![Inferact's $150M Seed Round: How vLLM Became a $800M Startup [2026]](https://tryrunable.com/blog/inferact-s-150m-seed-round-how-vllm-became-a-800m-startup-20/image-1-1769123320324.png)
Inferact's 800M Startup
There's a moment in every technology cycle when the infrastructure layer suddenly becomes more valuable than the applications built on top of it. We might be watching that moment unfold right now.
In January 2026, Inferact announced a
Inferact didn't appear from nowhere. The company emerged from the open-source project v LLM, which has quietly become the industry standard for running large language models efficiently. The creators—led by Simon Mo—took their tool from a research project into a venture-backed company, signaling that the race to optimize AI inference isn't just an engineering problem anymore. It's becoming the next major venture capital battleground.
Here's what makes this moment significant: as AI models have gotten more capable, the actual cost of running them at scale has become the limiting factor. Training massive models is expensive, but deploying them profitably is brutal. Enter v LLM and projects like it. These tools can reduce inference costs by 50-70% while actually improving performance. In an industry obsessed with model capability, the companies solving the cost problem might end up being the most valuable.
This isn't an isolated funding round. Barely a week before Inferact's announcement, another open-source inference project—SGLang—spun out as Radix Ark with a $400 million valuation. Both projects emerged from the same lab at UC Berkeley (led by Ion Stoica, a Databricks co-founder). That's not a coincidence. It's a pattern.
The inference market is exploding, and everyone from cloud providers to edge device manufacturers is paying attention. Let's break down what's actually happening, why it matters, and what comes next.
TL; DR
- Inferact raised 800M valuation in seed funding, backed by a 16z and Lightspeed
- v LLM is now a company, transitioning from open-source research to commercial infrastructure
- Inference optimization is the new frontier, reducing deployment costs by 50-70% while improving speed
- Major tech companies already use v LLM, including Amazon Web Services and major e-commerce platforms
- The pattern is real: SGLang launched as Radix Ark weeks earlier with a $400M valuation, proving investor appetite for inference solutions

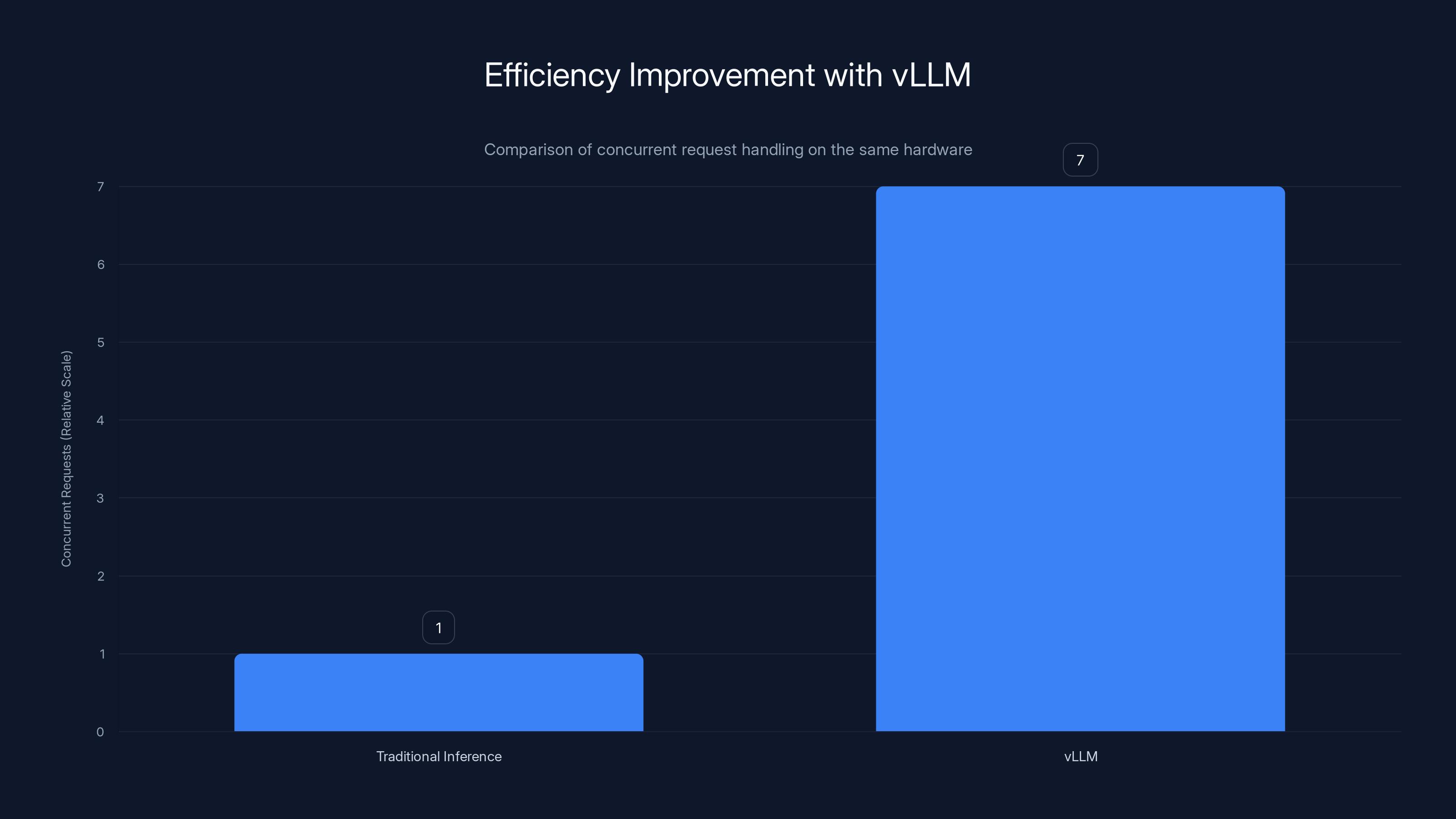
vLLM can handle 3-10x more concurrent requests than traditional inference methods, significantly improving GPU utilization. Estimated data based on typical improvements.
What Is Inference, and Why Does It Matter More Than Training?
Let's start with the basics, because this is where the entire economic story hinges.
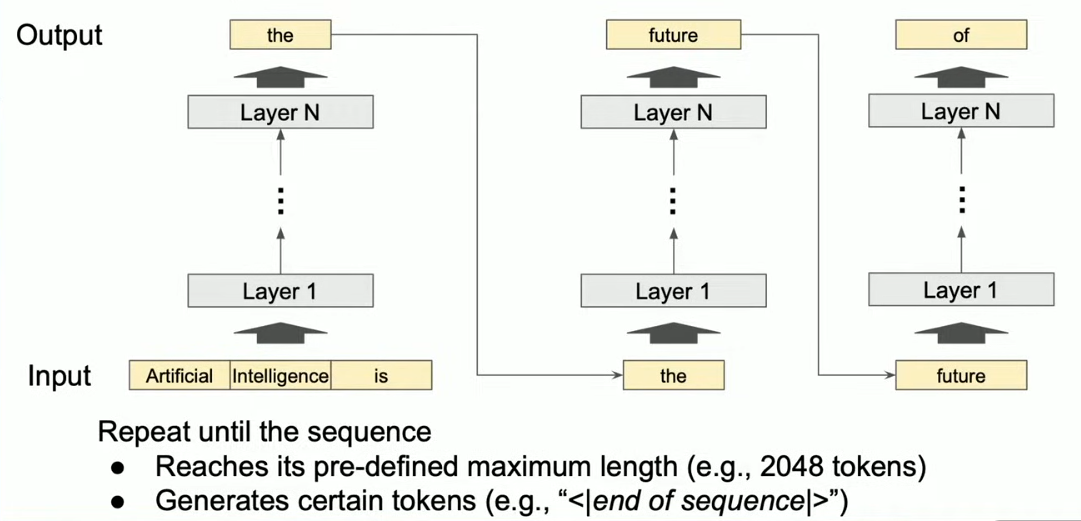
When you hear about AI models, there are two completely different phases: training and inference. Training is when the model learns patterns from massive datasets—it's expensive, happens once per model, and requires specialized hardware. Inference is when the model actually runs and answers a user's question. That happens billions of times per day.
