![Data Leadership & Strategy: The Foundation of AI Success [2025]](https://tryrunable.com/blog/data-leadership-strategy-the-foundation-of-ai-success-2025/image-1-1771515441806.jpg)
Data Leadership & Strategy: The Foundation of AI Success [2025]
Introduction: Why Data Leadership Determines AI Outcomes
It's tempting to think AI adoption is about choosing the right model or deploying the flashiest algorithm. But here's what I've learned after years watching enterprises struggle: the real bottleneck isn't the technology. It's the data.
Picture this. A Fortune 500 retailer invested $12 million in an AI recommendation engine. Six months later? It was recommending winter boots in July and suggesting products customers had already purchased. The AI wasn't broken. The data feeding it was: incomplete customer profiles, outdated inventory records, duplicate entries from three different legacy systems.
That's the reality most organizations face. McKinsey's research shows 75% of organizations are implementing AI in at least one business function, but the majority struggle to see tangible returns. Why? Data integrity.
Data leadership isn't about hiring more data scientists or buying shinier tools. It's about establishing a strategic foundation where data quality, governance, and accessibility work in concert to enable AI systems that actually deliver value. Think of it as the difference between building on solid rock versus quicksand.
This guide breaks down exactly how enterprise leaders—from Chief Data Officers to engineering teams—can build data strategies that make AI work in the real world. We'll explore data quality management, governance frameworks, privacy compliance, and organizational alignment. More importantly, we'll show you the measurable business outcomes when data leadership is done right.
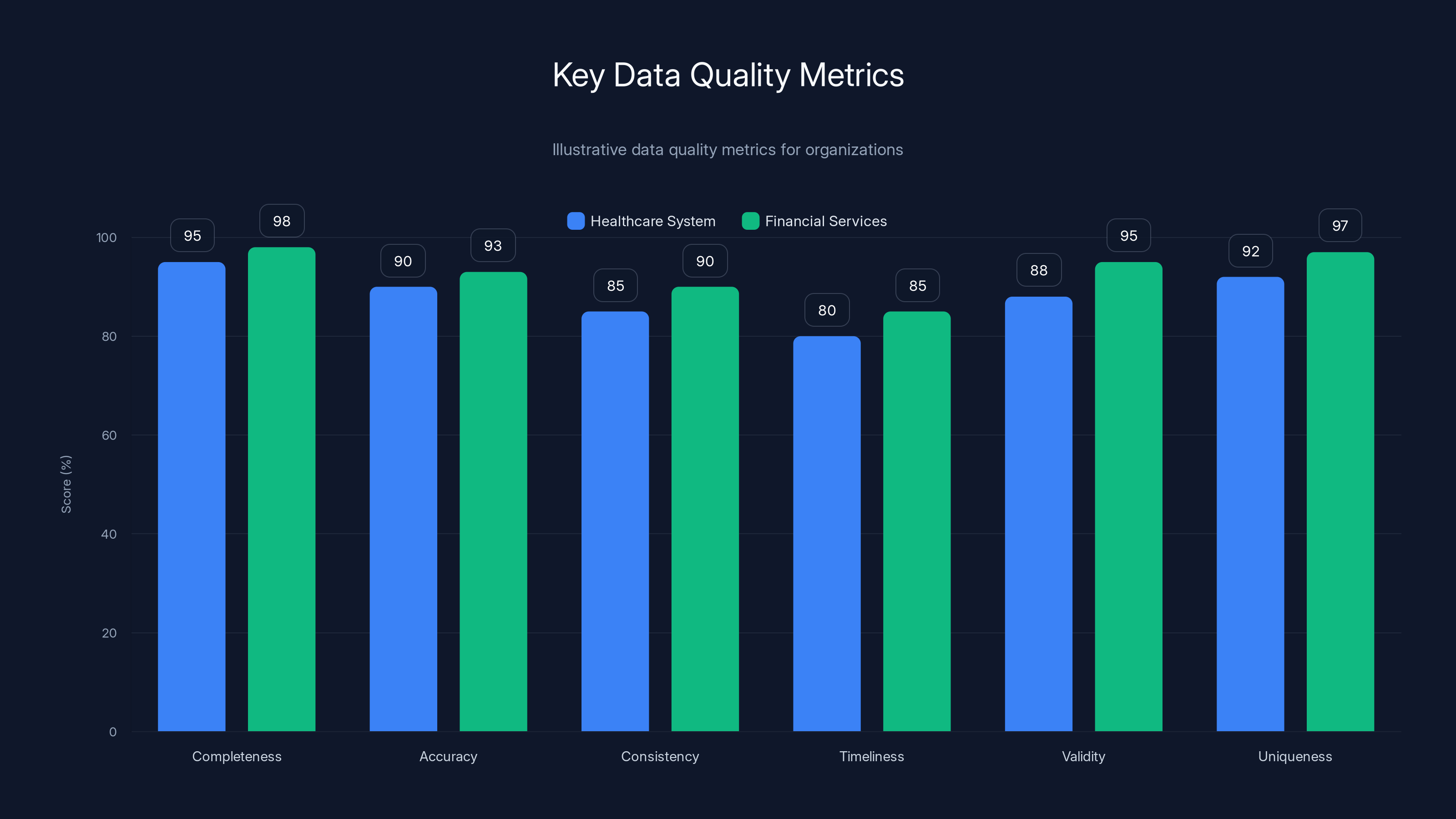
Estimated data showing that financial services often prioritize accuracy and validity, while healthcare systems focus on completeness and uniqueness.
TL; DR
- Data Quality Crisis: Only 12% of organizations report having data of sufficient quality for effective AI implementation, despite AI influencing 60% of data programs
- Governance as Foundation: 71% of enterprises now operate with defined data governance programs, and those that do report 58% improvements in data quality
- Regulatory Pressure: GDPR, EU AI Act, and emerging data regulations require robust governance structures before AI deployment
- Cost of Failure: Poor data quality leads to delayed decisions, inflated costs, customer dissatisfaction, and potential regulatory violations
- Strategic ROI: Organizations with mature data strategies report improved analytics, faster insights, better compliance, and higher stakeholder confidence
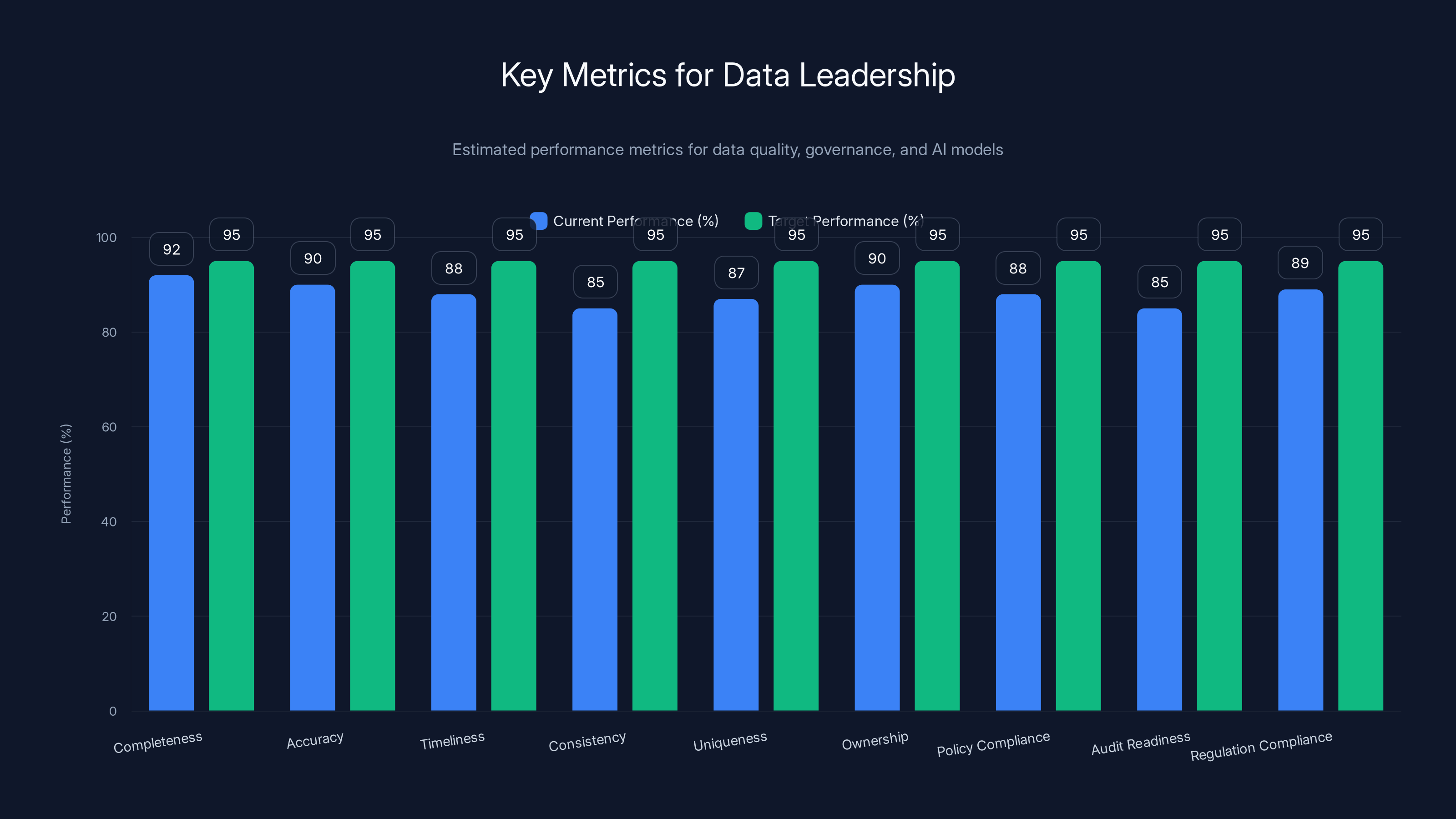
Estimated data shows current performance slightly below target for key data leadership metrics. Focused improvements are needed to reach the 95% target across all areas.
