![Enterprise Agentic AI's Last-Mile Data Problem: Golden Pipelines Explained [2025]](https://tryrunable.com/blog/enterprise-agentic-ai-s-last-mile-data-problem-golden-pipeli/image-1-1771506423462.jpg)
Enterprise Agentic AI's Last-Mile Data Problem: Golden Pipelines Explained
Your enterprise just landed the budget for agentic AI. You've got the models, the infrastructure, the talented engineers. Everything's ready to ship.
Then you hit the wall.
It takes your team fourteen days to manually prepare data for a single AI feature. Raw operational data arrives messy, inconsistent, and unstructured. Your engineers spend weeks writing regex scripts, handling edge cases, and debugging transformations that break every time the data format shifts.
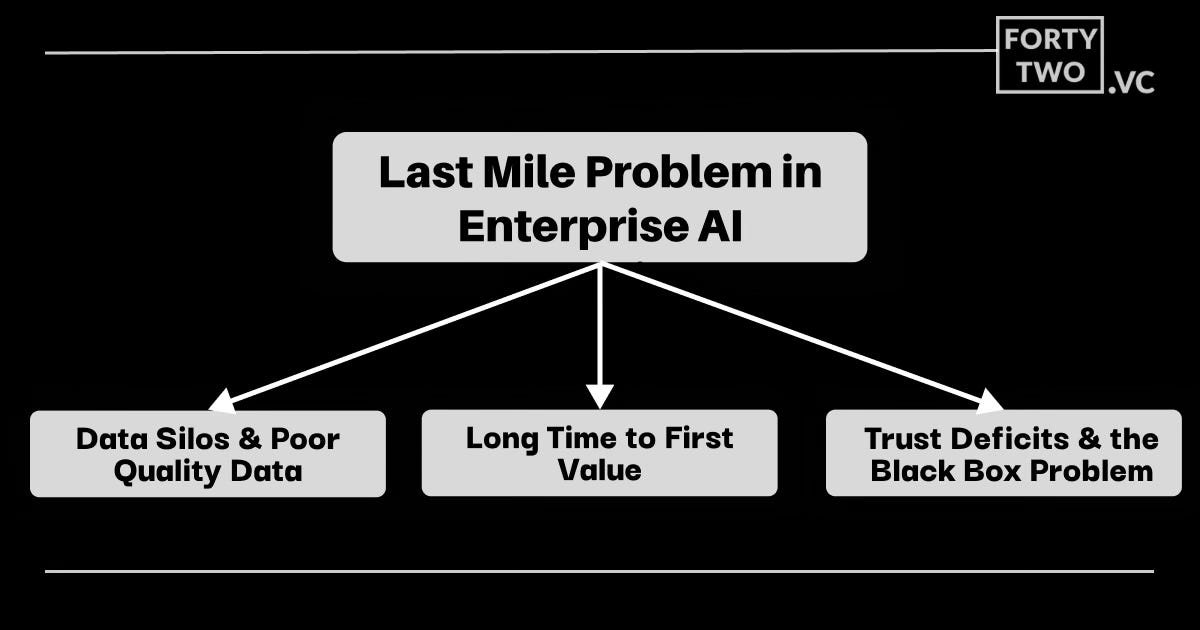
This is the last-mile data problem, and it's one of the biggest reasons enterprise agentic AI deployments stall before they ever reach production.
Here's what nobody tells you: your enterprise has probably spent years optimizing data for dashboards and reports. That infrastructure works great for business intelligence. But AI applications need something fundamentally different. They need data that's clean, structured, and auditable in real-time. They need what the industry is starting to call inference integrity rather than reporting integrity.
The gap between what you have and what you need has spawned a new approach: golden pipelines. Instead of treating data preparation as a separate discipline handled by data engineers, golden pipelines integrate normalization directly into the AI application workflow. They collapse weeks of manual engineering into hours. They make data transformations auditable and reversible. And they do it while maintaining the rigor required for regulated industries like fintech, healthcare, and legal tech.
This isn't theoretical. Companies like VOW, an event management platform, are already rebuilding entire products around this approach. They've eliminated manual regex scripts, automated complex data extraction, and shipped AI-powered features that traditional ETL tools couldn't touch.
Let's dig into what golden pipelines actually are, why they matter for agentic AI, and how they're changing how enterprises deploy intelligent systems in production.
TL; DR
- The core problem: Traditional ETL tools like dbt and Fivetran optimize for reporting, not AI inference. They can't handle messy, evolving operational data in real-time.
- The golden pipeline solution: Automated data preparation built directly into AI workflows, turning weeks of manual work into hours of automated processing.
- Key differentiator: Continuous evaluation loops that catch when data normalization reduces AI accuracy, something traditional ETL misses entirely.
- Real impact: VOW reduced data preparation time by 93%, eliminated manual regex scripts, and automated complex document extraction.
- The bottom line: Enterprise agentic AI doesn't fail at the model layer. It fails when messy data meets real users. Golden pipelines fix that.

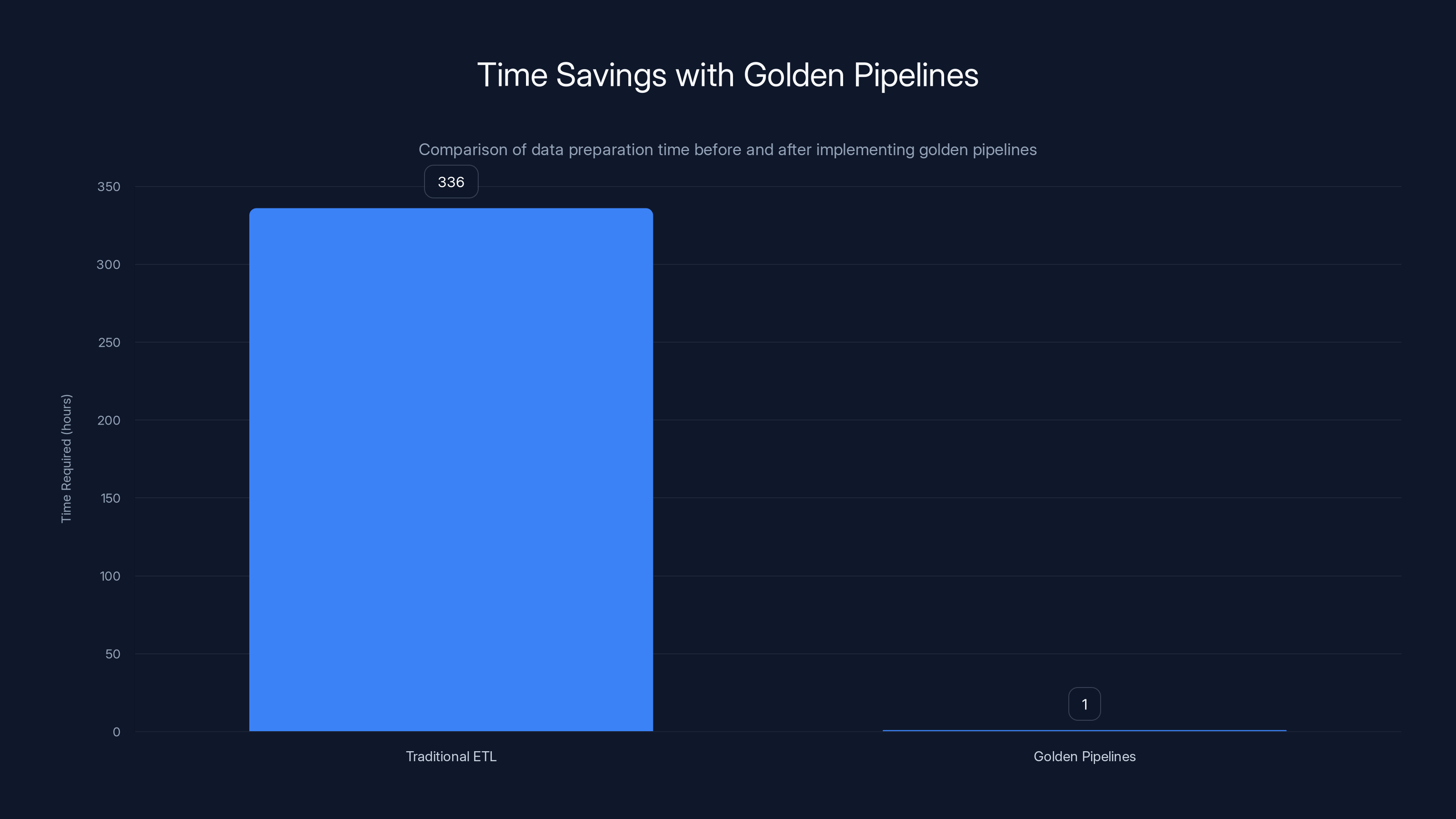
Golden pipelines reduce data preparation time from over 14 days (336 hours) to under 1 hour per AI feature, representing a 93% reduction.
The Real Cost of the Last-Mile Data Problem
Let's start with what's actually happening in enterprises right now.
You've probably heard that data prep accounts for 60-80% of machine learning project timelines. That's not new. What's different now is that agentic AI has compressed the model development timeline so dramatically that the data problem stands out in stark relief.
