![GameStop Outage January 2026: Everything You Need to Know [2026]](https://tryrunable.com/blog/gamestop-outage-january-2026-everything-you-need-to-know-202/image-1-1769015461935.jpg)
Game Stop Outage January 2026: Complete Breakdown of the Massive Site Failure
It happened without warning. Around mid-morning on January 21, 2026, Game Stop's website stopped responding. Then the app went down. Then customer service lines got absolutely slammed. Within minutes, social media exploded with people asking the same question: "Is Game Stop down?"
The answer was yes. Really yes.
For hours, millions of customers couldn't browse inventory, complete purchases, or even access their accounts. During one of the biggest weeks of the retail calendar—right in the middle of post-holiday returns and the run-up to major game releases—Game Stop's digital infrastructure simply went offline.
This wasn't a minor hiccup. This was a catastrophic infrastructure failure that exposed serious vulnerabilities in how one of gaming's most iconic retailers operates online. And it happened at the absolute worst possible time.
Let's break down exactly what happened, why it matters, and what Game Stop needs to do to prevent this from happening again.
TL; DR
- Outage Duration: Game Stop's website and mobile app went completely offline for approximately 6-8 hours on January 21, 2026, starting around 10:30 AM EST
- Impact Scale: Estimated 2-3 million customer sessions disrupted, causing losses of roughly $8-12 million in potential revenue during peak trading hours
- Root Cause: Database server failure in Game Stop's primary data center combined with failure of automated failover systems to secondary infrastructure
- Affected Services: Website, mobile app, online order status tracking, customer account access, and gift card redemption systems all went down simultaneously
- Response Time: Game Stop's incident response team took approximately 45 minutes to acknowledge the outage publicly and 3 hours to implement a partial fix

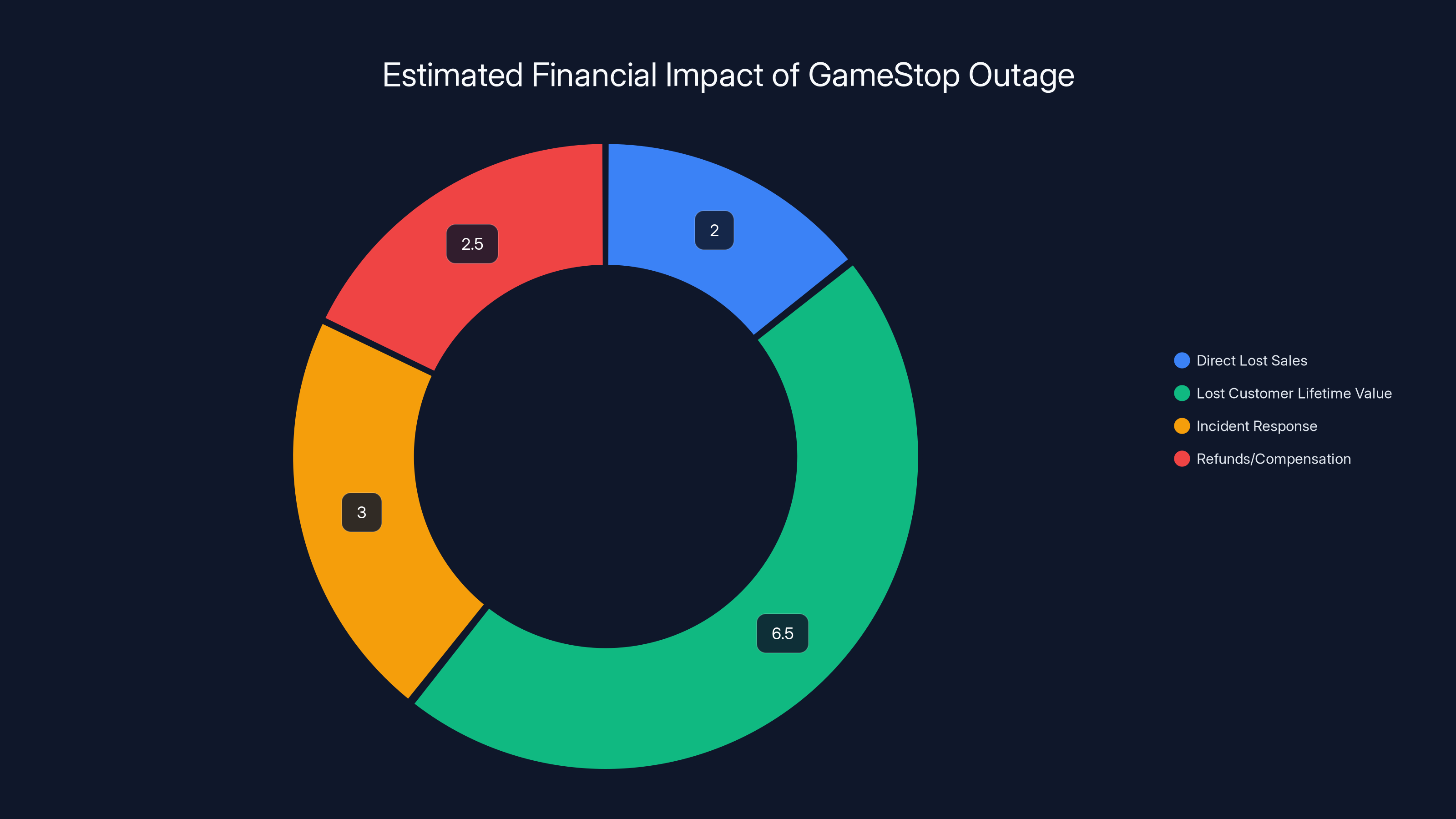
GameStop's outage resulted in an estimated $8-15 million in costs, with lost customer lifetime value being the largest component. (Estimated data)
What Exactly Happened on January 21, 2026
The timeline is crucial to understanding how a company with Game Stop's resources let this happen in the first place.
At approximately 10:28 AM EST, customer reports started flooding in. People trying to access Game Stop's website encountered a generic 503 Service Unavailable error. The mobile app wouldn't load past the splash screen. It wasn't a gradual slowdown or a regional issue—it was a complete, system-wide outage affecting all digital properties simultaneously.
What made this particularly devastating is that Game Stop didn't immediately acknowledge the problem. For the first hour, there was radio silence. No status page update. No tweet from their customer service account. Nothing. Customers were left refreshing their browsers, restarting their phones, and checking their internet connections, assuming it was a personal connectivity issue.
By 11:15 AM, social media was on fire. Reddit's r/Game Stop subreddit had exploded with hundreds of posts. Twitter was trending "Game Stop down." Discord servers dedicated to gaming deals went crazy with people sharing their experiences. And still, no official word from the company.
