![Reused Enterprise SSDs: The Silent Killer of AI Data Centers [2025]](https://tryrunable.com/blog/reused-enterprise-ssds-the-silent-killer-of-ai-data-centers-/image-1-1769119689458.jpg)
The Hidden Crisis No One's Talking About
Your data center is probably hiding a ticking time bomb right now, and you might not even know it. Enterprise SSDs are being pulled from old systems, wiped clean, and shoved back into high-demand AI workloads. It sounds efficient. It sounds pragmatic. It sounds like the kind of cost-cutting that Wall Street loves to hear about.
It's also exactly wrong.
When flash storage fills with data repeatedly, the transistors inside degrade. There's no software patch that fixes this. No clever algorithm that reverses it. Physical degradation is permanent, and as those SSDs get older, the chances of catastrophic failure skyrocket when they're forced to handle the relentless write patterns of modern AI systems.
A senior Dell executive recently went on record calling this trend "exactly the opposite of what AI and mission-critical workloads require" according to TechRadar. That's not hyperbole. That's a direct assessment from someone who's spent years watching data center infrastructure fail in spectacular, expensive ways.
The shortage of enterprise-grade SSDs has created a perfect storm. Demand for storage is crushing supply. Prices are climbing. Delivery timelines are extending into months. So operators are doing what humans always do under pressure: they're taking shortcuts. They're pulling aging SSDs from retired systems, refurbishing them, and treating them like new hardware. On a spreadsheet, it looks like genius. In production, it's a recipe for data loss that could bring down AI training pipelines, inference systems, and the critical applications that depend on them.
This isn't theoretical risk. This is what happens when you ignore the physical realities of silicon.
Let's break down exactly what's happening, why it matters, and what you need to do about it.
Understanding Flash Degradation: The Physics Nobody Wants to Discuss
Flash memory works through electrical charges trapped in silicon transistors. Every time data gets written to a cell, the oxide layer protecting that charge weakens slightly. This isn't a metaphor. It's a measurable, irreversible physical process.
NAND flash comes in different architectures: SLC (single-level cell), MLC (multi-level cell), TLC (triple-level cell), and QLC (quad-level cell). Most enterprise SSDs today use TLC or QLC, which pack more bits into the same physical space by storing multiple voltage levels in each cell. This makes them cheaper and higher capacity. It also makes them more vulnerable to wear, because those voltage levels get harder to distinguish as the oxide layer deteriorates.
Here's where it gets serious: when you run an SSD in a data center, especially one handling AI workloads, you're subjecting it to constant write operations. Large language models training on billions of parameters need to read and write massive amounts of intermediate data. Each write cycle ages the flash. After a certain threshold, reads become unreliable. Writes start failing. Then the whole drive can become corrupted or unusable.
The degradation curve isn't linear. It's exponential. A drive at 50% wear isn't half as reliable as a new drive. It's dramatically more likely to fail suddenly, without warning. And because the failure happens at the physical level, no amount of redundancy at the software layer can save you.
Write Amplification: The Hidden Killer
Write amplification is a concept that keeps storage engineers awake at night. When you write 1GB of data to an SSD, the actual amount written to the flash cells can be 2GB, 3GB, or higher depending on how the drive manages wear leveling and garbage collection.
Say you have a data center running an AI training job that needs to write 100GB of checkpoint data every hour. The SSD controller might actually write 300GB of data to the flash cells due to wear leveling. Over a month, that's 216TB of internal writes from just 3.6TB of user data. A reused SSD that's already consumed 60% of its lifecycle will hit critical wear levels in weeks, not years.
Older drives have worse write amplification because their controllers are less sophisticated and their NAND is already degraded. This creates a vicious cycle: worn flash requires more internal writes to maintain data integrity, which accelerates the wear further.
The Temperature Factor
Flash degradation accelerates with heat. A reused SSD running at 55°C will age twice as fast as one at 40°C. Data centers are getting warmer due to AI workloads clustering in tight racks, and older SSDs are often less efficient at thermal management.
When you combine high temperatures with high write loads on a worn drive, you're not looking at normal degradation curves anymore. You're looking at accelerated failure modes that can appear suddenly.

