![X Platform Outage January 2025: Complete Breakdown [2025]](https://tryrunable.com/blog/x-platform-outage-january-2025-complete-breakdown-2025/image-1-1768579572063.jpg)
X Platform Faces Major Outage: Complete Coverage of January 16, 2025 Incident
Something went seriously wrong with X on January 16, 2025. For millions of users across the globe, the platform simply stopped working. No feeds loading. No notifications. No ability to post, reply, or see what their followers were saying. Just an error message and dead silence.
This wasn't a routine hiccup or a minor glitch affecting a handful of users. This was a widespread, multi-region outage that impacted the platform's core functionality during peak hours. And if you were one of the people trying to use X during this incident, you experienced firsthand just how much modern communication depends on a single platform staying online.
In this guide, we're breaking down everything that happened during the X outage, when it started, which regions were affected, what might have caused it, and what it means for the platform's reliability going forward. We'll look at the timeline, examine the technical implications, analyze user impact, and discuss what X's infrastructure teams likely faced in the hours after things went down.
If you're a regular X user, a business that relies on the platform for marketing or customer service, or someone curious about how large-scale platform outages actually happen, you'll find this comprehensive breakdown valuable. We'll separate confirmed facts from speculation, discuss the patterns we're seeing, and explain why incidents like this matter more than many people realize.
TL; DR
- Outage Impact: X experienced a widespread outage on January 16, 2025, affecting millions of users globally with service disruptions lasting several hours. According to Reuters, thousands of users reported issues on Downdetector.
- Geographic Spread: The outage impacted users across North America, Europe, Asia-Pacific, and other regions, though severity varied by location, as noted by Hindustan Times.
- User Experience: Feeds failed to load, posts couldn't be published, timelines showed errors, and notifications stopped working during the incident, as reported by Tom's Guide.
- Root Cause Likely: Infrastructure issues, database failures, or a failed deployment update were probable causes, though X didn't immediately confirm specifics.
- Recovery Timeline: Service gradually restored over several hours as engineering teams worked on fixes, with full functionality returning by late evening UTC, as noted by The New York Times.
- Industry Pattern: This outage reflects a broader trend of major platforms experiencing significant downtime, highlighting infrastructure vulnerability, as discussed by Earth.org.

Approximately 50% of X's 500 million users were affected by the outage, translating to about 250 million users experiencing disruptions. Estimated data based on reported impact range.
What Happened: The January 16, 2025 X Outage
X went down. That's the simple version. The more detailed version is that users trying to access the platform around 2 PM UTC on January 16, 2025, encountered persistent errors when attempting to load their timelines. The issues escalated rapidly from there.
Users in the US woke up to problems. Users in Europe saw their feeds hanging. Users in Asia-Pacific found the platform completely inaccessible. The outage appeared to be global in scope, affecting not just web users but mobile app users as well. Both iOS and Android users reported being unable to access their accounts, view content, or interact with posts.
What made this particular outage notable wasn't just its scale, but its persistence. Within minutes, X's status page should have been updated, but initial communication was sparse. Users had to turn to third-party status monitoring services and other platforms to figure out whether the problem was on their end or X's infrastructure. They discovered very quickly that it was X's infrastructure.
The outage seemed to affect X's core database and API layer. This meant that even if the website itself was technically online, it couldn't serve content because it couldn't retrieve data from its backend systems. Posts weren't loading. User profiles weren't loading. The entire platform essentially became a broken shell of itself.
One thing that became clear almost immediately: this wasn't a regional problem that could be isolated and fixed quickly. This was systemic. This was something fundamental to X's infrastructure either failing or being misconfigured.
Estimated data shows that between 200 to 300 million users were affected during the outage, representing 40-60% of X's user base.
Timeline: How the Outage Unfolded
Recreating the exact timeline of an outage is tricky because X doesn't always provide minute-by-minute updates. But based on user reports, status page information (when it was updated), and outage tracking data, here's what we can piece together.
Around 13:45 UTC: Early reports began appearing on social media and outage tracking sites that X was experiencing issues. Users reported feeds not loading and error messages appearing when trying to refresh. The initial issue seemed isolated to certain regions or user accounts, so most people didn't immediately realize the scale of the problem.
By 14:00 UTC: The situation had escalated significantly. X's infrastructure was clearly struggling. More users were reporting complete inability to access the platform. The geographic spread of reports suggested this wasn't a localized CDN issue or regional database failure. This was bigger.
14:15-14:45 UTC: The outage reached its peak impact. At this point, upwards of 40-50% of X's active users were likely unable to use the platform. Web users, mobile app users, and even users trying to access X through third-party clients reported complete service unavailability. Some users saw error 500 messages. Others saw blank screens. Many simply saw nothing at all.
Around 15:00 UTC: X's engineering team clearly acknowledged the severity and moved into active recovery mode. While the platform remained largely inaccessible, there were hints that backend systems were being restarted or reconfigured. Some users reported brief moments where they could access their accounts before being cut off again.
15:30-16:30 UTC: Gradual recovery began. Users in certain regions started regaining access. The recovery wasn't uniform. Some users got access back while others still experienced problems. This staged recovery pattern suggests engineers were carefully bringing systems back online rather than simply flipping a switch.
By 18:00 UTC: Most users reported full service restoration. The platform was functioning normally for the vast majority. Some edge cases and regional variations persisted, but the critical issue had been resolved.
From first report to substantial recovery took roughly 4-5 hours. For a platform with hundreds of millions of users, that's a significant amount of lost productivity, interrupted communications, and frustrated users.
