![Artists vs. AI: The Copyright Fight Reshaping Tech [2025]](https://tryrunable.com/blog/artists-vs-ai-the-copyright-fight-reshaping-tech-2025/image-1-1769215330881.jpg)
The Artist Revolt: Why Hundreds Are Fighting Back Against AI
Imagine waking up one morning and discovering that a company trained its artificial intelligence system on your life's work without permission. No email. No contract. No payment. Just your art, your voice, your creative identity, scraped from the internet and fed into an algorithm that now generates content eerily similar to what you spent years perfecting.
That's not hypothetical anymore. That's the reality hundreds of artists are confronting right now.
In late 2024, a groundswell of creative professionals—from Hollywood actors to digital illustrators—joined forces in what's becoming the most significant pushback against AI companies since the technology went mainstream. The movement isn't just about money. It's about creative ownership, artistic integrity, and fundamental questions about who controls culture in the age of artificial intelligence.
Scarlett Johansson's public criticism of OpenAI became a lightning rod for something much larger. Her experience highlighted what countless creators have been privately fuming about: AI systems trained on their work without consent, generating content that competes directly with their livelihoods. The campaign these artists launched doesn't just say "stop." It says: "There's a better way, and it's time we built it."
This article breaks down the artist uprising, what's really at stake, and where this confrontation is heading next. Whether you're a creator worried about your future, a tech leader trying to understand the backlash, or someone curious about how AI actually works with creative content, here's what you need to know.
TL; DR
- Hundreds of artists including major Hollywood names launched an organized campaign against unauthorized AI training on their creative work
- Copyright concerns are legitimate: AI companies often train models on copyrighted material without licenses or payment, raising serious legal and ethical questions
- The financial impact is real: Artists lose income and control as AI systems generate similar content, undercutting original creators
- A better framework exists: Licensing agreements, consent-based training, and fair compensation models can allow AI innovation while protecting creators
- This fight will reshape AI development: How this resolves in courts and Congress will determine whether AI companies can use creative work freely or must compensate artists

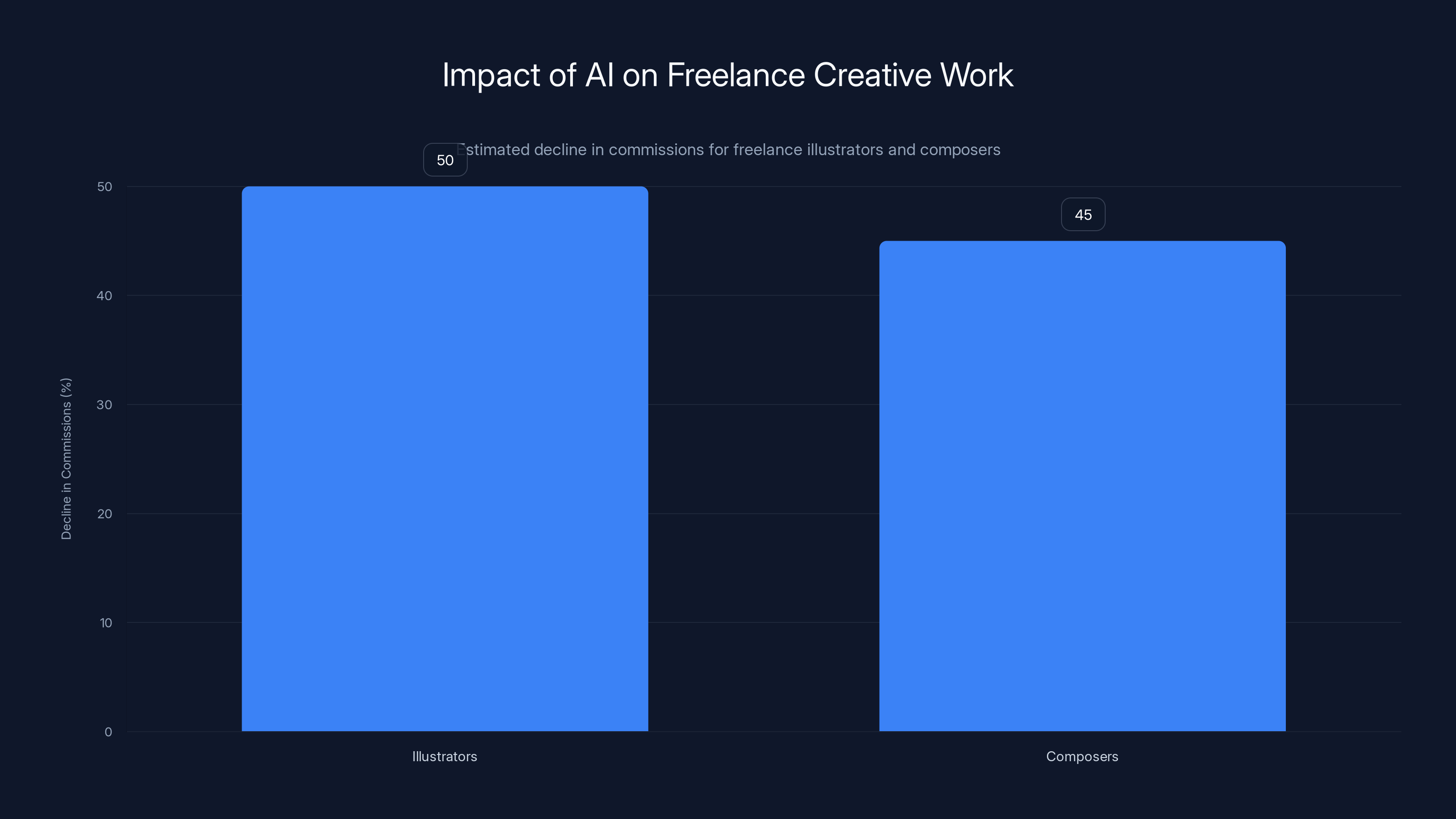
Freelance illustrators and composers have experienced an estimated 40-60% decline in commission work due to AI competition. Estimated data.
Why Artists Are Calling AI Training "Theft"
Here's the technical reality that fuels the anger: training modern AI models requires vast amounts of data. Billions of images, text samples, audio files. Tech companies discovered they could scrape this data from the internet essentially free. Stock images. Artistic portfolios. Character designs. Voice recordings. All of it became training fuel.
The legal argument is straightforward. Copyright law protects original works. When you create something—a painting, a song, a photograph—you own it. You can decide who uses it and under what terms. Nobody gets to photocopy your work and sell it without permission. Nobody gets to license it to others without your agreement.
But copyright law was written for a different era. It doesn't clearly address machine learning. Tech companies exploit this ambiguity, arguing that training AI models falls under "fair use"—a legal doctrine allowing limited copying for purposes like research or commentary. The argument goes: we're not using your art to display it or sell it directly. We're using it as data to train algorithms.
Artists see this as semantic games. From their perspective, the outcome is identical: their creative work gets exploited to build a competitive product they don't benefit from. When an AI system trained on millions of digital paintings generates artwork that undercuts the market for human artists, is that really fair use?
The anger intensifies when you look at specifics. Artists discovered that popular AI image generators were trained on their work after searching their own names in training datasets. Some found their distinctive style replicated so accurately that AI outputs look like forgeries. Others watched as AI systems pumped out derivative work that directly competed with commissions they were bidding on.
This isn't abstract philosophical debate. It's income displacement happening in real time.