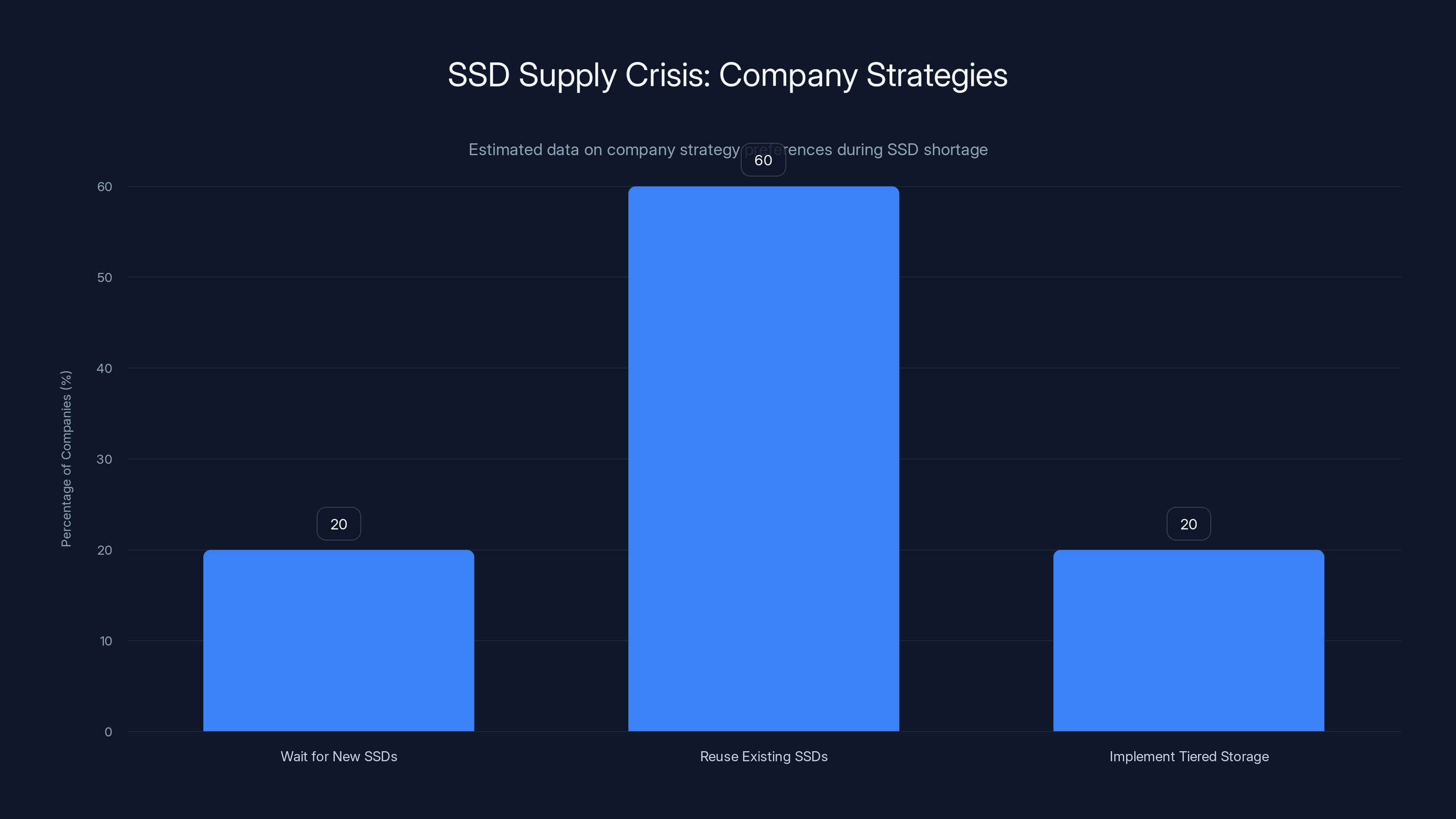
Estimated data shows that 60% of companies prefer reusing existing SSDs due to immediate cost savings, despite the risks involved. Estimated data.
Why AI Workloads Make This Problem Worse
AI systems are unique in how they stress storage infrastructure. Traditional databases might see 20-30% of capacity dedicated to writes on any given day. AI training loops can sustain 70-90% write patterns continuously.
Consider a large language model training on 100 billion parameters. The system needs to:
- Load training batches from storage repeatedly
- Write gradient updates and intermediate results
- Save checkpoints every few iterations
- Shuffle and resample data constantly
- Write logs and metadata for monitoring
All of this happens simultaneously across multiple GPUs and TPUs. The storage system sees relentless, unpredictable access patterns. This is the worst-case scenario for a worn SSD.
Inference Adds Another Layer of Risk
While training is write-intensive, inference systems are read-intensive but require consistent, low-latency access. If an SSD starts experiencing bit errors due to wear, inference latency becomes unpredictable. You might get results in 50ms one moment and 5 seconds the next, as the drive's error correction kicks in.
For real-time AI applications like recommendation systems, ad serving, or autonomous systems, this variability is unacceptable. And it happens silently. The drive doesn't fail outright. It just degrades, and your system performance craters.
Cascading Failures in Production
When a reused SSD fails in a production AI system, it doesn't fail gracefully. Here's the typical sequence:
- First signs appear as occasional latency spikes
- Rare read errors get logged, but users might not notice
- The drive's internal error correction starts working harder
- Performance degrades more noticeably
- Writes start failing in unpredictable ways
- The entire training job or inference pipeline becomes corrupt
- Hours or days of work are lost, or worse, bad data gets published
That's not just a technical problem. That's a business problem. If your model inference returns wrong answers because the storage was unreliable, you have liability issues. If your training job loses weeks of progress, you have financial losses.
