![Meta's Manus Acquisition: What It Means for Enterprise AI Agents [2025]](https://tryrunable.com/blog/meta-s-manus-acquisition-what-it-means-for-enterprise-ai-age/image-1-1767116423817.png)
Introduction: The Shift From Chat to Execution
When Meta announced its $2 billion acquisition of Manus in late 2024, the tech industry didn't react as it typically does to big acquisitions. There were no breathless headlines about disruption or game-changing technology. Instead, serious people in enterprise software started asking a more fundamental question: what does this signal about where AI competition is actually heading?
For the past two years, the AI narrative has revolved around model quality. Who has the smartest transformer? Whose reasoning engine can solve the hardest problems? It's been a genuinely compelling story. OpenAI releases GPT-4, Microsoft bakes it into Office, Google ships Gemini. The pattern repeats. Companies hire based on whose foundation model is most capable.
But Meta didn't spend two billion dollars on a foundation model. Manus isn't a model company. It's an execution company, and that distinction matters more than you probably realize.
Here's the thing: you can have the world's best reasoning engine sitting in a box somewhere, but if you can't actually get it to complete real work without human intervention, supervision, or fixing halfway through, then that capability is mostly theoretical. It's the difference between a chess engine that can calculate ten moves ahead and a chess player who actually wins games. The agent that finishes the job beats the agent that just thinks harder.
Manus spent its first year proving it could do something most AI agents struggle with: actually complete multi-step tasks in the real world. Not in controlled benchmarks. Not in demo videos. In actual production, with actual users, handling real work that needed to get done.
The acquisition signals that Meta—along with OpenAI, Google, and every other major tech platform—now understands that the next battlefield in AI is execution. Who builds the infrastructure that lets AI agents handle complex workflows? Who owns the layer where AI reasoning becomes actual work product? Who can reliably turn a prompt into a finished artifact?
That's where the money is moving. And that's why this deal matters for your enterprise AI strategy, whether you're evaluating AI tools for your team or building agent infrastructure for your company.
TL; DR
- Meta's $2B Manus acquisition signals the industry is shifting from model competition to execution layer control, meaning agents that reliably complete tasks now matter more than raw reasoning power
- Manus proved execution at scale, handling 147 trillion tokens and 80 million virtual computers while outperforming OpenAI's Deep Research agent on real-world task benchmarks by 10%+
- Enterprise agents fail on execution, not reasoning, meaning robustness against tool failures, context drift, and task resumption are now critical differentiators
- The integration path matters, as Meta will likely merge Manus capabilities into broader AI infrastructure, changing how enterprises access and deploy production-grade agents
- Enterprise procurement is shifting from buying individual AI tools to building orchestration layers that can coordinate multiple agents, models, and services reliably

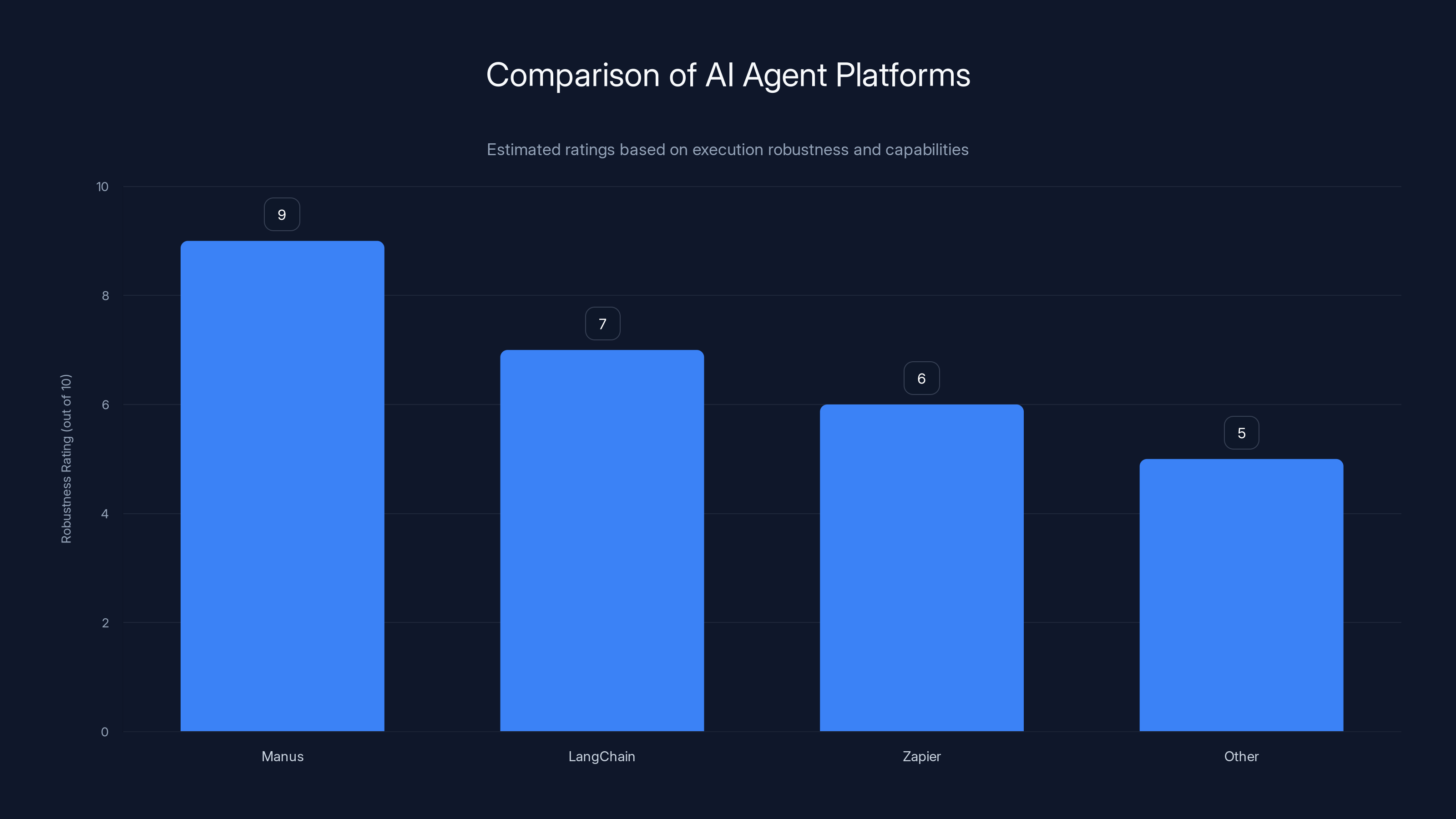
Manus leads in execution robustness with a rating of 9, surpassing LangChain and Zapier. Estimated data based on platform descriptions.
Why Model Quality Alone Isn't Enough
Let's start with the problem that nobody wants to admit when demoing new AI systems: reasoning capability and actual task completion are two very different things.
You can have a foundation model that understands the problem perfectly. It can break down a complex research task into logical steps. It can identify exactly which information it needs. But somewhere between understanding the task and delivering the finished work, things fall apart in ways that are almost embarrassing to enumerate.
A tool call fails silently, and the agent doesn't notice it never actually got the data it requested. Intermediate results don't format correctly for the next step, and the agent either repeats the same failed attempt or hallucinates that the step succeeded when it didn't. A long-running task takes six hours, something times out, and the system can't resume it from where it left off, so the work just disappears.
These aren't philosophical problems. They're not edge cases that appear once every thousand runs. They're the reason why when you try to use an early-generation AI agent to actually do something useful—not just write sample code or brainstorm ideas, but actually complete work—it tends to get about 60% of the way there and then require human handoff.