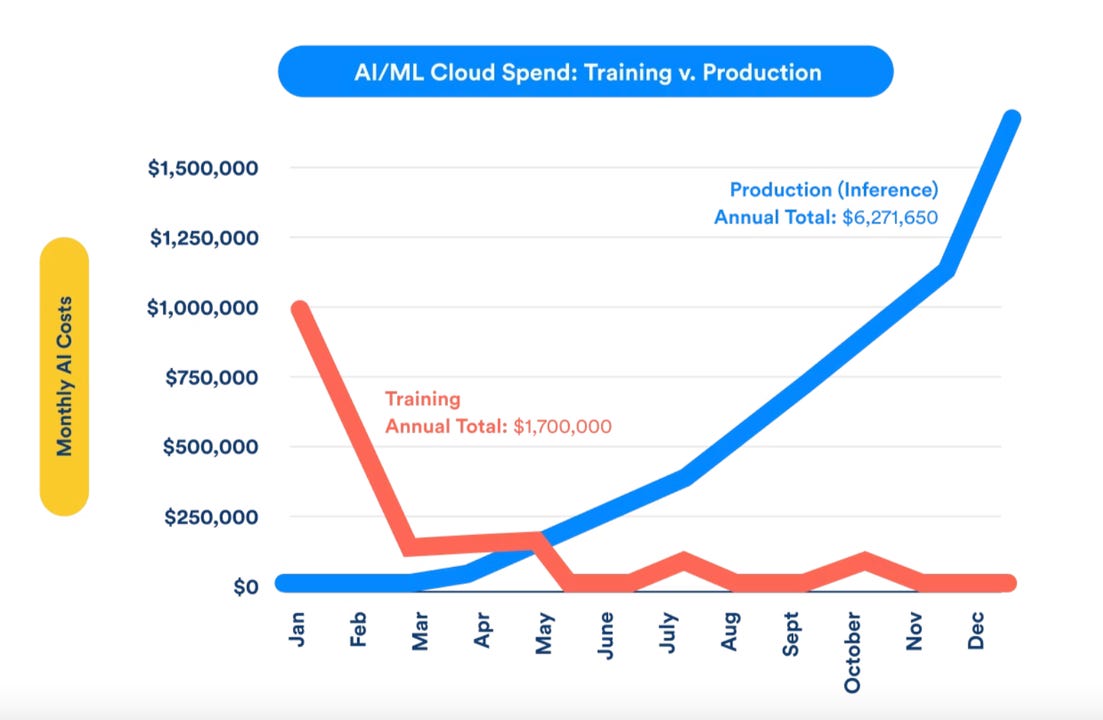
Here's the counterintuitive part: inference is more expensive than training for most deployed models. A single LLM might cost millions to train once, but if it serves millions of users daily, the cumulative inference costs dwarf the training investment. At scale, this becomes the dominant cost factor.
Consider Amazon Web Services. They run inference workloads constantly—processing natural language queries, generating recommendations, analyzing customer feedback. Every millisecond of latency costs money. Every percentage point improvement in hardware utilization saves millions annually. That's why they're already using v LLM. They didn't have a choice. Either optimize inference or watch margins disappear.
Traditional inference works like this: load the model, process the request, return the response. Simple. But when you're handling thousands of concurrent requests on shared hardware, everything breaks down. Memory gets fragmented. Context switching creates latency. GPU utilization plummets. What should be simple becomes a nightmare of coordination problems.
v LLM solves this by introducing a technique called paged attention. Instead of treating the key-value cache (the part of the model that remembers context) as a single contiguous block of memory, paged attention breaks it into pages. This is inspired by operating system memory management—a concept computer scientists have perfected over 40 years. By borrowing proven techniques from systems programming, v LLM achieves something that seemed impossible: near-perfect GPU utilization with dramatic improvements in throughput.
The math is straightforward. Traditional inference might achieve 40-50% GPU utilization on concurrent requests. v LLM gets to 80-90%+. That means the same hardware serves 2-3x more requests. Or equivalently, you need 2-3x less hardware to serve the same load. At scale, this difference is worth billions.
This is why Inferact's valuation makes sense. They're not selling a feature. They're selling a fundamental efficiency multiplier. In the infrastructure business, that's how you get billion-dollar valuations in seed rounds.
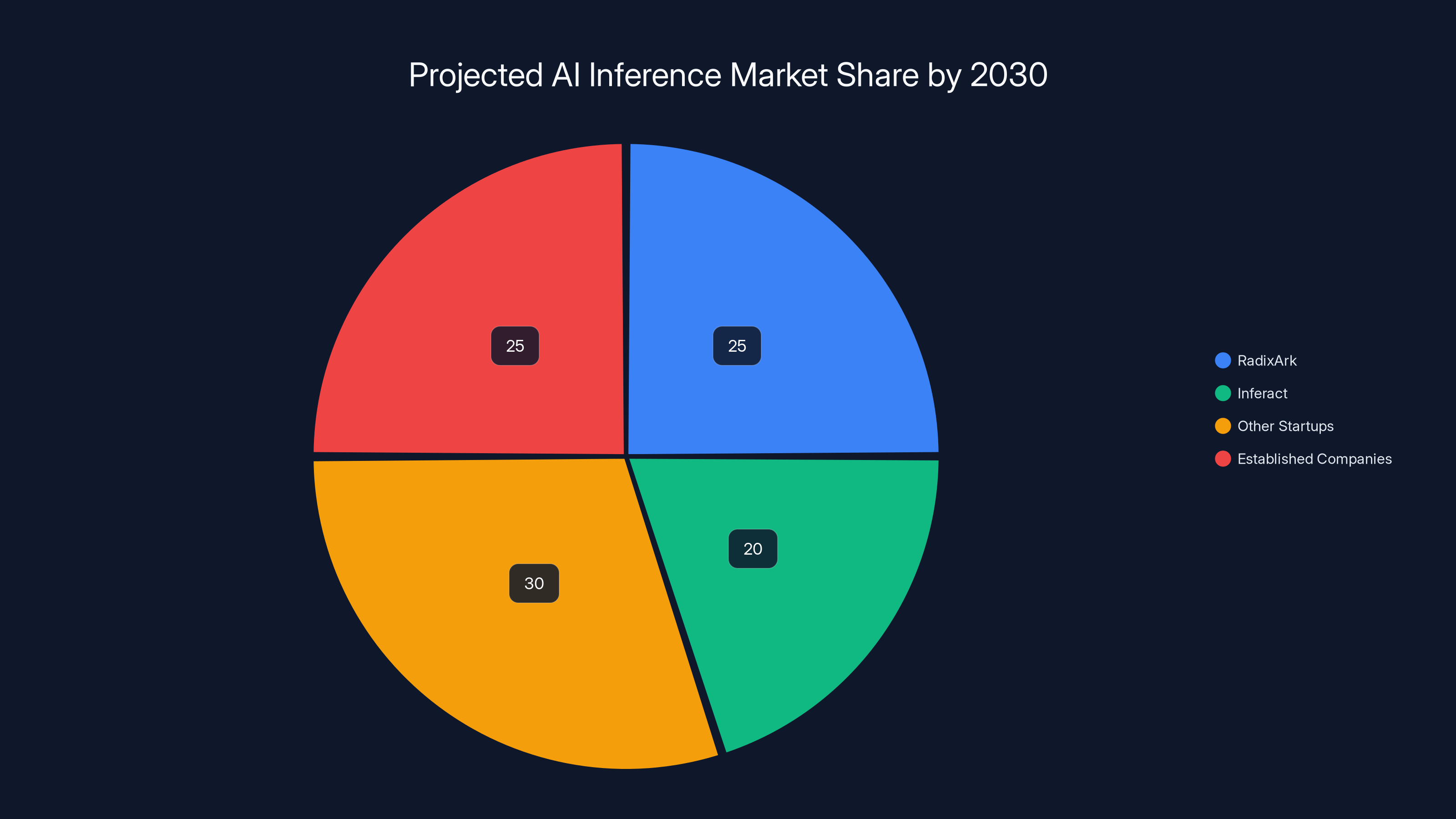
Estimated data suggests RadixArk and Inferact could capture significant portions of the AI inference market by 2030, with other startups and established companies also holding substantial shares.