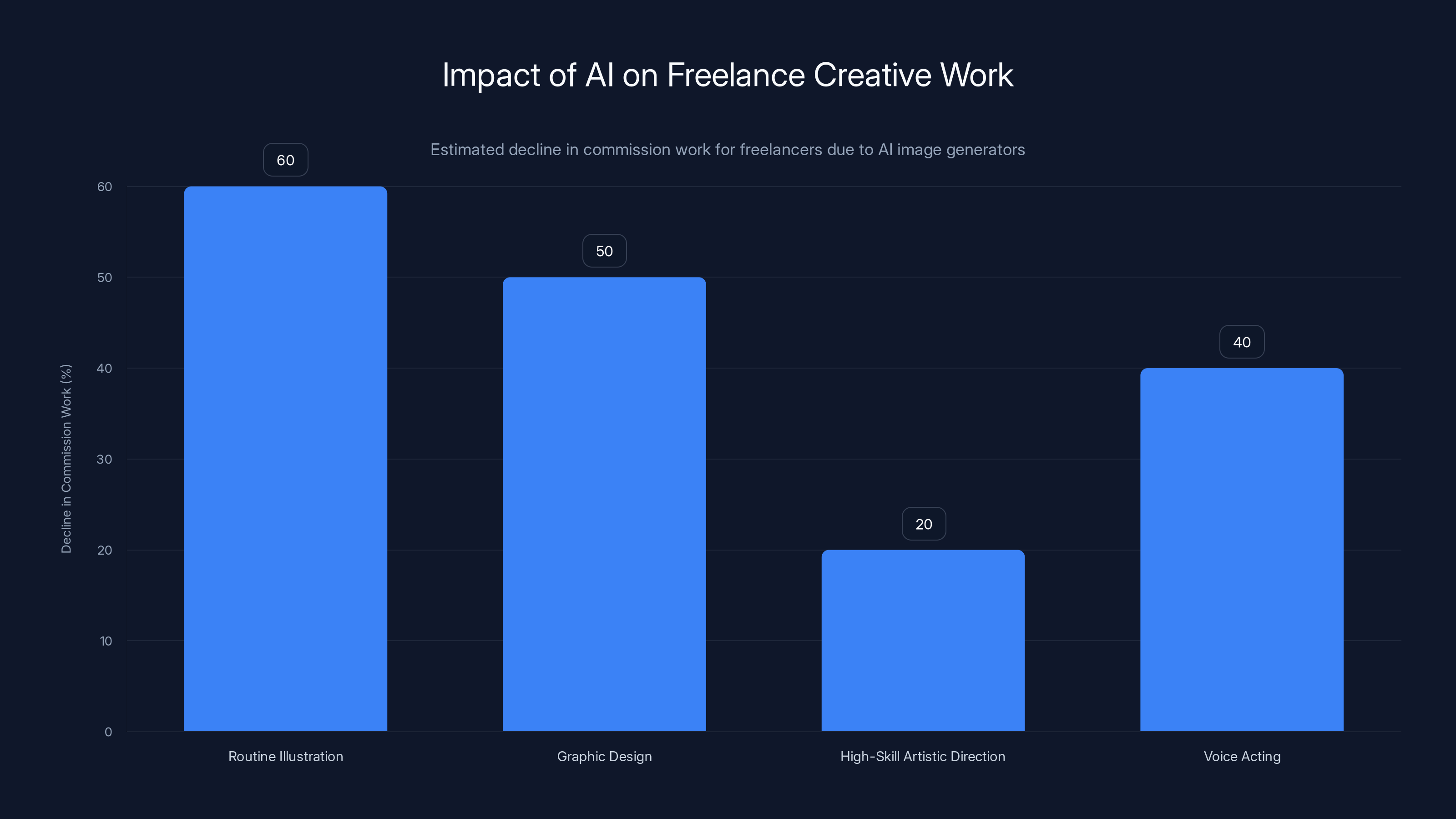
Freelance creative professionals report a 40-60% decline in commission work due to AI, with routine illustration being the most affected. Estimated data.
Scarlett Johansson's Story: When Celebrities Become the Face of the Movement
In September 2024, Scarlett Johansson made headlines by accusing OpenAI of creating an AI voice suspiciously similar to hers without permission. The timing mattered. OpenAI had released a voice mode for ChatGPT featuring a female voice called "Sky." Several users noted the vocal similarity to Johansson's distinctive breathy tone and cadence.
Johansson claimed she'd previously declined OpenAI's request to license her voice for the project. Yet the voice showed up anyway. Whether intentional or coincidental, the message was clear: even a major Hollywood actor with legal resources couldn't prevent her vocal likeness from being appropriated.
Her public statement became a rallying point because it humanized something that felt abstract to most people. AI voice cloning isn't just a technical trick. It's someone else's identity being reproduced without consent. For actors, this hits differently—their voice and likeness are literally their commodity.
But Johansson's complaint was the tip of something much larger. While she had the power to go public and demand answers, thousands of lesser-known artists were facing identical problems with zero ability to fight back. The movement she helped galvanize gave them a platform.
What makes her involvement significant is the precedent it sets. If a globally recognized actor can't protect her identity from unauthorized AI reproduction, what hope do mid-career voice actors, independent musicians, or digital artists have? The case became a proxy for everyone's vulnerability to this technology.
OpenAI eventually changed the voice mode and offered a more transparent process for future voice partnerships. But the damage was done. The incident crystallized fears that had been building among creators for months: AI companies move fast and apologize slowly, if at all.

