![Grok's Gaming Problem: Why xAI is Testing AI on Video Games [2025]](https://tryrunable.com/blog/grok-s-gaming-problem-why-xai-is-testing-ai-on-video-games-2/image-1-1771613007860.jpg)
Grok's Gaming Problem: Why x AI is Testing AI on Video Games [2025]
When x AI delayed a Grok model release because the chatbot couldn't properly answer questions about Baldur's Gate, something peculiar happened. Not the delay itself—companies optimize for different metrics all the time. But the fact that Elon Musk pulled senior engineers off foundational AI research to debug a fantasy RPG walkthrough tells us something important about how AI companies actually prioritize work.
It's easy to dismiss this as a billionaire's vanity project. Funny take: "Musk wants his chatbot to beat Baldur's Gate, so engineers waste time on game walkthroughs instead of solving alignment." But that's exactly the wrong read. What actually happened is far more interesting—and reveals deep truths about AI capability assessment, the gap between benchmarks and real-world performance, and how even the smartest companies evaluate their own models.
This wasn't about gaming optimization for gaming's sake. It was about treating a complex, nuanced domain as a meaningful test of AI competency. A test that, it turns out, AI systems were failing at before the team's intervention.
Let's unpack why this story matters, what it reveals about x AI's engineering practices, and what it tells us about where AI development is actually heading in 2025.
TL; DR
- x AI delayed a model release because Grok couldn't answer detailed Baldur's Gate questions to Musk's standard, requiring senior engineers to be diverted from other projects
- This reveals a critical gap between benchmark performance and real-world domain competency, even for frontier AI models
- Video game walkthroughs are surprisingly hard because they require narrative understanding, mechanical knowledge, and contextual reasoning
- Grok improved significantly after focused engineering effort, eventually matching competitors like Chat GPT and Claude in game-specific testing
- The real lesson isn't about gaming—it's about how AI companies actually test models and where they discover performance gaps

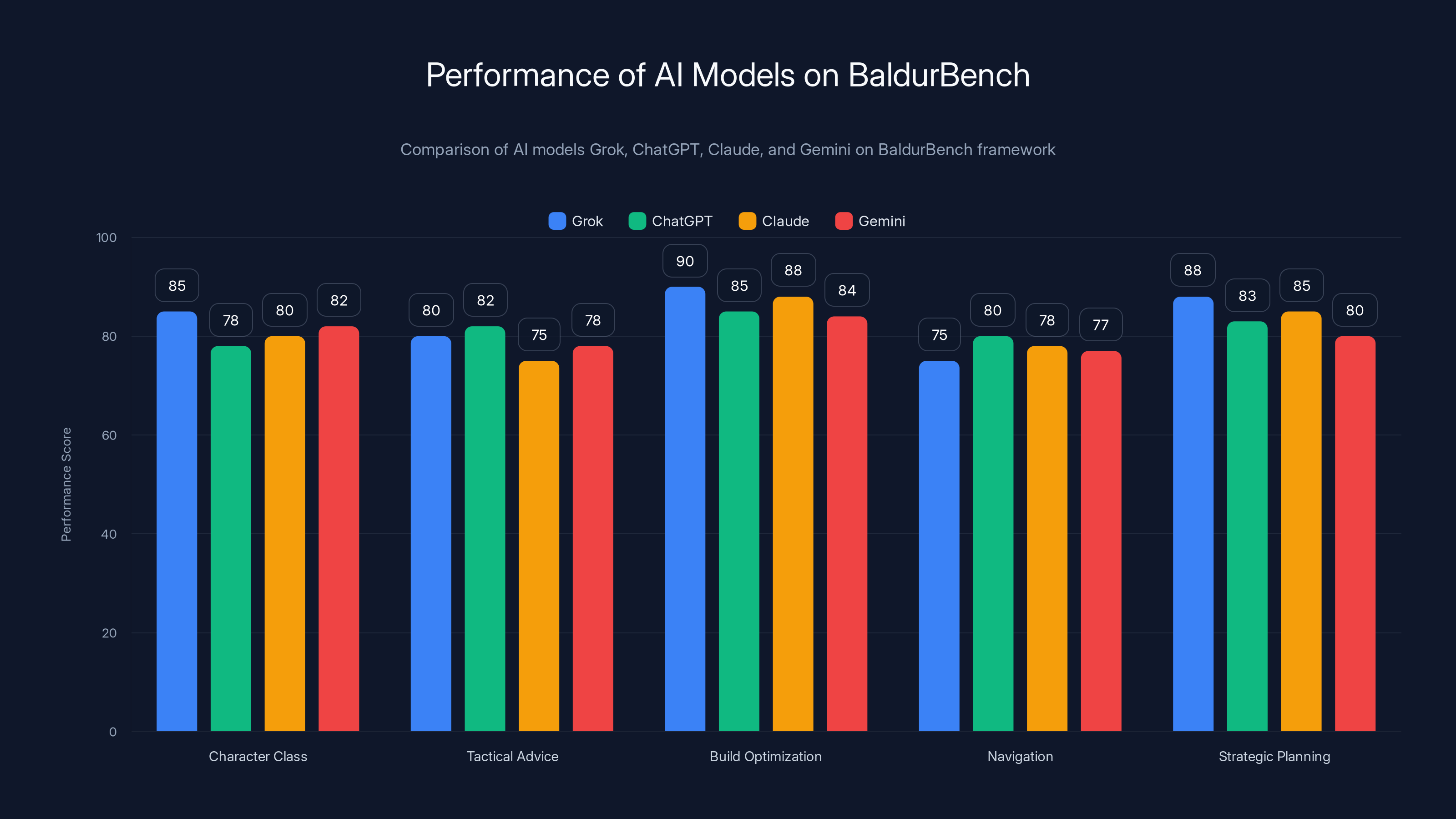
Grok excelled in build optimization and strategic planning, highlighting its strengths in theory-crafting and detailed explanations. Estimated data based on framework insights.
The x AI Engineering Dilemma: When Core Projects Get Sidelined
Imagine being a senior engineer at x AI in late 2025. You've been working on fundamental problems of AI reasoning, interpretability, or training efficiency. Your project roadmap is clear. Your deadlines are set. And then Slack pings with an urgent message: we need you to help the model understand Baldur's Gate party compositions.
The frustration is understandable. Engineers join frontier AI labs to work on hard problems. Debugging why a model thinks a Rogue is better than a Cleric for a specific combat scenario doesn't sound like "hard problem" material. It sounds like homework.
But this is where the story gets more nuanced. If the CEO of the company—the same person who founded Space X and runs Tesla—is making this call, something deeper is going on. Musk doesn't typically micromanage technical decisions. When he does, it's because he sees something others don't.
The question becomes: was this actually a misallocation of resources, or was it strategic testing that needed urgent fixing?
Consider what answering detailed Baldur's Gate questions requires. A model needs to:
- Hold complex rule systems in working memory (AC, attack rolls, saving throws)
- Understand character class interactions (synergies, penalties, trade-offs)
- Synthesize tactical advice from strategic principles
- Recognize when insufficient information makes a question unanswerable
- Distinguish between optimal play and "viable but suboptimal" play
These aren't gaming skills. They're reasoning skills that transfer to dozens of professional domains. An AI that can't reason through a Baldur's Gate party composition probably also struggles with system architecture decisions, resource allocation problems, or workflow optimization—all domains where similar reasoning applies.
So when Grok was failing Baldur's Gate questions, x AI wasn't just facing a gaming problem. The team was seeing a canary in the coal mine. The model had a reasoning gap that manifested in this specific domain but probably existed elsewhere too.
Why AI Models Struggle With Video Game Walkthroughs
Modern AI systems like Chat GPT, Claude, and Gemini are trained on internet text. That text includes gaming guides, forum discussions, Reddit threads about optimization, and thousands of hours of documented player experience.
So why aren't video game questions trivial for these systems?