Manus's entire design philosophy was built around solving exactly this problem. The team recognized that the constraint on AI productivity in enterprise environments isn't model intelligence anymore. It's robustness. It's reliability. It's the ability to handle failures gracefully, maintain context across hours of work, and produce audit trails so humans can understand what actually happened.
When you look at the use cases Manus users were actually executing, the pattern becomes clear. People weren't using Manus for one-off questions. They were using it for things that would normally require human hours to complete: building comprehensive travel itineraries with budget research, generating multi-section research reports with original analysis, creating detailed engineering proposals with constraints and calculations.
These aren't tasks that come from a single prompt. They're the kind of work that usually involves opening twelve browser tabs, consulting three different sources, comparing options, calculating trade-offs, and synthesizing the results into a coherent output. The kind of work that takes a knowledge worker three to four hours.
Manus users were reporting that agents completed these tasks. Not perfectly—nothing is perfect—but with enough reliability and quality that the output could be used as a real starting point rather than a rough draft that needs complete reworking.
The Manus Story: From Startup to Acquisition in 18 Months
Manus launched publicly in early 2025 and became a textbook case of the kind of startup that catches everyone's attention because it solves a real problem that nobody else has solved yet.
The founding team came from a strong background in AI systems. The company was founded in Singapore, which provided some distance from the coastal U.S. tech scene and probably contributed to the founder team's decision-making to focus on execution rather than chasing narrative. When you're not in the echo chamber of venture capital and AI hype, you tend to focus on what actually matters.
Manus positioned itself explicitly as an agentic execution layer rather than as yet another conversational interface. The pitch was simple: here's a system designed to handle the messy, multi-step work that needs to actually get done. We've built it to handle failures, to maintain state across long operations, to invoke tools correctly, and to produce usable output.
The response was immediate. Manus accumulated 2 million users on its waitlist before officially launching. Two million people wanted to try an AI agent that claimed it could actually complete complex tasks. Not two million curious observers. Two million people with active interest in using the system.
When Manus published its initial performance benchmarks on the GAIA benchmark (a framework designed specifically to test how well AI agents complete real-world, multi-step tasks), it showed 10% improvement over OpenAI's then-current state-of-the-art agent, which was powered by the o 3 model. That's a significant margin in AI benchmarking. It's not a rounding error.
More importantly, Manus was actually shipping updates at a pace that showed the team was listening to what users were doing and building tools to solve real problems they encountered. In October 2024, the company shipped Manus 1.5, which focused specifically on the failure modes that plague long-running agent tasks: context loss, task stalling, inability to recover from intermediate errors.
By the time Meta announced the acquisition, Manus had processed 147 trillion tokens and created 80 million virtual computers. Those numbers don't come from a startup running demos. Those are production-scale metrics. Millions of users, millions of real tasks, running at that volume.
That's the kind of traction that gets acquisition offers from tech giants. Especially when that tech giant is Meta, which has been investing heavily in AI as a strategic priority for several years.

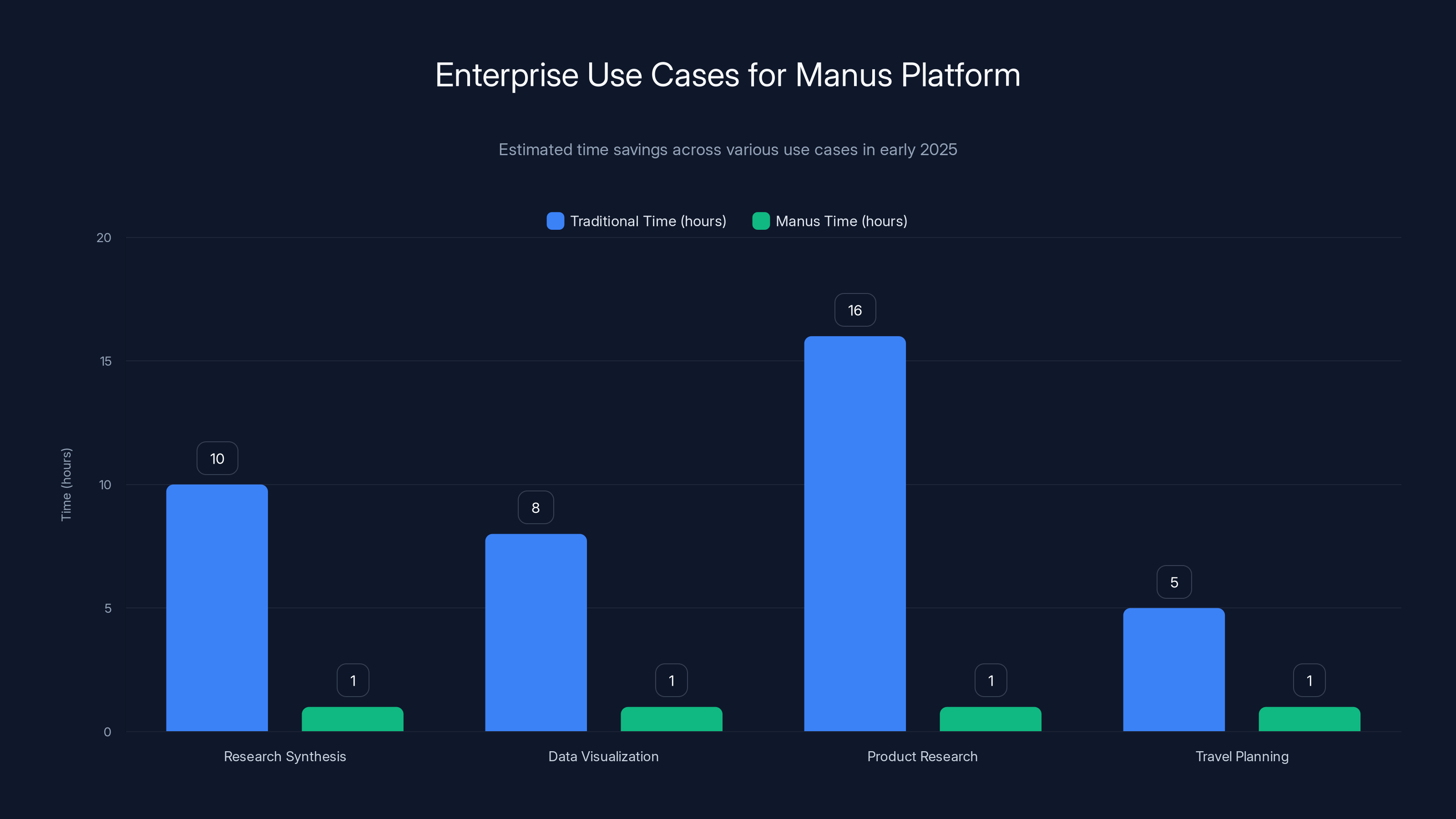
Manus significantly reduces task completion time across various enterprise use cases, with tasks typically taking 8-16 hours reduced to under an hour. Estimated data.
What Enterprises Were Actually Using Manus For
The most revealing aspect of Manus's adoption wasn't the marketing materials or the benchmark comparisons. It was what users were actually building with the platform.
In early 2025, Manus community members shared real examples of agent workflows they'd created, and the pattern that emerged showed how enterprise work actually happens when you give people reliable execution infrastructure.
One category of heavy use was research synthesis. Users were sending agents to analyze climate change impacts over the next century and having the system return comprehensive, multi-section reports with citations and data integration. This isn't trivial work. This requires reading multiple sources, integrating conflicting information, making projections based on models, and synthesizing everything into coherent narrative. A typical knowledge worker would spend eight to twelve hours on this kind of project. Manus users were reporting completion in under an hour.
Another major category was data-driven visualization. Users would send agents requests like "create an NBA efficiency chart comparing these players across their entire career" and receive not just a chart but the underlying analysis, the selection criteria, and the data validation. This requires pulling from multiple sources, cleaning data, performing calculations, creating a visualization, and validating the output makes sense.