The Copyright Case: What the Law Actually Says
Let's get into the legal weeds, because this is where the fight gets serious. Multiple lawsuits are currently working through the courts, pitting artists and authors against AI companies. The outcomes will fundamentally shape how AI development happens in the future.
The primary case involves major publishers and authors suing OpenAI and Microsoft for training language models on copyrighted books without permission. The plaintiffs argue this is straightforward infringement. OpenAI trained ChatGPT on books scraped from the internet. Those books are protected by copyright. No license was obtained. No payment was made. Open and shut.
OpenAI's defense relies on fair use. They argue that training machine learning models qualifies as transformative use—you're not copying the book to read or sell it, you're using it as training data to create something new. Fair use doctrine does protect some copying for purposes like research, criticism, or parody. The question is whether machine learning training fits that category.
The counterargument is compelling: fair use was never meant to allow wholesale copying of entire copyrighted works just to avoid licensing costs. If OpenAI wanted to train a model responsibly, they could license books from publishers. They didn't because they could build a profitable business without paying. Fair use shouldn't become an excuse for cost-cutting.
Another critical case involves visual artists suing Stability AI and Midjourney over image generation systems trained on millions of copyrighted artworks. These cases raise slightly different questions than the text-based lawsuits. When Midjourney generates an image after you prompt it, is that fair use? Is it derivative work? These distinctions matter legally.
The challenges are substantial. Fair use doctrine is genuinely murky in the context of machine learning. Courts have traditionally been skeptical of transformative arguments when the copying is comprehensive and the defendant profits directly. But they've also been willing to allow substantial copying when the purpose is truly transformative. Where does machine learning training fall on that spectrum?
International law complicates things further. Copyright is protected globally through treaties, but enforcement mechanisms vary. The EU has been more protective of creators' rights, implementing regulations requiring AI companies to disclose training data and provide opt-out mechanisms. The US has been slower to regulate, relying more on courts to figure it out.
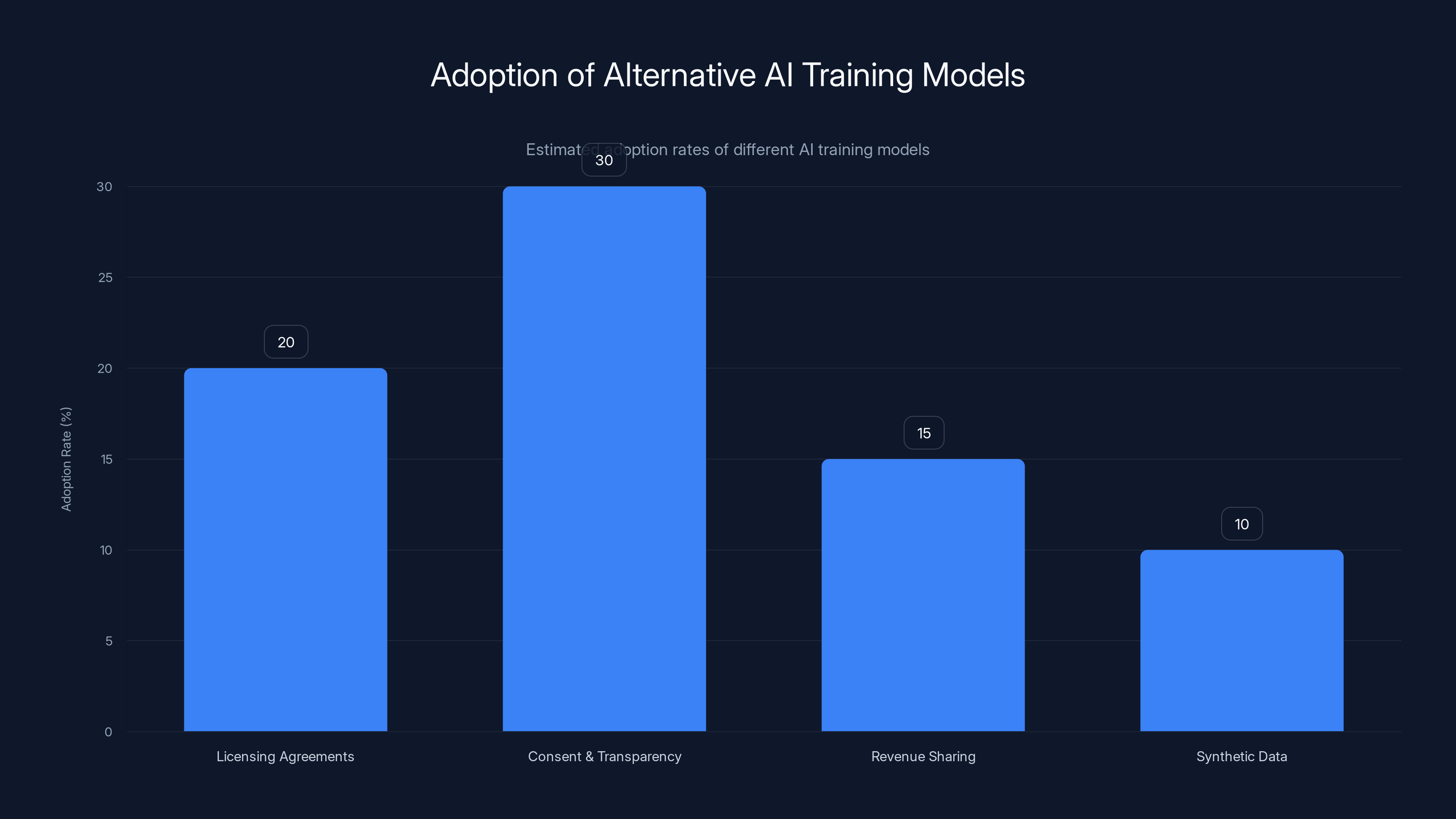
Licensing agreements and consent models are gaining traction as alternatives to traditional data scraping methods. Estimated data shows varying adoption rates among these models.
Who's Fighting Back: The Coalition of Creators
The anti-AI campaign isn't a ragtag group of angry artists. It's organized. It includes major trade associations, established authors, prominent actors, and emerging digital creators. Understanding the coalition reveals how unified the opposition has become.
Writers' organizations were early to mobilize. The Authors Guild, representing thousands of authors, joined litigation against OpenAI. Major publishing houses—Penguin Random House, Hachette, Harper Collins—launched their own suit. These aren't small players. They're established industries with legal teams and public influence.
Hollywood got involved too. The Screen Actors Guild (SAG-AFTRA) made AI protections a major issue in their 2023 contract negotiations. The union secured language limiting studios' ability to use AI to replicate actors' voices and likenesses. It was a significant win, showing that organized labor could push back against AI companies.
Visual artists created their own coalition. Organizations representing illustrators, photographers, and digital artists began tracking which companies trained on their work. Some artists started watermarking their images with metadata designed to confuse AI training algorithms—an arms race between creators and the technology.
Independent musicians and sound engineers joined the movement, concerned about voice cloning and AI-generated music that could displace studio work. As audio generation technology improved, their concerns shifted from theoretical to immediate.
What unites this diverse coalition is a simple principle: creators should control their own work. They should know when it's being used. They should be compensated if it generates value. This isn't radical. It's how intellectual property rights have functioned for centuries.
The Financial Impact: Real Loss, Real Consequences
This fight isn't just about principle. Money is changing hands. Or rather, money that used to change hands is evaporating.
Consider a freelance digital illustrator. She's spent 10 years building a portfolio and reputation. Clients hire her for
This isn't hypothetical. Illustrators have reported 40-60% declines in commission work since AI image generators became accessible. Some have given up freelancing entirely. Others have pivoted to supervising AI output—less creative fulfillment, lower rates.
The same dynamic plays out in music. A composer produces original orchestral pieces. They make money through licensing, commissions, and streaming. Now they're competing with AI-generated orchestral tracks that are... fine. Not perfect. But available instantly and costing nothing.
Large-scale studies on AI's impact on creative professions are still emerging, but the pattern is clear: when AI can do something 80% as well as humans for 5% of the cost, market prices collapse. The remaining 20% of quality difference matters less than the 95% price advantage.
Here's what particularly infuriates creators: they subsidized this disruption. The AI systems that now compete with them were trained on their work without compensation. It's like a manufacturing company training a robot on how you do your job, then using that robot to replace you, while keeping the profits from your displaced labor.
The broader economic question is whether this is innovation or predation. Technological disruption can create new opportunities even as it displaces existing work. The cotton gin destroyed hand-spinning but created textile manufacturing. Were that shift to happen today, would the hand-spinners be compensated for their obsolescence? Would there be transition support?
Current AI disruption is happening with minimal acknowledgment that any compensation is owed. Tech companies argue they're driving innovation. Artists argue they're being exploited. The gap between these positions feels unbridgeable.

