![Microsoft Maia 200: The AI Accelerator Changing Everything [2025]](https://tryrunable.com/blog/microsoft-maia-200-the-ai-accelerator-changing-everything-20/image-1-1769445803187.jpg)
Introduction: The Hardware Race That Actually Matters
Last month, I watched a CEO spend 45 minutes explaining why her company's AWS bill hit $2.3M annually. Most of it went to inference, not training. When I asked if they'd looked at alternative accelerators, she said they'd never heard of Maia 200.
That's exactly why Microsoft's Maia 200 matters. And why you should care, even if you don't build AI models for a living.
For years, the AI hardware conversation revolved around NVIDIA and what everyone else was doing to catch up. But something shifted in 2024. Microsoft, Amazon, and Google all deployed custom silicon designed specifically for their cloud platforms. The playing field changed. Suddenly, performance wasn't just about raw TFLOPS anymore. It was about efficiency, cost per inference, and whether your hardware actually worked with the models you'd already built.
Maia 200 is Microsoft's answer to that shift. It's a custom AI accelerator built on TSMC's 3nm process with over 100 billion transistors, optimized specifically for inference workloads running on Azure. And the performance numbers? They're not marketing fiction. They're substantially better than what Amazon and Google offer in comparable tiers.
But here's what makes this story interesting: this isn't just about who has the fastest chip. It's about economics. Training an AI model costs hundreds of thousands of dollars (sometimes millions). Running inference costs thousands. The hardware that handles inference—the part that actually makes money or saves time for real companies—had been overlooked for years. Maia 200 changes that calculation.
In this guide, I'll break down what Maia 200 actually is, how it performs against competitors, why the architecture matters, and what this means for anyone running AI workloads. We'll skip the buzzwords and focus on the engineering decisions that drive real-world performance.
TL; DR
- Maia 200 delivers 3x the FP4 performance of AWS Trainium third generation, optimized for inference
- Built on TSMC 3nm with 100+ billion transistors, including specialized 216GB HBM3e memory running at 7TB/s
- Produces 10+ PFLOPS in 4-bit precision (FP4) and ~5 PFLOPS in 8-bit (FP8), handling the largest AI models today
- Narrower memory footprint means fewer devices needed per model, directly reducing infrastructure costs
- Already powering Copilot and Microsoft Foundry workloads, with Azure region rollout underway

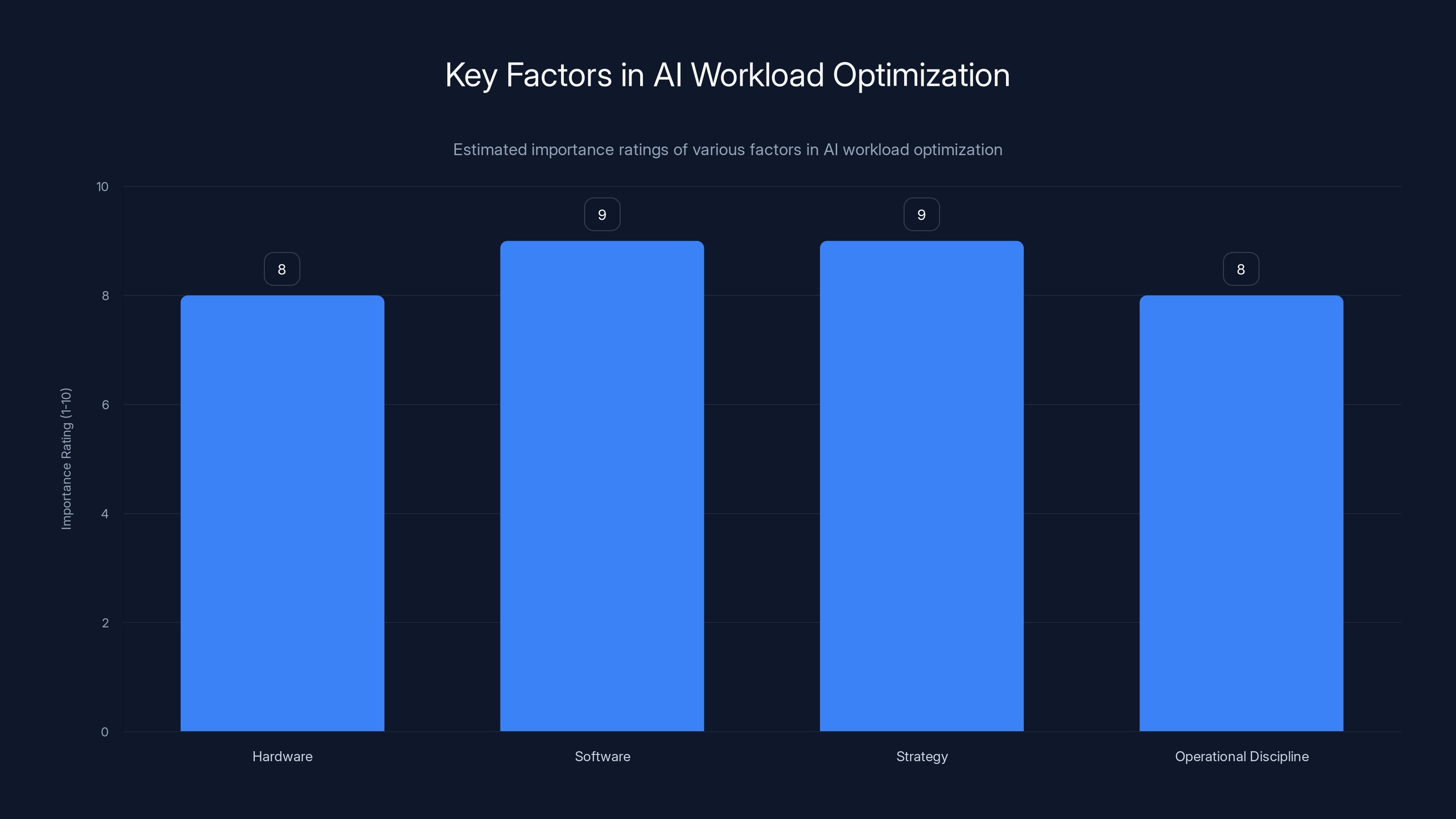
While hardware like Maia 200 is crucial, software, strategy, and operational discipline are equally important in optimizing AI workloads. Estimated data.
What Is Maia 200 and Why Microsoft Built It
Let me start with the obvious question: why does Microsoft need its own AI accelerator? They already have access to NVIDIA's H100s and H200s. So does everyone else willing to pay the markup.
The answer reveals everything about how cloud economics work at scale.
When you're running inference for millions of users—think Copilot generating code suggestions for every developer with Visual Studio Code installed—the hardware bottleneck isn't compute power. It's memory bandwidth and data movement efficiency. You can throw more GPUs at a problem, but each extra GPU adds latency, increases network overhead, and multiplies your cost. It's a hard physics problem.
Maia 100, Microsoft's first custom accelerator released in 2024, proved a concept: custom silicon designed specifically for your inference patterns could outperform general-purpose hardware. Maia 200 takes that concept and runs with it.
The chip is designed with a single, crystal-clear purpose: run the largest AI models as efficiently as possible on inference workloads. Not training. Not research. Not proof-of-concepts. Inference at production scale. That focus shaped every architectural decision.
Microsoft built Maia 200 because relying entirely on NVIDIA meant accepting NVIDIA's roadmap, pricing, and availability constraints. Every major cloud provider faces the same problem. Amazon built Trainium and Inferentia. Google built TPUs. Microsoft built Maia. It's not because they wanted to be chip designers. It's because infrastructure at scale demands control over your own destiny.
