![Rapidata's Real-Time RLHF: Transforming AI Model Development [2025]](https://tryrunable.com/blog/rapidata-s-real-time-rlhf-transforming-ai-model-development-/image-1-1771510339479.jpg)
Rapidata's Real-Time RLHF: How AI Development Is Getting Radically Faster
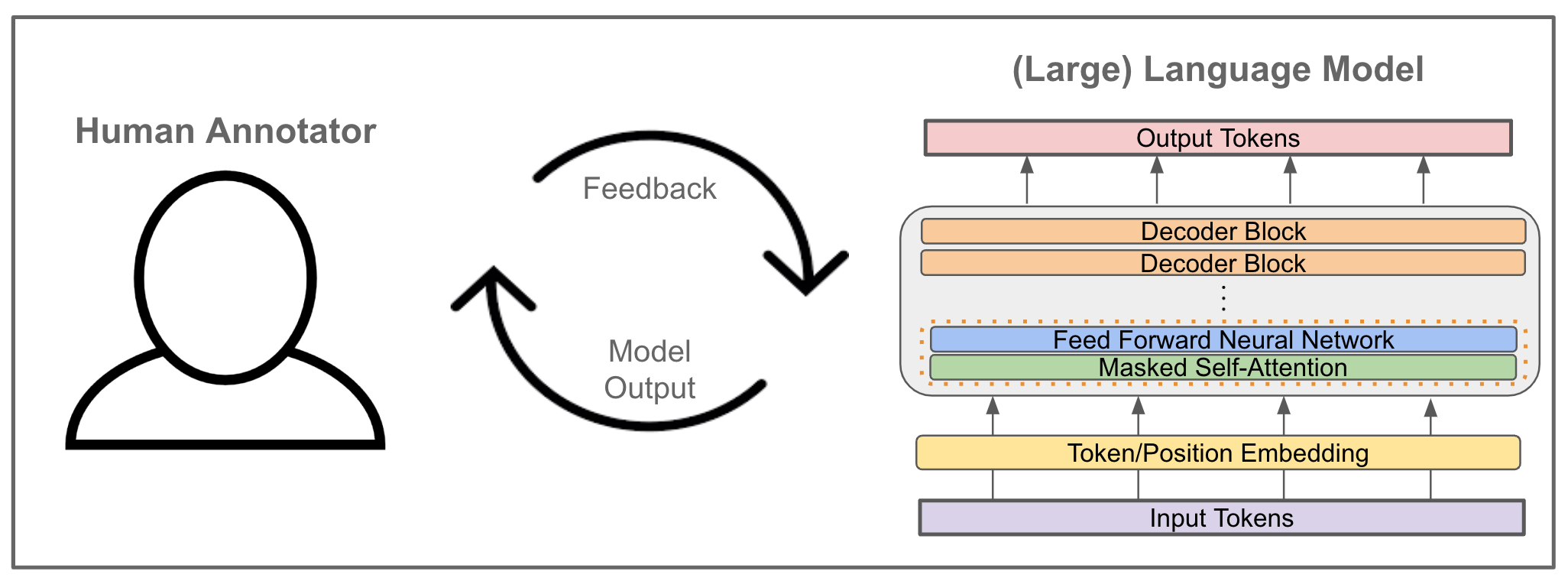
Let's talk about the awkward secret nobody wants to admit: AI's "intelligence" still depends on an army of humans sitting in front of computers making judgment calls. Companies like Open AI, Anthropic, and Meta spend millions annually hiring contractors to rate and rank model outputs during training. It's called reinforcement learning from human feedback, or RLHF. And it's a bottleneck that's been holding back AI progress since the transformer era began.
But here's what's changed: a new startup called Rapidata is treating RLHF like it's infrastructure, not a hiring problem. Instead of recruiting thousands of contractors in low-cost regions and waiting weeks for feedback batches, Rapidata pipes training tasks to millions of mobile app users globally—people using Duolingo, Candy Crush, and other apps who complete micro-tasks in seconds as an alternative to watching ads.
The result? Feedback that used to take weeks now takes hours. Model iteration cycles that lasted months now take days. And the startup just raised $8.5 million to scale this from a proof of concept into a genuine infrastructure layer for AI development, as reported by VentureBeat.
I'll be honest: when I first heard this pitch, it sounded too clever. But after digging into how it actually works, why it matters, and what it means for the future of AI development timelines, I realized this is one of those rare moments where someone's solved a genuinely hard problem that's been hiding in plain sight.
TL; DR
- RLHF has been the AI bottleneck: Traditional human feedback loops take weeks or months, forcing model iteration into discrete release cycles rather than continuous improvement.
- Rapidata inverts the labor model: Instead of hiring concentrated contractor pools, the platform gamifies feedback tasks across 15–20 million global mobile app users, collecting 1.5 million annotations per hour.
- Speed is the killer feature: Development timelines compress from months to days because feedback cycles run in near-real-time rather than batched weeks later.
- Quality control via reputation: The platform builds expertise profiles for users over time, routing complex judgments to humans with proven track records on similar tasks.
- The infrastructure play: By treating RLHF as a scalable system rather than a labor sourcing problem, Rapidata positions itself as essential to every serious AI lab's development pipeline.
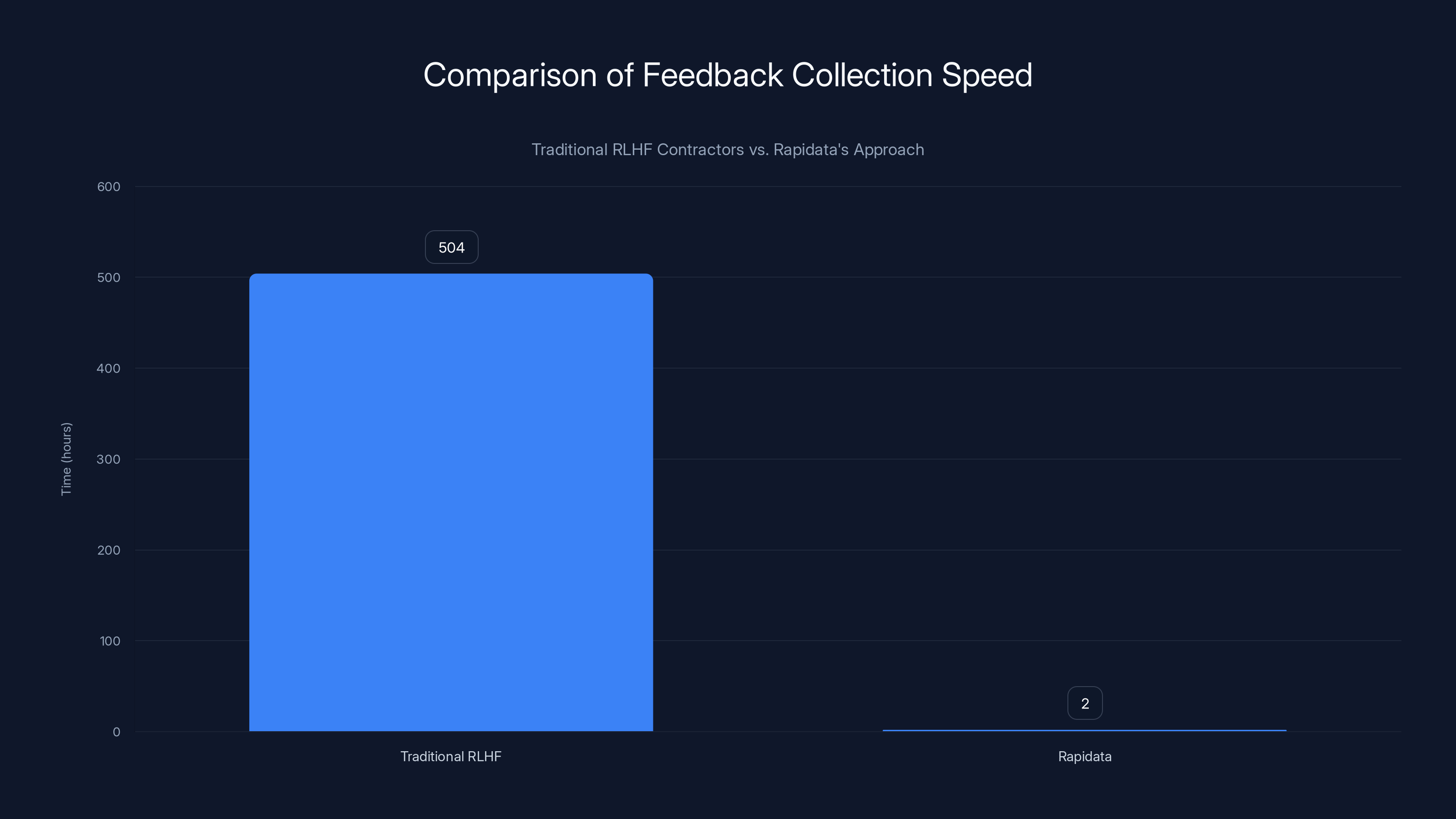
Rapidata's approach significantly reduces feedback collection time from weeks (504 hours) to just a few hours (2 hours), enhancing scalability and efficiency.
Why RLHF Became the Unexpected Bottleneck in AI Development
Here's what most people don't understand about how modern AI models actually get smart: the training process has two completely different phases.
