![RadixArk Spins Out From SGLang: The $400M Inference Optimization Play [2025]](https://tryrunable.com/blog/radixark-spins-out-from-sglang-the-400m-inference-optimizati/image-1-1769038631428.jpg)
The Inference Layer Just Got a $400 Million Competitor
There's a moment in every AI startup's life when the product stops being a research project and becomes a business. For SGLang, that moment happened last August when the team spun out to create Radix Ark, a company focused on making AI models run faster and cheaper on existing hardware. According to TechCrunch, Radix Ark is valued at $400 million, highlighting the market's appetite for cost-cutting infrastructure.
But here's what makes this spinout noteworthy: it's not about building new models. It's about optimizing the invisible layer between your question and the AI's answer. That layer, called inference, is where companies burn through millions in server costs every month. And the founders of Radix Ark figured out something simple: if you can make inference faster, you make everything cheaper.
Raising
What's fascinating is that Radix Ark didn't start from a business plan. It started from Ion Stoica's lab at UC Berkeley, the same place that produced Databricks, Apache Spark, and now apparently a lineup of startups focused on making AI run better. Stoica has a track record of looking at problems in computing and building infrastructure that entire industries later depend on. Inference optimization might be the next one.
The timing is perfect. Companies like x AI and Cursor are already using SGLang in production. Intel's CEO personally backed the company in an angel round. And the entire industry is watching as the inference optimization space becomes a multi-billion dollar market. This isn't hype. This is the boring infrastructure layer that actually moves needles for companies trying to stay profitable while running expensive AI models.
What Is Inference, and Why Does It Matter So Much?
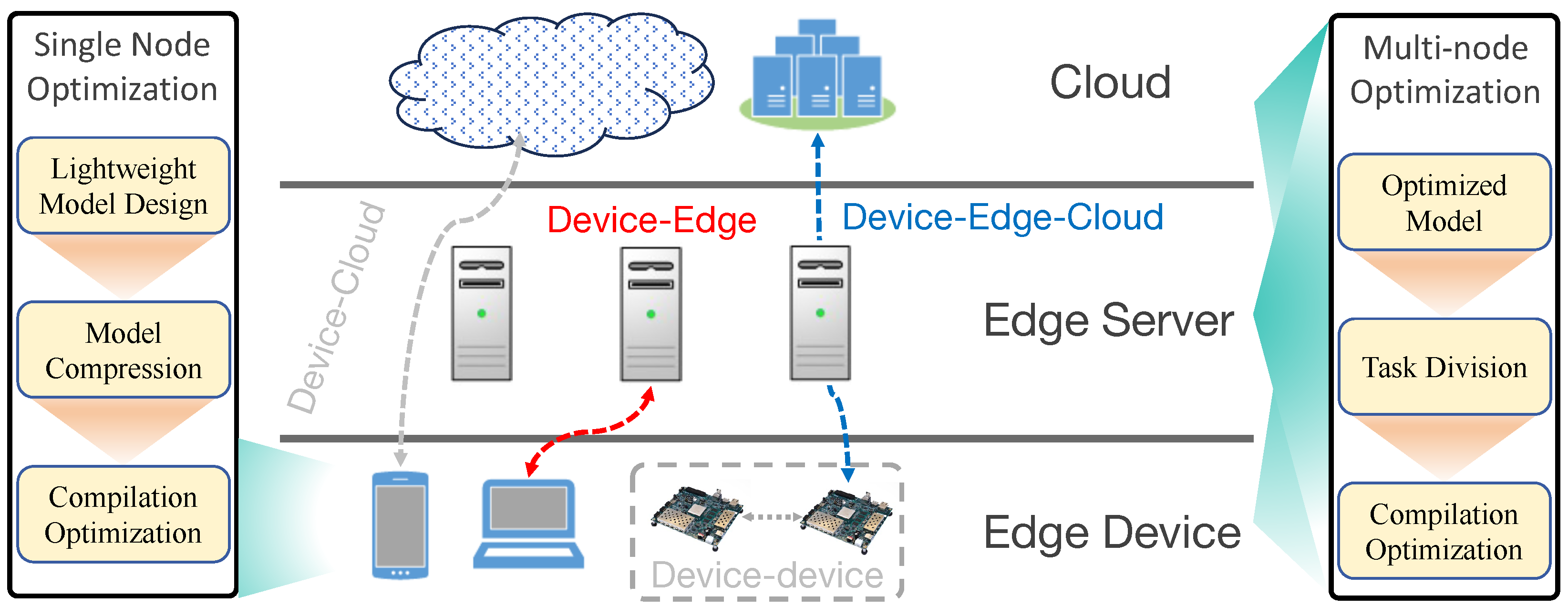
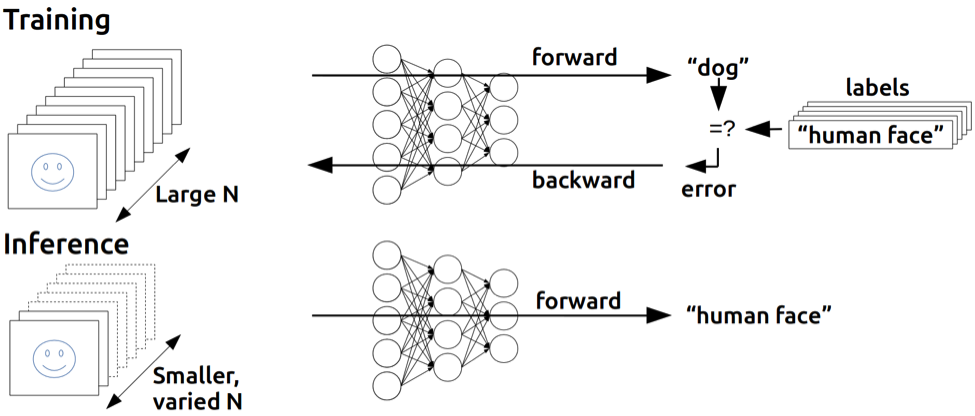
Let's start with the basics, because this is where the entire story makes sense. When you ask Chat GPT a question, two things happen on the server side: training (which happens once, on expensive hardware, to create the model) and inference (which happens every single time someone uses the model).
Training is the expensive phase where the model learns patterns. Inference is when the model applies what it learned to answer your specific question. For most companies running AI in production, inference is where the real cost lives. A company might spend $10 million training a model once. But if that model serves millions of users, inference costs can easily exceed training costs by 10x or 100x.
Here's the math: if your inference takes 2 seconds per request, and you handle 1 million requests per day, you're spending roughly
This is why Radix Ark's pitch is so compelling. Companies aren't interested in inference optimization because it's intellectually interesting. They're interested because it directly impacts their bottom line. An engineer at a startup running inference workloads probably got pulled into a meeting last quarter where someone said, "We need to cut cloud costs by 30% without cutting features." Inference optimization is how you actually do that.
The inference layer has become the most fought-over piece of the AI infrastructure stack. It's not as sexy as building better models. But it's where the money actually is. Training a cutting-edge model costs millions. Running that model for millions of users costs billions. The infrastructure that reduces that cost doesn't just create value, it creates survival for companies operating on thin margins.
