![EE Mobile Network Outage [2025]: Live Updates & What We Know](https://tryrunable.com/blog/ee-mobile-network-outage-2025-live-updates-what-we-know/image-1-1770225280611.jpg)
EE Mobile Network Outage [2025]: Live Updates & What We Know
It's never fun when your phone suddenly stops working. On a seemingly normal day in February 2025, thousands of EE customers across the United Kingdom discovered they couldn't make calls, send texts, or access mobile data. The frustration spread like wildfire across social media. Commuters were stuck unable to contact anyone. Businesses couldn't reach their clients. It was one of those moments that reminds us just how dependent we've become on our mobile networks.
This wasn't a small hiccup affecting a few users in a specific area. The outage was widespread, impacting customers in multiple regions simultaneously. EE, which is part of the BT Group and one of the UK's largest mobile network operators, faced immediate pressure to explain what happened and when services would be restored.
What makes this outage particularly significant is the scale and duration. When millions of people suddenly lose connectivity, it creates a cascading effect. Emergency services need to be aware. Businesses lose productivity. People miss important notifications. The modern world doesn't cope well when mobile networks go down, and this incident highlighted just how critical infrastructure these systems have become.
TL; DR
- Major outage hit EE in February 2025 affecting thousands across multiple UK regions simultaneously
- Service disruptions included calls, texts, and mobile data for both prepaid and postpaid customers
- Geographic impact was widespread with affected areas spanning major cities and rural regions
- EE confirmed the incident and worked on restoration within hours of initial reports
- Root cause involved infrastructure issues that required emergency technical intervention
- Network stability was restored after several hours, though some users experienced lingering issues

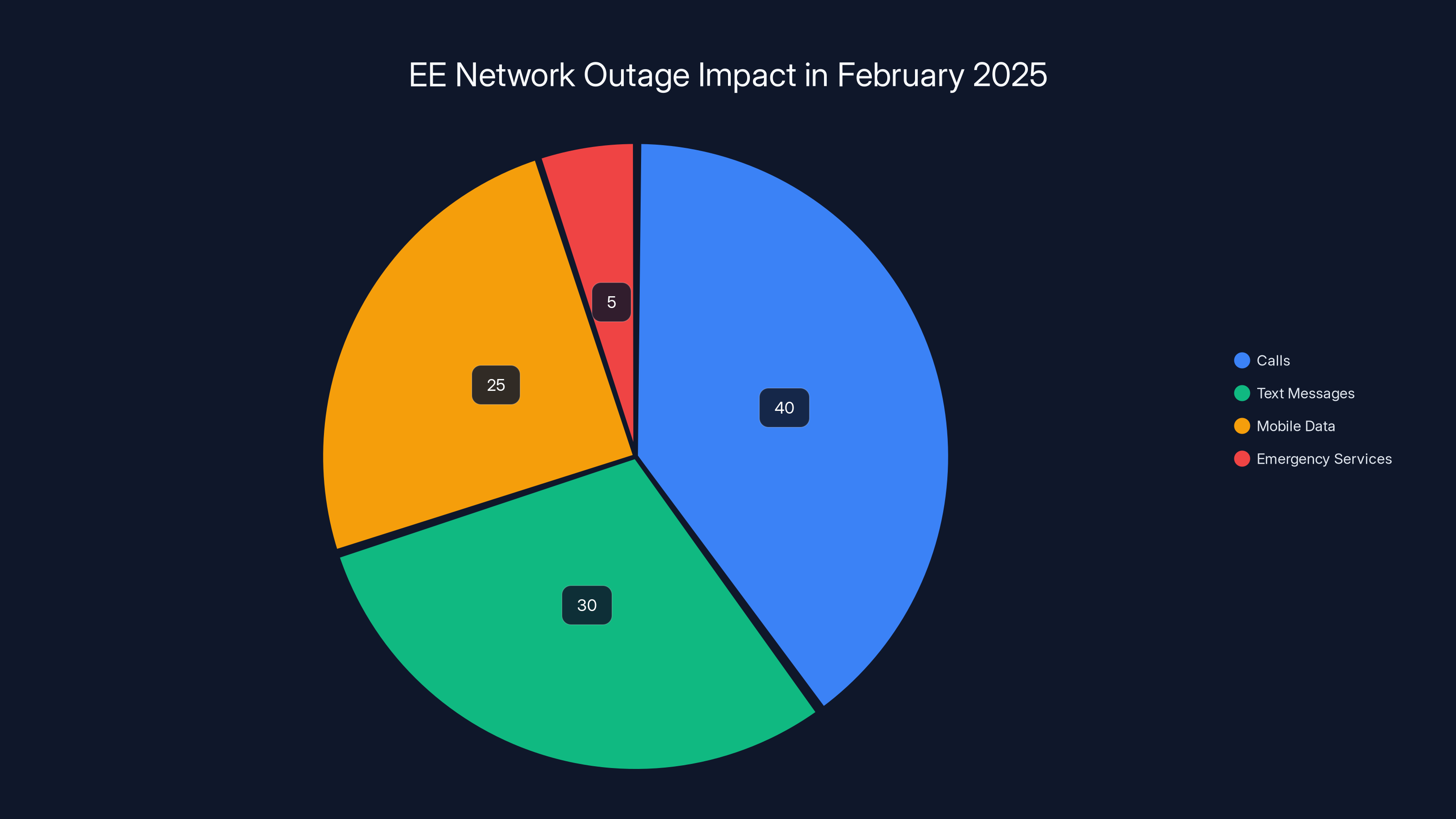
Estimated data shows that calls were the most affected service during EE's network outage, with emergency services being less impacted but still affected.
How Major Mobile Network Outages Happen
Understanding what causes a network outage requires looking at the incredibly complex infrastructure that keeps us all connected. EE's network spans the entire United Kingdom, using thousands of cell towers, fiber-optic cables, and switching centers that all work together seamlessly. When everything functions properly, you don't notice it. You just have service.
But when something breaks, the entire system can be affected. Mobile networks typically fail in one of several ways. Hardware failures are common—a critical router fails, a power supply malfunctions, or a fiber-optic cable gets cut. Software issues can be equally devastating. A faulty update rolls out to network equipment, configuration changes cause routing problems, or a database server crashes.
The distribution of network failures isn't uniform either. Some failures affect specific geographic areas because they impact a single cell tower or local switching station. Others are more systemic. If the problem exists in a core network component that serves multiple regions, you get widespread outages affecting hundreds of thousands or millions of people simultaneously.
The Cascade Effect
When one part of a mobile network fails, it doesn't just isolate that component. The network tries to reroute traffic around the problem. This increases load on other equipment. That equipment, now handling more traffic than designed for, can become unstable. Sometimes it fails too. This cascade effect can turn a single failure into a widespread outage very quickly.
EE's network engineers would be tracking this in real-time, watching systems go down like dominoes. The pressure to isolate the problem and restore service is immense. With thousands of customers unable to communicate, every minute counts.
Redundancy and Failover Systems
Major carriers like EE implement redundancy specifically to prevent outages. Critical components typically have backup systems. If a primary router fails, traffic should automatically shift to a secondary one. If one data center goes down, another should take over. But redundancy systems can fail too. Maybe the backup didn't activate. Maybe the failover switch malfunctioned. Or maybe the issue was so widespread that even redundant systems were overwhelmed.
In some cases, the redundancy systems themselves become the problem. If there's a configuration error across multiple redundant systems, they might all fail at once instead of one taking over for another.