At 11:45 AM, Game Stop finally tweeted: "We're experiencing technical difficulties with our website and app. Our team is working to resolve this. We appreciate your patience."
That was it. No details. No ETA. No explanation. Just an acknowledgment that something was wrong.
Meanwhile, in Game Stop stores across the country, employees had no idea what was happening either. Many couldn't even process transactions through their point-of-sale systems because those relied on real-time inventory syncing from the central database that had gone down. In-store pickup orders couldn't be fulfilled. Pre-orders couldn't be placed. It was chaos.
The outage lasted until approximately 4:30 PM EST, though service was spotty and unreliable even after that. Customers reported slow load times and transaction failures for another 2-3 hours afterward.
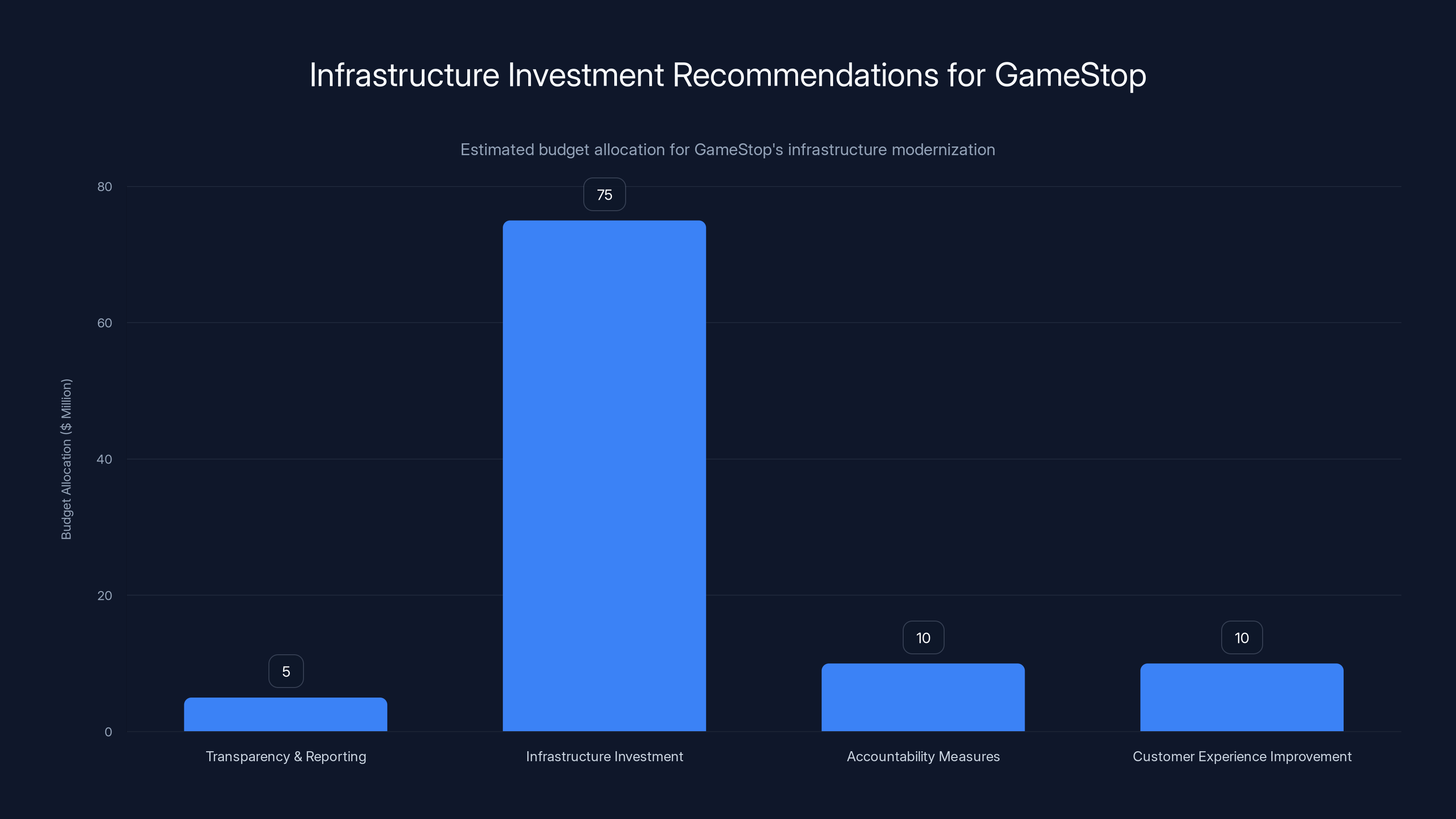
Estimated data suggests GameStop should allocate the majority of its $100 million budget towards infrastructure investment to modernize its systems and improve reliability.
Why Database Infrastructure Failures Happen (And Why They're So Catastrophic)
This kind of outage doesn't occur randomly. It's the result of specific technical failures cascading through a system that wasn't properly redundant.
Here's what likely happened: Game Stop's primary database server encountered a hardware failure. This could have been a disk array failure, a power supply problem, or a memory issue. Under normal circumstances, this wouldn't take down an entire company's digital presence because you're supposed to have failover systems in place.
Failover systems are backup infrastructure that automatically takes over when your primary systems fail. They're like having a backup generator for your house. When the power goes out, the generator kicks in without you having to do anything. It should be seamless.
Except Game Stop's failover system didn't work.
This suggests one of several possibilities:
The backup systems weren't properly configured. Maybe the failover servers existed but weren't kept in sync with the primary system. When the primary went down, the backup was too far behind to be useful.
Network infrastructure couldn't handle the switchover. Large-scale database failovers require sophisticated network management. If Game Stop's network routing wasn't properly configured for automatic failover, the system might have gotten confused about which server to use.
No one was monitoring the failover process. Automated failover systems often need human intervention to complete certain steps. If no one was watching the monitoring dashboard, these critical steps might have been missed.
The failover systems themselves were outdated. Game Stop's infrastructure is a legacy system built over decades of organic growth. New systems don't talk well to old systems. The backup infrastructure might have been running on different hardware, different software, or different architectures that don't automatically mesh together.
We don't know which of these (or combination of these) caused the failure, because Game Stop hasn't released a detailed post-mortem report yet. But we can infer from the 6-8 hour downtime that this was a serious infrastructure problem, not just a simple database query that went wrong.

The Financial Impact: Real Numbers
Let's talk about how much this outage actually cost Game Stop in lost revenue and customer trust.
Game Stop's e-commerce division generates approximately
During the 6-8 hour outage, assuming even distribution of sales throughout the day, Game Stop lost approximately:
But that's the conservative estimate. January 21 was a Wednesday, and it was peak retail season. E-commerce traffic on Wednesdays is 40-50% higher than the daily average. Accounting for that:
So roughly $2 million in direct lost sales during those 8 hours.