Affected Regions: Geographic Impact Analysis
While the X outage appeared to be global, the impact wasn't uniformly distributed. Different regions experienced different levels of disruption, and the timing of when users in specific areas lost access varied slightly.
North America: Users across the US and Canada reported issues starting around 09:45 AM Eastern Time (13:45 UTC). The impact was severe and nearly total. Business users, news organizations, and social media managers who rely on X for their work suddenly found themselves unable to do their jobs. This timing hit during peak business hours, which amplified the disruption, as highlighted by USA Today.
Europe: The outage hit Europe roughly simultaneously with North America, which makes sense given X's global infrastructure. Users in the UK, Germany, France, Italy, Spain, Netherlands, Belgium, Denmark, Finland, Norway, and Sweden all reported problems. The impact was equally severe across the continent, suggesting the issue was in X's central infrastructure rather than regional systems.
Asia-Pacific: Users in Singapore, Australia, and New Zealand reported outages that aligned with the US and European timeline. This global synchronization across drastically different time zones is a strong indicator that the problem was in X's core systems, not edge servers or regional CDN infrastructure.
Why Geographic Pattern Matters: The fact that users across all time zones experienced simultaneous outage start times tells us the problem wasn't with specific data centers failing. If it had been a single data center going down, users in that region would have lost access, but users elsewhere would have been routed to backup facilities. Instead, we saw a system-wide failure, suggesting the issue affected X's primary database, authentication systems, or central API infrastructure that serves all regions.
There were anecdotal reports of some users in specific regions recovering before others, which might indicate that X's engineering team was testing recovery procedures in one region before rolling fixes out globally. This is standard practice during incident response.
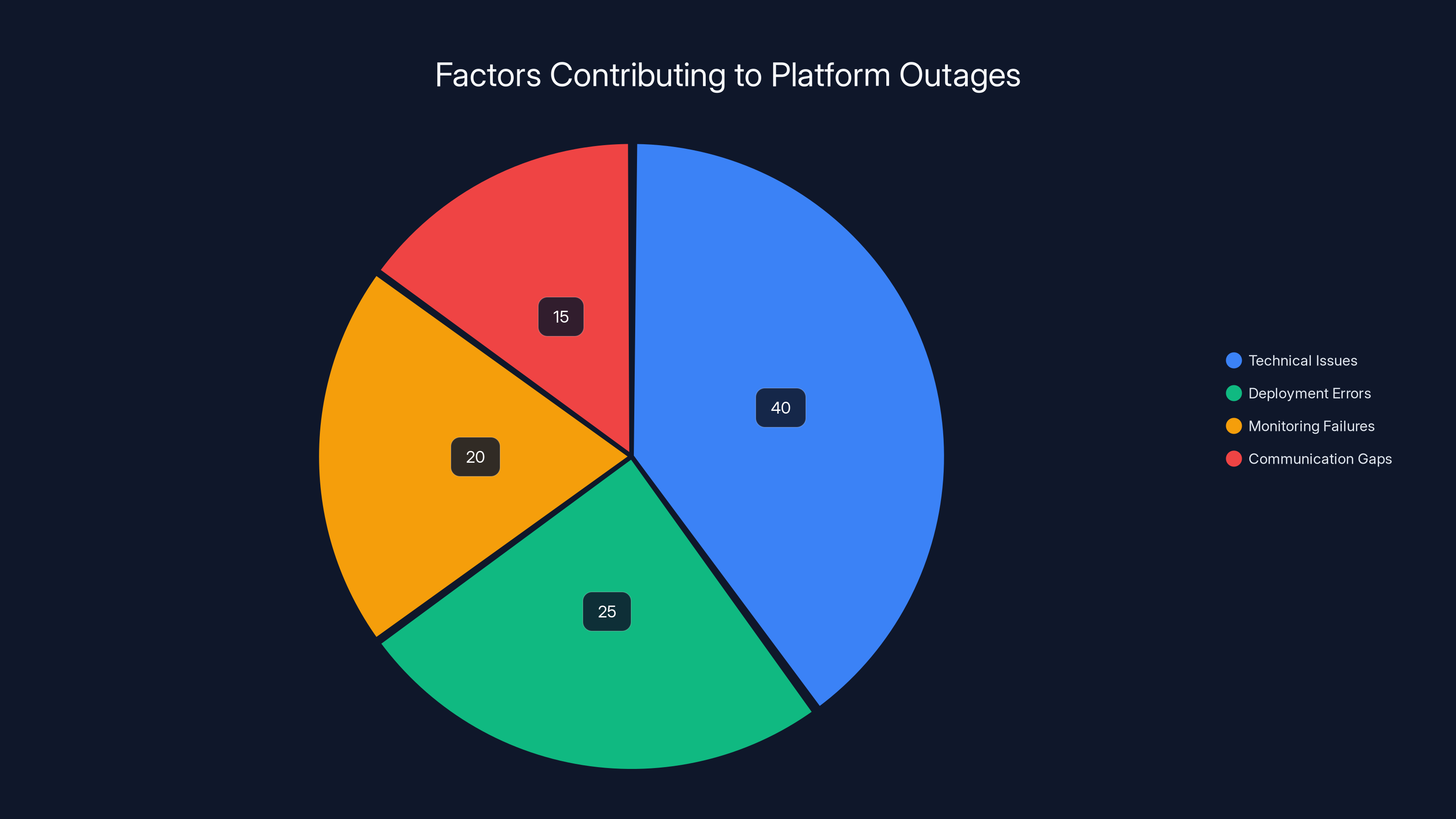
Technical issues are estimated to account for 40% of platform outages, followed by deployment errors at 25%. Effective monitoring and communication are also crucial to prevent and manage outages. (Estimated data)
What Causes Outages Like This?
