![Blackstone's $1.2B Bet on Neysa: India's AI Infrastructure Revolution [2025]](https://tryrunable.com/blog/blackstone-s-1-2b-bet-on-neysa-india-s-ai-infrastructure-rev/image-1-1771203974295.jpg)
India's AI Infrastructure Moment: Why Blackstone Bet $1.2 Billion on Neysa
Last month, something quietly shifted in the global AI landscape. Blackstone, one of the world's largest private equity firms, announced a hefty commitment to Neysa, an Indian startup most people outside tech circles have never heard of. We're talking up to
Now, here's why this matters beyond just another mega-funding round.
For years, the AI infrastructure story centered on a handful of Western players. You had your hyperscalers like AWS, Google Cloud, and Azure dominating the compute space. You had Nvidia controlling the chip supply chain with an iron grip. The story felt inevitable: Silicon Valley builds the infrastructure, the world uses it.
But that narrative is breaking down. And fast.
India's been watching this play out and thinking: why are we reliant on foreign compute capacity to train and deploy AI models for Indian users, Indian businesses, and Indian regulatory requirements? Why should data sovereignty concerns mean slower AI adoption? Why not build something local?
Enter Neysa.
This isn't a story about a scrappy startup with a cool idea. This is a story about how geopolitics, infrastructure gaps, and trillion-dollar technology shifts are creating entirely new business categories. It's about what happens when traditional venture capital meets the uncomfortable reality that AI infrastructure, like semiconductors before it, is becoming a strategic asset. As noted by Analytics India Magazine, Blackstone's investment is a strategic move to address these gaps.
Let's break down what's actually happening here, what the numbers mean, and why this single deal tells you everything you need to know about the next decade of AI infrastructure.
The GPU Shortage That Never Really Ended (But Evolved)
Remember 2023? GPUs were impossibly hard to get. Nvidia H100s were trading on the gray market. Companies were paying 10x markups. Everyone was screaming about AI compute scarcity.
You'd think the situation resolved by now. It hasn't. It just got more subtle.
The shortage didn't end because demand simply outpaced supply. Every month, new large language models required more compute to train. Every quarter, enterprises wanted to fine-tune models for their specific use cases. Governments started pushing for homegrown AI capabilities. The total addressable market for GPU-scale compute didn't shrink. It exploded.
But here's the shift: the scarcity isn't about availability anymore. You can buy GPUs now (if you have money). The scarcity is about access on your terms. Access where you need it. Access with the support you need. Access that respects your regulatory requirements.
Consider the traditional hyperscalers. AWS, Google Cloud, and Azure are incredible platforms. They're also relatively hands-off. You spin up infrastructure, you figure out the optimization yourself, you compete with thousands of other workloads for resources. The support model is ticketing-based, asynchronous, and built for massive scale (not specialized attention).
Now imagine you're a financial services company in India. You've got regulatory requirements saying data can't leave the country. You need to fine-tune a model using proprietary customer information. You can't just throw it at AWS and hope for the best. You need local compute, local support, and local compliance frameworks.
Or you're an AI lab that's grown past small-scale experimentation. You need dedicated GPU clusters, not shared infrastructure where your training jobs compete with thousands of others. You need 24/7 support because your training runs take weeks, and a single misconfiguration costs millions. You need engineers who understand your specific use case.
This is the world Neysa operates in. This is the world that Blackstone's $1.2 billion bet is betting will get very, very large.
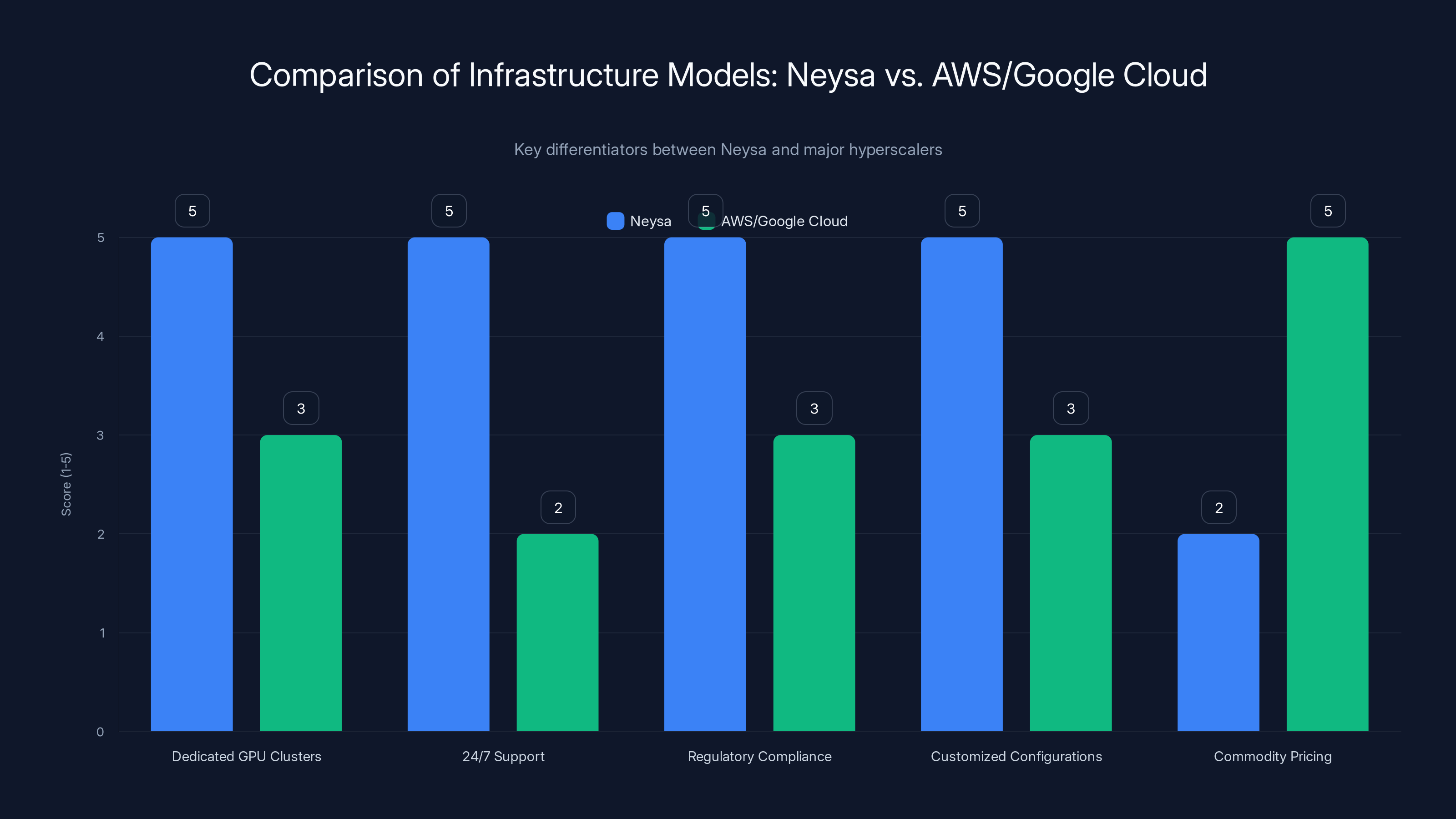
Neysa excels in providing dedicated GPU clusters, 24/7 support, regulatory compliance, and customized configurations, whereas AWS and Google Cloud focus on commodity pricing and scalability.
Who Is Neysa, Actually?
Neysa was founded in 2023 by Sharad Sanghi (CEO and co-founder) and team. As of the Blackstone announcement, the company has about 110 employees spread across Mumbai, Bengaluru, and Chennai.
The company operates dedicated GPU infrastructure optimized for AI workloads. They build custom clusters, they manage the networking, they handle the storage infrastructure, and they provide the operational support that comes with it. Think of them as the opposite of a hyperscaler: smaller, more focused, more hands-on.
Sanghi's operating philosophy is clear: provide the kind of support and customization that hyperscalers can't offer at scale. "A lot of customers want hand-holding, and a lot of them want round-the-clock support with a 15-minute response and a couple of our resolutions," he told TechCrunch. "Those are the kinds of things that we provide that some of the hyperscalers don't."
This is radical honesty about the market gap. Hyperscalers built their economics on self-service. Neysa's building theirs on specialized support.
As of the announcement, Neysa had about 1,200 GPUs live. The company is targeting deployments of more than 20,000 GPUs over time as customer demand accelerates. Sanghi indicated the company expects to more than triple capacity next year, with some conversations "at a fairly advanced stage" that could accelerate the timeline to nine months.
The capital will be deployed across compute clusters (the bulk), networking infrastructure, storage systems, and software platforms for orchestration (managing which jobs run on which GPUs), observability (monitoring performance and resource utilization), and security.

