![Enterprise Cloud Waste: How AI Detects Hidden Inefficiencies [2025]](https://tryrunable.com/blog/enterprise-cloud-waste-how-ai-detects-hidden-inefficiencies-/image-1-1769614915671.png)
Introduction: The Hidden $100 Billion Problem in Enterprise Cloud
Every second, enterprises around the world are hemorrhaging money on cloud infrastructure they don't need.
It's not dramatic or obvious. There's no alarm. Nobody gets paged at 2 AM. But the numbers are staggering. According to research from major cloud analysts, up to 32% of enterprise cloud spending is pure waste—duplicated workloads, outdated code that still consumes compute cycles, inefficient database queries that run hourly for no reason, and infrastructure provisioned for peak loads that never arrive.
Let that sink in. If your company spends
Here's what makes it worse: traditional cost management tools are fundamentally broken for solving this problem. They show you dashboards. They tell you what you already spent. They forecast next month's bill. But they don't actually stop the waste from happening. They're financial tools trying to solve an engineering problem, which is like asking an accountant to perform surgery.
A new class of platforms has emerged to flip this approach entirely. Instead of asking finance teams to spot inefficiencies they can't fix, these systems scan cloud infrastructure at the code level, trace waste back to the specific developer or engineer responsible, and deliver fixes directly into their workflow. They treat cloud waste the same way security teams treat vulnerabilities: as something to detect, map, and remediate automatically.
The shift from "visibility tools" to "remediation platforms" represents a fundamental rethinking of how enterprises should govern cloud spend. And companies like Ticketmaster aren't waiting around—they're already implementing these solutions to reclaim millions of dollars that would otherwise disappear.
This guide explores how the next generation of cloud optimization actually works, why traditional Fin Ops approaches are failing, and what engineering teams need to do right now to stop the bleeding.
TL; DR
- 32% of cloud spend is wasted on inefficient code, redundant resources, and outdated infrastructure
- Traditional Fin Ops tools are broken because they're financial solutions trying to solve engineering problems
- Cloud-to-code platforms automatically trace waste back to specific code lines and engineering teams
- "Shadow waste" affects AI workloads heavily, especially provisioned throughput for LLMs that's set incorrectly
- Engineering-first remediation is 10-100x faster than asking finance teams to negotiate with business units

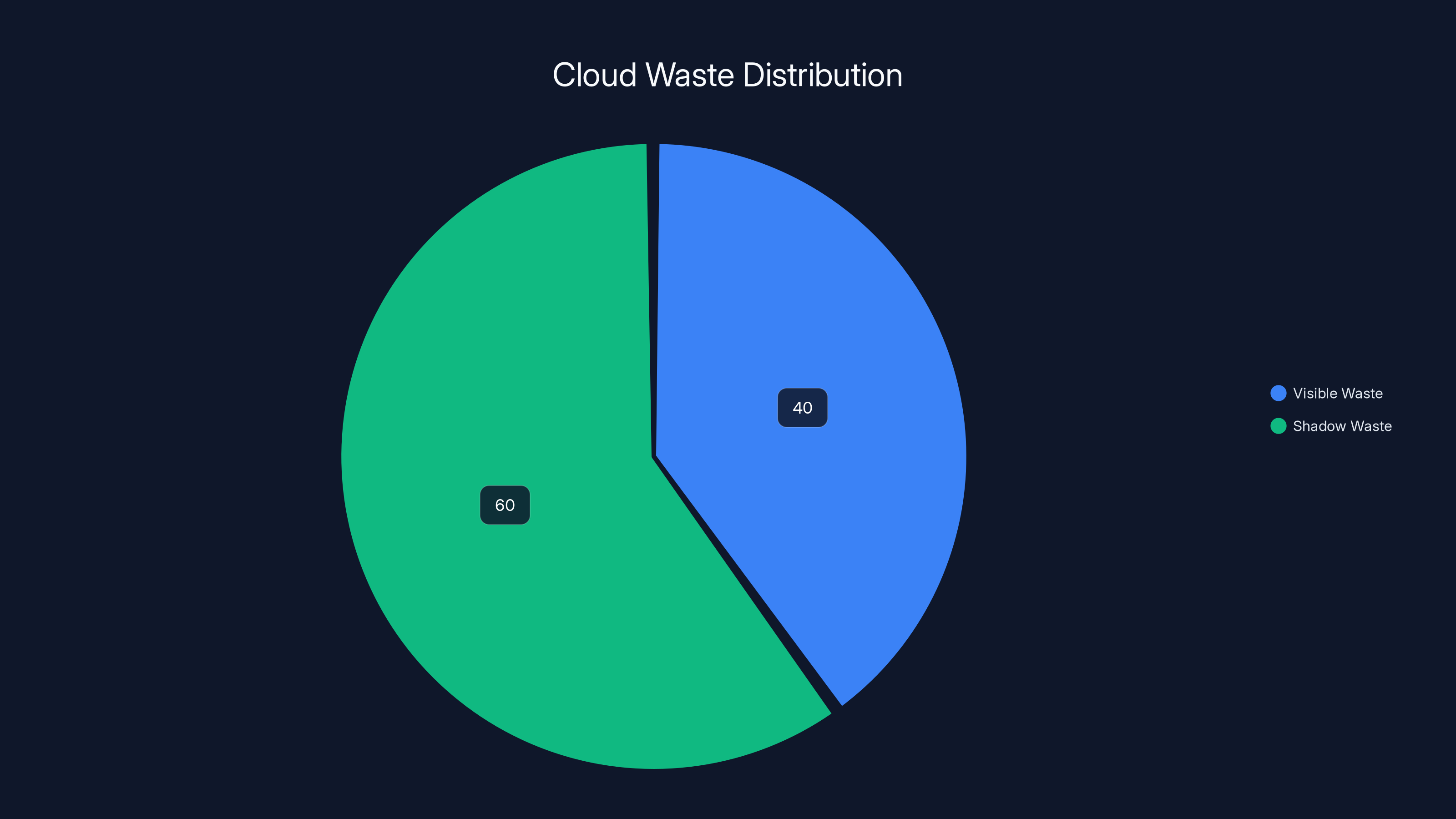
Shadow waste accounts for 60% of total cloud waste, often overlooked by traditional tools. Estimated data.