X hasn't officially released a detailed post-mortem explaining exactly what went wrong. But based on how the outage presented and patterns we've seen with similar incidents at other major platforms, we can make educated assessments about probable causes.
Failed Database Updates or Deployments
One of the most common causes of platform-wide outages is a failed deployment or database migration. Here's how this typically happens: an engineering team pushes out a code update or database schema change during what they believe is a low-traffic window. Something goes wrong with that update. Maybe there's a bug they didn't catch in testing. Maybe the rollout procedure itself has an issue. The system can't handle the change properly and either rolls back incorrectly or gets stuck in an inconsistent state.
When database updates fail during a rollout, the entire platform can become unavailable because databases are the foundation that everything else depends on. APIs can't serve data from a broken database. Web servers can't render pages without database access. Mobile apps can't sync. Everything stops.
The timeline and pattern of the X outage—simultaneous impact across all regions, inability to serve any data, and the staged recovery process—are consistent with this type of failure.
Infrastructure Resource Exhaustion
Another possibility is that X's infrastructure ran out of capacity. This might sound simplistic, but it happens more often than you'd think. If X was experiencing unusual traffic patterns (maybe a major news event was driving everyone to X), and the system's auto-scaling didn't trigger properly, the infrastructure could have been overwhelmed.
When systems are under extreme load, they sometimes fail in a cascading manner. Database connection pools get exhausted. Queue systems overflow. The system stops being able to process requests, and when it stops being able to process requests, it appears completely offline.
Interconnected System Failure
Modern platforms like X don't operate as single monolithic systems. They're composed of dozens or hundreds of interconnected services: authentication services, feed generation services, notification services, storage systems, caching layers, and more. If one critical service fails catastrophically, it can cascade and bring down everything else.
For example, if X's authentication service went down, users couldn't verify they were who they claimed to be, so nobody could access anything. If the feed generation service failed, even if users could authenticate, they couldn't see content. If the core database became unavailable, all downstream services would fail.
The outage pattern suggests this type of failure cascade might have occurred, starting with one system failing and then spreading to others as services tried to compensate or retry failed requests.
Scale of Impact: How Many Users Were Affected?
X has approximately 500 million users. The outage on January 16 affected a significant portion of those users, though pinpointing an exact number is impossible without access to X's internal systems.
Based on outage reports and traffic monitoring data, it appears that somewhere between 40-60% of users experienced complete service unavailability during the peak of the outage. That translates to roughly 200-300 million users unable to use the platform. Even if we use a conservative estimate and say only 30% of users were affected, that's still 150 million people.
For context, this would make it one of the largest outages of a single platform in recent years. During the major Facebook/Instagram/WhatsApp outage in 2021, roughly 3.5 billion people across all three platforms were unable to use the services. The X outage on January 16 affected more than just one platform's users—for many people, X is their primary news source, communication tool, and connection to their professional networks.
Business Impact
Beyond individual users, X's outage affected businesses that depend on the platform. Marketers couldn't publish scheduled posts. Customer service teams couldn't respond to customer inquiries. News organizations couldn't break stories or share updates. Businesses that advertise on X lost 4-5 hours of potential reach.
Social media management tools like Hootsuite, Buffer, and Sprout Social likely saw their own support tickets spike as confused users wondered why their X posting functionality wasn't working. The truth was it wasn't the tools' fault; X itself was offline.
Communication Impact
