![SurrealDB 3.0: One Database to Replace Your Entire RAG Stack [2025]](https://tryrunable.com/blog/surrealdb-3-0-one-database-to-replace-your-entire-rag-stack-/image-1-1771337264405.jpg)
Introduction: The Multi-Database Complexity Problem
Here's the thing that keeps data architects up at night: building AI agent systems in 2025 means juggling PostgreSQL for structured data, Pinecone for vectors, Neo4j for graphs, Redis for caching, and whatever else handles agent memory. You're not alone if this sounds insane. It is.
Every time an AI agent needs to answer a question, it bounces between five systems. Query one returns customer data. Query two fetches similar case embeddings. Query three traverses relationship graphs. Then your application code stitches everything together, hopes nothing changed between systems, and prays the latency stays acceptable. Spoiler: it doesn't.
The synchronization overhead? Real. The consistency headaches? Worse. The development time exploding from weeks to months? That's the part that actually hurts.
This is the problem SurrealDB 3.0 is targeting. The Guildford, UK-based company just closed a
Before you dismiss this as another "unified platform" hype pitch (and there have been many), let's dig into what actually changed and whether this architecture fundamentally solves real problems or just moves complexity around.
The RAG Stack Explosion: Why We Got Here
Retrieved-augmented generation wasn't supposed to be this complicated.
In theory, RAG was simple: take a user question, fetch relevant documents, feed everything to an LLM, get an answer. In practice? The moment you wanted that answer to be correct, you ran into architecture problems.
Start with structured data. Most companies have relational databases with customer records, transaction history, product catalogs. That's your source of truth. But LLMs don't work well with raw SQL results. They need context, relationships, semantic understanding.
So you add vector search. Your documents get embedded into high-dimensional space. Now queries return semantically similar content rather than exact keyword matches. Better results. New problem: embedding vectors live in a different system than your structured data.
Then you realize your data has relationships. A customer is connected to orders, which connect to products, which connect to reviews. Traversing these relationships through sequential SQL queries is slow and doesn't capture the full context graph. Enter graph databases. Neo4j, Amazon Neptune, whatever you choose. But now you're running three systems.
Then AI agents entered the conversation. Agents don't just answer one question and stop. They maintain memory across conversations. They need to remember what they learned about this specific customer, what worked last time, what failed. That memory needs to be fast, transactional, and deeply integrated with the reasoning process.
Caching layers entered the chat. Redis for hot data. Memcached for distributed caching. Your application code now orchestrates queries across seven different systems, tries to keep everything in sync, and prays nothing goes stale.
The result? A team of three experienced engineers can spend six months architecting this stack. Maintenance becomes a nightmare. Consistency bugs hide for months. And worse, your AI agent operates with a fragmented view of reality because no single query can see everything.
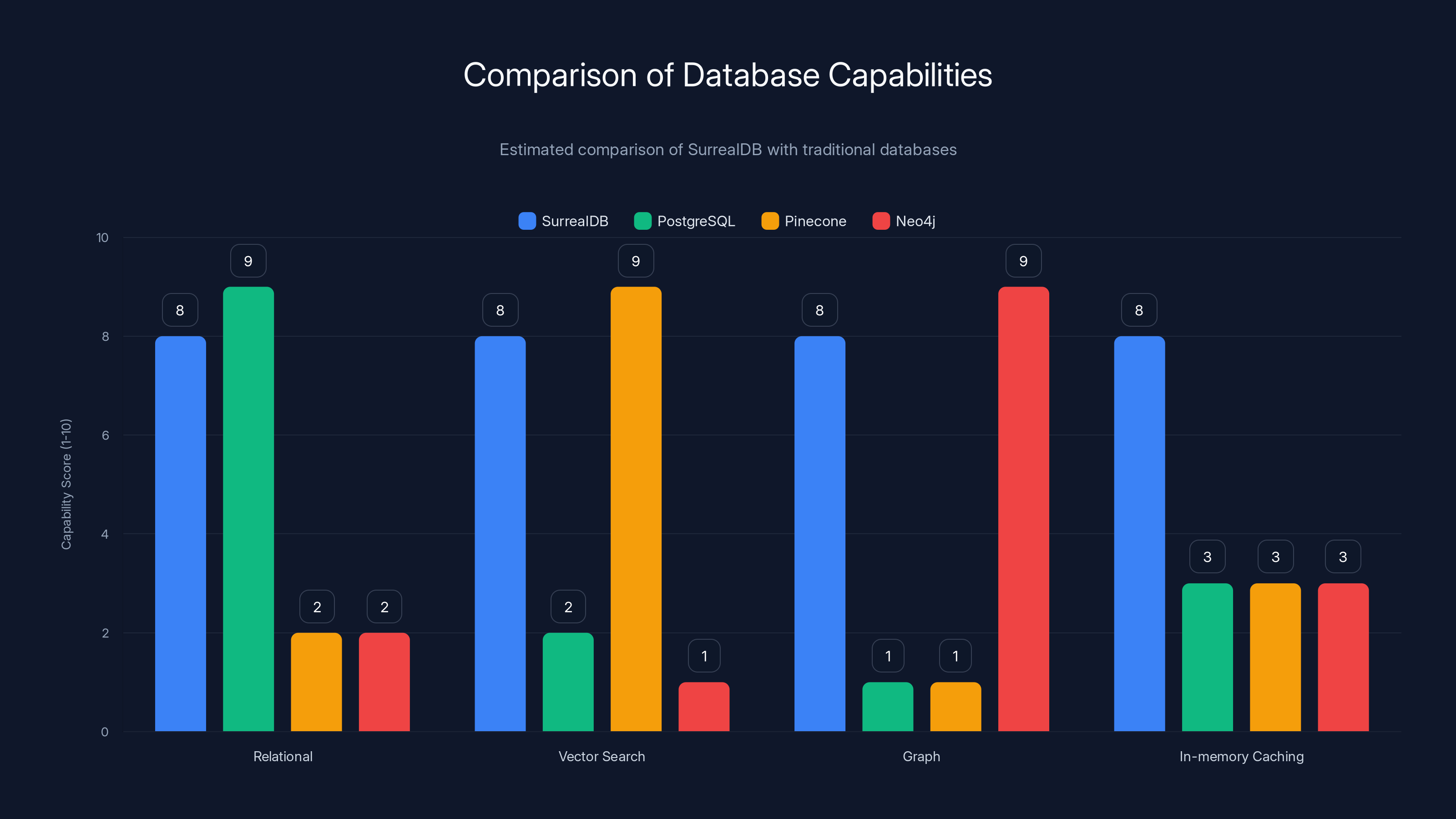
SurrealDB offers a unified solution with high capability across relational, vector, graph, and caching functionalities, unlike traditional databases which specialize in specific areas. Estimated data.