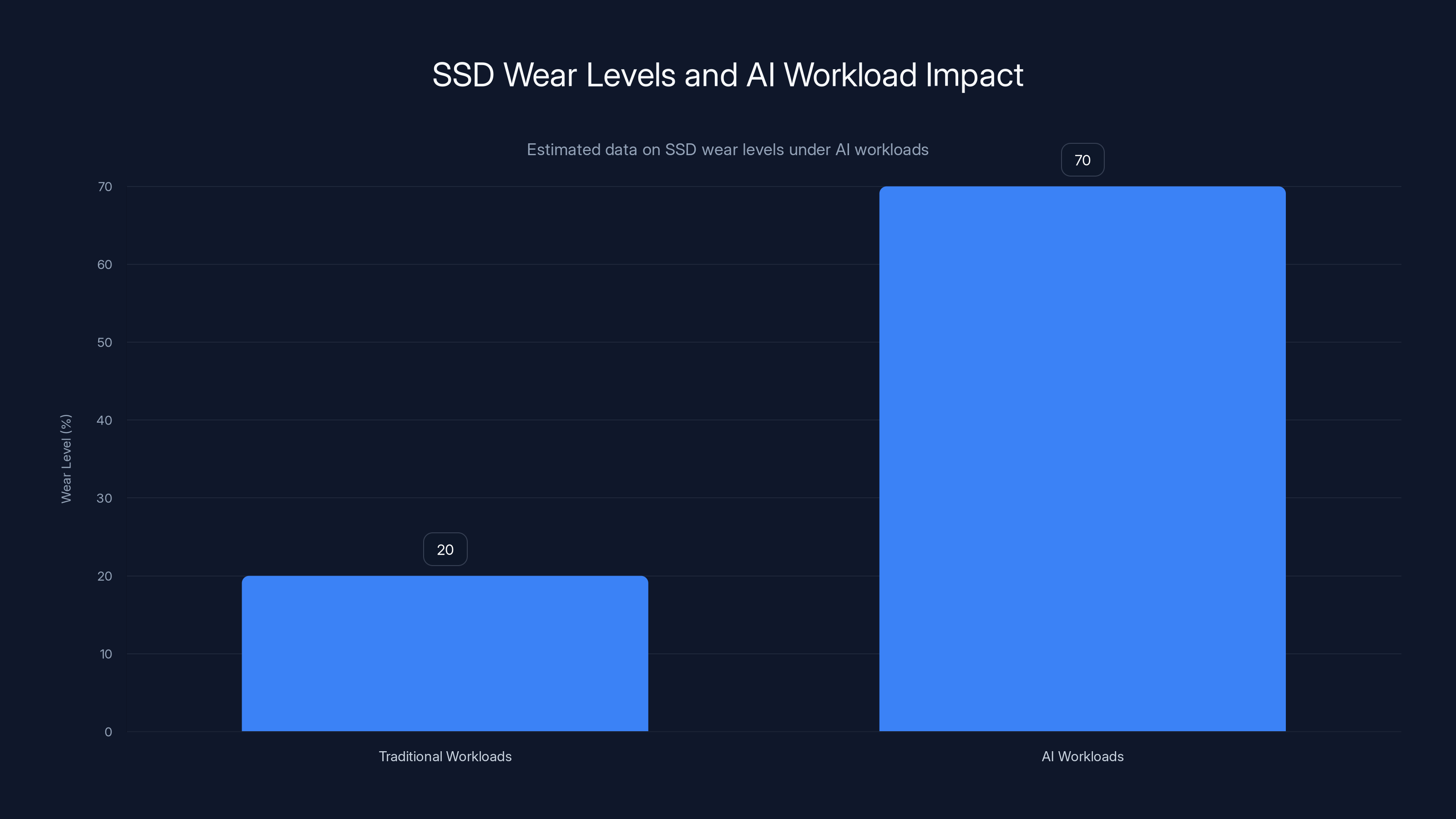
Estimated data shows that AI workloads can accelerate SSD wear levels significantly faster than traditional workloads, reaching critical wear levels quickly.
The SSD Supply Crisis: Why Companies Are Taking Risks
We're in the middle of a genuine flash shortage. This isn't artificial scarcity created by marketing. Real demand from AI data centers, cloud providers, and consumer electronics has outpaced production capacity. According to MSN News, hard drives have been on backorder for two years due to AI data centers triggering HDD shortages, forcing a rapid transition to QLC SSDs.
NAND flash production takes years to scale up. A new fab costs billions of dollars and takes 18-36 months to reach full production. You can't snap your fingers and create more supply. The shortage will persist through 2025 and likely into 2026.
In this environment, operators face a choice:
Option 1: Wait for new SSDs. Cost: guaranteed wait times of 90-180 days, capacity constraints, higher prices.
Option 2: Reuse existing SSDs. Cost: lower upfront, but catastrophic failure risk.
Option 3: Implement tiered storage. Cost: higher architectural complexity, but reliable.
Most companies are choosing Option 2 because it's the easiest in the short term.
The Vendor Perspective
Software-defined storage vendors like VAST Data have promoted flash reclamation as a solution. Their pitch: use tiered storage and intelligent data placement to extend the capacity of aging drives. The marketing sounds reasonable. The reality is that no amount of software can fix degraded hardware.
This puts vendors in a difficult position. They need to solve the capacity problem for their customers. They can't magic new flash into existence. So they're providing tools to manage risk on reused flash. But managing risk isn't eliminating risk.
Dell, on the other hand, has been explicit: flash wear is a physical problem. Software solutions don't work. The only reliable approach is to combine new flash with cheaper spinning media for less-critical data.
This tension reflects a fundamental disagreement about how to respond to the shortage. Dell is saying, "Be patient and build a proper architecture." Software vendors are saying, "Use what you have and optimize with software."
Both approaches have merit. But when it comes to mission-critical AI systems, patience is the better strategy.

The Economics of Failure: What Reused SSD Failure Actually Costs
Let's do the math. Say you save $10,000 by reusing SSDs instead of buying new ones. Your system runs for six months before a drive fails catastrophically.
What's the actual cost?
- Lost compute time: If the SSD fails during a training run, you lose all the work since the last checkpoint. For large models, that could be 24-72 hours of GPU time. At 5,000-15,000 in wasted compute.
- Operational overhead: Your team spends 8-16 hours diagnosing the failure, recovering data, replacing the drive, and restarting the system. That's $2,000-5,000 in labor cost.
- Potential data loss: If you can't recover the checkpoint data, you might lose entire training runs or corrupted model weights. The cost to retrain is astronomical.
- Reputational damage: If this failure cascades into production and affects customer-facing systems, the damage is immeasurable.
- Regulatory and compliance issues: Some industries require audit trails and data integrity guarantees. A storage failure might create compliance violations.
That $10,000 savings evaporates within days of a failure. You're making a bet that the drive won't fail. It's a bet most companies will lose if they run SSDs past their rated lifespan.
