![HPE's AI-Driven Network Powers 2026 Winter Olympics [2025]](https://tryrunable.com/blog/hpe-s-ai-driven-network-powers-2026-winter-olympics-2025/image-1-1771050951224.jpg)
Building the Network for Winter Olympics History: How HPE Became the Tech Backbone of Milano-Cortina 2026
When you think about the Olympic Games, you picture athletes competing at peak performance, crowds roaring from stadium seats, and the world watching on screens worldwide. What you don't typically see is the invisible infrastructure making all of it possible: the networks humming beneath every venue, the systems processing petabytes of data in real-time, the technology ensuring that coaches can communicate with athletes, broadcasters can deliver crystal-clear footage, and fans experience the action without a single dropped frame.
For the 2026 Winter Olympics in Milano-Cortina, that invisible backbone belongs to Hewlett Packard Enterprise (HPE). And here's the kicker: they didn't just build a network. They built something entirely new. A network designed from the ground up for artificial intelligence, automated security, and self-healing capabilities that can adapt in milliseconds to changing conditions.
The scale alone tells part of the story. Milano-Cortina 2026 is unprecedented in its geographic distribution. The games are spread across three distinct regions in northern Italy, sprawling across 22,000 square kilometers. That's roughly the size of El Salvador. Athletes, media personnel, organizers, and spectators will occupy over 40 different venues and sites. More than 3,000 athletes from around the world will compete. And all of them will depend on a network that doesn't just work, but anticipates problems before they happen.
This isn't about speeds and feeds anymore. That's what HPE realized when planning the infrastructure. A network that stays "up" isn't necessarily a network that performs when milliseconds matter. When a broadcaster needs to capture a live moment, when a coach needs real-time athlete biometrics, when security systems need to identify potential threats across dozens of venues simultaneously, traditional networking architecture simply doesn't cut it.
The Traditional Network Problem: Legacy networks were built for a different era. They were designed for predictable traffic patterns, stable connections, and human-paced operations. The modern Olympic Games operate at machine speed, with artificial intelligence making decisions about traffic routing, security threats, and performance optimization constantly. A traditional network is essentially reactive. Something fails, you fix it. A network experiences congestion, you manage it after the fact. An AI-native network, by contrast, is predictive. It sees problems coming and prevents them from occurring.
What makes Milano-Cortina 2026 particularly challenging is the combination of factors converging at once. You have massive crowds entering and leaving venues throughout the day. You have hundreds of camera feeds broadcasting simultaneously in multiple languages. You have IoT devices monitoring athlete performance, venue conditions, and crowd flow. You have security systems analyzing footage in real-time. You have the Olympic broadcast center distributing content globally. All of this creates a landscape of dynamic, unpredictable demand that would paralyze a traditional network.
HPE's solution wasn't to build a bigger traditional network. It was to reimagine what a network could be when you design it with artificial intelligence as a first principle, not an afterthought.
The Scale of Infrastructure: What 4,900 Access Points Actually Means
Let's talk numbers, because they illustrate the magnitude of what HPE deployed. To support the 2026 Winter Olympics, the company installed:
- 4,900+ access points providing wireless coverage across all venues
- 1,500 EX Ethernet switches handling wired connectivity and data switching
- 70+ MX universal routers managing traffic flows and network routing
- 50+ SRX next-generation firewalls protecting against threats and enforcing security policies
- 30+ smart session routers optimizing specific types of traffic and application flows
If you're not in the networking world, these numbers might seem arbitrary. But consider what they represent in practice. Those 4,900 access points aren't distributed evenly. They're strategically placed to ensure that a spectator in the furthest corner of a stadium receives the same quality signal as someone sitting ringside. They're positioned to handle peak capacity moments when tens of thousands of people suddenly shift locations (like between events). They're engineered to provide redundancy so that if one access point fails, adjacent points seamlessly absorb the load.
The Ethernet switches are the nervous system of the physical network. Every wired connection runs through them. Cameras, broadcasting equipment, security terminals, operations centers, timing systems, scoreboard displays—all of it flows through these switches. The sheer volume of data they handle is staggering. Think about it: a single 4K camera feed running 60 frames per second requires significant bandwidth. Multiply that by hundreds of cameras across dozens of venues, and you're talking about bandwidth requirements that exceed what most enterprise networks process in a year.
The Router Architecture: The routers deserve special attention because they represent a fundamental shift in how Olympic networks operate. Traditional routers simply forward traffic from point A to point B. Modern routers like the MX series can make intelligent decisions about how to route traffic based on dozens of variables: current network congestion, latency requirements, security policies, application type, and user identity. At the Olympics, this means that a live broadcast feed gets priority routing to ensure it never buffers, while a journalist's email gets routed efficiently but with lower priority.
The SRX firewalls represent the security layer, and at an event where cybersecurity threats are genuine (not theoretical), this is critical infrastructure. These aren't simple packet filters. They're next-generation firewalls that use machine learning to identify suspicious patterns in traffic. A large group of connections from unexpected geographic locations? Flagged. Traffic patterns that don't match normal application behavior? Investigated. Attempts to exploit known vulnerabilities? Blocked before they reach their target.
What's remarkable isn't any individual component. The remarkable part is how all 6,050+ pieces of hardware work together as a unified, intelligent system. That's where HPE's Mist platform enters the picture.