Part 1: Understanding the Data-AI Dependency
The AI Quality Paradox: Why More Data Isn't Better Data
Here's a counterintuitive truth that catches most executives off guard: more data doesn't equal better AI. In fact, it often makes things worse.
When an organization dumps raw, unvalidated data into a machine learning model, the model learns to replicate patterns—including errors, biases, and corrupted entries. A chatbot trained on poor-quality customer service interactions will become a bad customer service representative. A predictive model built on incomplete financial data will make inaccurate forecasts. A recommendation algorithm trained on dirty customer data will alienate users.
Consider how this plays out in real applications. Streaming services like Netflix and Spotify depend on accurate customer metadata—age, location, viewing history, preferences—to deliver recommendations that feel "magic." When that data is inaccurate or outdated, the experience collapses. You get recommendations that make no sense, the algorithm tanks engagement metrics, and users churn.
The paradox deepens when you consider scale. A retail organization might have customer records spread across point-of-sale systems, e-commerce platforms, loyalty programs, and CRM tools. Consolidating that data reveals duplicate entries, conflicting information, and gaps. Should the AI system trust the phone number from the legacy system or the mobile app? Which address is current? Is that phone number from 2019 still valid? These questions multiply across millions of records.
The result is what I call "confident inaccuracy." The AI system produces outputs with conviction, but the outputs are built on faulty foundations. Decision-makers trust the AI because it seems sophisticated, but it's actually steering the business toward poor choices.
The 60-12 Gap: Why Most AI Initiatives Underperform
Let's look at the numbers that should wake up every technology leader.
AI influences data programs at 60% of organizations. That's massive adoption. But only 12% of those organizations report having data of sufficient quality and accessibility for effective AI implementation. That's a 48-percentage-point gap between ambition and capability.
What does this gap look like in practice?
Companies are spinning up AI initiatives—building teams, purchasing tools, defining use cases—while their foundational data infrastructure is still fragmented. Teams are running data quality assessments and discovering that source systems have incomplete records, inconsistent naming conventions, missing values, and conflicting information. Some datasets are stale by months. Others lack the granularity needed for the AI models that teams want to build.
So the initiative stalls. Teams spend weeks or months in data preparation—cleaning, validating, transforming, reconciling. What was supposed to be a "six-month AI deployment" becomes an 18-month data cleanup project. Stakeholders get frustrated. Budget gets reallocated. The initiative loses momentum.
The organizations closing this gap—the 12% with high-quality, accessible data—typically share a common pattern: they started with data governance before launching AI. They invested in data quality infrastructure. They established clear data ownership and accountability. They made data strategy a business priority, not an afterthought.
How AI Amplifies Data Problems
Here's why data leadership matters more with AI than with traditional analytics: AI scales problems.
With traditional business intelligence, you might query a database to answer a specific question. "How many customers churned last month?" If the underlying data has a few errors, you get a slightly inaccurate number, but the impact is bounded. You might make a decision that's 5% off optimal.
With AI systems running continuously, making decisions autonomously or influencing critical business decisions, errors compound. An AI model trained on biased data doesn't just make a biased decision once—it makes biased decisions at scale, every single day, affecting millions of customers or transactions.
Consider a lending AI system trained on historical loan data where certain demographic groups were systematically underrepresented in approval data. The model learns to replicate that bias. It denies loans to qualified applicants from those groups at higher rates. Now you have discrimination at scale, potential regulatory violations, and reputational damage.
Or consider a supply chain optimization AI trained on incomplete inventory data from three different warehouse systems that don't sync perfectly. The model makes decisions based on inaccurate stock levels. It over-orders some products and under-orders others. Warehouses run out of critical items while other products accumulate dust, tying up capital.
The cost of errors scales with adoption. Which is why data quality and governance aren't "nice to have" initiatives—they're foundational requirements before AI deployment.
Part 2: Data Quality as a Strategic Asset
Building the Data Quality Framework
Data quality doesn't happen by accident. It requires a deliberate framework that combines people, processes, and technology.
The framework starts with clear definitions. What does "quality" actually mean for your organization? For a healthcare system, quality might mean: complete patient records with no missing diagnostic results, accurate medication history, consistent dates across systems, validated clinical codes. For a financial services firm, quality might mean: accurate transaction records, complete KYC (Know Your Customer) documentation, validated regulatory classifications, timely data updates.
These definitions become the baseline for measurement. You can't improve what you don't measure. So the framework includes data quality metrics: completeness (what percentage of required fields are populated?), accuracy (do records match real-world truth?), consistency (do different systems agree?), timeliness (how current is the data?), validity (do values fall within acceptable ranges?), and uniqueness (are there duplicate records?).
Once you have metrics, you implement automated validation processes. This is critical. Manual data quality management doesn't scale. You need systems that:
- Validate incoming data against business rules and real-world benchmarks before it enters systems
- Flag anomalies that suggest data corruption or entry errors
- Reconcile conflicts when the same entity appears in multiple systems with different information
- Monitor data drift over time (watching for gradual degradation in quality)
- Alert teams when quality drops below thresholds
For example, if your e-commerce system receives customer data that includes an age of "437" or a phone number that's invalid, automated validation catches it immediately. If you're pulling customer records from three systems and one shows they opened an account in 2025 while another shows 2023, reconciliation logic flags the discrepancy for human review.
This automation is where platforms like Runable can help orchestrate data quality workflows—automating validation, generating quality reports, and alerting stakeholders when issues arise. The combination of policy, technology, and continuous monitoring prevents quality degradation.
Real-World Data Quality Failures and How to Prevent Them
Let me walk you through three common data quality failures I've seen derail AI initiatives, and how strategic organizations prevent them.
Failure #1: The Duplicate Data Trap
A mid-market retail company consolidates customer data from three channels: in-store POS, e-commerce site, and a direct mail program. Same customer, three records. The same Jane Smith appears as:
- jane.smith@email.com (from web)
- j.smith@oldomain.com (from legacy mail system)
- Jane Smith (from in-store with no email)
When they build an AI recommendation engine, it treats these as three separate customers. Customer 1 gets recommendations based on online browsing. Customer 2 gets recommendations based on mail order history from 2015. Customer 3 gets nothing because there's minimal transaction history. The actual customer, Jane Smith, gets a fragmented, poor experience.
Prevention requires data deduplication logic—matching on email, phone, address, or a combination—and a single customer master record. This is where governance matters: clear rules about which system is the "source of truth" for each data element, and processes that keep it updated.
Failure #2: The Stale Data Problem
A financial services firm builds a credit risk model using training data from 2022. The model goes live in 2024 using current application data but was trained on patterns from two years ago. Economic conditions have shifted, employment has changed, spending patterns have evolved. The model makes predictions based on outdated patterns and fails to adapt.
Prevention requires monitoring data recency. How old is the training data? When was it last updated? For production AI systems, you need automated checks that flag when source data is outdated and trigger retraining workflows.