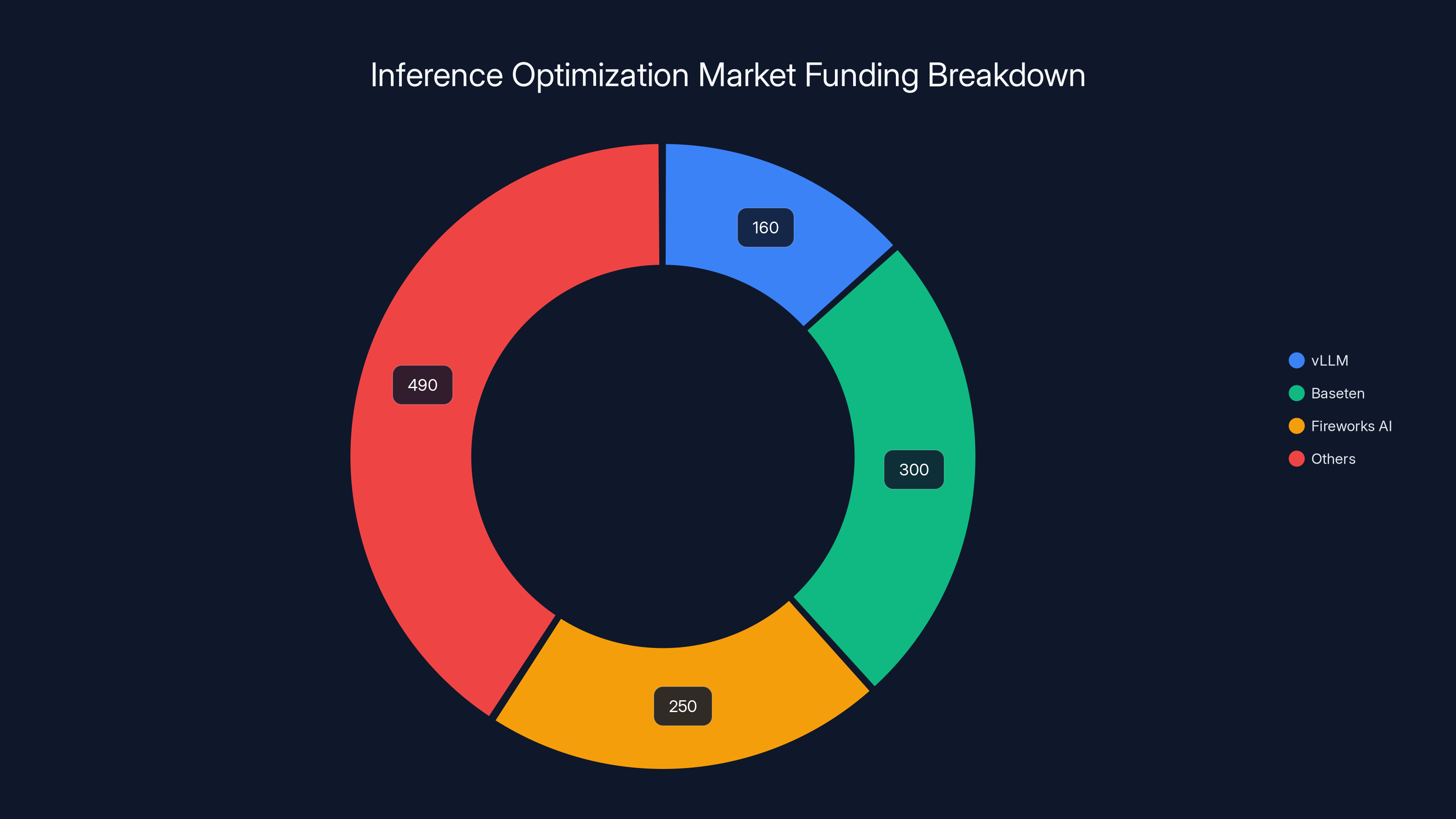
In 2024, inference optimization startups raised approximately $1.2 billion. Key players like Baseten and Fireworks AI secured significant portions, indicating strong investor confidence in diverse optimization approaches. Estimated data.
How SGLang Became Radix Ark: From Research to Revenue
SGLang started in 2023 as a research project inside Ion Stoica's UC Berkeley lab, which sits at the intersection of academic computer science and practical startup infrastructure. The goal was simple: what if you could take the theoretical work on language model optimization and actually make it work for real-world production systems?
The project caught fire faster than anyone probably expected. Companies building at scale immediately saw the value. x AI needed ways to serve models efficiently. Cursor, the AI-powered code editor, needed inference to be fast because their users expect responses in milliseconds. Both ended up using SGLang in production, which is how you know the technology actually works.
But there's a gap between "researchers built something cool that works" and "a company that can scale this across enterprises." That gap is called business execution, and it's where Radix Ark comes in. The startup was announced last August as the commercial entity that would take SGLang from an open-source project maintained by academics and enthusiasts to a full-blown product company.
Ying Sheng, who had been a key contributor to SGLang and previously worked at x AI under Elon Musk, made the jump to become Radix Ark's CEO. This is a crucial detail. She wasn't some marketing hire or finance guy brought in to "commercialize" the project. She was already deep in the technology, already knew what companies needed, and had direct experience shipping inference products at scale at x AI.
The funding round that valued Radix Ark at $400 million included Accel, a venture firm known for betting on infrastructure plays early. It also included Lip-Bu Tan, Intel's CEO, who brought both capital and credibility to the round. Having Intel's CEO as an investor signals something important: major semiconductor and infrastructure companies see this space as critical.
What's notable about Radix Ark's approach is that they're not trying to replace SGLang with proprietary code. They're continuing to develop SGLang as an open-source project while building commercial products and services on top. This is the same playbook that worked for companies like Docker, Elastic, and Cloud Flare. Open-source is the moat. Commercial services are the revenue.
The Inference Optimization Market Just Exploded
Radix Ark's $400 million valuation isn't happening in a vacuum. The entire inference optimization space is experiencing what you might call a funding avalanche. This is what happens when investors realize a market tier is actually valuable.
Consider what happened with v LLM, another inference optimization tool that also came out of Ion Stoica's lab. In December 2024 and into early 2025, v LLM raised funding at a
Then there's Baseten, which raised
What's happening is this: the venture market is collectively deciding that inference infrastructure is as important as training infrastructure. This makes sense from a market perspective. Every AI company that achieves real-world success eventually hits the same wall: inference costs are too high. The tools that solve this problem don't need to compete on features or innovation. They just need to work reliably and save companies money.
The market dynamics are favorable for companies in this space. They're not fighting a winner-take-all dynamic where one company dominates. Instead, different optimization approaches work better for different workloads. Some companies need speed above all else. Others need efficiency at scale. Still others need to optimize for specific hardware. This means there's room for multiple companies to exist simultaneously and own different slices of the market.

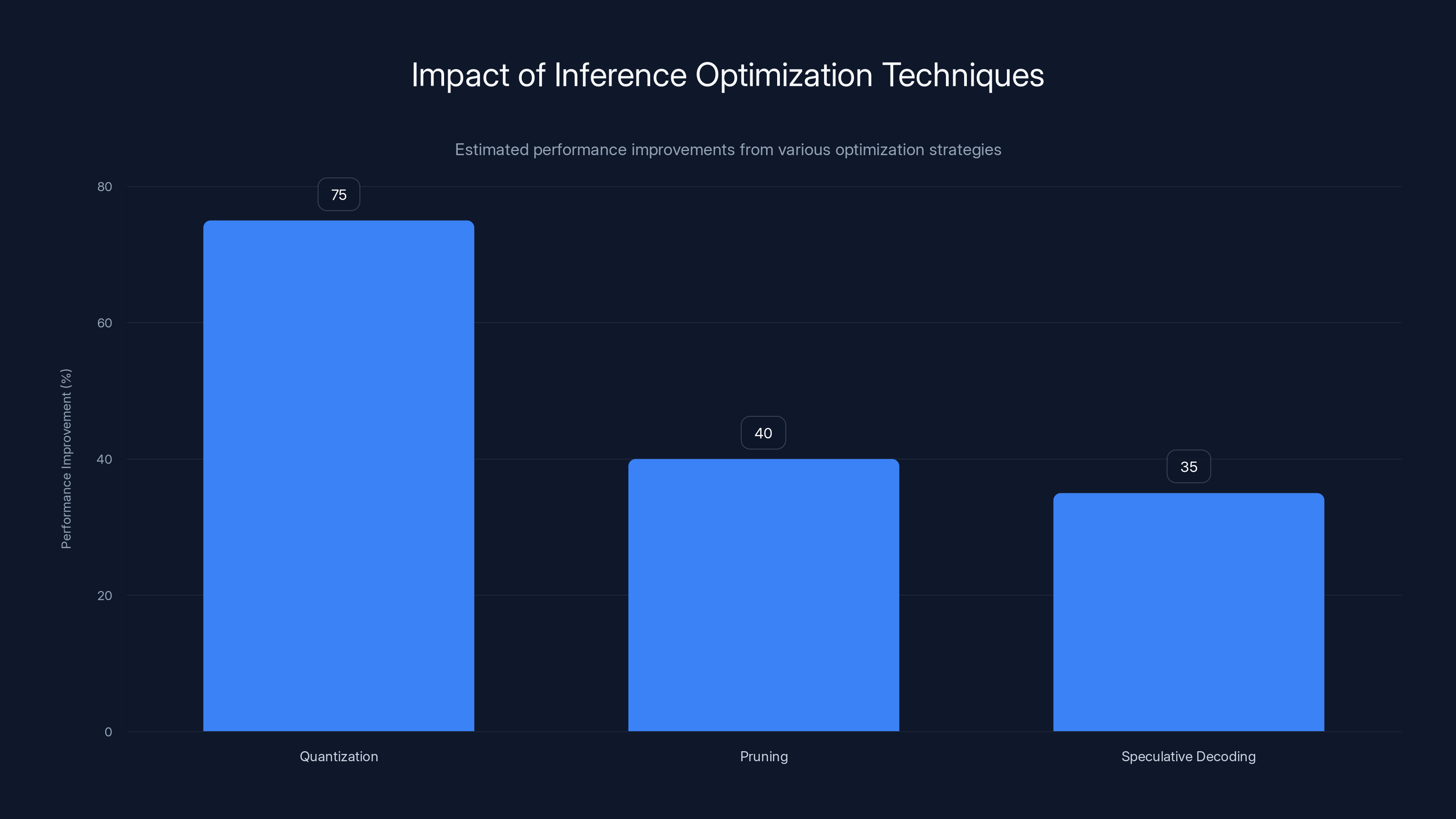
Quantization significantly reduces memory usage, while pruning and speculative decoding enhance computation speed and reduce latency, respectively. Estimated data.