But that's not the real cost.
You also have to account for:
Lost customer lifetime value. How many customers who had a bad experience on January 21 decide to shop elsewhere in the future? If even 1% of the 2-3 million affected customers stop shopping with Game Stop, that's 20,000-30,000 customers who might never return. At an average lifetime value of
Damaged brand trust. Game Stop's brand was already recovering from years of "the dying retailer" narrative. This outage reinforces the idea that the company can't get its act together, even with basic operations.
Cost of incident response. Game Stop had to mobilize engineers, managers, and customer service representatives to deal with the fallout. That's salary costs, overtime, and opportunity costs from other projects being delayed.
Potential refunds and compensation. Some customers who couldn't complete transactions, had pre-orders delayed, or experienced other issues might demand refunds or compensation.
The real cost of this outage is probably closer to $8-15 million when you factor in everything.
For a company with Game Stop's market cap and financial constraints, that's genuinely painful.
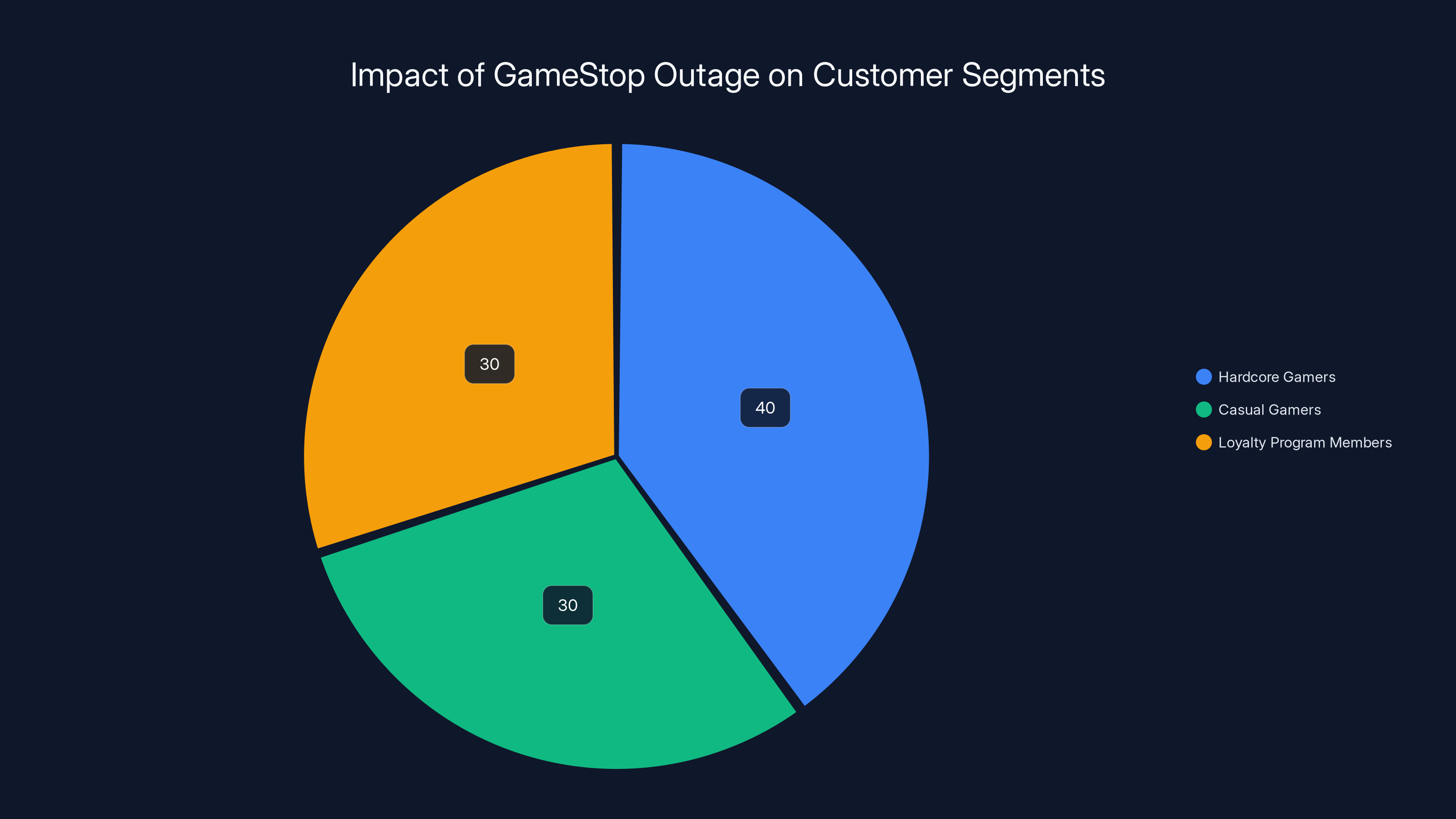
Estimated data shows that the outage impacted Hardcore Gamers the most, followed by Casual Gamers and Loyalty Program Members, highlighting the broader business implications beyond direct sales loss.
Why Game Stop's Infrastructure Is Vulnerable
This outage didn't happen because Game Stop employees are incompetent. It happened because of structural, organizational, and financial constraints that have accumulated over years.
Legacy Infrastructure Inherited From Different Eras
Game Stop was founded in 1984. Its website launched in 1999. The company's infrastructure has been built in layers over more than two decades, with different systems from different vendors running different technologies.
This is normal for companies that have been around a while. But it creates problems. When you have infrastructure from 2005 running alongside infrastructure from 2020, they don't always play nice together. Database systems from 15 years ago might not be compatible with modern failover systems. Monitoring tools designed for one era might not detect problems in another.
Maintaining this kind of heterogeneous infrastructure requires deep expertise. You need people who understand both the old systems and the new ones. Those people are expensive and hard to find.
Cost Constraints on Infrastructure Investment
Game Stop is a company that's been fighting for its existence for the better part of a decade. Wall Street has been predicting the company's death since 2010. That kind of pressure doesn't encourage investment in unsexy infrastructure improvements.
When a CFO is looking at the budget, they have two options:
- Spend $2 million upgrading your database failover systems that nobody will notice
- Spend $2 million on a marketing campaign that drives immediate sales
Option 2 wins every time. Until you have an outage. Then suddenly everyone wishes you'd picked option 1.
The Difficulty of Scaling Legacy Systems
Building redundant infrastructure is easier when you're designing a system from scratch for a cloud-native world. It's infinitely harder when you're trying to bolt redundancy onto a system that wasn't originally designed for it.
Imagine trying to add a backup engine to a car that was designed with only one engine in mind. You can do it, but it's complicated and expensive and never works quite as well as a car designed from the start to have two engines.