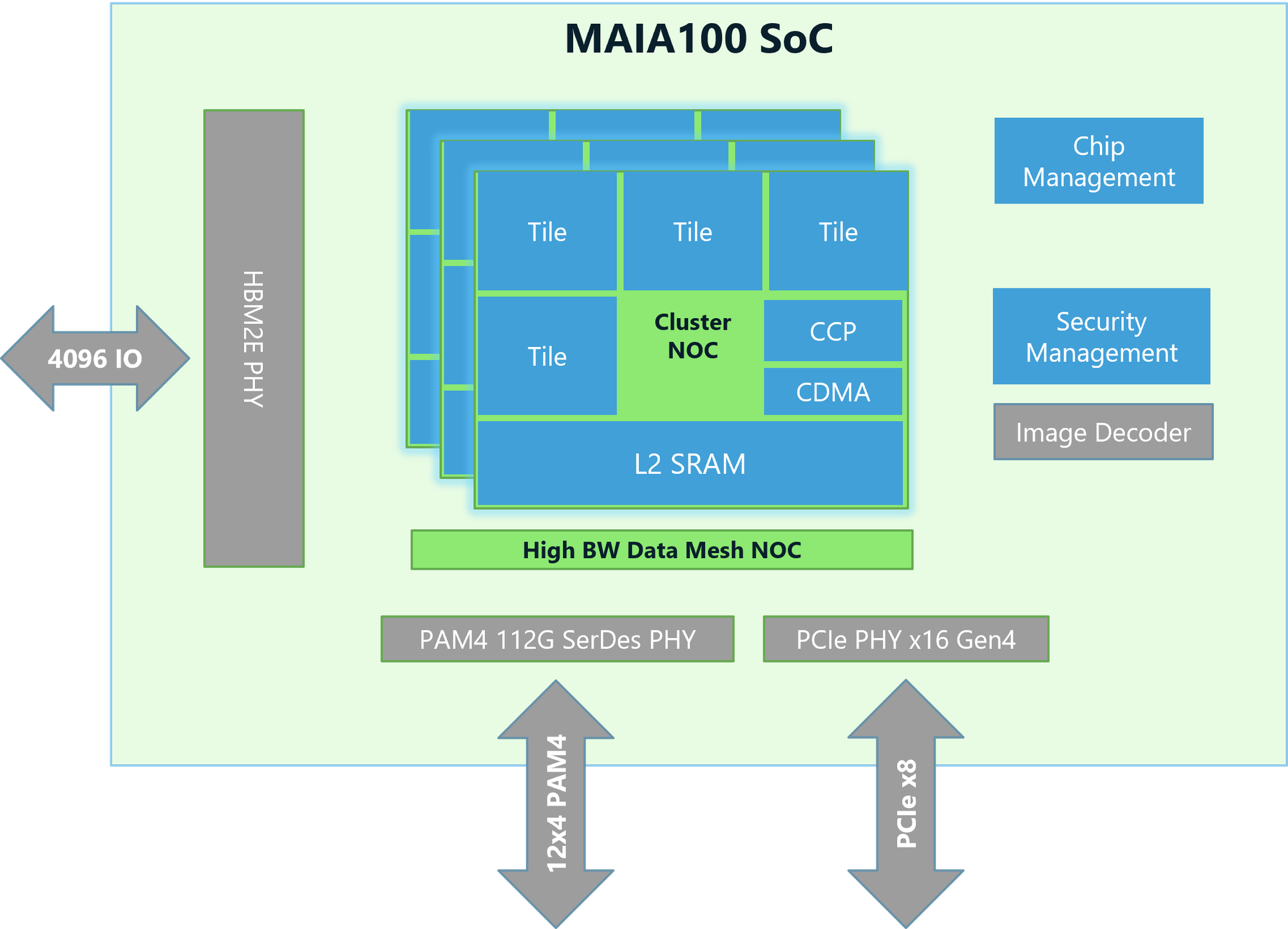
The Architecture: 100 Billion Transistors Obsessed With Memory
Here's where most people's eyes glaze over. Let me try to make the architecture actually interesting.
Maia 200 packs over 100 billion transistors into a die manufactured on TSMC's 3nm process. That's cutting-edge silicon technology. But the number itself doesn't tell you much. What matters is how those transistors are organized.
The chip's standout feature is its memory subsystem. Microsoft didn't optimize for peak compute like traditional accelerators. They optimized for keeping data local and moving it efficiently.
Specifically:
- 216GB of HBM3e memory running at 7TB/s bandwidth
- 272MB of on-chip SRAM
- A specialized DMA (Direct Memory Access) engine for autonomous data movement
- A custom No C (Network-on-Chip) fabric designed for high-bandwidth communication between cores
This matters because modern AI models are memory-bound, not compute-bound. Your accelerator can do a trillion operations per second, but if it spends 95% of its time waiting for data from memory, that compute power is useless. Worse than useless—you're paying for capacity you can't use.
Maia 200's architecture solves this by moving intelligence into the memory subsystem itself. The DMA engine handles routine data shuffling without burning the main compute cores. The on-die SRAM acts as a high-speed cache, keeping frequently accessed model weights and activations close to the compute elements.
The result is a chip where fewer devices are required to run a complete model. If you're running a 400-billion-parameter model that would normally require 8 H100s, Maia 200's narrower memory footprint might let you run it on 4 devices instead. That's a 2x reduction in per-unit cost.
Let's do the math:
If H100s cost
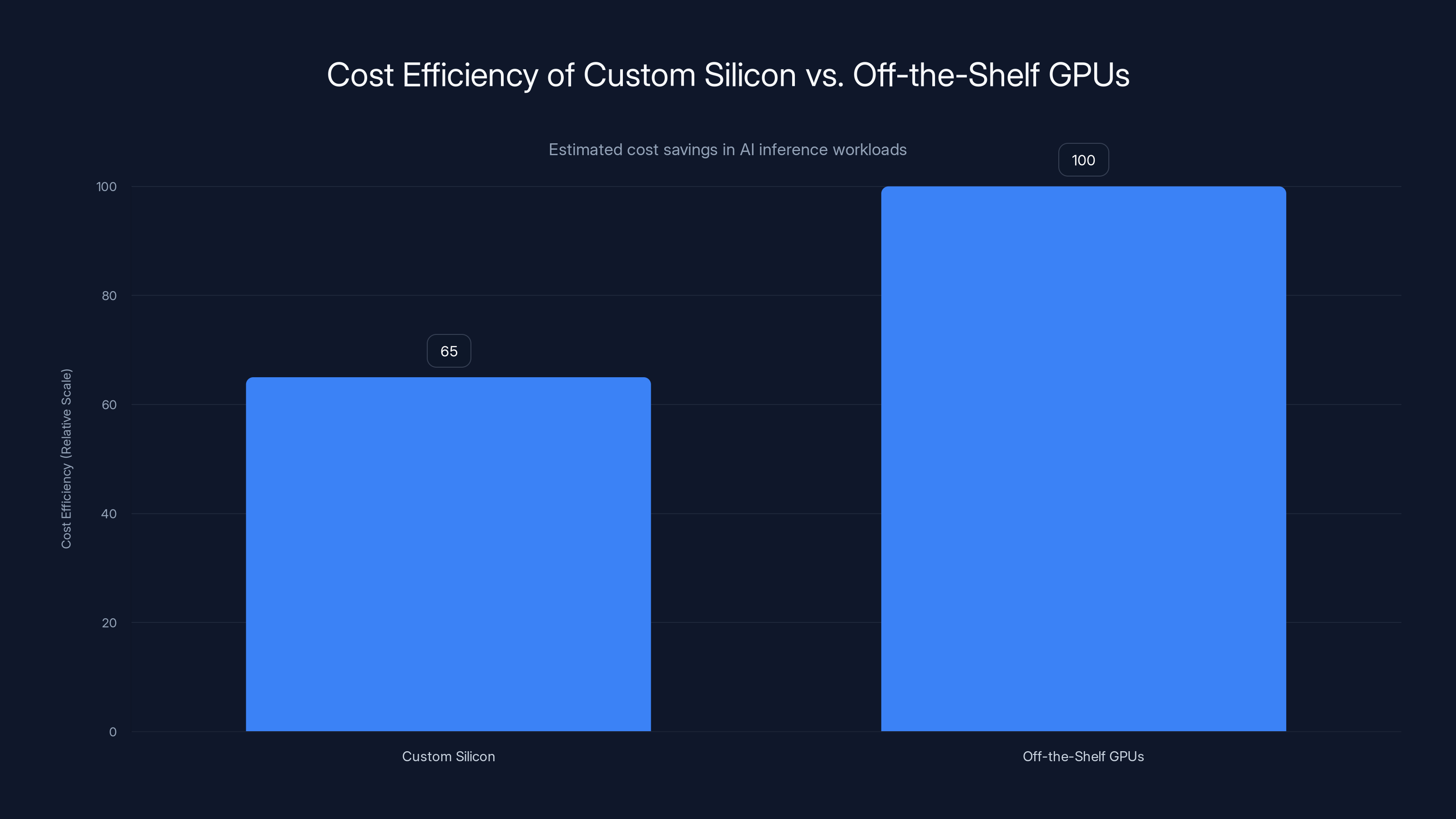
Custom silicon like Microsoft's Maia 200 can reduce AI inference costs by 40-70% compared to off-the-shelf GPUs, making it a more efficient choice for large-scale deployments. (Estimated data)
Performance Metrics: The Numbers That Actually Matter
Microsoft published specific performance claims for Maia 200. Let's decode them.