Failure #3: The Context Loss Problem
A manufacturing company pulls maintenance records from their equipment database to train a predictive maintenance AI. The raw data: equipment ID, date, failure type. But critical context is missing: equipment age, operating environment, maintenance history, operator experience. Without context, the model can't learn nuanced patterns.
Prevention requires data enrichment workflows. Before feeding data to AI systems, ensure it has sufficient context and dimension. This often means joining datasets: equipment data with maintenance history, environmental sensors, operator logs. The enrichment process itself should be documented and version-controlled.
The common thread: all three failures were preventable with structured data quality practices, clear ownership, and automated monitoring.
Measuring Data Quality ROI
Here's the business case that justifies data quality investment.
Organizations with strong data quality practices report:
- 58% improvement in data insights and analytics (Forrester research on data governance maturity)
- Faster decision-making: Analysts spend less time validating data, more time interpreting insights
- Reduced operational costs: Fewer errors mean less rework, fewer failed processes, less customer churn
- Higher AI model accuracy: Models trained on clean data outperform models trained on dirty data by 15-40% depending on the domain
- Improved compliance: Clean, auditable data reduces regulatory risk
The ROI calculation looks like this:
Cost of poor data quality = operational errors + rework + lost revenue + regulatory penalties + customer churn
Gartner estimates this totals $12.9 million annually for mid-market organizations.
Cost of data quality investment = infrastructure + headcount + training
Typically $1-3 million for a mature program.
Payback period = 1-2 years if you prevent just a portion of failures.
The math is compelling. Yet many organizations still underinvest in data quality because the benefits feel diffuse. They're hard to attribute. That's changing as more organizations measure the correlation between data quality improvements and AI model performance.
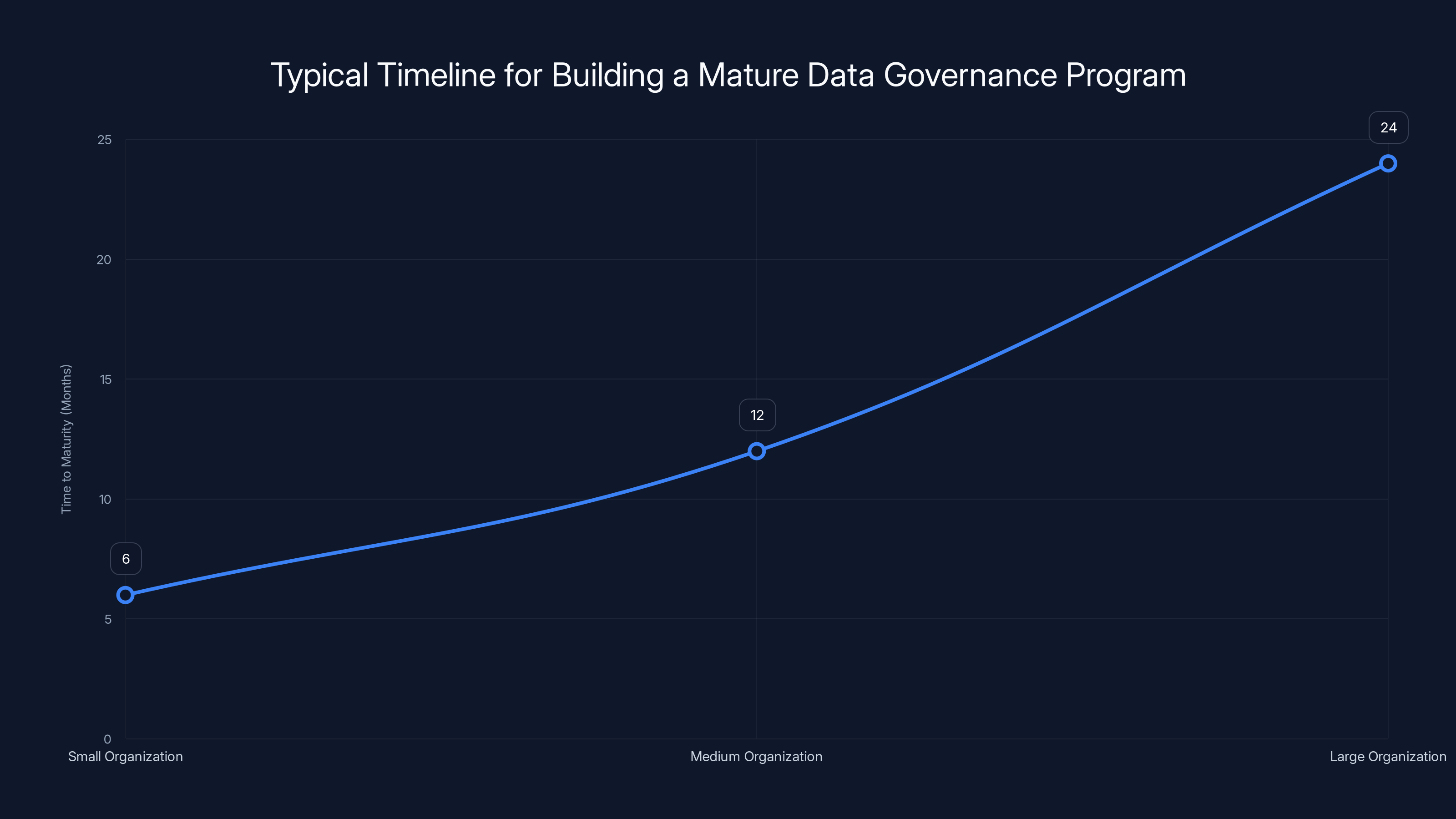
Estimated data suggests that small organizations may achieve data governance maturity in about 6 months, while larger organizations could take up to 24 months.
Part 3: Data Governance as Strategic Discipline
Why Data Governance is Non-Negotiable for AI
Data governance sounds bureaucratic. In practice, it's the opposite. It's the framework that actually enables AI adoption at scale.
Think about what happens when an AI system makes a critical decision. A lending AI denies a mortgage. A hiring AI rejects a candidate. A medical AI recommends a treatment plan. If that decision turns out to be wrong, wrong in a way that harms someone, who's accountable?
Without governance, the answer is murky. Was the training data biased? Was the model evaluated on the right metrics? Where did the training data come from? Who validated it? Was the model's decision explainable?
With governance, there's a clear chain of accountability. You know the lineage of the data (where it came from), the custodians (who owns it), the validation steps it went through, the policies governing its use, and the audit trail of decisions made with it.
This matters legally. GDPR requires organizations to explain how they're using personal data. The EU AI Act imposes strict requirements for high-risk AI systems, including detailed documentation of training data, testing, and decision logic. If you can't demonstrate governance, you can't demonstrate compliance.
It also matters operationally. When data is governed—when there's clarity about ownership, quality standards, and usage policies—teams can collaborate without friction. Data scientists know where to find trusted data. Business teams know which datasets are production-ready. Legal teams understand how data is being used.
The organizations that have embraced this trend are seeing results. Forrester reports that 71% of organizations now operate with a defined data governance program, up from around 40% five years ago. Those with mature programs report 58% improvements in data quality.
Building a Data Governance Operating Model
Governance isn't a system you buy. It's a model you build, tailored to your organization's structure, culture, and risk profile.
The model typically includes five components:
1. Data Governance Structure (The Who)
Clear roles and responsibilities:
- Chief Data Officer or Data Governance Lead: Strategic oversight, policy, alignment with business
- Data Stewards (by domain or business unit): Day-to-day data management, quality monitoring, ownership
- Data Custodians (IT/infrastructure): Technical implementation, access control, storage
- Data Governance Council: Cross-functional oversight, policy decisions, conflict resolution
Without clarity on roles, governance becomes a finger-pointing exercise. Everyone assumes someone else is responsible for data quality. Nobody is.
2. Data Inventory and Metadata Management (The What)
You can't govern what you don't know exists. A data catalog—a searchable inventory of all data assets with metadata—is foundational.
The catalog includes:
- What data exists (datasets, fields, tables)
- Where it lives (source system, data lake, warehouse)
- Who owns it (data steward, business owner)
- Data quality metrics (completeness, accuracy, timeliness)
- Sensitivity classification (public, internal, confidential, regulated)
- Lineage (where it comes from, what systems use it)
- Policies governing its use (retention, access, sharing)
For an organization with thousands of data sources, a data catalog is essential. It's the central repository of truth. Without it, you get silos where teams don't know what data exists elsewhere, leading to duplicate data ingestion and conflicting versions of truth.