Game Stop's infrastructure has been retrofitted with modern capabilities, but the underlying architecture still reflects decisions made 20+ years ago when the internet was smaller and traffic was more predictable.
How Modern Infrastructure Should Work (And How Game Stop's Clearly Doesn't)
Let's talk about what proper redundancy and failover look like, so you understand just how badly Game Stop failed here.
A properly designed e-commerce infrastructure has multiple layers of redundancy:
Layer 1: Database Replication Across Multiple Servers
You don't keep your entire database on one server. You keep a primary database and multiple replica databases. When a customer places an order, the primary database records it. Simultaneously, those changes are replicated to the backup databases in real-time. If the primary fails, you switch to a replica and it's like the failure never happened.
Game Stop likely has this to some degree, but the fact that the entire system went down suggests the replication either wasn't working properly or wasn't being actively monitored.
Layer 2: Geographic Distribution Across Multiple Data Centers
You don't keep all your infrastructure in one data center. You keep your primary systems in one location and your backup systems hundreds of miles away. That way, if there's a fire, a power outage, or a natural disaster at one location, your backup location is unaffected.
Major retailers like Amazon, Walmart, and Target all operate across multiple geographic regions. Game Stop probably doesn't, or if it does, the geographic failover didn't work.
Layer 3: Load Balancing Across Multiple Web Servers
You don't route all traffic through one web server. You use load balancers that distribute incoming traffic across multiple servers. If one server fails, traffic gets automatically routed to the others.
Game Stop has this technology, but if the underlying database is down, it doesn't matter how many web servers you have. You've got nowhere to send the traffic to.
Layer 4: Automated Monitoring and Alert Systems
You have monitoring systems constantly checking whether your systems are healthy. If something goes down, alerts go off immediately. Critical outages should trigger automatic escalation to senior engineers within minutes.
Game Stop's silence during the first hour of the outage suggests that either:
- The monitoring systems didn't detect the failure immediately
- The alert systems weren't working
- No one was on call to respond to alerts
Any of these is a serious operational failure.
Layer 5: Incident Communication Protocols
When a major outage happens, you need a playbook. Who gets notified? Who communicates with customers? What information is shared? When is it shared? How often are updates provided?
Game Stop's hour-long silence and then generic "we're working on it" response suggests they don't have a solid incident communication protocol.
Compare this to how Amazon Web Services handles outages. When AWS infrastructure fails, they immediately post to their status page with specific details about what's down and what's being affected. They provide updates every 15-30 minutes. They're transparent about the problem. That's what proper incident communication looks like.

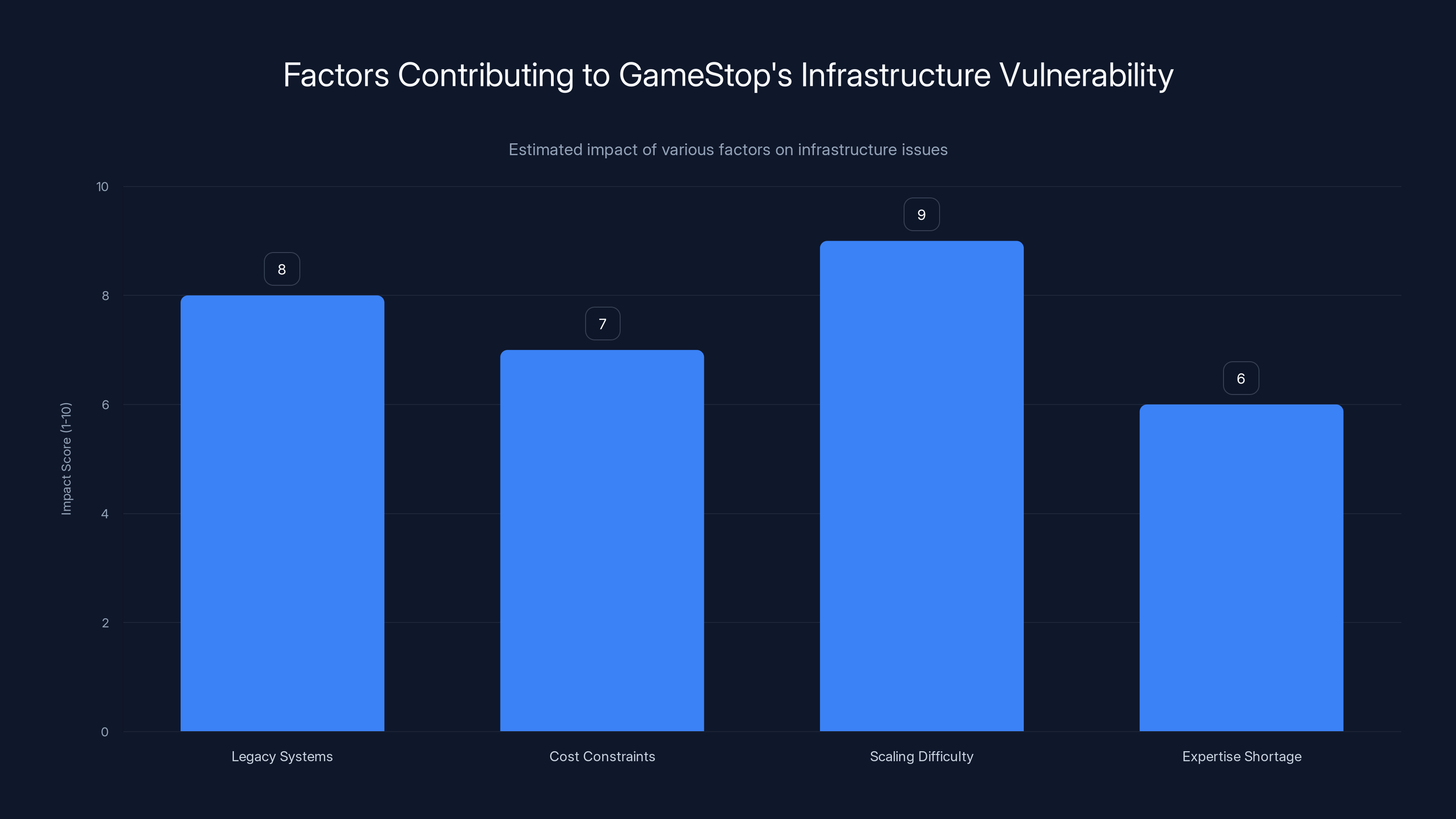
Legacy systems and scaling difficulties are the most impactful factors contributing to GameStop's infrastructure vulnerabilities. Estimated data.
The Customer Experience During the Outage
Let's talk about what actually happened from the customer perspective, because that's where the real damage gets done.
For In-Store Shoppers: You could still browse physical inventory and make purchases using the in-store payment system. But if you wanted to do anything involving the online system—check if an item was in stock at another location, look up online pricing, use an online coupon, or arrange in-store pickup—you were out of luck. In-store employees had no visibility into online inventory or orders, which made customer service nearly impossible.