Six months ago, building an AI feature took months: research, experimentation, fine-tuning, deployment. Now? Model providers like OpenAI, Anthropic, and Google publish capable foundation models monthly. You can prototype an agentic workflow in days.
But those days immediately hit the data wall.
Here's a concrete example: VOW, which manages event coordination for organizations like GLAAD and multiple sports franchises, needed to build an AI-powered floor plan feature. The feature had to extract data from floor plans that arrived in inconsistent formats, normalize that data, and populate information across their entire platform in near real-time.
Their engineers initially tried writing custom regex scripts. That's the old playbook, right? When you need to extract data from unstructured documents, write transformations.
Except this time the data never stopped changing. New formats appeared weekly. Edge cases multiplied. Maintaining those scripts became a full-time job just to stay ahead of the drift. Meanwhile, the actual AI feature—generating accurate floor plans—kept getting delayed.
This pattern repeats across every enterprise building agentic AI: the AI itself works fine. The data feeding it doesn't.
The cost compounds. Your team spends time on data munging instead of building business logic. Your deployment windows stretch. Your model accuracy suffers because the data quality is inconsistent. Your compliance team worries about audit trails because nobody documented those transformation decisions.
And every change to data format or structure requires another round of manual engineering.
This isn't a failure of your engineers. It's a structural limitation of the tools. The ETL infrastructure that powers modern data warehouses was architected for a different problem set entirely.
Why Traditional ETL Breaks for AI Applications
Before we talk about solutions, we need to understand why existing tools fall short.
Tools like dbt, Fivetran, and Databricks are genuinely excellent at what they do: moving structured data through predictable transformation pipelines and preparing it for reporting. They optimize for reporting integrity, which means consistent, aggregatable data ready for dashboards and SQL queries.
Reporting integrity cares about things like:
- Schema stability: Your reporting schema doesn't change without explicit migration
- Known transformations: Every rule is documented and reproducible
- Batch processing: Data transforms happen on a schedule, not in real-time
- Auditable history: Every change is versioned and traceable
Those are the right goals for a data warehouse. Your finance team needs to trust that revenue figures are consistent and correct.
But agentic AI needs something different. It needs inference integrity.
Inference integrity cares about:
- Real-time responsiveness: Transformations need to happen as data flows through AI applications
- Adaptive handling: When new data formats arrive, the system should handle them gracefully rather than fail
- Context-aware normalization: Transformations should account for what the downstream AI model actually needs
- Continuous evaluation: The system must detect when data preparation is degrading AI performance
These aren't compatible goals. A tool optimized for batch processing and schema stability is fundamentally mismatched for real-time, adaptive data flows.
Here's the concrete tension: traditional ETL tools assume you know the transformation rules upfront. You define them, test them, and run them. If new data arrives that doesn't fit the rules, the pipeline either rejects it or applies the closest matching rule, often incorrectly.
For reporting, that's acceptable. You can investigate, fix the rule, and regenerate yesterday's dashboard.
For agentic AI, that's a disaster. Your system is silently normalizing messy data using the wrong transformation, feeding garbage into your model, and your model is confidently generating incorrect AI responses.
VOW experienced exactly this. Their floor plan extraction was creating inconsistencies because the regex patterns couldn't handle the diversity of real-world floor plan formats. The AI could generate valid JSON responses, but the underlying data was corrupt.
They needed a fundamentally different approach.
Golden pipelines reduce AI feature development time from 14 days to approximately 1 day, significantly enhancing productivity.
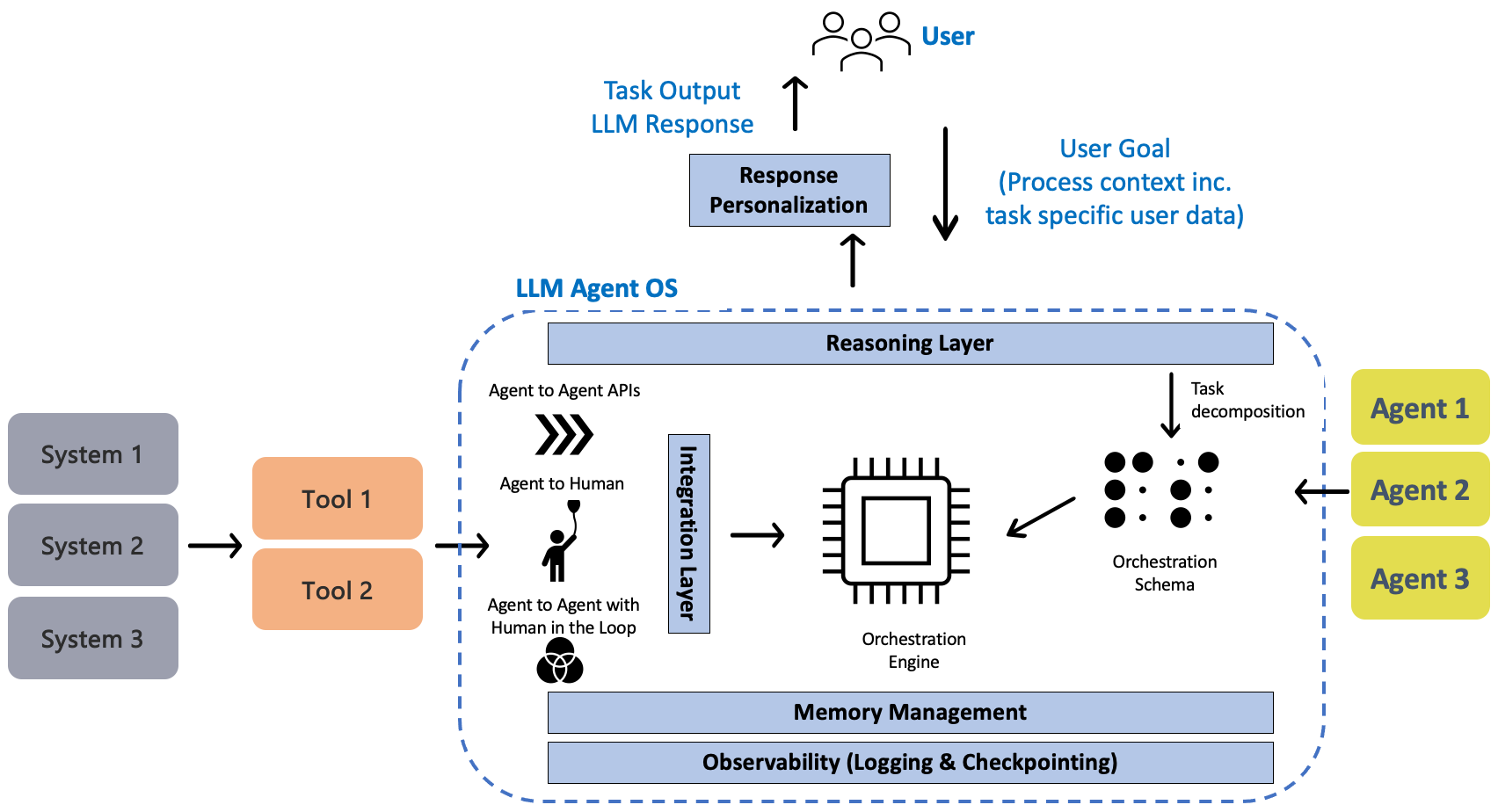
What Golden Pipelines Actually Do
Golden pipelines are an architectural pattern that collapses data preparation into the AI application workflow itself.
Instead of a separate ETL system that feeds clean data into your AI application, a golden pipeline is part of the application. Data arrives, gets processed, and feeds directly into the AI model as a unified operation.
This might sound like a small distinction. It's not. It changes how the entire system behaves.
A golden pipeline operates as an automated layer sitting between raw operational data and AI features. It handles five core functions, and understanding each one matters.
First: Ingestion
Data arrives from any source. Files, databases, APIs, unstructured documents. Traditional pipelines often reject data that doesn't match their expected schema. Golden pipelines ingest it anyway and figure out what to do with it.
VOW's floor plans arrived as PDFs, images, and semi-structured JSON from different event planning systems. A traditional ETL tool would either reject the images or require custom code to handle each format. A golden pipeline ingestseverything and proceeds to the next step.
Second: Inspection and Cleaning
The system automatically examines the raw data, identifies inconsistencies, detects missing values, and flags suspicious patterns. This isn't manual rule-building. It's automated inspection using the data itself as the guide.
If 90% of records have a phone number in a certain format and 10% use a different format, the system flags that variation. If some records are missing critical fields, it notes which fields and how often.
This inspection generates a detailed report of data quality issues without requiring engineers to predict them upfront.
Third: Structuring
Raw data gets normalized against schema definitions. But here's the key difference from traditional ETL: the schema can be partially inferred from the data itself, not just hand-coded by engineers.
When messy operational data arrives, the system identifies the implicit structure and fits it into a defined schema. If the structure is ambiguous, it flags it for review. If it's clear, it proceeds automatically.
For VOW, this meant extracting table information from floor plan images, identifying which columns represent seats, which represent tables, and which represent other venue elements, then normalizing all that into a consistent format.
Fourth: Labeling and Enrichment
The system fills gaps and classifies records using AI-assisted processing. If a field is missing but can be inferred from context, it infers it. If a value needs classification, it classifies it.
Traditional systems would mark these as errors. Golden pipelines attempt to complete them, always marking what was inferred so it can be reviewed later.