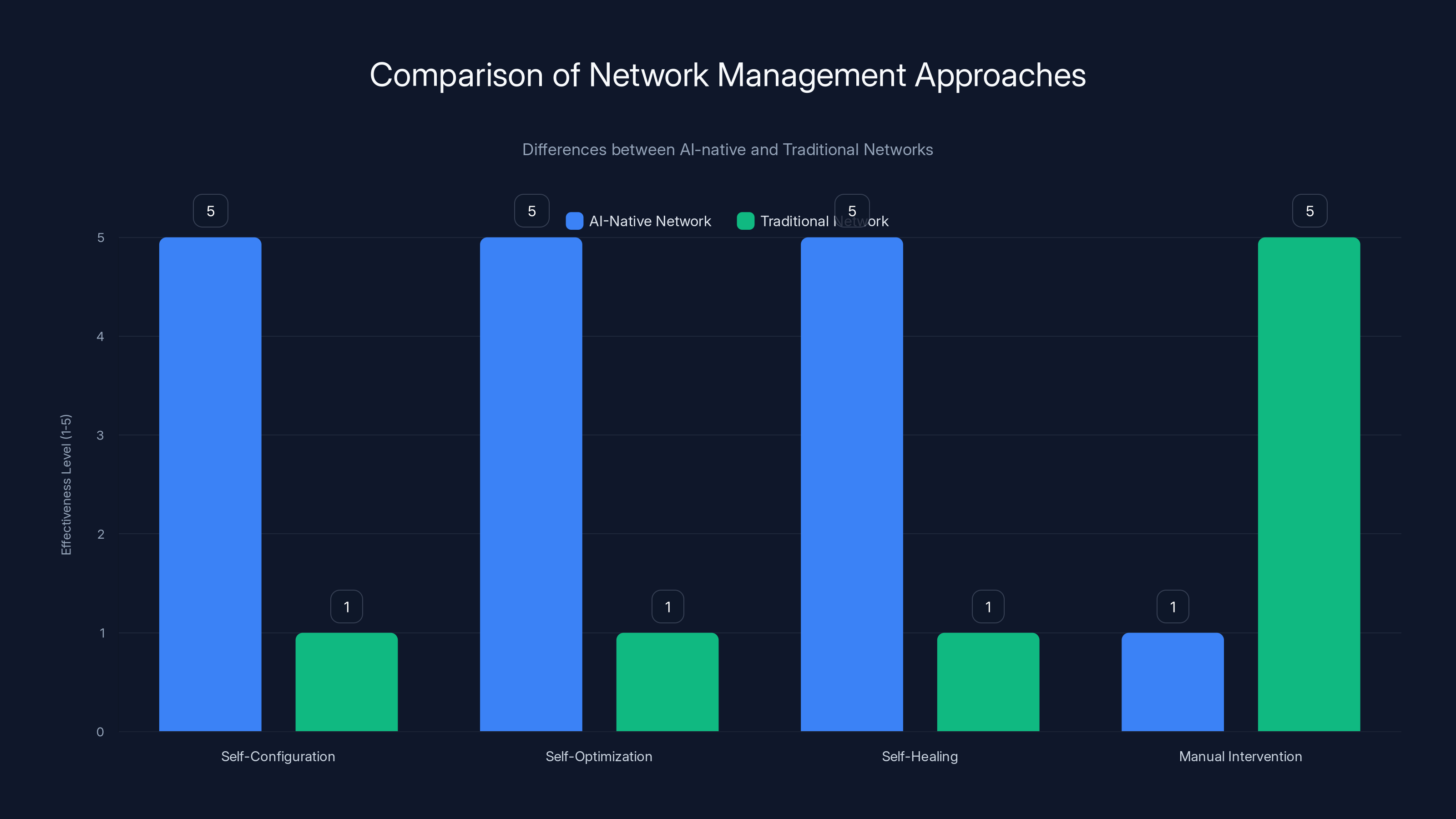
AI-native networks like Milano-Cortina excel in self-configuration, optimization, and healing, minimizing manual intervention compared to traditional networks. Estimated data.
The AI Brain: How HPE Mist Manages an Olympics-Scale Network
You can deploy the most sophisticated networking hardware in the world, but if you're managing it with traditional network operations tools, you've just bought yourself a much more complicated problem. Traditional network management is reactive: you monitor what's happening, you see something wrong, you troubleshoot it. At the Olympics, where issues might arise affecting thousands of people simultaneously, reactive management is too slow.
HPE Mist is the AI-driven management layer that turns all that hardware into a coordinated system. Think of it as the brain directing the body. It monitors the health and performance of every device connected to the network—not just the HPE hardware, but also the third-party devices that users bring, the IoT sensors collecting data, the broadcast equipment, everything.
Mist operates in the cloud, which means it's not dependent on local servers at the Olympic venues. If there's an issue at one venue, the system has visibility into every other venue simultaneously. It can instantly understand whether a problem is localized or systemic. A single access point experiencing congestion? No big deal, Mist can redistribute traffic. Multiple access points across different venues all experiencing similar issues? That suggests a network-wide problem that needs different treatment.
The Predictive Analytics Engine: What separates Mist from traditional network management tools is its predictive capabilities. The platform ingests telemetry from millions of points across the network constantly. It understands normal baseline behavior for different times of day, different event types, different crowd sizes. When something starts to deviate from expected patterns, Mist doesn't wait for an alert to trigger. It proactively investigates.
Imagine a scenario: An event ends, and 10,000 spectators all reach for their phones to share videos and photos from what they just witnessed. That's a predictable surge. Mist knows this pattern. Before the surge happens, it's already optimizing network paths, increasing available bandwidth in venue WiFi zones, and preparing backhaul capacity to handle the spike. The spectators experience excellent network performance, completely unaware that the network just rewired itself to accommodate them.
Now imagine a different scenario: An unexpected situation occurs at a venue. Security responds, hundreds of additional personnel move to one location, they start using radios and mobile devices to coordinate. Mist detects that a particular venue's network is receiving unusual traffic patterns that don't match any known event scenario. Rather than wait for someone to file a support ticket, Mist alerts operations, provides data about what's happening, and suggests adjustments before anyone experiences degradation.
Training and Upskilling: One of the hidden benefits of an AI-driven network management system is how it affects the people running the network. Traditional network operations require extensive expertise—you need to understand routing protocols, switch configuration, firewall rules, and dozens of other technologies. But when you have an AI system that provides recommended actions, explains its reasoning, and learns from human feedback, you're essentially creating a training tool.
The network operations team at Milano-Cortina works closely with Mist. When they make decisions, they're learning from an AI system that has seen patterns across thousands of networks worldwide. When they override Mist's recommendations, the system learns why that decision was better. Over time, this interaction upskills the team faster than traditional training ever could.