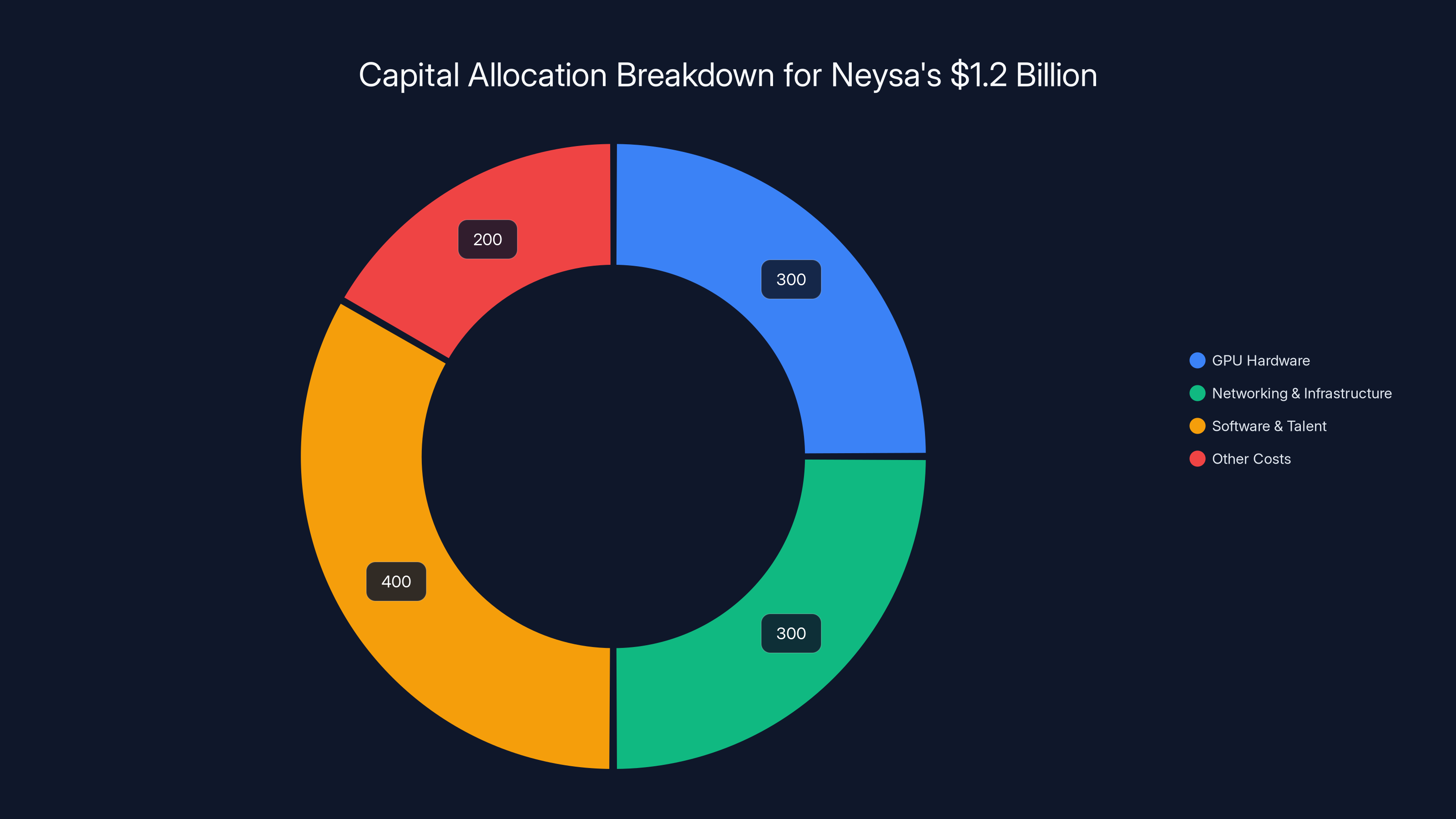
Estimated data suggests that Neysa allocates 50% of its capital to GPU hardware and infrastructure, with the remaining 50% invested in software, talent, and other operational costs.
Blackstone's AI Infrastructure Thesis: From Data Centers to AI Infrastructure Providers
Blackstone isn't some random mega-fund throwing money at AI startups. The firm has a specific thesis about infrastructure and AI, and they've been betting on it for years.
Prior to Neysa, Blackstone backed QTS (a large-scale data center operator), Air Trunk (Asia-Pacific data center platform), Core Weave (specialized AI infrastructure provider in the US), and Firmus (AI infrastructure provider in Australia). Notice the pattern? Blackstone is systematically building positions across geographic regions and infrastructure specializations.
Ganesh Mani, a senior managing director at Blackstone Private Equity, laid out the reasoning: "A lot of customers want hand-holding, and we believe India currently has fewer than 60,000 GPUs deployed. We expect the figure to scale up nearly 30 times to more than two million in the coming years." This statement aligns with TechBuzz's analysis of the market potential.
That's not a casual estimate. That's based on internal analysis of government demand, enterprise regulatory requirements, and India's position as a major AI research hub. Mani cited three specific drivers:
Government demand: India's pushing to build domestic AI capabilities. Why? Strategic independence. Data sovereignty. Developing indigenous AI applications for a 1.4 billion person population.
Enterprise regulatory requirements: Financial services, healthcare, and other regulated sectors need to keep data local. They can't always use cloud platforms where data might transit through multiple countries.
AI developer concentration: India has massive populations of AI researchers, machine learning engineers, and startups. Many global AI labs (Open AI, Anthropic, Google Deep Mind) count India among their largest user bases. That means growing demand for local compute capacity to reduce latency and meet data residency requirements.
Blackstone's thesis is straightforward: as AI workloads distribute geographically (driven by regulation and performance requirements), specialized regional providers will capture value that hyperscalers can't because they're optimized for global scale, not local requirements.