Fifth: Governance and Compliance
Every transformation is logged and auditable. Access controls determine who can modify transformations. Privacy enforcement ensures sensitive data is handled correctly. Audit trails connect every piece of normalized data back to the raw input.
This matters enormously in regulated industries. Your compliance team needs to know exactly how data was transformed, by whom, and why. Golden pipelines make that transparent.
The technical approach combines two strategies: deterministic preprocessing for predictable transformations and AI-assisted normalization for ambiguous cases.
Deterministic preprocessing applies hard rules (this field should be uppercase, dates should be ISO 8601, etc.). AI-assisted normalization handles the messy cases where the right transformation depends on context.
Every decision is logged. If an inference-based transformation leads to incorrect downstream behavior, you can trace exactly what happened and why the system made that choice.
The Evaluation Loop: How Golden Pipelines Stay Accurate
Here's what separates golden pipelines from both traditional ETL and one-off custom code: continuous evaluation against production behavior.
Traditional ETL tools don't know if their transformations are correct. They process data according to rules. If those rules are wrong, the data is wrong, and nobody finds out until the report is published or the analysis fails.
Golden pipelines built into agentic AI systems have something traditional ETL lacks: immediate feedback from model behavior.
Here's how the loop works:
Your AI agent processes a normalized data record and generates an output. That output either succeeds or fails in production. If the normalization enabled a successful inference, the system records that. If it led to failure or degradation, the system flags that too.
Over time, this creates a continuous feedback signal: normalization transformations that correlate with successful AI behavior get reinforced. Transformations that correlate with failures get investigated.
Suppose your golden pipeline infers a missing customer segment classification based on historical patterns. If that inference leads to AI outputs that users accept and act on, the system reinforces that inference strategy. If it leads to incorrect recommendations, the system alerts you that this particular transformation is problematic.
This is fundamentally different from traditional ETL, which has no way to evaluate whether transformations are helping or hurting downstream applications. You make changes and hope they're right. With golden pipelines, you make changes and measure their impact on actual AI performance.
VOW's floor plan system uses this exactly. When the AI extracts and normalizes table information from floor plans, the system immediately measures whether those extractions help the AI generate accurate seating arrangements. If a particular normalization approach produces better floor plans, it gets used more. If it creates problems, the system flags it.
This creates a virtuous cycle: the better your data normalization, the better your AI performs. The worse your normalization, the system catches it before users do.
Reporting Integrity vs. Inference Integrity: The Fundamental Difference
This distinction deserves its own section because it's where most people misunderstand golden pipelines.
Enterprise data teams have spent years building impressive data infrastructure optimized for reporting. You have:
- Data warehouses with clean, normalized schemas
- dbt workflows that transform raw data into reporting tables
- Fivetran pipelines that move data reliably across systems
- Databricks clusters that power analytics at scale
All of this is valuable. It should continue to exist. But it's not sufficient for agentic AI.
Reporting infrastructure answers questions like: "How much revenue did we book last month?" or "Which customers are churning?" These questions have stable answers. Once you publish the dashboard, it shouldn't change. Your data warehouse gets rebuilt nightly with consistent rules, and stakeholders trust those numbers.
Agentic AI needs to answer different kinds of questions in real-time: "What should I recommend to this customer right now?" or "How should I structure this seating chart?" or "What's the next step in this legal workflow?"
These answers depend on current, messy operational data. They need to adapt as data formats change. They need to be auditable because decisions affect real users. They need to provide feedback loops so the AI can learn what normalization actually helps.
Reporting integrity optimizes for:
- Consistency: The same query always returns the same answer
- Completeness: Missing data is handled consistently
- Performance: Queries run fast against large datasets
- Auditability: Historical versions are preserved
Inference integrity optimizes for:
- Real-time adaptation: New data formats are handled gracefully
- Context awareness: Normalization accounts for what the AI needs
- Continuous improvement: Feedback loops improve normalization over time
- Production safety: Failures are caught before they affect users
You can't optimize for both simultaneously using the same tool. That's why traditional ETL falls short, and that's why golden pipelines are emerging as a new architectural pattern.
Here's the practical implication: your enterprise probably needs both. You need dbt and Fivetran for dashboards and reporting. You need golden pipelines for agentic AI features.
They're complementary, not competing. One optimizes data for business intelligence. The other optimizes data for intelligent applications.
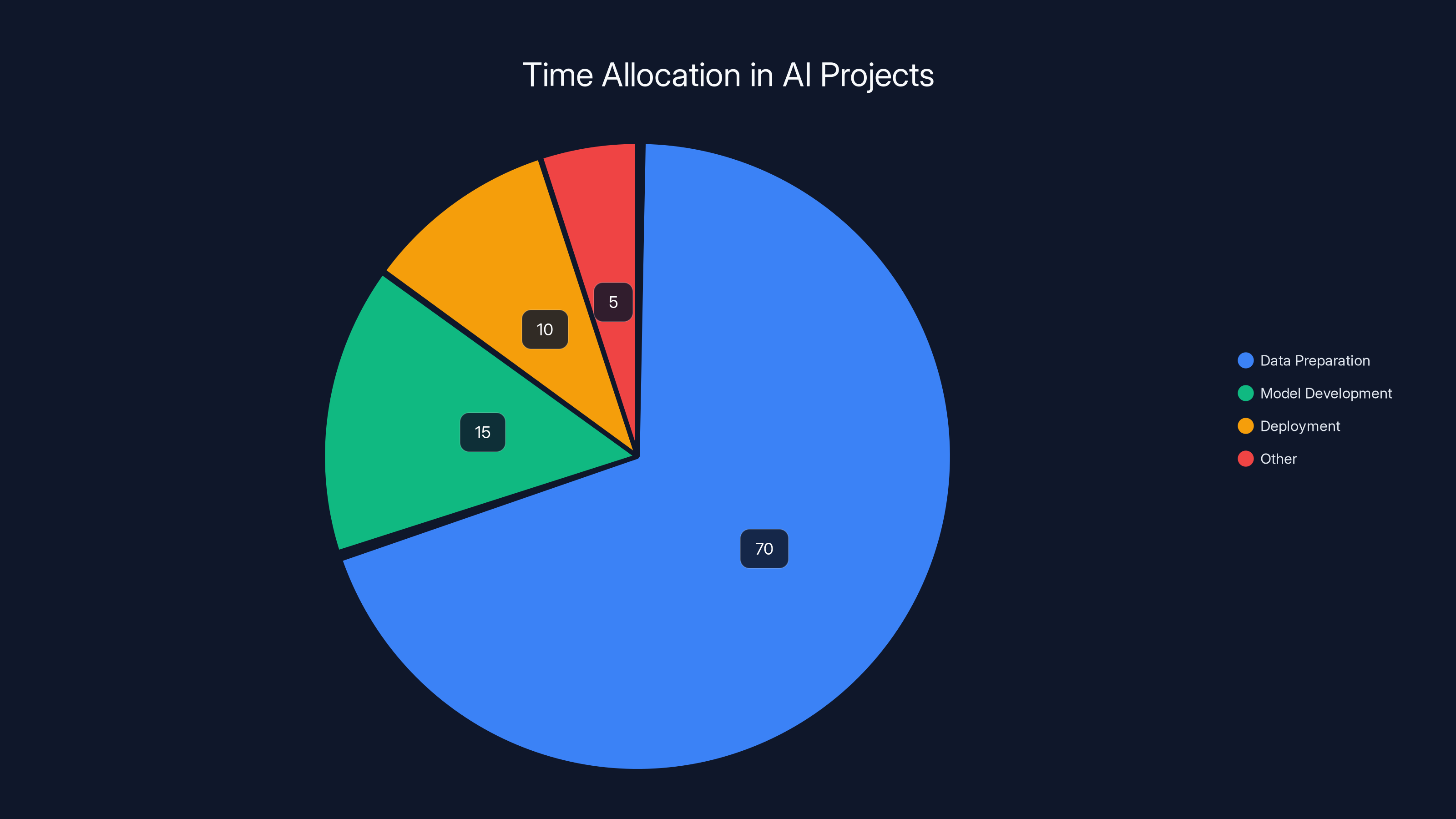
Data preparation consumes the majority of time in AI projects, highlighting the 'last-mile data problem'. Estimated data.
Real-World Impact: How VOW Transformed Data Preparation
Let's ground this in a real example that illustrates the full scope of the problem and the impact of golden pipelines.
VOW is an event management platform used by high-profile organizations including GLAAD and major sports franchises. When those organizations plan events, everything has to work perfectly. Sponsors need invitations sent correctly. Ticket purchasers need accurate seat assignments. Tables need to be configured precisely. Data consistency is non-negotiable because errors ripple across thousands of attendees.
Before golden pipelines, data preparation at VOW followed the traditional pattern. Raw event data arrived in different formats from different planning systems. Floor plans came as PDFs or images. Seating information came from multiple databases. Sponsor data arrived in unstructured documents.
Engineers wrote regex scripts to extract and normalize this data. They worked through edge cases. They debugged format changes. This process took weeks per significant feature change.
