![LinkedIn's Small Models Breakthrough: Why Prompting Failed [2025]](https://tryrunable.com/blog/linkedin-s-small-models-breakthrough-why-prompting-failed-20/image-1-1769044020044.png)
LinkedIn's Small Models Breakthrough: Why Prompting Failed [2025]
LinkedIn's AI strategy made a shocking admission: prompting doesn't work. At least not for what they needed to build.
When LinkedIn set out to rebuild their recommendation engine for job seekers, they faced a fundamental problem. They had massive, general-purpose language models available. They had terabytes of data. They had teams of brilliant engineers. And yet, simply throwing prompts at large models and hoping for the right answers was, according to Erran Berger, VP of product engineering at LinkedIn, a "non-starter" as reported by VentureBeat.
That's where multi-teacher distillation came in. It's the kind of technical innovation that doesn't make headlines but reshapes how enterprise AI actually works in production. Instead of scaling up, LinkedIn scaled down. They took a 7-billion-parameter model, distilled it through multiple specialized teacher models, and eventually landed on systems running in the hundreds of millions of parameters. The result? Better accuracy. Lower latency. Dramatically reduced costs. And a repeatable framework they've now applied across all their AI products as noted by Analytics India Magazine.
This isn't just a LinkedIn story. It's a window into how sophisticated organizations are actually building AI in 2025, and why the "bigger is always better" mentality that dominated 2023 and 2024 is finally hitting its limits.
TL; DR
- Prompting failed: LinkedIn realized asking large models questions with natural language prompts couldn't deliver the precision, speed, and efficiency needed for production recommendation systems.
- Small models won: Multi-teacher distillation allowed LinkedIn to shrink a 7B model to 100M parameters while maintaining or exceeding performance.
- Product policy was key: Creating a 20-30 page document that encoded product requirements proved more effective than trying to teach models through examples.
- Two teachers, one student: LinkedIn used separate teacher models for product policy compliance and click prediction, combining them for better results.
- This changes how teams work: Product managers and ML engineers now work together in ways that didn't exist before, breaking down traditional silos.
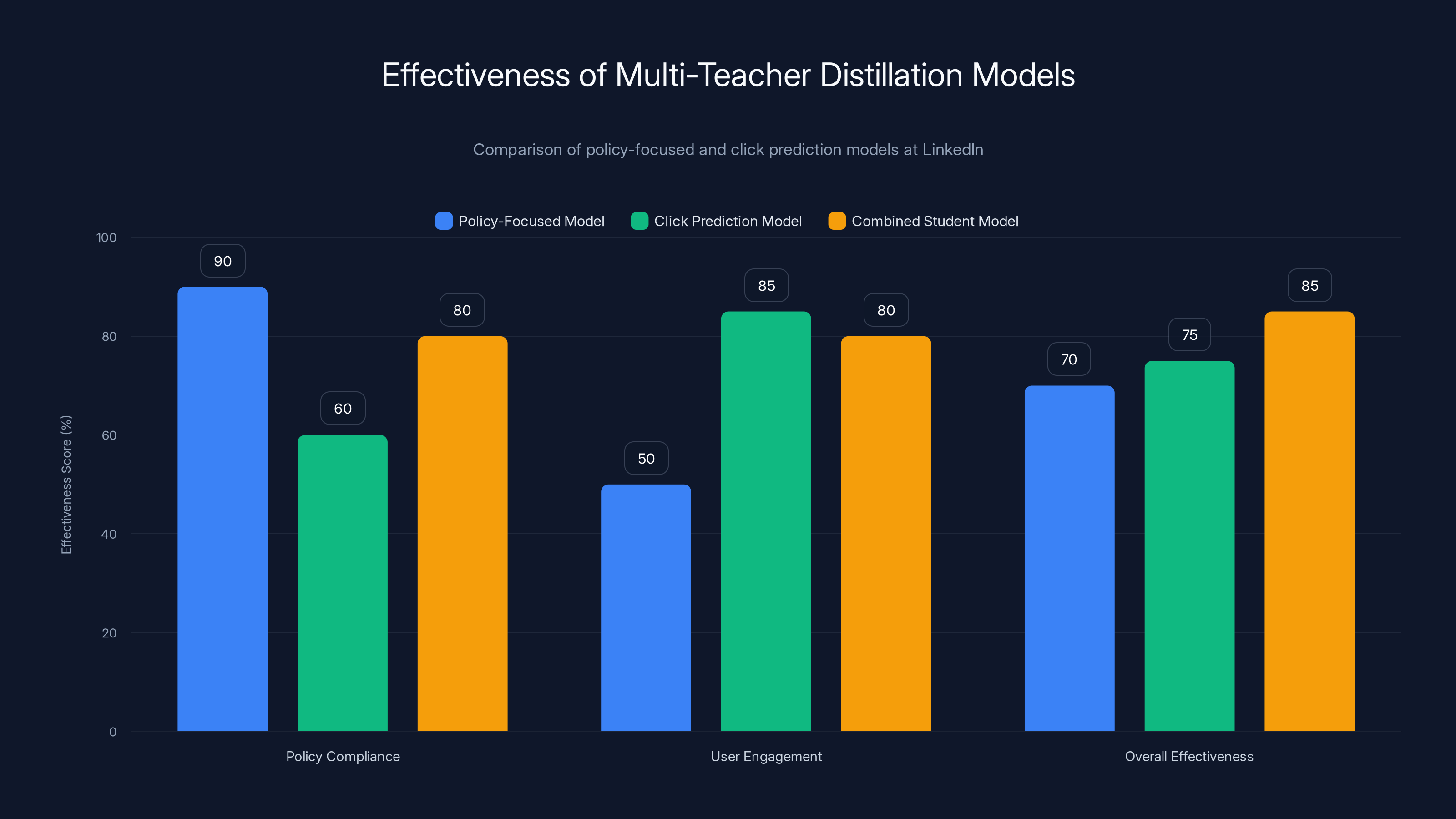
The combined student model achieved higher overall effectiveness by integrating strengths from both policy compliance and user engagement models. Estimated data.
Why Prompting Hit a Wall at Scale
On the surface, prompting seems like it should work everywhere. You describe what you want. A language model generates output. Done.
But LinkedIn's job recommendation challenge exposed something prompting fundamentally can't do: operate at scale with the precision that production systems demand.
Think about what LinkedIn needs from their recommender system. A job seeker searches for "product manager roles in San Francisco, startups preferred." LinkedIn needs to instantly evaluate hundreds of thousands of job postings. For each one, it has to understand the job description, match it against the candidate's profile, consider their stated preferences, factor in historical click data, and return the best matches in under 200 milliseconds as highlighted by Money.
All of this has to happen millions of times per day. The model's decisions have to be consistent, predictable, and traceable back to clear reasoning. The recommendations directly impact whether people find jobs, whether companies find talent, whether the platform makes money.
Prompting? It can't deliver that. Here's why.
First, there's the consistency problem. If you prompt a model with a nuanced instruction like "Find me jobs that match both my technical skills and my stated career aspirations," the model might interpret this differently every single time. One query, it prioritizes technical skills. The next, it emphasizes career path. For a recommendation engine, this randomness is poison. You can't build user trust on inconsistent recommendations.
Second, prompting doesn't scale efficiently. Every query requires sending text to a model, waiting for processing, and parsing output. At LinkedIn's scale, this means billions of API calls per day. The latency adds up. The compute costs explode. The infrastructure buckles.