Understanding Surreal DB's Architecture
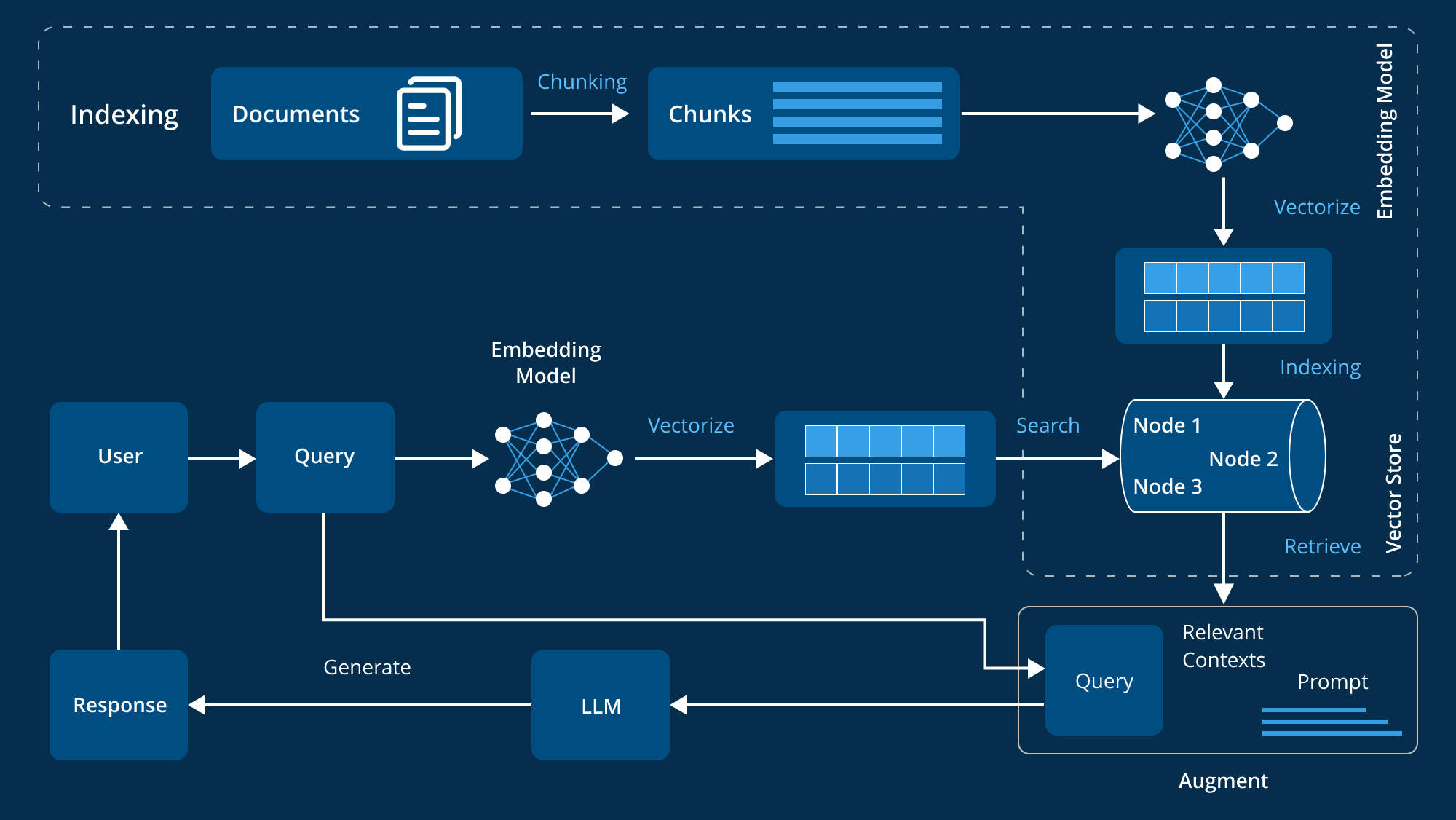
Surreal DB takes a fundamentally different architectural approach. Instead of separate systems, it's a single Rust-native engine that stores everything as binary-encoded documents with embedded graph relationships.
