![Observational Memory: How AI Agents Cut Costs 10x vs RAG [2025]](https://tryrunable.com/blog/observational-memory-how-ai-agents-cut-costs-10x-vs-rag-2025/image-1-1770761336535.jpg)
Observational Memory: How AI Agents Cut Costs 10x vs RAG [2025]
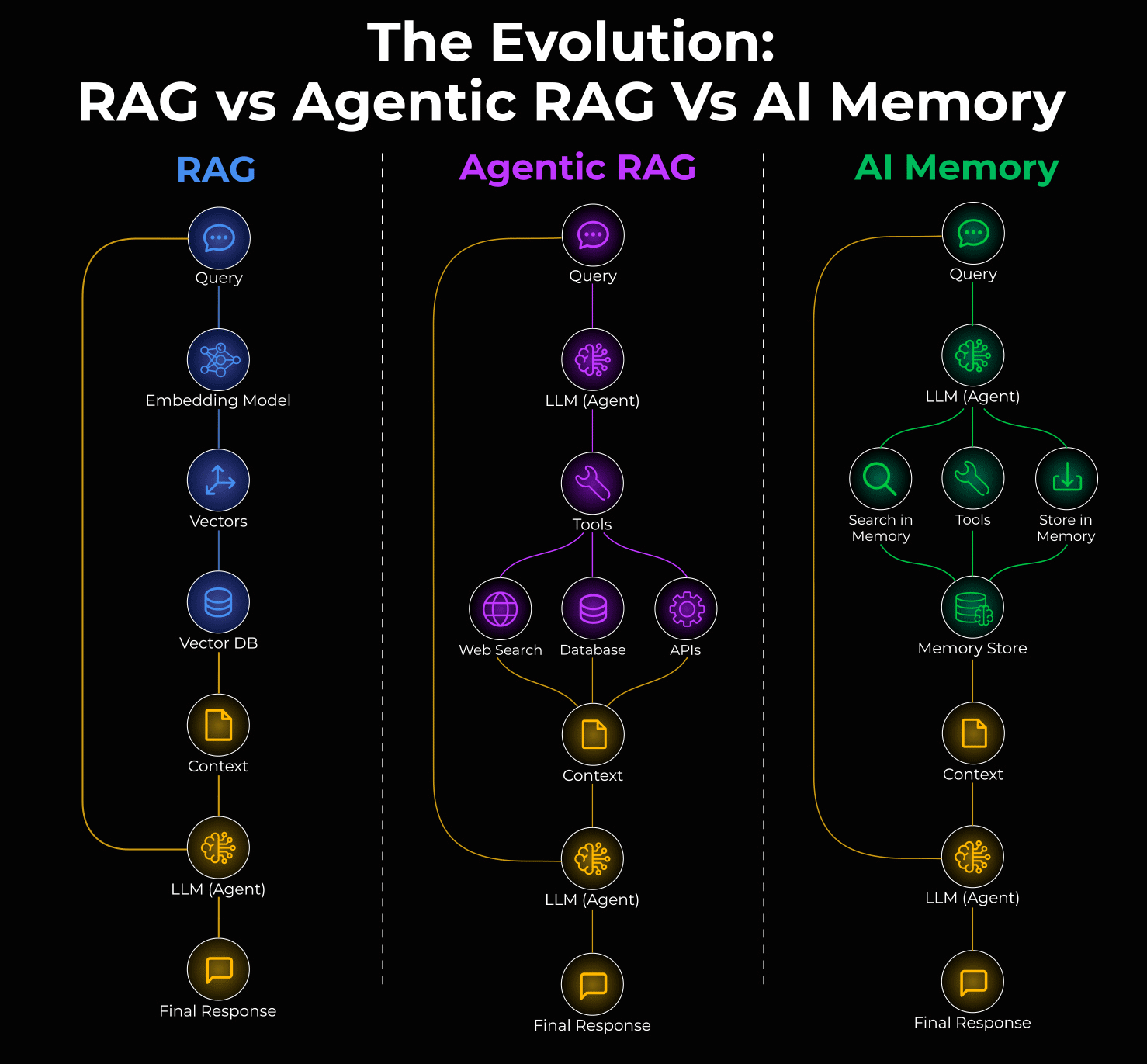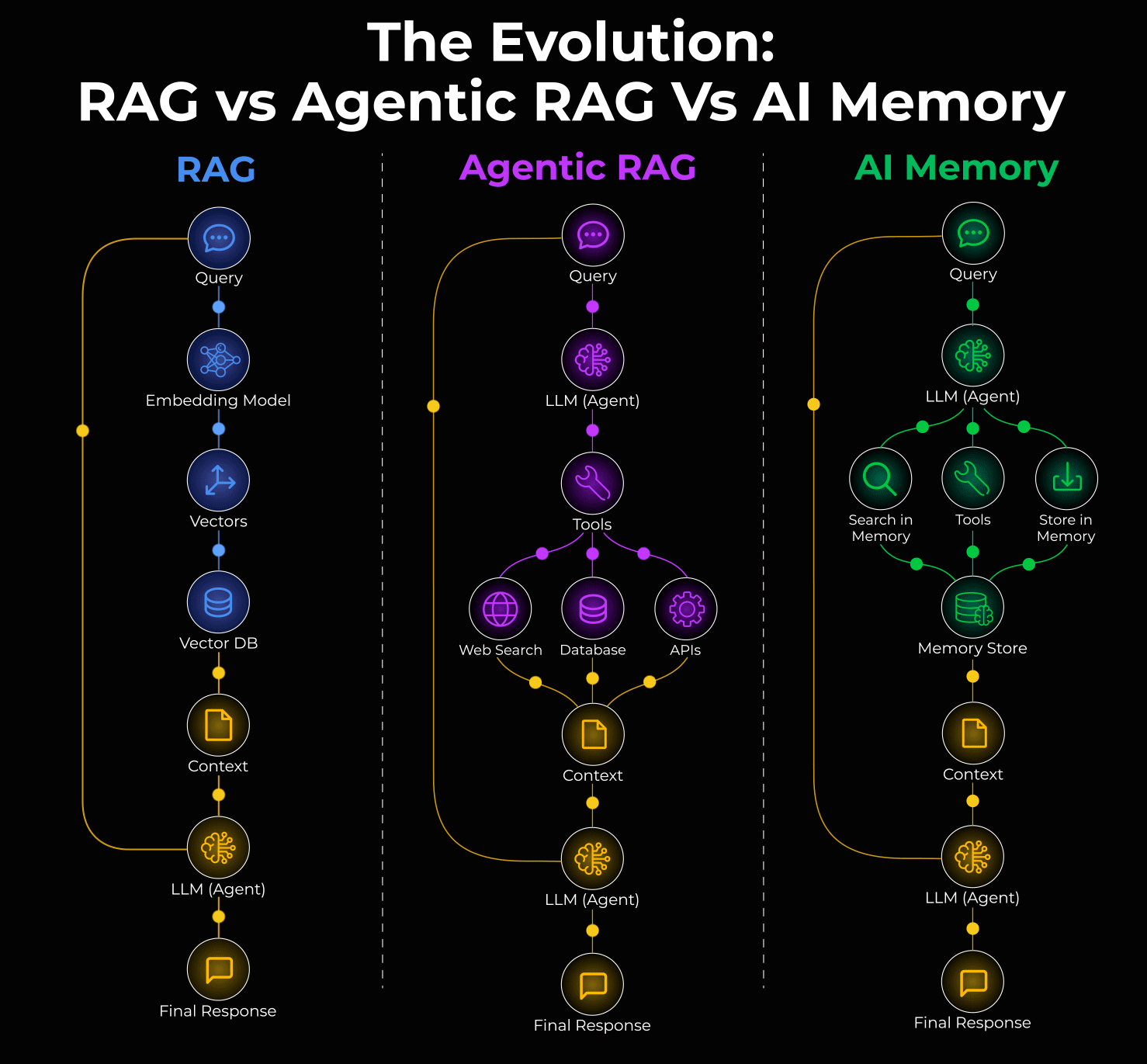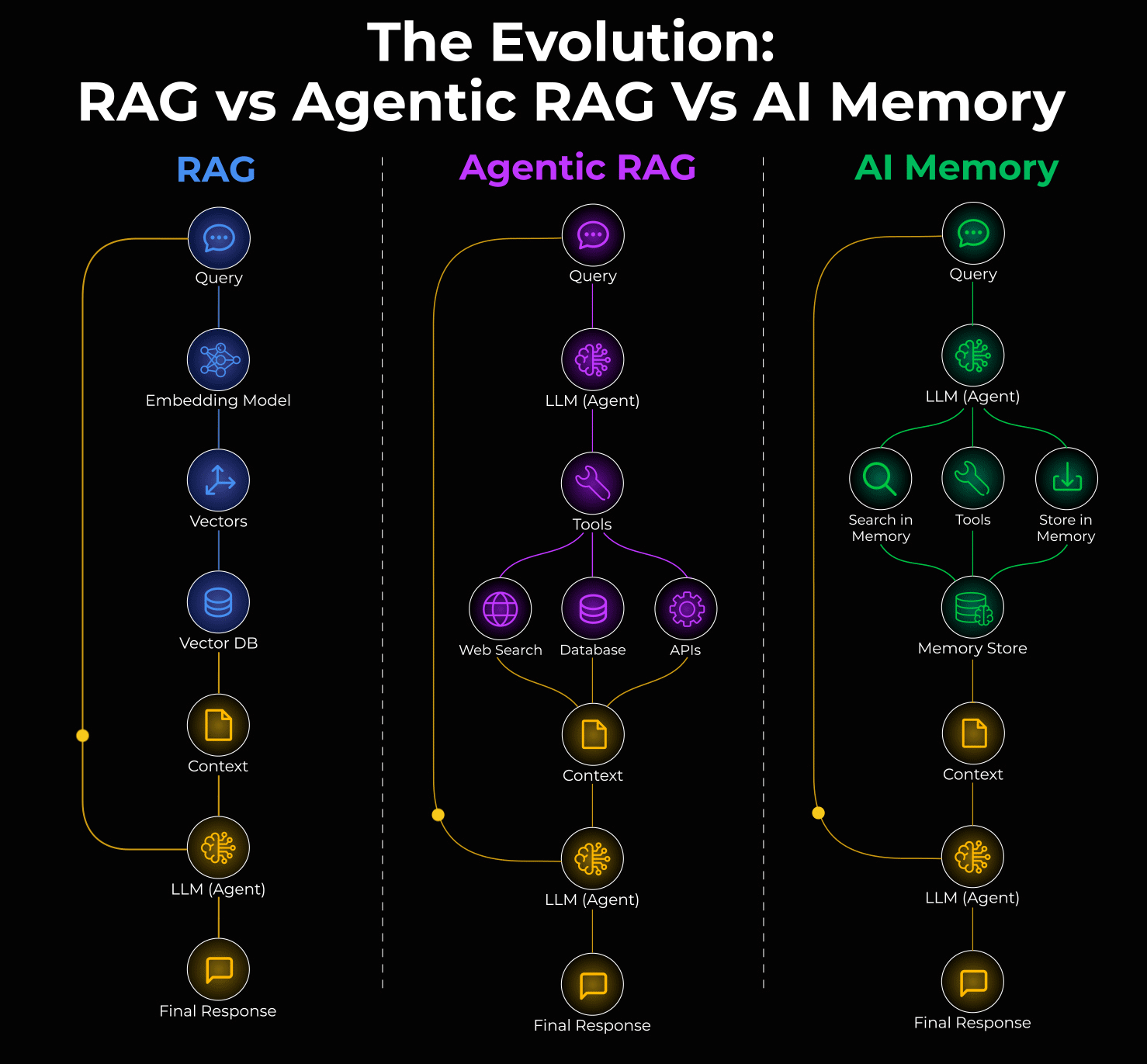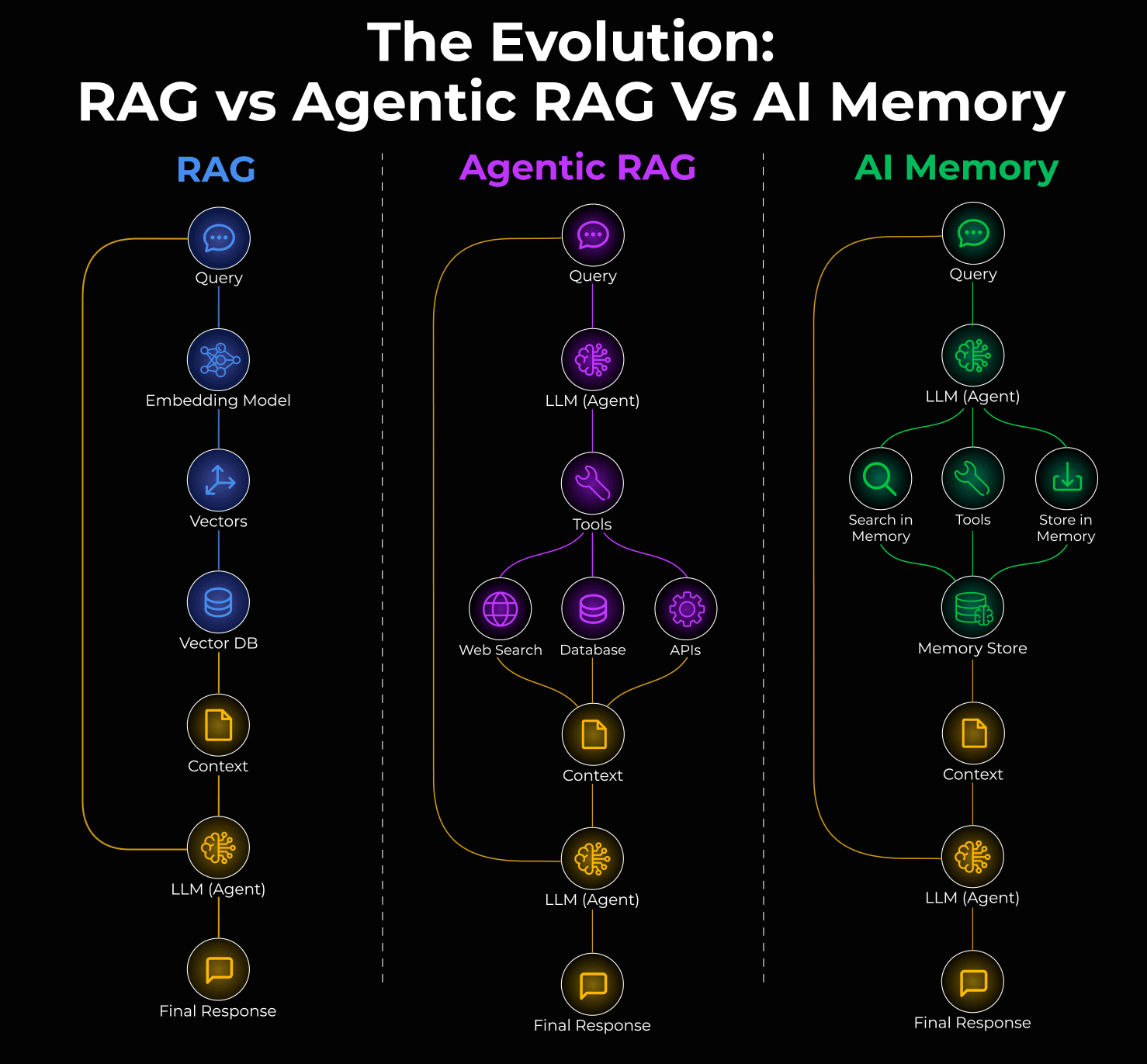
You've probably heard the pitch before: retrieval-augmented generation (RAG) solves the knowledge problem. Your AI system searches a vector database, finds relevant documents, injects them into context, and suddenly your chatbot knows everything. But here's what actually happens in production when you deploy these systems at scale.
Your RAG system starts fresh every turn. It dynamically retrieves context, which means your prompt changes constantly. That kills prompt caching, the one mechanism that could make AI agents economically viable. Your token costs spiral. Your budget forecast becomes fiction. And worst of all, RAG often retrieves the wrong documents when you need specific decisions from earlier in the conversation.
There's a different approach emerging that flips this problem on its head: observational memory.
Instead of searching backwards dynamically, observational memory compresses conversation history into a stable, dated observation log that stays in context and gets cached. The system scores higher on long-context benchmarks than traditional RAG while cutting token costs by up to 10x. It doesn't need vector databases, graph stores, or complex retrieval pipelines. Just two background agents doing the compression work asynchronously.
This isn't theoretical. Teams are already using it in production for customer support agents that run for weeks, data analysis workflows that require perfect recall of earlier decisions, and tool-heavy automation that needs to stay consistent across hundreds of interactions.
Let's dig into how this works, why it's faster and cheaper than RAG, and when you should actually use it versus sticking with traditional approaches.