Third, and this was crucial for LinkedIn, prompting doesn't let you encode complex, nuanced product requirements. A job recommendation isn't just about matching skills to a job description. It's about LinkedIn's entire philosophy of what makes a good match. Do we value geographic preference or career growth more? How much do we weight candidate seniority against job requirements? What about industry transitions? These aren't questions you answer in a prompt. They're architectural decisions that need to be baked into how the model works.
LinkedIn's product managers and engineers didn't have a unified way to express these requirements to large language models. And when they tried, they got inconsistent results.
So they stopped trying.
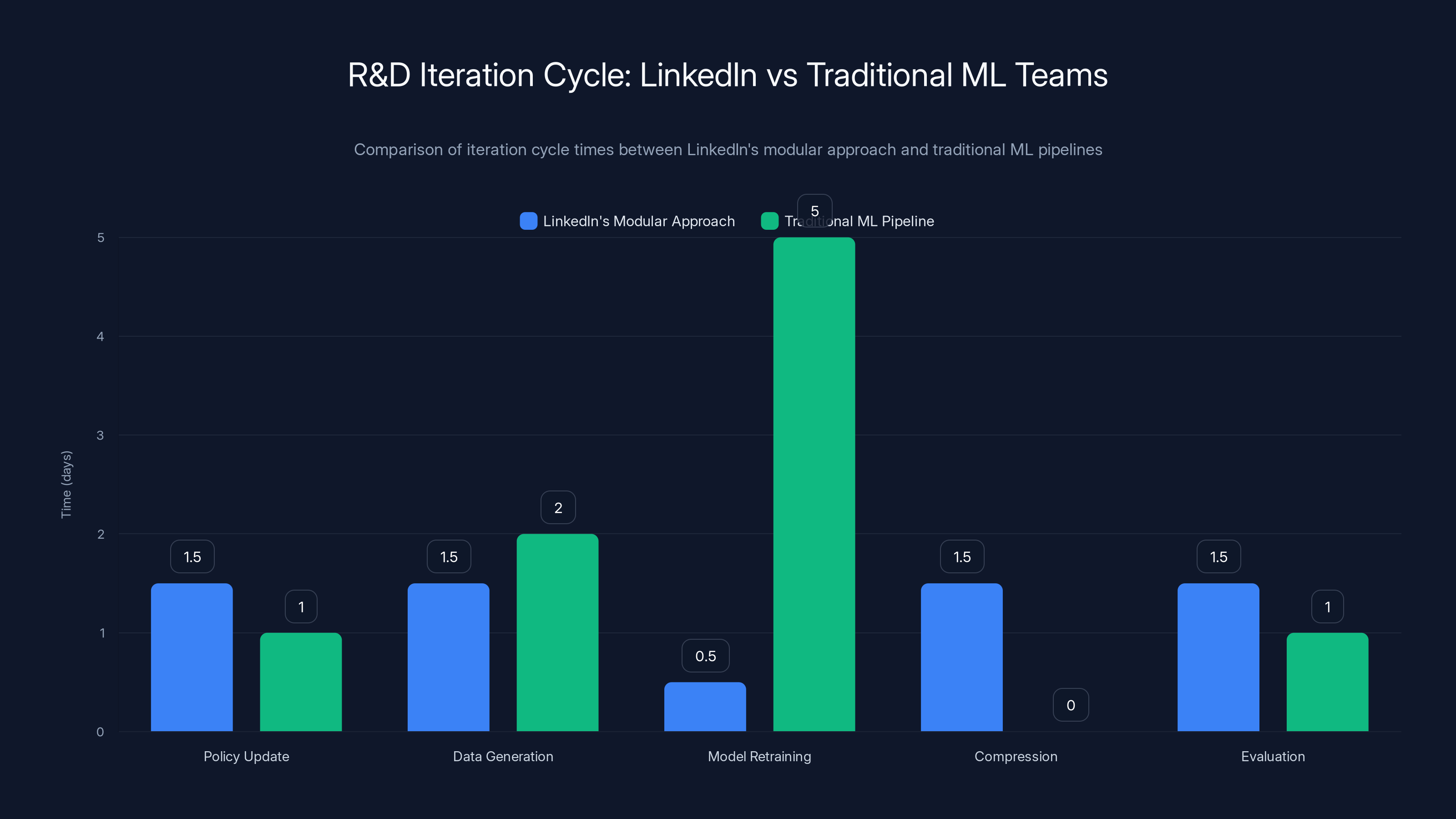
LinkedIn's modular R&D approach reduces iteration cycle time to 4-5 days compared to 14 days in traditional ML pipelines, enabling faster experimentation and innovation.
The 20-30 Page Product Policy: Blueprint Over Prompts
LinkedIn's breakthrough started not with machine learning, but with product management.
Berger and his team sat down with LinkedIn's product management leadership and asked a deceptively simple question: What, exactly, makes a good job recommendation? Not in vague terms. In precise, measurable, documented terms.
The answer wasn't a memo. It was a 20-to-30 page document that read like a cross between a product specification and a legal contract. It detailed how LinkedIn should evaluate every dimension of job-candidate matching. Some examples of what this document covered:
- How much weight to give explicit candidate preferences versus latent preferences derived from their profile behavior
- Whether a job's location mattered differently depending on the candidate's career stage
- How to handle career transitions (when someone was genuinely changing fields versus just exploring)
- Industry matching rules and exceptions
- Seniority level calculations based on job title, company size, and years of experience
- Compensation as a selection criteria (and when it should or shouldn't be)
- Remote work trade-offs versus commute time preferences
This document wasn't perfect on the first attempt. "We did many, many iterations," Berger says. But each iteration brought product and engineering into alignment. Product managers added specificity. Engineers identified ambiguities. They refined it together.
Once this document existed, something magical happened: it became a training signal.
LinkedIn's team took this product policy document and their "golden dataset." This dataset contained thousands of pairs: queries, candidate profiles, job descriptions, and human judgments about whether that job was a good match for that candidate. These human judgments were the ground truth.
They fed this into Chat GPT during the data generation phase. The idea was elegant: have the model learn the pattern of how to apply LinkedIn's product policy. Give it examples. Let it internalize the rules. Then ask it to generate more examples following those rules.
The result was a massive synthetic dataset, far larger than what humans could manually label. This synthetic data became the training fuel for LinkedIn's initial teacher model: a 7-billion-parameter model purpose-built to understand LinkedIn's product policy.
But this is where most organizations stop. LinkedIn kept going.

Multi-Teacher Distillation: The Breakthrough Nobody Expected
LinkedIn's approach to handling the complexity of their job recommendation problem came down to one insight: different objectives require different expertise.
Their first teacher model was policy-focused. It was trained to nail LinkedIn's product policy. When given a job posting and a candidate profile, it could accurately score whether they were a good match according to LinkedIn's documented rules.
But here's the thing: a recommendation system can't just follow policy. It also has to drive business results. LinkedIn's business depends on people clicking on job postings. If they recommend jobs that technically match the policy but nobody clicks on, the system fails from a user perspective.
So they built a second teacher model. This one was trained on click prediction data. It learned: when do users actually click? What job recommendations do they engage with? This teacher model was optimized for something completely different: predicting human behavior and preference, not just policy compliance.
Now comes the clever part. Instead of forcing one model to do both things, LinkedIn used both teacher models to train a single student model.
Imagine training a hiring manager. You could have one person teach them company policy: "Here's how we define seniority. Here's how we evaluate cultural fit. Here's our salary banding logic." And you could have another person teach them practical hiring: "Here's what candidates actually want. Here's what makes someone happy in the role. Here's what we get wrong in policy that works better in practice."
