![Managing 20+ AI Agents: The Real Debug & Observability Challenge [2025]](https://tryrunable.com/blog/managing-20-ai-agents-the-real-debug-observability-challenge/image-1-1768664225684.png)
Managing 20+ AI Agents: The Real Debug & Observability Challenge [2025]
Introduction: The AI Agent Scaling Problem Nobody's Talking About
You've heard the hype. AI agents are everywhere now. Marketing agents, support agents, content agents, scheduling agents. Every SaaS company is racing to deploy them, and the deployment tools keep getting better. But here's what nobody's actually discussing: once you have 20, 50, or 200 AI agents running autonomously across your operations, making thousands of decisions every single day, how do you even know when something's wrong?
The story that sparked this whole conversation happened recently at a major SaaS company. They discovered a bug where one of their AI agents was still sending invitations to an event that had already happened. Seems simple enough to fix, right? The actual fix took maybe 20 minutes. But finding which of their 20+ autonomous agents was responsible? That took forever.
And that's the problem we're going to be dealing with for the next two years.
Deploying AI agents is getting easier by the week. Every major AI platform now offers agent frameworks. You can build a functional autonomous agent in hours, not months. But managing them at scale? Debugging them when things go wrong? Monitoring their outputs for quality and consistency? That's still in the stone age. We're applying 1990s observability thinking to a fundamentally different problem.
This isn't just a technical problem. It's going to be one of the defining infrastructure challenges of 2026 and 2027. Companies that figure out AI agent management will have a massive competitive advantage. Everyone else will be drowning in chaos.
Let's talk about why this problem exists, what we need to build to solve it, and what's already emerging in the market.

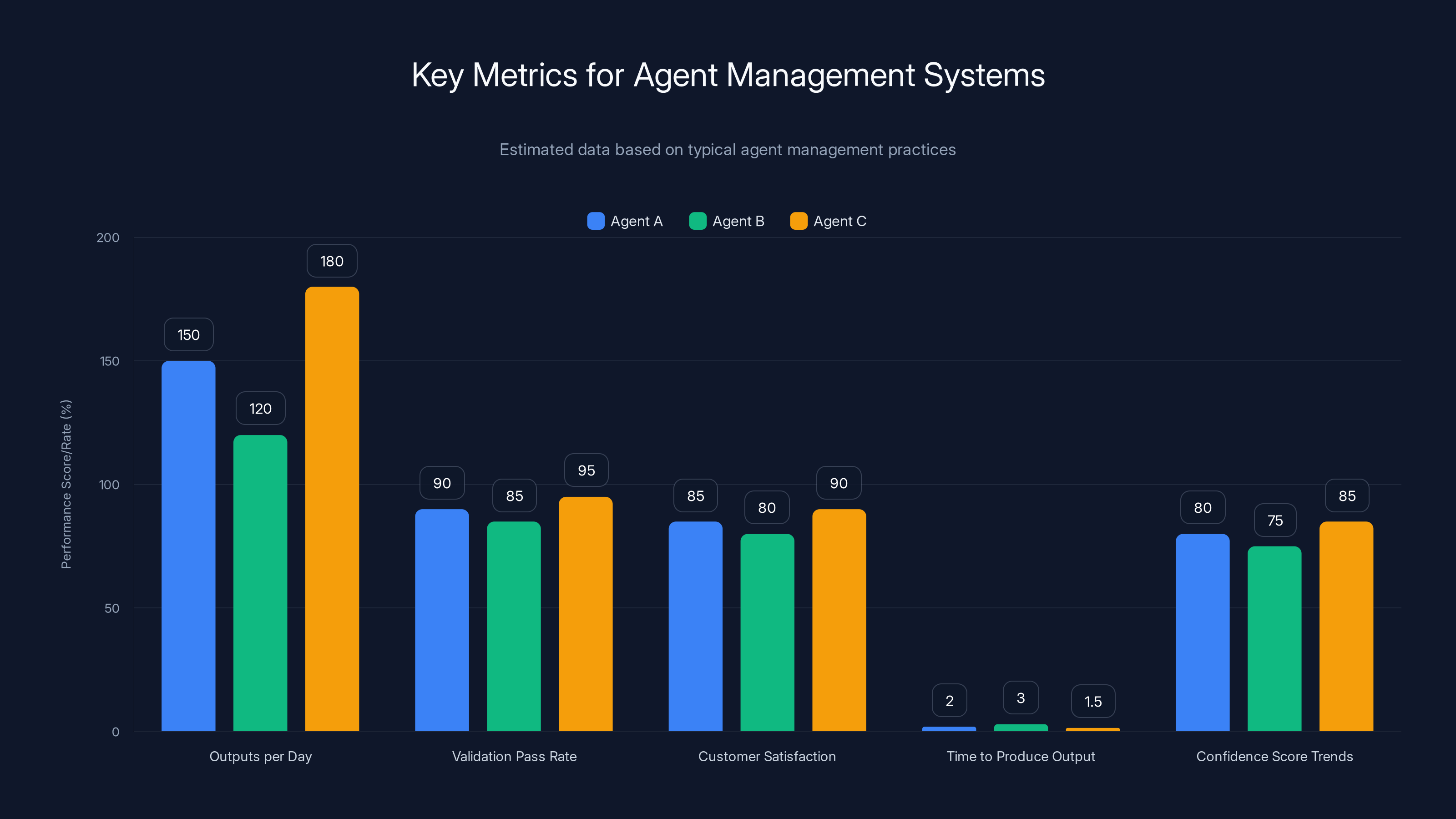
Estimated data shows Agent C leads in output volume and validation pass rate, while Agent A maintains a strong customer satisfaction score. Estimated data.
