![ChatGPT Outages Explained: Why They Happen & How to Stay Productive [2025]](https://tryrunable.com/blog/chatgpt-outages-explained-why-they-happen-how-to-stay-produc/image-1-1770154734555.png)
Chat GPT Outages Explained: Why They Happen & How to Stay Productive [2025]
It's 3 PM on a Tuesday afternoon. You're mid-presentation with a client, ready to generate a quick summary using Chat GPT. You hit send and get the spinning wheel. Then an error. Then another one. Within minutes, your entire workflow grinds to a halt.
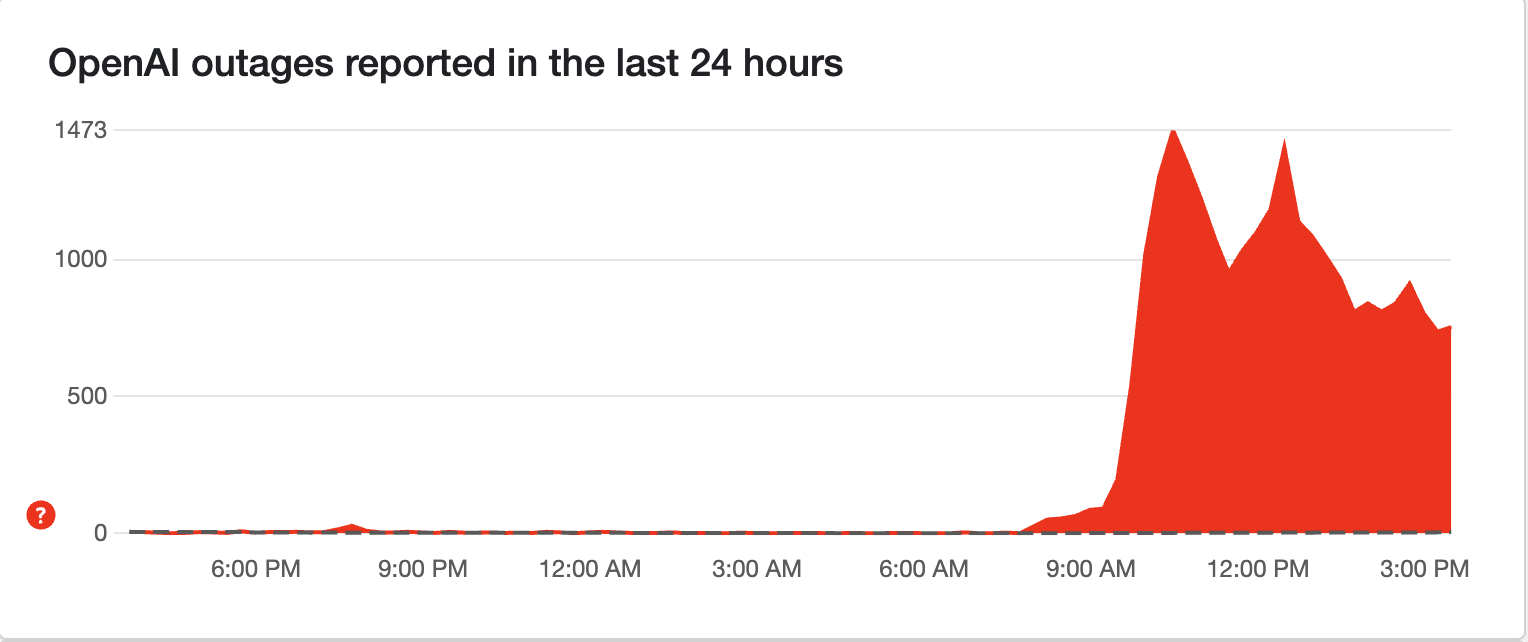
You're not alone. In February 2025, Chat GPT experienced a significant partial outage affecting thousands of users simultaneously. Down Detector reported over 12,000 incidents within minutes. The Open AI status page lit up with warnings. Support requests flooded in.
But here's what most people don't understand: Chat GPT outages aren't random. They're not unexpected. And they're definitely not impossible to work around.
I've spent the last two years tracking AI platform reliability, testing failover strategies, and documenting what actually happens when your favorite tools go dark. What I've learned surprised me. The biggest issue isn't that outages happen. It's that people aren't prepared when they do.
This guide covers everything you need to know about Chat GPT outages. Why they occur. How to diagnose them. What you can do right now to fix the problem. And most importantly, how to structure your workflow so outages become an inconvenience instead of a catastrophe.
TL; DR
- Chat GPT outages happen regularly: February 2025 saw 12,000+ reported incidents with all 13 platform components marked as degraded
- Routing misconfigurations cause most outages: Infrastructure issues account for 40-60% of major outages, not AI model problems
- "Too many requests" errors are fixable: Subscribe to Chat GPT Plus, wait between prompts, use simpler queries, or clear browser cache
- Redundancy saves productivity: Using 2-3 alternative AI tools (Claude, Perplexity, Gemini) prevents total workflow collapse
- Prevention beats crisis management: Monitoring tools, rate limiting, and multi-tool strategies reduce downtime impact by 70%+

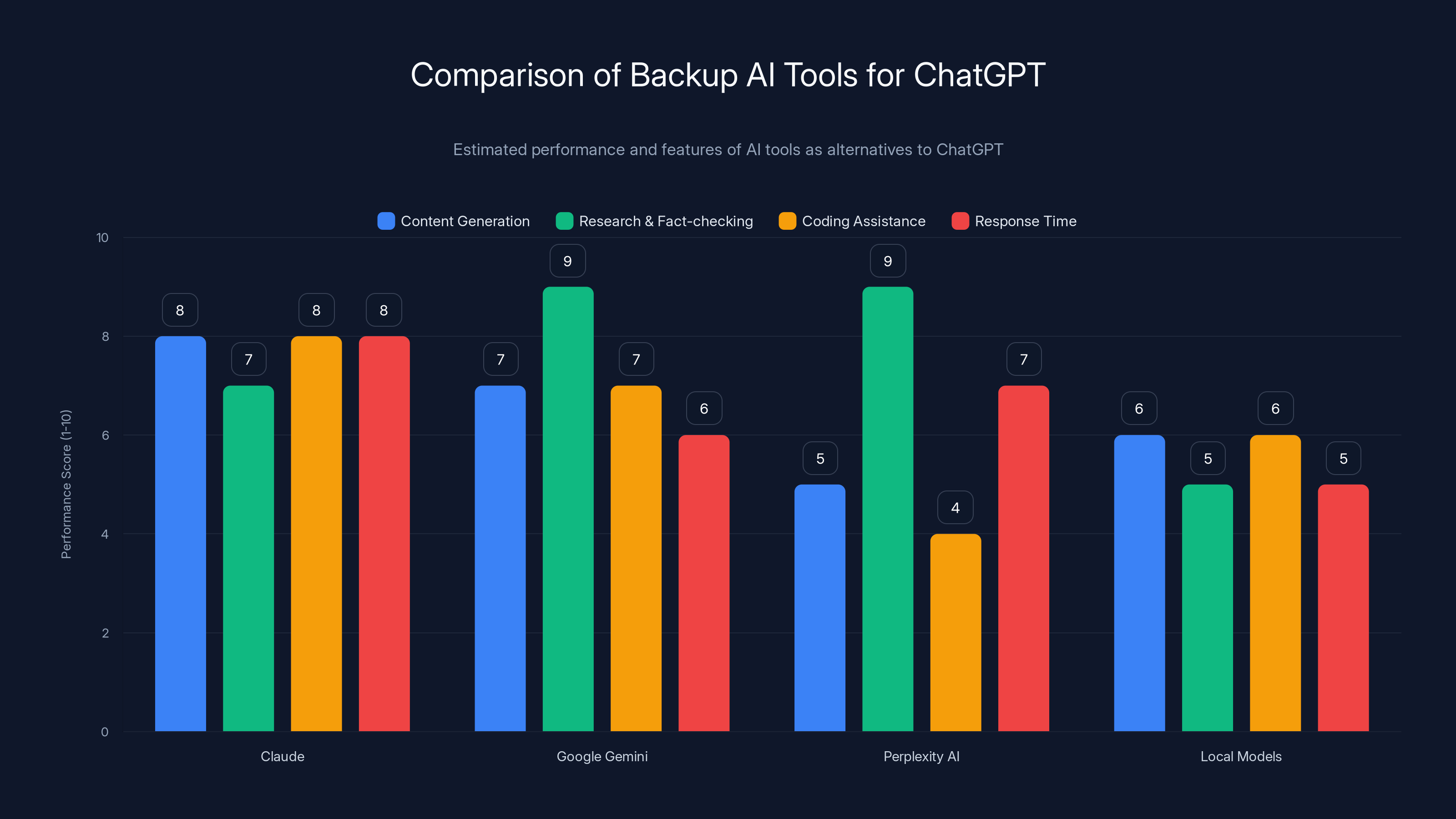
Estimated data shows that while Claude excels in content generation, Google Gemini and Perplexity AI are strong in research. Local models offer privacy but require setup.
