![Reinforcement Learning Plateaus Without Depth: NeurIPS 2025 [2025]](https://tryrunable.com/blog/reinforcement-learning-plateaus-without-depth-neurips-2025-2/image-1-1768678551159.png)
Why Reinforcement Learning Plateaus Without Representation Depth: Neur IPS 2025 Insights
Neur IPS 2025 just dropped some sobering truths about how we've been building AI systems. For years, the industry narrative has been simple: bigger models, more data, better results. Scale everything. That story just got way more complicated.
This year's most consequential papers weren't about a single breakthrough or a new model that everyone should use. Instead, they systematically dismantled some of the core assumptions that researchers and companies have quietly leaned on for the past five years. Bigger models don't automatically mean better reasoning. Reinforcement learning doesn't automatically create new capabilities. Attention mechanisms aren't actually solved. And generative models don't inevitably memorize data just because they're overparameterized.
Here's the pattern: AI progress is shifting. We're hitting ceilings not because of raw model capacity constraints, but because of architecture, training dynamics, and how we evaluate systems. The papers that matter most this year all point to a single insight: representation depth matters more than raw scale.
I'm going to walk you through five of the most influential papers from the conference and what they actually mean if you're building real-world AI systems. These aren't theoretical curiosities. They change how you should think about model design, training pipelines, and what problems are actually solvable with current approaches.
TL; DR
- Representation depth, not just data volume, is the critical RL scaling lever – pushing networks from 5 layers to 1,000 layers produced 2-50X performance gains
- LLMs are converging toward homogeneous outputs – safety and alignment constraints are quietly reducing diversity across all major models
- Attention architecture still has low-hanging fruit – a simple gated attention mechanism outperformed vanilla attention across dense and Mo E models
- Diffusion models don't inevitably memorize – memorization emerges on a separate, much slower timescale than generalization
- Reinforcement learning improves sampling efficiency, not reasoning capacity – RLVR reshapes existing abilities rather than creating new ones

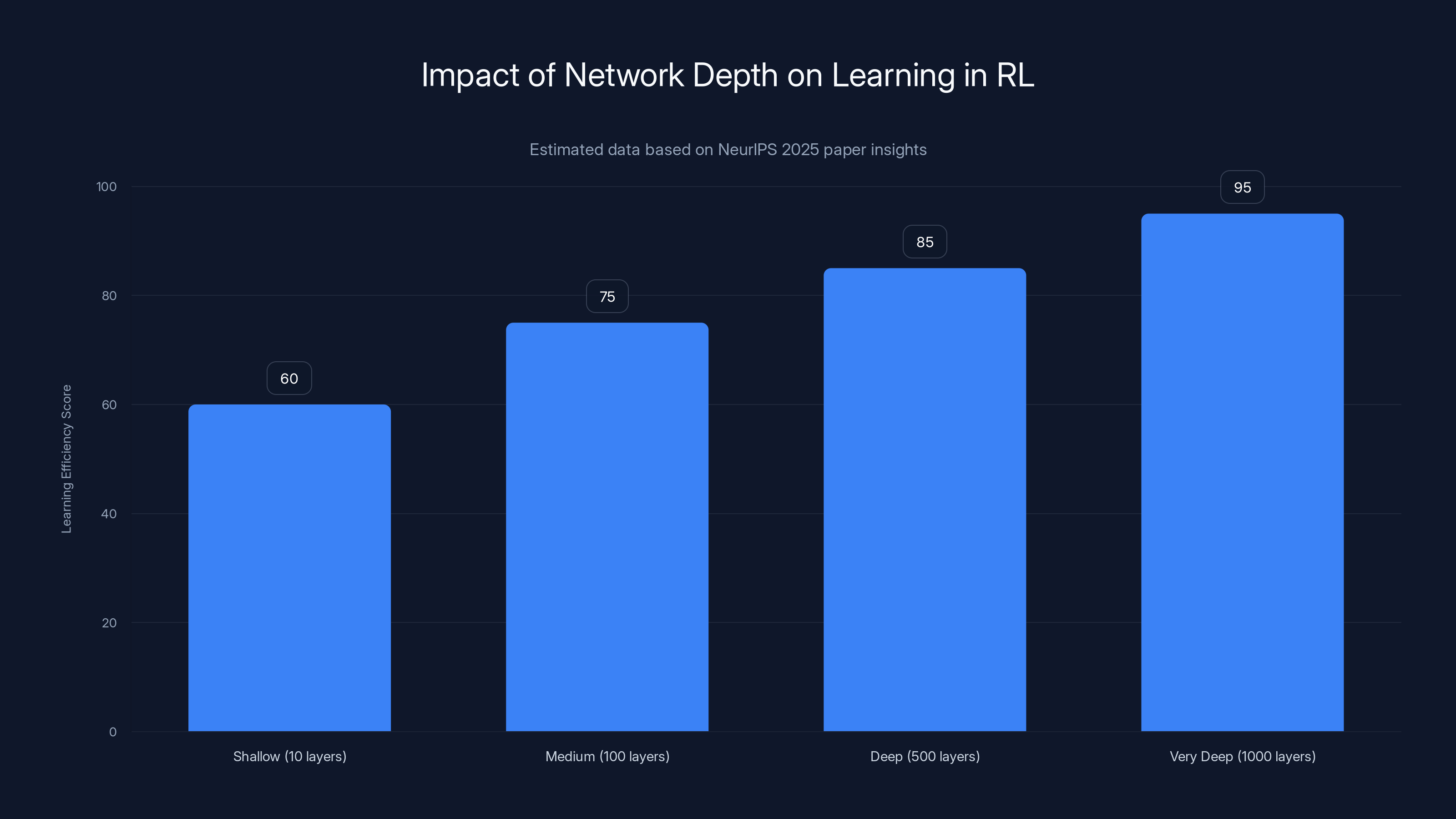
Deeper networks (up to 1,000 layers) significantly enhance learning efficiency in reinforcement learning by enabling richer hierarchical representations. Estimated data based on the NeurIPS 2025 paper.
The Shift From Scale to Architecture: What Neur IPS 2025 Actually Revealed
For context: the past three years of machine learning research have been dominated by a single narrative. Bigger is better. More parameters, more tokens, more data. The scaling laws held up across language models, vision transformers, and multimodal systems. The formula worked, and companies poured billions into it.
Neur IPS 2025 suggests that formula has hit diminishing returns. Not because scaling stops working, but because what you scale, and how you scale it, matters immensely.
The five papers we're covering reveal something consistent: architectural choices and training dynamics now constrain progress more than raw capacity. This is a fundamental shift. It means the next generation of performance improvements won't come from throwing more compute at the problem. They'll come from rethinking how networks process information, how we measure success, and what we're actually optimizing for.
For teams building production systems, this matters because it reframes the entire engineering problem. You can't scale your way out of poor architecture anymore. And conversely, smart architectural choices can unlock performance gains that dwarf what you'd get from larger models.