The Fin Ops Industry Is Solving the Wrong Problem
The cloud cost management industry has been built on a fundamentally flawed premise for over a decade: that visibility equals control.
Generation 1 Fin Ops tools—the dashboards and forecasting platforms—operate on this logic: show companies their spending trends, and they'll optimize behavior. It sounds rational. It doesn't work. The tools became expensive windows into expensive problems. Finance teams could see their AWS bill climbing, but they had almost no ability to actually fix it. They'd send emails asking engineering teams to "optimize costs." Engineering teams, drowning in feature development, would acknowledge the email and move on.
The disconnect is profound. A Fin Ops engineer has no ability to modify code. They can't refactor a Python function or optimize a database query. They can negotiate volume discounts or shift workloads to reserved instances, but they can't address the root cause: inefficient engineering.
Meanwhile, the engineers writing the code have no visibility into cloud costs. They optimize for performance, scalability, and feature velocity. Nobody incentivizes them to care about the infrastructure bill. So they provision generously to avoid traffic spikes, they duplicate code without knowing it, they leave services running for projects that ended months ago.
This creates a structural problem that no dashboard can solve.
The platforms that are actually reducing cloud waste operate on a completely different principle: find the waste at the code level, trace it back to the engineer who created it, deliver a fix they can review in 30 seconds, and let them ship it. This requires understanding cloud infrastructure at unprecedented depth.
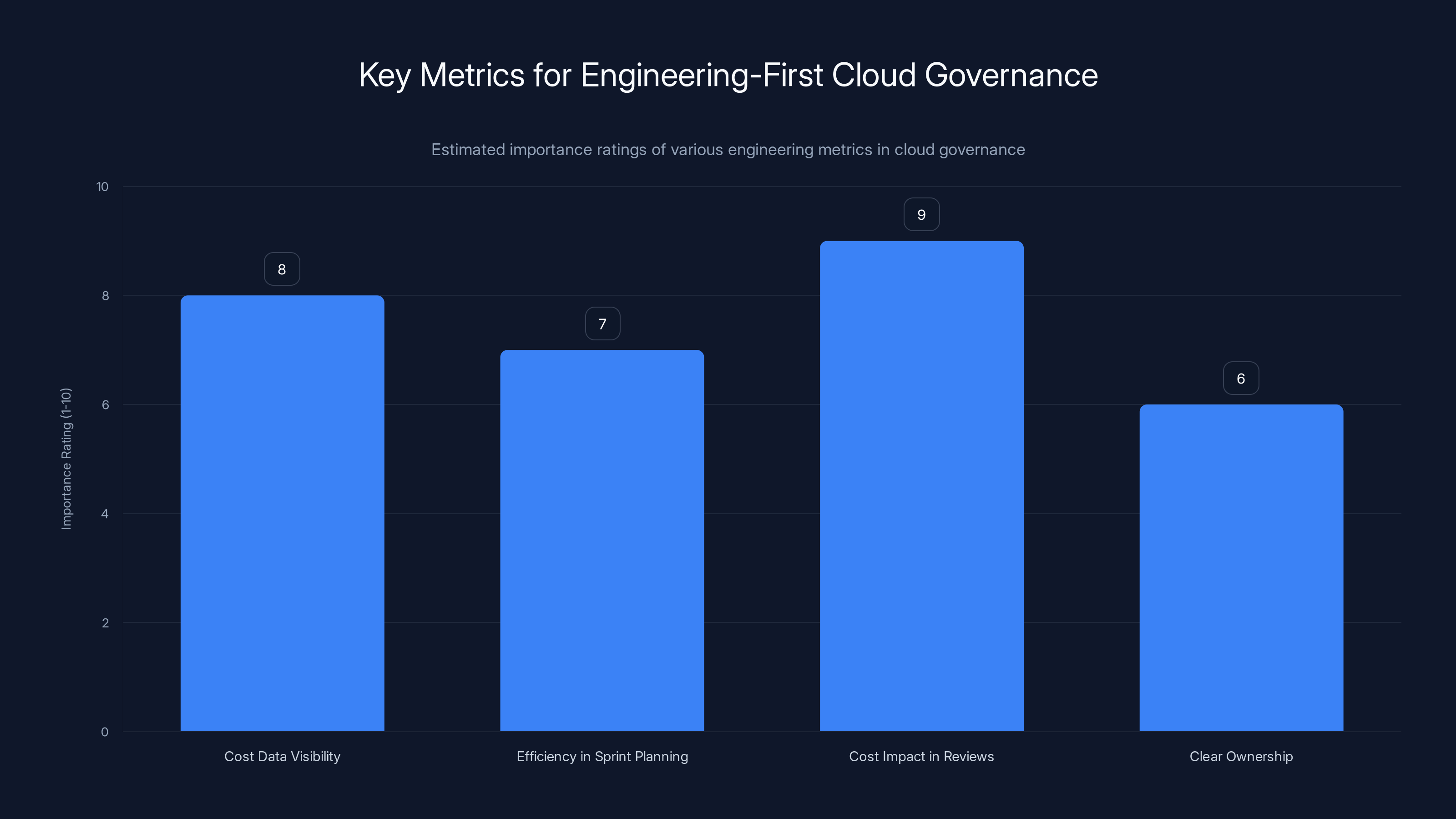
Estimated data shows that integrating cost data visibility and cost impact in engineer reviews are crucial for engineering-first cloud governance.
Understanding "Shadow Waste": The Hidden Inefficiencies Cost Tools Miss
When you ask most finance teams what causes cloud waste, you get predictable answers: idle servers that should be shut down, compute instances provisioned for peak loads, databases with too much storage allocated.