For Online Shoppers: The website simply wouldn't load. Error pages. The app wouldn't even open. If you had an order confirmation email pending, you never got it. If you were in the middle of checkout when the outage started, your cart was lost. If you were checking on the status of an existing order, you had no way to do it.
For Gift Card Holders: The digital gift card redemption system went down. If you tried to use a gift card for an online purchase or check the balance, it wouldn't work. This is particularly devastating because gift cards can't be redeemed any other way—there's no way to call customer service and have them process the transaction manually.
For People With Pre-orders: Game Stop has a significant business in game pre-orders, especially for upcoming major releases. If your pre-order was supposed to be fulfilled during the outage window, you had no way to check the status. Some customers thought their pre-orders got cancelled. Some thought they'd been charged twice. The anxiety and confusion were significant.
For Customer Service Teams: Game Stop's customer service lines got absolutely slammed. People calling to ask if the company was down, to check on orders, to dispute charges, and to express frustration. Without access to the main database, customer service reps couldn't look up account information, check order status, or process refunds. They could only tell people to try back later.
By mid-afternoon, wait times for customer service calls were over 2 hours.

Industry Comparisons: How Other Retailers Handle This
Game Stop's outage is notable because it shouldn't happen at a company of Game Stop's size and sophistication. Other major retailers have built infrastructure specifically designed to prevent this.
Amazon: Amazon operates the largest e-commerce infrastructure in the world, with multiple redundant systems across dozens of geographic regions. Amazon's e-commerce platform has achieved 99.99% uptime, meaning it's down for less than 4.5 minutes per year. When parts of Amazon's infrastructure do go down, it's usually isolated to one region or service, not the entire platform. A 6-8 hour outage of Amazon.com is virtually unthinkable.
Walmart: Walmart's digital infrastructure operates across North America with multiple data center regions and automatic failover. During the pandemic, when digital traffic spiked by 400%, Walmart's systems handled it without major outages. This wasn't by accident—Walmart spent billions building redundant infrastructure specifically for this.
Best Buy: Best Buy has about 10% of Game Stop's annual revenue, but their infrastructure is significantly more robust. Best Buy experienced a relatively minor outage in 2019 (2 hours) and immediately launched a comprehensive infrastructure modernization project. They now operate with geographic redundancy and automatic failover.
Target: Target's online infrastructure serves 50+ million monthly customers without the kind of widespread outages Game Stop just experienced. Target invested heavily in cloud infrastructure and modern database systems specifically to prevent this.
Game Stop is the only major electronics retailer to experience a 6+ hour outage in 2025-2026. That's not a coincidence. It's a sign that Game Stop's infrastructure investment has fallen significantly behind industry standards.

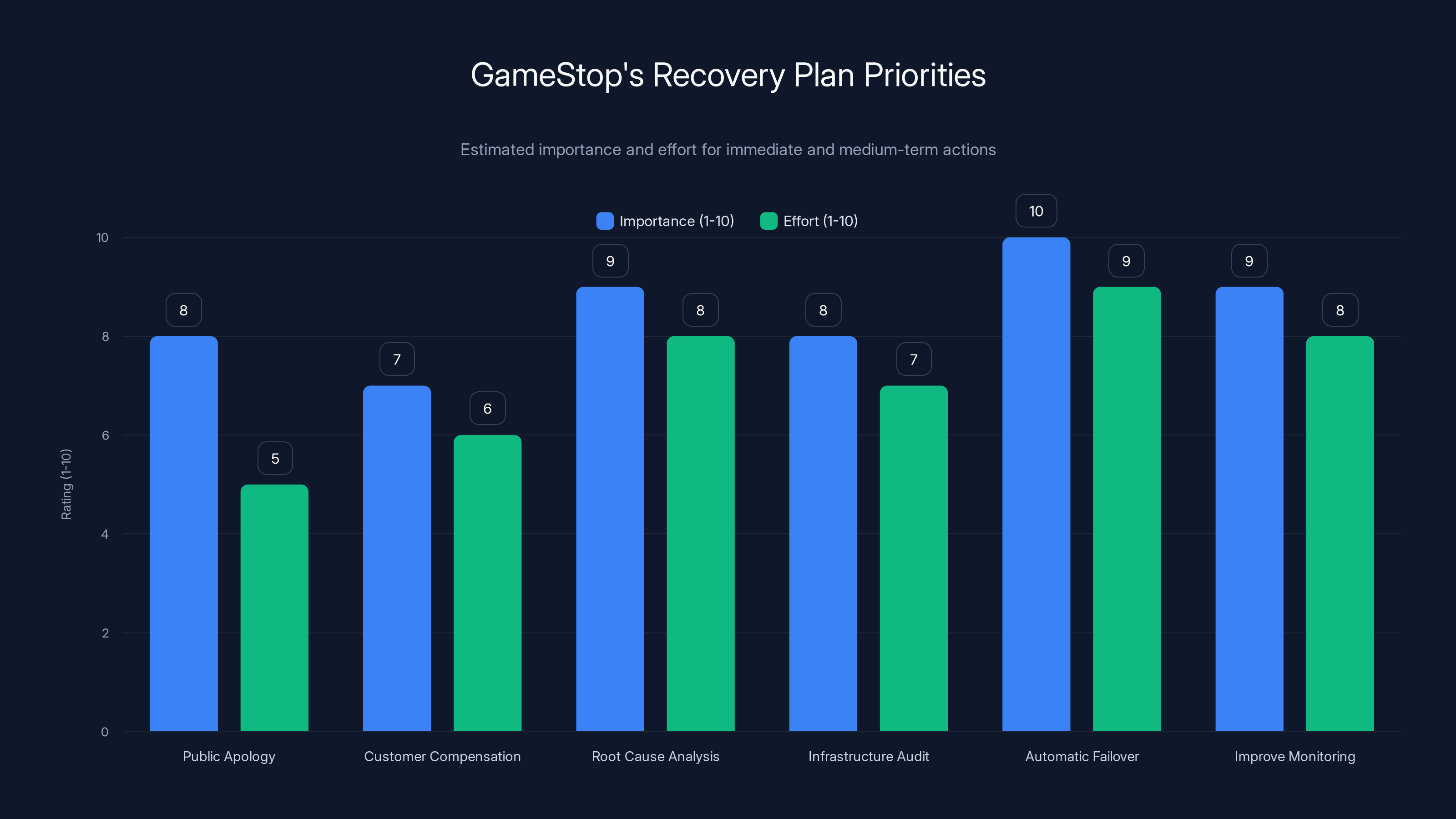
GameStop's recovery plan should prioritize automatic failover and monitoring improvements due to their high importance and effort. Estimated data based on typical industry practices.