First, you train a model on massive amounts of text, code, images, or video pulled from the internet. This happens on GPUs and TPUs, and it scales beautifully. Throw more compute at it, you get better results. This part works.
But here's where everything grinds to a halt. After that initial training, the model's still making mistakes. It sounds robotic. It doesn't understand nuance. It gives technically accurate but useless answers. So you need humans to step in and teach it what actually matters.
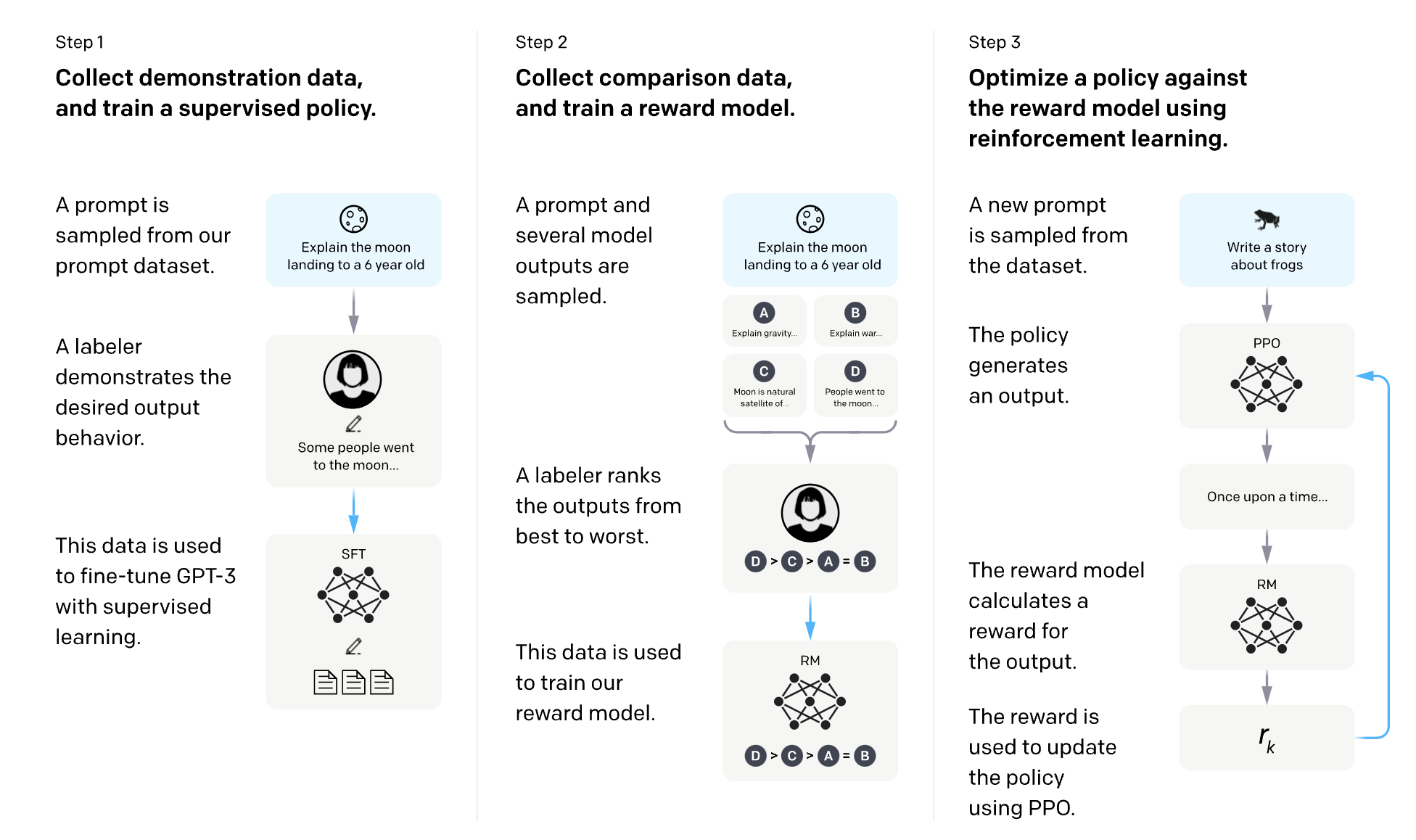
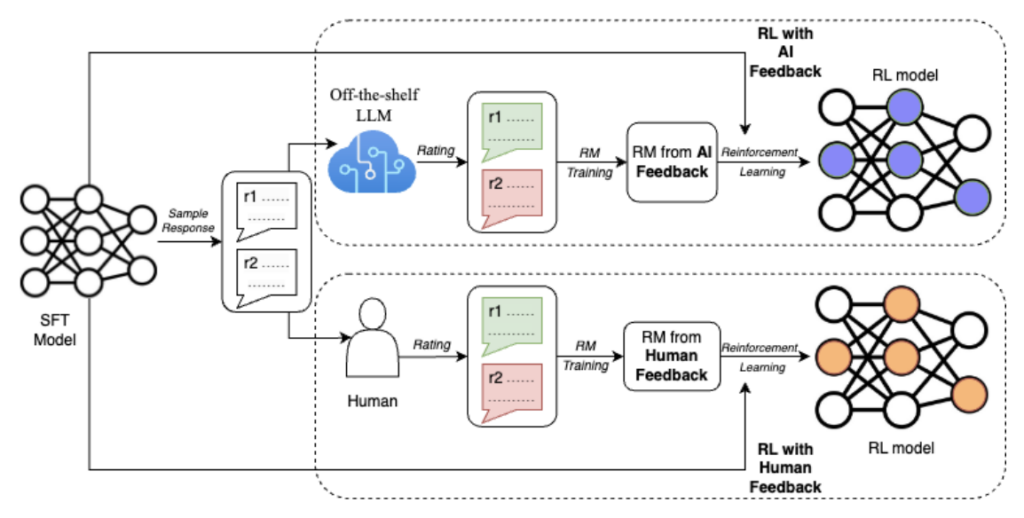
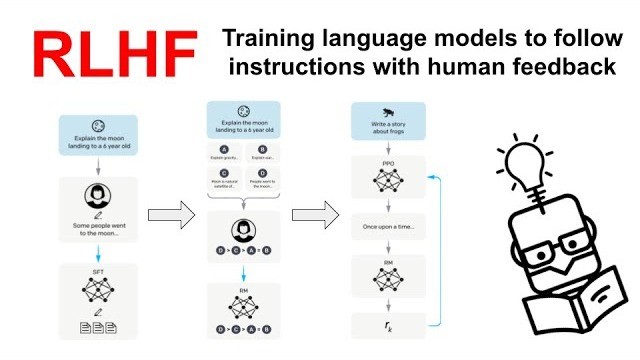
This is RLHF. And it works like this: you give your model a prompt. It generates multiple possible responses. Human raters look at those responses and rank them—this one's best, this one's second best, this one's garbage. The model learns from those rankings and adjusts its internal weights to produce higher-ranked outputs next time.
Sounds simple, right? It's not.
The problem is that human judgment can't be parallelized the same way compute can. You can't buy 10 million more GPUs and have them rate model outputs faster—you need actual humans, and humans are slow, expensive, and geographically concentrated.
So what happened in practice? AI labs built sprawling contractor networks. Reuters reported that Open AI employed armies of contractors, often in Kenya and the Philippines, paying them between
The result was absurdly inefficient. Model progress looked less like exponential improvement and more like discrete jumps at each batch release. Plus, there were all the PR nightmares: exploitative wages, labor arbitrage, the whole ethical minefield of how AI companies source human judgment at scale.
Rapidata, founded by Jason Corkill, a roboticist and ETH Zurich graduate, saw this differently. Instead of asking "how do we hire more contractors," he asked: "what if we treated human judgment as a service that's available on demand, globally, and instantly?"