These are real problems. They're also about 40% of the total waste problem. The other 60%—the "shadow waste"—is invisible to traditional tools because it requires understanding code, architecture patterns, and application-level inefficiencies.
Shadow waste manifests in several forms, and most organizations are completely blind to them.
Inefficient Resource Allocation Across Architecture
Consider a common scenario: an engineering team migrates a batch processing job from a legacy on-premise system to AWS. The job runs once daily, processes a data warehouse update, and takes about 90 minutes to complete.
To ensure it finishes before the morning dashboards need fresh data, the team provisions a machine with 64GB of RAM and 16 CPU cores. The job actually needs about 8GB and 4 cores—but it needs to finish before 6 AM, and the team isn't sure exactly how much spare capacity they need. They over-provision for safety.
The job runs every day. It wastes 56GB of RAM and 12 CPU cores for 90 minutes, unused. That's roughly $400/month for a single inefficient migration. Multiply this across dozens of teams running hundreds of jobs, and you're looking at millions in waste.
Traditional cost tools see a running instance. Modern optimization platforms see:
- Which application created the instance
- The actual resource utilization (8GB of 64GB used)
- How long it's been this way
- The likely cause (over-provisioning for safety)
- The fix (resize to 16GB, monitor for errors, scale back up if needed)
- Who shipped the initial job (serve the fix to that engineer)
Application-Level Inefficiencies That Compound Over Time
Here's another class of shadow waste that invisible: old code running inefficiently on new infrastructure.
Suppose a team wrote a critical service in Python 3.8 five years ago. They haven't touched it—it works, it's stable, so nobody modernizes it. Meanwhile, Python releases version 3.12, which includes significant optimizations for CPU-intensive operations. The old code is now running at 60% efficiency compared to what it could be with a simple version bump.
The service handles 50 million requests daily across 100 compute instances. Upgrading Python versions might reduce compute requirements by 15% (a conservative estimate for certain workload types). That's $50K-100K annually saved on a single service update that takes an engineer maybe 4 hours to execute and test.
But here's why it doesn't happen: the Fin Ops team doesn't know about it, the engineering team doesn't think about it, and nobody connects the dots between the Python version and the monthly bill.
Intelligent optimization platforms scan code repositories, identify old dependency versions, correlate them with infrastructure performance, and flag the opportunity directly to engineers. The fix is trivial. The savings are massive.
Provisioned Throughput Mismatch for Modern AI Workloads
The newest category of shadow waste emerged with the explosion of AI infrastructure.
When you run a large language model on managed services like AWS Bedrock or Anthropic Claude, you typically face a critical decision: how much throughput should you commit to? Most platforms charge less per token if you commit in advance (similar to AWS Reserved Instances for compute).
Engineers new to LLMs face a terrible choice: commit too little, and you hit throttling during peak usage, degrading user experience. Commit too much, and you're paying for capacity you never use.
Most teams commit conservatively—or over-commit for safety. The result: they're paying 20-40% more than necessary for LLM inference because their actual usage pattern is 60% of their committed capacity.
A modern optimization engine analyzes your actual inference patterns—request timing, token counts, latency requirements—and recommends the exact commitment level needed. This is genuinely hard to do manually. It requires weeks of monitoring and analysis. A good platform delivers the recommendation automatically.

How Cloud-to-Code Detection Works: From Infrastructure Back to Engineering
The breakthrough enabling modern cloud optimization is something called "Cloud-to-Code" detection. This is the technical capability that separates genuine optimization from the previous generation of tools.
Here's the challenge: traditional systems can tell you "Instance i-0a 3f 2c 9d is consuming 12 v CPU hours daily and costs $400/month." They can tell you it's over-provisioned. But they can't tell you which engineer created it, when, or why. They can't explain the business logic that led to this decision.
Cloud-to-Code changes this. The system maintains a real-time mapping between infrastructure resources in your cloud account and the specific lines of code, configuration files, and infrastructure-as-code (Ia C) that created them.
The Technical Implementation
The mechanism is surprisingly elegant. Most modern infrastructure uses Infrastructure-as-Code tools like Terraform, Cloud Formation, or Kubernetes manifests. These files—stored in your git repositories—contain the complete definition of your infrastructure.
An optimization platform with read-only access to your cloud APIs can:
- Enumerate all cloud resources across AWS, GCP, Azure, and managed services like Kubernetes, Databricks, Snowflake
- Retrieve metadata including creation timestamps, IAM role information, and resource tags
- Cross-reference Ia C files in your version control system using resource identifiers and metadata patterns
- Match resources to specific commits and the engineers who authored them
- Trace efficiency issues back to the code that created them
Once this mapping is complete, the system can detect problems and deliver fixes in the right place: directly in the engineer's workflow, in the tools they use daily (Jira, Slack, Service Now, Git Hub).
Why This Matters More Than Conventional Optimization
Conventional cost optimization tells you to buy Reserved Instances, consolidate databases, or negotiate volume discounts. These approaches are effective, but they're also: (1) one-time optimizations that require manual effort, (2) focused on procurement rather than efficiency, and (3) limited by the fact that no amount of discounting fixes genuinely wasteful engineering.
Cloud-to-Code detection finds permanent efficiency improvements. Once an engineer fixes an over-provisioned resource or updates a dependency version, the improvement is sustained across future deployments. The fix compounds.
Moreover, these fixes align engineering incentives with cost efficiency for the first time. Engineers see their own code flagged for optimization, delivered into their review workflow, with a clear understanding of the efficiency improvement and cost impact. It's direct, measurable, and actionable.
