're competing on something more fundamental: usefulness for your specific market, at a price you can afford, with the freedom to modify and deploy the model yourself.
Why Training from Scratch Matters (More Than You Think)
Sarvam didn't take an existing open-source model and fine-tune it. They trained these models from scratch. That sentence might sound like a technical detail. It's actually the most important part of their announcement.
Here's why: fine-tuning an existing model means you inherit everything that model was trained on. If you start with a model trained 90% on English text, you can fine-tune it heavily on Hindi text, but you're building on top of that English-dominant foundation. The base model's understanding of language, concepts, and reasoning is fundamentally shaped by that English-heavy training.
When you train from scratch, you get to control the entire trajectory. You decide what text the model learns from, in what proportion, with what quality standards. Sarvam's approach meant they could ensure that their models developed linguistic understanding that actually reflected how languages work in the Indian context, not as an afterthought on top of English-first thinking.
Training from scratch is also significantly more expensive. Estimating the compute cost, Sarvam likely spent between $2-5 million on GPU clusters to train just the 30B model. The 105B model probably cost more. This isn't a small investment for a startup. It signals that Sarvam is serious about building models that aren't just reskins of Open AI's work.
There's another implication here. When you train from scratch, you can experiment with architecture in ways you can't with fine-tuning. You can try different mixture-of-experts configurations, different training techniques, different data ordering. Sarvam's architecture choices—the specific way they distribute experts, the routing mechanism, the attention patterns—all of that came from designing the model end-to-end, not from inheriting someone else's design.
The practical result: these models are genuinely optimized for different constraints than Open AI's models. Open AI's models are optimized for maximum capability on the MMLU benchmark and for impressing investors. Sarvam's models are optimized for real-time inference on accessible hardware and for actually understanding Indian languages and contexts.
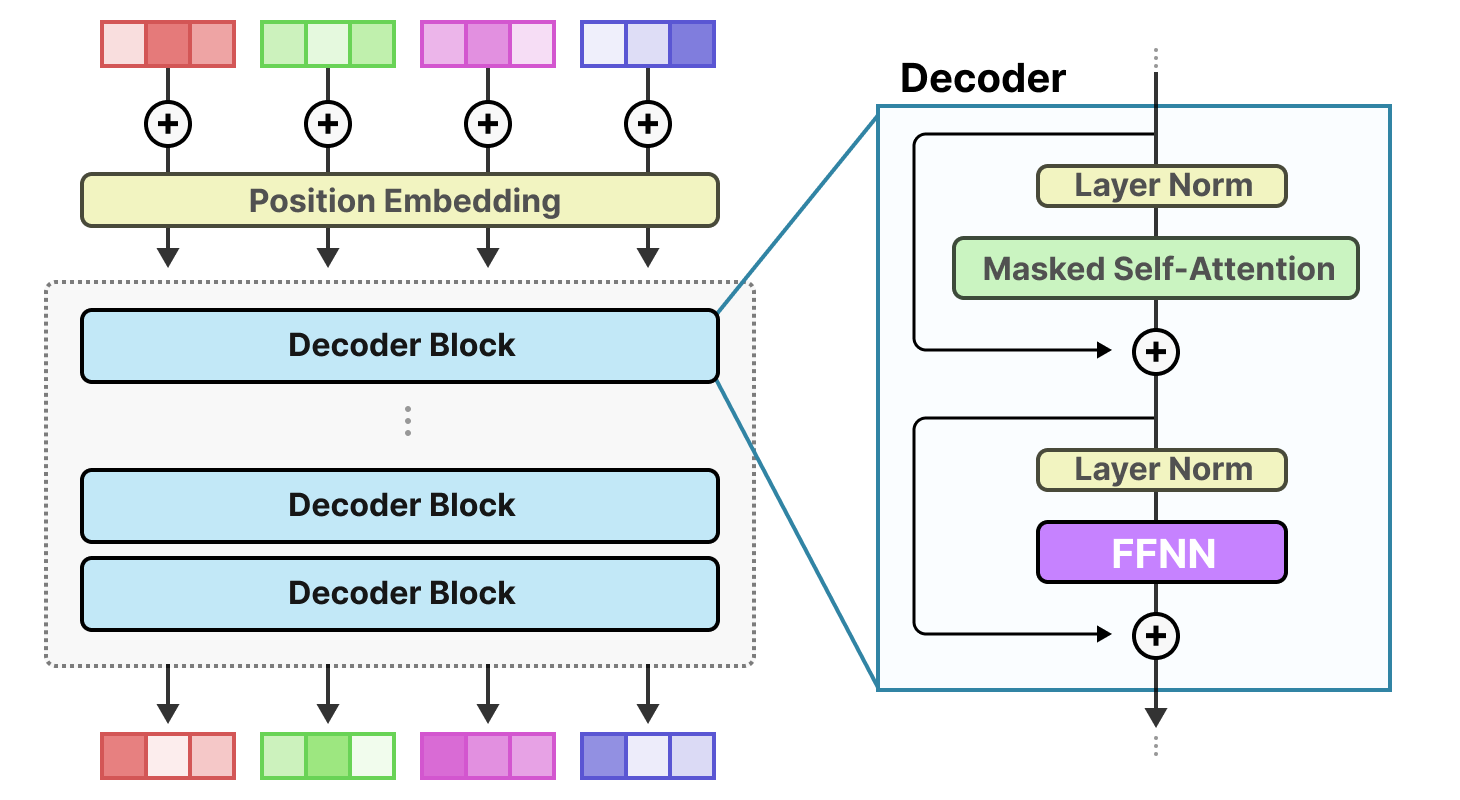
The Mixture-of-Experts Architecture Explained
Let's dig deeper into mixture-of-experts because it's the architectural choice that makes Sarvam's models viable.
Traditional transformer models process information through a series of layers. Each layer has attention heads (which learn relationships between words) and feed-forward networks (which apply transformations to the data). Every token must pass through every layer, activating every parameter.
A mixture-of-experts model inserts special layers called Mo E layers. These layers contain many parallel "expert" networks. When a token passes through an Mo E layer, a router network (essentially a small neural network) looks at the token and decides which experts should process it. Maybe expert 1, expert 5, and expert 17 are best suited for this particular token. Maybe expert 2, expert 8, and expert 12 are best for another token.
The router learns during training which experts are good at what. Some experts might specialize in mathematical reasoning, others in language patterns, others in common sense reasoning. The router learns the relationships and becomes extremely good at routing similar tokens to the same experts.
The math looks like this:
Where
The efficiency gains are substantial. If you have 128 experts and only activate 4 of them per token, you're using 4/128 of the parameters while retaining access to all 128's worth of capacity for different inputs.