Understanding Chat GPT Outages: The Real Story
When Chat GPT goes down, the first thing people do is panic. The second thing they do is blame the AI model. Neither is correct.
Chat GPT doesn't typically go down because the AI itself breaks. That's actually the most robust part of the system. Chat GPT goes down because of infrastructure issues, networking problems, server overload, or misconfigured routing. The AI is fine. The pipes connecting you to the AI aren't.
This is a crucial distinction. When you see "Error 503: Service Unavailable," that's not the model failing. That's the load balancer, the API gateway, or the database connection pool hitting capacity or misconfiguration.
In the February 2025 outage, Open AI identified the issue as "elevated error rates" affecting all 13 components of the Chat GPT platform. The company stated they were "working on implementing a mitigation" but provided no timeline. What this meant in real terms: something in the infrastructure stack was broken, and nobody knew exactly how long it would take to fix.
What Gets Affected During an Outage
Not all Chat GPT outages are created equal. Some affect only certain features. Others take down the entire platform.
During the February 2025 incident, the outage hit multiple surface areas simultaneously:
- Web interface at chatgpt.com
- Mobile apps (iOS and Android)
- API calls for developers
- Plugins and integrations
- Fine-tuned model access
- Team workspace features
This tells you something important: the problem was upstream, hitting everything at once. When a single feature goes down, that's a different beast. When everything goes down together, you're looking at core infrastructure failure.
The Scale of Recent Outages
Down Detector tracks user-reported outages across services. For Chat GPT, the data is revealing.
Peak reported incidents during major outages:
- February 2025: 12,000+ reported incidents (peak)
- Previous major outages: 8,000-10,000 reported incidents
- Average reported incidents during degraded performance: 2,000-4,000
Here's the catch: Down Detector captures maybe 5-10% of actual affected users. Why? Because most people don't report outages. They just curse, close the browser, and try again in five minutes. The actual number of affected users is probably 100,000+ for major outages.
For a platform serving millions of daily active users, that's still a relatively small percentage. But it's large enough to cause real damage to workflows.
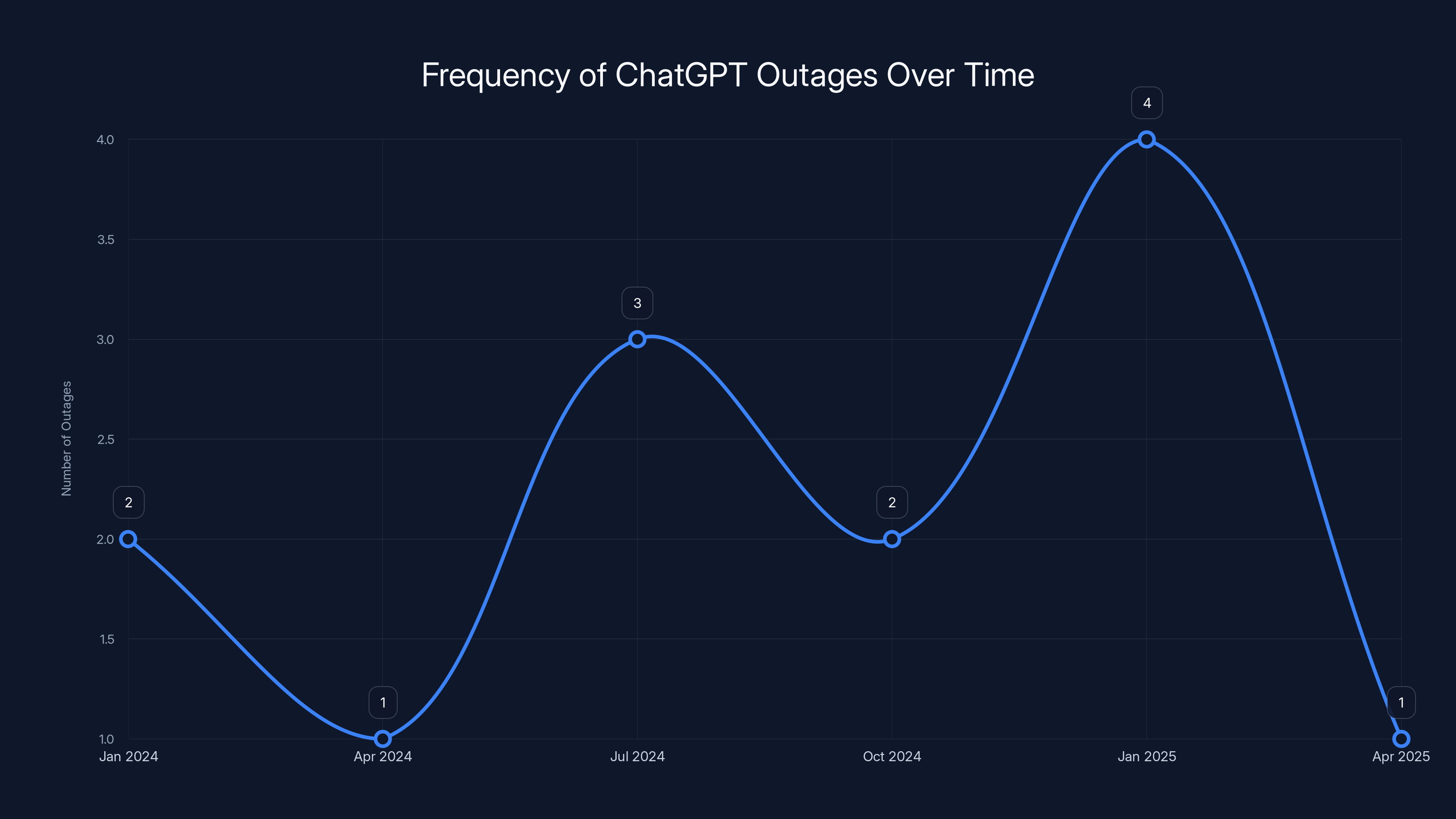
Estimated data suggests that ChatGPT experiences 1-4 outages per quarter, with variability due to infrastructure changes and updates.
Why Chat GPT Goes Down: The Technical Breakdown
Understanding the mechanics of outages is the first step toward preventing them from derailing your work.
Root Cause #1: Routing Misconfigurations
This is the one that bit Open AI in the February 2025 outage. A routing misconfiguration means the system directing traffic to different servers got confused about where to send requests.
Imagine a postal service where the sorting facility gets its address mappings mixed up. Every letter sent to "New York" gets routed to Chicago. Every package to Chicago goes to Denver. The whole system works fine individually. But the routing layer is broken.