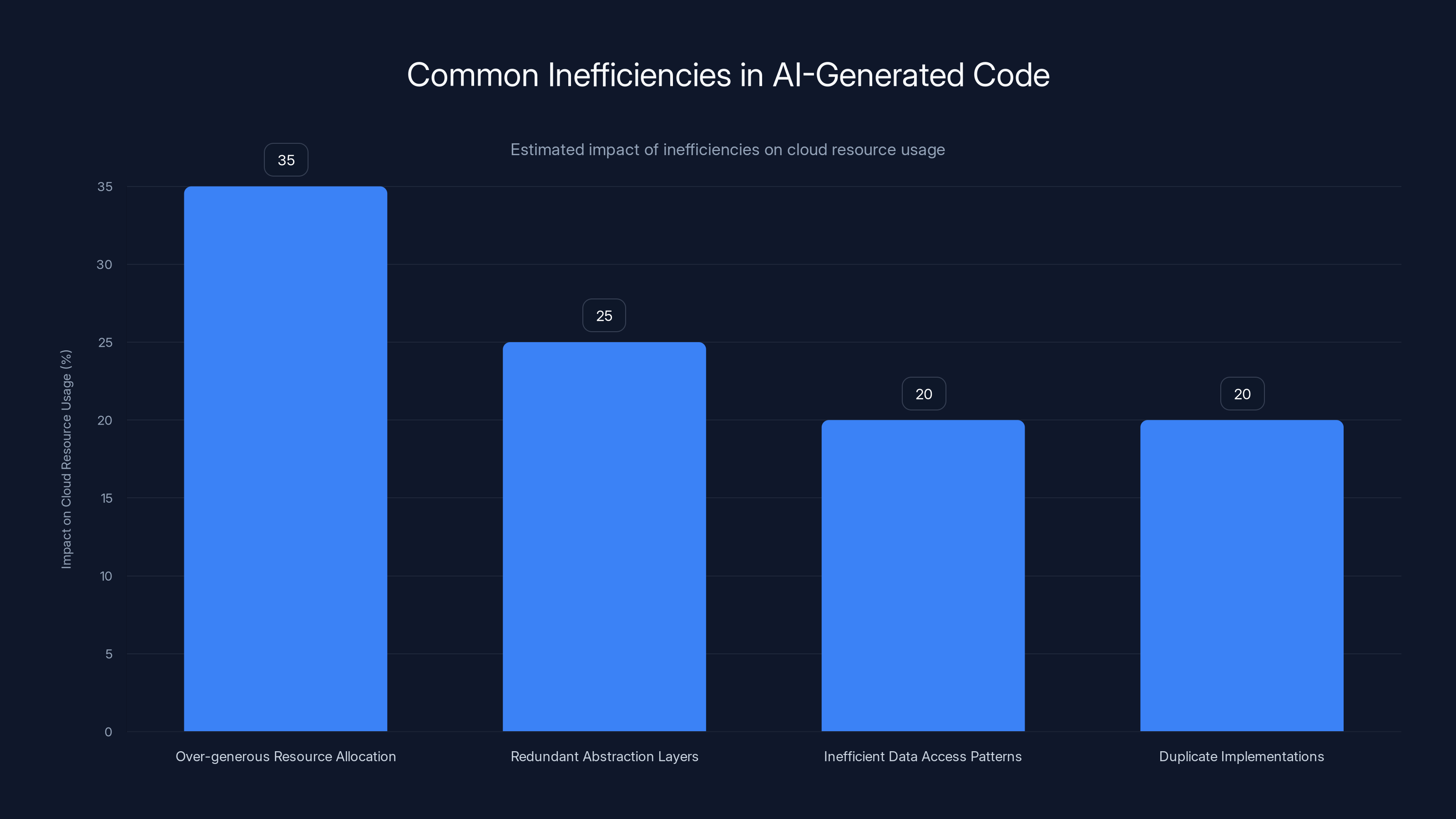
Estimated data shows that over-generous resource allocation is the most significant inefficiency in AI-generated code, contributing to 35% of cloud resource waste.
The Three Pillars of Modern Cloud Optimization Platforms
Not all optimization platforms are built equally. The most effective ones operate on three technical pillars that traditional tools completely lack.
1. Code-Level Intelligence
Modern platforms don't just analyze cloud resource specifications—they understand the code generating those specifications and the application logic consuming those resources.
This means analyzing:
- Dependency versions and security patches that impact efficiency
- Code patterns that are known to be inefficient at scale
- Architectural decisions in Ia C that were reasonable at small scale but are wasteful at scale
- Application logic that consumes more resources than necessary due to algorithm choices or caching decisions
For example, a platform might detect that a service uses a linear algorithm (O(n) complexity) where an indexed lookup (O(log n)) would be appropriate. At small scale, this doesn't matter. At scale—processing 100M records daily—it burns billions of CPU cycles unnecessarily.
2. Real-Time Detection with Actionable Remediation
Historical Fin Ops tools operated on monthly cycles: analyze last month's bill, generate a report, wait for feedback. Modern platforms operate in real-time, with continuous analysis and immediate recommendations.
As soon as a resource is provisioned inefficiently, or as soon as utilization patterns reveal over-provisioning, the system generates a fix and delivers it to the responsible engineer.
Crucially, the fixes are actionable: not vague recommendations, but concrete, tested, ready-to-merge code changes or configuration updates that the engineer can review in seconds.
3. Multi-Layer Visibility Across Infrastructure Stack
Cloud infrastructure is complex. A modern data pipeline might span:
- Compute (EC2, Kubernetes)
- Storage (S3, EBS, RDS, Snowflake)
- Networking (VPCs, load balancers, data transfer costs)
- Managed services (Lambda, Bedrock, API Gateway)
- Third-party data platforms (Databricks, Kafka)
Each layer has its own cost dynamics and optimization opportunities. Most tools focus on one layer—usually compute or storage. The best platforms see across all of them and understand how changes in one layer affect costs in others.
For example, moving data processing from EC2 to a managed service might increase base service costs but decrease data transfer costs, storage requirements, and engineering time. The net impact is impossible to evaluate without seeing all layers simultaneously.