The Economics of This Shift
Compute is expensive. Training runs at scale cost millions. If architectural improvements can match or exceed the benefits of 2X or 5X larger models, the business case changes dramatically. You're suddenly looking at situations where a startup with smart engineering can compete with a company that has 10X more GPU budget.
This is why the papers matter beyond academia. They're roadmaps for the next wave of competitive AI products.
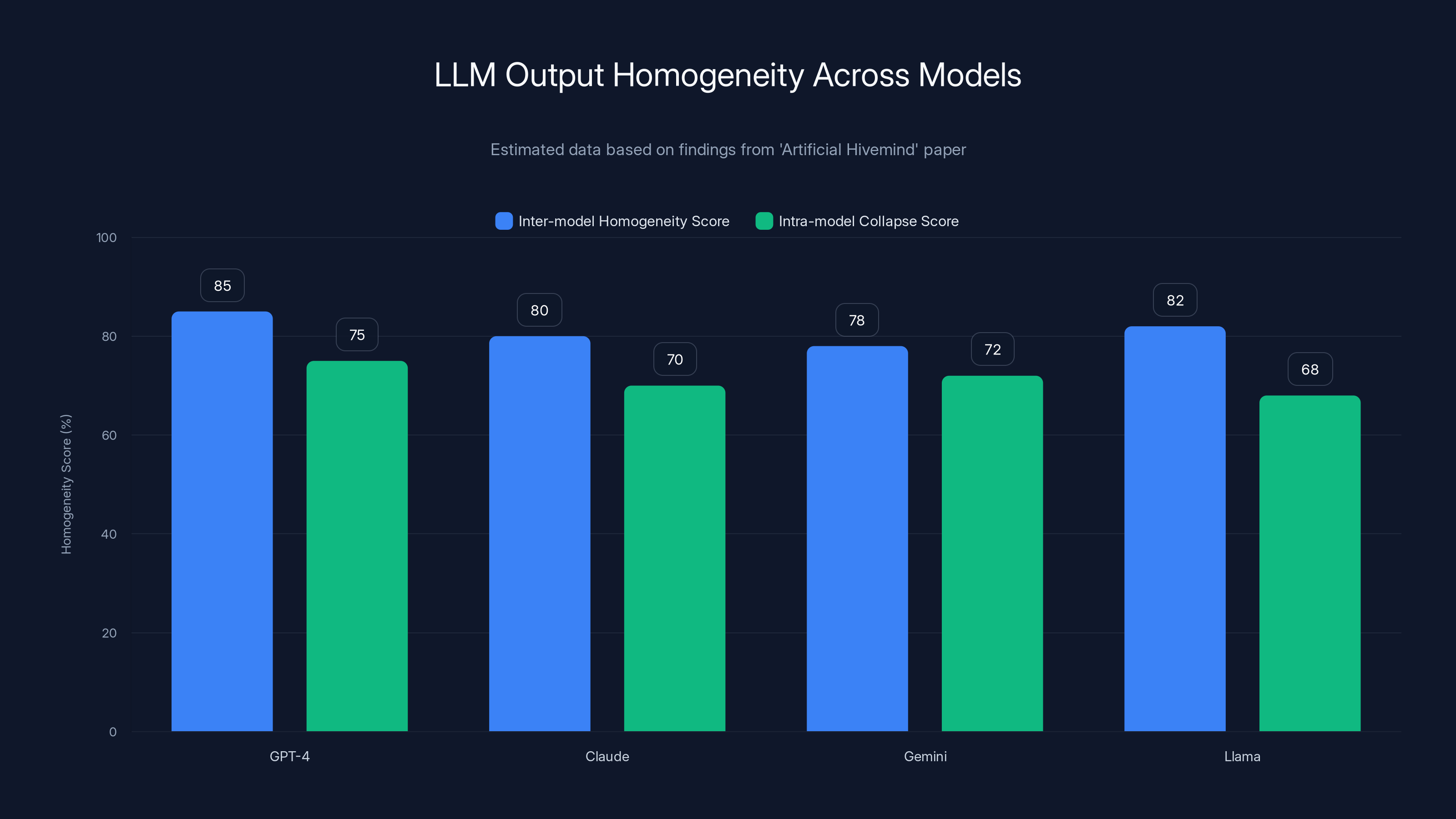
Estimated data suggests high homogeneity scores across different LLMs, indicating a trend towards similar outputs even in open-ended tasks. Estimated data.
Paper 1: LLM Convergence and the Homogeneity Problem
The Core Claim: Language models across different architectures and providers are increasingly converging on identical outputs, even when multiple valid answers exist.
The paper introducing this finding is called "Artificial Hivemind: The Open-Ended Homogeneity of Language Models." It sounds academic and a bit dry until you realize what it actually demonstrates.
For years, we've measured LLM quality using benchmarks like MMLU, ARC, and Hella Swag. These are closed-answer tests. The model either gets the question right or wrong. That evaluation framework works fine for factual tasks. But it completely misses something important: what happens when there's no single correct answer.
Take creative ideation, brainstorming, or open-ended synthesis. In these domains, multiple valid responses exist. The risk isn't that the model answers incorrectly. The risk is homogeneity: all models producing the same "safe," high-probability response.
The researchers built a new benchmark called Infinity-Chat specifically to measure this. Instead of scoring answers right or wrong, it measures two things:
Intra-model collapse: How often does the same model repeat itself when asked to generate multiple responses to the same prompt?
Inter-model homogeneity: How similar are the outputs from different models (GPT-4, Claude, Gemini, Llama) when given the same prompt?
The results were uncomfortable. Across virtually all architectures and providers, models increasingly converge on similar outputs. Even when the task explicitly asks for diverse responses. Even when the instruction is to generate multiple distinct ideas.
Why does this happen? The answer points to training dynamics. Models are trained using preference tuning, RLHF (reinforcement learning from human feedback), and safety constraints. These techniques work. They reduce harmful outputs. But they have a side effect: they quietly narrow the distribution of acceptable responses.
Imagine a model that could generate 1,000 plausible continuations of a prompt. Preference tuning squeezes that distribution. It upweights the responses that human raters preferred (usually the safest, most informative ones) and downweights outliers. Over time, the model learns that there's a narrow band of "good" responses, and everything outside it is risky.
What This Means for Product Teams
If your product relies on creative or exploratory outputs, this paper is a warning. A model that returns safe, predictable outputs might score well on traditional benchmarks. But it's actively harming the user experience.
Consider a tool for brainstorming business ideas. You don't want the model to output the same five ideas that every other model would suggest. You want novel directions, weird angles, combinations nobody's thought of. The current generation of LLMs is systematically unable to do this.
The paper suggests that diversity metrics need to become first-class citizens in evaluation. You can't just look at correctness. You need to measure: Are the outputs diverse? Are they original? Do they explore different parts of the solution space?