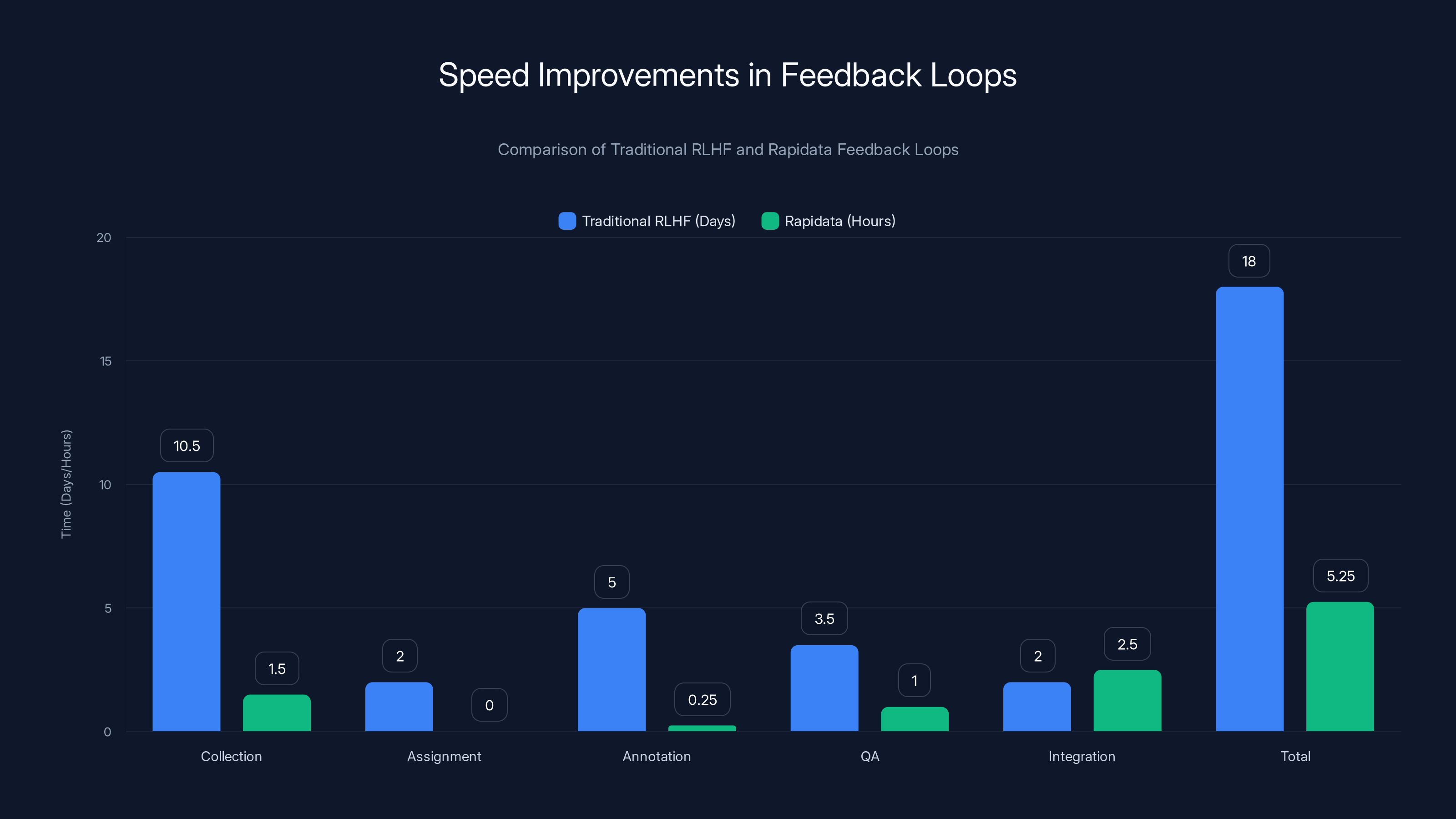
Rapidata feedback loops achieve a 50-100x speed improvement over traditional RLHF, reducing total time from weeks to mere hours. Estimated data.
The Genesis: From Frustration to First Principles
Corkill's lightbulb moment didn't come in a boardroom. It came over beers in Zurich while he was struggling through his own robotics research.
Every time he needed human annotations for a dataset, his entire project ground to a halt. He could work through nights pushing compute further, iterating on architecture, optimizing code. But the moment he needed humans to label data or rate outputs, everything stopped. He'd submit requests to a contractor pool, and then—wait.
"Always when you needed humans or human data annotation, that's kind of when your project was stopped in its tracks," Corkill told me in describing this period. "You could move it forward by just pushing longer nights. But when you needed large scale human annotation, you had to go to someone and then wait for a few weeks."
He realized the fundamental problem: compute scales exponentially. The number of GPUs you can provision grows predictably. But human labor doesn't scale the same way. Traditional hiring is slow. Onboarding takes weeks. Payment infrastructure is fragmented across regions. Contractor pools are sticky to specific geographies. You can't just scale human feedback the way you scale GPU clusters.
What if you inverted the problem? Instead of asking contractors to come to you, what if you went to where billions of humans already were: on their phones, in apps they were already using?
That insight became Rapidata.
How Rapidata Actually Works: The Technical Architecture
Okay, so let's get into the mechanics. How does a platform actually deliver 1.5 million human annotations per hour?
First, understand the partnership model. The company partners with major mobile apps—we're talking about massive user bases like Duolingo, Candy Crush, and others. When you're using one of these apps and you see an ad coming up, the app now offers you a choice: watch the ad, or spend 10 seconds answering a question for an AI training pipeline.
The task itself is simple. Rate this image quality on a scale of 1–5. Does this response sound natural? Which of these summaries is more accurate? You answer, and the data gets transmitted back to Rapidata's infrastructure instantly.
Now, here's where it gets clever. Rapidata doesn't just collect random opinions from random people. The system builds reputation profiles for every user who participates.
Say you're really good at identifying AI-generated images because you spend a lot of time on design forums. The platform notices. Next time Rapidata gets a batch of "detect AI-generated imagery" tasks, your tasks get routed to you specifically. You're matched to domains where you have implicit expertise.
The platform tracks: accuracy on known-answer questions, consistency with other raters, speed, reliability. Users earn a reputation score. Complex, high-stakes judgments get routed to high-reputation users. Quick, straightforward tasks go to anyone.
This solves the quality control problem that's haunted crowdsourcing forever. Traditional RLHF contractors get assigned whatever comes their way. Amazon Mechanical Turk suffers from massive quality variance. But Rapidata's matching system means each task goes to the human most likely to nail it.
Second, the scale is genuinely global. Rapidata reaches between 15 and 20 million users across app partnerships. This isn't localized to one region or time zone. When an AI lab on the West Coast needs annotations, there are millions of available raters spread across every continent. Time zones don't matter anymore.
Third, the parallelism is genuine. Because the tasks are so short (usually 10–30 seconds), and because there are millions of people completing them simultaneously across different time zones, the platform can aggregate massive batches of feedback in parallel. Hence, 1.5 million annotations per hour.
Compare that to traditional RLHF: you collect feedback from maybe 100 contractors, and it takes a week to get 100,000 annotations. Rapidata does the same volume in four minutes.
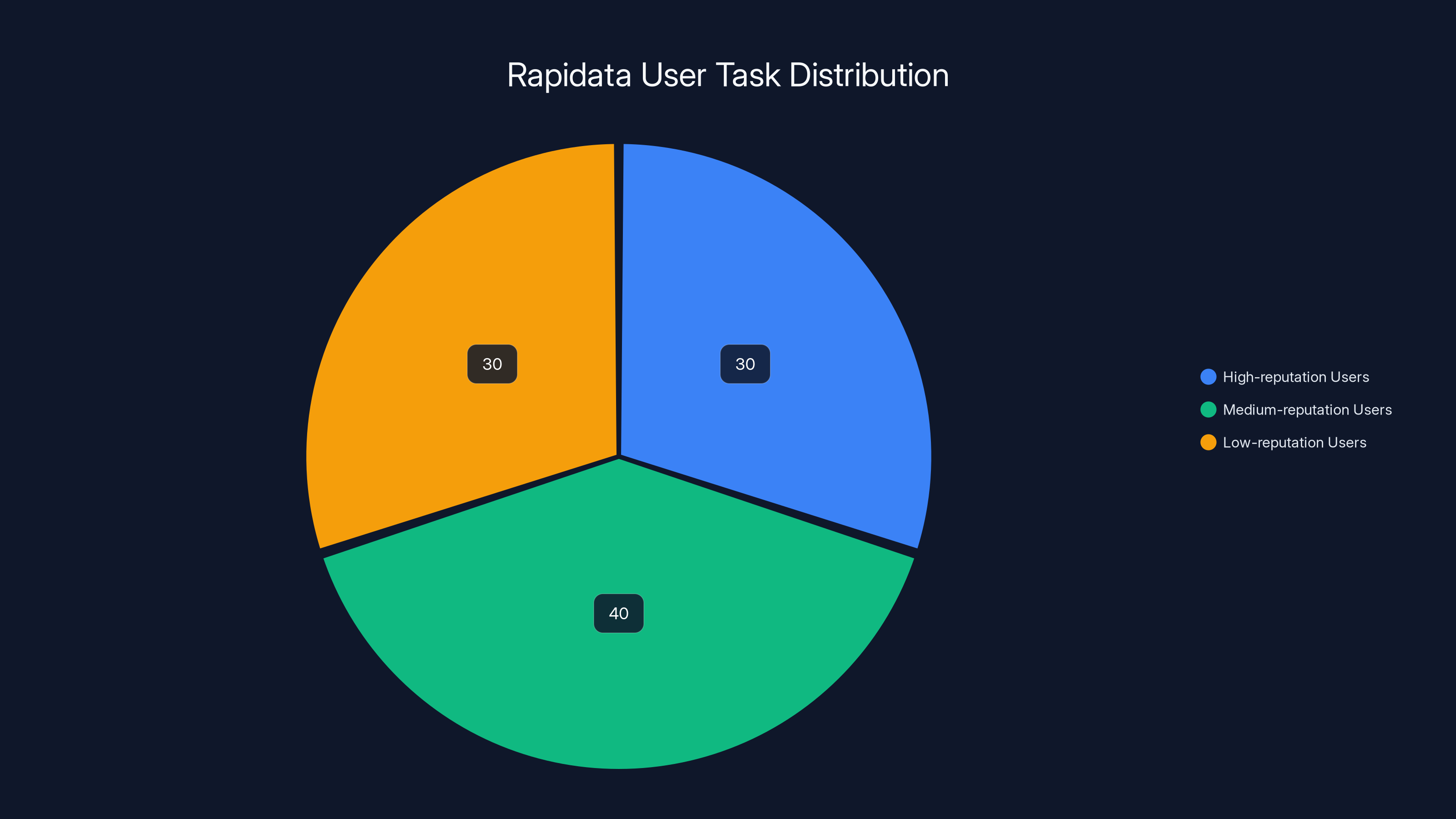
Estimated data suggests that tasks are distributed based on user reputation, with high-reputation users handling more complex tasks. Estimated data.