TL; DR
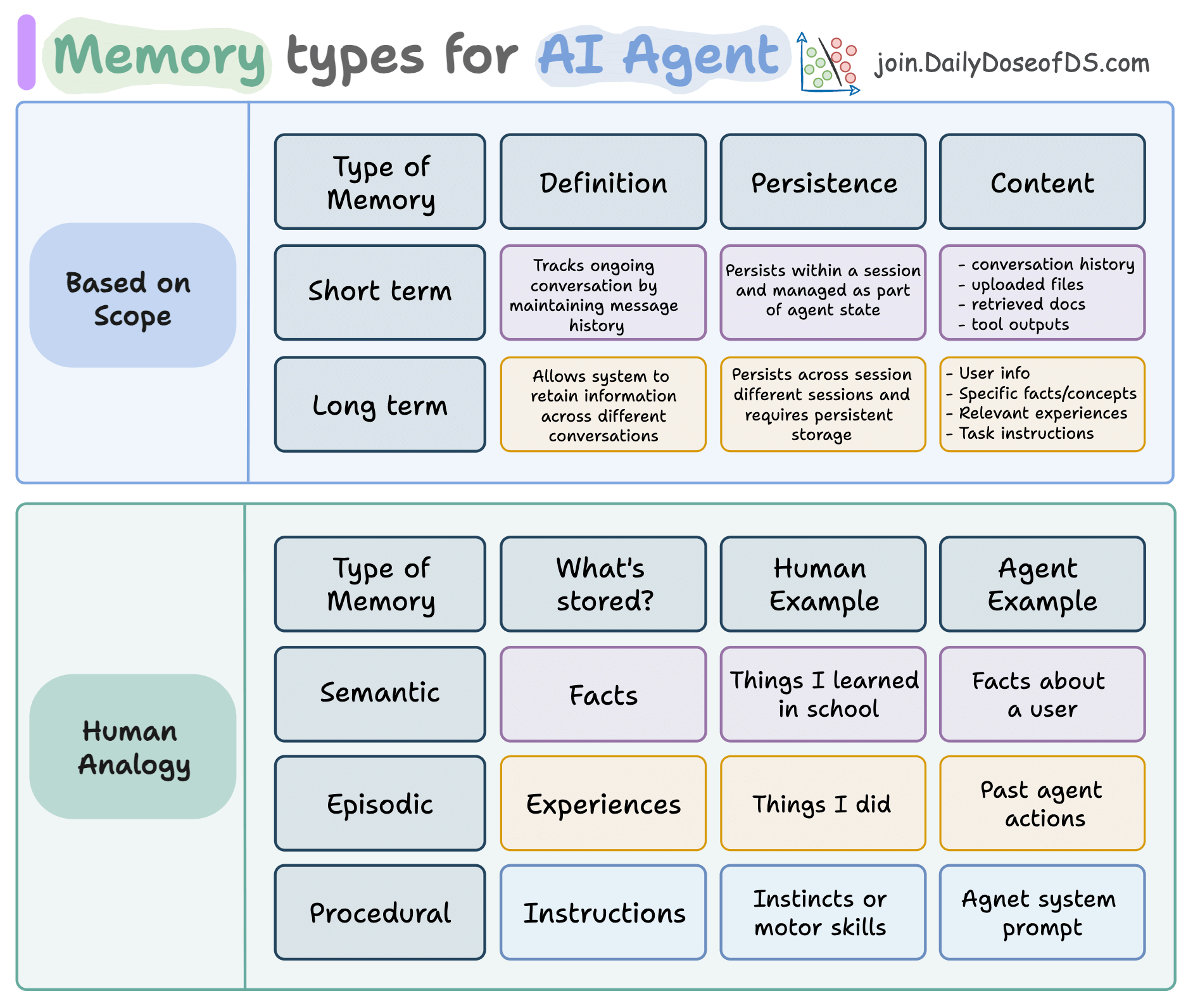
- Observational memory replaces RAG retrieval with stable, cached context windows using two background agents (Observer and Reflector) that compress conversation history into dated observations
- Cost reduction reaches 10x through prompt caching, since stable context can be cached across turns while dynamic RAG retrieval invalidates the cache on every turn
- Performance exceeds RAG on long-context benchmarks, achieving 94.87% on Long Mem Eval with GPT-4o-mini versus 84.23% on standard benchmarks, while reducing average context size to 30,000 tokens
- Compression ratios hit 5-40x for tool-heavy agent workloads, with 3-6x compression for text content through structured observation logs instead of documentation-style summaries
- Best for long-running agents, tool interactions, and stable decision logs, but less suitable for open-ended knowledge discovery or compliance-heavy recall requiring external corpus searches
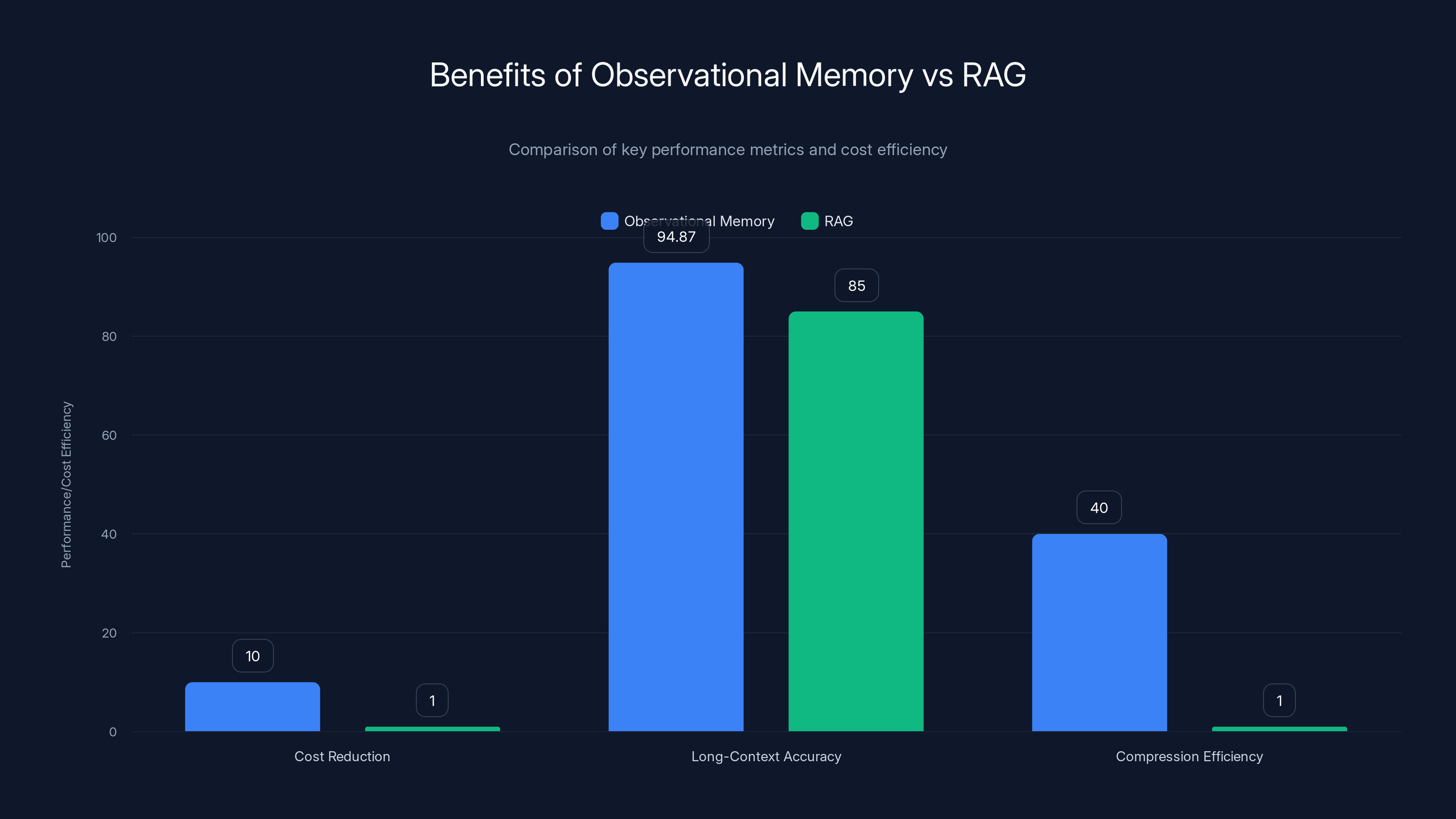
Observational memory offers up to 10x cost reduction, 94.87% accuracy on long-context tasks, and 40x compression efficiency compared to RAG. Estimated data for RAG.
The Problem With RAG in Production Agent Workflows
Let's be honest: RAG works great for demos. You ask a question, the system finds relevant documents, synthesizes an answer. Clean. Simple. Impressive in a boardroom.
But RAG was designed for retrieval, not for agentic workflows. And those are fundamentally different problems.
When you deploy an AI agent that runs for hours, days, or weeks, making decisions and calling tools repeatedly, RAG breaks down in specific ways. The first problem is caching. Modern AI providers like Anthropic and OpenAI charge 4-10x less for cached tokens than fresh tokens. If you're using RAG, you're invalidating that cache on every single turn because your prompt context changes. You retrieve different documents, inject them into the prompt, and now the system sees a completely new input. The cache gets flushed. You pay full price.
For a long-running agent handling hundreds of turns, this cost difference isn't academic. It's the difference between a cost-effective system and one that burns through your budget in a week.
The second problem is relevance. RAG relies on vector similarity to find relevant documents. But when an agent has made three decisions earlier in a conversation, and those decisions directly affect what should happen next, keyword similarity doesn't capture that. The agent needs specific decisions, not topically relevant documents. Traditional vector retrieval often surfaces the wrong context because it's optimizing for semantic similarity, not decision continuity.
The third problem is complexity. RAG requires infrastructure: vector databases, embeddings models, retrieval pipelines, ranking systems. Each piece adds latency, failure points, and operational overhead. In production, that's not trivial.
And then there's the fourth problem: knowledge cutoff and drift. Your vector database gets stale. Documents change. New information arrives. Your RAG system either stays frozen in time or you're constantly re-embedding and updating everything, which is expensive and error-prone.
These aren't hypothetical issues. Teams running production agents at scale report all of them. Budget surprises. Agents making decisions without proper context. Complex operations just to stay current. The observational memory approach attacks all four problems simultaneously.