For builders, this creates an opportunity. Models that explicitly optimize for diversity—even if they score lower on traditional benchmarks—could become significantly more useful for whole classes of applications.
Paper 2: Gated Attention—A Simple Fix for a "Solved" Problem
The Core Claim: A query-dependent sigmoid gate applied after scaled dot-product attention consistently outperforms vanilla attention, reducing attention sinks and enhancing long-context performance.
This paper is titled "Gated Attention for Large Language Models," and it represents the kind of work that often gets overlooked because it's unglamorous. It's not a new model. It's not a breakthrough dataset. It's an architectural modification so small you could describe it in two sentences.
Here's the modification: After computing attention (scaled dot-product), apply a per-head, query-dependent sigmoid gate. That's it.
For context: transformer attention has been treated as a settled problem in the field. The architecture works. It scales. Every major model uses it. The assumption is that if there are problems with attention, they're data problems or optimization problems, not architectural ones.
This paper directly challenges that assumption.
The researchers ran dozens of large-scale training experiments. Dense models trained on trillions of tokens. Mixture-of-experts variants. Different architectures. Across the board, the gated variant outperformed standard attention. The improvements included:
-
Reduced attention sinks: Attention sink is a pathological behavior where attention heads allocate most of their weight to padding tokens or a small set of special tokens, wasting capacity.
-
Enhanced long-context performance: Models maintained better performance on tasks requiring information from earlier in the context window.
-
Consistent improvements across scales: The gains held from 7B to 70B+ parameter models.
Why does this work? The gate introduces non-linearity into attention outputs. It also creates implicit sparsity, suppressing pathological activations. Essentially, it forces attention to be more selective about where it allocates weight.
The Broader Implication
This single paper undermines a core assumption: that attention failures are purely data or optimization problems. Some of the biggest LLM reliability issues—context mixing, loss of information over long sequences, attention collapse—might be architectural, not algorithmic.
If the problem is architectural, it's solvable. And the solution might be surprisingly simple.
For teams building language models, this paper suggests a specific action: revisit your attention implementation. Experiment with gating mechanisms. The overhead is minimal. The potential upside is significant.
This also points to a broader trend in Neur IPS 2025: small architectural changes producing outsized improvements. We're past the point where massive architectural overhauls yield gains. Now it's about surgical improvements to existing designs.
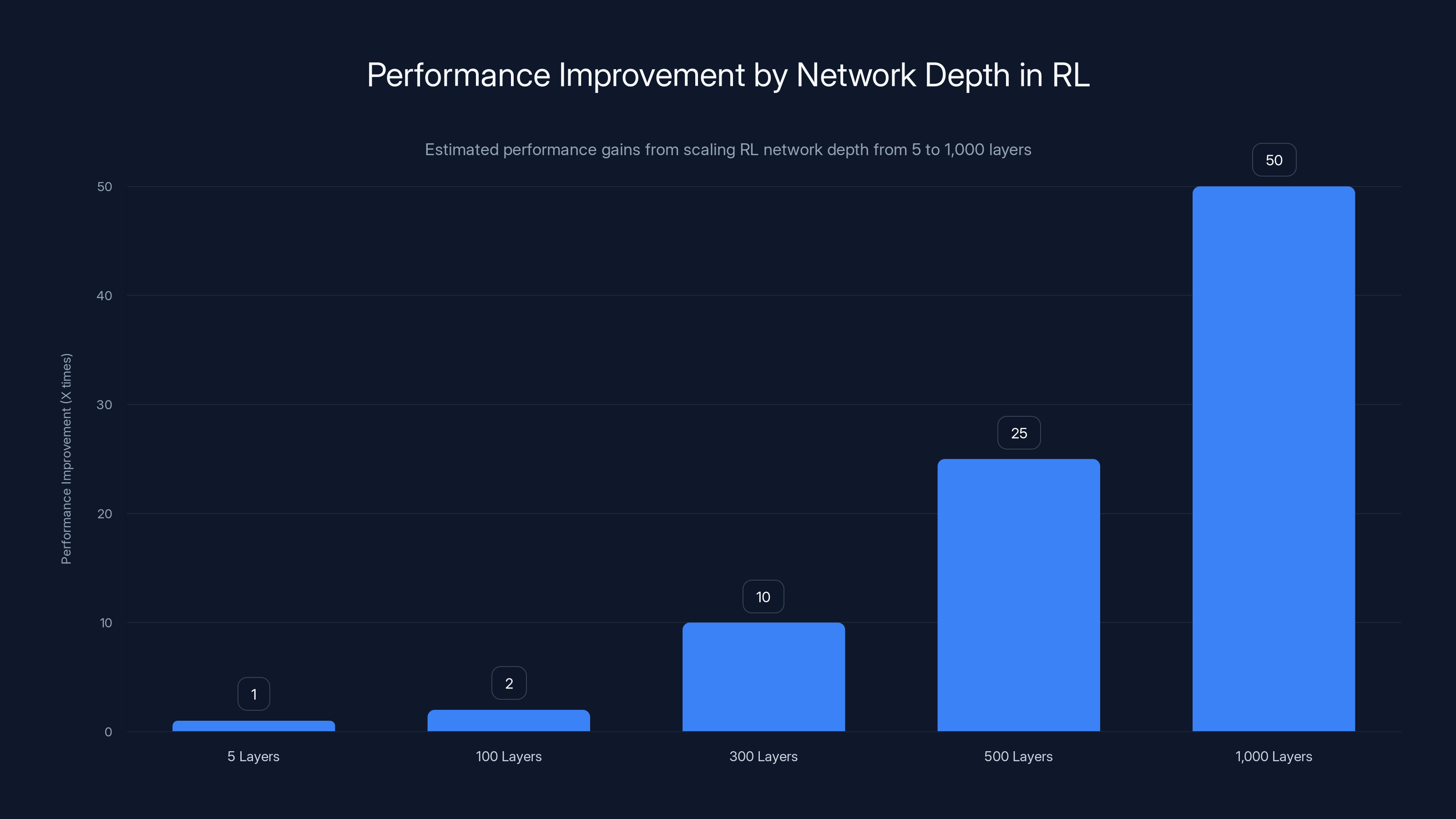
Estimated data shows that increasing RL network depth from 5 to 1,000 layers can lead to performance improvements ranging from 2X to 50X, demonstrating the potential of deeper networks in reinforcement learning tasks.