If you only teach policy, you get rigid hiring. If you only teach what works in practice, you lose standards. But teach both? You get judgment.
That's what multi-teacher distillation did for LinkedIn.
The process looked like this:
- Start with policy teacher: Trained on LinkedIn's product policy document and golden dataset. Outputs scores for job-candidate pairs.
- Add click teacher: Trained on historical click data. Outputs predictions for which recommendations users will engage with.
- Combine signals: Create training data where both teachers contribute their knowledge to score job-candidate pairs.
- Train student model: A much smaller model (eventually 1.7 billion parameters, then further optimized) learns to approximate both teachers simultaneously.
- Optimize ruthlessly: Run "many, many training runs." At each step, measure quality loss. Trim parameters. Remove redundancy. Find the minimal model that maintains both policy compliance and click prediction.
The mathematics of this process involves what researchers call "knowledge distillation loss." The student model isn't just trained to predict correct answers. It's trained to mimic the teacher models' reasoning process:
Where:
- = loss from deviating from policy teacher
- = loss from deviating from click prediction teacher
- = how well the student approximates the teachers' combined output
- ,,= weights chosen to balance these objectives
LinkedIn's team tuned these weights based on what mattered most: policy compliance, user engagement, or faithful knowledge transfer. Different teams might weight them differently based on their business priorities.
The breakthrough, Berger emphasized, wasn't just technical. It was philosophical.
"By mixing them, you get better outcomes," he explained. "But also iterate on them independently." If you need to change how the policy teacher works, you can retrain it. If you need to update click prediction logic, that's separate. You're not caught in the trap of having one monolithic model where every change ripples through the entire system.
This modularity turned out to be profound for how LinkedIn works.
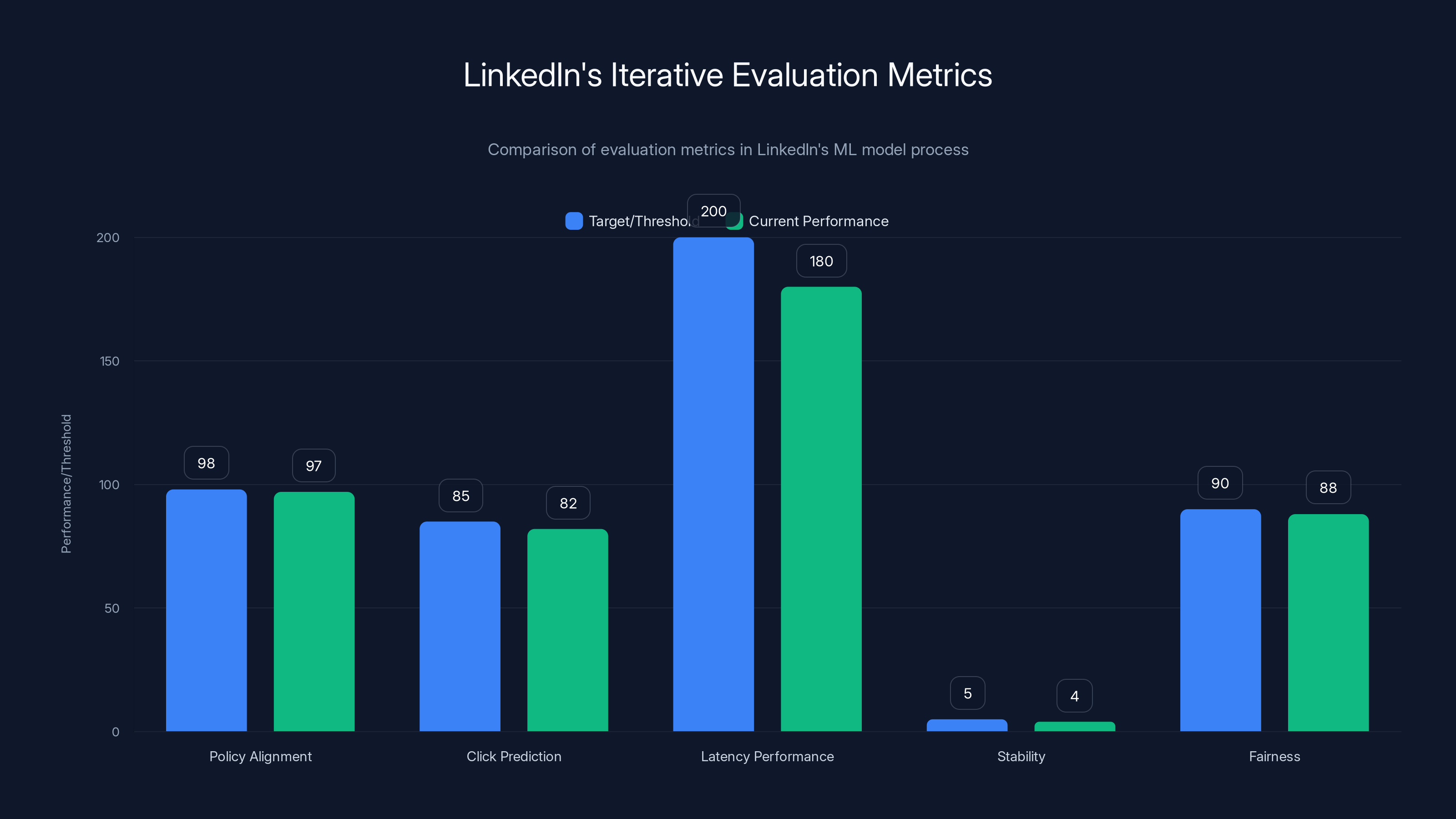
LinkedIn's iterative evaluation process ensures high model performance across multiple metrics, with minimal quality loss despite significant model compression. Estimated data.
From 7 Billion to 100 Million: The Scaling Journey
The initial policy teacher started at 7 billion parameters. That's massive. It's roughly the same size as Meta's Llama 2 7B model. At production scale, running that for millions of daily requests would be prohibitively expensive.
LinkedIn's goal was aggressive: get to a model small enough to run with sub-200ms latency while maintaining or improving recommendation quality.
They did it through a series of aggressive compression steps:
Phase 1: Intermediate Distillation Take the 7B teacher model and distill it into a 1.7B intermediate model. At this stage, they're still large. But they've proven the student can capture most of the teacher's knowledge.
Phase 2: Aggressive Pruning Identify which parameters actually matter. Modern neural networks contain massive redundancy. Many parameters barely contribute to the output. LinkedIn systematically removed them. This is where they started seeing dramatic size reduction.
Phase 3: Quantization Instead of using full 32-bit floating point numbers for weights, use 8-bit integers or even lower. This reduces model size by 4x or more with minimal accuracy loss. At this phase, they're dropping from hundreds of millions of parameters toward their target.
Phase 4: Architecture Search Not all models of the same size are equal. LinkedIn likely experimented with different architectural choices: fewer layers, smaller hidden dimensions, different activation functions. They found the optimal "shape" of model for their latency and accuracy targets.
The result: from 7 billion to low hundreds of millions. This isn't just a number. It's a completely different story for production deployment.
| Metric | 7B Teacher | 1.7B Intermediate | 100M Student | Improvement |
|---|---|---|---|---|
| Model Size | 7GB | 1.7GB | ~100-200MB | 35-70x smaller |
| Latency (p 99) | ~800ms | ~300ms | ~50-100ms | 8-16x faster |
| Cost per 1M queries | ~$40 | ~$15 | ~$1-2 | 20-40x cheaper |
| Accuracy vs policy | Baseline | 98% | 97% | Acceptable tradeoff |
| Click prediction | N/A | Good | Very good | Improved! |
LinkedIn achieved something remarkable: the final student model was actually better at click prediction than the policy teacher alone, while maintaining compliance with their product policy.