The Insurance Angle
Here's another angle: what does your insurance cover? If a reused SSD failure causes data loss, does your cyber insurance cover it? Most policies exclude failures from deprecated or unsupported hardware. You might be self-insuring your risk without realizing it.
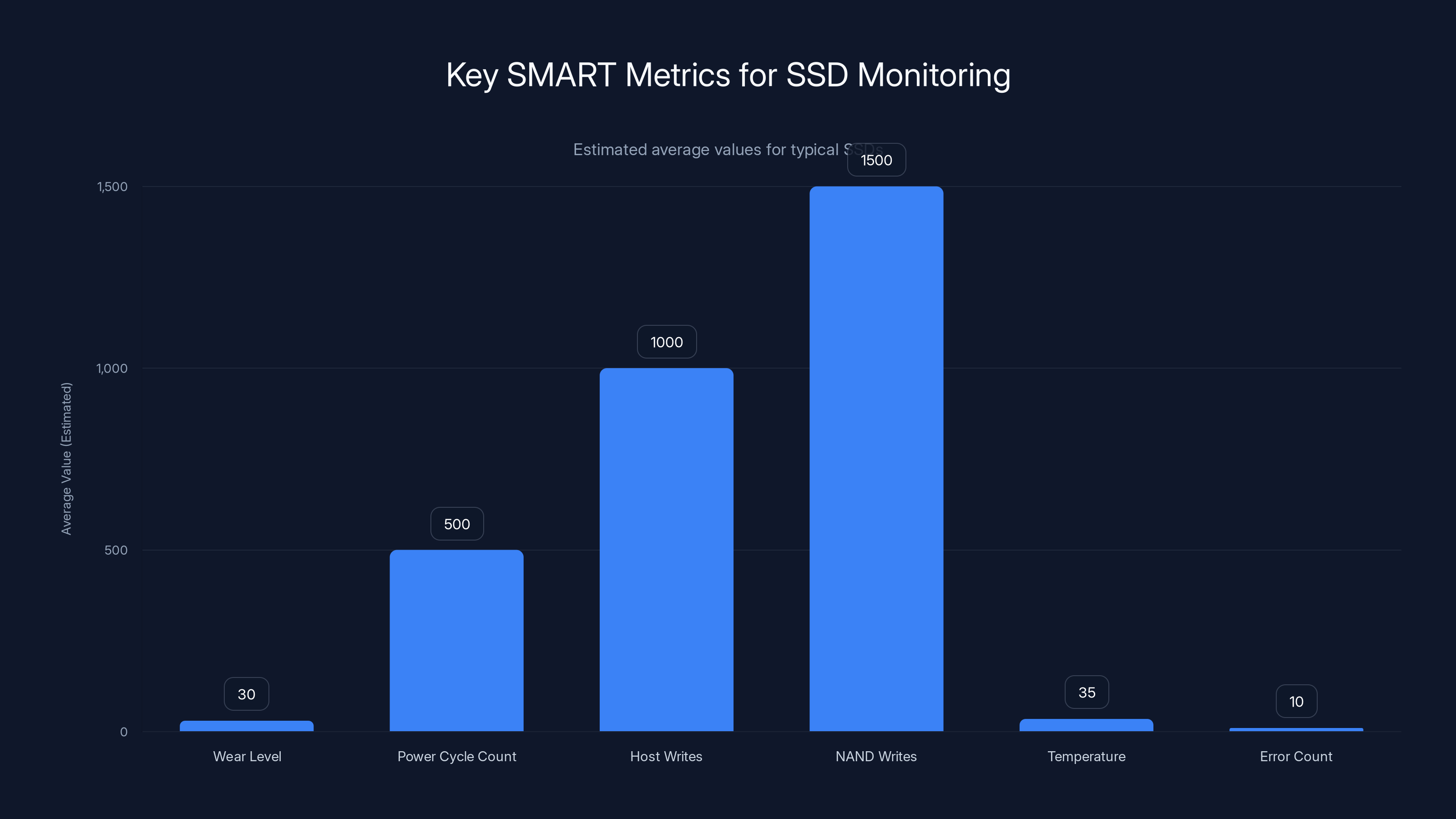
Estimated data shows typical values for key SMART metrics in SSDs. Monitoring these can help identify trends but not predict sudden failures.
Tiered Storage: The Real Solution
Dell and other enterprise storage vendors advocate for tiered storage architectures. This isn't a new concept, but it's been overlooked in the rush to go all-flash.
The idea is simple: not all data needs to be on flash. You can use a tiered approach where:
- Tier 1 (Flash): Hot data, actively being processed. NVMe or high-performance SSDs. Latest hardware only.
- Tier 2 (SATA SSD): Warm data, accessed regularly but not constantly. Newer SSDs, but not the bleeding edge.
- Tier 3 (HDD): Cold data, accessed infrequently. Spinning media. Cheap but much slower.
Automated policies move data between tiers based on access patterns. The AI system doesn't need to know which tier a file is on. The storage controller handles it automatically.
This approach has several advantages:
- Better resilience: You're not betting everything on expensive, scarce flash
- Lower cost: Spinning media is dramatically cheaper than SSDs
- Flexibility: You can adjust the tier distribution as your workload changes
- Longevity: By reducing the write load on flash, you extend its lifespan
The downside is complexity. You need more sophisticated controllers and monitoring. You need to understand your data access patterns. But for mission-critical systems, this is worth the investment.
Case Study: The Tiered Approach in Production
Consider a company running large language model training on 100 GPUs. Their traditional architecture was all-NVMe. They had 200TB of NVMe capacity costing roughly $400,000.