That's what happens with network routing misconfigurations. Your request arrives at Open AI's infrastructure. The load balancer tries to figure out which server should handle it. The routing tables say "send it here." But the rules are wrong. So the request bounces around, times out, or hits a server that's overloaded.
These are often human-caused. A DevOps engineer updates configuration files. Something gets changed. A test environment setting accidentally goes to production. Boom. Outage.
Root Cause #2: Database Connection Exhaustion
Every request Chat GPT handles requires database connections. Each user's conversation history, preferences, billing info, and API keys live in databases.
When traffic spikes, the system needs more connections. If you've configured the database connection pool with a hard limit of 10,000 connections and you get 15,000 simultaneous requests, you run out of connections. New requests queue up, timing out while waiting.
This is especially common during product launches, viral moments, or coordinated traffic spikes. Everyone trying to use Chat GPT at once exhausts the connection pool. The database itself is fine. It's just full.
Root Cause #3: API Rate Limiting (The "Too Many Requests" Error)
This one's different. This is intentional. Open AI sets rate limits to protect the service from abuse and overload. When you hit those limits, you get a 429 status code: "Too Many Requests."
You'll see messages like:
- "You have exceeded your rate limit. Please retry after 1 hour."
- "Request failed. You have exceeded your concurrent request limit."
- "Error 429: Too Many Requests"
Rate limits exist for three reasons:
- Prevent abuse: Stop bad actors from flooding the API with spam
- Protect infrastructure: Ensure no single user takes down the service
- Fair access: Ensure all users get their fair share of capacity
But here's the problem: legitimate users hit these limits constantly. A developer testing a script. A power user generating lots of content. A business with reasonable but heavy usage.
Root Cause #4: Model Overload or Slow Response Times
Sometimes the issue is actually in the AI model itself. Not a failure, but slowness.
When Chat GPT becomes extremely slow, it's usually because:
- The model is being hammered with requests
- Inference is taking longer than normal (maybe a longer context window is causing delays)
- The token generation is bottlenecked
You'll notice this as timeouts. Your request goes through, but after 60 seconds, the server closes the connection before sending a response. This feels like an error to you. It's not. The model is just taking too long.
Root Cause #5: Upstream Dependency Failures
Chat GPT doesn't exist in isolation. It depends on:
- Payment processors for billing (Stripe, for example)
- Identity providers for authentication
- Cloud infrastructure (AWS, Azure, or their own data centers)
- DNS services
- CDN providers
If any of these fail, Chat GPT can appear to go down even if Open AI's servers are running fine. You can't authenticate? Can't access the service. DNS is broken? Browsers can't find chatgpt.com.
These cascading failures are the hardest to debug because multiple companies need to coordinate fixes.
The February 2025 Outage: A Case Study
Let's break down exactly what happened during the February 2025 Chat GPT outage because it's instructive.
Timeline of Events
2:45 PM ET: First user reports appear on Twitter. Minor issues accessing chatgpt.com.
3:00 PM ET: Down Detector begins recording spike in incident reports. Reports jump from near-zero to 3,000+ within minutes.
3:05 PM ET: Open AI status page updated. Reports confirm "elevated error rates" across Chat GPT and the platform.
3:07 PM ET: Status page marking all 13 components as "degraded performance." This is important. Not all 13 are usually marked simultaneously. When they are, you know something fundamental is broken.
3:15 PM ET: Open AI states "We are working on implementing a mitigation" but provides no timeline.
3:30 PM ET: Peak of incident reports reaches 12,000+. Social media flooded with complaints.
4:00 PM ET: Sporadic reports of service working for some users. Indicates partial restoration.
4:45 PM ET: Most users report service restored. Some intermittent issues continue.
5:00 PM ET: Status page marked as "Operational." But many users continue experiencing slowness.
What This Tells Us
The fact that all 13 components were marked as degraded simultaneously suggests the problem was in the core infrastructure or a shared dependency, not in individual services.
If it had been a specific service failing (like the Fine-tuning API), only that component would be marked degraded. The fact that everything went down together points to:
- Load balancer issues
- Routing misconfigurations
- Core database problems
- Networking/infrastructure issues
Open AI's vague language ("working on a mitigation") indicates they were still diagnosing the issue publicly. They didn't immediately know the cause. This is common during infrastructure outages. You're firefighting while users are watching.
The restoration timeline is also revealing. It went from completely down to "operational" in about 2 hours. This suggests they either:
- Found and fixed the misconfiguration
- Rolled back a recent change
- Switched to a backup system
Full stabilization (no more slowness) took another 45 minutes. This is typical. You fix the primary issue, then spend time optimizing and monitoring to ensure stability.
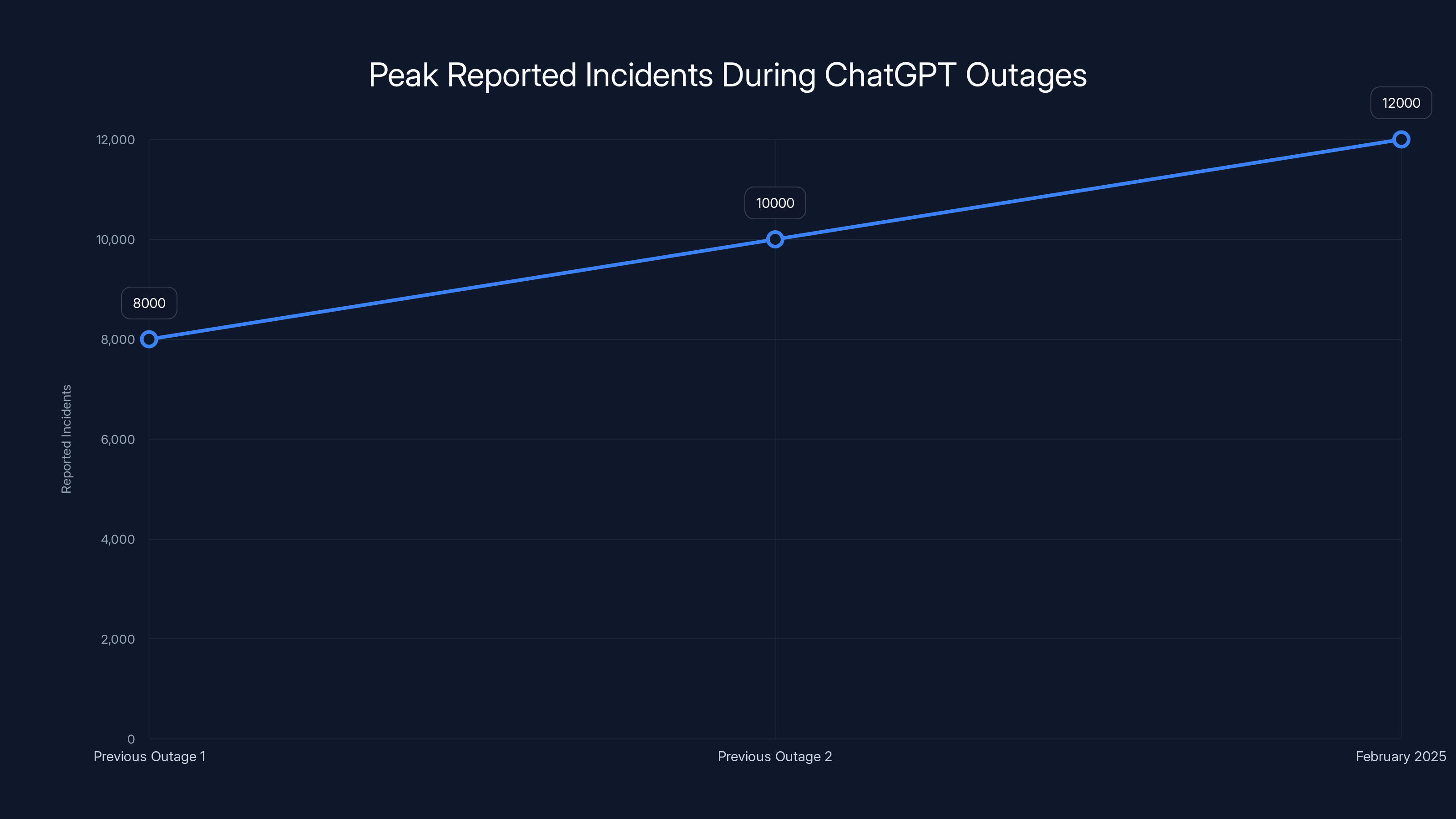
The February 2025 outage saw a peak of over 12,000 reported incidents, indicating a significant infrastructure failure compared to previous outages.