Product and market research was another significant use case. "Compare every Mac Book model across Apple's history" sounds simple until you actually try to do it comprehensively. You need to find release dates, technical specifications, pricing data across years, convert currencies for international pricing, and synthesize it all into a comparable format. This is the kind of work that a product manager might delegate to an analyst, expecting two days of work. Agents were producing usable output in under an hour.
Complex travel planning with full logistics emerged as a surprising use case. Users would describe a multi-country trip with budget constraints, and agents would return complete itineraries including flight options, accommodation research with price comparisons, activity planning, timeline logistics, and budget summaries. This combines research, calculation, planning, and synthesis all at once.
Technical research and academic work showed up heavily. Users were having agents summarize recent research in specialized domains, propose research directions for Ph.D. candidates, and outline novel approaches to technical problems. This requires reading dense technical papers, extracting key concepts, understanding implications, and synthesizing novel ideas.
Engineering design work was another category. Users would specify constraints (geographic location, self-sufficiency, budget parameters) and agents would return detailed designs including material specifications, system architecture, cost breakdowns, and feasibility assessments.
The common thread across all these use cases: they're not tasks that break down into simple prompts. They require planning, multi-step execution, tool invocation, error recovery, and synthesis. They're the kind of work that actually creates value in enterprise environments.
The GAIA Benchmark: Why Agent Execution Matters
When you look at how AI agent capability is being evaluated, the shift away from conversation quality and toward task completion is becoming official and standardized.
The GAIA benchmark (Grounded AI Agent Interactions) was specifically designed to test how well AI systems complete multi-step, real-world tasks. Unlike benchmarks that test pure reasoning or language understanding, GAIA measures whether an agent can actually get work done.
The benchmark tests agents on tasks like:
- Multi-source research synthesis: Find information across multiple sources, integrate conflicting data, and produce a coherent analysis
- Tool invocation with error recovery: Use available tools correctly, handle failures, and try alternative approaches
- Long-context reasoning: Maintain relevant information from earlier steps and apply it correctly in later steps
- Verification and validation: Confirm that intermediate results are correct before proceeding
When Manus published its results, it showed 10% improvement over the then-current state-of-the-art (OpenAI's o 3-powered agent). In competitive AI benchmarking, a 10% improvement isn't just better. It's meaningfully better. It's the difference between an agent that completes tasks 73% of the time and an agent that completes them 82% of the time.
That difference compounds. Over fifty tasks, that's approximately five additional successful completions. That's five hours of knowledge work that doesn't require human handoff or repair.
But the GAIA benchmark is designed to be realistic, which means it's harder than you'd think. It includes tasks that have multiple valid approaches, ambiguous requirements, and trade-offs that require judgment. It includes failure modes like tools that return unexpected results, missing data sources, and conflicting information.
If an agent can score 82% on GAIA, it means that agent has been designed and trained specifically for robustness in the real world. That's not accidental. That's intentional architecture.
Meta's Strategic Interest in Execution Layers
Meta's acquisition of Manus shouldn't be read in isolation. It's one move in a broader strategic shift that Meta, Google, Microsoft, and other tech giants are making in parallel.
Meta has been investing in AI systematically for years. The company open-sourced Llama and built significant internal AI capabilities. But building models is table stakes at Meta's scale. The question that executives at Meta (and similar companies) are asking is: how do we create unique value that competitors can't easily replicate?
If the best foundation models are increasingly commoditized, then the defensible competitive advantage is in infrastructure. It's in who owns the orchestration layer, the execution layer, the integration points where AI reasoning becomes actual work product.
Meta owns several strategic properties: Facebook and Instagram, which serve billions of users; WhatsApp; and increasingly, infrastructure and developer tools. If Meta can build an execution layer that makes it easy to deploy reliable AI agents across those properties, suddenly Meta has a unique offering.
Consider the implications: imagine agents that can help businesses manage Facebook advertising, create Instagram content, manage customer support on WhatsApp, and synthesize data from all those sources. Imagine an AI agent that understands your entire customer journey across Meta's platforms and can optimize advertising spend, suggest content ideas, and identify customer churn risks—all automatically.
That kind of integrated experience requires two things: access to proprietary data (which Meta has) and reliable execution infrastructure (which Manus provides).
It's the same strategic logic that drove Microsoft's integration of OpenAI models into Office products. The model is the ingredient, but the orchestration layer is the actual product.
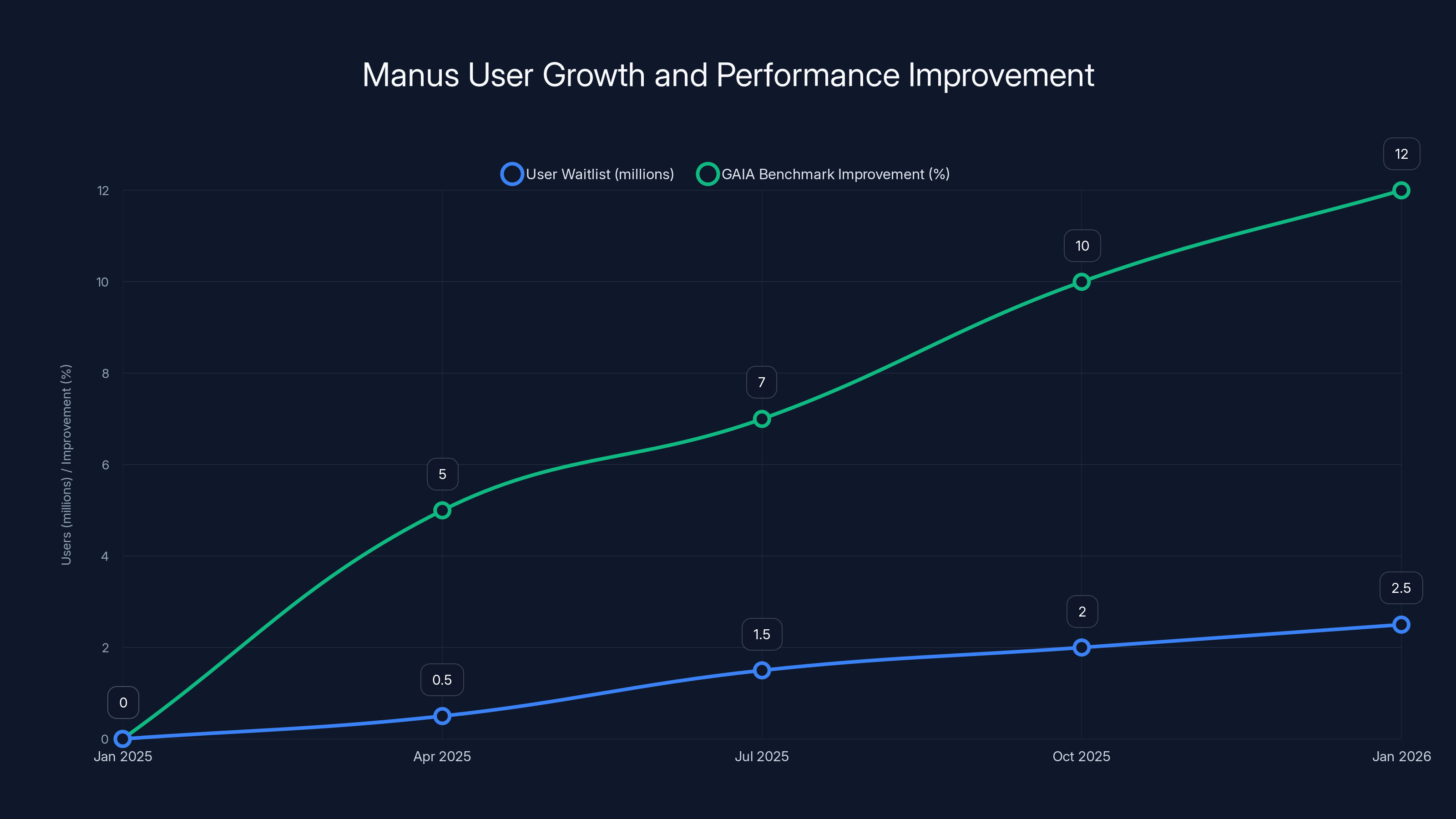
Manus experienced rapid user growth, reaching 2 million on the waitlist within months, while consistently improving its performance on the GAIA benchmark by 10% over competitors. Estimated data.