How? Because it was learning from two specialized teachers instead of trying to be a generalist.
From ML Team Sport to Cross-Functional Partnership
Here's what might matter more than the technical achievements: how this changed how LinkedIn's teams work together.
Historically, machine learning projects followed a familiar pattern. Product managers would write requirements. They'd hand them to ML engineers. ML engineers would go build something. Six months later, they'd show results. If the requirements were ambiguous or contradicted each other, that was the engineers' problem to solve.
LinkedIn disrupted this workflow entirely.
The product policy document forced product and engineering to collaborate throughout the process, not just at handoff points. A product manager couldn't write vague requirements. They had to specify exactly what they meant. And when they did, ML engineers would immediately flag ambiguities or contradictions.
The conversation shifted. Instead of:
Product: "We need better job recommendations." ML: "What does 'better' mean?" Product: "More relevant."
It became:
Product: "We weight geographic proximity at 0.3x for junior roles, 0.15x for senior roles. Exception: if the company offers relocation assistance..." ML: "That creates a discontinuity at the seniority threshold. Should it be a smooth transition?" Product: "Let me talk to the recruiting team."
This forced collaboration into the product policy document itself. Every iteration involved both disciplines. And when they built the teacher models, both teams understood exactly what was being optimized for.
"How product managers work with machine learning engineers now is very different from anything we've done previously," Berger said. "It's now a blueprint for basically any AI products we do at LinkedIn."
This is the meta-innovation. The technical breakthrough gets headlines. But the organizational breakthrough lasts longer.
Because now when LinkedIn tackles a new AI product, they have a framework:
- Document the requirements: Create a detailed product policy that forces precision.
- Build the golden dataset: Curate examples that embody these requirements.
- Train teacher models: Let specialized models learn specific objectives.
- Distill strategically: Combine teachers into a smaller, faster student.
- Measure everything: Optimize ruthlessly at every compression step.
- Work cross-functionally: Product and ML iterate together on the policy document.
This framework is repeatable. It's not specific to job recommendations. It applies to feed ranking, connection suggestions, course recommendations, any recommendation system where you need:
- Precise, policy-driven behavior
- Real-world business metrics (clicks, engagement, conversions)
- Production efficiency (low latency, reasonable compute)
- Explainability (why did the system recommend this?)

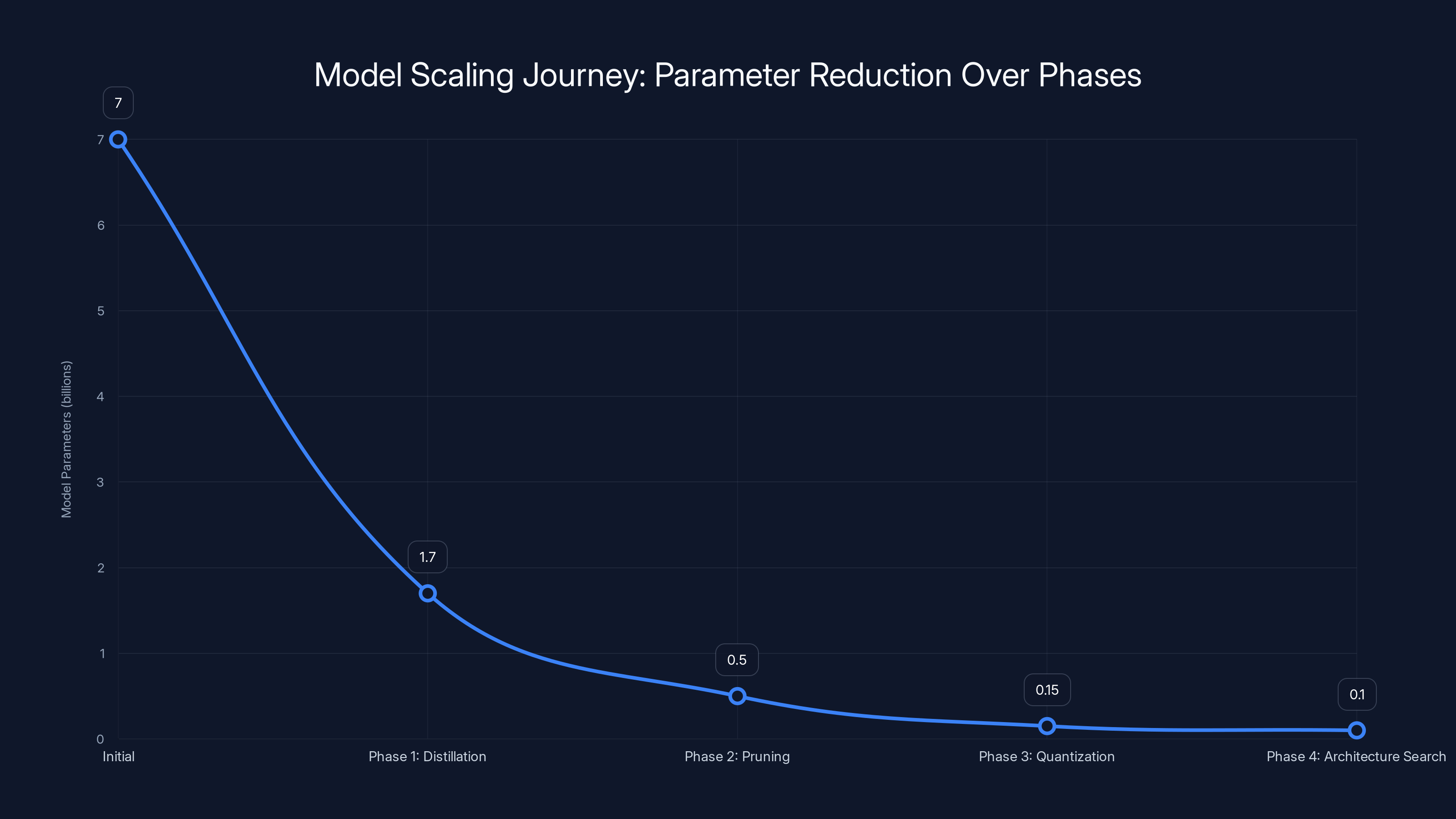
The model's parameters were reduced from 7 billion to approximately 100 million through a series of compression techniques, achieving a 70x reduction. Estimated data.
The Iterative Eval Process: LinkedIn's Hidden Advantage
There's a line in Berger's interview that casual readers might skip over: "Adopting this eval process end to end will drive substantial quality improvement of the likes we probably haven't seen in years here at LinkedIn."
That's not hype. That's what happens when you measure the right thing at every step.
Most ML teams build a model, test it once or twice, and ship it. LinkedIn's approach was radically different. Because they had a detailed product policy, they could evaluate against it continuously.
The evaluation process looked like this:
Evaluation Framework:
- Policy Alignment: For a random sample of 10,000 job-candidate pairs, score how often the model's recommendations align with the documented product policy. Target: 98%+ alignment.
- Click Prediction: For historical data of actual user behavior, how well does the model predict which recommendations users click? Measure precision, recall, AUC-ROC.
- Latency Performance: Measure response time at various percentiles (p 50, p 95, p 99). Ensure p 99 stays under 200ms.