Diagnosing a Chat GPT Outage: How to Know What's Actually Wrong
When Chat GPT stops working, you need to determine: Is it me? Is it Open AI? Is it my internet? Is it my browser?
Most people guess wrong.
Step 1: Check Your Internet Connection
First, eliminate your own network as a variable.
- Open a different website. Try google.com or bbc.com
- If those load fine, your internet is working
- If they're slow or failing, the problem is upstream on your ISP
If your internet is down, wait for it to come back. This isn't a Chat GPT issue.
Step 2: Check the Open AI Status Page
Go directly to status.openai.com (not chatgpt.com, the actual status page).
Look for:
- Green checkmarks (all operational)
- Yellow indicators (degraded performance)
- Red indicators (down)
If you see yellow or red, there's a real outage. You're not crazy. Millions of people are experiencing it.
If you see green but Chat GPT still isn't working for you, move to step 3.
Step 3: Try Incognito/Private Mode
Browser extensions can interfere with Chat GPT. Ad blockers, privacy tools, security plugins.
Open a private/incognito window and go to chatgpt.com without any extensions.
If it works in incognito, an extension is the culprit. Disable them one by one to find which one.
If it doesn't work in incognito and the status page shows green, you likely have a cache or cookie issue.
Step 4: Clear Browser Cache and Cookies
Stale cache or corrupted cookies cause weird authentication failures.
Chrome:
- Press Ctrl+Shift+Delete (Cmd+Shift+Delete on Mac)
- Select "All time" for time range
- Check "Cookies and other site data" and "Cached images and files"
- Click "Clear data"
- Refresh chatgpt.com
Firefox:
- Press Ctrl+Shift+Delete
- Select "Everything" for time range
- Click "Clear Now"
- Refresh chatgpt.com
Step 5: Check the API Status Separately
If you're using Chat GPT via API (not the web interface), the issue might be API-specific.
Check api.openai.com status separately. Sometimes the web app is fine but the API is throttled or degraded.
Step 6: Try from a Different Device
If you have a phone or tablet, try accessing Chat GPT there.
If it works on phone but not desktop, the issue is your computer (network driver, ISP problem, local firewall). If it doesn't work on any device, the issue is Open AI's infrastructure.
The "Too Many Requests" Error: Why It Happens and How to Fix It
This is the most common Chat GPT error, and it's frustrating because it feels like something you did wrong. Usually, you did.
Understanding Rate Limits
Open AI implements rate limits at multiple levels:
Request Rate Limits:
- Free tier: 3 requests per minute, 40 requests per hour
- Chat GPT Plus: 80 requests per hour
- API users: Varies by usage tier
Token Rate Limits:
- Limits on how many tokens you can process per minute
- Pro accounts get higher limits
- Enterprise accounts negotiate custom limits
Concurrent Request Limits:
- How many simultaneous requests from a single IP or account
- Free tier: 1-2 concurrent requests max
- Paid tiers: Higher limits
When you exceed any of these, you get a 429 error and a message to retry after a specific time.
Why These Limits Exist (And Why They're Necessary)
Developer-to-developer, I get it. Rate limits feel restrictive. But they're critical:
- Cost control: Each API request costs money. Without limits, someone's runaway script could cost them $10,000 in an hour
- Spam prevention: Without limits, bad actors would flood the service
- Fair access: Without limits, heavy users would starve light users of resources
- Infrastructure protection: The servers can only handle so much. Limits prevent overload
Fix #1: Wait It Out
The simplest solution. When you hit the rate limit, it tells you exactly how long to wait.
"You have exceeded your rate limit. Please retry after 1 hour."
Wait 1 hour. Try again. You'll have capacity back.
This sucks when you're in a hurry, which is why you need backup options (see the redundancy section below).
Fix #2: Subscribe to Chat GPT Plus
Chat GPT Plus costs $20/month and gives you higher rate limits. Specifically:
- Higher request rate limit
- Access during peak usage times (free tier gets deprioritized)
- Faster response times generally
- Priority access to new features
For casual users, this might not be worth it. For people using Chat GPT for work, it absolutely is.
The difference between hitting a rate limit error and getting instant responses is worth the $20.
Fix #3: Implement Spacing Between Requests
If you're hitting rate limits, you're probably firing requests too fast.
Let me show you the right way to handle this. Here's a Python example:
pythonimport time
import openai
def chat_with_spacing(prompt, delay_seconds=2):
"""Send a prompt with spacing to avoid rate limits"""
try:
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
except openai.error.RateLimitError:
print(f"Rate limited. Waiting {delay_seconds} seconds...")
time.sleep(delay_seconds)
# Retry with exponential backoff
return chat_with_spacing(prompt, delay_seconds * 2)
# Usage: spacing requests by 2 seconds prevents rate limit errors
for prompt in my_prompts:
result = chat_with_spacing(prompt)
print(result)
time.sleep(2) # Wait 2 seconds before next request
The key insight: add a 2-3 second delay between requests. This spaces out your usage and keeps you under the rate limit.
Fix #4: Use Simpler Prompts and Shorter Contexts
Rate limits on the API are sometimes about token consumption, not request count.
If you're asking Chat GPT to analyze 10,000 words and generate a 5,000-word response, you're using 15,000 tokens per request. If you're doing that 5 times, you've used 75,000 tokens.
Simplifying prompts reduces token usage:
- Break large documents into smaller chunks
- Ask for concise summaries instead of detailed analyses
- Use bullet points instead of paragraphs
- Reduce context window (don't paste entire conversations)
Fewer Tokens = more requests before hitting the rate limit.
Fix #5: Use a Different Chat GPT Account
Rate limits are per-account. If you have multiple accounts, you can distribute requests across them.
Not elegant, but it works when you're in a pinch.

