![MiniMax M2.5: Open-Source AI Model Costing 1/20th of Claude [2025]](https://tryrunable.com/blog/minimax-m2-5-open-source-ai-model-costing-1-20th-of-claude-2/image-1-1770928649096.png)
Introduction: The AI Cost Revolution Nobody Saw Coming
For the past three years, cutting-edge artificial intelligence felt like a luxury sport. If you wanted to use Claude Opus or GPT-4, you watched your token meter like a nervous driver watching a fuel gauge on a cross-country road trip. Every API call cost money. Every task burned through your budget. Organizations built entire cost-management systems just to prevent surprise bills.
Then Mini Max, a Shanghai-based AI startup, walked in and changed the math entirely.
In 2025, Mini Max released M2.5 and M2.5 Lightning, two language models that deliver performance matching Anthropic's Claude Opus 4.6 while costing 95% less to run. This isn't a marginal improvement or a niche advantage. This is a fundamental shift in how organizations should think about AI deployment, scaling, and economic viability.
The implications ripple far beyond cost savings. When intelligence becomes cheap, developers stop building chatbots and start building agents—autonomous systems that can work for hours without breaking the bank. When a task costs fifteen cents instead of three dollars, you start automating problems you'd never automate before. When your bill becomes invisible, the limiting factor switches from economics to engineering.
This matters because it signals the industry's transition from the "AI as consultant" phase to the "AI as worker" phase. The frontier is moving from "how smart can we make this" to "how often can we afford to use it."
Let's dig into what Mini Max actually built, how they built it, why it works, and what it means for the next wave of AI applications.
TL; DR
- M2.5 costs 3.00 for Claude Opus — delivering 95% cost reduction while matching performance on coding benchmarks
- Mixture of Experts architecture activates only 10 billion of 230 billion parameters per token, enabling efficiency without sacrificing capability
- 80% of Mini Max's newly committed code is now generated by M2.5, proving real-world viability for agentic workflows
- SWE-Bench Verified score of 80.2% matches Claude Opus 4.6, with additional strengths in tool calling and multi-language coding
- Lightning variant delivers 100 tokens/second, making real-time AI applications economically feasible for enterprise teams

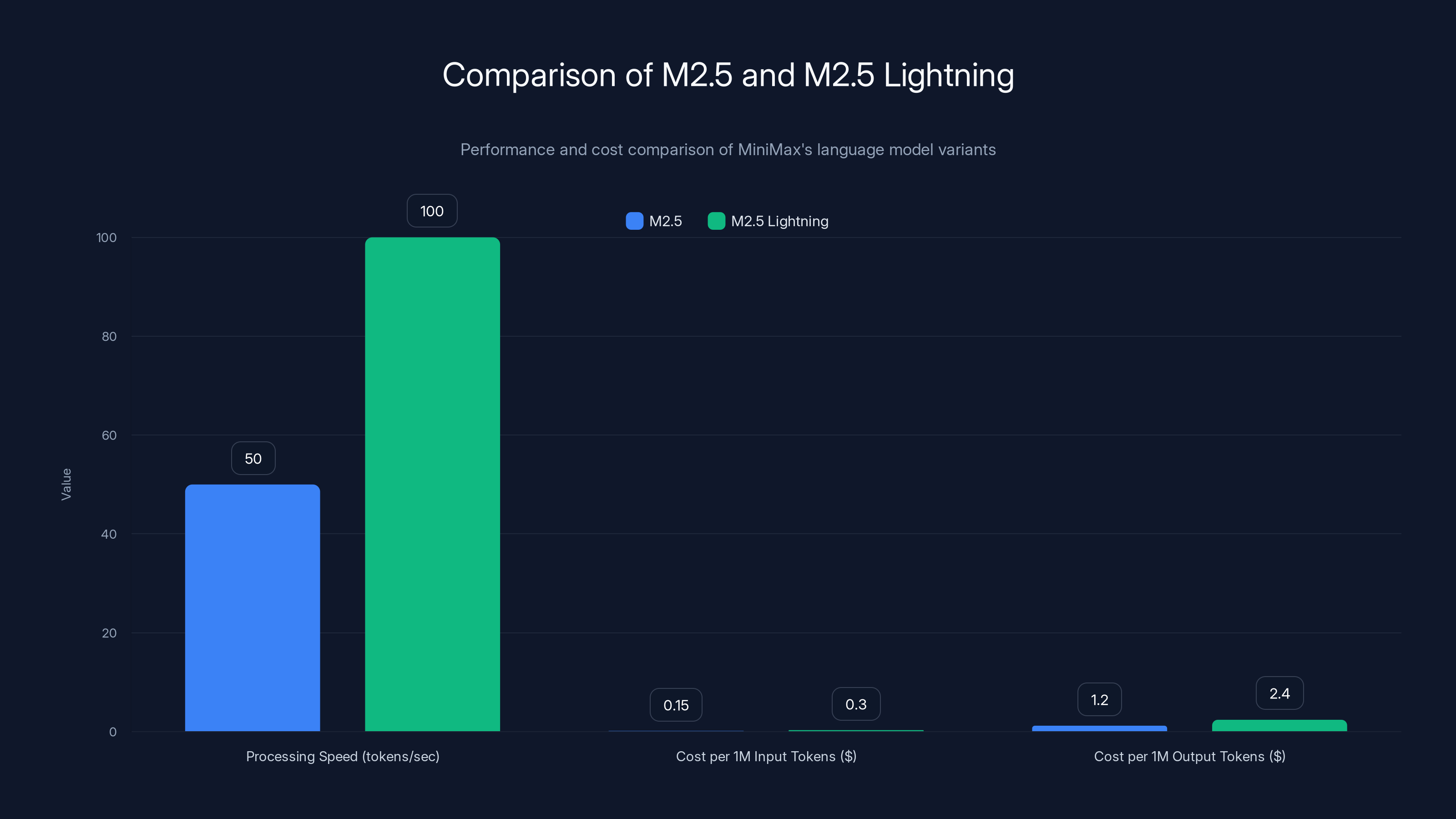
M2.5 Lightning offers double the processing speed of standard M2.5 but at a higher cost per token, making it suitable for real-time applications.
The Economic Problem AI Actually Solves
Before we talk about Mini Max, we need to acknowledge the actual problem the industry faces. It's not about intelligence anymore. It's about access.
Large language models work. They're effective. They solve real problems. But they're priced like premium consulting services, not utilities. When you deploy Claude Opus at scale, your cost structure looks wrong. You're paying thousands of dollars monthly for something that feels like it should cost hundreds.
This creates a bizarre economic incentive structure. Teams build smaller, cheaper models even when better models exist. Organizations build caching layers, rate-limiting systems, and retrieval strategies just to keep bills reasonable. Engineers spend hours optimizing prompts not because it produces better outputs, but because it reduces token consumption.
It's solving the wrong problem.
Mini Max approached this differently. Instead of asking "how can we make models cheaper by cutting corners," they asked "how can we deliver frontier-level performance at a price where cost optimization becomes unnecessary."
That's a fundamentally different engineering challenge.
The psychological shift matters as much as the numerical one. When every query feels expensive, developers build differently. They batch operations. They oversimplify requests. They avoid experimentation. When cost becomes invisible, behavior changes. Developers start building agents that think through problems iteratively, try multiple approaches, and refine solutions—exactly what you want from AI, but exactly what you can't afford when per-token costs are high.