How Enterprise AI Projects Currently Fail
To understand why Meta's acquisition of Manus is significant, you need to understand how enterprise AI projects typically fail in 2025.
The failures almost never happen because the model wasn't smart enough. Companies building serious AI applications have access to the best models: GPT-4, Claude, Gemini. These are sophisticated systems that can reason about complex problems.
The failures happen in the execution layer.
Here's a common scenario: a company wants to build an AI agent that analyzes customer support tickets, researches relevant solutions from the knowledge base, and drafts responses. The core idea is sound. The model can understand the problem. But when you actually build it, you hit a series of problems:
The agent calls a tool to fetch knowledge base articles, but sometimes the tool returns results that are tangentially related rather than directly relevant. The agent doesn't validate the results; it just uses them. The drafted response mentions a solution that doesn't actually apply to the customer's problem.
Or the agent hits the knowledge base API rate limit halfway through processing a batch of tickets. The operation fails. There's no built-in resumption mechanism, so you have to restart from the beginning.
Or the agent gets into a loop where it tries the same failed tool invocation five times because it doesn't recognize that the failure is systematic rather than transient.
Or the operation succeeds but takes so long (because of waiting on external APIs) that the context window fills up and the agent loses earlier information it actually needed.
Or nobody can explain what the agent actually did, where it found its information, or why it made the decisions it made. There's no audit trail.
These aren't hypothetical problems. They're the standard failure modes that operations teams deal with when deploying AI agents at scale. They're the reason that most early-stage agent deployments end up requiring significant human supervision or handoff.
Manus was specifically designed to solve these problems. The architecture includes:
- Robust error handling: Distinguish between transient failures and systematic ones, implement backoff strategies, and use alternative tools when primary tools fail
- State management: Maintain context across long operations, checkpoint progress, and resume from specific points if an operation fails
- Tool validation: Verify that tool results are reasonable before proceeding, and validate against expectations
- Audit logging: Maintain complete traces of what the agent did, which tools it invoked, what results it received, and why it made decisions
- Orchestration: Coordinate multiple tools and services, handle dependencies, and sequence operations correctly
These are not trivial engineering problems. They're the hard stuff that separates a production AI system from a prototype.
The Integration Question: What Does Manus Become Inside Meta?
Meta's statement about the acquisition indicated that Manus would "continue operating and selling the Manus service while integrating it into Meta AI and other products." That's diplomatic language, and it's worth unpacking what it probably means.
In practice, acquisitions of this type usually follow a pattern: the acquired company's product maintains separate operations for some period, but the underlying technology and team get absorbed into the parent company's broader initiatives.
For Meta, that likely means:
The Manus infrastructure becomes an internal execution layer that powers AI features across Meta's products. Meta might use Manus's agent orchestration system to power things like content suggestions, customer support automation, or advertising optimization.
The Manus consumer product remains as a standalone offering at least for the short term, providing Meta with real-world data about how users deploy agents and what failure modes come up. That feedback loops back into Meta's broader AI infrastructure.
Teams and technology are integrated into Meta's AI organization, which means the Manus team's expertise in robust agent execution becomes part of Meta's standard infrastructure.
API access might become available to developers building on Meta's platforms, allowing developers to use reliable agent execution as a component of their own applications.
The strategic play is that Meta ends up with proprietary infrastructure for reliable agent deployment, similar to how Google owns significant amounts of internal ML infrastructure that powers Google products.
Comparing Manus to Other Agent Approaches
Manus isn't the only way to think about AI agent execution. There are several architectural approaches competing in the market, and understanding the trade-offs helps you evaluate what makes sense for your own infrastructure decisions.
Lang Chain and framework-based approaches: Tools like Lang Chain provide libraries and abstractions for building agent workflows. The advantage is flexibility—you can customize exactly how your agent behaves. The disadvantage is that you're responsible for handling all the failure modes yourself. You need to build your own tool validation, error recovery, state management. The framework provides structure, but not execution robustness.
Orchestration platforms like Zapier and Make: These excel at coordinating multiple services and creating workflows. But they're designed more for routing and sequencing than for complex reasoning. An AI model can reason, but the orchestration platform ensures the plan gets executed. The limitation is that they require pre-defining workflows; they're not agents that can reason about novel problems dynamically.
Agent-specific platforms like Auto GPT and Llama Index: These focused on agent capabilities but often punted on the execution layer problem. They were good at demonstrating what agents could do in controlled environments, but struggled with real-world robustness.
Manus's approach: Build execution robustness into the core architecture. The assumption is that the reasoning (handled by a foundation model) and the execution (handled by purpose-built infrastructure) need to be co-designed. You can't just strap a reliable execution layer onto a generic reasoning system; they need to be built for each other.
This is a meaningful difference in how these systems actually behave in production. A Lang Chain agent might fail silently when a tool doesn't work. A Manus agent is designed to notice that the tool failed and try alternative approaches. That design difference compounds across thousands of operations.

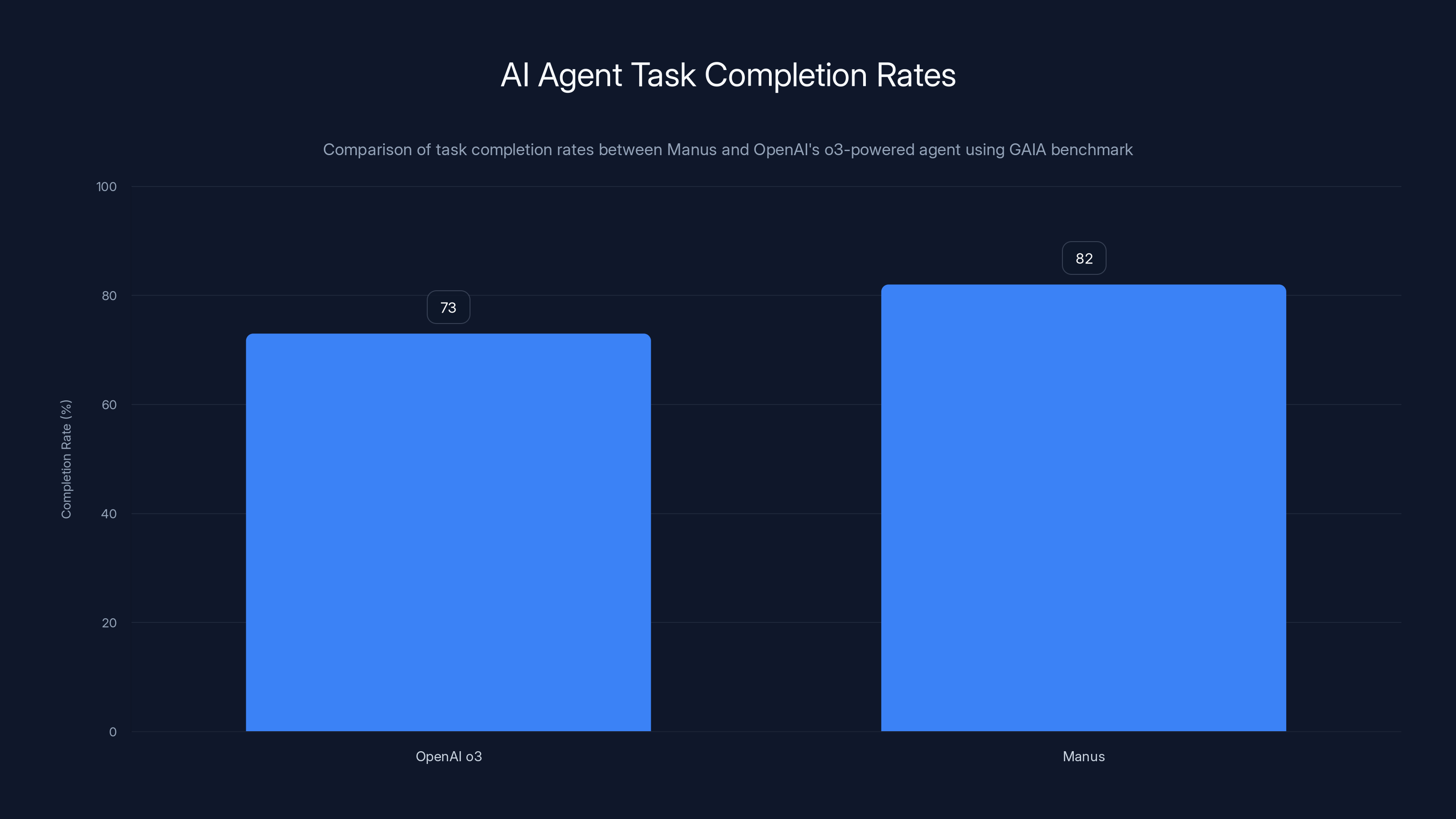
Manus achieved a 10% improvement over OpenAI's o3-powered agent, increasing task completion from 73% to 82% on the GAIA benchmark.