The v LLM Project: From Research to Revenue
v LLM didn't emerge from nothing. Understanding its origin story is key to understanding why investors are suddenly so excited about inference.
Like SGLang, v LLM started at UC Berkeley's Sky Computing Lab, directed by Ion Stoica. In 2023, researchers there were wrestling with a specific problem: how do you run large language models efficiently at scale? Not just theoretically—practically, with actual code that works in production environments.
The team published their findings, released open-source code, and something unexpected happened: the community embraced it. Within months, v LLM became the de facto standard for inference optimization. Companies started basing their entire infrastructure stacks on it. Not because anyone mandated it, but because the alternative—writing custom inference engines—was so painful that open-source was obviously better.
This is the classic pattern for infrastructure dominance. Postgre SQL didn't win because it was closed-source and proprietary. Linux didn't win because a company owned it. They won because they were so good at solving fundamental problems that building on top of them was the obvious choice.
v LLM followed the same trajectory. By the time Inferact was incorporated, the project already had significant production adoption. Amazon was using it. Major AI startups had built it into their stacks. The open-source community had contributed thousands of improvements.
The genius move was timing the commercialization correctly. Too early, and the technology isn't proven. Too late, and someone else has already built a proprietary alternative. Inferact launched at the sweet spot: proven, widely adopted, still open-source enough that contributors felt ownership.
Simon Mo, the CEO and one of the original creators, understood something important. You don't kill the open-source project when you commercialize. You enhance it. You hire the best contributors. You invest in making it even better. The open-source version stays free—that's your distribution channel and community moat. The commercial version adds enterprise features, support, and optimization work that the open-source community couldn't fund.
This approach is fundamentally different from the traditional startup playbook of building something closed and hoping to grow. It's closer to how Red Hat commercialized Linux or how Automattic approached Word Press. Start with community trust, layer on commercial services, watch the network effect do the work.
The $150M Seed Round: Why This Valuation Makes Sense
Let's talk about the number.
But here's the thing: Inferact isn't a typical startup. They're not raising capital to prove a concept or build an MVP. They're raising capital to scale something already proven.
Consider the competitive moat. v LLM isn't just software—it's an inference efficiency standard. Once models are optimized for v LLM's architecture, competitors face a significant switching cost. Moving to a different inference engine means reoptimization, retesting, and risk. For large enterprises, that friction alone justifies paying for commercial support and features.
Second, the market size is clearly enormous. Every company running language models at scale needs better inference efficiency. That includes Amazon, Google, Microsoft, Meta, all the AI startups, all the enterprises adopting AI. The addressable market is in the hundreds of billions annually. A seed round valuation of $800 million is trivial next to that opportunity.
Third, the team has already proven they can execute. They didn't just conceive of paged attention—they implemented it, debugged it, deployed it to production, and maintained it while thousands of external developers contributed. That execution track record matters more than a standard business plan.
Andreessen Horowitz and Lightspeed understand infrastructure better than most. They've invested in Databricks, Stripe, and Figma—companies that created categories by solving fundamental problems. v LLM has that same energy. It's not trendy. It's not hype-driven. It's essential infrastructure that everyone uses but nobody thinks about until it breaks.
The valuation also reflects the competitive dynamics. Inferact needed enough capital to stay ahead of:
- In-house solutions from hyperscalers like AWS, Google Cloud, and Azure—they have resources to build competing inference engines
- Dedicated competitors like Radix Ark and other startups pursuing inference optimization
- International competition from teams in China and other countries building alternative inference systems
- The open-source community itself—which could theoretically fragment the v LLM project if Inferact makes poor decisions
With $150 million, Inferact can hire top talent, maintain the open-source project generously, build enterprise features quickly, and establish partnerships with cloud providers and hardware manufacturers. It's the right size to be credible against large competitors while maintaining startup velocity.
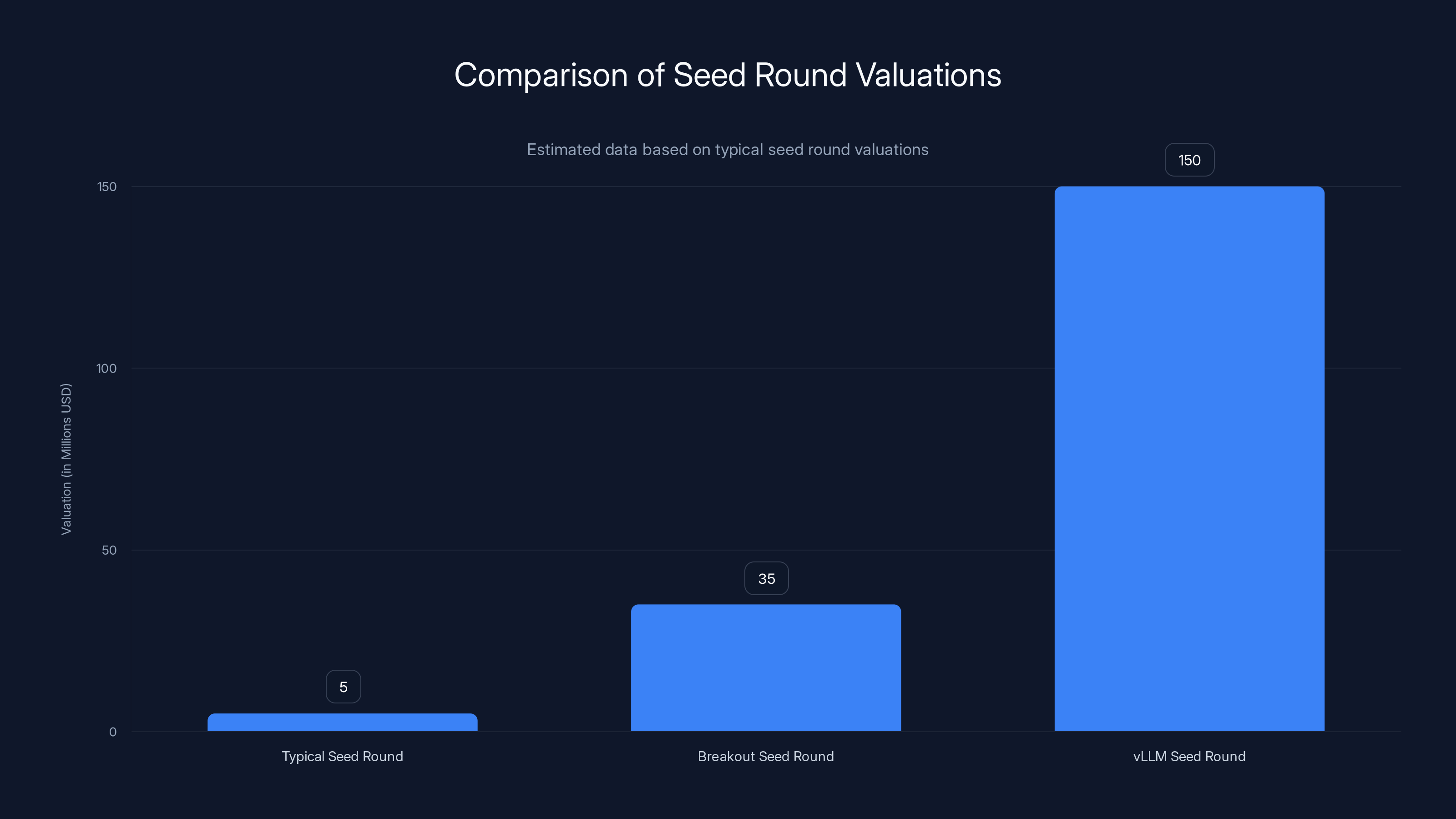
The $150M seed round for vLLM is significantly higher than typical and breakout seed rounds, highlighting its unique market position and potential. Estimated data.