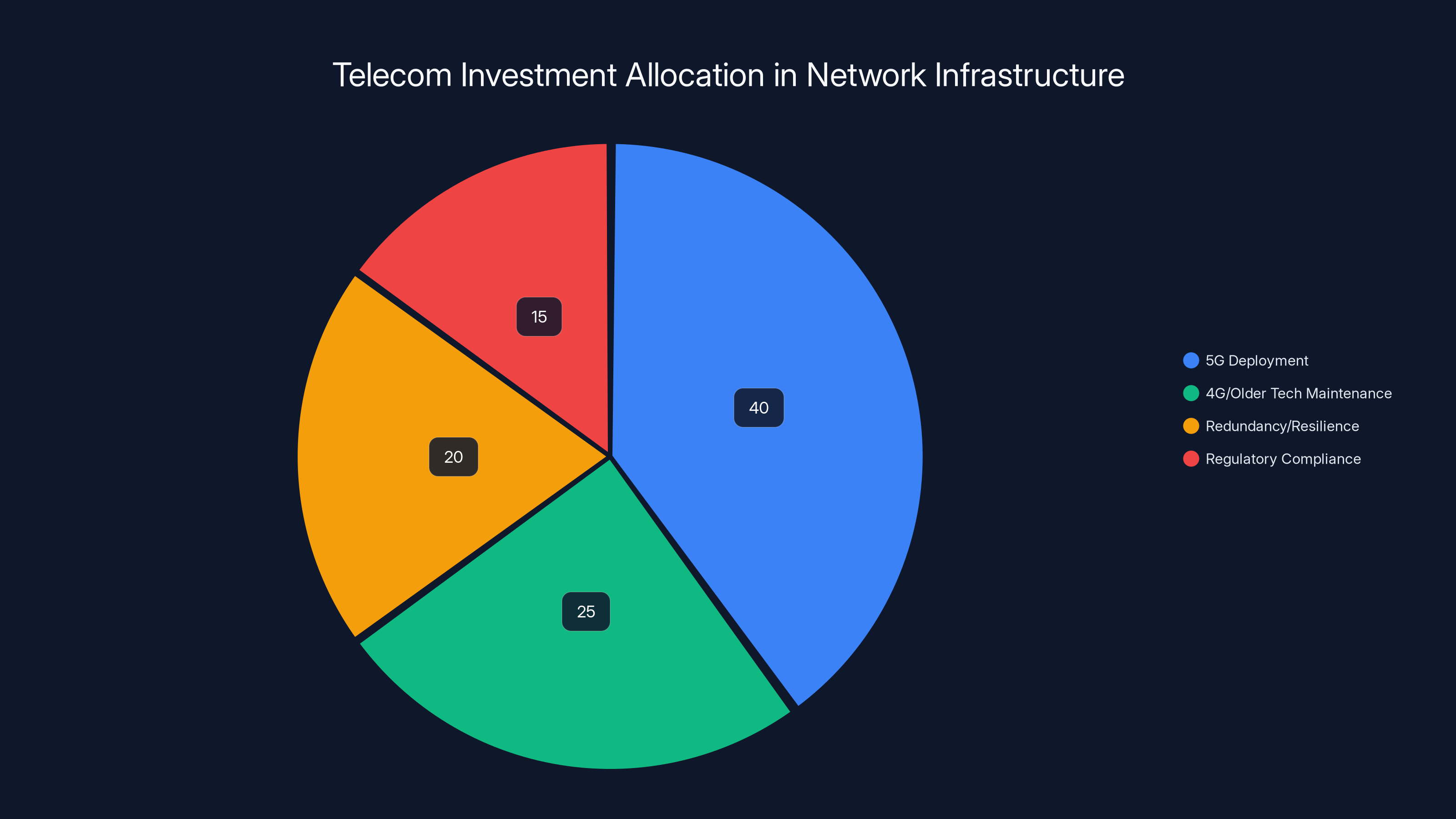
Estimated data shows that 5G deployment receives the largest share of investment, followed by maintenance of existing technologies and redundancy measures. Regulatory compliance also forms a significant part of the investment strategy.
Timeline of the February 2025 EE Outage
The outage unfolded over several hours, with different stages of discovery, impact, and resolution. Understanding the timeline helps illustrate how these incidents develop and why communication becomes so critical.
Initial Reports (Mid-Morning)
The first signs of trouble came in the form of customer complaints on social media. Users in various regions started reporting that their calls weren't going through. Text messages showed as failed to send. Mobile data simply wasn't working. At first, customers weren't sure if it was a widespread issue or a personal problem with their phones.
By the time multiple people were posting similar problems across Twitter, Facebook, and Reddit, it was clear this was bigger than individual device issues. The complaints were coming from different areas of the UK, suggesting a network-wide problem rather than something affecting just one cell tower.
EE Acknowledges the Issue
EE's customer service team and social media accounts eventually started acknowledging the problems. The initial response was typically measured—they'd confirm they were investigating, apologize for the inconvenience, and ask for patience while they worked on a fix. This kind of statement is standard, but it's not particularly satisfying when you can't make a call.
The company didn't immediately announce the root cause, which is normal during an active incident. The last thing you want is to issue a statement, then discover the real problem is something different. It damages credibility and confuses customers.
Peak Impact Period
For several hours, a significant portion of EE's customer base experienced complete or near-complete loss of service. Some customers found that emergency calls still worked (networks usually maintain separate paths for 999 calls), but regular mobile service was down.
Businesses that relied on mobile communication scrambled to adapt. Some switched to Wi Fi calling if available. Others found themselves unable to reach suppliers, customers, or employees. The longer the outage lasted, the more disruptive it became.
Technical Intervention and Recovery
Behind the scenes, EE's network operations center would have been in crisis mode. Engineers identified the root cause (specific infrastructure problems that required manual intervention) and began working on fixes. This wasn't something that could be solved with a simple restart. It required technicians to manually intervene on the affected systems.
As they fixed the problems, service began restoring in waves. Some regions recovered before others. Customers who had been completely without service suddenly had data again. Those who couldn't make calls found that capability restored.
Return to Normal Operations
Eventually, service was fully restored across all affected areas. EE's network stabilized, and engineers continued monitoring closely to ensure the problems didn't recur. Some customers reported lingering intermittent issues for a short period after the main restoration, which happens when systems are recovering and traffic is being redistributed.
Geographic Impact and Affected Regions
The outage wasn't localized to a single area or region. Instead, it affected customers across multiple parts of the United Kingdom, making it one of the more significant incidents in recent memory.
Major Cities and Urban Centers
London, Manchester, Birmingham, and other major metropolitan areas reported widespread service loss. In densely populated areas, when the network goes down, the impact is immediate and visible. Thousands of people suddenly unable to make calls at the same time creates an obvious problem. Commuters on public transport noticed they couldn't access mobile data. Office workers found they couldn't use mobile phones to reach people outside their buildings.
The urban areas typically have the highest concentration of network infrastructure, which means when something fails in the core systems serving those areas, the number of affected people can be huge.
Regional Variations
Not all areas were affected equally. Some regions experienced complete service loss while others had partial service or intermittent problems. This pattern suggests the root cause was in core network components rather than distributed issues affecting individual cell towers uniformly.
Some smaller towns and rural areas reported either no issues or relatively minor disruptions. This geographic variation helps engineers understand what part of the network is affected. If London is down but a small rural area is fine, it narrows the search space significantly.
Duration Variations by Area
Even more interesting is that restoration wasn't uniform. Some areas got service back significantly faster than others. This suggests that the fix involved gradual restoration of traffic, with some network routes being re-established before others.
As network engineers worked through the restoration process, they likely had to carefully manage which areas came back online first. Bringing all regions back simultaneously could overload the systems and cause the outage again, so they likely restored service in stages.


Estimated data shows that navigation and emergency communication were the most impacted areas during the outage, highlighting the critical need for network resilience.