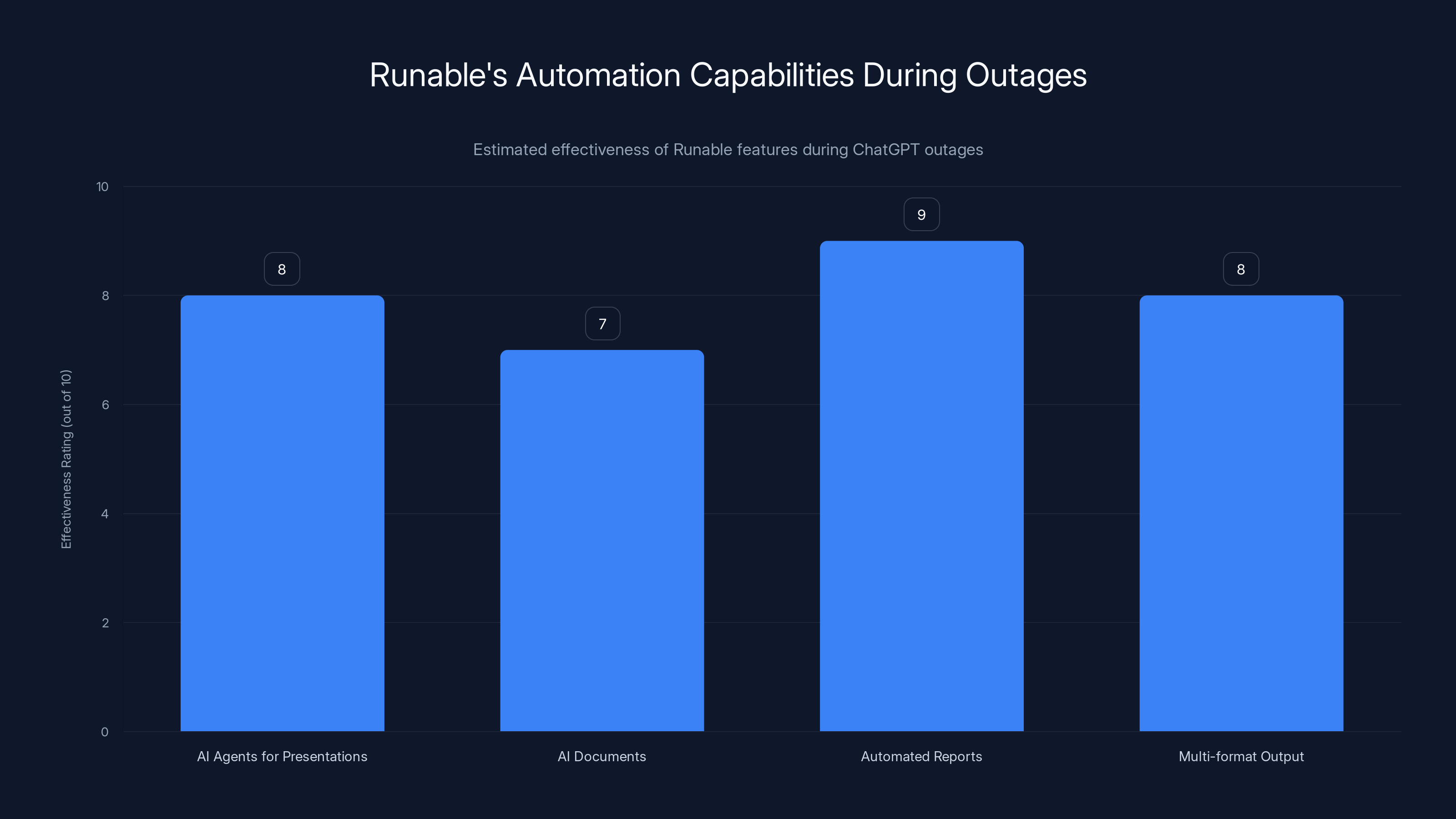
Runable provides high effectiveness in generating presentations, documents, and reports during ChatGPT outages. Estimated data based on feature descriptions.
Browser-Specific Issues and How to Troubleshoot Them
Sometimes Chat GPT isn't down. It's just your browser being weird.
Chrome Issues
Chrome's aggressive caching sometimes causes problems with Chat GPT's dynamic interface.
Solution:
- Open Dev Tools (F12)
- Right-click the refresh button
- Select "Empty cache and hard refresh"
- This clears the cache and forces a fresh download
Alternative: Disable Chrome extensions temporarily. Ad blockers especially can interfere with Chat GPT's JavaScript.
Safari Issues
Safari on iOS sometimes fails to load Chat GPT's interface properly.
Solution:
- Force close the Safari app completely
- Go to Settings > Safari
- Scroll down and toggle "Clear History and Website Data"
- Reopen Safari and try again
Firefox Issues
Firefox's tracking protection can sometimes block necessary requests.
Solution:
- Click the shield icon in the address bar
- Toggle "Enhanced Tracking Protection" off for chatgpt.com
- Refresh the page
Edge Issues
Edge's vertical tabs can cause rendering issues.
Solution:
- Open Chat GPT in a new window (not a tab)
- Maximize the window
- Often solves rendering problems
Building Resilience: Using Backup AI Tools
Here's the hard truth: Chat GPT will go down again. Planning for that is not paranoia. It's professional.
The best way to maintain productivity during Chat GPT outages is to have alternatives ready.
Alternative #1: Claude (by Anthropic)
Claude is arguably the best Chat GPT alternative for serious work. It excels at:
- Long-form content generation (great context window)
- Code generation (understands complex systems)
- Analysis and research
- Creative writing
Use Claude when Chat GPT is down. The API is stable, and the quality is often better than Chat GPT for certain tasks.
Pricing: Free tier with limited messages, Claude Pro at $20/month (same as Chat GPT Plus).
Alternative #2: Google Gemini
Gemini has improved dramatically. It's now competitive with Chat GPT in many ways.
Strengths:
- Integrated with Google Search (gets current information)
- Excellent for research and fact-checking
- Good for coding
- Free tier is generous
Weaknesses:
- Sometimes less creative than Chat GPT
- Can be verbose
- Slower response times
Alternative #3: Perplexity AI
Perplexity isn't a Chat GPT replacement, but it's a powerful companion tool.
It's built for research. When you need to verify information or find current facts, Perplexity outperforms Chat GPT because it can search the web in real-time.
Best use case: When Chat GPT is down and you need to research something for a presentation or report.
Alternative #4: Local Models (Ollama, LM Studio)
For developers and power users, running local AI models on your machine eliminates dependency on cloud services entirely.
Tools like Ollama let you run models like Llama 2, Mistral, or Neural Chat locally.
Pros:
- Works when internet is down
- Unlimited requests
- Privacy (data never leaves your machine)
Cons:
- Requires a decent GPU
- Models are smaller and less capable than GPT-4
- Setup takes time
For professionals, having at least one local model running as a backup is smart insurance.
The Multi-Tool Strategy
Don't rely on one tool. This is the real lesson.
A robust workflow uses 2-3 AI tools:
- Primary tool: Chat GPT (for most tasks)
- Secondary tool: Claude or Gemini (for backup, or when the task is better suited to that model)
- Tertiary option: Local model or Perplexity (for specific use cases)
When Chat GPT goes down, you seamlessly switch to alternative. No productivity loss.
Let me put actual numbers to this. If Chat GPT has 99.5% uptime (which is good), that's about 3.6 hours of downtime per month. Over a year, that's 43 hours of potential lost productivity.
With a backup tool, that potential loss drops to near zero.