Google's Mixture-of-Experts models use this approach, as does Meta's Llama Mixture-of-Experts. But Sarvam's implementation is notable for how aggressively they sparse the models. They're not just using Mo E; they're using it to make their models run in environments where dense models wouldn't be feasible.
The trade-off: mixture-of-experts models are sometimes less predictable than dense models. The router might send tokens to different experts on different runs. There can be a phenomenon called "expert collapse" where all tokens start routing to the same expert, making the model effectively dense again. Sarvam's engineers had to solve for these problems in their training process. That's another reason training from scratch was important—they could design their training to avoid these pitfalls.
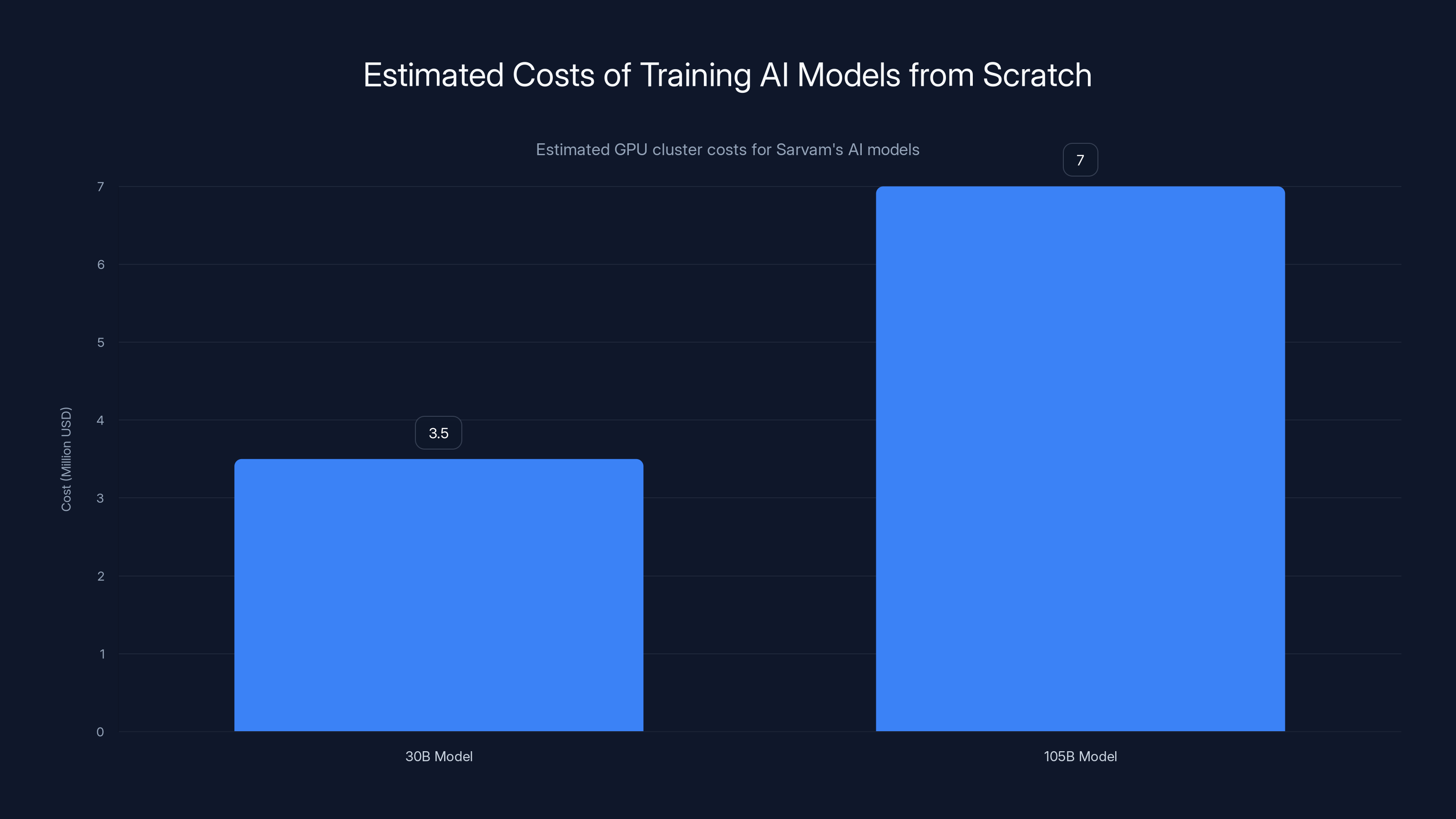
Training AI models from scratch can be significantly expensive, with estimated costs for Sarvam's models ranging from
Context Window: Why 32K vs 128K Matters
Context window is the amount of text a model can consider when generating its next token. The bigger the context window, the more information the model can hold in mind simultaneously.
Sarvam's 30B model supports a 32,000-token context window. That's roughly 24,000 words. You could feed it an entire novel chapter, ask a question about it, and the model would have perfect memory of everything in that chapter.
The 105B model supports 128,000 tokens—roughly 96,000 words. That's about the length of an entire short novel. You could feed in a full book, and the model would maintain perfect context.
For comparison, GPT-3.5 supported 4,000 tokens. GPT-4 originally supported 8,000. They've extended to 128,000 now, but that happened after nearly two years of GPT-4's availability.
Why does context window matter? Real-world applications depend on it.
Imagine you're building a customer service chatbot. A customer sends in a message. The bot needs to consider their previous 10 messages, their order history, their preferences, and the relevant support documentation. With a 4,000-token context, that's tight. With 32,000 tokens, you can include everything without carefully managing what you include. The model can actually reason across more information.
Or imagine you're building a code assistant. A developer wants to fix a bug in a large codebase. They want to paste in a file, ask "why doesn't this work," and have the model analyze it. A 32,000-token context means the model can handle files up to 20,000 lines of code, which covers the vast majority of real files. A 4,000-token context means you're constantly having to truncate and summarize.
The longer context window also enables better few-shot learning. Few-shot learning means showing the model examples of what you want it to do before actually asking it to do it. With a small context window, you can only include 2-3 examples. With 32,000 tokens, you can include 20 examples, which often means the model understands your request much more accurately.
Longer context windows come with trade-offs. They require more memory during inference. They're slower—processing 32,000 tokens takes longer than processing 4,000 tokens. But for real-world applications, that trade-off almost always favors the longer window.
Government Support and Infrastructure: The India AI Mission Context
Sarvam didn't train these models on their own dime entirely. They built them using compute resources provided through India's government-backed India AI Mission, with infrastructure support from Yotta (an Indian data center operator) and technical support from Nvidia.