Here's what that actually means:
When you store a customer record in Surreal DB, the vector embeddings don't live in a separate table somewhere. The relationship to their orders isn't stored as a foreign key reference that requires another query. Instead, the entire context lives together: structured fields, embeddings, relationships, and metadata all in one document.
This isn't a new idea. Document databases have done this for years. The difference is in the query engine. Surreal DB's query language, Surreal QL, can traverse these relationships, perform vector similarity searches, and execute relational joins all in a single query. No round-tripping between systems. No application code stitching results together.
Consider a practical example: an agent needs to handle a customer support issue. The query needs to:
- Fetch the current customer record (structured data)
- Find their previous support tickets (graph traversal through relationship edges)
- Find similar cases from other customers (vector similarity search across embeddings)
- Analyze the combined context to recommend next steps
In a traditional stack, you'd write four separate queries to four different systems. Your application code merges the results. If the customer updates their information between query one and query four, your result set is inconsistent.
In Surreal DB, you write one query. Everything executes transactionally. The customer's latest information is visible to all parts of the query. The similar cases are ranked by semantic distance using the same real-time data. Consistency is guaranteed.
How Agent Memory Works Inside Surreal DB
AI agents need memory to operate effectively. This sounds obvious until you try to implement it.
A basic agent might remember facts about the user: "They prefer email contact. They've purchased from us 47 times. They complained about late shipping last month." But effective agents remember more: decision patterns, what arguments worked in past conversations, what failed, the semantic similarity between current problems and historical ones.
Traditionally, this memory lives in application code, file stores, or external caching layers. The agent doesn't have direct access to the historical context that would improve its reasoning.
Surreal DB 3.0 introduces the Surrealism plugin system. This lets developers define exactly how agents build and query memory. The plugin runs inside the database, not in middleware. When an agent makes a decision or learns something new, it writes directly to the database as graph relationships and semantic metadata.
Imagine a customer service agent handling complaints. When it resolves an issue successfully, it doesn't just log the outcome somewhere. It creates a graph relationship: "Issue Type -> Resolution Strategy -> Success Rate." This relationship is queryable. Future interactions with the same issue type automatically have access to historical success patterns.
The agent asks: "What resolution strategies worked for similar billing disputes?" The query traverses the memory graph, finds related issues, pulls the semantic embeddings of successful resolutions, and returns the patterns. All in one transactional query with consistency guarantees.
Here's the architectural difference that matters: because memory lives inside the database and uses the same query engine as everything else, the agent operates with perfect knowledge consistency. It can't accidentally reference stale memory or experience race conditions where multiple queries conflict.
This becomes critical at scale. A single agent might maintain hundreds of thousands of memory relationships across thousands of conversations. Traditional architectures require complex invalidation logic, cache warming strategies, and eventual consistency patterns. Surreal DB's transactional approach means you don't have to think about this. It just works.

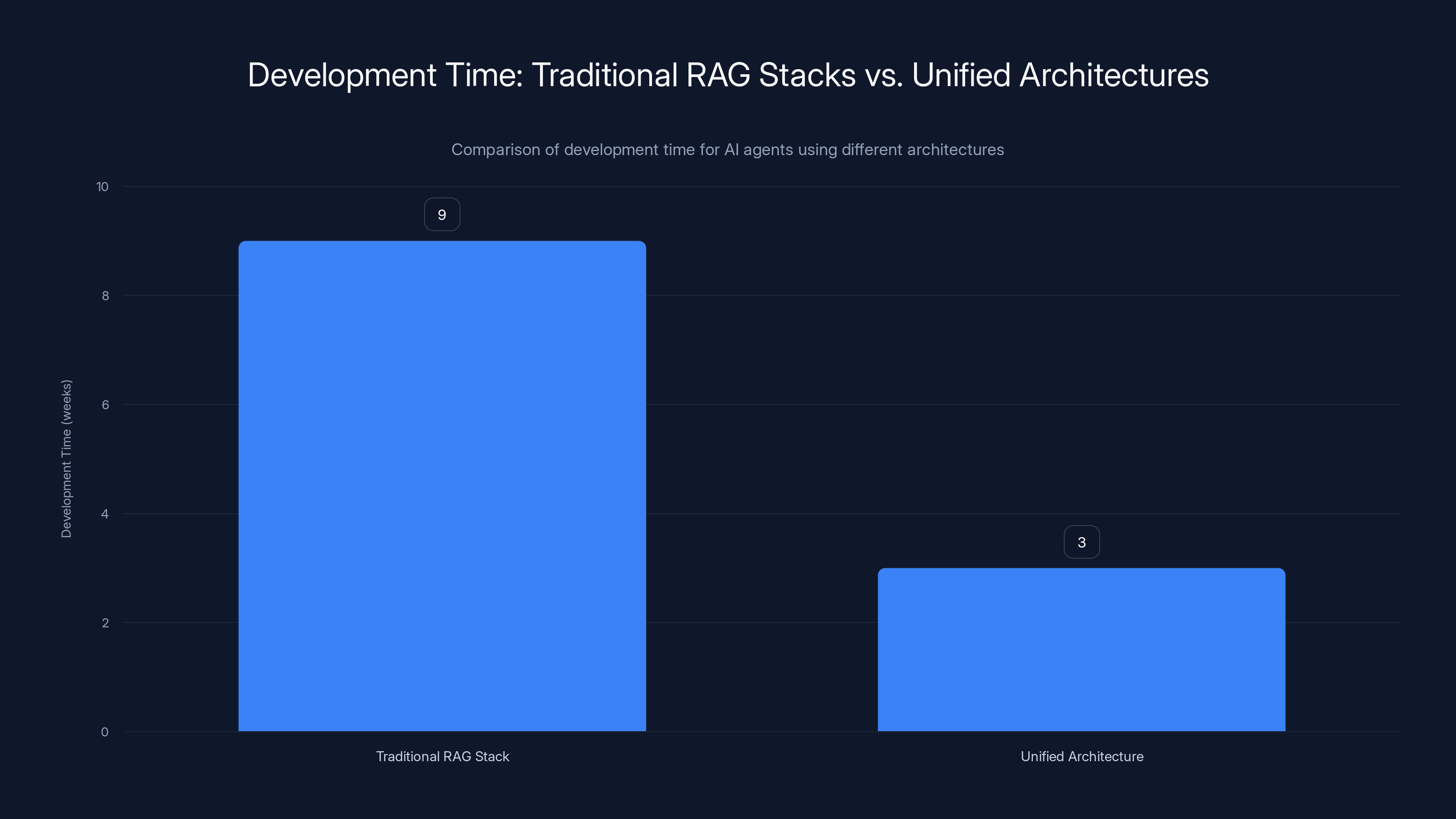
Unified architectures significantly reduce development time, from an average of 9 weeks for traditional RAG stacks to just 3 weeks. Estimated data based on typical project timelines.
Consistency at Scale: Every Node Sees Everything
Here's where Surreal DB's architecture claims to diverge dramatically from how people typically scale databases.