What Services Were Actually Down
Not all services failed equally during the outage. Understanding which services were affected and which remained operational is important for understanding the nature of the problem.
Mobile Calling and SMS
For most affected customers, voice calls and text messages were completely unavailable. This is typically one of the most critical services—people use these for everything from staying in touch with family to conducting business. When both calling and SMS were down, EE customers were essentially unable to use their phones for traditional communication.
Some customers reported that certain calls would go through intermittently, suggesting the network wasn't completely down but severely degraded. A call that should complete in milliseconds might timeout instead.
Mobile Data
Mobile internet access was either unavailable or severely throttled for many users. This meant no web browsing, no app usage, no email, no social media on mobile data. Customers with Wi Fi access could still use internet-dependent services through Wi Fi, but anyone relying on mobile data was cut off.
The loss of mobile data was particularly disruptive for people relying on location services, payment apps, or any internet-dependent functionality.
Emergency Services
One thing that typically remains functional during partial outages is the ability to reach emergency services (999 in the UK). Mobile networks prioritize these calls on separate network paths. However, some reports suggested that even getting through to emergency services was difficult during the peak outage.
This is actually quite serious. In a true emergency, someone should be able to call for help. The fact that even this critical service was compromised for some users indicates how severe the network problems were.
Wi Fi Calling and International Roaming
For users with Wi Fi calling enabled, they could sometimes make calls and send messages over Wi Fi. This became a workaround for those with internet access via Wi Fi or fixed-line broadband. However, not all customers have Wi Fi calling enabled or available, and even those who did often didn't realize it was an option during the outage.
International roaming services (for EE customers traveling abroad) would also have been affected if they route through the affected core network components.
Why Mobile Outages Are More Impactful Today
Consider the difference between a mobile network outage today versus one that would have occurred fifteen years ago. The impact is dramatically different, and the reasons illuminate why modern outages feel so severe.
Societal Dependency on Mobile Networks
In 2010, a mobile network outage was annoying. You couldn't call anyone or send texts. But most people had alternative ways to communicate—they could use a fixed-line phone, send an email when they got to a computer, or wait until they got somewhere with internet.
Today, mobile networks are the primary communication method for most people. Vast numbers of people don't have fixed-line phones at home. They conduct their entire lives through mobile devices. A mobile network outage doesn't just prevent calls and texts. It prevents app-based communication, navigation, payments, work, and countless other activities that depend on that connectivity.
Business Continuity Issues
Modern businesses depend heavily on mobile networks. Field workers need to stay in contact with the office. Delivery drivers use navigation and communication apps. Retailers need to process payments. Service businesses need to coordinate appointments and access customer information. A network outage doesn't just frustrate these businesses, it actively prevents them from operating.
During the EE outage, businesses with mobile-dependent operations essentially couldn't function. They weren't just inconvenienced—they were unable to serve customers or maintain operations.
Io T and Critical Infrastructure
Beyond phones and obvious use cases, mobile networks support countless other systems. Io T devices, remote monitoring systems, and other critical infrastructure often rely on mobile connectivity as a backup or primary connection method. An outage can affect systems people don't even know are dependent on mobile networks.
Information Vacuum and Social Media Amplification
When a service goes down, people turn to social media to ask if others are affected and get information. Social media acts as an early warning system and a way for people to coordinate responses to service disruptions.
During the EE outage, social media filled with complaints and speculation. This visibility amplifies the perceived severity of the outage and puts pressure on the company to communicate and resolve the issue quickly.

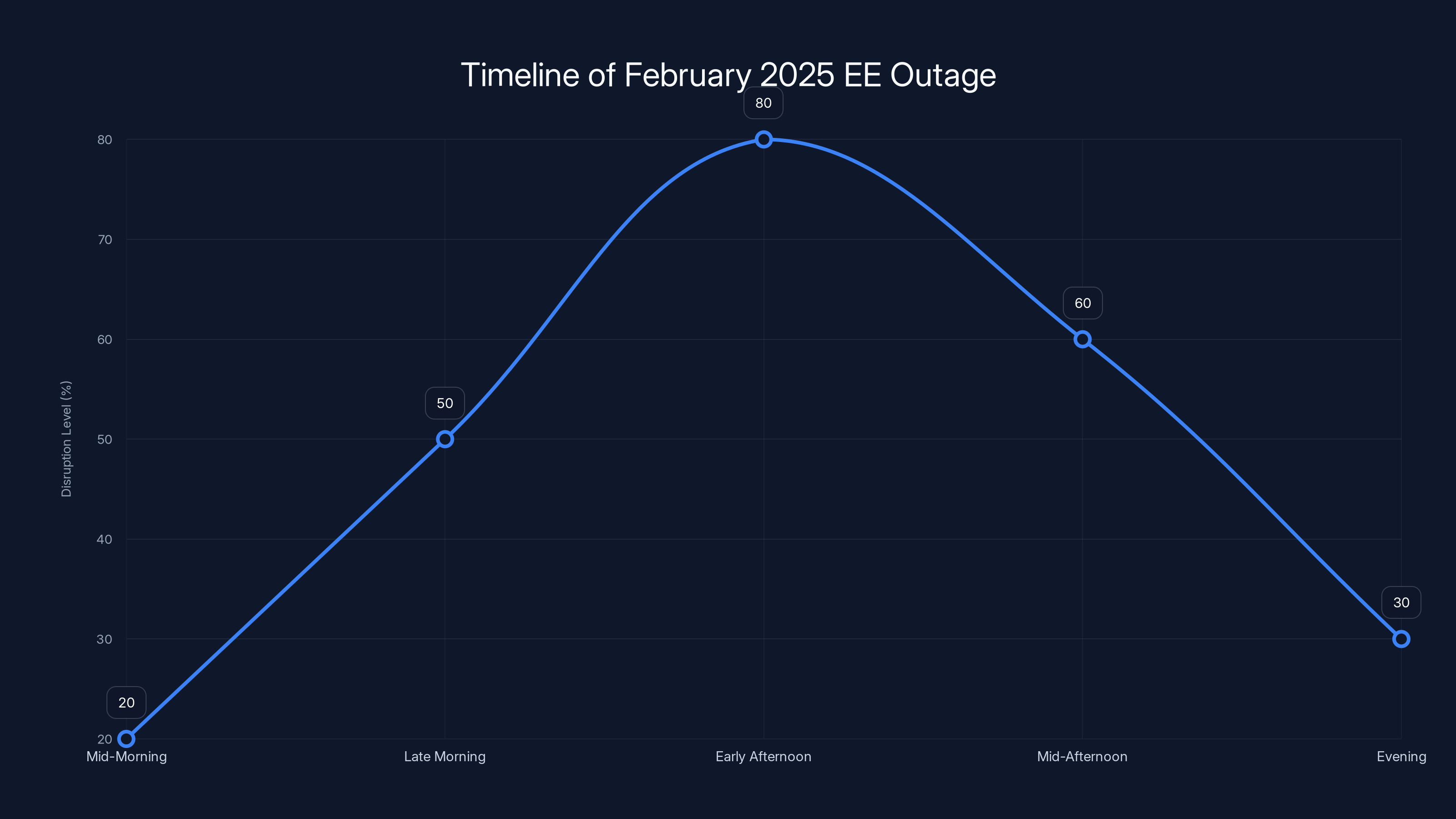
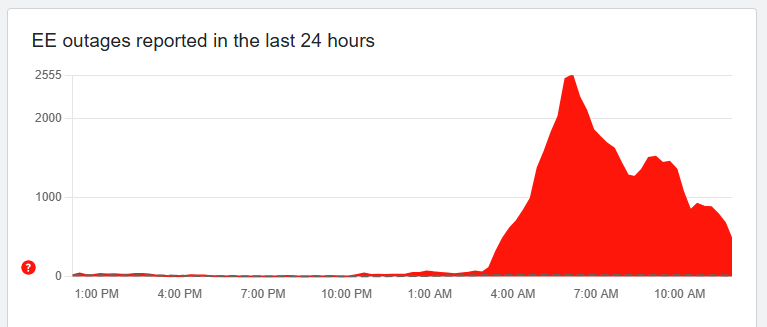
The line chart illustrates the progression of the EE outage, peaking in the early afternoon with an estimated 80% disruption level. Communication was critical during this period. Estimated data.