The Neo-Cloud Phenomenon: A New Category Emerges
There's a term floating around infrastructure circles: "neo-clouds." It refers to a new generation of infrastructure providers that aren't trying to be AWS 2.0. They're being something different.
Neo-clouds share specific characteristics:
Specialization: They focus on specific workloads (AI compute, GPU clusters) rather than trying to be everything to everyone.
Speed of deployment: They can spin up dedicated infrastructure faster than traditional hyperscalers because they're not managing massive multi-tenant environments.
Customization: They offer infrastructure tailored to specific requirements (regulatory, performance, latency) rather than one-size-fits-all cloud services.
Support model: They operate on managed services or dedicated support rather than self-service ticketing.
Regional focus: Many operate primarily in specific geographies where they understand local regulatory and market requirements.
Neysa fits this mold perfectly. Core Weave (which Blackstone also backed) operates as a neo-cloud. Crusoe Energy (which pairs AI compute with excess energy from oil and gas operations) is another example. Lambda Labs, which offers GPU-as-a-service for machine learning, is yet another.
The neo-cloud category exists because the traditional cloud economics don't work for specialized, high-compute workloads. Hyperscalers want you to buy variable compute, pay per minute, and move on. But when you're running a training job that takes three weeks, you want committed capacity, predictable pricing, and dedicated support.
It's the same reason why, despite the dominance of hyperscalers, specialized hosting providers and managed services companies still exist and thrive. Sometimes the economics of commoditization don't serve everyone equally.
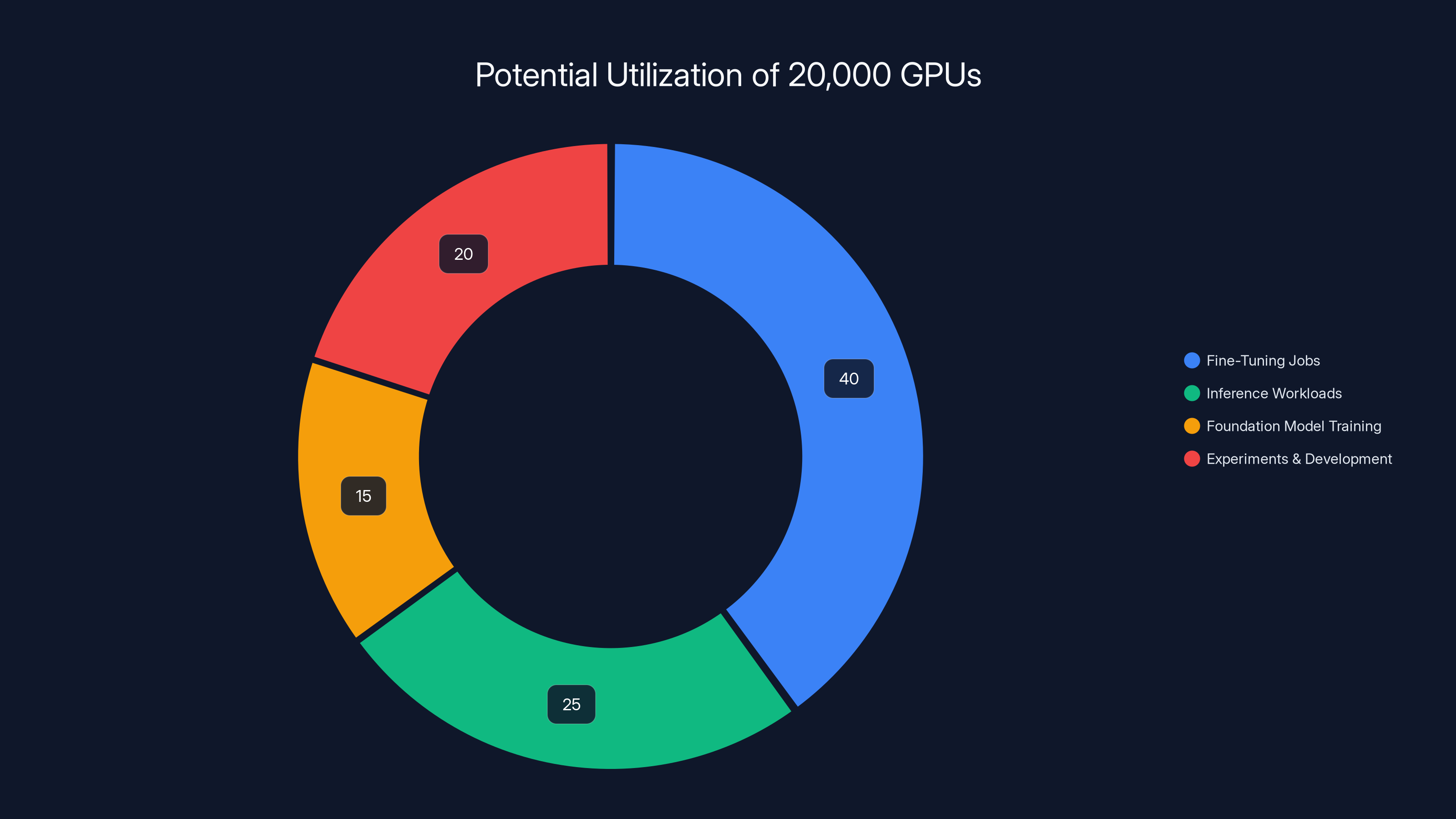
Estimated data shows 20,000 GPUs could be used for 40% fine-tuning jobs, 25% inference workloads, 15% foundation model training, and 20% experiments and development. Estimated data.
India's AI Ambitions and the Data Sovereignty Story
India's been somewhat quiet in the global AI conversation, but that's changing rapidly.
The country is home to massive engineering talent. Companies like TCS, Infosys, and Wipro employ thousands of engineers working on AI projects. Startups are emerging constantly. Research institutions like IIT Delhi, IIT Mumbai, and IISC Bangalore produce AI researchers at scale.
But there's been a structural gap: most of this talent is building on top of infrastructure owned and operated by American companies. Models are trained on AWS or Google Cloud. Deployments run on cloud platforms built by Western companies. Data, even when it should stay local for regulatory reasons, sometimes transits through multiple countries.
This creates several problems:
Cost: Compute running on international cloud platforms is more expensive for Indian enterprises. Latency adds up. Data transfer costs accumulate.
Compliance: Regulated sectors (banking, healthcare, insurance) face complex compliance regimes. Indian regulatory bodies increasingly expect data residency (data staying within India). Cloud platforms designed for global distribution make this complicated.
Sovereignty: There's a clear strategic interest in not being entirely dependent on foreign infrastructure for something as critical as AI development. Governments worldwide are realizing that AI infrastructure is as important as semiconductors used to be.
Performance: Latency matters for certain workloads. If you're deploying models that serve Indian users, running compute in India means lower latency, better performance, and better user experience.
Neysa exists to address exactly these gaps. The company positions itself as an infrastructure provider that understands Indian regulatory requirements, can provide local support, and can build dedicated compute capacity specifically for Indian enterprises and AI developers.
Blackstone's $1.2 billion bet is essentially saying: "This gap is going to close, and whoever owns the infrastructure as it closes will capture enormous value." It's infrastructure as a strategic asset.
The Numbers: What $1.2 Billion Actually Means
Let's break down the capital structure because it tells you something important about how Neysa plans to build.
$600 million in primary equity: This is Blackstone's equity investment in the company. Blackstone gets majority ownership. This is significant because it signals serious, long-term commitment (not just a quick financial engineering play).
**
Total capital: $1.2 billion. But here's what's important: this isn't all being spent on GPUs.
Sanghi indicated that the bulk of capital goes toward "deploy[ing] large-scale GPU clusters, including compute, networking and storage." But a meaningful portion goes toward software platforms for orchestration, observability, and security.
This is smart capital allocation. You can't just rack and stack GPUs. You need sophisticated software to:
Orchestrate workloads: Deciding which job runs on which GPU, managing multi-GPU jobs, handling spillover, optimizing utilization.
Observe performance: Collecting metrics, identifying bottlenecks, tracking GPU utilization, understanding job performance, alerting on failures.
Secure infrastructure: Access control, encryption, audit logging, compliance tracking, network isolation.
All of this is non-trivial. It's why someone can't just use leftover GPUs and a spreadsheet. Building at scale requires serious software engineering.
Neysa's targeting more than 20,000 GPUs over time. At an average cost of
The debt financing component is typical for infrastructure plays. You borrow against cash flows or committed customer contracts. This is how data center companies have historically financed their expansion.