The answer is that surface-level knowledge—knowing that Rangers can use two-weapon fighting or that Wizards need Intelligence—isn't the same as understanding the why behind strategic decisions. A model might know the rules but fail to integrate them into coherent tactical reasoning.
Take a concrete question: "What's a good party composition for a first playthrough of Baldur's Gate for someone who doesn't min-max?"
The naive approach is to scrape gaming forums and return the most common answers: "Fighter, Mage, Thief, Cleric is the classic setup." That's knowledge retrieval. But actually understanding the question requires recognizing that:
- "First playthrough" means the player values exploration and story over efficiency
- "Doesn't min-max" means the player wants flexibility, not a mathematically optimized build
- The answer should balance versatility, survivability, and fun factor—not just DPS output
When Grok initially failed these questions, it was probably because the model was pattern-matching to forum posts without understanding the meta-layer of reasoning that makes the advice actually useful.
Here's what the testing probably revealed:
Problem 1: Jargon Sensitivity
AI models sometimes struggle with domain-specific terminology when it's used in unexpected contexts. "Save-scumming" (repeatedly saving and reloading to get favorable RNG outcomes) is obvious to gamers but might confuse a model that primarily encounters "save" in a financial context. Early versions of Grok probably either didn't recognize the term or treated it as noise.
Problem 2: Contextual Adaptation
When someone asks "Is a pure mage viable?", the useful answer depends on context:
- For competitive speedrunning? No, too squishy
- For a first playthrough? Yes, with careful play
- For tactical problem-solving? No, lacks versatility
- For story immersion? Yes, if that's your goal
Models that score well on benchmarks sometimes fail this test because they prioritize one dimension ("most optimal") without recognizing that the questioner is asking for something different.
Problem 3: Uncertainty Expression
Good advice includes phrases like "that can work if," "generally avoid unless," and "depends on playstyle." Models sometimes flatten this nuance into false certainty. Saying "Rangers are bad" is wrong; saying "Rangers are strong if you understand weapon synergies but weak if you just take generic attacks" is right. The latter is harder to generate.
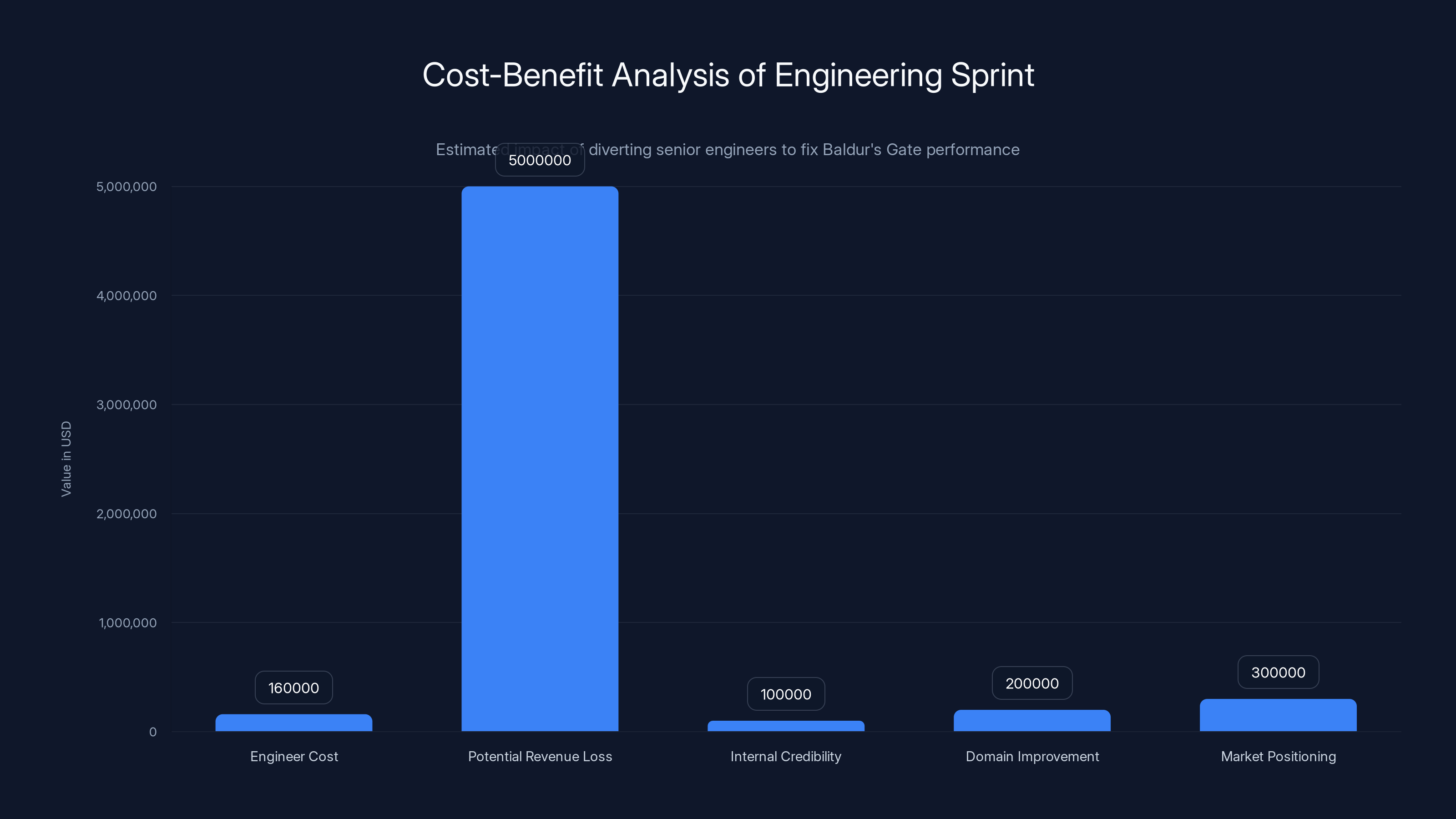
The estimated direct cost of the engineering sprint was $160,000, but potential revenue loss and other benefits could justify the redirection of resources. Estimated data.
The Baldur Bench Testing Framework: How x AI Actually Measured Progress
Once the engineering team focused on the problem, they needed a way to measure whether improvements were real or just cosmetic. Enter Baldur Bench, a five-question benchmark specifically designed to test how well different models answered Baldur's Gate questions.
This is where things get interesting from a testing methodology perspective. Baldur Bench wasn't a lab-created academic benchmark. It was a practical test built by actual gamers (specifically, one of Tech Crunch's reporters who played RPGs) asking questions they actually wanted answered.
The five questions weren't published in full, but the framework tested:
- Character class combinations and party synergies
- Tactical advice for specific scenarios
- Build optimization and theory-crafting
- Navigation and quest-related questions
- Strategic planning across the game's progression
Running Grok, Chat GPT, Claude, and Gemini through the same test provided something valuable: apples-to-apples comparison from the perspective of actual user needs, not abstract benchmarks.
What the results showed was fascinating:
Grok's Strengths Post-Engineering Sprint:
- Accurate mechanical knowledge (damage calculations, class features, interactions)
- Well-organized responses using tables and structured formats
- Strong theory-crafting guidance for optimization-focused players
- Detailed explanations of why certain builds work or don't work
Grok's Weaknesses (Still):
- Heavy jargon density without always explaining terms for newcomers
- Sometimes over-optimizes for competitive play when the questioner wanted casual advice
- Verbose in explaining concepts that other models delivered more concisely
Comparison Results:
- Chat GPT: Preferred bullet-point formatting, balanced accessibility with detail, generally excellent across all question types
- Claude: Explicitly concerned with spoilers and player autonomy, sometimes too cautious in offering advice ("Don't stress, just play what sounds fun")
- Gemini: Heavy use of bold formatting and emphasis, good at highlighting key decisions, but sometimes missed nuance in follow-up questions
The surprise element in Claude's responses is worth examining. Anthropic's model showed explicit concern about spoiling the game experience. This reflects Claude's constitutional AI training—the model was genuinely worried about ruining someone's fun.