3. Data Policies and Standards (The How)
Governance requires codified policies:
- Data Classification Policy: How data is categorized by sensitivity, type, and regulatory status
- Data Quality Standards: Expectations for completeness, accuracy, timeliness by data type
- Data Access Policies: Who can access what data, under what conditions
- Data Retention Policies: How long data is kept before deletion (required by GDPR and other regulations)
- Data Integration Standards: How data from multiple sources is consolidated and reconciled
- Metadata Standards: Consistent naming, documentation, and description of data assets
These policies aren't meant to restrict data usage. They're meant to clarify expectations and reduce friction.
4. Data Quality Monitoring and Remediation (The Validation)
Ongoing monitoring systems that:
- Track quality metrics against standards
- Alert teams when quality drops
- Trigger escalation workflows for critical data
- Log remediation efforts for audit purposes
This is where automation matters. You can't manually monitor quality across thousands of datasets. You need systems that check data continuously and alert when problems arise.
5. Compliance and Audit Capabilities (The Proof)
Documentation systems that prove governance is working:
- Access logs showing who accessed what data when
- Change logs showing how data definitions evolved
- Data lineage documentation showing data flow and transformations
- Policy compliance reports showing adherence to standards
- AI audit trails showing what training data was used for AI systems
These aren't just for regulators. They're for internal accountability. When something goes wrong, audit logs help you trace the issue back to the root cause.
Governance and Regulatory Compliance
Organizations today navigate a complex regulatory landscape: GDPR in Europe, CCPA in California, industry-specific regulations like HIPAA for healthcare and PCI-DSS for payments, and emerging frameworks like the EU AI Act.
Each regulation imposes requirements on how data is collected, stored, used, and protected. GDPR gives individuals the "right to explanation"—they can ask, "Why did you make this decision about me?" If that decision was made by an AI system trained on data the individual didn't consent to, you have a problem.
Governance is how you solve that problem. Strong governance means:
- Clear consent tracking (who consented to what use of their data)
- Data lineage documentation (which personal data fed into which AI models)
- Model explainability (you can explain why the AI made a specific decision)
- Audit trails (proof that you followed your policies)
Without this, you're exposed to regulatory fines, class action lawsuits, and reputational damage.
The organizations that have built governance as a strategic discipline—that see it as enabling business outcomes rather than constraining them—are the ones deploying AI confidently.

Part 4: Privacy, Ethics, and Responsible AI
The Privacy-Innovation Tension
There's an assumption that privacy and innovation are opposed. Privacy slows things down. Privacy restricts data usage. Privacy complicates AI development.
That's partially true. Privacy does add constraints. But framing it as a constraint is like framing quality as a constraint. Yes, it requires discipline and planning. But the alternative—shipping products that expose customers or violate regulations—is worse.
The real insight is that privacy and innovation aren't opposed. They're interdependent. Organizations with strong privacy practices build customer trust, which enables richer first-party data collection, which actually improves AI outcomes.
Consider the contrast. A company that collects personal data without clear policies and uses it in ways customers don't understand erodes trust. Customers give you incomplete information. They opt out of programs. They churn when a competitor offers better privacy terms. Meanwhile, a company that's transparent about data usage and implements strong privacy controls builds customer loyalty. People are more willing to share data when they trust it's protected.
This has real business implications. First-party data—information customers willingly share—is becoming more valuable as third-party data (cookies, data brokers) gets regulated out of existence. Companies that have customer trust can gather first-party data at scale. Companies that don't get increasingly reliant on questionable data sources.
Building Privacy Into AI Systems
Privacy doesn't happen at the end of development. It needs to be built in from the start.
Privacy by Design Principles:
-
Data Minimization: Collect only the data you actually need for the stated purpose. Don't collect data "just in case" you might use it later. This reduces exposure if data is breached or misused.
-
Purpose Limitation: Use data only for the purpose you collected it for. If you collected email addresses to send marketing, you don't use them to train models without explicit consent.
-
Storage Limitation: Don't keep data longer than necessary. Implement automated deletion. If customer data is no longer needed for a specific purpose, delete it. Set retention periods for different data categories.
-
Consent Management: Get explicit consent for data usage, particularly for AI training. Consent should be informed (they understand what they're consenting to) and granular (they can consent to some uses but not others).
-
Transparency: Document what data is collected, why, how it's used, and who has access. Make this information available to individuals.
-
Right to Erasure: Implement technical capabilities to delete personal data on request (required by GDPR). This is more complex than you'd think—if personal data was used in AI training, how do you remove its influence from a trained model?
-
Data Minimization in AI: Use techniques like differential privacy (adding noise to data to prevent identification while preserving statistical properties) or federated learning (training models on data that stays on-device rather than centralizing it).
These principles require discipline. It's tempting to collect every data point that might be useful. It's tempting to keep data "just in case." Strong privacy practices push back on that temptation.
Ethical AI and Bias
People use the terms "ethical AI" and "responsible AI" loosely, but in practice, they're about specific, measurable practices.
The central challenge is bias. AI systems trained on biased data amplify that bias at scale. Historical hiring data that shows men were promoted more frequently than women will encode that bias into a hiring recommendation system. Credit data that shows certain groups were approved for loans less frequently will encode discrimination.
Bias can be introduced at multiple stages:
- Data bias: Training data isn't representative of the population you're applying the model to
- Algorithm bias: The model architecture itself has built-in assumptions
- Evaluation bias: You're measuring success on metrics that favor certain groups
Addressing bias requires:
-
Dataset documentation: Who does the training data represent? Are certain groups underrepresented? If so, did you account for that?
-
Fairness metrics: Define what "fair" means for your use case. For hiring, fairness might mean the approval rate is similar across demographic groups. For lending, fairness might mean the default rate is similar. Measure these metrics explicitly.
-
Adversarial testing: Test your model on scenarios where you expect it might fail or be biased. Can the model be tricked? Does it perform worse for certain populations?
-
Diverse teams: Homogeneous teams miss blind spots. Diverse teams—in background, expertise, demographic identity—catch problems that others miss.
-
Human oversight: For high-stakes decisions (lending, hiring, healthcare), don't let AI decide autonomously. Use AI to flag risky decisions and let humans make the final call.
The organizations that do this well are explicit about it. They document assumptions, test for bias, and maintain human oversight. They understand that "ethical AI" isn't a marketing claim—it's a commitment to measurable practices.
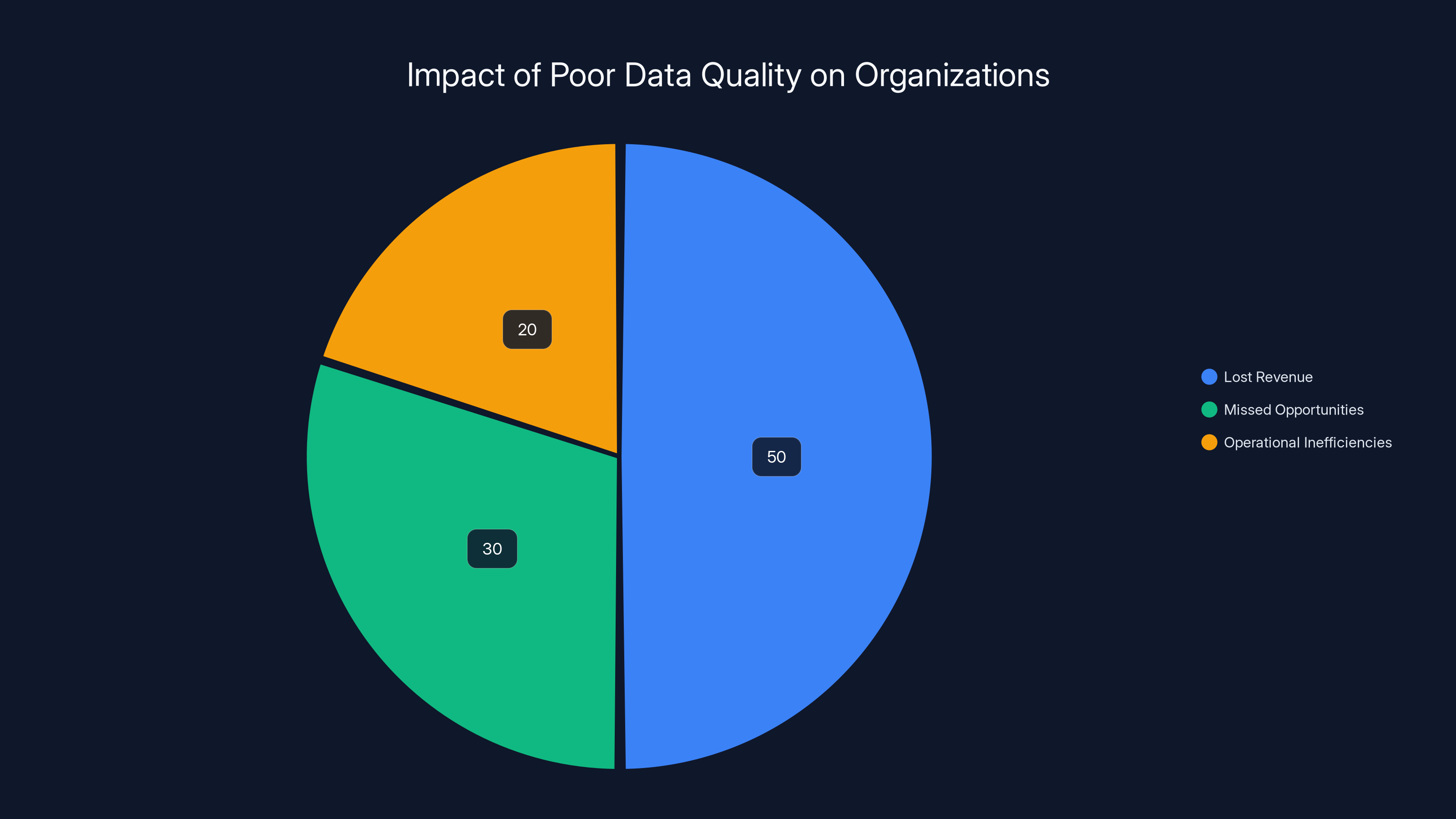
Estimated data shows that poor data quality costs organizations significantly, with lost revenue being the largest contributor, followed by missed opportunities and operational inefficiencies.