They switched to a tiered approach:
- 40TB NVMe (Tier 1): Active checkpoint data and training batches currently in use. $80,000.
- 80TB SATA SSD (Tier 2): Recently used training data, intermediate results from the last few hours. $40,000.
- 200TB HDD (Tier 3): Archive of completed training runs, historical data. $30,000.
- Automated tiering software: $10,000.
Total cost:
The performance difference? Training throughput dropped by 2-3% because occasionally data moved from cold storage had to be fetched from slower tiers. But the system remained reliable, and the write load on NVMe dropped by 60% because cold data wasn't staying on flash.
Two years in, they're still using the original NVMe drives. Zero failures. The savings multiplied because they didn't need to replace failed SSDs or deal with catastrophic data loss.
What Happens When You Ignore the Warnings
Let's talk about real failures. Data center operators aren't publishing case studies of catastrophic failures from reused SSDs, because that's embarrassing. But the pattern is consistent across the industry:
Pattern 1: The Silent Corruption
A team at an AI startup decided to reuse SSDs from their old high-performance computing cluster. They carefully wiped them and validated that they worked. For the first month, everything seemed fine.
Then, checkpoint files started showing corruption errors. Not always. Intermittently. The training system would restore from an earlier checkpoint and continue, losing hours of progress. This happened four or five times before they realized the issue was storage.
When they finally replaced the SSDs with new hardware, the corruption stopped. They never definitively proved that the old SSDs were the culprit (because the failures appeared random), but the timing was too convenient. They'd lost two weeks of training time and had no choice but to buy new SSDs anyway.
Pattern 2: The Cascading Failure
A different company reused SSDs in their inference cluster. This was a production system serving millions of requests per day. For a while, it worked.
Then, one drive started showing elevated latencies. Not failure. Just slowness. The load balancer routed traffic around the slow machine, but that concentrated load on other machines. Those machines saw higher write loads, which accelerated aging on their SSDs.
Within 48 hours, multiple drives had elevated latencies. The cluster performance degraded across the board. Customer-facing inference was slower. The company had to implement circuit breakers and fallback logic. Eventually, they replaced all the SSDs, but not before taking a reputation hit.
Pattern 3: The Recovery Nightmare
A research group used reused SSDs for their model training infrastructure. When a drive failed completely, they couldn't recover the checkpoint data. The training run was lost entirely. The data recovery services quoted $15,000-20,000 to recover the drive.
They decided to just restart training from an earlier checkpoint, losing three weeks of work. The cost of reused SSDs was negative when you factor in the lost research time.
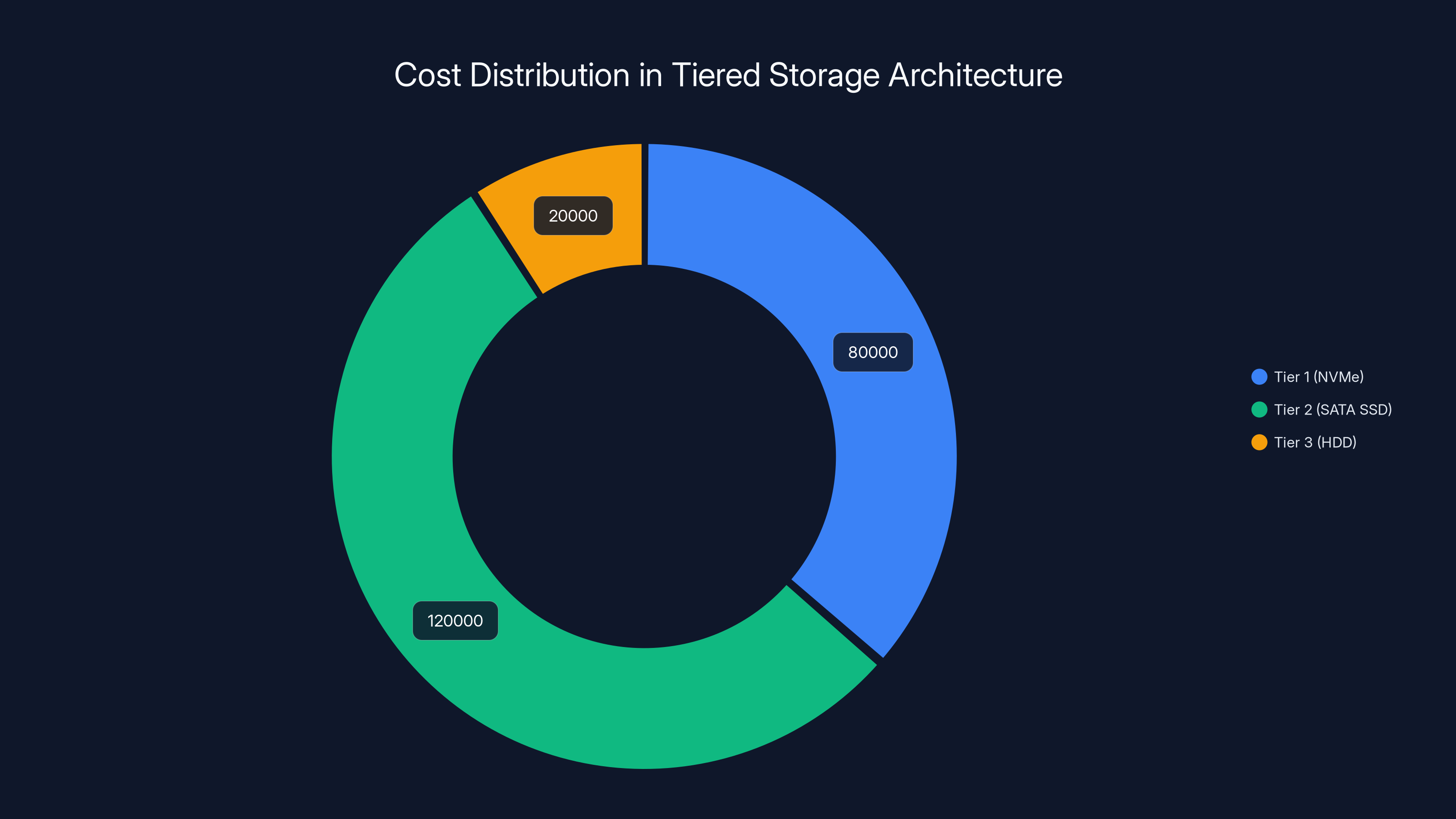
Estimated data shows that using a tiered storage approach can significantly reduce costs compared to an all-NVMe setup. Tier 1 (NVMe) is the most expensive, while Tier 3 (HDD) offers the lowest cost.
