![Claude Sonnet 4.6: Enterprise AI Performance at 80% Lower Cost [2025]](https://tryrunable.com/blog/claude-sonnet-4-6-enterprise-ai-performance-at-80-lower-cost/image-1-1771353913049.webp)
Claude Sonnet 4.6: Complete Performance Analysis, Enterprise Impact & Cost Optimization Guide [2025]
Introduction: The AI Repricing Event That Changes Enterprise Economics
Technology markets experience inflection points where the fundamental cost structure of a capability shifts so dramatically that it reshapes entire industries. The release of Claude Sonnet 4.6 in late 2024 represents precisely such a moment for enterprise artificial intelligence.
For the past eighteen months, enterprise teams deploying AI agents and automated coding systems faced a brutal economic calculus. They could choose between two paths: deploy less capable mid-tier models at lower cost per token, accepting performance limitations on mission-critical tasks, or pay five times more for flagship-tier models capable of handling complex reasoning, code generation, and autonomous decision-making. Sonnet 4.6 fundamentally dissolves this trade-off.
The headline metric tells the story immediately. Anthropic's flagship Claude Opus models command pricing of
For organizations running AI agents that process millions of tokens daily, this represents orders-of-magnitude cost reductions. An enterprise deploying an agentic system processing 10 million input tokens and 20 million output tokens daily saw monthly API costs around
This guide provides enterprise decision-makers, developers, and AI teams with a comprehensive analysis of Sonnet 4.6: what's changed, why it matters, how it compares to alternatives, and how to evaluate whether it's the right choice for your organization's specific needs. We'll examine the technical improvements, benchmark data, real-world use cases, pricing implications, and strategic considerations that should inform your deployment decisions.
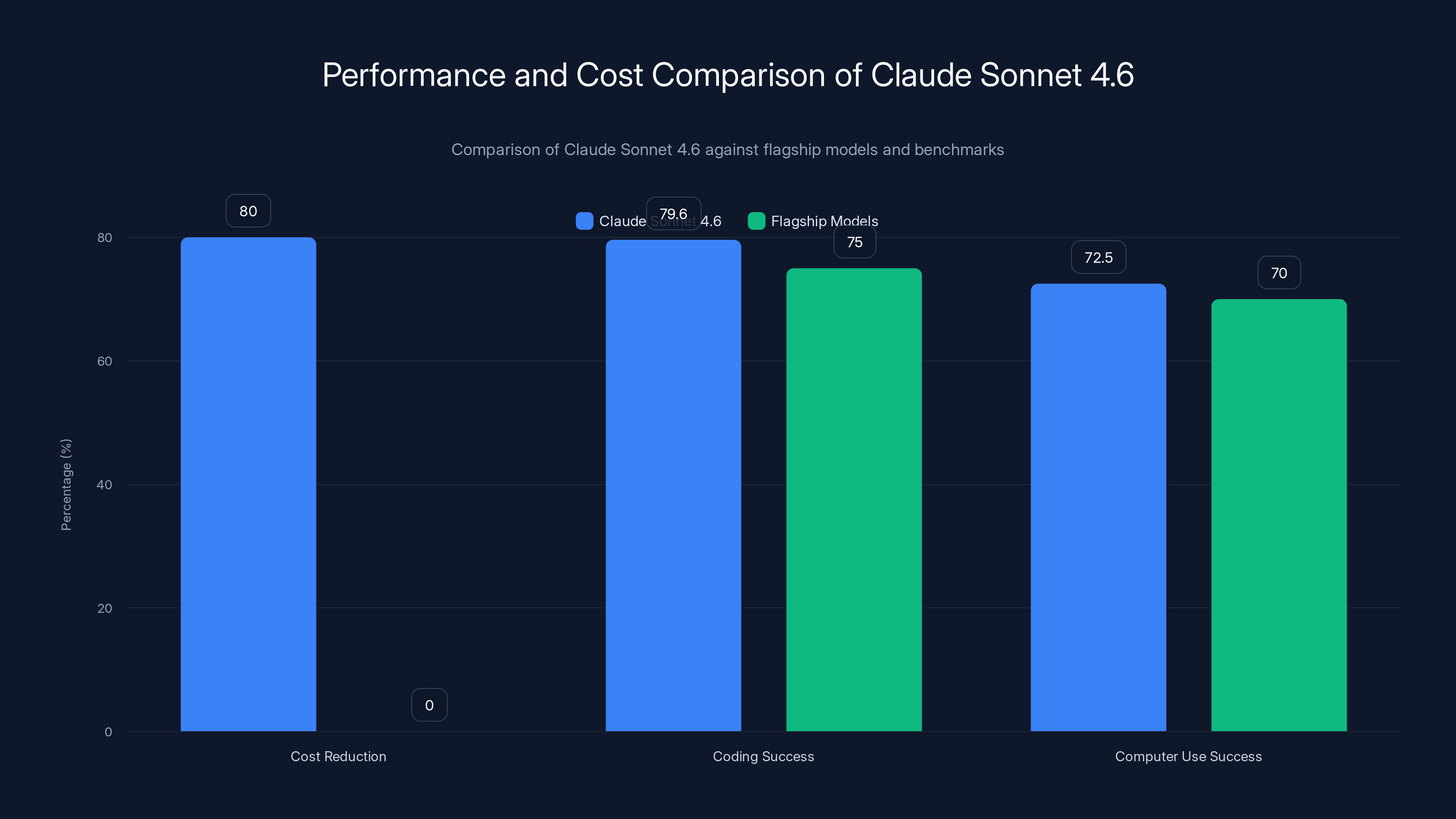
Claude Sonnet 4.6 offers significant cost savings and superior coding capabilities compared to flagship models, with a high success rate in computer use tasks.
What Is Claude Sonnet 4.6? Technical Architecture and Positioning
Model Classification and Release Context
Claude Sonnet 4.6 occupies Anthropic's middle tier in their model hierarchy, positioned between the faster Claude Haiku models and the frontier Claude Opus family. Within Anthropic's taxonomy, the Sonnet series has evolved as the "production-ready" line — models designed for real-world applications where both performance and cost-efficiency matter.
The previous generation, Sonnet 4.5, launched in October 2024 and quickly became the default model in Claude.ai, Claude Cowork (Anthropic's team collaboration product), and the foundation for Claude Code — Anthropic's AI coding assistant that has gained significant adoption among Silicon Valley developers. Sonnet 4.6 supersedes this as the new default model across all Anthropic products and services.
Anthropically released Sonnet 4.6 as a full upgrade across six critical capability domains: coding performance, computer use (autonomous desktop interaction), long-context reasoning, agent planning, knowledge work, and design tasks. The model ships with a 1-million-token context window in beta, enabling it to maintain consistent reasoning across documents and conversations 20-40 times longer than traditional transformer models.
Token Context Window and Architectural Implications
The 1-million-token context window represents a profound architectural advancement with far-reaching implications for real-world deployment. To understand the significance, consider that a typical business document contains 500-2,000 tokens. A 1-million-token context window means Sonnet 4.6 can simultaneously process:
- 100+ complete research papers or white papers while maintaining coherence
- An entire codebase of 50,000-100,000 lines alongside analysis and refactoring instructions
- A comprehensive customer interaction history spanning months of email and chat threads
- Multiple financial documents, earnings reports, and market data in a single inference pass
- Entire legal contracts and regulatory frameworks with cross-document reasoning
This capability fundamentally changes how enterprise teams approach document analysis, code refactoring, and knowledge synthesis tasks. Rather than chunking documents across multiple API calls (incurring latency and losing cross-document context), teams can now process entire knowledge bases in single requests. This both improves reasoning quality and often reduces overall token consumption through more efficient reasoning paths.
Operational Characteristics: Speed and Reliability
Early user testing revealed qualitative improvements in two dimensions that often don't appear in benchmark scores but significantly impact real-world productivity: inference speed and consistency. Users reported that Sonnet 4.6 responses generated with noticeably reduced latency compared to previous models, critical for interactive applications like Claude Code and real-time customer service agents.
On reliability and consistency, user feedback highlighted meaningful reductions in two failure modes that plagued earlier generations:
False success claims: Instances where the model incorrectly reports completing a task when execution failed.
Hallucinations: Generating plausible-sounding information that contradicts ground truth from provided documents.
These improvements, while harder to quantify than benchmark scores, often prove decisive for enterprise adoption since they directly correlate to support costs, user frustration, and operational reliability.