Part 5: Building an AI-Ready Data Organization
Organizational Alignment and Data Culture
Even if your data quality is excellent and governance is mature, AI initiatives fail if the organization isn't aligned.
Here's what I mean. A Chief Data Officer builds a beautiful data governance framework. It's comprehensive, well-designed, aligned with best practices. But business unit leaders see it as bureaucracy. They're evaluated on speed and revenue, not data quality. So they bypass the framework. They build their own data pipelines, use shadow data sources, train models on data that hasn't been validated. The framework collapses because it lacks organizational buy-in.
The fix requires alignment from the top. The CEO and executive team need to understand that data maturity isn't optional—it's foundational for AI. They need to make data quality a factor in performance evaluations. They need to allocate budget for data infrastructure, not just for AI models.
It also requires cultural change. Organizations need to shift from a mindset of "data is a cost center" to "data is a strategic asset." That means:
- Investing in data infrastructure: Not grudgingly, but strategically
- Valuing data stewardship: Recognizing that good data custodians deserve compensation comparable to software engineers
- Making decisions from data: When data suggests a strategy isn't working, being willing to change course
- Tolerating transparency: Acknowledging data quality problems rather than hiding them
Organizations like Airbnb and Netflix have built this culture. They're known for data-driven decision-making. That's not because they have better data scientists. It's because they've embedded data into how decisions get made.
Cross-Functional Collaboration Models
AI initiatives require collaboration across silos: data teams, AI/ML teams, business teams, legal/compliance, engineering.
Without structure, that collaboration is chaotic. AI teams build models without understanding data limitations. Data teams don't know what questions business teams need answered. Legal doesn't know what data is being used until an audit triggers discovery.
Mature organizations implement structured collaboration models:
AI Centers of Excellence (Co E)
A cross-functional team that oversees AI strategy, capability building, and governance. The Co E sets standards, reviews AI projects for compliance and bias, shares best practices, and manages partnerships with vendors.
Data Product Teams
Instead of treating data as a shared resource, some organizations create "data products"—curated datasets with clear definitions, quality guarantees, and documented lineage. Teams can use these products with confidence. The data product owner is responsible for quality and documentation.
Integrated AI Projects
For significant AI initiatives, embed representatives from all stakeholders on the project team: data engineer, ML engineer, business analyst, privacy officer, domain expert. This prevents siloed decision-making.
Regular Governance Meetings
Quarterly or monthly meetings where data governance, AI, and business teams align. Discuss data quality issues, new data policies, upcoming regulations, and AI project updates.
The key is reducing friction and improving information flow. When teams have regular touchpoints and clear roles, they can move faster and make better decisions.
Skill Development and Talent Strategy
Build AI on poor data and poor governance, and no amount of talent can salvage it. But conversely, have solid data infrastructure and governance, and good talent can build amazing things.
Which means talent strategy is inseparable from data strategy.
Organizations need:
- Data Engineers: Building pipelines, ensuring data flows from source systems into usable formats
- Data Analysts: Understanding data, identifying insights, defining data requirements for AI
- ML Engineers: Building, testing, and deploying AI models
- Data Stewards: Managing data ownership, quality, and governance
- Domain Experts: Understanding the business context that data represents
- Data-Literate Business Leaders: Understanding data, capable of asking good questions
The gap isn't in AI specialists. It's in foundational data expertise. McKinsey's talent research shows organizations struggling to find people who can bridge data and business.
The fix requires development, not just hiring. Companies like Google and Amazon have invested heavily in internal training programs. They teach software engineers data fundamentals. They teach business teams statistics. They cultivate a common language across silos.
This is where training platforms and internal documentation matter. Organizations that document their data practices—data definitions, governance policies, quality standards, best practices—make it easier for new hires to get up to speed and for teams to maintain consistency.

Part 6: Technology Stack for Data-Enabled AI
Modern Data Architecture Patterns
The technology you choose matters, but less than the architecture you build with it.
Modern organizations are moving away from centralized data warehouses (all data in one place) toward data mesh architectures (distributed data ownership with centralized governance). The difference is meaningful.
In a traditional warehouse architecture, a central data team owns all data. They build pipelines to ingest data from source systems, transform it, and load it into the warehouse. Business teams query the warehouse.
This works when you have a small number of data sources and a clear set of business questions. It breaks down when you have hundreds of data sources and constantly evolving business needs. The data team becomes a bottleneck. New data sources require infrastructure changes. Business teams can't self-serve.
In a data mesh architecture, business units own their data as products. They're responsible for data quality, documentation, and access. A central data platform team provides infrastructure and governance standards. Business units can publish their data products. Other teams can discover and use them.
This distributes responsibility. It enables faster iteration. But it requires clear governance—if every team publishes their own data products, you quickly end up with chaos without standards.
In practice, most organizations land somewhere in the middle: a core data warehouse for critical business data, plus distributed data lakes for exploratory analysis, plus modern tools for self-service.
Key architectural components:
- Data Ingestion Layer: Tools that pull data from source systems (transactional databases, APIs, Saa S applications) and load it into central storage
- Data Transformation Layer: Tools that clean, validate, and enrich data
- Data Storage: Data warehouse (structured, optimized for queries) or data lake (flexible, schema-on-read)
- Data Serving Layer: APIs and tools that let downstream applications access data
- Data Governance Layer: Metadata management, access control, audit logging
The specific tools matter less than the architecture. But the best data stacks today include components like:
- Ingestion: Talend, Fivetran, Airbyte
- Transformation: dbt, Apache Spark
- Storage: Snowflake, Google Big Query, Databricks
- Governance: Collibra, Alation
When evaluating tools, ask: Does it scale to our volume of data? Does it integrate with our source systems? Does it support governance requirements? Can teams self-serve, or does it require central IT?
AI Development Infrastructure
AI models require different infrastructure than traditional applications. They're resource-intensive (lots of compute), iterative (you train many versions), and experimental (you test many approaches before finding one that works).
Organizations need:
ML Platforms
Tools that manage the full lifecycle: feature engineering, model training, evaluation, serving, monitoring. Examples: MLflow, Vertex AI, Amazon Sage Maker.
Feature Engineering Tools
Features are the variables that AI models learn from. Good features matter more than fancy algorithms. Tools that make feature engineering easier: Tecton, Feast.
Model Monitoring and Observability
Once a model is in production, you need to know when it's degrading. Is accuracy dropping? Are predictions drifting? Tools: Arize, Fiddler.
Experiment Tracking and Reproducibility
When teams train hundreds of models, they need to track what worked and why. Tools: Weights & Biases, MLflow.