Online RLHF: The Architecture Shift That Changes Everything
Now, what Rapidata is enabling is something genuinely different from historical RLHF workflows. The company calls it "online RLHF."
Traditional offline RLHF works like this: you take your base model, freeze it, run it against a huge set of prompts, collect all the outputs, send everything off to your contractor pool for ranking, wait weeks, get feedback back, retrain the entire model from scratch, and release a new version.
It's batch processing. Discrete releases. Monthly updates if you're fast.
Online RLHF is different. Your model runs. It generates outputs. Human feedback comes back in real-time. The model learns continuously. You don't release new versions—you continuously improve an existing deployment.
Think of it like this: traditional RLHF is like publishing a newspaper. You write everything, send it to print, release it all at once. Online RLHF is like running a live news website where you're updating content constantly based on reader feedback.
The implications are massive. With traditional RLHF, if your model has a problem—maybe it's generating biased outputs in a specific domain—you need to wait until the next batch cycle to gather evidence, then wait weeks for feedback, then retrain. With online RLHF, you'd notice the problem immediately, gather targeted feedback within hours, and improve the model that same day.
For model development speed, this is transformational. Let's run some math.
Say you're training a new AI model. With traditional RLHF:
- Week 1: Collect 500,000 outputs from your base model
- Weeks 2–4: Wait for contractor feedback
- Week 5: Incorporate feedback and retrain
- Week 6: Evaluate new version
- Month 2: Identify issues, collect more data
- Months 3–4: Another feedback cycle
Total development cycle: 4 months from base model to production-ready version.
With Rapidata's online RLHF:
- Day 1: Deploy base model with Rapidata feedback integration
- Days 2–4: Continuous feedback collection and model improvement
- Day 5: Identify issues, route targeted feedback tasks, get results in hours
- Day 6: Apply improvements
- Days 7–8: Final testing and deployment
Total development cycle: 8 days from base model to production.
That's the difference between quarterly releases and weekly improvements. For competitive advantage in AI, this compounds into months of development advantage.
The Global Human Network: 15–20 Million Users as Infrastructure
Here's what's genuinely wild about Rapidata's scale: 15 to 20 million users is more than most countries' populations. It's larger than the entire population of Australia.
For comparison, when Anthropic was building Claude, they probably used a few hundred full-time contractors. When Open AI was fine-tuning GPT-4, they might have scaled to a few thousand contractors globally.
Rapidata just flipped the leverage. They have access to a user base 10,000 times larger than traditional contractor pools.
And these aren't people sitting in offices waiting for tasks. They're real humans using real apps in real contexts. When someone's waiting for their next Duolingo lesson to load, they see a task: "Rate this image quality." 10 seconds. Done. They move on. Meanwhile, their response is part of a dataset that's training the next generation of AI models.
The geographic distribution matters too. When it's 3 AM in San Francisco, it's noon in Singapore. It's 6 PM in London. It's 9 AM in Lagos. The sun never sets on Rapidata's user base. For AI labs that need feedback round-the-clock, having annotators distributed across all time zones means feedback never stops flowing.
There's also the diversity factor. Traditional RLHF contractor pools in Kenya or the Philippines have certain demographic characteristics. They share similar economic backgrounds, education levels, cultural perspectives. This can introduce systematic bias into training data.
But Duolingo users span the entire world. They include billionaires and students, people from every culture, every education level, every economic context. When you're training a global AI model, getting feedback from genuinely global humans reduces demographic skew.
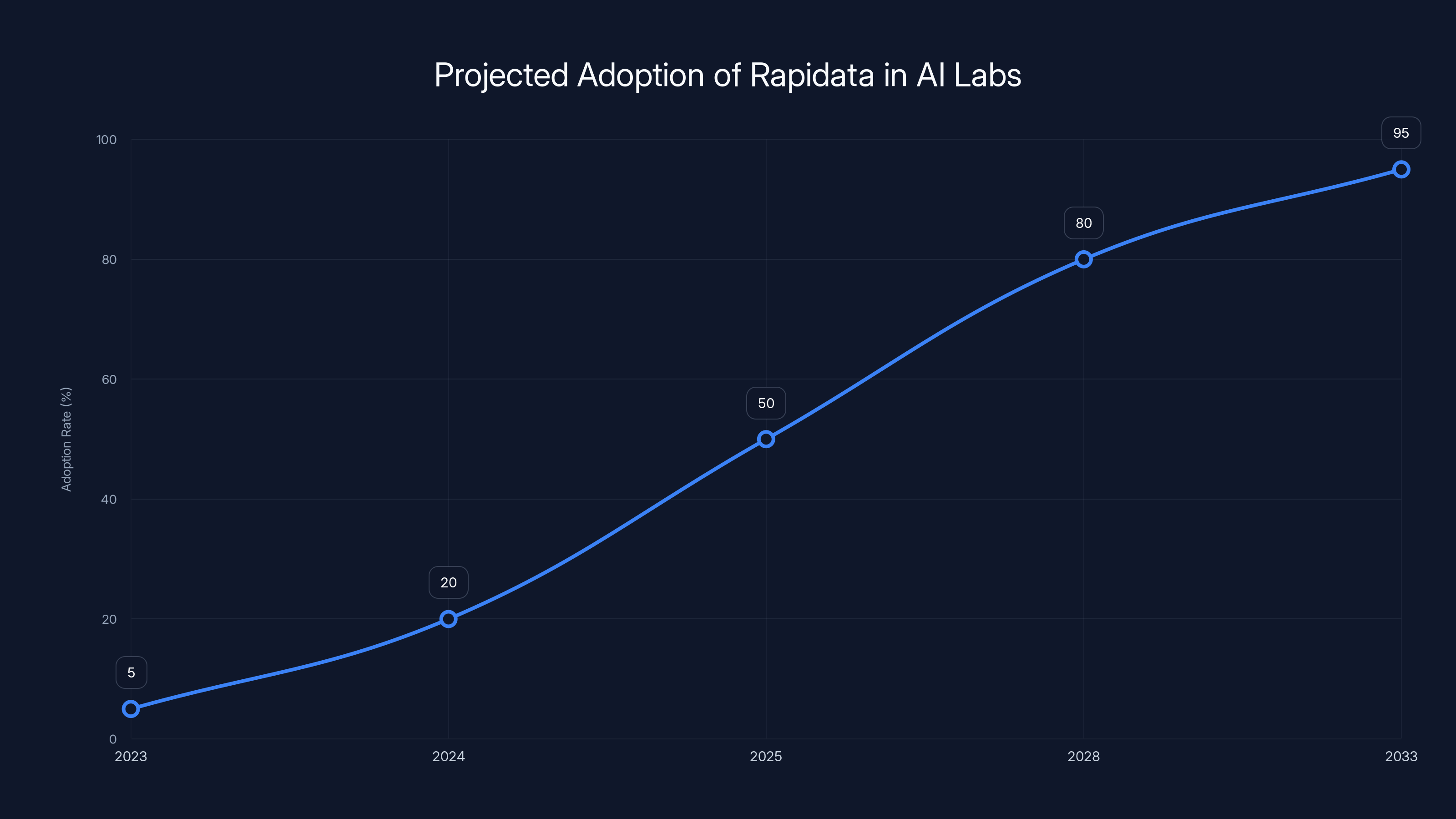
Estimated data shows Rapidata's adoption in AI labs could reach 50% by 2025 and become a standard by 2033, similar to cloud computing today.
The Reputation System: Making Crowdsourcing Actually Work
Every crowdsourcing platform ever has the same problem: quality is inconsistent. Some people take it seriously. Some people spam. Some people are genuinely better at certain tasks than others.
Amazon Mechanical Turk tried to solve this with requester ratings. Appen uses contractor tiers. But most crowdsourcing still suffers from the fundamental problem: you can't know if a person is good at a task until after they've already done it badly.
Rapidata solves this differently. The platform learns about raters not from static applications but from continuous behavioral signals.
First, there are known-answer questions mixed in. You're rating image quality, and every 10th question is an image you've already rated before or an image with objectively obvious quality. If you get these wrong consistently, the system knows you're not paying attention.
Second, there's inter-rater reliability. When multiple users rate the same task, the system compares their responses. If you're consistently rating things differently from everyone else in ways that don't make sense, your reliability score drops.
Third, there's domain expertise inference. You rate a lot of coding-related tasks accurately? Your "code expertise" score increases. You're terrible at identifying art styles? That domain gets marked as weak. Future tasks are routed accordingly.
The result is a reputation system that improves over time. Your first task might be assigned randomly. By your 100th task, you're being routed specifically to domains where you have proven expertise.
This is fundamentally different from traditional contractor relationships. With RLHF contractors, you hire someone based on a resume and past projects. You might not discover they're bad at your specific task type for weeks. With Rapidata, the system knows within hours.