Detection and Monitoring: Can You Predict Failure?
Modern SSDs publish SMART metrics that tell you about wear and health. Every drive reports:
- Wear level: Percentage of the drive's lifespan consumed (0-100%)
- Power cycle count: How many times it's been powered on/off
- Host writes: Total data written by the host system
- NAND writes: Total data written internally (usually higher due to write amplification)
- Temperature history: Peak temperatures, current temperature
- Error count: Uncorrectable read errors, CRC errors, etc.
If you monitor these metrics, can you predict when a drive will fail? Theoretically, yes. In practice, no.
The issue is that SSD failures often happen suddenly. A drive can look healthy according to SMART data, and then fail abruptly. SMART metrics are useful for understanding wear trends, but they're not reliable predictors of catastrophic failure.
Reliability studies show that drives with high wear levels fail more frequently, but the correlation isn't perfect. Some heavily used drives last for years. Others fail at unpredictable times.
The Monitoring Strategy
A better approach is continuous monitoring combined with proactive replacement:
- Dashboard all SMART metrics in your monitoring system. Track wear level, temperature, error rates.
- Set aggressive thresholds for replacement. Replace drives at 40-50% wear, not 70-80%.
- Correlate SMART data with performance metrics. If you see latency spikes correlated with high wear, that's a red flag.
- Test failed drives separately. When a drive fails in production, remove it and run diagnostics. Document the failure mode.
- Build institutional knowledge about which drives fail soonest in your workload.
Over time, you'll develop a sense for which drives and manufacturers are reliable in your environment, and which ones should be replaced earlier.
Industry Response and Standards
The storage industry is split on how to handle the shortage. Some vendors are promoting flash reclamation. Others are doubling down on reliability and tiered architectures.
No major industry standard has emerged for defining what "reused" or "reconditioned" SSDs should meet. Unlike used servers or networking equipment, there's no standard benchmarking for used storage drives. This means the quality of reconditioned SSDs varies wildly depending on who's doing the reconditioning.
What Enterprise Buyers Should Demand
If you're evaluating SSDs (new or reconditioned), here's what you should require:
- Wear level attestation: Proof of the drive's P/E cycle consumption and remaining warranty
- Complete diagnostic report: SMART data from the last 90 days of operation
- Workload history: What was the drive used for? Was it in a data center or consumer environment?
- Replacement warranty: If a drive fails, what's the replacement guarantee?
- Transparent pricing: What's the discount relative to new drives? It should reflect the remaining lifespan
Most reconditioned SSDs can't provide this documentation. That's a red flag.

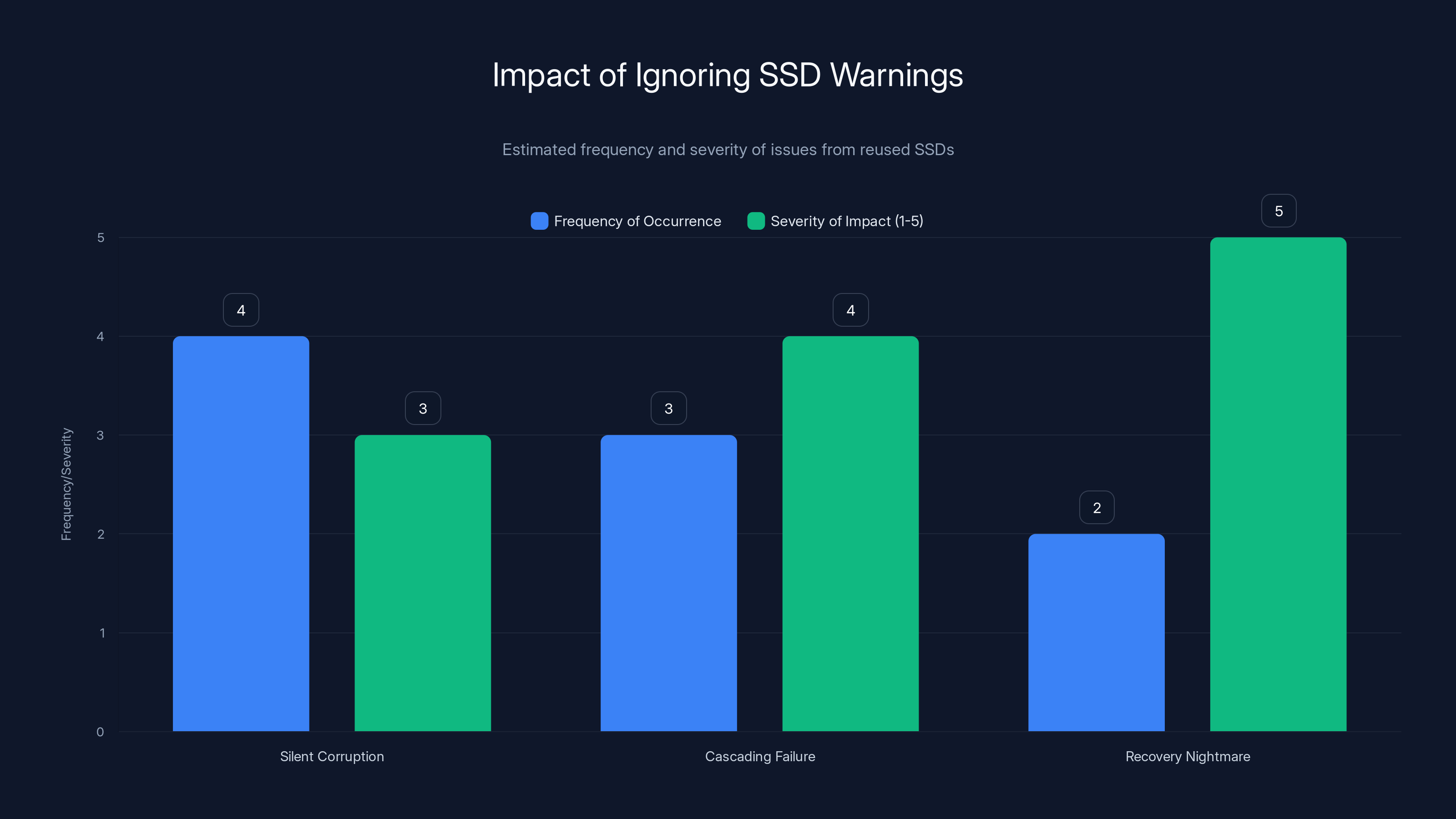
Ignoring warnings about reused SSDs can lead to various failure patterns, with 'Recovery Nightmare' being the most severe. Estimated data based on anecdotal evidence.
The Future: What Happens When Supply Normalizes
Eventually, the SSD shortage will ease. New fabs will come online. Older fabs will retool for increased production. Demand will likely plateau as the AI buildout reaches saturation.
When that happens, companies that bit the bullet and bought new SSDs will be in a strong position. Companies that tried to stretch aging SSDs will have paid for it through failures and operational overhead.
The interesting question is whether the industry will learn from this. Will companies invest in proper tiered storage architectures that remain efficient even when flash is cheap? Or will they go back to all-flash systems and repeat the same mistakes when the next shortage hits?