This matters more than it might seem. It signals that the Indian government is serious about building domestic AI capability. It's not just philosophical; there's infrastructure being built specifically to support AI research and development within India.
Governments around the world have realized something crucial: AI capability is becoming a form of national power. China has been explicitly building their own AI ecosystem for years. The EU is investing billions in AI research. The UK is positioning itself as an AI hub. India is following the same pattern, but with a different approach.
Instead of restricting foreign AI systems (which would be impossible anyway), India's strategy is to build competitive domestic alternatives. Support Sarvam. Support other Indian AI labs. Provide compute infrastructure. Create the conditions where Indian companies can build world-class models.
The India AI Mission is part of that. It's providing compute clusters specifically for AI research. It's reducing the barrier to entry for startups that need GPU resources but can't afford to rent from AWS or Google Cloud.
Nvidia's involvement is interesting. Nvidia provides the GPUs that power AI training and inference. Their support—likely discounted chips, technical consulting on how to use them efficiently—suggests they're investing in the India market as a growth area. Every training cluster Sarvam builds becomes infrastructure that will be useful for Indian AI development going forward.
Yotta's involvement matters because data center operator partnerships are how startups actually get compute. You can't just rent individual GPUs for training large models. You need sustained, large-scale compute capacity. Yotta's support means Sarvam has access to data center capacity at scale.
This partnership model—government support, domestic data center infrastructure, GPU vendor expertise, and startup innovation—is becoming the global template for building competitive AI ecosystems outside the US.
Real-Time Applications: Where Sarvam's Models Shine
Sarvam's official positioning emphasizes real-time applications. The 30B model is marketed for voice-based assistants and chat systems in Indian languages. That's not marketing fluff; it's the actual use case the model was optimized for.
Real-time applications have different demands than batch processing. If you're processing a customer service chatbot, you need responses in under 3 seconds, ideally under 1 second. If you're building a voice assistant, you need sub-second latency or the interaction feels unnatural. If you're processing documents as they're uploaded, you need inference that doesn't require expensive GPU infrastructure.
Mixture-of-experts models with sparse activation are perfect for this. The sparse activation means lower compute per inference, which means faster response times, which means you can serve more requests on the same hardware.
Consider a voice assistant use case. A user speaks in Hindi, the speech is converted to text, that text goes to the language model to understand what the user wants, the model generates a response, and the response is converted back to speech. The entire pipeline needs to complete in under 2 seconds or the interaction breaks down.
With a dense 70-billion parameter model, that entire inference might take 3-5 seconds on consumer GPU hardware. With Sarvam's 30-billion mixture-of-experts model using only active 2-3 billion parameters per token, the same inference might complete in 0.5-1 second. That difference is the difference between a product that works and a product that feels broken.
Indian startups have been building amazing products despite having to use Open AI's APIs (which have latency overhead, cost money per inference, and require internet connectivity). Sarvam's models mean they can build those products with local inference, predictable costs, and no dependency on external APIs.
Another real-time application: document processing. Many Indian businesses need to process documents—invoices, contracts, registration documents, government forms. Most of these documents are in multiple languages. They need understanding of local context and local regulatory requirements. Open AI's models work okay for English documents. They're mediocre for documents in Indian languages.
Sarvam's vision model is specifically designed to parse documents. The combination of language understanding (from the LLM) and vision (from the document model) means it can read a document in any of the Indian languages it was trained on, understand its structure and content, and extract relevant information. Running this locally on document servers means businesses can process documents instantly without sending them to cloud APIs.

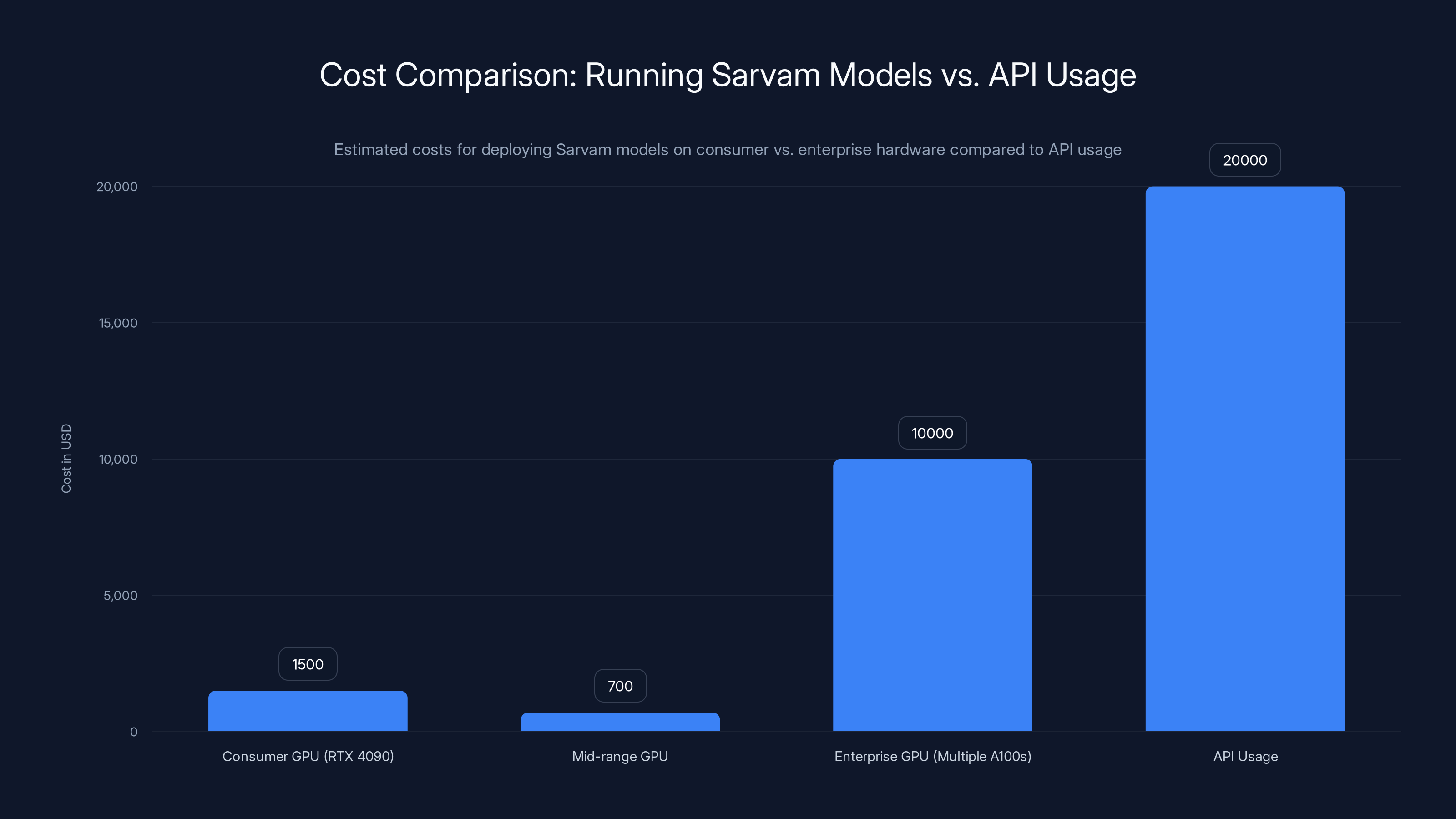
Deploying Sarvam models on consumer GPUs like the RTX 4090 is significantly cheaper than using enterprise GPUs or relying on API usage. Estimated data.