Mini Max didn't just release cheaper models. They released the first models that make the economic problem go away.

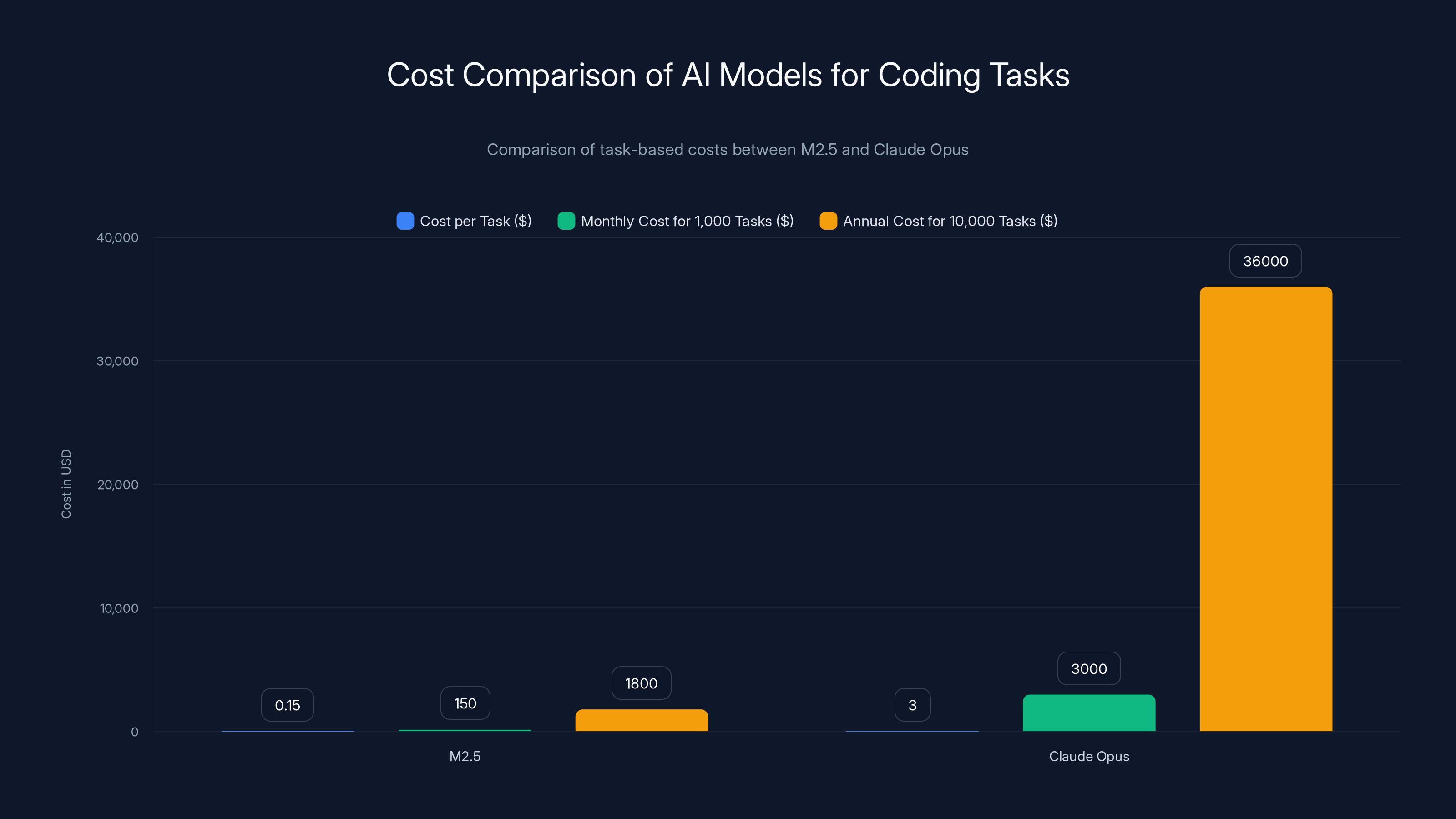
M2.5 provides significant cost savings over Claude Opus, reducing task costs by 95% and enabling substantial annual savings for enterprises.
The Technical Architecture: Sparse Activation and Reinforcement Learning
Mini Max's achievement rests on three interconnected technical choices: Mixture of Experts architecture, custom reinforcement learning, and a novel training stability formula. Understanding each reveals why this matters.
Mixture of Experts: Efficiency Without Reduction
Traditional large language models run all their parameters for every single token generated. If a model has 70 billion parameters, every word output requires computation across all 70 billion. It's comprehensive but computationally expensive.
Mini Max took a different approach. M2.5 contains 230 billion total parameters, but activates only 10 billion per token. This is called sparse activation, and it's implemented through Mixture of Experts (MoE) architecture.
Here's how it works in practice: The model has multiple specialized sub-networks (experts). When processing input, a router network decides which experts are relevant for the current task. Only those experts activate. The remaining parameters stay dormant, saving computation without reducing capability.
The math looks something like this:
Where
This isn't new technology—Google and other labs have experimented with MoE. But implementing it effectively requires solving several non-obvious problems. The router must be stable and learned efficiently. The experts must develop meaningful specialization. The model must maintain reasoning depth despite sparse activation.
Mini Max solved these problems, and the result is a model that feels as capable as a dense 230B parameter model but computes at the speed of a 10B model.
Custom Reinforcement Learning Framework (Forge)
Building MoE models is one problem. Training them effectively is another.
Mini Max developed a proprietary reinforcement learning framework called Forge specifically designed for sparse architectures. The idea is elegant: instead of training the model on static datasets, they trained it through interaction with thousands of simulated work environments.
The model learned by attempting real tasks—coding, tool usage, research—and receiving feedback on performance. This is closer to how humans learn: by doing, failing, getting feedback, and improving.
Olive Song, an engineer on the Mini Max team, explained on the Thursd AI podcast that this approach was instrumental to achieving strong performance despite the sparse architecture. The reinforcement learning process took approximately two months, with the model practicing in multiple virtual environments simultaneously.
This matters because traditional supervised learning (training on labeled examples) doesn't teach models how to use tools, debug code, or handle uncertainty well. Reinforcement learning does. A model trained through tool use in simulated environments actually learns to use tools when deployed in real applications.
The practical result: M2.5 handles agentic workflows—autonomous tool use, planning, and multi-step reasoning—better than models trained purely on supervised data.
CISPO: Training Stability Through Clipping Optimization
Training sparse models with reinforcement learning introduces instability problems. The sparse activation pattern can cause the router to collapse (always selecting the same experts). The policy updates can be too aggressive, causing sudden performance drops. The model can forget earlier learning while optimizing for new tasks.
Mini Max addressed this through a formula called CISPO (Clipping Importance Sampling Policy Optimization). This mathematical technique prevents the policy updates from being too large or too aggressive:
Where
In practical terms: CISPO keeps training stable by preventing the model from making radical changes in its behavior. This allows extended training periods without collapse, which was essential for developing the model's reasoning capabilities.
Mini Max published this formula publicly, which is noteworthy because it suggests confidence in their approach and perhaps a desire to become the reference implementation for sparse model training.
