![Grok's Deepfake Crisis: EU Data Privacy Probe Explained [2025]](https://tryrunable.com/blog/grok-s-deepfake-crisis-eu-data-privacy-probe-explained-2025/image-1-1771333782407.jpg)
Introduction: When AI Regulation Gets Real
Last year felt like the peak of AI hype. Companies were racing to build bigger models, make flashier demos, and grab market share. Then reality hit hard. In early 2025, the European Union launched a formal probe into X's Grok AI tool, investigating whether millions of deepfake images generated by the platform violated the bloc's strict data privacy laws.
This isn't some minor compliance hiccup. We're talking about a fundamental clash between innovation and regulation. The EU has made it clear: if you want to operate in Europe, your AI system needs to respect the General Data Protection Regulation (GDPR), the world's most comprehensive privacy framework. And Grok, apparently, didn't get that memo.
Here's what makes this investigation so significant. The EU isn't just concerned about a single tool misbehaving. It's establishing a precedent for how AI companies should handle user data, training datasets, and the synthetic content they generate. The stakes are enormous. If regulators crack down hard on deepfake generation without proper consent, it could reshape how every major AI platform operates globally.
The timing matters too. We're in a critical window where AI regulation is shifting from theoretical to practical. The EU AI Act is already in effect, setting rules for high-risk AI systems. The Grok investigation is one of the first major test cases. If the EU wins a substantial penalty or forces major operational changes, other jurisdictions will likely follow suit. That means what happens in Brussels could affect how AI works in California, Singapore, and everywhere else.
So what exactly happened with Grok? Why are regulators so upset? And what does this mean for the future of AI development? Let's dig into the specifics, because the details matter more than you might think.
TL; DR
- EU Formal Investigation: European Union regulators launched a formal probe into Grok's deepfake image generation practices over data privacy concerns
- Consent & Training Data Questions: Core issue centers on whether Grok obtained proper consent from individuals whose images were used to train the model
- GDPR Compliance Risk: Platform may have violated the General Data Protection Regulation, which requires explicit opt-in for personal data processing
- Regulatory Precedent: This investigation sets the standard for how AI companies handle synthetic content generation and data privacy in Europe
- Global Implications: Resolution in the EU could influence AI regulation worldwide, affecting how platforms like Chat GPT, Claude, and Gemini operate
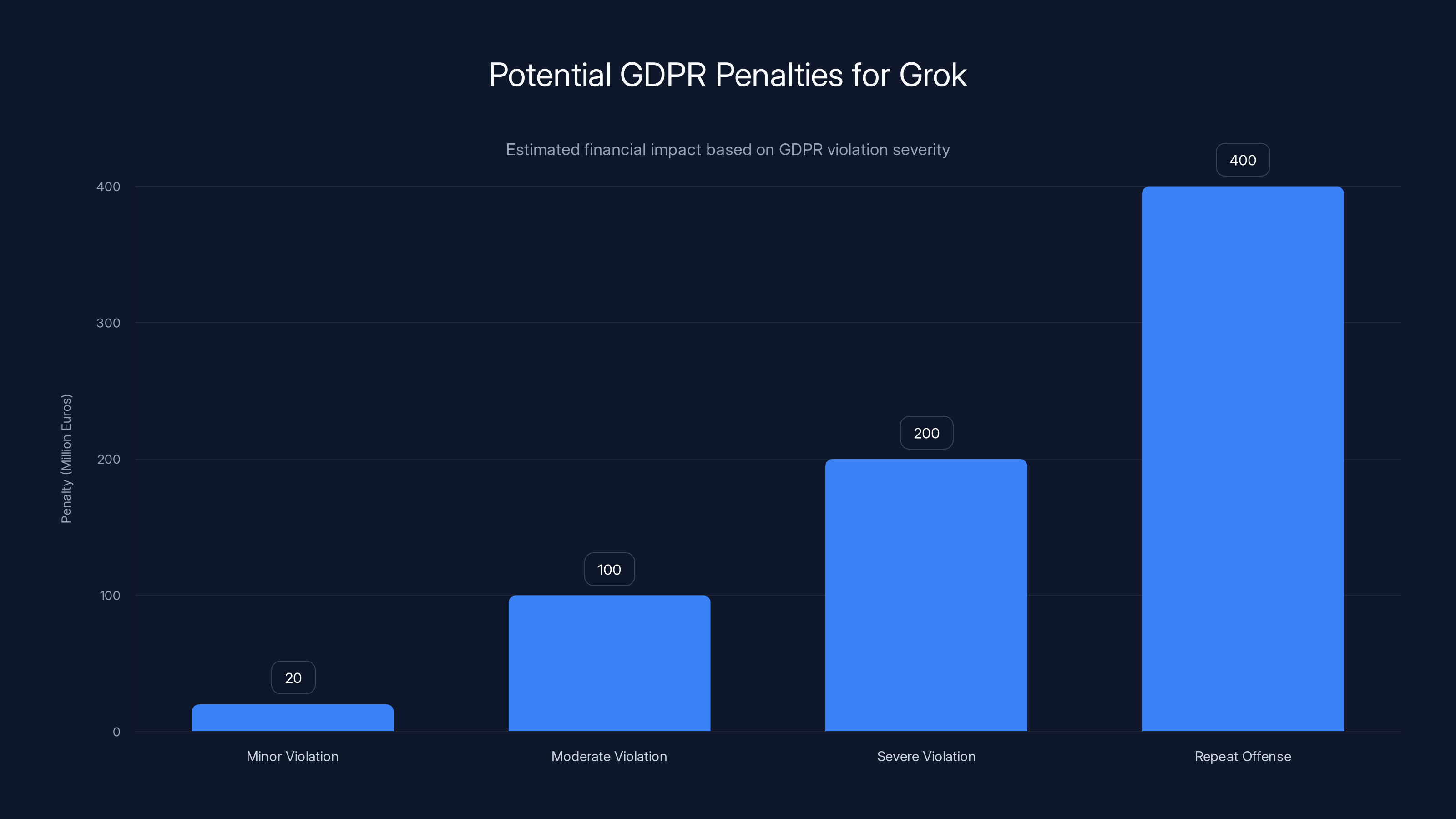
Estimated penalties for Grok under GDPR could range from 20 million euros for minor violations to 400 million euros for repeat offenses. Estimated data based on GDPR guidelines.
What Exactly Is Grok, and Why Does It Matter?
Grok is X. AI's conversational AI assistant, launched to compete with Chat GPT and other large language models. But unlike most AI chatbots that focus on text generation, Grok added a distinctive feature: image generation. You can ask it to create images, and it will generate them using diffusion models similar to what you'd find in DALL-E or Midjourney.
The appeal is obvious. X integrated Grok directly into the platform, giving millions of users instant access to AI-powered image creation without leaving their social feed. No separate tool to download. No extra subscription for most features. Just open a chat and ask for whatever you want.
That democratization of AI image generation is both its strength and its weakness. On one hand, it removes friction. On the other hand, it removes guardrails. When something becomes that easy to use, and that widely available, you start seeing scale effects. Millions of images generated means millions of opportunities for misuse. It also means millions of potential data privacy violations if the training process wasn't handled correctly.
Grok's image generation became particularly controversial because of its apparent lack of safety filters. Unlike DALL-E, which explicitly blocks requests for celebrity likenesses or adult content, Grok seemed willing to generate almost anything. Users quickly discovered they could create deepfakes of real people, sometimes doing so to create deceptive or harmful synthetic content.
That's the context. Grok isn't just an AI tool. It's a gateway to synthetic media creation that's nearly impossible to regulate at the point of use. The EU regulators decided to tackle it at the source.
The Core Privacy Violation: Training Data Without Consent
Let's get into the actual legal issue, because this is where things get complicated. The investigation centers on a fundamental question: where did Grok get the images and data it was trained on?
