![Arcee's Trinity Large: Open-Source AI Model Revolution [2025]](https://tryrunable.com/blog/arcee-s-trinity-large-open-source-ai-model-revolution-2025/image-1-1769801803417.jpg)
Introduction: The American Open-Source Counteroffensive
When you look at the large language model landscape right now, there's a story nobody's talking about loudly enough. Chinese AI labs are shipping models with stunning efficiency metrics. Meta quietly stepped back from the frontier. OpenAI controls the commercial conversation. But buried in this reality is something genuinely rare: a U.S.-based AI company just released a 400-billion parameter open-source model trained entirely domestically, and it's forcing us to rethink what "open" actually means.
Arcee's Trinity Large isn't just another model release. It's a philosophical statement about model transparency, computational efficiency, and what happens when you build under constraint instead of with unlimited resources. More importantly, it ships with something almost nobody else does: a raw checkpoint called True Base that shows you what a model actually learns before researchers polish it into a helpful assistant.
This matters because the AI world has been operating with a hidden assumption for years. We get the finished product. We see the helpful chatbot. We don't see what the model actually knows, the biases it picked up from raw data, or the decisions made during post-training that shaped its behavior. Arcee's approach cracks that open.
The technical achievement here is worth understanding in depth, not just as another news headline but as a genuine shift in how frontier AI development works. We're talking about extreme sparsity in mixture-of-experts architecture, novel training techniques to solve stability problems, and a $20 million training run that took 33 days instead of months. This is engineering under constraint, and it's producing results that should matter to anyone building with AI or trying to understand how these systems actually work.
Let's break down what's actually happening, why it matters, and what it means for the AI landscape moving forward.
The Context: Why This Release Matters Right Now
Timing matters in AI. It always does. Trinity Large arrives at a specific moment when the open-source landscape is shifting in ways that caught many observers off guard.
Meta, which dominated the open-source conversation for years with its Llama family, hit a credibility wall. After releasing Llama 4 in April 2025 to mixed reviews, it emerged that the company had been using multiple specialized versions of the model to inflate benchmark scores. Yann LeCun, Meta's chief AI scientist, even acknowledged this publicly. That kind of moment doesn't just hurt a company's reputation. It creates a vacuum. Enterprises and developers who want open-source models but also want to trust the numbers suddenly have fewer places to look.
Meanwhile, Chinese alternatives have flooded the market with surprising competence. Alibaba's Qwen, Zhipu's z. AI, Deep Seek, Moonshot, and Baidu aren't just shipping models. They're shipping them with architectural innovations that prioritize efficiency. These aren't slow, bloated systems. They're lean, mean models that work well on consumer hardware. For developers operating on tight budgets, that efficiency matters more than raw parameter count.
Into this context, OpenAI released its gpt-oss family in summer 2025, signaling that even the most commercially successful AI company recognizes the long-term value of open contributions. But OpenAI's focus remains on its commercial products. The company isn't betting the company on open source.
Arcee, by contrast, is. The San Francisco lab has made open-source models central to its identity since founding. Trinity Large represents the culmination of that commitment: a model trained entirely from scratch domestically, released publicly, with actual innovation in how the model works internally.

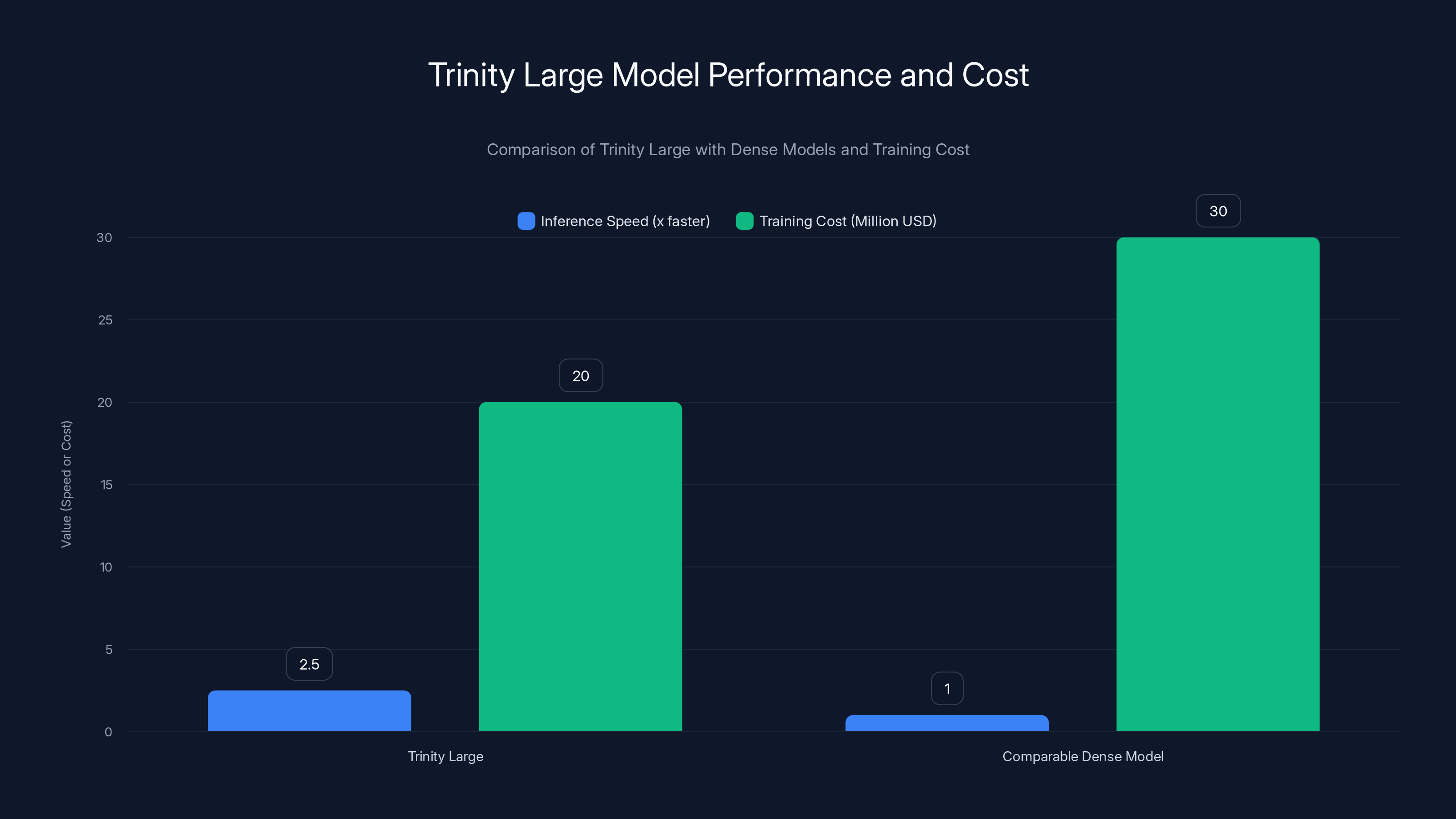
Trinity Large achieves 2-3x faster inference speeds than dense models while maintaining similar quality, and it was trained at a cost of $20 million, which is lower than typical dense model training costs. Estimated data for dense model cost.
What Trinity Large Actually Is: Architecture and Scale
Here's where the technical details matter because they explain why people in the field are paying attention.
Trinity Large is a 400-billion parameter model. That's the total parameter count. But here's the critical part: it's a mixture-of-experts (MoE) architecture with extreme sparsity. At any given moment, only 1.56% of those parameters are active. We're talking about 13 billion active parameters per inference.