Breaking the Performance Ceiling: Benchmark Results That Matter
Architecture is interesting academically. But real-world impact depends on whether the model actually works.
Mini Max's benchmark results suggest it does, decisively.
SWE-Bench Verified: Matching the Frontier
SWE-Bench Verified is a rigorous benchmark that measures software engineering capabilities. The test involves solving real GitHub issues end-to-end, with the model responsible for understanding the problem, generating a solution, testing it, and fixing it when necessary.
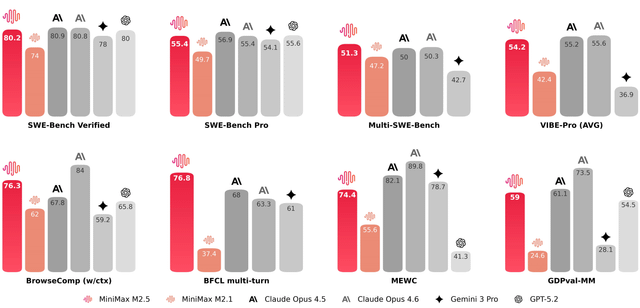
M2.5 scored 80.2% on SWE-Bench Verified, matching Claude Opus 4.6 exactly. This is significant because it means Mini Max's model handles the most complex coding tasks—the ones that require sustained reasoning, debugging, and adaptation—just as effectively as Anthropic's most expensive model.
For context, this 80.2% score represents state-of-the-art performance. Most open-source models score between 30-50%. Enterprise codebases use models at this level. This isn't theoretical capability; this is production-grade performance.
Tool Calling and Agentic Workflows (BFCL Score: 76.8%)
BFCL (Berkeley Function Calling Leaderboard) measures how reliably models can call external functions—APIs, databases, file systems, etc. This is critical for agentic systems.
M2.5 scored 76.8% on BFCL, indicating very high reliability for tool use. This matters because reliability compounds. In agentic workflows, unreliable tool calling breaks the entire chain. A model that calls the wrong API, passes incorrect arguments, or misinterprets responses becomes useless in production. The 76.8% score suggests M2.5 can be trusted to autonomously interact with external systems.
Mini Max specifically trained the model with senior professionals in finance, law, and social sciences to ensure real-world capability. This suggests the benchmark reflects actual production use, not cherry-picked metrics.
Multi-Language Coding: 51.3% SOTA
Most benchmarks focus on Python and JavaScript. Real-world engineering involves dozens of languages: Go, Rust, Java, C++, TypeScript, etc.
On Multi-SWE-Bench (which includes these less-common languages), M2.5 achieved 51.3%, claiming state-of-the-art performance. This is valuable because it means the model's reasoning generalizes across language paradigms, not just the languages it was trained most heavily on.
Browse Comp: Search and Information Retrieval (76.3%)
For agentic systems, searching for information and interpreting search results is crucial. Browse Comp measures this capability.
M2.5 scored 76.3%, leading competitors on this benchmark. This suggests the model is effective at autonomous research and information gathering—valuable for agents that need to augment their knowledge with current information.
These benchmarks paint a consistent picture: M2.5 is not a cost-optimized compromise. It's a fully-capable frontier model that happens to cost substantially less. The performance didn't come from cutting corners; it came from smarter architecture and training methodology.

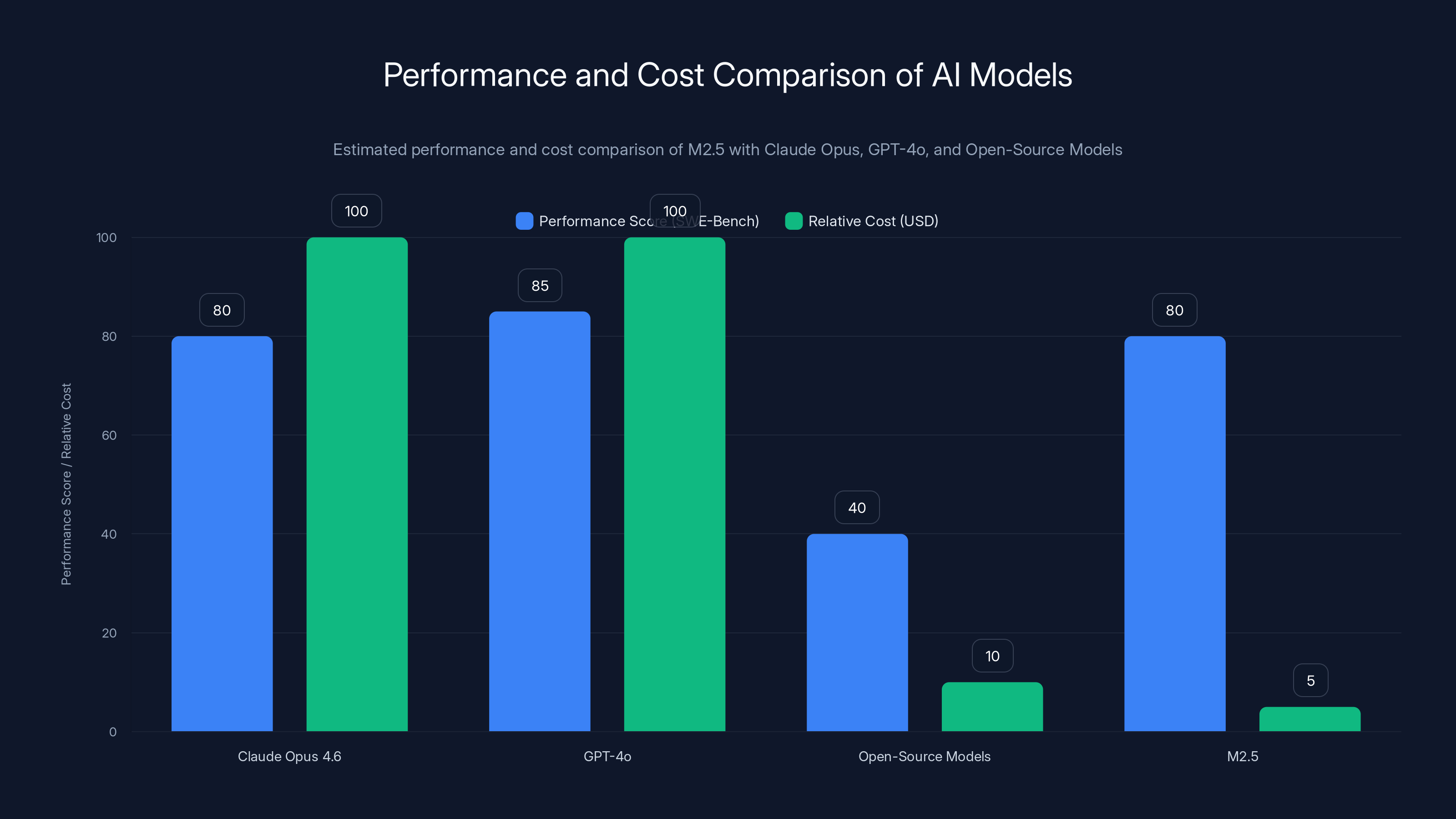
M2.5 offers competitive performance on coding tasks at a significantly lower cost compared to Claude Opus and GPT-4o. Open-source models are cheaper but less performant. (Estimated data)
The Economics: 95% Cost Reduction and What It Enables
Performance matters, but price matters more when you're deciding whether to deploy something at scale.