TL; DR
- The Problem is Real: Debugging issues across multiple autonomous AI agents is exponentially harder than traditional software debugging because agents make judgment calls, not deterministic outputs
- Scale Makes It Impossible: At 20 agents, debugging is annoying. At 200 agents, you can't manually track issues. At 1,000+ agents, you need automated solutions or chaos ensues
- Current Tools Are Insufficient: Traditional observability platforms like Datadog and New Relic weren't designed for AI agent complexity and non-deterministic behavior
- Master Agents Are Coming: The next infrastructure layer will be AI systems designed specifically to monitor, debug, and manage other AI agents in real-time
- Time is Running Out: Companies need to invest in agent management frameworks now, before their agent fleets become unmanageable
- Practical Solution: Implement agent logging, output validation, cross-agent consistency checks, and begin building or adopting Master Agent frameworks immediately
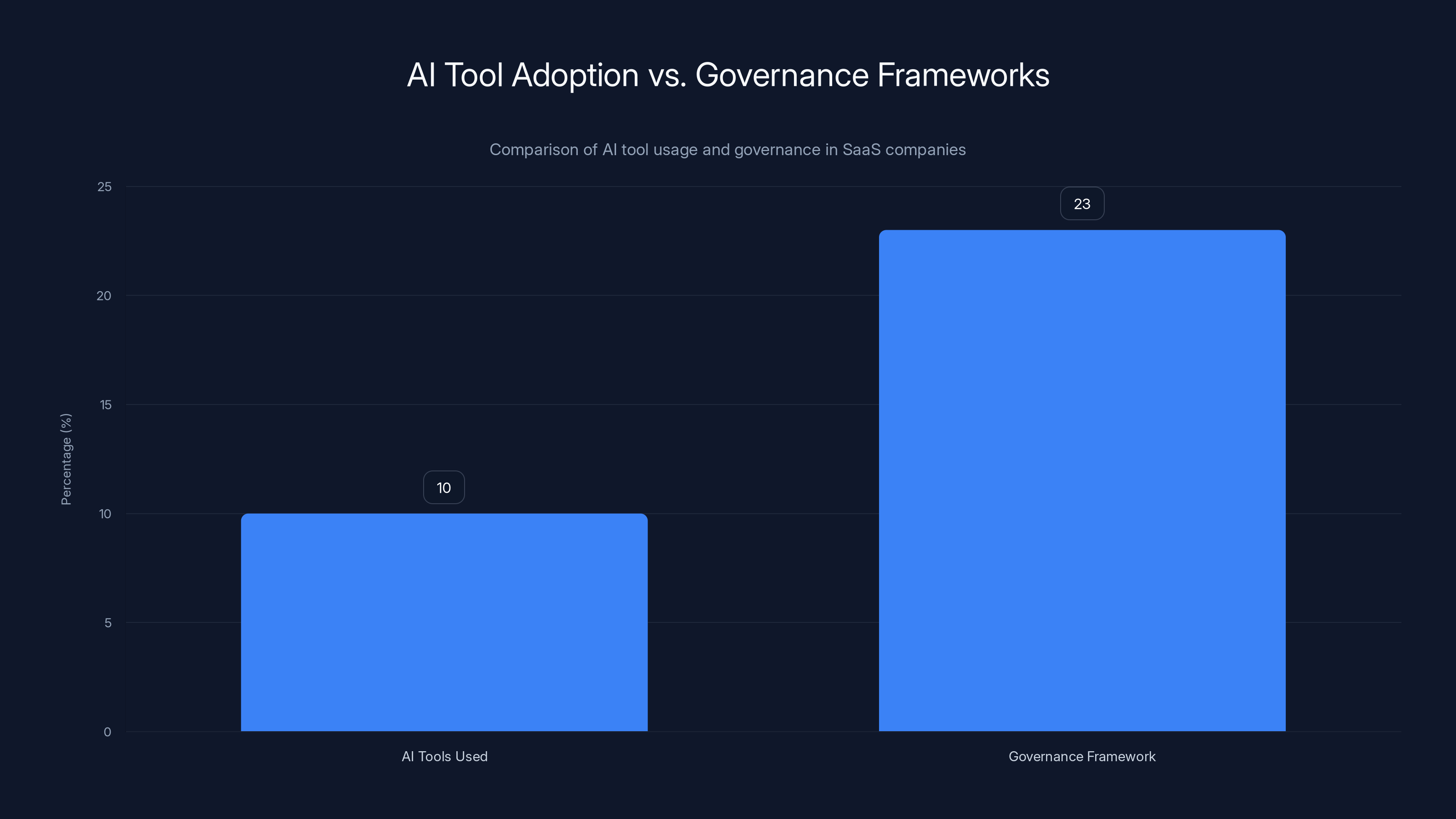
While SaaS companies use an average of 10 AI tools, only 23% have a formal governance framework, highlighting a significant management gap. (Estimated data)
The Current State: AI Agents Are Shipping Faster Than We Can Manage Them
The speed at which AI agents are being deployed is genuinely impressive. Platforms like Replit, Cursor, Anthropic's Claude, and OpenAI have made it trivially easy to spin up autonomous agents. You write a prompt. Define some tools. Set it running. Done.
The barrier to entry is basically zero now. Which means adoption is skyrocketing. Companies that were skeptical about AI six months ago now have teams building agent swarms to handle everything from customer support to content creation to sales prospecting.
But here's what's happened: the infrastructure for deploying agents scaled 10x faster than the infrastructure for managing them.
When you have one or two agents, you can manually audit their outputs. You can spot-check their work. You can have a human reviewing key decisions. It feels manageable.
But once you cross into double digits, the problem becomes exponential. A team of three people cannot manually review the outputs of 20 autonomous agents making thousands of decisions per day. It's mathematically impossible.
And that's where most teams are right now. They've deployed their agents. Things are working... mostly. But they have no visibility into the 5-10% of decisions those agents are making incorrectly. They don't know which agent sent that wrong email, scheduled that meeting incorrectly, or gave outdated information to a customer.
They're operating blind.
The Deployment-to-Management Gap
There's a massive, expanding gap between how easy it is to deploy an AI agent and how hard it is to manage one. Consider the timeline:
2023-2024: AI agent frameworks emerged. Building agents went from "requires a PhD" to "requires a decent prompt engineer." The barrier dropped precipitously.
2025: Agent deployment tools matured. Now you can deploy 20 agents in parallel. You can connect them to APIs, databases, and customer systems. You can automate entire workflows end-to-end.
2025-2026: The management problem explodes. Teams realize they have no idea what their agents are actually doing at scale.
This pattern has happened before. In the early cloud days, provisioning infrastructure became trivially easy, but observability didn't keep pace. We had to build Datadog, New Relic, Splunk. We had to invent logging frameworks, distributed tracing, and metrics aggregation.
We're about to replay that same cycle with AI agents. Except it's messier, because agents aren't deterministic.
Why Traditional Observability Doesn't Work for AI Agents
You might think you can just throw a traditional observability platform at the problem. Use Datadog or New Relic to monitor your agents the same way you monitor your backend services.
Nope.
Those tools were designed for deterministic systems. They track error rates, latency, resource usage, and state changes. When something goes wrong, there's usually a clear cause. A memory leak. A timeout. A database connection failure.
With AI agents, the failure modes are completely different:
Judgment call errors: The agent made a decision that was technically correct but semantically wrong. It recommended a competitor's product instead of yours. It misinterpreted customer intent. These aren't errors in the traditional sense. The system didn't crash. No exception was thrown. The agent just... made a bad call.
Emergent behavior failures: Two agents interacting with each other produce unexpected behavior. Agent A tells the system to do X. Agent B independently decides to do Y. Combined, they create a contradiction or loop. This kind of failure barely exists in traditional software.
Context drift: An agent was trained on data from three months ago. It doesn't know about the new product launch, the pricing change, or the policy update. Its outputs are confidently, completely wrong. But it's not a bug. It's working as designed. It just has stale information.
Majority failures: 85% of the agent's outputs are perfect. 15% are wrong or outdated. Traditional observability would ignore this as "acceptable error rates." But in customer-facing scenarios, that 15% can destroy trust.
Traditional monitoring tools have no way to detect these failure modes. They can tell you the agent ran. They can tell you it completed. They can't tell you whether the agent's output was actually good.
You need something fundamentally different.
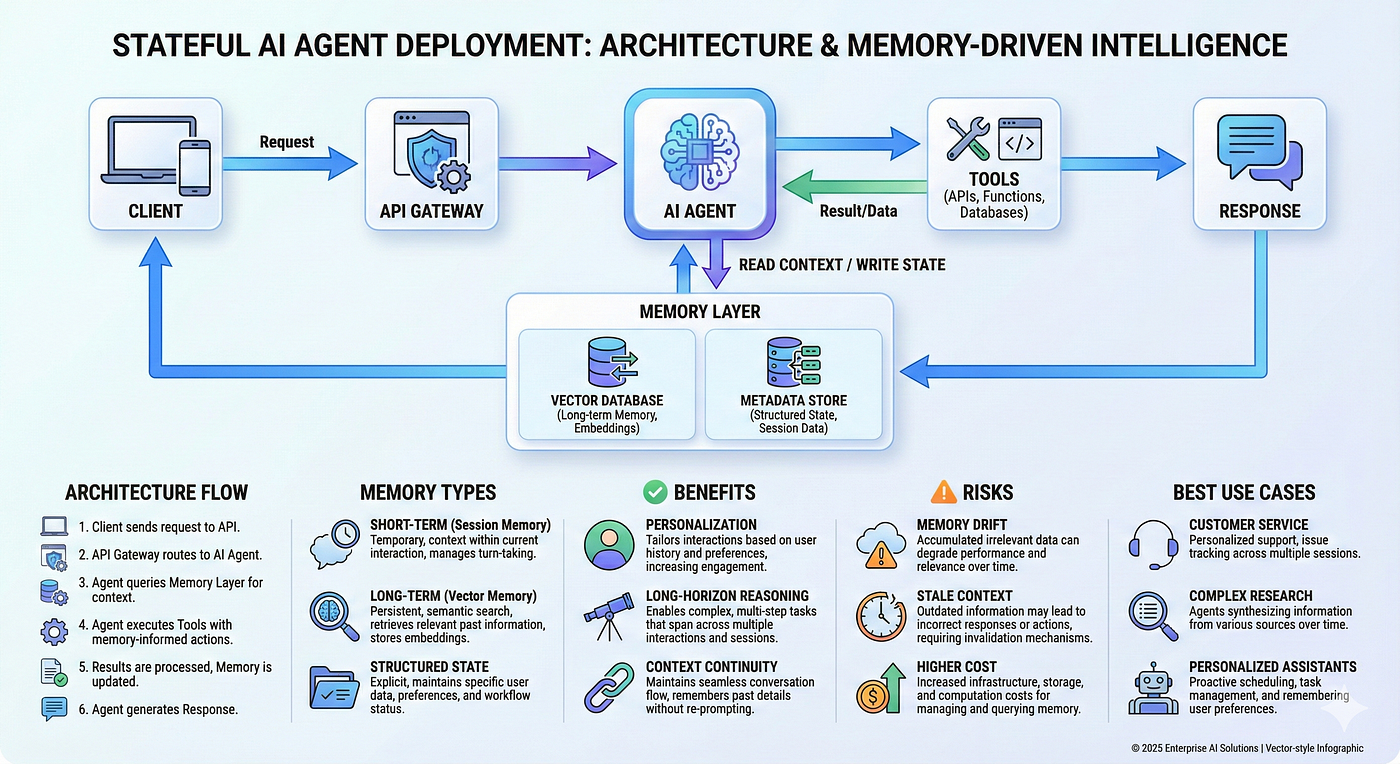
The Real Story: One Bug Across 20+ Agents
Let's walk through what actually happened, because it's illustrative.