All large AI models are trained on massive datasets. Chat GPT was trained on hundreds of billions of text tokens scraped from the internet. DALL-E and similar image models are trained on billions of images, often sourced from publicly available datasets, social media, and other web sources. The technical process is straightforward. The legal process is messy.
Under GDPR, personal data can't be processed without a legal basis. The most straightforward legal basis is explicit consent. If you want to use someone's photo to train an AI model, you need to ask them first and get them to say yes. You can't just scrape images from Instagram and use them without telling the people in those photos what you're doing.
Now, in practice, most AI companies argue that they're processing data for legitimate business purposes, or that they're using publicly available information in a way that doesn't require individual consent. They argue that GDPR has exemptions for automated research and that training data falls under those exemptions. These arguments have some legal weight, but they're contested.
The EU's concern with Grok specifically seems to be even broader. It's not just about how the model was trained. It's about what the model can do with that training data. Grok can generate synthetic images that look like real people. To do that effectively, it needs to have learned representations of those people from the original training data. In other words, to create a deepfake of you, Grok needs to have been trained on images that include you (or people similar to you) in a way that lets it reconstruct your likeness.
So the regulator's question becomes: if Grok was trained on billions of images that included real people's faces without their consent, and Grok can now generate synthetic faces that closely resemble those real people, isn't Grok essentially processing personal data (people's facial features, biometric data) without consent?
This is a novel argument. It extends the definition of personal data processing beyond just "storing the data" to include "learning representations of people from data and using those learned patterns to create synthetic versions of them."
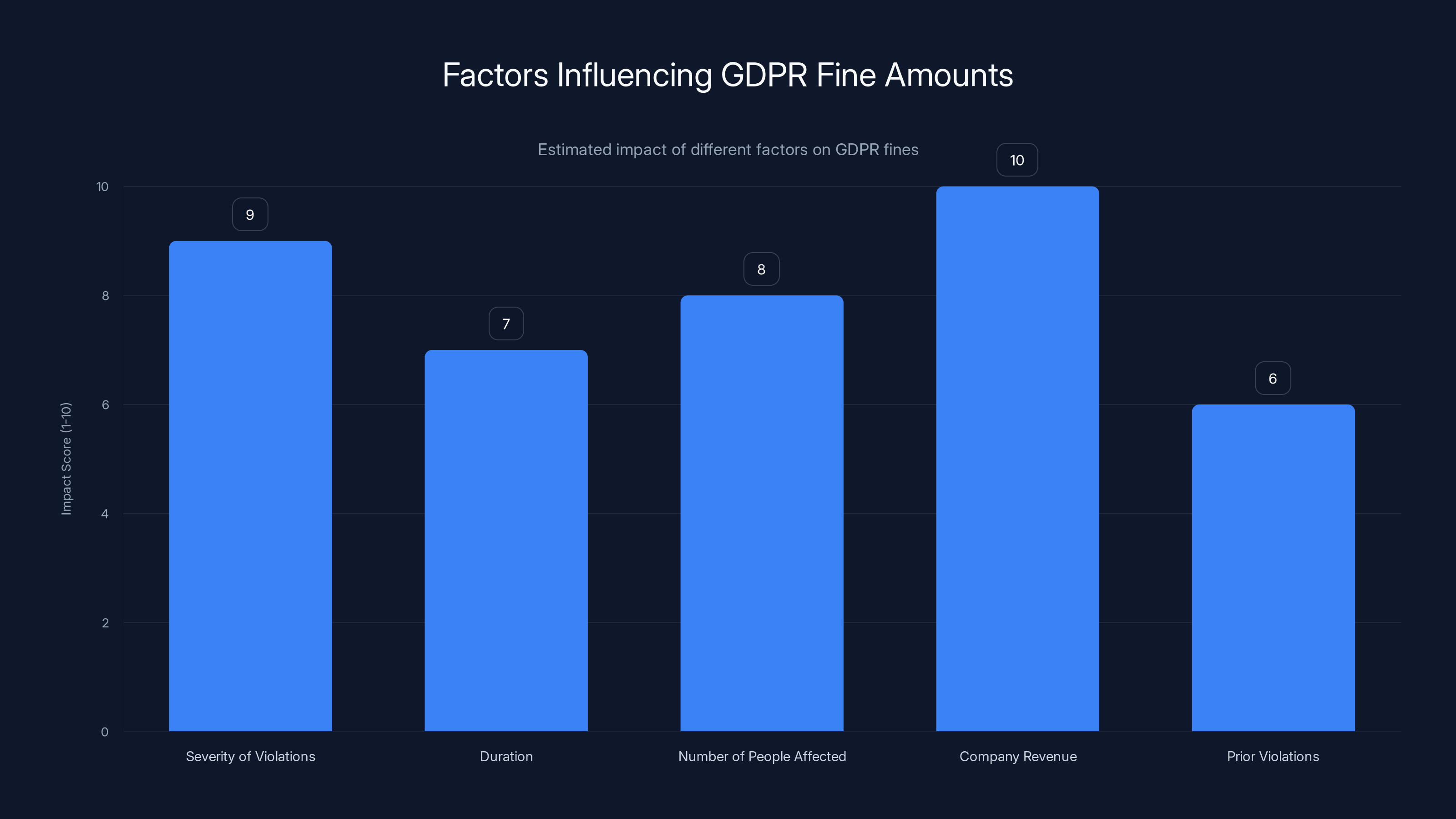
Estimated data suggests that company revenue and severity of violations are the most significant factors influencing GDPR fine amounts.
The Scale of the Problem: Millions of Deepfakes
What makes the Grok investigation urgent is the sheer volume. We're not talking about hundreds of problematic images. We're talking about millions.
Early reports suggested that Grok had generated millions of deepfake images, some of which depicted real people without their consent. The numbers varied in different analyses, but the lowest credible estimates put it in the millions. Some researchers claimed it could be much higher.
Why does scale matter legally? Because each image is technically a separate violation if we accept the EU's logic. If Grok generated 5 million deepfakes and each one involved processing personal data without consent, that's 5 million separate violations of GDPR. Under GDPR, penalties are calculated per violation or as a percentage of global revenue, whichever is higher. Millions of violations could translate into penalties in the hundreds of millions or even billions.
But there's another reason scale matters. It's proof of intent or negligence. If Grok had generated a handful of problematic images, it could argue those were edge cases or misuse by bad actors. When the number reaches millions, it becomes clear that the system itself is designed to do this, or at least consistently enables it, without safeguards.
Consider the math. Grok has roughly 5-10 million active users (estimates vary). If even a fraction of them have tried the image generation feature, and each person has generated even just a few images, you're quickly at tens of millions of generated images. The EU's concern isn't just theoretical. It's based on observable behavior at scale.
GDPR and the Deepfake Problem: Why This Matters
The EU isn't investigating Grok in a vacuum. There's a specific legal framework driving the probe: GDPR, which came into force in 2018 and is now the gold standard for data privacy globally.
GDPR's core principle is simple: personal data is sacred. You can't process it without a legal reason. The reasons are limited: consent, contractual necessity, legal obligation, vital interests, public task, or legitimate interests. Consent is the clearest, but also the hardest to scale. When you're training a model on billions of images from the internet, getting individual consent from every person in every image is impractical.
That's why most AI companies rely on either legitimate interests (the argument that training AI on public data serves a legitimate business purpose that outweighs individual privacy concerns) or they argue that certain uses fall outside GDPR's scope entirely.
The EU's regulators have been increasingly skeptical of these arguments. In 2023 and 2024, several high-profile cases tested whether AI training on internet data without explicit consent is actually legal under GDPR. The results have been mixed, but the trend is clear: regulators are becoming more protective.