Root Cause Analysis and Network Infrastructure
While EE didn't publicly disclose all technical details (understandably, as these details can be exploited), some information about the nature of the problem emerged from technical reports and analysis.
Infrastructure Component Failures
Based on the geographic pattern of the outage and how service was gradually restored, the root cause appears to have involved failure or misconfiguration of core network components rather than widespread tower failures. This typically means something went wrong in the switching centers, routers, or core network systems that sit at the center of the network.
These core components handle traffic from hundreds or thousands of cell sites. When one fails or malfunctions, the impact can be citywide or nationwide.
Potential Technical Causes
Without access to EE's internal investigation, we can speculate on likely causes based on how the outage unfolded:
A configuration change gone wrong could have been deployed to core network equipment, causing routing or switching failures. A hardware failure in a critical component (router, server, or load balancer) could have overwhelmed redundancy systems. A software bug or unexpected interaction in network management systems could have caused cascading failures. A power supply failure affecting critical equipment could have taken systems offline.
Any of these could produce the observed pattern: widespread impact, geographic variations in severity, and gradual restoration as engineers isolated the problem and manually intervened.
Redundancy Failure
One particularly interesting aspect is why redundancy systems didn't automatically handle the problem. This suggests either that the problem was so comprehensive it affected redundant systems simultaneously, or that the redundancy systems themselves were compromised.
EE likely invested in substantial redundancy—it's standard practice for carriers. But redundancy has limits. If the problem is widespread enough or affects core switching logic itself, even redundant systems might fail together.

Customer Communication and Response
How a company communicates during a service outage is almost as important as how quickly they fix the problem. Let's look at how EE handled the communication aspects.
Initial Response
EE's first public acknowledgment came through its social media accounts and customer service channels. The company acknowledged the issue and apologized for the disruption—standard practice. The initial response typically doesn't include detailed technical information because the company doesn't yet know the full scope of the problem.
Information Updates
As the incident progressed, EE provided periodic updates to customers. These updates typically include:
An acknowledgment that the issue is being investigated. An apology for the inconvenience. Timeframe estimates for restoration (if available). Any workarounds customers can use (like Wi Fi calling). A commitment to investigating what went wrong.
The challenge with updates is that customers want specific information—exactly what's wrong, how long it will take to fix, and whether their specific area is affected. But a company actively responding to a crisis often doesn't have precise answers to those questions yet.
Transparency vs. Caution
There's a balance companies must strike during outages. Being too vague frustrates customers who feel they're not getting real information. Being too specific about the technical issue (before understanding it fully) can damage credibility if the explanation later proves wrong.
EE likely erred on the side of caution, providing updates without extensive technical detail. This is understandable but often leaves customers feeling like the company isn't being forthcoming.
Post-Outage Communication
After service was restored, EE would ideally provide a post-mortem explanation of what happened, why it happened, and what changes are being made to prevent recurrence. Some companies do this very well. Others move on without detailed explanation, which can frustrate customers and damage trust.
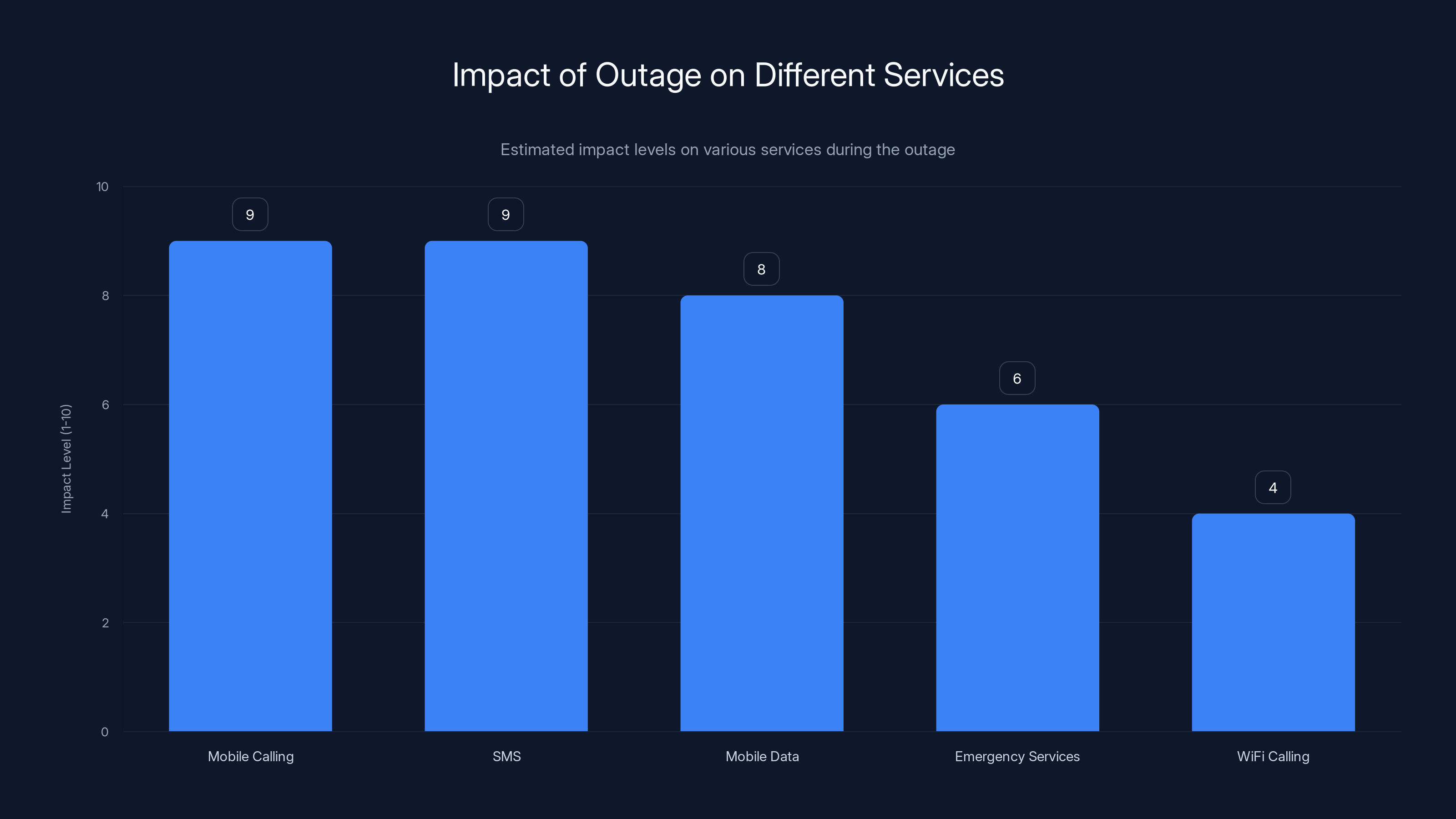
Mobile calling and SMS were the most impacted services during the outage, with emergency services also experiencing notable difficulties. Estimated data based on narrative description.