Radix Ark's Product Strategy: Open Source Plus Premium Services
Radix Ark's business model is worth examining because it tells you a lot about how infrastructure startups can actually make money in 2025. They're not trying to sell licenses to SGLang, the core open-source project. Instead, they're building three revenue streams:
First, continued development of SGLang as an open-source project. This is the moat. Companies use it because it works, it's free, and they can contribute back to it. The companies that adopt it become invested in its success. They contribute bug reports. Their engineers submit pull requests. The project becomes better because thousands of engineers are using it and improving it.
Second, Miles, a specialized framework for reinforcement learning. This is the proprietary tool that companies can't get elsewhere. Reinforcement learning is how you train models to improve over time based on feedback. It's how you make an AI assistant better at answering questions in your specific domain. It's how you fine-tune models for specific use cases. Companies willing to pay will, because it creates real competitive advantage.
Third, hosting and managed services. This is where the recurring revenue lives. Companies that want to run inference but don't want to manage their own infrastructure can use Radix Ark's hosted service. They pay per request, or per month, or however the pricing works. This is boring enterprise Saa S, but it's also where the revenue scale actually comes from.
This strategy has worked for other companies. Look at Hashi Corp, which built Terraform as open-source but monetizes through cloud services and premium features. Look at Canonical with Ubuntu, where the operating system is free but they make money on support and managed services. The pattern is consistent: open-source attracts users, premium services convert them to customers.
The Competition: Why There's Room for Multiple Winners
You might be thinking: if v LLM already exists and raised
v LLM is a more mature project. It's been around longer, it has more users, and it's had more time to become the default choice for certain workloads. But maturity doesn't mean it's perfect for every use case. SGLang was designed from the start with a different philosophy about how to approach inference optimization.
The way these technologies work, they optimize different parts of the inference pipeline. Some tools focus on batching (doing multiple requests at once). Others focus on memory management (keeping the model's weights in the right place in memory). Still others focus on token prediction (predicting what the model will need next and pre-computing it). Different tools excel at different optimizations.
This means a company might use v LLM for one workload and SGLang for another. Or they might use v LLM for general-purpose language models and SGLang for specialized applications that need different optimization patterns. The market is big enough for multiple approaches to succeed simultaneously.
There's also a geographic and organizational angle. v LLM has tremendous adoption in Asia. SGLang is strong in North America and Europe. Companies might prefer SGLang because they like the team, or the community, or because the tool better fits their specific infrastructure setup. These network effects matter in infrastructure software.
Why Ion Stoica's Lab Keeps Producing Billion-Dollar Companies
There's something unusual happening at UC Berkeley's computer science lab, where Ion Stoica is a professor. Over the past decade, this lab has produced Databricks, now valued at over $40 billion. It's produced Apache Spark, which became the standard for distributed computing. It's now producing SGLang, which is becoming critical infrastructure for inference. And it's probably going to produce several more major infrastructure companies before Stoica retires.
Why does this keep happening? Part of it is luck. You can't intentionally produce billion-dollar companies. But part of it is a specific research approach that Stoica and his team follow: they identify real problems that industry is facing, they build the simplest possible solution, and they make it open-source so practitioners can use it immediately.
This is different from the typical academic research approach, which produces papers and proofs but rarely ships software that real companies use. It's also different from the typical startup approach, which tries to build a proprietary moat immediately and keep everything secret. Stoica's approach combines the rigor of academic research with the pragmatism of industry engineering.
The result is that engineers at real companies actually use the software coming out of his lab. They find bugs. They suggest improvements. They contribute back. The software gets better. Eventually, someone realizes that building a company around this software makes sense. And by that time, the software is already proven, already widely adopted, and already trusted by major companies.
This is the infrastructure play that actually works. You can't teach this in business school because it requires a specific combination of academic credibility, engineering skill, and the ability to recognize problems that are about to become really important but aren't quite on most people's radar yet.
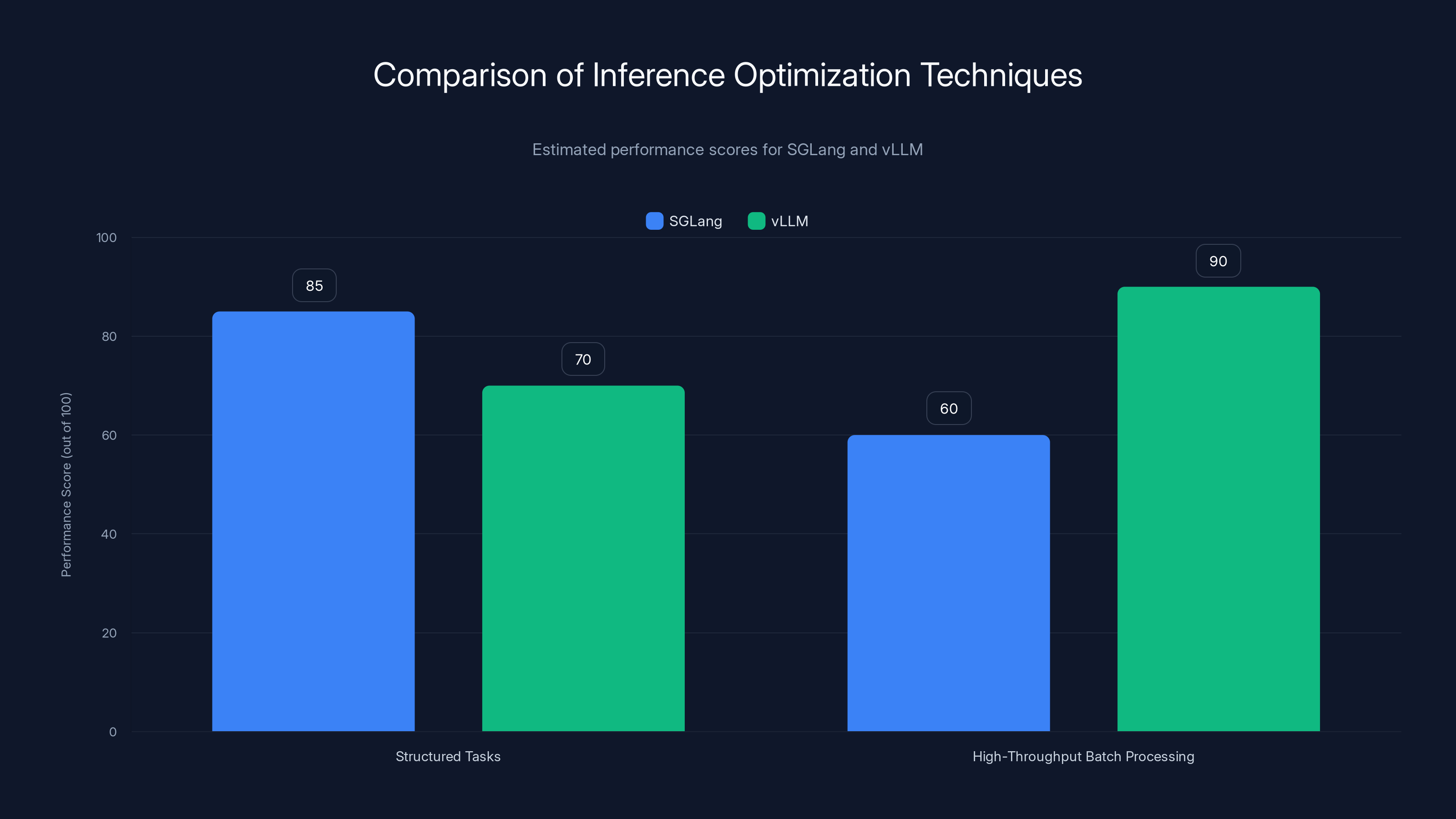
SGLang excels in structured tasks with a performance score of 85, while vLLM leads in high-throughput batch processing with a score of 90. Estimated data.