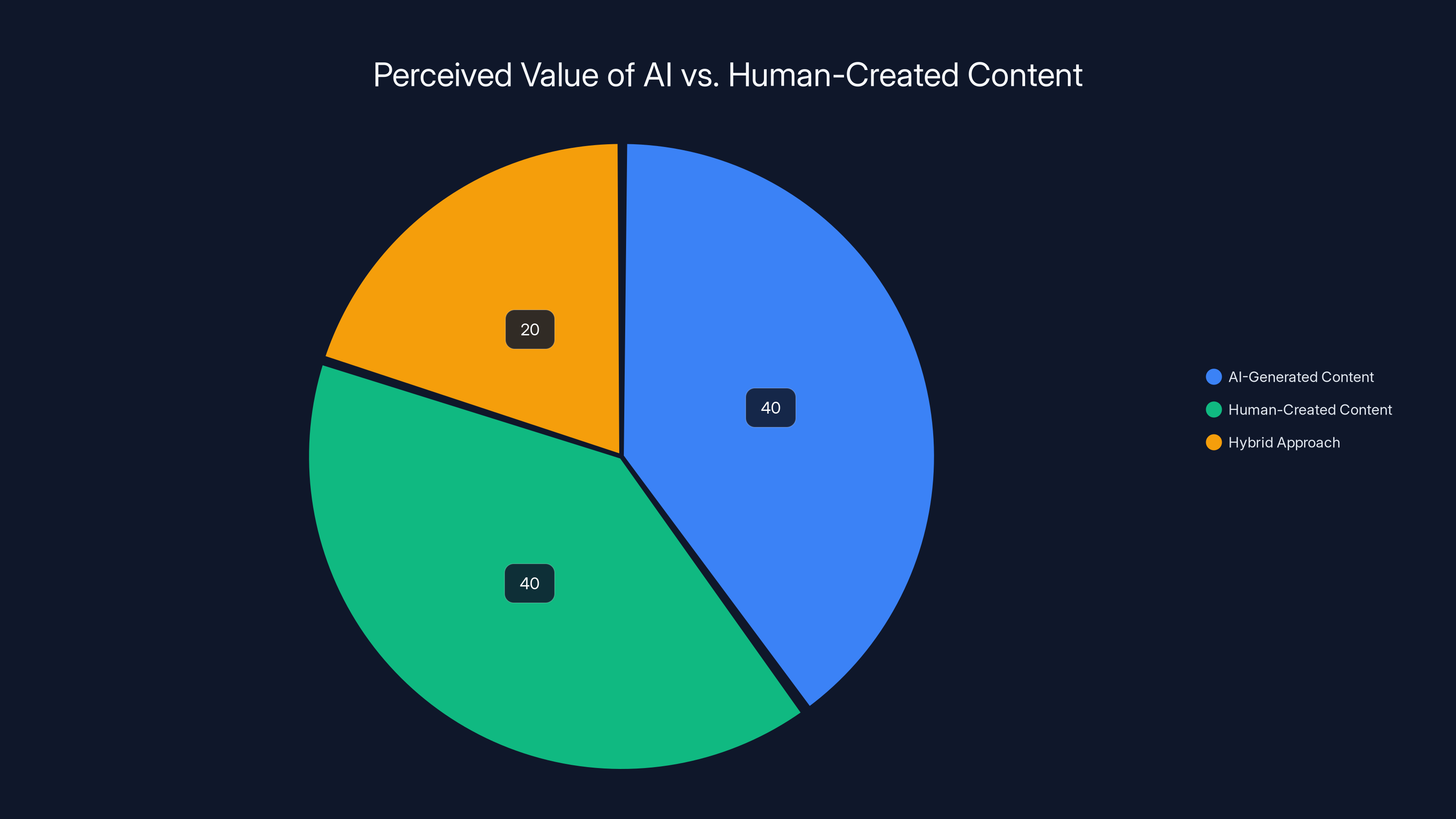
Estimated data suggests a balanced market preference between AI-generated and human-created content, with a notable segment favoring a hybrid approach.
The Arguments from AI Companies: Why They Say It's Fair
It's important to understand the AI industry's counterarguments. They're not entirely unreasonable, even if you disagree with them.
First, they argue that training data must come from somewhere, and restricting data access would slow beneficial innovation. AI systems trained on limited datasets perform worse. Restricting training data means slower progress on medical applications, scientific research, and tools that genuinely help society. The trade-off isn't clean—restrict training to be fair to artists, but slow down AI development that could save lives.
Second, they claim that what they're doing isn't that different from what humans do. When artists learn to draw, they study thousands of existing artworks. Musicians learn by listening to and analyzing existing music. Writers read extensively before writing their own work. Where's the line between legitimate inspiration and theft?
The distinction AI companies assert: machine learning isn't copying—it's abstracting. Training algorithms extract patterns and concepts, not literal reproductions. If Midjourney's system "understood" that blue skies and grass go together, that sunset lighting creates mood, that certain compositions feel balanced—these are abstract learnings, similar to what a human artist internalizes by studying existing work.
They also argue that much of the copyrighted work already available online, particularly on sites like Deviant Art or Art Station. Artists posted this work publicly. Was there an expectation that it wouldn't be analyzed by algorithms? The argument stretches here, but the logic is: if you put it on the public internet, aren't you accepting the internet will access it?
Finally, they contend that even if training on copyrighted work was technically infringement, it's been industry standard practice for years. Retroactively punishing AI companies for something that was considered acceptable in 2022-2023 seems unfair. The rules should be clarified going forward, but massive damages for past behavior seems disproportionate.
None of these arguments solve the fundamental problem: creators weren't asked, weren't informed, and weren't compensated. But understanding why AI companies resist restrictions helps explain why compromise is so difficult. Both sides have legitimate grievances.