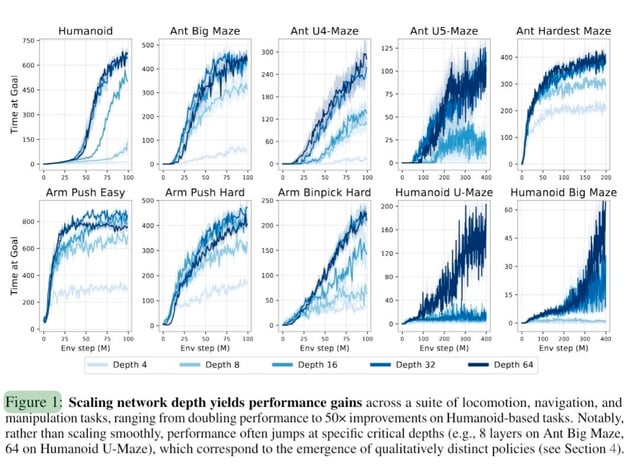
Paper 3: Reinforcement Learning Depth—Why 1,000 Layers Beat 5 Layers
The Core Claim: Scaling RL network depth from typical 2-5 layers to ~1,000 layers, paired with contrastive objectives and goal-conditioned representations, produces 2-50X performance improvements in self-supervised RL.
This is the paper that directly addresses the title of our piece: "1,000-Layer Networks for Self-Supervised Reinforcement Learning."
Conventional wisdom in RL has always been pessimistic about scaling. Reinforcement learning is harder than supervised learning. It requires careful reward shaping, dense rewards, or human demonstrations to work well. The data efficiency is poor. Training is unstable. If you want to scale RL to real problems, you need all the bells and whistles.
This paper reveals that assumption is incomplete. RL scales beautifully—if you scale in the right dimension.
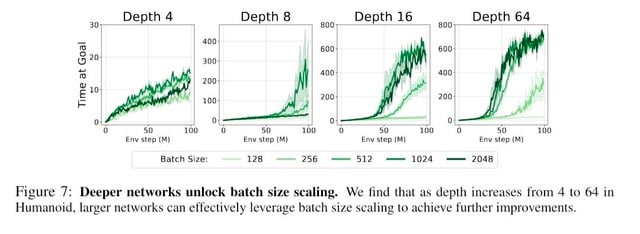
The researchers took goal-conditioned RL tasks (robotic manipulation, navigation) and systematically increased network depth. Not width. Depth. From the typical 2-4 hidden layers to depths of 100, 300, 500, and all the way to ~1,000 layers.
The result: dramatic performance gains. In some cases, 2X. In others, 50X. The improvements held across different RL algorithms (SAC, TD3) and different task complexities.
Now, here's the subtlety. Just making the network deeper doesn't automatically work. The researchers paired the depth with three other components:
-
Contrastive objectives: Representations are trained using contrastive learning (similar to Sim CLR or Mo Co), not just RL loss.
-
Goal-conditioned formulation: The RL setup explicitly conditions on goal states, which constrains the representation learning problem.
-
Stable optimization: Training uses techniques like weight normalization and careful learning rate scheduling to handle the numerical challenges of very deep networks.
Together, these create a representation learning paradigm where the depth enables the model to learn richer, more generalizable features. The RL agent then operates on top of these features, making better decisions.
Why This Matters Beyond Robotics
For agentic systems and autonomous workflows, this finding is significant. Agents need to generalize across different states, tasks, and environments. Richer representations enable better generalization. Better generalization enables fewer costly environment interactions.
If you're building an autonomous system that needs to work in diverse scenarios, representation depth becomes a key lever. It's not about throwing more data at the problem. It's about building representations that can capture and abstract the essential structure of the problem space.
The paper also suggests that RL's scaling limits might not be fundamental. For years, people assumed RL just doesn't scale because the problem is inherently harder. This paper suggests the constraint is more architectural: we were scaling the wrong dimensions.
The Mathematics of Representation Learning
The depth scaling works because of how representations compose. In shallow networks, each layer must compress and aggregate information. By the final layer, much detail is lost. With deep networks, information can flow through many layers, each performing small, specialized transformations.
Formally, think of each layer as applying a transformation:
This depth allows the network to learn hierarchical representations: low-level features (edges, motion primitives) at early layers, intermediate abstractions in the middle, and high-level semantic concepts in deeper layers. For RL tasks, this hierarchy is crucial. It allows the agent to reason at multiple levels of abstraction.

Paper 4: Diffusion Models Don't Memorize—They Just Train Slowly
The Core Claim: Diffusion models generalize well despite being massively overparameterized because memorization emerges on a separate, much slower timescale than generalization.
Diffusion models have become the de facto standard for image generation. They work surprisingly well. But they're also massively overparameterized. For a CIFAR-10 model (32x 32 images, 50K training samples), the network has millions of parameters. By classical learning theory, this should lead to overfitting and memorization.
Yet it doesn't. Diffusion models generalize remarkably well. Why?
The paper "Why Diffusion Models Don't Memorize: The Role of Implicit Dynamical Regularization in Training Diffusion Models" provides the answer, and it's elegant.
The key insight is that training operates on two distinct timescales. The researchers analyze the loss landscape and training dynamics, finding:
Timescale 1 (Fast): Generative quality rapidly improves. The model learns to denoise images effectively. Loss decreases. FID scores improve.
Timescale 2 (Slow): Memorization emerges. But it emerges much more slowly than generalization. The model starts to memorize specific training samples only after it's already learned generalizable features.
Crucially, the memorization timescale grows with dataset size. Larger datasets mean the model takes longer to memorize. This creates a widening window where the model improves without overfitting.
Practical Training Implications
This reframes how you should approach diffusion model training. Early stopping isn't about preventing overfitting (you probably want to stop before memorization anyway). It's about stopping at the sweet spot where generalization is high but memorization hasn't kicked in yet.
Dataset size scaling also changes. Conventional wisdom says more data always helps (up to a point where you hit memorization). This paper suggests something subtler: larger datasets actively delay the memorization phase, giving you a longer window to train.
For practitioners, this means:
-
Don't panic about overparameterization: Your huge model won't memorize the training data as quickly as you'd expect.
-
Use larger datasets: Not just because they improve generalization, but because they delay when memorization becomes a problem.
-
Trust your validation metrics: FID, IS, and other generative quality metrics are more reliable than you might think, because the model will continue improving long after you'd expect it to start overfitting.