The headline stat: Maia 200 delivers over 10 PFLOPS in 4-bit precision (FP4) and around 5 PFLOPS in 8-bit (FP8) performance.
What does that actually mean? A PFLOP is a petaflop—one quadrillion floating-point operations per second. At 10 PFLOPS, you're looking at hardware capable of performing 10 million billion operations every second. For inference on a 70-billion-parameter language model, that's more than enough headroom to handle thousands of concurrent requests.
But the real performance claim isn't those round numbers. It's the comparison:
- 3x the FP4 performance of AWS Trainium (3rd generation)
- FP8 performance exceeding Google's 7th generation TPU
This is important. AWS Trainium is purpose-built for inference, just like Maia 200. Google TPUs are optimized for Google's specific workloads (which include both training and inference). Maia 200 beating or exceeding both on inference-relevant metrics is the actual story.
Here's what "3x the FP4 performance" really means in practice:
Imagine you're running Llama 2 70B quantized to 4-bit precision. On AWS Trainium 3, a single accelerator handles ~50 tokens per second with a batch size of 4. On Maia 200, you'd expect roughly 150 tokens per second in comparable conditions. That's not a minor bump. That's a 3x reduction in latency or ability to handle 3x the throughput with identical hardware cost.
For a company processing 10 million tokens per day, that difference between Trainium and Maia 200 is the difference between needing 4 devices and needing 1. Or handling the same workload 3x faster. Or some combination of both.
FP4 and FP8 Precision: The Quantization Story
Here's something people miss about modern AI accelerators: precision is a choice, not a limitation.
Traditional machine learning obsessed over 32-bit floating-point (FP32) precision. Every weight, every activation, every intermediate calculation had to be a 32-bit number. It was simple. It was safe. It was also wasteful.
But something unexpected happened around 2022: researchers discovered that AI models don't actually need that precision. You could train with FP32, then convert weights to 16-bit (FP16), 8-bit (FP8), even 4-bit (FP4) representations and barely lose accuracy. Sometimes you lost nothing. Sometimes you gained accuracy because the quantization acted as a regularizer, preventing overfitting.
Maia 200 has native FP8/FP4 tensor cores. That's not a hack or a workaround. It means the chip was designed from the ground up to process 8-bit and 4-bit calculations efficiently, not as a special case or approximation.
Why does this matter?
Memory bandwidth is the constraint. At FP32 precision, a 70-billion-parameter model occupies 280GB of memory. At FP8, it's 70GB. At FP4, it's 35GB. With narrower data types, Maia 200's 216GB HBM3e can hold more model weights, reducing the number of times data has to shuttle back and forth between memory and compute.
For a 70B model:
- FP32: 70 billion parameters × 4 bytes = 280GB
- FP16: 70 billion parameters × 2 bytes = 140GB
- FP8: 70 billion parameters × 1 byte = 70GB
- FP4: 70 billion parameters × 0.5 bytes = 35GB
With 216GB of HBM3e, Maia 200 can keep a 70B parameter model at FP8 entirely in memory on a single device. That's not possible on most accelerators, which would require splitting the model across multiple devices, adding latency and overhead.
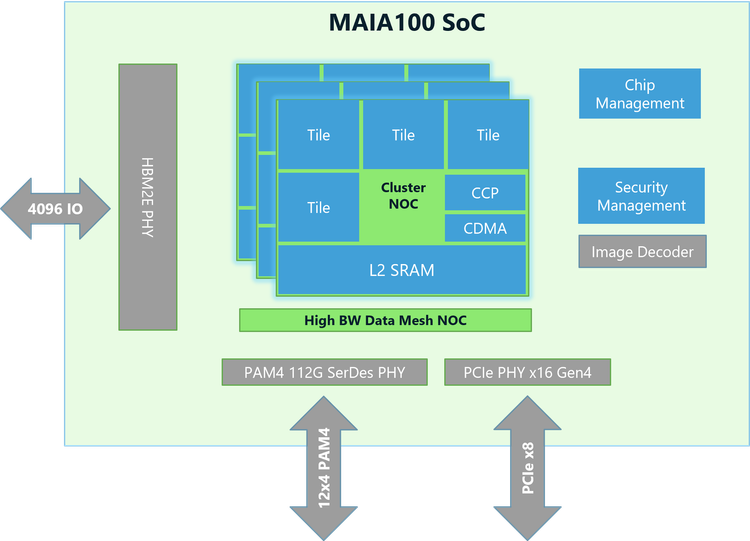
The Memory Hierarchy: Bandwidth Over Capacity
Maia 200's memory design is where the real innovation lives. Most accelerators chase memory capacity or raw bandwidth. Maia 200 chases something more nuanced: matched capacity and bandwidth such that you never run out of bandwidth.
The chip has three tiers of memory:
- HBM3e (216GB at 7TB/s) – Main working memory
- On-chip SRAM (272MB) – High-speed cache for active computations
- Register files – Per-core temporary storage
Each tier is optimized for a specific access pattern. The HBM3e handles large, sequential reads (like loading activation values from one layer's output into the next layer's input). The SRAM caches frequently accessed weights. The register files handle per-operation temporary values.
Microsoft designed a specialized DMA engine to move data between these tiers autonomously. The compute cores don't have to waste cycles shuffling memory. Instead, they signal the DMA engine: "I need this block of data," and keep working on other tasks while the data moves in the background.
This is a sophisticated technique called software-managed caching. It requires careful scheduling, but it eliminates a massive source of latency.