A major SaaS platform discovered that their AI agents were still promoting an event that had already occurred. Specifically, they were telling prospects to sign up for a conference happening on December 1-2. Except it was already December 17.
The fix itself: update the agent's context to note that the event is over. Maybe add a filter to prevent past events from being promoted. Thirty minutes of work, tops.
The actual problem: which of the 20+ agents was doing this?
Think about that. The company had:
- Marketing agents sending outreach emails
- Support agents answering customer questions
- Content agents updating website copy
- Scheduling agents managing calendars
- Qualification agents pre-screening leads
- And more
Any one of them could have been promoting this event. The agents didn't know about each other. They had different contexts, different knowledge bases, different instructions. One of them had stale information about the event schedule.
Finding which one required:
- Auditing email logs to see which outreach mentioned the event
- Checking which agent sent that email
- Reviewing that agent's instruction set
- Finding the stale context
- Fixing it
- Verifying the fix
That's not 30 minutes. That's hours.
And that was with 20 agents. Imagine scaling this to 50 agents. 100 agents. 500 agents. At some point, you can't manually debug anymore. You don't have the person-hours. You don't have the visibility.
Why It Took So Long
The fundamental issue is that each agent was operating in its own context. The marketing agent had its own knowledge base. The support agent had a different one. The content agent had yet another.
There's no single pane of glass showing you all agent activity. No central dashboard. No unified debugging interface.
Compare this to traditional microservices debugging. Your service is acting weird? You check the logs. All services output to a central logging system. You can trace a request through the entire stack. You can see exactly which service caused a problem.
With AI agents, there's no central logging framework, at least not yet. Most companies cobbling together home-grown solutions using basic logging tools. Some agent outputs go to Slack. Some go to email. Some go to a database. Some disappear into the void because nobody set up logging.
It's chaos.
And that chaos multiplies as you add more agents. At some point, the problem becomes genuinely unmanageable without a different infrastructure approach.
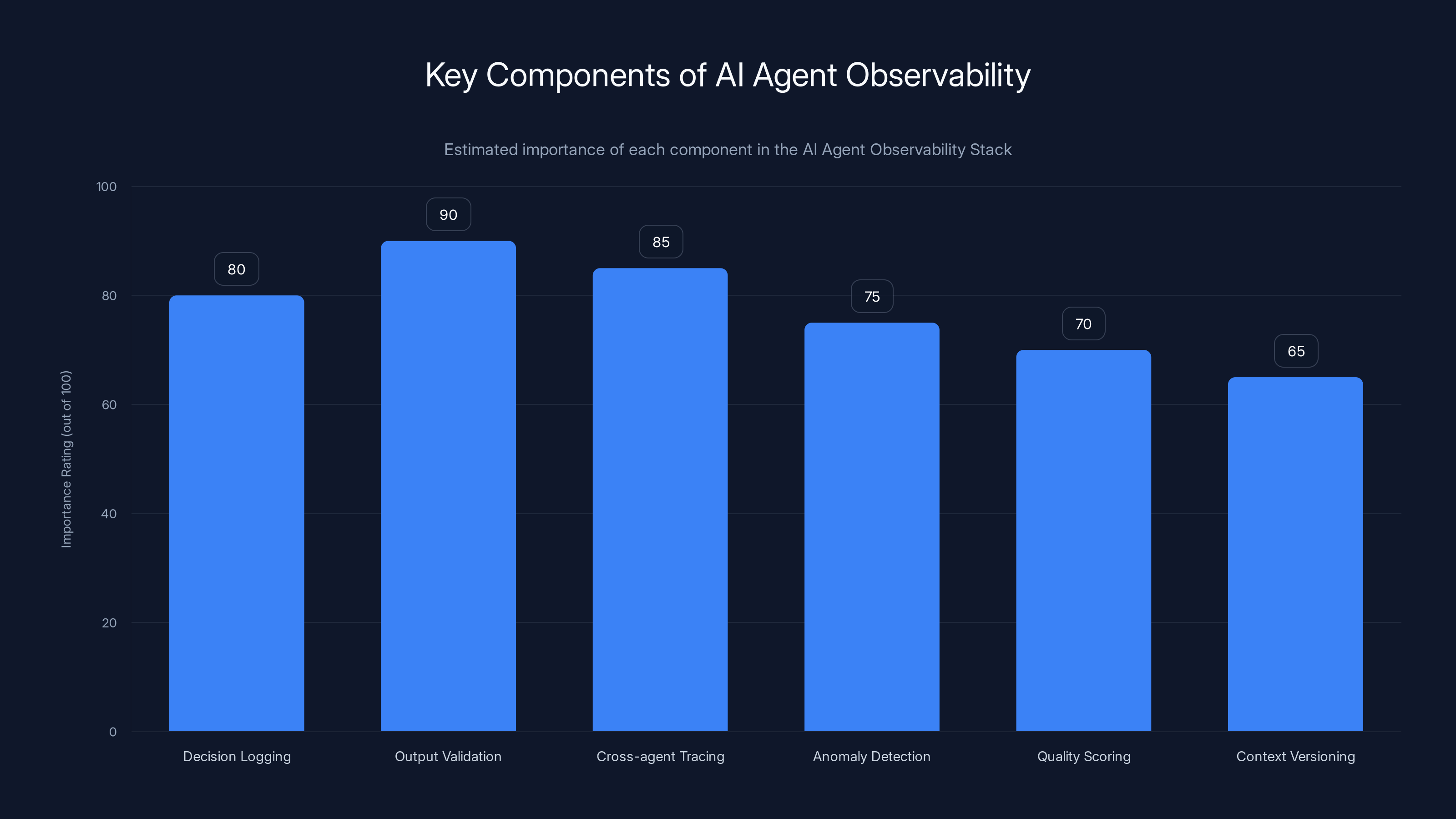
Output validation is estimated to be the most critical component, accounting for 40% of the observability problem. Estimated data.
The Exponential Problem: From 20 Agents to 200 Agents
Here's the thing about scaling AI agent systems: the problem doesn't scale linearly. It scales exponentially.
At 5 agents, you can manually oversee everything. One engineer can keep track.
At 20 agents, you need systems. Logging, monitoring, some kind of dashboard. But you can still manually debug when something goes wrong.
At 50 agents, manual debugging becomes painful. You need automated detection of anomalies.
At 200 agents, manual debugging is impossible. You need automation or you're dead.