Real-World Case Study: When Optimization Saves Millions
Large enterprises running complex cloud infrastructure regularly discover that shadow waste accounts for 15-25% of their total cloud bill. For a company with
Here's how this materializes in practice: a mid-sized streaming platform spent $8M annually on cloud infrastructure. A comprehensive optimization analysis revealed:
-
Database over-provisioning: $1.2M annually. Multiple database instances were provisioned for peak load but operated at 30% utilization 90% of the time. Implementing auto-scaling policies and consolidating underutilized instances was achievable in weeks.
-
Redundant machine learning pipelines: $800K annually. Three separate teams had built similar recommendation engines independently. Nobody knew about each other's work. Consolidating to a single platform reduced compute and storage requirements by 70%.
-
Stale infrastructure from deprecated products: $600K annually. Two product lines had been sunset, but their cloud resources—databases, caches, compute nodes—had never been decommissioned. They'd been running for 18 months unused.
-
Inefficient batch processing: $2.1M annually. Legacy batch jobs written for on-premise systems were running with 10x over-provisioning due to architect assumptions that didn't apply in cloud. Modernizing these jobs with cloud-native approaches reduced costs by 60%.
-
Suboptimal caching strategies: $1.3M annually. Application-level caching was misconfigured, causing redundant database queries. Fixing this reduced database load by 40%.
Total annual waste:
For a company with $50M+ in cloud spend, similar economics apply. Recovering 15-20% of cloud spend through optimization is standard. For many enterprises, this is more achievable than negotiating volume discounts or rearchitecting workloads.

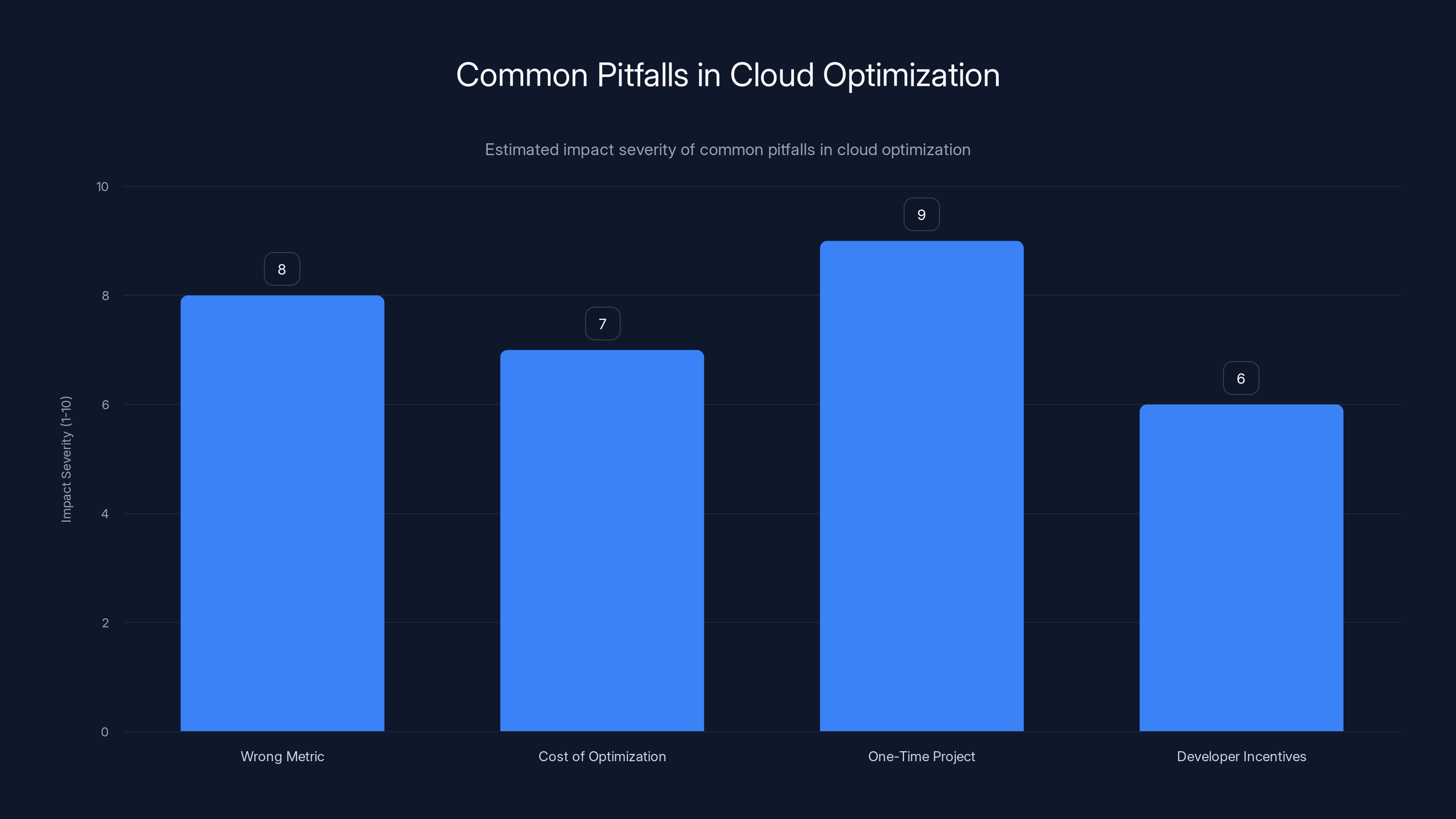
This chart estimates the severity of common pitfalls in cloud optimization, highlighting the importance of continuous and well-aligned optimization strategies. Estimated data.
The AI Paradox: Why Generative AI Accelerates Cloud Waste
Here's an uncomfortable truth: the AI boom has simultaneously accelerated cloud spending and cloud waste.
Engineers are shipping code faster than ever. AI-assisted development tools like AI coding agents make it trivial to generate solutions quickly. But "quick" doesn't always mean "efficient." Code written with AI assistance is often structurally sound but resource-inefficient—it works, but it wastes compute cycles.
This creates a paradox: the tools that make teams most productive are also the tools that make them most wasteful.
Why AI-Generated Code Tends Toward Inefficiency
Large language models trained on internet-scale code repositories inherit the efficiency characteristics of that code. Since the majority of code in public repositories was written without strict efficiency constraints, the AI models learn to generate code that's correct but not optimal.