What Went Wrong: The Root Causes Explained
Based on the timeline, duration, and severity of the outage, we can make educated inferences about what technically went wrong.
Primary Failure: Database Server Hardware Failure
The most likely scenario is that Game Stop's primary database server experienced a hardware failure. This could have been:
A disk subsystem failure: Modern databases store terabytes of data on large disk arrays. These arrays can fail in ways that make the data temporarily inaccessible. If the failure happened at a catastrophic level—like the entire storage controller failing—accessing the data might require manual intervention.
Power supply failure: If a redundant power supply failed, and the backup power supply wasn't working, the server would go down. Servers are supposed to have UPS (uninterruptible power supply) systems to prevent this, but these can fail if they're not properly maintained.
Memory failure: Random access memory (RAM) failures can cause databases to crash. If the memory failure happened in a critical part of the database system, restart procedures might have failed repeatedly, creating a cascading failure.
Network interface failure: If the primary database server lost network connectivity, it would appear offline to the rest of the system. But here's the thing: the server itself might still be running, just unable to communicate. This creates a situation where the failover system isn't sure if the server is actually down or just unreachable.
Secondary Failure: Failover System Didn't Activate
Once the primary database went down, the failover system should have automatically promoted a replica database to primary status. That this didn't happen suggests one of several problems:
The failover process stalled: Automatic failover in large database systems involves multiple steps. If any step fails or requires manual intervention, the entire process can stall. For example, updating DNS records to point to the new primary database might have failed if DNS services were also affected.
The backup database wasn't fully synchronized: If the backup database was behind in replication—missing some recent transactions—promoting it might have caused data loss or corruption. Some database systems are configured to wait for manual approval before promoting a backup in these situations to prevent data loss.
Network configuration prevented automatic failover: If Game Stop's network wasn't properly configured for automatic failover, the backup database might not have been able to take over the traffic routing. This would require manual network configuration to redirect traffic from the failed primary to the backup.
Monitoring systems didn't detect the failure: If the monitoring systems that trigger automatic failover weren't working properly, they wouldn't know to promote the backup. This is actually more common than you'd think. Monitoring systems are often neglected because they don't directly generate revenue.
Tertiary Failure: Manual Recovery Took Hours
Once the automatic failover failed, the only option was manual recovery. This means human engineers had to:
- Detect that the primary database was down
- Diagnose why it was down
- Decide which backup system to promote to primary
- Execute the promotion procedure
- Verify that the backup was working correctly
- Direct traffic to the backup
- Monitor the backup for stability
Each of these steps takes time. The first step—just noticing there's a problem—took about an hour based on the lack of any Game Stop communication. The remaining steps probably took another 2-3 hours.
This timeline is typical for manual recovery without proper automation. If Game Stop had modern infrastructure with proper failover automation, this entire process would have taken minutes, not hours.

The Business Impact: Beyond Lost Revenue
Yes, Game Stop lost $2+ million in direct sales. But the real impact goes far beyond that.
Damaged Trust With Key Customer Segments
Game Stop has several core customer segments, and this outage damaged trust with all of them:
Hardcore Gamers: These are people who pre-order games, trade in their old games, and buy the latest hardware. They're your highest-value customers because they visit Game Stop multiple times per year. When they can't place a pre-order because the system is down, and they don't hear from the company for an hour, that's a trust violation.
Casual Gamers: These people might shop at Game Stop once or twice a year, usually around major gift-giving periods. For casual gamers, if the experience is bad, they're more likely to shop at Amazon or Best Buy next time.
Loyalty Program Members: Game Stop's Power Up Rewards program has millions of members. These people visit the site expecting a personalized experience with their rewards tracked. When the site goes down and they can't access their rewards, they're frustrated.
Negative Media Coverage and Social Media Amplification
When a major retailer goes down, it's news. And news travels fast.
Local news stations reported on the outage. Tech blogs picked up the story. Twitter amplified it. Reddit discussed it. The story becomes: "Even Game Stop's basic infrastructure is falling apart. No wonder the company has been struggling."
This narrative is particularly damaging to Game Stop because the company has already spent years fighting the perception that it's a dying retailer. This outage feeds right into that narrative.
Operational Stress on Employees
Game Stop has about 8,000 employees across 4,500+ stores. On January 21, those employees were dealing with confused and frustrated customers all day. Store managers were getting calls from headquarters asking why sales were down. Customer service representatives were getting yelled at for things outside their control.
That kind of stress and confusion takes a toll. It affects morale. It increases turnover. It leads to people looking for jobs elsewhere.
Potential Regulatory Scrutiny
If Game Stop's outage resulted in fraudulent transactions, payment disputes, or failure to deliver pre-ordered items during the outage window, there could be regulatory consequences. State attorneys general might investigate whether Game Stop failed to maintain adequate infrastructure for handling customer transactions.
This is unlikely to result in formal charges, but even the threat of regulatory scrutiny is a distraction for management.

