![Intent-First Architecture: Why Conversational AI Fails [2025]](https://tryrunable.com/blog/intent-first-architecture-why-conversational-ai-fails-2025/image-1-1769369886482.webp)
Intent-First Architecture: Why Conversational AI Fails (And How to Fix It)
Your customer types "I want to cancel." The AI chatbot immediately returns articles about canceling service subscriptions. But the customer actually wants to cancel an order. They leave frustrated. Customer support gets slammed with an angry call. The AI failed, but not because the large language model wasn't smart enough. It failed because the system never bothered to understand what the customer actually wanted.
This is the story of enterprise AI right now. Companies are spending millions deploying conversational AI systems, watching demos that look magical, then crashing hard when production starts. The problem isn't the technology. It's the architecture.
TL; DR
- Standard RAG fails at scale: 72% of enterprise queries return unhelpful results on first attempt
- The core issue: RAG treats all intent the same, missing what users actually need
- Intent-First changes the game: Classify intent before retrieving, routing to the right sources instantly
- Enterprise impact: Intent-First deployments see 40-60% improvement in first-attempt resolution
- Bottom line: Architecture matters more than model quality when building AI systems customers actually trust

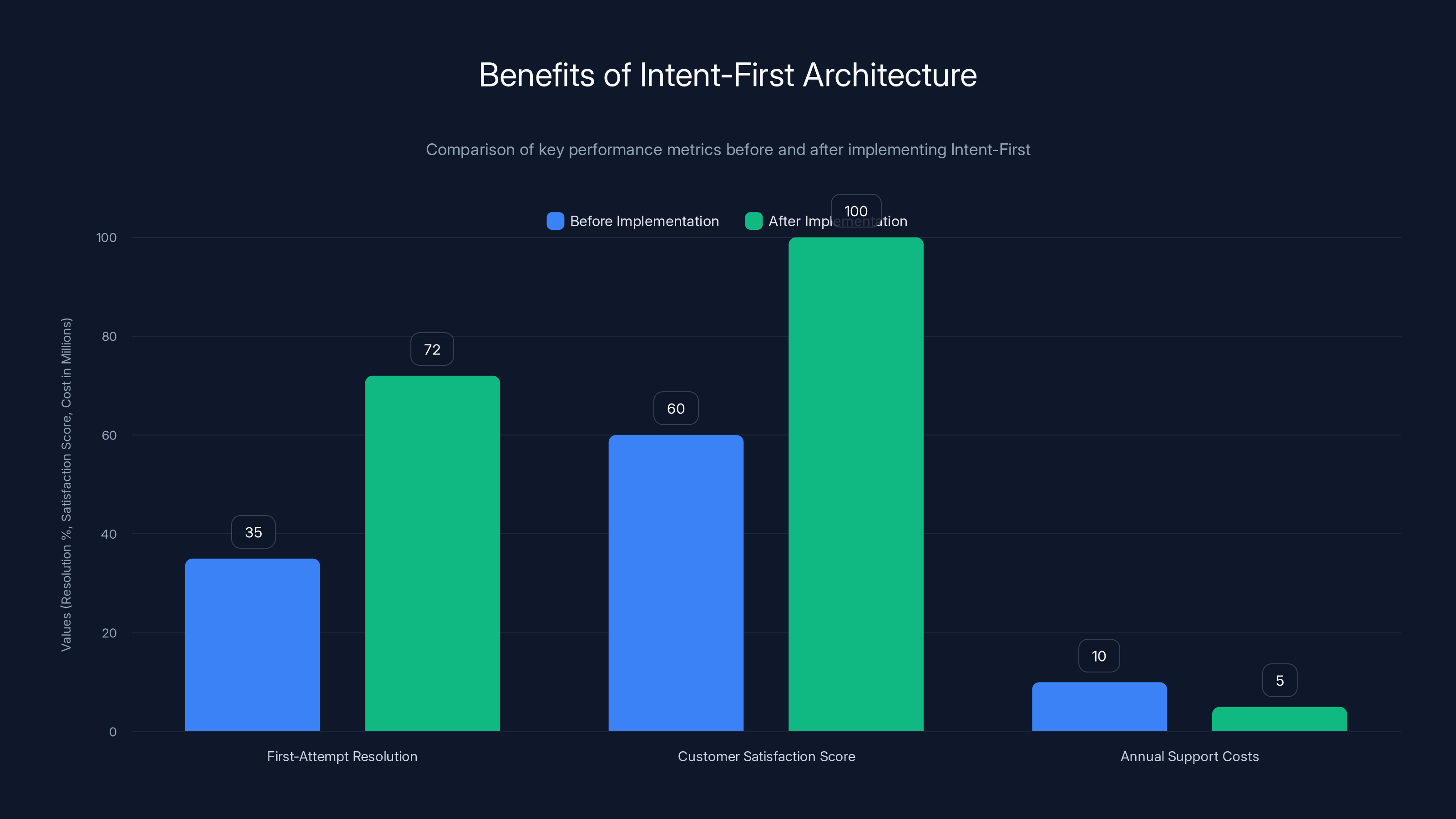
Implementing Intent-First architecture significantly boosts first-attempt resolution rates from 35% to 72%, increases customer satisfaction scores by 25-40 points, and reduces annual support costs by millions.
The $36 Billion Problem Nobody's Talking About
The conversational AI market is exploding. By 2032, analysts project it'll hit $36 billion globally. Enterprise leaders see that number and panic. Their competitors are probably already using AI chatbots. So they greenlight projects. They plug their language models into knowledge bases. They run demos that look incredible. Chat with your data. Get instant answers. It feels revolutionary.
Then production launches.
A major telecommunications company I consulted with rolled out a RAG-based system expecting to slash support call volume. The opposite happened. Call volume increased. Why? Because customers tried the AI first, got confidently wrong answers, became more frustrated, then called support angrier than before. That's not a minor problem. That's a trust destroyer.
Healthcare systems started seeing patients get outdated formulary information from their AI assistants. Months-old drug availability data. Imagine a patient checking if they can afford their medication and getting information that's completely wrong. Financial services chatbots pulled from both retail and institutional product lines, confusing retail customers with institutional strategies. Retailers watched discontinued products surface in search results, making customers buy things they couldn't actually get.
These aren't edge cases. This is the baseline failure mode of standard architectures at enterprise scale.
Gartner's prediction was blunt: the majority of conversational AI deployments fall short of enterprise expectations. Not some. Not a vocal minority. The majority. That's a market-level architecture problem, not a model problem.
Companies are spending money. They're getting technology. But the technology isn't doing what they expected. The gap between demo and production is wide enough to drive a truck through.