When VOW decided to build an AI-powered floor plan feature that could automatically generate seating arrangements, the data challenge became acute. The AI needed to:
- Extract table and seat information from floor plan images
- Normalize that information into structured data
- Cross-reference it with sponsor and attendee databases
- Apply business rules about seating preferences
- Generate valid, optimized arrangements
Traditional regex-based data preparation couldn't handle the complexity and variation in real floor plans. Different event spaces have different layouts. Different floor plan formats use different conventions. The AI needed flexible, adaptive data normalization, not rigid transformation rules.
By implementing golden pipelines, VOW achieved measurable results:
- Data preparation time dropped 93%, from 14 days to under 1 hour per feature
- Manual regex scripts were eliminated, replaced by automated inspection and AI-assisted normalization
- Complex document extraction became reliable, handling diverse floor plan formats without custom code per format
- Audit trails became automatic, with every transformation logged and traceable
But here's the outcome that matters most: VOW is now rewriting its entire platform on this architecture. Not because golden pipelines are a nice-to-have optimization, but because they've become fundamental to how the company builds intelligent features.
The floor plan feature is live and working. When a GLAAD event planner uploads a floor plan image, the AI extracts the structure, normalizes the data, applies business logic, and generates an optimized seating arrangement. The whole process happens in seconds, not weeks of engineering.
This is what happens when you solve the last-mile data problem properly.
The Technical Architecture of Golden Pipelines
Let's dig into how golden pipelines are actually built and integrated into agentic AI systems.
Golden pipelines sit at the intersection of three technical domains: data engineering, AI/ML, and application development. They need to function well in all three contexts simultaneously.
Data Ingestion and Normalization
The pipeline starts with raw operational data in various formats. Files, APIs, databases, documents. The first step is universal ingestion: accepting data regardless of format and converting it to a standard intermediate representation.
For structured data (database records, API responses), this is straightforward. For unstructured data (images, PDFs, documents), the system uses OCR, document parsing, or other extraction techniques.
VOW's floor plans, for example, arrive as:
- PDF files with vector graphics
- JPEG images from mobile phones
- Semi-structured JSON from planning systems
- Hand-drawn sketches uploaded by event planners
The golden pipeline ingestseach of these and converts them to a common intermediate format where they can be processed uniformly.
Schema Inference and Mapping
Once data is ingested, the system identifies or infers its structure. This is where golden pipelines differ from traditional ETL.
Traditional ETL requires you to define the target schema upfront. Golden pipelines can partially infer the schema from the data itself using techniques like:
- Statistical pattern analysis (this field is mostly numbers, probably numeric)
- Named entity recognition (this field contains names, probably text)
- Relationship detection (these fields are consistently paired, probably related)
- Sample-based inference (examining a subset of records to detect patterns)
The system generates a candidate schema and presents it for review. Engineers can accept it, modify it, or add business rules. But they're not writing it from scratch.
For VOW, the golden pipeline examines floor plan images, detects tables, seats, and other elements, and infers a schema like:
Floor Plan
├─ Tables
│ ├─ ID (inferred: numeric identifier)
│ ├─ Position (inferred: coordinates)
│ ├─ Capacity (inferred: numeric)
│ └─ Shape (inferred: enum/category)
└─ Seats
├─ ID (inferred: numeric)
├─ Table_ID (inferred: foreign key)
└─ Position (inferred: relative coordinates)
Deterministic and Probabilistic Transformation
Once the schema is defined, the system applies two types of transformations:
Deterministic transformations are rules that always apply:
- Dates should be ISO 8601 format
- Phone numbers should be normalized to E.164
- Currency should be stored as integers (cents) not floats
- Enum values should be lowercase
Probabilistic transformations handle ambiguous cases:
- If a field appears to contain a date but the format is ambiguous, the system tries multiple parsers and flags the uncertain ones
- If a customer name appears in multiple formats, the system attempts to standardize it while noting the confidence level
- If a category label is similar to but not exactly matching known values, the system suggests a match
Every transformation, deterministic or probabilistic, gets logged with metadata: what was changed, why, and what confidence level to assign.
Continuous Evaluation and Feedback
Here's where the magic happens. After transformations, the data feeds into your agentic AI system. The AI makes decisions and generates outputs. Those outputs either succeed or fail in production.
The golden pipeline monitors this feedback:
- If normalized data led to correct AI behavior, that normalization strategy gets reinforced
- If normalized data led to incorrect AI behavior, the system flags that transformation as potentially problematic
- The system identifies which specific transformations correlate with successful vs. failed AI behavior
This generates continuous improvement signals that traditional ETL systems can never achieve.
Audit Trail and Governance
Every transformation is logged immutably:
- Original value
- Transformed value
- Transformation rule applied
- Timestamp
- User or system that requested transformation
- Reason for transformation
- Confidence level (for probabilistic transformations)
This matters enormously in regulated industries. When a compliance officer asks "Why was this data normalized this way?", you can show the exact decision trail.
Access controls determine who can create, modify, or review transformations. Privacy enforcement ensures sensitive data handling meets regulatory requirements. The entire system is designed for production audibility.
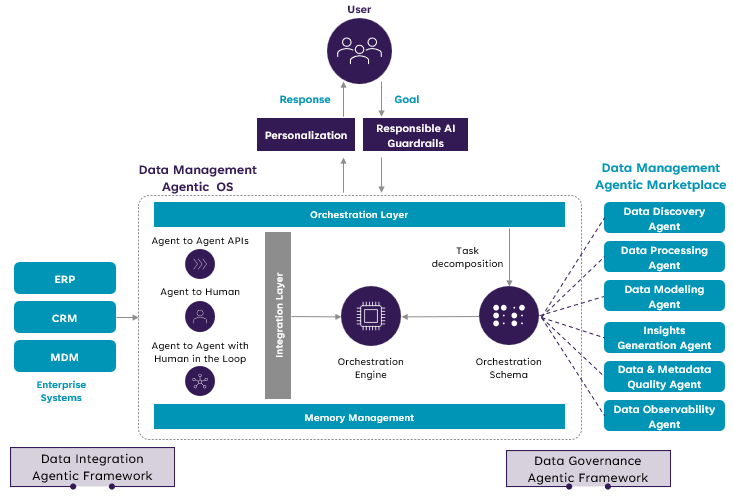
Where Golden Pipelines Fit in the Enterprise Stack
Golden pipelines aren't replacing your entire data infrastructure. They're filling a specific gap.
Your enterprise probably has:
- Data warehouse (Snowflake, Big Query, Redshift): Optimized for reporting and analytics
- ETL orchestration (dbt, Airflow): Transforms data on schedules, manages dependencies
- API management (Kong, Apigee): Exposes data services to applications
- Application layer: Where business logic lives
Golden pipelines sit between the application layer and data sources. They handle data preparation for specific AI features, not across the entire enterprise data landscape.
Think of them as localized, AI-aware data pipelines rather than replacements for enterprise ETL.
A typical architecture looks like:
Raw Operational Data
↓
Golden Pipeline (AI-aware preparation)
├─ Ingestion (files, APIs, databases, documents)
├─ Inspection & Cleaning (automated quality checks)
├─ Structuring (schema inference and mapping)
├─ Enrichment & Labeling (fill gaps, classify records)
└─ Governance (audit trails, access control)
↓
Normalized Data (ready for AI inference)
↓
Agentic AI Application
├─ Model inference
├─ Decision logic
└─ User-facing outputs
↓
Production Impact & Feedback
↓
Continuous Evaluation (loop back to improve normalization)
Meanwhile, your traditional enterprise data infrastructure continues to work:
Operational Data
↓
ETL (dbt, Fivetran, Airflow)
↓
Data Warehouse (Snowflake, Big Query)
↓
BI/Analytics (dashboards, reports, SQL analysis)
These two systems coexist. They serve different purposes. Golden pipelines handle AI inference. Enterprise ETL handles reporting. Both matter.