The "Better Way" Alternative: Licensing and Consent Models
The campaign's framing—"a better way exists"—is crucial. The fight isn't "shut down AI." It's "do this differently."
Several alternative models exist and are being piloted:
Licensing Agreements: Companies could license training data from creators and rights holders. Instead of scraping the internet for free, they'd pay for curated, consented datasets. This increases costs but creates legitimate compensation. Stock photo and music licensing already work this way—why not training data?
Some forward-thinking companies are exploring this. There are now licensing marketplaces where artists can sell permission to train AI on their work for a one-time fee or ongoing royalties. It's not widespread yet, but the infrastructure exists.
Consent and Transparency: At minimum, creators should know when their work is being used for training. Datasets could be published with clear identification of copyrighted material. Artists could opt-out, having their work excluded from training. OpenAI eventually began offering opt-out mechanisms for websites, acknowledging the principle even if implementation is clunky.
Revenue Sharing: If AI systems are trained on an artist's work and that training directly contributes to the AI's profitability, shouldn't the artist see some of that revenue? Potential models include:
- Per-use fees when AI output resembles training data
- Percentage of revenue from systems trained on their work
- Licensing pools similar to music performance royalties
These are administratively complex but technically feasible. The music industry manages royalty distribution to millions of artists. Similar systems could work for AI.
Synthetic Data: Companies could generate training data synthetically rather than scraping copyrighted work. This is harder and produces lower quality datasets, but it's possible. As generation techniques improve, synthetic data becomes more viable. Some companies are investing heavily here specifically to avoid copyright conflicts.
The interesting thing about these alternatives is they're not mutually exclusive with innovation. Responsible AI companies are already implementing some version of these practices. They're slightly more expensive and more complicated than simply scraping. But they're far cheaper than defending copyright lawsuits for the next decade.
The campaign's genius is positioning these alternatives not as restrictions, but as enlightened self-interest. Companies that implement ethical training practices position themselves as trustworthy partners in the creative industry. Those that resist look like they're simply optimizing for short-term profit at creators' expense.

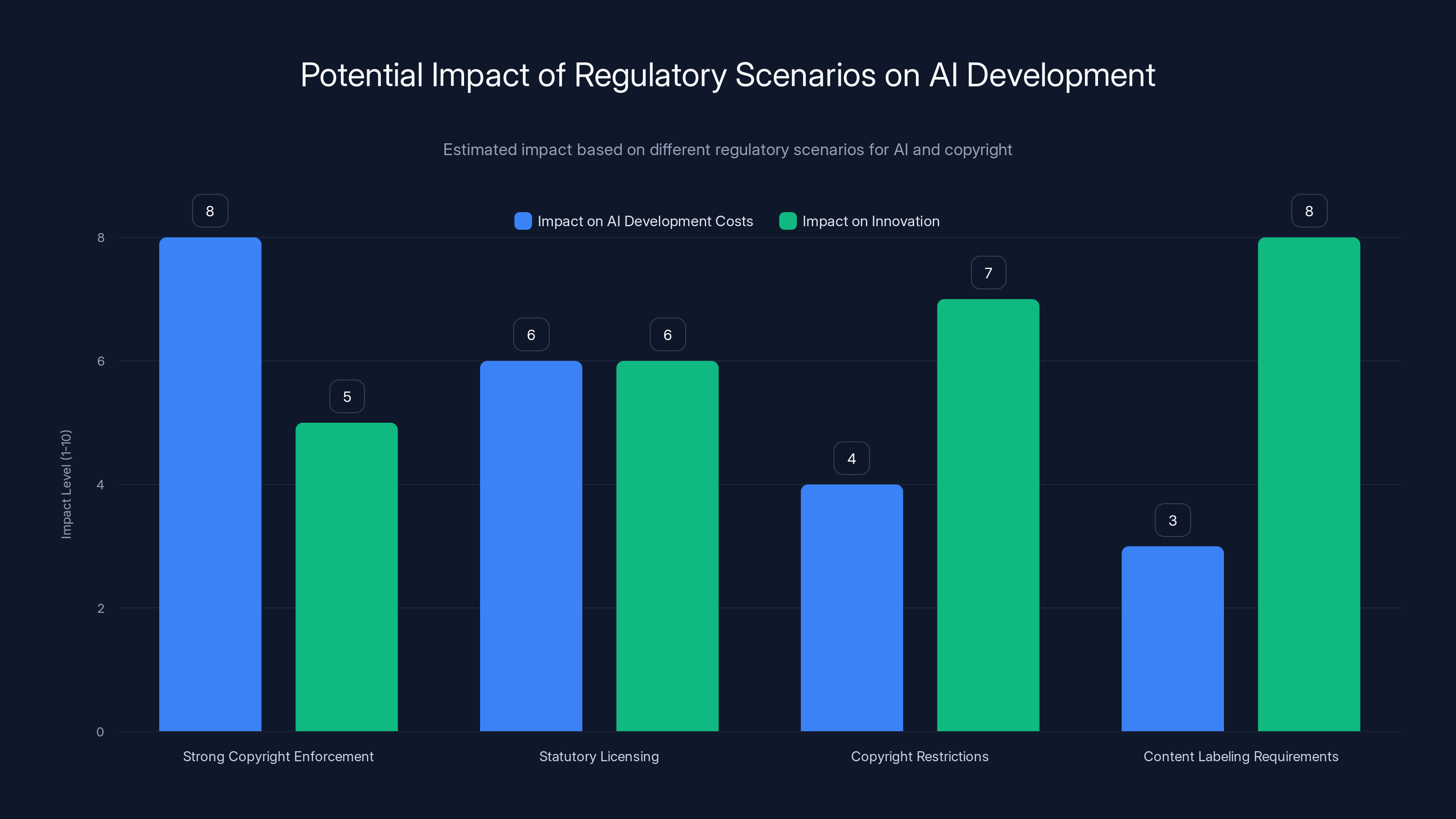
Estimated data shows that strong copyright enforcement could significantly increase AI development costs, while content labeling requirements may have the least impact on costs but could influence innovation positively.
International Responses: How Different Countries Are Handling This
The regulatory landscape is diverging significantly across borders, and this will ultimately pressure AI companies to adopt more ethical practices globally.
The European Union moved first and furthest. EU regulators increasingly require transparency about training data. The proposed AI Act includes provisions protecting creators' rights. Some EU countries are exploring statutory licenses—essentially automatic licenses for AI training with mandatory compensation to creators, similar to music broadcasting licenses.
The UK has been more permissive than the EU but still more protective than the US. British regulators are watching the copyright cases closely and may implement regulations depending on court outcomes.
Canada is developing its own approach, with discussions about fair dealing doctrine potentially being clarified to address machine learning. Australian regulators have also begun examining the issue.
The United States remains the laggard. Congress hasn't meaningfully addressed AI copyright issues, leaving everything to courts and voluntary industry practice. This puts US-based AI companies in an odd position: they face stricter regulations for operating in Europe but fewer restrictions at home. The logical outcome is companies will eventually implement European-standard practices globally rather than maintaining different systems.
This international divergence actually creates leverage for creators. If European regulations require licensing and transparency, US companies operating globally will likely adopt similar practices to maintain a unified product. They can't train one way for the US and another way for Europe.