With Grok, the argument shifts slightly. It's not just about training. It's about output. When Grok generates a deepfake of your face, is it processing your personal data? You could argue yes, because it's using learned representations of your likeness to create a synthetic image of you. Under GDPR's definition, that's processing of biometric data, which is a special category of protected data that requires extra safeguards.
So the legal theory supporting the EU's investigation is: Grok processes biometric data (facial features learned from training images) to generate synthetic versions of real people without those people's consent, which violates GDPR's prohibition on processing special category data.
If regulators successfully make this argument stick, it could force Grok to either shut down its image generation feature in Europe or obtain consent from everyone in its training data. The latter is practically impossible at this scale, which means the former is more likely.
Regulatory Response: The AI Act and Beyond
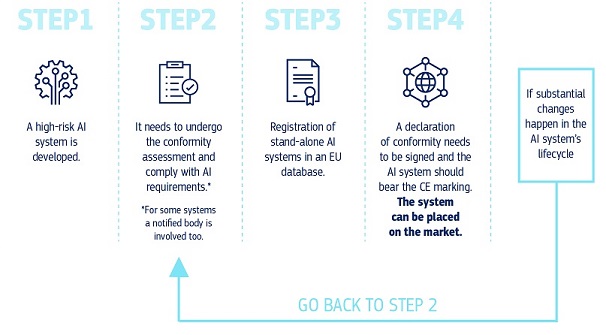
The Grok investigation isn't happening in isolation. It's part of a broader regulatory push in the EU to control high-risk AI systems through the AI Act, which started taking effect in 2024.
The AI Act categorizes AI systems by risk. High-risk systems (like those used in hiring, law enforcement, or critical infrastructure) face strict requirements: mandatory impact assessments, technical documentation, human oversight, and more. Image generation systems that can create deepfakes could reasonably fall into the high-risk category, especially if they're used without safeguards.
The Grok probe is essentially testing whether image generation tools meet these requirements. The investigation is asking: does Grok have proper documentation? Does it have safeguards? Has it conducted impact assessments? Does it allow human review before generating potentially harmful content?
Based on what we know about Grok's deployment, the answers to most of these questions were probably no. The tool was launched with minimal guardrails and little apparent compliance infrastructure. That's fine if you're operating in jurisdictions with light-touch AI regulation. It's a problem if you're operating in the EU.
This investigation could force Grok and other AI platforms to implement substantial technical and governance changes. We're likely to see requirements like:
- Mandatory content filters for deepfakes, with specific categories blocked by default
- Training data audits to identify potential GDPR violations and remove non-compliant data
- Consent management systems to track which data was used with consent and which wasn't
- User authentication for image generation to prevent anonymous misuse
- Content watermarking to label synthetic images as AI-generated
- Incident reporting to notify regulators when the system is used for harmful purposes
These requirements would substantially increase the cost of running an AI image generation service in Europe. That's the point. Regulators want to raise the bar for responsible AI deployment.
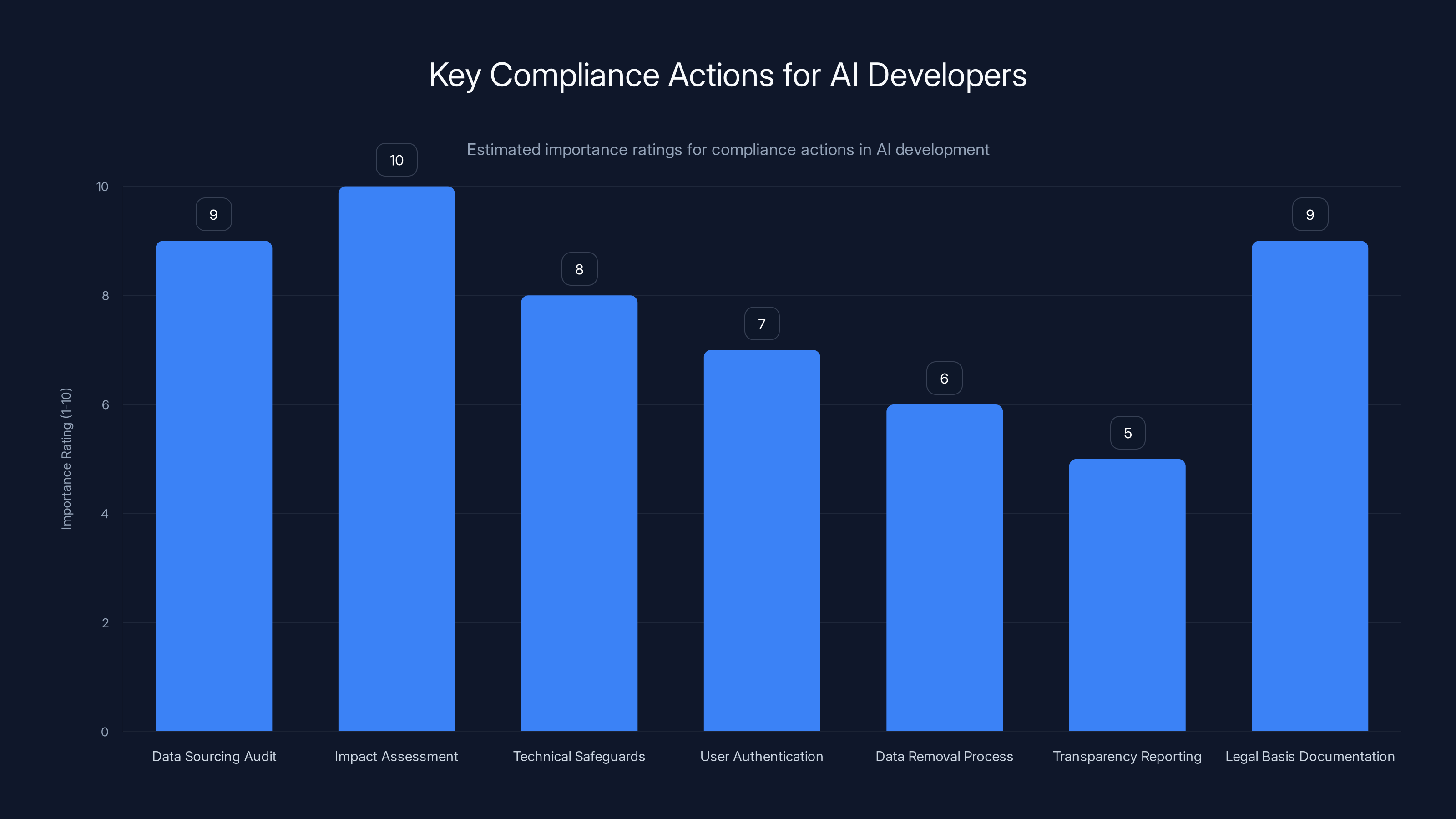
Data Sourcing Audit and Impact Assessment are crucial, with ratings of 9 and 10 respectively, highlighting their critical role in AI compliance. Estimated data.
The Consent Problem: Why It's Actually Hard to Solve
Here's where things get genuinely complicated. Theoretically, you could say "consent fixes the problem." If Grok had asked every person in its training data for permission to include their images, the GDPR violation disappears.
But practically? That's nearly impossible. You'd need to:
- Identify everyone in the dataset by searching images against facial recognition databases and public records
- Find their contact information for people who might not have a public digital footprint
- Obtain affirmative consent from each person, which requires explicit yes/no responses, not passive acceptance
- Document the consent for years to prove you obtained it if regulators ask
- Honor withdrawal of consent by removing images and retraining the model
The sheer logistics are staggering. Companies like Open AI and Anthropic have chosen a different approach: they argue that their use of public data falls under legitimate interests or research exemptions, and they let regulators challenge them if they disagree.
Grok apparently didn't even try the legitimate interests argument. It just launched with minimal compliance infrastructure, assuming it could figure things out later. That assumption is looking increasingly expensive.