A few specific patterns emerge consistently:
-
Over-generous resource allocation: AI models generate code that provisions conservatively (more resources than necessary) to avoid performance issues. This is the safe choice, so it's the common pattern in training data.
-
Redundant abstraction layers: AI tends to add abstraction layers for flexibility, even when the use case doesn't require it. This adds computational overhead.
-
Inefficient data access patterns: AI models struggle with optimization knowledge that's implicit in specialized domains. For instance, AI might generate code that does full table scans where indexed lookups would be more efficient.
-
Duplicate implementations: When AI is used to generate similar features across multiple codebases, it often recreates the same logic independently rather than reusing existing solutions.
The irony is that these inefficiencies are easily fixed—sometimes by running that same AI code through a different AI system designed to optimize rather than generate.
The LLM Provisioning Problem
The newest source of waste comes from incorrect provisioning decisions for large language models.
When you run inference on hosted LLM services, you face a fundamental tradeoff: pay per-token with no commitment, or commit to a token throughput level and pay less per-token. Most companies over-commit because they're afraid of hitting capacity limits and degrading user experience.
Analyzing six months of production data from companies running LLMs at scale, typical patterns are:
- Peak load: 100K tokens/minute (during peak hours)
- Average load: 40K tokens/minute (across full 24-hour period)
- Commitment level: 90K tokens/minute (conservative to avoid throttling)
This company is paying for 90K but using 40K on average. They're paying a premium for idle capacity 75% of the time.
The optimization? Commit to 50K tokens/minute, monitor for throttling (which will reveal itself immediately if peak loads exceed the commitment), and adjust if needed. This saves 40-45% on LLM inference costs.

Building an Engineering-First Cloud Governance Strategy
Transitioning from finance-first to engineering-first cloud governance requires organizational changes, not just technology.
Reframing Cost as an Engineering Metric
First, cloud efficiency must become a core engineering metric—tracked the same way teams track latency, error rates, and throughput.
This means:
- Surfacing cost data in engineering dashboards, not hiding it in finance reports
- Including efficiency metrics in sprint planning, so teams consider cost alongside performance
- Connecting cost impact to engineer reviews, so optimization is recognized as valuable work
- Creating clear ownership, so each team knows which infrastructure they control and what it costs
Most companies have this backwards. Engineers optimize for performance. Finance tries to optimize for cost. The two goals conflict because the teams aren't connected.
Creating Feedback Loops Between Code and Cost
Engineers need visibility into how their code impacts cloud costs in real-time, not in retrospective monthly reports.
This requires:
- Cost attribution at the service level, so teams see the total cost of their infrastructure
- Deployment-time cost predictions, so engineers know the cost impact before shipping code
- Monitoring dashboards that show efficiency metrics (cost per request, cost per transaction, cost per user)
- Alerts when efficiency degrades, similar to performance alerts
When an engineer ships a code change that doubles infrastructure costs, they should know immediately, not discover it three weeks later in a finance report.
Automating Remediation to Reduce Manual Effort
The most sophisticated organizations automate not just detection, but remediation.
Instead of flagging inefficiencies and requiring manual fixes, systems deliver proposed solutions directly:
- A pull request with the specific code change, tested and ready to merge
- A Slack notification with the 30-second overview and the CTA to review
- Integration into the engineer's existing workflow (Jira, Git Hub, Slack)
This removes friction from optimization. Rather than treating it as a special project, it becomes part of the normal development process.
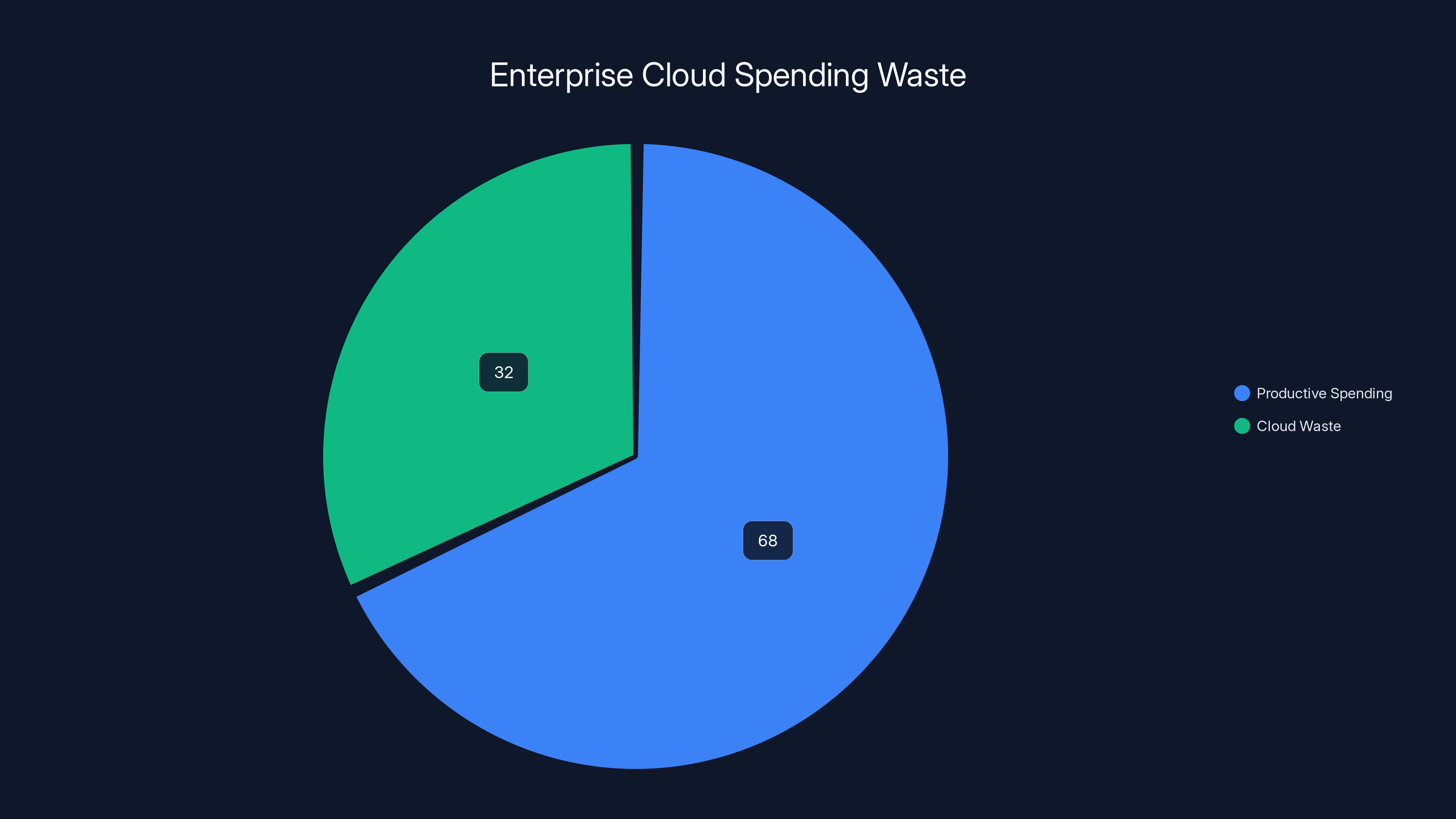
Industry research indicates that up to 32% of enterprise cloud spending is wasted on inefficiencies such as idle resources and over-provisioned infrastructure.