The Market Implication: Execution Infrastructure as Strategic Property
Meta's acquisition of Manus signals something broader about how the AI market is reshaping:
Foundation models are becoming commoditized. This isn't controversial. Within eighteen months, you can build a multi-million parameter model at reasonable cost. Inference of existing models is increasingly cheap. The barrier to entry for "I have a good model" is lower than it's ever been.
But execution infrastructure—the systems that actually make agents work reliably—remains rare and valuable.
That creates a market dynamic where the players that own both the reasoning capability (foundation models) and the execution layer will win market share, and players that are trying to build execution infrastructure without owning models will win niches.
Meta's two-billion-dollar investment in Manus is Meta saying: "We're not competing on model quality. We're competing on reliable execution of AI-powered work."
That's a significant strategic signal.
It also suggests that enterprises evaluating AI infrastructure should be asking different questions than they might have asked two years ago. Don't just ask "which model is smartest?" Ask "which execution layer is most robust? Which platform has thought through state management and failure recovery? Which system can actually complete the work we need to do?"
Building Enterprise Agent Infrastructure
For companies building AI into their operations, the Manus acquisition has implications for architecture decisions.
If you're building a significant AI agent application (not just calling an API, but actually deploying agents into your operational workflows), you need to decide: do you build your own execution layer, use an existing platform, or wait for platforms to offer execution-as-a-service?
Building your own execution layer is expensive and time-consuming. But it gives you total control and deep customization. You'd essentially need to hire the kind of engineers that Meta just hired (by acquiring Manus) and have them solve all these problems for you. That probably makes sense if you have very specific requirements that general-purpose platforms can't handle.
Using an existing platform like Lang Chain with custom error handling and state management is middle-ground. You get development velocity from existing abstractions, but you need to build production-grade reliability on top of the framework yourself.
Waiting for platforms to offer execution-as-a-service is increasingly the practical option. Meta will eventually expose Manus-like capabilities through APIs. Google is building similar capabilities. OpenAI is investing in agent infrastructure. In 12 to 24 months, you'll probably be able to use reliable agent execution as a service, similar to how you use cloud compute or databases today.
The strategic choice for most enterprises is probably: build your initial agent prototype using available tools (Lang Chain, Llama Index, whatever framework makes sense for your use case), validate that agents actually solve your problem, then migrate to production infrastructure as it becomes available.

Token Scale and Virtual Computers: What the Metrics Actually Mean
Manus announced that it had "processed 147 trillion tokens and created 80 million virtual computers." These numbers get thrown around, but understanding what they actually represent matters.
Tokens processed is a measure of scale. A token is roughly a word or fraction of a word. 147 trillion tokens means the system has handled enough language data to process something equivalent to thousands of complete books per second over an extended period. That's a massive scale. That suggests millions of concurrent users running real workloads, not a small beta test.
"Virtual computers" is Manus-specific language that refers to agent instances—essentially, the number of individual agent executions the system has managed. 80 million virtual computers means the system has coordinated 80 million separate agent instances. Some of those ran to completion, some failed, some are still running. The point is, the infrastructure has proven it can handle that kind of load.
These metrics matter because they move Manus from "interesting startup" to "proven production system." When you acquire a company, you're not just acquiring their team and intellectual property. You're acquiring their evidence that their approach actually works at scale.
For Meta, these metrics validate the acquisition decision. This isn't a technology that might work someday. It's technology that's already handling enterprise workloads at significant scale.
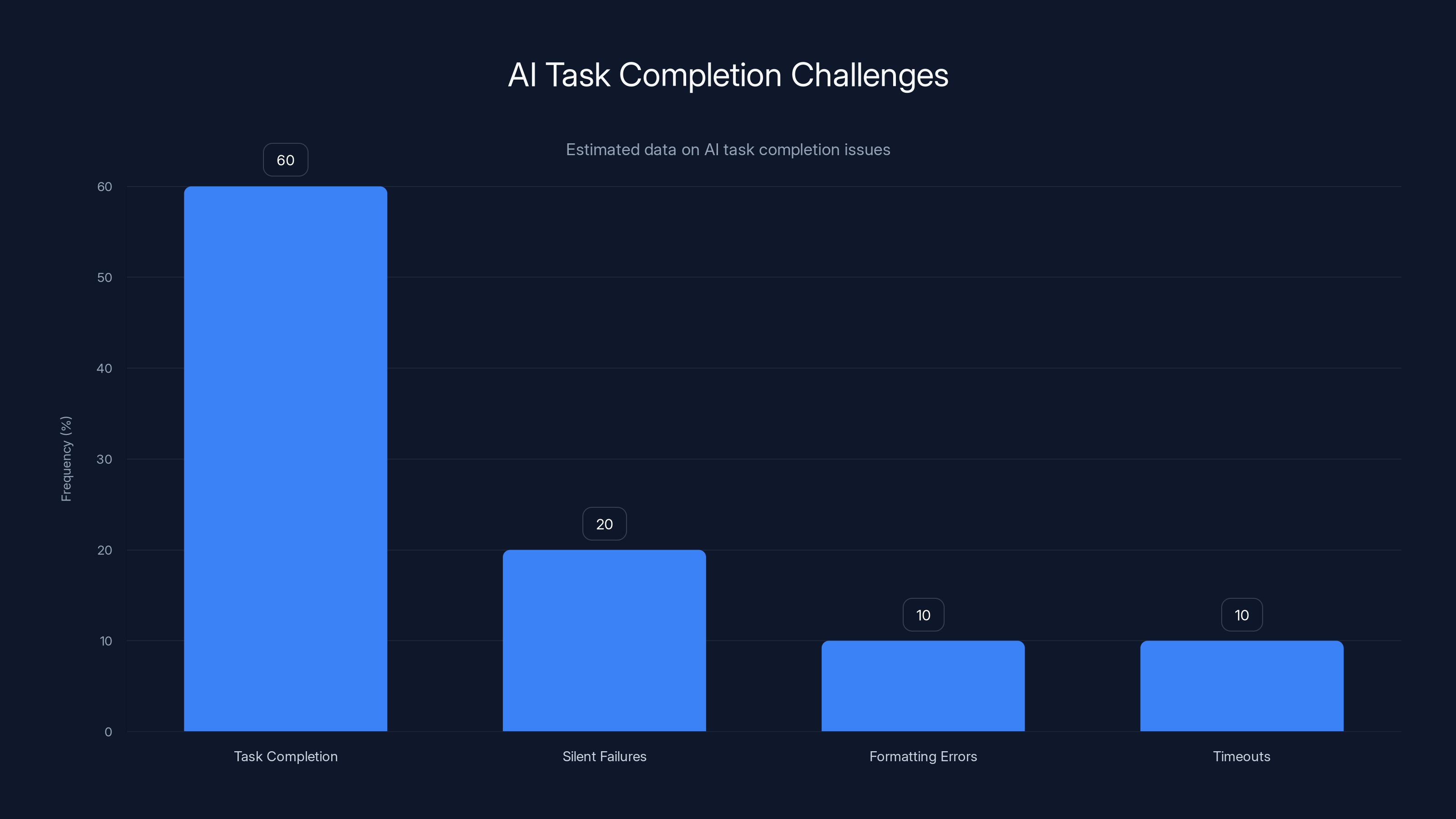
Estimated data suggests that AI systems complete about 60% of tasks successfully, with silent failures, formatting errors, and timeouts being common issues.