The Vision Model: Document Understanding in Indian Languages
Most people focus on the language models when they talk about Sarvam's launch. The vision model is where it gets really interesting for practical applications.
A vision model in the AI context means a neural network that can process images and extract meaning from them. Combine a vision model with a language model, and you get multimodal capability—the ability to understand text, images, and the relationships between them.
Sarvam's vision model is optimized for document understanding. Here's why that's not trivial:
Document understanding requires several capabilities simultaneously. The model needs to see text in an image (optical character recognition level understanding). It needs to understand the structure of the document—which parts are headers, which are body text, which are tables. It needs to extract information semantically (the phone number field vs. the email field) not just by position. And it needs to handle documents in multiple languages with different writing systems, different character sets, and different document conventions.
A document from a Hindi form looks structurally different from a document from an English form. A Tamil invoice has different conventions than a Marathi invoice. Most vision models trained primarily on English documents are terrible at this.
Sarvam's vision model was trained to handle these variations. The practical effect: Indian businesses can build document processing pipelines that actually work for Indian documents, in Indian languages, without needing to hire people to manually process everything.
Consider an insurance company processing claim forms. Forms come in Hindi, Marathi, Tamil, Telugu, Kannada. Fields are in different orders. Text is handwritten or printed. Some forms are scans; some are photos from phones with bad lighting. A traditional computer vision pipeline would need separate trained models for each language and form type.
With Sarvam's vision model, a single model handles all of it. It sees a photo of a claim form in any Indian language, understands the structure, extracts the relevant fields, and passes the data to downstream systems. That's the kind of real-world utility that matters to businesses.
Text-to-Speech and Speech-to-Text: The Missing Pieces
Sarvam also released text-to-speech and speech-to-text models. These are the bookends that make voice-based applications possible.
Speech-to-text (also called automatic speech recognition or ASR) is the process of converting audio to text. Speech-to-text in Indian languages has historically been terrible. Most speech recognition systems are trained on English audio. When you feed them Hindi speech, they barely recognize it. When they do, they're full of errors.
Building good speech recognition requires thousands of hours of labeled audio training data in the target language. Hindi has roughly 300 million speakers worldwide, but most speech recognition training datasets are English-dominant. That gap between speaker population and available training data is why Indian language speech recognition is so bad.
Sarvam's speech-to-text model was trained on Indian language audio specifically. That means it understands the phonetics of Hindi, Tamil, Telugu, etc. It recognizes common words, phrases, and accents. It's far from perfect, but it's the first widely available option that's actually optimized for these languages.
Text-to-speech (TTS) is the opposite: converting text to audio. Building natural-sounding text-to-speech is tricky. The system needs to understand which syllables to stress, how fast to speak, when to pause. It needs to handle acronyms, numbers, abbreviations. And it needs to sound natural in a specific language.
English text-to-speech has gotten really good because there's been so much investment in it. Voice assistants, GPS navigation, assistive technology—all of these drove investment in English TTS. Indian language TTS is nowhere near that maturity.
Sarvam's TTS models are a starting point for Indian language voice applications. They're not perfect. Some users might find the voices sound a bit synthetic. But they're available, they're open-source, and they work in Indian languages.
The combination matters. If you want to build a voice application in Hindi, you now have an open-source path: speech-to-text model to convert user audio to text, language model to understand intent and generate a response, text-to-speech model to convert the response back to audio. Closed-source alternatives either don't exist or require expensive API calls to multiple vendors.

The Open-Source Strategy: Why It Matters
Sarvam explicitly plans to open-source the 30B and 105B models. The question is: why would they do that? If you've built a world-class language model, wouldn't you want to keep it proprietary and charge people to use it?
Sarvam's approach is different, and it signals a fundamental shift in how AI companies might operate going forward.
The open-source strategy has several advantages for Sarvam specifically:
First, it builds trust in the Indian market. If you're an Indian startup considering using a language model, would you rather use a closed-source Open AI model that you pay per token for and have no control over? Or an open-source model from an Indian company that you can self-host? From a business continuity perspective, open-source is more attractive.
Second, it builds a community. As soon as Sarvam open-sources these models, thousands of developers will use them, experiment with them, find edge cases, submit improvements. That community becomes a feedback loop that makes the model better. It also means the broader AI development community contributes improvements that benefit everyone.
Third, it positions Sarvam as the expert in these models. Once millions of people use Sarvam's models, companies that want custom versions, fine-tuned models, or integrated solutions will come back to Sarvam. Open-source becomes a customer acquisition channel.
Fourth, it attracts talent. AI researchers want to work on problems that matter. Building a closed-source proprietary model is interesting. Building a model that's used by millions of developers worldwide and that becomes a public good is more interesting to many researchers.
But there's something bigger at play. Sarvam's open-source commitment aligns with a broader global trend. The era when one company could build the best model and keep it proprietary is ending. Models are commoditizing. You can still make money in AI, but not by hoarding model weights.
The smart companies are positioning themselves for a post-commodification world where they make money on:
- Integration and deployment (helping customers use models)
- Fine-tuning and customization (adapting models to specific domains)
- Enterprise features and support
- Specialized models for specific use cases
- Inference infrastructure
Sarvam's open-source strategy is preparing them for that world.