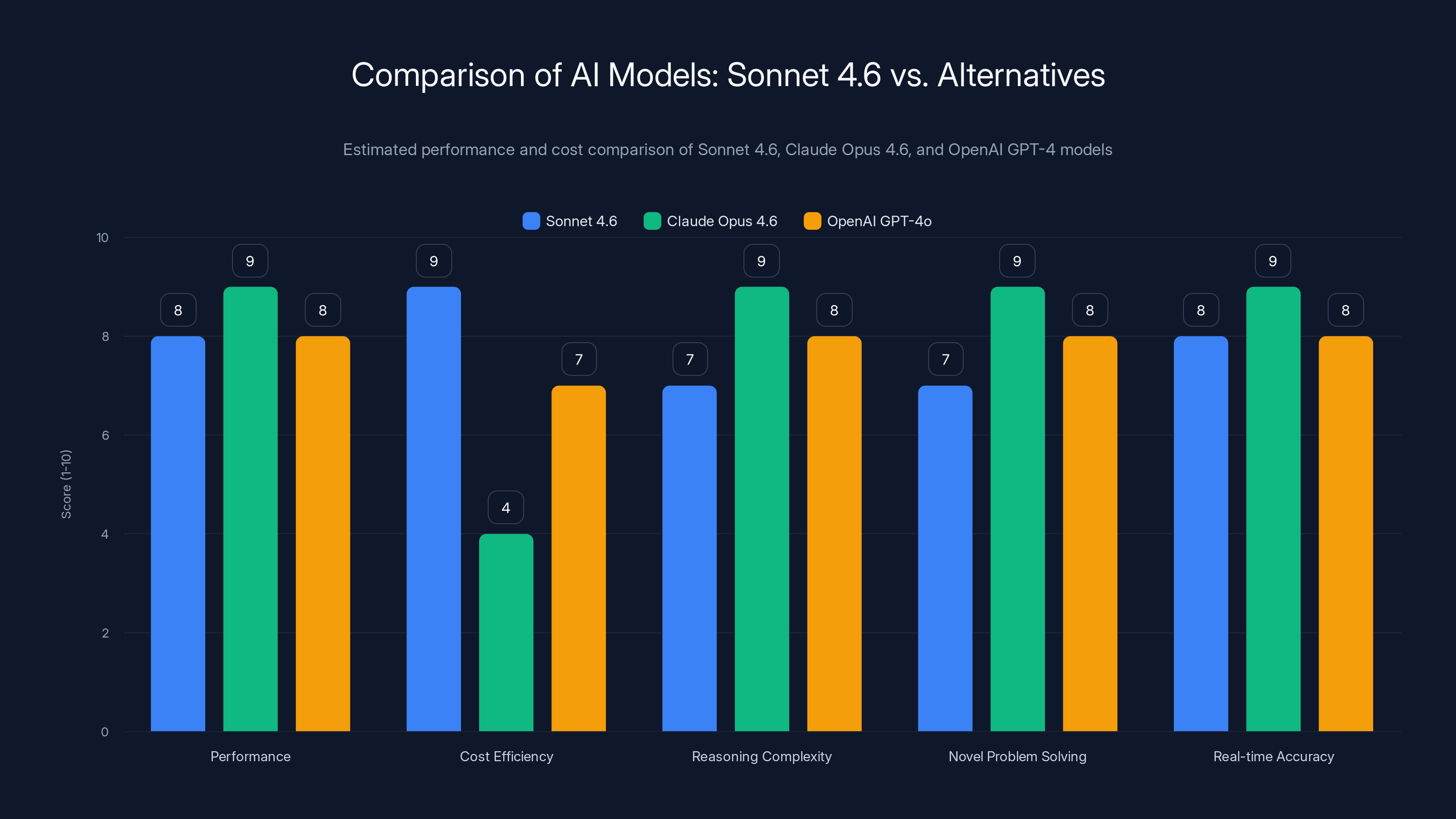
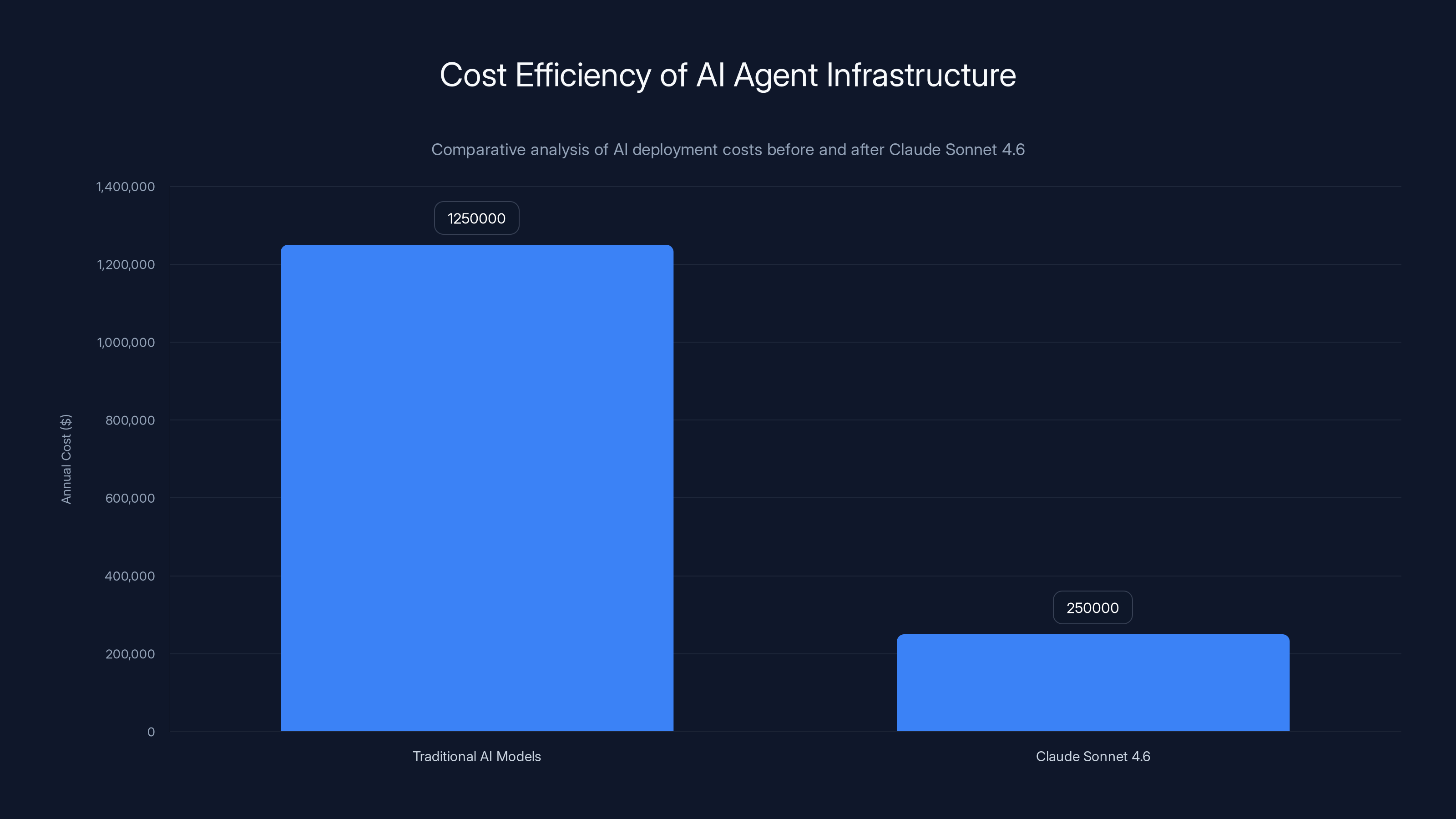
Sonnet 4.6 offers high performance and cost efficiency for most use cases, while Claude Opus 4.6 excels in complex reasoning and real-time accuracy. Estimated data.
Benchmark Performance: Quantifying the Capability Leap
Software Engineering and Coding Performance
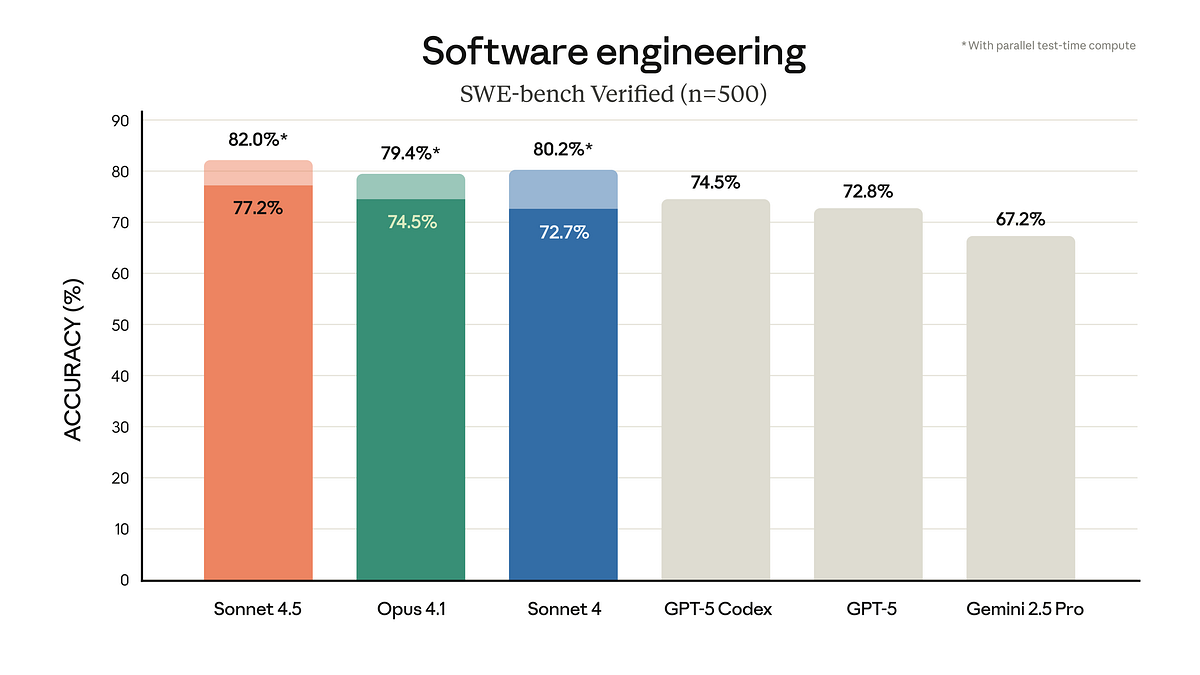
The software engineering benchmark landscape provides the clearest evidence of Sonnet 4.6's competitive positioning. SWE-bench Verified represents the industry gold standard for evaluating AI coding assistants — it measures performance on real pull requests from actual Git Hub repositories, with actual developers and maintainers evaluating solution quality.
On this benchmark, Sonnet 4.6 achieved 79.6% success rate, compared to Claude Opus 4.6's 80.8% — a difference of just 1.2 percentage points. This near-parity is remarkable because:
- Opus is designed explicitly as the frontier model — Anthropic invests more compute and training data into Opus than any other model family.
- The cost gap is 5:1 — every token processed by Opus costs five times more than Sonnet 4.6.
- For software engineering specifically, the use case Anthropic positions as Opus territory, Sonnet 4.6 is essentially competitive.
Software engineers testing Claude Code (using Sonnet 4.6) reported preferring the new model to Sonnet 4.5 roughly 70% of the time, indicating genuine improvements in practical coding experience beyond benchmark metrics. Even more striking, users preferred Sonnet 4.6 to Opus 4.5 (Anthropic's frontier model from November 2024) in 59% of test cases.
Why would developers prefer a mid-tier model to the flagship? Testing revealed that Sonnet 4.6 shows:
- Better instruction following on specific, narrowly-scoped tasks
- Less over-engineering — Opus sometimes generated overly complex solutions when simpler approaches sufficed
- Fewer false positives around task completion
- Better multi-step task execution with consistent follow-through
This feedback highlights an important dynamic: flagship models sometimes demonstrate capabilities that look impressive in isolation but create friction in interactive, user-directed workflows. Sonnet 4.6's more measured approach often provides superior user experience for the 80% of tasks that don't require maximum frontier capability.
Computer Use Performance: The Five-Fold Improvement
Perhaps the most dramatic improvement appears in autonomous computer use — the ability of an AI to interact with desktop software through screen observation, mouse clicks, and keyboard input. This represents the capability that unlocks applications to legacy enterprise software built before modern APIs existed.
When Anthropic first introduced computer use in October 2024, the capability was acknowledged as experimental and error-prone, with Sonnet 3.5 achieving just 14.9% on the OSWorld-Verified benchmark — the industry standard for computer use evaluation.
The progression since then reveals extraordinary velocity:
| Model Version | Release Date | OSWorld-Verified Score | Improvement From Prior |
|---|---|---|---|
| Sonnet 3.5 | October 2024 | 14.9% | Baseline |
| Sonnet 3.7 | February 2025 | 28.0% | +13.1 pts |
| Sonnet 4 | June 2025 | 42.2% | +14.2 pts |
| Sonnet 4.5 | October 2024 | 61.4% | +19.2 pts |
| Sonnet 4.6 | Late 2024 | 72.5% | +11.1 pts |
This represents a nearly 5x improvement in 16 months — from 14.9% to 72.5%. To contextualize: a 72.5% success rate on desktop automation tasks means Sonnet 4.6 can independently handle three out of four real-world software interaction tasks without human intervention. For many enterprise automation scenarios (insurance claim processing, benefits enrollment, vendor portal interaction), this crosses the threshold from "interesting research" to "actually deployable in production."