At 1,000 agents, you don't even have a centralized human team anymore. You need systems that manage systems.
Let's think about the math. If your 200 agents each make 100 decisions per day, that's 20,000 decisions daily. If just 2% go wrong (which is actually pretty good), that's 400 broken decisions per day. 400 incorrect emails, wrong recommendations, outdated information, bad customer experiences.
No human team can audit 400 broken decisions per day and fix them manually. You'd need dozens of people doing nothing but auditing agent outputs.
So the industry will face a hard choice: build automated management systems, or stop scaling agents.
Everybody's going to choose the first option.
The Timeline to Unmanageability
Let's project what's coming:
2025 (Now): Companies aggressively deploying agents. 5-20 per organization. Debugging is still manual but painful. The first companies to hit 30-40 agents start experiencing serious management issues.
2026: Mid-market SaaS companies hit 50-100 agents. Manual debugging becomes impossible. Emergency management tools emerge. Companies start investing in agent infrastructure.
2027: Enterprise SaaS and tech companies hit 200-500 agents. The "AI Dev Ops" category explodes. Every major infrastructure company launches AI agent management tools.
2028: Mature organizations have 1,000+ agents. Humans are basically out of the debugging loop except for exception handling. Master agents managing agent swarms become standard.
Right now, we're in the early stages of 2025. Which means the problem is about to hit hard for a lot of companies.
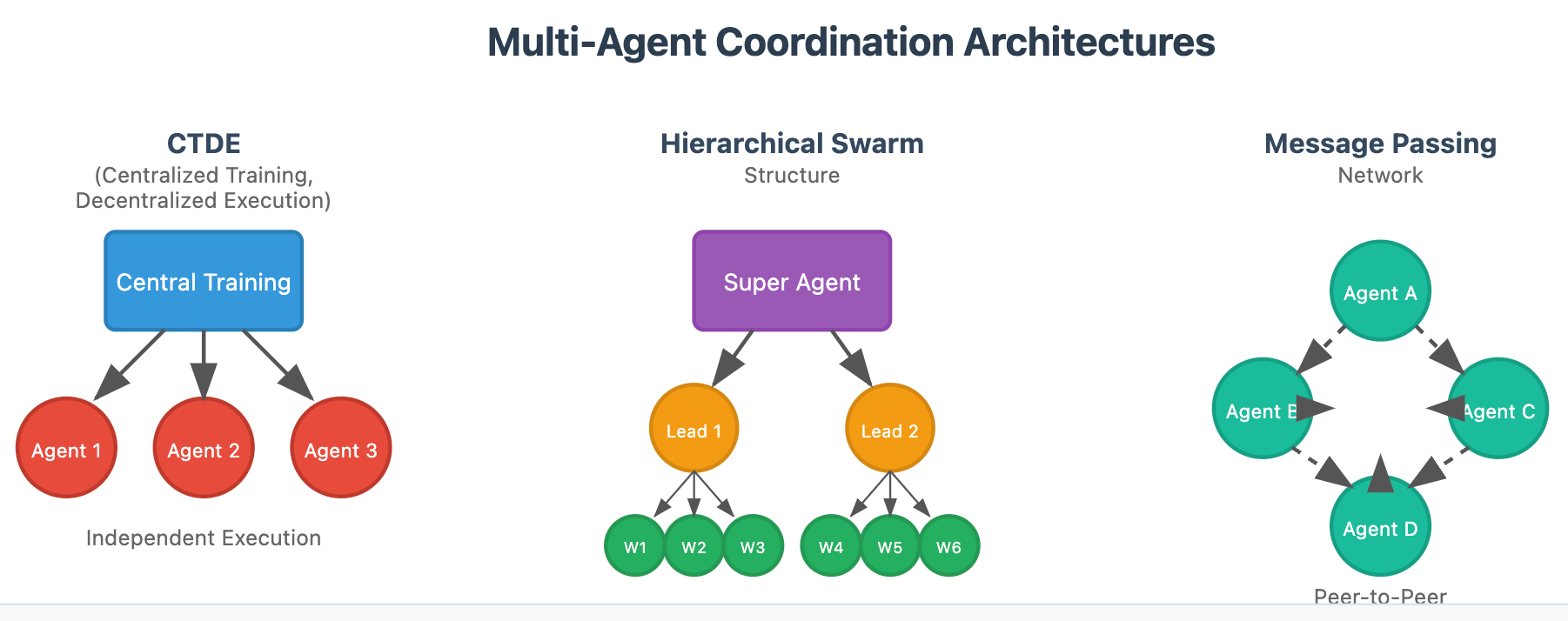
The Interagent Coordination Problem
Scaling isn't just about having more agents. It's about agents interacting with each other in ways you didn't anticipate.
Agent A triggers Agent B, which feeds information to Agent C, which makes a decision that conflicts with Agent D, creating a loop that wastes resources.
Agent A says "this customer is high-value." Agent B independently concludes "this customer is risky." Your system gets conflicting signals.
Agent A updates customer context in the database. Agent B hasn't refreshed yet and operates on stale information, making a bad decision.
These coordination problems barely matter at 5 agents. They become critical at 100+ agents.
Traditional software handles coordination through APIs, schemas, and explicit contracts between services. Two microservices have a defined interface. Both teams agree on the contract. If one team breaks it, the other team's tests catch it.
With AI agents, those contracts are implicit and linguistic. Agent A says "I'm going to update the customer status." Agent B happens to also update the same field. Now you have a race condition, except it's happening in natural language and nobody's catching it.
You need explicit agent coordination frameworks. You need ways to say "Agent A owns this decision, Agent B must defer to it." You need conflict resolution policies. You need transactional consistency across agent outputs.
None of this exists yet at scale. It's coming, but it doesn't exist.
Master Agents: The Emerging Solution
So what's the answer? How do we manage 200, 500, 1,000 autonomous agents?
The answer that's emerging is beautifully recursive: use AI agents to manage other AI agents.
Enter the Master Agent.
A Master Agent is an AI system whose sole job is monitoring, debugging, and managing downstream worker agents. It sits above the operational agents and continuously:
- Monitors their outputs for quality
- Detects inconsistencies and conflicts
- Catches outdated information
- Flags brand voice violations
- Traces customer issues back to root cause
- Suggests fixes
- Potentially implements fixes autonomously
Think of it like this: if your 100 operational agents are workers on a factory floor, the Master Agent is the factory supervisor walking around, spotting problems, and coordinating activity.
Or if your agents are like microservices, the Master Agent is like your observability platform and your Dev Ops team rolled into one intelligent system.
The beauty of this approach is that it's scalable. One Master Agent can oversee hundreds of worker agents because it doesn't manually check every output. It uses AI to detect anomalies, spot patterns, and surface issues to humans for final review.
What Master Agents Actually Do
Output validation: Master agent checks every agent output against a set of rules. Is this information current? Does it match brand voice? Is it consistent with other agent outputs? Does it align with company policy? Flag anything that fails validation.
Cross-agent consistency: Two agents gave contradictory information to the same customer? Master agent catches it. Agent A says the feature ships next week. Agent B says next month. Master agent escalates.
Context freshness detection: This agent's information comes from March training data. It's now December. Master agent flags the information as potentially stale and either refreshes context or pulls the agent from answering that type of question.
Root cause tracing: Customer complained that an agent gave them outdated pricing. Master agent traces back through logs, identifies which agent made the error, reviews that agent's context, and reports the finding.
Autonomous fixing: Master agent detects a systematic issue (all agents are using old pricing). Master agent autonomously updates their context. Workers don't need to be restarted. The fix happens in real-time.
Performance monitoring: Master agent tracks which agents are performing well, which are underperforming, and suggests which should handle certain types of questions.
Learning loop: Master agent sees patterns in mistakes and suggests adjustments to agent prompts, context, or decision-making frameworks.
This is fundamentally different from traditional monitoring because the Monitor is itself an AI system that understands context, can reason about problems, and can make sophisticated decisions about what's actually broken versus what's just different.