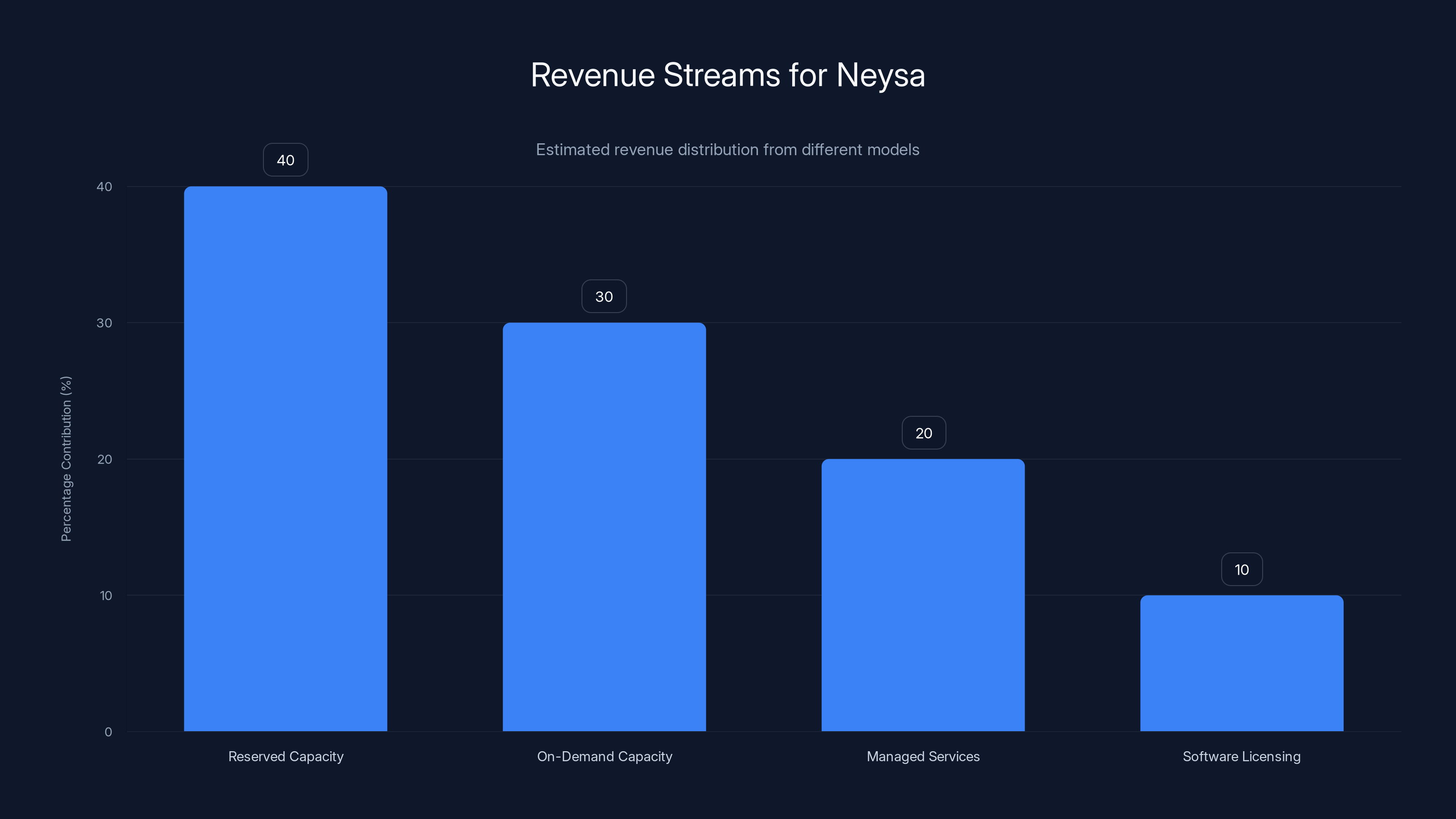
Estimated data suggests reserved and on-demand capacities are major revenue contributors, with managed services and software licensing providing additional income.
GPU Economics: Why 20,000 GPUs Matters
To understand why Neysa's targeting 20,000 GPUs, you need to understand what that infrastructure can actually support.
A single H100 GPU can train smaller language models or fine-tune larger ones. But modern AI workloads often require GPU clusters. An 8-GPU cluster can train larger models faster. A 256-GPU cluster (or larger) is how you train foundation models at scale.
Here's a rough breakdown:
- 1-8 GPUs: Fine-tuning, inference, experimental work
- 32-128 GPUs: Training small-to-medium models, large-scale inference
- 256+ GPUs: Training large foundation models, massive inference workloads
So 20,000 GPUs could theoretically support:
- 80+ simultaneous fine-tuning jobs (if using 256-GPU clusters)
- 500+ parallel inference workloads (if using 32-40 GPU inference clusters)
- 2-4 large foundation model training runs (depending on model size and cluster configuration)
- Hundreds of smaller experiments and development workloads
The actual utilization depends entirely on customer demand. Sanghi indicated demand is strong enough that the company expects to "more than triple capacity next year." That suggests customers are actively requesting infrastructure, not theoretical demand.
At current Indian pricing for cloud infrastructure (roughly 20-30% cheaper than Western pricing due to lower operating costs), 20,000 GPUs could generate:
Conservative estimates:
These are rough numbers, but they illustrate why Blackstone is comfortable with $1.2 billion in capital. The addressable market is large, the supply constraints are real, and the competitive position is defensible.