That's not a limitation. It's a different priority. Anthropic optimized Claude for avoiding harm, even when the "harm" is learning something you didn't ask to know about a fictional game world. It's a design choice that reveals company values.
What's crucial here is that after the engineering sprint, Grok's performance was roughly equivalent to competitors. Not better. Not worse. Equivalent. This means x AI successfully closed the specific gap Musk identified, but it also means the investment had limits—you can improve a model on a specific domain through focused effort, but you're likely improving relative position, not absolute capability.
The Opportunity Cost Question: Was the Engineering Sprint Worth It?
Let's do a rough cost-benefit analysis of diverting senior engineers from core projects to fix Baldur's Gate performance.
The Cost Side:
If x AI has 50-100 senior engineers (reasonable estimate for a frontier lab), and they pulled maybe 5-10 engineers for "several days" (let's say 5 business days), that's roughly 25-50 engineer-days of work redirected.
What could those engineers have done instead?
- Improved training efficiency (saving millions in compute costs)
- Advanced interpretability research (critical for safety)
- Optimized inference latency (important for production deployment)
- Built new capability areas entirely
- Fixed other domain-specific performance gaps
In monetary terms, if each engineer costs
The Benefit Side:
What did x AI gain?
- A fixed model release: Delaying models is expensive—customers waiting, competitors shipping, momentum lost
- Internal credibility: Engineers see the CEO care about quality across all domains
- A domain-specific improvement: Grok now performs competitively on gaming questions
- Testing methodology: The Baldur Bench framework can be applied to other domains
- Market positioning: "Grok is good at X" is a potential marketing angle
If the delay would have cost x AI a major customer, lost $5M in revenue, or delayed a significant Grok feature release, then the engineering cost is trivial by comparison. If it was purely about Musk's gaming satisfaction, that's a different story.
The most likely scenario: it was somewhere in the middle. Musk cares about quality across the board, recognized a real gap, and made a decision that was both personally motivated and strategically sensible.
What This Reveals About AI Company Priorities
Different AI labs have famously different focuses:
Open AI historically prioritized consumer accessibility and broad capability (hence Chat GPT's focus on being helpful across domains)
Anthropic emphasizes safety and alignment (hence Claude's caution and constitutional AI approach)
Google/Deepmind splits between research breakthroughs and product integration
Meta focuses on open-source deployment and scale
x AI, based on this Baldur's Gate anecdote and other public statements, seems to prioritize comprehensive capability across domains, even niche ones. This suggests a philosophy: "Our model should be competent at anything a human can understand."
That's a different bar than "our model should excel at professional tasks" or "our model should be safe above all else." It's more holistic.
This philosophy has implications for how x AI trains, evaluates, and deploys models:
- Broader training data prioritization (not just professional domains)
- More diverse benchmark testing (including niche areas)
- Different resource allocation (willing to optimize for specificity)
- Different go-to-market strategy (positioning Grok as universally competent)
None of this is wrong. It's a valid approach to AI development. But it does mean x AI engineers spend time on tasks that, from a pure capability frontier perspective, might seem tangential.
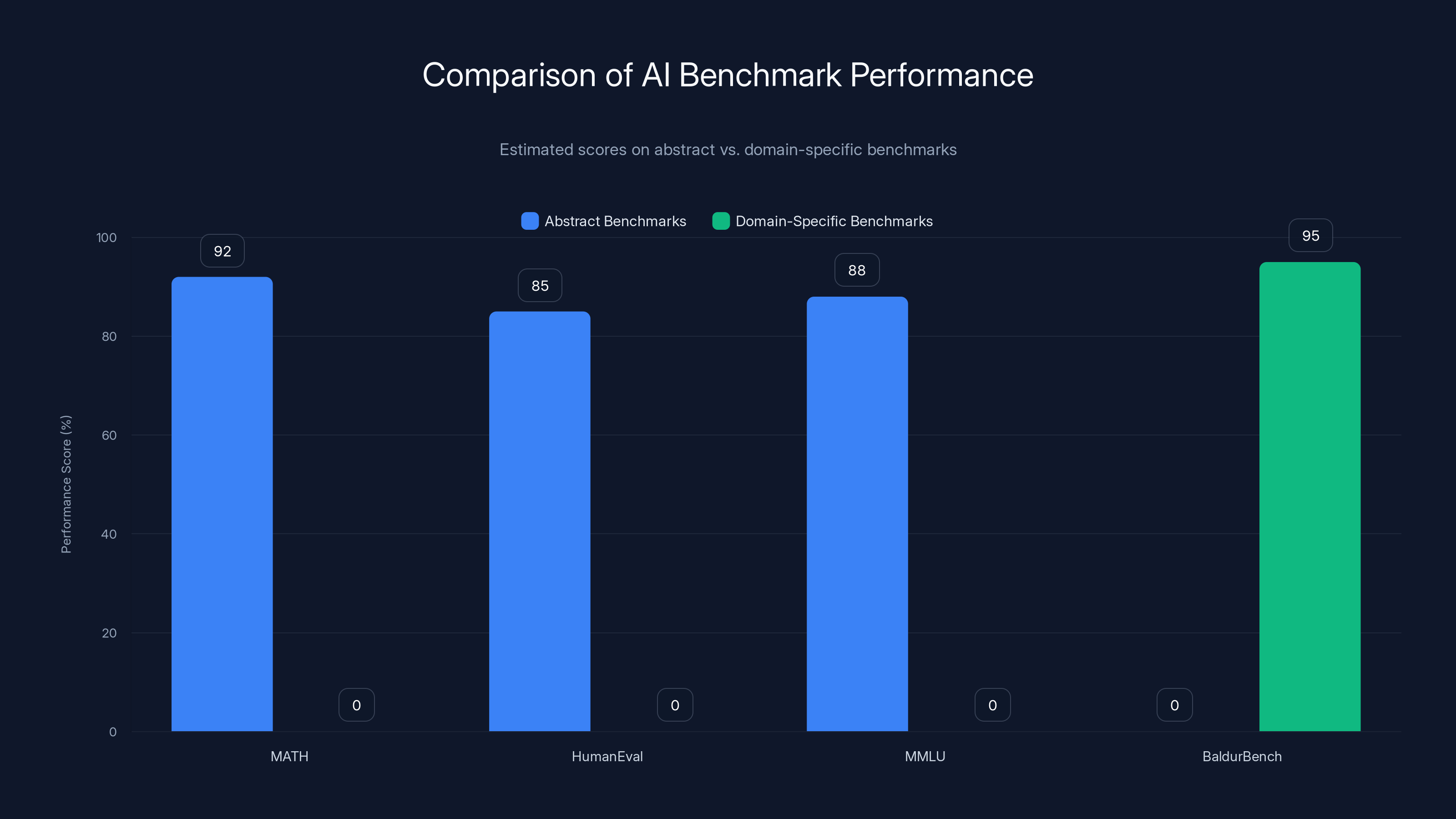
Estimated data shows that while models score highly on abstract benchmarks like MATH (92%), they excel on domain-specific tests like BaldurBench (95%), highlighting the importance of real-world testing.
Domain-Specific Testing as a Development Tool
Here's the critical insight that most people miss: x AI wasn't testing Grok on Baldur's Gate because they wanted to market "great at gaming." They were using a complex domain as a testing ground for reasoning capabilities.
Consider an analogy. When Deep Mind developed Alpha Go, they weren't doing it to beat humans at Go. Well, they were, but that was the proxy test. The real goal was to advance neural network capabilities, planning algorithms, and reinforcement learning. Go was the domain; deep learning was the objective.
Similarly, Baldur's Gate questions aren't the goal for x AI. They're a proxy test for:
Reasoning Under Uncertainty: The game has incomplete information, probabilities matter (dice rolls), and sometimes there's no "correct" answer
Multi-dimensional Optimization: Party composition requires balancing offense, defense, utility, survivability, and playstyle preference simultaneously
Domain Knowledge Integration: The model must integrate rule knowledge with tactical intuition with community best practices
Contextual Adaptation: The right answer to "is this viable" depends entirely on the context of who's asking
If a model can't handle these aspects in gaming, it will struggle elsewhere too. Medical diagnosis, legal advice, business strategy—all require similar reasoning patterns.