The Legal Battles: What's Actually Happening in Court
Several major cases are working through the legal system right now, and their outcomes will reverberate for years.
The Authors Guild v. OpenAI case is the most prominent. Authors including Michael Chabon, John Grisham, and Sarah Silverman sued for unauthorized training on copyrighted books. OpenAI argues fair use, plaintiffs argue willful infringement. The discovery process has revealed internal OpenAI communications discussing awareness of copyright issues—not helpful to their defense.
Visual artists have filed multiple class-action suits. Sarah Andersen v. Stability AI represents thousands of artists whose work was scraped without consent. Similar cases are being litigated against Midjourney, Deviant Art, and others. These cases will determine whether copyright protections apply to image generation systems.
Music composers are filing complaints, though fewer large-scale lawsuits have materialized yet. The music industry is watching carefully, having already fought similar battles with file-sharing in the 1990s and streaming in the 2000s.
What's significant about these cases is they force companies to justify their practices under oath. Depositions reveal business models, training decisions, profit motives. Communications showing deliberate choices to use copyrighted material without licensing become evidence of willfulness—which can increase damages.
Courts have been unpredictable historically on fair use in new technological contexts. But the comprehensive nature of copyright infringement here—training on billions of copyrighted works without any attempt to license or compensate—creates a strong plaintiff case.
Experts expect some cases to result in significant damages. Others may be dismissed on fair use grounds. Likely outcome: mixed decisions that force legislative clarification.

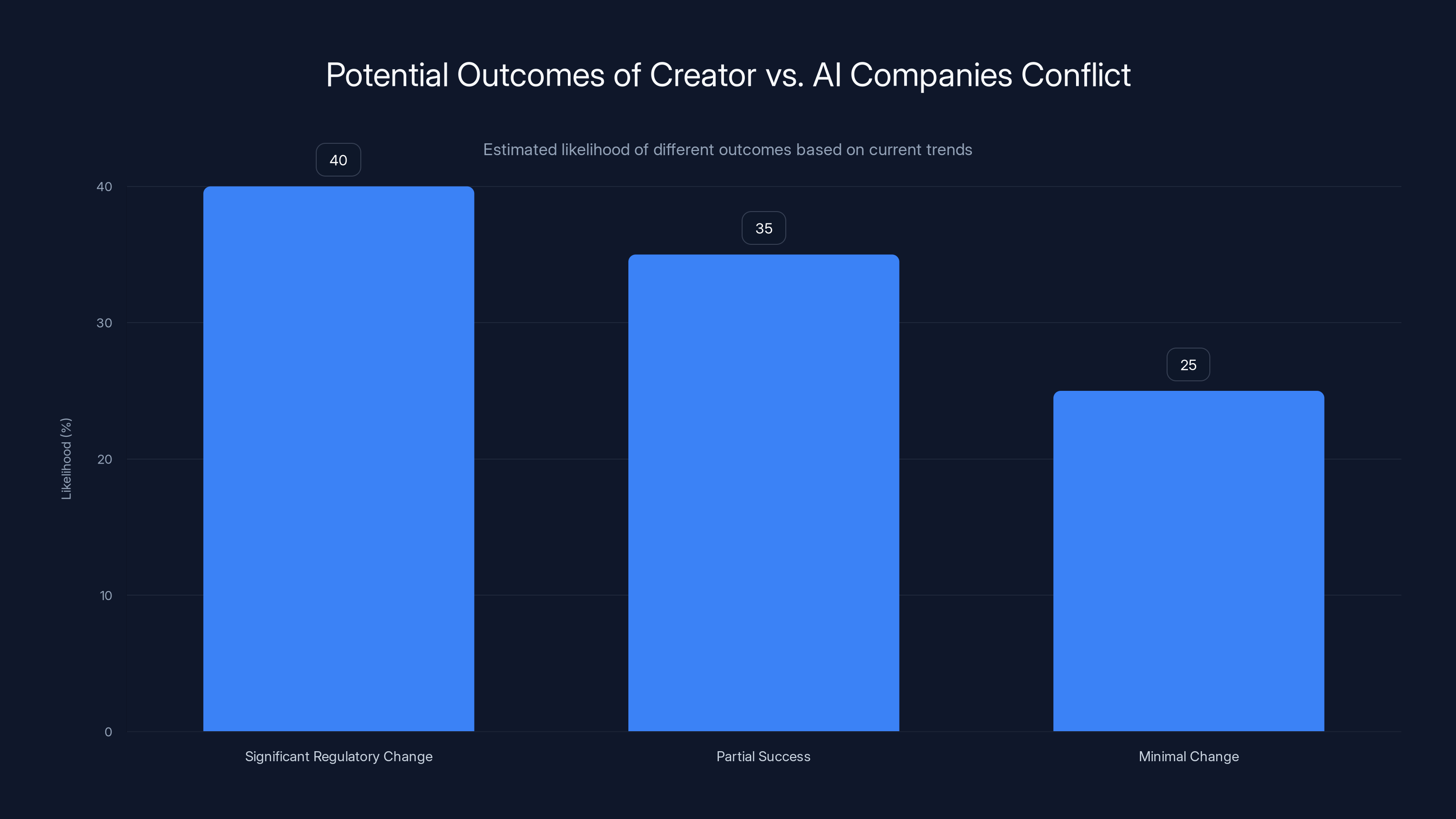
Estimated data suggests a 40% chance of significant regulatory change, a 35% chance of partial success, and a 25% chance of minimal change in the conflict between creators and AI companies.
AI Generated Content: The Quality vs. Authenticity Dilemma
Here's a question nobody in the tech industry wants to answer directly: if AI-generated content becomes visually and functionally indistinguishable from human-created content, does it matter anymore?
From one angle, no. If a client needs a logo and Midjourney produces something perfect for their needs for
But that framing misses something important about why people value human creativity. There's value in knowing that the work you're seeing came from someone's mind, someone's choices, someone's lived experience. That authenticity has commercial value even if the visual output is identical.
This is why music listeners still prefer human-composed orchestral music despite AI being capable of producing competent symphonies. There's something about knowing a human spent months on the composition—wrestling with it, making deliberate choices, pouring themselves into it—that makes it more valuable.
Likewise, when you commission an illustrator, you're not just paying for a visual. You're paying for their unique perspective, their problem-solving, their creative judgment. The relationship matters.
AI can replicate visual output. It hasn't replicated this aspect. Yet. Whether it ever will depends on questions of consciousness and authenticity that philosophers are still debating.
The practical implication: there will always be a market for certifiably human-created content. The question is how large that market is and what price it commands. As AI improves, that market may shrink and prices may fall. But it probably won't vanish entirely.
This is the future creators are actually fighting for: the right to operate in a diminished but viable market where their human authenticity is recognized and compensated. Not a world where AI is banned, but one where it's not their exclusively free competition.

The Generational Divide: Emerging Artists vs. Established Creators
Interestingly, the anti-AI movement isn't monolithic. Emerging creators sometimes see things differently than established professionals.
An illustrator who got her start in 2000 built her career in a world where becoming a professional meant years of practice, building a portfolio, convincing clients to take a chance. She has a vested interest in making that gatekeeping persist because it protected her professional status.
An illustrator trying to break in now sees AI differently. Maybe it's a threat to commissions she'll never get. But maybe it's also a tool she can use to rapidly iterate, to show more variety, to compete for work despite limited experience. AI democratizes certain types of creative output.
This generational divide creates odd political dynamics. Some young artists are furious about AI disruption. Others are enthusiastically adopting it as a tool. And some see it as both threat and opportunity—something to negotiate with rather than resist.
The anti-AI campaign is predominantly led by established professionals with the most to lose from disruption. Some emerging artists are part of it, but others are conspicuously absent. This split weakens the movement slightly but also makes the campaign's core argument stronger—it's not just resistance to change, it's about fair compensation and consent for the change that's coming anyway.