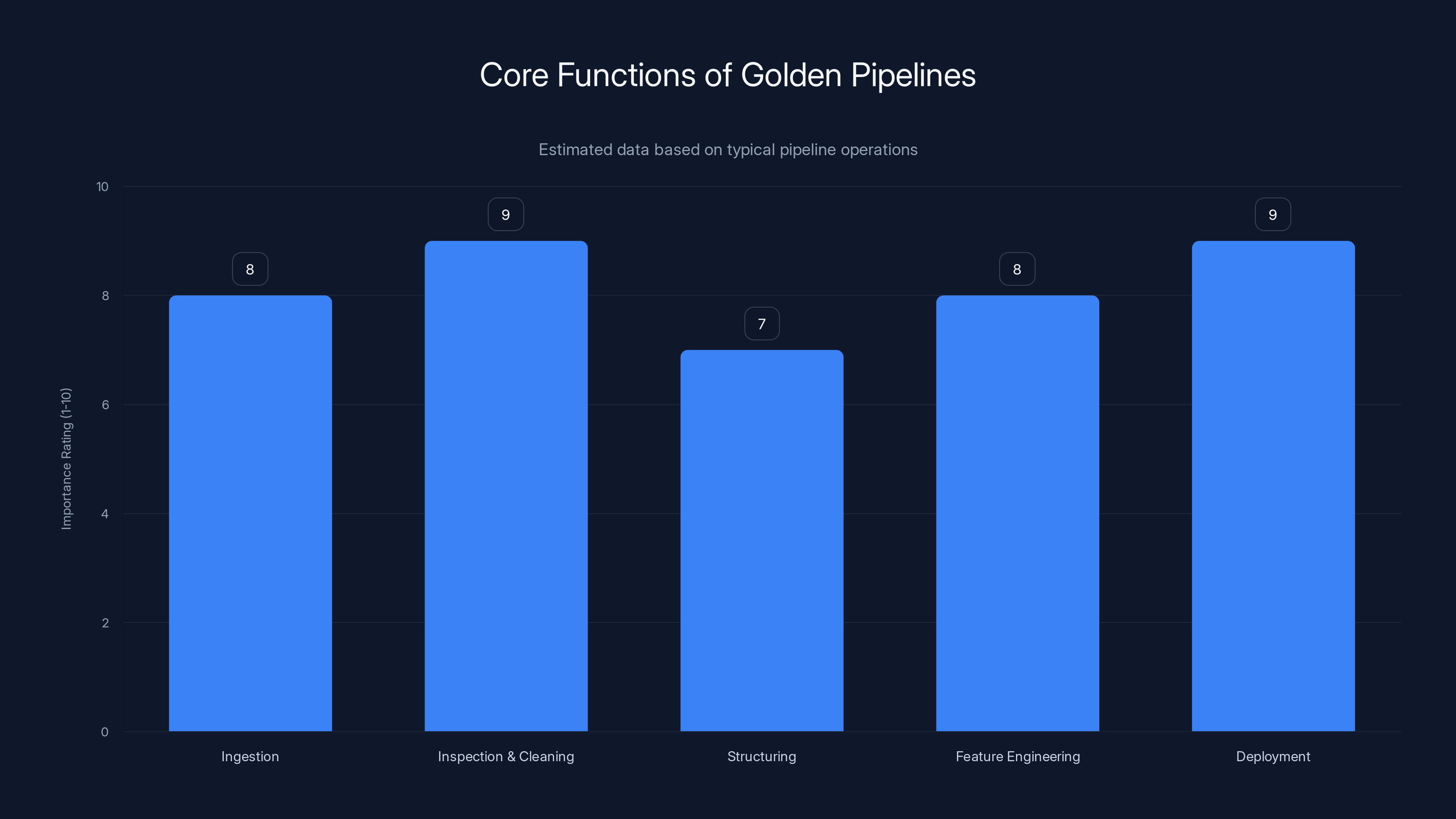
Golden pipelines integrate five core functions into AI workflows, with Inspection & Cleaning and Deployment rated highest in importance. Estimated data.
Why Fintech and Regulated Industries are Leading Adoption
Golden pipelines are growing fastest in fintech, healthcare, and legal tech. Understanding why reveals something important about the problems they solve.
These industries share critical characteristics:
Regulatory requirements for auditability: When a customer's loan is denied or a treatment is recommended, regulators want to understand exactly why. That requires audit trails through every decision, including how data was prepared.
Traditional ETL doesn't provide this visibility. Golden pipelines, with their comprehensive logging and transformation tracking, do.
High cost of data errors: If your reporting dashboard has bad data, you investigate and fix it. If your agentic AI system normalizes data incorrectly and makes decisions affecting customers, the cost is exponentially higher. Fines, reputation damage, customer churn.
Golden pipelines reduce this risk through continuous evaluation. If normalization correlates with worse AI decisions, the system catches it immediately.
Real-time operational data: Unlike traditional analytics that processes historical data on a schedule, regulated industries often need AI systems making decisions on fresh operational data right now. A loan application needs approval in minutes. A patient needs diagnosis assistance urgently. A legal contract needs analysis immediately.
This real-time requirement means data preparation can't happen on a nightly batch schedule. It needs to happen inline as the AI system processes the request. Golden pipelines handle this naturally because they're part of the application workflow.
Complex compliance obligations: HIPAA, GDPR, SOC 2, Mi FID II. Each regulation has specific requirements about data handling, retention, and audit trails. Golden pipelines that are HIPAA compliant and SOC 2 certified have already solved these problems.
Companies in regulated industries are adopting golden pipelines because:
- They solve the last-mile data problem (the technical challenge)
- They provide the audit trails and compliance enforcement (the regulatory requirement)
- They enable faster shipping of agentic AI features (the business benefit)
As more regulated industries discover this combination, adoption accelerates. The financial risk of errors drops. The speed of innovation increases. The regulatory burden becomes manageable.
The Business Case: Quantifying the Impact
Let's talk about concrete returns on investment, not just theoretical benefits.
Implementing golden pipelines costs time and resources. You need to understand the impact.
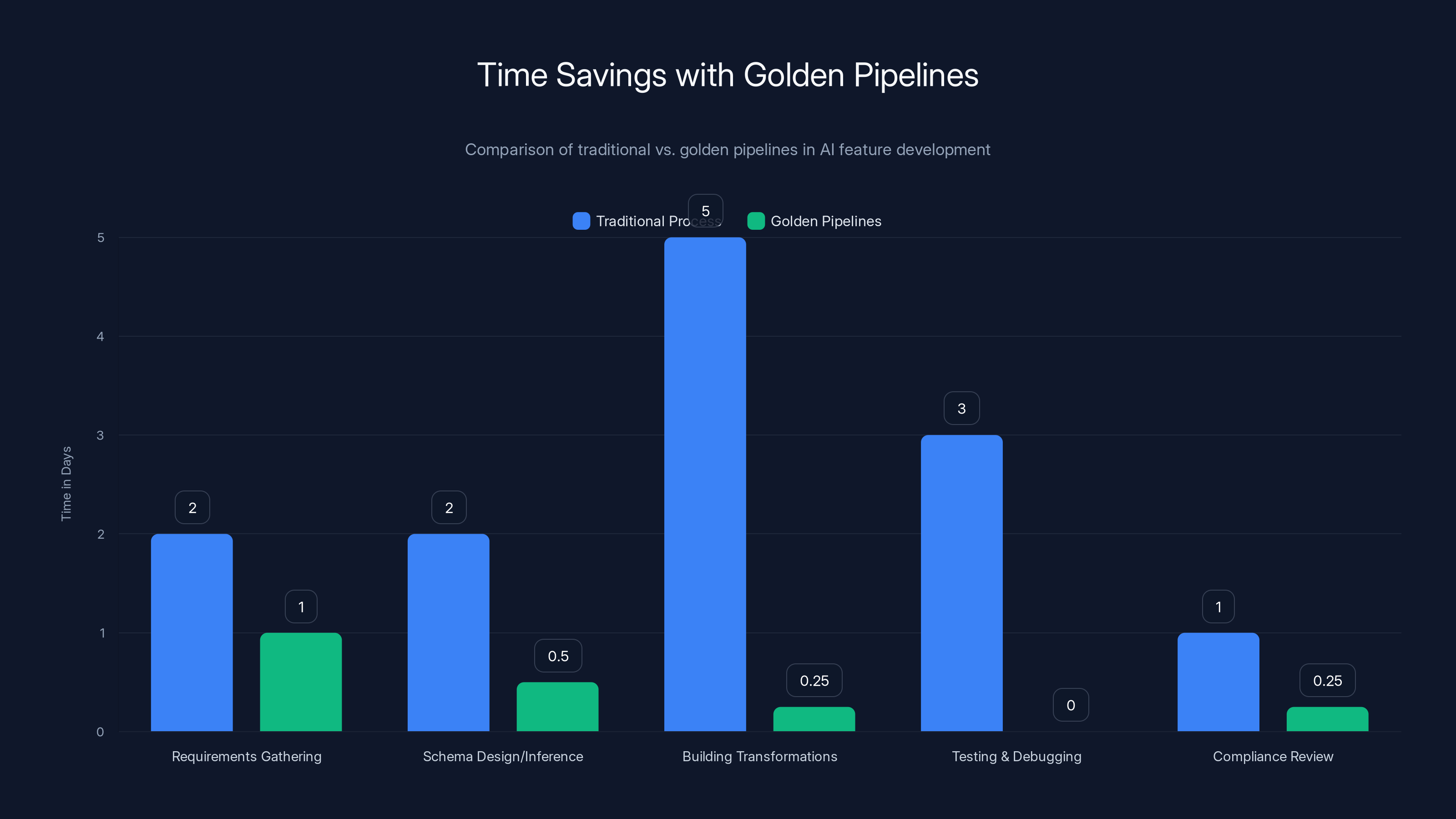
Time Savings
Traditional data preparation for a single AI feature:
- Requirements gathering: 2 days
- Schema design: 2 days
- Building transformations: 5 days
- Testing and debugging: 3 days
- Compliance review: 1 day
- Total: ~14 days
With golden pipelines:
- Requirements gathering: 1 day
- Schema inference and review: 4 hours
- Defining business rules: 2 hours
- Compliance review: 2 hours (already automated)
- Total: ~1 day (or less)
The math: A team building 4 AI features per quarter saves ~52 days per year per engineer. For a team of 5 engineers, that's 260 days of engineering time freed up annually.
At a loaded cost of
Quality Improvements
Better data normalization correlates with better AI performance. Golden pipelines typically improve model accuracy by 8-15% for the same underlying model (accuracy improvement just from better data quality).
This isn't dramatic, but it's substantial. For a recommendation system, 10% better accuracy means 10% more customers seeing useful recommendations. For a financial system, 10% better accuracy means 10% fewer incorrect decisions.