Measuring the Impact: Key Metrics for Cloud Optimization
When you shift to engineering-first optimization, you need new metrics to measure success.
Cost per Unit of Value
Instead of "total cloud spend," track cost per meaningful unit of value:
This metric isolates cost efficiency from business growth. A company can grow revenue 50% while reducing cost per transaction by 15%—the only metric that matters is the ratio, not the absolute spend.
Resource Utilization Rate
For each major resource category, track actual utilization vs. provisioned capacity:
Healthy services operate at 40-70% utilization (high enough to justify the cost, low enough to handle spikes). Anything below 30% is over-provisioned. Anything above 80% is under-provisioned.
Waste Detection and Remediation Velocity
Measure how quickly organizations detect waste and implement fixes:
- Detection latency: Time from waste manifestation to identification
- Remediation latency: Time from identification to fix deployment
- Automation rate: Percentage of fixes that are automatically applied vs. requiring manual intervention
Organizations using modern optimization platforms report detection latencies of hours to days (vs. weeks to months for manual analysis) and remediation latencies of days to weeks (vs. months for traditional Fin Ops processes).
The Multi-Cloud Optimization Challenge
As enterprises distribute workloads across AWS, Google Cloud, Azure, and specialized platforms like Databricks and Snowflake, optimization becomes exponentially more complex.
Each cloud has different pricing models, different resource types, different optimization opportunities. A strategy that works on AWS (buy Reserved Instances) might be suboptimal on GCP (use Committed Use Discounts with different dynamics) or Azure (use Hybrid Benefit).
Modern optimization platforms address this by understanding each cloud's unique characteristics:
- AWS: EC2 instance sizing, Reserved Instances, Spot Instances, data transfer costs
- Google Cloud: Committed Use Discounts with different commitment periods, sustained use discounts, recommendation engine
- Azure: Hybrid Benefit, Reserved Instances, savings plans
- Databricks: Cluster auto-scaling, job batching, photon acceleration
- Snowflake: Warehouse auto-suspend, scaling policies, materialized views vs. on-demand queries
Optimizing across all these simultaneously requires understanding not just cost, but also the performance and reliability implications of each optimization decision.
Common Pitfalls and How to Avoid Them
Pitfall 1: Optimizing for the Wrong Metric
Many teams optimize for absolute cloud spend reduction without considering the business impact.
Reducing spend by 30% while increasing latency by 500ms might be a terrible trade-off if you run a real-time platform where latency directly impacts user experience. Optimizing infrastructure cost while degrading reliability is penny-wise and pound-foolish.
Solution: Optimize for cost per unit of value (cost per transaction, cost per user, cost per revenue dollar), not absolute cost reduction.
Pitfall 2: Ignoring the Cost of Optimization Itself
Some optimization efforts require engineering effort that costs more than the savings they generate.
If you spend three engineer-months rearchitecting infrastructure to save
Solution: Measure the ROI of optimization efforts before committing. Quick wins (configuration changes, version upgrades) should be prioritized over architectural changes.
Pitfall 3: Treating Optimization as a One-Time Project
Cloud environments are dynamic. Code changes, workloads shift, new services launch. Yesterday's optimal configuration is today's inefficiency.
Organizations that optimize once then never revisit waste find themselves right back where they started within 12-18 months.
Solution: Implement continuous optimization as an ongoing process, not a one-time initiative. Automate detection and remediation so optimization happens continuously without significant engineering effort.
Pitfall 4: Failing to Align with Developer Incentives
If engineers don't feel ownership over cloud costs, they won't prioritize optimization.
Solution: Make engineers directly responsible for the cost of infrastructure they control. Surface cost metrics in their monitoring dashboards. Include cost efficiency in performance reviews and promotions.

Future Trends: Where Cloud Optimization Is Heading
The cloud optimization landscape continues to evolve rapidly.
AI-Native Optimization
Optimization platforms themselves are becoming AI-native. Rather than applying hand-coded rules ("if utilization < 30%, recommend downsizing"), systems now use machine learning to identify optimization opportunities by analyzing complex patterns in utilization, cost, and performance data.
This enables detection of subtle inefficiencies that would be invisible to rule-based systems.
Predictive Resource Sizing
Instead of reacting to current utilization patterns, predictive optimization systems forecast resource needs based on historical growth patterns and future workload projections.
This allows teams to right-size infrastructure proactively rather than reactively, reducing both over-provisioning and under-provisioning.