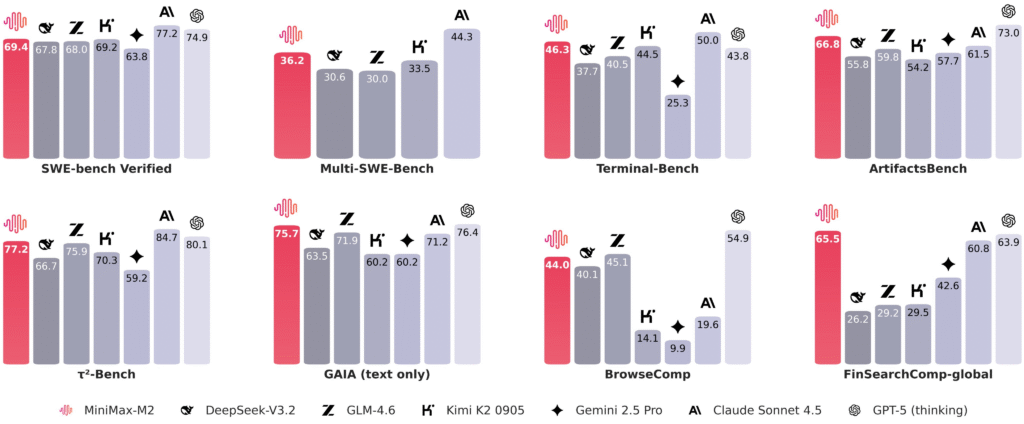
Mini Max offers M2.5 through two pricing tiers: the standard M2.5 (
For comparison, Claude Opus 4.6 costs
But the per-token comparison undersells the actual cost difference. According to analysis from the Thursd AI podcast, a typical complex task costs approximately
The Task-Based Cost Model
Here's where it gets interesting. Instead of thinking about cost per million tokens, think about cost per task:
Coding task (e.g., implementing a feature):
- M2.5: ~$0.15
- Claude Opus: ~$3.00
- Difference: $2.85 per task
For an enterprise organization processing 1,000 coding tasks monthly:
- M2.5: $150
- Claude Opus: $3,000
- Monthly savings: $2,850
Annually: $34,200 in cost reduction.
For a larger organization with 10,000 tasks monthly, annual savings reach $342,000. This moves AI from a cost-control problem to a leverage opportunity.
The cost reduction enables a behavioral shift. When tasks are cheap, you automate more of them. When the per-task cost is invisible, optimization becomes about engineering capability, not cost management. Teams deploy agents that iteratively refine solutions, run multiple approaches in parallel, and validate outputs thoroughly—all things that would be economically insane with 100x higher per-token costs.
Lightning Variant: Speed Over Cost
The Lightning variant runs at 100 tokens per second (versus 50 for standard M2.5), making it suitable for latency-sensitive applications. It costs double the standard version but remains 50 times cheaper than Claude Opus.
This matters for real-time applications where users wait for responses. A customer support agent needs to respond within 2-3 seconds. A code completion tool needs suggestions in under a second. The Lightning variant makes these use cases economically viable.
Real-World Deployment: Mini Max's Internal Validation
Mini Max didn't just release M2.5 and hope people used it. They deployed it internally across their entire organization, creating the strongest possible proof point.
The numbers are striking: 30% of all tasks at Mini Max headquarters are now completed by M2.5. For newly committed code, the proportion reaches 80%. This isn't a pilot project or a limited experiment. This is organizational-scale deployment of their own model.
This matters because it proves several things simultaneously:
-
The model works in production. If M2.5 was unreliable, broken, or prone to failure, internal teams would revert quickly. The high adoption rate suggests the model reliably handles real work.
-
The economics justify adoption. Internal teams have no incentive to use M2.5 if it's slower or more expensive than alternatives. The high adoption means the cost/performance ratio is genuinely compelling.
-
The model handles diverse tasks. Mini Max operates across multiple domains: infrastructure, frontend, backend, research, operations. If M2.5 works across this diversity, it's genuinely general-purpose.
-
The team trusts the output. Code generated by M2.5 makes it to the main codebase (80% of newly committed code). This requires more than capability; it requires reliability. Developers must trust the generated code enough to review and merge it.
This internal deployment is the strongest possible validation. It's not a marketing claim; it's organizational behavior.
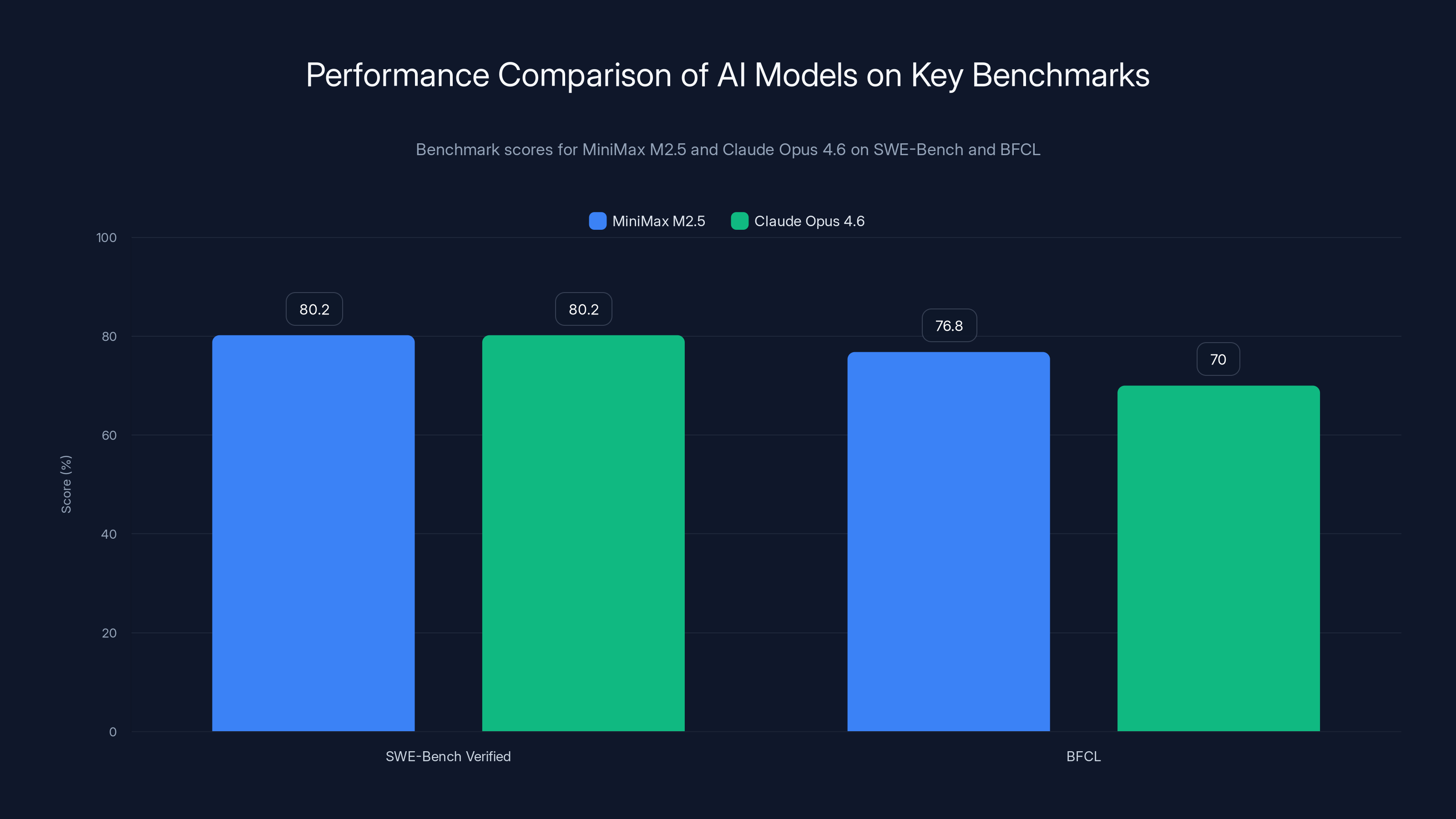
MiniMax M2.5 matches Claude Opus 4.6 on SWE-Bench with 80.2% and outperforms it on BFCL with 76.8%, indicating strong performance in complex coding tasks and reliable tool calling.