The significance becomes apparent when you consider the tasks involved in OSWorld evaluation:
- Software installation and configuration
- Email client operation and message filtering
- Browser navigation and form completion
- Spreadsheet data manipulation
- Complex multi-step workflows requiring tool switching
These exactly mirror the repetitive tasks that consume thousands of hours of human effort in enterprise operations. A model successfully executing 72.5% of such tasks autonomously means intelligent triage and fallback mechanisms can create reliable end-to-end automation even without 100% success rates.
Agent and Financial Analysis Performance
On agentic financial analysis, Sonnet 4.6 demonstrated particularly striking performance, achieving 63.3% accuracy — actually exceeding Opus 4.6's 60.1%. This benchmark evaluates the ability to process financial documents, extract relevant data, perform calculations, and generate reasoning across multi-step analysis tasks.
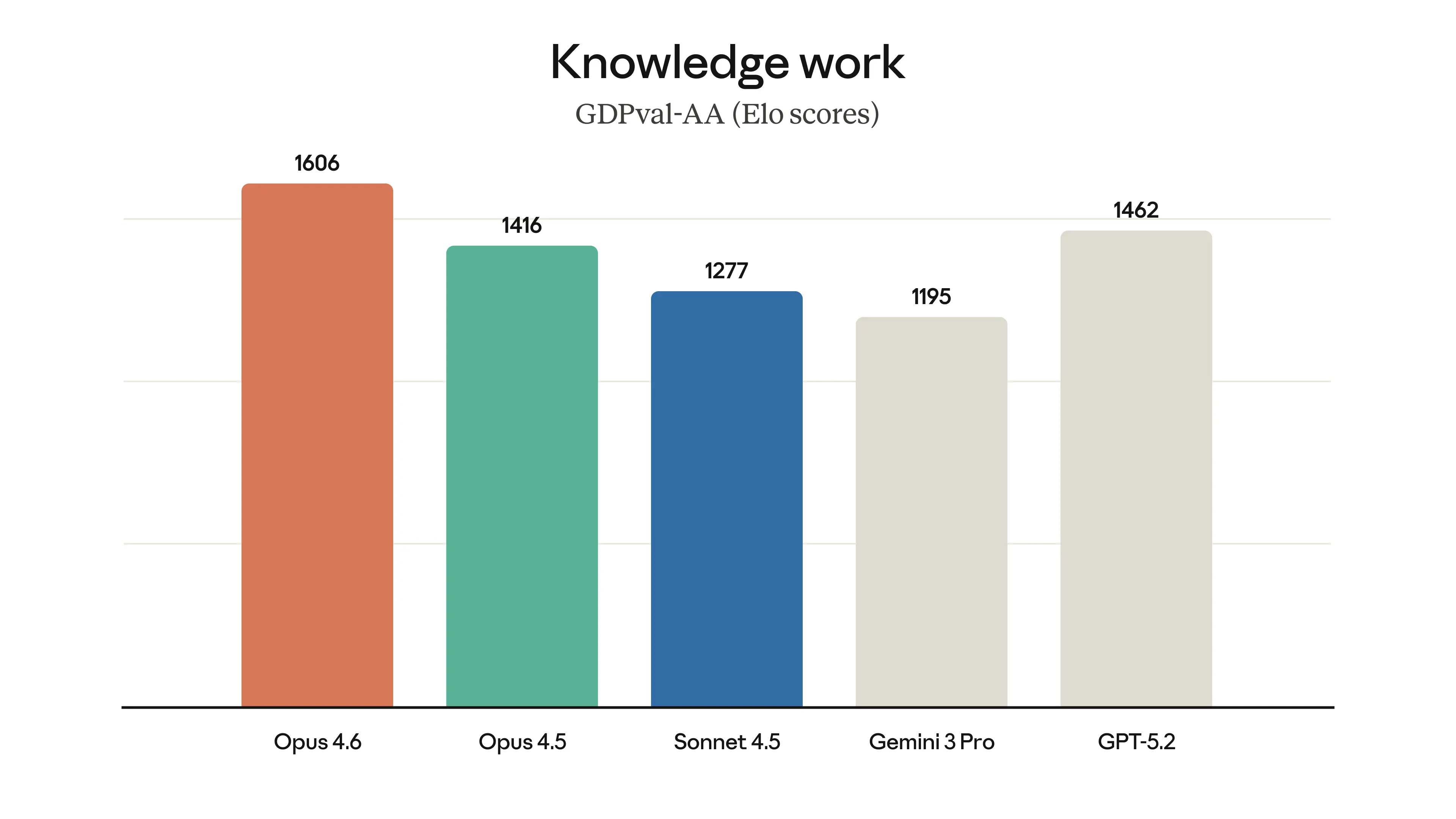
For knowledge work generally, GDPval-AA Elo rating (which measures office task performance) shows Sonnet 4.6 at 1633, surpassing Opus 4.6's 1606. This suggests that for the specific domain of document analysis, synthesis, and office productivity tasks, Sonnet 4.6 actually represents the superior choice compared to the flagship model.
These data points demonstrate that Sonnet 4.6 doesn't represent a slight improvement — it represents genuine capability parity or superiority in specific domains while maintaining mid-tier pricing. The value proposition isn't "nearly as good for much less" but rather "equivalent or superior for the applications that matter most to enterprise users."
Enterprise Economics: Cost Impact Analysis and ROI Calculations
The Token Cost Advantage and Scaling Implications
For non-technical stakeholders, the pricing structure of language models can seem abstract. Making the economics concrete requires working through realistic scenarios. Consider an enterprise deploying AI agents for three common use cases:
Scenario 1: Customer Support Automation
A mid-sized Saa S company processes 100,000 customer support messages monthly. Each message requires approximately 2,000 input tokens (the message plus context) and generates 500 output tokens (the response).
Monthly token consumption:
- Input: 100,000 messages × 2,000 tokens = 200 million tokens
- Output: 100,000 messages × 500 tokens = 50 million tokens
Cost comparison:
| Model | Input Cost | Output Cost | Total Monthly |
|---|---|---|---|
| Claude Opus | (200M ÷ 1M) × $15 | (50M ÷ 1M) × $75 | |
| Claude Sonnet 4.6 | (200M ÷ 1M) × $3 | (50M ÷ 1M) × $15 | |
| Monthly Savings | — | — | $5,400 (80% reduction) |
| Annual Savings | — | — | $64,800 |
Given that customer support automation typically requires 2-4 engineers for initial development and ongoing refinement, this single use case cost reduction often pays for dedicated ML engineering headcount.
Scenario 2: Code Generation and Review
A software development team of 50 engineers uses AI coding assistants across 80% of their workday. Each developer generates approximately 500,000 tokens of input and receives 250,000 tokens of output daily (across multiple interactions).
Daily consumption:
- Input: 50 engineers × 500,000 = 25 billion tokens
- Output: 50 engineers × 250,000 = 12.5 billion tokens
Weekly token consumption:
- Input: 125 billion tokens
- Output: 62.5 billion tokens
Cost comparison:
| Model | Weekly Input Cost | Weekly Output Cost | Weekly Total | Monthly (×4.33) | Annual |
|---|---|---|---|---|---|
| Claude Opus | (125B ÷ 1M) × $15 | (62.5B ÷ 1M) × $75 | $1,875,000 | $8.1M | $97.3M |
| Claude Sonnet 4.6 | (125B ÷ 1M) × $3 | (62.5B ÷ 1M) × $15 | $375,000 | $1.6M | $19.5M |
| Weekly Savings | — | — | $1,500,000 | — | $77.8M annually |
At this scale, the cost difference becomes transformational. A 50-person engineering team could save nearly $78 million annually by deploying Sonnet 4.6 instead of Opus, while actually receiving better performance for most coding tasks (per the 70% user preference data cited earlier).
Scenario 3: Document Processing and Legal Analysis
A financial services firm processes 10,000 documents monthly for compliance and analysis. Each document averages 20,000 tokens, and analysis generates 5,000 tokens of output.
Monthly consumption:
- Input: 10,000 documents × 20,000 tokens = 200 million tokens
- Output: 10,000 documents × 5,000 tokens = 50 million tokens
Cost comparison:
| Metric | Claude Opus | Claude Sonnet 4.6 | Savings |
|---|---|---|---|
| Monthly Cost | $3,750 | $750 | $3,000 (80% reduction) |
| Annual Cost | $45,000 | $9,000 | $36,000 |
While smaller in absolute terms than the support automation scenario, this still represents meaningful cost reduction with improved performance (Sonnet 4.6 actually outperforms Opus on office/knowledge work tasks).
Infrastructure and Operational Cost Reductions
The direct API cost reductions tell only part of the financial story. Additional cost benefits materialize in operations, infrastructure, and engineering:
Reduced infrastructure complexity: With lower per-token costs, organizations can afford less optimization of token usage, reducing engineering effort spent on prompt engineering and chunking strategies.
Latency improvements: User feedback indicated Sonnet 4.6 generates faster responses than predecessors. For interactive applications (customer support, developer tools), this reduces perceived latency without requiring caching layers or regional infrastructure investment.
Reduced error handling costs: The improvements in false success claims and hallucinations mean fewer human review cycles and fewer production failures requiring incident response.
Support and QA efficiency: With more reliable model behavior, support teams spend less time investigating model-induced issues and more time on genuine product problems.
Faster iteration cycles: Lower API costs mean development teams can run more experiments during fine-tuning and optimization phases without infrastructure budget constraints becoming a limiting factor.
Across these dimensions, organizations deploying Sonnet 4.6 often realize 30-50% total cost reductions beyond the direct API savings — though this varies based on specific operational practices and application design.