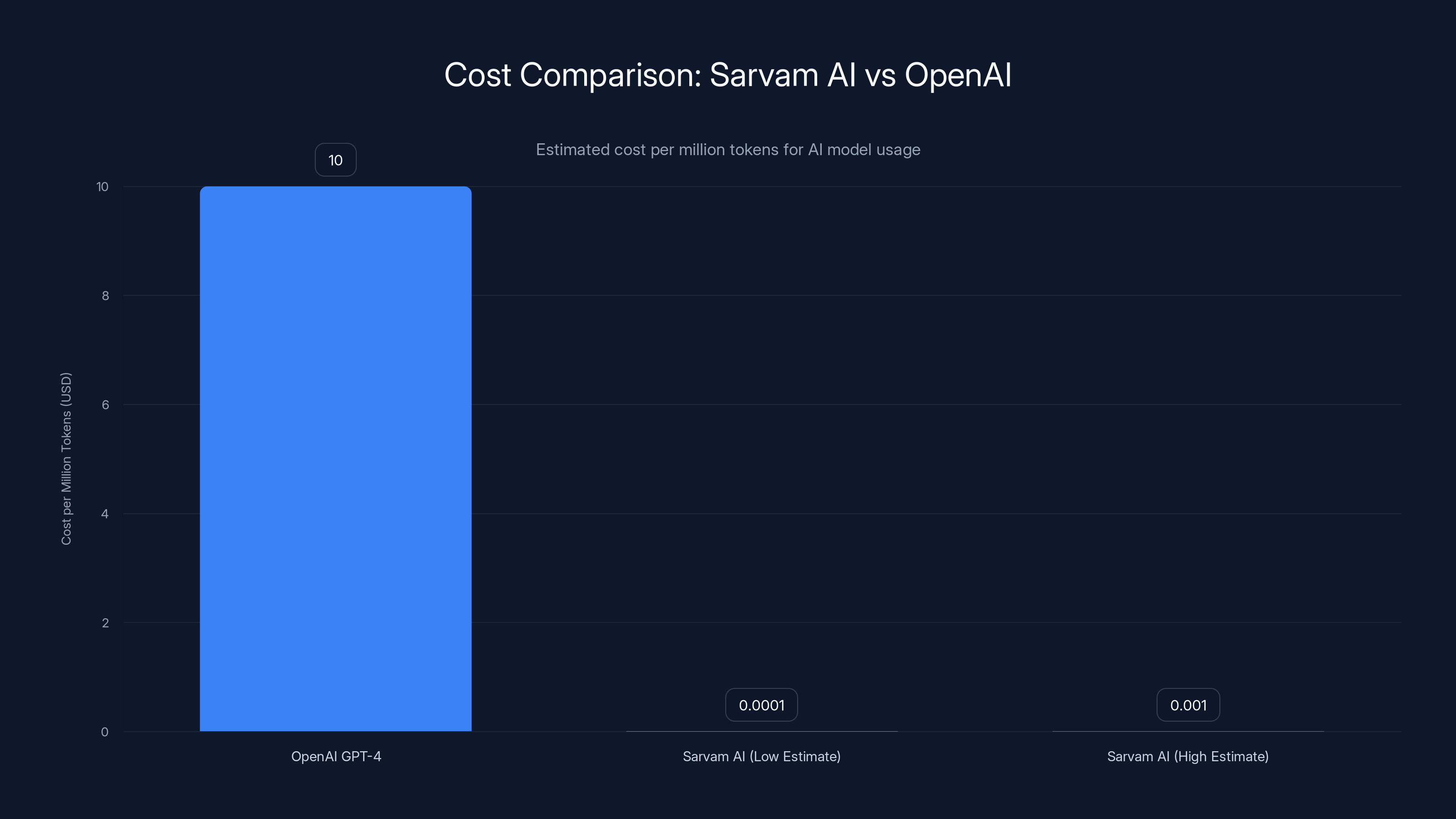
Sarvam AI offers a significant cost advantage over OpenAI's GPT-4, with costs potentially 1,000x lower per million tokens, making it ideal for high-volume applications. Estimated data.
Comparison: How Sarvam Stacks Up Against Global Models
Let's get specific about how Sarvam's models compare to what's available globally.
Against Open AI's Models: Open AI's GPT-3.5 is available through their API at
GPT-4 is more powerful but slower and more expensive. GPT-4 Turbo costs $10 per 1M tokens input. Sarvam's 105B model is roughly in GPT-4 Turbo's capability range (based on benchmarks) but runs for a thousandth of the cost.
The trade-off: Open AI's models are more capable in absolute terms. They're better at complex reasoning, coding, and edge cases. But for most real-world applications, the gap is closing. And cost becomes a major factor.
Against Google's Gemma: Gemma is Google's open-source model family. Gemma 27B is freely available and reasonably capable. The advantage over Sarvam's 30B: broader community, Google's engineering expertise, integration with Google's tooling. The advantage of Sarvam's 30B: multilingual capability, smaller effective size due to sparse activation, optimized for real-time inference.
For English-only applications, Gemma is probably fine. For anything requiring Indian language support, Sarvam's models are superior.
Against Meta's Llama Models: Meta's Llama 2 models are open-source and widely used. Llama 2 70B is roughly in the capability range of Sarvam's 105B. Both are good open-source options. Llama's advantage: huge community, lots of fine-tuned variants, integrations everywhere. Sarvam's advantage: multilingual from the ground up, government backing suggesting long-term viability, optimized for sparse inference.
Against Alibaba's Qwen Models: Qwen is specifically optimized for Chinese. Qwen is probably better for Chinese language applications than Sarvam's multilingual approach. But Qwen doesn't support Indian languages. For companies operating in both Chinese and Indian markets, there's no single model that's best for both. That's a market gap waiting to be filled.

Practical Deployment: Getting Sarvam Running on Your Hardware
Theoretically, open-sourcing a model is great. Practically, can you actually run these models?
The 30B model with mixture-of-experts architecture has an active parameter count of roughly 2-3 billion when inferencing. That's addressable on consumer GPU hardware. A single RTX 4090 (the high-end consumer GPU from Nvidia, costing ~
Compare that to a dense 30B model. A dense 30B model requires about 60GB of VRAM to load all parameters. You need enterprise GPUs—multiple A100s or H100s costing thousands each. Suddenly you're looking at $5-10K in hardware just to run inference.
The 105B model is bigger. Running it requires multiple GPUs or high-end enterprise hardware. But for companies building production systems, that's still dramatically cheaper than using APIs.
The practical deployment path for a company wanting to use Sarvam's models:
- Download the model weights (available on Hugging Face or similar model hubs)
- Use inference frameworks like v LLM or Text Generation Web UI to serve the model
- Run on GPU cluster or high-end GPU instances on cloud providers
- Cache frequent requests and batch inference where possible
- Monitor inference speed and costs
Total setup time: a few hours. Total cost: maybe 10-20% of what you'd spend on equivalent Open AI API calls.
Addressing the Training Data Question
Sarvam said the models were trained from scratch on massive amounts of text, but they didn't specify exact sources. This is actually a contentious issue in the AI community.