The Agentic AI Implication: From Chatbots to Workers
Mini Max frames their release as a transition from AI as chatbot to AI as worker. This framing matters more than it might initially appear.
For the past few years, most AI applications were conversational: ask a question, get an answer. Chat GPT, Claude, Gemini—all position themselves as interactive assistants. You type a prompt. The model responds. Repeat.
This conversational model is limited. It assumes the human is in the loop. It assumes someone reviews every output. It assumes latency doesn't matter much. It assumes cost doesn't constrain behavior.
Agents are different. An agent is software that operates autonomously without constant human supervision. Instead of "write this report for me," you say "write a weekly report every Monday at 9 AM with current data, send it to stakeholders, and notify me if anything requires attention." The agent works independently.
This requires different model capabilities:
- Planning: The ability to break complex problems into steps rather than jumping straight to implementation
- Tool use: Reliably calling external APIs, databases, and systems
- Iteration: Attempting something, evaluating the result, and refining the approach
- Long context: Maintaining state across many steps without losing track
- Stability: Operating for extended periods without degrading
Claude Opus could theoretically do these things, but the cost prevents deployment. An agent that costs
Mini Max built M2.5 specifically to excel at agentic workflows. Their reinforcement learning training emphasized tool use in simulated environments. Their benchmark suite includes tool calling and search capabilities. Their internal deployment focuses on code generation—a quintessential agentic task.
The model wasn't designed as a chatbot alternative. It was designed as agent infrastructure.

Comparison to Existing Alternatives
Where does M2.5 fit in the competitive landscape?
Versus Claude Opus 4.6 (Anthropic)
Claude Opus remains more capable on certain tasks, particularly those requiring nuanced reasoning and constitutional AI principles. But on software engineering benchmarks, they're equivalent. The key difference is economics.
For teams using Claude extensively, M2.5 offers immediate cost savings. For teams avoiding Claude due to cost, M2.5 makes it practical. The performance equivalence on coding tasks means the decision becomes purely economic.
Anthropic has better brand recognition and larger enterprise adoption, but price dynamics favor Mini Max for cost-sensitive applications.
Versus GPT-4 and GPT-4o (Open AI)
Open AI's models excel at multimodal tasks (image understanding, text, and reasoning combined). M2.5 is text-focused currently. GPT-4o's vision capabilities are stronger.
But on pure text-based coding and tool use tasks, M2.5 is competitive or superior, depending on the benchmark. The pricing gap is similar to Claude: M2.5 costs roughly 20x less.
For vision-required applications, GPT-4o remains necessary. For text-based agentic workflows, M2.5 is the more economical choice.
Versus Open-Source Models (Llama, Mistral, Deepseek)
Open-source models are free (though inference costs money). Llama 3.1 and Mistral variants are solid, but they typically score 30-50% on SWE-Bench Verified—half M2.5's performance.
M2.5 isn't open-source (weights haven't been released), so you pay for API access. But the performance advantage is significant.
The tradeoff: Open-source offers privacy and control. M2.5 offers better performance at lower cost than frontier models. Different applications favor different choices.
Versus Specialized Coding Models
Some models specialize in coding: Copilot, Code Llama, etc. These are often cheaper and optimized for specific languages.
M2.5 is general-purpose, not specialized. It handles coding, reasoning, tool use, and search. Specialized models can be better at specific tasks, but M2.5's generality makes it more broadly applicable.

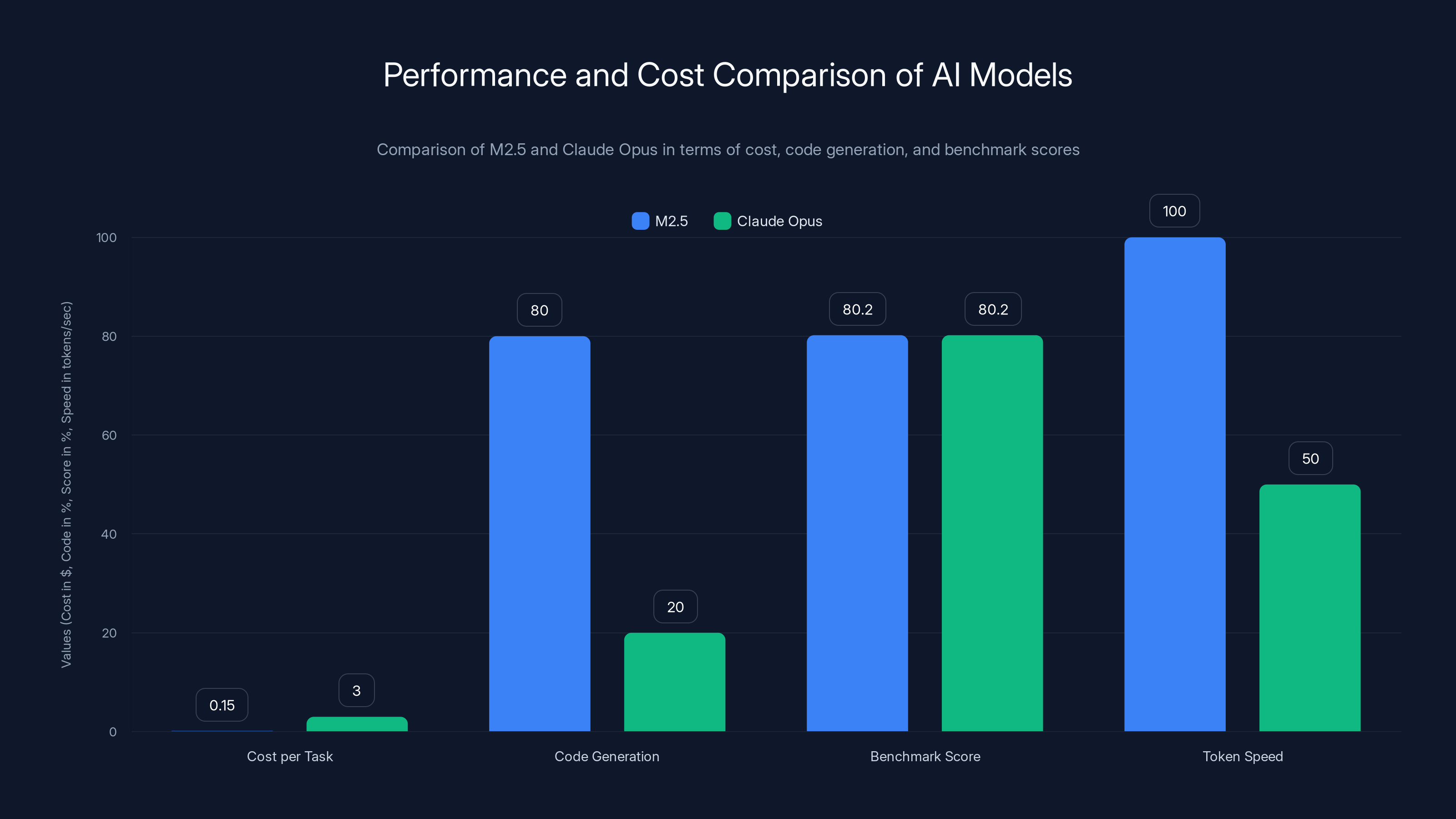
M2.5 offers a 95% cost reduction compared to Claude Opus, while matching its benchmark score and significantly outperforming in code generation and token speed. Estimated data for code generation and token speed.