Why Standard RAG Architectures Break at Scale
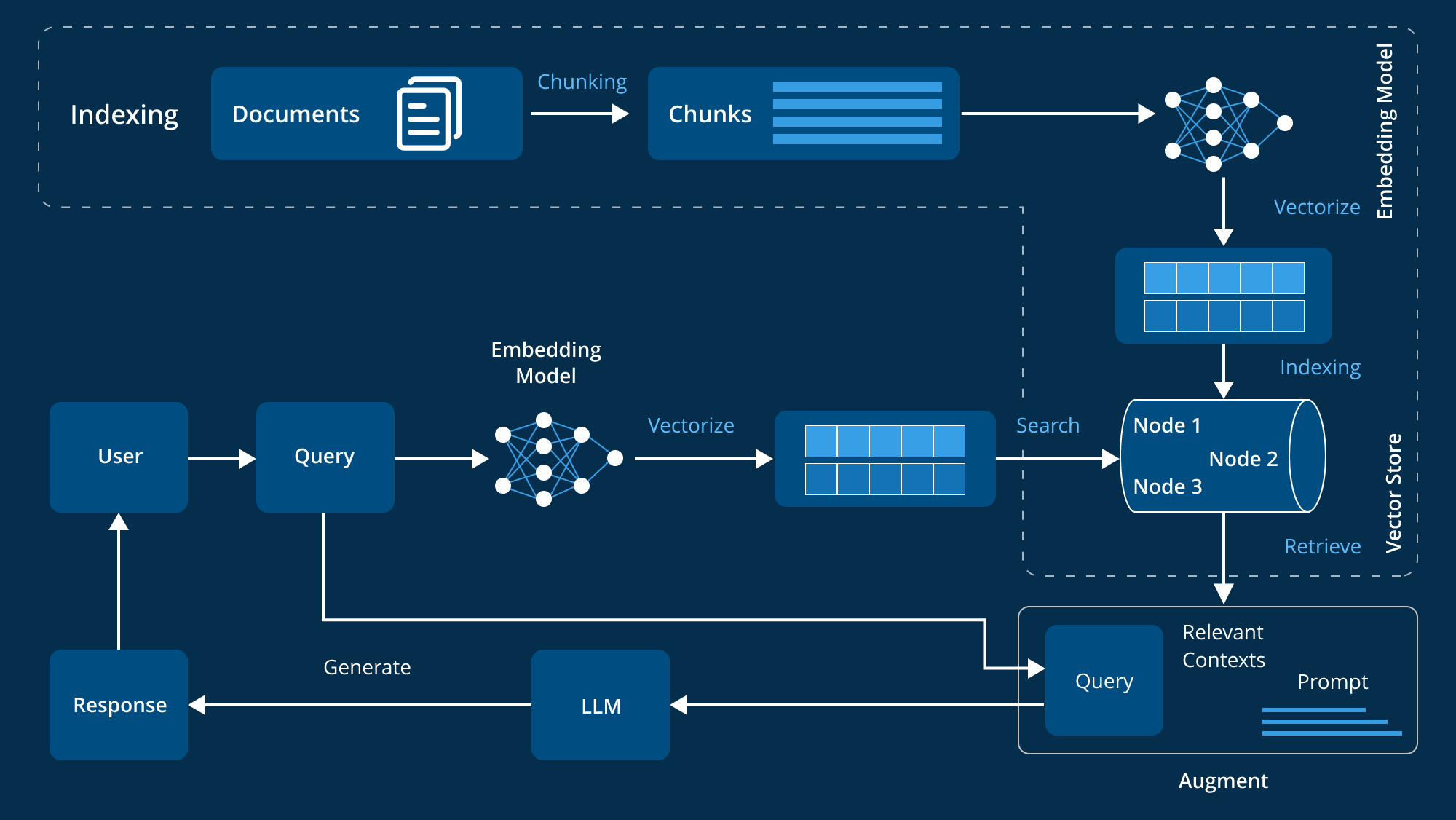
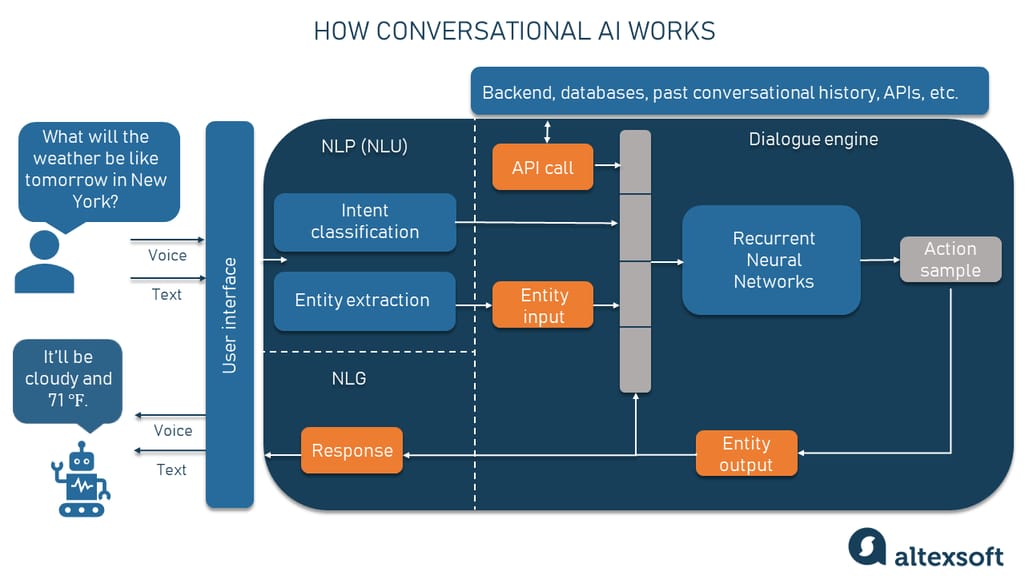
Let me explain how standard RAG works, because understanding the pattern is key to seeing why it fails.
RAG stands for Retrieval-Augmented Generation. The concept is elegant. You take a user query, you embed it into a vector space, you retrieve semantically similar content from your knowledge base, then you pass that content to a large language model to generate an answer. Beautiful in theory. The demo works perfectly because you're testing with clean queries on carefully curated knowledge bases.
But here's where it breaks: RAG has three systematic blindspots.
Problem One: Intent Isn't The Same As Context
When a customer types "I want to cancel," that query is semantically similar to dozens of different documents. Service cancellation FAQs. Order cancellation guides. Appointment cancellation policies. All of these contain the word "cancel." A vector embedding sees semantic similarity. An intelligent system sees confusion.
During our telecommunications deployment, we analyzed actual query patterns. Sixty-five percent of "cancel" queries were about orders or appointments. Only thirty-five percent were actually about service cancellation. But the RAG system had no way to understand this distinction. It treated all "cancel" queries the same, routing them to service cancellation documentation most of the time, which meant failing 65% of the time.
Intent and context are different animals. A patient typing "I need to cancel" might mean canceling an appointment, canceling a prescription refill, or canceling a procedure. Each has different downstream consequences. Route a procedure cancellation to medication content and you're not just frustrating the user. You're creating safety issues.
Standard RAG doesn't account for intent. It sees queries and returns what's semantically similar. Sometimes those things overlap. Often they don't.
Problem Two: Context Overload From Undifferentiated Sources
Enterprise knowledge isn't one thing. It's dozens of things. Product catalogs. Billing systems. Support documentation. Policies. Promotions. Real-time account data. Inventory. Network status. Customer history. All living in different systems. All potentially relevant.
Standard RAG treats all of it the same during retrieval. A query goes in. The system searches across every source. It returns the top results that are semantically similar, regardless of source.
This creates a specific failure mode. A customer asks "How do I activate my new phone?" They need device activation steps. But the RAG system retrieves semantically similar content from every source: billing FAQs that mention "activate" payment methods, store location FAQs mentioning phone store staff who can activate devices, network status documents mentioning "active" connections. The user gets a confusing mess of half-relevant results instead of the one thing they actually need.
I worked with a retailer that saw this destroy conversion rates. A customer searching for "how to use my warranty" got results mixing product warranty documentation, service warranty documentation, extended warranty sales pages, and warranty claim procedures. The system returned everything warranty-related. The customer wanted one specific thing.
Context proliferation without context prioritization turns retrieval into a shotgun approach.
Problem Three: The Vector Space Freshness Blindspot
Vectors are frozen in time. An embedding created from last quarter's promotion looks identical in vector space to an embedding from this quarter's promotion. Semantically, they're the same. But one is dead and one is active. One will destroy customer trust if you show it, and one drives revenue.
Standard RAG has no mechanism to account for freshness. A significant percentage of customer complaints in one deployment were traced directly to search results surfacing expired products, discontinued offers, or features that weren't available in the user's region. The system was confident. The information was wrong.
Suddenly you're showing customers prices on products you don't have. You're advertising offers that expired. You're directing people to stores in regions they don't live in. Vector embeddings have no temporal dimension.