The Consolidation Wave: Who Else Is Buying Agent Infrastructure?
Meta's acquisition of Manus isn't happening in isolation. Across the tech industry, major players are consolidating control over agent infrastructure.
OpenAI invested in and partnered with multiple AI companies building on top of GPT models, understanding that GPT-4 alone isn't the moat—the ecosystem and applications built on top of it are. The company is being strategic about which companies get early access and deep integration.
Google acquired multiple AI companies over recent years (including companies building in areas from robotics to medical AI) with a clear strategy of building an integrated AI stack rather than just offering models.
Azure (Microsoft's cloud platform) has been aggressive about partnerships and acquisitions that would strengthen its positioning as the platform for enterprise AI workloads. Microsoft's OpenAI partnership is the most visible piece, but there are other acquisitions and partnerships building capability across the stack.
This consolidation pattern is typical in platform markets. You see it in cloud (where Amazon, Google, and Microsoft own compute, data infrastructure, and application services), in mobile (where Apple and Google own OS, hardware, and app stores), and now in AI (where Meta, Google, Microsoft, and OpenAI are racing to own models, infrastructure, and execution layers).
The companies that end up dominating will be the ones that own the full stack: from models to infrastructure to applications to user-facing products.

Implications for Enterprise Procurement and Vendor Strategy
For enterprises, the Manus acquisition has practical implications for how you should be thinking about vendor relationships and technology procurement.
Three years ago, the enterprise software market was still functioning on the model where you bought point solutions: you bought an analytics tool, a CRM, an HR system, and they all ran separately and you integrated them manually. That model is breaking down in the age of AI agents.
With reliable agents, you need orchestration layers that can coordinate multiple services, tools, and decision points. You need infrastructure that can handle complex workflows across multiple systems. You need platforms where agents can reason about your entire business context, not just individual problems.
This changes vendor strategy. Instead of buying individual tools, enterprises increasingly need to buy into platforms: Meta's ecosystem, Google's ecosystem, Microsoft's ecosystem, or some combination thereof. The platforms that own reliable agent execution will become the hubs that everything else connects to.
For procurement teams, this means:
Ask vendors about execution robustness, not just model capability. "Can your agents handle tool failures? Can they maintain state across multi-hour operations? Can you provide audit trails of what the agent actually did?"
Evaluate the full stack, not just the language model. The model matters, but the execution infrastructure matters more for real-world performance.
Watch for consolidation and integration announcements from major platforms. Acquisitions like Meta's Manus acquisition are signals about where those companies are investing and what capabilities will become available as services.
Plan for migration to platform-native services. If you're building on point solutions today, plan for the possibility that those solutions might become commodity layers offered as part of larger platforms in 12-24 months.
The Talent Implication: Where AI Engineering Is Happening
Acquisitions like Manus's are also signals about where AI engineering talent is needed and being valued.
Meta paid two billion dollars for what is essentially a talented team that solved a specific problem well: making AI agents reliable in production. That's not a comment on market overheating (though that's probably true). It's a comment on where the hard engineering work actually is.
Building foundation models is still hard, but it's increasingly becoming standardized. You can read papers, implement architectures, hire researchers, and build a competitive model. Multiple companies have done it.
Building reliable execution infrastructure? That's less standardized. There's no paper that lays out the complete answer. It's the kind of problem that requires deep systems thinking, careful error handling, and lots of production experience to get right. That's the kind of team that becomes valuable when acquired.
For engineers and technical leaders, this signals where the interesting work is. If you're optimizing language models, you're in a crowded field. If you're solving production reliability problems for AI systems—how to handle failures, how to maintain state, how to audit and verify agent behavior—you're working on problems that companies are willing to pay billions to solve.

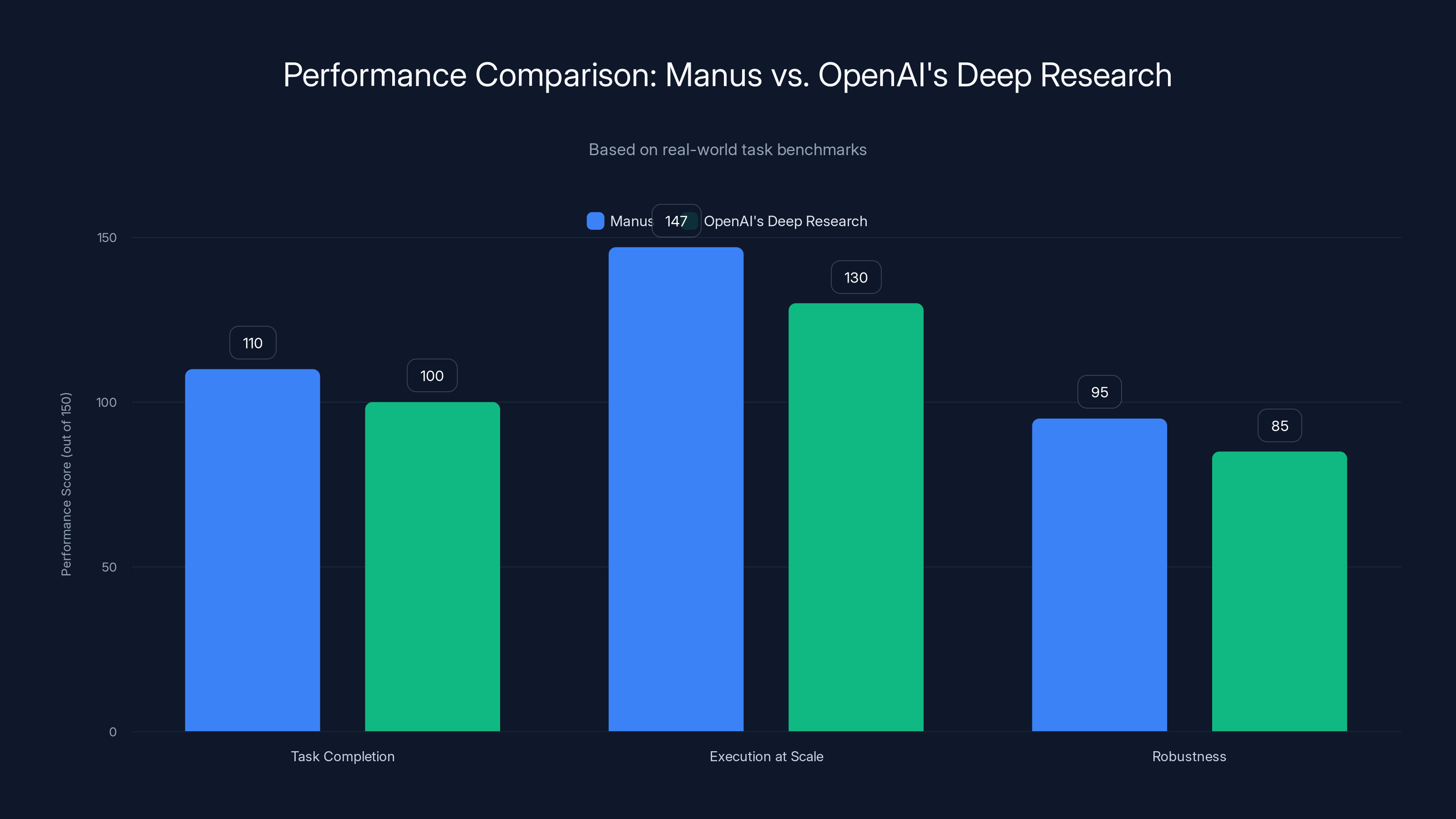
Manus outperforms OpenAI's Deep Research by over 10% in task completion and execution at scale, highlighting its superior robustness and integration capabilities. Estimated data.