Paged Attention: The Technology That Changed Everything
Now let's actually understand the innovation that makes v LLM special. Because if you only understand the funding narrative, you miss why this matters.
Traditional transformer-based language models process requests sequentially. Request one comes in, the model processes it, stores the attention weights and values (the "context"), then moves to request two. If request one isn't finished, request two waits. This is fundamentally inefficient.
The challenge is that attention mechanisms require storing massive intermediate states. For a language model processing a 2,000-token context window, you're storing attention key-value pairs for every position. With concurrent requests, these states compete for GPU memory. Fragmentation becomes inevitable.
Paged attention reimagines this problem. Instead of treating each request's key-value cache as a single contiguous block, break it into fixed-size logical pages. These pages don't need to be contiguous in GPU memory—they're managed by a page table, just like virtual memory in a computer's operating system.
What does this achieve practically?
Eliminated fragmentation: When a request finishes and deallocates its cache, you're not left with scattered, unusable memory fragments. You're left with freed pages that can be reallocated to new requests.
Shared prefix optimization: If multiple requests start with the same prompt ("Analyze this customer feedback..."), they can share the same key-value pages for the common prefix. Suddenly, batch processing identical prompts uses 10x less memory.
Token-level allocation: Rather than allocating memory for entire sequences upfront, allocate one token's worth at a time. As requests grow, add pages as needed. No waste.
The performance gains aren't marginal. In benchmarks, v LLM achieves 10-20x higher throughput than traditional inference engines on concurrent requests. On a single GPU, you might serve 50 requests per second with v LLM versus 5 with naive implementations.
Scale that to a data center with thousands of GPUs, and the differences become absurd. You're talking about reducing your inference infrastructure costs by 50-70% while getting lower latency. That's not an optimization. That's a fundamental rethinking of how inference should work.

Production Adoption: Amazon, E-Commerce Giants, and Beyond
Here's where theory meets reality. Inferact's seed round isn't speculative. It's backed by actual production deployments.
Amazon Web Services is running v LLM. That's public knowledge at this point. AWS wouldn't use external inference infrastructure if it wasn't better than their internal alternatives. AWS could build their own custom inference engine. They have the resources. They did it anyway because v LLM was superior.
A major e-commerce platform mentioned in reports is also using v LLM. This matters because e-commerce companies operate at massive scale. A single percentage point improvement in inference efficiency saves millions in infrastructure costs. They don't use technology for resume value. They use it because the economics force them to.
Think about what this means. Both companies that could build proprietary solutions instead adopted v LLM. They're not early adopters gambling on unproven technology. They're pragmatists choosing the best tool available. That's the strongest possible validation in infrastructure.
The enterprise adoption curve shows a similar pattern. Startups building on top of language models almost universally use v LLM. Why would they build custom inference when a battle-tested solution exists? It makes sense to invest engineering time in product differentiation, not in reinventing inference from scratch.
The adoption isn't even limited to pure software companies. Robotics companies, autonomous vehicle manufacturers, financial services firms—anyone deploying language models at scale faces the same inference cost problem. v LLM works for all of them.
This production adoption provides Inferact with several advantages:
Proven product-market fit: The technology isn't theoretical. Thousands of deployments exist. The product works at scale.
Customer acquisition advantage: Inferact doesn't need to convince customers that v LLM is good. They already use it. The conversation shifts to "How do we get enterprise support, additional features, and optimization for your specific use case?"
Data for continuous improvement: Every deployed instance generates data about what works and what doesn't. Inferact can use this feedback to guide development priorities.
Defensibility: The longer v LLM remains the industry standard, the more expensive it becomes for customers to switch. Switching costs create sustainable competitive advantages.

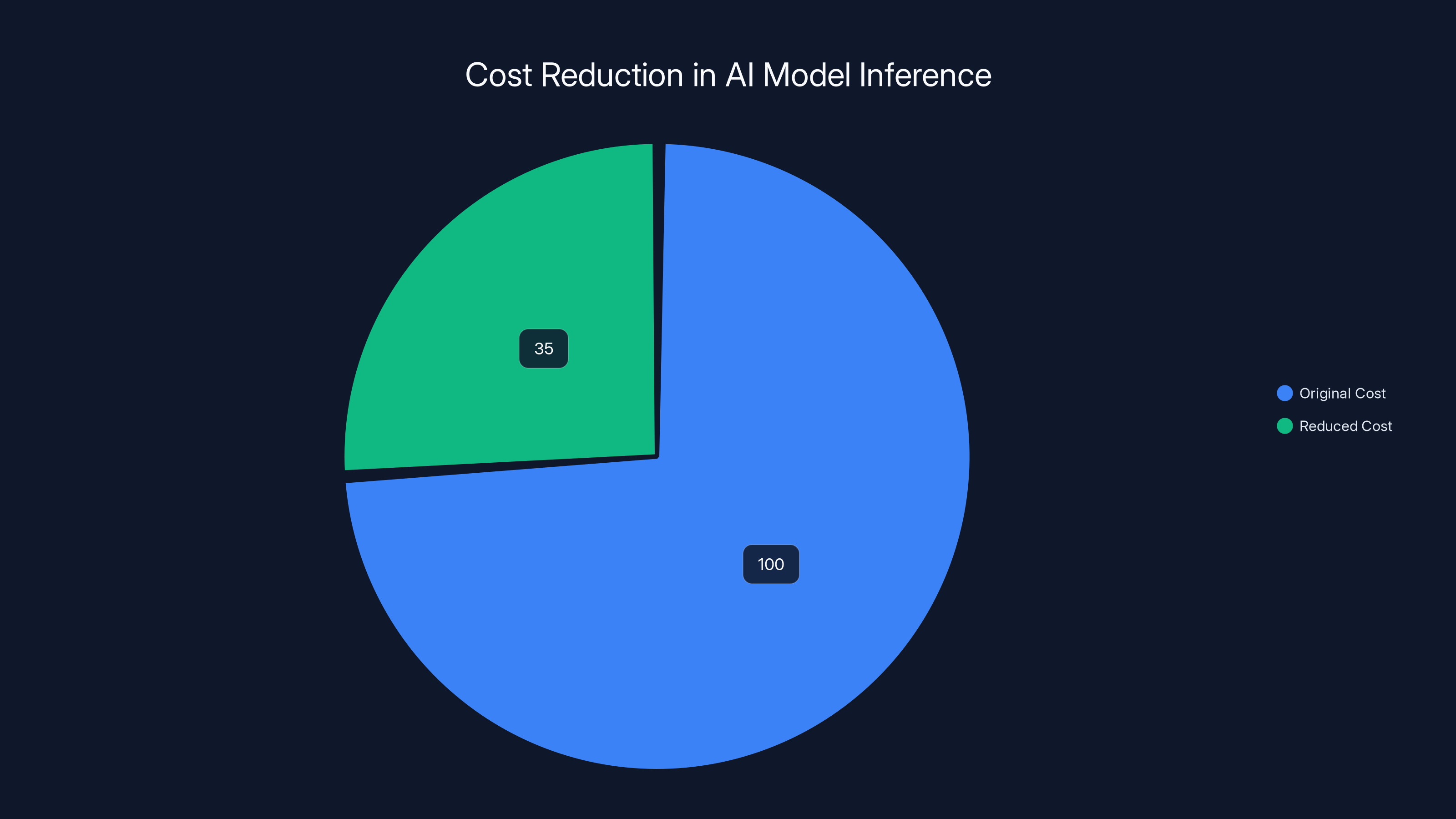
vLLM can reduce AI inference costs by 50-70%, making it a valuable tool for cost-efficient AI model deployment. Estimated data.