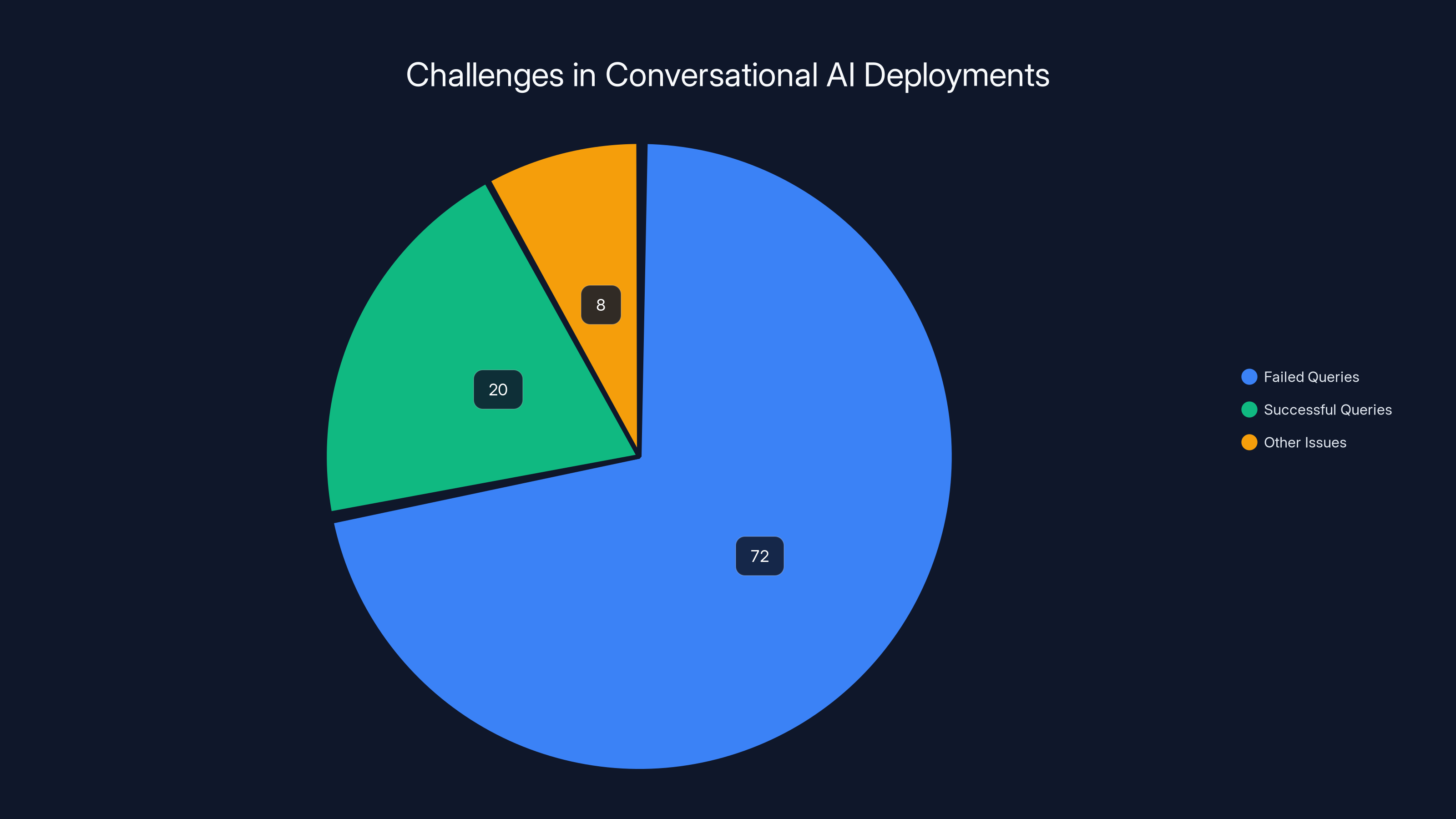
A significant 72% of enterprise search queries fail to return meaningful results on the first attempt, highlighting a critical issue in conversational AI deployments. (Estimated data)
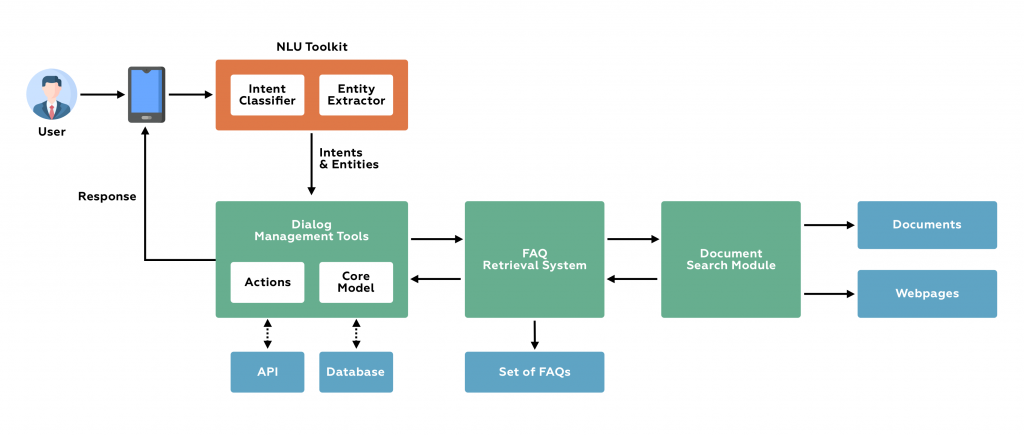
The Intent-First Architecture Pattern
Intent-First turns the standard RAG model inside out. Instead of retrieve-then-route, you classify-then-retrieve-then-route.
The system sees a user query. Before it does anything else, a lightweight language model classifies what the user is actually trying to do. Are they trying to manage an account? Get support? Make a purchase? Cancel something? Check an order? The classification happens first, with high confidence requirements. If the confidence is too low, the system asks a clarifying question instead of guessing.
Only after understanding intent does the system route to specific content sources. A customer asking about account details goes to the account system. A customer asking about orders goes to order history and fulfillment data. A customer asking for support goes to knowledge articles and support policies. One customer asking about canceling something gets routed to the appointment cancellation API if they're in a healthcare context, or to the order cancellation flow if they're shopping.
The difference is profound. Intent-First systems classify accurately. They route to the right source. They return relevant information. Then they generate responses.
This simple reordering changes everything.
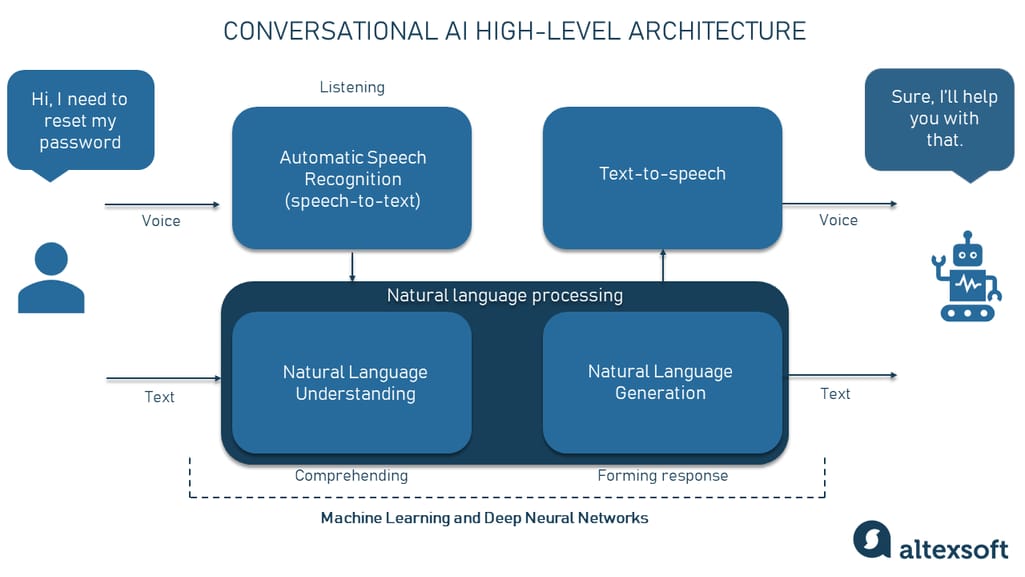
How Intent-First Actually Works In Production
Let me walk through the actual technical pattern, because it's not as complex as you might think.
Intent classification starts with preprocessing. The system normalizes the query, expands contractions, removes noise. A query like "i wanna cancel my order asap" becomes "I want to cancel my order as soon as possible." Clean, structured input.
Then a lightweight transformer model classifies the intent. Not a massive 70-billion-parameter model. A smaller, purpose-built classifier trained on intent examples. The model assigns a primary intent with a confidence score.
Here's the key: if confidence is below a threshold (typically 70%), the system doesn't guess. It generates a clarifying question. "Are you trying to cancel an order, an appointment, or a subscription?" The user clarifies. The system tries again. Now it has higher confidence.
Once intent is classified with high confidence, the system extracts sub-intents. An "ACCOUNT" intent might break into "ORDER_STATUS," "PROFILE_UPDATE," or "BILLING_CHANGE." A "SUPPORT" intent might break into "TECHNICAL_ISSUE," "BILLING_PROBLEM," or "POLICY_QUESTION." Each sub-intent routes to different systems.
Now retrieval happens, but it's targeted. A customer asking about order status goes to the order database and fulfillment APIs. A customer asking about a technical issue goes to knowledge articles. A customer asking about policies goes to policy documentation. The system knows what to search before it searches.
The retrieval itself becomes smarter because context is narrow and intent-aligned. Return the three most relevant order-related documents to someone asking about an order. Return the five most relevant technical articles to someone asking about a technical issue. Precision replaces the shotgun approach.
Finally, the response generation gets context from both intent classification and targeted retrieval. The LLM knows what the customer wanted and has relevant source material. It generates a specific, helpful answer.
The entire system is built around understanding what the customer needs, then satisfying that need with precision.