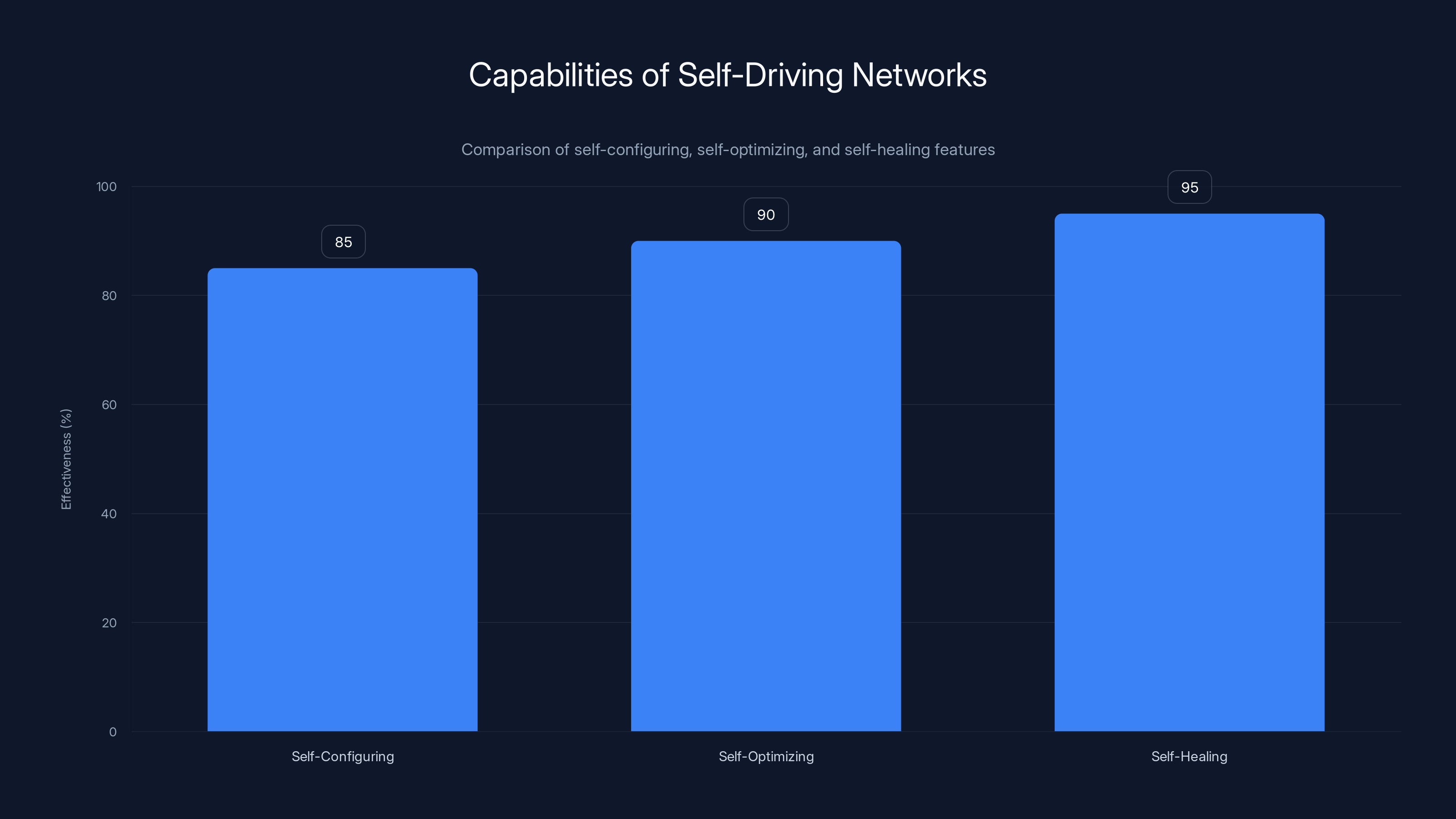
Self-driving networks excel in self-healing with an estimated 95% effectiveness, making them highly resilient to failures. Estimated data.
Marvis: The AI Assistant That Thinks Like a Network Engineer
If Mist is the brain managing the network, Marvis is the assistant that helps network engineers think. Marvis is an AI assistant specifically trained to understand network problems, and it's available to the operations team whenever they need it.
Here's the real-world application: A user at a venue reports that their connection is slow. In a traditional network, this triggers a support ticket. Someone manually gathers information: What device are you using? Where are you located? When did this start? What are you trying to do? Then they begin systematically testing connectivity, checking configurations, reviewing logs. This process can take hours.
With Marvis, the network engineer describes the problem to the AI: "We're getting reports of slow connectivity in the north venue, primarily from broadcast crew using laptops over WiFi." Marvis immediately synthesizes data from thousands of devices in that venue. It identifies that yes, there's a pattern of slow performance for that specific device type and location. It suggests several probable causes, ranked by likelihood. Maybe it's RF interference from new equipment. Maybe it's a switch configuration issue. Maybe it's backhaul saturation. Marvis points to the data supporting each hypothesis.
Now instead of spending hours investigating, the engineer can spend minutes validating Marvis's suggestions. The problem that might have taken three hours to diagnose and fix now takes thirty minutes. Multiply that across dozens of issues occurring throughout the Olympics, and you're talking about literally hundreds of hours saved.
The Catch with AI Assistants: Here's where I'm being honest: Marvis isn't perfect. AI systems sometimes make confident recommendations that are subtly wrong. An experienced network engineer can catch these mistakes before they cascade. The real value of Marvis isn't replacing the engineer's judgment—it's augmenting it, making the engineer's expertise far more effective.
For the Olympics, this matters enormously. The operations team is watching events that are literally happening on television as they're happening. If there's an issue, there's no time for extensive troubleshooting. You need answers quickly, and they need to be right. Marvis provides the information and analysis that makes fast, accurate decisions possible.

Self-Driving Networks: What Actually Happens When Networks Automate Themselves
HPE's vision for the Milano-Cortina network goes beyond just managing existing infrastructure. The company calls it a "self-driving network," and the concept is worth understanding because it represents where networking is heading.
A self-driving network has three capabilities:
-
Self-configuring: The network automatically adapts its configuration based on what it detects. New devices appear, the network automatically provisions them. A security policy changes, it propagates automatically. New applications are added, the network automatically creates the necessary traffic paths. This eliminates the need for manual configuration changes, which are both time-consuming and prone to errors.
-
Self-optimizing: The network continuously monitors performance and automatically adjusts settings to improve it. Specific routes are experiencing congestion, the network automatically load-balances traffic across alternative paths. Certain applications are experiencing latency, the network automatically prioritizes them. Security threats appear, the network automatically adapts policies to defend against them. All of this happens without human intervention.
-
Self-healing: When something fails, the network automatically detects the failure and routes around it. A switch fails, traffic automatically reroutes through alternate switches. An access point experiences issues, the network shifts load to adjacent access points. A fiber link fails, the network activates redundant paths. The system continues operating smoothly because it's designed with multiple paths and automatic failover.
The practical result is that the network doesn't just tolerate failures—it's indifferent to them. A traditional network experiences a component failure as a crisis requiring immediate attention. A self-driving network experiences a component failure as a non-event that users never notice.
Real-World Implications at the Olympics: Consider what this means during the actual games. An athlete is preparing for competition. Their coach is reviewing performance metrics from training on a specialized application. That application generates specific types of traffic that are latency-sensitive. The self-driving network detects that this traffic type is present, understands its requirements, and automatically ensures it gets the lowest-latency path through the network. The coach sees data in real-time, the athlete gets coaching feedback, performance improves slightly—or maybe that slight improvement is the difference between gold and silver.
In the broadcast center, a camera feed suddenly starts experiencing micro-drops. In a traditional network, this takes minutes to even detect, then longer to troubleshoot. By that time, viewers worldwide have already seen glitches. In a self-driving network, the micro-drops are detected immediately, the traffic is automatically rerouted through backup paths, and viewers at home never know anything happened.
For security, the implications are even more significant. A sophisticated cyberattack isn't a single attempt; it's a series of probes, escalating attempts, and multi-vector attacks. A human-managed security team might detect the attack midway through. A self-driving network with AI-powered security detection catches the first unusual traffic pattern and automatically begins defensive measures before the attack even fully manifests.