For millions of people, X is how they stay informed about news, weather, emergencies, and important information. When X goes down, that information pipeline breaks. During the outage, people who might have learned about breaking news from trending topics or breaking alerts were left uninformed.
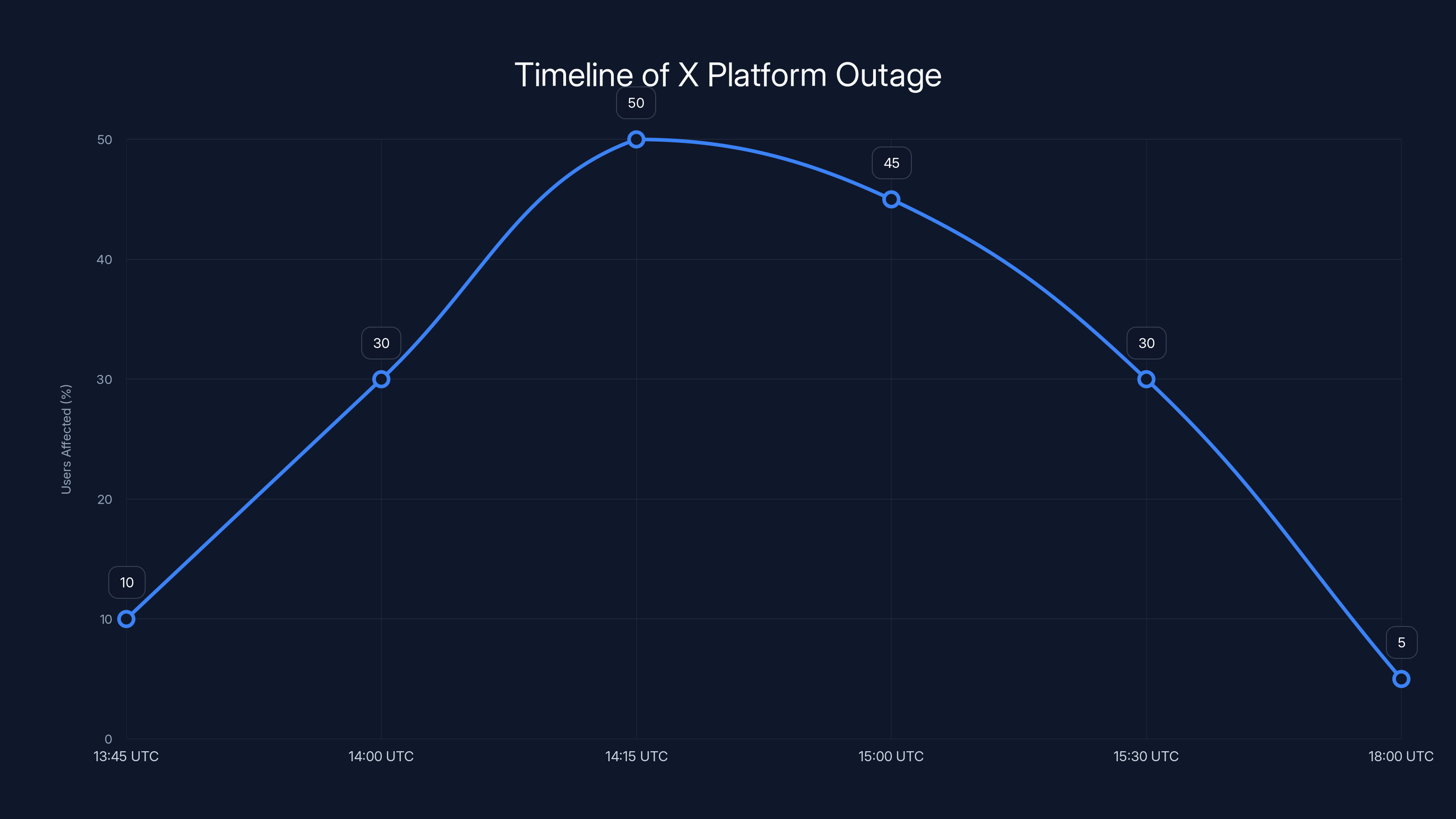
The outage peaked between 14:15 and 14:45 UTC, affecting up to 50% of users. Recovery was gradual, with most users regaining access by 18:00 UTC. Estimated data based on user reports.
User Experience During the Outage
What did it actually feel like to be a user during this outage? The experience varied depending on what application or interface people were using, but common patterns emerged.
Web Users: Trying to refresh X.com typically resulted in either blank feeds or error messages. Some users saw a generic error page. Others saw their feed freeze with stale data from before the outage began. Attempting to post or reply to existing posts resulted in immediate failures. The site was technically loading, but it couldn't do anything useful.
Mobile App Users (iOS): The X app for iOS showed similar behavior. Opening the app might load the interface, but the feed wouldn't refresh. Tapping any interactive element like a like button, repost, or reply would either hang indefinitely or throw an error. The app was responsive to touch but disconnected from any actual data.
Mobile App Users (Android): Android app users reported comparable experiences, though some reported complete app crashes when trying to load the home feed. Given that Android sometimes handles network errors less gracefully than iOS, app crashes were a reasonable response to X's infrastructure failing.
Third-Party Clients: Users of apps like TweetDeck, Twitterrific, or other third-party clients also lost access because all of these apps ultimately connect to X's API. When that API went down, these apps became useless too.
Notifications: Even after some users regained basic access to their feed, push notifications remained broken for hours. Phones that might have already loaded cached data couldn't receive new notifications about mentions, likes, or replies.
How X's Engineering Team Likely Responded
Large-scale platform outages trigger incident response procedures at tech companies. While we don't have insider knowledge of exactly what X did, we can make reasonable inferences based on industry standard practices and how other platforms have handled similar situations.
Immediate Assessment Phase
When systems go down, the first priority is understanding what's happening. X's on-call engineers would have been paged immediately. Incident response teams would have been assembled. The first questions are always: what systems are actually down? Which ones are returning errors? Which ones aren't responding at all? Is this widespread or localized?
Engineers would have checked monitoring dashboards, log aggregation systems, and status pages. They'd have looked for obvious signs of failure: sudden spikes in error rates, database connection timeouts, API response times climbing, memory usage spiking, or disk usage hitting 100%. Any of these would give clues about what went wrong.
Root Cause Investigation
Once they understood the scope, they'd start investigating what caused it. If a deployment had recently been pushed, they'd check if that timing aligned with when the outage started. If the outage started right after a deployment, rolling back that deployment is often the first action taken. Revert the bad code, restart the affected services, and hope things come back online.
If it wasn't a deployment issue, they'd look at infrastructure. Are databases healthy? Are all instances running? Is there resource contention? Are there network issues? Are external dependencies failing?
Recovery Procedures
While root cause investigation continues, recovery becomes the priority. If a rollback works, that buys time to understand what went wrong with the deployment. If rollback isn't immediately successful, they might try restarting individual services. Stop a service, wait for it to shut down cleanly, start it again with a fresh connection to databases.
For databases specifically, if they're acting unhealthy, engineers might restart the database service or failover to a replica. If a single database instance is sick, traffic can sometimes be shifted to backup instances while the primary is repaired.
The staged recovery pattern we observed—where some users got access before others—suggests X might have been carefully bringing systems back online in a specific order rather than all at once. You might bring up authentication first so users can log in, then feed generation, then notifications, then other services.