The Reinforcement Learning Advantage: Why It Matters
Mini Max spent two months training M2.5 with custom reinforcement learning. This extended training period distinguishes M2.5 from models trained purely on supervised learning.
What's the difference?
Supervised Learning: Train the model on examples of inputs and correct outputs. The model learns to pattern-match and reproduce seen examples. It's fast and requires limited compute. But it doesn't teach the model to reason through novel problems or recover from mistakes.
Reinforcement Learning: Train the model by having it attempt tasks, receive feedback on performance, and adjust its approach. The model learns cause-and-effect relationships. It learns to correct itself. It learns strategy, not just pattern matching. It's slower and more computationally expensive, but produces better problem-solving.
Mini Max combined both: supervised learning for foundational capabilities, then reinforcement learning in simulated environments to develop planning and tool use skills.
This two-phase approach is computationally expensive, which is why most labs don't do it at this scale. But the results suggest it's worth it. Models trained this way handle novel problems better than models trained purely on supervised learning.
The practical implication: M2.5 is better at reasoning through unfamiliar problems, debugging broken code, and adjusting strategies when initial approaches fail. These are exactly the capabilities that matter for autonomous agents.

The Open-Source Question and Licensing
Mini Max describes M2.5 as "open source," but with important caveats.
The model weights (parameters) haven't been released yet. The code hasn't been posted. The exact license terms are undefined. What's "open" is primarily the API access through Mini Max and partner platforms.
This creates an interesting distinction: the model is accessible (through API) but not open-source in the traditional sense (code and weights freely available). It's more accurate to describe M2.5 as "openly available" rather than "open-source."
This matters because:
- Control: You can't run M2.5 locally without Mini Max's infrastructure. You're dependent on their API.
- Costs: You pay per token. You can't avoid usage charges by self-hosting.
- Privacy: Requests go through Mini Max's servers. This is fine for non-sensitive data but problematic for confidential information.
- Customization: You can't fine-tune M2.5 on proprietary data (at least not without explicit licensing).
For many applications, these tradeoffs are acceptable. The cost and performance advantages are compelling enough to outweigh the lack of full open-source freedom. But for organizations requiring data privacy, full control, or customization, alternatives might be necessary.
Mini Max has indicated they may release weights and code eventually, but timing is uncertain.

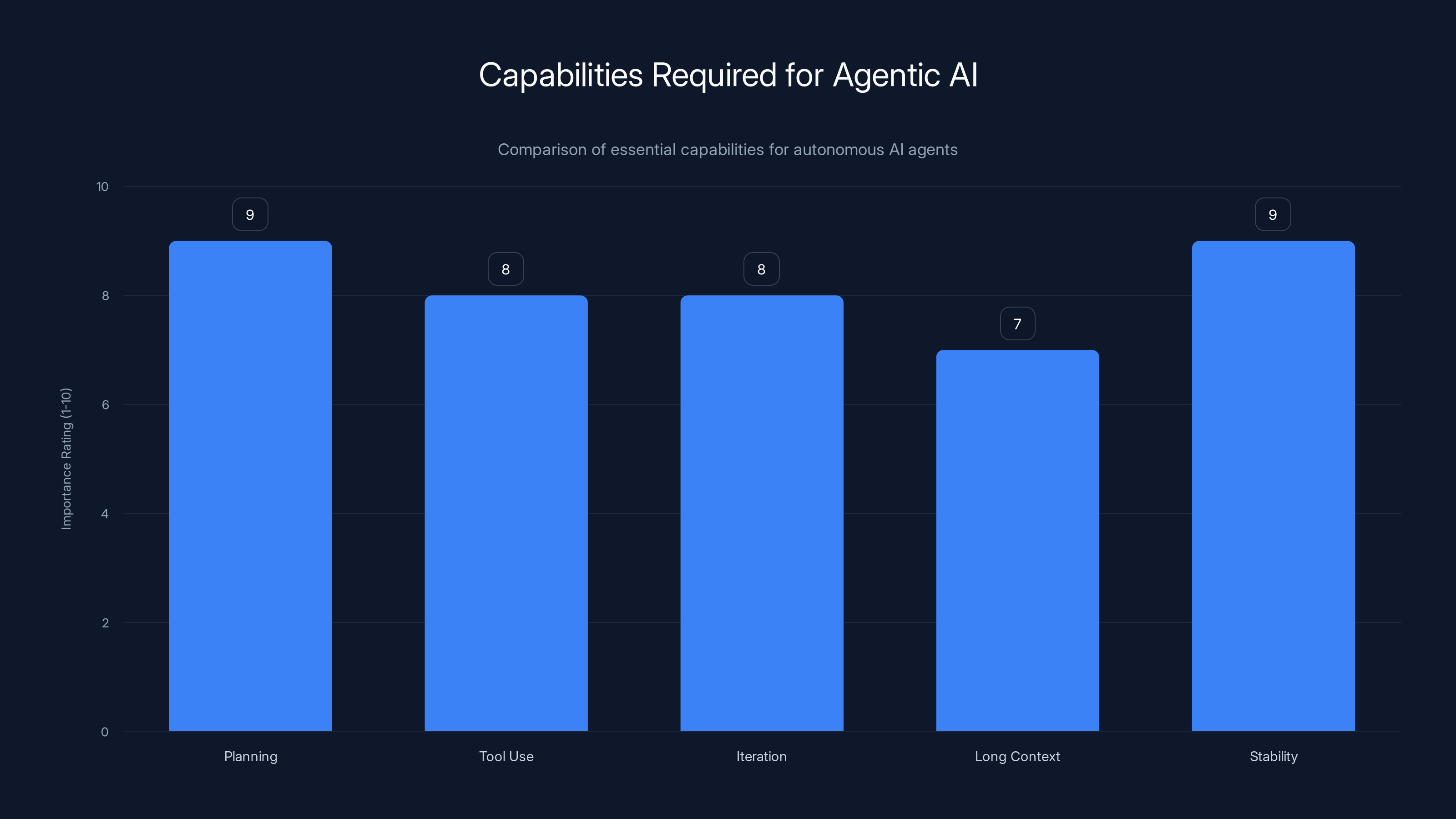
Agentic AI requires high proficiency in planning and stability, with tool use and iteration also being crucial. Estimated data.