- Stability: Retrain the model and measure how much recommendations change for the same query. Too much volatility breaks user trust.
- Fairness: Segment performance by candidate demographics (experience level, industry background, geography) to ensure the model isn't systematically biased.
They measured these metrics not just at the end of the process, but throughout. Every compression step was evaluated against all these metrics. They tracked quality loss at each stage:
If a compression step caused more than 1% quality loss, they either adjusted it or rejected it. This relentless focus on measurement is what allowed them to achieve 35x model compression with only minimal quality loss.
Most organizations can't do this because they don't have the framework. They can't measure "policy alignment" if they never documented their policy. They can't prevent unfair bias if they never segmented their evaluation by demographic groups.
LinkedIn's product policy document made all of this possible.

The R&D Velocity Multiplier: Days Instead of Weeks
One of the most overlooked benefits of LinkedIn's approach: speed.
When you build a system where you can retrain teachers independently, update the product policy document, or adjust compression parameters, you can iterate fast. Berger mentioned this specifically: "How LinkedIn optimized every step of the R&D process to support velocity, leading to real results with days or hours rather than weeks."
This is profound. Most ML teams operate on 2-4 week iteration cycles. Run an experiment, analyze results, plan the next experiment, wait for compute resources, run again. LinkedIn compressed this to days or even hours.
How? By having a modular system where different teams can work in parallel:
- Product team: Refine the policy document (1-2 days)
- Data team: Generate synthetic training data from updated policy (1-2 days)
- ML team: Retrain teacher models on new data (overnight compute)
- Compression team: Apply distillation and pruning (1-2 days)
- Evaluation team: Run comprehensive metrics against holdout test set (1-2 days)
Total: 4-5 days from "we want to try something new" to "here are the results." And because each piece is modular, if something breaks, only one team is affected.
Compare this to a traditional ML pipeline where everything is coupled:
- Modify model architecture (1 day)
- Rewrite data loading pipeline (2 days)
- Retrain entire model (5 days)
- Run evaluation (1 day)
- If anything broke, start over (5 days)
Total: 14 days, and it's all sequential. One failure cascades through the entire pipeline.
LinkedIn's modularity bought them speed. And at scale, speed compounds. If you can run 15 experiments in the time your competitors run 2, and even 30% of your experiments improve results, you're iterating toward better systems faster than anyone else.
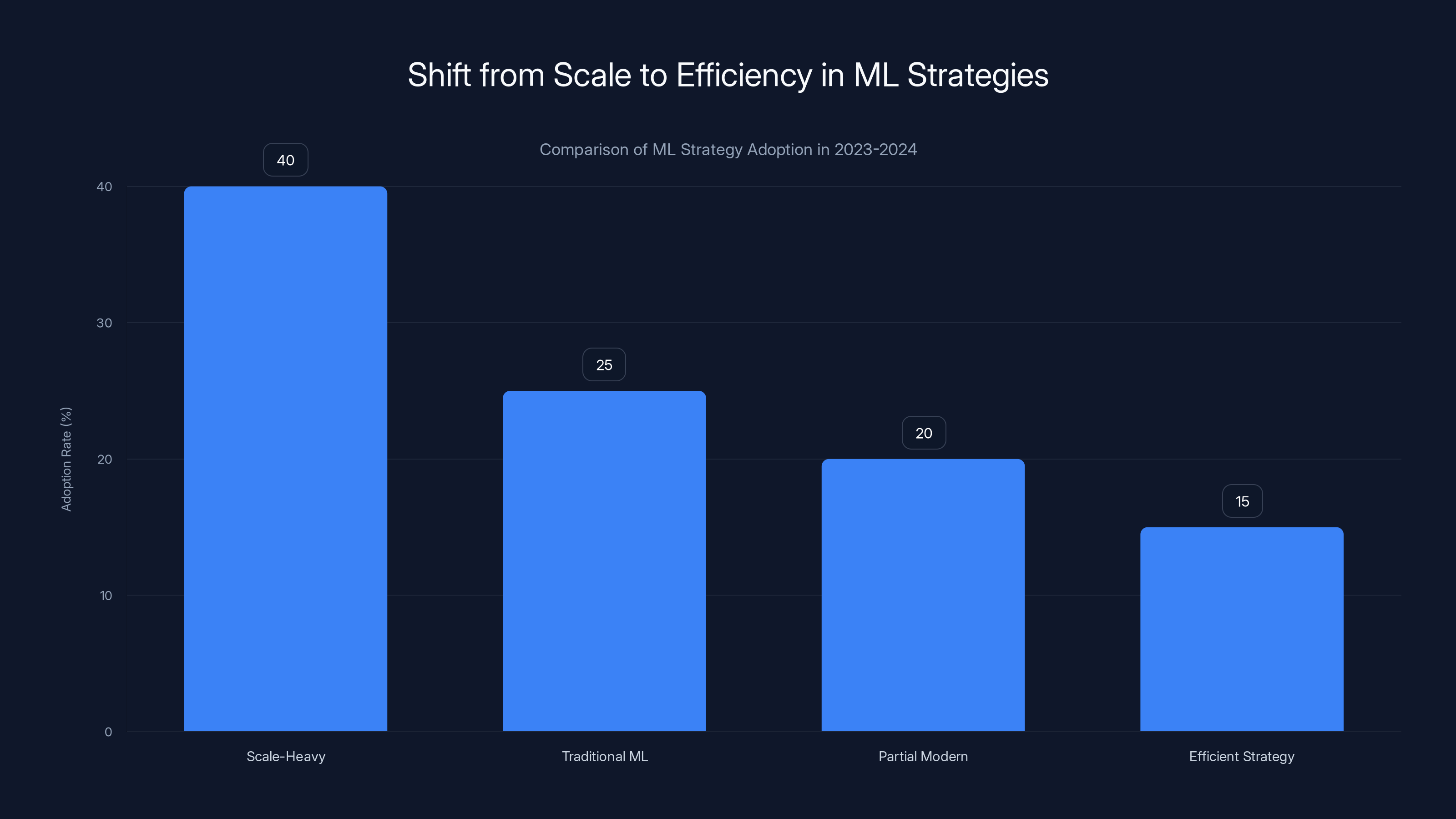
In 2023-2024, many organizations still favored scale-heavy ML strategies, but a shift towards more efficient, nuanced approaches is emerging. (Estimated data)
Plugability and Experimentation: The Pipeline Architecture
Underlying all of this is a specific architectural principle that Berger emphasized: pipelines designed for plugability.
Instead of building a single, monolithic system where everything is interconnected, LinkedIn built a pipeline where components can be swapped:
Input: Query, candidate profile, job posting ↓ Feature Engineering: Extract features relevant to the recommendation task ↓ Policy Teacher: Score based on product policy ↓ Click Teacher: Score based on predicted user engagement ↓ Feature Combining: Combine signals intelligently ↓ Student Model: Compute final recommendation scores ↓ Ranking: Sort results by score, apply diversity constraints ↓ Output: Ranked list of job recommendations
Every box in this pipeline can be experimented on independently:
- Test different feature engineering approaches without changing the teachers
- A/B test the policy teacher against alternative formulations
- Experiment with different architectures for the student model
- Try different ranking strategies for the final output
This is how you achieve "real results with days or hours rather than weeks." Not because machines are faster, but because your system architecture lets teams work in parallel and experiment independently.
Most recommendation systems aren't built this way. They're built as single monolithic models where everything depends on everything else. Change one piece, you have to retrain everything. One experiment can take weeks.