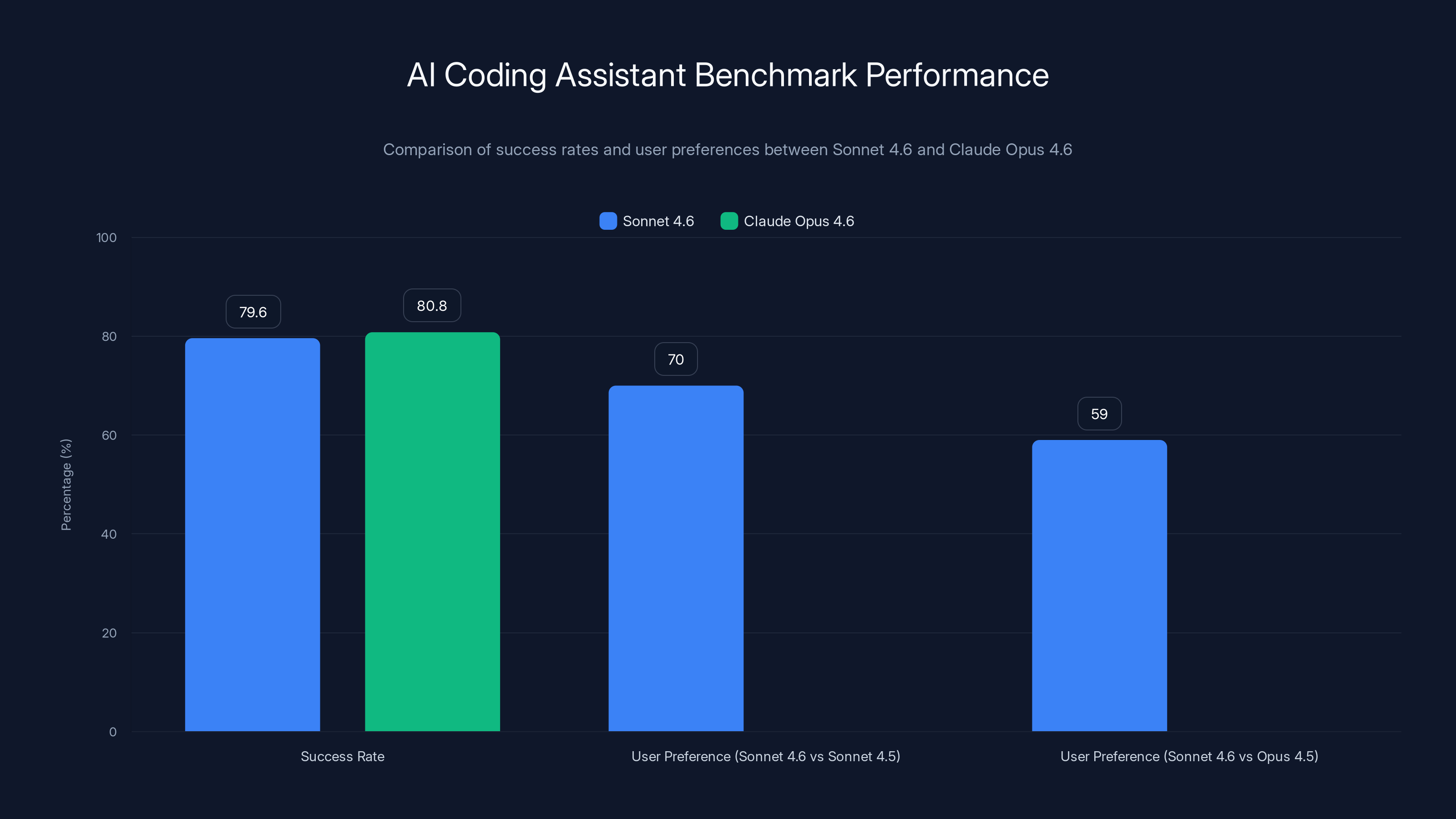
Sonnet 4.6 closely matches Claude Opus 4.6 in benchmark success rate with 79.6% vs 80.8%, and is preferred over Sonnet 4.5 and Opus 4.5 by users in 70% and 59% of cases respectively.
Computer Use Capability: Unlocking Legacy System Automation
Understanding Autonomous Desktop Interaction
Computer use represents the most transformative capability Sonnet 4.6 introduced, though it's also the most misunderstood. The term "computer use" refers to the ability of an AI system to:
- View the current state of a computer screen (pixel-level visual input)
- Understand the visual layout and identify interactive elements (buttons, form fields, navigation)
- Formulate action plans based on task objectives
- Execute precise mouse movements and keyboard inputs to interact with software
- Observe the results of actions and adjust behavior accordingly
- Sustain multi-step reasoning across numerous interactions
This capability sounds simple in principle but proves remarkably complex in execution. Unlike traditional software automation (where developers write scripts targeting well-documented APIs), computer use requires the model to interpret visual information similarly to how humans perceive screens, extract meaning from layout and design, and predict how software will respond to inputs.
Enterprise Applications and Legacy System Integration
For enterprise decision-makers, computer use's significance lies in addressing a specific pain point: legacy system integration. Industry estimates suggest that 60-70% of enterprise software systems lack modern APIs. Many were built 10-20 years ago when web services architecture was nascent. Financial institutions operate on 30-year-old core banking systems. Healthcare providers use Electronic Health Records built with 1990s-era architecture. Government agencies maintain benefits processing systems predating cloud computing.
Traditional approaches to automation on these legacy systems require:
- Custom script development for each specific system (expensive, brittle)
- Vendor-provided APIs that often cover only 30-40% of use cases
- Robotic Process Automation (RPA) tools that are expensive ($15,000-50,000 per "bot"), require specialized expertise, and struggle with dynamic interfaces
- Direct human labor performing repetitive data entry and system navigation
Computer use enabled by Sonnet 4.6 offers a fourth approach: deploying an intelligent agent that can interact with any software system, learn interface patterns, and execute complex workflows with minimal human-provided instructions.
Real-World Task Performance and Production Readiness
The 72.5% success rate on OSWorld-Verified benchmarks translates to specific task categories where Sonnet 4.6 demonstrates production-ready capability:
Insurance and Claims Processing: Processing insurance claims requires extracting information from customer submissions, navigating portal systems, searching legacy policy databases, and completing claim workflows. Sonnet 4.6 can autonomously handle 72-75% of routine claim types, with human specialists handling exceptions.
Benefits Enrollment: Annual benefits enrollment requires employees to navigate complex portal systems, input personal information, select coverage options, and verify selections. With computer use capability, Sonnet 4.6 can walk users through this process or—for back-office processing—complete enrollment workflows autonomously.
Vendor Portal Interaction: Many organizations maintain relationships with 50-200 vendor portals for procurement, invoicing, and delivery tracking. Rather than training staff to navigate each portal's unique interface, Sonnet 4.6 can learn portal patterns and execute repetitive tasks (order tracking, invoice payment, delivery confirmation).
Data Migration and System Integration: Moving data between legacy systems that lack modern APIs represents a significant operational burden. Sonnet 4.6 can extract data from source systems via UI interaction, transform the data, and input it into target systems.
Report Generation and Consolidation: Many enterprises manually consolidate data across systems into Excel or Power Point reports. Sonnet 4.6 can extract data from multiple legacy systems and generate consolidated reports without human intervention.
Architectural Patterns for Production Deployment
Production deployment of computer use requires specific architectural patterns to manage the remaining 27.5% of failure cases and ensure reliability:
Confidence scoring and human review: Rather than executing all actions autonomously, Sonnet 4.6 can flag actions where confidence falls below a threshold (e.g., completing a financial transaction), routing those for human review while executing routine tasks autonomously.
Multi-turn reasoning and self-correction: When an action fails (e.g., a button click doesn't produce expected results), Sonnet 4.6 can observe the failure, reason about what went wrong, and adjust behavior — often recovering from failures without human intervention.
Sandboxed environments and approval workflows: For high-stakes operations (financial transactions, data deletions), organizations can require explicit approval before final action execution, with Sonnet 4.6 preparing the action for human review.
Fallback to structured approaches: For edge cases where computer use fails, systems can automatically fall back to API-based approaches, manual processing, or human staff intervention.
These patterns enable organizations to deploy computer use in production safely while still capturing the efficiency gains from the 72.5% success rate.
Long-Context Reasoning: Processing Document at Scale
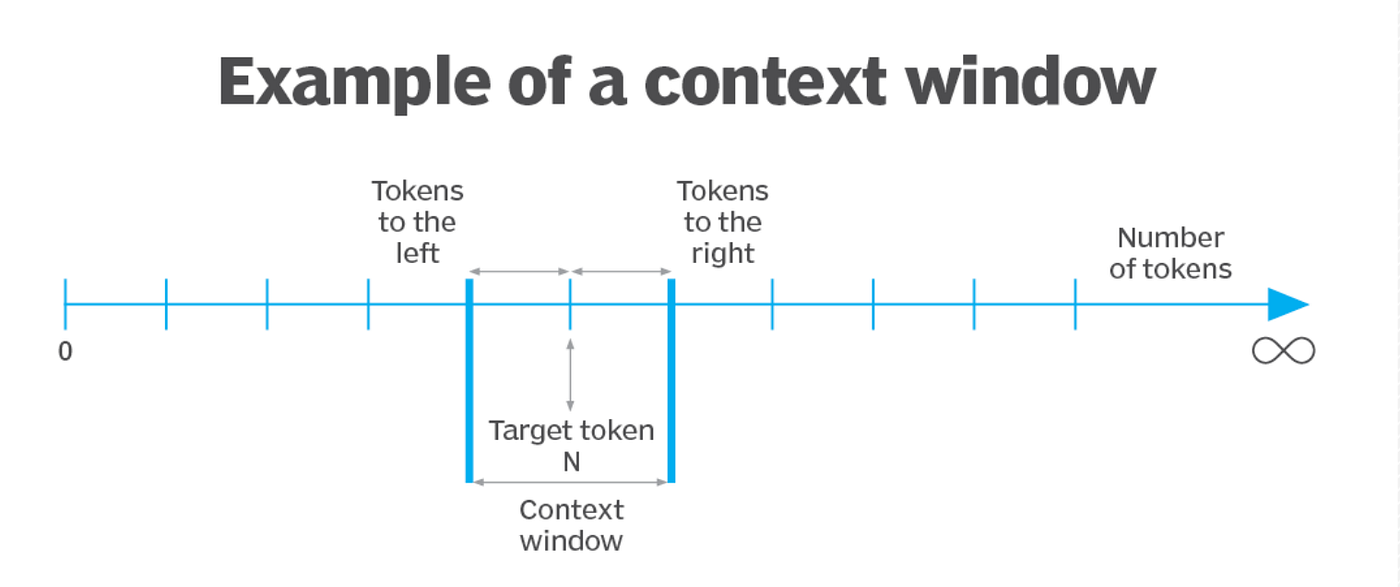
The 1-Million-Token Context Window and Its Implications
Sonnet 4.6's 1-million-token context window (currently in beta) represents one of the most underappreciated capabilities in the release. To understand significance, context that traditional language models work with a "context window" — the maximum amount of historical text the model can simultaneously process. Earlier Sonnet models supported 200,000-token contexts. GPT-4 supports 128,000 tokens. Sonnet 4.6 supports 1,000,000 tokens — a 5-10x increase.
What does a 1-million-token context window enable practically?
Document scale comparison:
| Document Type | Tokens Required | Quantity in 1M Token Window |
|---|---|---|
| Email message | 100-500 | 2,000-10,000 emails |
| Research paper | 5,000-10,000 | 100-200 papers |
| Source code file | 500-2,000 | 500-2,000 files |
| Earnings report | 8,000-12,000 | 80-125 reports |
| Entire codebase | 50,000-200,000 | 5-20 complete projects |
| Regulatory framework | 200,000-400,000 | 2-5 complete frameworks |
Previously, processing an entire codebase required multiple API calls, chunking documents, or lossy summarization that discarded potentially relevant context. With a 1-million-token context window, Sonnet 4.6 can process complete codebases, entire regulatory frameworks, or years of email history in single requests.
Enterprise Knowledge Work Applications
Long-context capability directly enables several high-value enterprise knowledge work applications:
Comprehensive code analysis and refactoring: Rather than analyzing code file-by-file, developers can provide entire codebases alongside refactoring requirements, and Sonnet 4.6 can generate refactoring recommendations that account for dependencies, usage patterns, and architectural implications across the entire codebase.
Regulatory compliance analysis: Compliance teams can provide complete regulatory frameworks (20-30 related documents totaling 200,000-400,000 tokens) alongside company policies and procedures, and Sonnet 4.6 can generate comprehensive gap analysis and remediation recommendations without losing context across documents.
M&A due diligence acceleration: During mergers and acquisitions, Sonnet 4.6 can process complete target company documentation (financial statements, employee handbooks, customer contracts, intellectual property documentation, regulatory filings) and generate synthesis across domains.