What Enterprises Need to Do Now
If you're responsible for AI strategy or technology decisions at your company, Meta's acquisition of Manus suggests several action items:
Start with a pilot project if you haven't already. Understand what agents can actually do for your business. Use existing frameworks and models. Don't wait for perfect infrastructure—good enough infrastructure will become available, and you need to validate the use case first.
Map your integration points. Where would AI agents create actual value? Which systems and data sources would agents need to access? What decisions would they need to make? This informs what kind of execution infrastructure you'll need.
Evaluate your operational readiness. Agents introduce new failure modes and operational challenges. Can your team monitor agent behavior? Can you audit and explain agent decisions? Can you handle failures gracefully? These are more important questions than model capability right now.
Monitor platform announcements from major cloud providers. Meta, Google, Microsoft, and others will be releasing agentic capabilities as services. Understand what's coming so you can make procurement decisions accordingly.
Build relationships with AI-native vendors, but don't lock yourself into any single vendor. The market is still consolidating, and vendor strategies are still evolving. Flexibility is valuable.
Hire or develop internal expertise in prompt engineering and agent design. The people who understand how to design agents that work reliably in your specific operational context will become increasingly valuable.
The Future: Where Agent Infrastructure Goes From Here
Looking forward, Meta's acquisition of Manus is probably the first of several consolidation moves that will reshape the AI market.
Over the next 18 to 24 months, expect:
Agent infrastructure becoming a platform feature rather than a standalone product. Just as cloud providers now offer databases, caching, message queues, and other infrastructure primitives, they'll offer reliable agent execution. By 2026 or 2027, you'll be able to deploy agents as easily as you deploy containers.
Standardization around agent protocols and interfaces, similar to how REST became standard for web APIs. This makes it easier to build agents that can integrate with multiple services and data sources.
Specialization and verticalization of agents. The first generation of agents is general-purpose. The next wave will be domain-specific: agents built specifically for finance, healthcare, e-commerce, manufacturing. These will have baked-in knowledge of domain-specific problems and solutions.
Improved agent safety and alignment as agents take on more autonomous decision-making. Right now, agents are largely consulting systems that inform human decisions. As they become more autonomous, the industry will need better mechanisms to ensure agent behavior aligns with organizational goals and values.
Emergence of agent marketplaces where companies can access pre-trained, domain-specific agents rather than building from scratch. Similar to how app stores work for mobile, you might browse an agent marketplace and deploy pre-built agents for specific business functions.
The underlying story is that AI is moving from being a feature (like a chatbot) to being infrastructure (like compute or databases). Once it's infrastructure, the competition moves from "who has the best model" to "who has the most reliable, most integrated, easiest-to-use infrastructure."
Meta's acquisition of Manus is early evidence of that shift.

Building Your Own Manus: Should You?
One question enterprises should ask: could we build our own Manus-like execution infrastructure instead of buying access to it from a platform?
The honest answer is maybe, but probably not. Here's why:
Building production-grade execution infrastructure requires solving hard problems: tool reliability, state management, error recovery, long-context reasoning, monitoring and observability. Each of these is a multi-person-year project if you want to do it right.
Manus spent 18 months building this before launching publicly, and the team had deep expertise in distributed systems and ML. They still hit problems and had to iterate.
You could hire that team (though Meta just did), or you could hire a team with similar skills. You'd need systems engineers, distributed systems experts, ML infrastructure engineers, and people with operational experience in production AI systems. That's expensive and time-consuming to assemble.
The alternative is to focus your team on what makes your business unique: your domain expertise, your data, your operational processes. Let platform providers handle the infrastructure.
However, if your business requires truly custom agent behavior that general-purpose platforms can't provide, or if your operational requirements are unique enough that off-the-shelf solutions won't work, then building internally might make sense. But that should be a deliberate decision, not default.
Lessons From Manus: What Made the Company Valuable
Meta didn't acquire Manus for the size of its user base (2 million on the waitlist is significant but not massive by tech standards). Meta acquired Manus for three specific things:
Proven execution robustness backed by real production data. Manus handled 147 trillion tokens and 80 million agent executions. That's not a small number. It means the infrastructure has proven it can handle real-world scale and real-world failure modes.
Talented team with specific expertise in solving the hard problems of agent infrastructure. The founders came from deep ML backgrounds and had built systems that worked. That expertise is valuable and hard to replicate.
Product-market fit and user validation. Manus users were doing real work with the platform, not just experimenting. That validation matters when you're making a $2 billion investment.
For other startups building in the agent space, this provides a clear lesson: don't just build a chatbot or a general-purpose agent that's slightly better than existing options. Solve a specific, hard problem that existing solutions don't handle well. Build it so well that enterprises can rely on it in production. Prove that your solution works at scale. Then you'll be valuable to acquirers.

Practical Steps: Evaluating AI Agent Platforms
If you're evaluating AI agent platforms for enterprise deployment, here's a framework:
Ask about execution reliability: How does the platform handle tool failures? What happens if an API times out? Can it resume failed operations? What's the error recovery mechanism?
Ask about state management: Can the platform maintain context across operations that take hours to complete? What happens if a server restarts mid-operation? How does state persistence work?
Ask about observability: Can you see exactly what the agent did, which tools it invoked, what data it received? Can you replay operations for debugging or compliance?
Ask about failure modes: What kinds of failures have they encountered in production? How did they solve them? What are the known limitations?
Ask for production references: Not just companies using the platform, but companies using it for mission-critical operations. The difference matters.
Evaluate the roadmap: Is the platform betting on execution reliability, or are they optimizing for other factors? Does their roadmap suggest they understand the problems you'll face?
These questions get at whether a platform has actually solved the hard infrastructure problems, or whether it's still mostly focused on the easy parts (language understanding, reasoning) and leaving you to handle the hard parts (reliability, state, failure recovery).
FAQ
What exactly is Manus?
Manus is an AI agent platform built specifically for reliable execution of multi-step tasks. Rather than being primarily a conversational interface, Manus is designed as an execution engine that can handle complex workflows, invoke tools, manage failures, and produce usable output. The platform proved its capability by achieving 147 trillion tokens processed and 80 million virtual computers orchestrated in its first year, handling tasks like research synthesis, data analysis, planning, and content generation at production scale. Meta acquired the company for more than $2 billion in late 2024.
Why did Meta acquire Manus for $2 billion?