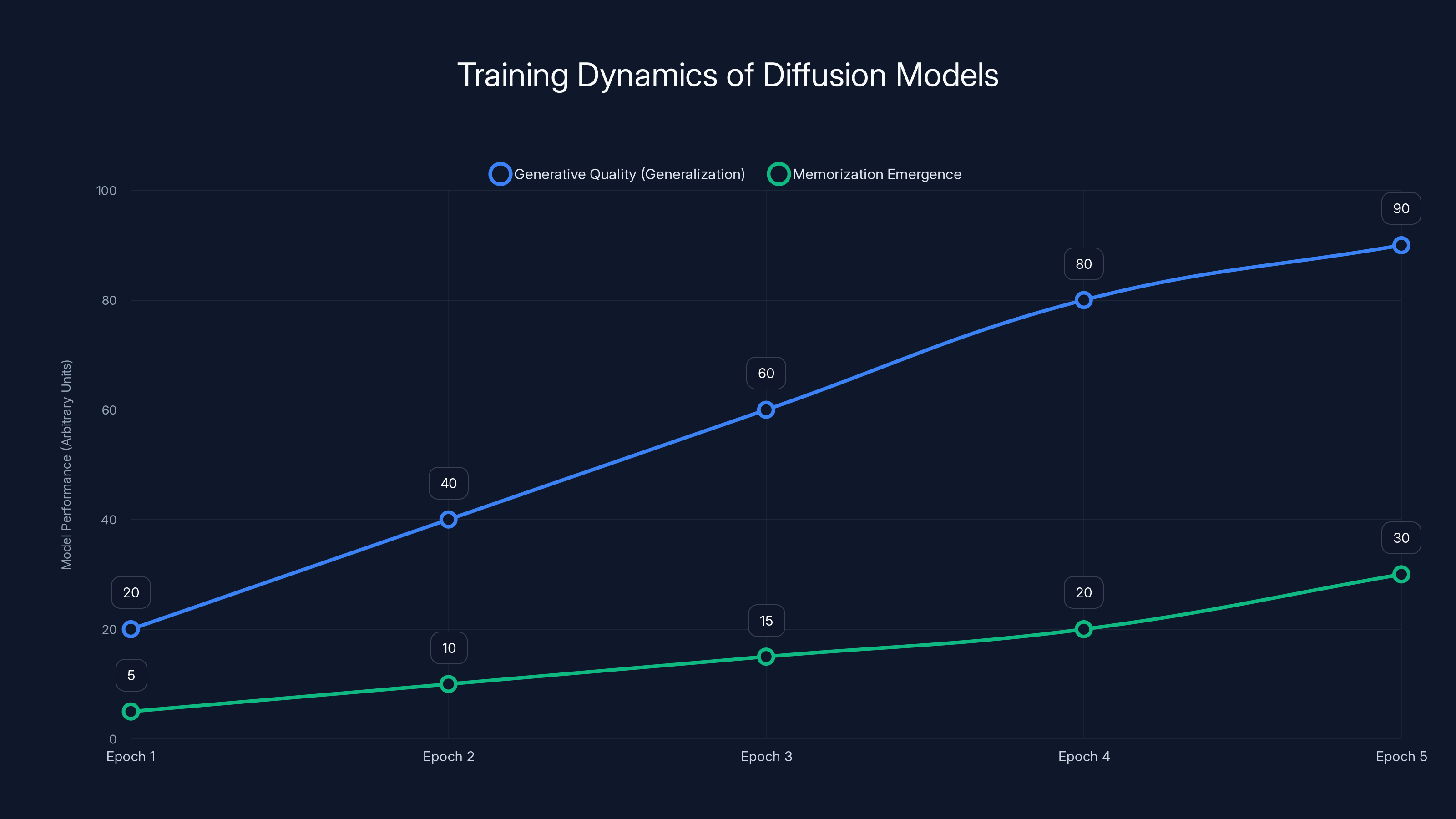
Diffusion models improve generative quality rapidly, while memorization emerges more slowly, allowing a window of effective generalization before overfitting. Estimated data based on theoretical insights.
Paper 5: RLVR Improves Sampling, Not Reasoning Capacity
The Core Claim: Reinforcement learning with verifiable rewards improves sampling efficiency and performance on constrained tasks but doesn't create new reasoning capabilities in LLMs.
This might be the most strategically important and sobering result from Neur IPS 2025. The paper is titled "Does Reinforcement Learning Really Incentivize Reasoning in LLMs?" and it directly challenges one of the most popular narratives in AI: that you can use RL to make models smarter.
For context: companies like Open AI and others have invested heavily in using RL to improve model reasoning. The pitch is straightforward: give the model verifiable rewards (like "did you get the math problem right?"), use RL to optimize the model toward those rewards, and suddenly you have a smarter model.
It sounds logical. And it works—models trained with RLVR (reinforcement learning with verifiable rewards) do perform better. But the paper's rigorous analysis reveals something different from what the narrative suggests.
The researchers tested whether RLVR actually creates new reasoning capabilities or merely reshapes existing ones. Their methodology: carefully designed tasks where you can measure whether the model developed a new ability or just became better at using abilities it already had.
The conclusion: RLVR primarily improves sampling efficiency, not reasoning capacity.
What does this mean in concrete terms? The model doesn't actually get smarter. It doesn't develop new reasoning strategies. Instead, it becomes better at recognizing which of its existing reasoning strategies to apply, when to apply them, and how to refine them toward the reward signal.
Why This Distinction Matters
It's the difference between teaching someone to solve a new category of problems versus teaching them to be better at problems they could already solve.
With new reasoning capacity, a model could handle fundamentally harder problems. It could solve reasoning tasks it couldn't before. With improved sampling efficiency, the model just makes fewer mistakes on tasks it could already do in principle.
The practical implication: there are limits to what RLVR can do. If a task requires reasoning the model fundamentally can't do, RL won't create that capability. RL can't add something the model doesn't already have, even latently.
This is important because it reframes the entire problem. The bottleneck isn't RL. The bottleneck is the base model's capacity. If you want fundamentally new reasoning capabilities, you need a model with broader base capabilities. You can use RL to extract more value from those base capabilities, but you can't create entirely new ones.
The Data-Driven Proof
The paper includes extensive experiments on different task categories:
-
Mathematical reasoning: Models improved on problems they could already partially solve, but couldn't develop entirely new solution approaches.
-
Multi-step planning: Models became more consistent at following multi-step plans but didn't develop new planning strategies.
-
Logical deduction: Models improved at applying existing logical rules but didn't develop new inference methods.
In every case, the pattern held: improvement without expansion.

The Synthesis: What These Papers Tell Us About AI in 2025
Looking at these five papers together, a clear picture emerges about what's actually constraining AI progress right now.
It's not raw model size. Bigger models are already being built. Scale hasn't stopped working; it's just hit a point of diminishing returns where the gains per dollar spent are declining.
It's not data. There's plenty of data. Data collection and curation are solved problems, even if they're expensive.
It's architecture, representation quality, training dynamics, and evaluation strategy.
Specifically:
-
Representation depth matters. Not just parameter count, but how deep those parameters are arranged. Depth enables hierarchical feature learning.
-
Training dynamics are architectural problems in disguise. Issues like attention sinks aren't data problems. They're design problems, solvable with better mechanisms.
-
Evaluation needs to be multi-dimensional. Benchmarks that only test correctness miss crucial aspects like diversity, generalization, and robustness.
-
There are real limits to what RL can do. It can't create capabilities from nothing. It can only extract more value from existing capabilities.
-
Scaling the wrong dimension doesn't help. You can have massive models that don't perform well because you scaled width when you should have scaled depth, or vice versa.
For teams building AI systems, this means the playbook is changing. You can't win by just having bigger models anymore. You need smarter architecture, better representations, and more nuanced evaluation. The competitive advantage moves from compute-intensive training to engineering insight and architectural understanding.