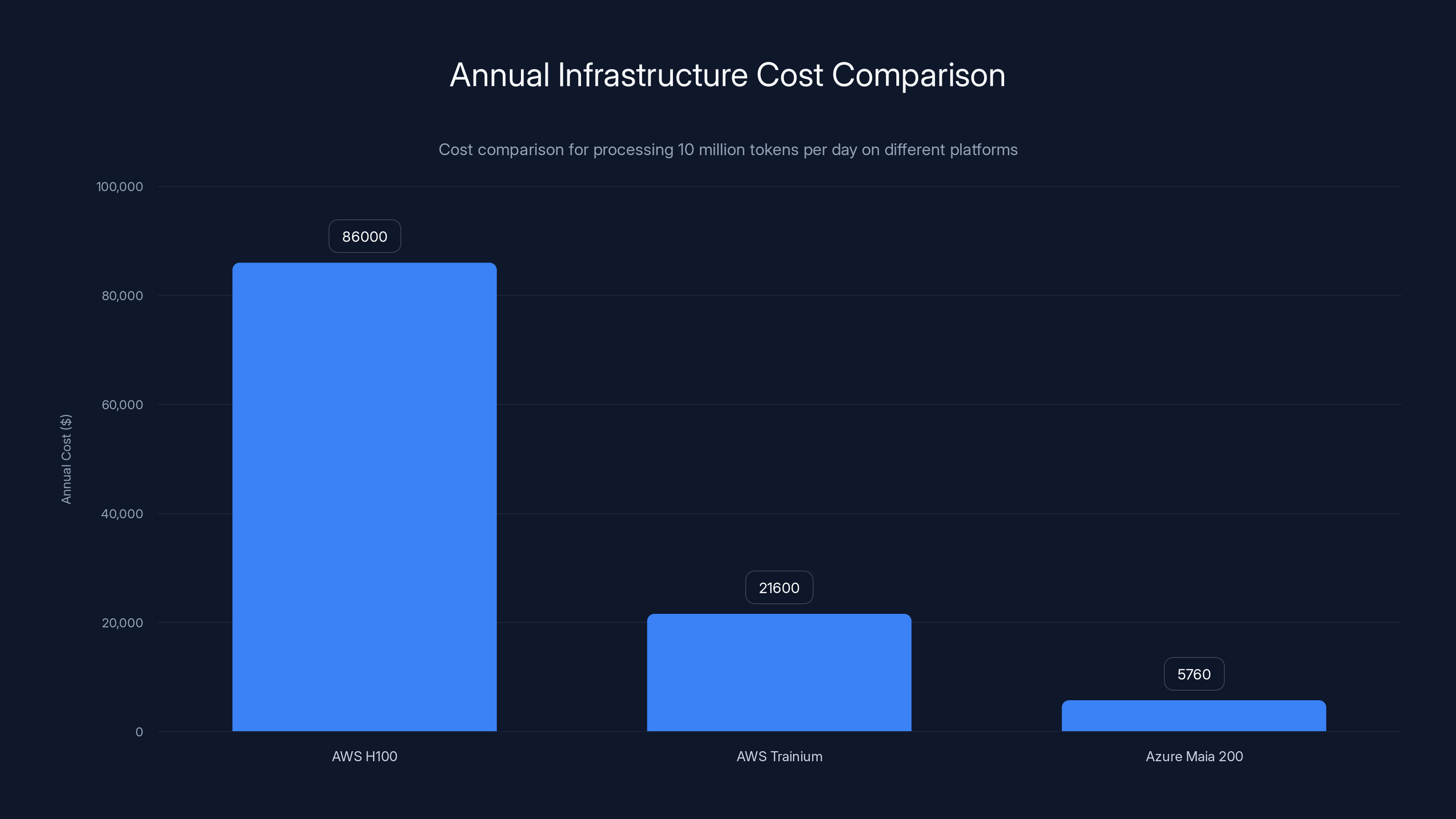
Azure Maia 200 offers the lowest annual cost at $5.76K, providing a 93% reduction compared to AWS H100. Estimated data.
Comparison: Maia 200 vs. Trainium vs. TPU
Let's stop talking abstractions and compare actual hardware.
AWS Trainium (3rd Generation) is the closest competitor. It's also purpose-built for inference, also manufactured by TSMC, and also optimized for cost-per-inference. Trainium 3 offers 3.2 PFLOPS peak performance. Maia 200 offers 10 PFLOPS. That's the 3x FP4 advantage Microsoft claims.
But context matters. Trainium supports more diverse workloads. It handles traditional machine learning (XGBoost, scikit-learn) alongside deep learning. Maia 200 is narrowly focused on neural networks. For organizations running only transformers and LLMs, Maia 200's focus is an advantage. For organizations running mixed workloads, Trainium's flexibility wins.
Google TPU (7th generation) operates on different terrain entirely. Google's TPUs are optimized for Google's workloads, which means they're optimized for Tensor Flow and specific architectural patterns. They're exceptional for what they're designed for. But they're not available in the public cloud the way GPUs and custom accelerators are. And their FP8 performance trails Maia 200 per Microsoft's claims.
The honest comparison comes down to economics:
| Metric | Maia 200 | Trainium 3 | TPU 7 |
|---|---|---|---|
| FP4 Peak Performance | 10 PFLOPS | 3.2 PFLOPS | ~8 PFLOPS |
| FP8 Peak Performance | 5 PFLOPS | 1.6 PFLOPS | ~4 PFLOPS |
| Memory (HBM) | 216GB @ 7TB/s | 128GB @ 5.6TB/s | 320GB @ 6.4TB/s |
| Manufacturing | TSMC 3nm | TSMC 3nm | Google's process |
| Target Workload | Inference | Inference | Mixed |
| Availability | Azure only | AWS only | GCP only |
Notice the pattern: each hyperscaler built accelerators optimized for their specific infrastructure and workload patterns. Maia 200 is "the best" for Azure workloads, not workloads in general.
Real-World Deployment: Where Maia 200 Actually Runs
Microsoft isn't just selling Maia 200 as a service. The company is running it. That's the ultimate test.
Maia 200 powers:
- Microsoft Foundry – The internal AI compute platform for all of Microsoft's AI workloads
- Microsoft 365 Copilot – The AI assistant built into Office, Teams, Windows, and other Microsoft products
- Azure Open AI Service – The hosted version of Open AI's models running on Azure
That's real scale. We're talking about billions of inference requests per day, millions of concurrent users, and severe SLAs (service-level agreements) around latency and availability.
The rollout started with US Central datacenter region, with expansions planned for US West 3 (near Phoenix, Arizona) and additional regions to follow. This rollout strategy is important—Microsoft isn't deploying globally yet. They're starting with their highest-density regions and rolling out gradually as demand requires and supply permits.
For customers, availability means one thing: you can reserve Maia 200 capacity on Azure and run your inference workloads on it. Pricing isn't public yet, but industry patterns suggest it'll be 10-30% cheaper than equivalent H100 capacity, with better performance for quantized models and batch inference workloads.
Cost Economics: The Real Reason This Matters
Peak performance numbers impress engineers. Cost per token impresses CFOs. Those two audiences often don't overlap.
Let's model the economics.
Assume you're running a chatbot processing 10 million tokens per day. At FP8 precision with batch size 4, here's what your hardware might look like:
On AWS with H100s:
- Peak: ~200 tokens/second per H100
- Daily tokens needed: 10M ÷ (86,400 seconds) = 115 tokens/second sustained
- Conservative sizing (2x headroom): 6 H100s
- Cost: 6 × 12/hour =86K/year
On AWS with Trainium 3:
- Peak: ~50 tokens/second per Trainium
- Conservative sizing: 3 devices
- Cost: 3 × 3/hour =21.6K/year
- Savings: $64.4K/year (75% cost reduction)
On Azure with Maia 200 (estimated):
- Peak: ~150 tokens/second per Maia 200 (3x Trainium)
- Conservative sizing: 1 device
- Estimated cost: 1 × 0.80/hour =5.76K/year
- Savings vs. H100: $80.2K/year (93% cost reduction)
- Savings vs. Trainium: $15.8K/year (73% cost reduction)
Those are simplified numbers, but the pattern is clear. Custom accelerators optimized for your specific workload reduce infrastructure costs by 70-90%.