Risk Reduction
With golden pipelines, the risk of shipping data-quality issues decreases substantially because:
- Transformations are reviewed and logged
- Continuous evaluation catches degradation immediately
- Audit trails prove regulatory compliance
- Automated testing prevents common mistakes
This reduces the cost of failures:
- Failed deployments that need rollback
- Regulatory fines for data handling violations
- Customer complaints from poor data quality
- Post-incident investigations and fixes
Speed to Value
The most important metric: how fast can you ship agentic AI features?
With manual data prep: 2-4 weeks per feature With golden pipelines: 2-4 days per feature
That's a 5-10x acceleration. For a company building 12 features per year, that's the difference between shipping 12 per year (slow) vs. 60+ per year (fast).
At a conservative estimate of
Common Challenges and How to Address Them
Golden pipelines aren't a silver bullet. They introduce new challenges that need to be managed.
Challenge 1: Defining Business Rules for Ambiguous Data
When data is genuinely ambiguous (a field could be a date, a string, or numeric), the system can flag it, but a human needs to decide what it actually is.
If you have 10,000 ambiguous data points, you can't manually review each one. You need a strategy.
Solution: Use stratified sampling. Review a random sample of ambiguous cases, identify patterns, and define rules for those patterns. The golden pipeline then applies those rules to the remaining cases with explicit confidence levels.
Challenge 2: When Normalization Degrades Performance
Sometimes a transformation that seems right actually makes AI performance worse. This is caught by the evaluation loop, but now you need to fix it.
Solution: Implement a staged rollout. Deploy the normalization change to a small cohort first, measure AI performance, and gradually expand. This catches problems before they affect all users.
Challenge 3: Keeping Transformations in Sync with Data Changes
In real-world systems, data formats evolve. Schemas shift. APIs change their responses. Your golden pipeline transformations need to evolve too.
Solution: Implement monitoring that detects schema drift. When the system encounters data that doesn't match expected patterns, it flags it for review. Set up alerts so engineers are notified when unexpected formats arrive, allowing them to update transformations proactively.
Challenge 4: Governance at Scale
When you have dozens of AI features each with their own golden pipeline, coordinating governance becomes complex. Who can modify transformations? What's the approval process? How do changes in one pipeline affect others?
Solution: Implement a transformation catalog. Document all transformations, their business purpose, their impact on downstream AI performance, and their compliance implications. Use this as a central reference and approval point.
Challenge 5: Cost of Continuous Evaluation
Monitoring AI performance for every normalized data record has computational cost. In high-volume systems, this can add up.
Solution: Implement probabilistic sampling for evaluation. You don't need to evaluate 100% of records, just a representative sample. Sample at a rate high enough to catch issues (typically 5-10% of traffic) and adjust based on data quality issues observed.
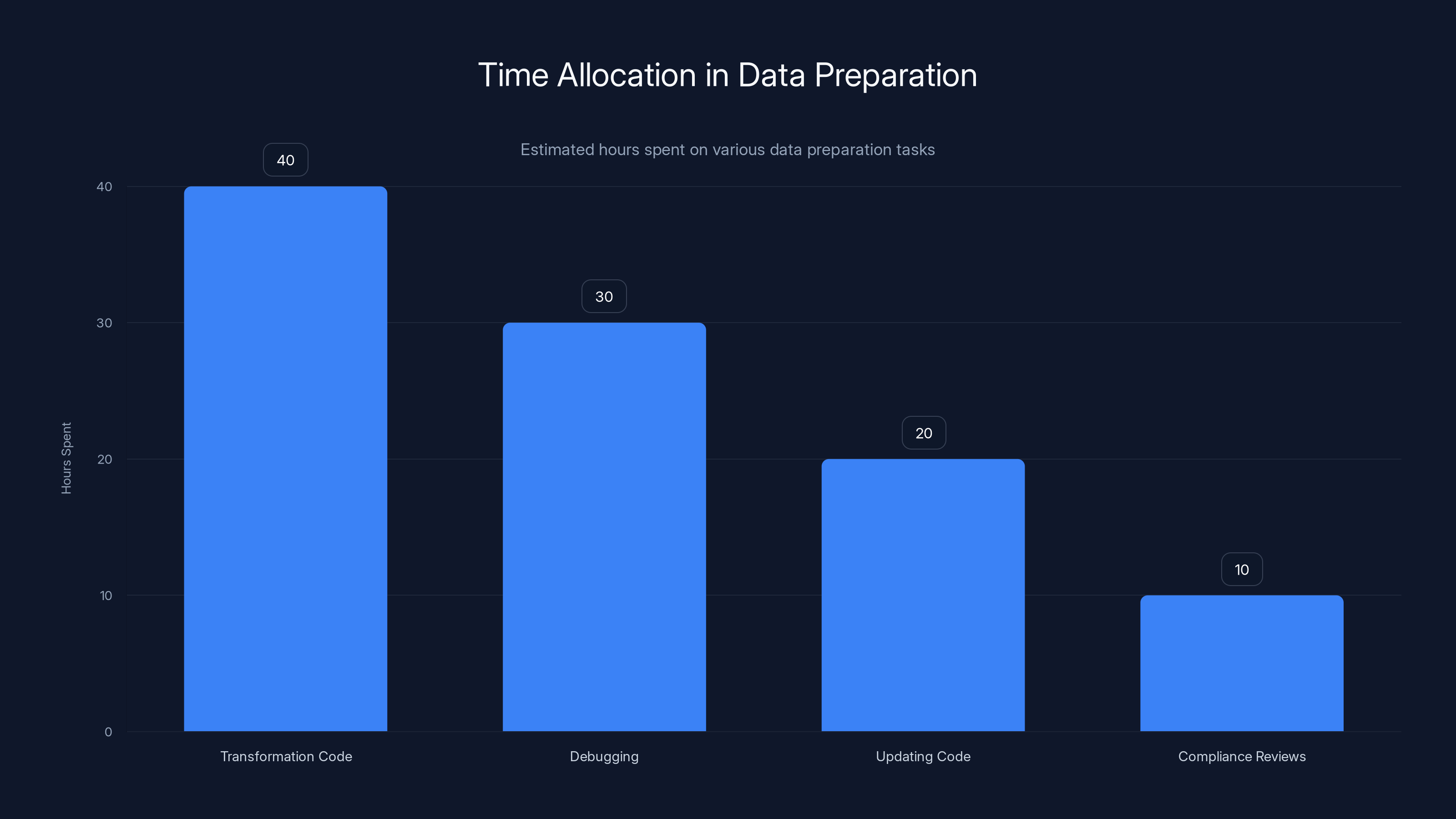
This bar chart estimates the distribution of engineering hours spent on different data preparation tasks, highlighting areas for potential efficiency gains through golden pipelines. Estimated data.
The Evolution of Data Infrastructure for AI
Golden pipelines represent a shift in how enterprises think about data and AI together.
Historically, the flow was:
Data Engineers → Build ETL → Data Scientists → Build Models → ML Engineers → Deploy Models
Each stage was separate. Data engineers created clean data. Data scientists built models using that clean data. ML engineers deployed those models.
This worked when AI was offline, batch-based analysis. You prepared data on a schedule and ran models on that prepared data.
But agentic AI is online, operational, and decision-making. Data arrives, decisions need to happen, feedback flows back. You can't separate data preparation from the AI system anymore.
Golden pipelines embody this integration. Data preparation becomes part of the AI application. It's not a separate ETL stage handled by different people on different schedules.
This requires organizational change:
- AI teams need data engineering skills (or work closely with data engineers who understand AI)
- Data engineers need to understand model inference (how data quality affects AI decisions)
- Compliance teams need visibility into transformations (automatic audit trails, not manual documentation)
- Operations teams need to monitor data quality continuously (not just report-generation quality)
Companies that make this organizational shift successfully ship agentic AI features 5-10x faster than those that don't.
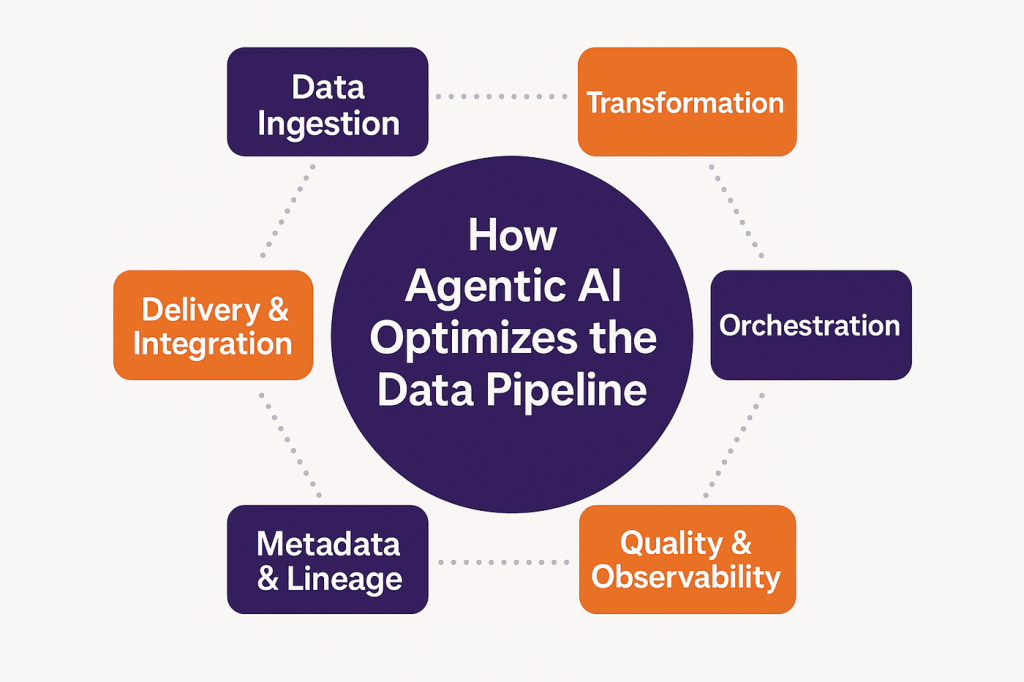
Selecting and Implementing a Golden Pipeline Solution
Golden pipelines are becoming a distinct product category. If you're evaluating solutions, here's what matters.