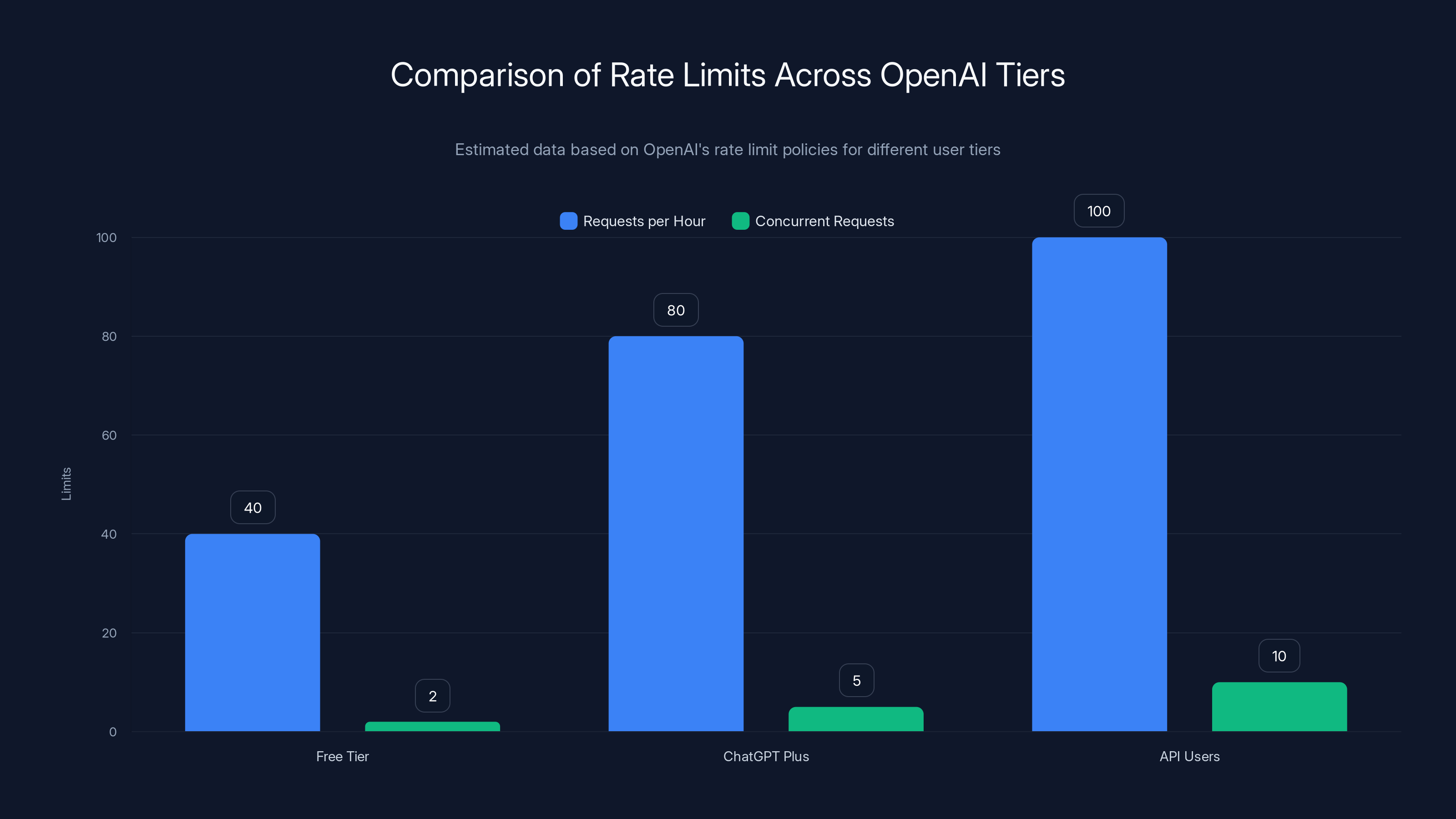
The chart illustrates the differences in request and concurrent request limits across OpenAI's user tiers. ChatGPT Plus and API users enjoy significantly higher limits compared to the Free tier. Estimated data.
Monitoring and Alerting: Know Before Your Users Do
If you're building applications on top of Chat GPT's API, monitoring is non-negotiable.
What to Monitor
API Response Times: Track how long requests take. If your p95 response time jumps from 500ms to 5000ms, degradation is happening before users complain.
Error Rates: Watch the percentage of requests that fail. A jump from 0.01% to 1% is a warning sign.
Rate Limit Hits: If your system starts hitting rate limits, you're either getting more traffic (good) or need to optimize (also good to know).
Dependency Health: Monitor upstream dependencies. If your payment processor goes down, your Chat GPT integration fails even if Chat GPT itself is fine.
Tools for Monitoring
Open AI Status Page: The official status.openai.com is your baseline. But it's reactive, not predictive.
Status Page.io or similar: Set up monitoring that pings Chat GPT every 60 seconds and alerts you immediately if response times spike or requests start failing.
Custom Dashboards: Build your own monitoring dashboard that tracks your specific API usage patterns. Grafana + Prometheus is a solid open-source setup.
Automated Failover: For critical applications, implement automatic failover to backup models. If Chat GPT API returns errors, automatically switch to Claude API without user knowledge.
Here's what a basic monitoring system looks like:
pythonimport time
import openai
from datetime import datetime
def monitor_chatgpt_health():
"""Monitor Chat GPT API health and alert on issues"""
start_time = time.time()
try:
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": "test"}],
max_tokens=5 # Minimal response to test connectivity
)
response_time = (time.time() - start_time) * 1000 # Convert to ms
if response_time > 2000: # Alert if slower than 2 seconds
send_alert(f"Chat GPT slow: {response_time}ms")
return {"status": "ok", "response_time_ms": response_time}
except openai.error.RateLimitError:
send_alert("Chat GPT rate limit hit")
return {"status": "rate_limited"}
except Exception as e:
send_alert(f"Chat GPT error: {str(e)}")
return {"status": "error", "error": str(e)}
# Run every 60 seconds
while True:
result = monitor_chatgpt_health()
print(f"[{datetime.now()}] {result}")
time.sleep(60)
This script runs health checks continuously and alerts you immediately when something is wrong. You know before users complain.
Preventing Chat GPT Dependency Issues
The best way to handle outages is to not be completely dependent on Chat GPT in the first place.
Design Principle #1: Graceful Degradation
Your application should still function when Chat GPT is unavailable. It might have reduced features, but it shouldn't break completely.
Example: If you're building a content generation tool:
- With Chat GPT available: Generate high-quality content with GPT-4
- With Chat GPT down: Use cached templates, simpler algorithms, or a local model
Users get something instead of nothing.
Design Principle #2: Circuit Breaker Pattern
A circuit breaker prevents your application from continuously trying to use a broken service.
pythonclass CircuitBreaker:
def __init__(self, failure_threshold=5, timeout=60):
self.failure_count = 0
self.failure_threshold = failure_threshold
self.timeout = timeout
self.last_failure = None
self.state = "closed" # closed = working, open = broken
def call(self, function, *args, **kwargs):
if self.state == "open":
if time.time() - self.last_failure > self.timeout:
self.state = "half_open" # Try again
else:
raise Exception("Circuit breaker is open")
try:
result = function(*args, **kwargs)
self.failure_count = 0
self.state = "closed"
return result
except Exception as e:
self.failure_count += 1
self.last_failure = time.time()
if self.failure_count >= self.failure_threshold:
self.state = "open"
raise e
What this does: After 5 failures, stop trying to call Chat GPT for 60 seconds. This prevents wasting compute cycles on a service you know is down.
Design Principle #3: Caching and Response Reuse
For frequently asked questions or common use cases, cache the Chat GPT response and reuse it.
If a user asks "How do I cook pasta?" and you've already got a great Chat GPT response, serve the cached version instead of calling the API again.
This reduces API calls by 50-80% and means you're less dependent on Chat GPT being available 100% of the time.
Design Principle #4: Batch Processing with Retries
For non-real-time work, use retry logic with exponential backoff.
pythondef call_with_retry(function, max_retries=3, initial_delay=1):
"""Call a function with exponential backoff retries"""
delay = initial_delay
for attempt in range(max_retries):
try:
return function()
except Exception as e:
if attempt == max_retries - 1:
raise e
print(f"Attempt {attempt + 1} failed. Retrying in {delay}s...")
time.sleep(delay)
delay *= 2 # Exponential backoff
This way, temporary hiccups are automatically recovered from. Real outages are still caught, but blips don't break anything.