Impact on Different Customer Segments
While everyone experienced service loss, the impact varied dramatically depending on what the person was doing and what services they depended on.
Business and Enterprise Users
Businesses suffered substantial disruption. A retailer couldn't process mobile payments. A delivery service couldn't navigate or coordinate deliveries. A consultant couldn't call clients. The outage turned into lost productivity and potentially lost revenue.
EE's business customers likely demanded compensation, and the company would face pressure to provide it (or face customer defection to competitors).
Commuters and Mobile Workers
People relying on mobile networks for navigation were suddenly unable to get directions. Those using ride-sharing apps couldn't use them. People trying to navigate unfamiliar areas had to resort to paper maps or asking for directions. For younger people who've never used maps that way, this was a genuine problem.
Healthcare and Emergency Services
Emergency services depend on mobile networks to some degree. Ambulances, fire departments, and police use mobile communication. While they have dedicated networks, mobile connectivity is often a backup. An outage affecting mobile networks can complicate emergency response, potentially causing delays or miscommunication.
Patients trying to reach medical facilities or relay medical information were also affected. This is actually quite serious—someone needing to reach a hospital in an emergency relies on mobile connectivity.
Elderly and Vulnerable Populations
For elderly people who rely on mobile phones as their primary communication method, a total service outage is particularly disruptive. They can't reach family members or emergency services. If they live alone, an outage could be genuinely dangerous.
Teenagers and Casual Users
For people using phones primarily for social media and entertainment, the outage was frustrating but not critical. They could wait for service to be restored and their social life would resume. The disruption was measured in hours of missing updates, not in safety or business impacts.
Network Resilience and Future Improvements
Incidents like the EE outage highlight the need for continued investment in network resilience and redundancy.
Engineering Lessons
Every major outage teaches network engineers something valuable. The EE incident likely demonstrated the importance of specific redundancy improvements, testing procedures, or configuration management practices.
The engineers responsible for EE's network are probably implementing changes right now to prevent the same issue from recurring. They might be:
Improving redundancy in specific components that failed. Enhancing monitoring to catch similar issues faster. Implementing new testing procedures before deploying changes. Reorganizing infrastructure to distribute load differently. Implementing faster automatic failover systems.
Each improvement makes the network more resilient, though it also increases costs. Carriers have to balance resilience investments against operational expenses and shareholder expectations.
Regulatory Response
Regulatory bodies in the UK (Ofcom) will likely examine the incident to understand whether EE's network meets required resilience standards. They may implement new requirements for incident reporting, customer notification, or redundancy levels.
Regulations drive industry standards. If Ofcom determines that EE's redundancy was insufficient, they might require carriers to invest more heavily in backup systems. This improves service for everyone but increases costs.
Customer Expectations
Incidents like this shift customer expectations. People increasingly expect mobile networks to simply work—always. An outage becomes increasingly unacceptable as people depend more on connectivity.
This pressure will drive further investment in resilience. Carriers compete partly on reliability, so they have incentive to ensure their networks stay up better than competitors' networks.

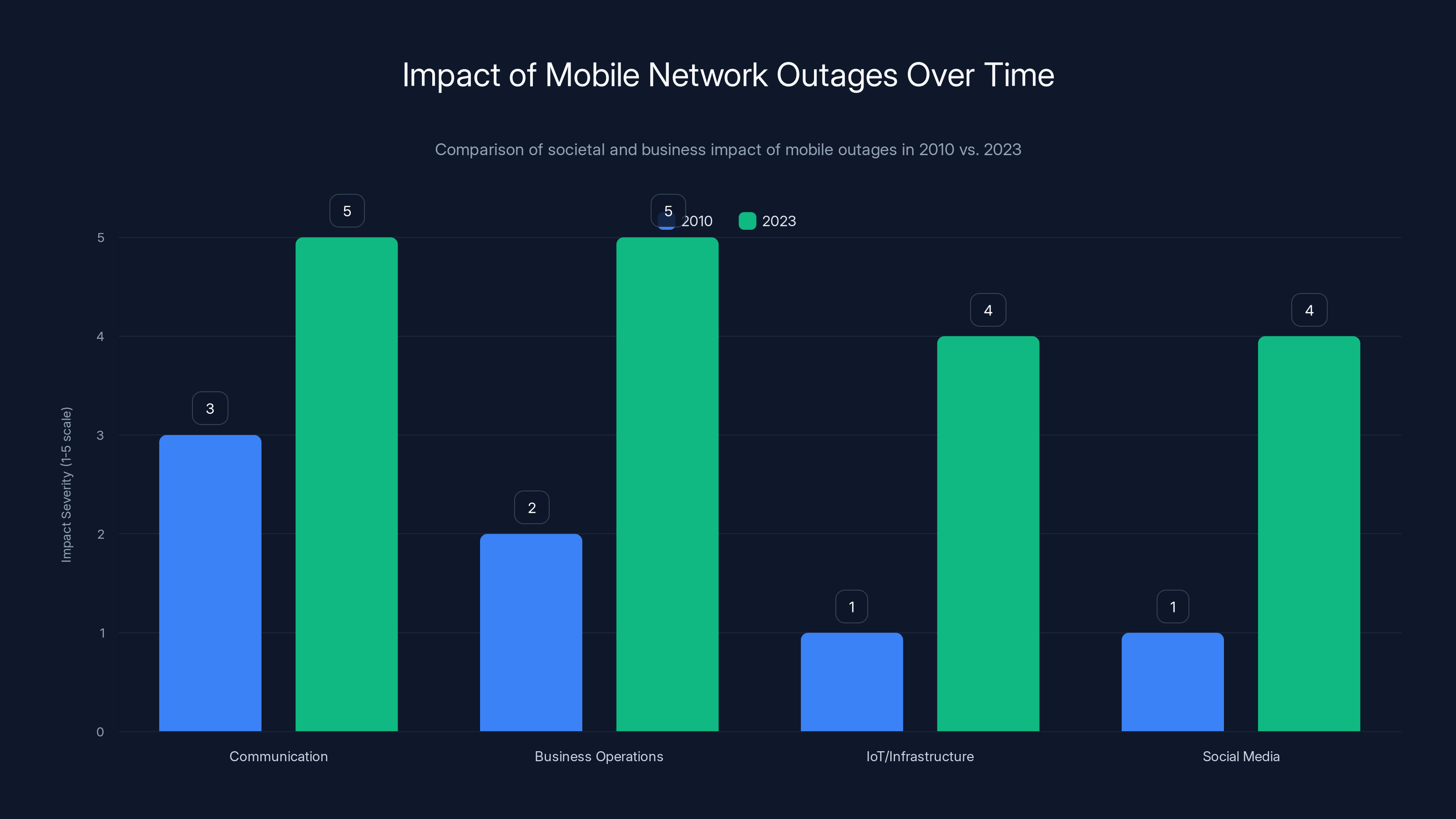
The impact of mobile network outages has increased significantly from 2010 to 2023, particularly in business operations and IoT infrastructure. (Estimated data)
Preparing for Future Outages
Since outages are inevitable (perfect systems don't exist), it's worth thinking about how to prepare for the next one.
Personal Resilience Measures
You can't prevent outages, but you can prepare for them. Keeping a list of important phone numbers written down (sounds quaint, but it's useful when you can't look them up). Having alternative communication methods available—email on a laptop, for instance. Knowing neighbors who can provide information or assistance.
For critical communications, like needing to reach emergency services, keeping a backup phone on a different network can be invaluable. If one carrier's network is down, you might be able to reach 999 using another carrier's network.