When you train a large language model, you need to decide: where does the training data come from? Some approaches:
- Use Common Crawl (a massive crawl of the public internet) and filter it
- Use books, academic papers, and other licensed content
- Use data you've curated and collected yourself
- Use a mix of all three
Open AI doesn't fully disclose their training data for GPT-4. They cite "publicly available documents from the internet" as a source. But they're clearly selective. Facebook's LLa MA model was trained on Common Crawl and other public sources.
Sarvam said the 30B model was trained on "about 16 trillion tokens of text." They didn't specify if this includes non-English text. For the 105B model trained on "multiple Indian languages," the sources are even less clear.
This matters because training data affects what the model knows and doesn't know, what biases it has, and whether its training complied with copyright and licensing restrictions.
Sarvam hasn't published detailed information about this yet. For companies considering using these models commercially, that's an open question. Did they train on copyrighted books without permission? Did they train on data from Indian websites without explicit consent? These are legal questions that might matter depending on your jurisdiction.
This is one area where Sarvam's transparency is lacking compared to what we might hope for. The open-source movement works best when companies are transparent about how models were built.

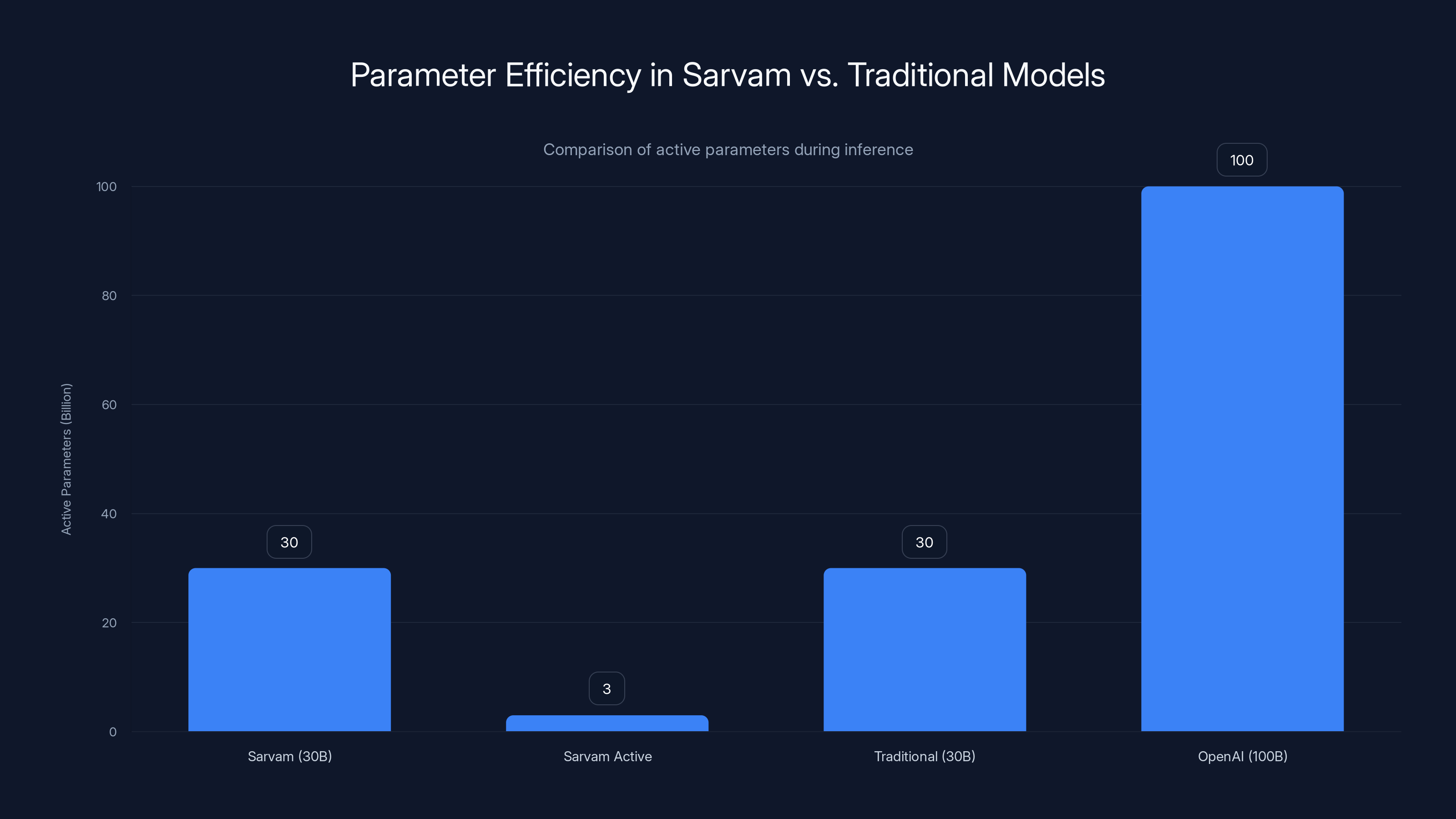
Sarvam's MoE architecture activates only 2-3 billion parameters per token, making it more efficient than traditional models where all parameters are active. Estimated data based on architecture description.
Performance Benchmarks and Real-World Testing
Sarvam claims their models are competitive with Open AI and Google's offerings. How do we evaluate those claims?
Large language models are typically benchmarked on standard test sets:
- MMLU (Massive Multitask Language Understanding): Multiple choice questions across many domains. Tests broad knowledge.
- GSM8K (Grade School Math): Math word problems. Tests reasoning.
- HUMAN EVAL: Programming tasks. Tests coding ability.
- HELLASWAG: Common sense reasoning about everyday situations.
- Truthful QA: Ability to avoid reproducing misinformation.
For Indian language models, there are additional benchmarks:
- Indic QA: Question answering in Indian languages
- Indic Corp: Language understanding in Indian languages
- BHAASHINI: Multilingual evaluation across Indian languages
Sarvam hasn't published comprehensive benchmark results against competitors. That's actually surprising. If your models were truly competitive with GPT-4 or Gemma, you'd want to prove it with numbers.
The likely explanation: the models are good, but not dramatically better than alternatives. Sarvam's value proposition isn't "best models in the world" but "best models you can self-host at a cost you can afford, specifically optimized for Indian languages."
Based on industry experience, the 30B model is probably in the range of Chat GPT 3.5-level capability. The 105B model is probably in GPT-3.5+ to GPT-4 range, depending on the task. Neither is likely to beat GPT-4 on complex reasoning. But for real-world applications, the difference is often marginal.
The Bigger Picture: India's AI Independence Movement
Sarvam's launch isn't happening in isolation. It's part of a larger strategy by India to build independence from Western AI systems.