The Hyperscaler Problem: Why Neysa Can Exist
One natural question: why can't AWS or Google Cloud just meet this demand? They have global infrastructure, massive engineering teams, and existing customer relationships.
They actually can. But they probably won't, at least not in a way that competes with Neysa.
Hyperscalers are engineered for economies of scale through commoditization. They want customers to use self-service, standard configurations, and pay variable pricing. This maximizes utilization and minimizes operational overhead.
But Neysa's customer needs (specialized support, regulatory compliance, local presence, dedicated infrastructure) require the opposite economics. They require relationship-based sales, custom configurations, and committed capacity pricing. These are explicitly not how hyperscalers want to operate.
Moreover, hyperscalers' cost structure assumes global efficiency. They build massive regions and rent capacity globally. This works great when customers are globally distributed. It works less well when a significant portion of customers are legally or practically required to keep data local.
So Neysa doesn't compete with AWS head-to-head. Instead, it competes for the customers AWS doesn't want: those who need local infrastructure, hands-on support, regulatory compliance, and are willing to pay for it.
This is a "focus" strategy in classic Porter terms. Neysa focuses on a specific customer segment (Indian enterprises with data residency requirements, local AI labs, government projects) and builds infrastructure specifically optimized for their needs.
Hyperscalers can match any individual feature, but matching the entire package at scale would require fundamentally reorganizing their business. So they don't.

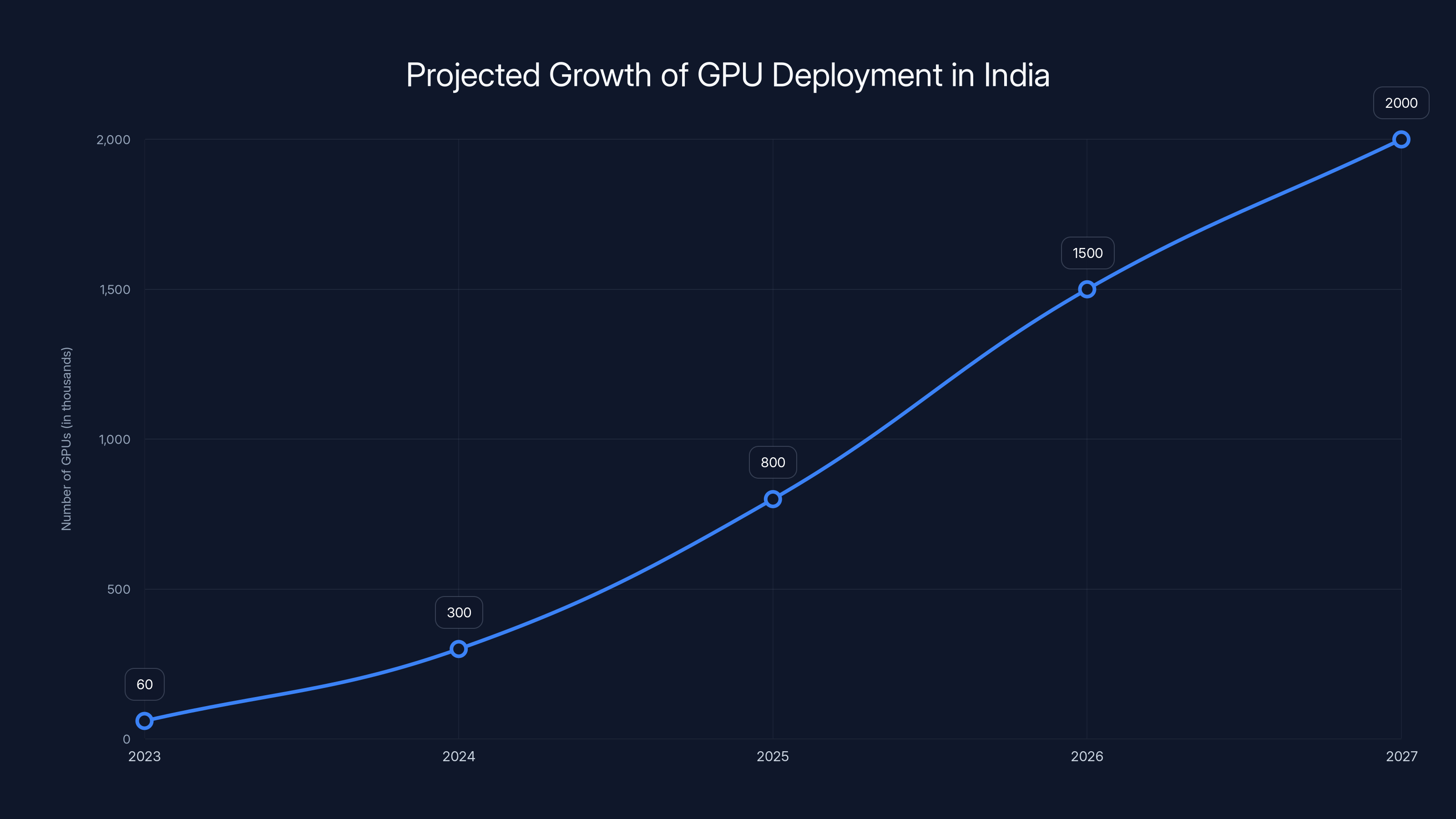
India's GPU deployment is expected to grow from under 60,000 in 2023 to over 2 million by 2027, driven by increased demand from government, enterprises, and AI developers. Estimated data based on market trends.
Competitive Landscape: Neysa Isn't Alone (But It's Well-Positioned)
Neysa isn't the only company building specialized AI infrastructure. But it's one of the best-capitalized.
Core Weave (also backed by Blackstone) operates a similar model in North America and Europe. They've raised massive funding and are executing on GPU infrastructure deployment.
Lambda Labs offers GPU clusters as a service, primarily targeting researchers and AI companies. They're cheaper than hyperscalers but less comprehensive.
Crusoe Energy pairs AI compute with excess energy from energy operations. The model is interesting but more limited in customer base.
Paperspace offers GPU infrastructure and development platforms. They're more developer-focused and less enterprise-focused than Neysa.
Modal is building containerized infrastructure for serverless compute. Different positioning but similar underlying thesis.
Within India specifically, Neysa's the clear leader in terms of capital raised and infrastructure deployed. But there's room for multiple players to succeed. India's AI infrastructure market is emerging, not mature. Having $600 million in equity capital (and majority backing from Blackstone) gives Neysa significant advantages:
- Capital for growth: They can invest in infrastructure faster than bootstrapped competitors
- Credibility: Blackstone's backing signals seriousness to enterprise customers
- Operational expertise: Blackstone brings data center and infrastructure operations expertise
- Network effects: Blackstone's portfolio companies (other infrastructure providers) can learn from Neysa's execution