For AI labs, this means RLHF quality reaches professional contractor levels while operating at crowdsourced scale. You're not sacrificing accuracy for volume.
Speed Metrics: From Weeks to Hours
Let's talk about the concrete speed improvements, because this is where the value becomes obvious.
Traditional RLHF feedback loops:
- Collection phase: 1–2 weeks (gathering outputs from model, preparing tasks)
- Assignment phase: 1–3 days (routing tasks to contractors)
- Annotation phase: 3–7 days (waiting for contractors to complete tasks—contractors are slow)
- QA phase: 2–5 days (checking quality, discarding bad annotations)
- Integration phase: 1–3 days (incorporating feedback, retraining)
- Total: 9–25 days minimum, typically 3–4 weeks
Rapidata feedback loops:
- Collection phase: 1–2 hours (outputs generated and task structure created)
- Annotation phase: 2–15 minutes (1.5 million annotations per hour)
- QA phase: 1 hour (algorithmic consistency checks, no manual review needed)
- Integration phase: 1–4 hours (feedback applied to model)
- Total: 4–8 hours typical
That's roughly a 50–100x speed improvement in the feedback loop itself.
But the downstream effects are even bigger. With faster feedback, you can iterate more frequently. Which means you catch problems faster. Which means you can do more model experiments per month. Which compounds into serious competitive advantage.
Consider this scenario: two AI labs are both building a new model class. Traditional RLHF lab iterates monthly (one improvement cycle per month). Rapidata-powered lab iterates weekly. After 6 months, the Rapidata lab has run 26 full improvement cycles while the traditional lab is on cycle 6. Even if each cycle brings 2% improvement, the Rapidata lab's model is dramatically better due to compound effect.
The gap grows exponentially. By month 12, the Rapidata lab has run 52 cycles while the traditional lab is on 12. The performance gap becomes insurmountable.
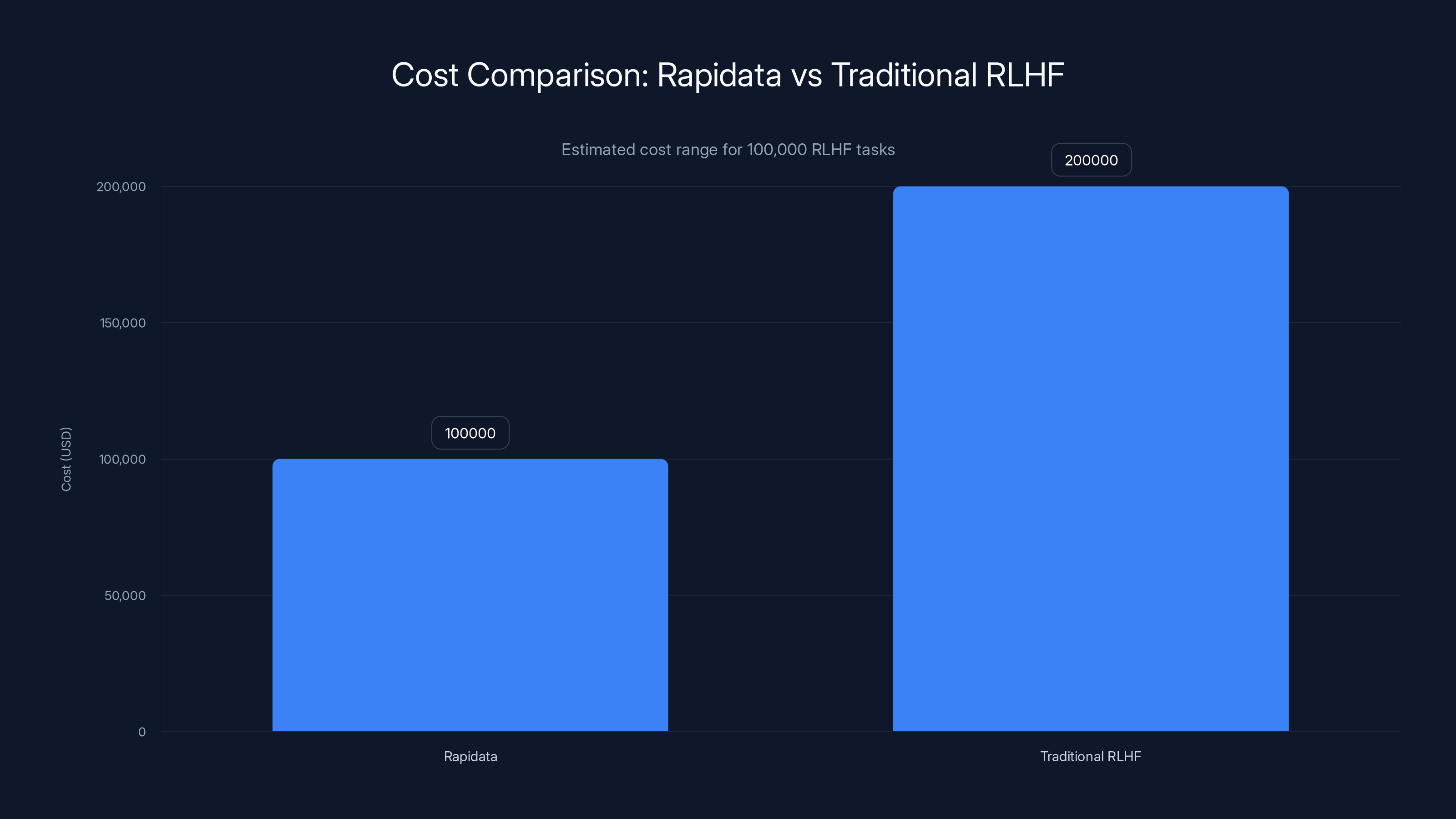
Rapidata offers a cost-effective solution for AI labs, with estimated costs significantly lower than traditional RLHF methods. Estimated data based on content.
Privacy and Anonymity: The Trust Architecture
Now, there's something that matters a lot here that gets overlooked: privacy.
When you're collecting human feedback at global scale from app users, there's an obvious privacy concern. Are you collecting personally identifiable information? Are you selling user data? Are you tracking people across apps?
Rapidata does this differently. The platform assigns each user an anonymized identifier. You're "User 4782649" in the system, not "Sarah Jones from San Francisco." Rapidata doesn't collect your name, location, email, or any PII.
But here's the clever part: within the Rapidata ecosystem, you maintain continuity. You're consistently User 4782649, so the system can build your reputation and route tasks intelligently. Your identity is pseudonymous. You're not exposed to the AI labs that are training on your feedback.
This solves multiple problems simultaneously:
- User privacy: App users aren't being tracked across platforms or sold to AI companies.
- Data security: Rapidata isn't storing millions of people's personal information (reducing risk).
- Compliance: Easier to operate in jurisdictions with strict data privacy laws.
- User trust: People are more likely to participate if they know their identity is protected.
For app partners like Duolingo, this is critical. They have millions of users who trust the platform. If Duolingo started selling user data to AI companies, the backlash would be immediate. But with pseudonymous RLHF task participation, there's no privacy violation, and the user experience is actually improved—free to play instead of watching ads.
The Business Model: Why This Captures Value
Rapidata doesn't charge app users. Instead, the revenue comes from AI labs that commission RLHF tasks.
An AI lab running a batch of 100,000 annotation tasks might pay Rapidata
For app partners, this is essentially free money. They're offering ads to users anyway. Swapping in an RLHF task instead of an ad reduces user friction and generates revenue sharing. Win-win.
For AI labs, the unit economics are favorable compared to traditional RLHF. A contractor-based RLHF batch costs more when you factor in contractor wages, management overhead, quality control, and waiting time. Rapidata compresses costs through scale and speed.
The venture capital validates this. An $8.5 million seed round co-led by Canaan Partners and IA Ventures, with participation from Acequia Capital and Blue Yard, signals that serious investors see this as infrastructure-scale opportunity.