The Cost-Cutting Imperative Driving Inference Optimization
To understand why Radix Ark's $400 million valuation makes sense, you need to understand the financial pressure driving AI adoption. Companies that successfully deploy AI models in production immediately hit a cost wall. The model works great. Users love it. But the compute costs are unsustainable.
Here's a realistic scenario: a company builds an AI-powered customer support tool. It works beautifully. Every customer question gets a relevant, helpful answer. The company is using Open AI's GPT-4 API for each response, which costs roughly $0.015 per 1,000 tokens. That seems cheap until you realize that a typical customer support question and answer might use 2,000 tokens.
If the company handles 10,000 customer support questions per day, that's 20 million tokens per day. At
Now, what if the company could run their own model and optimize the inference to reduce latency by 40%? Suddenly they're using 40% fewer tokens (because the model is faster and more efficient). They're also able to run the model on cheaper hardware because optimization means they need less GPU power. They just cut their annual infrastructure costs from
For a company that raised
The money being invested in Radix Ark, v LLM, Baseten, and Fireworks AI isn't coming from nowhere. It's coming from the fact that these tools are addressing a real, quantifiable financial problem that hundreds of companies are experiencing right now. This is why all of them are raising massive funding rounds even though they're not household names. They're solving a problem that directly impacts profitability.
Technical Foundations: How Inference Optimization Actually Works
To appreciate why Radix Ark is raising $400 million, it helps to understand the technical approach. Inference optimization isn't a single technique. It's a combination of strategies applied at different layers of the inference pipeline.
At the most basic level, there's quantization, which means storing the model's weights in lower precision formats. Instead of using 32-bit floating-point numbers for every weight, you use 8-bit or 4-bit integers. This reduces memory requirements by 4x or 8x. The tradeoff is slight accuracy loss, but for most applications, you don't notice any difference. The math works like this:
For a model stored in 32-bit precision quantized to 8-bit, that's a 4x reduction. The model that used to require 80GB of GPU memory now requires 20GB. That means you can run it on cheaper, smaller GPUs, and you can serve more requests in parallel on the same hardware.
Then there's pruning, which means removing weights that don't contribute much to the model's predictions. Some weights in a neural network contribute 90% of the useful computation, while others are nearly redundant. By removing the redundant weights, you can speed up computation by 30-50% with minimal accuracy loss. The technique is like removing dead code from a software program.
There's also speculative decoding, which is where SGLang innovates. The idea is that when the model is generating output, sometimes you can predict what it's going to generate next without running the full model. You use a smaller, faster model to predict the next token. If you're right, you skip running the large model for that step. If you're wrong, you run the large model anyway and correct course. This technique can reduce latency by 30-40% on tasks where the output is somewhat predictable.
There's continuous batching, which means you don't wait for a batch to fill up before processing. Instead, you process requests as they arrive and continuously pack them into batches on GPU. This reduces latency for individual requests while still maintaining high throughput. It's like a supermarket checkout where cashiers process customers as they arrive instead of waiting for a line of exactly 10 customers.
Finally, there's kernel optimization, which means writing custom GPU kernels for specific operations that the model frequently performs. By-products like Flash Attention optimize the attention mechanism, which is often a bottleneck in transformer models. These specialized kernels can improve performance by 2x or more.
What SGLang and Radix Ark are doing is combining these techniques intelligently. They're building a framework that knows how to apply the right optimization for the right workload. For a task that requires accuracy above all else, they might go light on quantization but heavy on batching. For a task that requires speed, they might go heavy on quantization and speculative decoding.
The Business Model: How Radix Ark Actually Makes Money
Here's something interesting: Radix Ark's business model is still emerging. They've been announced as a company for only a few months. The core funding round closed recently. The business strategy is probably still being refined. But based on what's known, there are several revenue streams the company can pursue.
First, managed hosting. Companies that want to run SGLang but don't want to manage infrastructure can use Radix Ark's hosted service. They pay per inference request or per month. This is the Saa S model that works for companies at every scale. Even fortune 500 companies with enormous engineering teams often choose to outsource inference hosting because operational headaches aren't worth the minor cost savings.
Second, on-premise consulting and support. Some companies need to run inference on their own infrastructure for regulatory or security reasons. Radix Ark can help them set up, optimize, and maintain their SGLang installations. This is a high-margin professional services business that scales with their reputation.
Third, Miles premium features. While the core inference optimization is open-source and free, the reinforcement learning framework might include premium features that companies pay for. Think: advanced scheduling, hardware-specific optimization, custom model architectures.
Fourth, enterprise support contracts. Large companies that depend on SGLang for critical workloads will pay for priority support, SLA guarantees, and direct access to engineers who maintain the technology.
The revenue model for infrastructure companies like this typically breaks down as: 20% from open-source ecosystem and community (indirect value generation), 30% from hosting and managed services, 30% from enterprise support and professional services, 20% from premium features and proprietary tools.
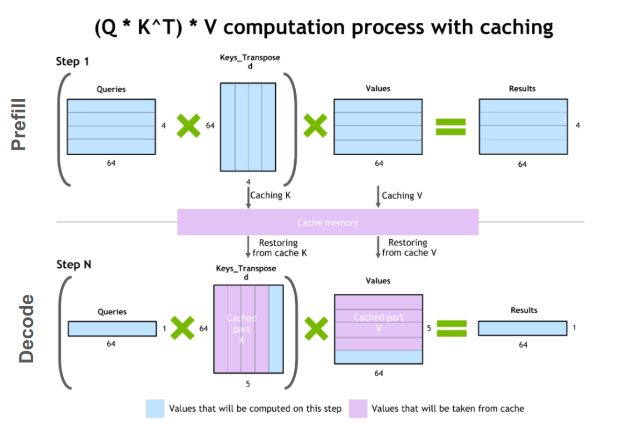
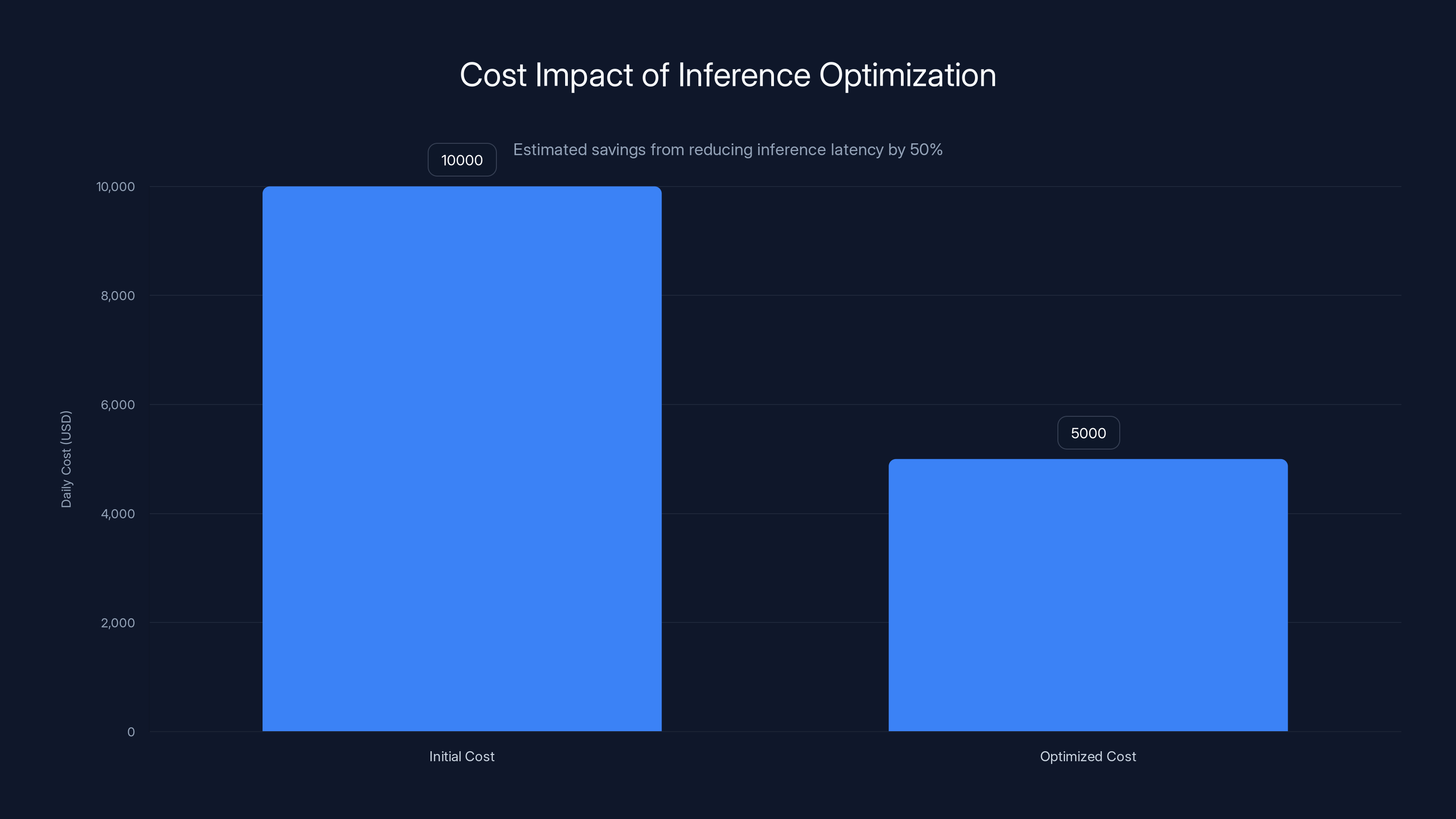
Reducing inference latency by 50% can lead to a 50% reduction in daily compute costs, saving $1.8 million annually. Estimated data.