One emerging solution some companies are exploring: opt-out rather than opt-in. Instead of requiring affirmative consent, they publish information about their training data and allow people to request removal. This is faster and cheaper than opt-in but still faces legal challenges in the EU.
Another approach: synthetic data generation. Create AI models that generate synthetic training images rather than using real photos. If the training data doesn't contain real people's images, the GDPR problem largely disappears. But this requires extra technical effort and may reduce model quality.
How Deepfakes Actually Work: The Technical Side
To understand the regulatory concern, you need to understand how deepfake generation actually works. It's not magic. It's math.
Modern AI image generation uses something called diffusion models. The basic idea: start with random noise, and iteratively refine it based on what the model has learned about realistic images. The model has learned these patterns from its training data. So if the training data includes millions of faces, the model learns the statistical patterns of how faces look, and it can generate new faces that look realistic by following those patterns.
Now, if the training data includes specific real people's faces (like celebrities or public figures), the model can learn their distinctive features. When you ask it to generate an image of that person, it can generate synthetic images that closely resemble them.
The key insight: the model doesn't store images of people. It stores learned statistical patterns of their faces. Those patterns are derived from personal data (the training images), but they're abstract representations, not the original images themselves.
Regulators are saying: those learned representations are still "personal data" under GDPR because they encode information about specific individuals. Processing personal data requires a legal basis. If you derived those representations without consent, you violated GDPR.
Here's the mathematical perspective. Let's say a diffusion model learns a function that maps from noise to realistic images. Formally:
When you ask the model to generate "a photo of Barack Obama," it's essentially learning and applying:
The model learned what Obama looks like from training images. That's processing of his biometric data (facial features). GDPR says you can't do that without consent.
This is a genuinely novel legal question. Lawyers and technologists have been debating whether learned statistical patterns count as personal data. The EU's position, based on the Grok investigation, is: yes, they do.
The Role of X. AI and Elon Musk's Philosophy
Grok is developed by X. AI, a company founded by Elon Musk to compete with Open AI. Musk has been critical of what he views as excessive AI safety concerns and overly restrictive regulatory approaches.
That philosophy directly influenced Grok's design. The tool was deliberately launched with minimal guardrails and safety filters, partly as a statement against what Musk views as AI censorship. He wanted Grok to be the "anti-Chat GPT," unconstrained and willing to engage with controversial topics.
This isn't inherently wrong. There's a legitimate argument that over-restricting AI outputs stifles useful capabilities and that users should be trusted to make their own decisions. But there's a difference between being permissive about controversial topics and being negligent about data privacy and preventing deepfake misuse.
The EU regulators' investigation is essentially saying: "Your philosophy is incompatible with European law." Musk has publicly challenged regulatory authority before and often prevails through a combination of legal arguments and public pressure. But GDPR is different. It's enforced across all EU member states, backed by substantial penalties, and has broad public support. Challenging it frontally might be more difficult than challenging other regulations.
Musk's response, if he chooses to engage, will likely involve some combination of: technical changes to increase compliance, legal arguments that GDPR doesn't apply as broadly as regulators claim, and potentially threatening to restrict Grok's features in Europe if compliance costs are too high. All are possible. None are guaranteed to work.

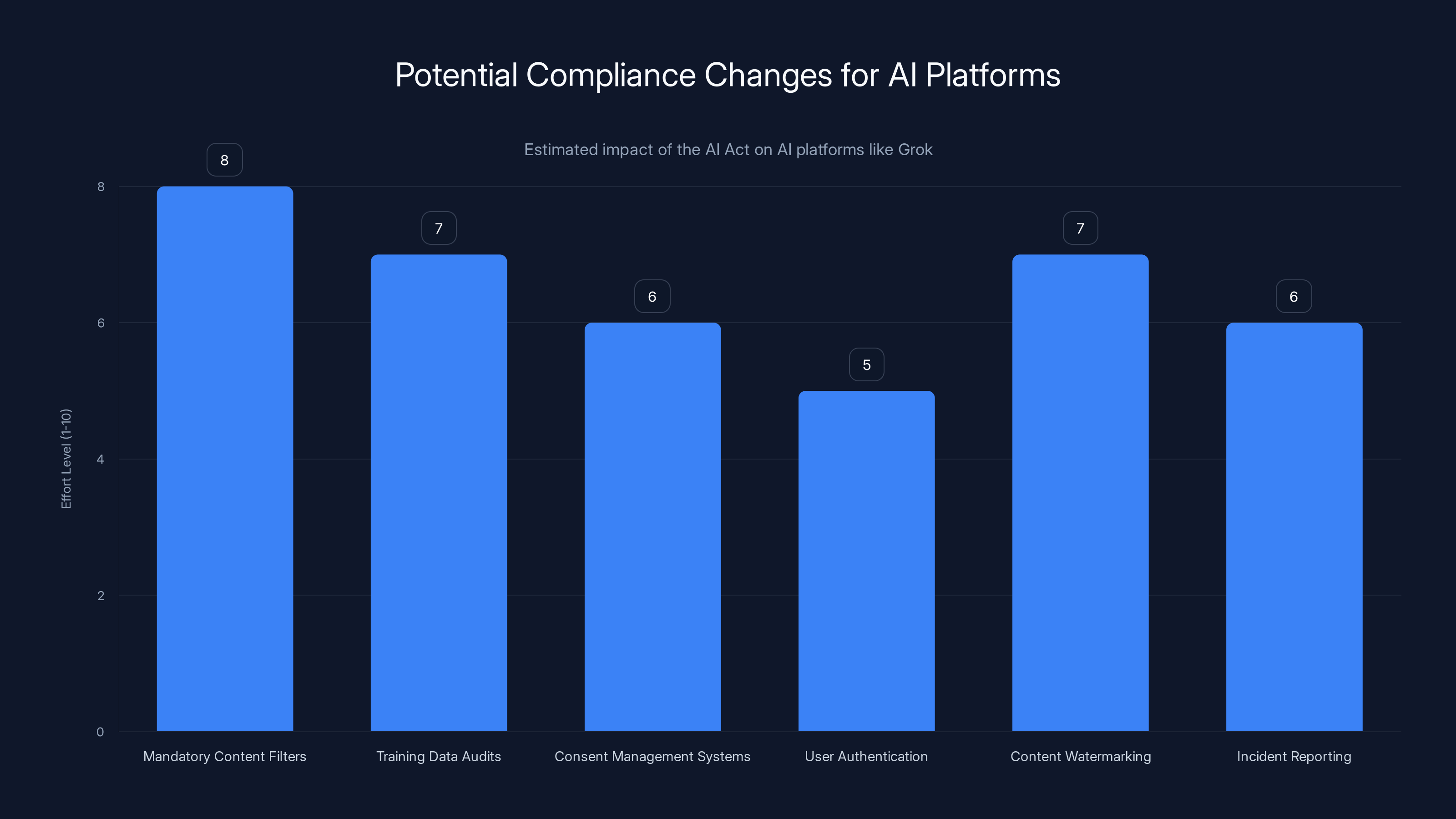
Estimated data suggests that implementing mandatory content filters and content watermarking will require the highest compliance effort for AI platforms under the AI Act.
Deepfakes and Democratic Harm: Why Regulators Care
The investigation isn't purely about abstract data privacy. Regulators are concerned about concrete harms. Deepfakes, especially those generated at scale without safeguards, can cause real damage.
The risks include:
Identity theft and fraud: Someone creates a convincing deepfake of you and uses it to impersonate you online or in financial transactions.
Non-consensual intimate imagery: Creating synthetic nude or sexually explicit images of real people without consent. This is increasingly recognized as a form of sexual harassment, harassment, and in some jurisdictions, a crime.