What Happens If Artists Win: Regulatory Scenarios
If the anti-AI campaign succeeds fully, what does that world look like?
Scenario 1: Strong Copyright Enforcement Courts rule that training AI on copyrighted material requires licensing. AI companies must pay rights holders or exclude copyrighted content. This increases AI development costs and potentially slows innovation. Companies license content, creators are compensated, but training datasets become more expensive.
Scenario 2: Statutory Licensing Legislators create mandatory licensing schemes similar to music licensing. AI companies must pay into a licensing pool, funds distributed to creators. Creators don't have to opt-in—it's automatic. This balances innovation with compensation.
Scenario 3: Copyright Restrictions Legislators explicitly carve out exceptions to copyright for AI training, but require disclosure and consent. Companies must tell creators when their work is used and provide opt-out mechanisms. Creators are informed but not necessarily compensated unless they negotiate licensing deals.
Scenario 4: Content Labeling Requirements Regulators require AI-generated content to be clearly labeled. Markets develop for both AI-generated and human-created content. Consumers choose based on preference. Creators can market their human-generated work as premium/authentic.
Most likely outcome: some combination of these. Strong protections in EU and Canada, weaker in US. Mandatory disclosure and opt-out mechanisms become standard. Some licensing requirements get established. AI companies adjust business models accordingly.
The worst outcome for tech companies would be massive retroactive damages from lawsuits combined with strict forward-looking regulations. But even if that happens, AI development continues—just with higher costs and more transparency.

What Happens If AI Companies Win: The Implications
Conversely, if AI companies successfully defend their practices legally, what unfolds?
The precedent would essentially be: copyrighted material can be used for machine learning training without licensing or compensation under fair use doctrine. This accelerates AI development. Companies freely scrape all available content. Training datasets become enormous and comprehensive. AI systems improve faster.
For creators, this means competing with AI systems trained on their own work without receiving any benefit from that training. The disruption to creative industries intensifies. Prices for creative work likely fall further as AI output becomes more competitive.
There would be a brutal efficiency gain for the tech industry and companies using AI: fewer humans needed to produce content. Remaining human creators increasingly work in AI supervision roles—fixing and directing AI output rather than creating from scratch.
Creators would eventually organize around content labeling and transparency anyway. A movement would emerge demanding certification of human-made content and clear labeling of AI-generated work. Markets would segment: premium human-created content for people who value authenticity, cheap AI-generated content for everyone else.
This outcome empowers tech companies in the short term but creates social friction that eventually demands regulatory response. It's not stable long-term. Societies generally don't accept large groups being substantially harmed for efficiency gains without compensation mechanisms.
The Role of Workforce Transition: Rethinking Creator Support
One narrative missing from most coverage: even if creators win copyright battles and force licensing agreements, that doesn't solve the underlying disruption.
AI will displace creative workers just as photography disrupted portrait painters and digital tools disrupted hand drafting. That displacement is happening regardless of who wins the copyright fight. The question isn't whether change will come, but how that change gets managed.
Robust transition support seems ethical and practical. This could include:
- Retraining programs for displaced creatives to work with AI tools
- Income support during the transition period
- Tax benefits for companies that hire human creators alongside AI
- Public investment in human creative output (arts funding, subsidized commissions)
- Portable benefits for freelance creators
None of this is standard tech industry practice, which typically treats workforce displacement as a personal problem for the disrupted workers. But creative professions have unique social value beyond just economic output. Societies invest in arts for cultural reasons, not just market reasons.
Forward-thinking policy would combine copyright protections with transition support. Companies compensate creators for past training through licensing fees and damages. Those funds could be reallocated to support the professional transition of displaced creators.
This is complex and expensive. But it's more humane and more stable than allowing creative industries to collapse while tech companies optimize everything away.

The Movement's Momentum: What's Changed in 2024-2025
The anti-AI campaign has gained real momentum. Here's what's actually shifted:
Political Attention: Congress and regulatory bodies are paying attention in ways they weren't two years ago. Specific legislation is being drafted in multiple countries. Politicians recognize creator constituencies care about this issue.
Corporate Response: Even AI companies skeptical of regulation are implementing some creator protections voluntarily. Transparency about training data is becoming standard. Opt-out mechanisms are proliferating. Some companies are starting licensing initiatives.
Cultural Narrative: The story has shifted from "AI is amazing" to "AI is amazing but raises serious questions about creative ownership." Nuance is entering mainstream conversations.
Legal Pressure: Multiple lawsuits working through courts with discovery processes revealing embarrassing internal communications. Companies can't simply declare victory and move forward—they have to defend their practices.
Public Awareness: Creators' concerns are no longer niche complaints. When Scarlett Johansson speaks, media coverage explodes. The issues are mainstream now.
Industry Bifurcation: Some AI companies are positioning themselves as responsible operators, respecting copyright and implementing ethical practices. This creates competitive pressure on competitors to do the same.
None of this guarantees creators will win. But the landscape has fundamentally changed. The days of companies silently scraping billions of copyrighted works without consequences appear to be ending.

Building Toward Resolution: Compromise Models
Optimal resolution probably isn't one side winning completely. More likely is negotiated settlement that reflects both interests.
Consider how this might work:
For Past Training: Courts or Congress establish reasonable damages for past copyright infringement. Not punitive damages that bankrupt companies, but meaningful compensation—perhaps a percentage of training costs or a percentage of subsequent revenues from models trained on copyrighted material.
For Future Training: New requirements that AI training on copyrighted material requires licensing. But licensing becomes standardized, not ad-hoc—perhaps through a centralized clearinghouse similar to music licensing. Licensing fees reflect genuine costs but don't prohibitively restrict training.
For Transparency: Companies disclose which copyrighted works were used in training. Creators can opt-out and have their work excluded from future training. This allows consent to be meaningful.
For Synthetic Data: Companies are incentivized (through tax breaks or regulatory preferences) to develop synthetic training data and prove-of-concept systems that don't require copyrighted material.
For Attribution: When AI output closely resembles training data, the system provides attribution to the training source. This helps creators understand when their work influenced output.
This compromise doesn't make everyone happy. Tech companies pay more. Creator compensation isn't lavish. But it's more sustainable than either extreme. Creators maintain some control and receive some benefit. Companies can still develop AI—just more responsibly.
The challenge is getting from current positions to this middle ground. Both sides are still fighting for maximum advantage. But eventually, exhaustion and mounting legal costs will probably push toward settlement.

The Broader Question: Who Owns Culture in the AI Era?
Underlying all these specific disputes is a philosophical question: who owns culture?
Traditionally, creators own their creations. Copyright law reflects the idea that artistic works belong to the people who create them. They can share, sell, or restrict use as they choose.
But data-driven AI creates tension with this model. AI systems learn from vast cultural commons. They extract patterns from millions of creative works. In some sense, AI represents a new kind of authorship—not individual human creativity, but pattern recognition and synthesis from collective cultural material.
This raises questions: Should AI trained on cultural commons be owned exclusively by the company that trained it? Should the benefits of training on millions of creative works accrue entirely to tech companies? Or should there be some acknowledgment that AI leverages humanity's accumulated creative output?
Different societies will probably answer these questions differently. The US might lean toward protecting tech company interests. The EU might implement stronger creator protections. The result will be a patchwork of regulations that companies navigate globally.
What seems clear: pure free-for-all scraping without compensation isn't acceptable. Creators will fight, courts will eventually rule, and regulations will emerge. The exact form remains uncertain, but some form of acknowledgment that creators' work has value seems inevitable.