Examples Already Emerging
Some of this already exists in limited form. Replit has multi-agent frameworks where senior agents coordinate junior agents. Cursor has similar concepts for code generation.
But these are within single applications, orchestrated by the platform itself.
What's missing is the general-purpose Master Agent framework that works across your entire agent fleet, regardless of where agents are deployed or what they're doing.
That's coming. Probably 2026.

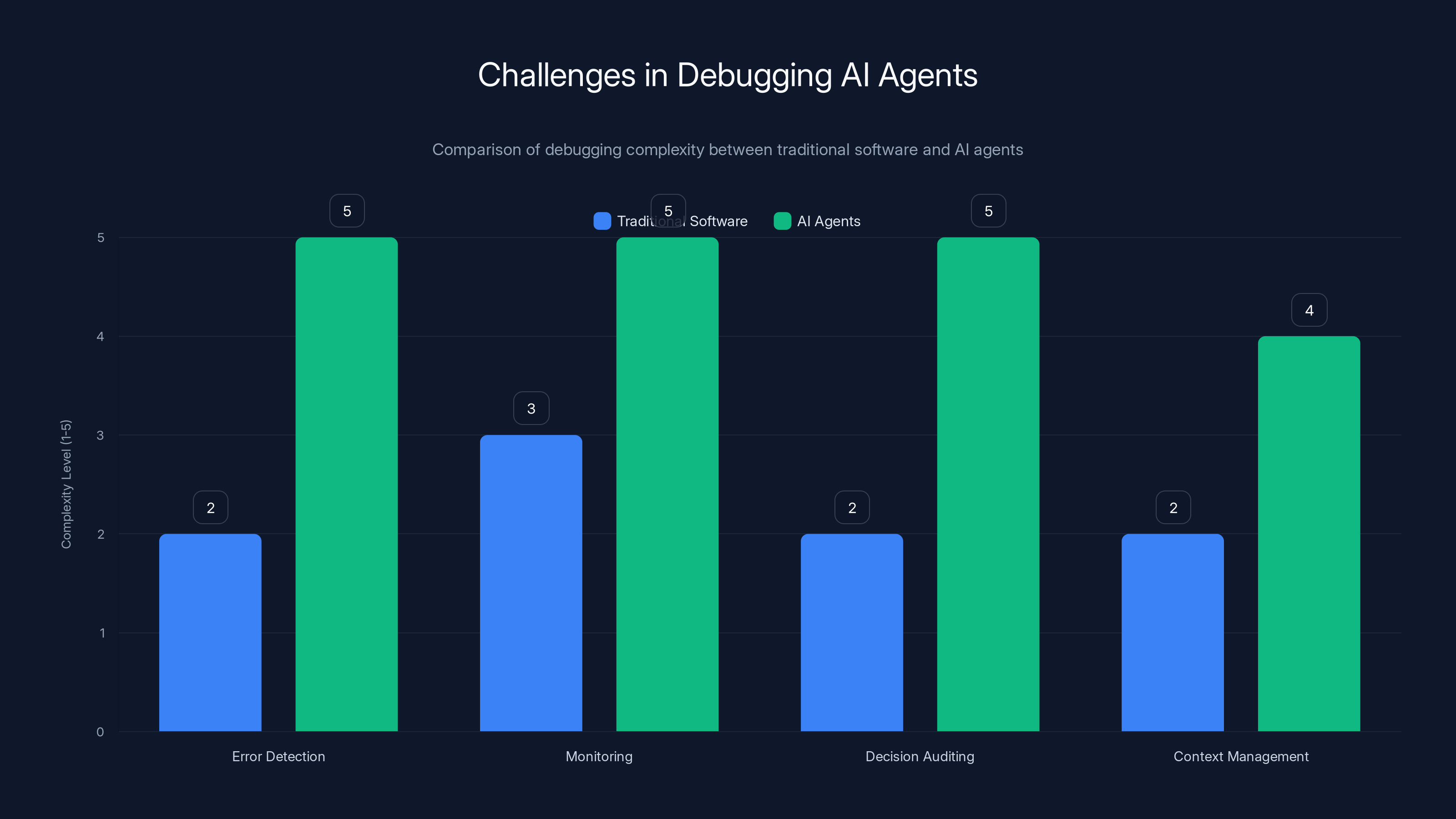
AI agents present higher complexity in debugging due to probabilistic behavior and lack of unified monitoring, compared to traditional software. Estimated data.
The Observability Problem: We Need New Tools
Master Agents are part of the solution, but they require underlying observability infrastructure that largely doesn't exist yet.
Traditional observability solves three problems:
- Logging: Where and why did an event happen?
- Metrics: What's the overall system health?
- Tracing: How did a request move through the system?
For AI agents, we need something completely different.
The AI Agent Observability Stack
Decision logging: Every decision an agent makes needs to be logged with full context. What was the input? What reasoning did the agent apply? What was the output? What was the confidence level? This is way more detailed than traditional request logging.
Output validation framework: You need a framework for checking agent outputs against rules. Output validation is probably 40% of the observability problem, and almost nobody has this set up.
Cross-agent tracing: A customer got bad information from Agent A, which received that information from Agent B. The system needs to trace this chain automatically. Traditional distributed tracing exists for microservices, but AI agent tracing is more complex because the "call" is implicit and linguistic.
Anomaly detection: You can't manually spot all the issues. You need ML models that learn what normal agent behavior looks like and flag deviations. "Agent usually has 92% confidence. Today it's at 54%. Something's wrong."
Quality scoring: Each agent output gets a quality score: How accurate is it? How helpful? How consistent with brand voice? Over time, you can trend these metrics and spot degradation.
Context versioning: When did this agent last update its knowledge base? What version of context is it operating on? Two agents using different context versions could produce inconsistent outputs. You need to track and flag this.
Failure pattern recognition: The system sees that Agent A fails 15% of the time when handling a certain type of question. The system recommends removing Agent A from that domain or updating its training.
None of these pieces are standardized yet. Every company that's seriously building agent infrastructure is homebrewing their own version of this stack.
But the market will standardize this. Just like we standardized on the traditional observability stack in the 2010s.
The Missing Layers
If you're building agent systems right now, you're going to discover that standard observability platforms are insufficient. Here's what's missing:
Agent-specific metrics: Traditional metrics are things like latency, error rate, CPU usage. For agents, you need different metrics. Confidence scores. Output quality. Cross-agent consistency. Decision speed. Reasoning clarity.
Semantic understanding: Traditional tools can tell you "this request failed." Agent tools need to tell you "this agent is making judgment errors that are semantically problematic but technically valid."
Context awareness: Traditional tools track state changes. Agent tools need to track context quality and freshness. Is this information still accurate? Has the business changed?
Prompt visibility: When an agent behaves unexpectedly, you need to see its prompt. Its system message. Its few-shot examples. Traditional monitoring doesn't capture this.
Reasoning traces: You need to understand not just what decision the agent made, but why. What reasoning chain led to it? What information did it weight? This requires agents to output their thinking, then tools to capture and analyze it.
Building all this is non-trivial. But it's about to become table stakes.

The Risk of Not Solving This Now
Companies that ignore the agent management problem are going to hit a wall hard.
Here's what the wall looks like:
6 months from now: You've deployed 30 agents across your operation. They're handling customer support, lead qualification, content generation, scheduling. Most outputs look fine. Then you get a customer complaint: "Your agent recommended your competitor's product." You have no idea which agent did this, why, or if it's happening to other customers too.
9 months from now: You've deployed 50 agents. You're starting to see patterns of problems but no systematic way to track them. You have three engineers spending half their time debugging agent issues instead of building product. You're missing your roadmap.
12 months from now: You've deployed 80 agents because your team loves agent technology. But you're drowning. You have no idea what your agents are actually doing at scale. Your customer support is being handled by agents you don't fully understand. You have zero visibility. Risk is extremely high.