When you scale PostgreSQL, you use read replicas. Your write leader handles all updates. Read queries distribute across replica nodes. This works well for read-heavy workloads. Netflix built massive systems this way.
But here's the catch: read replicas introduce lag. A query on a replica might not see the most recent write. For RAG systems where agent memory is constantly updating and decisions depend on absolute freshness, replica lag creates accuracy problems.
Surreal DB claims to solve this differently. Every node in a cluster maintains transactional consistency. When an agent writes new context to node A, a query on node B immediately sees that update. No caching. No read replicas. No eventual consistency patterns.
How? The architecture uses a different approach to distributed consensus. Rather than copying data to replicas after the primary commits, Surreal DB coordinates writes across all nodes simultaneously. Every node sees writes in the same order. Every query runs against the complete, current dataset.
The trade-off is obvious: write coordination across many nodes introduces latency. Traditional databases optimize for read-heavy workloads specifically because writes are expensive. Surreal DB optimizes for workloads where reads and writes happen frequently and freshness matters more than absolute throughput.
For most OLAP (analytical query) workloads, this is the wrong choice. If you're analyzing petabytes of historical data that never changes, you want a columnar data warehouse, not Surreal DB.
But for operational systems where agents continuously learn and update context? The calculus flips. You're willing to accept higher write latency if it means every agent query sees consistent, up-to-date memory.
CEO Tobie Morgan Hitchcock emphasized this in a recent talk: "A lot of our deployments are where data is constantly updated and the relationships, the context, the semantic understanding needs to be constantly refreshed. So no caching. There's no read replicas. In Surreal DB, every single thing is transactional."
This is a fundamentally different design philosophy than how companies scaled relational databases for the last 20 years. Whether it's better depends entirely on your workload.
Comparing Traditional RAG Stacks vs. Unified Architectures
Let's break down how these architectures actually differ in practice.
A traditional RAG stack for an AI agent might look like this:
Data Layer: PostgreSQL stores customer records, transactions, product data. Every query requires explicit schema definition and SQL.
Vector Layer: Pinecone or Weaviate stores embeddings of your documents. Queries return the top-k most similar items based on embedding distance.
Graph Layer: Neo4j maintains relationships between entities. Queries traverse edges to find connected data.
Memory Layer: Redis caches frequently accessed data. Application code manages invalidation and warming strategies.
Orchestration: Your application code writes the logic that queries all four systems, merges results, and formats them for the agent.
Development time for a new agent: 6-12 weeks typically. You need engineers who understand each system's query language, performance optimization for each, and how to handle consistency between them.
A unified architecture in Surreal DB looks like this:
Single Query Engine: Vectors, graphs, structured data, and relationships all live in one system. One query language. One consistency model.
Development: Define your schema once. Write the agent logic. Deploy.
Hitchcock claims development time drops to days for basic implementations, weeks for complex ones.
The practical trade-off: Surreal DB won't outperform specialized systems in their specific domains. A query that only needs vector similarity search will be slightly slower in Surreal DB than pure Pinecone. A pure relational query might be slower than optimized PostgreSQL.
But the moment you need multiple data types together, the unified architecture wins because you don't have the overhead of querying five systems and merging results in application code.
Real-World Deployments and Use Cases
Surreal DB isn't theoretical. The company claims 2.3 million downloads and 31,000 GitHub stars, with actual deployments across several domains.