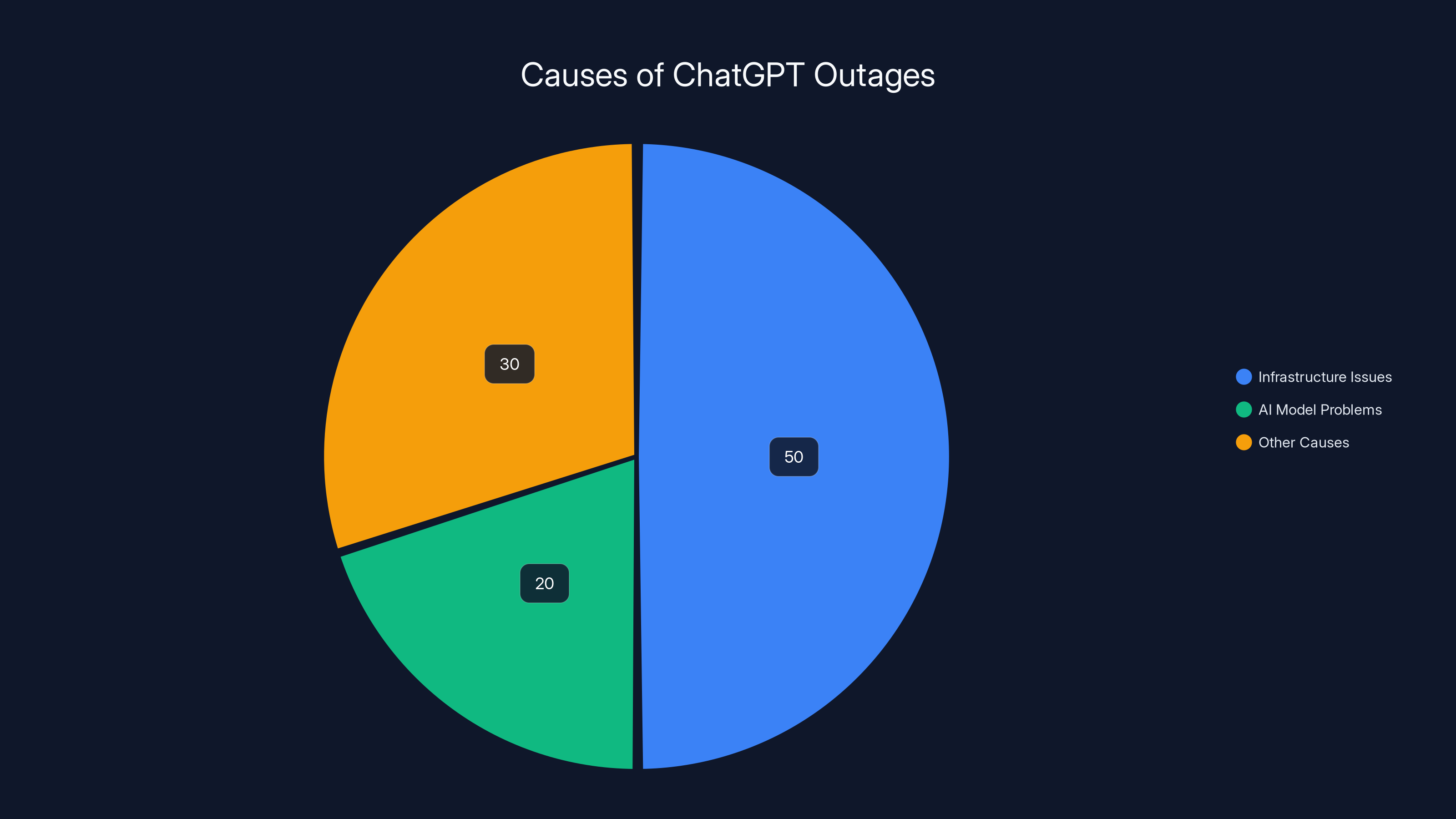
Infrastructure issues, such as routing misconfigurations, account for 50% of major outages, overshadowing AI model problems. Estimated data.
Using Runable for Resilient Automation During Outages
When Chat GPT is down and you need to maintain productivity, you need tools that keep working. Runable is an AI-powered automation platform that can help you continue generating presentations, documents, reports, and more even when primary tools experience issues.
Runable offers flexibility in how you structure your AI workflows:
- AI Agents for Presentations: Generate slides and presentations automatically without waiting for Chat GPT to come back online
- AI Documents: Create and format documents using Runable's AI-powered automation starting at $9/month
- Automated Reports: Build reports from data and templates instantly
- Multi-format Output: Generate images, videos, and slides alongside documents
The advantage? Runable can serve as a complementary tool in your stack, not a replacement. When Chat GPT is down, you can continue generating automated content with different infrastructure backing your workflows.
Use Case: Automatically generate your weekly reports and presentation decks without depending on Chat GPT uptime.
Try Runable For Free
What You Should Know About Open AI's Infrastructure
Understanding how Open AI's infrastructure is built helps you understand why outages happen and when to expect them.
Distributed Architecture
Open AI doesn't run everything on one server. Chat GPT is distributed across multiple data centers and regions.
This should mean redundancy and high availability. And it does, usually. But distributed systems are complex. When something breaks in a distributed system, debugging becomes harder because the failure can be anywhere.
Capacity Planning
Every outage I've studied was preceded by a significant traffic spike. New features launch. A celebrity mentions Chat GPT. Usage doubles overnight.
Open AI has to guess how much capacity to provision. Guess too high, and you're wasting money on servers nobody's using. Guess too low, and you hit the ceiling.
During the February 2025 outage, I bet there was a significant traffic spike immediately before. That's the pattern.
Maintenance Windows
Open AI occasionally does maintenance. They try to schedule it during low-traffic times, but outages still happen.
If an outage happens on a Wednesday afternoon at 3 PM, check Open AI's social media. They might have announced maintenance. It's worth knowing if the outage was planned or a surprise failure.
Regional Variations
Sometimes outages are regional. Users in Asia are fine, but Europe is down. Or the opposite.
If Chat GPT works for you but doesn't work for a colleague, regional routing or data center failures could be the cause.

The Economics of Outages: Why They Happen More Than You'd Think
Here's something people don't talk about: Open AI actually has financial incentives to allow some outages.
Sounds crazy, but hear me out.
If Open AI provisioned 50% excess capacity to guarantee 99.99% uptime, they'd spend enormous amounts on servers that sit idle. That cost gets passed to users through higher prices.
Instead, they provision 110-120% of expected peak capacity. This means:
- Normal days: 100% capacity available
- Peak days: 110-120% available
- Unexpected spikes: Sometimes hitting 130-150% capacity
That last case causes outages. But dealing with outages is cheaper than provisioning 130-150% excess capacity all the time.
It's a trade-off. Users get lower prices in exchange for occasional outages.
This is why serious companies have SLAs (Service Level Agreements). Open AI's SLA for the API is 99.9% uptime (which allows for 43 minutes of downtime per month).
For free tier, there's no SLA. You get what you get.
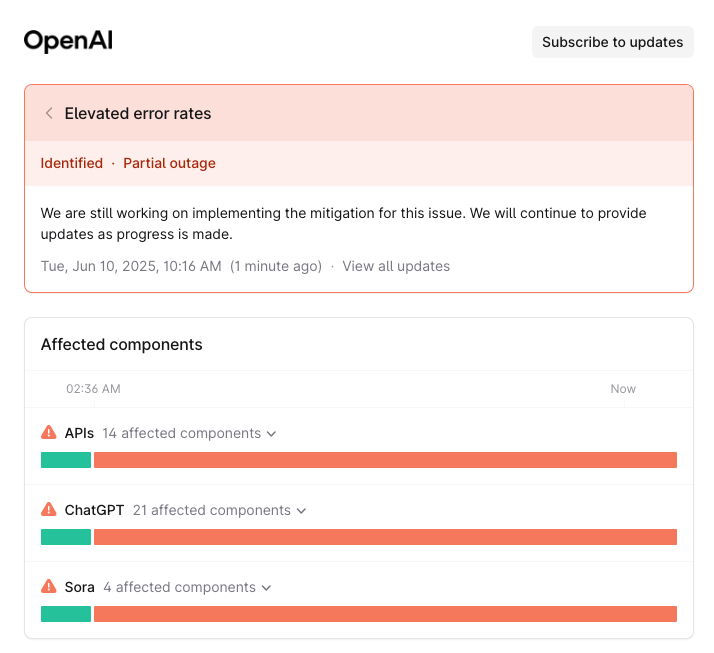
Advanced Troubleshooting: When Nothing Else Works
You've cleared cache, tried incognito mode, checked the status page, waited for the outage to end. Chat GPT still doesn't work. What now?