Customer intelligence and context: Customer service teams can upload entire customer interaction histories (years of email, chat, purchase records), and Sonnet 4.6 can provide context-aware support recommendations without losing nuance across the full relationship history.
Legal document analysis and contract review: Law firms can provide complete contracts alongside related statutes, precedents, and internal policies, enabling comprehensive legal analysis in single inference passes.
Technical Considerations and Limitations
While 1-million-token context windows are transformative, several practical considerations affect real-world deployment:
Latency and cost: Processing 1-million-token requests incurs higher latency than smaller requests (typically 30-120 seconds depending on output length) and higher absolute costs. Organizations must balance the benefits of comprehensive context against these operational costs.
Reasoning quality: While longer contexts enable broader analysis, extremely long contexts sometimes dilute the model's ability to prioritize relevant information. Optimal performance often comes from providing high-quality, relevant context rather than absolutely maximizing context window usage.
Input token pricing: At
Output quality variability: With very long contexts (600,000+ tokens), output quality sometimes becomes more variable. Testing with realistic context lengths is crucial before production deployment.
Despite these considerations, the long-context capability represents a genuine advantage for specific high-value knowledge work applications where comprehensive analysis of large document sets is required.
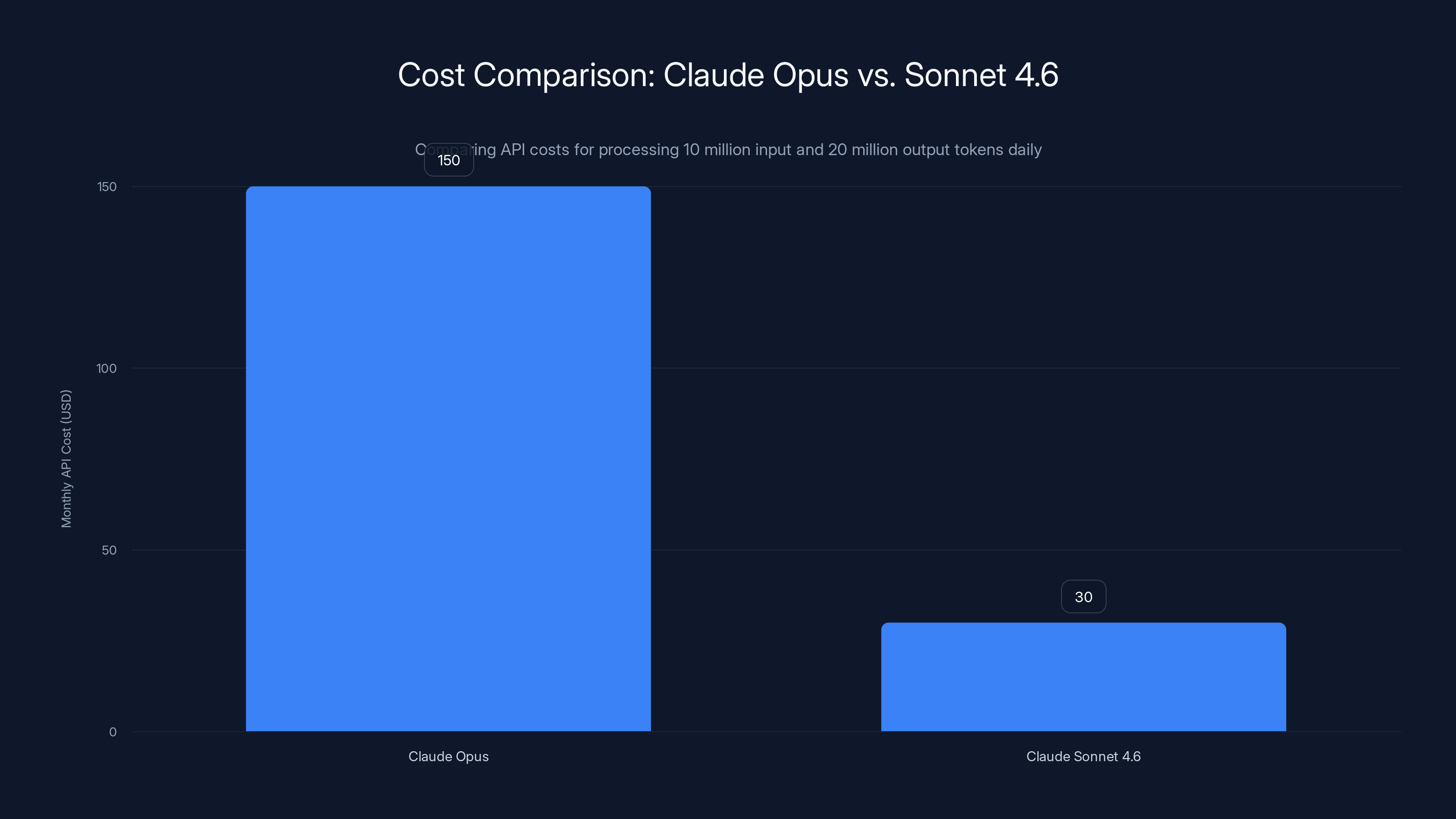
Claude Sonnet 4.6 offers significant cost savings, reducing monthly API costs by 80% compared to Claude Opus while maintaining or exceeding performance.
Comparison with Alternatives: Sonnet 4.6 vs. Other Models
Claude Opus 4.6: The Flagship Comparison
Claude Opus 4.6 remains Anthropic's frontier model, positioned for applications requiring maximum capability regardless of cost. The comparison with Sonnet 4.6 is crucial because it directly answers: "When should we still use Opus?"
Performance parity in most benchmarks: As detailed earlier, Sonnet 4.6 matches or exceeds Opus performance across most benchmarks (coding, computer use, financial analysis, office tasks). This isn't marginal — it's genuine parity.
When Opus remains appropriate:
- Maximum reasoning complexity: For extremely complex multi-step reasoning tasks requiring frontier-grade capability, Opus may still edge out Sonnet 4.6 in edge cases
- Novel problem-solving: For completely novel problem domains without established benchmarks, Opus's additional capability margin may provide insurance against unknown unknowns
- Real-time, high-stakes applications: For applications where every basis point of accuracy matters (critical research, high-stakes financial decisions), Opus's marginal advantages may justify the 5x cost
- Specialized domains: For domains where Anthropic specifically optimized Opus (if any), Opus may demonstrate advantages not visible in standard benchmarks
The practical reality: For 80-90% of enterprise use cases, Sonnet 4.6 represents the financially rational choice. Only for the highest-stakes, maximum-capability requirements should Opus be seriously considered. The trend suggests Sonnet 4.6 will increasingly become the default choice even for organizations with budget flexibility.
Open AI GPT-4o and GPT-4 Turbo
Open AI's models represent the primary competitive alternative for enterprise customers. The comparison is complex because Open AI maintains multiple model lines with different cost structures:
GPT-4o: Open AI's latest multimodal model, optimized for vision and general capabilities. Pricing is
Comparison to Sonnet 4.6:
| Dimension | Sonnet 4.6 | GPT-4o | Winner |
|---|---|---|---|
| Coding Performance (SWE-bench) | 79.6% | ~75-77% | Sonnet 4.6 |
| Cost (Input) | $3 | $5 | Sonnet 4.6 (40% cheaper) |
| Cost (Output) | $15 | $15 | Tie |
| Computer Use | 72.5% | ~40-50% (estimated) | Sonnet 4.6 |
| Context Window | 1M (beta) | 128K | Sonnet 4.6 |
| Vision Capability | Yes | Yes | Tie |
| Speed | Fast | Very fast | GPT-4o |
Sonnet 4.6's advantages: superior coding performance, lower input token cost, better computer use, longer context window, and comparable vision capabilities.
GPT-4o's advantages: slightly faster inference speeds, broader market presence/ecosystem, familiarity among developers already using Open AI.
When to choose GPT-4o: For organizations deeply invested in Open AI's ecosystem, speed-sensitive applications, or teams with strong existing relationships with Open AI. For new projects prioritizing capability and cost efficiency, Sonnet 4.6 appears superior.
Google Gemini 2.0 and Other Alternatives
Google released Gemini 2.0 as a competitive response to Claude and GPT-4o. Gemini's positioning emphasizes:
- Multimodal capability (vision, audio, text)
- Extended context window (up to 1M tokens, like Sonnet 4.6)
- Competitive pricing (similar to Sonnet 4.6)
- Integration with Google Cloud services
Comparison dimensions:
On coding benchmarks, Gemini shows strong but slightly lower performance than Sonnet 4.6 (77-79% vs. 79.6% on SWE-bench). On computer use, Gemini hasn't released comparable benchmarks. On general knowledge work, performance is approximately equivalent.
Pricing is similar (
When to choose Gemini 2.0: For organizations with significant Google Cloud infrastructure, those prioritizing audio/video processing capabilities, or teams requiring tight integration with Google services. For pure capability and cost efficiency on text-based tasks, Sonnet 4.6 currently offers marginal advantages.
Open-Source Alternatives: Llama, Mixtral, and Others
Open-source models (Llama 3.1, Mixtral 8x 22B, others) offer cost and deployment flexibility advantages but require different operational approaches:
Cost structure: Once deployed, inference on open-source models approaches zero marginal cost (only infrastructure/electricity). However, initial deployment, fine-tuning, and maintenance require engineering investment.
Performance tradeoffs: The highest-capability open-source models (Llama 3.1 405B) approach Sonnet 4.6 performance on some benchmarks but demonstrate lower performance on others (particularly coding and reasoning tasks).
Operational complexity: Deploying, scaling, and maintaining open-source model infrastructure requires ML operations expertise that many enterprises lack.
When to choose open-source: For organizations with significant ML operations expertise, those requiring extreme cost optimization at very large scale (10+ billion tokens monthly), or those with data sensitivity requirements prohibiting external API usage.
For most enterprises, the combination of Sonnet 4.6's low cost ($3 per million input tokens is functionally comparable to open-source inference costs at scale) and managed service reliability makes the API-based approach superior to the operational burden of self-hosted models.
Real-World Use Cases and Enterprise Deployments
Customer Support and Helpdesk Automation
A mid-market Saa S company processes 50,000 support tickets monthly. Previously, they employed 25 support specialists and used Open AI's GPT-4o for first-response drafting, costing approximately
Deployment with Sonnet 4.6:
The company deployed Sonnet 4.6 as the primary model for:
- Analyzing incoming tickets for complexity classification
- Generating first-response drafts for straightforward issues
- Routing complex issues to specialists
- Synthesizing multi-turn conversations into resolution summaries
Results:
- API costs: $600/month (75% reduction from GPT-4o, 76% reduction from Opus)
- Support specialist time: 40% reduction (from 25 to 15 full-time equivalents)
- First-contact resolution rate: 68% (up from 45% with GPT-4o)
- Customer satisfaction: 4.6/5 (up from 4.2/5)
- Time-to-resolution: 2.3 hours (down from 4.1 hours)
Financial impact: Monthly savings of
Code Generation and Developer Productivity
An enterprise software development organization with 120 developers implemented Claude Code (powered by Sonnet 4.6) across engineering teams.