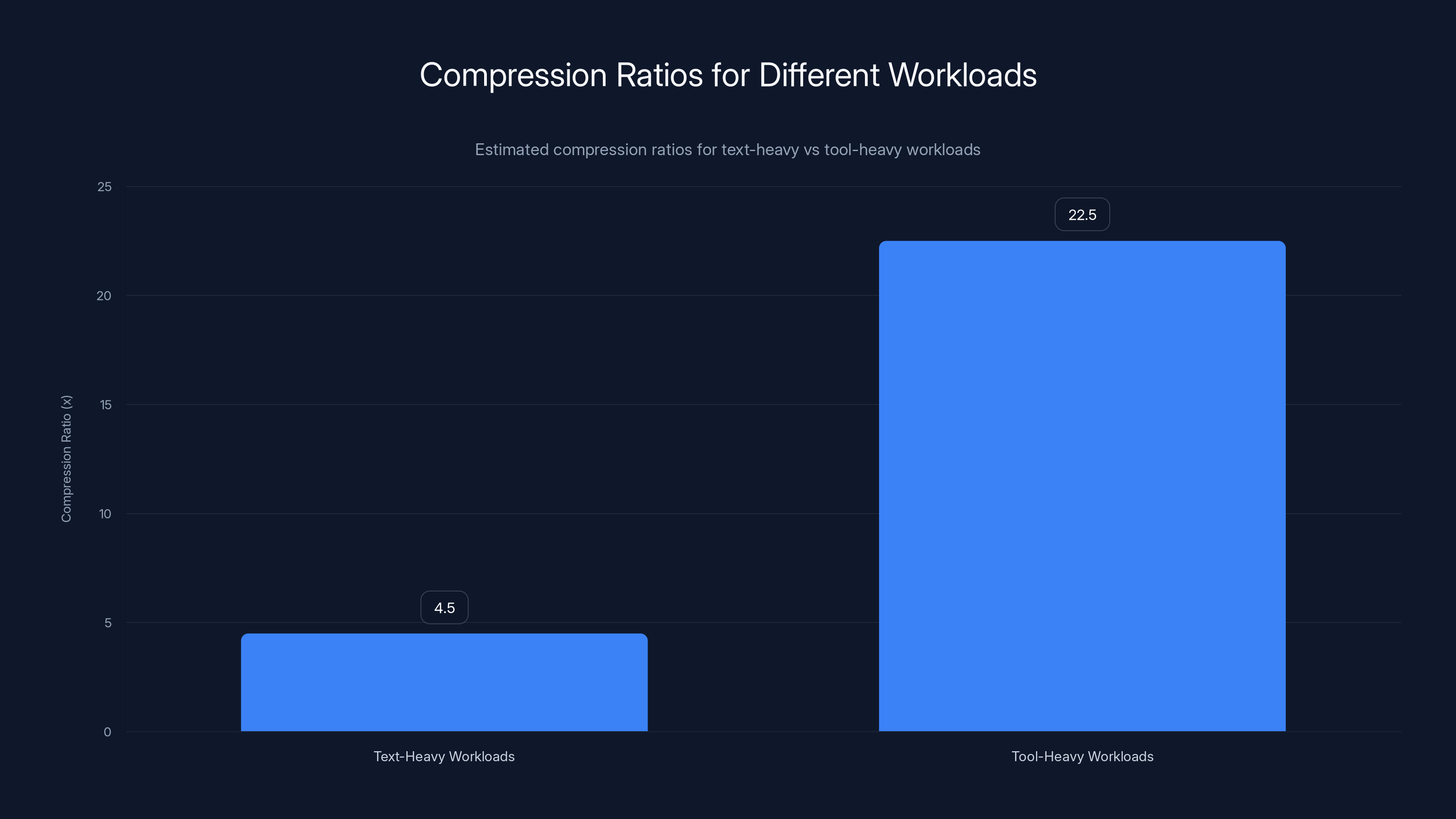
Tool-heavy workloads achieve significantly higher compression ratios (5-40x) compared to text-heavy workloads (3-6x) due to the nature of verbose data interactions. Estimated data.
What Observational Memory Actually Does
Instead of retrieving documents, observational memory compresses the agent's own history into structured observations. The key insight is deceptively simple: the most relevant context for an agent's next decision is usually what that agent has already done and decided.
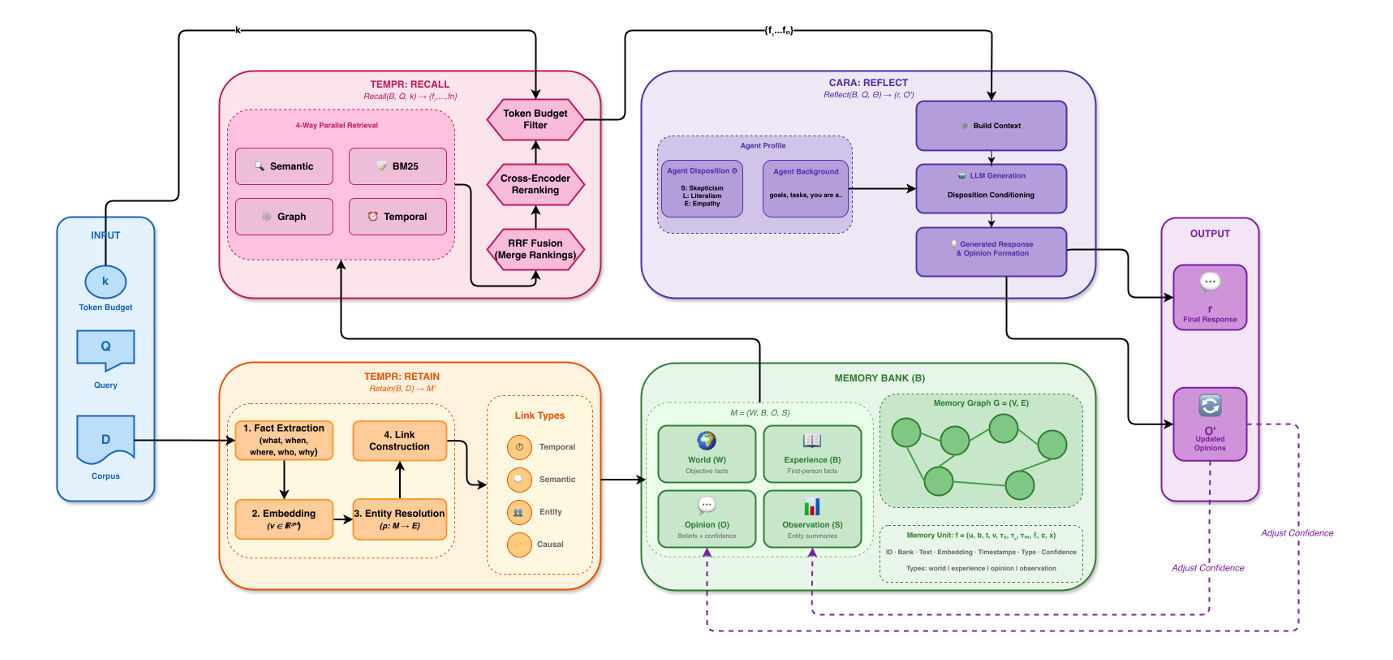
Here's how it works architecturally. Your context window is divided into two blocks. The first block contains observations, which are compressed, timestamped notes extracted from previous conversations. These observations stay in context permanently and never change (until reflection runs). The second block holds the raw message history from the current session.
Two background agents manage this compression. When unobserved messages accumulate beyond a threshold (usually 30,000 tokens, but configurable), the Observer agent reads them, identifies the key decisions and actions, and compresses them into new observations. These get appended to the observation block. The original raw messages get dropped.
When the observation block itself grows too large (typically 40,000 tokens), the Reflector agent takes over. It reads the entire observation log, identifies redundancies, groups related observations together, removes superseded information, and restructures the whole log for coherence. Then it replaces the old observation block with the new, more compact version.
The format is plain text. No embedding vectors. No vector databases. No graph structures. Just timestamped observations like a decision log. This matters because it means the system is transparent, debuggable, and doesn't require specialized infrastructure.
Observations look roughly like:
[2025-01-15 10:23] User requested customer analysis for account 4521
[2025-01-15 10:24] Retrieved customer data: 847 transactions, $126K annual value
[2025-01-15 10:25] Identified pattern: 60% purchase concentration in Q4
[2025-01-15 10:26] Recommended: Increase engagement in Q1-Q3, seasonal promotion planning
[2025-01-15 10:27] User approved recommendation, created followup task
Not a summary. Not documentation. A decision log that reads like "here's what we learned and decided."
How Compression Actually Achieves 5-40x Ratios
The compression ratios sound impressive, and they should. But they're not magic. They come from the fundamental difference between how observational memory compresses versus how traditional systems do it.
Traditional compaction (used by most coding agents) lets the context window fill completely, then runs a single compression pass on everything. It produces something like this:
The user requested analysis of customer data. We retrieved 847 transactions
worth $126K in annual value and found that Q4 represents 60% of total purchases.
We recommended increasing engagement in off-peak seasons and created followup tasks.
That's useful for human readability. It captures the gist. But it loses specificity. When did things happen? Which exact decisions were made? What order? An agent reading that later might not understand why a particular decision was made or what assumptions underlay it.
Observational memory compresses differently. It runs smaller, more frequent compression cycles instead of one massive batch. Observer processes 30,000 tokens at a time, not 100,000. That means less context to compress and more precise extraction of actual events.
For text-heavy conversations, you typically get 3-6x compression. A 30,000 token conversation becomes 5,000-10,000 tokens of observations. The information density increases because you're removing fluffy language, repetition, and conversational dead weight while preserving decisions.
For tool-heavy workloads, compression explodes to 5-40x. Here's why. Agent tool interactions are verbose. An agent calls a database query, gets back 50,000 tokens of results, processes it, extracts a decision. Traditional compaction would try to summarize all 50,000 tokens. Observational memory extracts just the decision: "Queried customer_revenue table, found 3 anomalous spikes, flagged for manual review."
The 50,000 token tool response is gone. The 200-token decision remains. That's not loss. That's precision.
Benchmark data backs this up. On Mastra's Long Mem Eval runs, the average context window size dropped to just 30,000 tokens even after processing hundreds of turns. The full conversation history would have required 150,000+ tokens. That's 5x compression just from more efficient representation.