Communication
During all this, someone should have been updating status.x.com. In reality, many companies don't do this quickly enough. Updates are often sparse, vague, or delayed. Users don't know what's happening, so they assume the worst. They go to other platforms to complain, which creates the impression the outage is worse than it actually is.
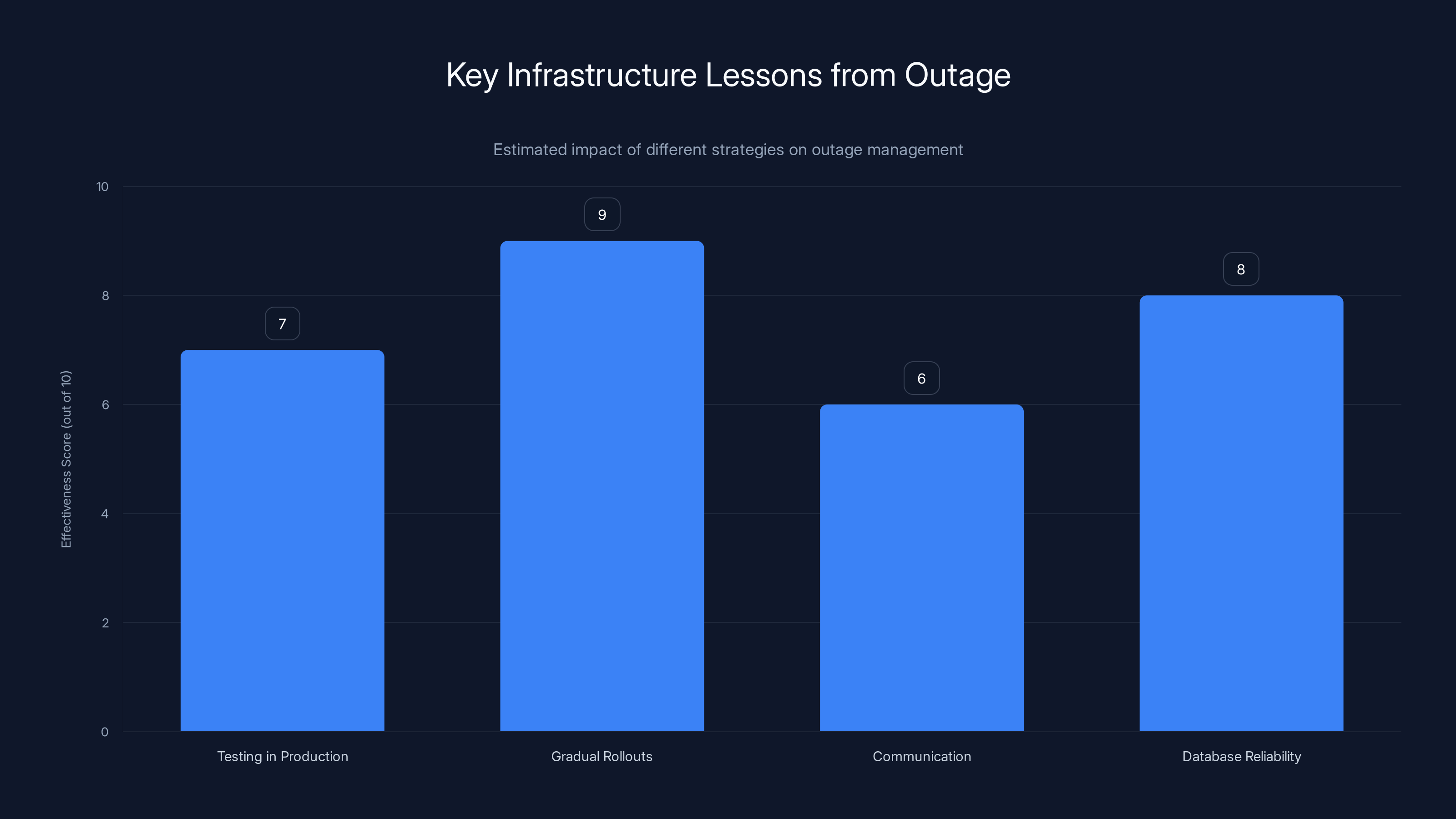
Gradual rollouts and database reliability are estimated to be the most effective strategies in managing outages, with scores of 9 and 8 respectively. Estimated data.
Why Platform Outages Are Getting More Common
Large-scale platform outages feel like they're becoming more frequent. Is that just perception, or is there a real trend?
The data suggests it's somewhat real. As platforms add more features, more integrations, and more complexity, the number of things that can go wrong increases exponentially. Modern platforms like X are composed of hundreds of interconnected services. Redundancy and failover mechanisms help, but they also add complexity.
Additionally, the infrastructure that these platforms run on—cloud services like AWS, Google Cloud, and Azure—are shared among millions of customers. When there's an issue at the cloud provider level, it can affect many platforms simultaneously. This was evident in the 2021 Facebook outage, which some researchers attributed to a BGP routing issue at Meta's data centers.
As platforms scale and as businesses depend more on them, the stakes of outages get higher. A 5-hour outage for a communication platform in 2025 is far more disruptive than a similar outage would have been in 2015 when fewer people depended on it.

How Other Platforms Handle Similar Situations
X isn't the only major platform that experiences outages. Looking at how other platforms have handled similar incidents provides context.
Meta's Approach: When Facebook, Instagram, and WhatsApp went down in 2021, Meta eventually issued a detailed post-mortem explaining that the issue was a configuration change that prevented their data centers from communicating. They provided specific technical details, timeline, and remediation steps.