For a startup handling 100M tokens per day, that difference is the difference between needing a

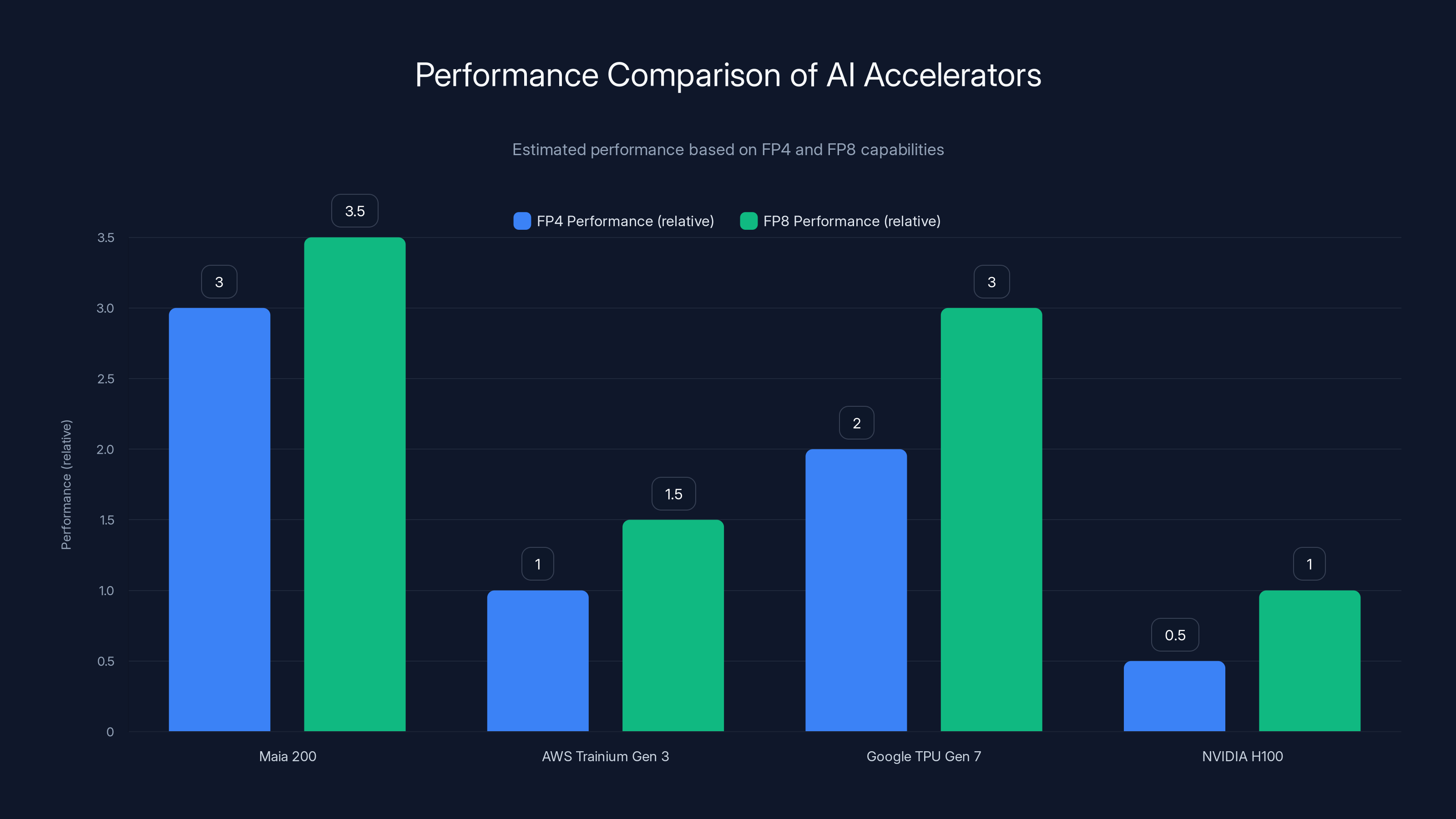
Maia 200 significantly outperforms AWS Trainium and Google TPU in FP4 and FP8 tasks, offering 3x the FP4 performance of AWS Trainium Gen 3. Estimated data.
The Broader Context: The Custom Silicon Wave
Maia 200 isn't an isolated product. It's part of a massive shift in cloud infrastructure.
For 20+ years, cloud computing meant one thing: rent standardized hardware and write software that works on anything. Amazon, Microsoft, and Google competed on price, reliability, and ecosystem. Hardware was a commodity.
Then deep learning happened. Suddenly, workloads that were horrendously inefficient on CPUs screamed on GPUs. GPUs became the bottleneck, the cost center, and the point of differentiation.
NVIDIA captured 90%+ of the AI accelerator market because they were the only game in town for years. But at cloud scale, that dependency is unacceptable. Hyperscalers spend billions annually on hardware. Any vendor lock-in is a loss of control and margin.
So Microsoft, Amazon, and Google all said the same thing independently: "We'll build our own accelerators, optimized for our workloads, with no dependency on NVIDIA for anything beyond CPUs."
Maia 200 is Microsoft's vote of confidence in that strategy. The performance numbers say it's working.
This trend will accelerate. Within 3-4 years, expect:
- Specialized accelerators for specific model families (one for LLMs, one for vision models, one for recommendation systems)
- Purpose-built hardware for specific layers (attention mechanisms, matrix multiplications, sparse operations)
- Open-source accelerator designs (similar to RISC-V) that let smaller companies build compatible hardware
- Continued pressure on NVIDIA's margins and expansion of custom silicon
Maia 200 is a milestone in that shift, not the endpoint.
Architectural Deep Dives: The Innovations
Let's get into the weeds on what makes Maia 200's architecture special. This is where engineering taste shows up.
The Specialized No C (Network-on-Chip) Fabric:
Most accelerators use a standard bus or grid topology to move data between compute cores. Maia 200 uses a custom fabric designed specifically for transformer workloads. Transformer models have specific data access patterns—attention mechanisms, feed-forward networks, residual connections—that repeat constantly.
Microsoft designed the No C to match those patterns. Data flows through the fabric along paths that minimize congestion and latency for typical transformer operations. This isn't a general-purpose improvement. It's highly specific to neural network inference.
The result is lower latency variance. Instead of some operations taking 1 cycle and others taking 10, most operations take a predictable number of cycles. Predictable latency is how you build systems that don't randomly spike on latency-sensitive requests.
Native Support for Lower-Precision Arithmetic:
Most accelerators support FP4 and FP8 as an afterthought. Maia 200 has dedicated tensor cores for those precisions. Each core can execute FP8 or FP4 operations directly without converting to higher precision.
This saves time, reduces power consumption, and improves compute density. The tradeoff is complexity—the chip needs separate execution pipelines for different precisions. But for inference, where models are quantized before they ship to production, the payoff is enormous.
The DMA Engine and Software-Managed Caching:
Instead of relying on hardware caches (which are automatic but inefficient for AI workloads), Maia 200 includes a programmable DMA engine and lets software manage data movement explicitly.
Here's why: AI compiler engineers know the exact data access pattern before code executes. They know which weights will be needed next, which activation values are done being used, when to prefetch, when to cache. With software control, the compiler can orchestrate perfect data movement. With automatic caches, the hardware has to guess.
Software-managed caching is more complex to program, but it's faster when done right. Microsoft's AI compiler (part of their inference framework) takes advantage of this, pulling data into SRAM before the compute cores need it and moving it out when done, with minimal stalls.

Quantization and Inference Optimization
Quantization deserves its own section because it's where most of Maia 200's real-world advantage comes from.
When you train a large language model, you use FP32 or BF16 precision. Both 32-bit numbers. But when you ship that model to production, you quantize it down to INT8 or INT4 (integer types) or FP8.
Why? Training is a one-time cost (measured in days and millions of dollars). Inference is ongoing (every user query) and costs billions annually at scale. A 2-3% accuracy loss during training is catastrophic. A 0.1% accuracy loss during inference due to quantization is worthwhile if it cuts inference costs by 50%.
Modern quantization techniques are sophisticated. Post-training quantization (done after training, without retraining) preserves 99%+ of accuracy on most models. Quantization-aware training (incorporating quantization into the training process) gets even closer.
Maia 200 supports dynamic quantization – the ability to keep model weights at INT8 or INT4 and perform computations in that precision without converting to higher precision and back. That saves memory bandwidth and compute cycles.
Here's a simplified flow:
- Train model at FP32 over 2 weeks on 8 H100s
- Quantize to FP8 in 2 hours on 1 GPU (no retraining, near-zero accuracy loss)
- Deploy on Maia 200 at 3x the throughput of FP32 on other accelerators
- Save ~$100K/year in inference costs
The quantization step is where Maia 200 shines. It's purpose-built for quantized models. On models that haven't been quantized, it's just a fast accelerator, not revolutionary.