The Broader Inference Market: Why Radix Ark and the Competition Matter
Inferact didn't exist in isolation. The same moment saw Radix Ark's emergence—another inference optimization startup spun out of the same UC Berkeley lab, backed by Accel, valued at $400 million.
This isn't competition in the traditional sense. It's validation that the inference market is real and large enough for multiple companies. When two projects from the same lab both get well-funded in quick succession, it signals that the underlying market opportunity is recognized broadly.
SGLang (Radix Ark's underlying technology) takes a different approach to inference optimization. Where v LLM focused on memory efficiency through paged attention, SGLang emphasizes throughput optimization through advanced scheduling and batching. Both solve overlapping problems but with different trade-offs.
In a mature infrastructure market, you get multiple solutions because different use cases have different priorities. Some applications need minimum latency. Others prioritize maximum throughput. Some need to minimize GPU utilization for cost reasons. Others need predictable performance with tight SLA guarantees.
Inferact and Radix Ark competing in the same market is actually healthy. It means:
Innovation accelerates: Both teams will push each other to improve. The competitive pressure creates better products faster.
Market expansion: Competition validates the opportunity and attracts more startups, expanding total market awareness.
Customer choice: Enterprises get options instead of being locked into a single solution.
Specialization: Companies differentiate by targeting specific use cases. Inferact might focus on cloud deployment while Radix Ark focuses on edge inference.
The total addressable market for inference optimization is enormous. According to various estimates, the global AI inference market will exceed $100 billion annually by 2030. Cost optimization being worth even 10-20% of that market would justify multiple well-funded companies.

The UC Berkeley Lab Effect: Why This Specific Lab Is Producing Unicorns
Both Inferact and Radix Ark emerged from Ion Stoica's lab at UC Berkeley. This isn't coincidence. It reflects something deeper about how transformative infrastructure gets built.
Stoica's background is in distributed systems and cloud computing. He co-founded Databricks, which scaled to a $43 billion valuation by solving data engineering problems. He understands how to identify fundamental bottlenecks and how to design elegant solutions.
The Sky Computing Lab has attracted researchers passionate about systems problems. They're not trying to compete with Open AI at model training. They're solving the unglamorous but essential problems that everyone faces once you actually deploy models to production.
This lab represents a shift in AI research priorities. Five years ago, everyone wanted to build bigger models. Now the conversation is about deploying them efficiently. That's a maturation signal. The industry moved from the frontier ("Can we build AGI?") to operational reality ("How do we serve a billion inference requests per day?")
The lab's structure also matters. It's at a university, which means researchers come and go. When they leave, they take their insights with them. Some spin out companies. Some join existing companies and bring advanced techniques. Knowledge diffuses through the ecosystem.
Compare this to proprietary research happening inside companies. Techniques get locked away behind corporate structures. The lab model democratizes cutting-edge knowledge. University researchers publish findings. Companies implement them. Startups commercialize the most valuable ones. The entire ecosystem moves faster.
Inferact and Radix Ark are essentially bets that academic research leadership in systems design will translate to commercial success. So far, it's working. Both companies raised significant capital on the strength of proven research.

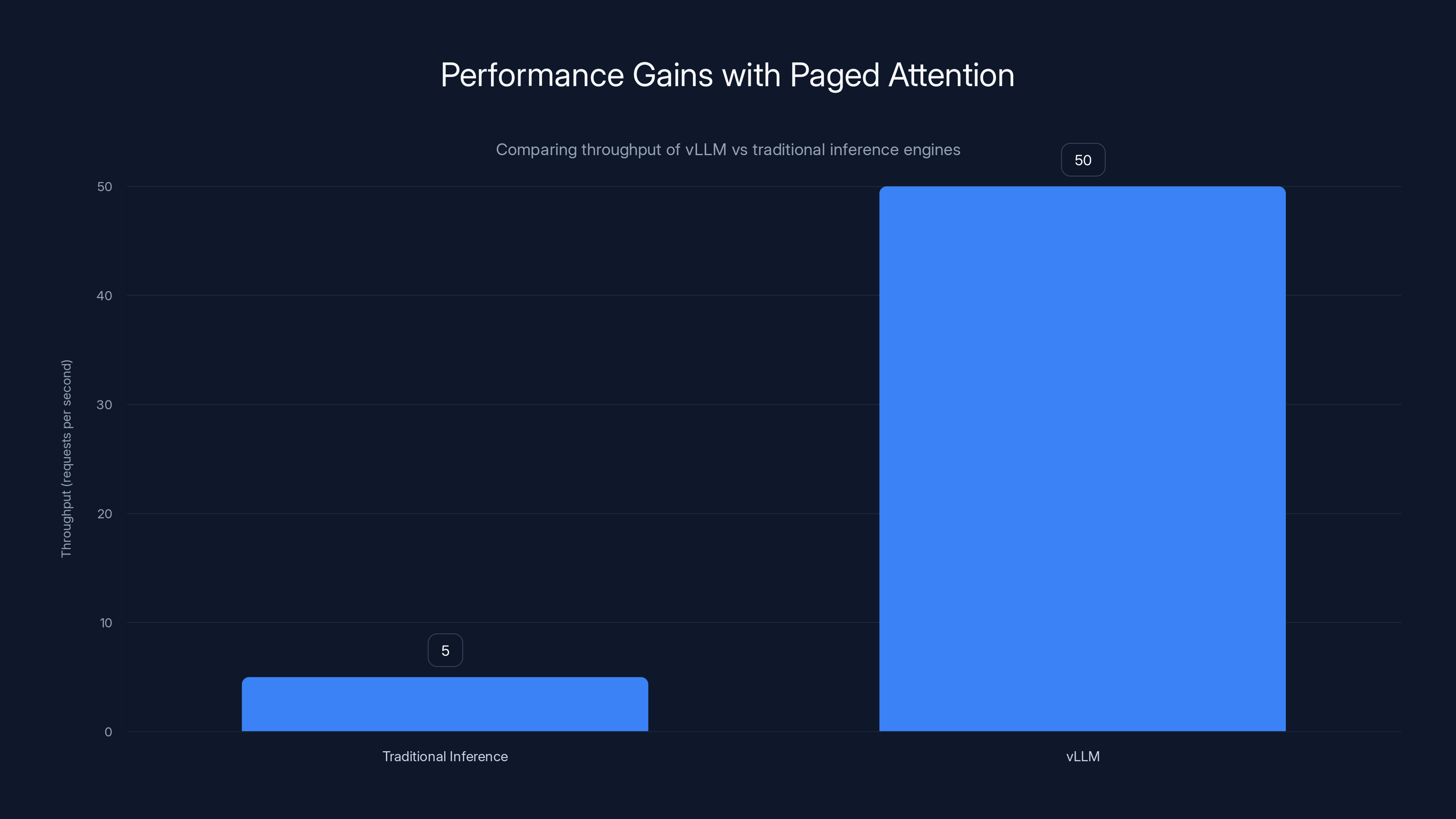
Paged attention technology enables vLLM to achieve 10-20x higher throughput compared to traditional inference engines, significantly enhancing performance on concurrent requests.
Market Dynamics: Cloud Providers and Hardware Manufacturers
When Amazon Web Services deploys your technology, you're not just getting a customer. You're getting validation that shapes the entire industry.
Cloud providers control massive hardware footprints. They buy hundreds of thousands of GPUs. Any technique that improves efficiency multiplies across their infrastructure. A 10% improvement in inference efficiency might translate to hundreds of millions in reduced hardware costs annually.
This creates incentives that work in Inferact's favor. Cloud providers could build proprietary inference solutions, but they need those solutions to work across different model architectures from multiple vendors. A standard like v LLM is actually more valuable than a proprietary solution, because it works universally.