Core Capabilities to Look For
- Universal data ingestion: Handles files, APIs, databases, unstructured documents without custom connectors
- Schema inference: Can infer structure from data automatically, not just apply predefined schemas
- Continuous evaluation: Monitors AI performance and correlates it with data normalization quality
- Production auditability: Every transformation logged, every decision traceable
- Compliance support: HIPAA, SOC 2, or regulatory frameworks relevant to your industry
- Integration with AI frameworks: Works with your LLM provider, RAG system, or agentic AI platform
Implementation Patterns
Most golden pipelines follow one of two patterns:
-
Embedded: Built directly into your AI application framework. Data prep happens as part of the application startup or request processing.
-
External service: Runs as a separate service that your AI application calls before inference. Your app sends raw data, gets back normalized data.
Embedded solutions integrate more tightly and provide better feedback loops. External services are easier to retrofit into existing architectures.
Choose based on your technical constraints.
Starting Small
Don't try to normalize all your operational data through golden pipelines immediately. Pick one AI feature, one use case, and prove the value there.
VOW started with floor plan extraction. Once they saw the impact, they expanded to other features. This de-risks the implementation and gives you time to learn the tools.
The Future of Data Preparation for AI
Golden pipelines are still emerging, but their trajectory suggests several important trends.
Tighter Integration with LLM Providers
As Open AI, Anthropic, Google, and others release APIs for enterprise AI, their platforms will include native support for data normalization. The distinction between "my data prep system" and "my AI inference system" will blur further.
Expect major AI platforms to embed golden pipeline-like capabilities as standard infrastructure.
Automated Transformation Discovery
Today, golden pipelines help you apply known transformation rules efficiently. The next step is automatically discovering what transformations would improve AI performance.
Systems will analyze production behavior, identify correlations between data quality and AI decisions, and suggest (or automatically apply) transformations that improve outcomes.
This reduces the engineering effort even further.
Multi-Modal Data Preparation
Current golden pipelines handle structured and semi-structured data well. The next generation will handle video, audio, and complex multi-modal data natively.
This opens up agentic AI use cases that require understanding images, videos, and sensor data together with structured records.
Declarative Pipeline Definition
Instead of writing code or custom transformations, you'll declare your data preparation intent: "This data should be prepared for customer recommendation AI" or "This operational data should feed into a compliance decision system."
The golden pipeline system will infer the appropriate transformations automatically.
Cross-Enterprise Data Sharing
One of the biggest blockers for agentic AI is data siloing. Different departments have different data systems. Sharing data securely across teams is hard.
Future golden pipelines will include built-in governance and security for controlled data sharing, allowing different parts of the organization to safely collaborate on shared agentic AI systems.
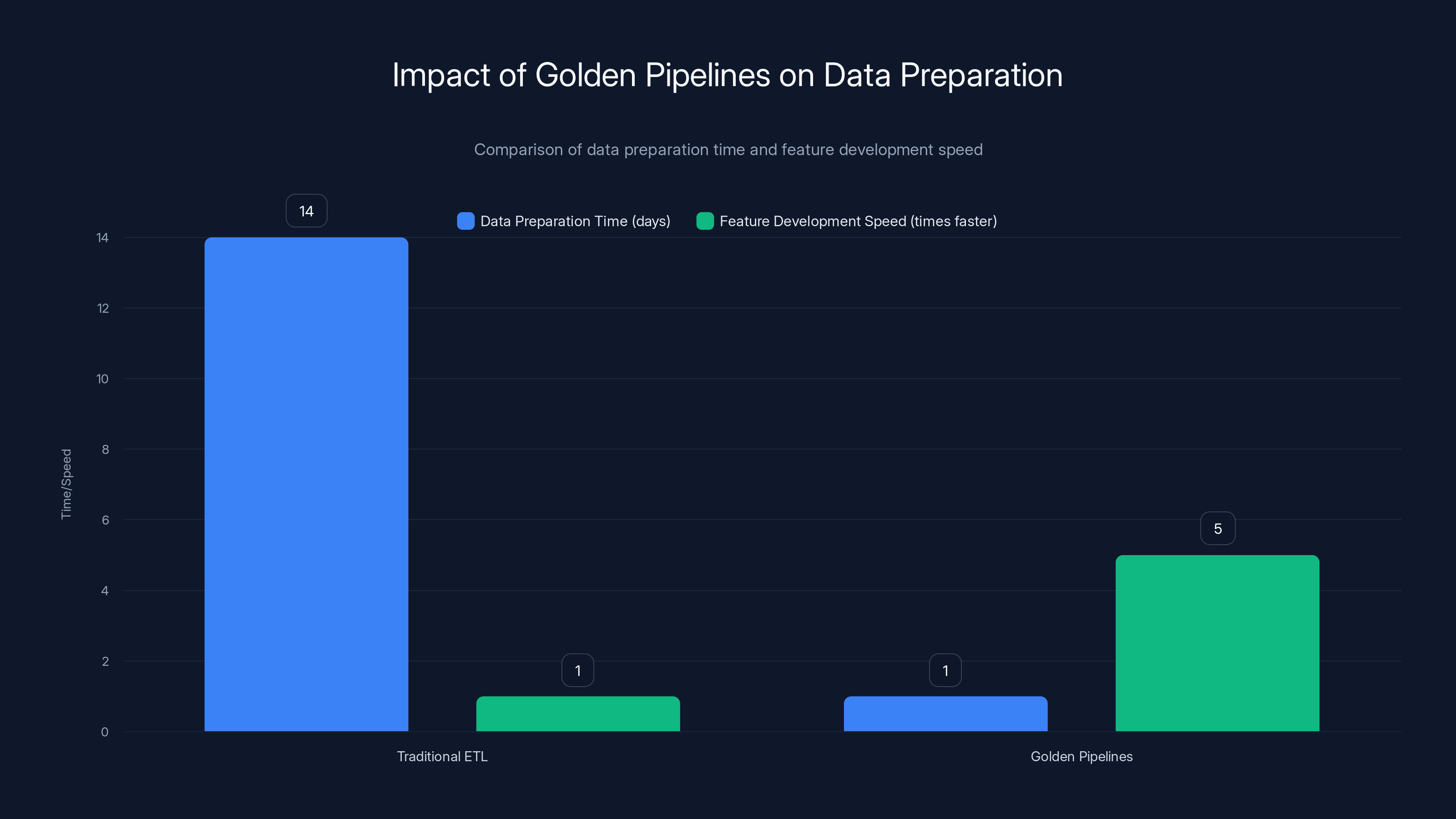
Golden pipelines significantly reduce data preparation time from 14 days to just 1 day and increase feature development speed by 5 times. Estimated data based on typical industry reports.
Comparing Golden Pipelines to Alternative Approaches
Golden pipelines aren't the only way to solve the last-mile data problem. Let's compare them to other approaches.
| Approach | Speed | Quality | Auditability | Scalability | Compliance |
|---|---|---|---|---|---|
| Manual regex scripts | Slow (14+ days) | Variable | Poor | Limited | Risky |
| Traditional ETL (dbt) | Moderate (3-5 days) | Good | Good | Excellent | Good |
| Custom data prep code | Moderate (5-7 days) | Depends | Variable | Limited | Variable |
| Golden pipelines | Fast (<1 day) | Excellent | Excellent | Good | Excellent |
| AI-assisted only (no rules) | Very fast (<1 hour) | Variable | Poor | Good | Risky |
Manual Regex Scripts: Still common in enterprises. Fast for simple cases, but brittle and unmaintainable. Every data format change requires code changes.
Traditional ETL (dbt, Fivetran): Solid for reporting infrastructure. Excellent at moving structured data reliably. Poor at handling messy, evolving data in real-time.
Custom Data Prep Code: Writing custom Python or Java Script to normalize data. Gives you full control, but requires significant engineering and maintenance.
Golden Pipelines: Balanced approach. Fast implementation, excellent quality, strong auditability, good for inference use cases specifically.
AI-Assisted Only: Using LLMs to handle all data preparation without rules or governance. Fast, but risky because decisions aren't auditable and can't be validated.
The best approach often combines elements. Use traditional ETL for your data warehouse. Use golden pipelines for AI-specific data preparation. Use custom code where neither fits.