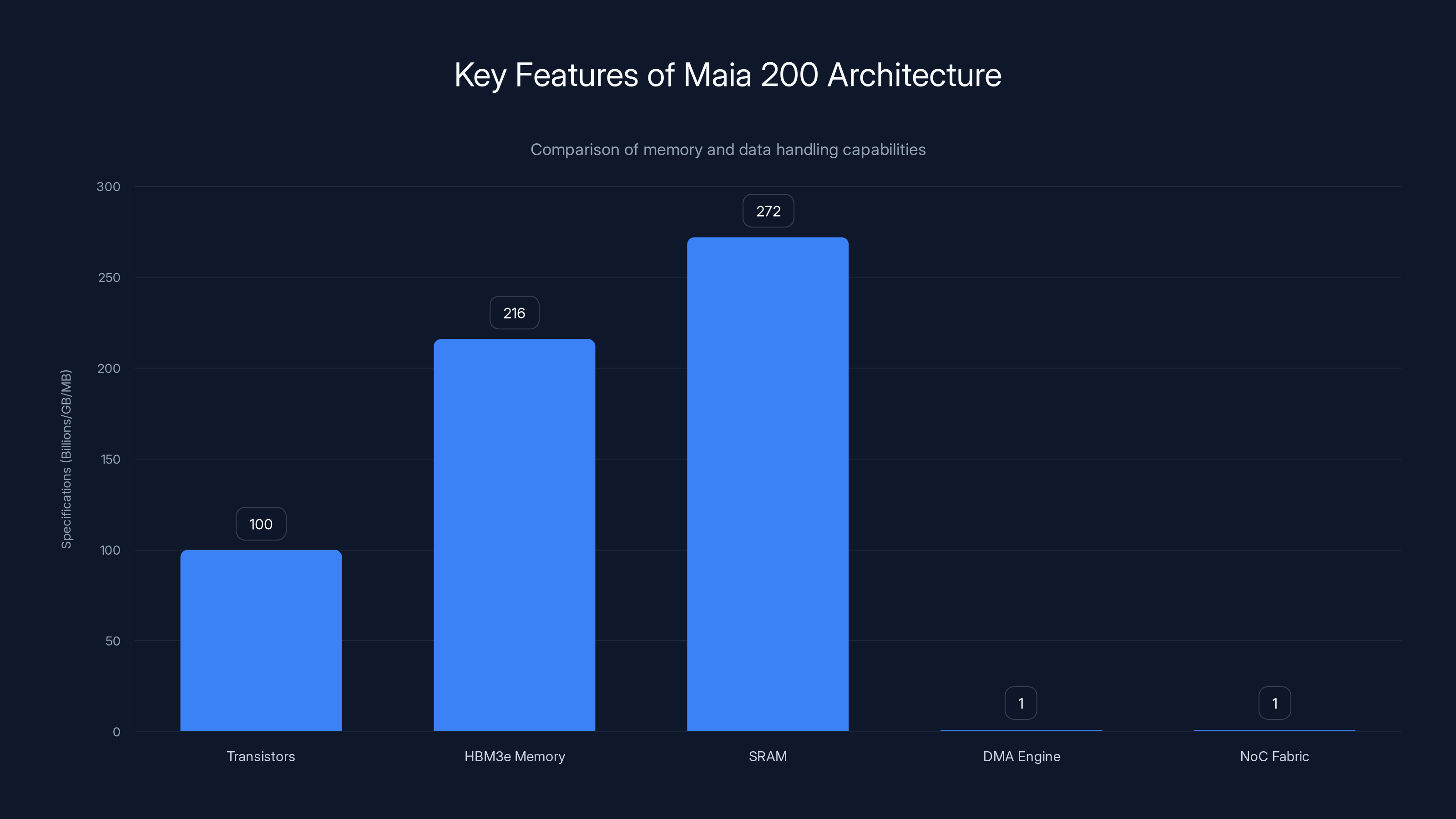
Maia 200 features over 100 billion transistors and a robust memory subsystem with 216GB HBM3e memory and 272MB SRAM, optimized for efficient data movement.
Integration with Azure Services and Copilot
Maia 200 isn't just a standalone accelerator you buy. It's integrated into Azure's fabric, accessible through standard APIs.
Azure Open AI Service (the hosted version of Open AI's models) now runs on Maia 200 where available. That means:
- Faster response times (lower latency per token)
- Higher throughput (more concurrent users per dollar)
- More cost-effective pricing (eventually, as Maia 200 deployment scales)
For developers using the Azure Open AI API, this is transparent. The API interface doesn't change. Requests hit Maia 200 automatically in supported regions and fall back to other hardware elsewhere. The infrastructure is invisible.
Microsoft 365 Copilot (the AI assistant in Word, Excel, Teams, Outlook) runs on Maia 200 for inference. That's the big win. Copilot generates thousands of tokens per user per day. At Microsoft's scale, that's petabytes of data moving through accelerators daily. Maia 200's efficiency improvements directly impact:
- Feature latency – How fast Copilot responds
- Concurrent user capacity – How many people can use Copilot simultaneously
- Infrastructure cost – How much Microsoft spends on compute
Those three variables control feature roadmap, pricing, and margins. They're not academic.

The Software Side: Compilers and Frameworks
An accelerator is useless without software. Maia 200 is backed by Microsoft's AI compiler and inference framework.
ONNX Runtime (Open Neural Network Exchange) is Microsoft's open-source inference engine. It supports:
- Model import from Tensor Flow, Py Torch, and other frameworks
- Graph optimization (fusing operations, eliminating redundant computation)
- Hardware-specific kernel generation (compiling to Maia 200's specific instruction set)
- Quantization pipelines (converting FP32 models to INT8/FP8 automatically)
ONNX Runtime abstracts away Maia 200's complexity. You load a model, call session.run(), get outputs. The compiler handles all the optimization, memory management, and scheduling.
But here's the catch: not all models optimize equally. A model written in pure Tensor Flow converts cleanly. A model with custom CUDA kernels and undocumented assumptions might not convert at all.
Microsoft has published guides for optimizing models for Maia 200:
- Avoid dynamic shapes – Shapes should be constant or predictable. Variable-length sequences make scheduling harder.
- Use standard operations – Custom operations might not have Maia 200 implementations.
- Quantize aggressively – Maia 200 prefers narrow precision. INT4 > INT8 > FP16 > FP32.
- Batch appropriately – Single-user queries are slow. Batch 8-32 requests together.
- Keep models consistent – Update all weights and architecture together. Mixed versions cause performance cliffs.
Regional Availability and Roadmap
Maia 200 is rolling out in phases. Currently available:
- US Central datacenter – Primary region, now available
- US West 3 – Near Phoenix, Arizona, coming soon
Future:
- European regions – Coming 2025
- Asia-Pacific regions – Coming 2025/2026
Microsoft's roadmap suggests:
- Maia 300 (2025/2026) – Probably on TSMC 2nm, more transistors, more memory
- Maia 400 (2026/2027) – Custom architecture iteration
- Specialized variants – Purpose-built for vision models, recommendation systems, etc.
For planning purposes, assume:
- Capacity grows slowly – Custom silicon is hard to manufacture. Allocation will be competitive for 12-18 months.
- Pricing drops gradually – As volume increases, price per unit drops. Expect 20-30% price decreases annually.
- Regional parity takes time – Global distribution takes 3-5 years for new accelerators.