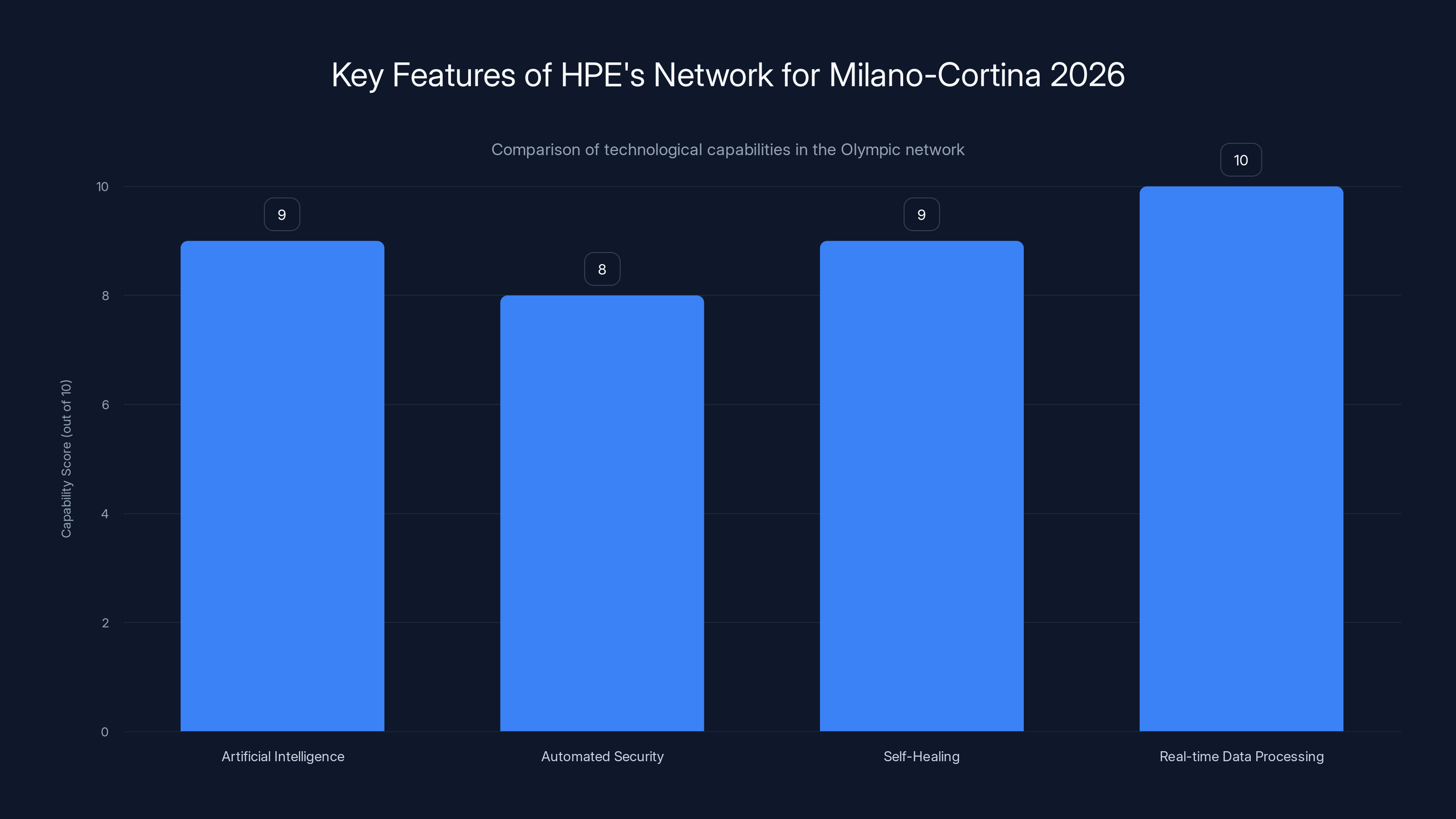
HPE's network for the 2026 Winter Olympics excels in real-time data processing and self-healing capabilities, crucial for seamless event execution. Estimated data.
The Data Challenge: Petabytes, Not Gigabytes
HPE executives talk about the network transferring petabytes of data across over one million connected devices. To put that in perspective, a petabyte is 1,000 terabytes. A terabyte is 1,000 gigabytes. Most companies measure their annual data volumes in terabytes. The Olympics is moving that volume in days or weeks.
This isn't just theoretical traffic. Every 4K camera feed is roughly 25 gigabits per second. There are hundreds of these feeds. Every smartphone in the stadium is a connected device potentially uploading photos, videos, or streaming content. Security camera feeds from hundreds of locations need to be recorded and often analyzed in real-time. Broadcast center equipment is editing and transcoding video constantly. Timing systems are capturing microsecond-level data about athlete performance. Biometric sensors are streaming data from athletes. Crowd counting systems are monitoring flow patterns.
Add it all up, and petabytes isn't hyperbole—it's conservative estimation.
The Problem with Volume: More data is more traffic, which means more congestion, which means more latency, which means worse user experience. A traditional network typically handles congestion by hoping you don't use all the available bandwidth simultaneously. That's essentially a prayer as a network design strategy. An AI-driven network handles congestion by understanding demand patterns and optimizing allocation in real-time.
It's like the difference between having a single cashier at a grocery store versus having a smart system that opens additional registers before lines form. One is reactive to problems. The other is proactive.

Security at Scale: Why Olympics-Grade Security Requires AI
When you have the world's attention focused on a single event happening across multiple venues, security isn't just important—it's existential. A successful cyberattack could compromise athlete data, steal intellectual property from broadcasters, interfere with operational systems, or even impact live coverage. The potential impact is so large that sophisticated actors are certainly interested.
Traditional network security operates on the principle of "trust but verify." You create perimeter defenses, you monitor traffic for known attack patterns, you respond to incidents. The assumption is that you're trying to keep bad actors out and bad behavior down to acceptable levels.
AI-driven security, by contrast, operates on the principle of "verify everything." Every connection is evaluated. Every user is assessed for risk. Every packet of data is analyzed for suspicious patterns. This sounds computationally expensive—and it is. But an AI system can process information at machine speed, analyzing millions of connections per second in ways that would be impossible for humans.
Behavioral Analysis: The SRX firewalls HPE deployed use behavioral analysis to understand what normal looks like for different applications and users. A developer in an engineering team in the US normally doesn't make connections to Chinese IP addresses at 3 AM. If that suddenly starts happening, the firewall notices. Not because of a signature or a known attack pattern, but because it's abnormal behavior for that user.
Another example: Broadcast equipment typically generates specific types of traffic—outbound connections to broadcast centers, video feeds flowing through known paths, control signals from specific locations. If broadcast equipment suddenly starts making connections to random IP addresses on the internet, or if it's sending data to unusual destinations, behavioral analysis flags it as abnormal.
This is especially important at the Olympics because attackers often test a network before launching a major attack. They probe for vulnerabilities, they look for systems that are poorly configured, they map the network topology. A system based purely on known signatures might miss these probes. But behavioral analysis catches the reconnaissance activity itself, allowing security teams to respond before any real attack happens.
Threat Intelligence: The SRX firewalls are connected to global threat intelligence feeds. They know about the latest malware, the newest attack techniques, current campaigns being executed by known threat actors. This information is continuously updated, so the Olympics network isn't fighting yesterday's battles with yesterday's defenses. It's fighting today's threats with today's knowledge.