Historically, the industry doesn't learn well from shortages. Prices drop, people forget about the pain, and then everyone overprovisioning with expensive technology again. That cycle is likely to repeat.

Regulatory and Compliance Implications
If you're in a regulated industry, reusing SSDs might create compliance issues you haven't considered.
Data Residue and Security
When an SSD is wiped and refurbished, old data is theoretically gone. But NAND flash isn't like magnetic media. You can't overwrite it the same way. Even after multiple passes of overwriting, forensic techniques might recover deleted data.
If you're selling an old SSD externally, or even reusing it internally, and it later fails in a way that someone could recover data from it, you might have a breach. For companies handling sensitive data (healthcare, finance, government), this is a serious liability.
Audit Trail Requirements
Some regulations require you to maintain an audit trail of where data has been stored and how it's been protected. If an SSD fails and you can't prove that it was reliably maintained for compliance purposes, you might be violating regulations.
A storage failure isn't just a technical incident. It might be a compliance incident.
Insurance and Liability
Check your cyber insurance and liability policies carefully. Many policies have exclusions for failures related to deprecated, unsupported, or refurbished hardware. If a reused SSD causes a data breach or loss event, your insurance might not cover it.

The Right Way to Handle the Shortage
If you're facing the SSD shortage and pressure to cut costs, here's a practical approach:
Step 1: Assess your workload. Which systems truly need high-performance flash? Which can tolerate slower access? You probably have 20-30% of systems that are flash-critical and 70-80% that could use tiered storage.
Step 2: Invest in tiering infrastructure. This means controllers with intelligent data movement, monitoring systems, and policies. It's more complex than single-tier storage, but the savings are worth it.
Step 3: Prioritize new flash for mission-critical systems. Your AI training clusters, real-time inference systems, and customer-facing databases absolutely need reliable, new flash.
Step 4: Use tiered or secondary storage for less critical data. Historical data, logs, backups, and non-critical applications can use older SSDs or even spinning media with careful architectural design.
Step 5: Plan for replacement. You're not solving the shortage. You're managing it. Have a replacement schedule for SSDs as they age. As new supply comes online, gradually refresh your aging drives.
Step 6: Monitor relentlessly. You're running on older hardware. You need visibility into performance, reliability, and wear levels. This isn't optional.

Building a Resilience Culture
Ultimately, the SSD shortage is forcing data center operators to think more carefully about resilience. And that's not a bad thing.
Companies that weather this shortage successfully will be those that:
- Plan for component failure. Assume SSDs will fail. Build systems that can tolerate it.
- Understand their workloads. Know which data actually needs flash. Stop treating all data the same.
- Invest in observability. Monitor storage health, performance, and reliability continuously.
- Make long-term architectural decisions. Don't patch problems with duct tape and hope.
- Communicate honestly about risk. If you reuse SSDs, everyone should know about it and understand the tradeoffs.
The companies that ignore these lessons and just push worn drives into production will eventually pay for it. The question is how much it will cost before they learn.

Key Takeaways for Your Organization
If you take nothing else from this, remember these points:
Flash degradation is real. NAND flash cells have a finite lifespan. Reusing worn drives increases failure risk exponentially, not linearly.