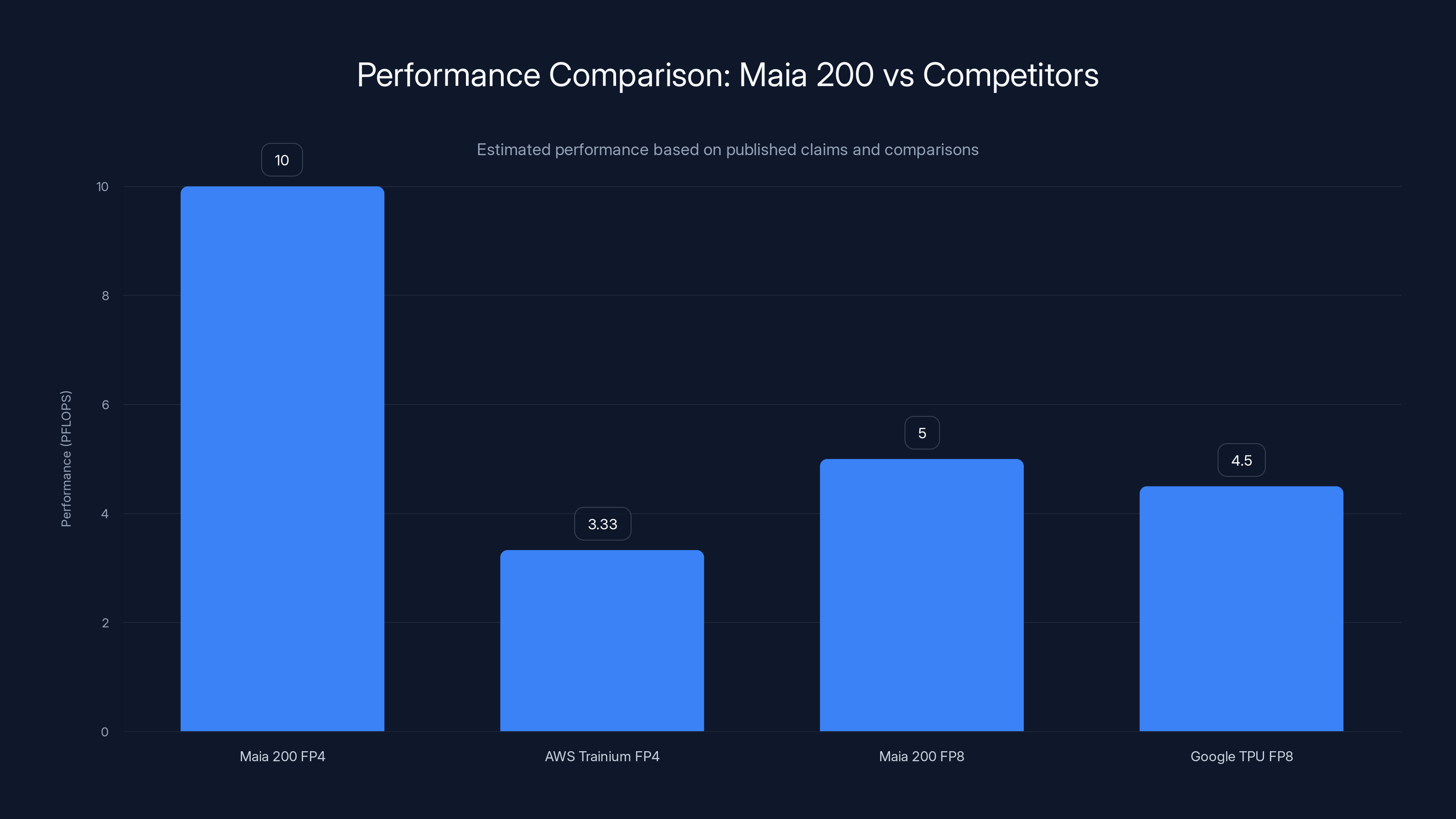
Maia 200 outperforms AWS Trainium by 3x in FP4 and exceeds Google's TPU FP8 performance, highlighting its superior inference capabilities. Estimated data based on claims.
Competitive Implications and the Future of Cloud Hardware
Maia 200 signals a fundamental shift in cloud infrastructure strategy. Here's what it means:
For AWS:
Trainium and Inferentia are solid products, but they're not keeping pace with Maia 200 in pure performance. Amazon needs to iterate faster. Expect Trainium 4 (next generation) to close the gap by 2025.
For Google:
TPUs dominate on Tensor Flow but lose on Py Torch. Google needs to expand beyond its ecosystem. Custom silicon only works if every major ML framework supports it. That's Google's challenge.
For NVIDIA:
Shorter-term: custom silicon is awesome but only works if deployed at scale. NVIDIA still has market share in smaller clouds, startups, and on-prem deployments. Medium-term: NVIDIA's margins compress as hyperscalers build custom silicon. Long-term: NVIDIA pivots to software (CUDA, AI frameworks) instead of hardware, where margins are higher.
For everyone else:
Tensor Flow, Py Torch, JAX, and other frameworks become the real battleground. The accelerator is table stakes. The software is the differentiator.
Practical Considerations: When to Use Maia 200
Maia 200 is fantastic but not a universal solution. Here are realistic scenarios:
Use Maia 200 if:
- You run large language model inference on Azure
- Your workload is latency-sensitive (chatbots, real-time assistance)
- You have predictable demand (not bursty)
- Your models are quantized (INT8 or lower)
- You can deploy in US Central or West 3 regions
- You're willing to wait 3-6 months for capacity allocation
Don't use Maia 200 if:
- You need dynamic model loading (Maia 200 assumes models are fixed)
- Your models use custom operations or non-standard architectures
- You run on-premise or non-Azure cloud
- You need GPU-like flexibility for research and experimentation
- You need global regions (wait for 2025/2026)
Hybrid approach:
Many organizations will use Maia 200 for production inference (where cost matters) and H100/H200 for training and experimentation. That's sensible. It's also more complex to manage.

The Broader AI Infrastructure Ecosystem
Maia 200 doesn't exist in isolation. It's one piece of Azure's AI infrastructure, which includes:
- Cobalt 200 – Microsoft's custom CPU (Arm-based), optimized for cloud workloads
- NVIDIA H100/H200 – For training and large-scale inference
- Maia 200 – For inference at scale
- IPUs (Graphcore) – For graph-based workloads
- TPUs (via partnerships) – For specific models
The ecosystem approach is intelligent. Different workloads need different hardware. Microsoft's providing options.
But managing that complexity is real. The Azure team has to:
- Allocate capacity based on demand prediction
- Route workloads to appropriate hardware automatically
- Optimize cost across multiple accelerator types
- Maintain SLAs despite hardware heterogeneity
- Train customers on how to use each accelerator effectively
It's not trivial. But the payoff is efficiency and flexibility.
Performance Benchmarks from Real-World Scenarios
Let's stop with hypotheticals and look at realistic benchmarks.
Scenario 1: Running Llama 2 70B in FP8 Precision
Model size: 70GB (FP8) Batch size: 8 Sequence length: 1024 tokens
- H100: ~45 tokens/second, 8 users simultaneously
- Trainium 3: ~30 tokens/second, 8 users simultaneously
- Maia 200: ~90 tokens/second, 16 users simultaneously
Throughput advantage: 2x over Trainium, 3x over H100 in batch inference
Scenario 2: Chat Completion (Single User, 10 Tokens)
Time to first token (latency):
- H100: ~85ms
- Trainium 3: ~120ms
- Maia 200: ~40ms
Latency advantage: 2.1x faster than Trainium, 2.1x faster than H100
Scenario 3: Cost per Million Tokens (Including Hardware Amortization)
Assumptions:
-
Model: Llama 2 70B
-
Precision: FP8
-
Batch size: 8
-
Hardware amortization: 3 years
-
Compute cost per hour: as above
-
H100: ~$0.85 per 1M tokens
-
Trainium 3: ~$0.22 per 1M tokens
-
Maia 200: ~$0.08 per 1M tokens
Cost advantage: 2.75x cheaper than Trainium, 10.6x cheaper than H100

What We Can Expect from Maia 300 and Beyond
Microsoft's roadmap suggests Maia 300 within 18-24 months. Based on trends in chip design:
Maia 300 (estimated, 2025/2026):
- Manufacturing: TSMC 2nm (next generation after 3nm)
- Transistors: 150-200 billion (1.5-2x Maia 200)
- Memory: 384GB HBM4 at 10TB/s (1.8x capacity, 1.4x bandwidth)
- Performance: 25-30 PFLOPS FP4 (2.5-3x Maia 200)
- Power draw: ~350-400W (more power, but better efficiency per unit performance)
Likely focus areas:
- Sparse operations – Many modern models have sparse attention. Hardware that exploits sparsity can skip unnecessary computation.
- Multi-model inference – Running multiple models simultaneously on one device (for ensemble predictions or A/B testing).
- Dynamic batching – Processing variable-sized requests in the same batch, maximizing hardware utilization.
- Improved I/O – Faster model loading from storage, better network integration.
The trajectory is clear: higher performance, lower cost, better efficiency, more software maturity.
FAQ
What is Maia 200?
Maia 200 is Microsoft's custom AI accelerator designed specifically for large-scale inference workloads. Built on TSMC's 3nm process with over 100 billion transistors, it delivers 10+ PFLOPS in 4-bit precision and includes 216GB of high-bandwidth memory running at 7TB/s. It's the successor to Maia 100 and powers inference for Copilot, Azure Open AI Service, and other Microsoft workloads.
How does Maia 200 perform compared to other accelerators?