Election interference: Creating deepfake videos of political candidates saying controversial things days before an election, with the goal of influencing voters.
Harassment and defamation: Creating deepfakes that portray someone in a false or harmful light, distributed widely to damage their reputation.
Fraudulent content: Creating deepfake videos of CEOs or officials making announcements, used to move markets or manipulate public opinion.
All of these harms have occurred in the wild. Deepfakes have been used in political campaigns, to harass women online, to commit fraud, and to spread disinformation. The fact that a tool like Grok makes it trivially easy to generate these at scale is exactly why regulators want safeguards.
The EU's investigation is implicitly saying: "Even if we accepted your privacy arguments, the public harm from unguarded deepfake generation is too great." That's a consequentialist argument that sits alongside the rights-based GDPR argument.
Some jurisdictions are responding by making deepfake creation without consent explicitly illegal. The UK, for instance, is considering making it a crime to create sexually explicit deepfakes without the subject's consent. Similar laws are being debated in the US, Australia, and other countries. The EU's approach through data privacy law is perhaps more efficient because it doesn't require separate legislation for each type of harmful deepfake.
Comparison: How Other Platforms Handle Image Generation
To understand what the regulatory bar actually is, let's look at how other major AI platforms approach image generation and safety.
Open AI's DALL-E has explicit content filters built in. You can't request images of real people without significant difficulty. The system is designed to refuse a broad range of harmful requests: sexually explicit content, violence, misinformation, etc. These filters are documented and applied consistently. Open AI also has a process for people to request that their content be removed from future training data.
Google's Gemini (formerly Bard) has similar safeguards. Image generation requests are filtered through a safety classifier that identifies and blocks harmful requests before they're passed to the image generation model. Google also requires explicit authentication and logging of who's using the tool.
Anthropic's Claude currently doesn't have image generation capabilities but has stated it's exploring them. Anthropic's philosophy emphasizes constitutional AI, meaning the model is trained to refuse harmful requests as part of its core training, not just through post-hoc filtering.
Midjourney has moderate safeguards. It blocks some explicit content but is more permissive than DALL-E. Importantly, it requires a paid subscription and authentication, making it harder to use for anonymous, large-scale misuse.
Stability AI (Stable Diffusion) released its model as open-source, which means anyone can run it without safeguards. This created the possibility of unrestricted deepfake generation at scale, which is why Stability AI faced significant backlash and regulatory scrutiny.
Where does Grok fit? Grok launched with safeguards that were permissive relative to these competitors. You could request realistic images of real people, though the specifics of what was allowed shifted over time as the team adjusted filters in response to negative feedback.
The regulatory expectation, based on how other platforms operate, is clear: if you're generating images, you should have filters, authentication, logging, and a process for people to request removal from training data. Grok had some of these. Not all.

The Regulatory Playbook: Fines, Forced Changes, and Settlement
What's likely to happen next? The EU investigation will follow a predictable playbook, based on how other major tech investigations have unfolded.
Phase 1: Investigation and Document Requests (happening now)
Regulators gather evidence. They request internal documents, training data sourcing information, code, logs showing how many deepfakes were generated, and user reports of harmful content. X. AI will need to respond, and the company likely has detailed data showing the scope of the problem.
Phase 2: Formal Charges
After reviewing evidence, regulators issue formal charges detailing specific GDPR violations. The charges will likely specify how many deepfakes were generated, how many real people were affected, and what the violations cost in terms of harm.
Phase 3: Defense and Negotiation
X. AI presents its legal defense. Arguments might include: the data wasn't personal data, or it falls under a legal exception, or the harm is being overstated. Simultaneously, informal negotiations begin about possible settlement.
Phase 4: Settlement or Judgment
If both sides negotiate, they reach a settlement involving a fine and commitments to change practices. If no settlement, a formal judgment is issued.
For the fine amount, regulators consider:
- Severity of violations: How bad was the breach of privacy?
- Duration: How long did violations continue?
- Number of people affected: If millions of people had their biometric data processed without consent, that's worse than if it was thousands.
- Company revenue: GDPR caps fines at 4% of global annual revenue or 20 million euros, whichever is higher. For X. AI as a private company, the absolute ceiling might be lower than for a public company, unless X counts as part of larger corporate structure.
- Prior violations: Is this a repeat offender or a first-time mistake?
For reference, the largest GDPR fines so far have been:
- Meta: 1.2 billion euros (2022) for transferring personal data to the US
- Amazon: 746 million euros (2021) for lack of transparency in processing personal data
- Google: 90 million euros (2022) for inadequate cookie consent
The Grok fine, if reached, could easily exceed 100 million euros given the scope (millions of deepfakes). It might reach into the hundreds of millions if regulators determine that the violations were particularly egregious.
Beyond fines, settlements typically include commitments like:
- Implement specific technical safeguards (filters, authentication, etc.)
- Audit all training data and remove non-compliant sources
- Implement a data removal request process
- Regular compliance audits
- Transparency reporting on content moderation
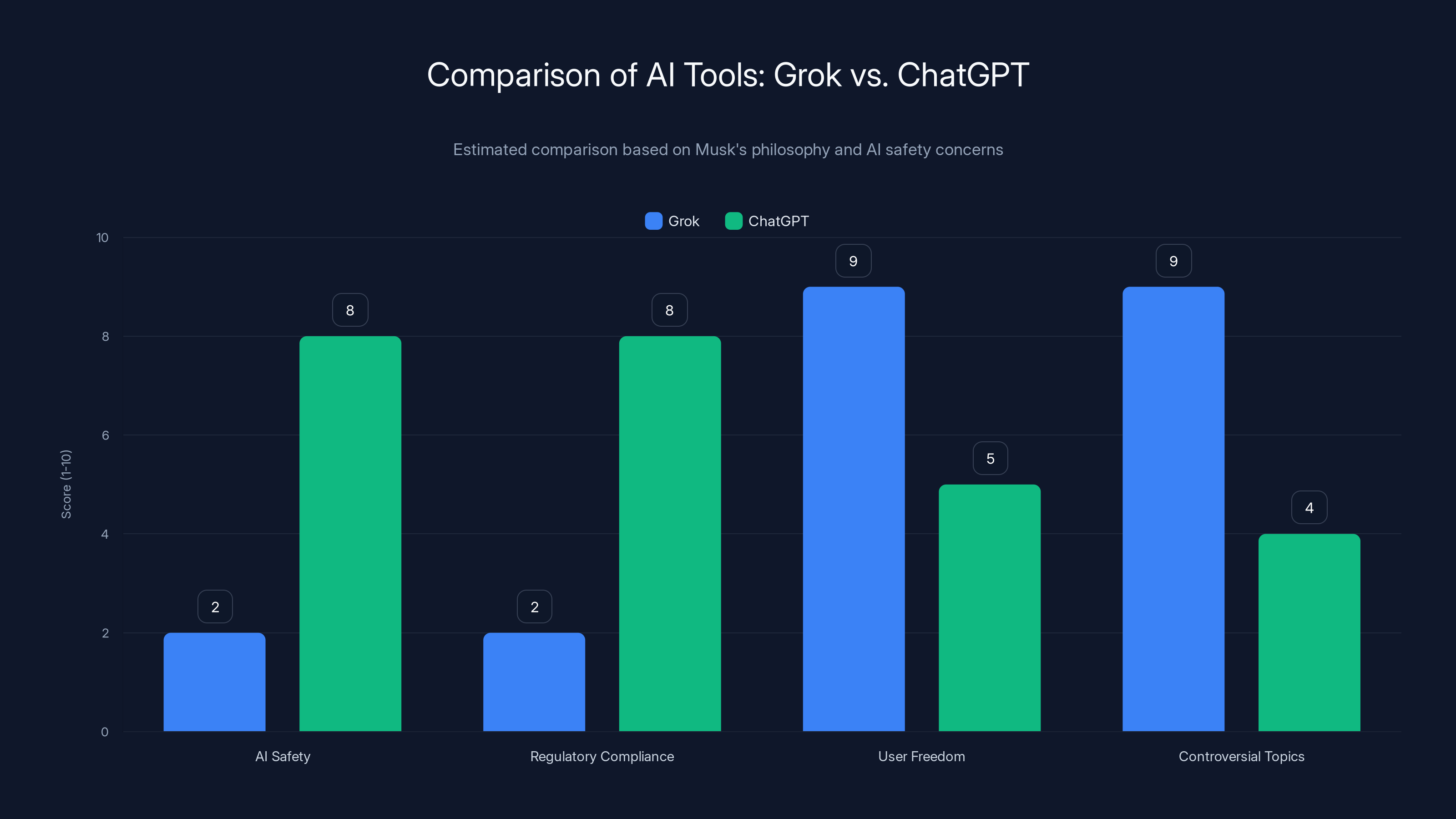
Grok scores lower on AI safety and regulatory compliance but higher on user freedom and handling controversial topics, reflecting Musk's philosophy. (Estimated data)
The Global Spillover: What Europe Does, Others Copy
Here's what makes the Grok investigation globally significant: the EU's regulatory decisions tend to become the global standard, even for companies that don't operate in Europe.