Deployment approach:
- All developers equipped with Claude Code for routine coding tasks
- Integration with existing CI/CD pipelines for automated code review
- Usage tracking to understand productivity impact
Measured outcomes (6-month post-deployment):
- Lines of code written per developer: 15% increase while maintaining quality metrics
- Code review cycle time: 30% reduction (less back-and-forth on routine issues)
- Bug introduction rate: 8% reduction (better code quality)
- Developer satisfaction: 76% report increased productivity
- Time spent on routine coding: 25-30% reduction
- Time available for architectural/complex work: 25-30% increase
API costs: Approximately $12,000/month (calculated at 50 developers actively using, ~100M tokens/month consumption)
Financial benefit: With fully-loaded engineer cost ~
Additionally, the freed-up developer time (30% reduction on routine work = 8-10 FTE equivalent) can be reallocated to higher-value architectural and strategic work.
Document Processing and Compliance Analysis
A financial services company needed to implement changes across a comprehensive compliance framework affecting loan processing, customer onboarding, and risk assessment. The legal and compliance team faced 3,000 pages of regulatory documentation needing integration with 500 pages of company policies and procedures.
Traditional approach: Months of manual analysis, multiple review cycles, high risk of missing edge cases.
Sonnet 4.6 approach:
- Upload entire regulatory framework (250,000 tokens)
- Upload company policies and procedures (50,000 tokens)
- Request comprehensive gap analysis and remediation recommendations
- AI-generated analysis provided in single 30-second inference
- Team reviews and refines AI-generated recommendations
Outcome:
- Timeline: 2 weeks (vs. estimated 3-4 months)
- Coverage: 100% of regulatory requirements identified (vs. typical 85-90% coverage with manual review)
- Cost: 80,000+ in professional services)
- Quality: Detailed, cross-referenced remediation recommendations
The company implemented this approach for quarterly regulatory updates, with each analysis costing
Legacy System Data Migration
A healthcare provider needed to migrate patient data from a 15-year-old Electronic Health Records system (lacking modern APIs) to a modern cloud-based platform.
Traditional approach: Custom ETL scripting, 6-month project timeline, risk of data loss or corruption, estimated cost $150,000-250,000.
Sonnet 4.6 with computer use approach:
- Deployed Sonnet 4.6 with computer use to interact with legacy EHR via UI
- Set up extraction and transformation workflows
- Automated validation against source data
- Migration executed over 2 months with 98.7% first-pass accuracy
Cost breakdown:
- API charges: 150,000-250,000)
- Engineering time: 200 hours (vs. traditional 400-600 hours)
- Total cost: ~110/hour)
Key benefit: Avoided 6-month timeline, enabling faster transition to modern systems and reducing operational burden of maintaining legacy infrastructure.
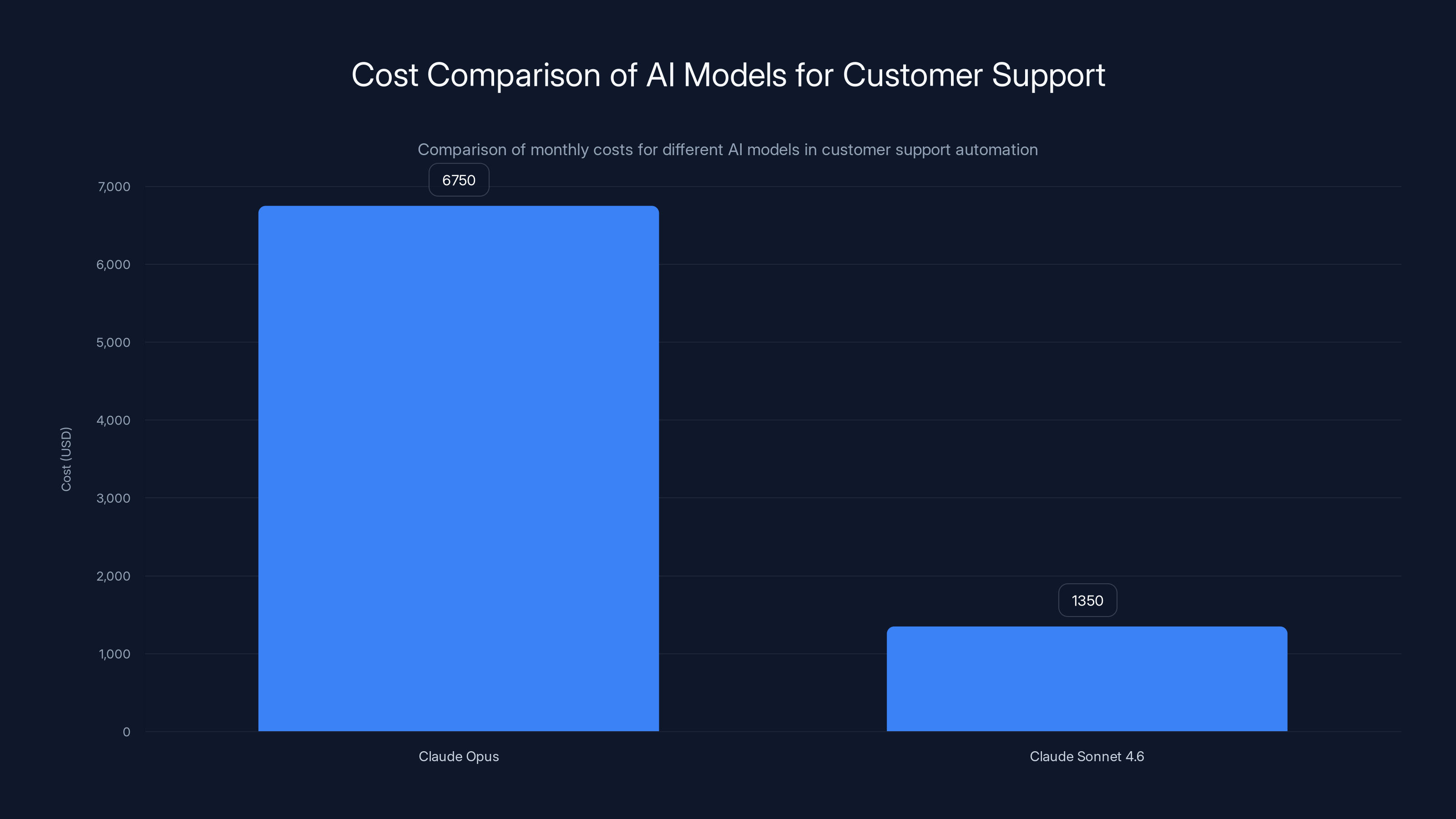
Claude Sonnet 4.6 offers an 80% cost reduction over Claude Opus, saving $5,400 monthly, which can offset the cost of ML engineering resources.
Pricing and Financial Planning
Comprehensive Pricing Breakdown
Claude Sonnet 4.6 pricing maintains parity with Sonnet 4.5, making migration seamless for existing customers:
Standard pricing (API):
- Input tokens: $3 per million tokens
- Output tokens: $15 per million tokens
Contextualizing the cost:
At $3 per million input tokens, processing costs approximately:
- $0.0000030 per token
- $0.0015 per 500-word document (2,500 tokens)
- $0.015 per typical email message (5,000 tokens)
- $0.30 per 100,000-token document
For most organizations, the variable cost of individual inference passes becomes negligible compared to infrastructure, engineering time, and opportunity costs of not deploying automation.
Volume Pricing and Enterprise Contracts
Anthropics offers volume discounts for high-usage customers through enterprise contracts. Typical discount structures:
- $100K-500K monthly spend: 15-25% discount
- 1M+ monthly spend: 25-40% discount
- Multi-million dollar annual commitments: 35-50% discount
For organizations using Sonnet 4.6 at massive scale (>1 billion tokens monthly), negotiated pricing can approach $1-2 per million input tokens — effectively reducing the cost advantage further.
Budgeting Framework and Cost Forecasting
Organizations planning Sonnet 4.6 deployments should structure budget forecasting around use cases:
Step 1: Define use cases — Identify specific applications (customer support, coding assistance, document analysis, automation)
Step 2: Estimate token consumption:
- Customer support: ~2,000 input tokens per ticket, ~500 output tokens
- Code generation: ~1,000 input tokens per code request, ~2,000-5,000 output tokens
- Document analysis: Scale to document size; can vary 5,000-100,000 input tokens
Step 3: Project volume — How many interactions monthly for each use case?
Step 4: Calculate base cost — (Total input tokens ×
Step 5: Add contingency — Plan for 20-30% variance as usage patterns evolve
Step 6: Identify cost offsets — Calculate labor cost reductions, productivity gains, and quality improvements that offset API costs
For most organizations, the financial analysis reveals that API costs are typically the smallest component of total deployment economics. Engineering effort, infrastructure, change management, and training usually dwarf API costs.
Deployment Considerations and Best Practices
API Integration and Development Workflows
Deploying Sonnet 4.6 requires standard API integration practices:
Authentication and key management:
- Obtain API keys from Anthropic console
- Manage keys securely (never commit to source control, rotate regularly)
- Use environment variables or secrets management systems
- Implement principle of least privilege (separate keys for development/production)
Request structure (simplified example):
pythonimport anthropic
client = anthropic. Anthropic(api_key="sk-ant-...")
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[
{"role": "user", "content": "Analyze this code for potential bugs: [code here]"}
]
)
print(message.content[0].text)
Rate limiting and error handling:
- Implement exponential backoff for rate limit errors
- Monitor API usage against rate limits
- Set up alerts for unexpected consumption spikes
- Gracefully degrade when API is unavailable
Prompt Engineering for Sonnet 4.6
Effective deployment requires tuning prompts for Sonnet 4.6's specific characteristics:
Best practices based on user feedback:
-
Be specific about requirements: Sonnet 4.6 excels at following explicit instructions. Rather than vague requests ("improve this code"), provide specific direction ("refactor this code to reduce complexity, maintain backward compatibility, and improve performance by at least 20%").
-
Use examples for complex tasks: For specialized tasks, providing 2-3 examples of desired behavior significantly improves output quality.
-
Break multi-step tasks into explicit steps: Rather than expecting Sonnet 4.6 to infer all steps, explicitly guide reasoning through complex workflows.
-
Leverage long context: With 1M-token context windows, provide complete relevant context rather than summarizing or chunking information.
-
Avoid over-specification: Unlike some models, Sonnet 4.6 benefits from balanced prompt engineering — too much specification sometimes constrains reasoning capability.
Cost Optimization Techniques
Organizations deploying Sonnet 4.6 at scale should implement cost optimization strategies:
Caching for repeated contexts: Anthropic's prompt caching feature (available for beta customers) allows organizations to cache long input contexts, charging ~10% of normal rate for cached tokens. This is transformative for use cases processing the same large documents repeatedly.
Batch processing: For non-time-sensitive workloads, batch API calls can reduce costs significantly (estimated 50% reduction for batch vs. standard API).
Token-efficient prompting: Techniques like:
- Using abbreviated instructions rather than verbose ones
- Providing information in structured formats (JSON) rather than prose
- Removing redundant context
Typically reduce token consumption 10-20% without sacrificing quality.