This is fundamental to understanding why Trinity Large performs the way it does. You don't need to activate a massive system to get massive system performance. By routing each token through only the relevant experts, the model maintains knowledge equivalent to a 400B system while maintaining the inference speed of something dramatically smaller.
The practical result: Trinity Large runs approximately 2-3x faster than comparable models on the same hardware. That's not a minor optimization. That's the difference between a model you can run on a single GPU and a model that needs specialized infrastructure.
The architecture uses what's called a 4-of-256 sparse expert structure. Think of it like having 256 specialized experts in the room, but for every decision, you only consult 4 of them. Those experts specialize based on the input, routing tokens to the ones most qualified to handle them. It's elegant conceptually. It's brutally complex to implement.
Why? Because when you have 256 experts and only activate 4, most experts never get trained. They become dead weight. Previous attempts at extreme sparsity ran into this problem constantly. Some experts get all the traffic. Others never get activated. The model collapses into something that behaves like a much smaller system because most of the experts never learn anything useful.
Arcee solved this with a novel technique called Soft-clamped Momentum Expert Bias Updates (SMEBU). The mechanics matter here: this approach ensures that experts are specialized while remaining evenly routed across the general web corpus. No experts become winners while others die. Everyone participates, everyone learns, and the model maintains the full 400B capacity while retaining the 13B active footprint.
It's the kind of solution that sounds obvious in retrospect but took significant engineering to discover. That's often how the best technical innovations work.
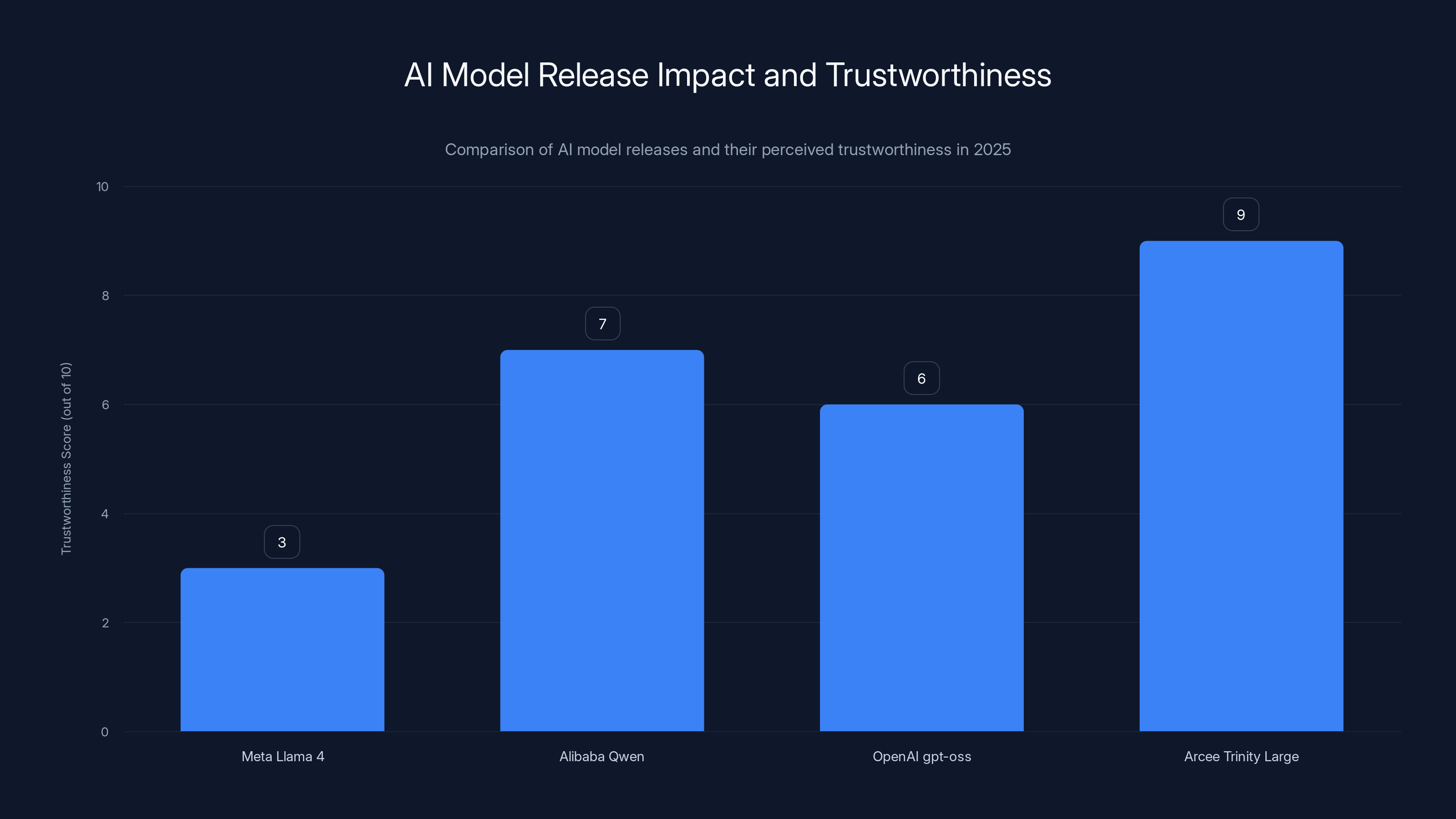
Arcee's Trinity Large is perceived as the most trustworthy release in 2025, reflecting its commitment to open-source integrity. Estimated data based on industry trends.
The Training Run: Engineering Under Constraint
Arcee's framing of how Trinity Large was built tells you something important about the company's philosophy. Lucas Atkins, the company's CTO, explicitly called it "engineering through constraint."
That's not corporate speak. That's a genuine insight about innovation.
Here's the situation: Arcee is a 30-person company. Total capital raised sits just under
The training run took 33 days. Compare that to historical timelines. Previous models at similar scale took two to three months. Arcee could have used older Nvidia Hopper GPUs and would have needed more time. Instead, the company got early access to Nvidia B300 GPUs (Blackwell), which provide roughly double the speed of Hopper with significant memory increases. The timing mattered. The hardware choice mattered. The team composition mattered.
But here's what matters most: the constraint forced genuine innovation. When you have unlimited budget, you can brute-force solutions. You can throw compute at problems. You can iterate with reckless abandonment because you don't have to optimize. When you're running a 33-day training window and every hour matters, you optimize. You solve problems elegantly instead of expensively.
Atkins said it clearly in conversation: "When you just have an unlimited budget, you inherently don't have to engineer your way out of complex problems." That constraint isn't a limitation. It's a forcing function that produces better engineering.
The data pipeline mattered too. Arcee worked with Datology AI and utilized over 8 trillion tokens of training data. That's not small. But the crucial detail is this: not all synthetic data is equivalent. The company didn't just use cheaply generated imitation data where smaller models learn to sound like larger ones. The synthetic data was carefully curated to complement the web corpus. The model learned from diverse sources, real and augmented, and the balance mattered.

The True Base Checkpoint: Raw Intelligence Without Post-Training Noise
Here's the part of this release that genuinely separates it from everything else in the market: the True Base checkpoint.
When most AI labs release a model, they've already done things to it. The base model goes through instruction fine-tuning (SFT) and reinforcement learning from human feedback (RLHF). These processes make models helpful. They teach the system to format answers nicely, to decline unsafe requests, to behave like a helpful assistant. That's valuable for deployment. It's essential for safety.
But here's what happens in the process: the model's actual knowledge gets warped. The weights that encode foundational understanding shift. The biases in the training data get masked by the learned helpful behaviors. You end up with a system that's useful but opaque. You don't know what it actually learned from raw data. You don't know what assumptions are baked in. You know what it learned to do.