18 months from now: You're hearing from investors that your agent infrastructure is a liability, not an asset. You've spent months building it but you have no way to ensure quality at scale. You have a choice: shut down agents and go back to traditional software, or invest 6 months in building infrastructure you should have built 12 months ago.
This is going to happen to a lot of companies. Not because they made a bad decision to use agents. But because they thought deployment was the hard part.
The hard part is management.
Real Risks
Brand damage: Your agent says something offensive or wrong to a customer. It wasn't caught by your system. Customer posts about it on social media. You have no explanation because you have no visibility.
Compliance issues: Your agent makes a decision that violates a policy or regulation. Because you're not monitoring agent decisions, you don't catch it. Lawyer gets involved.
Operational chaos: Your agents contradict each other. Customer gets told one thing by Agent A and the opposite by Agent B. Your team can't explain why.
Information security: Your agent leaks sensitive information. Because you're not monitoring outputs, you don't notice the breach immediately. By the time you find it, the damage is done.
Lost productivity: Your team spends half their time debugging agent behavior because the infrastructure doesn't exist to automate debugging.
All of these are avoidable. But only if you invest in agent management infrastructure now.

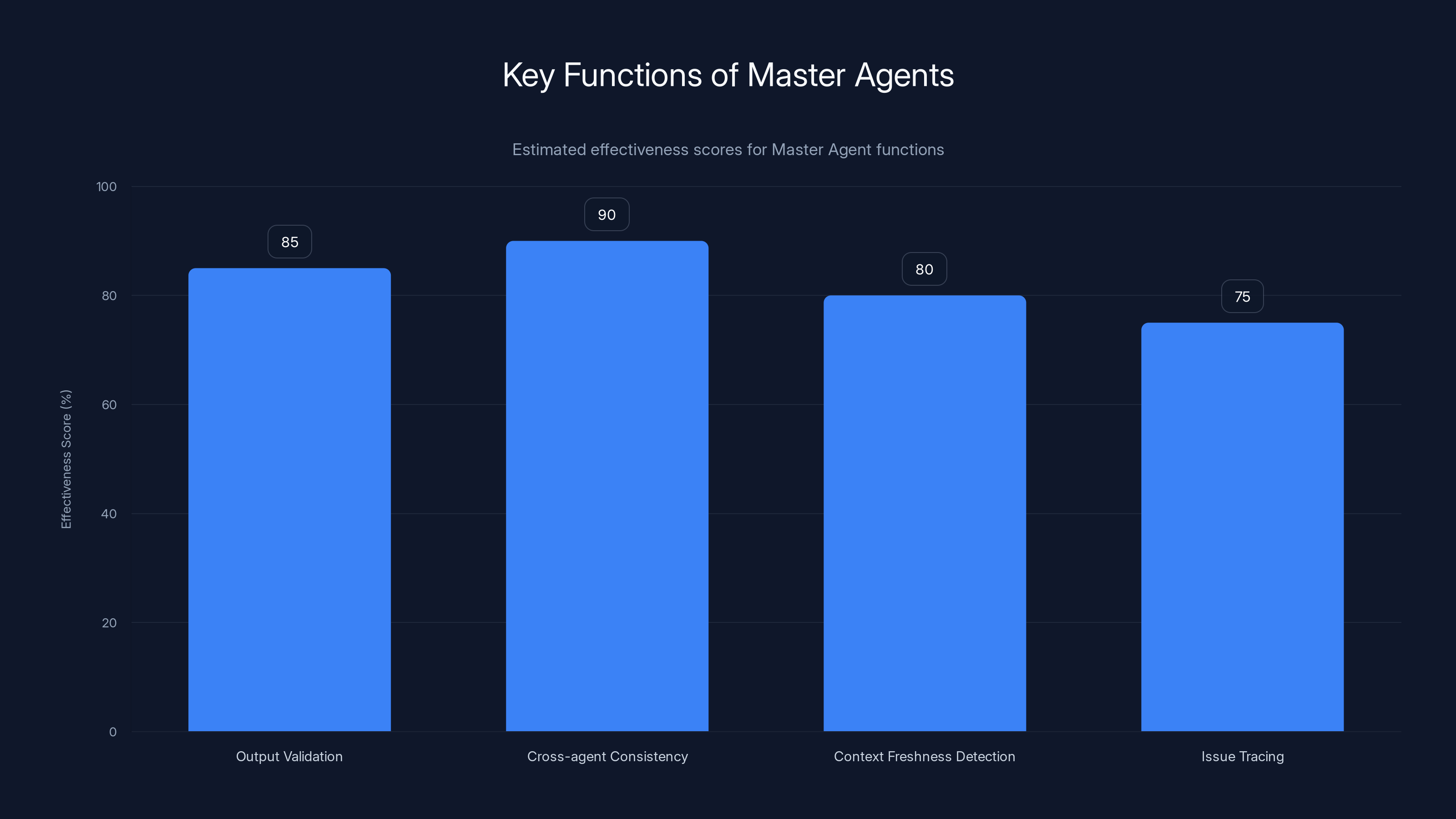
Master Agents are highly effective in managing AI workers, with cross-agent consistency scoring the highest at 90%. Estimated data.
How to Start Building Agent Management Today
You don't need to wait for perfect tooling to exist. You can start now with sensible practices.
Step 1: Establish Unified Logging
Every agent output goes to a single place. Not Slack. Not email. A logging database.
What gets logged:
- Agent name and ID
- Timestamp
- Input (what triggered the agent)
- Output (what the agent produced)
- Confidence scores
- Context version (when was this agent's knowledge base last updated)
- Metadata (which customer, which session, etc.)
This is foundational. Everything else builds on this.
Step 2: Build Output Validation Rules
Define rules that every agent output must pass before it reaches customers:
- Output contains current information (no outdated dates, prices, details)
- Output matches brand voice and tone standards
- Output doesn't contradict known facts in your system
- Output is compliant with legal and policy requirements
- Output is actually responsive to the input
Automate these checks. Every agent output is validated automatically. Failures are logged and flagged.
Step 3: Implement Cross-Agent Consistency Checks
Build systems that detect when two agents give contradictory information:
- Agent A says feature ships next week. Agent B says next month. System flags the contradiction.
- Agent A recommends Product X. Agent B recommends Product Y for the same use case. System escalates for review.
- Agent A marks customer as "high value." Agent B marks same customer as "risky." System asks which is correct.
Step 4: Create Agent Performance Dashboards
For each agent, track:
- How many outputs per day
- Output validation pass rate
- Customer satisfaction with outputs (if you can measure it)
- Time to produce output
- Confidence score trends
- Error patterns
Dashboard lets you quickly see which agents are degrading, which are performing well, and where to focus attention.
Step 5: Build Context Freshness Tracking
Every agent's context has a "last updated" timestamp. System automatically flags outputs from agents whose context is older than X days.
When you update context (new pricing, new features, policy changes), you update a central registry. System tracks which agents have been updated.
Step 6: Implement Root Cause Tracing
When a customer reports an agent gave them bad information, you need to trace it:
- Which agent made the statement?
- What was the agent's context at that time?
- What input triggered the response?
- Why did the agent make that decision?
This requires comprehensive logging and good tooling around it. But once you have it, debugging becomes 10x faster.
Step 7: Plan for Master Agents
Don't build one yet if you only have 20 agents. But start architecting for it.
When you do implement a Master Agent, what will it need?
- Access to all agent logs
- Ability to validate outputs
- Ability to detect contradictions
- Ability to assess context freshness
- Ability to suggest or implement fixes
- Ability to update agent context
Design your systems now with this in mind. Make sure agents are modular enough that a Master Agent could update their context or configuration.
Tools and Frameworks Emerging in the Space
The market is starting to recognize this problem. Some tools are emerging to address it.
Specialized Agent Frameworks
Anthropic's Claude has been pushing on extended thinking and structured outputs, making agent reasoning more transparent.
OpenAI is moving toward more observable agent architectures with improved logging and tracing.
LangChain provides some observability hooks for agents, though they're still pretty basic.