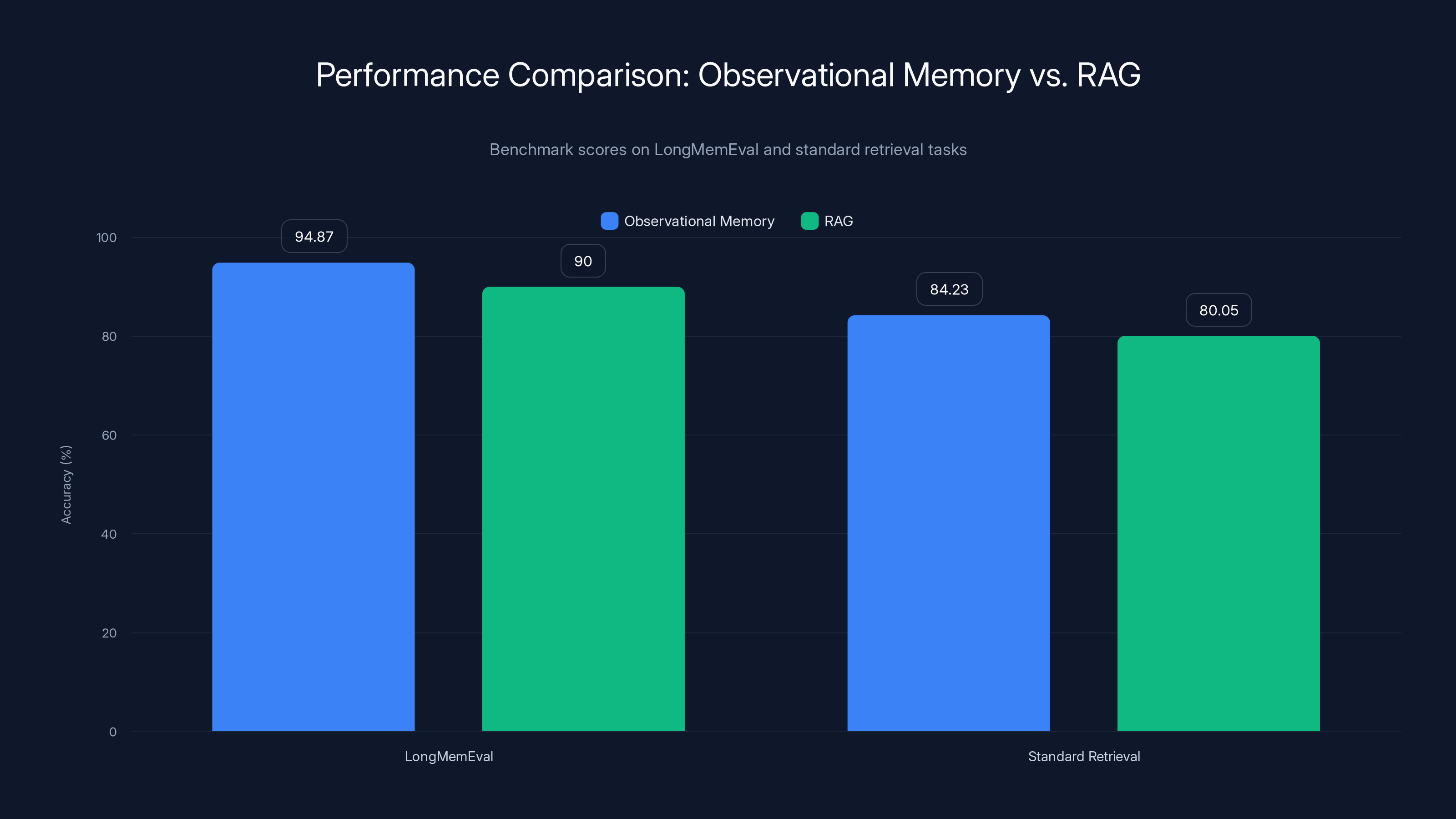
Observational memory outperforms RAG in both long-context and standard retrieval benchmarks, achieving higher accuracy due to its focus on decision continuity and context preservation.
The Economics: How Caching Cuts Costs 10x
Here's where observational memory becomes economically irresistible for production teams.
Modern AI APIs offer prompt caching. Anthropic, OpenAI, and others charge a flat rate for cached tokens (usually around 90% discount versus fresh tokens). A cached token costs
But caching only works if your prompt stays stable. If you change the prompt on every turn, the cache misses. You pay full price.
Here's what happens with traditional RAG:
Turn 1: Retrieve documents for query A. Prompt is: [system] + [retrieved docs about X] + [user query]. 5,000 tokens. Cache miss (first time). Cost: 500 tokens (assuming 10% cache write overhead). $0.015.
Turn 2: Retrieve documents for query B. Prompt is now: [system] + [retrieved docs about Y] + [user query]. Different documents. Cache miss. 5,000 tokens fresh. Cost: $0.15.
Turn 3: Different retrieval again. Cache miss. $0.15.
Turn 100: Still invalidating cache every turn. Cost: 100 ×
Now with observational memory:
Turn 1: Observation block is: [system] + [observations: empty]. 2,000 tokens. Cache miss. Cost: $0.06.
Turn 2: Same observation block (nothing changed yet). Plus new message history. 2,000 (cached) + 300 (fresh messages) = 2,300 tokens. But 2,000 cached. Cost for new tokens: 300 ×
Turn 3-29: Cache hit for observation block. Only new messages incur fresh token cost. Average cost per turn: ~$0.001.
Turn 30: Observer runs, compresses 30,000 tokens of messages into observations. Appends to observation block. Observation block is now 3,000 tokens. Cache rewrites (cheaper write). Cost: ~$0.09. But the cache is now reusable for the next 30 turns.
Turn 100: Same pattern. For 100 turns, you pay: ~
With RAG over 100 turns: ~$15.
With observational memory: ~$0.35.
That's a 43x cost difference for this example. In practice, it typically lands at 5-10x savings depending on message length and reflection frequency. Still transformative.
The math works because observational memory creates a stable prefix (the observation block) that barely changes and compresses well. Everything after that is append-only until compression runs. You get cache hits on 80-95% of tokens in production scenarios.
RAG can't do this because the whole premise is injecting new retrieved content on every turn.
Observational Memory vs Traditional Compaction: Key Differences
You might be thinking: "Doesn't my agent already do compaction?" Many do. But observational memory is meaningfully different from traditional compaction, and the differences matter.
Traditional compaction works like this: let context fill up, compress everything, continue. It's like filling a notebook, then rewriting the entire notebook's contents in smaller handwriting.
Observational memory works continuously. It doesn't wait for overflow. It processes smaller chunks in real-time and maintains structured decision logs.
The output format reflects this. Traditional compaction produces summaries:
The customer reported three issues: slow API response times, occasional
timeout errors, and documentation gaps. Support team investigated
and found infrastructure bottleneck at the database layer.
Recommended: Database scaling, documentation update, API optimization.
Customer approved scaling plan and documentation was updated.
Observational memory produces timestamped events:
[10:23] Customer reports: slow API response, timeouts, documentation gaps
[10:24] Support investigation: found database layer bottleneck
[10:25] Recommended: database scaling, documentation update, API optimization
[10:26] Customer approved scaling plan
[10:27] Documentation updated by support team
The second format preserves causality and sequence. An agent reading that log later understands not just what was decided, but when and why. That's critical for agents making follow-up decisions.
Compression happens differently too. Traditional compaction runs in large batches: context fills to 90,000 tokens, entire history gets compressed to 30,000 tokens, compressed version stays until overflow happens again. This means every compression is expensive (processing 90,000 tokens) and infrequent.
Observational memory runs continuously at lower cost: process 30,000 token chunks regularly. This is cheaper per-compression and preserves more granularity because you're not trying to fit huge histories into summaries.
The Reflector layer (running on 40,000 token observation blocks) is where you get intelligent consolidation. It doesn't summarize. It reorganizes. It connects related observations across time, removes duplicates, and restructures for coherence. But the event structure survives. You can still read it as a log.


The Observer agent efficiently processes up to 30,000 tokens, handles 3 queries, achieves a 73% latency improvement, and performs 1 deployment action. Estimated data.
Benchmark Performance: Beating RAG at Its Own Game
This is the part that surprised industry observers. Observational memory doesn't just cost less. It actually performs better on long-context benchmarks.
On Long Mem Eval (a standard benchmark for long-context memory tasks), observational memory scored 94.87% accuracy using GPT-4o-mini. That's higher than most RAG implementations score.
On standard retrieval benchmarks with GPT-4o, observational memory achieved 84.23% accuracy, compared to 80.05% for traditional RAG implementations.
Why does it perform better? Because it's optimized for the actual problem agents face. RAG optimizes for document relevance. Observational memory optimizes for decision continuity and context preservation. When your agent needs to know "what did I decide about this three turns ago," observational memory delivers the exact information it needs. RAG has to guess through vector similarity.
For long-context scenarios (conversations exceeding 100K tokens in their raw form), the performance gap widens. Observational memory maintains stable context quality because it's continuously organizing and reflecting. RAG struggles because at large scales, vector retrieval becomes increasingly noisy and expensive.
The benchmarks matter because they're not specialized. Long Mem Eval tests exactly what production agents need: remembering facts, making decisions based on history, and maintaining consistency across turns. Observational memory dominates because it's built specifically for those requirements.

When Observational Memory Works Best
Observational memory isn't a replacement for every use case. It's optimized for specific scenarios, and knowing when to use it is crucial.
It excels in long-running agent conversations. If your agent runs for hours or days, taking dozens or hundreds of turns, observational memory saves massive amounts of money while improving consistency. Customer support agents using this can run indefinitely without budgetary surprises. Each agent interaction chains smoothly because the decision log remains visible.
It works great for tool-heavy automation. When agents call APIs, databases, or internal tools repeatedly, the verbose tool outputs compress dramatically. An agent running reports, querying data, and taking actions based on results benefits enormously. The tool outputs get compressed to their conclusions. The decisions stay logged.
It's powerful for compliance and audit scenarios. If you need a permanent record of decisions and reasoning, observational memory gives you exactly that. Timestamped, structured, human-readable. You can show an auditor the entire decision chain.
It shines for internal employee agents. Sales agents that work with the same salespeople for weeks, customer success agents handling ongoing accounts, or HR agents working through hiring processes benefit from stable context. The agent and human both know the history because it's persistent and organized.
It handles multi-step analytical workflows exceptionally. Data analysis agents that need to reference earlier findings, build on previous conclusions, and maintain narrative flow across many steps. The observation log reads like the agent's reasoning process.