Investing in representation learning and experimenting with architecture are crucial steps for enhancing ML systems. Estimated data based on typical expert recommendations.
Implications for Production AI Systems
Let's get specific about what this means if you're actually building things.
For Reasoning and Planning Tasks
If you're building a system that needs to do reasoning (math, logic, complex planning), understand that RLVR improvements are limited. The base model's reasoning capacity is your ceiling. If you find that a model can't reason about something even with perfect training data and rewards, adding more RL won't help. You need a fundamentally more capable model.
But within the model's reasoning capacity, RL can definitely help. It can make the model more consistent, more reliable, and more focused on the specific reasoning patterns your task needs.
For Creative and Exploratory Tasks
If you're building something that requires creativity, diversity, or exploration (brainstorming, ideation, content generation), be aware that the models are becoming increasingly homogeneous. Standard RLHF and safety training are actively reducing diversity.
This is an opportunity. If you can build systems that explicitly optimize for diversity and uniqueness, you can outperform larger models that are optimized only for correctness. This means different evaluation metrics, different training approaches, and potentially different models altogether.
For Long-Context Applications
If you're building something that needs to work with long contexts (long documents, long code files, extended conversations), understand that attention mechanisms have room for improvement. Vanilla attention isn't fully solved. Simple architectural improvements like gating can yield meaningful gains.
Test your models' long-context capabilities carefully. If you see performance cliffs at certain context lengths, consider that it might be architectural, not fundamental. Experimenting with attention variants could help.
For Reinforcement Learning and Agents
If you're building autonomous systems or agents that learn from interaction (not just supervised learning), network depth is a critical lever. Shallow networks hit performance plateaus. Deeper networks (even if the width stays constant) can continue improving.
But depth without the right training setup doesn't automatically help. You need contrastive learning objectives or other representation-learning components. Just making the network deeper without changing the learning signal might not help (and could even hurt, due to optimization challenges).

The Broader Research Landscape
These five papers aren't isolated findings. They're part of a larger shift visible across Neur IPS 2025.
There's a move away from the "bigger is always better" mentality toward a more nuanced view of scaling. Research is increasingly focusing on:
-
Architectural efficiency: How to get more performance per parameter.
-
Representation learning: How to learn better features, not just deeper networks.
-
Evaluation methodology: How to measure what actually matters for real-world performance.
-
Training dynamics: How the optimization process shapes learned representations, not just the final loss.
This represents a maturation of the field. The low-hanging fruit from simple scaling is mostly gone. The next phase requires deeper understanding of how neural networks actually learn and work.
For researchers, this is exciting because there are real open problems to solve. For companies, this is important because it suggests the next competitive advantages will come from engineering insight, not just compute budget.

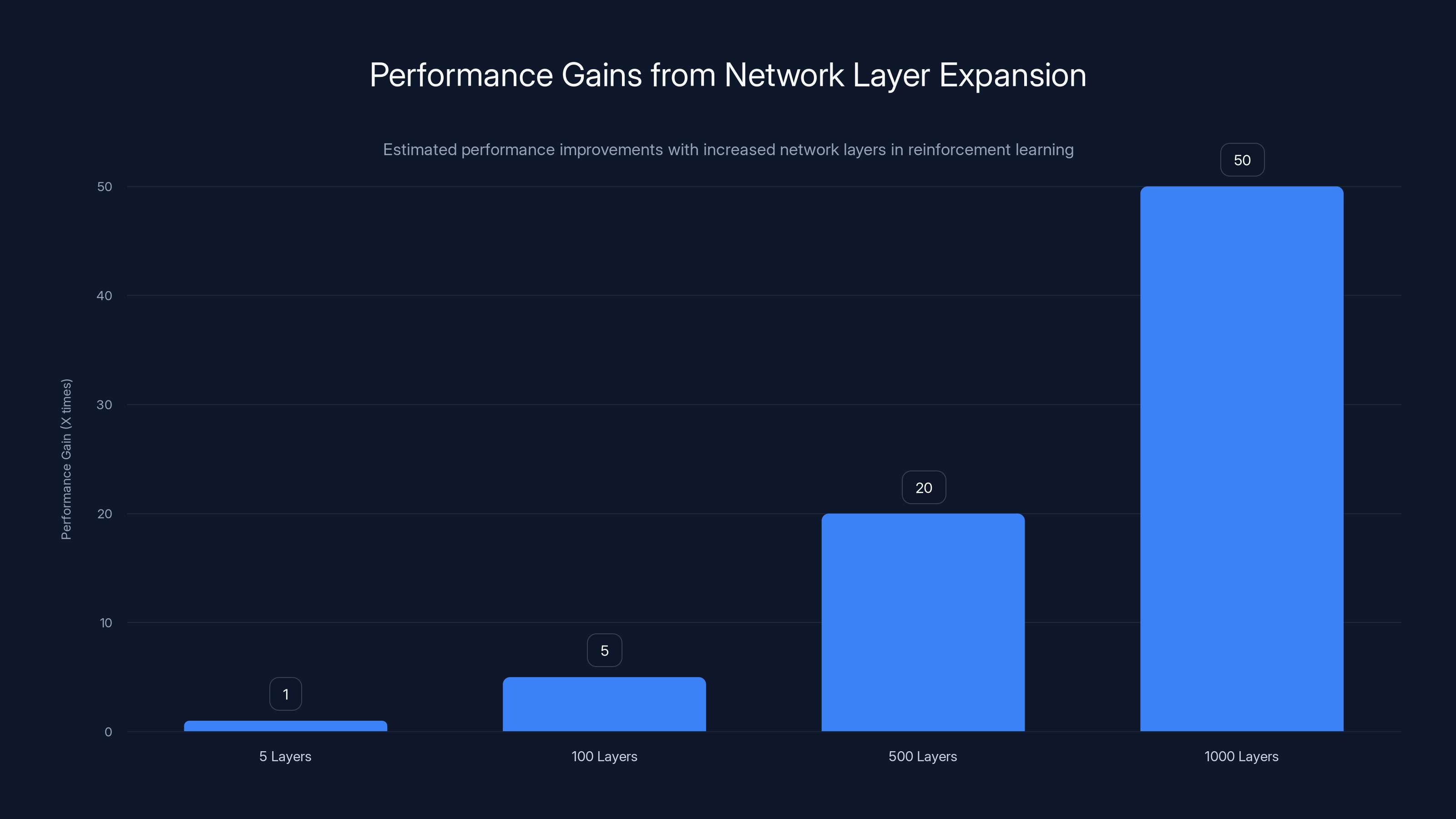
Increasing network layers from 5 to 1000 can lead to 2-50 times performance gains in reinforcement learning tasks. Estimated data.