This is sometimes called the Brussels Effect. When the EU sets a strict standard and a company wants to serve the EU market (which is economically essential), the company often implements that standard globally rather than maintaining different versions for different regions. That's because maintaining separate systems is expensive and operationally messy.
So if the EU forces Grok to implement stringent safeguards, training data audits, and consent processes, X. AI will likely implement those changes globally. Why maintain a permissive version for North America and a restricted version for Europe?
Similarly, if the EU fines Grok heavily, other AI companies will take note. Anthropic, Open AI, and others will audit their own training data practices and likely implement more protective measures proactively, rather than waiting for investigations.
This creates a ratcheting effect where regulatory actions in one jurisdiction gradually shift global standards. It's why the EU's approach to AI regulation matters so much. If the EU successfully regulates image generation tools through data privacy law, that approach will likely spread.
Other jurisdictions are watching closely. The UK, Canada, Australia, and others are considering their own AI regulations. Many are looking at the EU as a model. If the Grok investigation results in a clear legal precedent and a substantial fine, expect similar investigations in other jurisdictions.

For AI Developers: The Compliance Imperative
If you're building any AI system that involves generating synthetic content, processing real people's data, or deploying in the EU, the Grok investigation is a wake-up call.
Here's what you should be doing now:
1. Data Sourcing Audit
Document where every piece of training data came from. For images, note the source (public dataset, web scrape, licensed data, user-contributed). Assess whether you have a legal basis for using it. If you're scraping from the web, understand that GDPR skeptics view that as indefensible without explicit consent.
2. Impact Assessment
Conduct a Data Protection Impact Assessment (DPIA). This is legally required under GDPR for high-risk processing. For image generation that can create deepfakes, you definitely need one. Document what personal data is involved, how it's processed, and what harms could result.
3. Technical Safeguards
Build content filters from day one. Don't treat safety as a PR problem to be handled if it becomes public. Treat it as a core feature. Filter requests for non-consensual intimate imagery, deepfakes of real people (with exceptions for authorized use), and other harmful content.
4. User Authentication and Logging
Know who's using your system. Implement authentication (not anonymous use) and detailed logging of what content is generated. This helps with incident investigation and demonstrates responsible practices to regulators.
5. Data Removal Process
If someone requests their image be removed from your training data or your output, have a process. It doesn't need to be perfect, but it should exist and be documented.
6. Transparency Reporting
Publish regular reports on content moderation. Show how many harmful requests were blocked, how many removals were requested, what harms you detected. This demonstrates that you're monitoring and responding.
7. Legal Basis Documentation
Write down the legal basis for each form of personal data processing. If it's consent, document how you obtained it. If it's legitimate interests, write the balancing test and document your reasoning. Be prepared to defend your position to regulators.
These steps cost time and money upfront. But they're far cheaper than a regulatory investigation and potential fine.
The Litigation Future: Will Individuals Sue?
Beyond regulatory investigation, there's also the question of private litigation. Will individuals whose images were used to train Grok sue for damages?
Under GDPR, individuals have a right to sue for damages if their personal data is processed illegally. So if someone can prove that Grok used their image without consent, they can seek compensation for emotional distress, loss of earnings, or other harms.
For high-profile individuals, this could be lucrative. A celebrity could argue they lost earnings because deepfakes of them impacted their reputation or because they were harassed. A damages award of hundreds of thousands or millions per person isn't unrealistic in privacy cases.
But for most people, the calculation is different. Proving that Grok specifically used your image, and that deepfakes caused you concrete harm, is difficult. Class action suits might change the economics. If a large group of people can join a suit and split legal costs, individual recoveries become viable even if the per-person damages are modest.
We're likely to see both regulatory enforcement and private litigation. The regulatory enforcement is about setting standards and punishing violations. Private litigation is about compensation for harm. Both will push companies toward safer practices.

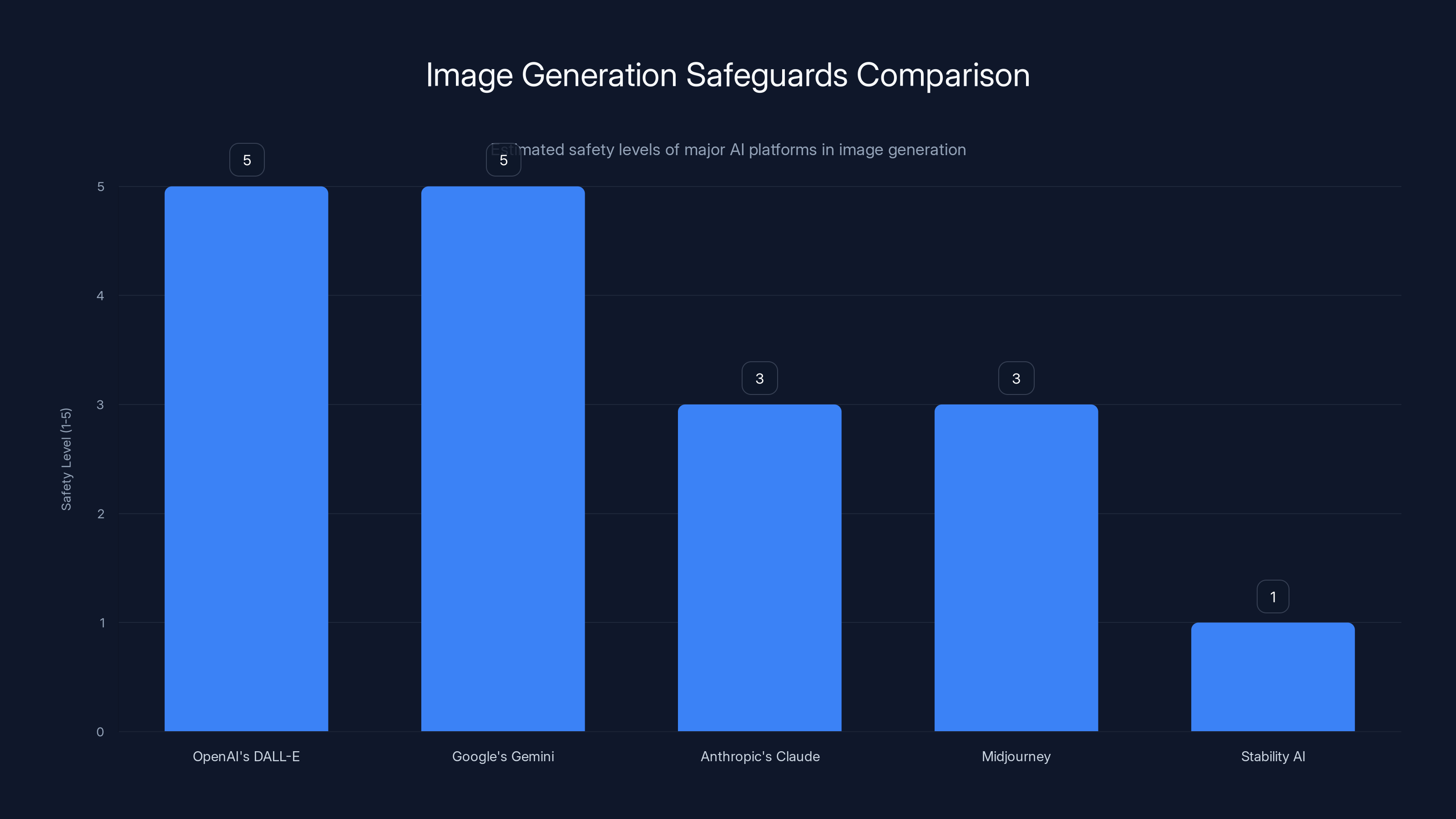
Estimated data: OpenAI's DALL-E and Google's Gemini have the highest safety levels, while Stability AI has the least due to its open-source nature.