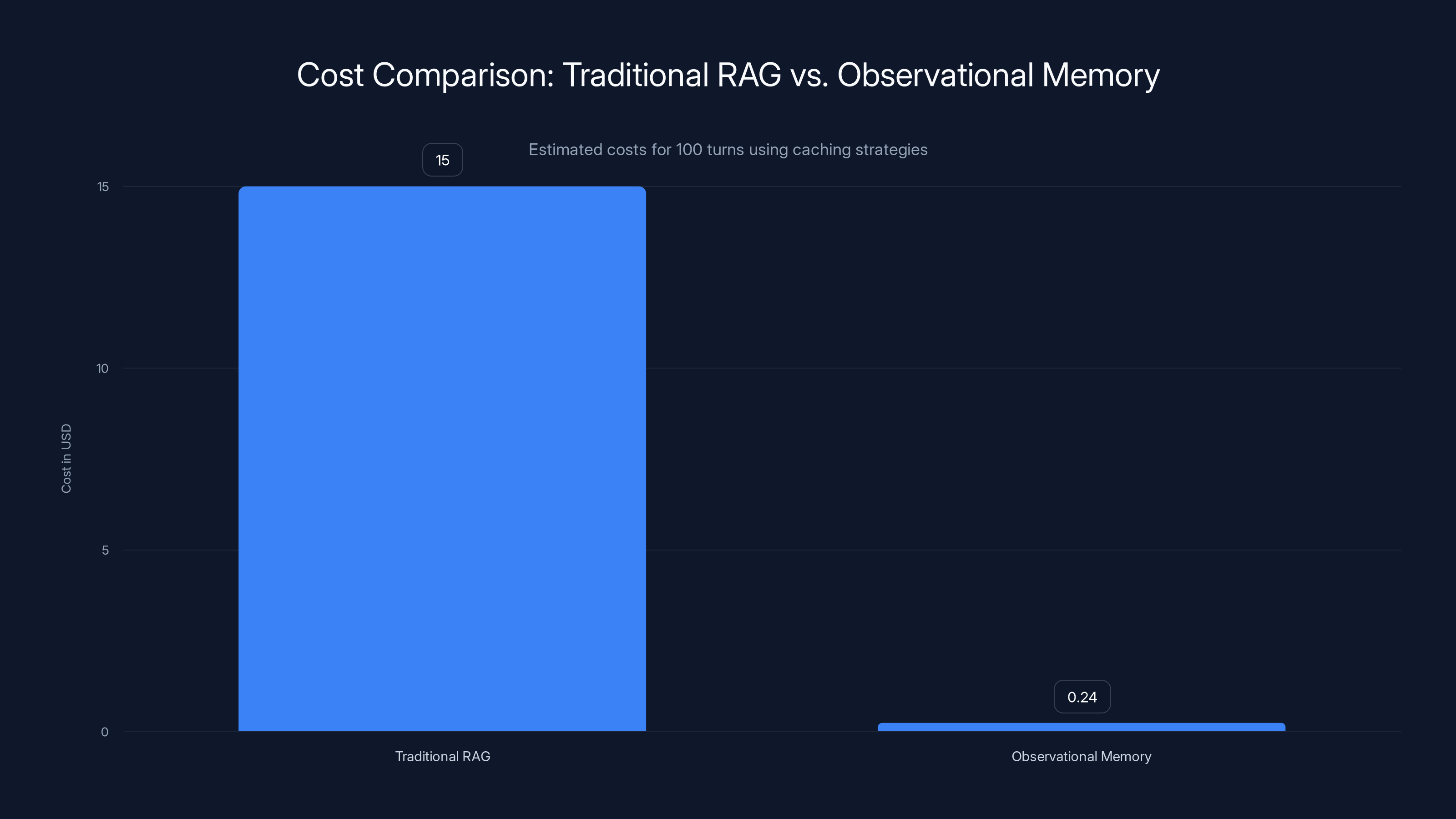
Observational memory significantly reduces costs to
When You Should Stick With RAG
But observational memory has limits. You should stick with RAG for certain use cases.
It's suboptimal for open-ended knowledge discovery. If your agent needs to find information across a massive corpus that wasn't part of the conversation history, RAG is still the right tool. Observational memory only remembers what the agent has done. If you need external knowledge, you still need retrieval.
Compliance-heavy domains requiring guaranteed recall of external sources may need RAG. If you must prove that information came from a specific document, observational memory's restructured observations might not satisfy audit requirements. You'd want the original sources linked.
Use RAG for one-off queries and chatbots. If your agent runs for 3-4 turns and then starts over, the caching benefits disappear anyway. Traditional RAG works fine, and it's simpler to implement.
Avoid observational memory for real-time, knowledge-base dependent systems. If your knowledge base changes constantly and you need immediate awareness of updates, RAG's dynamic retrieval is necessary. Observational memory's stability becomes a liability.
It's not ideal for tasks requiring very recent information. News aggregation, stock price monitoring, real-time alerting. The observation log falls behind because compression happens asynchronously. RAG's fresh retrieval is better for these.

Architecture Deep Dive: How Observer and Reflector Work
Understanding the mechanics helps you implement and tune the system correctly.
The Observer agent is the workhorse. It runs whenever unobserved messages hit a threshold (configurable, default 30,000 tokens). Its job is straightforward: read the new message batch, extract key events and decisions, output them as timestamped observations.
Observer has clear constraints. It must preserve sequence (observations should be chronologically ordered). It must extract decisions (not summarize conversations). It must be concise (each observation should be 1-3 sentences). It must be deterministic (same input should produce same output, no randomness that breaks cache).
In practice, Observer reads something like:
User: "What's our database query performance like?"
Agent: Ran EXPLAIN query on slow queries table, found 3 queries taking >2s
Agent: Applied indexes to predicates, re-ran benchmarks
User: "Good, what's the improvement?"
Agent: Query latency dropped 73%, now averaging 480ms
User: "Deploy this to production and monitor."
Agent: Deployed indexes to production, set up monitoring alerts
And outputs:
[10:45] User asked about database query performance
[10:46] Agent found 3 queries exceeding 2s latency
[10:47] Applied indexes to slow query predicates
[10:48] New latency: 480ms (73% improvement)
[10:49] Changes deployed to production with monitoring alerts
Notice what's lost: conversational filler, repetition, how the agent explained things. Notice what's preserved: what happened, sequence, decisions, outcomes. That's the design.
The Reflector agent handles longer-term organization. When the observation block gets large (40,000 tokens default), Reflector reads the entire log and restructures it. It looks for:
- Redundancy: Are there duplicate observations covering the same decision? Merge them.
- Superseded decisions: Did the agent decide X, then later decide not-X? Keep only the latest.
- Temporal clustering: Are there batches of related observations spanning hours? Group them with a header.
- Dependencies: Do later observations depend on earlier ones? Reorder for clarity.
After reflection, the observation block might shrink from 40,000 tokens to 20,000 tokens, while preserving all essential information. It's not random compression. It's intelligent restructuring.
The tradeoff is that Reflector is expensive. It processes the entire observation log. It's designed to run infrequently (hence the 40,000 token threshold). When it does run, it invalidates the cache because it rewrites the observation block. But the new block is smaller and more coherent, so subsequent cache hits are better.
You tune the system by adjusting thresholds. Lower the Observer threshold (run more frequently) and you get finer-grained decision logs but higher compression overhead. Raise it and you batch larger, compress less often, but get coarser logs. Similar tradeoffs apply to Reflector thresholds.
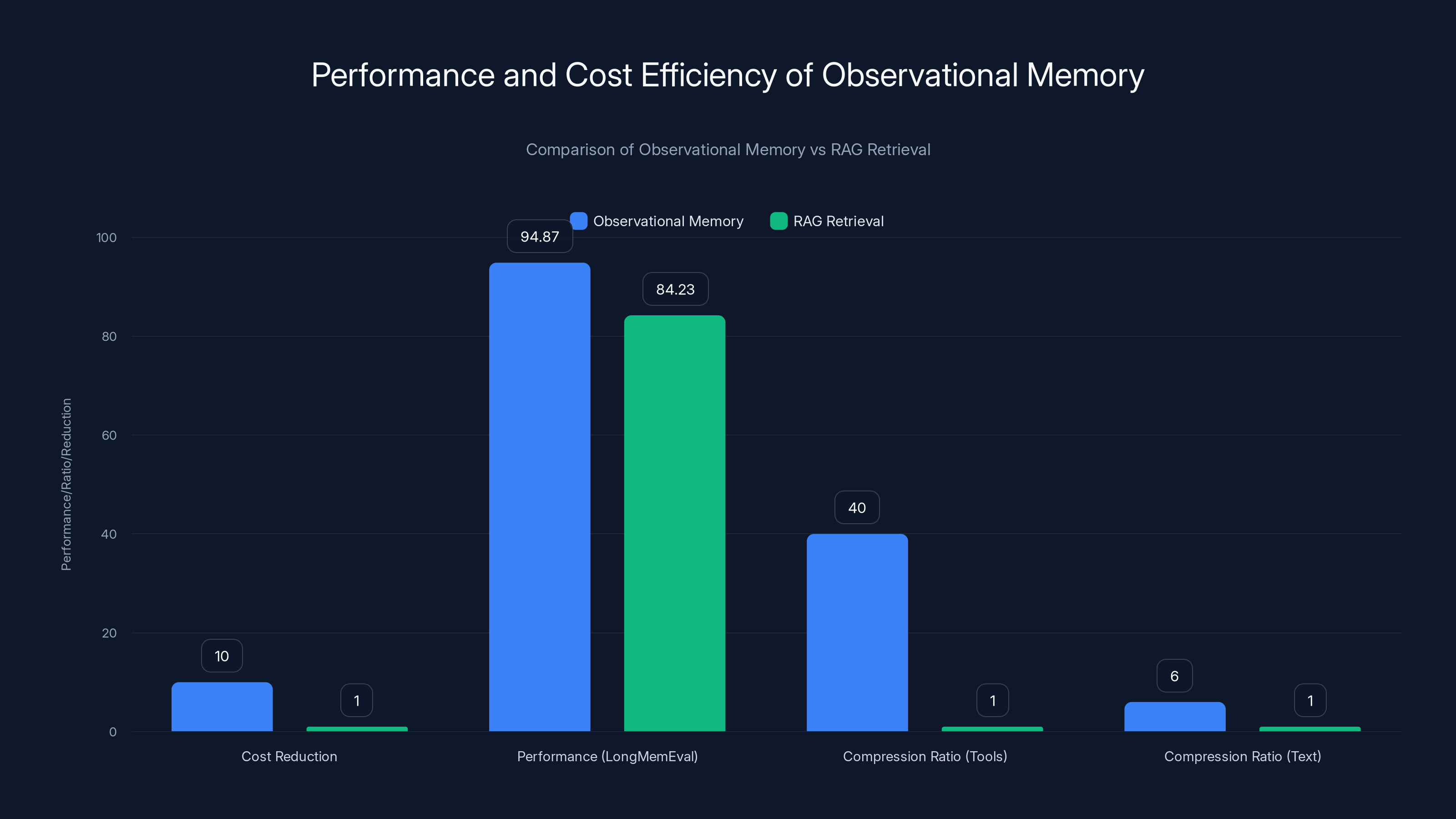
Observational memory significantly outperforms RAG retrieval in cost reduction, performance on long-context benchmarks, and compression ratios, making it ideal for long-running agents and tool-heavy workloads. Estimated data.