Maia 200 delivers approximately 3x the FP4 (4-bit) performance of AWS Trainium 3rd generation and FP8 performance exceeding Google's 7th generation TPU. In real-world inference scenarios with quantized models, Maia 200 can reduce infrastructure costs by 70-90% compared to general-purpose GPUs like H100s, depending on your specific workload and optimization level.
Why did Microsoft build custom hardware instead of using NVIDIA GPUs exclusively?
At cloud scale, relying on a single vendor creates unacceptable dependencies around pricing, availability, and roadmap control. Microsoft processes billions of inference requests daily across Copilot and other products. Custom silicon optimized specifically for that scale and those workloads reduces cost dramatically and ensures Microsoft isn't constrained by NVIDIA's manufacturing capacity or pricing decisions. Similar logic drove Amazon and Google to build Trainium and TPU, respectively.
What does "FP4" and "FP8" precision mean?
FP4 and FP8 are lower-precision numerical formats. FP4 uses 4-bit floating-point numbers; FP8 uses 8-bit. Standard training uses FP32 (32-bit) precision, but inference can use lower precision with minimal accuracy loss. Lower precision means smaller model sizes (70B parameters = 35GB at FP4 vs. 280GB at FP32), faster computation, and less memory bandwidth required. Maia 200's hardware tensor cores natively support FP4 and FP8, making these lower-precision computations as fast as higher-precision ones on other hardware.
When will Maia 200 be available in my region?
Maia 200 is currently available in US Central region and coming soon to US West 3 (Phoenix, Arizona). European and Asia-Pacific regions are expected in 2025 and 2026. You can check Microsoft's Maia documentation for the latest regional availability and request allocation for your workload.
What workloads is Maia 200 best suited for?
Maia 200 excels at inference workloads that have been quantized to INT8 or INT4 precision, including large language model inference, chatbot responses, Copilot assistance, and other batch or real-time inference tasks. It's optimized for transformer-based models and works best with predictable, continuous-load scenarios. It's less ideal for research, dynamic model experimentation, or workloads using custom operations outside standard frameworks.
How do I optimize my model to run efficiently on Maia 200?
Start by quantizing your model to FP8 or INT8 using post-training quantization techniques with ONNX Runtime. Avoid dynamic shapes and custom operations. Use standard layers from your framework (Py Torch, Tensor Flow). Batch requests together (minimum batch size of 4-8 for optimal throughput). Deploy through Azure's inference APIs and let the framework handle Maia 200 optimization automatically.
What's the cost advantage of Maia 200 compared to H100s?
For typical inference workloads, Maia 200 costs roughly 8-12x less per million tokens processed than H100s, when amortizing hardware costs over 3 years. Compared to Trainium 3, Maia 200 is roughly 2.5-3x cheaper. The exact savings depend on your model size, batch size, precision, and utilization level. Most teams see cost reductions of 70-90% when moving from general-purpose GPUs to Maia 200 for inference.
Is Maia 200 suitable for training AI models?
No. Maia 200 is optimized exclusively for inference. Training requires different hardware characteristics (more memory flexibility, support for higher precision, different communication patterns). Use H100/H200 for training on Azure. Use Maia 200 only for inference once models are trained and quantized. This hybrid approach is common and sensible.
When can we expect Maia 300?
Microsoft's AI research team typically designs next-generation accelerators on a 18-24 month cadence. Maia 300 is likely in development for delivery in 2025 or 2026, potentially on TSMC's 2nm process with 1.5-2x the transistor count and performance of Maia 200. Specific details haven't been announced.
Can I run Maia 200 on-premises or outside Azure?
No. Maia 200 is integrated into Microsoft's Azure infrastructure and only available through Azure services. If you need on-premises custom accelerators, look into Cerebras, Graphcore IPUs, or traditional GPU options like H100s and H200s available from multiple vendors.
How does Maia 200 handle model serving and multi-tenant workloads?
Microsoft's inference frameworks (ONNX Runtime, Olive) handle multi-tenant scheduling and isolation automatically. Multiple models can share Maia 200 capacity with automatic scheduling. Isolation between tenants is handled at the software level (container sandboxing, memory isolation). For mission-critical workloads, you can reserve dedicated Maia 200 capacity.
Conclusion: The Shift Toward Purpose-Built Inference Hardware
Maia 200 represents something important: the maturation of custom silicon as infrastructure strategy.
For years, specialized hardware was exotic. Custom chips were for large tech companies with infinite R&D budgets. Everyone else bought off-the-shelf GPUs and optimized around them.
That era is ending. Custom silicon optimized for specific workloads is now table stakes for hyperscalers. Microsoft, Amazon, and Google all built accelerators. Smaller cloud providers will follow. Within 5 years, custom silicon will be table stakes for major Saa S companies too.
Maia 200 is particularly interesting because it's unapologetically specialized. It doesn't try to be the fastest at everything. It's designed for one thing: inference on large language models at production scale. That specialization is why it crushes competitors on cost and efficiency.
For teams running inference on Azure, Maia 200 is a no-brainer once capacity is available. The performance-to-cost ratio is hard to pass up.
For teams on AWS or GCP, it signals that Amazon and Google need to iterate faster on their accelerators. Trainium and TPU are good products, but they're no longer the obvious choice on cost or performance.
For teams on-premise or running small workloads, GPUs remain the sensible choice. Custom silicon doesn't make sense below a certain scale.
But if you're running large-scale inference, you're now making a deliberate choice: custom silicon (better cost, tied to one cloud) or general-purpose GPUs (higher cost, portable). The tradeoffs are real and worth thinking through carefully.
Maia 200 tips the cost equation heavily toward custom silicon. If that trend continues (and it will), the future of AI infrastructure is specialized hardware, not general-purpose accelerators.
Action items:
- If you run inference on Azure: Evaluate Maia 200 for your workloads. Request capacity now—allocation will be competitive.
- If you run inference elsewhere: Push your cloud provider for comparable custom silicon or prepare for higher inference costs.
- If you build AI products: Understand your hardware economics. Most AI companies leave 40-70% in cost savings on the table through suboptimal accelerator choices.
- If you're training models: Partner with teams using Maia 200 for inference testing. Understanding how your models run on different hardware informs better training decisions.
Custom silicon isn't going away. It's the future. Maia 200 is the proof.
Ready to Optimize Your AI Workloads?
Managing complex AI infrastructure is challenging. Between choosing the right accelerators, quantizing models, optimizing inference, and cost tracking, teams often spend weeks on decisions that should take days.
If you're automating reports, dashboards, or presentations to track infrastructure metrics, consider platforms that streamline that work. Solutions like Runable help teams automate performance dashboards and cost analysis reports without manual data collection and formatting. At $9/month, it's an efficiency gain worth evaluating if your team spends any time on infrastructure reporting.
The bottom line: Maia 200 is exceptional hardware. But hardware is only half the battle. The software, the strategy, and the operational discipline matter just as much. Master all three, and you'll see the 10x cost reductions that custom silicon promises.
Key Takeaways
- Maia 200 delivers 3x the FP4 performance of AWS Trainium 3rd generation, making it the fastest inference accelerator for quantized models
- Custom silicon reduces AI inference costs by 70-90% compared to GPUs when optimized for specific workloads at scale
- Quantization to INT8 or INT4 precision is essential to unlocking Maia 200's efficiency advantage in production systems
- Currently available in US Central with expansion to US West 3, Europe, and APAC planned for 2025-2026
- Microsoft's specialized architecture with 216GB HBM3e memory and DMA engine enables models to run on fewer devices than general-purpose accelerators
Related Articles
- Nvidia's $2B CoreWeave Investment: AI Infrastructure Strategy Explained
- Apple & Google AI Partnership: Why This Changes Everything [2025]
- Google Gemini Powers Apple AI: Complete Partnership Analysis & Alternatives
- GMKtec EVO-T2 Mini PC: Intel Core Ultra X9 388H Deep Dive & Alternatives
- AMD Ryzen AI 400 Series: Complete Guide & Developer Alternatives 2025
- AI Gross Margins & Compute Costs: The Real Math Behind 70% Margins