So when x AI's engineering team fixed Grok's gaming performance, they were probably fixing something deeper. The visible improvement was "now answers Baldur's Gate questions well." The actual improvement was probably "now handles complex multi-dimensional optimization problems with better reasoning."

The Benchmark Problem: Why Real Tests Beat Abstract Metrics
Frontier AI labs publish benchmark scores constantly. MMLU (medical knowledge), Human Eval (coding), MATH (mathematical reasoning). These are important, but they have a critical limitation: they're abstract.
When a model scores 92% on MATH, that means it can solve standardized math problems. But that doesn't tell you how it would handle a real physicist's actual research problem, which might involve non-standard notation, missing information, and multiple valid approaches.
Similarly, benchmarks test peak performance on clean examples. They don't test robustness, contextual judgment, or the ability to know when to say "I don't have enough information."
Domain-specific tests like Baldur Bench bridge this gap. A model that does well on gaming questions probably also:
- Integrates disparate information sources
- Makes trade-off decisions
- Explains reasoning clearly
- Knows the limits of its knowledge
- Adapts tone to audience
These capabilities are harder to measure on abstract benchmarks but crucial in real-world deployment.
x AI's approach—taking Grok through an engineering sprint to improve gaming performance—is essentially saying: "We care about comprehensive capability. If there's a domain where we're weak, we'll fix it." This is more thorough than many competitors and suggests a commitment to breadth alongside depth.
Chat GPT, Claude, and Gemini: The Competitive Landscape
When Baldur Bench ran Grok against the three major competitors, it provided a snapshot of how different models approach the same problem.
Chat GPT's Approach: Clear, Accessible, Well-Structured
Chat GPT has become the default AI assistant for millions of people, and this shows in how it handles gaming questions. The model prefers bulleted lists and sentence fragments—formats that are easy to scan and digest.
Chat GPT doesn't assume the questioner knows gaming jargon. If it mentions "DPS," it explains "damage per second." If it mentions "AC," it explains "armor class." This accessibility is intentional and reflects Open AI's product philosophy: make AI that works for everyone.
For gaming advice specifically, Chat GPT was generally excellent across all five Baldur Bench questions. It provided multiple options ("here are three viable approaches"), explained trade-offs, and adapted to the presumed audience level.
Claude's Approach: Cautious, Spoiler-Conscious, Ethical
Anthropic's Claude took a noticeably different stance. When asked about good party compositions, Claude's response closed with: "Don't stress too much and just play what sounds fun to you."
This is fascinating because it reveals Claude's training. The model is genuinely concerned about spoiling the game experience. It's trying to protect user autonomy and enjoyment, even if that means providing less detailed optimization advice.
For someone seeking tactical optimization, Claude's caution might be frustrating. For someone playing their first game who wanted to be surprised by discoveries, it's perfect.
This suggests Anthropic is optimizing Claude for safety and user autonomy as much as helpfulness. The model is making a judgment call about what the questioner actually needs.
Gemini's Approach: Visual, Bold, Highlighter-Heavy
Google's Gemini showed strong visual formatting preferences. The model loves bold text, emphasizing key decisions, critical stats, and turning points.
This reflects Google's broader design philosophy—make information scannable and hierarchical. Gemini's responses were generally accurate and well-organized, though sometimes the heavy bold formatting made it harder to distinguish truly critical information from moderately important details.
Grok's Evolved Approach: Dense, Theoretical, Table-Heavy
After the engineering sprint, Grok developed a distinctive style: tables and theory-crafting. The model loves structured information and doesn't assume the questioner needs hand-holding through basic concepts.
For a player who's played Baldur's Gate before or has gaming experience, Grok's approach is efficient. For a complete newcomer, it might be overwhelming. This suggests x AI optimized Grok more for competence than accessibility.

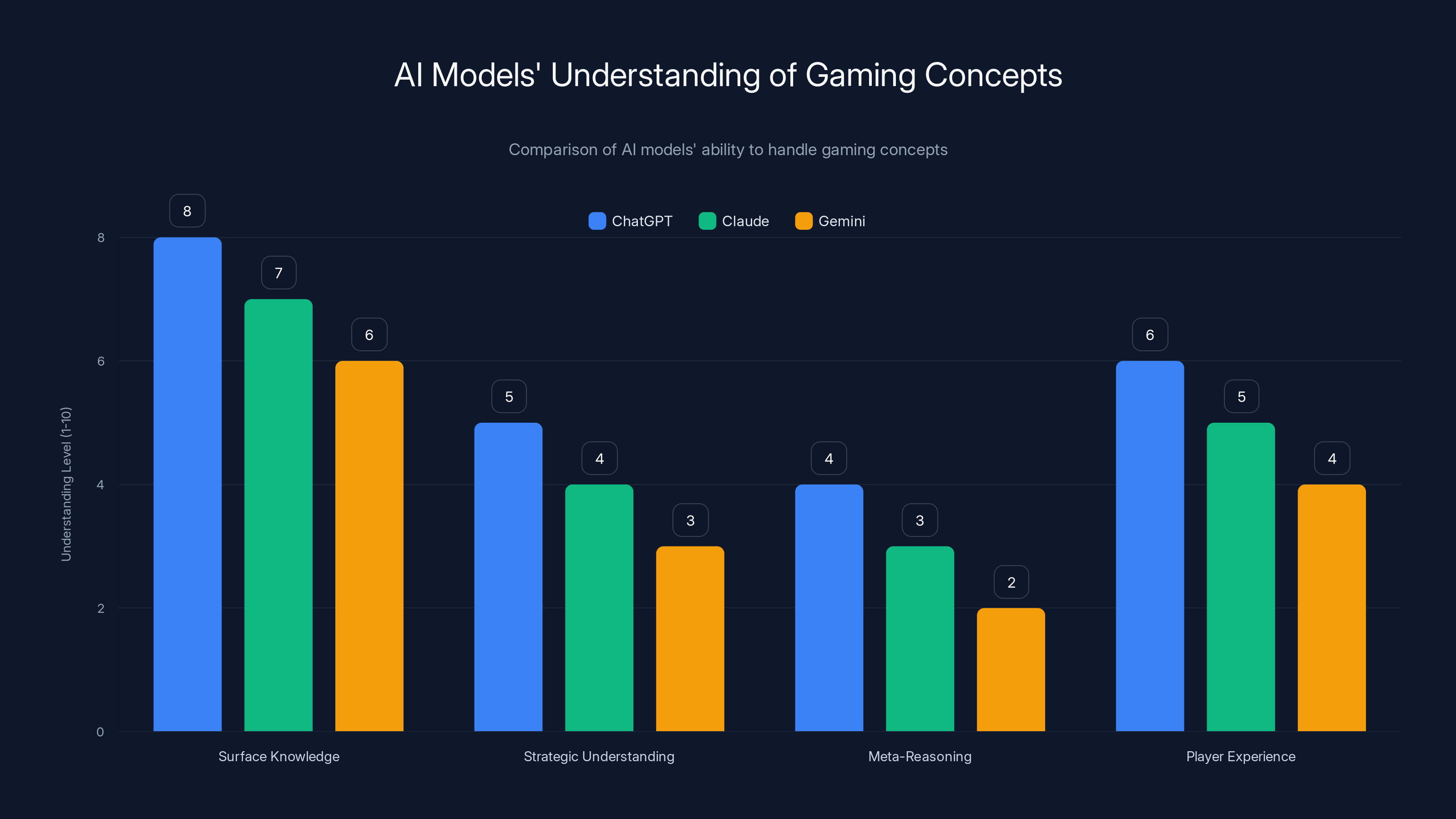
AI models like ChatGPT, Claude, and Gemini excel in surface-level gaming knowledge but struggle with deeper strategic understanding and meta-reasoning. Estimated data based on typical AI capabilities.