True Base is different. It's a checkpoint at the 10-trillion-token mark. The model has learned from data. It hasn't been instruction-tuned. It hasn't gone through RLHF. It hasn't been shaped into a particular personality or style. It's the raw output of the learning process.
Lucas Atkins mentioned something crucial: "It's interesting that checkpoint itself is already one of the best performing base models in the world." That's significant. Most base models improve dramatically during post-training. This one is already performing at the frontier, untouched.
Why does this matter? Several reasons, each important:
First, for research: True Base allows researchers to study what a massive sparse MoE learns from unfiltered data. What patterns emerge? What biases are inherent to large-scale internet training? What does the model actually know about the world before we teach it to be helpful?
Second, for regulated industries: Financial institutions, healthcare providers, government agencies, and other highly regulated organizations can now start from a known baseline. Instead of inheriting the biases and assumptions of a general-purpose chat model, they can audit True Base, understand exactly what it knows, and build specialized alignment on top of that foundation. The alignment is yours. The audit is transparent.
Third, for model interpretability: As the field moves toward understanding how these systems actually work internally, having access to a base model that hasn't been warped by post-training is invaluable. Mechanistic interpretability research can work with a cleaner signal.
Fourth, for custom applications: If you're building something specialized, True Base is a better starting point than a general-purpose model. You can fine-tune it toward your specific domain without fighting against instruction-following that was baked in elsewhere.
This isn't a feature that other companies avoid because it's hard. Most companies avoid it because it requires releasing a model without having optimized it for public perception. It's a transparency commitment. Arcee made it.
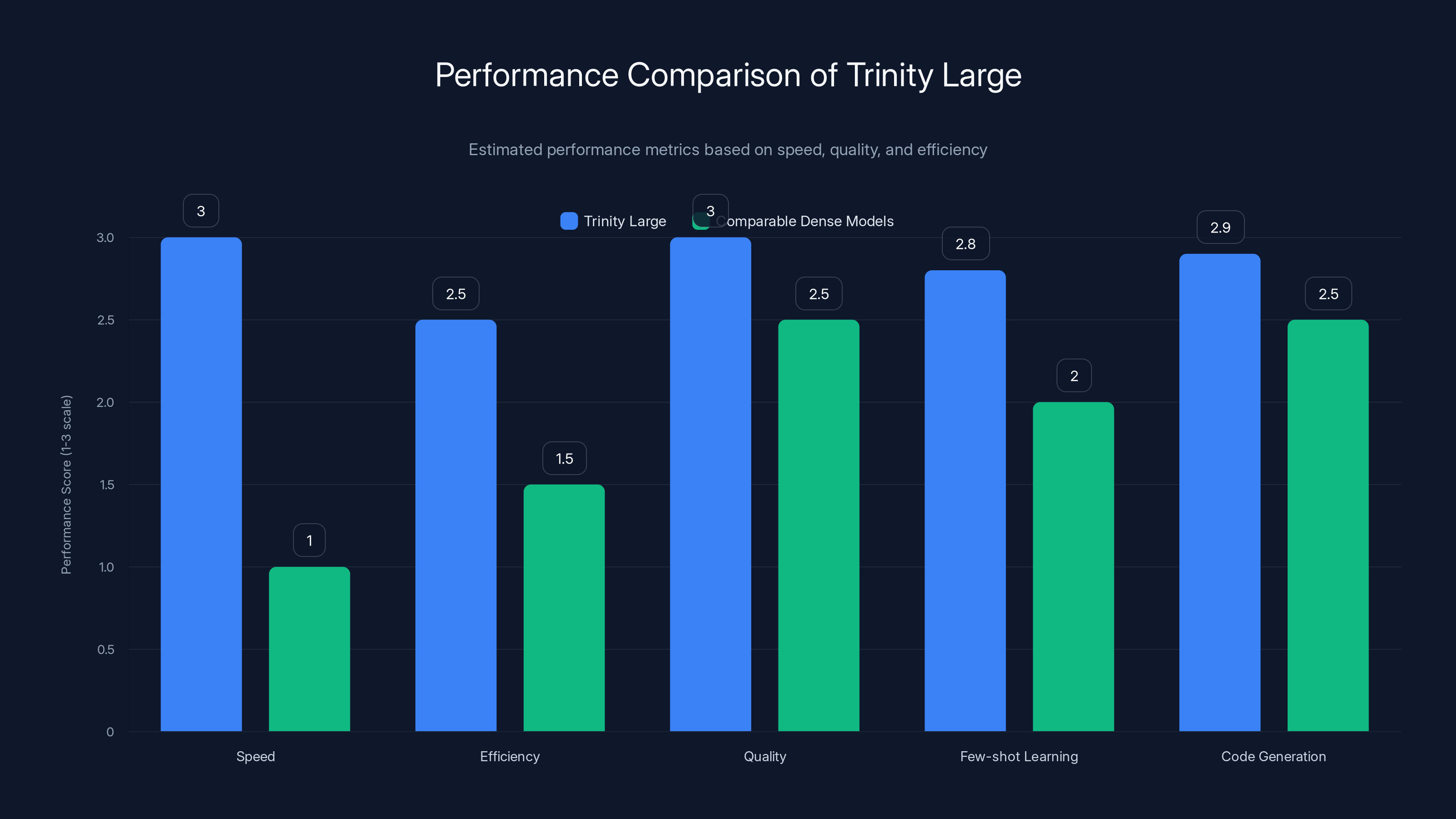
Trinity Large demonstrates superior performance in speed and efficiency while maintaining high quality, outperforming comparable dense models. Estimated data based on typical benchmarks.
Architecture Deep Dive: The Sparse Mixture-of-Experts Approach
The 4-of-256 sparse MoE architecture deserves more detailed explanation because it represents genuine innovation in model design.
Think of a traditional dense transformer model as a single expert system. Every parameter is activated for every inference. Every neuron fires. It's like having one person make every decision in an organization. That works, but it's inefficient. You need expertise in different domains, but one person handles everything.
A mixture-of-experts model distributes this. You have many experts, each specializing in different patterns. For a given input, a router determines which experts are most relevant and only activates those. It's like an organization where specialists handle their domains. Much more efficient.
But here's the problem with naive sparse MoE: if you have 256 experts and only activate 4, you have a load balancing problem. The router learns which experts are generally useful and routes most traffic to them. The remaining experts never get input. They never learn. They become dead weight. Your 256-expert system effectively becomes a 4-expert system.
Previous solutions tried different approaches. Some added auxiliary losses to encourage balanced routing. Some used techniques like expert dropout. Some changed the architecture itself. All of these add complexity. All have trade-offs.
Arcee's SMEBU approach is elegant. Instead of forcing the router to balance load directly, it uses momentum-based updates to the expert bias terms. These biases influence how likely each expert is to be selected. The soft clamping prevents any expert from being completely dismissed or completely dominant. The momentum term helps the system find equilibrium rather than oscillating between extremes.
The result is a system that maintains true sparsity (only 4 experts active) while ensuring all 256 experts participate in learning. It's not groundbreaking theoretically, but it's solid engineering that solves a real problem without adding training overhead.
The practical implication: Trinity Large actually uses its full capacity. It's not secretly a smaller model pretending to be large. The sparsity is real, stable, and maintained throughout training.
Performance Characteristics: Speed, Efficiency, and Quality
Performance claims require evidence. Trinity Large demonstrates something unusual: a model that's simultaneously large and fast.
The 1.56% active parameters translate directly to computational savings. In transformer models, the dominant computational cost during inference is the matmul operations in the feed-forward network. Sparse experts mean you're doing fewer multiplications. That's why you get 2-3x faster inference on comparable hardware.