Edge devices in automotive systems represent one interesting use case. Connected cars need to store vehicle data, sensor information, relationship graphs (this component connects to that assembly), and make decisions locally even when offline. A single database that handles structured data, relationships, and transactional memory fits this perfectly.
Defense systems apparently use Surreal DB for similar reasons: reliable local persistence, consistent queries, transactional guarantees without relying on cloud connectivity.
Product recommendation engines for major New York retailers represent another use case. Recommendations require understanding: customer purchase history (structured data), similarity between products (vector embeddings), category relationships and supply chains (graphs), and learning from what recommendations worked (agent memory). Surreal DB handles all four natively.
Android ad serving technologies use it for real-time ad selection. Serving ads requires ranking candidates by relevance to the user (vector similarity), applying business logic constraints (relational queries on business rules), understanding the ad's category relationships (graph traversal), and learning from performance (updating memory). Latency matters. Consistency matters. Surreal DB's architecture seems purpose-built for this.
These deployments suggest the technology works in production. Whether they represent the majority use case or carefully selected examples remains an open question.
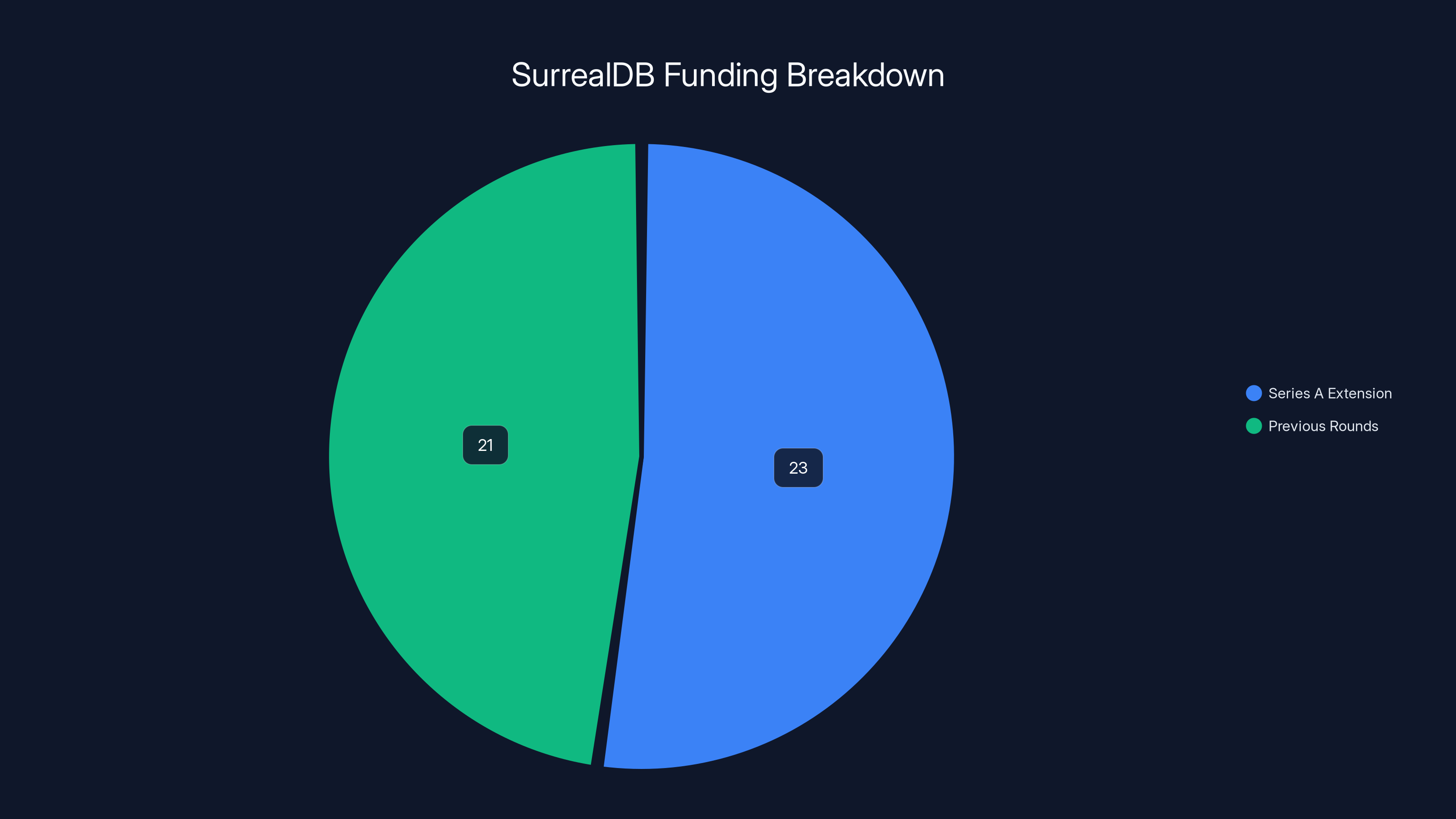
SurrealDB's Series A extension accounts for over half of its total $44 million funding, indicating strong investor confidence. Estimated data.
Performance Characteristics and Benchmarks
How fast is Surreal DB actually? That depends what you're measuring.
For pure vector similarity search on a dataset of 1 million embeddings, a specialized vector database like Pinecone will likely return results faster. Pinecone optimizes aggressively for this specific operation.