Software as the Differentiator: Orchestration, Observability, and Security
Here's something important that often gets overlooked: the real differentiation in modern infrastructure isn't the hardware anymore. It's the software on top of it.
GPUs are commodities. H100s from Nvidia are the same whether you buy them from Neysa or AWS. Networking hardware is standardized. Power supplies and cooling are engineered for performance and cost.
But the software that orchestrates, monitors, and secures the infrastructure? That's where differentiation lives.
Neysa is investing in three specific software capabilities:
Orchestration platforms: This is the software that decides which job runs on which GPU. It's complex because:
- Multi-GPU jobs need contiguous capacity
- Different jobs have different resource requirements
- You need to maximize utilization while minimizing context switching
- You need to handle failures gracefully
Think of it like an operating system for a GPU data center. Kubernetes is great for distributed systems, but GPU orchestration has specific challenges that generic container orchestration doesn't solve well.
Observability platforms: This is the software that monitors everything. Metrics, logs, traces, events. You need to know:
- Which GPUs are in use and for how long
- What's the performance of each job
- Are there bottlenecks (network, storage, compute)
- What's the utilization per customer
- Which jobs are failing and why
Without comprehensive observability, you're flying blind. You can't optimize, you can't troubleshoot, and you can't charge accurately.
Security platforms: This is about access control, encryption, audit logging, and compliance. For enterprise customers, especially in regulated sectors, security is non-negotiable. You need:
- Fine-grained access control (which teams/individuals can access which GPUs)
- Encryption in transit and at rest
- Audit logging (who accessed what, when, and why)
- Compliance automation (documenting compliance with regulations)
- Network isolation
Each of these software capabilities requires 10-50 engineers and multiple years of development. But once built, they become defensible advantages because they're tightly integrated with the infrastructure.

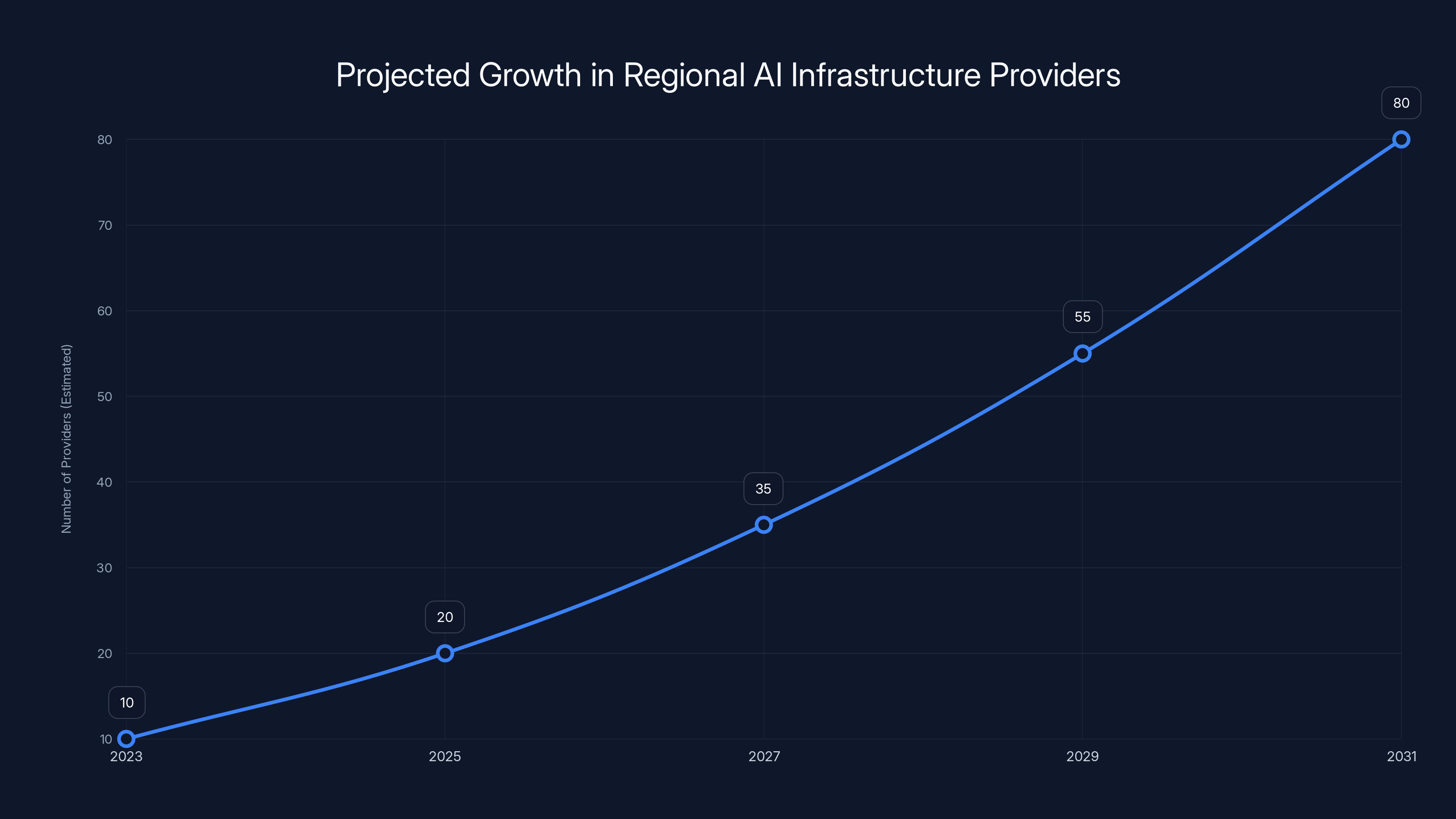
The number of regional AI infrastructure providers is expected to grow significantly over the next decade as demand for localized, specialized support increases. (Estimated data)
Revenue Model and Customer Economics
Let's talk about how Neysa actually makes money because this matters for understanding the investment thesis.
Neysa likely operates some mix of:
Reserved capacity: Customers commit to using a certain amount of GPU-hours per month, getting a discount. Neysa gets predictable revenue and committed utilization.
On-demand capacity: Customers pay per GPU-hour for additional capacity beyond their reservations. Neysa monetizes spare capacity and customer spikes.
Managed services: Customers may pay additional for managed fine-tuning, optimization consulting, or operations support.
Software licensing: In the future, orchestration/observability software could be sold separately to other infrastructure providers or enterprises.
The most common model for infrastructure providers is some blend of reserved + on-demand, with managed services adding incremental revenue.
At $0.50-0.75 per GPU-hour (competitive with hyperscalers but with better support), 20,000 GPUs running 18 hours per day at 70% utilization would generate:
But this assumes commodity pricing. Neysa's likely to command premium pricing (maybe 1.0-1.5x hyperscaler pricing) because of the support and customization. That could push revenue to $80-100+ million annually at full capacity.
Capital intensity is significant, though. Each 1,000 GPUs of capacity probably requires $25-35 million in infrastructure investment (including software, people, and operations). Operating margins for infrastructure providers typically run 30-40% at scale.
So the economics work. Blackstone's essentially betting that India's AI infrastructure market will grow large enough to support multiple winners, and Neysa's positioned to capture significant share through early-mover advantage, capital superiority, and specialized focus on Indian market requirements.