Competitive Dynamics: Radix Ark vs v LLM vs Everyone Else
The inference optimization space is shaping up to be a four-player market, at least for the next couple of years. You've got Radix Ark pushing SGLang. You've got v LLM with its slightly older but more mature approach. You've got Baseten and Fireworks AI positioning as turnkey inference platforms that abstract away the complexity of choosing between different optimization techniques.
These aren't perfectly overlapping competitors. They're occupying different niches. Radix Ark and v LLM are closer to the bottom of the stack, giving engineers fine-grained control over inference optimization. Baseten and Fireworks are higher level, targeting companies that want to say "run this model efficiently" without needing to understand the optimization tricks.
In the short term (next 12-24 months), the competition will play out as a battle for mindshare among engineering teams. Which tool do engineers hear about first? Which tool do they try? Which tool do they advocate for internally? This is where SGLang's existing popularity and the team's credibility matters.
In the medium term (2-3 years), consolidation is possible. A larger infrastructure company like Lambda Labs, Crusoe Energy, or even a cloud provider like AWS or Google Cloud might acquire one or more of these companies. This would give them vertically integrated control over the AI inference stack.
In the long term, the successful company will be the one that stays closest to the frontier of what's possible. Optimization techniques are improving constantly. Inference is getting faster through hardware improvements and algorithmic innovations. The company that keeps up with this frontier and helps customers implement the latest techniques will be the one that survives.
The Role of Open Source in Creating Defensibility
One thing that confuses people about open-source companies is how they maintain defensibility when anyone can use the code for free. The answer is that open-source creates defensibility through several mechanisms that proprietary software cannot match.
First, the community itself becomes a moat. If thousands of engineers contribute to SGLang, improve it, and maintain it, the project becomes more powerful than any single company could make it alone. Companies trying to build a proprietary closed-source alternative would need to hire all those engineers themselves or convince them to switch. This becomes practically impossible once network effects take hold.
Second, the managed service becomes defensible. Yes, companies could run SGLang themselves. But just like how companies use Heroku for Postgres even though Postgres is open-source, companies will use Radix Ark's managed service for convenience, reliability, and support. The open-source project isn't a liability; it's a customer acquisition channel.
Third, the data becomes valuable. As companies use Radix Ark's managed service, Radix Ark collects data about which optimizations work best for different workloads, different hardware, different models. This data can be leveraged to improve the product continuously. A company running SGLang in isolation doesn't have this advantage.
Fourth, the talent concentration becomes defensible. The best engineers working on inference optimization get attracted to the company that has both the open-source project and the resources to push the frontier further. Once a company gets a few top engineers, it becomes the place where the next top engineers want to work. This feedback loop creates sustainable competitive advantage.
This is different from traditional software, where keeping the source code proprietary provides defensive moat. For infrastructure software, making the source code open actually strengthens the company's position.
What This Means for Companies Using AI
If you're a company deploying AI models in production, Radix Ark's emergence and funding should change how you think about your infrastructure. For the past few years, the options were: use API providers like Open AI and pay per token, or build your own inference infrastructure and maintain it yourself. Neither option was ideal.
Now there's a middle ground. You can use open-source tools like SGLang to build efficient inference on your own infrastructure, or you can use managed services from Radix Ark to outsource the whole thing. This middle ground is where the smart companies are going to live.
The calculation is straightforward. If your inference costs are significant (and for most companies using AI in production, they are), you should be evaluating inference optimization tools. The cost of integrating a tool like SGLang is measured in weeks of engineering time. The payback comes in months of reduced infrastructure costs.
For a company with
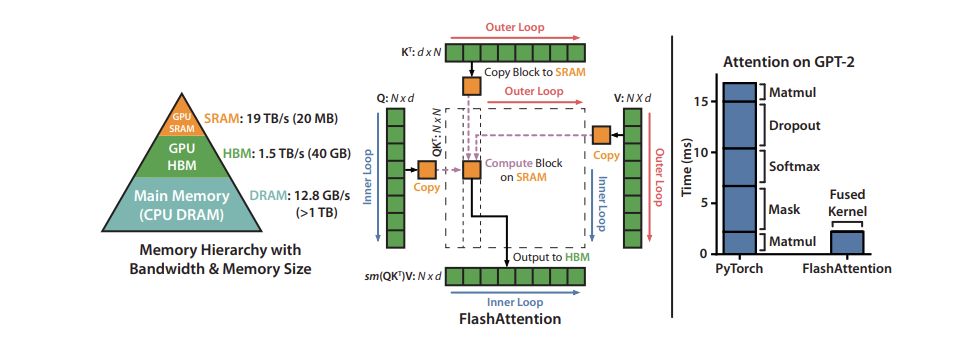
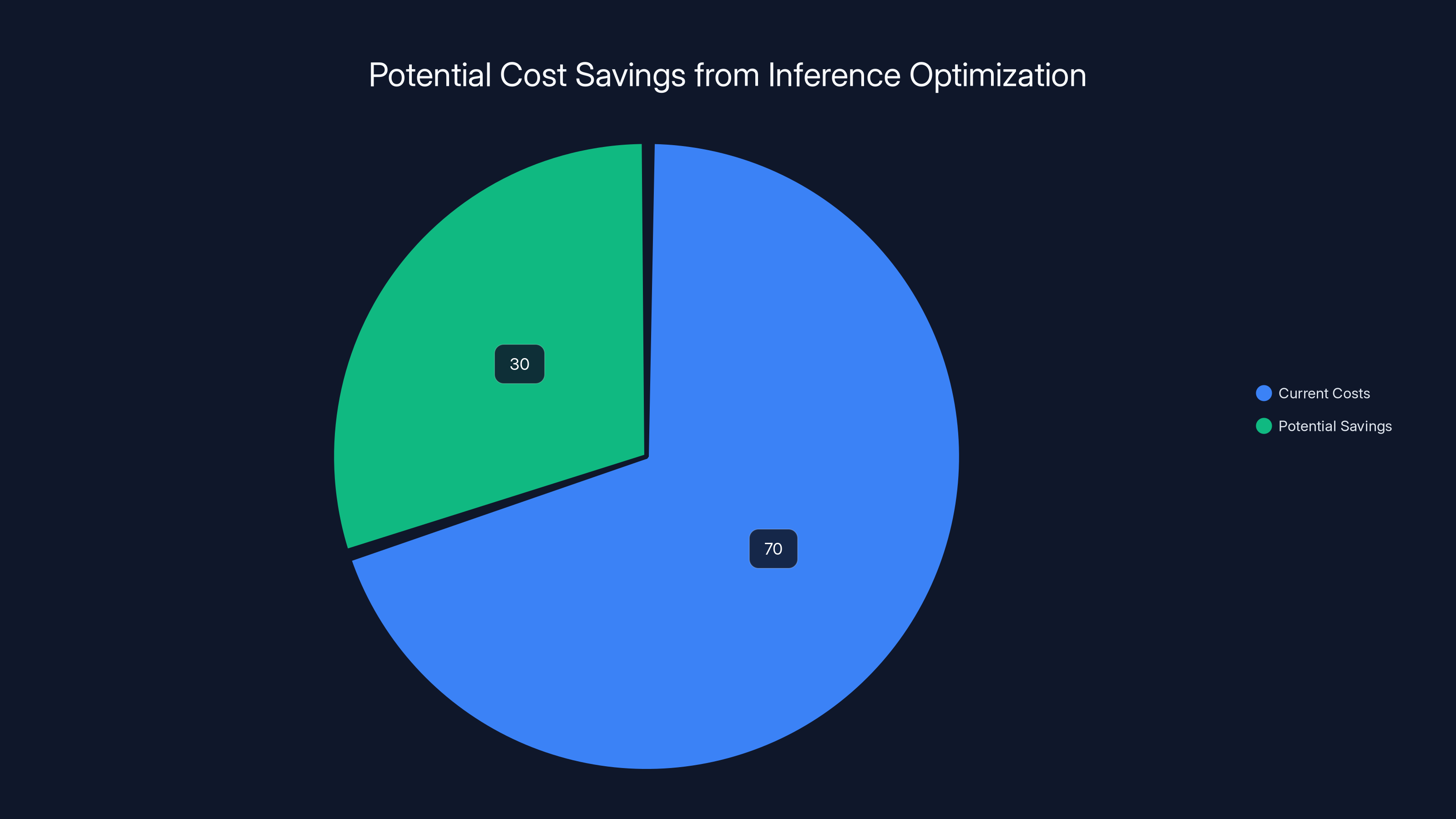
Optimizing the inference layer can potentially reduce AI infrastructure costs by up to 30%, offering significant savings for companies. Estimated data.