Meta's acquisition signals a strategic shift in how AI competition is evolving. Rather than competing on foundation model quality alone, Meta is competing on control of the execution layer, which is the infrastructure that actually makes AI agents work reliably in production. Manus had proven it could handle production-scale agent execution (147 trillion tokens, 80 million virtual computers) while outperforming competing systems on real-world task benchmarks. Meta gains both the technology and the team's expertise in solving hard infrastructure problems that make AI agents practical for enterprise deployment.
How does Manus's approach differ from other AI agent systems?
Manus is built specifically for execution robustness, whereas many other agent systems focus primarily on reasoning capability. While frameworks like Lang Chain provide flexibility, and platforms like Zapier provide orchestration, Manus combines reasoning with production-grade execution infrastructure. This means built-in error recovery, state management across long operations, tool validation, and audit trails. Manus handles failure modes that plague other agents: silent tool failures, context loss in long operations, inability to resume after interruptions, and lack of explainability about what the agent actually did.
What does the GAIA benchmark measure?
The GAIA benchmark (Grounded AI Agent Interactions) specifically evaluates how well AI agents complete real-world, multi-step tasks rather than measuring pure reasoning or language understanding. It tests agents on research synthesis, tool invocation with error recovery, long-context reasoning, and verification of intermediate results. Manus outperformed OpenAI's then-current state-of-the-art agent by approximately 10% on this benchmark, suggesting meaningful practical advantage in completing real-world work, not just marginal improvements in abstract capability.
What are the actual use cases enterprises are deploying agents for?
Based on real Manus user data, enterprise agents are being deployed for: research synthesis and report generation (analyzing complex topics and producing multi-section reports), data-driven analysis (creating visualizations and comparisons from multiple data sources), market and product research (comprehensive competitor or product analysis), complex planning (travel itineraries, project planning with full logistics), technical research (summarizing specialized research and proposing novel approaches), and engineering design (creating designs with constraints, specifications, and feasibility analysis). These are tasks that typically require 4-12 hours of knowledge worker time and are well-suited for reliable AI agent execution.
What's the "execution layer" and why does it matter?
The execution layer is the infrastructure component that actually carries out what an AI agent decides to do. It invokes tools, handles failures, maintains state across long operations, and produces final work products. It matters because having a brilliant reasoning engine is insufficient if the execution falls apart: tools fail silently, context gets lost, operations can't resume after interruption, or nobody can explain what actually happened. Most enterprise AI failures come from execution layer problems, not reasoning failures. That's why Manus's focus on robust execution is strategically valuable.
How will Meta integrate Manus into its products?
Meta indicated that Manus would continue operating as a standalone product while being integrated into Meta's broader AI organization and potentially powering features across Meta's platforms (Facebook, Instagram, WhatsApp). This likely means: the Manus infrastructure becomes internal execution layer for Meta's AI features; the Manus consumer product provides real-world usage data; the team's expertise in production agent infrastructure gets absorbed into Meta's AI stack; and potentially, developer APIs that expose agent execution capabilities to developers building on Meta's platforms. The timeline for integration typically spans 12-24 months.
What metrics demonstrate Manus's scale and production readiness?
Manus processed 147 trillion tokens, which represents an enormous volume of language data (equivalent to the content of thousands of books processed per second over extended periods). The system created 80 million virtual computers, meaning it successfully orchestrated 80 million separate agent instances. These metrics don't come from a startup running demos; they come from millions of real users executing real workloads. The scale demonstrates that the infrastructure isn't theoretical—it's proven in production at significant volume.
Should enterprises build custom agent infrastructure or use platforms?
For most enterprises, using platforms (either Manus if available directly, or similar services from major cloud providers) makes more sense than building custom infrastructure. Building production-grade agent execution requires solving hard problems (tool reliability, state management, error recovery, observability) that each require multi-person-year engineering effort. Unless your business requirements are so unique that general-purpose platforms can't meet them, it's more cost-effective to focus your team on domain-specific problems and let platform providers handle infrastructure. Startups with very specialized requirements might build custom infrastructure; enterprises generally shouldn't.
What should enterprises do now regarding AI agents?
Start with pilot projects using existing frameworks to validate that agents actually solve problems for your business. Map your integration points: where would agents create value? Which systems and data would they need to access? Evaluate your operational readiness: can your team monitor agents, audit decisions, and handle failures gracefully? Monitor announcements from major platforms (Meta, Google, Microsoft) about agentic capabilities being released as services, so you can make procurement decisions when those services become available. Avoid locking yourself into single vendors; the market is still consolidating and vendor strategies are evolving.
What's the competitive landscape for agent execution infrastructure?
The landscape is consolidating, with major tech platforms acquiring or building capabilities to own the execution layer. Meta acquired Manus; Google is building similar capabilities; Microsoft is integrating through partnerships and acquisitions; OpenAI is investing in agent infrastructure. The companies that will dominate are those that own the full stack from models to infrastructure to user-facing applications. The market is moving from point solutions to integrated platforms, which means vendor strategy for enterprises is shifting from buying individual tools to buying into platforms that offer orchestration, execution, and integration across services.

Conclusion: The Execution Frontier
When Meta announced the acquisition of Manus, the financial press reported the headline accurately but missed the deeper strategic significance: this was not a company buying a chatbot company or a model company. This was a company acquiring control of the execution layer.
The AI industry spent the past two years competing on model quality because model quality was the constraint. Who has the smartest reasoning system? Who can solve the hardest problems? Those questions still matter, but they're no longer the bottleneck.
The new bottleneck is execution. Given a sufficiently capable reasoning system (and frankly, all the major foundation models are sufficiently capable now), the limiting factor on real-world AI productivity is: can it actually complete the work without human handoff? Can it handle failures gracefully? Can it maintain state across long operations? Can anyone understand what it actually did?
Manus proved, at production scale, that these problems can be solved. That's why Meta paid two billion dollars for the company.
For enterprises, the strategic implication is clear: don't just evaluate foundation models anymore. Evaluate the full execution stack. Ask hard questions about reliability, state management, failure recovery, and observability. The companies with the best models won't necessarily win the market. The companies with the best execution infrastructure will.
The next 18 months will tell us whether Meta's bet on Manus was prescient or expensive. But regardless of the specific outcome, the direction of the market is clear: execution infrastructure is now where the competition is, and it's now where the value is being created.
If you're building AI into your enterprise operations, that's the shift you need to prepare for. The question isn't whether your models are good enough. The question is whether your execution layer is robust enough to actually get work done.
Key Takeaways
- Meta's $2B Manus acquisition signals the AI industry is shifting from model competition to execution layer control, meaning agents that reliably complete tasks now matter more than raw reasoning capability.
- Manus proved production-scale agent execution, processing 147 trillion tokens and orchestrating 80 million virtual computers while outperforming OpenAI's agents by 10% on real-world task benchmarks.
- Enterprise AI failures come primarily from execution layer problems (tool failures, context drift, no error recovery), not from model reasoning limitations—making robust execution infrastructure strategically valuable.
- Major tech platforms (Meta, Google, Microsoft, OpenAI) are consolidating control over agent infrastructure, signaling that platform vendors will eventually offer reliable agent execution as a service within 12-24 months.
- For enterprises, this means shifting procurement focus from individual AI tools to integrated platforms offering full orchestration, execution, and integration capabilities across business systems.
Related Articles
- Meta Acquires Manus: The AI Agent Revolution Explained [2025]
- The 32 Top Enterprise Tech Startups from TechCrunch Disrupt [2025]
- Meta Acquires Manus: The $2 Billion AI Agent Deal Explained [2025]
- AI Budget Is the Only Growth Lever Left for SaaS in 2026 [2025]
- Tech Resolutions for 2026: 7 Ways to Upgrade Your Life [2025]
- The Highs and Lows of AI in 2025: What Actually Mattered [2025]