These tools are only valuable if you're feeding them quality data and well-defined problems. Good data infrastructure is the foundation. The tools amplify that foundation.
Integrating Tools With Data Governance
Here's where it gets interesting. Modern data tools are increasingly adding governance capabilities. Data catalogs now include lineage tracking—showing how data flows through transformations. Data platforms now include access control and audit logging.
This is important because governance shouldn't be separate from operations. It should be embedded. When a data engineer builds a pipeline, they should be documenting it within the system, not in a separate wiki. When an analyst queries data, the system should know what data they're accessing (for audit purposes) and should surface data quality metrics.
Organizations that integrate tools effectively get:
- Automation: Governance checks run automatically, not through manual review
- Real-time awareness: Data quality issues trigger alerts, not monthly reports
- Reduced friction: Teams don't see governance as overhead, they see it as infrastructure
Looking ahead, platforms like Runable are automating data workflows and generating documentation automatically, making it easier for teams to maintain governance without losing velocity.

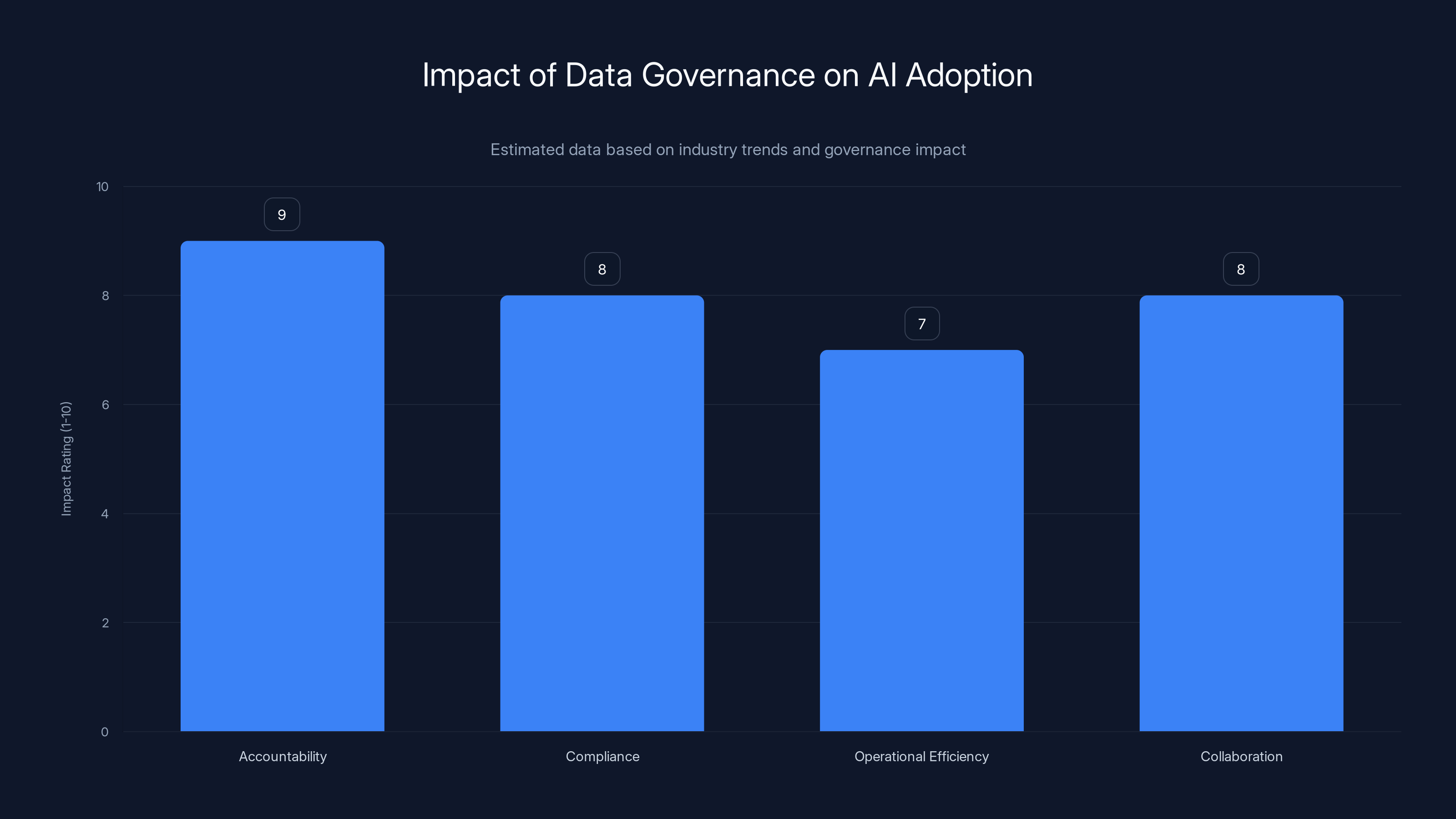
Data governance significantly enhances accountability, compliance, operational efficiency, and collaboration in AI adoption. Estimated data based on industry insights.
Part 7: Implementing Your Data Strategy
Phased Roadmap for Data Leadership
You can't build everything at once. Mature data organizations evolved their strategy over years.
Here's a typical progression:
Phase 1: Foundation (Months 1-6)
- Audit current data: What data exists? Where is it? What's the quality?
- Define a data governance structure: Who owns what? What are the policies?
- Establish data quality metrics: How do we measure quality?
- Choose core infrastructure: Where will data live? What tools will we use?
- Build data governance awareness: Training, documentation, communication
Deliverables: Data inventory, governance charter, quality metrics, infrastructure decisions.
Phase 2: Operationalization (Months 6-12)
- Implement automated data quality monitoring
- Build data pipelines for high-priority datasets
- Create self-service data discovery tools
- Begin data-driven decision-making pilots
- Expand data literacy training
Deliverables: Automated quality monitoring, initial AI-ready datasets, data catalog.
Phase 3: Scaling (Months 12-24)
- Expand governance to all critical data
- Build data products for different business units
- Scale AI model development
- Implement advanced governance: lineage, impact analysis
- Create centers of excellence
Deliverables: Data mesh architecture, AI models in production, governance at scale.
Phase 4: Optimization (Ongoing)
- Continuous improvement of data quality
- Advanced analytics and AI experimentation
- Privacy and ethics frameworks
- Organizational culture embedding data thinking
Deliverables: Continuous innovation, data-driven culture.
The timeline varies by organization size and starting point. A organization with mature infrastructure might move faster. An organization with fragmented legacy systems might take longer.
Common Pitfalls and How to Avoid Them
Pitfall 1: Infrastructure First, Strategy Second
Companies buy fancy data platforms (Snowflake, Databricks, Big Query) expecting it to solve data problems. The tool is powerful, but without strategy, it becomes a expensive data lake where data gets dumped.
Avoid this by defining strategy first: What are our business priorities? What data do we need? What does quality look like? Then choose infrastructure that supports that strategy.
Pitfall 2: Governance Without Culture
A CIO mandates data governance. Teams see it as bureaucracy. They circumvent it using shadow systems. Governance collapses.
Avoid this by building governance incrementally, with visible business value at each step. Show that governance enables speed, not just compliance.
Pitfall 3: Centralizing Everything
A central data team tries to own all data. They become a bottleneck. New business units wait months for data pipelines. Frustration builds. Decentralization happens informally (shadow data).
Avoid this by distributing responsibility with centralized standards. Business units own their data. The central team sets standards and provides tools.
Pitfall 4: Ignoring Legacy Systems
New cloud infrastructure is great. But if critical data still lives in legacy systems, AI only works on a subset of information.
Avoid this by creating a realistic modernization roadmap. Legacy systems often handle sensitive data reliably. Don't rip and replace. Integrate.
Pitfall 5: Data Quality as One-Time Project
Teams clean the data once for an AI project. Six months later, data quality has degraded. The project fails when rerun.
Avoid this by making data quality ongoing. Implement monitoring. Set quality SLAs. Budget for maintenance.

Part 8: Measuring Success and Business Impact
Key Metrics for Data Leadership
Data leadership creates business value. You need to measure it.
Data Quality Metrics:
- Completeness: % of records with all required fields populated
- Accuracy: % of records matching real-world data
- Timeliness: % of data updated within SLA
- Consistency: % of records that agree across systems
- Uniqueness: % records that are unique (no duplicates)
Target: 95%+ on all metrics for critical data.