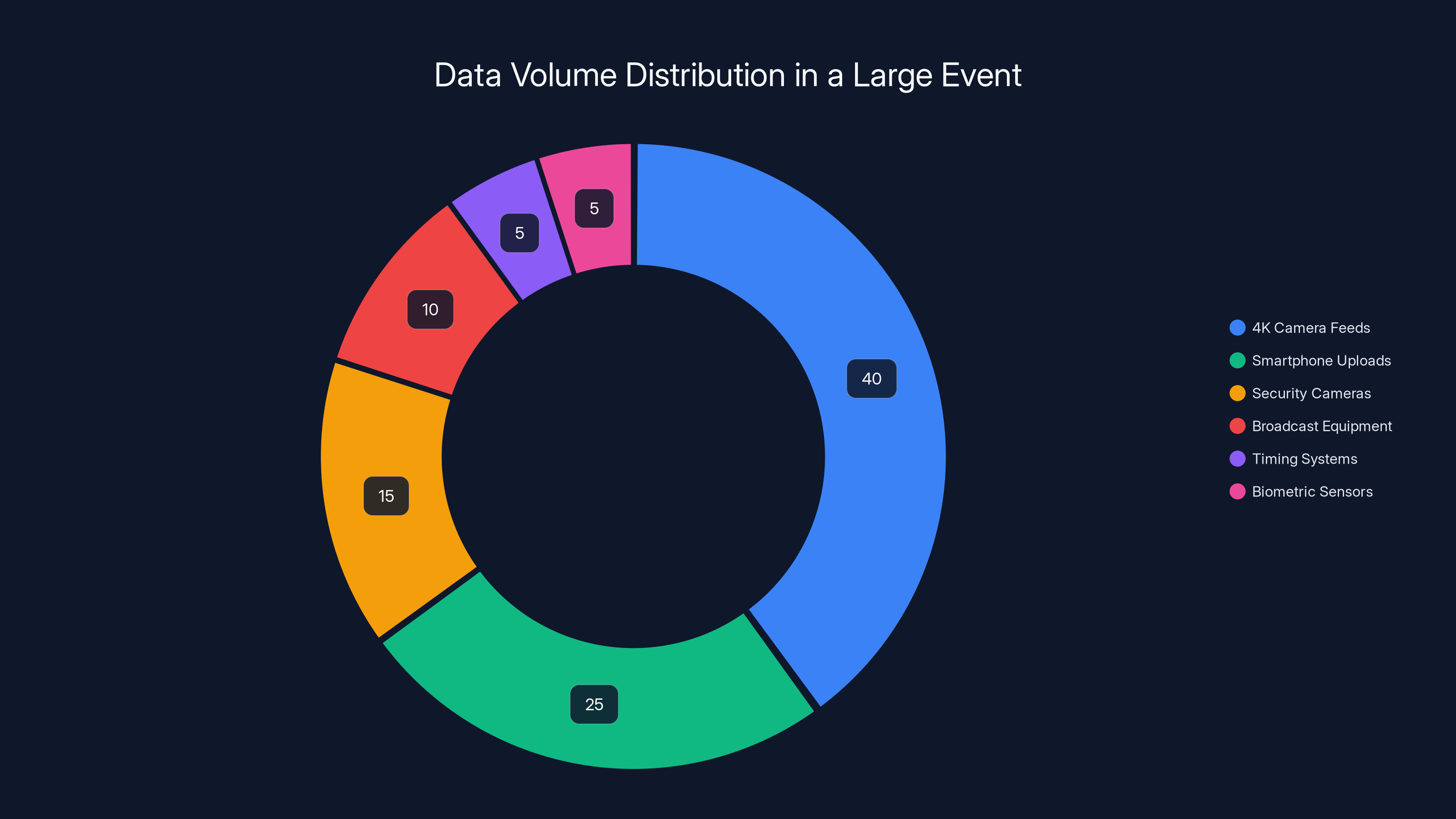
Estimated data shows 4K camera feeds contribute the largest share of data volume at a large event, highlighting the need for efficient network management.
The Ecosystem Approach: Why Proprietary Isn't the Answer
One of the interesting aspects of HPE's Olympic infrastructure is that it's not entirely proprietary. Yes, the core network uses HPE switches, routers, and firewalls. But the network also needs to handle devices from dozens of manufacturers: broadcast equipment, security systems, timing systems, IoT sensors, smartphones, and thousands of other devices. A network designed around the idea that only HPE devices are connected would be immediately impractical.
So HPE's approach is more sophisticated. The infrastructure is built on HPE equipment, but it's architected to be agnostic about endpoints. This is actually harder to design than a walled-garden approach. You can't control how non-HPE devices behave. You can't mandate their security posture. You have to be defensive against whatever they might do.
But this is also more realistic because it reflects actual modern networks. Your enterprise network isn't only your devices. It's contractors' laptops, cloud services, partner integrations, and devices you don't even know about. A network designed in 2026 that couldn't handle heterogeneous devices would be outdated before it was built.
HPE solved this through abstraction and orchestration. The underlying HPE infrastructure abstracts away the complexity of managing diverse endpoints. Higher-level orchestration tools (like Mist) handle the logic of how to treat different device types, different users, different applications.

Real-Time Analytics: When Decisions Matter in Milliseconds
During the Olympics, decisions need to happen at machine speed. An athlete's biometric sensor detects a potentially dangerous heart rate. That data needs to reach the medical team instantly. A security camera detects something abnormal in crowd behavior. That alert needs to reach security instantly. A broadcast feed starts dropping packets. The network needs to respond to restore quality instantly.
Traditional networks collect data and process it in batches or through scheduled reports. "Here's what happened in the last hour." At the Olympics, "the last hour" is ancient history. By the time you know something happened, you're already dealing with the consequences.
HPE's network processes analytics in real-time. The moment something unusual is detected, alarms trigger, dashboards update, and recommended actions are suggested to human operators. This is possible because the data is being processed locally where it's generated, not transported back to a central data center for processing.
For example, broadcast quality monitoring doesn't wait for delayed feedback from viewers. Instead, the sending equipment monitors the video stream it's sending, and the receiving equipment monitors the video stream it's receiving. If there's a mismatch—if packets are being lost in transit—this is detected within milliseconds, and corrective action is taken immediately.