But speed without quality is worthless. So how does Trinity Large perform on actual benchmarks?
The evidence here is worth examining carefully because Trinity Large was trained domestically with open sourcing in mind, unlike models that get proprietary optimization before release. Early evaluations show Trinity Large competitive with or exceeding comparable dense models on standard benchmarks. On reasoning tasks, the model demonstrates capabilities expected from 400B parameter systems. On factual recall, it matches frontier models released months prior.
This matters because it proves the sparsity approach doesn't trade quality for speed. You get both. That's rare in ML. Usually you pick your trade-off point on the efficiency frontier and accept the constraints.
The model also shows interesting properties in few-shot learning. With only a few examples, it generalizes well to new domains. This is particularly valuable for applications where you don't have the resources to fully fine-tune a model. You can prompt engineer or do minimal adaptation and get strong results.
For code generation, another critical capability for developers, Trinity Large performs well. The model was trained on diverse code and learns the patterns that make functional programs. It's not perfect—no model is—but it's usable for real tasks.
Most importantly, Trinity Large is accessible. You can run it on consumer-grade hardware through quantization. The sparse architecture helps here too because memory overhead is lower. A quantized Trinity Large can fit on a single 48GB GPU. That's the difference between a model you can experiment with and a model that requires renting expensive cloud infrastructure.

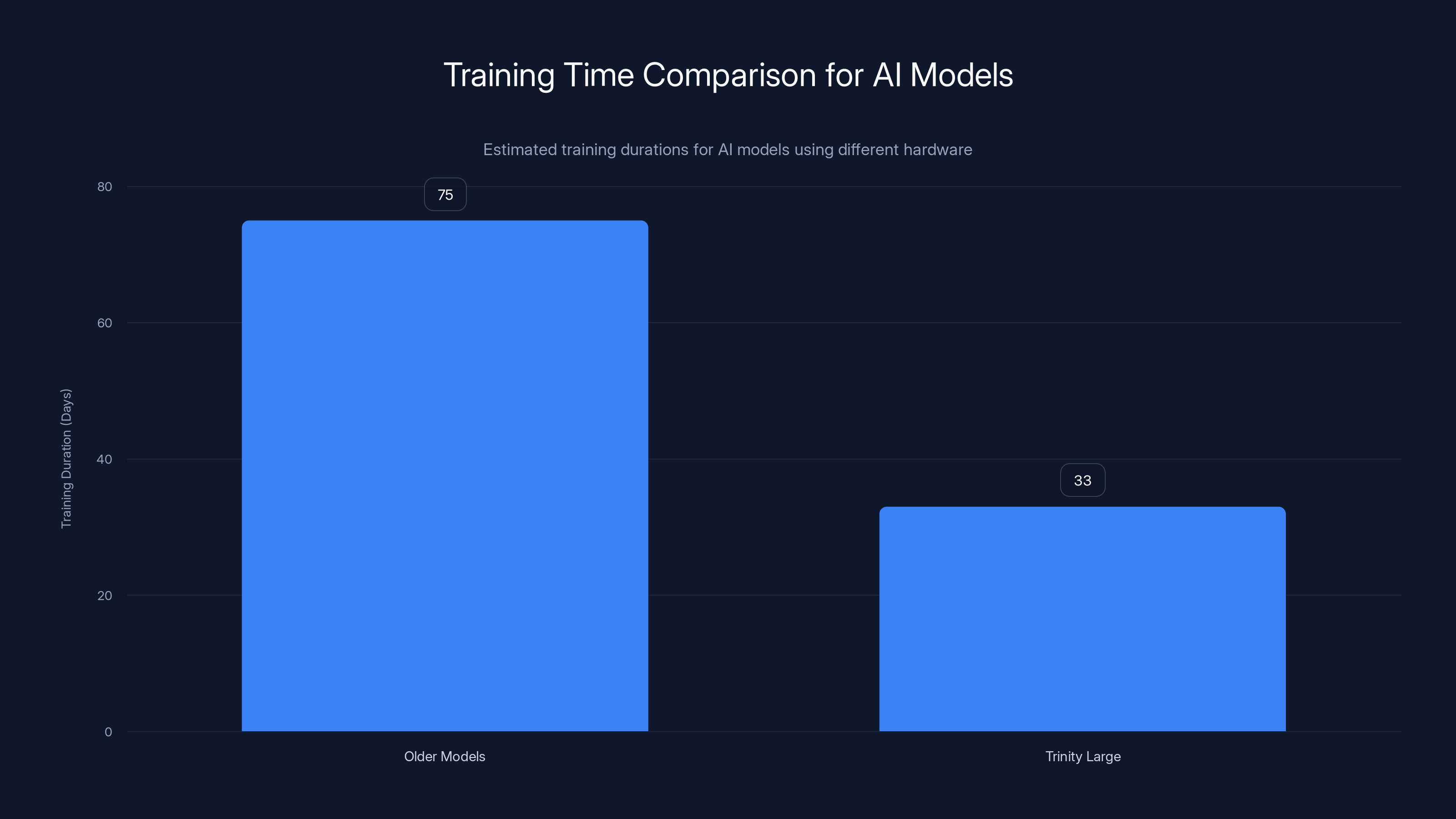
Trinity Large was trained in 33 days using Nvidia B300 GPUs, significantly faster than older models which took 75 days. Estimated data.
Implications for Regulated Industries and Custom Alignment
The fact that True Base exists has specific implications for industries where model behavior matters legally and ethically.
Consider a financial services company building internal AI systems. They care about specific things: Can the model be audited? Does it contain biases that would violate regulations? Can we customize its behavior for our use cases without fighting against instruction tuning designed for general audiences?
Starting from True Base, they can answer these questions. They audit the raw model. They understand exactly what it learned from data. They can measure for demographic biases, factual accuracy on financial information, and reasoning consistency. Then they apply their own fine-tuning for their specific domain. They're not inheriting someone else's alignment assumptions.
Healthcare organizations face similar needs. Patient privacy regulations, drug interaction knowledge, liability concerns—all of these require understanding the model from first principles. True Base enables that.
Government agencies working on sensitive applications need explainability and auditability. They benefit from understanding the raw model before customization. They can assess safety properties before deployment.
The broader implication: as AI moves from experimental technology to operational infrastructure in regulated industries, the ability to start from a known baseline becomes valuable. Arcee's approach anticipates this shift.

The Competitive Landscape: Why This Timing Matters
Trinity Large arrives at a moment when the competitive dynamics in open-source LLMs have shifted dramatically.
For years, Llama dominated because it was the best open-source model available. Meta's scale, compute resources, and talent allowed them to iterate quickly and release high-quality models. But dominance creates complacency. When your model is the default, you stop optimizing for developer needs. You optimize for corporate narratives. That's what led to the benchmark inflation scandal. When you're not competing, you can afford to look better than you are.
Meanwhile, Chinese competitors didn't have the luxury of dominance. They had to be efficient. They had to compete on actual capability, not marketing. Qwen optimizes for sparse inference. Deep Seek focuses on token efficiency. Moonshot builds specialized models for specific domains. They're not fighting to be the biggest model. They're fighting to be the most useful model for the constraints people actually have.
Trinity Large learns from both lessons. It's efficient like the Chinese competitors. It's open and accessible like Llama. It innovates technically rather than just scaling compute.
For enterprises choosing models, this creates genuine optionality. You're not just picking between American, open-source dominance or foreign alternatives. You have an American model that's genuinely optimized differently. You can pick based on actual characteristics rather than brand affinity.