The Real Cost of AI Development: Resource Allocation at Frontier Labs
This Baldur's Gate anecdote is important because it highlights something rarely discussed: the resource allocation challenges facing frontier AI labs.
x AI has limited engineering capacity. Every engineer pulled onto the gaming project is unavailable for:
- Training efficiency improvements
- Safety and alignment research
- Infrastructure and deployment optimization
- Building new capabilities
- Reducing latency and costs
All of these are also important. All of these compete for the same limited pool of talented engineers.
Musk's decision to prioritize gaming performance reveals his calculus:
- Quality matters across all domains (not just professional/important tasks)
- Release timing matters (delaying a model release is expensive)
- Comprehensive capability is a differentiator (being good at everything beats being best at some things)
- Visible, testable improvements matter (being able to point to better game advice is better than abstract capability gains)
This is a legitimate strategic choice, though it does mean other projects get deferred.
For comparison, consider how other labs allocate resources:
- Anthropic might redirect resources to safety testing before Anthropic could redirect to domain-specific optimization
- Open AI likely prioritizes user feedback and product feature requests alongside capability improvements
- Deep Mind historically optimized for research breakthroughs over production polish
Each approach is defensible. Each reveals different strategic priorities.
What the Baldur's Gate Sprint Tells Us About AGI Development
If you squint at this story a certain way, it hints at challenges we'll face as AI systems become more capable:
Problem 1: The Never-Ending Quality Bar
Once you decide "our model should be excellent at everything," you've set an impossible standard. There's always another domain where performance could be better. The Baldur's Gate optimization might have seemed urgent and necessary, but it's a symptom of a deeper issue: unlimited scope.
Frontier labs will eventually face a choice: optimize breadth (good at everything) or depth (excellent at high-value domains). This choice has resource implications that grow with company size.
Problem 2: The Difficulty of Progress Assessment
How do you know if an engineering sprint actually improved the model? Baldur Bench is specific enough to show measurable improvement, but generic enough that the same approach could apply to thousands of other domains.
Without clear prioritization, labs could spend disproportionate time optimizing narrow domains, mistaking domain-specific progress for general capability improvement.
Problem 3: The Strategic Decision Problem
When Musk decided gaming performance was important enough to delay the model release, he was making a judgment call about what matters. That judgment might be right (comprehensive capability is valuable), or it might be wrong (resources could have been better spent elsewhere).
The difficulty is that these decisions compound over time. Each domain optimization request, when approved, suggests that similar requests should be approved in the future. Eventually, engineering capacity gets spread thin across hundreds of optimization tasks, none of which alone seems unreasonable.

AI Model Architecture and Domain Performance: Why Some Models Handle Gaming Better Than Others
Underlying different model performance on gaming questions is architecture and training. Why did Grok initially struggle while Chat GPT handled it better?
A few possibilities:
Tokenization and Vocabulary: Different models use different tokenization schemes. If Grok's tokenizer broke "save-scumming" into tokens that don't have strong semantic relationships, the model would struggle with the concept. Chat GPT's tokenization might have handled gaming terminology more naturally.
Training Data Composition: If Chat GPT's training data included more gaming forums and walkthroughs proportionally, it would have more direct examples of how to answer these questions. This is actually likely—Open AI has historically trained Chat GPT on more diverse internet content.
Fine-tuning and RLHF: After initial training, models are fine-tuned through RLHF (Reinforcement Learning from Human Feedback). If human raters provided more gaming-related feedback for Chat GPT than for Grok, the model would learn better responses. x AI's engineering sprint probably involved collecting gaming-specific RLHF data.
Context Length and Reasoning Steps: Some models are better at maintaining context across long reasoning chains. Gaming advice often requires holding multiple considerations in mind simultaneously (character mechanics, role synergies, playstyle preferences). Models with better long-context performance might naturally excel here.
Safety Training Intensity: As noted, Claude's caution about spoilers suggests safety training might make models less willing to provide detailed strategic advice. This isn't bad; it's a design choice. But it does affect gaming question performance.
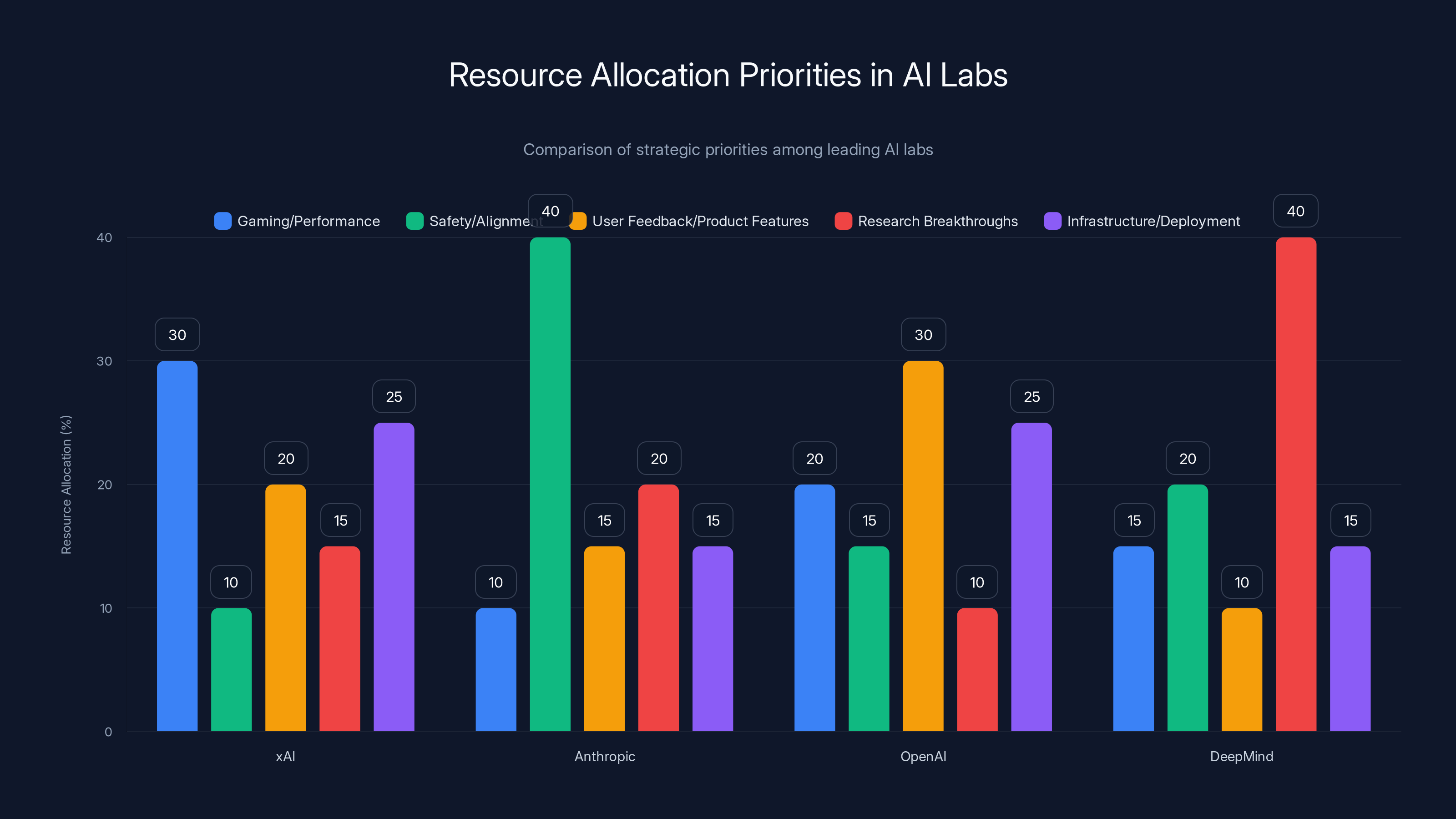
Estimated resource allocation shows xAI focuses more on gaming performance, while Anthropic emphasizes safety. OpenAI balances user feedback with capability improvements, and DeepMind prioritizes research breakthroughs.