The Broader Trend: Infrastructure Becoming the Bottleneck
What's happening with Radix Ark and the inference optimization space is part of a bigger shift in the AI industry. For the past two years, the conversation was all about model capability. Which model is better? Which model can solve harder problems? GPT-4 vs Claude vs Gemini.
That conversation is still happening, but it's increasingly beside the point for companies actually deploying AI. A model that's 10% better but costs 100% more is worse for business. A model that's 20% less powerful but costs 70% less might be the better choice.
This has happened before in software. In the 1990s and 2000s, everyone was obsessed with CPU performance. Companies competed on raw computational power. Then infrastructure and algorithms improved to the point that raw performance stopped being the limiting factor. What mattered became efficiency, reliability, and cost.
AI is moving through the same transition. Raw model capability is no longer the constraint for most applications. The constraint is now "how do I deploy this profitably?" This is why tools that answer that question are raising massive funding rounds.
Over the next 3-5 years, expect to see the AI industry segment into two camps. There will be frontier companies pushing the boundaries of what models can do. And there will be a much larger set of companies trying to deploy existing models efficiently. The efficiency companies will grow faster and be worth more because they're solving for the 99% of use cases that don't require cutting-edge capability.
Radix Ark is betting on this transition. And based on the funding they've raised, so are their investors.
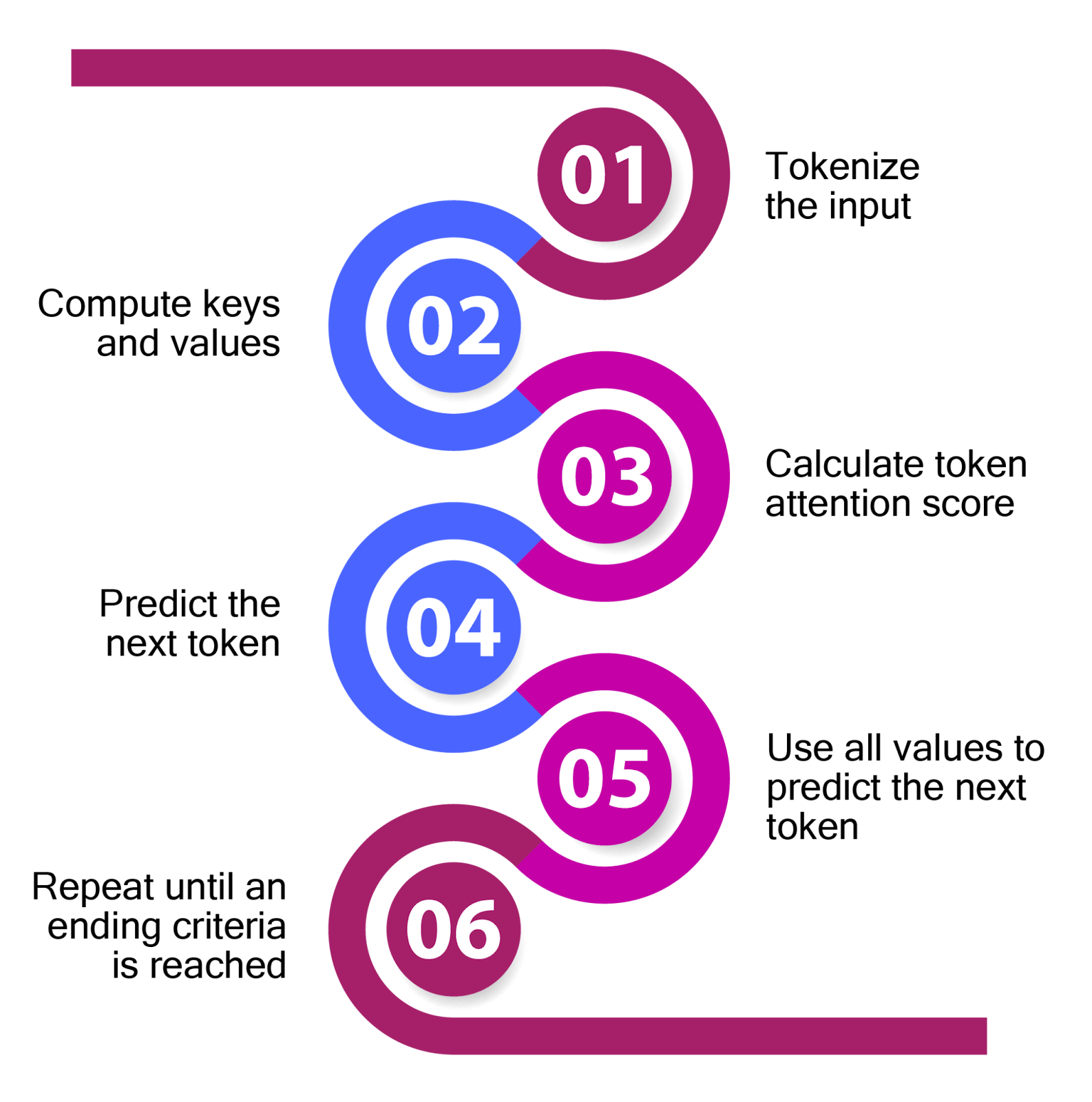
Technical Details: What Makes SGLang Different
If v LLM and SGLang are both inference optimization tools, what's actually different about SGLang? The answer lies in a technical architectural choice that might seem subtle but creates significant practical differences.
v LLM was designed around the principle of aggressive batching. It tries to pack as many requests as possible into each batch to maximize GPU utilization. This works great for workloads where latency isn't critical. For example, processing a batch of customer support responses overnight doesn't require low latency.
SGLang was designed with a different philosophy: optimize for specific structured patterns that language models frequently encounter. The name itself comes from "Structured Generation Language," which hints at the core insight. Many language model outputs follow predictable structures: JSON, key-value pairs, tables, and other formatted outputs. If you know the output will be JSON, you can optimize much more aggressively than if the output is freeform text.
This led to the development of techniques like structured decoding (constraining the model to only generate valid JSON) and speculative decoding (predicting what comes next before the model generates it). These techniques are more complex to implement than v LLM's batching approach, but they pay off in workloads where the structure of the output is known.
In practical terms, this means SGLang excels at structured tasks: AI-powered data extraction, code generation, API response generation. v LLM excels at throughput-critical tasks: batch processing of unstructured text, analysis of documents.
Companies will end up using both tools, just for different purposes. This is good news for Radix Ark because it means the market isn't zero-sum. It's expanding.