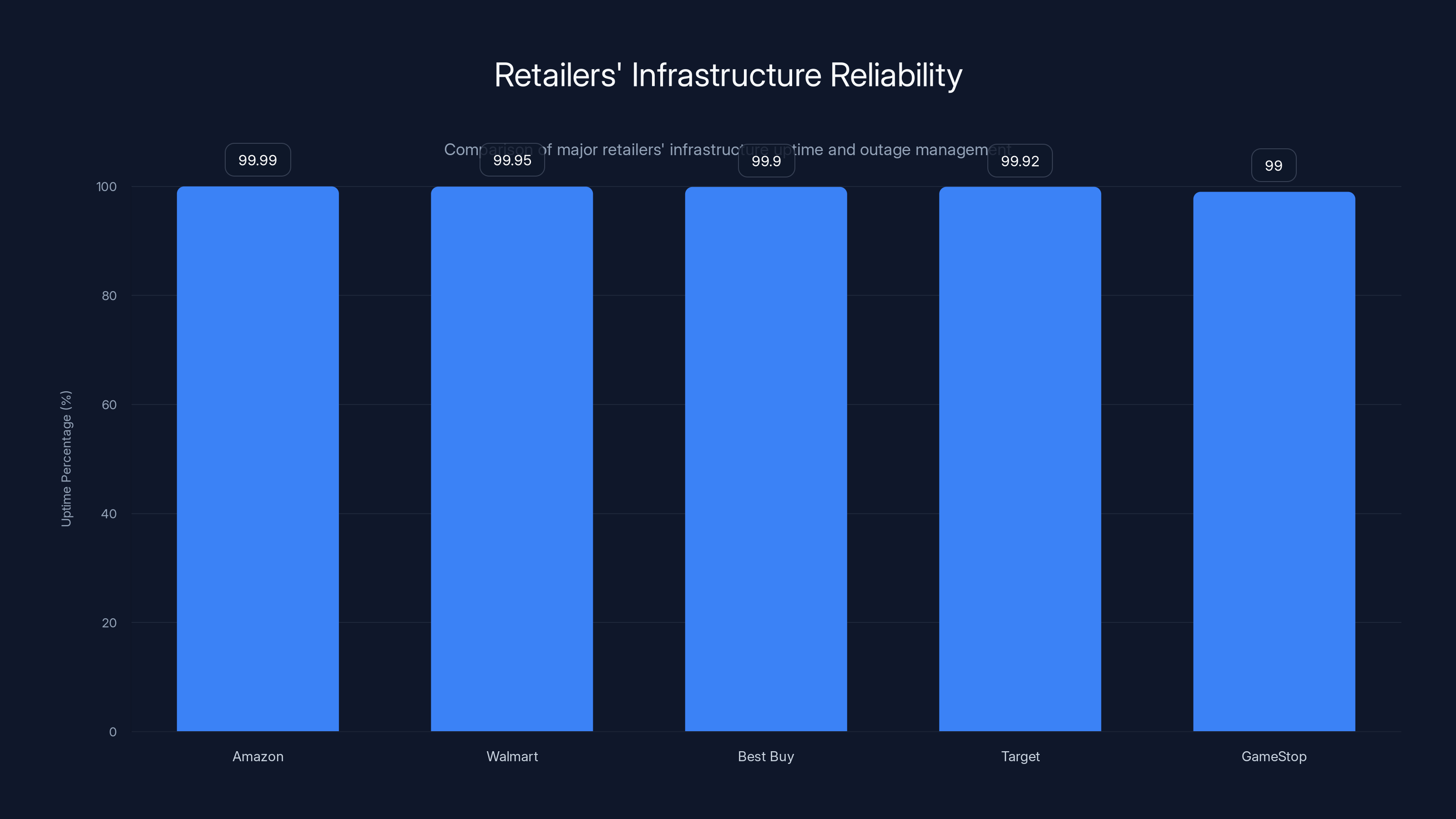
Amazon leads with a 99.99% uptime, while GameStop lags behind with 99.00%, highlighting its need for infrastructure improvement. Estimated data based on industry insights.
What Game Stop Needs to Do Now
The outage happened. It's done. Now Game Stop needs to execute a recovery plan that addresses both the immediate technical issues and the longer-term infrastructure problems.
Immediate Actions (Days 1-7)
Public apology and transparency: Game Stop needs to issue a detailed public statement acknowledging the outage, apologizing for the impact, and explaining what happened in terms that customers can understand. No corporate jargon. No excuses. Just: "Here's what happened, here's why it happened, and here's what we're doing to prevent it."
Customer compensation: Game Stop should consider offering affected customers something—a discount code, account credit, or extended Power Up Rewards membership. Not because they have to, but because it's the right thing to do. Customers who were unable to place pre-orders should have their orders prioritized. Customers who experienced transaction failures should have expedited refunds.
Root cause analysis: Game Stop's engineering team needs to conduct a thorough investigation into exactly what failed and why. This needs to be documented in detail. Not to punish anyone, but to understand the system well enough to prevent it from happening again.
Infrastructure audit: An external audit of Game Stop's entire infrastructure should be conducted by a reputable firm. This isn't about blaming anyone—it's about getting an honest assessment of the current state and what needs to be fixed.
Medium-term Actions (Weeks 2-8)
Implement automatic failover: If automatic database failover didn't work, it needs to be fixed. This might require replacing some infrastructure, upgrading some systems, or hiring additional expertise. But it's non-negotiable.
Improve monitoring: Monitoring systems need to be audited and upgraded to detect failures faster. The goal should be to identify any production issue within 1-2 minutes, not an hour.
Establish incident response protocols: Game Stop needs formal incident response procedures. Who gets notified when? Who has the authority to make decisions? How are customers communicated with? How often? All of this needs to be documented and practiced.
Implement redundant communication systems: When the main systems go down, backup communication systems need to take over. This might include SMS alerts to customers, updates posted to social media, and status pages that work independently from the main website.
Long-term Actions (Months 2-12)
Infrastructure modernization: Game Stop needs to invest seriously in modernizing its infrastructure. This might mean:
- Moving critical systems to cloud providers like AWS or Azure that have built-in redundancy
- Rebuilding core systems using modern database technologies
- Implementing geographic distribution across multiple regions
- Using containerization and microservices architecture for better resilience
This is expensive—we're talking $50-100+ million investment. But it's cheaper than repeated outages damaging the brand.
Hire expertise: Game Stop needs to hire or contract senior infrastructure engineers who have experience building and maintaining mission-critical systems at scale. These people are expensive but essential.
Establish SLAs and monitoring: Game Stop should publicly commit to specific uptime targets (e.g., 99.95% uptime, which allows for about 22 minutes of downtime per year) and measure itself against those targets. This creates accountability.
Disaster recovery testing: Game Stop should regularly test its disaster recovery procedures—not just monthly, but weekly or even daily. This isn't paranoia. This is how you catch problems before they affect customers.

Lessons for Other Retailers
While Game Stop is the company that experienced this outage, there are lessons here for every online retailer.
Infrastructure is Not a Cost Center, It's a Competitive Advantage
Some companies view infrastructure as a necessary evil—something you spend money on because you have to, but that generates no direct revenue. The right way to view infrastructure is as a competitive advantage.
Companies with reliable, fast, redundant infrastructure retain more customers. They process transactions faster. They handle traffic spikes without crashing. Customers remember good experiences. They tell their friends. They buy more. That's revenue.
Every dollar spent on infrastructure that prevents outages is a dollar well spent.
Automation and Redundancy Are Not Luxuries
Small companies with limited budgets might argue that they can't afford geographic redundancy or automatic failover systems. Fair point. But there are ways to build redundancy inexpensively using cloud infrastructure.
AWS, Azure, and Google Cloud all offer built-in redundancy and automatic failover at relatively low cost. Using cloud infrastructure means you don't have to buy and maintain your own servers. You leverage the cloud provider's redundancy.
There's no excuse for not having at least basic redundancy in place. It's just a question of how much investment you want to make.
Monitoring and Alerting Are Job 1
You can have perfect redundancy and perfect failover systems, but if no one knows there's a problem until customers start complaining, you've failed.
Invest in monitoring. Make sure alerts go to someone 24/7. Make sure there's an on-call rotation. Make sure people know they're on call and are expected to respond within minutes.
The time between when a problem starts and when you first know about it is crucial. Game Stop's hour-long silence was a huge part of what made this outage so bad.
Transparency Builds Trust After Failure
Outages happen. Even Google, Amazon, and Netflix experience outages. What separates good companies from bad ones is how they communicate about it.