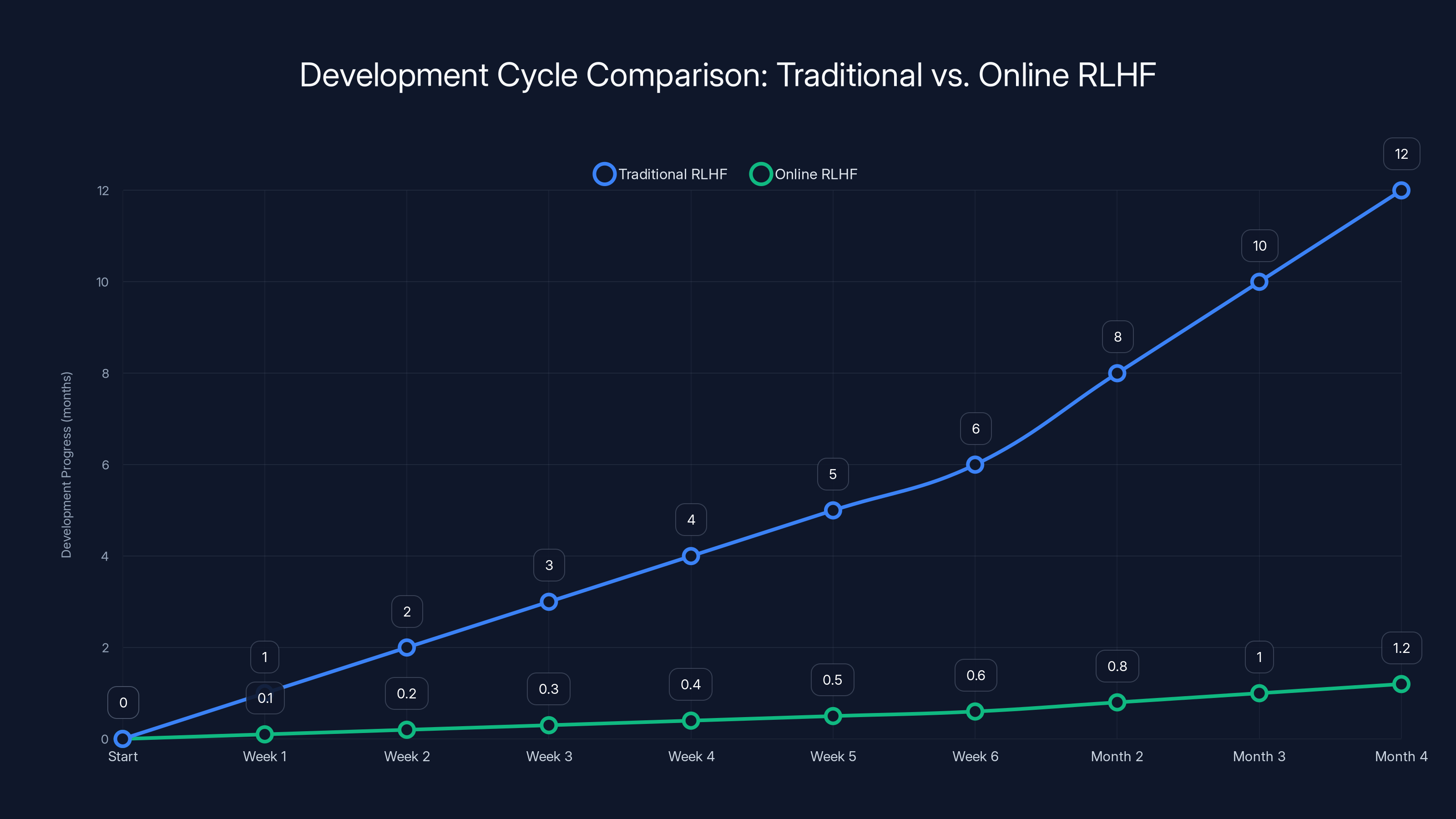
Online RLHF significantly reduces the development cycle from 4 months to approximately 1.2 months, enabling faster model improvements. Estimated data.
Who Benefits Most: The Customer Profile
Not every AI lab needs Rapidata equally. The value proposition depends on your constraints.
Maximum value for: Large AI labs that iterate frequently and need high-volume feedback. Companies like Open AI, Anthropic, Google, and Meta run dozens of models simultaneously and need constant feedback. For them, shaving weeks off each cycle compounds to months of competitive advantage.
High value for: Startups and mid-size labs building specialized models. If you're building a healthcare AI or legal AI that needs domain-specific feedback, traditional contractors are both expensive and hard to find. Rapidata's matching system lets you route tasks to medical professionals or lawyers who use Duolingo, getting expert feedback at scale.
Moderate value for: Open-source AI projects that rely on crowdsourced feedback. Projects like Hugging Face models could potentially use Rapidata to improve training data quality without hiring professional contractors.
Lower value for: Single-model companies with infrequent releases. If you're releasing twice a year, the speed advantage of online RLHF doesn't compound significantly.
The Competitive Landscape: Where Rapidata Fits
Rapidata enters a space that's currently fragmented. There's no dominant player in high-speed RLHF infrastructure.
On one end, you have traditional contractor platforms like Scale AI, which hire professional data annotators and offer quality guarantees. They're reliable but slow and expensive.
On another end, you have crowdsourcing platforms like Amazon Mechanical Turk and Appen, which are fast and cheap but have quality issues.
Rapidata fills the gap: fast, cheap, and good quality due to the reputation system. But unlike Scale or Appen, there's also a differentiated advantage—access to billions of dollars of app infrastructure (Duolingo, Candy Crush, etc.) that traditional platforms don't have.
This is why the company positions itself as infrastructure. They're not competing on price or quality metrics—they're competing on speed and scale simultaneously. That's a different game.
Looking Ahead: The Future of AI Development Infrastructure
If Rapidata pans out, a few things become inevitable.
First, RLHF stops being a bottleneck. Model iteration accelerates from discrete releases to continuous improvement. This could reshape how AI labs organize their development—instead of quarterly model releases, you'd have daily updates.
Second, other app platforms will copy the model. Instagram, Tik Tok, YouTube, and other massive platforms will start offering RLHF task options to their users. The supply of human feedback becomes abundant and cheap.
Third, the nature of model training changes. If feedback is cheap and available instantly, AI labs will train differently. Instead of doing careful, deliberate feature engineering before training, they'll do more rapid experimentation. The training process becomes more empirical and less planned.
Fourth, there are downstream implications for AI safety and alignment. Real-time feedback means you catch misalignment issues faster. But it also means less careful consideration in each feedback cycle. There are trade-offs.
Fifth, the geographic and economic dynamics shift. Traditional RLHF concentrated economic benefit in low-cost regions and specific contractor pools. Online RLHF distributed across billions of app users spreads economic benefit more widely. Someone in rural India gets paid for a few seconds of work just like someone in San Francisco.
Finally, this becomes table stakes. Within 3–5 years, any serious AI lab that's not using online RLHF infrastructure will be noticeably slower than competitors. It becomes a competitive necessity, like using cloud infrastructure became essential for startups.
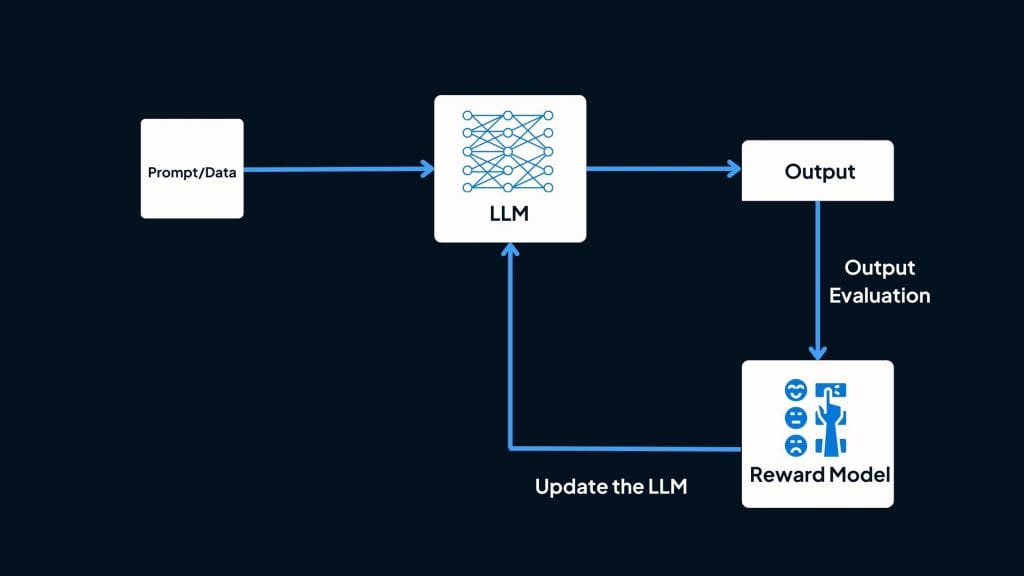
The Real Insight: Infrastructure, Not Labor
Here's what makes Rapidata conceptually different from previous RLHF companies.
Everyone else treated RLHF as a labor problem. "We need to hire more annotators. How do we scale contractor recruitment? How do we manage global teams?" The framing was inherently limited by labor economics.
Rapidata reframed it as an infrastructure problem. "How do we make human feedback available as a scalable, on-demand service like compute?" That's a completely different question, and it led to a completely different solution.
This is why the startup raised $8.5 million and not a series A. With an infrastructure approach, you build a platform. Platforms scale. They create network effects. They become essential. You're not selling a service—you're building infrastructure.
For the AI industry, this matters. The companies that control critical infrastructure in AI (compute via GPUs, data via datasets, models via weights) will have disproportionate leverage. If Rapidata becomes the standard for RLHF infrastructure, their position becomes very defensible.
But there's a flip side: if they don't execute well, another platform could replicate the model. The barrier to entry is more about partnership relationships and execution than technology patents.
Implementation: How AI Labs Actually Use This
Imagine you're Anthropic or a major AI lab. Here's how you'd integrate Rapidata:
-
Define your feedback taxonomy: What questions do you want humans to answer? Rate response quality on 1–5? Choose the better answer? Detect bias? Flag harmful content? You structure your feedback requirements.
-
Create task batches: You generate 100,000 model outputs from your latest model iteration. You convert these to RLHF tasks matching your taxonomy.
-
Submit to Rapidata: You upload tasks and specify any domain requirements. Need medical expertise? Coding knowledge? Native English speakers? Rapidata routes tasks accordingly.
-
Real-time feedback collection: Tasks appear in Duolingo, Candy Crush, and other app integrations. Users complete them over the next few hours. Feedback streams back continuously.