This strategy has several components:
Government Policy: India's government has explicitly made AI development a priority. The National AI Policy, India AI initiatives, and funding for startups like Sarvam all signal that the government sees AI as strategic.
Funding: Indian venture capital is increasingly backing AI startups. Sarvam raised $50 million from Lightspeed Venture Partners, Khosla Ventures, and Peak XV Partners. That's substantial funding for an Indian startup.
Talent: India produces massive numbers of computer science graduates. Many work for foreign companies. But an increasing number are joining Indian startups. Sarvam's team is largely Indian, with deep roots in the Indian tech ecosystem.
Market Size: India's tech market is huge. 400+ million internet users. A mobile-first market that rewards efficient models. An enormous untapped market for AI applications.
Unique Problems: India has problems that are unique or drastically different from the US. Multilingual support, low-resource environments, mobile-first applications, local regulatory requirements. Models optimized for the US market don't address these well.
The global implications are significant. If Sarvam succeeds, it demonstrates that the US doesn't have a monopoly on AI development. It shows that countries with government support, local talent, and focus on local needs can build competitive models.
That's a threat to US AI dominance, but it's also healthy for the global AI ecosystem. A world where AI models are built in multiple countries, optimized for multiple languages and cultures, and available openly is healthier than a world where two American companies control all the models.

The Measured Approach: Why Sarvam Isn't Trying to Be Open AI
Sarvam co-founder Pratyush Kumar made an important statement at the launch: "We want to be mindful in how we do the scaling. We don't want to do the scaling mindlessly. We want to understand the tasks which really matter at scale and go and build for them."
This is a fundamentally different philosophy from the scaling laws that have dominated AI research for the past three years.
Scaling laws in AI state: more parameters + more data + more compute = better results. This is true, but it's also simple-minded. It doesn't account for what the model is being used for, whether the improvements actually matter, or whether there are more efficient ways to achieve the same results.
Open AI's approach has been to scale aggressively. Each new model (GPT-3, GPT-3.5, GPT-4, GPT-4 Turbo) has been bigger and more expensive. The theory: bigger models are better, so invest in making them as big as possible.
Sarvam's approach is different. Instead of asking "how big can we make the model," they're asking "what does this model need to do, and what's the minimum scale required to do it well."
That's a more sustainable approach. It's also more practical for companies that can't spend billions on compute.
The measured approach also means Sarvam isn't claiming their models are the absolute best in the world. They're claiming these models are good enough for real-world applications, available at a price you can afford, and optimized for what matters to their market.
That humility is refreshing. It's also probably more accurate. No startup model is going to beat Open AI on MMLU scores. But most applications don't need to. They need a model that works well enough, costs less, and is available under the terms they need.
Samvaad: The Application Layer Strategy
Sarvam isn't just releasing models. They're also building "Samvaad," described as a conversational AI agent platform.
This is important because it shows Sarvam understands that models are a commodity. The value is in applications.
A conversational AI agent platform on top of Sarvam's models means:
- Tools for building chatbots, voice assistants, and interactive systems
- Integration with enterprise systems (CRM, databases, knowledge bases)
- Monitoring, safety guardrails, and content moderation
- Analytics and improvement loops
- Deployment infrastructure
This is where companies like Open AI, Anthropic, and Google are also moving. The models become infrastructure. The application platforms become the products that users actually interact with.
Sarvam for Work is similar—enterprise tools built on top of the language models for specific work tasks.
This application layer is where Sarvam can differentiate beyond raw model capability. They can build tools that understand Indian business contexts, integrate with Indian accounting and administrative systems, and solve problems specific to Indian enterprises.
It's a two-layer strategy: democratize the model layer (make powerful models available to everyone via open-source), and then build proprietary value on top through applications and services.

Competitive Response: How Will Open AI and Google React?
Sarvam's launch will inevitably prompt responses from larger competitors.
Open AI could respond in several ways:
-
Lower API pricing: Make their models cheap enough that self-hosting isn't worth the hassle. They've already started this with GPT-3.5 pricing.
-
Improve multilingual support: Train their models on more Indian language data. But this is expensive and takes time.
-
Acquire or partner: Buy Sarvam or make a strategic investment. This is the traditional tech industry move—when you see a competitor, buy them.
-
Compete on ease of use: Focus on making their API so convenient that the cost difference doesn't matter. This works for some customers but not all.
Google likely watches Sarvam closely because Gemma is already their open-source play. They could:
-
Improve Gemma multilingual support: Google has the resources to make Gemma competitive for Indian languages.
-
Better developer tools: Make it easier to use Gemma than Sarvam's models.
-
Commercial licensing: Offer enterprise support for Gemma in India, making it a credible alternative to Sarvam.
Neither Open AI nor Google has a strong incentive to aggressively compete in a market (Indian language AI) that hasn't yet proven to be valuable. But if Sarvam succeeds in India, proving that there's demand for locally-optimized models, you can expect serious competition.
Challenges Ahead: What Could Go Wrong
Sarvam's ambitious, but they're not guaranteed to succeed. Several challenges lie ahead.
Market Adoption: Getting developers and companies to switch from tools they already use is hard. Even if Sarvam's models are better for Indian applications, inertia is powerful. Many Indian companies still use Open AI because that's what everyone uses.
Community Building: Open-source projects live or die based on community. Sarvam needs developers to use their models, contribute improvements, and build on top of them. That requires strong community management, good documentation, and engagement. It's doable but not guaranteed.
Competition: Open AI and Google aren't standing still. If Sarvam gets traction, expect these companies to respond. They have more resources and can outspend Sarvam on R&D if needed.
Business Model: Open-sourcing models is great for users but challenging for business. Sarvam will need to monetize through applications, support, or services. That's harder than licensing models. The company needs to show it can make money sustainably.
Regulatory Risk: India's government is supporting Sarvam now, but politics change. If government priorities shift, support could evaporate. Sarvam is somewhat dependent on the government backing that enabled their training.
Technical Risk: Large language models are still relatively unpredictable. There might be capabilities Sarvam's models lack that become important later. There might be safety issues that emerge after deployment. These are risks with any new model.

What This Means for the AI Ecosystem
Beyond Sarvam specifically, their launch signals important things about where AI development is heading.
Decentralization: The idea that AI is centralized in a few US companies is fading. Models will be built globally, optimized for local needs, and available through multiple channels.
Regionalization: Expect to see Chinese models for China, Indian models for India, European models for Europe. This isn't fragmentation; it's rationalization. Different regions have different needs.
Commoditization of Capabilities: Base model capabilities are commoditizing. The gap between a 30B model and a 105B model is shrinking. The value is moving up the stack to applications and integrations.