Governance Metrics:
- Data assets with documented ownership: % of datasets with clear owner assigned
- Policy compliance: % of data usage following governance policies
- Audit readiness: % of decisions with documented data lineage
- Regulation compliance: % of systems in compliance with applicable regulations
Target: 95%+ on all metrics.
AI Model Performance:
- Model accuracy on holdout test data
- Model performance on production data (monitoring for drift)
- Time to model production: Days from problem definition to deployment
- Model ROI: Revenue impact or cost savings per model
Target: Accuracy > threshold for business use case; time to production < industry benchmarks.
Organization Impact:
- Data literacy: % of employees completing data training
- Self-service adoption: % of data questions answered without central data team
- Faster decision-making: Days reduced to make data-driven decisions
- Cost reduction: Operational costs avoided due to data quality improvements
- Revenue impact: Revenue influenced by AI models or data-driven decisions
Calculating ROI:
For example:
- Revenue gained from AI recommendations: $2M
- Costs avoided from data quality improvements: $5M
- Data program cost: $3M
- ROI = ((2M + 5M) - 3M) / 3M × 100 = 233%
This becomes your business case for ongoing investment.
Building the Business Case
Data leadership requires budget. You need to justify it.
The business case should include:
Problem Statement: What business problems are we solving?
Example: "Customer data is fragmented across three systems. Marketers can't get a single view of the customer. We're making recommendations based on incomplete information. Customer lifetime value is 15% below benchmark."
Proposed Solution: What's our approach?
Example: "Consolidate customer data into a single platform. Implement governance and quality standards. Build AI recommendation engine using unified data."
Expected Benefits (quantified):
- Faster marketing decisions: 30 days faster
- Improved recommendation accuracy: 25% lift
- Revenue uplift: $5M annually
- Cost avoidance: $2M from reduced customer churn
Costs:
- Infrastructure: $1M
- Personnel: $1.5M (team of 5)
- Consulting/implementation: $0.5M
- Tools: $0.3M
Total: $3.3M
Payback Period: (3.3M) / (7M) = 5.7 months
3-Year ROI: (21M benefits - 3.3M costs) / 3.3M = 535%
With this business case, securing budget is straightforward. Finance leaders see clear ROI.

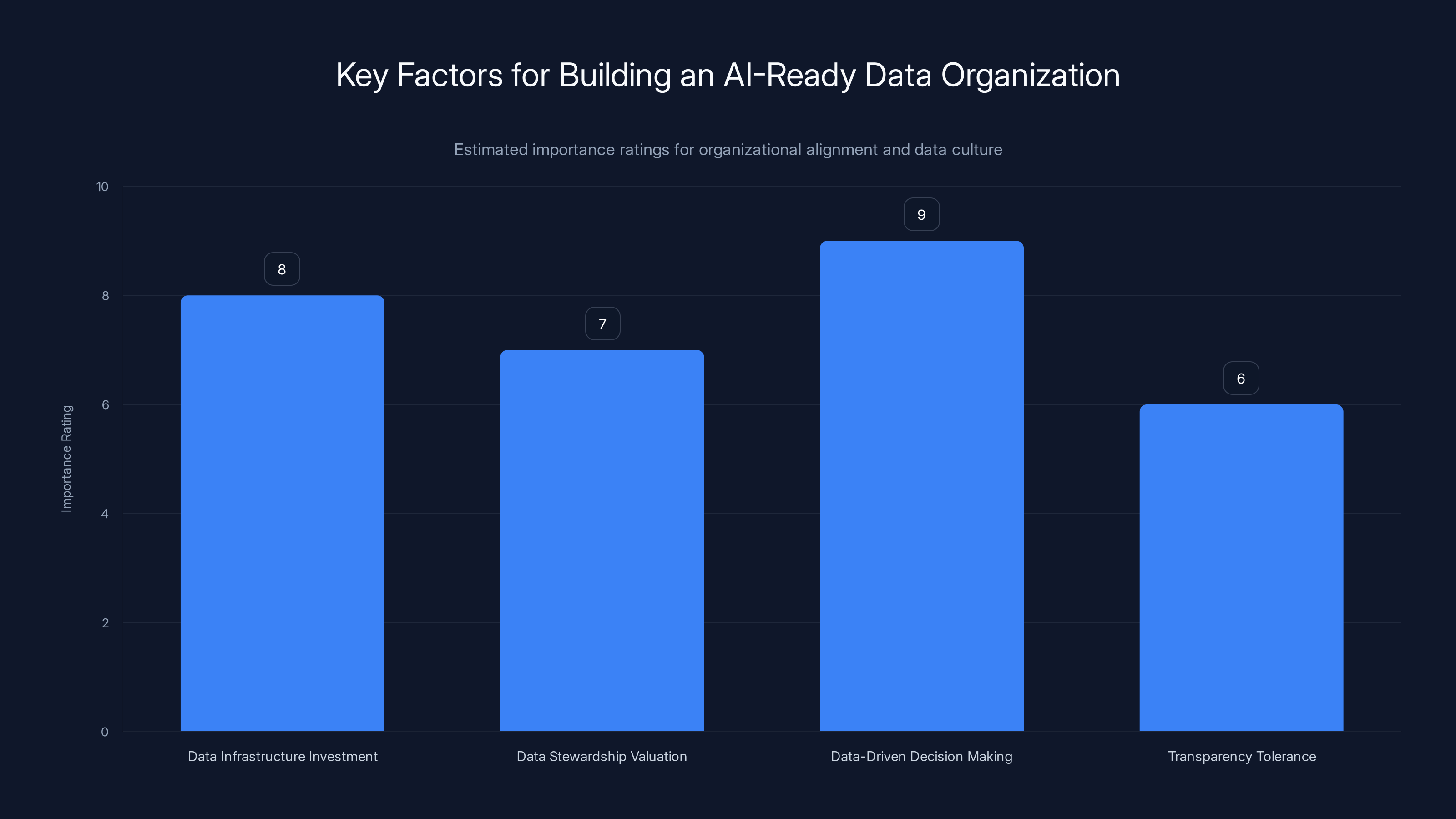
Building an AI-ready organization requires strategic investment in data infrastructure, valuing data stewardship, making data-driven decisions, and tolerating transparency. Estimated data.
Part 9: The Future of Data Leadership
Emerging Trends Shaping Data Strategy
Real-Time Data and Streaming
Historically, organizations analyzed data in batches: daily overnight runs that processed the day's transactions. Real-time use cases require different architecture.
Streaming platforms like Apache Kafka and Google Pub/Sub enable organizations to process data as it's created. This is critical for AI systems that need to respond instantly: fraud detection that flags suspicious transactions in real time, recommendation engines that adapt to current behavior, customer service AI that processes live conversations.
Synthetic and Augmented Data
Organizations increasingly can't collect enough real data for training AI models. The data is private (healthcare, financial), or collecting enough volume is expensive.
Synthetic data—artificially generated data that preserves statistical properties of real data—solves this. Tools like Gretel generate synthetic data that's useful for AI training while protecting privacy.
This is particularly valuable for training models on edge cases. If you need data on fraud scenarios that rarely occur, synthetic data lets you generate them.
AI-Powered Data Quality
We've discussed automated data quality monitoring. The next step is AI-powered remediation.
Instead of flagging data quality issues for humans to fix, AI systems can learn patterns in data and fix errors automatically. If a customer's age is recorded as "437," the system can infer the likely correct value. If a phone number is formatted inconsistently, the system can standardize it.
This is still emerging, but tools like Data Dirt and Tamr are making headway.
Ethical AI as Regulatory Requirement
The EU AI Act, proposed regulations in other countries, and class action lawsuits are making AI ethics a compliance requirement, not just a nice-to-have.
Future-ready data strategies will include:
- Bias detection and remediation as standard
- Explainability capabilities for regulated AI systems
- Impact assessments before high-risk AI deployment
- Ongoing monitoring for fairness metrics
Federated Learning and Privacy-Preserving AI
Training AI models requires centralizing data. Centralizing sensitive data creates risk.
Federated learning—training models on data that stays on-device—preserves privacy. Apple uses federated learning for on-device AI features. This trend will expand as privacy regulations tighten.
Building a Future-Ready Data Strategy
To prepare for these trends, organizations should:
-
Invest in flexibility: Choose infrastructure and tools that can adapt. Don't lock into proprietary solutions.
-
Build technical depth: Your team needs to understand not just data tools, but the underlying concepts: streaming architectures, ML fundamentals, privacy-enhancing techniques.