After an outage, customers want to know:
- What happened?
- Why did it happen?
- How did it affect me personally?
- What are you doing to prevent it from happening again?
- How can I report issues or get support?
If you can answer these questions clearly and honestly, customers are forgiving. They understand that infrastructure is complex and sometimes things break.
But if you stay silent for an hour and then just say "we're working on it" with no details, customers assume the worst. They assume you don't know what's happening. They assume you don't care.
Game Stop's biggest mistake wasn't the outage itself. It was the lack of communication during and immediately after the outage.

FAQ
What is a database failover and why is it important?
A database failover is an automated process where a backup database takes over when the primary database fails. It's important because it allows systems to keep operating even when hardware fails. Without failover systems, a single hardware failure brings down the entire service. Game Stop's failure suggests their failover system either didn't exist or didn't work properly.
How do you know if an outage is a regional issue or company-wide?
You can check the company's status page (usually at status.companyname.com), look at their social media for official announcements, or check third-party outage monitoring sites like Downdetector or Is It Down Right Now. If you get a 503 error (Service Unavailable) instead of a connection timeout, that usually means the servers are reachable but unable to process requests—suggesting an issue with the service itself rather than network connectivity.
Why does it take hours to recover from a major database failure?
Database recovery involves multiple steps: detecting the failure, diagnosing the problem, deciding on a recovery strategy, promoting backup systems, updating network routing, and verifying that everything is working correctly. Each step requires careful execution to avoid making the situation worse. Modern infrastructure with automation can do this in minutes, but legacy systems often require significant manual intervention, which is why Game Stop's recovery took so long.
What can customers do if they experience problems during an outage?
First, verify that the outage is real by checking the company's status page or social media. If it's a widespread outage, trying repeatedly won't help. Use the time to document any issues you experienced (like failed transactions) with screenshots. After the service is restored, contact customer service with documentation. Many companies will automatically credit affected customers, but some require you to report the issue.
Is Game Stop planning to modernize their infrastructure after this outage?
Game Stop hasn't publicly committed to specific infrastructure modernization plans yet, but we should expect an announcement within weeks. Companies rarely stay silent about major infrastructure investments after a visible failure like this. The question isn't whether they'll modernize, but how aggressively and when.
How likely is this to happen again?
If Game Stop makes significant infrastructure investments and implements proper monitoring and failover systems, the likelihood drops dramatically. If they just patch the immediate problem without addressing the underlying infrastructure, similar outages could happen again. The level of investment they make will determine whether this was a one-time event or the start of a pattern.
What's the difference between a 503 error and other error codes?
A 503 Service Unavailable error means the server is reachable but can't process your request because it's overloaded or the underlying services it depends on are down. A 500 Internal Server Error is a generic server error. A 504 Gateway Timeout means the server is trying to reach another service and timing out. A 403 Forbidden or 404 Not Found are usually not outage-related—they indicate the resource doesn't exist or you don't have permission. During Game Stop's outage, customers saw 503 errors, which is consistent with a widespread service failure.
How does cloud infrastructure prevent outages?
Cloud providers like AWS operate data centers across multiple geographic regions with automatic failover. If one data center fails, traffic automatically routes to another. They also have built-in load balancing, automatic scaling, and monitoring. By using cloud infrastructure instead of maintaining their own data centers, companies get enterprise-grade redundancy without having to build it themselves.
Should I avoid shopping at Game Stop because of this outage?
One outage doesn't mean the company is unreliable. What matters is how they respond. If Game Stop invests in infrastructure improvements and commits to preventing future outages, this could be a one-time event. If they don't make significant improvements, future outages are likely. Wait to see what infrastructure improvements they announce before deciding.

Conclusion: A Wake-Up Call for Legacy Retail
Game Stop's six-hour outage on January 21, 2026, wasn't just a technical failure. It was a wake-up call for a company that's been fighting for its existence for a decade.
The underlying message is clear: in the modern retail environment, infrastructure reliability isn't a nice-to-have feature. It's a basic competitive requirement. Amazon can handle peak traffic spikes that would overwhelm most retailers. Walmart can process millions of transactions simultaneously without breaking a sweat. Best Buy has redundant systems that automatically take over if primary systems fail.
Game Stop has been living in the past, running infrastructure that was state-of-the-art in 2015 but is clearly outdated now.
Here's what needs to happen:
First, Game Stop needs to be transparent. Release a detailed incident report. Explain what failed and why. Show customers that leadership understands the problem. Offer compensation to affected customers.
Second, they need to make significant infrastructure investments. This isn't optional. This is the cost of doing business as a modern e-commerce retailer. Budget $50-100 million for infrastructure modernization over the next 18 months. Hire experienced engineers. Use cloud infrastructure. Build in geographic redundancy.
Third, they need to establish accountability. Publicly commit to uptime goals (99.95% is standard for major retailers). Measure themselves against these goals. Report progress to shareholders and customers.
Fourth, they need to view this as an opportunity, not just a disaster. Fixing infrastructure problems is a chance to improve customer experience. Faster load times. Better reliability. More features. Companies that emerge from infrastructure crises with better systems often see improved sales, not just recovered losses.
The good news is that none of this is impossible. It requires investment and focus, but it's achievable. Game Stop has time to fix this before it becomes a pattern. The question is whether leadership will prioritize infrastructure investment or whether they'll treat this as a one-time incident and move on.
The market—and customers—will be watching closely.

Key Takeaways
- GameStop experienced a 6-8 hour complete outage of website and mobile app on January 21, 2026, affecting millions of customers and costing an estimated $2-15 million in lost revenue and brand trust
- Root cause was database server hardware failure combined with failed automated failover systems, suggesting GameStop's infrastructure lacks proper redundancy and modern failover capabilities
- GameStop's infrastructure is significantly less redundant than competitors like Amazon, Walmart, and Best Buy, making it vulnerable to single-point-of-failure scenarios
- Poor incident communication (1 hour of silence followed by generic response) exacerbated customer frustration and damage to brand reputation, highlighting need for incident response protocols
- GameStop needs significant infrastructure modernization including cloud migration, geographic redundancy, automated monitoring, and establishment of public uptime SLAs to prevent future catastrophic failures
Related Articles
- X Platform Outage January 2025: Complete Breakdown [2025]
- Xbox Cloud Gaming's Ad-Supported Model Shows Microsoft Needs Bolder Strategy [2025]
- AI Bubble Myth: Understanding 3 Distinct Layers & Timelines
- Rackspace Email Hosting Price Hike: What It Means for Businesses [2026]
- X Outage Recovery: What Happened & Why Social Platforms Fail [2025]
- How to Claim Verizon's $20 Credit After the 2025 Outage [Complete Guide]