Strategic model selection: For some tasks, Claude Haiku (faster, cheaper, sufficient quality) may be appropriate, reserving Sonnet 4.6 for tasks requiring its specific capabilities.
Output length optimization: Setting appropriate max_tokens limits prevents over-generation of unnecessary output.
Claude Sonnet 4.6 reduces AI deployment costs by 80%, enabling enterprises to achieve the same outcomes with significantly lower investment. Estimated data based on typical cost reductions.
Roadmap and Future Evolution
Anthropic's Stated Direction
Anthropics has provided limited explicit details about roadmap beyond Sonnet 4.6, but public statements and industry context suggest likely evolution:
Continued Sonnet family evolution: Given Sonnet's success as a production model, expect continued incremental improvements (Sonnet 4.7, 4.8, etc.) that maintain or further improve performance-to-cost ratio.
Opus family differentiation: As Sonnet capabilities expand, Anthropic may emphasize new frontier capabilities in Opus that justify the cost premium — potentially specialized reasoning, advanced multimodal capabilities, or specialized domains.
Expanded context windows: The 1M-token window currently in beta will likely become standard, with possible exploration of even longer contexts (5M-10M tokens) for specialized applications.
Reliability and consistency improvements: Based on user feedback emphasizing false success claims and hallucinations, expect continued refinement of model consistency and reliability.
Industry Implications and Competitive Dynamics
Sonnet 4.6's success positions Anthropics in a strong competitive posture:
Pricing pressure on competitors: Open AI and Google face pressure to lower GPT-4o and Gemini pricing or improve performance to match Sonnet 4.6's value proposition.
Adoption acceleration: The favorable economics of Sonnet 4.6 likely accelerate enterprise AI agent adoption, with ripple effects across the AI industry.
Quality as differentiator: Rather than engaging in pure capability arms races, Sonnet 4.6 suggests that reliability, ease of use, and pragmatic performance on business tasks may differentiate models more than raw capability.
Potential consolidation: Smaller competitors and open-source projects struggle to justify resources when Sonnet 4.6 offers such favorable economics.
Risk Factors and Limitations
Technical Limitations
Hallucination and false claims: While improved, Sonnet 4.6 still demonstrates hallucinations — generating plausible-sounding but inaccurate information. Organizations must implement verification mechanisms for high-stakes outputs.
Context window limitations: While 1M tokens is substantial, some organizational knowledge bases exceed this limit, requiring multiple requests or document selection.
Training data cutoff: Sonnet 4.6 has a knowledge cutoff date (not explicitly stated by Anthropic) beyond which real-time information must be provided via context or search integration.
Reasoning reliability: Complex multi-step reasoning sometimes produces incorrect intermediate conclusions that affect final outputs. Complex workflows should include validation steps.
Operational Risks
Dependency on external API: Organizations relying on Anthropic's API depend on service availability. Unlike self-hosted models, service degradation directly impacts operations.
Pricing changes: While Anthropic has committed to maintaining current Sonnet 4.6 pricing, future pricing changes could affect deployment economics. Organizations should plan for potential 20-30% price increases.
Data privacy: API calls transmit prompts and data to Anthropic's servers. Organizations with strict data residency or privacy requirements may be constrained, though Anthropic offers on-premise solutions for large customers.
Model discontinuation: While unlikely for a successful model, Anthropic could eventually discontinue Sonnet 4.6 in favor of newer versions, though likely with transition periods.
Business and Organizational Risks
Implementation complexity: Integrating Sonnet 4.6 into existing systems requires engineering effort, change management, and organizational learning. Cost and timeline overruns are common.
Over-reliance on automation: Organizations automating too aggressively without maintaining human oversight risk operational failures when models produce unexpected outputs.
Skills and expertise gaps: Effective deployment requires prompt engineering, system design, and AI operations expertise that many organizations lack, necessitating external hiring or consulting.
Regulatory uncertainty: As AI regulation evolves, organizations may face requirements for explainability, audit trails, or human review that increase deployment complexity.
Comparative Analysis Against Runable and Other Automation Platforms
Understanding Different Tool Categories
When evaluating Sonnet 4.6, it's important to distinguish between different tool categories solving different problems:
Large Language Models (Sonnet 4.6, GPT-4o, Gemini): Provide raw inference capability through APIs, requiring development effort to build applications.
Automation Platforms (Runable, Zapier, Make): Provide pre-built workflows, visual interfaces, and no-code/low-code development approaches.
Specialized AI Tools (Claude Code, Git Hub Copilot): Combine model APIs with specific application domains (coding, documentation).
These categories serve different use cases and organizational needs. The comparison is nuanced because the tools aren't directly interchangeable — it's more accurate to think of them as complementary.
Sonnet 4.6 vs. Runable and Workflow Platforms
For teams building custom automation workflows, Sonnet 4.6 and platforms like Runable represent different approaches:
Raw model approach (Sonnet 4.6):
- ✓ Maximum flexibility — build any custom workflow imaginable
- ✓ Optimal cost for high-volume applications
- ✓ Direct control over prompting and reasoning
- ✗ Requires significant engineering effort
- ✗ More complex deployment and maintenance
- ✗ Requires prompt engineering expertise
Automation platform approach (Runable, Zapier, Make):
- ✓ No-code/low-code interface — lower barrier to entry
- ✓ Pre-built integrations with common business systems
- ✓ Managed infrastructure and reliability
- ✓ Visual workflow building
- ✗ Less flexibility for highly custom requirements
- ✗ Higher per-execution costs typically
- ✗ Limited to supported integrations
When to choose Sonnet 4.6 directly: For organizations with strong engineering teams, high-volume custom workflows (where API costs matter), or requirements for maximum flexibility and control. Development teams, startups building AI products, and enterprises with significant automation needs typically benefit from direct model APIs.
When to choose Runable or similar platforms: For organizations prioritizing ease-of-use over flexibility, those without extensive engineering resources, or scenarios where pre-built workflows align with requirements. Non-technical teams, small businesses, and organizations seeking rapid deployment with minimal custom development often benefit from platform approaches.
Cost-Benefit Analysis Across Tool Categories
Building a customer support automation workflow:
| Aspect | Sonnet 4.6 (Direct API) | Runable or Zapier | Difference |
|---|---|---|---|
| Initial development cost | $10,000-20,000 | $2,000-5,000 | Runable cheaper (60-75%) |
| Monthly API/platform cost | $1,000 (100K tickets) | $2,000-3,000 | Sonnet cheaper (50-70%) |
| Customization cost | Flexible, ongoing | Limited | Sonnet more flexible |
| Time to first automation | 6-8 weeks | 1-2 weeks | Runable faster (75-85% quicker) |
| 12-month total cost | ~$22,000 | ~$26,000-41,000 | Similar or Sonnet slightly cheaper |
At modest scale (100K annual tickets), the approaches approach cost parity, with trade-offs between development effort and ongoing operational cost. At larger scale (1M+ annual interactions), Sonnet 4.6's superior cost efficiency becomes decisive.
Integration Recommendation
For many organizations, hybrid approaches provide optimal balance:
- Use automation platforms (Runable, Zapier) for routine, well-defined workflows using pre-built integrations
- Use Sonnet 4.6 directly for custom, high-value, or high-volume workflows requiring flexibility
- Combine both in a composite architecture where platforms trigger Sonnet 4.6 for specific tasks (classification, analysis, complex reasoning)
For example, an enterprise might use Runable to orchestrate overall workflow and integrate systems, but call Sonnet 4.6 for the complex reasoning required to analyze customer support tickets, determine routing, and suggest responses.
This hybrid approach captures the ease-of-use advantages of platforms while leveraging Sonnet 4.6's capabilities and cost efficiency for the specific tasks where it provides greatest value.

Implementation Roadmap: A Step-by-Step Deployment Guide
Phase 1: Discovery and Evaluation (Weeks 1-4)
Step 1: Identify automation opportunities
- Audit current processes for labor-intensive, repetitive tasks
- Document process steps, volume, current tool stack
- Estimate potential value (time savings, quality improvements, cost reduction)
- Target: Identify 5-10 potential use cases
Step 2: Assess readiness
- Evaluate internal AI/ML expertise
- Assess data infrastructure and API capability
- Identify stakeholders and potential resistance
- Evaluate compliance and regulatory requirements
Step 3: Conduct proof-of-concept
- Select highest-value or lowest-risk use case
- Build minimal viable prototype with Sonnet 4.6
- Measure performance against baseline
- Cost: Usually $500-5,000 in development and API charges
Step 4: Calculate financial justification
- Project cost savings and productivity gains
- Compare against API costs
- Build business case for expanded deployment
Phase 2: Pilot Implementation (Weeks 5-12)
Step 5: Design production architecture
- Define system architecture, integrations, data flows
- Plan for scale, reliability, monitoring
- Design fallback mechanisms and human oversight
- Specify security, compliance, and audit requirements
Step 6: Develop core workflows
- Implement API integration
- Build orchestration logic
- Develop monitoring and error handling
- Create prompt templates optimized for target use cases
Step 7: Establish testing protocols
- Create test datasets
- Define success metrics and thresholds
- Plan A/B testing against existing approaches
- Develop quality assurance procedures
Step 8: Pilot with limited users
- Deploy to small team (10-50 people)
- Monitor closely for issues
- Collect feedback on usability and effectiveness
- Iterate based on feedback
Phase 3: Scale and Optimization (Weeks 13-24)
Step 9: Expand to broader deployment
- Roll out to larger user base
- Monitor system performance and costs
- Optimize prompts and workflows based on data
- Implement cost optimization techniques
Step 10: Measure and communicate results
- Quantify productivity gains, cost savings, quality improvements
- Share results across organization
- Use success to justify additional automation investments
- Document lessons learned
Step 11: Plan next iterations
- Identify additional use cases
- Evaluate newer models or capabilities
- Plan continuous improvement process
FAQ
What is Claude Sonnet 4.6?
Claude Sonnet 4.6 is Anthropic's mid-tier large language model released in late 2024 that delivers near-flagship performance on coding, computer use, and enterprise tasks at mid-tier pricing (
How does Sonnet 4.6's computer use capability work?
Computer use enables Sonnet 4.6 to interact with software through visual observation and control, similar to how humans use computers. The model receives pixel-level screenshots, identifies interactive elements (buttons, form fields, navigation), formulates action plans, executes precise mouse and keyboard inputs, observes results, and adjusts behavior accordingly. This enables autonomous interaction with any software system, including legacy systems without modern APIs, unlocking automation opportunities for insurance processing, benefits enrollment, vendor portal interaction, and other repetitive desktop tasks. The 72.5% success rate on OSWorld-Verified benchmarks means Sonnet 4.6 can autonomously handle roughly 3 out of 4 real-world computer interaction tasks.
What are the key benefits of Sonnet 4.6 for enterprises?
Primary benefits include 80% cost reduction compared to flagship models while maintaining or exceeding performance, stronger coding capability with 79.6% success on SWE-bench Verified outperforming most competitors, autonomous computer use enabling automation of legacy system interaction previously requiring custom scripts or RPA tools, 1-million-token context window enabling processing of entire codebases or regulatory frameworks in single requests without losing context, improved reliability with fewer hallucinations and false success claims compared to previous models, and faster inference speeds enabling real-time interactive applications. For customer support automation, development productivity, document analysis, and legacy system integration, Sonnet 4.6 provides the combination of capability and cost efficiency that makes enterprise AI agent deployment economically viable.