The x AI Philosophy: Elon's Vision for Comprehensive AI
The Baldur's Gate incident reveals something about how Musk thinks about AI development. It's not enough for Grok to be good at coding, math, and professional tasks. The model should be reliably competent across all domains.
This isn't necessarily better than alternative philosophies (like Anthropic's focus on safety or Open AI's focus on accessibility). It's just different. But it does suggest x AI will continue to allocate resources toward domain-specific optimization in ways competitors might not.
We should expect to see similar engineering sprints for:
- Complex medical scenarios
- Legal document analysis
- Specialized technical fields (semiconductor design, financial modeling)
- Creative domains (fiction writing, music composition)
- Edge cases and adversarial examples
If Grok struggles with any domain, Musk's track record suggests engineers will be tasked with fixing it. This could be a competitive advantage (comprehensive capability) or a competitive disadvantage (resource spread too thin). History will tell.

Lessons for AI Users: How to Evaluate Models on Your Own Use Cases
If x AI taught us anything, it's that published benchmarks don't tell the full story. When evaluating AI models for your actual needs, you need domain-specific testing.
Here's a framework:
Step 1: Define Your Use Cases
List the specific tasks you need the model to handle. Don't abstract—use real examples. "Help with email" is vague. "Draft professional emails to C-suite executives using our specific brand voice" is concrete.
Step 2: Create a Test Set
Build 10-20 realistic test cases representing different difficulty levels. For Baldur's Gate, the test cases were gaming questions. For your use cases, they're your actual problems.
Step 3: Test Systematically
Run each model through the same test set. Record not just whether they got the answer right, but the quality of the reasoning, the accessibility of the explanation, and how well they adapted to your specific context.
Step 4: Evaluate Qualitatively
Benchmarks show pass/fail. Domain testing shows how the model thinks. A model that gets the right answer for the wrong reasons might fail when you need the reasoning for subsequent decisions.
Step 5: Consider Resource Trade-offs
Some models will excel at your use cases. But they might be slower, more expensive, or require more infrastructure. Baldur Bench found Grok performed well after engineering optimization, but that optimization cost resources. Is spending engineering effort to improve your AI justified? Sometimes yes, sometimes no.
The Future of AI Competitive Differentiation: Niche Capabilities
As frontier models (GPT-4, Claude 3, Gemini 2.0, Grok) converge on similar levels of general capability, competitive differentiation will increasingly come from niche optimization.
One model will be best for code. Another for medical questions. Another for creative writing. Another for gaming advice (apparently).
Companies will need to make choices:
- Breadth Strategy: Be competent across all domains (x AI's apparent approach)
- Depth Strategy: Be exceptional at high-value domains (likely approach for industry-specific tools)
- Balance Strategy: Be very good at core domains, acceptable elsewhere (probably most common)
The Baldur's Gate optimization suggests x AI is pursuing breadth. This makes sense if Grok is positioning itself as a general-purpose assistant that can replace Chat GPT for mainstream users. But it does mean engineering resources get allocated toward domain optimization rather than fundamental research.
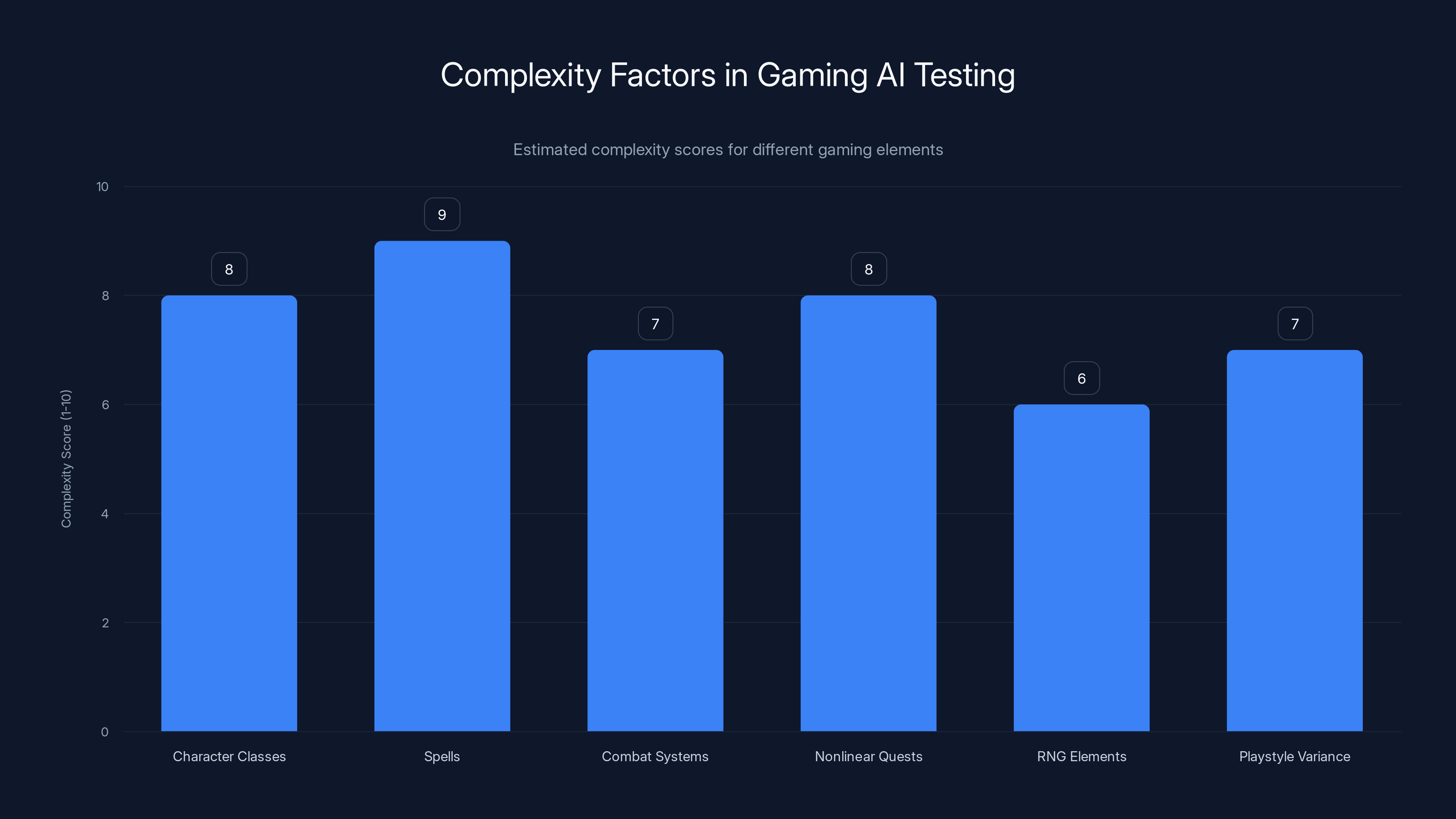
Character classes and spells present the highest complexity for AI systems in gaming, due to their vast variety and intricate interactions. Estimated data based on typical game mechanics.
Challenges in the Gaming Domain: Why This Testing Area Is Harder Than It Seems
Since we've spent considerable time on Baldur's Gate performance, let's drill deeper into why this domain is genuinely challenging for AI systems.
Baldur's Gate is based on Advanced Dungeons & Dragons 2nd Edition rules, a system with:
- 50+ character classes and kits with distinct mechanics
- Hundreds of spells with specific rules interactions
- Complex armor and combat systems involving THAC0 (to hit armor class 0), saving throws, spell resistance
- Nonlinear quests where order and approach matter significantly
- RNG elements where randomness affects outcomes
- Playstyle variance where "optimal" changes based on difficulty and player preferences
For a model to give good Baldur's Gate advice, it needs to:
- Hold all these mechanical rules in working memory simultaneously
- Understand how rules interact in non-obvious ways
- Apply rules to hypothetical scenarios
- Explain reasoning so humans can verify it or learn from it
- Adapt recommendations based on player skill level and preferences
This is genuinely hard. It's not as hard as creating new physics breakthroughs, but it's harder than most benchmarks suggest.