-
Incorporate into training: As feedback arrives, you incorporate it into your model's reward model. The model learns continuously.
-
Evaluate and iterate: You measure whether the feedback improved your model. You refine your task taxonomy and do it again tomorrow.
The whole cycle, from task definition to improved model, takes less than 24 hours. With traditional RLHF, it took 3–4 weeks.
This isn't theoretical. Companies like Open AI and Anthropic are already approaching the limits of traditional RLHF scaling. They're hiring more contractors every month and still can't get feedback fast enough. Rapidata solves that problem operationally.
The Catch: What Could Go Wrong
Look, Rapidata is solving a real problem. But there are legitimate concerns.
Quality at scale: Getting 1.5 million annotations per hour is great. But are they consistently good? The reputation system helps, but at that volume, some noise is inevitable. The better question: is Rapidata quality good enough for model training? Early signs suggest yes, but long-term data will tell.
Task complexity: Simple tasks (rate image quality, choose the better answer) work great at scale. But what about nuanced tasks? Can you get reliable feedback on subtle bias, or cultural appropriateness, or domain-specific correctness? This likely has complexity limits.
App partnership dependency: Rapidata's scale depends on partnerships with major apps. What if Duolingo decides to stop offering RLHF tasks? What if app user bases decide they don't want to participate? The platform has concentration risk.
Regulatory risk: If regulators start scrutinizing how AI companies source training data, could app-based RLHF face restrictions? It's unlikely, but it's a tail risk.
Data quality at the margins: With 20 million users, you'll have quality variance. Some users will be incredibly reliable. Others will be bad. The reputation system addresses this, but there's a floor on how good you can make the median annotator.
International complexity: Operating globally with app partnerships across 100+ countries creates compliance complexity. GDPR, data residency laws, local regulations—each adds friction.
None of these are dealbreakers. But they're real constraints that the company will need to navigate.
What This Means for the Broader AI Ecosystem
Rapidata represents a shift in how AI development infrastructure gets built.
For a decade, the constraint was compute. GPUs and TPUs were the bottleneck. Companies that could access massive compute had an advantage. Nvidia built enormous value by controlling compute.
Now, the constraint is data quality and feedback speed. Training is cheap. Inference is getting cheaper. But getting humans to teach models at scale is still hard. Rapidata removes that constraint.
This could democratize AI development. If you don't need to hire a specialized contractor team in a low-cost region, the barrier to entry for building serious models drops. More players can compete. Competition increases. Innovation accelerates.
For developers and startups, this is good news. You can iterate faster. You can build better models without hiring hundreds of contractors.
For AI safety researchers, this is complicated. Faster iteration is better for catching problems early. But it also means less deliberate, careful evaluation at each step. The tradeoff depends on how you weight development speed against caution.
For workers in traditional RLHF contractor positions, this is concerning. Demand for their labor decreases as automated matching and crowdsourced feedback become mainstream. Wage pressure could increase. Geographic concentration of RLHF work could decrease, which has economic consequences for regions that built economies around contractor work.
The Bottom Line: Why This Matters Now
We're at an inflection point in AI development. Models are getting bigger. Training takes longer. But more importantly, improvement has hit compute limits. You can't just scale model size anymore—you hit rendering costs and other constraints.
The next source of competitive advantage is feedback quality and iteration speed. The companies that can improve their models fastest will pull ahead.
Rapidata solves for speed by solving for feedback availability. They're making human judgment a commodity that's instantly available globally. That's a genuine innovation in infrastructure.
Is it going to be the final solution? Probably not. In five years, there might be better approaches—maybe AI-powered feedback that eliminates humans entirely, or different compensation models, or new app partnerships.
But for the next few years, Rapidata represents a meaningful change in how serious AI labs operate. And that makes it worth paying attention to.
The $8.5 million seed round isn't just capital. It's validation that this approach works, is defensible, and scales. Within 12–24 months, you'll likely see multiple AI labs publicly using Rapidata or similar platforms. Within 3–5 years, it becomes standard. Within 10 years, not using online RLHF infrastructure will seem quaint, like not using cloud computing does today.
Use Case: Accelerate your workflow documentation and process automation using AI-powered tools that generate reports, documents, and presentations instantly
Try Runable For Free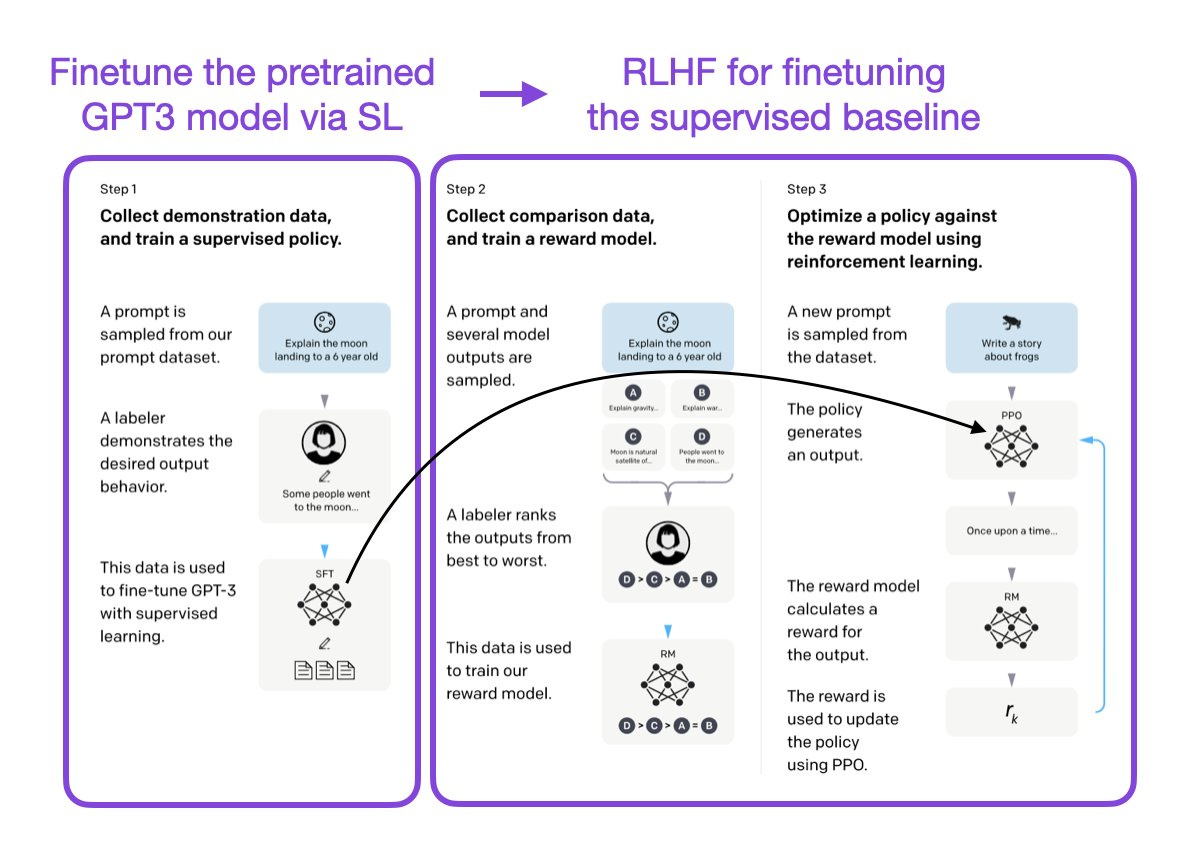
FAQ
What is RLHF and why is it important for AI models?