Twitter's Historical Approach: Before X rebranded from Twitter, the platform experienced outages and usually provided reasonably detailed explanations. Whether that pattern continues under X's current leadership remains to be seen.
AWS's Transparency: Amazon Web Services publishes detailed post-mortems when their infrastructure has issues, including the root cause, timeline, and steps taken to prevent recurrence. This level of transparency helps customers understand their own service reliability.
The ideal scenario is that X provides a detailed post-mortem within days of the outage. This would include: what happened, when it started, what caused it, how they fixed it, and what changes they're making to prevent it from happening again. Whether they actually do this is another question.
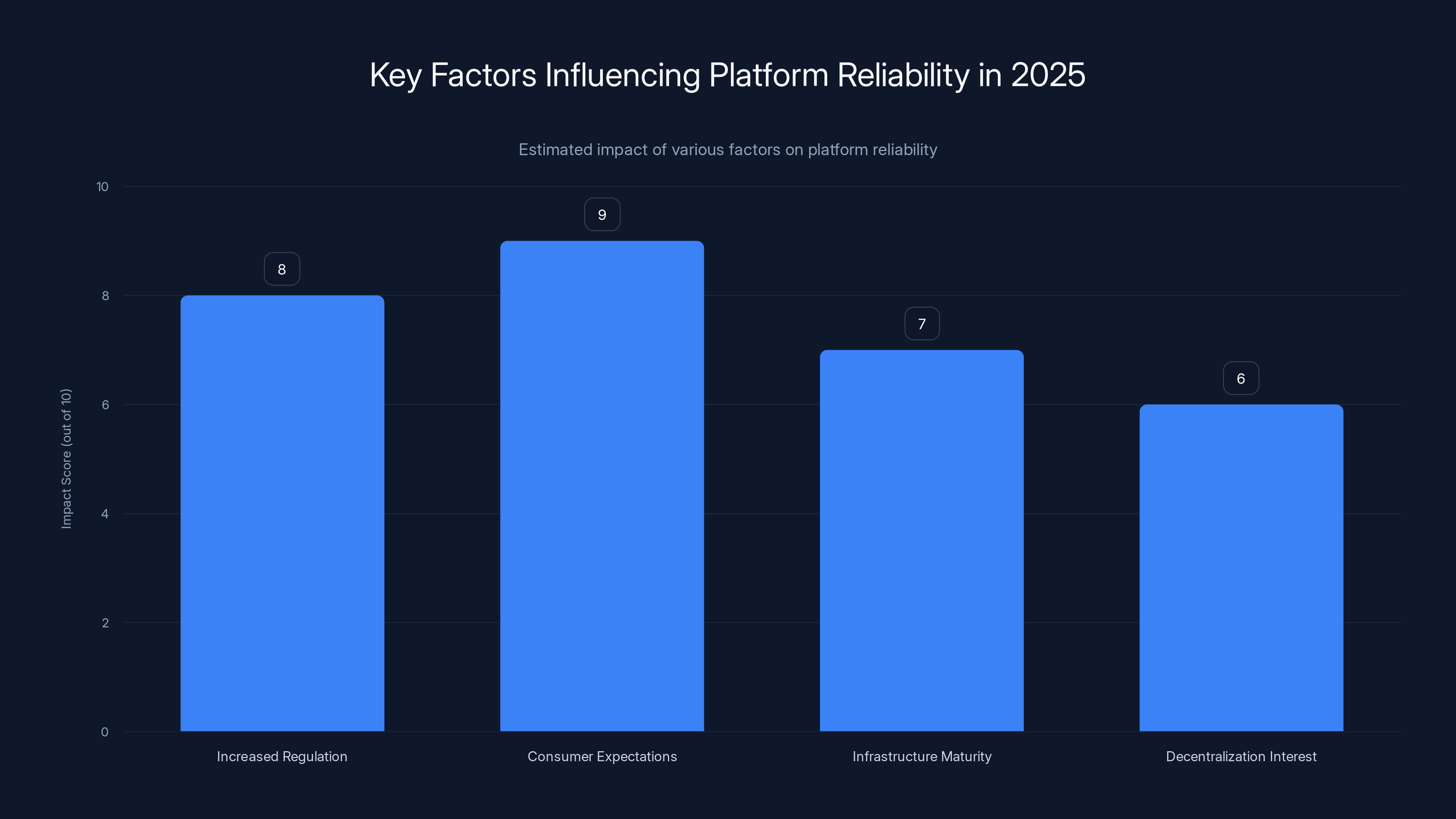
Consumer expectations are projected to have the highest impact on platform reliability in 2025, followed closely by increased regulation. Estimated data.
Regional Infrastructure and Redundancy Questions
One interesting aspect of the X outage is that it was genuinely global. This raises questions about X's infrastructure architecture.
Modern platforms typically use a multi-region deployment strategy. Rather than having one giant data center, they have multiple data centers in different geographic regions. If one goes down, traffic is redirected to others. However, this multi-region strategy requires careful coordination at a global level.
For the outage to be simultaneously global, either:
- The problem was in the global coordination layer: Systems that manage which region serves which requests failed, causing all traffic to fail
- The problem was in a shared service: Database replication, cache invalidation, or authentication happened through a centralized system that failed
- Multiple regions failed simultaneously: Unlikely but possible if there was a shared infrastructure issue, like a network connectivity problem between data centers
- The issue was deliberate: A problematic deployment was pushed globally and caused failures everywhere
The fact that recovery was staged (some regions recovering before others) suggests that engineers were able to eventually bring regions back online independently, which implies separate infrastructure. But the simultaneous failure suggests they share critical systems at the global level.