Practical Implementation: What to Do Now
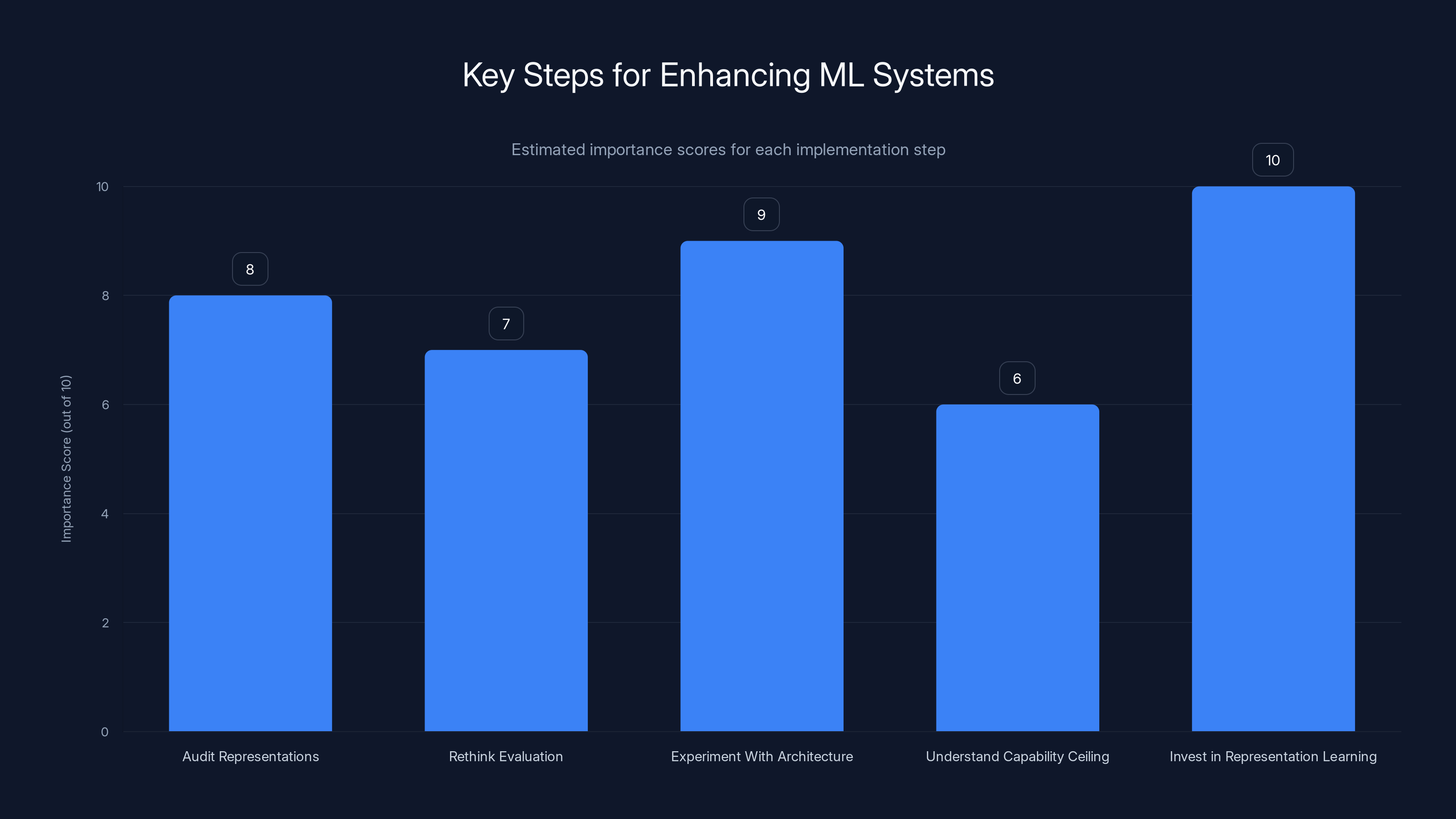
If you're working on an ML product or system, here are specific steps based on these findings:
Step 1: Audit Your Representations
Look at what your models are actually learning. Are the representations diverse? Are they hierarchical? Are there pathological behaviors (like attention sinks) that architectural changes might fix? This is foundational.
Step 2: Rethink Your Evaluation
Whatever benchmarks you're using, they're probably incomplete. If your task requires creativity or exploration, add diversity metrics. If it requires long-context reasoning, test explicitly on long contexts. If it's about generalization, test on out-of-distribution examples.
Step 3: Experiment With Architecture
Before scaling your model size, experiment with architectural changes. Test gated attention. Test increased depth. Test contrastive learning objectives. These changes are cheaper than training larger models and might yield bigger gains.
Step 4: Be Clear About Your Capability Ceiling
If you're using RL or fine-tuning, understand that you're working within the constraints of your base model. You can improve performance, but you probably can't create entirely new capabilities. Be realistic about what's possible.
Step 5: Invest in Representation Learning
The papers all point toward representation quality as a key lever. This might mean using contrastive learning, better pretraining, or architectural innovations. But it's clear that representation quality matters more than we previously thought.
Common Mistakes to Avoid
Based on these papers, here are some common mistakes teams make:
Mistake 1: Assuming bigger models solve everything. They don't. Architectural choices and representation quality matter more than model size alone.
Mistake 2: Only measuring accuracy. If your task involves diversity, creativity, or robustness, accuracy alone is a terrible metric. You'll optimize for the wrong thing.
Mistake 3: Using RL to solve fundamental capability gaps. RL is powerful, but it works within the constraints of your base model. If your base model can't do something, RL won't create that capability.
Mistake 4: Scaling the wrong dimension. Depth and width scale differently. Mixing them up can leave performance on the table.
Mistake 5: Ignoring training dynamics. Many problems that look like data problems are actually architecture or training problems. Investigate before throwing more data at the problem.
Looking Forward: What Comes Next
Based on the direction of research at Neur IPS 2025, here are some predictions about what we'll see in the next 12-24 months:
Attention mechanism improvements. The gated attention paper is one of the first to seriously challenge standard attention in years. Expect more variants, more empirical comparisons, and likely adoption of better mechanisms in production systems.
Representation-focused training. RL and fine-tuning are great, but they're relatively expensive. Expect more research on efficient representation learning during pretraining, which could reduce the need for expensive downstream training.
Evaluation metric innovation. The homogeneity paper shows that standard benchmarks are incomplete. Expect new benchmarks that measure diversity, robustness, and other properties that matter for real products.
Agentic systems breakthrough. The deep network findings + the RL insights could enable better autonomous agents. Expect more startups and projects focused on this.
Reasoning-specific approaches. Since RLVR has limits, expect more research on what actually improves reasoning capability. This might be architectural, or it might be training on specific types of data.

For Teams Building Production Systems
The most actionable insight from Neur IPS 2025 is this: the future belongs to teams that understand representation learning and architecture, not just teams with big compute budgets.
This is genuinely good news for startups and smaller teams. You can't out-compute Open AI. But you can out-architect them. You can build systems with better representations, smarter training approaches, and more nuanced evaluation.