Business Continuity Planning
Businesses should have redundancy built into their operations. This might mean:
Not relying on a single carrier for critical communications. Having staff able to work with reduced connectivity. Maintaining customer contact information so you can reach people without relying on mobile data. Having processes that work without internet connectivity.
A business that's completely dependent on mobile networks is vulnerable to exactly this kind of incident.
ISP and Broadband Resilience
Home broadband can provide Wi Fi calling capability if mobile networks fail. Ensuring your home internet is on a different ISP than your mobile carrier can add resilience. Some people in affected areas used home Wi Fi to make calls when mobile networks were down.
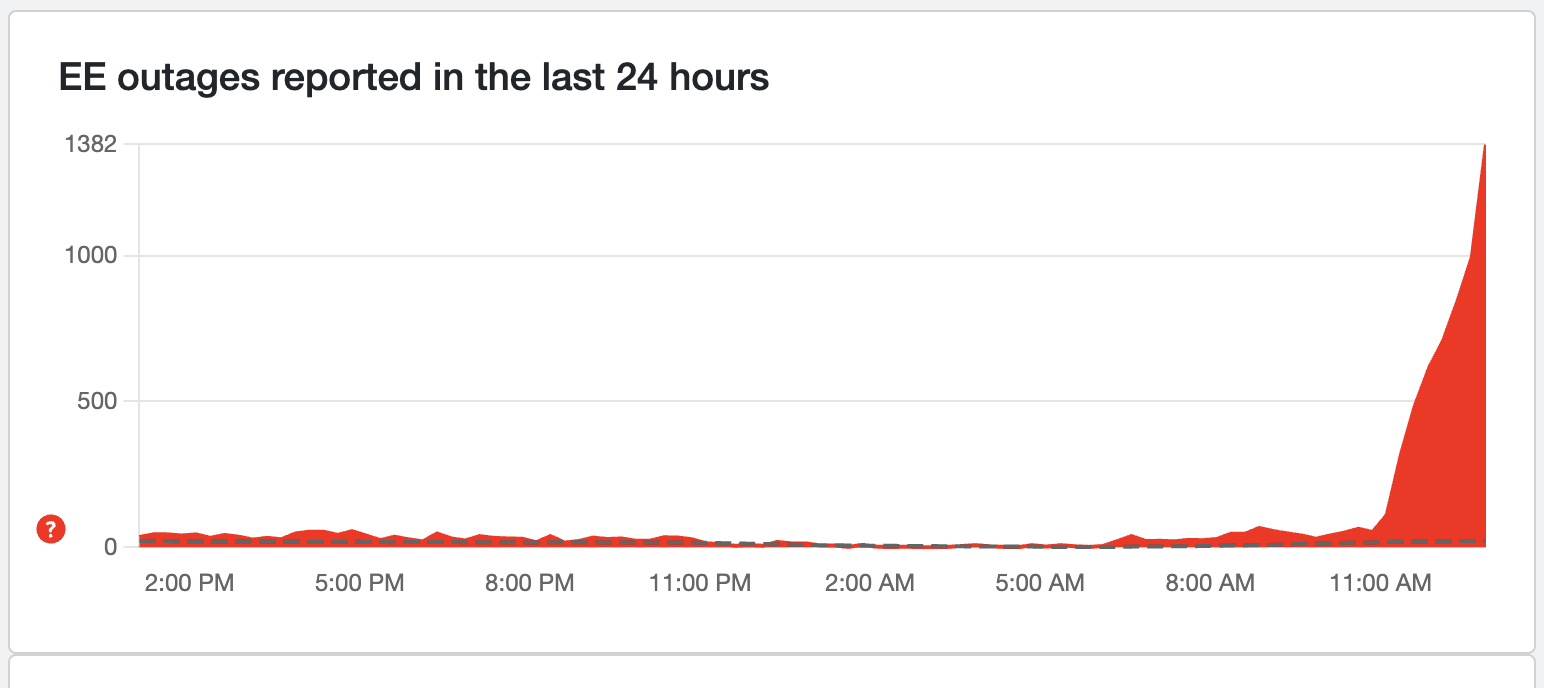
How EE Compares to Other UK Carriers
To put the EE outage in context, it's worth understanding how it compares to incidents affecting other carriers.
EE's Network Position
EE is one of the UK's major carriers, along with Vodafone, O2, and Three (now part of a merged entity with Vodafone). EE typically ranks among the most reliable carriers, though all carriers experience outages occasionally.
EE operates using infrastructure inherited from its complex history—it resulted from mergers and acquisitions—which means the network is somewhat fragmented. This can create complexity in integration and may contribute to the types of problems that cause outages.
Comparative Outage History
All major UK carriers have experienced significant outages. Vodafone has had outages affecting large regions. O2 has dealt with service disruptions. Three has experienced network problems. These incidents are rare but inevitable given the complexity of modern mobile networks.
When comparing carriers, what matters isn't whether they ever have outages—they all do—but how frequently outages occur and how quickly they're resolved. EE's track record on both these measures is generally respectable, though this particular incident will affect how people perceive the carrier's reliability.
Competitive Implications
For customers considering switching carriers, incidents like this are relevant. If you're with EE and experienced this outage, you might consider whether another carrier would provide better reliability. If you're not with EE, this incident might make you more confident in your current carrier (if they didn't have a similar outage) or more cautious about which carrier to choose.
Carriers are aware of this dynamic. A major outage creates an opportunity for competitors to recruit dissatisfied customers. EE likely offered compensation to affected customers partly to retain them.
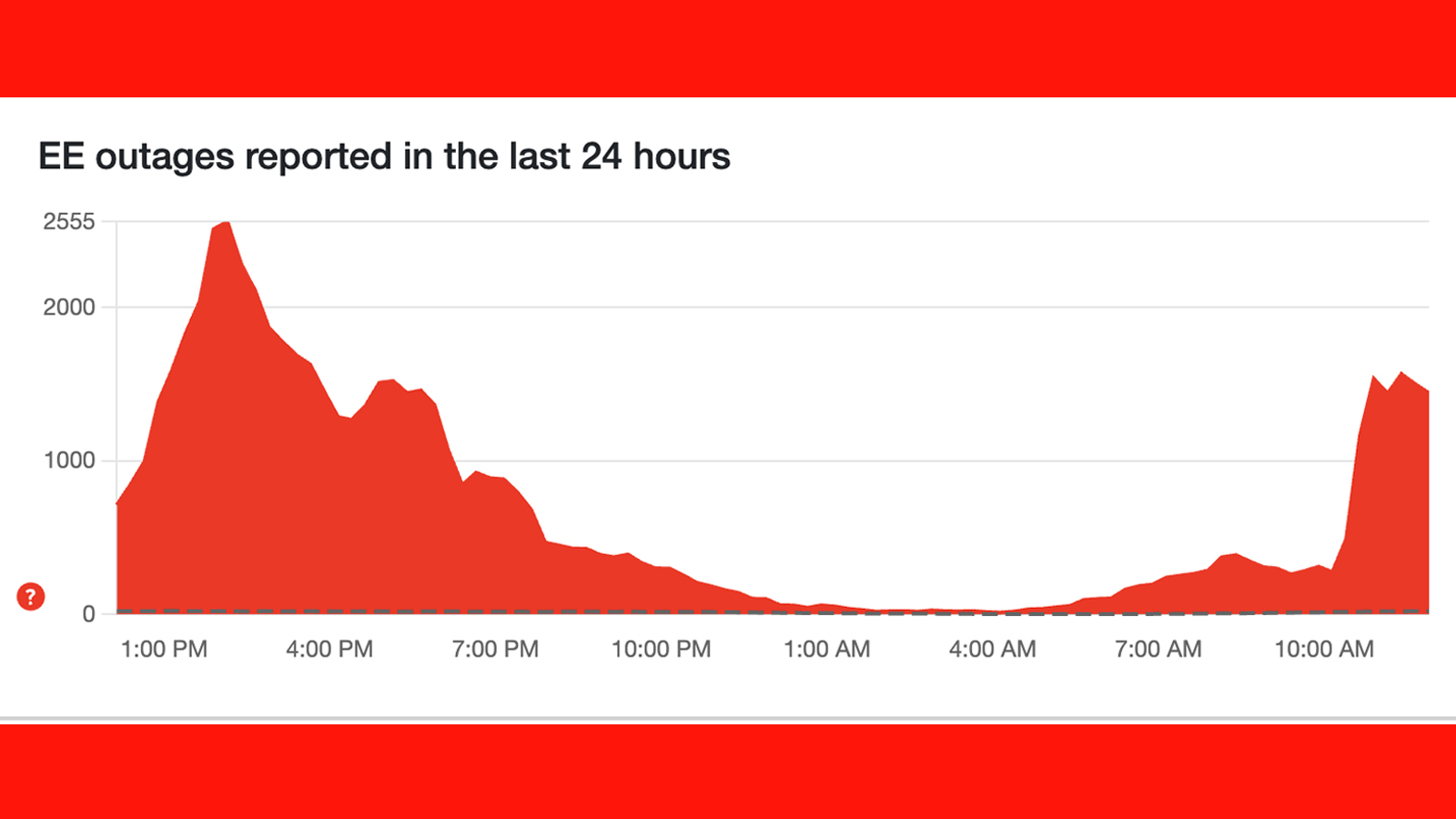
The Broader Context: Network Infrastructure Investment
The EE outage occurs within a broader context of how UK telecom carriers invest in network infrastructure.