AI workloads are brutal on storage. Training systems and large-scale inference push storage to its limits. Reused SSDs can't handle sustained write patterns from AI systems.
The cost of failure is catastrophic. A failed SSD might cost $500-1,000. The cost of data loss, lost compute time, and operational recovery is 10-100x higher.
Tiered storage is the solution. Not all data needs flash. Distribute your data intelligently and extend the lifespan of your SSDs.
Monitor everything. If you're using any older storage, aggressive monitoring and proactive replacement is essential.
Plan ahead. The shortage is temporary, but its effects will last years. Build your infrastructure with that timeline in mind.

FAQ
What is flash wear and why does it matter for AI systems?
Flash wear refers to the physical degradation of NAND transistors through repeated write cycles. Each time data is written to a flash cell, the protective oxide layer weakens slightly. In AI systems with constant write patterns, this degradation accelerates dramatically, potentially causing data loss or system failure within weeks or months if the SSD is already partially worn.
How can I tell if my SSDs are degraded and likely to fail?
You can check SMART metrics like wear level percentage, power cycle count, and unrecoverable error counts. However, SMART data isn't a reliable failure predictor—SSDs can fail suddenly even when SMART metrics look healthy. The best practice is to proactively replace SSDs once they reach 40-50% wear level rather than waiting for predictive signs of failure.
Why is reusing SSDs from old systems so risky for AI workloads?
AI systems have unique storage demands with extremely high write throughput. Large language model training can sustain 70-90% write patterns continuously, which is far more aggressive than traditional database or application workloads. A reused SSD that's already consumed half its lifecycle will hit critical wear levels within weeks under these conditions, whereas it might have lasted years in a less demanding environment.
What's the difference between tiered storage and just using older SSDs?
Tiered storage uses automated policies to move data between different storage types (NVMe, SATA SSD, HDD) based on access patterns. This reduces the write load on expensive flash by moving cold data to cheaper tiers, extending flash lifespan and improving reliability. Using older SSDs directly means all that wear-inducing traffic still hits the degraded drives—the workload doesn't change, only the hardware gets worse.
How much should I pay for a reconditioned enterprise SSD?
Reconditioned SSDs should be significantly cheaper than new ones, with the discount reflecting their remaining lifespan. If a drive has 50% wear consumed, it should cost roughly 50% less than a new drive, not 20-30% less. However, insist on documented wear-level attestation and a realistic warranty. If the seller can't provide this documentation, avoid the purchase entirely.
What happens when a reused SSD fails in production?
Failures typically progress from occasional latency spikes to intermittent read errors to eventual write failures. The critical issue is that this happens unpredictably, so your system might lose hours of training progress, serve incorrect inference results, or experience complete downtime. The recovery process often requires data recovery services ($15,000+) or restarting from an earlier checkpoint (losing days of work).
Are there compliance issues with using reused or refurbished SSDs?
Yes. Regulated industries have audit trail requirements that may not be met with reused drives. Additionally, if a reused SSD fails and data is lost, your cyber insurance might not cover it if the drive was unsupported or refurbished. Check your insurance policies and compliance requirements before using reconditioned hardware for regulated data.
How long will the SSD shortage last?
Analysts expect the enterprise SSD shortage to persist through 2025 and into 2026. New fab capacity is being built, but NAND production takes 18-36 months to scale up from announcement to full production. Supply constraints may ease gradually rather than suddenly resolving.
Should I go back to hard disk drives for everything to save money?
Not entirely, but strategic use of HDDs in a tiered architecture is smart. Spinning media is much cheaper per terabyte and reliable for sequential access patterns. However, you still need flash for hot data, real-time systems, and high-performance workloads. The goal is balance, not cost minimization at the expense of performance.
What's the first thing I should do to reduce SSD failure risk?
Start monitoring SMART metrics for all your SSDs immediately. Create a dashboard showing wear level, temperature, error counts, and power cycles. Set aggressive thresholds for replacement (40-50% wear) and swap out drives before they reach critical levels. This shifts you from reactive failure response to proactive replacement, dramatically improving reliability.

Conclusion: The Cost of Shortcuts
The SSD shortage has put data center operators in an uncomfortable position. The easy path is to reuse older drives and hope they last. The hard path is to invest in tiered architecture, accept longer delivery timelines for new hardware, and acknowledge that sometimes you can't have everything right now.
Easier paths usually look better until they don't. And when they fail, they fail spectacularly.
Every company facing this decision needs to ask itself: what's the actual cost of a storage failure? If you lose a training run, how much compute is that? If inference latency becomes unpredictable, how many customers does that affect? If data becomes corrupted, what's the cost of recovery or remediation?
Those numbers almost always exceed the savings from reusing SSDs.
The industry will move past this shortage. Supply will normalize. Prices will drop. And companies that invested wisely in reliable architecture will have systems that scale and perform. Companies that cut corners will be managing failures and paying for it in lost productivity and reputation damage.
Flash wear is physical. You can't argue with physics. You can only choose to respect it or ignore it. The successful data center operators will be those who respect it.

Related Articles
- Neurophos Optical AI Chips: How $110M Unlocks Next-Gen Computing [2025]
- AI Storage Demand Is Breaking NAND Flash Markets [2025]
- Responsible AI in 2026: The Business Blueprint for Trustworthy Innovation [2025]
- Copper Shortage Crisis: How Electrification Is Straining Global Supply [2025]
- Micron 3610 Gen5 NVMe SSD: AI-Speed Storage & QLC Advantage [2025]
- DDR5 Memory Prices Could Hit $500 by 2026: What You Need to Know [2025]