The Mixture of Experts Scaling Advantage
Why build with Mixture of Experts when dense models work fine?
The answer lies in scaling economics. Dense models scale by adding parameters, which increases all costs: training, inference, latency. A 100B dense model is roughly twice as expensive to train and run as a 50B dense model.
MoE models scale differently. You can increase total capacity (parameters) while keeping active capacity (parameters per token) constant. This means you can build arbitrarily large models without proportional cost increases.
For example, Mini Max could build a 500B parameter model (with 10B active) that costs the same to run as M2.5 (230B/10B active). This capability is genuinely powerful.
But MoE introduces complexity: routing stability, expert specialization, load balancing. Most labs haven't solved these problems at scale. Mini Max's CISPO formula addresses the training stability problem, which was the major blocker.
The practical implication: expect MoE-based models to become increasingly dominant. The cost advantages at scale are too significant to ignore.
Infrastructure and Ecosystem Implications
When frontier models become cheap, infrastructure decisions change.
Companies building AI systems historically faced a choice: use expensive frontier models sparingly, or use cheaper models more aggressively. M2.5 breaks this false binary. You can use frontier-level capability extensively because costs become manageable.
This drives several ecosystem shifts:
-
Caching becomes less critical. With expensive models, caching and retrieval systems (RAG) are cost-control mechanisms. With cheap models, you can afford to run end-to-end without caching.
-
Multipass reasoning becomes practical. With Claude Opus, running a task twice (for verification or alternative approaches) doubles cost. With M2.5, running twice adds 30 cents. The economic calculus shifts.
-
Autonomous agents become viable. Agents that make 100+ API calls for a single task require cheap models to be economically viable. M2.5's pricing makes this feasible.
-
Real-time applications expand. Latency-sensitive applications can now afford multiple inference passes, fallbacks, and error handling without cost becoming prohibitive.
-
A/B testing becomes standard. Teams can afford to test multiple approaches simultaneously, selecting the best one. With expensive models, you pick one approach and hope it works.
These ecosystem shifts matter more than any single feature or benchmark. They change how engineers think about AI infrastructure and what's economically possible.

Implementation Considerations for Teams
If you're evaluating M2.5 for your organization, several practical considerations matter:
Performance Requirements: M2.5 excels at coding, tool use, and reasoning tasks. If your application is purely conversational (simple Q&A), performance advantages are marginal. If your application is agentic or code-focused, M2.5 likely outperforms existing solutions.
Latency Sensitivity: Lightning variant for real-time needs (100 tokens/sec), standard variant for batch processing (50 tokens/sec). Measure your actual latency requirements before choosing; you might not need Lightning.
Cost Constraints: If you're currently using expensive models due to competitive pressure, M2.5 is a clear win. If you're already using cheaper models, the upgrade might be unnecessary unless performance is also a problem.
Data Privacy: M2.5 requires sending requests to Mini Max's servers. If data privacy is critical, this is a blocker. Wait for on-premise options or use alternatives.
Vendor Lock-in: Using M2.5 through API creates dependency on Mini Max's continued operation and favorable pricing. Diversifying models (using multiple APIs) reduces risk.
Testing and Monitoring: Before full deployment, run 2-4 week pilots with M2.5 on specific tasks. Measure quality, latency, and cost. Let data drive the decision.

The Broader Context: What Mini Max's Success Signals About AI
Mini Max's release matters beyond the specific product. It signals several important industry trends.
Commoditization is inevitable. Frontier performance is becoming commodified. Claude Opus isn't unique anymore. As more labs release capable models, pricing pressure increases. The days of sustainable 10x premiums for frontier models are ending.
Architecture matters more than scale. Mini Max didn't build the largest model. They built a smarter model using MoE and specialized training. This suggests raw parameter count is becoming less important than architectural efficiency.
Chinese labs are competitive. For years, there was a perception that Chinese AI labs were behind Western counterparts. M2.5 suggests this gap is closing rapidly. Expect more competitive Chinese models.
Agentic AI is becoming practical. M2.5's success confirms that cost, not capability, is the limiting factor for agentic systems. As costs drop, agentic applications become increasingly viable.
Vertical integration matters. Mini Max runs M2.5 internally at 30% task coverage. This proves models work better when teams understand and can optimize their own deployments. Expect more end-to-end integration.
Future Roadmap and Uncertainties
Mini Max hasn't publicly announced a detailed roadmap, but reasonable extrapolations suggest several developments:
Multimodal capabilities: M2.5 currently handles text. Vision capabilities would expand applicability. This is likely on the roadmap.
Larger and smaller variants: Mini Max might release M2.5 Tiny (fewer parameters, faster) and M2.5 Ultra (more parameters, better reasoning). The standard M2.5 is a middle ground.
Open weights release: Mini Max indicated openness to releasing weights. If they do, expect a significant ecosystem boost as researchers fine-tune and optimize further.
Specialized variants: Domain-specific versions (medical, legal, financial) might emerge, optimized for specific use cases.
On-premise deployment: For enterprise customers requiring data privacy, Mini Max might offer self-hosted options. This is technically possible and would address a major objection.
Uncertainties remain:
- Will Mini Max sustain this cost advantage, or will competition drive prices down further?
- Can Mini Max scale infrastructure to match demand without quality degradation?
- Will the open-source/open-access distinction create licensing concerns?
- Can Chinese models face regulatory headwinds that impact adoption?
These are important questions, but they don't diminish M2.5's current significance.

Practical Implementation Strategy
If your organization is considering M2.5, here's a structured approach to evaluation and deployment:
Phase 1: Pilot (Weeks 1-4)
- Identify 3-5 specific tasks where your current model is expensive or slow
- Set up M2.5 API access alongside your current solution
- Route 10% of traffic to M2.5, 90% to your current solution
- Measure quality, latency, and cost for both
- Document failure cases and performance differences
Phase 2: Evaluation (Weeks 5-8)
- If pilot results are positive, increase M2.5 traffic to 50%
- Run parallel benchmarks on your actual production data
- Test edge cases that caused failures in Phase 1
- Calculate true cost savings (including operational overhead)
- Assess latency impact on user experience
Phase 3: Rollout (Weeks 9-12)
- If Phase 2 results are positive, migrate fully to M2.5
- Keep fallback to previous solution for error handling
- Monitor continuously for quality regression
- Document best practices learned during transition
- Plan for ongoing optimization
This staged approach reduces risk while building confidence through data.
FAQ
What is Mini Max M2.5?
M2.5 is an open-source language model released by Mini Max, a Chinese AI startup. It contains 230 billion total parameters with 10 billion active per token (sparse activation), achieving state-of-the-art performance on coding benchmarks at 95% lower cost than Claude Opus. The model is available through Mini Max's API and partners, with two variants: standard M2.5 (optimized for cost) and M2.5 Lightning (optimized for speed).