At the same time, hardware manufacturers—NVIDIA, AMD, Intel, and others—care deeply about inference optimization. A tool that makes their hardware more efficient helps them sell more hardware. They want developers optimizing for their chips, not fighting against hardware limitations.
This creates interesting dynamics. Hardware companies might invest in inference infrastructure startups because better software multiplies the value of their hardware. Inferact isn't competing with NVIDIA. It's making NVIDIA more valuable.
The cloud provider relationship also opens interesting doors for Inferact:
Co-marketing opportunities: Cloud providers might promote v LLM as the inference standard for their platforms.
Integration partnerships: AWS might build v LLM support directly into their managed services.
Revenue sharing: Inferact could take a cut of inference workloads optimized through their system.
Feature development: Cloud providers might fund specific features they need.
These relationships don't show up in the seed round announcement, but they're likely being negotiated right now. Infrastructure companies often have multiple revenue streams beyond direct customer subscriptions.

The Economics of Inference Optimization
Let's put numbers on this to understand the actual economic impact.
Suppose a company runs a language model serving 1 million inference requests daily. Each request processes a 500-token input and generates a 100-token output. Using traditional inference without optimization:
Traditional approach:
- Requests per GPU per second: 10
- Requests daily per GPU: 10 × 86,400 = 864,000
- GPUs needed: 1,000,000 / 864,000 ≈ 1.2 GPUs
But that's oversimplified. Adding realistic factors like redundancy, caching, and model size:
More realistic traditional:
- Actual throughput per GPU: 5 req/sec (accounting for overhead)
- GPUs needed: 200 GPUs
- Cost per GPU annually: $10,000
- Total annual cost: $2,000,000
With v LLM optimization:
- Throughput per GPU: 15 req/sec (3x improvement from paged attention)
- GPUs needed: 67 GPUs
- Total annual cost: $670,000
- Savings: $1.33 million annually
For a company running this workload, a solution that saves
Scale this to hyperscalers running billions of inference requests daily, and the economics become staggering. A 50% reduction in inference infrastructure costs could mean hundreds of millions or billions in annual savings. Inferact's valuation of $800 million starts looking cheap.
This is the economic fundamentals that justify the seed round. It's not speculation about future potential. It's current, measurable savings being realized in production.
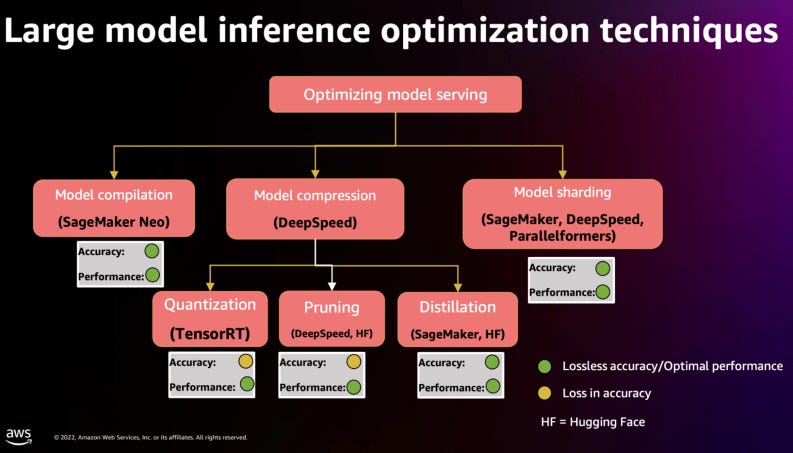
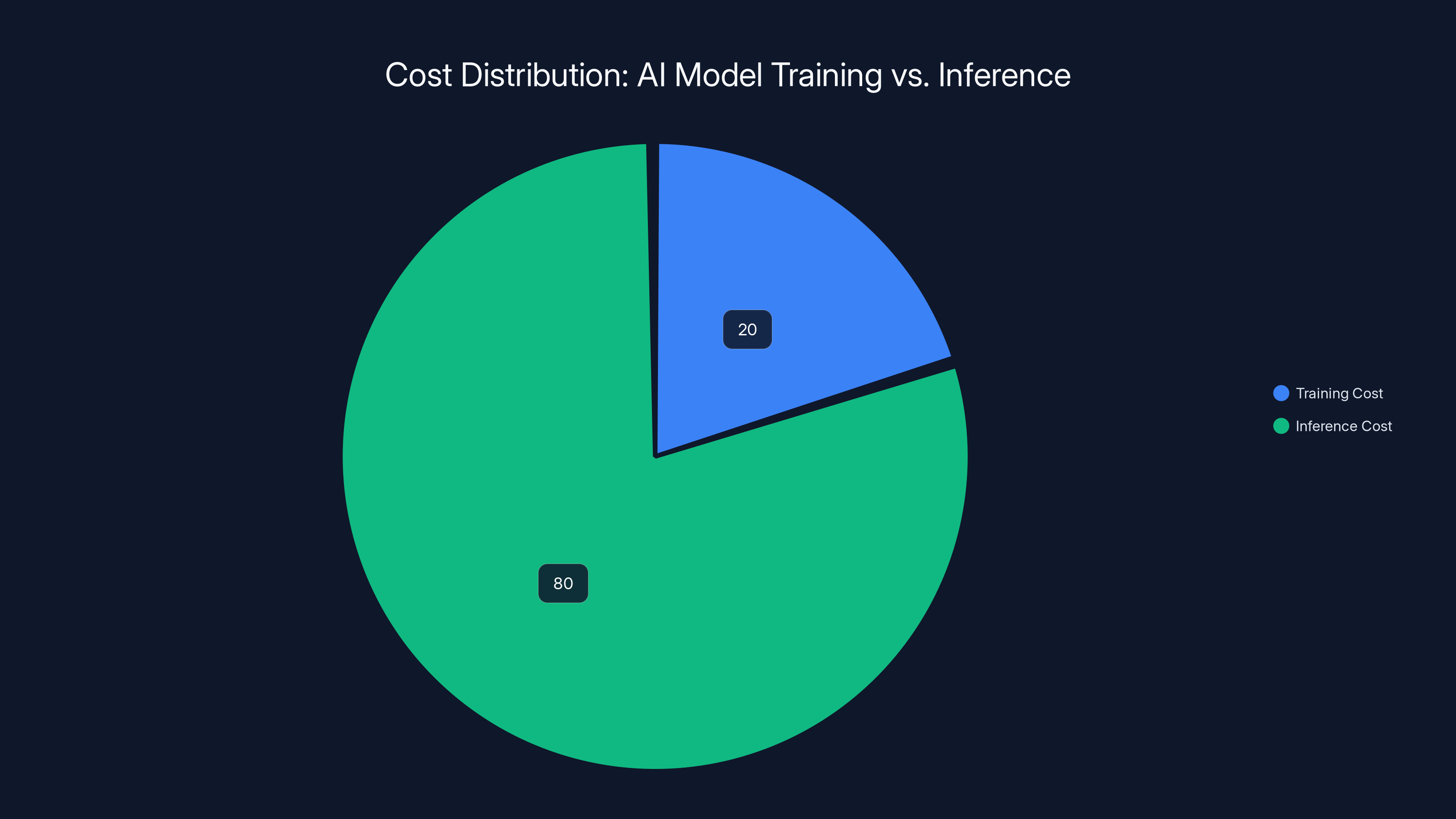
Inference costs can significantly exceed training costs for AI models due to the high frequency of user interactions. Estimated data.
Competitive Landscape: Who Else Is Building Inference Solutions?
Inferact and Radix Ark aren't the only players in this space. The inference optimization market is attracting competitors from multiple directions.
NVIDIA has invested in inference optimization through initiatives like Tensor RT, their inference optimization engine. NVIDIA will likely stay hardware-focused but might acquire or partner with software companies.
Open source alternatives like Ollama and Open LLM provide free or cheap inference solutions. These aren't direct competitors to Inferact—they target different use cases—but they affect pricing power.
Cloud-native solutions from providers like Hugging Face and Anyscale target developers building on managed platforms. Again, not direct competitors but adjacent players.