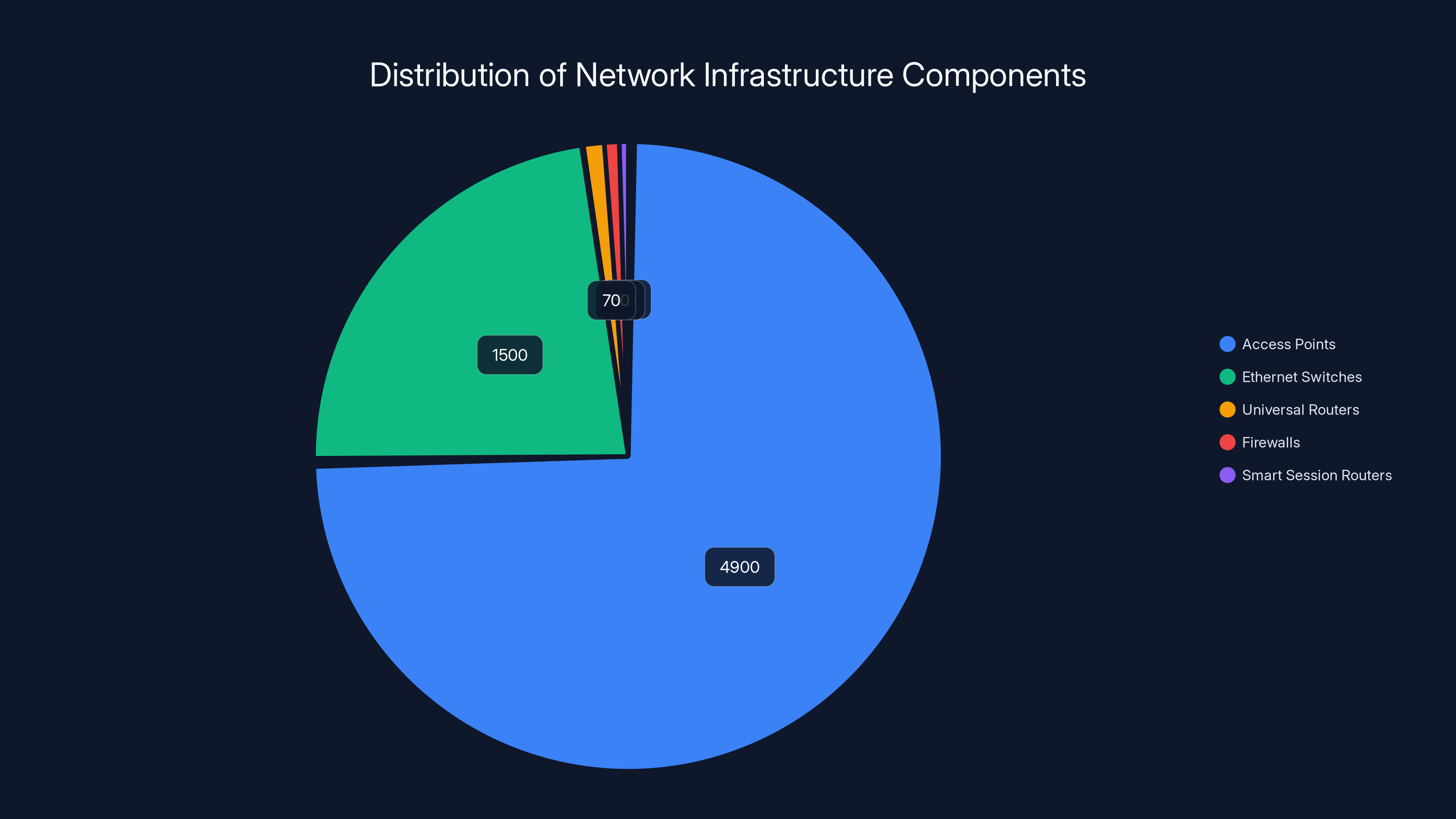
The pie chart illustrates the distribution of key network infrastructure components deployed by HPE for the 2026 Winter Olympics. The majority are access points, crucial for providing widespread wireless coverage.
Redundancy and Failover: Why Single Points of Failure Are Unacceptable
At the Olympics, there's no such thing as "accepting some downtime." When you're broadcasting to the world, when athletes are competing, when security systems are monitoring venues, every second of downtime is a problem.
This drives the redundancy approach throughout the network. There isn't one set of routers; there are multiple routers in multiple locations. If one fails, others seamlessly take over. There aren't single links connecting venues; there are multiple diverse paths. If one fails, traffic automatically routes through others.
But here's where it gets complicated: you can't just duplicate everything. That would be prohibitively expensive and would double the complexity of managing the network. Instead, you design for specific failure scenarios. A switch failure? The network can tolerate that. A router failure? Tolerable. Multiple simultaneous failures? Depends on the scenario. And critically, the network is designed so that most users experience no impact from most failures.
This is why the self-healing capability is so important. It's not just about tolerating failures; it's about making failures invisible to users. An athlete using a performance-tracking app has no idea that a switch somewhere in the network just failed. The broadcaster has no idea that a backup link just activated. The spectator watching video has no idea that packets are being rerouted around a problem. The experience is seamless.

Lessons for Future Events: Why Milano-Cortina Is a Template
When HPE and Olympics organizers discuss what they've built, they're not just thinking about this specific event. They're establishing patterns that will likely become standard for future Olympics, World Cups, major international events, and potentially large-scale distributed events more broadly.
The key insight is that events are becoming increasingly data-intensive and technology-dependent. An Olympics 20 years ago had far fewer connected devices, generated far less data, and relied on far less real-time decision-making. An Olympics 20 years from now will be even more data-intensive and technology-dependent.
Milano-Cortina is proving that AI-native, self-driving networks aren't theoretical concepts—they're practical solutions to real, present problems. Future event organizers will likely see this and demand similar capabilities for their events. The technologies HPE deployed will likely become standard infrastructure rather than cutting-edge innovation.
The template being established is: don't think about networks as static infrastructure. Design them as adaptive, learning systems that improve and optimize themselves continuously.