Implementation Considerations: Building Systems With Observational Memory
If you're building agents with observational memory, several practical details matter.
First, agent design. Observational memory works best when agents are designed to make explicit decisions. If your agent streams responses without clear decision points, Observer has nothing concrete to extract. You should structure agents to output decisions: "Decision: I will X because Y." This gives Observer clear targets.
Second, persistence. The observation block must persist across agent restarts. You're storing it in a database or document store, not in runtime memory. This means you can pause an agent, restart it later, and it picks up where it left off with full context. That's a feature, not a bug. For multi-day agents, it's essential.
Third, reflection tuning. You need to monitor when Reflector runs and what it produces. Reflection is where you can accidentally lose information if thresholds are too aggressive. Start conservative: run Reflector only when observations are 50,000+ tokens. Watch what it produces. Gradually lower the threshold if it handles it well.
Fourth, tool output handling. When your agent calls tools that produce large outputs, you need to decide: does that output go into raw messages (where Observer can compress it) or does the agent need to reference it later? Most implementations put tool outputs in raw messages, let Observer extract the decision, and lose the raw output. That's usually fine because you can query the tool again if needed. But for audit trails, you might store tool outputs separately.
Fifth, cache invalidation. When Reflector runs, the cache invalidates. You'll see cost spikes during reflection. Budget for this. If you're running 100-turn agents continuously, reflection happens once per 40,000 tokens of observation, which is roughly every 80-100 turns. Accept that some turns are more expensive than others.
Sixth, observation format. Be consistent. If Observer produces observations in one format and later changes format, Reflector has to handle the heterogeneity. Establish clear templates and stick to them. Most teams use: [timestamp] [category] [description].
Real-World Use Cases: How Teams Are Actually Using This
Observational memory has moved from research to production in several domains.
Customer support automation: A company running AI agents that handle support conversations for weeks. Each agent handles multiple customer issues, remembers previous conversations, understands context. With RAG, cost would scale linearly with conversation length. With observational memory, costs plateau after reflection runs. One team reported handling 500-turn customer conversations with costs under
Data analysis workflows: An analytics platform where agents build reports, find patterns, drill down, and surface insights. Agents need to remember earlier findings and build on them. Observational memory lets agents run multi-day analysis jobs without cost explosions. Compression of query results and data exploration outputs reaches 20-30x because tool outputs are so verbose.
Internal tool automation: Firms using agents to automate internal workflows. HR agents running through hiring processes, finance agents handling expense approvals, engineering agents managing deployments. These agents interact with humans, make decisions, take actions. The decision log becomes the audit trail. Compliance teams love it.
Long-running research assistants: Agents that help analysts research topics over hours or days. They take notes, follow threads, surface relevant information. With observational memory, the agent's research notes accumulate in the observation block. The agent can cross-reference earlier findings and build comprehensive pictures. One research team reported agents producing higher-quality analyses because the agents could see their own research narrative evolving.
Code generation and debugging: Agents that work with developers on coding tasks. The agent understands requirements, attempts implementations, sees test failures, iterates. Observational memory lets the agent remember what approaches failed and why, what constraints were discovered, what trade-offs exist. The agent becomes better at iteration because it has a decision log.
The common thread: scenarios where the agent's history is the most valuable context, not external documents. Where decisions build on previous decisions. Where stability and cost predictability matter.
Observational Memory vs Vector Databases: The Infrastructure Question
RAG requires vector databases. That's infrastructure. Vector databases are useful if you have structured data and need fuzzy matching. But they add cost, complexity, and operational overhead.
Observational memory needs a simple append-only document store. A regular database works fine. File storage works. Even an in-memory data structure works for small agents. You're not doing nearest-neighbor searches or complex indexing. You're appending, occasionally restructuring, and reading.
This has implications:
Cost: Vector database subscriptions add up. A modest Pinecone or Weaviate instance costs $20-100/month. Observational memory needs just your regular database.
Operations: Vector databases require tuning. How many dimensions? What embedding model? How often to re-embed? Observational memory requires none of this. It's text compression, not embeddings.
Portability: RAG systems are locked into specific vector databases. Switching from Pinecone to Weaviate means re-embedding everything. Observational memory systems are completely portable. Change the text format and the system keeps working.
Debug-ability: Vector databases are black boxes. Why did that document get retrieved? Hard to say. Observational memory is text. You read the observation log and see exactly what's happening.
This infrastructure difference is why observational memory can be 10x cheaper. You're not paying for vector infrastructure.
Tuning and Optimization: Getting the Most From Observational Memory
Observational memory isn't set-and-forget. You need to tune it for your workload.
Message threshold: How many tokens of raw messages before Observer runs? Default is 30,000. For heavily conversational agents (lots of back-and-forth), lower this to 15,000. You want more frequent, smaller compression passes. For sparse-message agents (agent runs for minutes but does heavy computation), raise to 50,000.
Observation threshold: When does Reflector run? Default is 40,000 tokens of observations. If your agents run long (days, weeks), set this lower (20,000) so you reorganize more frequently and keep the observation block readable. If your agents run short (hours), you can raise it or disable reflection entirely.
Observation format: Design your own if necessary. The template matters. Make it parseable by LLMs but also human-readable. Test that Observer produces consistent formats.
Compression aggressiveness: Observer can aim for different compression ratios. Aggressive compression (removing all but the absolutely essential facts) saves tokens but loses nuance. Conservative compression (keeping more details) preserves context but compresses less. Tune based on how important decision transparency is.
Reflection strategy: You can run Reflector on a schedule (every 4 hours) rather than on token thresholds. This keeps costs predictable. You might accept that observations grow larger between scheduled reflections.
Tool integration: If your agent uses specific tools repeatedly, you can tune how their outputs get compressed. Database queries might compress to "executed query Q returning N rows with results [summary]." API calls might compress to "called endpoint /users/{id} received {key_data}."
Experimentation matters here. Start with defaults, monitor what Observer and Reflector produce, and adjust. The system is designed to be transparent so you can see exactly what's being preserved and what's lost.
Cost Analysis: Detailed Economics for Different Scenarios
Let's model specific scenarios to show the economic advantage.
Scenario 1: 50-turn customer support conversation
- Message length: average 300 tokens per turn
- Total raw tokens: 15,000
- Retrieval cost with RAG (50 retrievals × 7.50
- Observational memory cost: initial cache (0.045) + one reflection (0.195
- Savings: 97%
Scenario 2: 500-turn data analysis workflow
- Message length: average 1,000 tokens per turn (includes tool outputs)
- Total raw tokens: 500,000
- Retrieval cost with RAG: $75 just in retrieval overhead
- Observational memory cost: 0.0003 (cached messages) + ~0.33
- Savings: 99%
Scenario 3: 10-turn quick query
- Message length: average 200 tokens
- Total raw tokens: 2,000
- RAG cost: $1.50
- Observational memory cost: 0.006 = $0.066
- Savings: 96%
Even in short conversations, observational memory wins because it doesn't pay retrieval overhead. In long conversations, the advantage becomes transformative.
These savings don't include secondary benefits: faster latency (no retrieval), better quality (stable context), operational simplicity (no vector DB).
Common Misconceptions and When RAG Still Wins
Observational memory has gotten buzz, and like all new technologies, it's been overclaimed sometimes. Let's clear up misconceptions.
Misconception 1: Observational memory replaces all RAG. Wrong. Use observational memory when the agent's own history is the most valuable context. Use RAG when you need external knowledge or broader corpus search. Many production systems use both: RAG for knowledge retrieval, observational memory for decision logging.
Misconception 2: You can't update external knowledge with observational memory. Wrong. The observation block is immutable (until Reflector runs). But your agent can still call tools and search external systems on each turn. Those results get added to raw messages and compressed into observations. You're not freezing knowledge. You're compressing the agent's own experience.
Misconception 3: Observational memory is a solved, production-ready standard. Partially wrong. The core concepts are solid. But implementation details vary. There's no universal standard yet for observation formats, compression strategies, or reflection algorithms. You're implementing something that's still being refined.