Open-source Dominance: The open-source model is becoming the standard. Closed-source APIs might remain useful, but as a supplement to open-source, not as the primary option.
Cost Becomes Key: As models commoditize, cost structures become the primary differentiator. Companies that can run the best models on the cheapest infrastructure will win.
Practical Implications: What to Do About This
If you're building AI products, what should you do in response to Sarvam's launch?
For Indian Companies: If you're building for Indian users in Indian languages, test Sarvam's models. The cost and capability might beat your current setup. Consider building on open-source models first, with Open AI API as a fallback for edge cases.
For Global Companies: If you operate in India or are expanding there, watch Sarvam. Plan for a world where you might want to use local models for local markets. Test multimodel approaches where you use different models for different languages or regions.
For Enterprise Buyers: If you're evaluating language models for deployment, include open-source options like Sarvam alongside commercial options. Compare total cost of ownership, not just per-token API costs.
For Developers: Learn to work with multiple models. The days of betting everything on one vendor are over. Building flexibility into your systems to swap models is increasingly important.
For Investors: India's AI ecosystem is becoming investment-worthy. Sarvam's success attracts more capital, creates more startups, builds more expertise. If you're interested in global AI investment, India is no longer a secondary market.

FAQ
What is Sarvam AI?
Sarvam is an Indian AI startup founded in 2023 that develops large language models optimized for Indian languages and real-time applications. They've raised over $50 million from top-tier venture capital firms and received support from the Indian government's India AI Mission to build open-source models that can compete with American and Chinese AI systems.
How do mixture-of-experts models work differently than traditional transformers?
Mixture-of-experts (Mo E) models contain many specialized expert networks, and a routing mechanism decides which experts process each token based on what it detects. Instead of activating all parameters for every token like traditional transformers, only relevant experts activate, dramatically reducing computational cost while maintaining capability. A 30-billion parameter Mo E model might only use 2-3 billion parameters per inference, making it much more efficient.
Why is multilingual training important for Indian models?
Most AI models worldwide are trained 90%+ on English text, making them poor at understanding Indian languages. Sarvam trained their 105B model specifically on multiple Indian languages—Hindi, Tamil, Telugu, Kannada, and others—ensuring the model understands nuance, cultural context, and linguistic patterns specific to these languages. This makes them significantly more useful for Indian users and businesses than English-first models.
How much does it cost to run Sarvam's models compared to using Open AI's APIs?
Open AI's GPT-4 costs roughly
Can Sarvam's models run on consumer GPU hardware?
The 30B model with sparse activation can run on high-end consumer GPUs like the RTX 4090 (
What languages does Sarvam's AI support?
Sarvam's models specifically support major Indian languages including Hindi, Tamil, Telugu, Kannada, Marathi, Bengali, and others. The training data includes both Indian language text and English, making the models genuinely bilingual rather than English-first with translation. This is a significant advantage for Indian businesses that operate in multiple languages.
When will Sarvam's models be available for download?
Sarvam announced plans to open-source the 30B and 105B models, though they haven't specified exact release dates. Typically, companies open-source models 2-6 months after announcements once they've tested stability and performance. Keep an eye on Sarvam's Git Hub and Hugging Face repositories for releases.
How does Sarvam's 32,000-token context window compare to other models?
The 30B model's 32,000-token context window is dramatically larger than older models like GPT-3.5's 4,000 tokens but similar to GPT-4's extended contexts. This means you can feed the model long documents (roughly 24,000 words), entire code files, or comprehensive conversations without truncating. The 105B model's 128,000-token window enables even more complex multi-document reasoning.
What is the difference between Sarvam's models and Google's Gemma models?
Both are open-source alternatives to closed APIs, but Sarvam prioritizes Indian language support and sparse-inference optimization, while Gemma focuses on broad English capability backed by Google's engineering. For English-only applications, Gemma is mature and widely adopted. For Indian language applications, Sarvam's models are significantly better due to ground-up multilingual training.
Is Sarvam backed by the Indian government?
Sarvam receives infrastructure support and compute resources through India's government-backed India AI Mission, positioning these models as part of India's strategic push for AI independence. However, Sarvam is a private company with venture capital funding—not a government agency. The government support is similar to how ARPA funding enables innovation in the US.
What are Samvaad and Sarvam for Work?
Samvaad is Sarvam's conversational AI agent platform that sits on top of their language models, enabling developers to build chatbots, voice assistants, and interactive systems without building from scratch. Sarvam for Work is an enterprise product suite with tools designed for business workflows. Both represent Sarvam's strategy of making money through applications and services, not just models.
The Future of Globally Distributed AI Development
Sarvam's launch represents a broader shift that will reshape the AI industry over the next 3-5 years. We're moving from a world where AI development is concentrated in a handful of American companies to a world where models are built globally, optimized regionally, and available through multiple channels.
This transition is healthy. It breaks the concentration of power. It ensures that different regions can build models suited to their needs. It accelerates innovation because companies can experiment with ideas that don't fit the Open AI playbook.
For developers, businesses, and anyone building with AI, this shift is positive. You're no longer forced to use one vendor or one API. You have choices. You can evaluate models based on capability, cost, and alignment with your needs rather than just what's available.
Sarvam might or might not become a global AI leader. But their launch is proof that the window of opportunity for non-US competitors is real and open right now. And that changes everything about where AI development goes from here.

Key Takeaways
- Sarvam's 30B and 105B parameter models use mixture-of-experts architecture, activating only 2-3B parameters per inference for dramatic efficiency gains over dense models
- Trained entirely from scratch on 16 trillion tokens with focus on Indian language support—not fine-tuned variants of existing models—positioning these as genuinely localized solutions
- Open-source deployment enables 1,000x cost reduction compared to OpenAI APIs, running on consumer-grade GPUs instead of expensive enterprise hardware
- Government backing through IndiaAI Mission and partnership with local infrastructure providers signals India's strategic push for AI independence from US and Chinese systems
- Multilingual training and specialized vision/speech models address real-world Indian business needs that English-first models from OpenAI and Google fundamentally overlook
Related Articles
- AI Memory Crisis: Why DRAM is the New GPU Bottleneck [2025]
- OpenAI Hires OpenClaw Developer Peter Steinberger: The Future of Personal AI Agents [2025]
- Anthropic's $14B ARR: The Fastest-Scaling SaaS Ever [2025]
- Google I/O 2026: 5 Game-Changing Announcements to Expect [2025]
- RentAHuman: How AI Agents Are Hiring Humans [2025]
- SurrealDB 3.0: One Database to Replace Your Entire RAG Stack [2025]