Deployment Timeline and Execution Risk
Sanghi said the company expects to "more than triple capacity next year." If that means going from 1,200 GPUs to 3,600+ GPUs, that's about
But here's the execution risk: deploying GPU infrastructure at scale is non-trivial.
Supply chain risk: Nvidia GPUs are still constrained. Even with Blackstone's backing, getting 2,000+ GPUs per quarter requires strong supplier relationships.
Physical infrastructure: You can't just plop GPUs in a garage. You need data center space, power infrastructure, cooling systems, networking. These take time to build or negotiate.
Power constraints: India has some power reliability issues in certain regions. Building data centers that reliably support massive GPU clusters requires redundant power infrastructure. This is expensive.
Talent: Hiring 200-300 additional engineers (Neysa would likely need to grow from 110 to 300+ employees to support 20,000 GPUs) in Indian tech markets is competitive. Neysa's competing with Google, Microsoft, and startups for talent.
Customer development: It's one thing to have capacity. It's another to have customers ready to use it. Enterprise sales cycles are long (6-12 months). Government procurement is longer. Neysa needs to have sales conversations turning into contracts turning into actual workloads.
These aren't deal-breakers, but they're real execution risks that separate the winners from the ambitious-but-failed in infrastructure.

Global Infrastructure Implications: What This Means Beyond India
While Neysa is India-specific, the broader pattern is globally significant.
Every country is asking the same questions: Do we want to be dependent on American cloud providers for critical AI infrastructure? Can we build indigenous capabilities? Should we prioritize data sovereignty?
China answered these questions years ago. The Chinese government invested heavily in local AI infrastructure and restricted reliance on foreign cloud providers. Europe's been pushing for sovereign cloud capabilities (though with less success than China or India).
Now India's joining the club. Japan, South Korea, and Southeast Asian countries are likely next. Not because they're anti-American, but because infrastructure is strategic, and strategic assets tend to be nationalized or heavily subsidized.
This creates a global opportunity for infrastructure providers like Neysa (and Blackstone's broader infrastructure portfolio). As AI compute becomes geographically distributed, regional specialized providers capture value that global hyperscalers can't. The winners will be companies that:
- Understand local regulatory requirements
- Have capital to invest in region-specific infrastructure
- Build software and operational expertise tailored to local needs
- Develop strong relationships with local customers and governments
Blackstone's thesis (invest in regional specialized providers) works whether the region is India, Southeast Asia, Europe, or somewhere else.

The Broader Context: Infrastructure as Strategic Asset
This deal is part of a larger trend: the recognition that AI infrastructure (like semiconductors before it) is becoming a strategic asset that nations want to control or at least not be wholly dependent on.
For decades, we've had the luxury of thinking of cloud infrastructure as a commodity service. You spin it up, you use it, you pay per minute. This commodification was actually good—it democratized access to computing resources.
But when the resource in question is GPUs and AI training capacity, and when the technology has military, economic, and geopolitical implications, the commodity model breaks down.
Governments are starting to restrict or tax exports of advanced semiconductors (like the US did with Nvidia chips to China). They're starting to mandate data residency for sensitive sectors. They're starting to invest in domestic semiconductor and infrastructure capabilities.
In this context, Neysa (and companies like it) exist to solve a specific problem: how do countries ensure they're not wholly dependent on foreign infrastructure for AI development? How do they balance the benefits of open technology with the risks of strategic dependence?
The answer, increasingly, is regional specialized infrastructure providers backed by serious capital.

Looking Forward: What Comes Next for Neysa
Sanghi indicated ambitions to "expand beyond India over time." What might this look like?
South Asia expansion: Deploying similar infrastructure in Pakistan, Bangladesh, or Sri Lanka. These countries have similar regulatory requirements and significant AI developer populations.
Southeast Asia expansion: Thailand, Vietnam, Indonesia, Philippines all have growing AI communities and regulatory preferences for local data.
Global hub strategy: Building a few regional hub cities (Mumbai, Tokyo, Singapore, São Paulo) with massive GPU capacity and local support, rather than trying to compete globally with hyperscalers.
Vertical integration: Moving up the stack into AI platforms, fine-tuning services, model marketplaces. Using infrastructure as the foundation for higher-margin business lines.
Partnerships: Rather than building everything independently, partner with other specialized infrastructure providers (Core Weave, Crusoe) to offer complementary services.
The most likely path is probably regional expansion within Asia first, leveraging existing expertise and relationships. Expanding globally takes a different set of skills (regulatory navigation, vendor relationships, customer acquisition in new markets).
But fundamentally, Neysa's long-term success depends on executing on three things:
- Deploying infrastructure reliably and at scale
- Acquiring and retaining customers who value specialized support over commodity pricing
- Building software and operational excellence that becomes defensible over time
If they execute, Neysa becomes a meaningful player in global AI infrastructure. If they stumble on any of these, they become a well-capitalized company that couldn't quite execute.

The Broader Startup Ecosystem Impact
Beyond Neysa itself, this deal signals something important to the Indian startup ecosystem: serious capital is willing to fund infrastructure plays.
India's had massive venture capital success in fintech, consumer apps, B2B Saa S, and marketplaces. But infrastructure was often seen as a non-venture business (too capital-intensive, too long payback periods, too operational).
Blackstone's $1.2 billion bet (with Blackstone taking majority ownership) signals that infrastructure can be a venture-scale business, especially when there's a market gap (AI compute in India) and serious demand drivers (regulatory requirements, government initiatives, enterprise needs).
This probably opens doors for other infrastructure founders to raise capital. If Neysa works, other founders will pitch similar infrastructure plays. Some will get funded. Some will succeed, some will fail. But the category's getting legitimacy.
You'd expect to see more infrastructure startups emerge in India around:
- Alternative compute (ARM processors, custom ASICs)
- Networking infrastructure (fiber, edge computing)
- Storage infrastructure (specialized for AI workloads)
- Power infrastructure (batteries, renewable energy, thermal management)
- Data infrastructure (databases, data pipelines optimized for AI)
These are all infrastructure plays that could follow Neysa's success.

Conclusion: Infrastructure Wars Are Just Beginning
Blackstone's $1.2 billion commitment to Neysa isn't just about one company succeeding. It's about a shift in how AI infrastructure gets built and distributed globally.
For too long, the narrative around AI infrastructure centered on a handful of hyperscalers in the US. That narrative is breaking down, not because hyperscalers are losing capability, but because they're not optimized for what customers increasingly need: local infrastructure, specialized support, regulatory compliance, and data sovereignty.
Neysa (and Blackstone's broader infrastructure bets) are betting that the future isn't consolidated hyperscaler infrastructure, but rather a network of specialized regional providers each optimized for their specific markets.
This plays out over the next 5-10 years as:
- AI workloads grow and distribute geographically
- Regulatory requirements for data residency tighten
- Countries invest in strategic infrastructure independence
- Enterprises demand specialized support over commodity pricing
The infrastructure category is going to be one of the biggest value creation stories in AI over the next decade. Not the models, not the applications, but the infrastructure underneath that enables everything else.
Neysa's positioned well. Blackstone's capital is serious. And the market opportunity is real.
But execution matters. Capital alone doesn't win infrastructure wars. The companies that win are the ones that deploy reliably, build strong customer relationships, understand local requirements, and evolve their software and operations as the market matures.
Watch this space. Neysa's success (or failure) will probably determine whether infrastructure becomes a viable venture category beyond just this one company.