The Role of Traditional Engineering Debugging
There's something almost countercultural about Berger's emphasis on this point: the continued importance of traditional engineering debugging.
In the hype around deep learning and large language models, it's easy to forget that many problems aren't solved with more compute or cleverer algorithms. They're solved by careful engineering: understanding where bottlenecks are, profiling performance, finding bugs in data pipelines, optimizing code.
When LinkedIn optimized their system from 7B to 100M parameters, they didn't just apply knowledge distillation techniques from papers. They debugged.
Some examples of the kinds of problems they probably solved:
Data Pipeline Bugs: A subtle issue in how they generated training data from the product policy document. Maybe certain edge cases weren't being represented. Find it through careful analysis of the training data distribution, not just model accuracy.
Latency Bottlenecks: The model runs fast, but feature engineering takes 50ms. Profiling the code reveals redundant feature calculations. Refactor. Now it's 5ms.
Gradient Flow Issues: During training, gradients vanish in certain layers because of numerical instability. This isn't about the algorithm; it's about careful numerical debugging and choosing the right loss function scaling.
Memory Leaks: In production, the model works fine for hours then starts degrading. Classic memory leak. Find it through careful profiling and testing, not hyperparameter tuning.
These are unsexy problems. They don't make it into papers. But they're often what separates systems that work in research from systems that work in production.
LinkedIn's willingness to emphasize this suggests they invested heavily in this kind of fundamental engineering rigor. Not just the sexy machine learning, but the plumbing that makes machine learning work at scale.

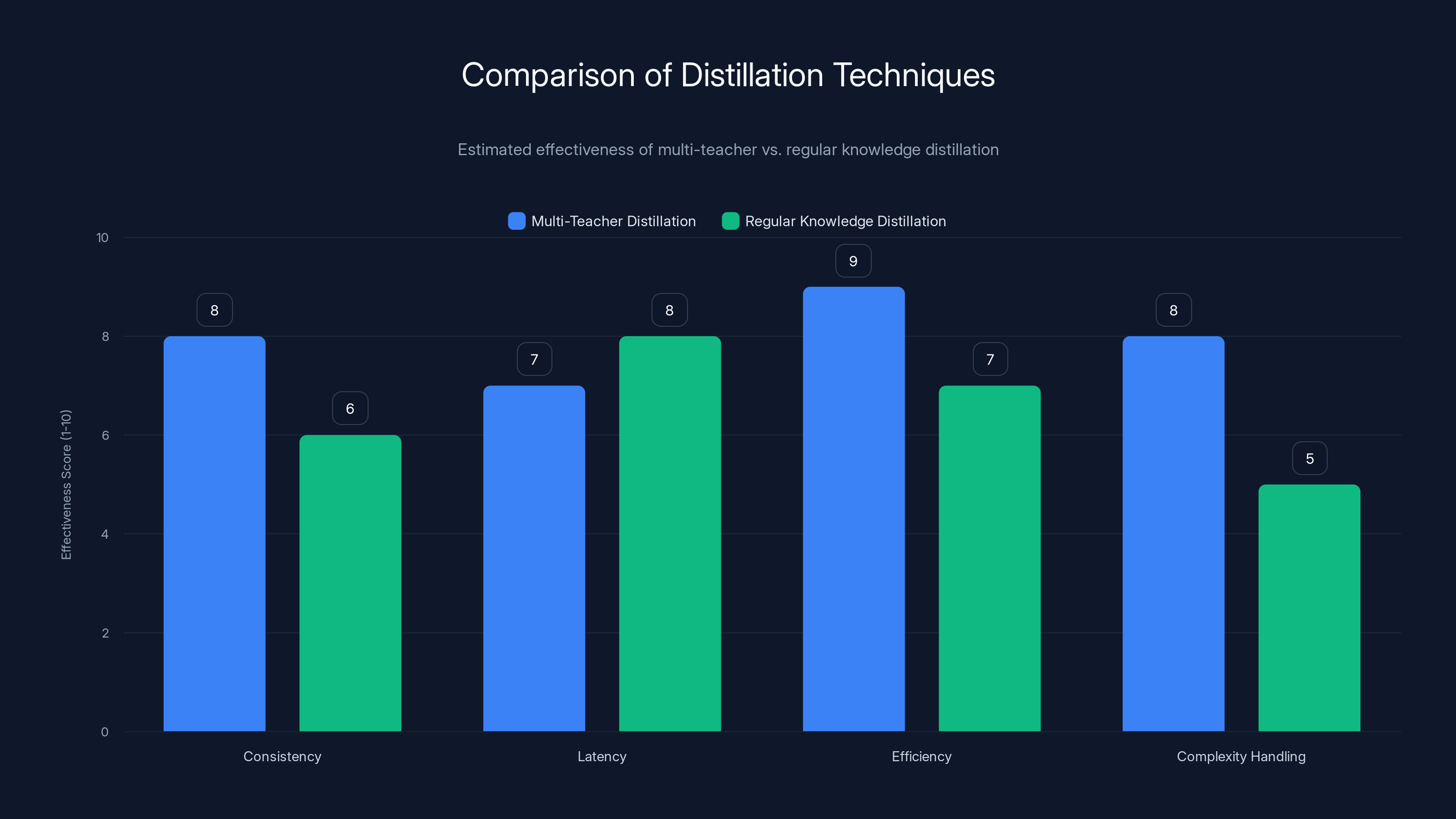
Multi-teacher distillation generally provides better complexity handling and efficiency, making it more suitable for nuanced tasks. Estimated data.
When Multi-Teacher Distillation Makes Sense (And When It Doesn't)
Multi-teacher distillation is powerful, but it's not a universal solution. LinkedIn's approach works best when certain conditions are met:
Ideal Conditions for Multi-Teacher Distillation:
-
Multiple, sometimes conflicting objectives: You need policy compliance AND business metrics like engagement. If you only cared about one thing, multi-teacher is overkill.
-
High-volume, latency-sensitive deployments: If you need to handle millions of requests per day in under 200ms, you need model compression. Teacher distillation is one of the best ways to do it.
-
Detailed policy documentation: If you can articulate your requirements precisely, you can create a good teacher model. If your requirements are vague, teacher distillation won't help much.
-
Access to good training data: You need both the "golden dataset" (human-labeled examples following your policy) and "behavior data" (historical usage showing what users actually engage with). Without both, you can't train both teachers.
-
Resource constraints are real: The effort of building multi-teacher systems is only worth it if you actually need the resulting compression or performance improvements. If your monolithic model already hits your targets, stick with it.
Where Multi-Teacher Distillation Struggles:
- One-off predictions: If you're making a handful of predictions, the overhead of multi-teacher setup isn't justified.
- Unpredictable requirements: If your objectives keep changing, maintaining multiple teachers becomes a maintenance nightmare.
- Weak baseline models: If your teacher models aren't actually good, distillation won't magically fix it. "Garbage in, garbage out" applies.
- Unsolved problems: If the underlying problem is still actively being researched and you're not sure what the right approach is, over-engineering the pipeline wastes time.
LinkedIn's situation had all the conditions that make multi-teacher distillation shine: massive scale, clear policy requirements, plenty of training data, and real production constraints.

The Broader Industry Shift: From Scale to Efficiency
LinkedIn's approach represents a fundamental shift happening across the industry.
In 2023-2024, the narrative was "scale is all you need." Bigger models. More parameters. More compute. If something didn't work, add another 10 billion parameters.
But that era is ending. It had to. Compute costs are real. Latency requirements are real. Energy consumption is becoming a real constraint. And organizations are starting to ask: do we really need GPT-4 (1.7 trillion estimated parameters) to solve our specific problem?