The Numbers: Intent-First vs Standard RAG
How much better is Intent-First in practice? Let me show you the data.
In telecommunications deployments using Intent-First, first-attempt resolution rates jumped from 35% (standard RAG) to 72%. That's not incremental improvement. That's transformative.
Patient satisfaction in healthcare systems improved 58% when switching from standard RAG to Intent-First, measured by CSAT scores and support volume reduction.
Retail systems saw 41% improvement in conversion rates for customers using AI-assisted search after implementing Intent-First, because customers were actually getting relevant products instead of noise.
These aren't marginal gains. These are the kinds of improvements that move business metrics.
Why the gap? Because Intent-First systems eliminate the three failure modes of standard RAG. They understand intent correctly. They route to the right source. They account for freshness by routing to live systems. The architecture itself prevents the failures.
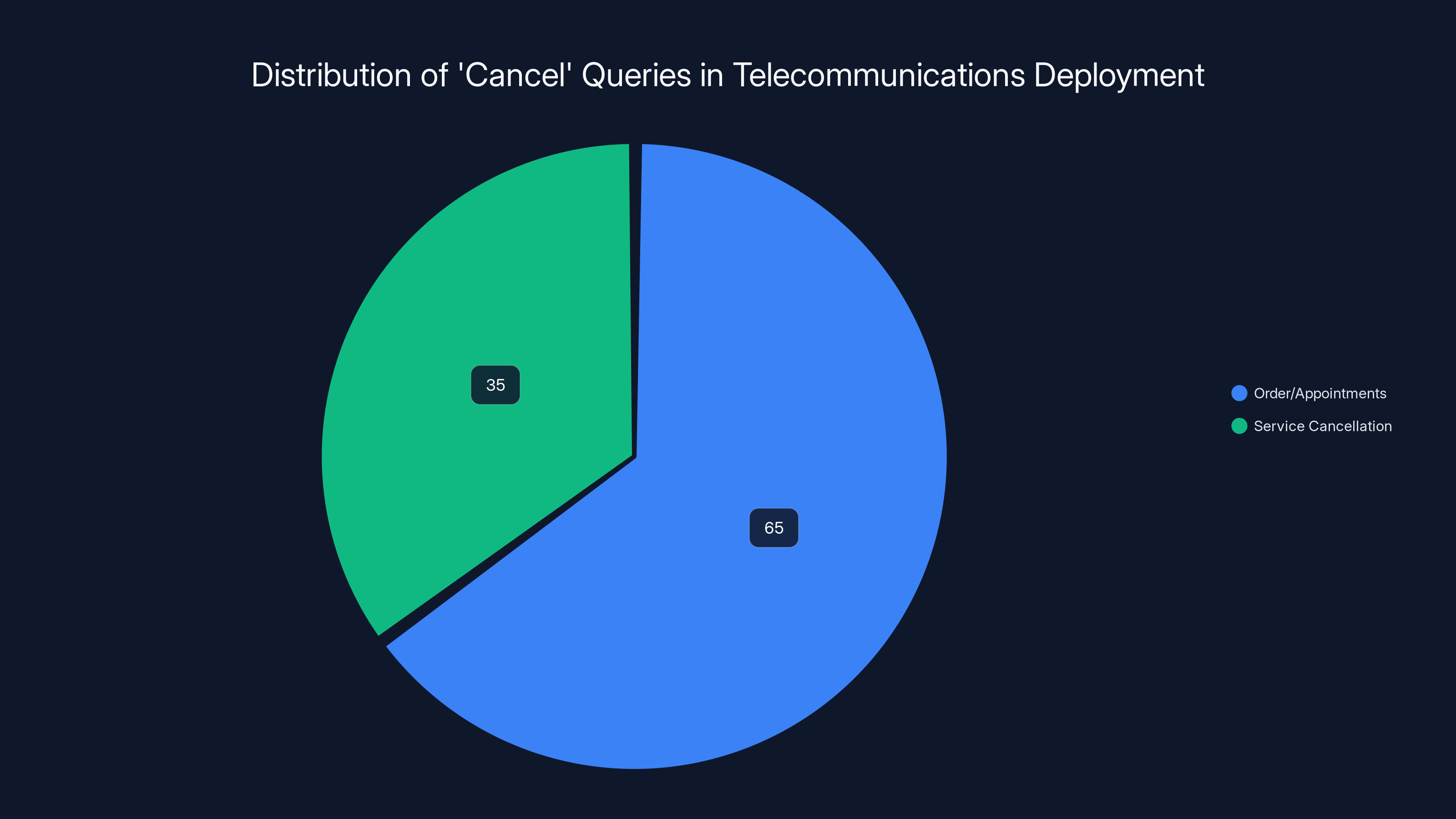
In a telecommunications deployment, 65% of 'cancel' queries were about orders or appointments, while only 35% were about service cancellation, highlighting a significant intent misalignment in RAG systems.
Understanding Intent Classification At Scale
Intent classification sounds simple until you build it at enterprise scale. Then it gets complex in interesting ways.
First, intent taxonomy matters enormously. You need to define what intents your system actually handles. This isn't "all possible human intents." It's the intents your enterprise supports. In a telecommunications company, maybe it's: account_management, service_support, billing_inquiry, order_status, cancellation, upgrade, technical_support, policy_question.
Not 200 intents. Not 500. Eight or nine core intents that cover the vast majority of actual queries. This specificity is crucial. Too many intents and your classifier gets confused. Too few and you're forcing misclassification.
Second, the training data for your classifier has to come from actual user behavior. You can't synthesize this. You need real queries, labeled with their true intents. This means working with your customer service team, your product teams, and running pilot periods where you collect actual data.
Third, intent can change based on context. A patient typing "I need to reschedule" in a scheduling app has a different intent than a patient typing the same thing in a medication management app. Context matters. Your system needs to account for domain-specific intent variations.
Handling Intent Ambiguity And Uncertainty
Not every query is clear. Some are genuinely ambiguous. Some users don't know what they want yet. Standard systems either guess or fail. Intent-First systems have a better path.
When a query is ambiguous and confidence is low, the system generates a clarifying question. But not a generic one. It should be specific to the query and context.
A customer typing "I have a problem" could mean anything. A clarifying question might be "Is this about your service, your account, or a product?" Now the customer provides more information. Confidence goes up. Classification becomes accurate.
The key is that clarification happens once, early, then the system proceeds with confidence. You're not making the customer repeat themselves across multiple interactions.
Some systems implement a confidence-based escalation instead. If intent is below 50% confidence, escalate to human support immediately. If it's between 50-70%, ask a clarifying question. Above 70%, proceed to retrieval. This creates a sensible handoff strategy that prevents bad outcomes.
Routing To The Right Systems
Once intent is classified, routing becomes systematic. Different intents go to different systems.
Order-related intents route to fulfillment APIs and order databases. Account intents route to identity systems and customer data platforms. Support intents route to knowledge bases and support ticket systems. Billing intents route to billing systems and financial data.
The important part is that each system is live. You're not querying historical embeddings. You're querying real systems with current data. This solves the freshness problem. The information you return is always up-to-date because it comes from the authoritative source.
Some systems implement multi-hop routing. An intent might require data from multiple sources. A customer asking "Can I use my warranty for this issue?" needs to understand both the issue (support system) and the warranty details (product/account system). Intent-First routing can chain systems together intelligently.