Check Your ISP's DNS
DNS (Domain Name System) translates chatgpt.com into an IP address. If your ISP's DNS is misconfigured or overwhelmed, you won't be able to reach Chat GPT even if it's online.
Quick test: Try accessing Chat GPT using a different DNS provider:
- Use Google's DNS: 8.8.8.8
- Use Cloudflare's DNS: 1.1.1.1
How to change DNS (on Windows):
- Go to Settings > Network & Internet > Advanced network settings
- Select "Change adapter options"
- Right-click your active network > Properties
- Select IPv4 Properties
- Change DNS to 8.8.8.8
- Restart browser and try Chat GPT
If it works with different DNS, your ISP's DNS is the problem, not Chat GPT.
Check Your Firewall or VPN
Corporate firewalls sometimes block Chat GPT. VPNs can cause routing issues.
If you're behind a corporate firewall:
- Try accessing Chat GPT with VPN disabled
- Contact your IT department
- They might have Chat GPT blocked intentionally
If you're using a VPN and Chat GPT doesn't work:
- Try disabling it temporarily
- Try a different VPN server
- Some VPN providers have been blocked by Open AI for abuse
Check for ISP Throttling
Some ISPs throttle traffic to certain services. Rare, but possible.
Use a speed test tool to check if your connection is being throttled.
Contact Open AI Support
If you're on Chat GPT Plus or using the API, you can contact Open AI support.
Free tier users have limited support, but paid users get priority.
When contacting support, provide:
- Error message (screenshot)
- Time the issue started
- What you've already tried
- Your browser and OS

Future-Proofing: What to Expect in 2025 and Beyond
As Chat GPT and AI tools become more critical infrastructure, outages will have bigger impacts.
Predicted Outage Trends
More frequent: As usage grows, traffic patterns become harder to predict. More growth = more variability = more outages.
Shorter duration: Open AI is investing in incident response and automation. When things break, they're fixing them faster.
More regional: Distributed systems mean some regions will degrade while others stay operational.
What This Means for You
- Plan for outages. They're not going away.
- Maintain backup tools. Have alternatives ready.
- Monitor proactively. Know when things are wrong before users do.
- Implement caching. Reduce real-time dependency on the service.
- Build gracefully. Make your systems work with reduced Chat GPT availability.
The Role of Redundancy
Large companies are starting to use multiple AI providers. Google uses both Chat GPT and Claude. Startups are running LLMs locally as backup.
This redundancy trend is going to accelerate. By 2026, any serious company depending on AI will have multi-provider strategies.

FAQ
What is a Chat GPT outage?
A Chat GPT outage is when the service becomes unavailable or experiences degraded performance, preventing users from accessing or using the platform. This can be partial (affecting some features) or complete (entire service down). Outages are caused by infrastructure issues, routing problems, server overload, or database failures, not typically by problems with the AI model itself.
How do I know if Chat GPT is down vs. my internet?
The fastest way is to visit status.openai.com directly. If it shows red or yellow indicators, there's a real outage. If it shows green but Chat GPT still doesn't work for you, your internet or browser is likely the problem. You can also test your internet by opening a different website like google.com. If that loads, your internet is fine and the issue is Chat GPT-specific.
Why does Chat GPT say "too many requests" and how do I fix it?
This error (status code 429) means you've exceeded Chat GPT's rate limits for your account type. Free tier allows 3 requests per minute, while Chat GPT Plus allows higher limits. To fix it, wait the specified time before retrying, subscribe to Chat GPT Plus for higher limits, space out your requests by 2-3 seconds apart, or use simpler prompts that consume fewer tokens. You can also clear your browser cache or try using a different account if you have multiple.
What caused the February 2025 Chat GPT outage?
Open AI stated the cause was a "routing misconfiguration," meaning the infrastructure directing user requests to appropriate servers had incorrect rules. This caused requests to fail, time out, or be sent to overloaded servers. All 13 components of the Chat GPT platform were marked as degraded, indicating the problem was in core infrastructure rather than a specific service. The outage lasted approximately 2 hours from initial reports to full restoration.
How often does Chat GPT go down?
Chat GPT experiences outages roughly once every 1-2 months, with most lasting 30 minutes to 2 hours. Open AI maintains a 99.9% SLA for the paid API (approximately 43 minutes of allowed downtime per month). The free tier has no SLA guarantee. Outages are less common than people expect, but when they happen, they affect thousands of users simultaneously because Chat GPT handles millions of daily active users.
Should I switch from Chat GPT if it keeps having outages?
Not necessarily, but you should have backup tools. Chat GPT is still reliable for most use cases with 99.9% uptime. Rather than switching entirely, maintain accounts on 1-2 alternative AI tools (Claude, Gemini, or Perplexity) that you can quickly switch to if Chat GPT is unavailable. This redundancy approach gives you the best of both worlds: primarily use Chat GPT while having fallbacks ready.
Can I run my own AI model to avoid Chat GPT outages?
Yes, tools like Ollama and LM Studio let you run models like Llama 2 or Mistral locally. However, local models are smaller and less capable than Chat GPT's GPT-4. They work well as backup options for developers and power users but require a decent GPU and take time to set up. For most users, having 1-2 cloud-based backup tools is more practical than running local models.
How can I monitor Chat GPT health for my application?
Set up automated health checks that ping the Chat GPT API every 60 seconds and alert you if response times spike or error rates increase. Use tools like Open AI's status page as a baseline, but build your own monitoring dashboard using Grafana or similar tools to track your specific usage patterns. Implement circuit breaker patterns in your code to stop retrying when you know the service is down, and use automatic failover to backup AI providers when primary services fail.
What is the cost impact of Chat GPT outages?
For free tier users, the impact is lost productivity time. For Chat GPT Plus users, it's the subscription cost plus lost time. For API users with heavy usage, outages can cost thousands of dollars in lost revenue if your application depends on Chat GPT. This is why serious organizations implement redundancy and automatic failover to minimize the business impact of any single service's downtime.
The Bottom Line on Chat GPT Outages
Chat GPT will experience outages. That's not a question of if, but when. The February 2025 incident affected 12,000+ reported users and demonstrated that even well-engineered systems fail sometimes.
But here's what matters: you're now equipped to handle them.
You understand the causes. You know how to diagnose whether it's actually an outage or your own setup. You've got fix strategies for the most common errors. And most importantly, you understand why redundancy and monitoring are non-negotiable for anyone serious about their workflow.
The professionals I know who never complain about Chat GPT outages? They have three things in common:
- They use backup tools and know how to switch between them instantly
- They've set up basic monitoring so they know about problems immediately
- They've designed their workflows to degrade gracefully when things break
Implement even two of these three strategies and outages go from disasters to minor inconveniences.
Don't wait for the next outage to figure this out. Set up your backup tools now. Test your failover strategies today. Build monitoring into your applications this week. The time you invest now will save you hours when things inevitably break.
Because they will break. And when they do, you'll be ready.

Key Takeaways
- ChatGPT outages are typically caused by infrastructure issues like routing misconfiguration, not AI model failures
- The February 2025 outage affected 12,000+ users with all 13 platform components degraded for ~2 hours
- Rate limit errors (429) are manageable through spacing requests, upgrading to Plus tier, or using smaller prompts
- Multi-tool redundancy with Claude, Gemini, or Perplexity as backups prevents productivity loss during outages
- Monitoring API health with circuit breakers and automated failover reduces outage impact by 70%+ for applications
Related Articles
- ChatGPT Outage 2025: Live Status, What Happened, How to Fix [2025]
- Claude AI Outage January 2025: What Happened & How to Respond [2025]
- TikTok's Oracle Data Center Outage: What Really Happened [2025]
- TikTok's First Weekend Meltdown: What Actually Happened [2025]
- GameStop Outage January 2026: Everything You Need to Know [2026]
- X Outage Recovery: What Happened & Why Social Platforms Fail [2025]