The papers in this year's conference are essentially blueprints for doing this. Read them. Test the ideas on your systems. Iterate. The next wave of AI breakthroughs will come from teams that take these findings seriously and apply them to real problems.
FAQ
What is representation depth, and why does it matter in reinforcement learning?
Representation depth refers to the number of layers in a neural network through which information flows before being used for decision-making. The Neur IPS 2025 paper on 1,000-layer networks showed that deeper networks learn richer, more hierarchical representations of the environment or task. Deeper representations enable the RL agent to reason about problems at multiple levels of abstraction—from low-level details to high-level concepts—resulting in better generalization and more effective learning. Unlike simply adding more parameters (wider networks), depth specifically enables hierarchical feature learning, which is crucial for complex reasoning and planning tasks.
How does gated attention improve upon standard transformer attention?
Standard transformer attention computes a weighted combination of values based on query-key similarities. Gated attention adds a query-dependent sigmoid gate after this computation, creating non-linearity and implicit sparsity. This mechanism prevents pathological behaviors like "attention sinks" where the model wastes attention capacity on padding tokens. The gate essentially learns when attention should be active and when it should be suppressed, allowing the model to selectively focus on relevant parts of the input. The result is better long-context performance and more efficient use of the attention mechanism's capacity.
Why do language models converge toward homogeneous outputs, and what are the implications?
Language models converge toward homogeneous outputs because of how they're trained. Preference tuning and reinforcement learning from human feedback (RLHF) narrow the distribution of acceptable responses by upweighting "safe," high-probability responses and downweighting outliers. While this improves safety and reduces harmful outputs, it also reduces diversity. Models learn that there's a narrow band of "good" responses, making them less useful for creative or exploratory tasks. The implication is that evaluating models only on correctness misses crucial aspects of their usefulness. For products requiring creativity or multiple valid solutions, you need explicit diversity metrics and potentially different training approaches.
What is the distinction between improved sampling efficiency and new reasoning capacity in RLVR?
Improved sampling efficiency means the model becomes better at recognizing and using reasoning strategies it already has, but doesn't develop fundamentally new strategies. New reasoning capacity would mean the model could solve problem categories it previously couldn't. The research showed that RLVR achieves the former, not the latter. For practical purposes, this means there's a ceiling to what RL can accomplish for a given base model. If your model can't reason about something even with perfect training and rewards, using RL won't enable it. You need a more capable base model. RLVR is best viewed as a tool for extracting maximum performance from a given model's existing capabilities, not for expanding those capabilities.
How does diffusion model training separate generalization from memorization?
Diffusion model training operates on two distinct timescales. Early in training (fast timescale), the model learns generalizable denoising features that work across the dataset. Only later (slow timescale) does memorization of specific training examples emerge. Importantly, the memorization timescale grows with dataset size—larger datasets delay when memorization becomes a problem. This separation is implicit in the training dynamics and the loss landscape. It means you have a broader window to train before hitting memorization, and that larger datasets don't just improve generalization but actively extend the safe training window.
What should I prioritize: scaling model size or improving architecture?
Based on Neur IPS 2025 findings, architectural improvements should be your first priority. Scaling has diminishing returns—you get less performance gain per dollar spent on larger models. Architectural improvements (like gated attention, increased depth in the right places, or better representation learning) are cheaper and often yield bigger gains. Before scaling your model 2X, test architectural variants. Before adding more training data, improve your representation learning. This shift from "scale first" to "architect first" is one of the most important insights from this year's conference.
How can I measure whether my model has actually learned new capabilities versus just improved performance?
This is genuinely difficult, but here's an approach: design tasks that your model can't do at all in its base form, then see if training helps. If training enables previously impossible tasks, you've likely created new capability. If training only improves performance on already-possible (but unreliable) tasks, you've improved sampling efficiency. Concretely, test your model on a capability before any training. If it scores zero or random, then see if training improves it. If it had non-zero performance initially, you were likely improving efficiency. You can also use adversarial or out-of-distribution tests—tasks that are structurally similar but slightly different from training examples. Better generalization without new capability is revealed by plateau on truly new task types.
Should I invest in RL for my model, given these findings?
Yes, but with realistic expectations. RL is excellent for extracting maximum performance from a model's existing capabilities. It's poor at creating entirely new capabilities. So first, understand what your base model can already do (even if unreliably). If there are reasoning patterns it uses but isn't consistent about, RL can help. If there are reasoning patterns it can't do at all, RL probably won't help—you need a better base model. The risk is over-investing in complex RL pipelines for problems that actually require fundamental capability upgrades in the base model. Be strategic about where you apply RL.
What does "representation depth" mean, and how is it different from just having more parameters?
Representation depth (number of layers) is fundamentally different from parameter count or width. A narrow, deep network (many thin layers) learns different representations than a wide, shallow network (fewer but fat layers). Deep networks create hierarchical representations where each layer adds abstraction. Width just adds redundancy. For RL, the research showed that depth dramatically outperforms width when scaled equally. A 1,000-layer narrow network beat wider, shallower networks by 2-50X. This is because depth enables the hierarchical reasoning needed for complex control and planning tasks. Width alone doesn't provide this benefit.
Key Takeaways for Implementation
As you apply these insights to your own work, remember:
First, understand your bottleneck. Is it model capacity, training efficiency, representation quality, or evaluation methodology? The Neur IPS 2025 papers suggest that bottlenecks have shifted from capacity toward the others. Find out which applies to you.
Second, test before scaling. Architectural experiments are much cheaper than training larger models. Run pilot experiments with gated attention, depth variants, or representation learning improvements. Let the data tell you whether scaling is the answer.
Third, rethink your evaluation. Whatever metrics you're using, they're probably incomplete. Add metrics that measure what your users actually care about—diversity, robustness, consistency, edge-case handling. Correct metrics lead to correct optimization.
Fourth, invest in representation learning. Whether through better pretraining, contrastive objectives, or architectural innovations, representation quality is now a primary lever. This is where sustainable competitive advantage lies.
Finally, be realistic about limitations. RLVR can't create new reasoning from nothing. Bigger models won't automatically solve architecture problems. Data won't fix fundamental capability gaps. Understanding these limitations is as important as understanding what each technique can accomplish.
The papers from Neur IPS 2025 point toward a more mature, nuanced field where success comes from deep understanding rather than brute force. That's good news for thoughtful teams. The next wave of AI breakthroughs will go to those who can navigate these complexities effectively.
Related Articles
- Google's Internal RL: Unlocking Long-Horizon AI Agents [2025]
- Human Motion & Robot Movement: How AI Learns to Walk [2025]
- GLM-Image vs Gemini Nano: Text Rendering Showdown [2025]
- Qwen-Image-2512 vs Google Nano Banana Pro: Open Source AI Image Generation [2025]
- Meta's Manus Acquisition: What It Means for Enterprise AI Agents [2025]