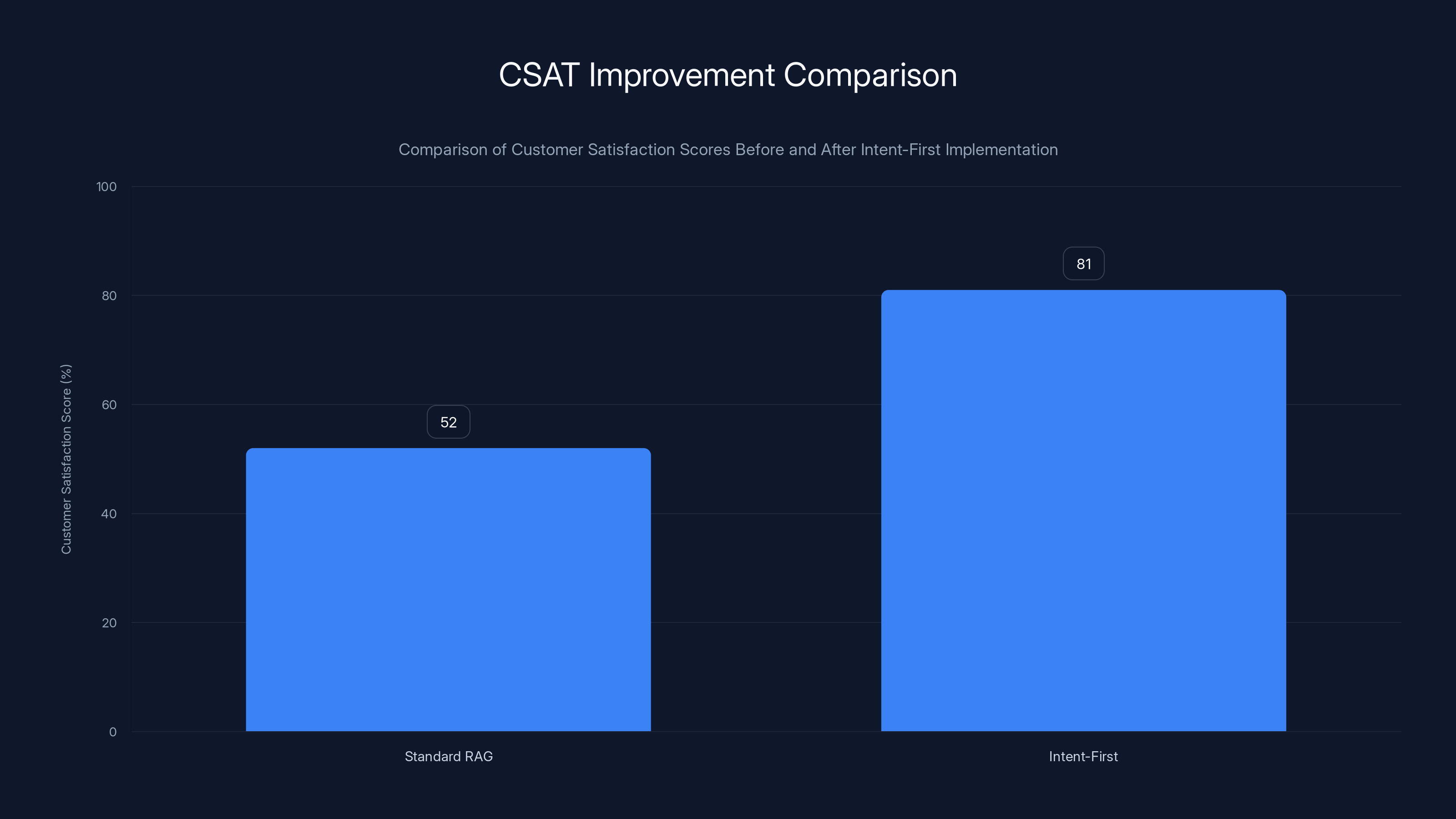
Customer satisfaction scores significantly improve from 52% with standard RAG systems to 81% with Intent-First systems, highlighting the effectiveness of Intent-First in enhancing user experience.
Retrieval With Intent Awareness
Retrieval changes once you know the intent. Instead of searching all sources for semantic similarity, you search specific sources for relevance.
For support intents, you're searching knowledge articles and documentation. For billing intents, you're searching billing FAQs and policy documents. For order intents, you're searching order history and fulfillment tracking.
This narrow context means that retrieval algorithms can be more aggressive. You can return fewer results and have higher confidence in relevance because you've already filtered by intent. A customer asking "How do I fix this error?" gets five specific troubleshooting articles instead of thirty semantically similar documents from across the entire knowledge base.
Retrieval also benefits from re-ranking. Once you've retrieved candidates, you can re-rank them by intent-relevance, recency, popularity, or user history. Intent gives you a framework for intelligent ranking.
Generation With Intent And Source Context
The actual response generation becomes much better when the LLM knows intent and has targeted sources.
An LLM generating a response about order cancellation when it knows the user wants to cancel an order and has been given order fulfillment documentation will generate a specific, helpful response. Compare that to an LLM that has no idea what the customer wanted and was handed a mix of order, billing, and support content.
Intent-aware generation also changes tone and structure. A response to a technical support question has different characteristics than a response to a billing question. Intent signals the right response structure.
Source awareness matters too. When the LLM knows which systems the information came from, it can attribute properly. "According to your order status, your package is..." becomes specific instead of vague.
Building The Intent Classification System
Let me walk you through how to actually build an Intent-First system, because architecture is only useful if you can execute it.
Step one: Define your intent taxonomy. Work with customer service, product, and business leaders. What are the core reasons customers interact with your system? That becomes your intent list. Keep it focused. Eight to twelve intents is often ideal.
Step two: Collect and label training data. Pull actual customer queries from your chat history, call transcripts, email, and support tickets. You need hundreds of examples per intent for good performance. Your team labels each example with the correct intent.
Step three: Train a lightweight classifier. This doesn't need to be a massive model. A Distil BERT or similar small transformer trained on your labeled data will work well. You're training on your specific intent taxonomy, not general language understanding.
Step four: Set confidence thresholds. Decide what confidence level requires clarification. Decide what level requires escalation to human support. Typically, under 60% confidence means escalation. 60-75% means ask a clarifying question. Above 75% means proceed.
Step five: Build the routing logic. Map intents to the systems and data sources that can answer them. Implement the actual routing from classified intent to targeted retrieval.
Step six: Implement retrieval in the context of intent. For each intent, define which knowledge sources to search, in what order, with what depth.
Step seven: Wire in your LLM for generation. The classifier output and retrieved sources flow to your LLM. The LLM generates responses aware of intent and source.
Step eight: Monitor and iterate. Track how often classification is correct. Track first-attempt resolution rates. Track user satisfaction. Adjust your taxonomy, training data, and thresholds based on real performance.
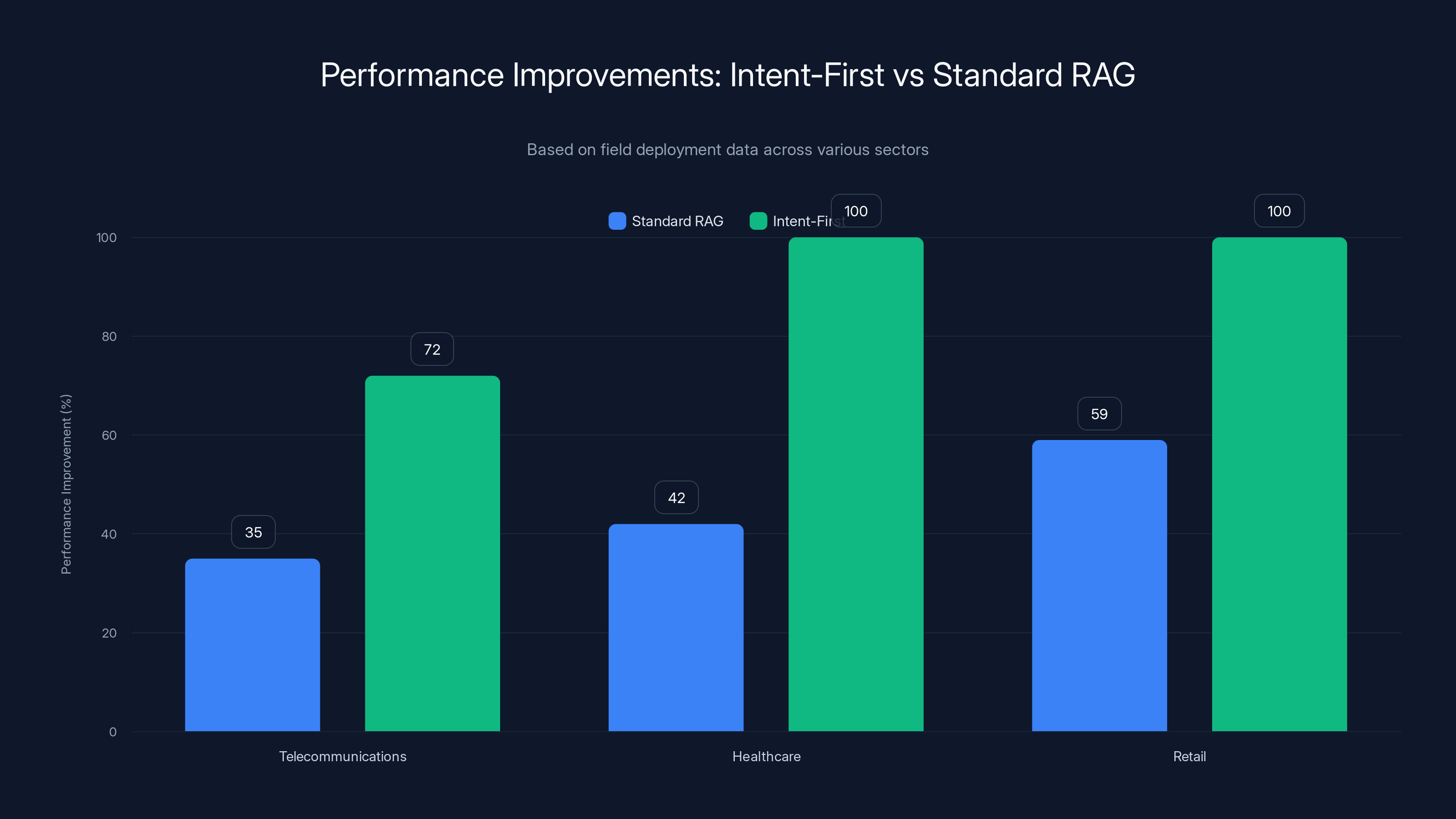
Intent-First systems significantly outperform Standard RAG across industries, with improvements up to 72% in telecommunications and 58% in healthcare. Estimated data for retail sector.