FAQ
What does it mean when artists say AI companies are stealing their work?
Artists argue that AI companies train their systems on copyrighted work—images, text, music, voices—without permission or payment. From artists' perspective, this is no different than photocopying someone's work without a license. The fact that the copying is done by algorithms rather than humans doesn't change the fundamental issue of unauthorized use of copyrighted material.
Why do AI companies say training on copyrighted material is legal?
AI companies rely on "fair use" doctrine, a legal principle allowing limited copying of copyrighted material for certain purposes like research or commentary. They argue that training AI models constitutes transformative use—they're not copying the work to display or sell it, but using it as data to train algorithms. Whether fair use actually protects this practice is still being decided in courts.
What happened with Scarlett Johansson and OpenAI?
Johansson claimed OpenAI created an AI voice called "Sky" that closely resembled her distinctive voice without her permission. She had previously declined OpenAI's request to license her voice. The incident highlighted that even famous people couldn't prevent their vocal likeness from being replicated by AI systems. OpenAI eventually changed the voice option, but the incident galvanized broader creator concerns about unauthorized AI replication.
How much money are artists actually losing to AI?
Accurate figures are difficult because the market disruption is ongoing and not systematically tracked. However, freelance creative professionals report 40-60% declines in commission work since AI image generators became popular. Impacts vary by field—routine illustration suffers most, while high-skill artistic direction remains more valuable. Overall, AI is reducing the market size for creative work while depressing rates for remaining work.
What would a "better way" of developing AI look like?
The campaign suggests licensing-based models where AI companies pay creators for training data rather than scraping it free. Other approaches include requiring consent and transparency (artists knowing when their work is used), revenue sharing (creators receiving a percentage of profits from models trained on their work), or using synthetic training data that doesn't rely on copyrighted material. These alternatives increase development costs slightly but create legitimate creator compensation.
Could AI companies simply avoid copyright lawsuits by using only consented training data?
Yes, but it would be more expensive and time-consuming. Creating curated, licensed training datasets costs significantly more than scraping the internet. Building synthetic training data to replace scraped content is technically challenging but possible. Some companies are exploring these approaches, but the cost structure incentivizes continued scraping unless regulations or legal judgments force change.
Will AI be banned or restricted heavily if artists win these cases?
Unlikely. Even in strongest-case creator victory scenarios, AI development continues. Companies would need to license more content and provide more transparency, but AI innovation wouldn't stop. The outcome is more likely a reshaped business model where AI companies pay for training data and operate with more disclosure, not a prohibition on AI development.
How might copyright law change in response to this conflict?
Possible changes include clarifying that fair use doesn't automatically protect AI training on copyrighted material, establishing mandatory licensing requirements for AI training on copyrighted work, requiring disclosure and consent mechanisms, or creating statutory licenses similar to music licensing where AI companies pay into a fund distributed to creators. Different countries will likely implement different approaches.
Are there any AI companies implementing ethical practices around creator copyright?
A few companies are beginning to differentiate themselves through more ethical practices. Some are implementing opt-out mechanisms for websites and creators. Others are exploring licensing approaches. These companies argue that transparency and fair dealing are good business practices that differentiate them from competitors, even if costs are higher. As regulatory pressure increases, more companies will likely follow.
What should creators do to protect their work from unauthorized AI training?
Options include watermarking images with metadata designed to confuse AI training algorithms, posting data with robots.txt restrictions to block scraping, joining legal actions or supporting creator organizations, staying informed about which platforms are training on uploaded content, advocating for regulatory protections, and considering how to adapt skills to work alongside AI tools rather than purely resisting them.

The Future Is Being Written Now
The battle between creators and AI companies is one of the defining tech conflicts of this decade. Unlike some tech controversies that eventually resolve into irrelevance, this one affects fundamental questions about ownership, compensation, and who benefits from technological innovation.
What makes this moment different from previous technological disruptions is the visibility and organization of creator pushback. Scarlett Johansson isn't powerless—she went public and demanded accountability. Thousands of artists organized around shared grievances. Legislators started paying attention. Courts are making decisions that will set precedent for years.
The outcome probably isn't predetermined. The campaign could succeed in forcing significant regulatory change and creator compensation. It could partially succeed, winning transparency and consent requirements but not strong compensation. It could fail, and AI companies could continue current practices with minimal change.
But one thing seems certain: the era of free, consequence-free scraping of creative work appears to be ending. Companies will have to justify their practices, compensate creators, or operate with more transparency. That was never going to happen without organized creator pushback.
For people building AI products or working in creative fields, paying attention to this conflict is essential. The regulatory environment is shifting. Creator expectations are changing. How companies navigate this transition will determine whether AI becomes a tool that supplements human creativity or something that appears to steal from it.
The campaign's genius was reframing the issue from abstract copyright law to something visceral: "a better way exists." That framing matters because it's not just criticism—it's a blueprint for an alternative. It says to tech companies: you can build profitable AI without doing this. You can be responsible. You can compensate creators.
Whether they listen will say a lot about the future of technology, creative industries, and whether disruption can happen ethically.
Use Case: Automating content creation reports that track which of your designs have been used in AI training datasets and generating compliance documentation for creator protection policies.
Try Runable For Free
Key Takeaways
- Hundreds of creators joined an organized campaign against AI companies training systems on copyrighted work without permission or compensation
- Scarlett Johansson's public fight with OpenAI over voice replication became a rallying point for broader creator concerns about AI appropriation
- Freelance creative professionals report 40-60% income decline since AI image generation became accessible, representing real financial disruption
- The legal argument centers on fair use doctrine: whether AI training qualifies as transformative use or wholesale copyright infringement
- Alternative models exist including licensing-based training, mandatory compensation, creator consent requirements, and synthetic data generation
- International regulation is diverging, with EU implementing stronger creator protections while US relies on court decisions
- Multiple copyright lawsuits are working through courts with discovery revealing company awareness of copyright issues
- The campaign's core message is that a better way exists: AI can develop responsibly while compensating and respecting creators
- Likely outcome is some form of licensing requirement and transparency mandate rather than AI prohibition or complete creator victory
Related Articles
- AI Slop Crisis: Why 800+ Creatives Are Demanding Change [2025]
- AI Identity Crisis: When Celebrities Own Their Digital Selves [2025]
- Wikipedia's Enterprise Access Program: How Tech Giants Pay for AI Training Data [2025]
- Meta Pauses Teen AI Characters: What's Changing in 2025
- ChatGPT Safety vs. Usability: The Altman-Musk Debate Explained [2025]
- How to Watch Blue Murder Motel Online Free [2025]