Specialized competitors are emerging. Companies building for specific use cases—robotics, edge devices, or specialized hardware—might build proprietary inference solutions.
The competitive landscape doesn't threaten Inferact's position, though. v LLM has too much momentum. The market is growing fast enough for multiple winners. And Inferact's team has the credibility and resources to stay ahead.
The real competitive threat wouldn't come from startups. It would come from hyperscalers deciding they want proprietary solutions for specific use cases. AWS or Google could theoretically build their own inference engine optimized specifically for their infrastructure. But that would fragment the market and reduce total ecosystem quality. Staying with open standards like v LLM is strategically better for everyone.
Enterprise Features and Commercial Strategy
The seed round gives Inferact capital to build beyond just the open-source v LLM project. What enterprise features make sense?
Professional support and SLAs: Enterprises need guaranteed response times for critical issues. v LLM support becomes a line-item business expense.
Customization and integration: Large companies have unusual requirements. Inferact can hire engineers to customize v LLM for specific workloads.
Compliance and security: Enterprises need auditing, encryption options, and compliance certifications. These take time and resources to implement.
Optimization services: Inferact can analyze customer workloads and recommend optimizations. This adds value beyond the software.
Managed v LLM service: Rather than customers running v LLM themselves, Inferact could offer it as a managed service on cloud platforms.
Model optimization tooling: Tools to help customers profile their models and identify bottlenecks.
Benchmarking and monitoring: Dashboards showing inference performance, cost per request, and optimization recommendations.
The commercial model likely layers on top of open-source. The open-source project remains free and fully featured. Enterprise features, support, and services are what drive revenue.
This aligns incentives perfectly. Every enterprise customer success story makes the open-source project more attractive, driving broader adoption. The virtuous cycle strengthens the overall platform.
The Inference Shift and What It Means for AI's Economics
We're witnessing a historical inflection point in AI economics. For years, the narrative focused on training. Who builds the biggest models? Who can gather the most data? Who invents the best architecture?
That story hasn't gone away, but it's now secondary to a more pressing question: how do we actually use these models profitably? Inference costs are the blocking factor for most AI applications.
This shift has profound implications:
Democratization accelerates: When inference is cheap, smaller companies can compete with large ones. You don't need billions in training compute to build AI products if inference is efficient.
Different winners emerge: Companies that win at inference might be different from companies that win at training. Open AI dominates model development. But Inferact might dominate deployment efficiency.
Applications become viable: Dozens of applications are only possible if inference is cheap enough. Real-time personalization, autonomous agents, constantly-running background processes—all require cheap inference.
Hardware economics shift: If inference becomes 10x cheaper through software optimization, demand for GPUs might actually decrease in some applications. Hardware companies need software efficiency to drive volume.
This is why Ion Stoica's lab and companies like Inferact matter. They're not just optimizing one technique. They're making the entire AI application ecosystem feasible.
The Road Ahead: What Comes After $150M
With $150 million in the bank, Inferact can execute on multiple fronts simultaneously. Here's what probably happens next:
H1 2026: Enterprise sales team and customer success infrastructure launched. First major enterprise customers signed. Series A discussions begin.
H2 2026: Managed v LLM service launches on major cloud platforms. Integration with hardware manufacturers announced. International expansion begins.
2027: IPO discussions might begin, depending on revenue growth. Acquisitions of complementary technologies. Expansion into related optimization problems (embeddings, retrieval, prompt optimization).
The path isn't guaranteed, but Inferact has the pieces. Proven technology, strong team, excellent investors, clear market opportunity, and adequate capital to execute.
The biggest risk isn't technical—v LLM is proven. It's organizational. Building a commercial company around open-source research requires balancing community interests with business needs. Inferact's leadership seems aware of this, but it's still the highest-risk execution item.
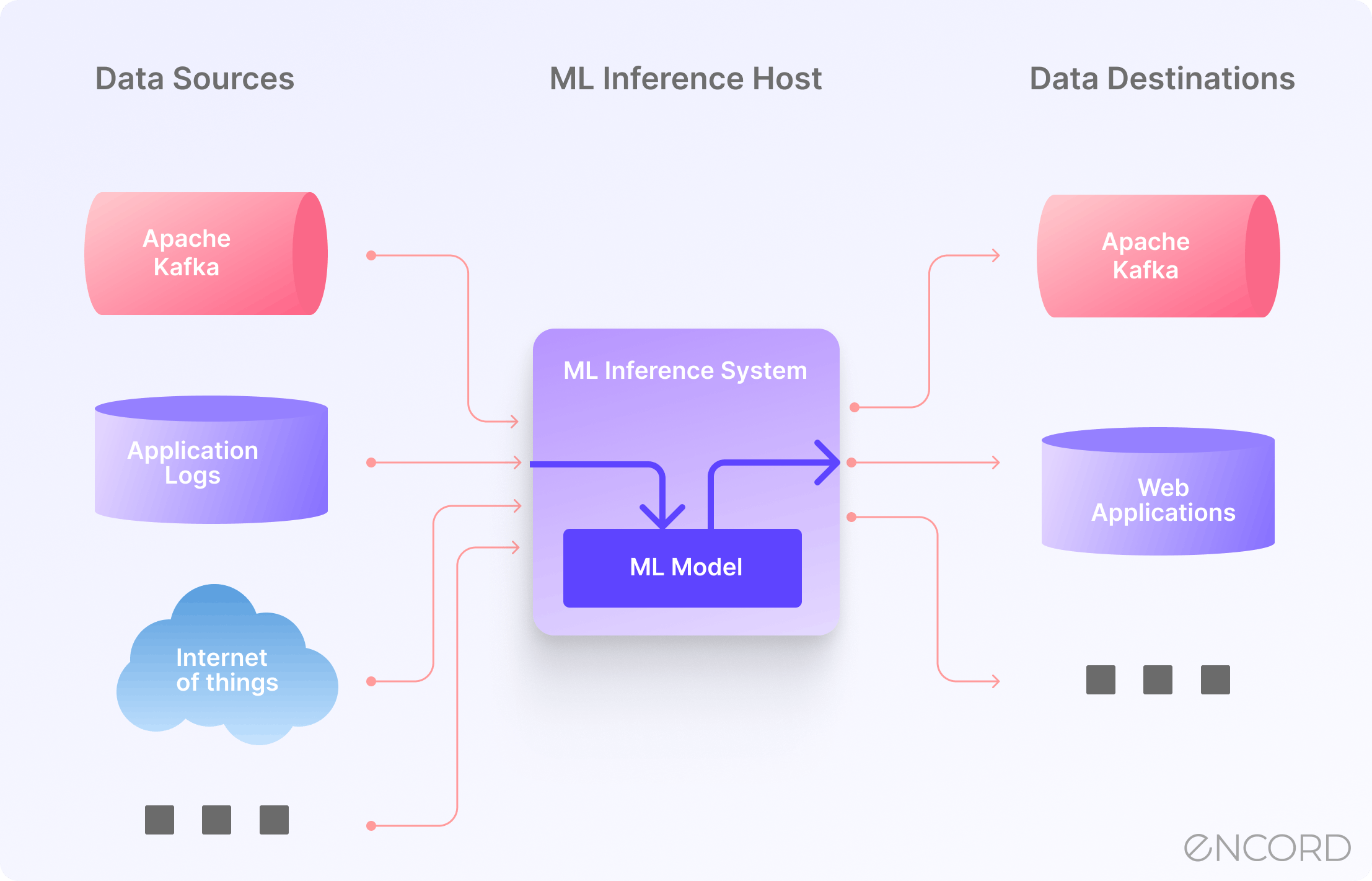
Implications for AI Builders and Developers
If you're building anything with language models, this funding round matters because it validates inference optimization as a core concern. It's not a nice-to-have optimization. It's becoming table stakes for production applications.
For developers right now, the implication is clear: use v LLM or similar tools as your default. Don't build custom inference engines unless you have very specific requirements that standard tools can't meet. The opportunity cost is usually too high.