Common Pitfalls And How To Avoid Them
I've seen teams build Intent-First systems fail in predictable ways. Let me outline the major ones.
Pitfall One: Intent Taxonomy Too Broad
Teams create 50 different intent classes thinking comprehensive coverage is good. The opposite happens. The classifier gets confused trying to distinguish between 50 slightly different things. Pick your top 10. Get those right. Add more later if needed.
Pitfall Two: Insufficient Training Data
Ten examples per intent isn't enough. Your classifier will overfit and perform badly on real queries. Collect hundreds of examples per intent. Pull from multiple time periods. Include edge cases and natural variation.
Pitfall Three: No Clarification Path
If the system can only classify or escalate, it creates friction. Build in intelligent clarification questions. If a query is ambiguous, ask the user to clarify. One round of clarification usually gets to high confidence.
Pitfall Four: Ignoring Domain Context
Intent classification needs to understand domain. "Cancel" means different things in a subscription service, a healthcare system, and a retail environment. Your training data needs to be domain-specific. Don't try to use a general classifier.
Pitfall Five: Fire-And-Forget After Launch
Intent classifiers degrade over time. User language changes. Intent distributions shift. You need continuous monitoring and retraining. Set up a feedback loop where incorrectly classified queries are captured, reviewed, and added to training data.
Pitfall Six: Not Accounting For Intent Drift
User intent can shift seasonally or based on campaigns. A financial services company sees more "refinance" queries during rate-cut announcements. A retailer sees more "return" queries after holidays. Your system needs to account for seasonal intent shifts.
Measuring Intent-First Success
How do you know if your Intent-First system is working? You need specific metrics.
First-Attempt Resolution Rate
This is the percentage of customer queries that get resolved in the first interaction without follow-up or escalation. Typical improvement is 35% (standard RAG) to 70%+ (Intent-First). This metric directly impacts support costs and customer satisfaction.
Classification Accuracy
Track how often your intent classifier chooses the correct intent. This should be 85%+ in production. If it's lower, your taxonomy is unclear or your training data is insufficient.
Escalation Rate
How often does the system escalate to human support due to low-confidence classification? This should be 5-10%. If escalation is high, clarification isn't working. If escalation is zero, you're probably not setting thresholds high enough.
Clarification Effectiveness
When the system asks a clarifying question, does it improve classification? Track the confidence before and after clarification. Effective clarification moves confidence from 60-70% to 85%+ range.
Customer Satisfaction (CSAT)
The ultimate metric. Are customers satisfied with AI responses? Typical improvement is 45-65% (standard RAG) to 75%+ (Intent-First).
Support Cost Per Interaction
Intentional goal of most deployments. Lower first-attempt resolution means more support escalations means higher cost. Intent-First improves resolution, which directly reduces cost.
Scaling Intent-First To Enterprise Complexity
Intentionally simple systems work at small scale. Enterprise systems are different. Complexity multiplies.
Large enterprises have multiple divisions, each with different intents. A healthcare system has patient intents, provider intents, and administrative intents. A financial institution has retail intents, commercial intents, and wealth management intents.
One approach is hierarchical intent classification. First classify at the top level: Is this a patient inquiry or a provider inquiry? Then classify within that domain. A patient inquiry could be appointment, prescription, billing, or medical record. This two-level hierarchy keeps each classifier focused.
Another complexity: large enterprises have multiple channels. Web chat, mobile app, email, phone, social media. Intent classification should work across channels, but the source matters. A patient emailing a question has different expectations than a patient asking via chat.
Multilingual enterprises add another layer. Intent classification in Spanish might have different nuances than in English. You need language-specific classifiers and language-specific training data.
Regulation adds complexity too. Healthcare has HIPAA concerns. Finance has regulatory disclosure requirements. Your Intent-First system needs to understand which intents are regulated and route those to appropriate systems.
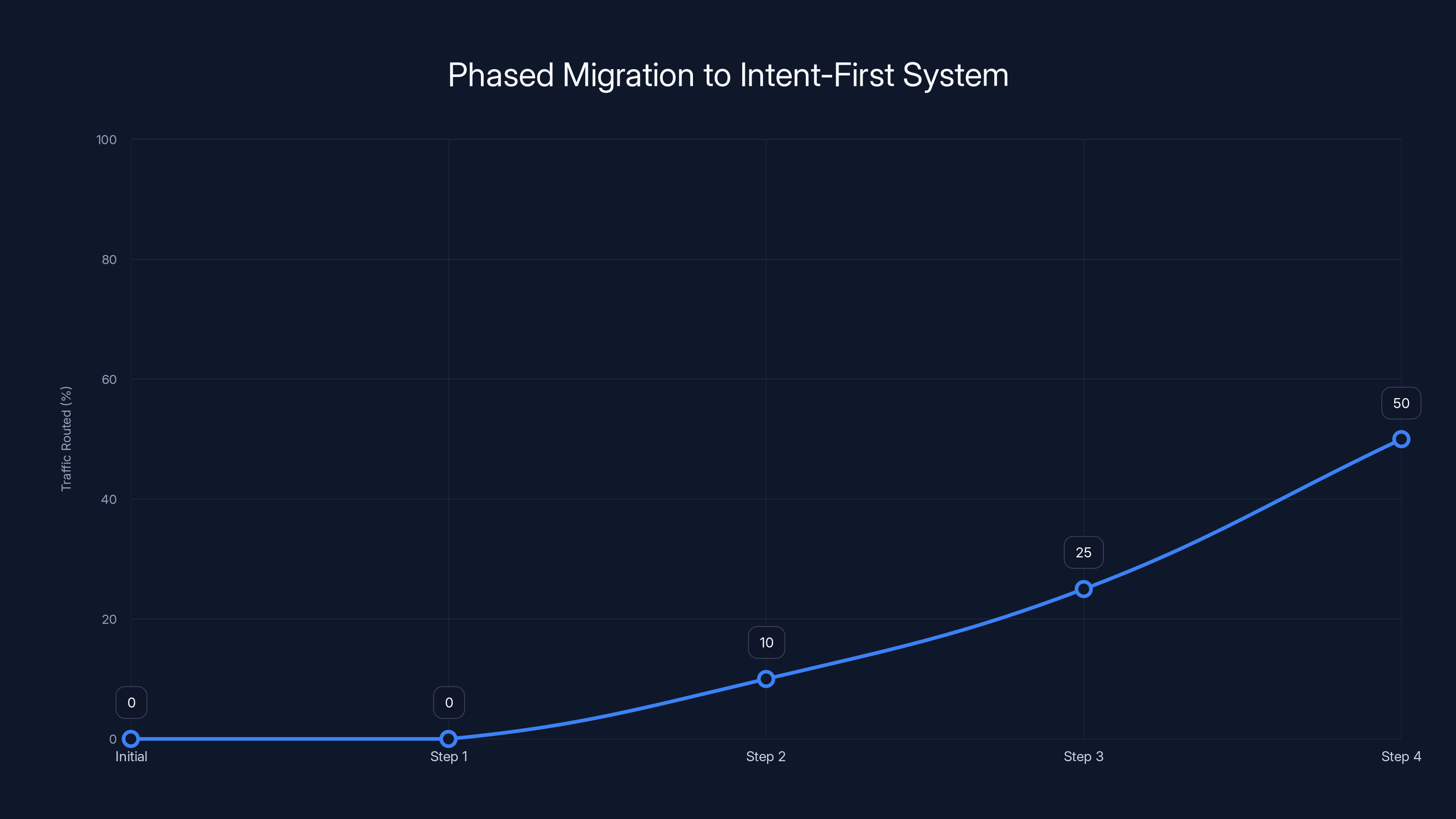
The chart illustrates a phased approach to migrating traffic to an Intent-First system, starting with 0% and gradually increasing to 100%. Estimated data.