Cost as a First-Class Design Constraint
As cloud costs become more visible and material, cost will shift from an afterthought to a core design constraint—similar to how performance and reliability are treated today.
Architecture decisions will explicitly trade off cost, performance, and reliability. Team will document cost implications alongside architecture decisions.

FAQ
What is cloud waste?
Cloud waste refers to unused or underutilized cloud infrastructure and resources that incur costs without delivering proportional value. This includes idle servers, over-provisioned databases, redundant workloads, outdated code running inefficiently, and infrastructure from deprecated projects that haven't been decommissioned. Industry research shows up to 32% of enterprise cloud spending is wasted on these types of inefficiencies.
How does cloud optimization actually reduce costs?
Cloud optimization works through detection, remediation, and continuous monitoring. Modern platforms scan your infrastructure and code to identify inefficiencies, trace them back to specific code or configuration, and deliver fixes directly to engineers. This is different from traditional approaches that only show you dashboards. By automating the identification and fixing of shadow waste, enterprises typically recover 15-25% of their cloud spending.
What's the difference between cloud cost management and cloud waste optimization?
Cloud cost management (traditional Fin Ops) focuses on financial visibility—showing you spending trends, forecasting future bills, and negotiating volume discounts. Cloud waste optimization focuses on engineering efficiency—identifying and fixing the underlying reasons for waste. Cost management answers "how much are we spending?" while optimization answers "why are we spending this much and how can we fix it?"
Why doesn't AI-generated code tend to be efficient?
AI language models are trained on millions of code repositories from the internet. Since the majority of this code was written without strict efficiency constraints, AI models learn to generate code that's correct and safe but not necessarily efficient. AI tends to over-provision resources to avoid failures, add abstraction layers for flexibility, and miss domain-specific optimizations that experts would implement. The code works, but it's wasteful.
How do you calculate ROI for cloud optimization initiatives?
ROI for cloud optimization is calculated as: (Annual Savings from Optimization) - (Cost of Optimization Effort) = Net Annual Benefit. Divide net benefit by total effort cost to get ROI percentage. Quick-win optimizations like dependency version updates or configuration changes typically have 10:1 to 100:1 ROI. More complex architectural changes might only have 2:1 to 5:1 ROI, so prioritizing quick wins first makes financial sense.
Can you optimize cloud costs across multiple cloud providers simultaneously?
Yes, but it requires understanding each cloud's unique pricing model and optimization strategies. AWS benefits from Reserved Instances, Google Cloud from Committed Use Discounts, and Azure from Hybrid Benefit. Modern multi-cloud optimization platforms understand these differences and apply provider-specific strategies while maintaining consistency in overall optimization approach across your entire cloud footprint.
What metrics should we track to measure cloud optimization success?
Key metrics include: cost per unit of value (cost per transaction, per user, or per revenue dollar), resource utilization rate (comparing actual usage to provisioned capacity), waste detection latency (how quickly inefficiencies are identified), remediation latency (how quickly fixes are implemented), and automation rate (percentage of fixes applied automatically vs. manually). Healthy organizations track all these metrics and trend them monthly.
How often does cloud waste re-accumulate after optimization?
Without continuous monitoring, cloud waste typically re-accumulates within 12-18 months as new code is deployed, workloads shift, and infrastructure patterns change. This is why treating optimization as a one-time project is ineffective. Organizations implementing continuous optimization—automated detection and remediation—maintain efficiency gains indefinitely. The key is automation; if fixes require manual engineering effort, the process won't sustain.

Conclusion: From Financial Problem to Engineering Solution
Cloud waste represents one of the largest unaddressed cost problems in enterprise technology. Yet for years, the industry tried to solve it with the wrong tools—financial dashboards that informed without enabling action, designed for accountants rather than engineers.
The shift underway now is fundamental: treating cloud waste as an engineering problem requiring engineering solutions. This means visibility, detection, and remediation at the code level. It means delivering fixes to the engineers who created the inefficiencies, in the tools they use daily, with clear explanations of the impact.
For enterprises with significant cloud spend—
The companies seeing the biggest results aren't the ones with the most advanced dashboards. They're the ones that automated detection and remediation into their development workflows. They're the ones that made cost a first-class metric, tracked alongside latency and error rates. They're the ones that trust engineers to optimize infrastructure efficiency, rather than asking finance teams to enforce cost discipline.
If 32% of your cloud spend is wasted—and statistically, it probably is—the question isn't whether you should optimize. It's how quickly you can implement optimization systems that enable your engineers to fix it. The longer you wait, the more money evaporates.

Key Takeaways
- 32% of enterprise cloud spending is wasted on inefficient code, over-provisioned resources, and redundant infrastructure
- Traditional FinOps tools are financial solutions trying to solve engineering problems—they show costs without enabling fixes
- Cloud-to-Code detection traces infrastructure back to specific code lines and engineers, enabling direct remediation in developer workflows
- Shadow waste (inefficiencies traditional tools miss) accounts for 60% of total waste and requires code-level intelligence to detect
- Engineering-first optimization automates detection and fix delivery, reducing remediation time from months to days and recovering 15-25% of cloud spend
- AI-generated code tends toward inefficiency due to training data bias, creating new optimization opportunities and challenges
- Enterprises with 7.5-12.5M annually through systematic shadow waste elimination
- Continuous optimization with automation is essential—waste re-accumulates within 12-18 months without ongoing monitoring
Related Articles
- GPU Memory Crisis: Why Graphics Card Makers Face Potential Collapse [2025]
- AMD vs Intel: Market Share Shift in Servers & Desktops [2025]
- How Cloud Storage Transforms Sports Content Strategy: Wasabi & Liverpool FC [2025]
- IT Spending Hits $1.4 Trillion in 2026: Where Money Really Goes [2025]
- OpenAI Ads in ChatGPT: Why Free AI Just Got Monetized [2025]
- Why Apple Chose Google Gemini for Next-Gen Siri [2025]