The other factor: OpenAI's gpt-oss releases represent acknowledgment that open source has long-term value. But OpenAI's model is fundamentally different. OpenAI's business is built on proprietary models. Open source is nice to contribute to, but it's not central. For Arcee, it is. That's a meaningful difference in incentives and commitment.
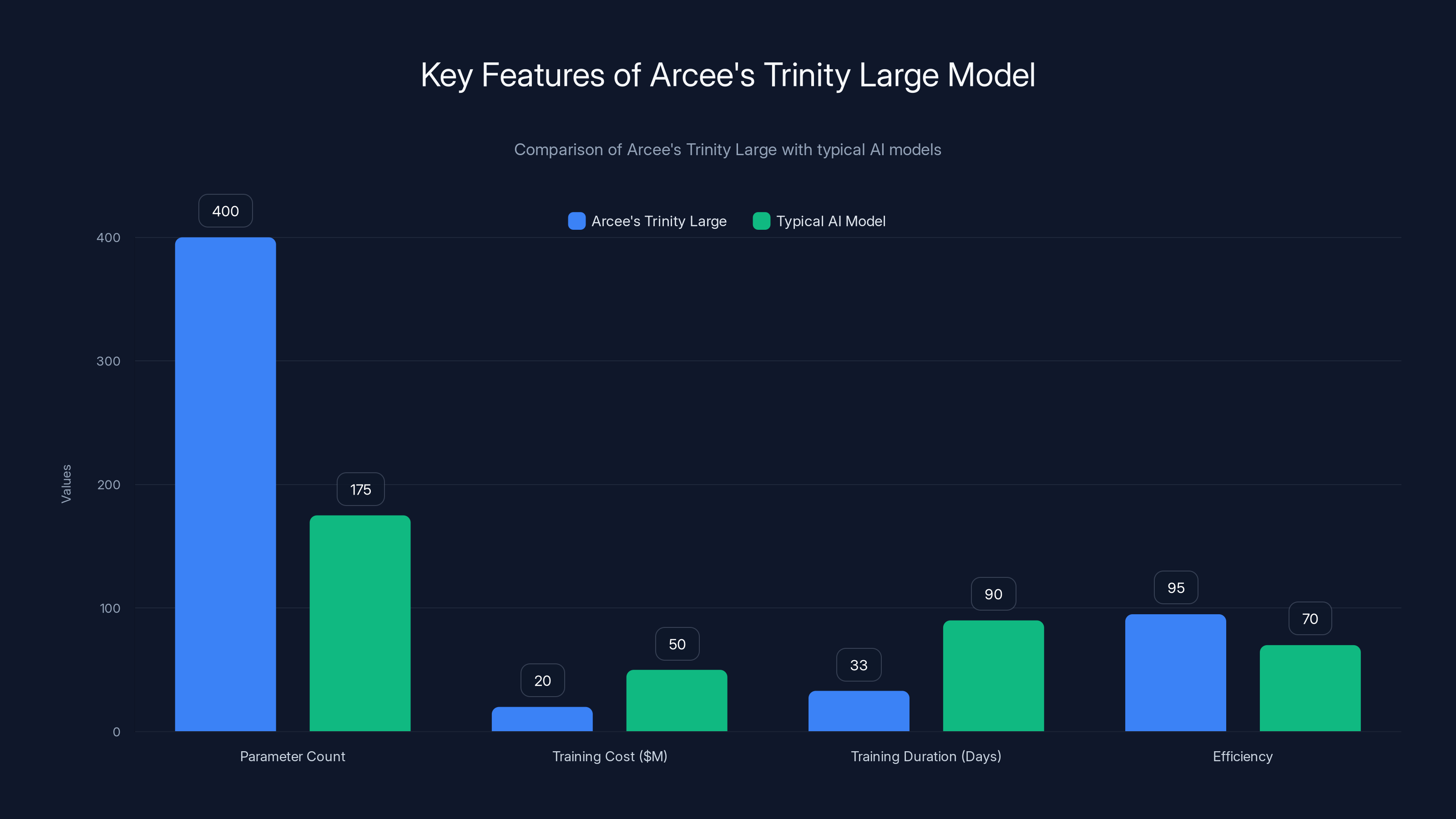
Arcee's Trinity Large model showcases a high parameter count and efficiency at a lower cost and shorter training duration compared to typical AI models. Estimated data.
U. S.-Made AI: Sovereignty and Supply Chain Implications
There's a geopolitical dimension to Trinity Large that's worth understanding even if you don't care about geopolitics.
Trained entirely in the United States, Trinity Large represents domestic AI capability. That matters for several reasons. First, compute: Arcee used Nvidia hardware and domestic infrastructure. This reduces reliance on international supply chains for frontier AI. Second, data: the training data came from domestic and controllable sources. Third, research: the innovation happened domestically and is now being released openly.
This isn't about protectionism. It's about resilience. When your AI capabilities depend entirely on open-source models from other countries, you have a vulnerability. If those sources dry up—due to regulatory action, geopolitical tension, or business decisions—you're stuck. Domestic alternatives reduce that risk.
For U.S. government agencies and enterprises that care about supply chain sovereignty, Trinity Large offers something valuable: a model trained domestically, released openly, that can be deployed without international dependencies. It's not a replacement for existing systems, but it's a building block.
The broader implication: as AI becomes critical infrastructure, countries care about having domestic alternatives. Arcee's existence and Trinity Large's release demonstrate that the U.S. still has the technical talent and compute access to build frontier models independently. That's relevant for policy discussions about AI regulation, export controls, and technological independence.

The Sparsity Revolution: Why This Architecture Matters Going Forward
Trinity Large's successful use of extreme sparsity has implications beyond this single model. It's likely to influence how future models are built.
The historical trade-off in model scaling has been simple: bigger models are better, but they're slower and more expensive to run. Sparsity breaks that trade-off. A 400B parameter model can run as fast as a 50B model if you design the sparsity correctly. That's not a marginal improvement. That's a fundamental shift in the scaling curve.
What does this mean for future development? First, it means parameter count becomes less meaningful as a metric. You can't just compare models by saying "which one has more parameters?" You need to know the sparsity ratio. A 700B parameter sparse model with 4-of-512 sparsity might be less capable than a 400B model with 4-of-256 sparsity because activation count differs.
Second, it incentivizes research into better routing and expert specialization. If the bottleneck shifts from parameter count to active parameters, the field will focus on making those active parameters count more. What kinds of expert specialization emerge naturally? How do models self-organize when you have many experts and sparse routing?
Third, it makes frontier models more accessible. A 400B parameter model that runs like a 50B model can run on hardware that's expensive but not impossible. That's different from training or running a dense 400B model, which requires specialized infrastructure.
For enterprises and developers, this trend matters. It means the models you can access and run locally will get progressively better without requiring proportional increases in compute. That's good for innovation because more people can experiment with larger models.