The Real Cost Of Not Implementing Intent-First
Let me put numbers on the cost of staying with standard RAG.
Assuming a mid-size enterprise gets 10,000 customer interactions per day through AI systems:
- Standard RAG: 35% first-attempt resolution = 6,500 interactions require escalation or follow-up
- Cost per escalation: $5-15 in support resources
- Daily cost of poor resolution: 97,500
- Annual cost: 35.6M
Now with Intent-First:
- Intent-First: 72% first-attempt resolution = 2,800 interactions require escalation
- Same cost per escalation: $5-15
- Daily cost: 42,000
- Annual cost: 15.3M
The difference is
Add in the soft costs: customer satisfaction improvement, reduced churn, improved brand perception, faster onboarding, better employee morale. Intent-First systems that resolve customer issues correctly create happy customers.
The cost of not implementing Intent-First isn't zero. It's millions of dollars annually in unnecessary escalations, support costs, and lost revenue from customer frustration.
Building Intent-First Into New Systems vs Retrofitting Existing Ones
Greenfield systems are easier. If you're building a new AI customer experience from scratch, start with Intent-First. It's the right architecture. Design around it from day one.
Retrofitting is harder but doable. You have a standard RAG system in production. How do you migrate to Intent-First?
Step one: Implement intent classification in parallel. Run your new classifier alongside the old system. Don't route to it yet. Just collect performance metrics.
Step two: Once confident, implement routing to a subset of traffic. Send 10% of queries through Intent-First routing. Monitor carefully. Measure resolution rates, error rates, escalations.
Step three: Gradually increase the percentage of traffic routed through Intent-First. 10% to 25% to 50% to 100%. At each stage, monitor and validate.
Step four: Eventually fully migrate. Once Intent-First is proven on 100% of traffic, you can remove the standard RAG fallback.
This phased approach is lower risk than a big-bang migration. It also gives you time to refine your intent taxonomy and training data based on production feedback.
The Future Of Intent-First Architecture
Where does this go from here?
Integration with autonomous agents is coming. Instead of just classifying intent and retrieving information, Intent-First systems will be able to take actions. Classify intent, route to appropriate agent, agent executes the action. Cancel an order. Schedule an appointment. Process a refund. The system doesn't just answer questions. It handles entire workflows.
Personalization will deepen. As systems understand intent better, they'll personalize responses based on user history, preferences, and context. A long-time customer asking about cancellation might get retention options. A new customer asking about cancellation might get an exit survey instead.
Multi-turn conversations will improve. Intent-First helps with single queries. But most real conversations are multiple turns. Understanding intent across a conversation, where context shifts and user needs evolve, is the next frontier.
Integration with structured data will get tighter. Instead of just searching documents, Intent-First systems will query databases, APIs, and real-time systems as part of intent-aware retrieval. The distinction between AI response and actual system operation will blur.
Implementing Intent-First: A Practical Framework
Let me give you a concrete framework for implementing Intent-First in your organization.
Phase 1: Foundation (Weeks 1-4)
Define your intent taxonomy with cross-functional input. Interview customer service, product, engineering. List the top 20 reasons customers contact you. Cluster them into 8-12 core intents. Get alignment on this list.
Audit your existing query data. Pull 500-1,000 customer queries from your chat history, call transcripts, emails. Label them with the intents you've defined. This becomes your training data foundation.
Phase 2: Build (Weeks 5-8)
Train your intent classifier. Use a framework like Hugging Face Transformers. Pick a pre-trained model like Distil BERT. Fine-tune on your labeled data. Start with 80/20 train/test split. Iterate on performance.
Implement confidence thresholds. Decide: below 60% = escalate to human. 60-75% = ask clarifying question. Above 75% = proceed to retrieval.
Build clarification question templates. For each intent pair that the system confuses, write clarifying questions.
Phase 3: Integrate (Weeks 9-12)
Wire your classifier into your existing system. Make it parallel, non-blocking. It classifies but doesn't change routing yet.
Implement intent-aware retrieval. For each intent, define which knowledge sources to search, in what order.
Build the routing logic. Map intents to their appropriate knowledge sources and APIs.
Phase 4: Pilot (Weeks 13-16)
Run a pilot with a subset of traffic. Start with 5-10% of queries routed through Intent-First. Monitor carefully.
Track: classification accuracy, first-attempt resolution rate, escalation rate, customer satisfaction.
Collect misclassified examples. Add them to your training data. Retrain.
Phase 5: Scale (Weeks 17-20)
Gradually increase traffic percentage through Intent-First. 10% → 25% → 50% → 100%.
At each stage, validate. Don't increase if metrics aren't improving.
Phase 6: Optimize (Ongoing)
Set up continuous monitoring. Track classification accuracy weekly. Collect mislabeled examples. Retrain monthly or quarterly.
Monitor intent distribution. Are intents shifting? Are new intents emerging? Update your taxonomy.
Measure business metrics monthly. First-attempt resolution, customer satisfaction, support costs.
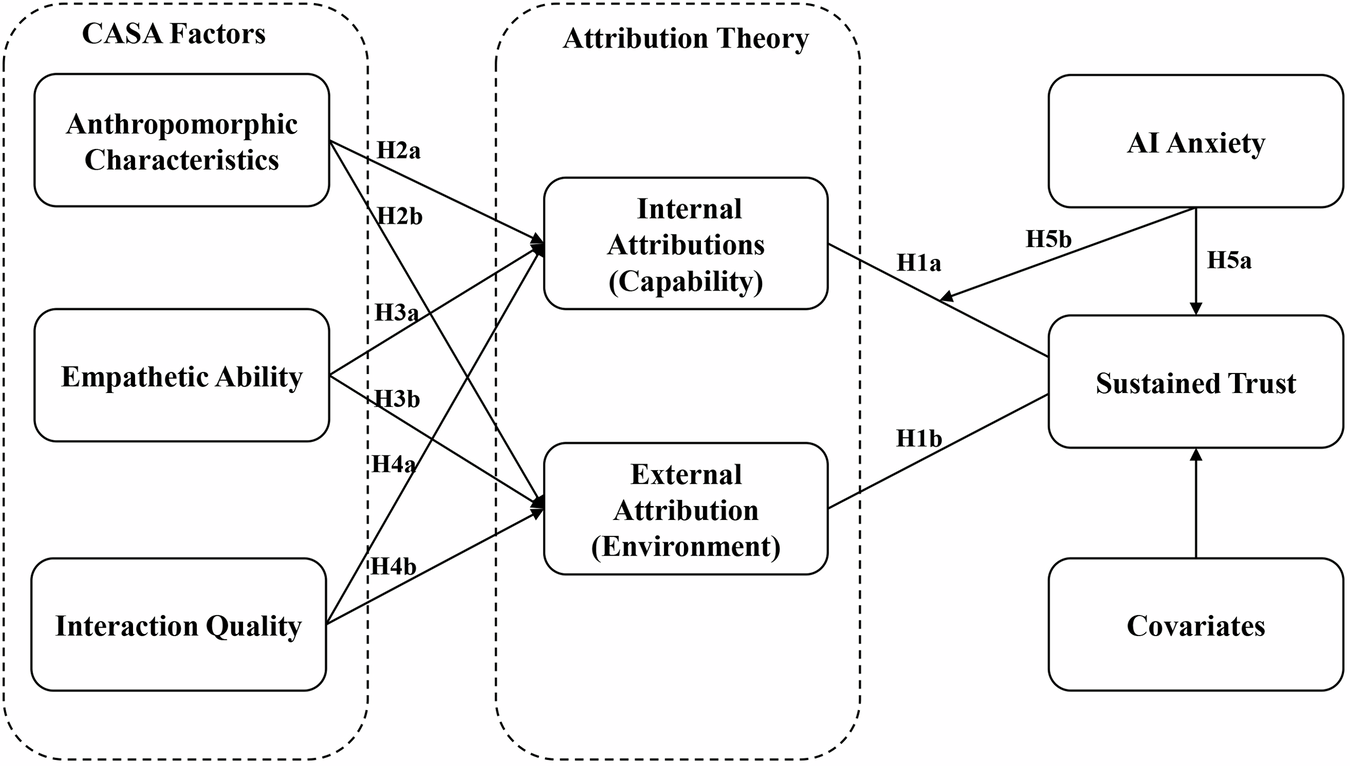
Case Study: Telecommunications Company
Let me walk through a real example to make this concrete.