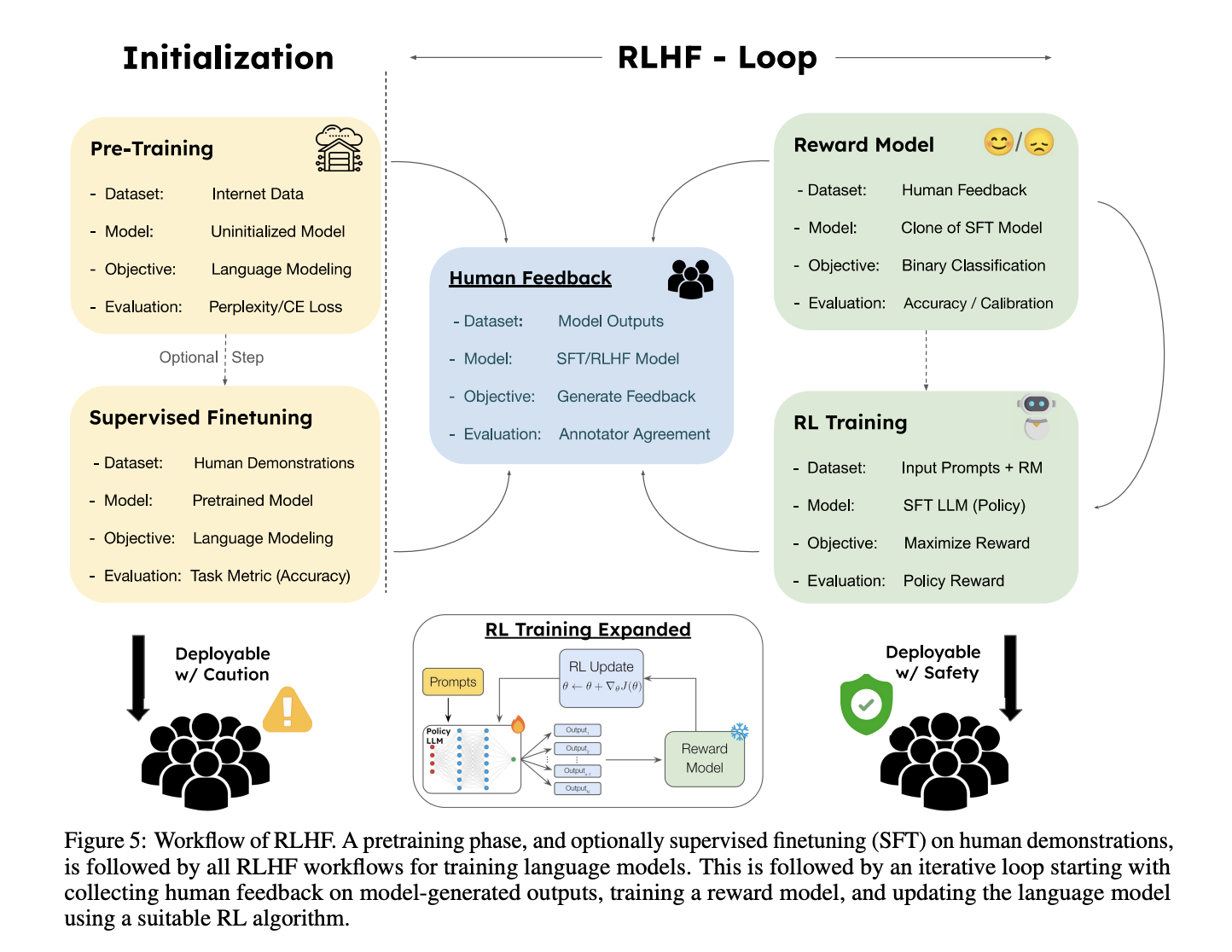
RLHF stands for reinforcement learning from human feedback. After an AI model completes initial training, humans provide feedback by rating and ranking its outputs, which teaches the model to generate better responses. This process is crucial for aligning AI behavior with human preferences, improving safety, reducing harmful outputs, and making models more useful. RLHF has been central to developing every major language model from Chat GPT to Claude to Gemini.
How does Rapidata's approach differ from traditional RLHF contractor models?
Traditional RLHF relies on hiring concentrated pools of professional contractors in specific geographic regions, usually in low-cost areas like Kenya or the Philippines. This creates significant delays—feedback batches take 3–4 weeks to complete. Rapidata distributes tasks to 15–20 million app users globally who complete them as micro-tasks (10–30 seconds each), with feedback arriving in hours rather than weeks. This creates a fundamentally faster, more scalable system for collecting human judgment.
What are the key technical innovations that make Rapidata's platform work at scale?
Rapidata combines several innovations: a reputation system that matches tasks to users with relevant expertise, geographic distribution across multiple time zones enabling round-the-clock feedback collection, anonymization protecting user privacy while maintaining continuity for reputation tracking, and algorithmic quality control that identifies inconsistent responses. These components together enable the platform to process 1.5 million annotations per hour while maintaining quality comparable to professional contractors.
How does the reputation system ensure quality when tasks are distributed to millions of users?
The platform tracks multiple signals for each user: accuracy on questions with known correct answers (included regularly in task batches), consistency with other users rating the same tasks, and domain-specific performance tracking. Users build reputation scores over time, and complex or high-stakes tasks are automatically routed to users with proven expertise in those domains. Simple tasks go to anyone, while nuanced judgments requiring domain knowledge go to high-reputation users, creating a naturally quality-sorted system.
What impact does online RLHF have on AI model development timelines?
Online RLHF compresses model iteration cycles from weeks or months to days or hours. Instead of batch processing feedback every 3–4 weeks, AI labs can incorporate feedback continuously. This enables faster experimentation, quicker problem detection, and more frequent model improvements. Mathematically, this compounds into dramatic competitive advantages—a lab running weekly improvement cycles after 12 months will have significantly better models than labs on monthly cycles, due to the multiplicative effect of continuous iteration.
What are the privacy implications of collecting feedback from app users?
Rapidata maintains user privacy by assigning anonymized identifiers rather than collecting personal information. Users remain "User 4782649" in the system—names, locations, and emails are not stored. This achieves two things: app users aren't exposed to AI labs or sold to third parties, and Rapidata doesn't maintain large troves of personal data (reducing risk). Within the Rapidata ecosystem, anonymized identities maintain continuity for reputation tracking, but across systems there's no linkability.
Which types of AI companies benefit most from Rapidata's platform?
Maximum value goes to large AI labs (like Open AI and Anthropic) that iterate frequently on multiple models and need constant feedback. High value for startups building specialized domain models (healthcare, legal, finance) because Rapidata's matching system routes tasks to domain experts. Moderate value for open-source projects needing crowdsourced improvements. Lower value for companies releasing models infrequently, where feedback speed advantage doesn't compound.
How does Rapidata's pricing compare to traditional RLHF contractors?
While exact pricing wasn't disclosed, unit economics favor Rapidata through volume and speed. A traditional RLHF batch of 100,000 annotations costs
What are the potential limitations or risks of crowdsourced RLHF?
Key concerns include: quality consistency at 1.5 million annotations per hour, task complexity limits (simple tasks work great, nuanced judgment may be harder), dependency on app partnership relationships, potential regulatory scrutiny on how AI companies source training data, and international compliance complexity. Additionally, while the reputation system ensures good average quality, there's inherent variance when distributing tasks to 20 million people. None are dealbreakers, but they're real constraints the company navigates.
How might Rapidata's emergence change the AI development landscape?
If adoption succeeds, RLHF stops being a bottleneck, model iteration accelerates from quarterly releases to daily updates, other platforms replicate the model creating abundant feedback supply, and the barrier to entry for building serious AI models decreases. This democratizes AI development—more companies can compete. However, it also potentially shifts economic impact away from specialized contractor regions and creates pressure on workers in traditional RLHF roles. Within 3–5 years, online RLHF becomes table stakes for competitive AI development.
What makes Rapidata different from other data annotation platforms?
While Scale AI emphasizes quality through professional annotators and Appen emphasizes low cost, Rapidata uniquely combines three things: professional-quality feedback through its reputation system, massive scale through app partnerships (15–20 million users), and near-real-time speed (hours instead of weeks). This "fast, cheap, and good" combination across all three dimensions is what differentiates it from competitors focusing on just one or two dimensions.
Conclusion
We're watching something genuinely important happen with Rapidata. Not because the company will necessarily be worth billions—though it might be. But because they're solving a real constraint that's been limiting AI development speed.
For the past five years, the narrative around AI focused on compute. Who has the most GPUs? Who can train the biggest models? That's important, but it misses a second constraint that's become equally limiting: feedback quality and iteration speed.
Traditional RLHF made sense when models were smaller and released infrequently. You'd train a model, wait weeks for human feedback, retrain, release. But that model breaks down at modern scale. AI labs need feedback now, not in three weeks. They need to iterate daily, not monthly.
Rapidata fixes that by taking a different approach. Instead of asking "How do we hire more contractors?" they asked "What if human feedback was infrastructure?" That reframe led to a completely different technical solution and a much bigger business opportunity.
Is the execution going to be flawless? No. There will be problems with quality consistency, app partnerships, regulation, and all the usual startup challenges. But the core insight—that human judgment can be delivered as a scalable, instant service—is sound.
Within 12 months, you'll hear about major AI labs using Rapidata or announcing similar platforms. Within three years, it will be standard for any serious model development. Within a decade, companies without online RLHF infrastructure will seem quaint, the way building apps without cloud infrastructure seems today.
The $8.5 million seed round is validation of that trajectory. The investors betting on Rapidata aren't betting on a service business. They're betting on infrastructure that becomes essential. And history shows that's where the real value ends up.
For anyone building AI products, this is worth tracking closely. The speed at which you can iterate on your models is about to become a major competitive advantage. And Rapidata is betting they're going to be central to that.
Key Takeaways
- RLHF feedback has been a critical bottleneck in AI model development, with traditional approaches taking 3-4 weeks per cycle.
- Rapidata inverts the labor model by distributing feedback tasks to 15-20 million global mobile app users instead of hiring concentrated contractor pools.
- Online RLHF enables 15x acceleration in development timelines (120 days → 8 days) and compounds into exponential competitive advantage through more frequent iteration cycles.
- The platform's reputation system matches tasks to users with relevant expertise, achieving professional-quality feedback at crowdsourced scale and speed.
- Real-time feedback enables daily model improvements instead of monthly releases, creating measurable performance advantages for AI labs using the platform.
Related Articles
- Nvidia and Meta's AI Chip Deal: What It Means for the Future [2025]
- MSI Vector 16 HX AI Laptop: Local AI Computing Beast [2025]
- AI Replacing Enterprise Software: The 50% Replatforming Shift [2025]
- Sarvam AI's Open-Source Models Challenge US Dominance [2025]
- Heron Power's $140M Bet on Grid-Altering Solid-State Transformers [2025]
- AI Memory Crisis: Why DRAM is the New GPU Bottleneck [2025]