How does M2.5 achieve lower costs than frontier models?
M2.5 uses Mixture of Experts architecture where only a fraction of the model's parameters activate per token, combined with specialized reinforcement learning training that emphasizes efficiency. Additionally, the sparse activation requires less compute to generate each token. These architectural advantages combined with custom training methodology (Forge framework and CISPO formula for stability) deliver frontier-level performance at the inference cost of much smaller models. The model is also trained specifically for tool use and agentic workflows, which reduces token usage for many tasks.
What are the main differences between M2.5 and M2.5 Lightning?
The standard M2.5 processes at 50 tokens per second and costs
How does M2.5 compare to Claude Opus and GPT-4?
On software engineering benchmarks like SWE-Bench Verified, M2.5 achieves 80.2%—matching Claude Opus 4.6 exactly. On tool calling (BFCL), M2.5 scores 76.8%, indicating reliable agentic capability. However, Claude and GPT-4 may outperform on certain nuanced reasoning tasks and multimodal applications. The key difference is economic: M2.5 is roughly 20x cheaper per task. For most teams, the decision comes down to whether cost savings justify potential capability tradeoffs, which typically favors M2.5 for production agentic systems.
Is M2.5 truly open-source?
No. Mini Max describes M2.5 as "open-source," but more accurately it's "openly available." The model weights and code haven't been released—you access it through Mini Max's API. This means you pay per token, can't customize or fine-tune it directly, and depend on Mini Max's infrastructure. True open-source models (like Llama) allow local deployment and full customization. Mini Max has indicated they may release weights eventually, but timing is unclear. For most commercial applications, API access is sufficient, but privacy-critical use cases may prefer traditional open-source alternatives.
What are agentic AI systems, and why does M2.5 excel at them?
Agentic AI systems are autonomous software that pursue multi-step goals with minimal human supervision, including planning, tool use, iteration, and decision-making. Unlike conversational AI that provides immediate responses to user queries, agents operate independently. M2.5 excels at agentic tasks because it was trained through reinforcement learning in simulated environments where it practiced tool use, planning, and task completion. Its high BFCL tool-calling score (76.8%) indicates reliable external API interaction. Most importantly, the low per-token cost makes extended autonomous operation economically viable—something impossible with $3-per-task alternatives.
What's Mixture of Experts architecture, and why is it important?
Mixture of Experts (MoE) uses multiple specialized neural networks (experts) and a routing function that decides which experts to activate for each input. This allows models with billions of parameters to activate only a fraction per token, reducing compute costs. M2.5 has 230B total parameters but activates only 10B per token. This is important because it enables frontier-level capability (from massive parameter counts) at the inference speed and cost of much smaller models. As models scale in the future, MoE is likely to become dominant because it avoids proportional cost increases with scale.
When should teams migrate to M2.5 versus staying with existing models?
Migrate to M2.5 if you're currently using expensive frontier models (Claude Opus, GPT-4) and your applications are text-based and agentic-focused. The 20x cost reduction alone justifies migration for many teams. Don't migrate if you require on-premise deployment, multimodal capabilities, extreme privacy guarantees, or have already optimized around cheaper models that are working well. Run a 2-4 week pilot with 10-20% of traffic before full migration. Measure quality, latency, and cost on your actual production tasks, not just benchmarks.
What is the CISPO formula, and why does it matter for model training?
CISPO (Clipping Importance Sampling Policy Optimization) is a mathematical technique Mini Max uses during reinforcement learning training to keep policy updates stable and prevent the model from degrading. Essentially, it prevents training updates from being too aggressive or changing the model's behavior too dramatically in a single step. This is particularly important for sparse models (like Mini Max's MoE architecture) where instability can cause training collapse. Mini Max published the formula publicly, suggesting confidence in their approach and potential interest in becoming the reference implementation for sparse model training.
What does Mini Max's internal deployment tell us about M2.5's production readiness?
Mini Max reports that 30% of all tasks at their headquarters use M2.5, with 80% of newly committed code generated by the model. This internal validation is stronger than any marketing claim because it represents organizational-scale deployment on diverse real-world tasks. It indicates the model is reliable enough to produce code that developers review and merge, fast enough to not impede workflows, and economical enough to justify adoption across the organization. This internal validation suggests M2.5 is genuinely production-ready for similar agentic and code-generation use cases in other organizations.

Conclusion: The Inflection Point in AI Economics
Mini Max's M2.5 release represents an inflection point in how artificial intelligence is deployed and utilized at scale.
For three years, frontier AI capability has been treated like a luxury commodity: expensive, carefully rationed, used only when absolutely necessary. This made sense when the best models cost dollars per task. It drove engineering focused on minimizing token usage, caching, and avoidance.
M2.5 breaks this paradigm by making frontier capability cheap. At fifteen cents per task, optimization becomes unnecessary. Cost is no longer the limiting factor. Engineering capability is.
This shift has immediate practical consequences: organizations can afford to deploy agents that work autonomously, iterate on solutions, and attempt multiple approaches. Real-time applications become economically viable. Experimentation becomes default behavior rather than exceptional.
But the deeper significance lies in what this reveals about AI's trajectory. Intelligence is commoditizing. Frontier performance is becoming accessible. Cost, not capability, is the differentiator. This suggests a future where the question isn't "can AI do this task" but rather "why isn't AI doing this task yet."
For teams building with AI today, M2.5 offers clear tactical value: immediate cost reduction and maintained (or improved) capability. But the strategic value is more important. Models like M2.5 prove that the agentic AI wave isn't theoretical. It's practical, deployable, and economically viable right now.
The question is no longer whether your organization should be building agentic AI systems. It's why you're not already.
If you're evaluating AI models for your team, Mini Max's M2.5 deserves serious consideration. Run a pilot. Measure results. The data will likely surprise you. And when cost stops being an obstacle, suddenly problems you thought unsolvable become remarkably straightforward.
That's the real significance of Mini Max's release. Not that they built a cheaper model, but that they made the frontier affordable. Everything that follows from that simple fact is what the next chapter of AI deployment actually looks like.
Key Takeaways
- M2.5 costs 3.00 for Claude Opus, enabling 95% cost reduction while maintaining equivalent performance
- Sparse Mixture of Experts activates only 10B of 230B parameters per token, delivering frontier capability at efficient inference speed
- 80.2% SWE-Bench score matches Claude Opus 4.6, with exceptional tool-calling (76.8%) and multi-language coding (51.3%) performance
- MiniMax's internal deployment shows 30% task coverage and 80% code generation adoption, validating production-grade reliability
- Agentic AI becomes economically viable at M2.5's pricing, enabling autonomous systems that were prohibitively expensive with previous models
Related Articles
- GLM-5: The Open-Source AI Model Eliminating Hallucinations [2025]
- Arcee's Trinity Large: Open-Source AI Model Revolution [2025]
- AI Inference Costs Dropped 10x on Blackwell—What Really Matters [2025]
- Mysterious Bot Traffic From China Explained [2025]
- CD Projekt Red Hires BioWare Veteran as AI Director for Witcher 4 [2025]
- John Carmack's Fiber Optic Memory: Could Cables Replace RAM? [2025]