Llama Index offers observability for retrieval-augmented generation (RAG) systems, which is related but different.
Platform-Level Solutions
Some platforms are starting to build agent management into their core offering:
Replit has multi-agent frameworks with some built-in coordination.
Cursor has agent coordination for code generation.
But none of these are comprehensive solutions yet. The market is waiting for the first company to build the equivalent of Datadog for AI agents.
Logging and Observability Adaptations
Datadog is starting to add AI-specific features.
New Relic is exploring agent monitoring.
Elastic has some AI observability features.
But they're all still in early innings.
The Gap
What's missing: a comprehensive platform that lets you deploy, monitor, debug, and manage a fleet of 100+ AI agents in production. Something purpose-built for agent infrastructure, not a retrofit of traditional observability tools.
That's the opportunity. Someone's going to build it. Probably 2026.
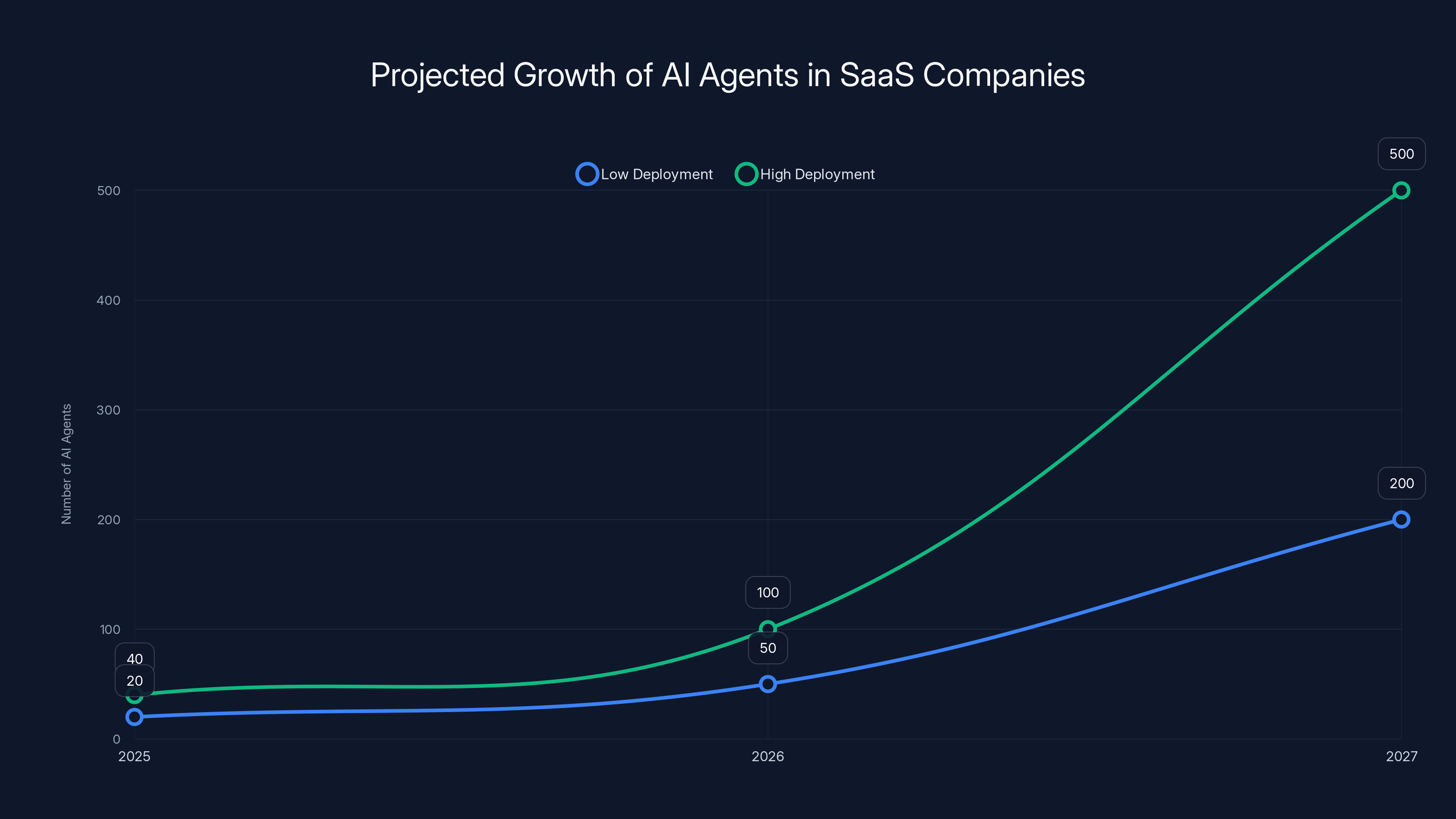
Estimated data shows a rapid increase in AI agent deployment, with companies moving from 20-40 agents in 2025 to potentially 200-500 agents by 2027. This growth necessitates advanced management systems.
Best Practices for Agent Teams Right Now
While the perfect tools are being built, here's how to operate responsibly with agents at scale:
Architecture Principles
Narrow agent scope: Don't build a single agent that does 10 things. Build 10 agents that each do one thing well. This makes debugging and accountability much clearer.
Clear boundaries: Each agent should have explicit boundaries. Agent X handles refunds. Agent Y handles returns. No overlap. No ambiguity.
Explicit handoffs: When Agent A needs to delegate to Agent B, make the handoff explicit and logged. Not implicit.
Centralized context: All agents should pull from the same context repository. Not copies of context. A single source of truth that all agents reference.
Synchronous validation: After an agent produces output, validate it before it reaches the customer. Don't ship first and debug later.
Operational Practices
Daily audits: Review a random sample of agent outputs every day. Track quality trends. If quality degrades, investigate immediately.
Incident post-mortems: Every time an agent makes a significant mistake, do a post-mortem. Why did it happen? How do we prevent it? Document the findings.
Context freshness discipline: Whenever business information changes (pricing, features, policy), immediately update agent context. Don't batch these updates.
Agent versioning: When you update an agent's system prompt or behavior, bump the version. Track which version is in production. Make it easy to roll back.
Customer feedback loops: When customers complain about agent outputs, capture that feedback. Feed it into your quality metrics. Track patterns.
Team Structure
Dedicated AI ops person: Even with 5-10 agents, you need someone responsible for agent infrastructure. Not someone who does it "sometimes." Someone dedicated.
Cross-functional reviews: When designing a new agent, involve marketing (for brand voice), legal (for compliance), engineering (for integration), product (for goals).
SLA clarity: Define what acceptable agent behavior looks like. What's the target error rate? What's the target confidence level? What's the target response time? Track against these SLAs.

Future State: Agent Mesh Architecture
Imagine the future state of agent infrastructure. Maybe 2027 or 2028.
You have 500 agents deployed across your organization.
Master agents monitor them continuously, 24/7. Output validation is automated. Inconsistencies are detected automatically. Context freshness is tracked.
When an agent misbehaves, the Master Agent investigates. It identifies the root cause. If it's a context issue, it fixes it autonomously. If it's a systemic issue with the agent's behavior, it escalates to your team.
A human reviews the escalation. Takes 5 minutes. Approves the fix. Moves on.
Your team never manually debugs an agent again. They design agents. They set policies. They handle exceptions. But the day-to-day management is handled by Master Agents.
Each agent has accountability. You can see exactly what Agent X did, when, why, and what the outcome was. If something goes wrong, you can trace it back and fix it.
Your agent infrastructure is trustworthy. You can deploy new agents confidently because you have visibility and management.
This isn't fantasy. This is what's coming. The companies that build it first will have massive competitive advantages.
Why This Matters for Your Business Right Now
If you're deploying AI agents, this isn't theoretical. This is going to hit you in 6-12 months.
Right now, while you have 5-10 agents, is the time to build infrastructure. To establish logging practices. To set up validation frameworks. To think about how you're going to manage 10x more agents.