For complex queries combining multiple data types, Surreal DB should theoretically win because you're executing one query instead of merging results from five systems. Real-world benchmarks would be valuable here, though publicly available data remains sparse.
The architectural approach suggests certain performance profiles:
Sequential queries combining multiple data types: Surreal DB likely wins. You're avoiding the network round trips and application-level merging overhead.
Pure relational queries: PostgreSQL likely faster due to decades of optimization specific to relational workloads.
Pure vector search: Pinecone likely faster due to specialized indexing structures.
Mixed workload with agent memory: Surreal DB likely wins because the agent doesn't have to chase data across multiple systems and consistency is guaranteed.
What's missing from public information: actual benchmarks comparing Surreal DB to a well-tuned multi-database stack on realistic agent workloads. The company makes claims, but independent verification would strengthen the narrative significantly.
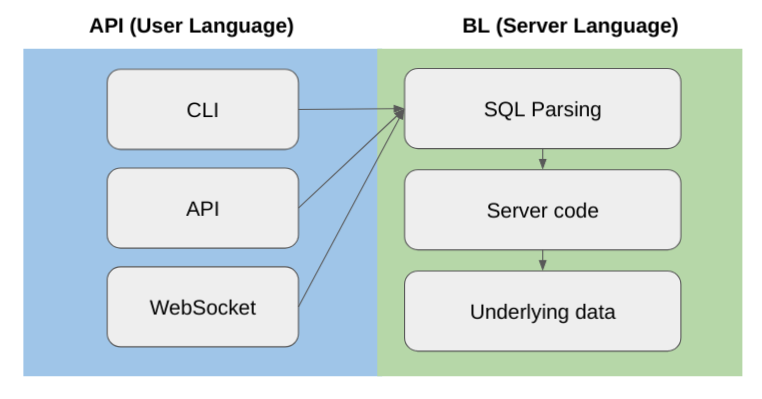
The Developer Experience: Surreal QL Deep Dive
Surreal QL is the query language you'll actually use to interact with Surreal DB. It combines concepts from SQL, document databases, and graph databases into a single syntax.
A basic structured query looks familiar:
sqlSELECT name, email FROM customers WHERE age > 30;
Vector similarity search extends this:
sqlSELECT name, email FROM customers
WHERE vector_distance(embedding, <query_vector>) < 0.15
ORDER BY vector_distance ASC
LIMIT 10;
Graph traversal uses edge notation:
sqlSELECT * FROM customer->purchase->product
WHERE purchase.date > '2024-01-01';
Combining all three in one query:
sqlSELECT customer.name, customer.email,
vector_distance(embedding, <query_vector>) as similarity,
related_issues.resolution_rate
FROM customer
LET customer->purchase->product as products
LET products->similar[?similarity > 0.8] as related_issues
WHERE vector_distance(embedding, <query_vector>) < 0.15
ORDER BY similarity ASC;
For developers coming from SQL, this feels relatively natural. For those with graph database experience, the traversal syntax is familiar. Vector operations extend naturally as additional functions.
The documentation matters here, and early user feedback suggests the learning curve isn't steep for developers experienced with modern databases.
What's genuinely different: the ability to express complex multi-type queries in a single statement with transactional guarantees. You're not writing application code that orchestrates between systems. You're writing queries that express intent directly.
Deployment Models: Cloud, Self-Hosted, Edge
Surreal DB offers multiple deployment options.
Cloud deployment through Surreal Cloud (their hosted service) handles infrastructure, scaling, and backups automatically. Pricing appears consumption-based, though specific numbers aren't widely published.
Self-hosted deployment is straightforward: run the open-source binary on your infrastructure. This matters for companies with data residency requirements, compliance constraints, or who want to avoid cloud vendor lock-in.
Edge deployment represents an interesting capability. You can run Surreal DB on embedded systems, edge devices, mobile devices. Sync data back to a central instance when connectivity exists. This enables offline-first architectures where local decisions happen immediately without waiting for cloud queries.
This flexibility matters practically. An automotive system runs Surreal DB locally on the vehicle, handles decisions instantly, syncs to the cloud when Wi-Fi connects. A retail store runs Surreal DB on-device for product recommendations, updates overnight. A mobile health app makes decisions locally with on-device data, syncs aggregate insights to the cloud.
Compare this to traditional stacks: if your vector database is cloud-hosted and your agent runs at the edge, you have a problem. Network latency kills performance. You need to replicate or cache data locally, which introduces all the consistency issues you were trying to avoid.
Surreal DB's support for edge deployment changes this equation.