Conversely, this domain is genuinely useful for evaluating whether models can:
- Learn complex rule systems
- Apply rules to novel scenarios (party compositions the model hasn't seen before)
- Reason about optimality under constraints
- Communicate complex information accessibly
All of these are transferable to professional domains. A model that can reason through Baldur's Gate mechanics can probably reason through legal code, medical protocols, or business process optimization.
The Human Feedback Loop: How RLHF Data Collection Probably Worked
When x AI engineers fixed Grok's gaming performance, they almost certainly used a structured approach:
Phase 1: Data Audit
Analyze what training data Grok has about Baldur's Gate. Are there enough gaming guides, forums, and discussions in the training set? If not, that's part of the problem.
Phase 2: Specific Test Development
Create the Baldur Bench questions—five representative prompts covering different aspects of gaming knowledge and reasoning.
Phase 3: Error Analysis
Run Grok through the test set and carefully analyze failures. Is the model providing wrong information, vague answers, inaccessible explanations, or something else?
Phase 4: RLHF Data Collection
Generate new model outputs on gaming questions. Have human raters (probably people with Baldur's Gate experience) score which responses are better, helping the model learn better patterns.
Phase 5: Fine-tuning
Use the newly collected RLHF data to fine-tune Grok, reinforcing better response patterns.
Phase 6: Validation Testing
Re-run Baldur Bench to confirm improvement, testing that fixes don't break other domains.
This process probably took weeks, not days. The "several days" of engineer time might refer only to oversight and architectural decisions, with much of the work distributed across contractors and RLHF raters.

Comparing to Competitor Approaches: How Other Labs Handle Domain Optimization
x AI's approach to fixing gaming performance isn't unique, but the visibility is rare. We don't usually get detailed accounts of how labs optimize specific domains.
Open AI's Approach
Open AI primarily relies on:
- Extensive diverse training data
- RLHF with human feedback at scale
- Iterative releases where each version is trained on user feedback
When Chat GPT performs well on a domain, it's usually because the training data includes lots of relevant content and RLHF raters corrected failures. Open AI doesn't usually do visible domain-specific engineering sprints.
Anthropic's Approach
Anthropic emphasizes:
- Constitutional AI (training against principles)
- RLHF with explicit safety criteria
- Detailed capability evaluation before release
Anthropic Engineers likely debug domain-specific failures through safety and capability testing, but the focus is on avoiding harmful outputs rather than optimizing for specific competencies.
Google's Approach
Google has resources for:
- Training on massive diverse datasets
- Multiple parallel model variants
- Targeted optimization for specific product use cases
When Gemini is optimized for a domain, it's often for products Google wants to ship (Gmail drafting, search summarization, etc.).
x AI's Approach
x AI seems willing to do visible, focused engineering on specific domains when the CEO thinks they're important. This is more hands-on and directive than competitor approaches, for better or worse.
Future Implications: How Niche Domain Optimization Will Shape AI Competition
As AI models approach commodity status—where Claude, GPT-4, Gemini, and Grok are all "good enough" for most tasks—companies will need to differentiate.
They can:
- Go deeper on core domains (become the best medical AI, best legal AI, best creative AI)
- Stay balanced (be very good everywhere, exceptional nowhere)
- Specialize by customer segment (AI for enterprises vs. AI for consumers)
- Build on emerging capabilities (multimodal, audio, video, real-time)
The Baldur's Gate optimization suggests x AI is choosing option #1: becoming excellent at specific domains, with gaming apparently being one of them.
We should expect to see:
- Announcement of specialized model variants ("Grok for Finance," "Grok for Science")
- Continued domain-specific optimization announcements
- Niche communities developing around specialized capabilities
- Competitive specialization where each lab becomes known for specific strengths
This fragmentation could be good (users find perfect tools for their needs) or problematic (ecosystem fragmentation, customer lock-in). Probably both.
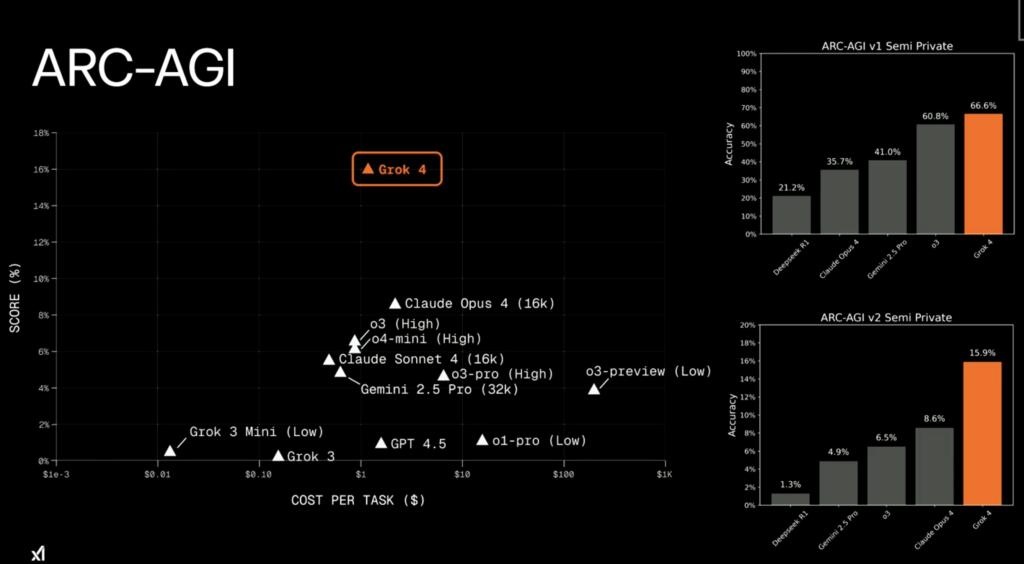
Ethical Considerations: Resource Allocation in AI Development
Here's the uncomfortable question: Was diverting engineers from core AI research to improve gaming advice the right call?
Arguments for the decision:
- Quality matters across all domains, not just "important" ones
- Users benefit from comprehensive capability
- Different domains reveal different capability gaps
- The engineering investment demonstrates commitment to polish
- Market competitiveness requires differentiation
Arguments against the decision:
- Limited engineering capacity should prioritize safety research
- Alignment and interpretability work is more urgent
- Domain-specific optimization is a "nice to have"
- Resource constraints should drive prioritization
- Other areas (training efficiency, latency) might have higher ROI
Musk's decision suggests he weights breadth and quality highly, perhaps more highly than safety or efficiency research. That's a legitimate choice, but it's a choice with implications.
Different people can reasonably disagree on whether Baldur's Gate gaming performance deserves engineering resources. The important thing is recognizing that resources are finite, and every decision involves trade-offs.
Making AI Work Better for Your Needs: Actionable Strategies
If you take away one lesson from the Baldur's Gate saga, let it be this: generic benchmarks don't predict performance on your specific use cases.
Here's how to get better AI results:
1. Create Domain-Specific Tests
Before adopting any AI model, test it on real examples from your actual work. Run the same test through multiple models. You'll discover gaps that benchmark scores don't reveal.
2. Understand Model Strengths and Weaknesses
Different models excel at different things. Chat GPT might be best for your use case, Claude for another, Grok for a third. Don't assume one model is universally best.
3. Optimize for Your Needs, Not Generic Capability
If you discover a model struggles with your specific domain, provide feedback, examples, and context. Many labs have ways to request optimization or can recommend adjustments.
4. Combine Models Strategically
You don't need to choose one model. Use Chat GPT for general tasks, Claude for safety-sensitive work, Grok for reasoning-heavy problems. Different tools for different jobs.
5. Invest in Prompt Engineering
Most of the time, you don't need model engineers to fix performance. You need better prompts, examples, and context. This is faster and cheaper than waiting for model optimization.