For startups building AI products, understand your inference costs deeply. They'll determine whether your business model works. Investigate v LLM, Radix Ark's SGLang, and other optimization techniques early in development. A startup that understands their unit economics and can achieve 50% inference cost savings over competitors has a massive advantage.
For enterprises, the signal is that inference optimization is becoming a first-class concern in vendor selection. When evaluating language model platforms, ask about optimization tools and inference efficiency. This will be a major purchase decision in the coming years.
For researchers, this validates that applied systems work—work that improves real-world efficiency—gets recognized by venture capital and the broader tech industry. If you're working on infrastructure problems, there's clearly an audience.
The Billion-Dollar Infrastructure Question
This might be the moment when we collectively realize that infrastructure is more valuable than applications. It's a pattern we've seen before. Stripe is worth more than most e-commerce companies. Cloudflare is worth more than most web companies. The companies solving fundamental problems for everyone end up being more valuable than the companies using those solutions.
v LLM might follow the same trajectory. Not because it's the only inference optimization tool, but because it solves the core problem so well that alternatives become the niche plays.
Inferact's $800 million seed valuation reflects confidence in this dynamic. The company isn't being valued on current revenue or even near-term projections. It's being valued on the expectation that inference optimization becomes a fundamental economic multiplier, and Inferact captures significant value from that shift.
Whether that confidence is justified depends on execution. But the market signal is clear: the infrastructure layer of AI is emerging as the highest-value opportunity right now. Companies optimizing how models run will probably end up more valuable than companies building the models themselves.
FAQ
What exactly is v LLM, and why was it built?
v LLM is an open-source inference optimization engine that dramatically improves the efficiency of running large language models in production. It was developed at UC Berkeley's Sky Computing Lab to solve a fundamental problem: traditional inference processes waste enormous amounts of GPU compute and memory when handling concurrent requests. v LLM introduces paged attention—a technique inspired by operating system memory management—that achieves near-perfect GPU utilization and enables systems to serve 3-10x more concurrent requests on the same hardware.
How does Inferact plan to make money from an open-source project?
Inferact follows the open-source infrastructure software model. The core v LLM project remains free and fully featured—this drives adoption and community contribution. Inferact generates revenue through enterprise services: professional support with SLAs, custom optimization work for large deployments, managed v LLM services on cloud platforms, compliance and security features for regulated industries, and professional services helping enterprises optimize their specific workloads. This approach worked successfully for companies like Red Hat with Linux and Canonical with Ubuntu.
Why is inference optimization suddenly so valuable?
Inference is far more expensive than training for models deployed in production. A model might cost millions to train once, but inference happens billions of times. For companies like Amazon running massive inference workloads, a 50% cost reduction means hundreds of millions in annual savings. This economic reality makes inference optimization one of the highest-ROI technology investments available. The $100+ billion annual inference market creates enormous opportunity for tools that improve efficiency.
Who is already using v LLM in production?
Public knowledge confirms that Amazon Web Services uses v LLM as part of their inference infrastructure, and a major e-commerce company mentioned in reports uses it at scale. Beyond public companies, thousands of startups building language model applications use v LLM as their default inference engine. The adoption is organic and production-proven—these aren't early adopters experimenting but pragmatists solving real cost problems.
How does v LLM compare to Radix Ark and SGLang?
v LLM and SGLang (Radix Ark's underlying technology) both optimize inference but with different approaches. v LLM emphasizes memory efficiency and GPU utilization through paged attention. SGLang focuses on throughput optimization through advanced scheduling and batching. Both solve overlapping problems, and both received major funding in January 2026, suggesting the market is large enough for multiple winners. The tools will likely specialize for different use cases rather than compete head-to-head.
Is v LLM proprietary to Inferact, or can anyone still use it for free?
v LLM remains open-source and free. Anyone can download it, modify it, and deploy it without paying Inferact. This is critical to the business model—open-source adoption is the foundation that makes the company valuable. Inferact's revenue comes from companies willing to pay for support, custom work, and commercial features built on top of the open-source foundation, not from licensing fees for the core technology.
What makes the $150 million seed round reasonable for Inferact?
Inferact's valuation reflects several factors: proven technology with 3-10x performance improvements in production, existing adoption by major companies like AWS, clear product-market fit (existing users are already building their infrastructure around v LLM), and enormous addressable market ($100+ billion inference market annually). Infrastructure companies that solve fundamental cost problems for entire industries command premium valuations. Additionally, the team has proven execution experience from their research work at UC Berkeley.
Could AWS or Google build their own inference optimization engine instead of using v LLM?
They could, but they'd rather not. Hyperscalers could build proprietary solutions, but open standards like v LLM are more valuable because they: work across different model architectures from multiple vendors, benefit from community contributions and improvements, reduce engineering burden on cloud providers, and make their platforms more attractive to customers who want portability. Using v LLM gives AWS competitive advantage without the full cost of development.
What's the practical impact of Inferact's funding on developers building AI applications?
Developers should recognize that inference optimization is now a first-class concern with major VC backing and corporate support behind it. This means: v LLM (and similar tools) will continue improving rapidly, your default choice for inference should be optimized tools rather than custom implementations, understanding inference costs should be a priority from day one of application development, and optimization expertise will become increasingly valuable in AI product teams.
Where does Inferact fit in the broader AI infrastructure landscape?
Inferact occupies the inference optimization layer of the AI stack. Other layers include model training (Open AI, Anthropic), data management (Databricks), model hosting (Together, Replicate), and application frameworks (Lang Chain, Llama Index). Inferact makes all the upper-layer companies more efficient by reducing their inference costs. This creates a value chain where Inferact's improvements benefit everyone building on top of language models. The company is fundamentally an infrastructure play—it makes the entire AI economy more efficient.
What This Means for the Future of AI Economics
Inferact's $150 million seed round and v LLM's commercialization represent something historically significant. We're watching the AI industry mature from the training frontier to the deployment efficiency frontier.
For the next decade, the companies that capture the most value might not be the ones building the biggest models. They might be the ones solving how to run models cheaply, quickly, and reliably at massive scale. Inferact is betting that inference efficiency is the new frontier. Based on the market dynamics, competitive pressure from multiple well-funded competitors, and production adoption by hyperscalers, that bet looks sound.
The broader implication extends beyond any single company. It signals that the AI industry is transitioning from "Can we build it?" to "How do we deploy it profitably?" That's a maturation signal. It means AI is no longer a research frontier—it's becoming operational infrastructure.
For builders, investors, and enterprises, Inferact's funding is a signal to pay serious attention to inference optimization. The money is real, the technology is proven, and the economics are compelling. This isn't speculation about future AI capabilities. It's optimization of present-day AI deployment. And optimization problems that save billions in costs don't stay niche for long. They become the foundation layer that everyone builds on.
Key Takeaways
- Inferact raised 800M valuation to commercialize vLLM, signaling that inference optimization is becoming more valuable than model training.
- vLLM's paged attention technique achieves 3-10x throughput improvement and 50-70% cost reduction in production inference workloads.
- Major companies like AWS already use vLLM in production, proving technology viability beyond academic research.
- The inference market is large enough for multiple winners—RadixArk commercialized SGLang with $400M valuation same week, validating market opportunity.
- Open-source infrastructure companies like Inferact generate revenue through enterprise support and services, not licensing the free core technology.
Related Articles
- RadixArk Spins Out From SGLang: The $400M Inference Optimization Play [2025]
- 55 US AI Startups That Raised $100M+ in 2025: Complete Analysis
- Startup Battlefield 2025: Glīd Founder Kevin Damoa's Winning Strategy [2025]
- Wellness Fund Boom: Inside Jenny Liu's $5M Venture Play [2025]
- General Fusion's $1B SPAC Merger: Fusion Power's Survival Strategy [2025]
- Telly's Free TV Strategy: Why 35,000 Units Matter in 2025