FAQ
What exactly is Neysa and what problem does it solve?
Neysa is an Indian AI infrastructure startup providing GPU-based computing capacity for enterprises, researchers, and government agencies. The company solves the problem of AI infrastructure scarcity in India, where there are fewer than 60,000 GPUs deployed despite massive demand from enterprises with data residency requirements, AI developers, and government initiatives building homegrown AI capabilities.
How does Neysa's infrastructure model differ from AWS or Google Cloud?
Neysa operates as a specialized infrastructure provider focused on dedicated GPU clusters with hands-on support, whereas hyperscalers like AWS and Google Cloud optimize for self-service, variable compute, and massive scale. Neysa targets customers who need 24/7 support, regulatory compliance for local data, and customized infrastructure configurations rather than commodity pricing. The support model is the key differentiator: Neysa promises 15-minute response times and dedicated problem resolution, whereas hyperscalers use asynchronous ticketing systems.
What does the $1.2 billion capital structure mean for Neysa's growth plans?
The capital breaks down into
Why did Blackstone specifically back Neysa rather than other infrastructure providers?
Blackstone has been systematically building a portfolio of infrastructure providers across geographies. The firm backed Core Weave in the US, Firmus in Australia, and previously backed large data center operators like QTS and Air Trunk. Blackstone's thesis is that as AI workloads distribute geographically and regulatory requirements for data residency tighten, regional specialized providers will capture significant value that global hyperscalers can't serve profitably. India represents a major opportunity within this thesis.
What are the biggest execution risks for Neysa?
Key risks include: (1) GPU supply chain constraints—even with Blackstone backing, sourcing 2,000+ GPUs quarterly is challenging; (2) Physical infrastructure—building data centers with reliable power, cooling, and networking takes time; (3) Power reliability in India—some regions have power limitations that require redundant infrastructure; (4) Talent acquisition—competing with Google and Microsoft for 200+ engineers; (5) Customer acquisition—enterprise and government sales cycles are long (6-12+ months).
How does India's regulatory environment favor a company like Neysa?
India's regulations increasingly require data residency (data staying within national borders) for regulated sectors like banking, healthcare, and insurance. This makes local infrastructure necessary rather than optional. Additionally, the Indian government is actively pushing homegrown AI infrastructure capabilities for strategic independence. These regulatory tailwinds create a protected market where local providers like Neysa have advantages over global hyperscalers.
What's the "neo-cloud" category and how does Neysa fit into it?
Neo-clouds are specialized infrastructure providers that focus on specific workloads (AI compute, GPU clusters) rather than trying to replicate all cloud services. They emphasize speed of deployment, customization, hands-on support, and regional focus over hyperscaler breadth and commodity pricing. Neysa fits this mold by specializing in GPU infrastructure with Indian market expertise, dedicated customer support, and local regulatory compliance. Other neo-clouds include Core Weave and Lambda Labs.
How sustainable are Neysa's unit economics at scale?
At commodity pricing (
Could hyperscalers like AWS simply replicate Neysa's model to compete?
Hyperscalers could technically offer similar services but likely won't because it conflicts with their core business model. Hyperscalers optimize for 60-70% utilization at commodity pricing through commodification and self-service. Neysa's model requires relationship-based sales, custom configurations, and committed capacity pricing—which are economically incompatible with hyperscaler scale objectives. Hyperscalers prioritize breadth over depth, while Neysa prioritizes depth (specific customer needs) over breadth.
What could derail Neysa's growth trajectory?
Potential challenges include: GPU oversupply (if Nvidia increases production faster than demand grows), hyperscaler pricing pressure (AWS or Google could offer regional discounts), customer concentration risk (if a few large customers represent >30% of revenue, their departure becomes existential), technology disruption (new chip architectures that displace H100 GPUs), or regulatory changes that limit data residency requirements. Competition from other well-funded infrastructure providers is also a risk.
What's the broader significance of this deal for global AI infrastructure?
This deal signals that infrastructure provision is becoming regionally specialized rather than globally consolidated. It demonstrates that capital and strategic importance are flowing toward regional providers optimized for local regulatory, performance, and support requirements. This pattern will likely repeat in other geographies (Southeast Asia, Europe, Japan) where countries want to avoid dependence on American hyperscalers for critical AI infrastructure. The infrastructure wars are just beginning, and companies like Neysa represent the emerging winners.

Bringing It All Together: What You Should Actually Remember
Blackstone's $1.2 billion bet on Neysa isn't a random funding event. It's a signal that infrastructure provision is becoming geographically distributed, and that regional specialized providers can capture enormous value by solving problems hyperscalers aren't optimized to solve.
India's AI infrastructure market is moving from scarcity to abundance, but not in the way people expected. Instead of one global hyperscaler dominating, multiple regional players are emerging to serve specific customer needs (regulatory compliance, local support, data sovereignty).
If Neysa executes on deployment, customer acquisition, and operational excellence, the company becomes a meaningful player in global AI infrastructure. More importantly, it validates the broader thesis that infrastructure wars are just beginning, and geography matters as much as technology.
The AI infrastructure story of the next decade isn't "AWS dominates everything." It's "regional specialized providers compete fiercely, each optimized for their specific markets and customers." Neysa's one of the early winners in this reorganization.

Key Takeaways
- Blackstone's 600M equity + $600M debt) signals serious institutional capital flowing toward regional AI infrastructure providers
- India currently has fewer than 60,000 GPUs deployed but is projected to scale to 2+ million GPUs as demand from regulated enterprises, government, and AI developers accelerates
- Neysa competes not with hyperscalers but serves a different customer segment prioritizing data sovereignty, local support, and regulatory compliance over commodity pricing
- The 'neo-cloud' category of specialized infrastructure providers is emerging to serve AI workloads that hyperscalers can't profitably serve due to their optimization for global scale
- Execution risks include GPU supply constraints, power infrastructure limitations, talent acquisition in India's competitive tech market, and long enterprise sales cycles
Related Articles
- OpenClaw Founder Joins OpenAI: The Future of Multi-Agent AI [2025]
- Anthropic's $14B ARR: The Fastest-Scaling SaaS Ever [2025]
- Lenovo Warns PC Shipments Face Pressure From RAM Shortages [2025]
- Why OpenAI Retired GPT-4o: What It Means for Users [2025]
- ChatGPT-4o Shutdown: Why Users Are Grieving the Model Switch to GPT-5 [2025]
- Moonbase Alpha: Musk's Bold Vision for AI and Space Convergence [2025]