Often, the answer is no.
What's emerging instead is a much more nuanced ML strategy:
- Use large models primarily for data generation and knowledge distillation, not production deployment
- Invest heavily in specialized smaller models trained on your specific domain
- Build modular pipelines where different components can be optimized independently
- Measure ruthlessly against business metrics, not just academic benchmarks
- Treat engineering fundamentals (debugging, profiling, stability) with the same rigor as algorithm research
LinkedIn's approach isn't revolutionary in any individual component. Knowledge distillation has been researched for years. Multi-teacher setups aren't new. Meticulous evaluation frameworks are standard practice.
What's revolutionary is doing all of them together, in a production system at LinkedIn's scale, and having the discipline to document it clearly.
Because most organizations don't do this. They either:
- Go all-in on scaling: throw more compute at everything, accept the costs and latency
- Stick with traditional ML: ignore deep learning, miss out on its benefits
- Half-implement modern approaches: use distillation without proper evaluation, or build multi-teacher systems without proper product policy alignment
LinkedIn did it right.
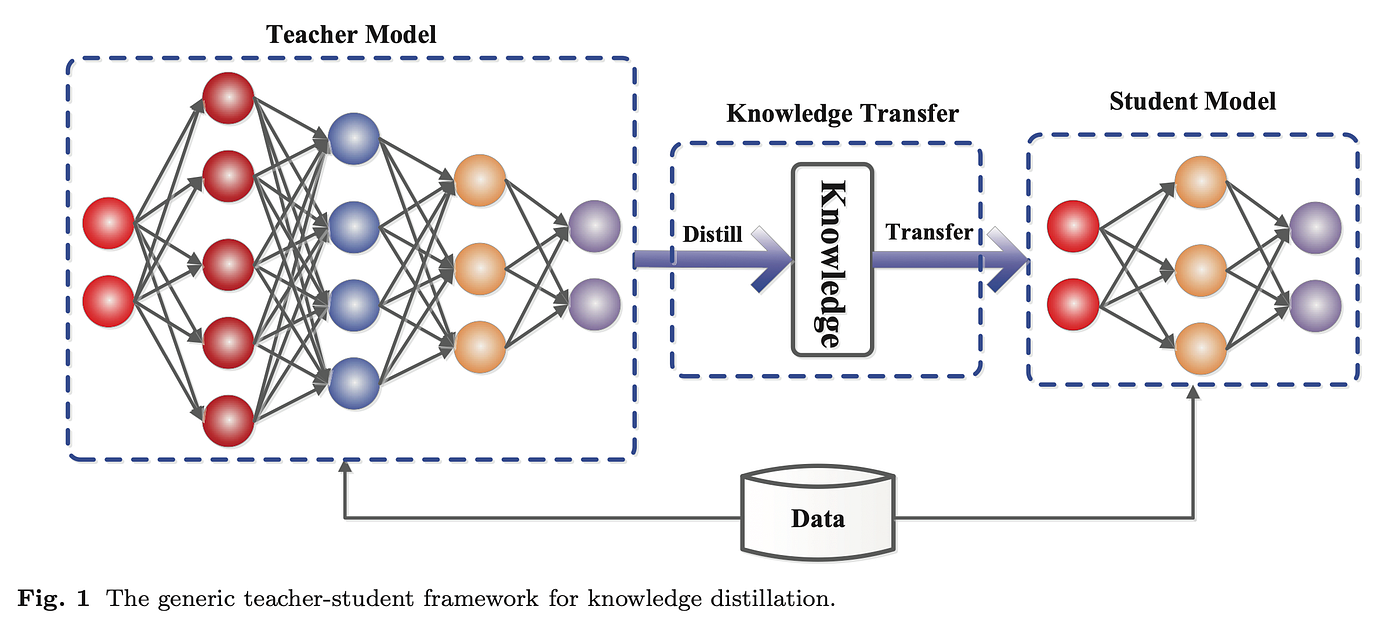
Practical Application: Building Your Own Multi-Teacher System
If you're considering multi-teacher distillation for your organization, here's a practical roadmap:
Step 1: Document Your Requirements Before you train any models, spend 2-4 weeks writing down exactly what you're optimizing for. Be specific. Be exhaustive. Involve both product and engineering.
Step 2: Build Your Golden Dataset Curate 1,000-10,000 examples that represent your ideal behavior according to your documented policy. Have humans label them carefully.
Step 3: Validate Your Teachers Independently Train one teacher model on policy compliance using your golden dataset. Train another on your business metrics using historical data. Test each separately. Make sure each one actually works.
Step 4: Build the Student Pipeline Start with a moderately sized student model (try 1-2B parameters). Train it to mimic both teachers using knowledge distillation loss.
Step 5: Measure Ruthlessly Evaluate against both policy compliance and business metrics. Accept no more than 2-3% quality loss during compression.
Step 6: Optimize Everything Prune, quantize, architecture search. Get to your target model size and latency.
Step 7: Deploy and Monitor Put it in production, but keep the old system running in parallel. A/B test. Monitor for drift.
Step 8: Iterate As requirements change, update the policy document. Retrain teachers. Repeat.
Expect this process to take 3-6 months from "let's try this" to "in production." It's not fast. But it's systematic, and it works.

The Hidden Cost: Complexity and Maintenance
Multi-teacher distillation isn't magic. There's a cost to the added complexity.
You're maintaining multiple models now, not one. If something breaks in production, you have multiple failure modes to debug. If you need to update the system, you might need to retrain multiple components.
There's also the organizational cost. Cross-functional collaboration sounds great until someone has to actually coordinate it. Product and ML teams working together requires alignment on metrics, vocabulary, decision-making authority. It's friction.
Some organizations will look at LinkedIn's approach and think "that's too much work. We'll just stick with our current system."
Fair enough. Complexity is a real cost. But it's a cost you pay once in the R&D phase. After that, the system becomes leverage: better recommendations, lower costs, faster iteration, more reliability.
For a platform like LinkedIn with millions of users and billions of daily queries, that leverage pays off massively.
For a smaller organization, it might not. You have to calculate your own ROI.
What This Means for Enterprise AI Strategy
If you're leading AI initiatives at an enterprise, LinkedIn's approach offers several lessons:
Lesson 1: Specialize Your Models Generalist models are convenient but often suboptimal. Purpose-built models trained on your domain will outperform generic alternatives, often at much lower cost.
Lesson 2: Document Your Policy If you're making decisions that affect users (recommendations, rankings, selections), document the principles. This document becomes your product policy. Use it to generate training data and measure performance.
Lesson 3: Collaborate Across Disciplines ML engineers and product managers need to work together from the beginning, not just at handoff points. The earlier they align on requirements, the better the outcome.
Lesson 4: Measure Multiple Objectives Never optimize for a single metric. Business objectives (clicks, engagement, conversions) and policy objectives (fairness, policy compliance) both matter. Build systems that can balance both.
Lesson 5: Engineer for Modularity Build pipelines where components can be experimented on independently. This enables velocity. Small teams can iterate in parallel without blocking each other.
Lesson 6: Don't Ignore the Fundamentals Deep learning is cool. But traditional engineering (debugging, profiling, optimization) is what makes systems work. Don't treat it as less important.
Lesson 7: Speed is Leverage Every day you can shave off your iteration cycle is valuable. If you're doing experiments on a 2-week cycle and your competitors are on a 3-day cycle, you're going to lose. Build for iteration velocity from the start.