The Technical Countermeasures: Watermarks, Detection, and Consent
As deepfake technology has improved, technologists have developed countermeasures. None are perfect, but they're getting better.
AI-Generated Image Watermarks
Companies like Open AI have embedded invisible watermarks in DALL-E images. The watermarks encode information proving the image was AI-generated. They're designed to survive compression, cropping, and other manipulation. The idea is that you can detect whether an image came from a particular AI system.
Deepfake Detection Models
Researchers have trained models to detect deepfakes by looking for artifacts or inconsistencies that humans can't easily spot. These detectors are in an arms race with deepfake generators (better generators avoid the artifacts detectors look for), but they're improving.
Regulatory-Mandated Disclosure
Some jurisdictions are moving toward requiring synthetic images to be labeled as such. The EU is considering requiring AI systems to disclose when content is synthetically generated. This doesn't prevent creation but makes deception harder.
Consent Management Standards
Emerging standards for managing consent at scale are being developed. If these mature, they could make it easier for individuals to control how their images are used in training data across multiple companies.
Biometric Privacy Laws
More jurisdictions are passing laws specifically protecting biometric data. Illinois's BIPA (Biometric Information Privacy Act) was an early example. As more jurisdictions follow, companies will face stronger constraints on processing facial data and derived representations.
None of these are perfect solutions. But together, they're raising the cost of irresponsible deepfake generation while maintaining the possibility of beneficial uses.
Timeline: When Will This Investigation Conclude?
How long will the Grok investigation take? Based on precedent, these things move slowly.
Major EU tech investigations typically take 2-4 years from opening to resolution. The Meta data transfer case took roughly 2 years. Google's cookie consent case took about 3 years. The Grok investigation likely started in late 2024 or early 2025, so a likely resolution timeframe is late 2026 through 2028.
That doesn't mean nothing happens in the interim. During the investigation, regulators will likely pressure Grok to voluntarily implement safeguards. The company might do so to reduce potential penalties. There will also be media coverage that impacts X's reputation and possibly its business.
If a settlement is reached, it could happen faster (2-3 years). If Grok fights and the case goes to formal judgment, it could take longer (4+ years).
For context, the timeline matters because regulation is glacially slow compared to technology. By the time the Grok investigation concludes, the technology will have evolved substantially. New AI systems will exist. Deepfake detection might be better. Regulatory standards might have shifted. The investigation is important less for Grok specifically and more for establishing legal precedent.

The Global Regulatory Landscape: Where Else Is This Happening?
The EU isn't the only jurisdiction investigating deepfakes and AI image generation. Here's where else action is happening:
United Kingdom: Considering explicit laws against creating sexually explicit deepfakes without consent. Also developing its own AI regulatory framework independent of the EU.
United States: The approach is more fragmented. Some states are passing deepfake laws. The federal government has explored regulation but hasn't reached consensus. The US generally favors lighter regulation than the EU.
Canada: Proposed AI legislation that would include requirements for high-risk AI systems, including content generation tools.
Australia: Developing its own AI regulation framework, likely influenced by but not identical to the EU's approach.
China: Has strict controls on AI content generation, requiring government approval for training data and usage.
The trend globally is toward more regulation, but the intensity and approach vary. The EU is the furthest along, which is why the Grok investigation is so significant. It's setting a template others will likely follow.
What Does This Mean for Users?
If you're a regular person using Grok or similar image generation tools, what should you know?
First, assume that everything you create might be logged and reviewed. If you're generating deepfakes for harmful purposes (non-consensual intimate imagery, fraud, deception), there's increasing risk of legal consequences. Not just from the platform, but from law enforcement as deepfake laws proliferate.
Second, understand that the platforms you use are facing increasing pressure to restrict what they allow. Features that are available today might be restricted tomorrow. That's not censorship (well, it is, but it's also regulation); it's companies responding to legal requirements.
Third, be skeptical of synthetic images. Deepfakes are getting better, and detecting them is getting harder. As a general principle, images from news sources should be scrutinized before you trust them. Check if they're from reputable sources with confirmation processes.
Fourth, if someone creates deepfakes of you without consent, there's increasing legal recourse. Different jurisdictions have different laws, but the trend is toward making it illegal or at least actionable.

Looking Ahead: The 2025-2026 Regulatory Agenda
The Grok investigation is one of several regulatory actions that will shape AI development over the next 2-3 years. Here's what else is coming:
AI Act Enforcement: The EU AI Act is now in effect, and regulators will start enforcing it more aggressively. Companies will face audits and inspections to ensure compliance.
Copyright Litigation: Ongoing lawsuits against Open AI, Meta, and others for using copyrighted material in training data. These could result in major legal precedent on what counts as fair use for AI training.
Biometric Privacy: More jurisdictions will pass laws restricting facial recognition and biometric data processing.
Consent Standards: Technical standards for managing consent at scale will mature, and regulations will increasingly require their use.
Deepfake-Specific Laws: Expect 5-10 major jurisdictions to pass explicit laws against non-consensual deepfake creation.
Transparency Requirements: More mandatory disclosures about training data, content moderation, and AI system behavior.
For AI companies, the implication is clear: 2025-2026 will be the years when regulatory compliance becomes a core business function, not a side concern. The companies that get ahead of these trends will have a competitive advantage.
Implications for Data Privacy Beyond AI
The Grok investigation also has implications for data privacy more broadly. It's establishing that you can't just collect data because it's publicly available. The fact that something is public doesn't mean you can process it without consent.
This affects marketing, analytics, surveillance, and many other industries. If regulators succeed in making the argument that "public data is still personal data when processed at scale without consent," it could reshape how data-driven business works.
It also elevates the importance of consent management. Companies that can build robust consent infrastructure will have a competitive advantage. Those that rely on exploiting regulatory gray areas will face increasing friction.
For individuals, the implication is that your rights over your data are becoming more enforceable. You can request removal, challenge processing, and potentially sue for damages. Privacy is shifting from a feature to a right.

The Path Forward: What Needs to Happen
For AI companies to operate responsibly in a regulated environment, several things need to happen:
Better Standards: Industry needs agreed-upon standards for consent, training data sourcing, and content safety. Right now, everyone's making it up as they go.
Better Tools: We need technical tools that make compliance easier. Consent management at scale is hard; better tools will help.
Better Communication: Companies need to clearly explain to regulators and users how their systems work. Transparency builds trust and reduces friction.