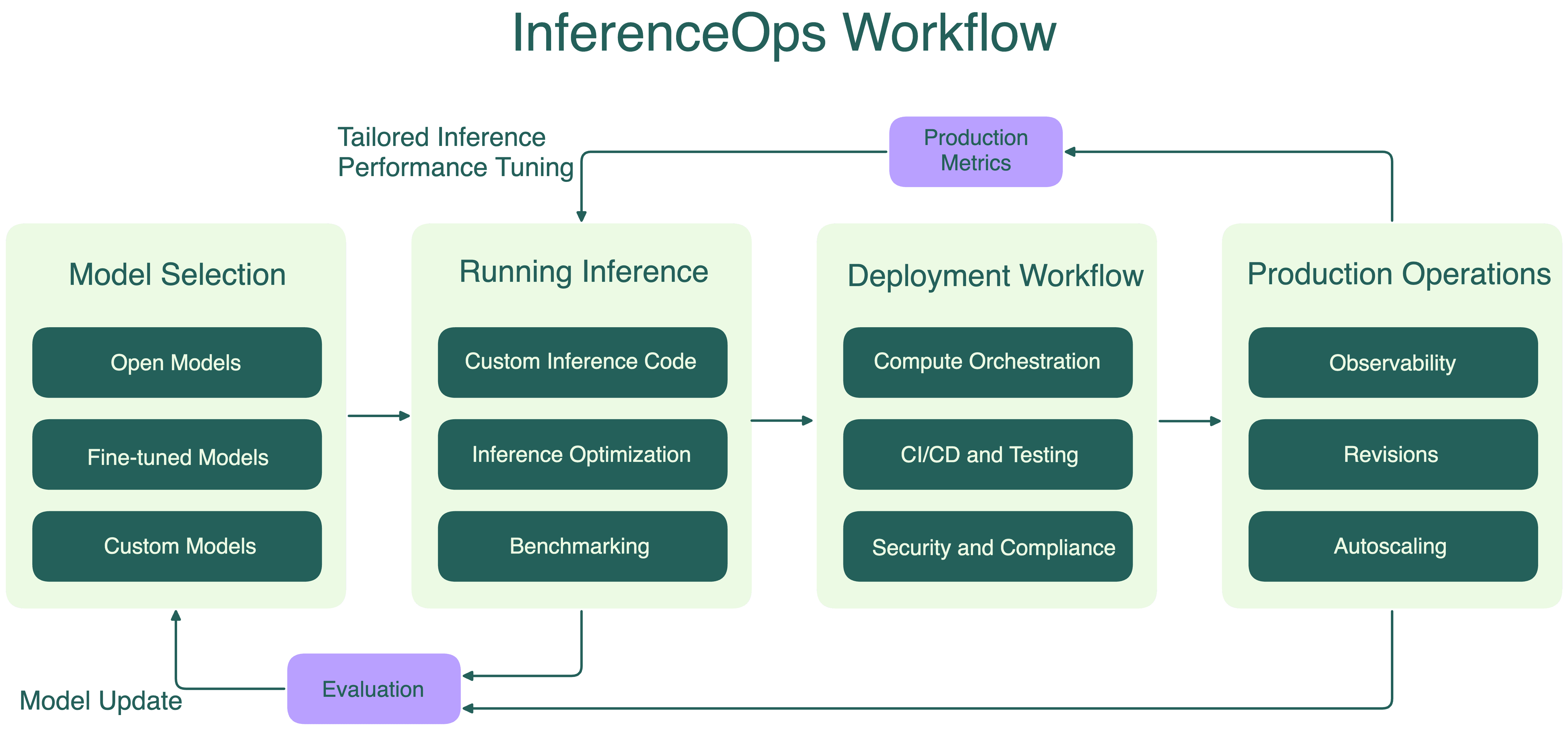
Future Roadmap: Where Inference Optimization Goes Next
If Radix Ark executes well, what's the next evolution of their technology? Based on trends in the field, several directions seem likely.
First, hardware specialization. Right now, inference optimization is mostly happening in software. As the field matures, companies will start building specialized hardware optimized for inference. Radix Ark could partner with hardware makers or eventually build its own silicon. This is the Tesla factory model: vertical integration to maximize efficiency.
Second, model-specific optimization. Today's tools optimize for generic transformers. Tomorrow's tools will include model-specific optimization for specific architectures. A tool that knows it's optimizing for GPT-3.5 style models can make assumptions that wouldn't work for multimodal models or mixture-of-experts models.
Third, distributed inference. As models get larger, running them on a single machine becomes impossible. Distributed inference across multiple machines introduces new optimization challenges: communication overhead, load balancing, fault tolerance. Tools that optimize for distributed inference will become critical.
Fourth, real-time adaptation. Inference optimization could become dynamic rather than static. The system could measure real-time performance metrics and adjust optimization strategy on the fly based on current hardware utilization, model load, and cost constraints.
Fifth, reinforcement learning integration. Radix Ark is already moving in this direction with Miles. As models become increasingly customizable through RL, the tools that help you train and serve RL-optimized models will become essential.
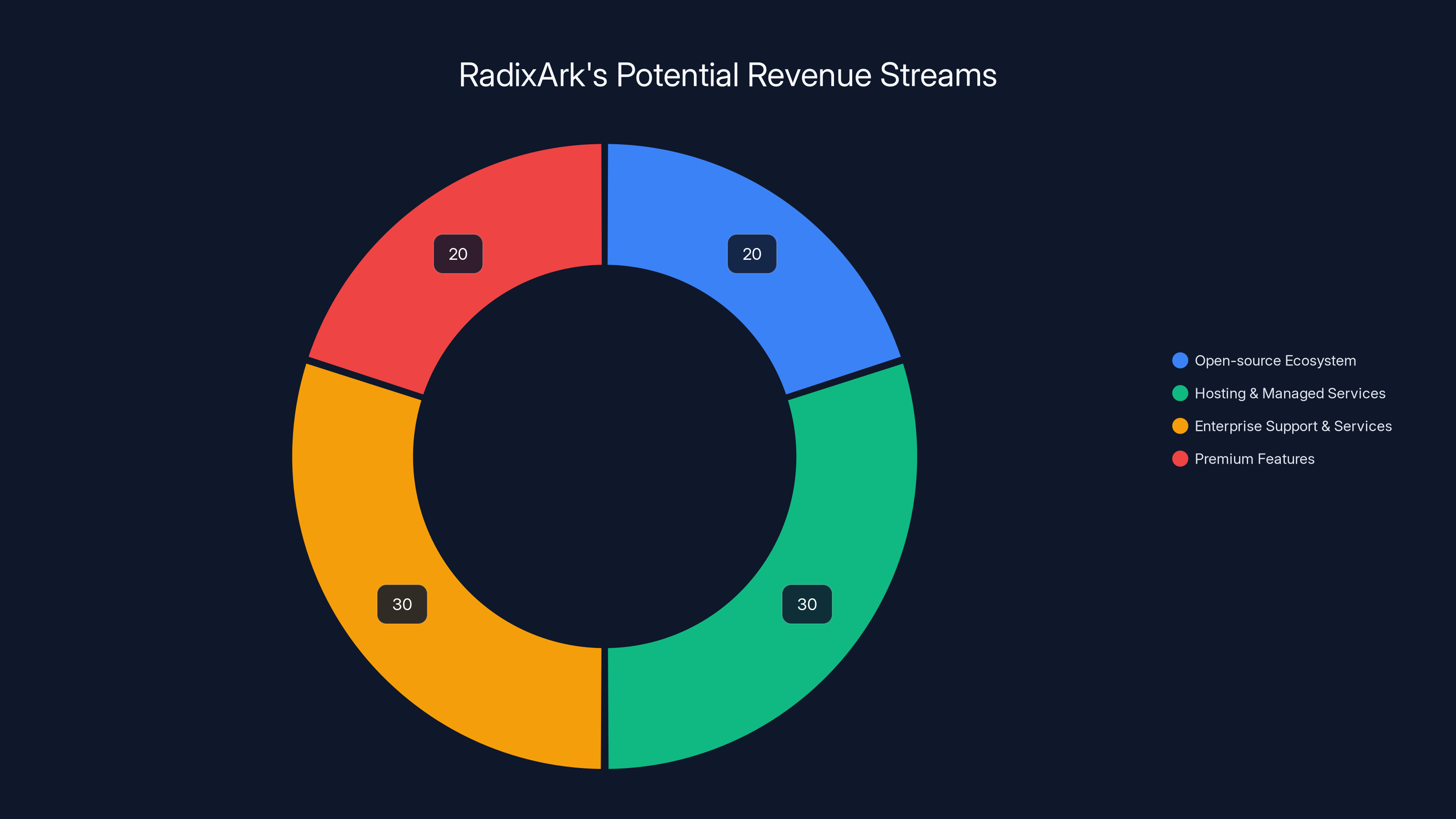
RadixArk's revenue model is projected to be 30% from hosting services, 30% from enterprise support, 20% from premium features, and 20% from open-source community contributions. Estimated data based on typical infrastructure company models.