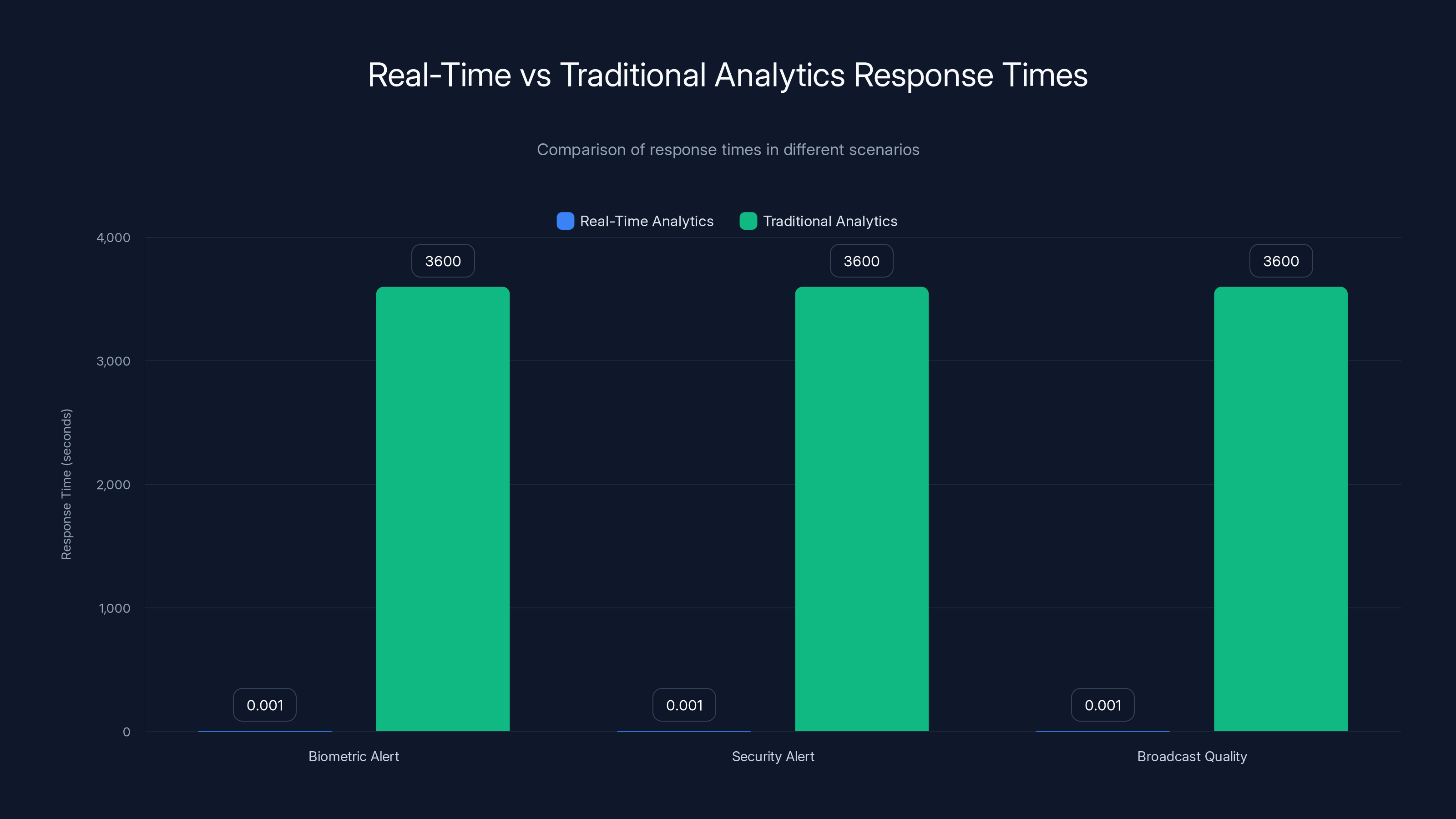
Real-time analytics provide responses in milliseconds, crucial for immediate action during events like the Olympics. Estimated data based on typical response times.
The Human Element: Why Technology Alone Isn't Sufficient
For all the sophistication of the network infrastructure, the most critical factor is the people managing it. Technology fails. Networks become congested. Systems have unexpected interactions. When something goes wrong, you need humans who understand what's happening and can make judgment calls.
HPE invested heavily in training and upskilling the operations team. The Mist platform provides recommended actions, but humans make final decisions. Marvis provides analysis, but engineers interpret that analysis. This collaboration between humans and machines is where the real value emerges.
A purely automated network that nobody understands would eventually face a problem it couldn't automatically solve. A purely human-managed network would be overwhelmed by the volume and speed of decisions required at the Olympics. The sweet spot is augmented intelligence: AI systems making the routine decisions and providing analysis for complex problems, while humans handle edge cases and make critical judgment calls.

The Cost of Excellence: What It Takes to Build an Olympics-Grade Network
Building and deploying this infrastructure isn't cheap. HPE doesn't publicly disclose the total investment, but when you add up 4,900+ access points, 1,500 switches, 70+ routers, 50+ firewalls, plus installation, configuration, testing, and ongoing operations, you're talking about a nine-figure investment easily.
But here's the thing: the cost is worth it because the alternative—network failures or degradation during the Olympics—is unacceptable. The organization can't say, "We're going to save money by deploying less redundancy and accepting that some users might experience connectivity issues." That's not an option.
This is fundamentally different from how most enterprises approach networking. Most organizations try to balance cost and performance. Olympic organizers prioritize performance and reliability above cost considerations. This allows them to build infrastructure that most enterprises wouldn't dream of deploying.
There's a lesson here for enterprises: identify your critical systems and invest appropriately in them. Your peak shopping season. Your customer-facing platform. Your security infrastructure. These deserve Olympic-grade networking, even if other parts of your network don't.

Future-Proofing: Building for Technologies That Don't Exist Yet
One of the challenges HPE faced was that the Olympics happen in 2026. Technology is moving so fast that predicting what will be important in 2026 is difficult. What if new AR/VR applications that don't currently exist become popular? What if athletes start using new types of biometric sensors? What if broadcast techniques evolve in unexpected directions?
The network needs to be capable of supporting these possibilities without being completely redesigned. This is why the abstraction approach matters. By separating the underlying network infrastructure from the specific applications running on top, HPE created a platform that can evolve.
New devices can connect without changing the core network. New applications can be deployed without rewriting network configurations. Emerging technologies can be integrated without tearing down existing systems. It's the difference between a network designed for specific use cases and a network designed for adaptability.

TL; DR
- Scale Challenge: Milano-Cortina 2026 spreads across 22,000 square kilometers with 40+ venues and 3,000+ athletes, requiring an infrastructure that can handle petabytes of data across one million connected devices.
- Hardware Foundation: HPE deployed over 4,900 access points, 1,500 switches, 70+ routers, and 50+ firewalls to create redundant, geographically distributed network coverage.
- AI-Driven Management: The Mist platform uses machine learning to predict and prevent network problems before they affect users, while the Marvis AI assistant helps network engineers diagnose issues faster.
- Self-Driving Networks: The infrastructure automatically configures itself, optimizes performance, and heals failures without human intervention—a model representing the future of enterprise networking.
- Security by Intelligence: Next-generation firewalls with behavioral analysis and real-time threat intelligence detect attacks before they manifest, protecting critical systems and data.
- Bottom Line: Milano-Cortina proves that modern major events require AI-native, self-optimizing networks rather than traditional static infrastructure, setting a template for future large-scale events.