Better Balance: Regulation needs to balance innovation with protection. Over-restrictive rules could stifle beneficial uses of AI. Too-permissive rules enable abuse.
Better Enforcement: Regulators need adequate resources and expertise to enforce rules fairly and consistently.
None of this is easy. But the alternative is a regulatory arms race where each jurisdiction passes increasingly strict rules, and companies are forced to choose between compliance in different regions or withdrawal.
FAQ
What exactly is Grok and why is it controversial?
Grok is X. AI's AI assistant and image generation tool that can create synthetic images from text prompts. It became controversial because it could generate deepfakes of real people without apparent safeguards, raising concerns about consent, data privacy, and potential misuse for creating non-consensual intimate imagery or spreading disinformation.
Why is the EU investigating Grok for data privacy violations?
The EU investigation centers on whether Grok was trained on images of real people without their consent, which would violate GDPR's requirements for processing personal data. The concern extends to whether Grok's ability to generate deepfakes of real people constitutes processing of biometric data (facial features) without consent, which is prohibited under GDPR except in narrow circumstances.
How does GDPR apply to AI image generation?
GDPR requires organizations to have a legal basis before processing personal data. When AI systems are trained on images containing people's faces, that's processing of personal data (and specifically, biometric data, which is a special category requiring extra protection). GDPR generally prohibits processing special category data without explicit consent, with limited exceptions. The EU is arguing that Grok failed to obtain proper consent and therefore violated GDPR.
What are the potential penalties for Grok?
Under GDPR, penalties can reach up to 4% of global annual revenue or 20 million euros, whichever is higher. For a company like X. AI, absolute penalties could range from 100 million to potentially several hundred million euros, depending on the severity of violations, the number of people affected, and whether regulators consider it a repeat offense. Beyond financial penalties, settlements typically require technical and operational changes to prevent future violations.
How do other AI image generation tools handle this differently?
Open AI's DALL-E has strict content filters that prevent users from requesting images of real people without difficulty. Google's Gemini similarly implements safety classifiers and requires authentication. Midjourney requires paid subscriptions and authentication, making large-scale anonymous misuse harder. These platforms have also been more proactive about content moderation, user logging, and demonstrating compliance with regulations. Grok, by contrast, launched with minimal guardrails, which is why regulators focused their investigation on it.
What is a deepfake and why are regulators concerned about them?
A deepfake is synthetic media (video, image, or audio) created using AI that realistically depicts someone doing or saying something they didn't actually do or say. Regulators are concerned because deepfakes can be used for fraud, harassment, non-consensual intimate imagery, election interference, and spreading disinformation. When deepfake generation becomes trivially easy (as with Grok), the potential for large-scale abuse increases substantially.
Will Grok be forced to shut down its image generation feature?
It's possible, though a more likely outcome is that Grok will be forced to implement substantial safeguards: content filters, user authentication, detailed logging, training data audits, and a process for people to request removal from future training data. The company might also face large financial penalties. An outright shutdown is less likely unless Grok refuses to comply with regulatory requirements, which would be a risky business decision.
How long will the Grok investigation take?
Based on precedent with other major EU tech investigations, the process typically takes 2-4 years from opening to resolution. The investigation likely began in late 2024 or early 2025, suggesting a likely resolution in late 2026 through 2028. However, regulators often pressure companies to voluntarily implement safeguards during the investigation, so changes might happen sooner.
Could this investigation affect other AI companies?
Yes. The Grok investigation is establishing legal precedent for how AI image generation should be regulated under GDPR. Even if a company isn't directly investigated, the outcome will influence regulatory expectations. Other companies like Anthropic and Open AI are likely auditing their own training data practices and implementing additional safeguards proactively to avoid similar investigations.
What is the "Brussels Effect" and how does it relate to Grok?
The Brussels Effect is the tendency for EU regulatory decisions to become global standards, even for companies that don't operate primarily in Europe. This happens because the EU market is economically essential and maintaining separate compliant and non-compliant versions of a product is expensive. If the EU forces Grok to implement strict safeguards, X. AI will likely implement them globally rather than maintaining different versions for different regions. This means the EU's regulatory decisions influence how AI works worldwide.
What should AI developers do to avoid similar investigations?
Developers should conduct data protection impact assessments, document training data sources and legal basis for use, implement technical safeguards (content filters, authentication, logging), establish user consent processes, create data removal request procedures, and maintain transparency reporting on content moderation. Treating compliance as a core feature rather than an afterthought significantly reduces regulatory risk and potential penalties.

Conclusion: The Inflection Point for AI Regulation
The Grok investigation represents an inflection point. For years, AI companies operated in a regulatory gray area, moving fast and avoiding explicitly harmful outputs while relying on arguments that their activities fell outside existing legal frameworks. That era is ending.
Regulators have decided that the gray area is gray no longer. They're creating clear rules: if your AI system processes personal data, you need a legal basis for that processing. If your system can generate synthetic versions of real people, you're processing biometric data. If you're processing biometric data without explicit consent, you're violating GDPR. It's that simple.
This shift has massive implications. It means AI companies will need to invest substantially in compliance infrastructure. It means training data sourcing will become far more complicated and expensive. It means companies will need to implement safeguards they might have preferred not to. It means the regulatory compliance function will grow from a side concern to a core business responsibility.
But there's an upside too. Clear rules, once established, create predictability. Companies can plan around them. Compliance costs are easier to forecast. And perhaps most importantly, the shift toward responsible AI development might reduce the genuine harms that deepfakes and uncontrolled synthetic media can cause.
The Grok investigation isn't the end of the story. It's the beginning. Over the next 2-3 years, we'll see similar investigations in other jurisdictions, similar enforcement actions against other companies, and gradual evolution of standards. The global AI landscape in 2027 will look substantially different from today, in large part because of cases like Grok.
For AI developers, the message is clear: compliance isn't optional. For users, the message is: your data and your image have legal protections, and those protections are increasingly enforceable. For regulators, the message is: your authority extends into AI, and companies will respond to that authority.
The era of regulatory gray area is over. We're in the era of specific rules, enforcement, and consequences. That's uncomfortable for some. But it's also the only way we'll ensure that AI development and deployment happen responsibly, at scale, and in the public interest.
The Grok investigation isn't about one company or one tool. It's about establishing the principle that AI companies can't ignore privacy laws, can't process biometric data without consent, and can't enable large-scale harm in the name of innovation. Once that principle is established in the EU, it will spread globally. That's how technology regulation works. The strictest jurisdiction sets the floor. Everyone else must clear it.
For those building AI systems, the time to act is now. For those using AI tools, the time to understand the legal landscape is now. The regulatory revolution in AI has begun, and the Grok investigation is its opening salvo.
Key Takeaways
- The EU launched a formal investigation into Grok for generating millions of deepfakes potentially in violation of GDPR data privacy laws
- Core legal question: whether learning from real people's images without consent, then generating synthetic versions of them, constitutes illegal personal data processing
- GDPR violations could result in penalties up to 4% of revenue or potentially hundreds of millions of euros, establishing costly precedent
- Investigation sets global regulatory standard through the "Brussels Effect," likely influencing how AI image generation tools are regulated worldwide
- AI developers must now treat compliance as core function, implementing content filters, consent management, training data audits, and transparency reporting
Related Articles
- SAG-AFTRA vs Seedance 2.0: AI-Generated Deepfakes Spark Industry Crisis [2025]
- AI Apocalypse: 5 Critical Risks Threatening Humanity [2025]
- Seedance 2.0 Sparks Hollywood Copyright War: What's Really at Stake [2025]
- EU Parliament Bans AI on Government Devices: Security Concerns [2025]
- Samsung's AI Slop Ads: The Dark Side of AI Marketing [2025]
- Seedance 2.0 and Hollywood's AI Reckoning [2025]