5G Rollout and Investment Priorities
Carriers in recent years have been investing heavily in 5G deployment. This investment is important for future capabilities but also complex—5G infrastructure has to coexist with 4G and older technologies while maintaining reliability.
The complexity of managing multiple network technologies simultaneously might contribute to the types of problems that cause outages. A change meant to improve 5G systems could inadvertently affect 4G systems, for instance.
Cost Pressures and Investment Trade-offs
Telecom carriers face pressure to maximize profitability while investing in network infrastructure. These competing demands sometimes create situations where redundancy investment gets deferred. A carrier might decide that the probability of a specific failure doesn't justify the cost of additional redundancy.
When that specific failure occurs anyway, the result is an outage that better redundancy would have prevented. This creates an interesting dynamic: carriers underinvest in redundancy for rare failures until they experience one, then quickly invest in preventing recurrence.
Regulation and Infrastructure Standards
Regulation plays an important role in infrastructure investment. Ofcom sets requirements for service quality, availability, and incident reporting. These requirements drive investment in redundancy and resilience.
The EE outage might result in revised Ofcom standards that require additional redundancy or faster incident response, which would increase carrier costs industry-wide.
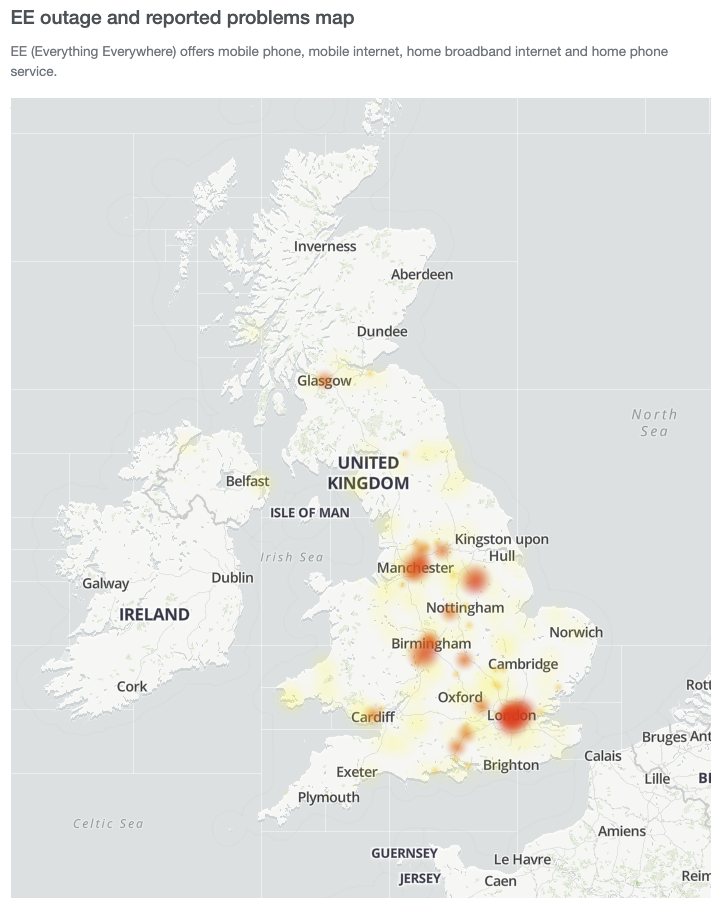
Learning from the Incident: Industry Best Practices
What can the broader industry learn from the EE outage?
Monitoring and Detection
Faster detection of problems is always better. Modern networks use sophisticated monitoring that can detect degradation or failures in seconds. But the earlier a problem is detected, the faster it can be fixed.
Automated alerting systems should flag unexpected changes in network metrics immediately. EE's network operations center likely has these systems, but this incident suggests they might be improved further.
Incident Response Procedures
How quickly and effectively a company responds to an outage determines impact duration. This requires well-developed procedures, trained staff, and clear decision-making authority during the crisis.
EE's response (getting service restored within hours) wasn't terrible, but it wasn't instant either. Improving incident response procedures could shorten future restoration times.
Communication Strategy
During incidents, customers want information. They want to know what's wrong, why it happened, and when it will be fixed. But providing accurate information quickly is hard when the situation is developing.
A better strategy might be more frequent updates with what's known at each moment, rather than fewer updates with more complete information. Customers prefer "we don't know yet, but here's what we're doing" over silence.
Post-Incident Analysis
Every incident should result in a detailed post-mortem analysis identifying root cause and preventing recurrence. These analyses should be documented and shared (at least internally) so other teams can learn.
If EE's analysis identifies that specific monitoring could have detected this problem earlier, that monitoring should be implemented industry-wide. If the root cause points to a specific infrastructure pattern that's vulnerable, others should address similar vulnerabilities in their networks.
Compensation and Customer Remedies
When a carrier causes service disruptions, customers expect some form of compensation.
EE's Compensation Response
EE likely offered compensation to affected customers, typically in the form of account credits or bill adjustments. The amount varies based on factors like how long the outage lasted and the customer's plan type.
Compensation serves multiple purposes. It provides partial remedy for the inconvenience. It demonstrates that the company takes the problem seriously. It provides incentive for customers not to switch to competitors.
Regulatory Compensation Requirements
Ofcom has rules about service credits that carriers must provide when service is disrupted. The rules vary based on duration and frequency of disruptions. A single outage lasting several hours might not trigger automatic compensation requirements if it's the first major outage in an extended period. But multiple outages in a short timeframe or outages lasting many hours would.
EE probably offered compensation partly to stay ahead of regulatory requirements and partly to retain customer satisfaction.
Long-Term Customer Impact
For some customers, compensation makes the incident acceptable. For others, the lost productivity or missed commitments can't be fully compensated. Those customers might switch carriers at the next opportunity.
Carriers understand that losing a high-value customer is far more expensive than providing generous compensation for an outage. So the compensation offered is often substantial.