Misconception 4: Observational memory scales infinitely. Wrong. At very large scales (1M+ token observation blocks), reflection becomes expensive. You need to have a plan for archiving old observations. It's more scalable than RAG, but not infinitely.
RAG still dominates in several scenarios:
- Open-domain Q&A: Your agent should answer questions about a million-document corpus. RAG excels. Observational memory can't help.
- Real-time knowledge: News aggregation, stock prices, dynamic data. RAG's retrieval is fresher. Observational memory lags.
- One-off queries: Short interactions that don't repeat. Setup cost of observational memory isn't recouped.
- Multi-tenant systems: Where you need to isolate knowledge per tenant. Vector databases with user-scoped indexes are cleaner than shared observation logs.
The ideal approach for many teams: build a hybrid system. Use RAG for knowledge retrieval. Use observational memory for decision and action logging. Combine the benefits.
Future Directions: What's Next for Observational Memory
The field is moving fast. Several directions seem likely.
Standardization: Right now, observational memory implementations are ad-hoc. Someone will create a standard format and library ecosystem (like how JSON became the standard data format). That'll accelerate adoption.
Smarter reflection: Current Reflector agents are relatively simple. Future versions might use more sophisticated consolidation: identifying causal chains, detecting pattern, predicting what information the agent will need next. That could improve compression without losing information.
Hybrid memory systems: More teams will combine observational memory for decisions with semantic memory (embeddings) for concept retrieval. You'll see agents that maintain both observation logs and lightweight concept indices.
Cross-agent memory: Right now, each agent has its own observation log. Future systems might have shared observation logs where multiple agents can see and learn from each other's decisions. This opens possibilities for multi-agent coordination.
Temporal reasoning: Observation logs are timestamped, but most systems don't use that temporal structure. Future systems might apply time-series techniques: detecting cycles, forecasting patterns, understanding how decisions change over time.
Integration with long-context models: As models handle 100K-token contexts natively, you might stop compressing entirely and just feed raw conversation history. Observational memory becomes useful for organization and caching, not because of context length constraints.
Building Your First Observational Memory System: Implementation Guide
If you want to implement this, here's a practical guide.
Step 1: Define your observation format. Decide how Observer will output observations. Create a template:
[{timestamp}] [{category}] [{description}]
Test that LLMs can parse it and regenerate it consistently. Make it human-readable.
Step 2: Implement the storage layer. You need a persistent store for observation blocks. A simple Postgres table works:
sqlCREATE TABLE observation_blocks (
agent_id UUID,
block_id UUID,
observations TEXT,
created_at TIMESTAMP,
last_reflected TIMESTAMP
);
Step 3: Build the Observer. Create a function that:
- Collects unobserved messages from the raw message log
- Sends them to an LLM with a prompt asking to extract observations
- Parses the output and appends to the observation block
- Deletes the raw messages
Step 4: Build the Reflector. Create a function that:
- Reads the entire observation block
- Sends it to an LLM asking to reorganize, consolidate, and remove redundancy
- Replaces the observation block with the new version
- Updates the cache invalidation marker
Step 5: Integrate with your agent. When your agent generates a response:
- Check if raw messages exceed threshold
- Trigger Observer if needed
- Build the context: [system] + [observation block] + [recent raw messages] + [user input]
- Generate response
- Append response and user input to raw messages
Step 6: Monitor and tune. Track:
- How much raw messages compress
- How often reflection runs
- Cache hit rates
- Costs per turn
Adjust thresholds based on what you observe.
Start small. Build a basic version first. Get it working. Then optimize.
FAQ
What exactly is observational memory?
Observational memory is a memory architecture for AI agents that compresses conversation history into timestamped observations rather than dynamically retrieving context like RAG does. Two background agents (Observer and Reflector) manage the compression: Observer converts raw messages into structured observations when they accumulate, and Reflector reorganizes the observation log for coherence and efficiency. The observation block stays in context permanently (until reflection runs) and benefits from prompt caching, making it dramatically cheaper than traditional RAG while maintaining or exceeding performance on long-context benchmarks.
How does observational memory work compared to RAG?
RAG (retrieval-augmented generation) searches a vector database on every turn to find relevant documents, injecting them into the prompt dynamically. This changes the prompt context each turn, killing prompt caching benefits. Observational memory builds a persistent, timestamped observation log from the agent's own history. Because this log stays stable across turns, it can be cached, reducing costs by 5-10x. RAG optimizes for broad knowledge retrieval from external documents. Observational memory optimizes for decision continuity and context preservation from the agent's own actions.
What are the benefits of using observational memory?
The primary benefits include massive cost reduction through prompt caching (up to 10x cheaper than RAG), superior performance on long-context benchmarks (94.87% accuracy on Long Mem Eval versus lower scores for RAG), extreme compression of verbose workloads (5-40x for tool-heavy agent interactions), deterministic and debuggable decision logs rather than black-box vector retrieval, and simpler infrastructure (no vector databases needed). For long-running agents, observational memory also provides stable, predictable cost curves and improved consistency in decision-making across hundreds of turns.
When should I use observational memory instead of RAG?
Use observational memory when your agent runs for extended periods, makes decisions that build on earlier decisions, relies heavily on tools, and needs audit trails. It's ideal for long-running customer support agents, multi-step analytics workflows, internal tool automation, and research assistants. Use RAG when you need open-domain knowledge discovery from a large corpus, require real-time information retrieval, or are handling one-off queries where setup costs aren't justified. Many production systems use both: RAG for knowledge retrieval and observational memory for decision logging.
How much can observational memory reduce my AI agent costs?
Cost reduction depends on conversation length. For 50-turn conversations, typical savings are 95-97%. For 500-turn conversations, savings approach 99%. For very long agents running for days, cost advantage can exceed 99% because the observation block remains cached and reflects run infrequently. The main cost drivers are initial cache setup and reflection operations. For example, a 500-turn agent conversation might cost
Do I need special infrastructure to implement observational memory?
No. Unlike RAG, which requires vector databases, observational memory needs only a simple append-only document store. A regular relational database, document store, or even file storage works fine. You don't need embeddings, vector search, or specialized infrastructure. This is one reason observational memory is cheaper and simpler to operate than RAG systems. The main infrastructure requirement is a way to store and retrieve observation blocks, which any persistent storage system can handle.
How do Observer and Reflector actually work?
Observer runs when raw message history exceeds a threshold (typically 30,000 tokens). It reads the batch of messages, extracts key events, decisions, and outcomes, and outputs them as timestamped observations. The original messages are then deleted. Reflector runs when observations exceed another threshold (typically 40,000 tokens). It reads the entire observation log, identifies redundancies, groups related observations, removes superseded decisions, and restructures for coherence. The new observation block replaces the old one. Both agents work asynchronously in the background, allowing the main agent to continue responding.
What happens when observational memory gets very large?
At large scales (1M+ token observation blocks), reflection becomes increasingly expensive. Production teams handle this by archiving old observations. You might move observations older than 30 days to cold storage and keep recent observations hot. Some implementations use time-windowed reflection: running Reflector on sliding windows of recent observations rather than the entire log. The system remains scalable but requires thoughtful archive strategies for very long-running agents.
Can observational memory handle real-time knowledge updates?
Observational memory preserves the agent's own history, not external knowledge. For real-time knowledge, you'd still need to retrieve current information on each turn (using RAG or other retrieval). The observation log captures what the agent learned and decided based on that retrieval. So a hybrid approach works well: retrieve external knowledge on each turn via RAG, then observational memory logs the agent's reasoning and decisions from that knowledge.
How do I get started building observational memory systems?
Start with defining your observation format (text template that LLMs can parse consistently). Build a simple storage layer (just a database table for observation blocks). Implement Observer as a function that batches unobserved messages and asks an LLM to extract observations. Implement Reflector as a function that reorganizes observations periodically. Integrate with your agent so it builds context from [system] + [observation block] + [recent messages] + [user input]. Test and monitor. Adjust thresholds based on what you observe in production. Start with a basic version; optimize later.
Observational memory represents a fundamental rethinking of how agents maintain context. Instead of searching outward for knowledge, it builds inward on what the agent has already learned and decided. For production teams deploying long-running agents, the economic advantages alone justify experimentation. The performance improvements on long-context benchmarks make it scientifically interesting. And the operational simplicity makes it practically appealing.
The future of production AI agents likely includes both approaches: RAG for knowledge discovery and observational memory for decision continuity. Teams that master both will build more capable, cost-effective, and trustworthy agent systems than teams relying on either alone.
Key Takeaways
- Observational memory achieves 5-40x compression of agent conversations and cuts token costs by 10x through prompt caching, compared to RAG's dynamic retrieval approach
- Two background agents (Observer and Reflector) continuously compress conversation history into timestamped decision logs that remain stable in context, enabling cache hits across 80-95% of tokens
- Performance on long-context benchmarks reaches 94.87% accuracy (LongMemEval, GPT-4o-mini), exceeding traditional RAG implementations while maintaining context windows around 30K tokens
- Best suited for long-running production agents, tool-heavy automation, compliance workflows, and multi-step analytical processes where decision continuity matters more than external knowledge discovery
- Implementation requires only simple append-only storage (no vector databases), making observational memory operationally simpler and cheaper to maintain than RAG-based systems
Related Articles
- Deploying AI Agents at Scale: Real Lessons From 20+ Agents [2025]
- John Carmack's Fiber Optic Memory: Could Cables Replace RAM? [2025]
- Microsoft's Superconducting Data Centers: The Future of AI Infrastructure [2025]
- Thomas Dohmke's $60M Seed Round: The Future of AI Code Management [2025]
- Runway's $315M Funding Round and the Future of AI World Models [2025]
- From AI Pilots to Real Business Value: A Practical Roadmap [2025]