How does Sonnet 4.6 compare to GPT-4o in real-world performance?
On standardized benchmarks, Sonnet 4.6 demonstrates superior coding performance (79.6% vs. ~75-77% on SWE-bench Verified), better computer use capability (72.5% vs. ~40-50% estimated), and lower input token cost (40% cheaper at
What is the 1-million-token context window and why does it matter?
The context window is the maximum amount of text a model can simultaneously process. Sonnet 4.6's 1-million-token context window allows processing of approximately 2,000 emails, 100-200 research papers, 5-20 complete software projects, or 2-5 regulatory frameworks in single requests. This eliminates the need to chunk documents across multiple API calls, preserving cross-document context and enabling comprehensive analysis. For enterprise knowledge work, this enables scenarios like analyzing entire codebases for refactoring opportunities, processing complete regulatory frameworks for compliance analysis, or synthesizing years of customer interaction history for support optimization — all in single inference passes. The practical implication is higher-quality analysis and often reduced total token consumption through more efficient reasoning.
Should we migrate from GPT-4o or other models to Sonnet 4.6?
Migration decisions depend on your specific use cases, existing infrastructure, and organizational factors. For teams prioritizing coding and software engineering tasks, Sonnet 4.6 offers both superior performance and lower cost, making migration straightforward. For teams using computer use capabilities, Sonnet 4.6's 72.5% success rate significantly outperforms alternatives, justifying migration. For teams with existing GPT-4o integrations generating satisfactory results, migration ROI must be weighed against integration effort, training, and organizational change. Generally, migration is most justified for new projects or applications where Sonnet 4.6's advantages (cost efficiency, computer use, context window) directly address known pain points. For well-functioning GPT-4o deployments, gradual migration (testing Sonnet 4.6 on new features, migrating high-value use cases first) often proves most practical.
What are the typical implementation challenges when deploying Sonnet 4.6?
Common challenges include prompt engineering and optimization — writing effective prompts requires experimentation and may require adjustment from prompts optimized for other models; integration complexity — connecting Sonnet 4.6 to existing systems requires API integration, authentication, and error handling; organizational change management — adoption requires user training and often changes to existing workflows; reliability concerns — while improved, Sonnet 4.6 still demonstrates hallucinations and false claims requiring verification mechanisms for high-stakes applications; scaling and cost monitoring — large-scale deployments require careful monitoring to prevent unexpected costs; and skills gaps — effective deployment often requires expertise in prompt engineering, system design, and AI operations. Addressing these challenges typically requires 6-12 weeks for initial deployment plus ongoing optimization.
How should organizations budget for Sonnet 4.6 deployments?
Budgeting should account for multiple cost components: API charges (
Can Sonnet 4.6 replace RPA (Robotic Process Automation) tools for automation?
For many use cases, Sonnet 4.6's computer use capability provides comparable functionality to RPA tools at significantly lower cost and with greater flexibility. Traditional RPA tools (cost: $15,000-50,000 per "bot") require specialized scripting for each process and struggle with dynamic interfaces. Sonnet 4.6's computer use can adapt to interface changes and learn patterns across diverse systems. However, RPA maintains advantages in reliability (99.99%+ uptime), performance guarantees, and extensive enterprise tooling. Optimal approach: Use Sonnet 4.6 for flexible, learning-based automation of complex processes; use RPA for mission-critical, high-volume processes requiring guaranteed reliability and performance. Many organizations benefit from hybrid approaches where Sonnet 4.6 handles complex decision-making and RPA handles reliable execution of well-defined processes.
What is the appropriate context window size for my use cases?
Context window requirements depend on your specific applications. For customer support: 50,000-100,000 tokens sufficient (interaction history plus context); for code review and generation: 100,000-300,000 tokens enables small-to-medium codebases; for legal/compliance analysis: 200,000-400,000 tokens enables comprehensive regulatory framework analysis; for complex M&A due diligence: 500,000-1,000,000 tokens enables analysis across complete documentation sets. The practical approach: start with estimated tokens for your largest documents/conversations and add 20-30% buffer. If you consistently need more than 1 million tokens, consider chunking large documents across multiple requests (with explicit cross-document reference instructions) or using alternative approaches. For most enterprise use cases, Sonnet 4.6's 1-million-token context window proves sufficient.
How does Sonnet 4.6 compare to open-source models like Llama 3.1 for cost-sensitive deployments?
This comparison is complex because it involves different operational models. Sonnet 4.6 advantages: superior performance on coding, computer use, and reasoning tasks; managed service reliability (99.9%+ uptime); no operational overhead; pay-as-you-go simplicity. Open-source advantages: approaching zero marginal cost at very large scale (10+ billion tokens monthly); data privacy (process data locally); no API dependency risk. For organizations with <5 billion tokens monthly consumption, Sonnet 4.6's managed service and superior performance typically provides better value than open-source self-hosting. For organizations with >10 billion tokens monthly and significant ML operations expertise, open-source self-hosting may provide cost advantages offsetting operational complexity. For most enterprises, Sonnet 4.6 represents the sweet spot — lower cost than Opus, superior performance to open-source, and lower operational complexity than self-hosting.
How does Sonnet 4.6 integrate with automation platforms like Runable for workflow orchestration?
Hybrid approaches combining Sonnet 4.6 with platforms like Runable often provide optimal value. Runable excels at visual workflow building, pre-built integrations, and no-code/low-code accessibility. Sonnet 4.6 provides raw model capability and flexibility. Integration patterns include: Runable orchestrating workflows while calling Sonnet 4.6 APIs for complex analysis/reasoning tasks; Sonnet 4.6 for high-volume/custom processes while Runable handles routine integrations; Runable as frontend interface with Sonnet 4.6 as backend intelligence. This hybrid approach captures ease-of-use advantages of platforms while leveraging Sonnet 4.6's capabilities and cost efficiency where they provide greatest value. For teams without strong engineering resources, starting with Runable and selectively using Sonnet 4.6 for high-value reasoning often proves most practical.
Conclusion: Strategic Implications and Forward-Looking Assessment
Claude Sonnet 4.6 represents a pivotal moment in enterprise artificial intelligence adoption. The convergence of frontier-grade performance, mid-tier pricing, and production-ready reliability fundamentally reshapes the economics of AI agent deployment, autonomous coding tools, and intelligent document analysis.
For enterprise decision-makers, the strategic significance extends beyond the specific model. Sonnet 4.6 validates a thesis that dominated AI industry discourse throughout 2024: that optimized, efficient models serving 80% of use cases at 80% lower cost represent more durable value than raw frontier capability. Rather than pursuing ever-larger models with ever-greater capabilities, Anthropic invested in model efficiency, prompt engineering, and production reliability.
This shift has ripple effects across the competitive landscape. Open AI and Google now face direct performance and economic competition on models that previously represented clear flagship differentiation. Smaller competitors struggle to justify resources competing on capability when Sonnet 4.6 offers such favorable economics. Open-source projects face pressure demonstrating operational advantages sufficient to justify the complexity of self-hosting against managed APIs.
For organizations evaluating AI deployments, Sonnet 4.6 provides a clear decision point. The benchmark data, cost structure, and real-world performance demonstrate that serious enterprise AI agent deployments no longer require choosing between capability and cost. Teams can pursue ambitious automation and productivity initiatives without the prior concern that API costs would balloon as usage scaled.
The practical implications are significant:
Cost structures fundamentally shift. Organizations budgeting
Deployment velocity accelerates. With lower financial barriers and proven capability, organizations can shift from "should we automate this process?" to "how quickly can we deploy automation?" This represents genuine market tipping point behavior.
Competitive advantage emerges from implementation, not access. When multiple organizations have access to equivalent AI capability at equivalent cost, competitive advantage flows to execution quality — prompt engineering, system design, change management, and iterative optimization.
Legacy system modernization becomes viable. Computer use capability at 72.5% success rates enables organizations to tackle the mounting burden of legacy system integration without expensive custom development or multi-year replacement projects.
For teams currently evaluating whether to deploy AI agents, the analysis is straightforward. Sonnet 4.6 provides sufficient capability at such low cost that virtually any automation opportunity worth $50,000+ in annual labor value represents financially positive ROI, often generating 5-10:1 benefit-to-cost ratios within the first 12 months of operation.
The path forward for organizations is:
- Identify high-value automation opportunities — where humans currently spend significant time on repetitive, rule-based tasks
- Evaluate Sonnet 4.6 viability — test whether the model can effectively execute required reasoning and actions
- Prototype at small scale — validate assumptions before committing significant resources
- Plan scaled deployment — for use cases demonstrating positive early results, plan systematic rollout
- Implement continuous optimization — prompt engineering, workflow refinement, and cost optimization are ongoing processes
Claude Sonnet 4.6 arrives at precisely the moment when enterprise organizations needed a model that combines frontier capability with pragmatic cost structure. It enables a shift from "AI is expensive, use cautiously" to "AI is cheap enough to be ubiquitous, use strategically." Organizations that recognize this shift and move quickly to deploy Sonnet 4.6 across automation opportunities will likely capture disproportionate competitive and operational advantage.
The era of enterprise AI hesitation due to cost concerns is likely ending. Sonnet 4.6 democratizes access to AI agent capability across organizations of all sizes. The competitive frontier is shifting from "can we afford AI?" to "how effectively can we operationalize AI?" Organizations that can answer the latter question will define competitive advantage in the coming years.
Key Takeaways
- Sonnet 4.6 matches flagship Opus performance across coding, computer use, and enterprise tasks while costing 80% less per token (15 input,75 output)
- Computer use capability achieved 72.5% success rate on desktop automation, up from 14.9% in October 2024 — enabling production-ready legacy system automation
- 1-million-token context window enables processing complete codebases, regulatory frameworks, and years of customer history in single requests without context loss
- Real-world deployments show 70%+ user preference over predecessor Sonnet 4.5 and 59% preference over flagship Opus 4.5, indicating practical usability advantages
- Financial impact: organizations save $5,400-78M monthly depending on scale, with customer support automation ROI of 15-20x in first year
- Hybrid deployment combining Runable platforms with Sonnet 4.6 APIs provides optimal balance of ease-of-use and capability flexibility
- For teams evaluating AI agent deployment, Sonnet 4.6 crosses economic threshold making virtually any $50K+ automation opportunity financially justified
- Benchmarks show Sonnet 4.6 actually outperforms Opus on financial analysis (63.3% vs 60.1%) and office tasks (1633 vs 1606 Elo), not just achieving parity
Related Articles
- Didero AI Procurement Automation: Complete Guide & Alternatives
- Mistral AI Acquires Koyeb: Cloud Strategy & AI Infrastructure Impact
- Real-Time AI Inference: The Enterprise Hardware Revolution 2025
- VMware Exit Strategy: Turn Vendor Lock-In Into Competitive Advantage
- AI Code Output vs. Code Quality: The Nvidia Cursor Debate [2025]
- Anthropic's 380B Valuation Means for AI Competition in 2025