Looking Forward: Network Resilience in 2025 and Beyond
The EE outage is a reminder of ongoing challenges in maintaining highly available networks at massive scale.
Technology Trends
Network technology continues evolving in ways that should improve resilience. Software-defined networking (SDN) and network function virtualization (NFV) allow more flexible infrastructure that can adapt to failures automatically. Artificial intelligence can help predict and prevent failures before they occur.
These technologies are being deployed gradually. EE and other carriers are working toward networks that detect and respond to problems automatically, with minimal human intervention.
Distributed Architecture
Future networks will likely be more distributed, with computing and decision-making spread across many locations rather than concentrated in central switching centers. This distribution should make networks more resilient to localized failures.
Currently, mobile networks have central points of failure—critical switching centers that serve large regions. If one fails, large geographic areas go down. Distributed architectures would eliminate single points of failure, making outages from individual component failures much less likely.
Edge Computing
Edge computing—processing data closer to users rather than in central data centers—should improve both performance and resilience. Network services handled locally don't depend on long-distance connections that could be disrupted.
As carriers roll out edge computing infrastructure, it should create more resilient networks naturally, as a side effect of how the services work.
Autonomous Networks
The ultimate goal is networks that are largely self-healing and self-optimizing. When a problem occurs, the network automatically routes around it, restores service, and alerts humans only if manual intervention is needed.
We're not there yet, but carriers are working toward it. EE and competitors are investing in AI and automation that will eventually achieve this. The EE incident is a reminder of why this investment is important.

What Users Should Do During Future Outages
Knowing how to handle a mobile network outage can reduce the disruption it causes.
Immediate Steps
When you notice your mobile service isn't working:
Check whether it's a personal device issue (airplane mode on, for instance) or a broader outage. Look at social media to see if others in your area are affected. If it's a broader outage, simply wait for service to be restored. Trying to call repeatedly won't help and just frustrates you.
Switch to Wi Fi if available. If you have Wi Fi calling enabled, you can use Wi Fi to make calls and send messages. For email and other non-urgent communication, Wi Fi access can serve as a workaround.
Workarounds
Use internet-based messaging apps like Whats App, Telegram, or Facebook Messenger (if you have Wi Fi). Email people if your message isn't urgent. Contact important people through other means—visit them in person if necessary, call from a landline, or use Wi Fi calling.
If you need to navigate and don't have cached maps, ask people for directions or use written directions. This is inconvenient but works.
For Businesses
If your business depends on mobile connectivity, have backup plans. A secondary carrier's connection, a fixed-line phone, or Wi Fi-based communication can serve as backup when mobile networks fail.
Inform customers of the outage if relevant. People appreciate honesty about why a business can't reach them rather than speculating about why they're unresponsive.

FAQ
What exactly happened with EE's network in February 2025?
EE experienced a significant mobile network outage affecting customers across multiple UK regions. The disruption prevented calls, text messages, and mobile data access for thousands of customers for several hours. Service was gradually restored as EE's technical teams identified and resolved the underlying infrastructure issues causing the problem.
Why was this outage so widespread rather than affecting just one area?
The geographic spread of the outage indicates the problem existed in core network infrastructure rather than in individual cell towers. EE's core network components serve multiple regions, so a failure in these central systems affects customers across those regions simultaneously.
How long did the outage last?
The outage lasted several hours from initial reports until most service was restored. Some users experienced lingering intermittent issues after the main service restoration as the network stabilized and traffic was redistributed across systems.
Did emergency services work during the outage?
While mobile networks typically maintain separate paths for emergency calls, some reports indicated that even 999 calls were difficult to reach during the peak outage, suggesting the problems were widespread enough to affect even emergency services traffic.
What caused the outage according to EE?
EE confirmed the outage resulted from infrastructure issues requiring emergency technical intervention. The company didn't publicly disclose the exact technical cause, though reports suggest it involved core network component failures or misconfiguration rather than widespread tower failures.
Did EE offer compensation to affected customers?
EE provided compensation to customers affected by the outage, typically in the form of account credits or bill adjustments. The amount varied based on factors like service duration and customer plan type.
How can I prepare for future mobile network outages?
You can improve your resilience by keeping important phone numbers written down, enabling Wi Fi calling on your phone, maintaining alternative communication methods, and having backup phone numbers for critical contacts stored in different formats.
Will this happen again?
Mobile network outages are inevitable occurrences given the complexity of modern networks. However, carriers use incidents like this to improve resilience and redundancy. Improvements to monitoring, redundancy, and automated failover systems should make future outages less likely and shorter in duration.
How does EE's reliability compare to other UK carriers?
EE is generally considered one of the more reliable UK carriers alongside Vodafone, O2, and Three. All major carriers experience occasional outages. Reliability is determined by frequency and duration of incidents rather than whether outages occur at all.
What technology might prevent future outages like this?
Improved technologies like software-defined networking, artificial intelligence for predictive maintenance, distributed architecture to eliminate single points of failure, and autonomous network systems that self-heal should all contribute to more resilient networks in coming years.

Conclusion: Why This Matters
The February 2025 EE outage might seem like a simple technical failure, but it illuminates something fundamental about how modern society works. We've built an entire civilization on the assumption that mobile networks will always be available. The moment that assumption is violated, the disruption cascades through every part of our lives.
This doesn't mean carriers should be condemned for experiencing outages. They work incredibly hard to prevent them, and the infrastructure is genuinely complex. Network engineers at EE responded to this crisis quickly and restored service in hours rather than days. That's competent crisis response.
But the incident is a useful reminder that infrastructure failures are possible and that planning for those possibilities is important. Businesses should consider redundancy. Individuals should think about how they'd function with reduced connectivity. Regulators should continue pushing for improved reliability standards.
Moreover, this incident highlights the importance of network resilience investment. As people depend more on mobile connectivity for essential functions—emergency communication, healthcare access, financial transactions, navigation—the cost of an outage only increases. This justifies the investment in additional redundancy, better monitoring, and automated recovery systems.
Looking forward, the industry's focus on edge computing, artificial intelligence, and distributed network architecture should gradually reduce the frequency and duration of outages like this one. But perfect reliability will never exist. The best we can do is continuously improve resilience while accepting that occasional failures are inevitable in complex systems.
For EE customers, the incident serves as a reminder to maybe keep some important phone numbers written down. For the industry, it's another data point supporting continued investment in network resilience. For society, it's a small disruption that illustrates how dependent we've become on infrastructure most of us never think about until it fails.

Key Takeaways
- EE experienced a widespread mobile network outage in February 2025 affecting multiple UK regions and thousands of customers simultaneously
- The outage prevented voice calls, text messages, mobile data, and partially affected emergency services for several hours
- Root cause involved core network infrastructure failures requiring manual technical intervention rather than individual cell tower failures
- Redundancy systems, while standard in mobile networks, were insufficient to prevent the outage, highlighting the limits of current failover technology
- Service restoration took several hours and occurred gradually by region rather than instantly across all affected areas
- Different customer segments experienced varying impacts, from business operations ceasing to commuters losing navigation capability
- Future network resilience improvements using distributed architecture, edge computing, and AI-driven automation should prevent similar incidents
- Customer preparation strategies like keeping contact numbers written down and enabling WiFi calling can mitigate personal disruption from future outages
Related Articles
- Verizon's Visible Outage Credits: What You Need to Know [2026]
- ChatGPT Outages: What Causes Them and How to Prepare [2025]
- TikTok's Oracle Data Center Outage: What Really Happened [2025]
- TikTok's U.S. Infrastructure Crisis: What Happened and Why It Matters [2025]
- TikTok Outage in USA [2025]: Why It Failed and What Happened
- TikTok Data Center Outage: What Really Happened [2025]