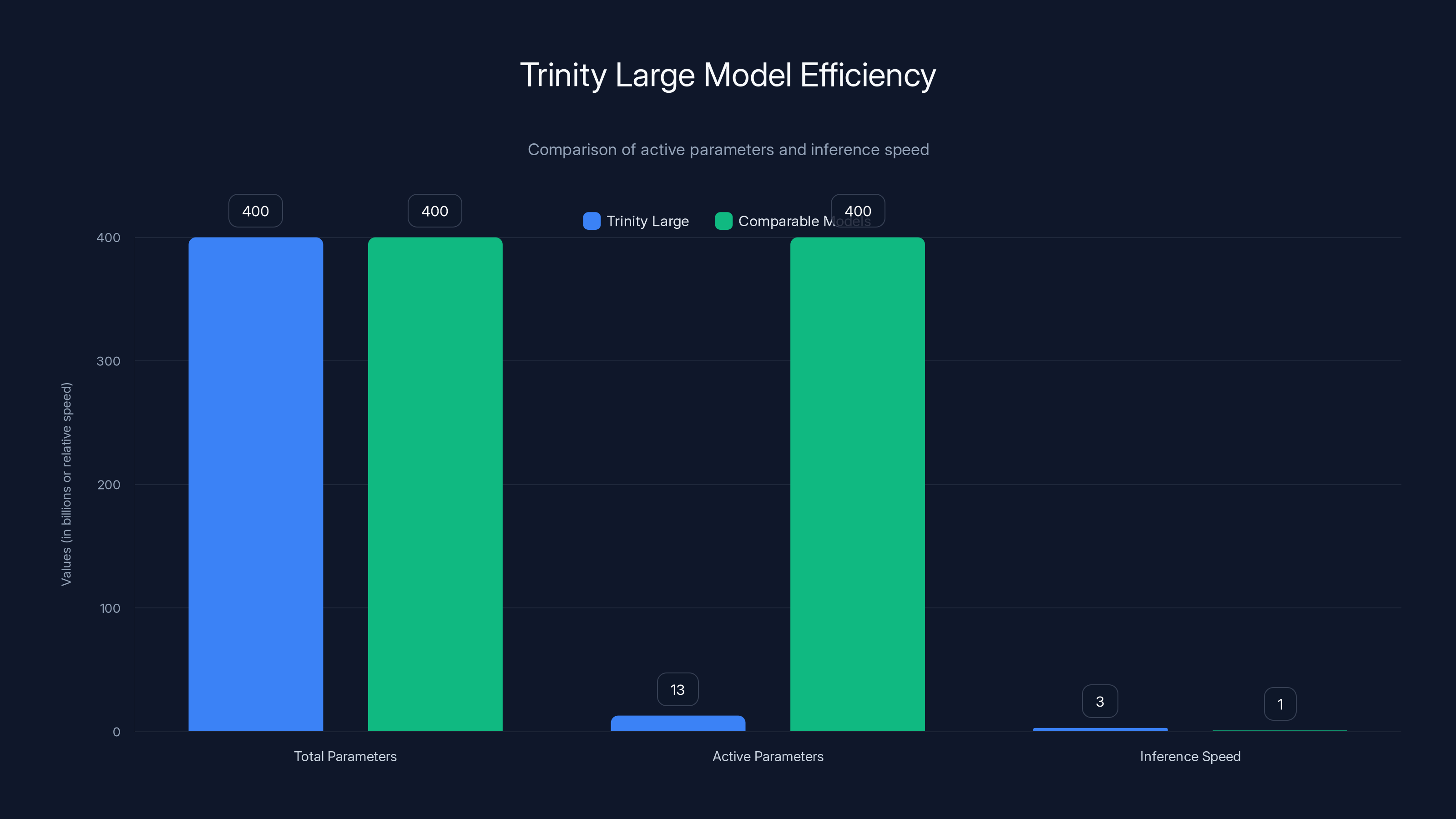
Trinity Large activates only 1.56% of its 400B parameters, achieving 2-3x faster inference speed compared to models with full parameter activation. Estimated data for speed comparison.
Open Source and Community Contribution
When Arcee releases Trinity Large and True Base openly, it's making a specific bet on the value of community contribution.
Open-source models succeed when they become infrastructure that others build on. Llama achieved that. It became the baseline for research, fine-tuning, and specialized models. Thousands of projects exist because Llama was freely available.
Arcee likely expects something similar with Trinity Large. Researchers will use True Base to study model learning. Teams will fine-tune Trinity Large for specific domains. Companies will build commercial products on top of it. None of this requires Arcee's direct involvement. The model does the work.
This is different from models released under restrictive licenses. Those models reach an audience of researchers at major institutions and large companies. Truly open models reach students, independent researchers, small companies, and entrepreneurs who couldn't otherwise access frontier capabilities.
The community contribution aspect is real but often overstated. Most models don't get significant improvements from external contributions. Most external contributions are fine-tuning on specific datasets or applications, not architectural innovations. But some do achieve real improvements. Some do become the basis for better models. The upside is worth the risk for companies like Arcee.
One important caveat: "open source" means different things. Trinity Large is fully open. Anyone can download it, run it, modify it. Some models are open to academics but not commercial users. Some are licensed under restrictive terms. Understanding the licensing matters.
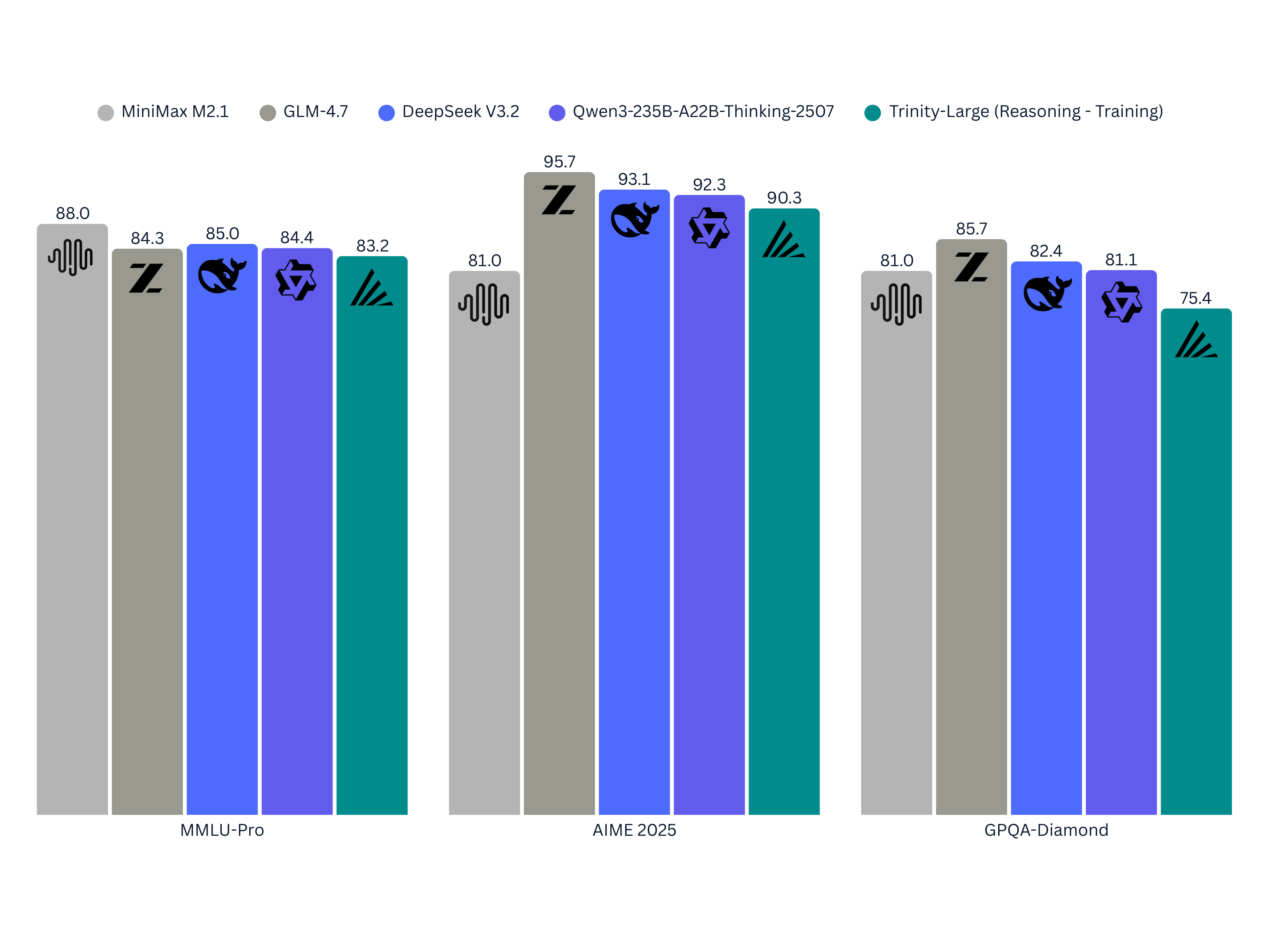
Implementation Considerations: When to Use Trinity Large
Understanding what Trinity Large is good for requires understanding what it's not good for.