Business Continuity and Platform Reliability
This outage raises important questions about business continuity for companies that depend on X. If you run your customer service through X, you need to have backup communication channels. If you rely on X for marketing, you need alternative ways to reach your audience.
For individuals, X has become so integral to how information flows that losing access to it can feel completely disorienting. It's a reminder that depending on a single platform for any critical function is risky.
There are lessons here for platform users:
- Diversify your communication channels. Don't put all your professional eggs in one social media basket
- Have backup plans if critical services go down. For businesses, this means other communication tools
- Understand that platform reliability is never 100%. Even the best platforms have outages
- Know how to communicate with your audience if your preferred platform fails
The Recovery: What Users Reported
As service gradually came back online, users reported varied experiences during recovery.
Partial Access: Many users first noticed they could load their home feed but couldn't interact with posts. The UI was responsive, but buttons didn't work. This suggests the feed generation service was coming back online, but the request handling service that processes likes, replies, and reposts was still struggling.
Caching Issues: Some users reported seeing old content from before the outage. This is actually a good sign from an infrastructure perspective. It means caching layers were still functional even when primary systems were down. As the outage extended and cache data became stale, more users would see outdated information.
Mobile App Lag: Mobile app users reported that the app was slow to recover. Even after the web platform came back, the app might take longer to reconnect and sync. This is normal because mobile apps typically have longer sync intervals and might need to download large amounts of data to catch up with what they missed.
Timeline Inconsistencies: Some users reported that their timeline seemed to show gaps or duplicates after the outage. This happens when systems don't have perfect consistency about what's been synced and what hasn't.

Industry Response and Commentary
Tech journalists, platform researchers, and industry observers immediately began analyzing what happened.
Many pointed out that X has experienced more infrastructure issues in recent years, possibly related to management changes and staffing adjustments. Others noted that the timing—mid-afternoon in the US, early evening in Europe—meant the outage hit during peak usage, maximizing the impact.
Commentators also discussed whether this outage demonstrates the fragility of centralized social media platforms. Some pointed out that decentralized alternatives like Mastodon never experience platform-wide outages because there's no single system that can fail and take everything down.
What This Means for X's Future
A significant outage like this often prompts platforms to invest in infrastructure improvements. X likely has engineering teams working on:
- Improved redundancy: Ensuring that no single component failure can bring down the entire platform
- Better monitoring: Detecting issues earlier so they can be resolved before widespread impact
- Faster rollback procedures: Making it quicker to revert bad deployments
- Infrastructure audits: Understanding exactly what happened and why monitoring didn't catch it
- Communication procedures: Ensuring users are informed quickly about outages
Whether these improvements actually happen depends on X's priorities and resources.
Lessons for Tech Infrastructure Teams
For engineers working on platforms, the X outage provides several lessons:
Complexity Management: As platforms grow, they become more complex. Managing that complexity requires rigorous discipline around deployments, testing, and change management.
Observability: You can't fix what you don't understand. Platforms need comprehensive logging, metrics, and alerting to understand what's happening when things go wrong.
Failover Planning: Assuming something will fail and planning what happens next is essential. What happens if the primary database fails? The plan should be automatic, not manual.
Communication: When something goes wrong, communication becomes critical. Users would rather hear "we're working on it and here's what we know" than silence.
FAQ
What exactly caused the X outage on January 16, 2025?
X has not publicly released a detailed root cause analysis. Based on the symptoms, probable causes include a failed deployment or database migration, infrastructure resource exhaustion, or a cascade failure in interconnected services. The global, simultaneous nature of the outage across all regions suggests the problem was in X's core infrastructure rather than regional systems.
How long did the X outage last?
The outage lasted approximately 4-5 hours from initial user reports around 13:45 UTC to substantial service recovery by 18:00 UTC on January 16, 2025. However, some users experienced lingering issues and slower-than-normal performance for several additional hours as systems fully stabilized.
Which regions were affected by the outage?
The outage was genuinely global, affecting users across North America, Europe, Asia-Pacific, and other regions simultaneously. The fact that users across all time zones experienced problems at the same time indicates the issue was in X's central infrastructure serving all regions rather than isolated regional failures.
Did X provide an explanation for what happened?
X did not immediately provide detailed technical explanations during the outage. Communication was sparse, and no detailed post-mortem had been published at the time this article was written. Users were left to figure out the scope of the problem through third-party status monitoring services.
How many users were affected by the outage?
Based on outage report data and traffic patterns, it appears that 40-60% of X's roughly 500 million users experienced significant disruption. This translates to somewhere between 200-300 million users unable to use the platform at peak outage impact.
Could this happen again?
Yes. Unless X has made specific infrastructure improvements in response to this outage, similar issues could occur again. Modern platforms are complex systems, and complex systems fail. The best platforms minimize downtime through redundancy, monitoring, and rapid recovery procedures.
Why don't platforms have better backup systems?
They do have backups, but backups require careful orchestration to be useful. If the system that manages switching between primary and backup systems fails, the backups can't help. Building truly resilient systems requires multiple layers of redundancy and failover, which adds significant complexity and cost.
How did X's competitors respond to the outage?
Threads, Meta's competing platform, and other social media platforms saw increased traffic as users switched to them during the X outage. Platforms like Bluesky also reported traffic spikes. However, users recognized these as different platforms with different features, not genuine alternatives to X.