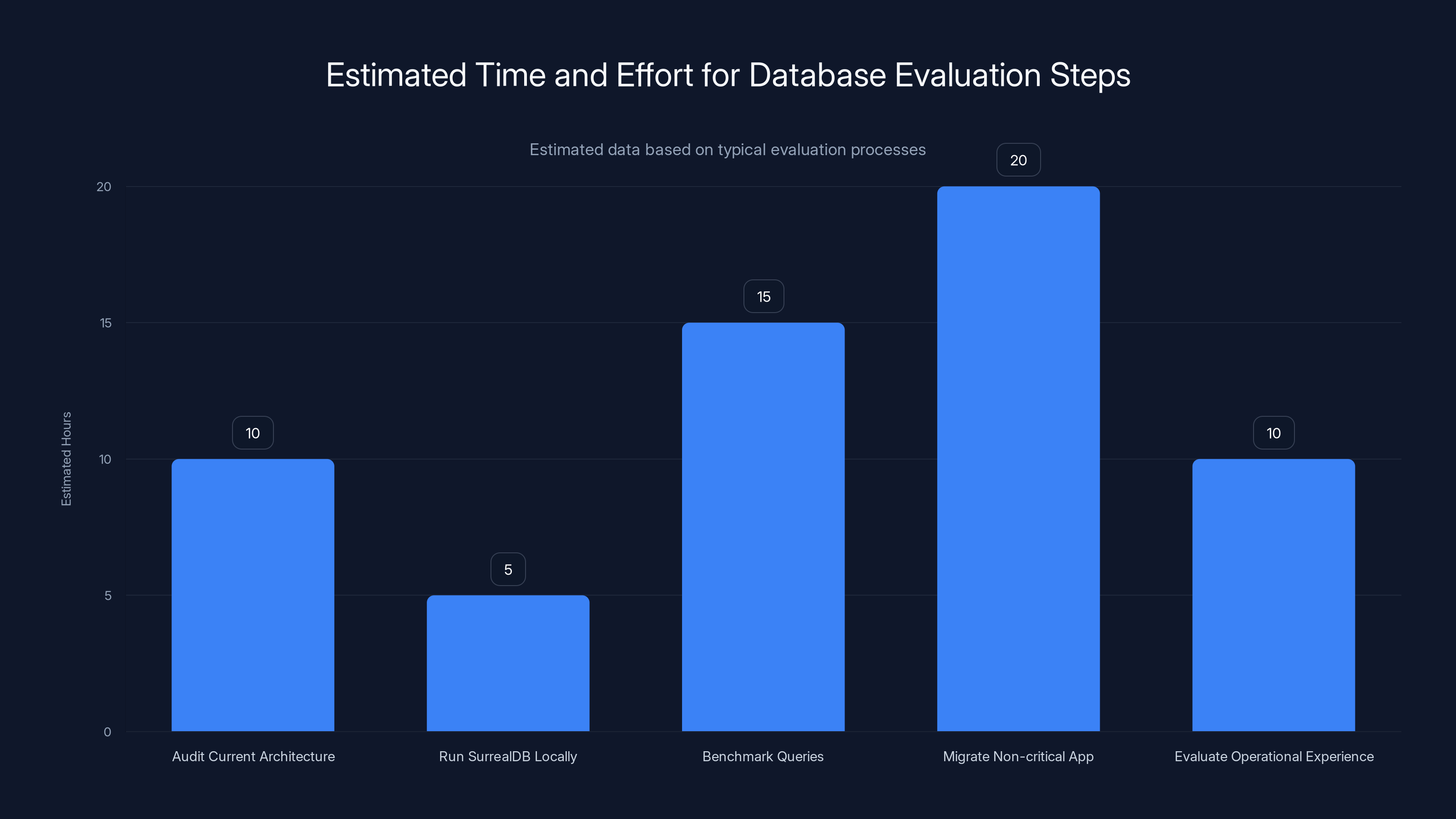
Estimated data shows that benchmarking queries and migrating a non-critical app are the most time-consuming steps in evaluating SurrealDB.
Integration Ecosystem and Developer Tools
How does Surreal DB fit into your existing development stack?
SDKs exist for JavaScript/TypeScript, Python, Rust, Go, and other popular languages. Query support through standard HTTP APIs means you can integrate from almost anywhere.
ORMs are beginning to emerge. The Surreal DB JavaScript SDK includes query builders that feel familiar to developers who've used other ORMs.
What's still developing: integrations with the broader data ecosystem. How does it fit with dbt for transformations? What about data pipeline tools like Airbyte? Apache Kafka integration? These gaps aren't blockers, but filling them would accelerate adoption.
The open-source nature means the community can build integrations. The project already has Surreal-to-GraphQL translation tools and various extension libraries.
For developers on their laptop, setting up a development environment takes minutes. Start the server, define schema, start querying. The barrier to experimentation is genuinely low.
When NOT to Use Surreal DB
Here's what Hitchcock said that matters: "It's important to say Surreal DB is not the best database for every task."
He's right. If your entire workload is analytical queries over petabytes of historical data that never changes, use a columnar data warehouse. Snowflake or BigQuery will crush Surreal DB. You don't need real-time transactional consistency. You need compression, query optimization for massive scans, and aggregations.
If you only need vector search, pure vector databases like Pinecone still offer better performance for that specific task. The overhead of running a unified system isn't worth it if you don't need the other capabilities.
If your data is so interconnected that graph traversal is the dominant access pattern, a dedicated graph database like Neo4j has optimizations you won't get from Surreal DB.
If you're building a user-facing application that doesn't involve AI agents or complex context reasoning, PostgreSQL is simpler, more mature, and better understood by most teams.
The inflection point for Surreal DB is precisely where you need multiple data types together and consistency matters. Agent systems. Real-time recommendations. Edge applications maintaining local consistency. Operational databases where decisions depend on current, complete context.

Implementation Timeline and Migration Path
If you're intrigued but not ready to rewrite your entire architecture, what does adoption look like?