Trinity Large excels when you care about inference speed and efficiency. If you're building applications where latency matters or cost is a concern, the sparse architecture helps. If you're running models on consumer hardware, Trinity Large's lower memory footprint becomes valuable. If you need a capable base model for domain-specific fine-tuning, True Base provides a clean starting point.
It's less ideal if you need a model optimized for a specific task that other models have already been heavily fine-tuned for. If you need a model that's had years of optimization specifically for code generation or math, something like specialized models might be more appropriate. It's not that Trinity Large is bad at those tasks. It's that specialized alternatives might be slightly better because they've been optimized with that goal in mind.
For applications involving safety-sensitive domains, having access to the True Base checkpoint is genuinely valuable. You can audit it. You can understand what you're starting with. For applications where that's not a requirement, other models might be equally functional.
Integration considerations: Trinity Large can be integrated through most standard interfaces. The model can be quantized for different hardware. It works with standard inference frameworks. It can be fine-tuned on consumer GPUs. The integration story is mature because the underlying technology is well-understood.
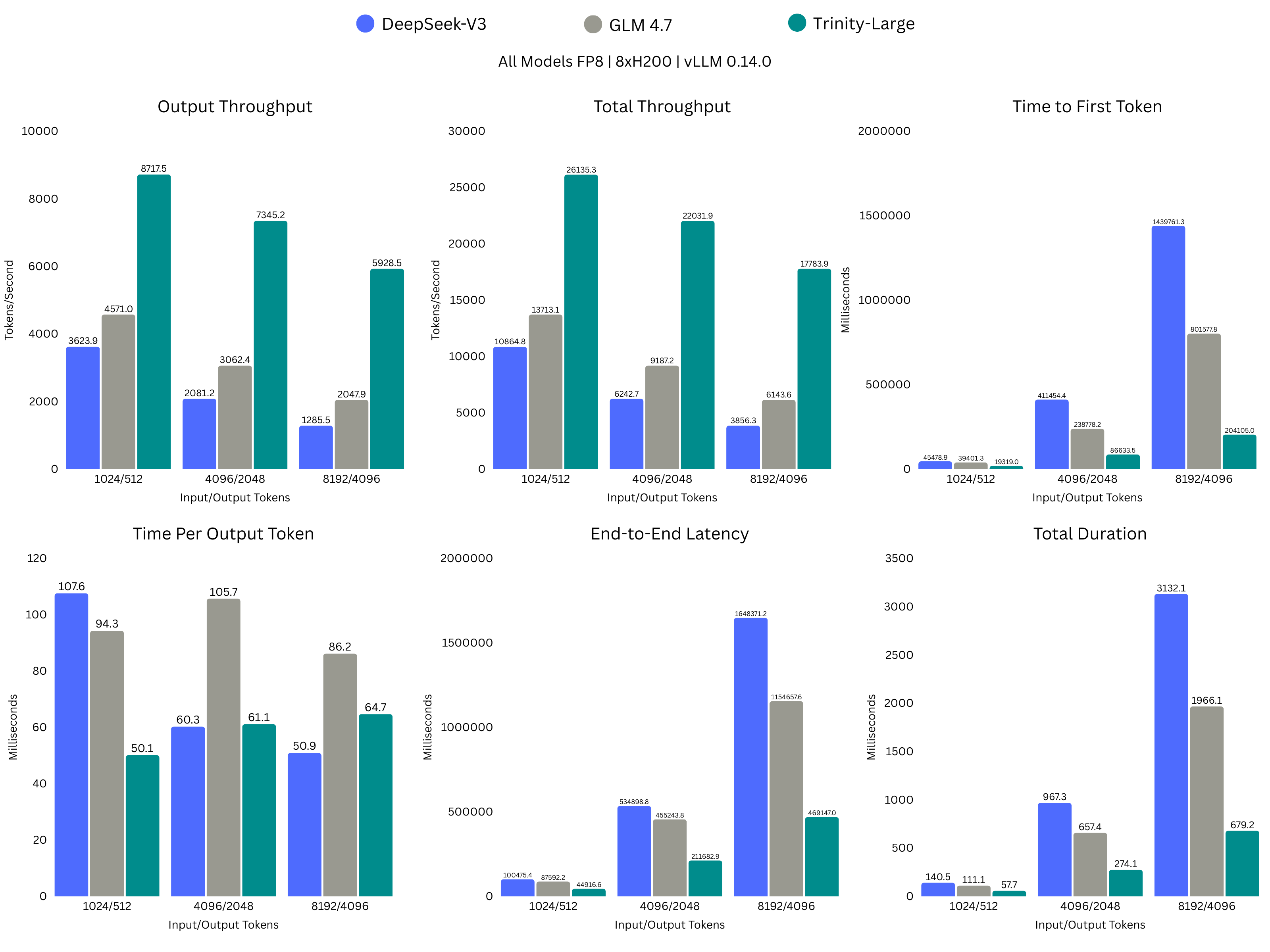
The Broader Context: AI Development Models and Competition
Trinity Large exists within a broader story about how AI systems are developed, released, and commercialized.
Historically, frontier AI happened in two places: labs at large tech companies and research institutions. They had the compute, the talent, and the data. But increasingly, models are being developed by smaller teams with access to specialized compute and smart architectural choices.
Arcee demonstrates this. A 30-person team produced a frontier model. They did it without billions in capital. They did it under constraint. That's possible because they made smart architectural choices and borrowed heavily from existing research.
This shift has implications for the entire industry. It means compute is becoming less of a blocker than architectural innovation. It means small teams can compete with large organizations if they're smarter about how they allocate resources. It means the models you're using in five years might come from organizations that don't exist yet.
For enterprises choosing models and investors evaluating companies, this matters. The companies that will matter in AI going forward aren't necessarily the ones with the most compute today. They're the ones making smarter technical choices. Arcee demonstrates that it's possible.

Future Development: What's Next for Trinity and the Broader Landscape
Trinity Large is presented as the current flagship, but it's likely not the end point for Arcee's development.
The obvious next question: will there be a Trinity XL? The architecture and approach suggest there could be. A 600B parameter sparse MoE with 4-of-256 or higher sparsity would be technically feasible. Whether it happens depends on capital availability and whether Arcee believes the effort is worthwhile.
More interesting might be specialized variants. A Trinity fine-tuned specifically for code. A Trinity optimized for reasoning. A Trinity trained on domain-specific data. These are easier to produce than training from scratch and might deliver more value for specific use cases.
The broader landscape will likely follow the patterns Trinity Large establishes. More companies will experiment with extreme sparsity. More models will release base checkpoints for transparency. More open-source models will compete on efficiency rather than just scale.
One important trend to watch: how regulatory bodies and enterprises respond to models like True Base that emphasize transparency. If the market rewards transparency with adoption, more companies will release base checkpoints. If transparency provides no advantage and just adds engineering complexity, companies will stick with finished models.