The Broader AI Landscape in 2025: Where Models Stand
The Baldur's Gate incident happened in late 2025, but it reflects a specific moment in AI development where frontier models have reached near-parity on general capability.
In early 2025, the landscape was:
- GPT-4 (via Chat GPT Plus): The consumer default, reliable across domains
- Claude 3 Opus: Strong reasoning, safety-conscious, slightly slower
- Gemini Advanced: Good breadth, slightly weaker on specialized reasoning
- Grok: Newer, developing, positioning as broadly capable
All four of these models perform well on most tasks. The differences are increasingly stylistic and domain-specific rather than fundamental capability gaps.
This convergence has implications:
- Price pressure: All models becoming equally good means commoditization
- Feature competition: Differentiation happens through features, not raw capability
- Niche specialization: Success comes from being best at specific domains
- Integration as strategy: Embedded AI (in phones, apps, services) becomes important
x AI's willingness to optimize Grok for gaming is part of a broader strategy: own some specific niches while being competitive everywhere else.
Conclusion: Why Baldur's Gate Matters More Than You Think
It would be easy to dismiss the Baldur's Gate optimization as a billionaire's indulgence. Elon Musk, already running multiple companies, decided to make sure his AI could beat video games, so engineers spent time on gaming advice. Ha ha, how silly.
But that misreads what actually happened. The real story is more interesting: a frontier AI lab recognized that one of their models couldn't handle a complex domain, allocated resources to fix it, and succeeded. The specific domain (Baldur's Gate) is almost irrelevant. What matters is the meta-lesson:
Companies that want to compete in AI are willing to optimize specific domains when they identify gaps.
This has been true for a while (Open AI optimizing for code, Anthropic for safety), but the Baldur's Gate incident makes it explicit and visible.
Moving forward, expect more of this. Companies will identify their model's weaknesses, fix them systematically, and compete partly on the breadth of their optimization work. Some will optimize broadly (x AI's strategy), others deeply (specialized AI companies), most somewhere in between.
For users, this means better AI tools but also fragmentation. For AI developers, it means resource allocation decisions that compound over time. For the field overall, it means we're moving from "frontier capability" as the main differentiator to "comprehensive competence" and "niche excellence."
We've entered an era where "Does your AI work?" is less important than "Does your AI work *for my specific needs?"" The Baldur's Gate optimization is a harbinger of how competition will evolve.
The game hasn't changed. But the way we measure AI progress has.
FAQ
What is Grok and why does x AI care about its gaming performance?
Grok is x AI's AI chatbot, designed to be a general-purpose assistant competitive with Chat GPT and Claude. x AI cares about gaming performance because it's part of a broader philosophy that their model should be comprehensively competent across all domains, not just professional tasks. Gaming performance serves as a proxy test for reasoning capabilities that transfer to other domains.
Why did x AI delay a model release over Baldur's Gate questions?
According to reporting, Elon Musk was dissatisfied with how Grok answered detailed questions about the video game Baldur's Gate. Rather than shipping a model with this weakness, x AI redirected senior engineers to improve gaming performance before launch. This reflects Musk's quality standards and x AI's commitment to comprehensive capability.
How does Baldur Bench work and why is it useful for testing AI?
Baldur Bench is a five-question test designed by gaming enthusiasts to assess how well AI models answer Baldur's Gate questions. It's useful because it tests complex reasoning about rule systems, multi-dimensional optimization, and contextual adaptation—capabilities that transfer to professional domains like medical diagnosis, legal analysis, and business strategy. Unlike abstract benchmarks, Baldur Bench tests real-world reasoning patterns.
How did Grok's performance compare to Chat GPT, Claude, and Gemini on gaming questions?
After x AI's engineering optimization, Grok performed roughly equivalently to competitors on the Baldur Bench test. Chat GPT excelled at accessible, well-structured explanations. Claude was cautious about spoilers and player autonomy. Gemini emphasized visual formatting with bold text. Grok preferred tables and theory-crafting. All four models provided useful gaming advice, with stylistic differences reflecting each company's design philosophy.
What does this incident reveal about AI company priorities?
The incident reveals that different AI labs have fundamentally different priorities: Open AI emphasizes accessibility, Anthropic emphasizes safety, Google emphasizes scale and product integration, and x AI emphasizes comprehensive capability. These priorities show up most clearly in edge cases like gaming advice, where tradeoffs between helpfulness, safety, and specificity become visible.
Should AI companies optimize for specific domains like gaming?
There's a legitimate debate. Arguments for: comprehensive capability is valuable, domain-specific optimization reveals reasoning gaps, and quality matters across all areas. Arguments against: limited engineering resources should prioritize safety research, alignment work is more urgent, and niche optimization is a lower-ROI use of scarce talent. The right answer depends on your values and strategic priorities.
How can I test whether an AI model performs well for my specific use case?
Create a domain-specific test with 10-20 realistic examples from your actual work. Run each model through the same test set. Evaluate not just whether they get answers right, but the quality of reasoning, accessibility of explanation, and adaptation to your context. Generic benchmarks miss crucial domain-specific gaps that only real-world testing reveals.
What does this tell us about the future of AI competition?
As frontier models converge on similar general capabilities, competition will increasingly focus on niche specialization. We'll see different models become known for specific strengths (one for code, one for medicine, one for creative writing). This fragmentation could be positive (perfect tools for specific needs) or problematic (ecosystem fragmentation and lock-in). Expect more announcements like the Baldur's Gate optimization as companies differentiate through specialized capability.
Why do different AI models respond differently to the same questions?
Different models reflect different training data, training objectives, and company philosophies. Chat GPT's training prioritizes accessibility. Claude's training emphasizes safety and user autonomy. Gemini's reflects Google's visual design preferences. Grok's reflects x AI's focus on comprehensive capability. These differences compound through fine-tuning and RLHF (Reinforcement Learning from Human Feedback), creating distinct model personalities.
Is the Baldur's Gate optimization wasteful or strategically sensible?
There are legitimate arguments both ways. It could be wasteful if safety research and interpretability work should be the priority. It could be strategically sensible if comprehensive capability is the key competitive differentiator. The resource allocation question has no objectively correct answer—it depends on your values, business model, and strategic vision. Musk's choice to prioritize comprehensive capability is defensible, as are competing choices by other labs.
Related Topics to Explore
Interested in AI capabilities and testing? Consider exploring how AI models are evaluated on medical tasks, how they perform on legal analysis, or what happens when companies test models on highly specialized domains. The same reasoning principles that apply to gaming performance show up everywhere AI systems encounter complex, real-world problems that require reasoning across multiple constraints.

Key Takeaways
- xAI delayed a Grok release to improve gaming performance, revealing company priorities around comprehensive capability
- Domain-specific testing like BaldurBench reveals reasoning gaps that generic benchmarks miss completely
- Different AI labs (OpenAI, Anthropic, Google, xAI) have fundamentally different strategic priorities reflected in their models
- Baldur's Gate's complex rule systems test AI reasoning about multi-dimensional optimization and contextual adaptation
- As frontier AI models converge on general capability, competitive differentiation increasingly comes from niche specialization
- Engineering resources are finite—every domain optimization decision involves opportunity cost tradeoffs
- Claude's caution about spoilers reveals how safety training affects model behavior across all domains
- ChatGPT's accessibility focus and Grok's theory-crafting preference reflect distinct design philosophies
- The real lesson isn't about gaming—it's about how companies discover and fix AI capability gaps systematically
Related Articles
- Gemini 3.1 Pro: Google's Record-Breaking LLM for Complex Work [2025]
- Orbital AI Data Centers: Technical Promise vs. Catastrophic Risk [2025]
- xAI's Mass Exodus: What Musk's Spin Can't Hide [2025]
- The xAI Mass Exodus: What Musk's Departures Really Mean [2025]
- Moonbase Alpha: Musk's Bold Vision for AI and Space Convergence [2025]
- xAI's Interplanetary Vision: Musk's Bold AI Strategy Revealed [2025]