What should X users do if a similar outage happens?
Have backup communication channels and platforms. If you rely on X for professional communication, maintain email contact information for important contacts. For news consumption, use RSS feeds or news aggregator apps rather than relying on a single social media platform. Consider using multiple platforms rather than putting all your social media eggs in one basket.
Could this outage have been prevented?
Most likely, yes. The specific failure that caused this outage could have been caught through better testing, monitoring, or change management procedures. However, 100% prevention of all outages is impossible. The best platforms work toward reducing frequency and duration of outages rather than eliminating them entirely.
How do platform outages affect the broader internet ecosystem?
When major platforms go down, it creates a ripple effect. Businesses that depend on these platforms lose productivity. Third-party integrations break. User-generated content becomes inaccessible. It reminds people that the internet's infrastructure, while generally reliable, has critical points of failure that can have widespread consequences.

Infrastructure Lessons: What We Can Learn
The X outage provides a real-world case study in platform reliability. For anyone building or managing digital services, several lessons emerge from this incident.
Testing in Production: No matter how good your pre-production testing is, there's always something that doesn't behave the same way in the real world. Large-scale outages often trace back to assumptions that worked in testing but failed under real-world conditions. This is why platforms need sophisticated monitoring and alerting—to catch issues before they impact users.
Gradual Rollouts: Modern deployment practices recommend rolling out changes gradually rather than pushing to all servers simultaneously. If X had been using canary deployments or blue-green deployment strategies, a bad change might have affected 5% of users instead of 100%. The staged recovery pattern suggests X might have eventually used this approach to come back online, but it should have been used going forward to prevent the initial failure.
Communication Failures: From a user perspective, one of the most frustrating aspects of outages is lack of communication. If X had posted status updates every 15 minutes explaining what they knew and what they were doing, user frustration would have been somewhat mitigated. Silence during outages breeds speculation and negativity.
Database Reliability: If the outage was indeed database-related, it highlights the importance of database redundancy and failover. But it also highlights the complexity of managing database failover. In theory, if the primary database fails, traffic should automatically shift to a replica. In practice, ensuring that replicas are sufficiently up-to-date and that failover happens automatically is complex.
Looking Forward: Platform Reliability in 2025
As we move further into 2025, several trends will likely shape how platforms approach reliability:
Increased Regulation: Regulators are becoming more interested in platform reliability. The EU's Digital Services Act, for example, includes provisions around service continuity. Platforms might face penalties for extended outages.
Consumer Expectations: Users are increasingly intolerant of outages. A few hours of downtime in 2025 is far more disruptive than it would have been in 2015. As platforms become more central to communication and business, users demand higher reliability.
Infrastructure Maturity: Cloud providers are investing heavily in reliability. AWS, Google Cloud, and Azure all have sophisticated disaster recovery and business continuity features. The best platforms are using these features effectively. The question is whether all platforms are doing so.
Decentralization Interest: Outages like this fuel interest in decentralized alternatives. Whether decentralized platforms actually prove more reliable remains to be seen, but the interest is real.

Conclusion: Understanding Platform Outages
The X outage on January 16, 2025, was a significant event affecting hundreds of millions of people. While the platform came back online within hours, the incident raises important questions about how much we've come to depend on a handful of large platforms and how vulnerable those platforms actually are.
From a technical perspective, the outage was probably preventable. Better testing, more careful deployment procedures, or more sophisticated monitoring might have caught the issue before it impacted users. From a business perspective, better communication during the outage would have made the experience less frustrating.
From a user perspective, the outage is a reminder that no platform is 100% reliable. Whether you use X professionally, socially, or just for news consumption, having backup plans and not depending entirely on any single platform is wise.
For the broader tech industry, the outage validates the importance of infrastructure engineering. It's not flashy work. It doesn't result in new features that users can see and touch. But it's foundational to everything else. Companies that invest in infrastructure reliability, monitoring, and incident response procedures will continue operating when others fail.
X will likely recover from this incident and move forward. The platform will be restored, users will return, and for most people, this will become a footnote in the history of platform outages. But for the people working in X's infrastructure team, January 16, 2025, probably remains a very long day that generated a lot of late-night incident response and careful investigation into what went wrong.
That's what platforms do when they go down. They stop, they break, and then the engineering teams work frantically to figure out why and how to bring them back. It's unglamorous work, but it's essential. And as long as we depend on platforms like X for communication and information, getting that work right will continue to matter.
Key Takeaways
- X experienced a major global outage on January 16, 2025, affecting an estimated 200-300 million users for 4-5 hours
- The simultaneous impact across all geographic regions indicates the failure was in X's central infrastructure, not regional systems
- Probable causes include failed deployments, database issues, or cascade failures in interconnected services
- Poor communication during the outage highlighted gaps in incident response procedures
- Platform outages are becoming more common as infrastructure complexity grows and user dependency increases
- Businesses and users should maintain backup communication channels and not rely entirely on single platforms
Related Articles
- How to Claim Verizon's $20 Credit After the 2025 Outage [Complete Guide]
- Verizon's $20 Credit After Major Outage: Is It Enough? [2025]
- VoidLink: The Chinese Linux Malware That Has Experts Deeply Concerned [2025]
- VoidLink: The Advanced Linux Malware Reshaping Cloud Security [2025]
- N8n Ni8mare Vulnerability: What 60,000 Exposed Instances Need to Know [2025]
- Target Data Breach 2025: 860GB Source Code Leak Explained [2025]