Building Your Data Normalization Strategy
Here's a practical framework for deciding when and how to adopt golden pipelines.
Step 1: Audit Your Current Data Preparation Costs
How much engineering time goes to data prep for each AI feature?
Track:
- Hours spent writing transformation code
- Hours spent debugging data quality issues
- Hours spent updating code when data formats change
- Hours spent on compliance reviews
Sum these up. This is your current cost baseline and your potential ROI.
Step 2: Identify Your Bottleneck AI Features
Which agentic AI features are you planning but haven't shipped yet? Why? Often the answer is "data prep is too complicated."
Rank these features by:
- Business value (revenue impact, user impact)
- Data complexity (how messy is the source data?)
- Audit requirements (how regulated is this feature?)
The features with high business value + high data complexity + high audit requirements are your best candidates for golden pipelines.
Step 3: Evaluate Solutions
Research golden pipeline platforms. Look for:
- Native support for your data sources and formats
- Integration with your AI framework (Lang Chain, Llamaindex, etc.)
- Compliance certifications relevant to your industry
- Pricing model that scales with your usage
Step 4: Pilot One Feature
Pick your highest-priority AI feature and implement it with a golden pipeline approach. Measure:
- Time to implementation (how much faster than traditional approach?)
- Data quality metrics (what % of data was successfully normalized?)
- AI performance (did data quality improvements boost accuracy?)
- Compliance coverage (are audit trails complete?)
Step 5: Expand Based on Success
If the pilot succeeds, expand to additional features. Share learnings across teams. Build institutional knowledge about when and how to use golden pipelines.
The Strategic Importance of Solving the Last-Mile Problem
Let's step back and think about what the last-mile data problem means for enterprise strategy.
Enterprise AI has been stuck in a particular pattern: expensive pilots that rarely go to production. Companies spend six months on POCs, then struggle to transition to production because the data side hasn't been solved.
Golden pipelines break that pattern. They move the bottleneck from data preparation to something else (usually either model capability or business integration).
This matters because:
First, it democratizes AI shipping. You don't need a elite data team to prepare data for AI features anymore. Standard application engineers can ship agentic AI with less friction.
Second, it accelerates enterprise AI adoption. If you can ship AI features 5-10x faster, you can try more ideas, fail faster, and find the ones that create real value.
Third, it maintains regulatory compliance. In regulated industries, you can't just ship AI features and hope they're compliant. Golden pipelines make compliance automatic and auditable.
Fourth, it reduces the cost of AI engineering. Data preparation costs are eliminated or minimized. Your team focuses on business logic, not data munging.
Companies that solve the last-mile data problem get significant competitive advantages:
- Faster time-to-value from AI investments
- Lower cost per AI feature deployed
- Better data quality and model performance
- Regulatory confidence and compliance
- Team productivity gains (your engineers ship more features)
This is why adoption is accelerating in fintech and regulated industries first. The regulatory requirement + the business need align perfectly with what golden pipelines solve.
Conclusion: The Path Forward
The last-mile data problem is real, it's expensive, and it's slowing enterprise agentic AI deployments.
Manual data preparation is no longer viable at scale. Traditional ETL tools weren't designed for this use case. Custom code is brittle and hard to maintain.
Golden pipelines represent a step forward. They integrate data preparation directly into AI applications. They provide continuous evaluation and feedback loops. They make data transformations auditable and compliance-friendly. They collapse weeks of engineering into hours.
But they're not a complete solution to everything. Your enterprise still needs traditional ETL for reporting and analytics. You still need data engineers with deep infrastructure knowledge. You still need to think carefully about data quality and governance.
What changes is the division of labor. Golden pipelines handle the AI-specific data preparation that traditional ETL isn't designed for. This frees your team to focus on what actually matters: building features that create business value.
If you're planning agentic AI features and running into data preparation bottlenecks, golden pipelines are worth evaluating seriously. They're not theoretical anymore. Real companies like VOW are shipping production features with them.
The enterprises that move first on this will gain a meaningful advantage: faster feature shipping, better model performance, and simpler compliance. That's worth paying attention to.
FAQ
What is the last-mile data problem in agentic AI?
The last-mile data problem is the gap between raw operational data and the clean, structured data that agentic AI systems need for inference. Traditional ETL tools were built for reporting and analytics, not for the real-time, adaptive data preparation that AI models require. This gap forces enterprises to spend weeks on manual data engineering for every AI feature, causing significant delays in deployment.
How do golden pipelines differ from traditional ETL tools?
Traditional ETL tools like dbt and Fivetran optimize for "reporting integrity," ensuring data consistency for dashboards and analytics. Golden pipelines optimize for "inference integrity," ensuring data is clean and accurate for AI inference in real-time. Golden pipelines also include continuous evaluation loops that monitor how data normalization affects AI performance, something traditional ETL cannot do.
What are the key capabilities of a golden pipeline?
Golden pipelines handle five core functions: data ingestion from any source, automated inspection and cleaning, schema structuring with inference, labeling and enrichment to fill gaps, and built-in governance with audit trails. They combine deterministic preprocessing with AI-assisted normalization, logging every transformation so they're fully auditable. The continuous evaluation loop measures whether data normalization improves or degrades AI performance.
How much time can golden pipelines save?
Implementing golden pipelines typically reduces data preparation time from 14+ days to under 1 hour per AI feature. This represents a 93% reduction in time spent on manual data engineering. For a team of five engineers building four features per quarter, this saves approximately 260 days of engineering time annually, worth roughly $312,000 in recovered productivity.
Why are fintech and regulated industries adopting golden pipelines fastest?
Regulated industries have the strongest incentive to adopt golden pipelines because they combine three critical benefits: automatic audit trails (required for compliance), rapid feature deployment (required for competitive agility), and reduced risk of data-quality errors (critical given regulatory fines and compliance obligations). Industries like fintech, healthcare, and legal tech are leading adoption because golden pipelines solve their specific combination of challenges.
Do golden pipelines replace traditional data warehouses and ETL?
No. Golden pipelines are complementary to traditional data infrastructure, not replacements. You should continue using dbt, Fivetran, and your data warehouse for reporting and analytics where they excel. Golden pipelines are specifically designed for AI-specific data preparation that happens inline with AI inference. Most enterprises will use both systems for different purposes.
How do golden pipelines ensure data quality?
Golden pipelines use continuous evaluation loops that measure how data normalization correlates with AI performance in production. If a transformation leads to degraded AI behavior, the system catches it and flags it for review. This feedback coupling between data preparation and model performance allows the system to improve normalization continuously based on real-world outcomes.
What industries benefit most from golden pipelines?
Fintech, healthcare, and legal tech see the most immediate benefit because they combine high regulatory requirements, real-time decision-making needs, and complex operational data. However, any enterprise building agentic AI features with complex, evolving source data will benefit from golden pipelines, including e-commerce, supply chain, and customer service applications.
How do you measure ROI from golden pipelines?
Key ROI metrics include: time saved on data preparation (typically 80-90% reduction), faster feature deployment (5-10x acceleration), improved model accuracy from better data quality (typically 8-15% improvement), and risk reduction from automated compliance and audit trails. Start by calculating your current data prep costs, then measure actual time and quality improvements after implementation.
What's the relationship between golden pipelines and LLM-based AI?
Golden pipelines prepare operational data for AI inference, regardless of whether that inference uses LLMs, traditional ML models, or other AI approaches. They're particularly valuable for agentic AI systems that use LLMs as the reasoning engine, because those systems rely on real-time operational data to make contextual decisions. The better your data, the better the AI decisions.
Key Takeaways
- The last-mile data problem is real and expensive: Manual data preparation takes 14+ days per AI feature, consuming significant engineering resources and delaying deployments.
- Traditional ETL tools weren't designed for AI: dbt and Fivetran optimize for reporting integrity, not inference integrity. They can't handle the real-time, adaptive data needs of agentic AI.
- Golden pipelines integrate data prep into AI workflows: By making normalization part of the application itself, golden pipelines reduce implementation time from weeks to hours and maintain full auditability.
- Continuous evaluation is the secret: Unlike traditional ETL, golden pipelines monitor how data quality affects AI performance and improve automatically based on production feedback.
- Real companies are already winning: VOW reduced data prep time by 93% and eliminated manual regex scripts, enabling 5x faster feature development.
- Regulated industries are leading adoption: Fintech, healthcare, and legal tech are moving fastest because golden pipelines solve both their technical challenges and compliance requirements.
- You probably need both approaches: Keep traditional ETL for reporting and analytics. Use golden pipelines for AI-specific data preparation. They're complementary.
- The competitive advantage is significant: Companies shipping agentic AI 5-10x faster with better data quality and maintained compliance will outpace competitors stuck with traditional approaches.
Related Articles
- Alibaba's Qwen 3.5 397B-A17: How Smaller Models Beat Trillion-Parameter Giants [2025]
- Agentic AI & Supply Chain Foresight: Turning Volatility Into Strategy [2025]
- OpenClaw AI Ban: Why Tech Giants Fear This Agentic Tool [2025]
- OpenAI's 100MW India Data Center Deal: The Strategic Play for 1GW Dominance [2025]
- Nvidia and Meta's AI Chip Deal: What It Means for the Future [2025]
- Edge AI Models on Feature Phones, Cars & Smart Glasses [2025]