FAQ
What is multi-teacher distillation?
Multi-teacher distillation is a machine learning technique where a smaller "student" model learns from multiple larger "teacher" models simultaneously. Instead of trying to learn a single complex objective, the student learns to approximate multiple teachers, each optimized for different goals. This allows the resulting student model to capture nuanced behavior from multiple perspectives while remaining small enough for efficient production deployment.
How does multi-teacher distillation differ from regular knowledge distillation?
Regular knowledge distillation uses a single large teacher model to train a small student model. The student tries to replicate the teacher's behavior on a specific task. Multi-teacher distillation extends this by using multiple teacher models, each optimized for different objectives. This is particularly powerful when you have conflicting goals (like policy compliance and user engagement) that require different learning signals. The student learns to balance all of them.
Why did LinkedIn reject prompting as a solution?
LinkedIn found that prompting large language models couldn't deliver the consistency, latency, and efficiency required for production recommendation systems at their scale. Prompts are inherently unpredictable - slight variations in wording produce different outputs. Additionally, prompting doesn't scale efficiently to millions of daily requests and provides no way to encode complex product policy requirements. LinkedIn needed deterministic, fast, policy-driven recommendations, which is better achieved through fine-tuned smaller models.
What is a product policy document and why does it matter?
A product policy document is a detailed specification (typically 20-30 pages) that articulates exactly how a system should make decisions. For LinkedIn, this included rules about job-candidate matching across multiple dimensions: geography, seniority, industry, experience level, and more. This document serves multiple purposes: it aligns product and engineering teams, it provides the training signal for policy-focused teacher models, and it enables objective evaluation of whether the system behaves according to intended principles.
What are the advantages of smaller models over larger ones?
Smaller models offer several critical advantages in production systems: dramatically lower latency (sub-200ms instead of seconds), much lower infrastructure costs (smaller GPU memory requirements, less compute), easier deployment (can run on CPU or edge devices), better environmental efficiency (less power consumption), faster iteration during development, and more straightforward debugging. For most enterprise use cases, a well-optimized smaller model beats a larger generic model.
How do you balance policy compliance and business metrics like engagement?
LinkedIn uses two separate teacher models: one trained on policy compliance (using their product policy document and golden dataset) and one trained on click prediction (using historical user behavior). During student model training, both teacher signals are combined using weighted loss functions. The weights can be adjusted to prioritize policy compliance, user engagement, or a balance of both, depending on business priorities. This modular approach allows teams to update each objective independently.
What are the main challenges of implementing multi-teacher distillation?
The primary challenges include: (1) Added complexity - maintaining multiple models requires more engineering effort, (2) Data requirements - you need both policy-aligned golden data and behavior data for multiple teachers, (3) Hyperparameter tuning - balancing the loss weights between teachers requires careful experimentation, (4) Organizational friction - cross-functional collaboration between product and ML teams adds process overhead, and (5) Debugging difficulty - when results are suboptimal, it's harder to diagnose whether the problem is in a teacher model or in how they're being combined.
How long does it typically take to build a multi-teacher distillation system?
Based on LinkedIn's experience and industry practices, expect 3-6 months from initial concept to production deployment. This includes: 2-4 weeks for documenting product policy, 4-6 weeks for building the golden dataset and initial teachers, 6-8 weeks for distillation and compression, and 4-6 weeks for evaluation and optimization. The timeline depends heavily on data availability and how quickly your teams can align on requirements.
Can multi-teacher distillation improve performance compared to single teachers?
Yes, often. Because the student model learns from multiple specialized teachers rather than trying to be a generalist, it can sometimes achieve better performance on specific metrics than either teacher alone. LinkedIn's final student model actually showed better click prediction than their policy-only teacher, despite being much smaller. This happens because the smaller model is forced to learn efficiently and focus on the most important signals from both teachers.
What metrics should you measure when evaluating a distilled model?
Measure at least these categories: (1) Accuracy metrics specific to your policy (policy alignment %, etc.), (2) Business metrics (clicks, engagement, conversions), (3) Performance metrics (latency at various percentiles, memory usage), (4) Stability metrics (how much recommendations change for the same query), and (5) Fairness metrics (segmented performance across demographic groups). Track how each metric changes during compression to ensure quality loss stays within acceptable limits.
When should you NOT use multi-teacher distillation?
Skip multi-teacher distillation if: (1) you only have one clear objective to optimize, (2) your requirements are still being actively developed and changing frequently, (3) your current monolithic system already meets all your performance targets, (4) you have very limited training data, (5) your scale doesn't justify the engineering complexity (under 100K daily queries), or (6) your use case can tolerate the latency and compute costs of running large models. Multi-teacher distillation is an optimization for specific, well-defined problems at scale.

Conclusion: Why This Matters Beyond LinkedIn
LinkedIn's breakthrough with multi-teacher distillation is significant not because it's the first organization to use knowledge distillation. It's significant because they've created a repeatable, well-documented framework for building production AI systems at enterprise scale.
The key insight isn't technical. It's philosophical: building great AI products isn't about using the biggest models or the fanciest techniques. It's about being deliberate about what you're optimizing for, measuring it carefully, and iterating systematically.
The fact that prompting was a "non-starter" for LinkedIn is telling. It suggests the era of "just ask Chat GPT" for your production systems is ending. That approach works for one-off tasks and creative exploration. But for systems that need to make consistent, policy-aligned decisions at scale while hitting latency and cost targets? You need something more specialized.
You need fine-tuned models. You need careful measurement. You need cross-functional teams working together. You need to sweat the engineering details that most people overlook.
LinkedIn did this, and it's paying off with better recommendations, lower costs, and faster innovation cycles.
Other organizations are starting to realize this. The conversation is shifting from "how do we use GPT-4 for everything" to "how do we build optimized systems for our specific needs."
Multi-teacher distillation is one tool for that. The product policy document is another. The cross-functional process is the third. None of them are flashy. None of them will make it into clickbait headlines.
But together, they represent how sophisticated organizations actually build AI in production.
If you're tasked with building or improving AI systems at your organization, this is the blueprint to study. Not because you need to copy every detail. But because it shows what disciplined, thoughtful AI engineering actually looks like.
And that's worth a lot more than just bigger models.

Key Takeaways
- Prompting large language models cannot deliver the consistency, latency, and cost efficiency needed for production recommendation systems at enterprise scale
- Multi-teacher distillation allows organizations to combine policy-driven objectives with business metrics (like click prediction) in a single optimized model
- A detailed 20-30 page product policy document serves as both a specification tool and a training signal for machine learning models
- Model compression can reduce a 7 billion parameter model to 100 million parameters while maintaining or improving specific performance metrics
- Cross-functional collaboration between product and ML teams, enabled by detailed product policy alignment, is as important as the technical innovation itself
- Modular, plugable pipeline architecture enables 3-4x faster iteration cycles compared to monolithic ML systems
- The shift in enterprise AI is from 'bigger models are always better' to 'specialized, optimized models solve real problems better and cheaper'
Related Articles
- AI Hallucinated Citations at NeurIPS: The Crisis Facing Top Conferences [2025]
- ServiceNow and OpenAI: Enterprise AI Shifts From Advice to Execution [2025]
- Why CEOs Are Spending More on AI But Seeing No Returns [2025]
- MIT's Recursive Language Models: Processing 10M Tokens Without Context Rot [2025]
- Humans&: The $480M AI Startup Redefining Human-Centric AI [2025]
- OpenAI's 2026 'Practical Adoption' Strategy: Closing the AI Gap [2025]