-
Partner strategically: You can't build everything in-house. Partner with vendors for specialized capabilities. But maintain the in-house expertise to evaluate and integrate those partnerships.
-
Stay informed: Data technology moves fast. Your data leaders should be reading research, attending conferences, experimenting with new tools.
-
Plan for regulation: Anticipate requirements around AI transparency, data privacy, and algorithmic fairness. Build governance now that will make compliance easier later.
Organizations that do this will be positioned to adapt to future changes. Those that don't will face disruption.

Part 10: Conclusion - From Data Leadership to Business Impact
Data leadership isn't a technical problem. It's a business problem.
Here's what we've covered: Organizations recognize AI's potential and are investing in it. But 75% of organizations deploying AI struggle to see tangible returns. The gap between aspiration and reality is the data strategy.
Companies that succeed at AI share a pattern. They've invested in data quality. They've built governance frameworks. They've created cultures where data is treated as a strategic asset. They've aligned their organization around data-driven decision-making.
These aren't separate initiatives. They're interconnected. Quality data enables better AI. Better AI requires governance. Governance requires organizational alignment.
The organizations that get this right—that see data quality, governance, privacy, and AI as an integrated strategy—are the ones that will compete in the next decade.
Starting the journey is simpler than many assume. Begin with a problem: customer churn, operational inefficiency, compliance risk. Solve that problem properly, with quality data, documented governance, and measured outcomes. Then expand from that foundation.
Data leadership compounds over time. Year one, you improve data quality on a single business area. Year two, you've expanded to five areas, and you're launching AI pilots. Year three, you have data-driven decision-making across the organization, AI models in production delivering measurable ROI, and governance as a competitive advantage.
The organizations starting this journey today will be the leaders tomorrow. The cost of waiting is higher than the cost of starting.

FAQ
What exactly is meant by data quality in the context of AI?
Data quality in AI refers to the completeness, accuracy, consistency, timeliness, validity, and uniqueness of the data used to train and operate AI models. Poor quality data—missing values, duplicates, outdated information—directly undermines AI model performance. An AI system trained on incomplete customer records can't make accurate recommendations. One trained on stale inventory data makes poor supply chain decisions. Quality means the data accurately represents reality and is current enough to be useful.
How does data governance actually enable faster AI deployment?
Data governance creates a foundation that accelerates AI development. When data is documented with clear lineage, quality standards, and ownership, teams don't waste weeks discovering what data exists or validating its reliability. Self-service data discovery tools let analysts find trusted datasets quickly. Clear policies eliminate ambiguity about what data can be used for what purposes. This reduces friction and enables teams to focus on building models rather than hunting for data or debating ownership.
What's the relationship between data privacy and AI ethics?
They're interconnected but distinct. Privacy focuses on protecting personal data from misuse. Ethics focuses on ensuring AI systems treat people fairly and transparently. Both require similar governance foundations: understanding what data is used in AI systems, having mechanisms to explain decisions, monitoring for bias or fairness issues, and maintaining audit trails. A system can be private (data is protected) but unethical (systematically discriminates). It can theoretically be ethical but violate privacy if data is mishandled.
How long does it typically take to build a mature data governance program?
Timelines vary significantly based on organizational size, existing infrastructure, and maturity. A small organization with modern systems might achieve governance maturity in 12-18 months. A large enterprise with legacy systems might take 3-5 years. The key is phasing it—don't try to govern everything at once. Start with your highest-impact data, prove value, and expand. Most organizations report seeing meaningful results within 6-12 months if they focus and resource the effort appropriately.
What should we do if we discover our AI models were trained on biased or poor quality data?
First, stop using the models for high-stakes decisions until you've remediated the issue. Then, assess the scope: how much data was affected, what decisions were made, what harm might have resulted? Audit the training data for bias and quality issues. Retrain the model on cleaned, representative data. For decisions already made, consider whether they need to be reversed or reconsidered. Document the issue and fixes for regulatory compliance and to prevent recurrence. This is where governance frameworks help—they make the discovery and remediation process systematic rather than ad-hoc.
How do we measure the ROI of data quality and governance initiatives?
ROI comes from quantifying benefits and costs. Benefits include revenue generated by better AI models, costs avoided from preventing data quality failures, time saved through faster decision-making, and risk reduced through better compliance. Costs include infrastructure, staffing, tools, and training. Create a baseline of current costs (how much time teams spend validating data, how many errors slip through), improve it with your initiatives, and calculate the difference. For example: if poor data quality costs
What's the difference between a data lake and a data warehouse for AI initiatives?
A data warehouse is structured storage optimized for query performance and analysis. Data goes through rigorous validation and transformation before loading. It's ideal for well-defined business questions and reporting. A data lake stores raw data with minimal processing. It's flexible but less organized. For AI, you typically need both: a data lake for exploration and experimentation, a warehouse for production AI systems that need reliability and performance. The key is governance—even in a lake, you need metadata, quality monitoring, and lineage tracking or it becomes a data swamp.
How should we handle data from multiple source systems with conflicting information?
Implement data reconciliation logic: define rules for which system is the source of truth for each data element. If customer contact info differs across CRM and e-commerce systems, decide which is authoritative based on recency or reliability. Establish a process for flagging conflicts and investigating. Don't just pick one—investigate why the conflict exists. Are systems not syncing? Is there a process error? Understanding the root cause prevents similar conflicts. Document reconciliation rules so they're consistent and auditable. This is a core part of data governance and data quality management.
What's the minimum viable data governance program to get started?
Start small and focused. Pick one high-impact data domain. Assign a data steward with clear responsibilities. Define what quality looks like for that data. Implement basic automated checks (completeness, validity). Document the data and governance policies in a simple catalog. Get buy-in from users of that data by showing quality improvements. Measure and communicate results. Then expand to the next domain. You don't need a comprehensive governance program day one. You need a functioning program focused on your highest-value data that you expand methodically.
How do we ensure our data strategy supports both current needs and future AI initiatives?
Build flexibility into your architecture: use cloud-based infrastructure that can scale, choose tools that integrate widely rather than locking into proprietary solutions, design data governance frameworks that can expand, and build teams with broad expertise rather than narrow specialization. Plan for regulatory changes by staying informed and building compliance capabilities ahead of requirements. Most importantly, treat data strategy as ongoing evolution, not a one-time project. Review and update it annually based on business changes and technology advances. This posture positions you to adapt to whatever the future brings.

How Runable Supports Data Leadership
While building data governance and AI-ready systems requires significant effort, Runable can accelerate several critical workflows. For teams managing data documentation, generating governance reports, or automating data quality alerting across stakeholders, Runable offers AI-powered automation starting at $9/month.
Specific applications include:
- Automating Data Governance Reports: Generate quarterly compliance documentation, policy updates, and audit summaries without manual compilation
- Creating Data Quality Dashboards: Automatically compile quality metrics into visual reports for stakeholder review
- Documenting Data Lineage: Generate data lineage diagrams and documentation from your data systems
- Scaling Data Literacy Training: Create training materials, FAQs, and best practice guides automatically from your governance policies
Use Case: Automatically generate weekly data quality reports and alert teams when metrics drop below thresholds, enabling faster issue identification and resolution.
Try Runable For Free
Key Takeaways
- Only 12% of organizations have data quality sufficient for effective AI, despite 60% deploying AI—revealing the critical gap between ambition and capability
- Data quality amplifies at scale with AI: errors that would cause a 5% decision variance in traditional analytics replicate across millions of AI decisions daily
- Strong data governance reduces friction, enables self-service data discovery, and accelerates AI deployment by eliminating weeks spent validating data reliability
- 71% of enterprises now operate with defined governance programs, and those with mature programs report 58% improvements in data quality and analytics
- Privacy and innovation are interdependent, not opposed: transparent data practices build customer trust, enabling richer first-party data collection that improves AI outcomes
- ROI from data strategy compounds over time: organizations that start now will have competitive advantage within 2-3 years through better decision-making and AI-driven innovation
Related Articles
- The AI Productivity Paradox: Why 89% of Firms See No Real Benefit [2025]
- AI Adoption Requirements for Employee Promotions [2025]
- Billions of Exposed Social Security Numbers: The Identity Theft Crisis [2025]
- The AI Agent 90/10 Rule: When to Build vs Buy SaaS [2025]
- VMware Customer Exodus: Why 86% Still Want Out After Broadcom [2025]
- TP-Link Texas Lawsuit: Chinese Hackers, Security Lies, and What It Means [2025]