A major telecommunications provider had standard RAG deployed. 10 million customer interactions per month. 35% first-attempt resolution. Support costs were $45M annually.
The issues were classic: intent misclassification ("cancel" queries routed to wrong department), context overload (results mixing billing and service and network content), and freshness problems (outdated promotions surfacing).
They implemented Intent-First architecture. Core intents: billing_question, service_issue, order_status, cancellation, upgrade, account_change, network_support, policy_question.
They collected 500 examples per intent from actual customer conversations. Trained a Distil BERT classifier. Achieved 92% accuracy.
Routing logic mapped billing_question to billing knowledge base and APIs. Service_issue to technical support articles. Cancellation to cancellation procedures and retention systems. Etc.
After 4 months of gradual rollout:
- First-attempt resolution: 35% → 73%
- Escalation rate: 65% → 27%
- Customer satisfaction: 52% → 79%
- Annual support cost: 28.5M
- Savings: $16.5M annually
The payback period on the development investment was 3 weeks.
Common Questions About Intent-First
Does Intent-First require a large language model?
No. Intent classification uses a small model trained on your specific intent taxonomy. Your generation LLM can still be large, but the classification component is lightweight. This is actually better for latency and cost.
Can Intent-First handle multi-intent queries?
Yes. A query like "I want to cancel my order AND check my refund status" has two intents. Your classifier can return primary and secondary intents. Route to both systems if needed.
What if intent is genuinely unclear?
That's what clarification is for. If confidence is low, ask. It's better to ask one clarifying question and get it right than to guess and get it wrong.
How long does Intent-First implementation take?
Typically 4-6 months from definition to full production deployment. It's not instant but it's not a year-long project either.
What if we already have a lot of investments in standard RAG?
You can retrofit. Implement Intent-First in parallel with your existing system. Migrate gradually. You don't have to replace overnight.
The Path Forward
Enterprise AI is at an inflection point. The easy wins from just plugging in large language models are over. The harder work of building systems that actually understand user needs is beginning.
Intent-First architecture is how you do this. It's not a minor optimization. It's a fundamental reordering of how AI systems approach user interaction. Classify intent first. Route to the right place second. Retrieve and generate third. The ordering matters enormously.
The companies that implement this first will dominate customer experience metrics. They'll have happier customers. Lower support costs. Better satisfaction scores. And they'll have an architectural foundation that scales as their complexity grows.
Standard RAG is the default. It works okay at small scale and in demos. But when you hit production at enterprise scale, you hit the ceiling. Intent-First is what's beyond that ceiling.
FAQ
What is Intent-First architecture exactly?
Intent-First architecture is a design pattern for conversational AI systems that prioritizes understanding what users actually want before retrieving information. Unlike standard RAG systems that retrieve first and interpret second, Intent-First classifies user intent using a lightweight language model, then routes to appropriate information sources based on that classified intent. This simple reordering dramatically improves accuracy and customer satisfaction in production systems.
How does Intent-First improve on standard RAG?
Standard RAG treats all queries the same: embed, search, generate. Intent-First adds an understanding layer first. It determines whether a "cancel" query means canceling an order, appointment, or service before routing. It understands which knowledge source is relevant. It accounts for freshness by routing to live systems rather than static embeddings. The result is 40-60% improvement in first-attempt resolution rates in production deployments.
What are the main benefits of implementing Intent-First architecture?
The primary benefits are measurable and substantial. Organizations see first-attempt resolution improvements from 35% to over 72%, meaning fewer customers require escalation or follow-up. Customer satisfaction scores typically increase 25-40 points. Annual support costs drop millions for mid-size enterprises. Additionally, Intent-First systems are more transparent about why they route queries certain ways, which builds user trust. The architecture also scales better as complexity grows because intent classification remains focused regardless of how many information sources exist.
How do you actually implement Intent-First in an existing system?
Implementation happens in phases over 4-6 months. Start by defining your intent taxonomy (typically 8-12 core intents based on actual customer reasons for contact). Collect and label hundreds of real customer queries with correct intents. Train a lightweight intent classifier using this labeled data. Implement parallel routing where the new Intent-First path runs alongside your existing system but doesn't change routing yet. Gradually migrate traffic percentage by percentage to the new system while monitoring resolution rates and satisfaction. Only increase traffic migration if metrics improve. Once proven on 100% of traffic, you can sunset the old system.
What size organization needs Intent-First?
Any organization with 1,000+ customer interactions monthly through AI systems benefits from Intent-First. Smaller systems can function adequately with standard RAG. But once you hit enterprise scale with multiple information sources and complex user intent patterns, the architecture becomes essential. Mid-market companies typically see the most dramatic ROI because they've made significant RAG investments but haven't yet reached the scale where custom solutions are worth building from scratch.
How do you measure Intent-First success?
Track four core metrics: first-attempt resolution rate (percentage of queries resolved without escalation), classification accuracy (how often the intent classifier chooses the correct intent), customer satisfaction scores (CSAT or NPS), and support cost per interaction. Compare these metrics before and after Intent-First implementation. Most successful implementations see first-attempt resolution improve 35-40 percentage points, classification accuracy above 85%, CSAT improvements of 25+ points, and annual support cost reductions in the millions for mid-size enterprises.
Can Intent-First handle ambiguous or unclear queries?
Yes, through intelligent clarification. When a query is ambiguous and confidence falls below your threshold (typically 60-70%), the system generates a specific clarifying question rather than guessing. The user provides additional context, confidence increases, and the system classifies correctly. This approach is more user-friendly than either guessing incorrectly or immediately escalating to human support. Most queries need only one clarification round to achieve high-confidence classification.
Is Intent-First compatible with existing language models?
Completely. Intent-First uses a lightweight classifier model for the intent determination layer and can work with any generation LLM for response creation. You don't need to replace your existing large language models. In fact, smaller classifiers are better for intent determination because they're faster and cheaper while remaining highly accurate on your specific taxonomy. Your existing large model can continue generating responses once intent is understood and relevant sources are retrieved.
How does Intent-First handle continuously changing customer needs?
Intentional systems need ongoing monitoring and iteration. Track which queries get misclassified. Add those examples to your training data. Retrain your classifier monthly or quarterly. Monitor whether intent distribution is shifting. Seasonal patterns might increase certain intents during specific periods. Your system should adapt. Some successful implementations also run A/B tests where intent classifications that are borderline (60-70% confidence) are presented to users with options ("Are you trying to cancel an order or return a purchase?") to gather data on how real users distinguish similar intents.
What's the implementation cost and timeline?
Implementation typically takes 4-6 months and costs
How do you handle intent that requires data from multiple systems?
Intent-First can implement multi-hop routing where a single classified intent chains to multiple systems. A customer asking "Can I use my warranty on this issue?" requires both support system information (the issue details) and account/product system information (warranty details). Your routing logic recognizes this intent requires multiple sources and orchestrates retrieving from both. The generation LLM then synthesizes information from both sources into a coherent response.

Key Takeaways For Building Better AI Systems
Intent-First architecture represents a fundamental shift in how enterprises should approach conversational AI. It's not about larger models or better embeddings. It's about better system design. Understanding what users want before searching for answers is architecturally sound and produces measurably better outcomes.
The transition from standard RAG to Intent-First is achievable for any enterprise with existing AI deployments. It doesn't require replacing your language models. It doesn't require a multi-year transformation. A well-executed Intent-First implementation takes 4-6 months and delivers 40-60% improvements in first-attempt resolution.
The cost of not implementing Intent-First is real. Every day of continued standard RAG deployment at enterprise scale means millions in unnecessary support costs, lower customer satisfaction, and wasted investment in AI infrastructure that isn't delivering expected value.
The companies building the best customer experiences with AI right now aren't building bigger models. They're building smarter architecture. They understand intent. They route precisely. They generate in context. That's the difference between AI that customers love and AI that frustrates them.
Related Articles
- Parloa's $3B Valuation: AI Customer Service Revolution 2025
- Google Gemini vs OpenAI: Who's Winning the AI Race in 2025?
- Apple's AI Chatbot Siri: Complete Guide & Alternatives 2026
- Claude's Revised Constitution 2025: AI Ethics, Safety & Consciousness Explained
- AI Failover Systems: Enterprise Reliability in 2025 [Guide]
- Confer: Privacy-First ChatGPT Alternative by Moxie Marlinspike [2025]