The Venture Capital Angle: Why Investors Are Flooding This Space
From a venture capital perspective, the inference optimization space is attractive for specific reasons. First, it's a horizontal problem. Nearly every company building AI needs to solve inference cost at some point. This makes the market enormous and not dependent on any single use case succeeding.
Second, it's relatively capital efficient compared to training infrastructure. Building better training tools requires massive compute resources. Building better inference tools requires engineering skill and understanding of systems. The capital requirements are lower, which means higher potential return on investment.
Third, it's a metrics-driven business. You can directly measure the impact of inference optimization: reduced latency, reduced cost, increased throughput. This makes it easy to track whether a company's product is actually valuable. It's not like social apps where value is subjective.
Fourth, the market is expanding rapidly. As more companies deploy AI in production, inference costs balloon. This creates an expanding market where new entrants can find customers even if incumbents exist.
Fifth, open-source creates acquisition risk. Companies like Google, Microsoft, Meta, and Amazon can look at successful open-source projects and either acquire them or build on top of them. If Radix Ark proves out the market, a larger tech company might acquire them for talent, user base, and technology. This exit path provides venture returns without requiring the company to become profitable.
Practical Implementation: How to Actually Use These Tools
If you're considering implementing inference optimization at your company, here's what the actual process looks like. First, you measure. You need a baseline of your current inference metrics: latency, throughput, cost per token, GPU utilization. Without this baseline, you can't tell if optimization is working.
Second, you profile. You identify which parts of your inference pipeline consume the most time and resources. Is it the model computation itself? Is it data loading? Is it tokenization? Different bottlenecks require different optimizations.
Third, you test incrementally. You don't switch your entire production inference pipeline to a new tool overnight. You set up a staging environment with the new tool. You compare performance against your baseline. You find the sweet spot between optimization aggressiveness and accuracy loss.
Fourth, you integrate gradually. You route a small percentage of production traffic to the optimized version. You monitor for any issues. As confidence builds, you increase the traffic percentage until the entire production pipeline uses the optimized version.
Fifth, you maintain and monitor. Inference optimization isn't a one-time change. As you add new models, as hardware changes, as traffic patterns evolve, the optimal optimization strategy changes. This requires ongoing attention and iteration.
Emerging Winners and Losers: The Inference Optimization Ecosystem
If you're tracking the companies in this space, Radix Ark's $400 million valuation should tell you something: the inference optimization market is real and worth competing for. But not all companies will win.
Winners will be companies that can do one of these things: provide tools that save companies more money than the cost of integration, scale to thousands or millions of customers, build network effects that make the product more valuable as more people use it, or offer something truly novel that competitors can't easily copy.
Losers will be companies that optimize for one specific use case too narrowly, companies that require customers to rewrite code to use their product, companies that depend on open-source and can't build commercial moats, or companies that raise too much capital too quickly and develop unrealistic burn rates.
Radix Ark is positioned as a winner because: they're solving a real financial problem that scales across industries, the team has credibility and operating experience, they're building on top of already-proven open-source software, and they have clear revenue opportunities through managed services and premium features.

The Regulatory and Industry Impact
One thing nobody talks about is how inference optimization affects the broader AI regulatory landscape. As companies optimize inference costs down, more companies can afford to run AI models in production. This democratizes AI capability but it also means more AI systems in production without proper governance structures.
Regulators are going to be watching companies that optimize inference to the point that accuracy suffers. If a company quantizes a medical AI model so aggressively that accuracy drops from 99% to 95%, that creates liability issues. The companies that succeed will be the ones that help customers optimize responsibly, providing tools to measure accuracy degradation alongside performance gains.
This creates an opportunity for companies to build governance tools on top of inference optimization. Tools that measure fairness, bias, and accuracy degradation become essential companions to tools that optimize latency and cost.

Conclusion: The Inference Layer is the New Battleground
Radix Ark's $400 million valuation signals something important: the venture capital market has decided that inference optimization is going to be a massive market. This isn't hype. This is capital allocation based on a real problem that hundreds of companies are paying to solve.
SGLang to Radix Ark is a case study in how modern infrastructure companies scale: start with a research project, open-source the core, build credibility through adoption, then create a company to commercialize it. The team executing this transition has the right experience, the market is ready, and the capital is available.
For companies deploying AI models, this is good news. More competition in inference optimization means better tools, lower prices, and faster innovation. The days of accepting massive inference bills because there was no alternative are over.
For venture investors, the inference space represents one of the most attractive infrastructure bets available. Large market, expanding rapidly, clear metrics for success, and multiple pathways to outsized returns.
For the broader AI industry, the rise of companies like Radix Ark means the frontier is moving. It's no longer just about building bigger, better models. It's about making those models actually practical to deploy in the real world. This is how technology matures: first capability, then efficiency.
Radix Ark is betting that you'll choose efficiency. And based on the market dynamics, most companies eventually will.
FAQ
What exactly is inference in AI models?
Inference is the process of using a trained AI model to generate predictions or responses based on input data. When you ask Chat GPT a question, that's inference: the model has already been trained (that happened once on expensive hardware), now it's applying what it learned to your specific input. For most AI companies, inference happens millions of times per day and represents the bulk of operational costs.
How does SGLang optimize inference differently than v LLM?
SGLang is specifically designed around structured generation, meaning outputs that follow predictable patterns like JSON or formatted data. It uses techniques like structured decoding to constrain outputs and speculative decoding to predict what the model will generate next. v LLM uses aggressive batching to maximize GPU utilization. Neither is universally better; they're optimized for different workload patterns. SGLang excels at structured tasks, v LLM at high-throughput batch processing.
Why would a company choose Radix Ark's managed service over running SGLang themselves?
Managed services eliminate operational overhead. Companies don't need to hire infrastructure engineers, manage deployments, handle scaling, or maintain hardware. They pay per inference request or monthly. For most companies, the convenience and reliability are worth the premium cost. It's the same reason companies use Heroku for Postgres instead of managing Postgres themselves, even though Postgres is free open-source software.
What does the $400 million valuation actually mean for Radix Ark?
The valuation reflects investor confidence in the company's future value. With Accel and Intel's CEO backing the company, they've signaled that the inference optimization market is large enough to support a multi-billion-dollar company. The
How much money can companies actually save using inference optimization?
The savings depend on your current setup and workload, but range from 30-60% of total inference costs. For a company spending
Is open-source still a defensible business model in 2025?
Yes, but not in the way proprietary software companies think. Open-source is defensible through managed services (customers pay for convenience and support), network effects (community contributions improve the product), talent attraction (best engineers want to work on important open-source projects), and data advantages (companies providing managed services collect usage data they can use to improve the product). Radix Ark's strategy of open-source core plus premium services is a proven playbook.
What's the relationship between inference optimization and AI model quality?
Inference optimization and model quality are different dimensions. Optimization makes models run faster and cheaper on the same hardware, but doesn't improve the quality of the model's predictions. You can optimize a bad model to run very fast (bad + fast = bad). The best approach is to have both good models and well-optimized inference. For most companies, optimizing inference is low-hanging fruit that delivers immediate value without requiring retraining better models.

Key Takeaways
- RadixArk's $400M valuation signals the inference optimization market has become a major infrastructure category attracting top-tier venture capital
- Inference optimization saves companies 30-60% on AI operational costs, making it a financially compelling infrastructure decision
- SGLang and vLLM both optimize inference but use different approaches—batching vs structured generation—allowing both to coexist
- Ion Stoica's track record (Databricks, Apache Spark) suggests RadixArk could become another multi-billion-dollar infrastructure company
- Open-source-first model plus managed services is proving to be the defensible business strategy for infrastructure companies in 2025
Related Articles
- OpenAI's 2026 'Practical Adoption' Strategy: Closing the AI Gap [2025]
- DeepSeek Engram: Revolutionary AI Memory Optimization Explained
- Why CEOs Are Spending More on AI But Seeing No Returns [2025]
- Physical AI: The $90M Ethernovia Bet Reshaping Robotics [2025]
- Humans&: The $480M AI Startup Redefining Human-Centric AI [2025]
- 55 US AI Startups That Raised $100M+ in 2025: Complete Analysis