FAQ
What makes the Milano-Cortina 2026 network different from traditional Olympics networks?
The Milano-Cortina network is specifically designed as an AI-native platform rather than simply a larger version of traditional networks. Instead of reactively responding to problems, it predictively identifies issues and automatically optimizes itself. Traditional networks require constant manual intervention and troubleshooting. The Milano-Cortina infrastructure self-configures, self-optimizes, and self-heals, allowing it to handle the unprecedented scale and complexity of a 22,000-square-kilometer event with seamless reliability.
How does HPE Mist manage over one million connected devices simultaneously?
HPE Mist operates as a cloud-based management platform that ingests real-time telemetry from every device, access point, switch, and router in the network. It establishes baseline patterns of normal behavior for different scenarios and times, then instantly detects deviations. When anomalies are detected, Mist automatically implements corrective actions—load balancing traffic, adjusting configurations, or alerting operations teams with specific recommended solutions. This allows it to manage millions of devices by making automated decisions about routine issues while surfacing critical decisions to human operators.
Why is AI necessary for an Olympics-scale network when traditional networks have worked for decades?
Traditional networks were designed for relatively predictable traffic patterns and slower operational speeds. The modern Olympics generates traffic at machine speed—hundreds of 4K video streams simultaneously, real-time biometric data from athletes, instant analysis of security camera footage, and global broadcast distribution happening concurrently. Traditional networks operate at human-response speed (it takes time for an engineer to notice a problem and implement a fix), but modern events require machine-response speed. AI systems can detect and respond to problems in milliseconds, making them necessary rather than optional for large-scale modern events.
What happens if the Mist platform experiences a failure or malfunction?
Mist is designed with redundancy and failover capabilities, but even if it were to fail, the underlying network infrastructure would continue operating. The switches, routers, and firewalls would maintain basic connectivity using their built-in intelligence and default configurations. However, performance would degrade because the automated optimization and self-healing capabilities would no longer function. Users would experience slower response times, and the network operations team would need to manually intervene to resolve issues. This is why HPE's design approach includes redundant management systems and why the underlying hardware is sophisticated enough to function independently if needed.
How does behavioral analysis security detect cyberattacks before they happen?
Behavioral analysis learns normal patterns for different users, devices, and applications by analyzing historical data. A user in a specific role typically connects to specific systems during specific times from specific locations. If that user suddenly makes connections to unusual locations at abnormal times, or if traffic from that user deviates significantly from historical patterns, the system flags it as potential malicious activity. Additionally, the system analyzes application behavior—broadcast equipment should generate specific types of traffic, security systems should behave in particular ways. When devices behave abnormally, it suggests a compromise or attack. This approach catches sophisticated attacks that use zero-day vulnerabilities (previously unknown exploits) because the attack itself creates abnormal behavioral patterns.
Can the Olympic network be adapted for use by commercial enterprises?
The architecture and principles behind the Milano-Cortina network are definitely applicable to large enterprises, though the scale would typically be smaller. Any organization that needs to support large numbers of devices, real-time decision-making, and high availability could benefit from self-driving network principles. However, most enterprises would implement these concepts more selectively—perhaps for their most critical systems like customer-facing applications or security infrastructure—rather than for their entire network. The cost-benefit analysis is different for enterprises than it is for Olympics organizers. An enterprise balances investment against expected returns, while Olympics organizers prioritize reliability above cost. That said, the technologies are the same, and we'll likely see enterprises increasingly adopt these approaches for their critical infrastructure.
What happens if one of the 4,900+ access points fails during a live event?
The network is designed with overlapping coverage, meaning that while each access point provides primary coverage for a specific area, neighboring access points can seamlessly absorb traffic if one fails. When an access point goes offline, the network automatically detects the failure (typically within seconds), and connected devices immediately shift to adjacent access points. The Mist platform ensures load balancing so that nearby access points don't become overwhelmed by the extra traffic. Depending on the specific location, some users might experience a brief moment of disconnection as they switch to a new access point, but most would experience seamless continuity. Operations teams are immediately alerted about the failure so they can dispatch technicians to repair or replace the device, but the event continues without impact.
How does the network prioritize traffic when demand exceeds capacity?
When the network experiences congestion (demand exceeds available capacity), the AI system uses intelligent traffic prioritization based on application type, user role, and business importance. Live broadcast feeds that are being transmitted globally receive the highest priority because buffering or quality degradation would affect global viewers. Athlete performance monitoring receives high priority because it's time-sensitive for safety and coaching. Social media uploads from spectators receive lower priority because slight delays are acceptable. The network doesn't simply operate on "first come, first served." Instead, it understands the business context of different traffic types and allocates bandwidth accordingly. This is why an AI-native network can serve a million devices where a traditional network would become completely congested.
What is the difference between the Mist management platform and the Marvis AI assistant?
Mist is the overarching management and orchestration system that monitors and controls the entire network infrastructure. It processes data from millions of points, makes automated optimization decisions, and provides visibility into network health. Marvis is a specialized AI assistant designed to help network engineers understand what's happening and troubleshoot problems faster. If a user reports connectivity issues, an engineer might ask Marvis to analyze that situation, and Marvis will synthesize relevant data, suggest probable causes, and recommend solutions. Mist operates automatically at scale across the entire network. Marvis augments human expertise by providing analysis and recommendations. Together, they create a system where machines handle routine optimization and decision-making while humans focus on complex problems and strategic decisions.
How will these network technologies evolve for the 2030 Olympics or beyond?
Based on current trends, future Olympics networks will likely feature even more sophisticated AI capabilities, likely including generative AI for network configuration and optimization. We'll probably see more edge computing, where processing happens closer to the source of data rather than being centralized. As new technologies like advanced AR/VR become mainstream, networks will need to support higher bandwidth requirements and lower latency demands. The principles being established at Milano-Cortina—self-driving networks, behavioral security, real-time analytics—will become standard rather than cutting-edge. Future networks might add capabilities like predictive maintenance that doesn't just fix problems when they occur but prevents them from occurring in the first place by predicting component failures before they happen.

The Broader Impact: Why This Matters Beyond Sports
The infrastructure HPE built for Milano-Cortina 2026 is significant not just for the Olympic Games but for what it demonstrates is possible for large-scale distributed events and operations more broadly. Smart cities that want to manage traffic, utilities, and emergency services across urban areas can learn from this model. Music festivals and major cultural events can apply these principles. Disaster response operations can use this architecture for managing relief efforts across large geographic areas.
What HPE proved is that when you design networks with AI as a first principle—not as an afterthought—and when you architect for self-management and adaptation, you create systems that are more reliable, more efficient, and more responsive to change than networks built on traditional principles. The Olympics happens to be a spectacular showcase of this capability, but the implications are much broader.
The shift from static to adaptive networks represents a fundamental change in how we think about infrastructure. It's a shift from networks designed to deliver a fixed service reliably toward networks that understand context, adapt to demands, and actively improve themselves. That shift is beginning now with Milano-Cortina, and it will define enterprise and infrastructure networking for the next decade.

Key Takeaways
- Milano-Cortina 2026 deploys AI-native networking infrastructure with 4,900+ access points and 1,500 switches across 22,000 square kilometers for the most geographically distributed Olympics ever
- HPE Mist cloud platform uses machine learning to predict and prevent network problems, automatically optimizing performance without human intervention
- Self-driving networks self-configure, self-optimize, and self-heal—representing a fundamental shift from reactive to predictive network management
- Behavioral analysis security with next-generation firewalls detects and stops cyberattacks before they manifest by identifying abnormal traffic patterns
- Real-time analytics and AI-driven optimization allow the network to process petabytes of data across one million devices while maintaining seamless user experience for athletes, broadcasters, and spectators
Related Articles
- Surfshark VPN Deal: Save 86% on Premium Plan Plus 3 Extra Months [2025]
- Why Your VPN Keeps Disconnecting: Complete Troubleshooting Guide [2025]
- NordVPN & CrowdStrike Partnership: Enterprise Security for Everyone [2025]
- How Hackers Are Using AI: The Threats Reshaping Cybersecurity [2025]
- Building AI Culture in Enterprise: From Adoption to Scale [2025]
- Who Owns Your Company's AI Layer? Enterprise Architecture Strategy [2025]