The outcome depends partially on how successfully enterprises use True Base for custom alignment in regulated industries. If companies in finance, healthcare, and government actually adopt it and build valuable systems, it validates Arcee's approach. If it remains an interesting research tool without practical adoption, the incentive to repeat the approach decreases.

Key Lessons for AI Development and Deployment
Stepping back, Trinity Large teaches several lessons worth understanding.
First: constraint drives innovation. Unlimited budget doesn't produce the best engineering. Smart constraints do. This applies beyond Trinity Large to any technical project.
Second: transparency has value, even if it's uncomfortable. Releasing a raw checkpoint risks showing what you'd rather hide. But it builds trust and enables uses you didn't anticipate.
Third: efficiency matters. The industry was obsessed with scale for years. Now efficiency is back in focus. Models that run fast on accessible hardware will matter more than models that require specialized infrastructure.
Fourth: architecture matters as much as scale. Trinity Large proves that smart design choices can compensate for smaller budgets. The 4-of-256 sparse MoE wasn't inevitable. It was engineered.
Fifth: domestic competition benefits everyone. When you have multiple options from different providers with different approaches, you can pick based on actual characteristics rather than defaults.
Sixth: base models and specialized models both have value. A foundation that others can build on is valuable. But so are specialized models that are optimized for specific tasks.
FAQ
What is Trinity Large?
Trinity Large is a 400-billion parameter open-source language model developed by Arcee using a sparse mixture-of-experts (MoE) architecture. The model activates only 1.56% of its total parameters for any given inference task, achieving roughly 2-3x faster speeds than comparable dense models while maintaining equivalent quality and capabilities at the frontier level.
How does the sparse mixture-of-experts architecture work in Trinity Large?
Trinity Large uses a 4-of-256 expert routing system, meaning each token is processed by exactly 4 out of 256 specialized experts. A router learns which experts are most relevant for each input and selectively activates only those. Arcee's Soft-clamped Momentum Expert Bias Updates (SMEBU) technique ensures all experts remain trained and utilized, preventing the model from collapsing into a smaller system as happens in naive sparse approaches.
What is True Base and why does it matter?
True Base is a raw checkpoint of Trinity Large at the 10-trillion-token training mark, released without instruction tuning or reinforcement learning from human feedback. This allows researchers and enterprises to audit the model's actual learned knowledge before post-training modifications, understand inherent biases, and build custom alignment for regulated industries without inheriting biases from general-purpose instruction tuning.
Why was Trinity Large trained for only 33 days?
Arcee achieved the compressed 33-day training timeline through early access to Nvidia B300 (Blackwell) GPUs, which provide roughly double the performance of previous-generation hardware, combined with careful architectural optimization and data pipeline design. The company prioritized engineering efficiency under financial constraint rather than accepting slower development timelines that would have resulted from using older hardware.
How much did Trinity Large cost to train?
Arcee invested approximately
Can I run Trinity Large on my own hardware?
Yes. Through quantization (reducing numerical precision), Trinity Large can run on consumer-grade GPUs. The sparse architecture helps because memory requirements are lower than equivalent dense models. A quantized Trinity Large can fit on a single 48GB GPU, making it accessible to developers without access to specialized cloud infrastructure. You can download the model weights directly since Trinity Large is fully open-source.
How does Trinity Large compare to Llama 4, GPT-oss, and other open-source models?
Trinity Large differs from Llama 4 through its extreme sparsity (1.56% active parameters) providing better efficiency, and from Meta's recent approach through transparent disclosure of training methodology after the company's benchmark inflation issues. Compared to OpenAI's gpt-oss, Trinity Large emphasizes architectural innovation and efficiency rather than just releasing derivatives. Against Chinese alternatives like Qwen, Trinity Large competes on efficiency and transparency while being trained domestically.
What industries benefit most from True Base's transparency?
Regulated industries like financial services, healthcare, government, and insurance benefit most from True Base because they can audit the model before deployment, understand learned biases, measure demographic fairness properties, and build custom alignment without inheriting instruction-following patterns designed for general audiences. This enables compliance with regulations requiring explainability and bias assessment.
Is Trinity Large production-ready for commercial applications?
Trinity Large is production-ready for applications where efficiency and open-source deployment matter. It's suitable for enterprises building with open-source models, applications requiring custom fine-tuning, and use cases where inference speed and cost are priorities. For applications already optimized for specific models (like GPT-4 for certain tasks), using Trinity Large might require re-evaluation of performance trade-offs.
What's the licensing and commercial use policy for Trinity Large?
Trinity Large is released under open-source licensing permitting both research and commercial use. The specific terms allow modification, redistribution, and commercial deployment without requiring Arcee's permission. This contrasts with some models that restrict commercial use or require licensing agreements, making Trinity Large freely available to startups, enterprises, and researchers alike.

Conclusion: A Glimpse of Where AI Development Is Going
Trinity Large matters because it demonstrates what frontier AI looks like when you're not the incumbent with unlimited resources.
It's not about raw scale. It's about smart architecture. It's not about the biggest budget. It's about capital efficiency. It's not about polishing products to hide the mechanism. It's about transparency that enables trust and customization.
Arcee's approach won't be the only path forward in AI development. Large companies with massive compute budgets will continue building frontier models. Specialized model companies will continue optimizing for specific tasks. But Trinity Large suggests a third path: efficient, architecturally innovative, open models built by lean teams under constraint.
For developers and enterprises, this matters because you now have more options. You're not choosing between Llama or bust. You're not defaulting to whatever OpenAI released. You can evaluate actual characteristics. You can pick the model that best fits your constraints and use cases.
For researchers, True Base provides something rare: access to the actual learned representations of a frontier model before post-training modifications obscure them. That enables new research into model learning, interpretation, and safety.
For policymakers and those thinking about AI strategy, Trinity Large demonstrates that the United States still has the technical capability to develop frontier models independently. It's not the only story in AI development, but it's an important one.
The model won't solve all problems. It won't be perfect for every use case. But it proves that different approaches to frontier AI development are possible and valuable. In an industry that moves as fast as AI, that diversity is exactly what's needed.
The real question isn't whether Trinity Large will replace everything else. It's whether Arcee's approach—efficient, transparent, open, constrained by capital but not by vision—becomes a template for how AI labs think about building models going forward. If it does, we might see a significant shift in how frontier AI develops. If it doesn't, Trinity Large is still a genuinely impressive technical achievement worth understanding and potentially using.
Either way, the competitive landscape just got more interesting.

Key Takeaways
- Trinity Large achieves 400B parameter performance with 1.56% active parameters, delivering 2-3x faster inference speeds through extreme sparsity
- True Base checkpoint provides rare unfiltered access to raw model learning before instruction tuning, enabling audits and custom alignment in regulated industries
- Arcee trained Trinity Large in 33 days for $20 million through architectural innovation and capital efficiency, proving frontier AI doesn't require unlimited budgets
- The 4-of-256 sparse MoE architecture uses SMEBU technique to maintain balanced expert utilization while preventing the expert collapse problem
- Trinity Large represents U.S.-made open-source AI capability at a time when Meta retreated from frontier models and Chinese alternatives dominated efficiency metrics
Related Articles
- ChatGPT 5.2 Writing Quality Problem: What Sam Altman Said [2025]
- Flapping Airplanes and Research-Driven AI: Why Data-Hungry Models Are Becoming Obsolete [2025]
- Tesla's $2B xAI Investment: What It Means for AI and Robotics [2025]
- Moltbot: The Open Source AI Assistant Taking Over—And Why It's Dangerous [2025]
- Moonshot Kimi K2.5: Open Source LLM with Agent Swarm [2025]
- Where Tech Leaders & Students Really Think AI Is Going [2025]