The companies that move fast on agent infrastructure will be able to scale their agent fleets fearlessly. They'll ship more agents, faster, with more confidence. They'll catch problems before customers do. They'll have competitive advantages.
The companies that ignore this problem will get stuck at 20-30 agents, drowning in complexity. They'll have no visibility. They'll be afraid to add more agents because they're not confident in their management. They'll watch competitors pull ahead.
This is similar to the microservices transition. Companies that invested in observability, deployment infrastructure, and operational practices early won. Companies that tried to manually manage 50 microservices without infrastructure lost.
History is about to repeat itself with AI agents.

The Bottom Line: Build for Scale Now
The deployment-to-management gap is real. Deploying AI agents is easy. Managing them at scale is hard. Really hard.
Right now, we're in a moment where deployment tooling is 5x better than management tooling. That gap will close, probably over the next 12-18 months. But in the meantime, companies need to be intentional about building management infrastructure.
Start now:
- Establish unified logging for all agent outputs
- Build output validation frameworks
- Implement consistency checking across agents
- Create agent performance dashboards
- Track context freshness
- Build root cause tracing capabilities
- Plan your Master Agent architecture
Do this while you have 5-10 agents, and scaling to 50, 100, or 500 agents becomes manageable. Skip it, and you'll be drowning in complexity by next year.
The bug hunt that took hours to find which of 20 agents caused a problem? That's going to be every day if you're not ready.
Be ready.
FAQ
What is an AI agent?
An AI agent is an autonomous system that can perceive its environment, make decisions, and take actions without constant human oversight. Unlike traditional chatbots that respond to individual queries, AI agents operate continuously, often managing complex workflows, making decisions, and interacting with other systems or people independently. Agents combine language models with planning capabilities, tool access, and memory to accomplish multi-step objectives.
How do AI agents differ from traditional software?
Traditional software operates deterministically—given the same input, it produces the same output. AI agents operate probabilistically and can make judgment calls. A traditional system either works or fails. An agent can "work" technically while producing semantically incorrect outputs. Traditional software failures usually have clear error codes. Agent failures are often subtle: outdated information, inconsistent reasoning, or decisions that don't align with business context. This makes monitoring and debugging fundamentally different.
Why is debugging multiple AI agents so difficult?
Debugging becomes exponentially harder as agent count increases because you lose visibility into which agent caused a problem. With traditional software, errors usually produce exceptions or clear failure signals. With agents, problems can be subtle: wrong judgment, outdated context, or emergent behavior from agent-to-agent interactions. Additionally, each agent operates in its own context with its own knowledge base, and there's typically no unified monitoring system to track cross-agent behavior. You'd need manual auditing of hundreds or thousands of daily decisions to catch problems, which isn't feasible at scale.
What is a Master Agent?
A Master Agent is an AI system designed specifically to monitor, manage, and debug other AI agents. It operates like a supervisor for your agent fleet, continuously validating outputs, detecting inconsistencies between agents, flagging outdated information, and tracing customer issues back to root causes. Master Agents can identify patterns in agent behavior, suggest improvements, or even implement fixes autonomously. They scale the management problem by replacing human-intensive debugging with AI-powered monitoring.
What observability tools should I use for AI agents?
Currently, no single tool comprehensively handles AI agent observability. Traditional platforms like Datadog and New Relic can capture some data but weren't designed for agent-specific challenges. Most companies currently combine basic logging infrastructure with custom dashboards and manual auditing. Best practice is to build your own framework: centralized logging of all agent outputs, automated validation rules, cross-agent consistency checking, and performance metrics tracking. Specialized tools for agent observability are emerging in 2025-2026, so evaluate new offerings as they launch.
How many agents can one person manage?
Manually? Roughly 20-50 before quality assurance becomes impossible. At 20 agents making thousands of decisions daily, one person cannot review and audit everything. This is why infrastructure becomes critical. With automated logging, validation, and Master Agent monitoring, a single person can theoretically manage hundreds of agents. But without infrastructure, even 30 agents is painful. The threshold for needing automated management is typically around 20-30 agents, depending on output volume and criticality.
When should I implement Master Agent systems?
Start building the foundation now, even with just 5-10 agents. Implement centralized logging, validation rules, and performance tracking immediately. These are lightweight and compound in value. When you reach 30-40 agents, begin architecting for Master Agent capability. When you hit 50+ agents, implementing actual Master Agent monitoring becomes necessary, not optional. The companies that wait until they have 100+ agents before tackling this will have a painful migration.
What's the cost of not building agent management infrastructure?
The costs compound over time. With 20 agents, inefficiency is annoying. With 50 agents, it's expensive (engineers spend half their time debugging). With 100+ agents, it's potentially catastrophic: customer-facing errors go undetected, contradictory information damages trust, compliance issues arise, and your team loses confidence in the entire system. Many companies ultimately have to pause agent rollouts and invest in infrastructure retroactively, losing 6-12 months of potential productivity. Building infrastructure proactively costs a fraction of fixing it later.
How do I ensure consistency across my agent fleet?
Three layers of consistency: First, all agents should pull from a single, centralized context repository (one source of truth for pricing, features, policies, etc.). Second, implement cross-agent validation that flags contradictions (Agent A says X, Agent B says Y about the same topic—system flags it). Third, establish clear boundaries between agents so there's minimal overlap and no ambiguity about who handles what. This prevents most consistency issues before they happen.
What happens when agents make mistakes?
Start by detecting them. Log all outputs, validate against rules, and spot-check quality. When you find mistakes, trace them back: which agent, what context did it have, what triggered it. Then fix systematically. If it's a context issue, update context. If it's a systemic agent problem, fix the prompt or behavior. If it's an emergent issue from agent interaction, add coordination rules. The key is having visibility so you can detect problems quickly and trace them to root cause.
What does agent infrastructure look like at scale?
At scale (100+ agents), you have: (1) centralized logging of all agent activity, (2) automated validation of all outputs against compliance and quality rules, (3) Master Agents continuously monitoring for anomalies and contradictions, (4) performance dashboards tracking each agent's quality and reliability, (5) automated root cause analysis when problems occur, (6) clear escalation paths for human review when needed. Humans focus on policy, goal-setting, and exception handling. Machines handle the operational complexity. This is similar to how cloud infrastructure moved from manual management to automated Dev Ops.

What's Next: Your Action Plan
If you're running AI agents, here's what to do this week:
-
Audit your current agent deployment. How many agents? Who manages them? What happens when something breaks?
-
Set up centralized logging if you haven't already. Every agent output goes to one place.
-
Define output validation rules. What does "good output" look like for each agent? Codify it.
-
Create a simple dashboard showing agent performance metrics.
-
Plan for the next 18 months. If you're growing agents 50% per quarter, you'll have 100+ agents by late 2026. Design your infrastructure for that scale now.
Your future self will thank you.
Key Takeaways
- Debugging AI agent issues scales exponentially in difficulty—finding which of 20 agents caused a bug took hours because there's no unified visibility across agent fleets
- Traditional observability tools weren't designed for AI agents because agents make judgment calls, not deterministic outputs, requiring fundamentally different monitoring approaches
- Companies deploying 50+ agents need Master Agents (AI systems managing other AI systems) for real-time validation, consistency checking, and automated debugging at scale
- The deployment-to-management gap is critical: shipping agents is easy, but managing them is hard, and most companies will hit a wall around 30-50 agents without infrastructure
- Start building agent management infrastructure now with centralized logging, output validation, consistency checks, and performance dashboards—waiting until you have 100 agents is too late
Related Articles
- Google's Internal RL: Unlocking Long-Horizon AI Agents [2025]
- Claude Cowork Now Available to Pro Subscribers: What Changed [2025]
- TSMC's AI Chip Demand 'Endless': What Record Earnings Mean for Tech [2025]
- Why Retrieval Quality Beats Model Size in Enterprise AI [2025]
- Amazon's Bacterial Copper Mining Deal: What It Means for Data Centers [2025]
- Anthropic's Claude Cowork: The AI Agent That Actually Works [2025]