Phase one typically involves running Surreal DB alongside existing systems. New features or agents get built on Surreal DB. Legacy systems stay on PostgreSQL and other databases.
Phase two involves migrating specific domains. Perhaps customer data moves to Surreal DB first. Then product data and relationships. The vector database becomes a cache rather than a primary store, since embeddings are now stored natively.
Phase three involves retiring legacy systems as more workloads move to the unified database.
This phase-in approach reduces risk. You learn the system. You debug problems incrementally. You don't bet the company on a single architectural migration.
The timeline varies wildly. A small team with a new application might do a full migration in weeks. An enterprise with decades of existing infrastructure might spend years gradually shifting workloads.
The key question: does the long-term benefit of a unified architecture justify the migration cost? For new greenfield projects, it's an easier yes. For entrenched systems, the calculus requires real analysis of operational burden and consistency problems in your current stack.
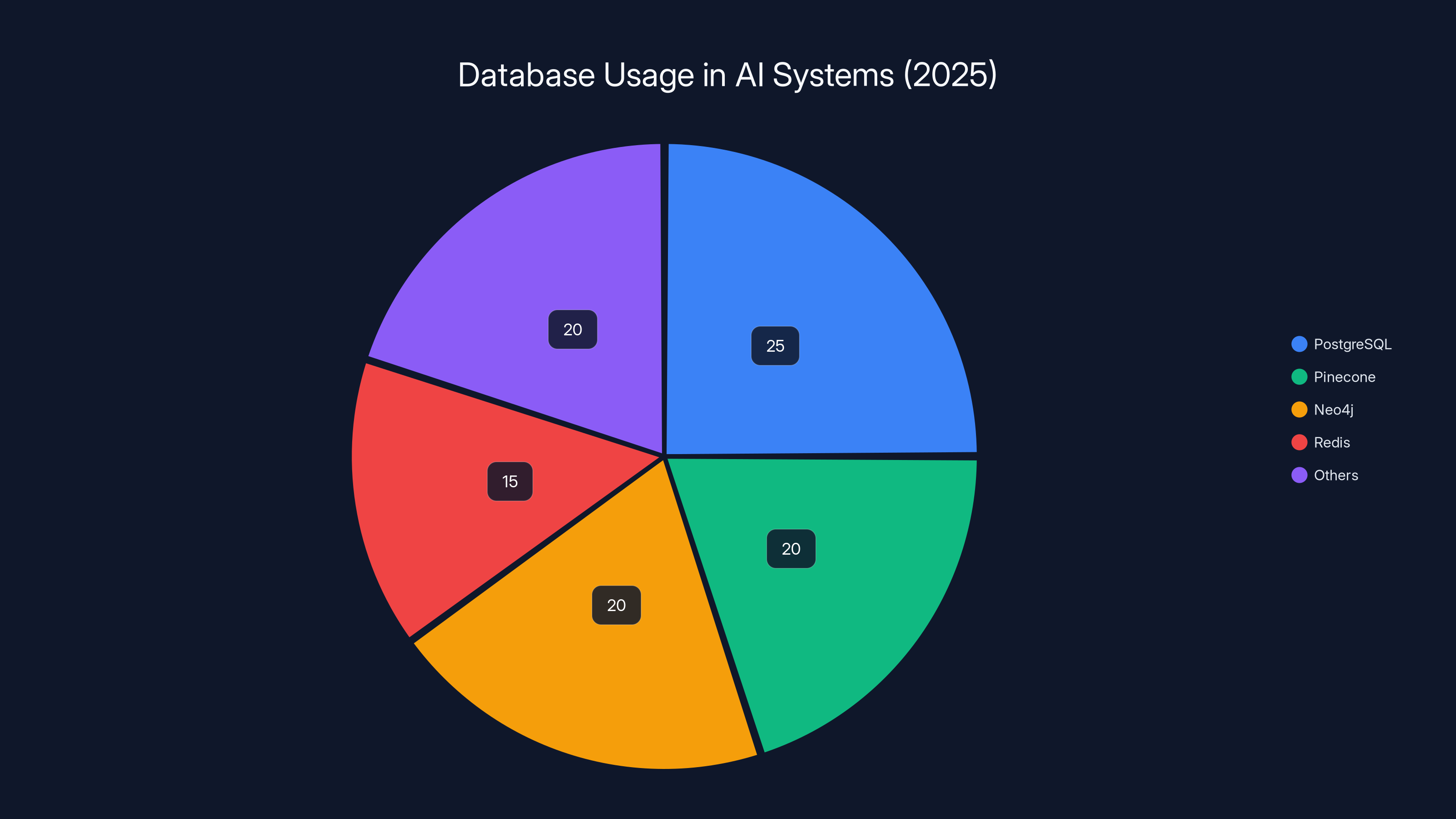
Estimated data shows diverse database usage in AI systems, with PostgreSQL and Neo4j among the most used. SurrealDB aims to unify these functionalities.
The Funding and Company Trajectory
Surreal DB raised
Funding amount matters. It signals investor confidence that the market problem is real and the solution has potential. $44 million is enough to fund several years of development, hire specialized talent, build enterprise features, and scale operations.
The timing also matters. As AI agents move from proof-of-concept to production, the pain of managing multi-database RAG stacks intensifies. Companies are increasingly looking for solutions. Surreal DB enters this market with a mature product and financial runway.
The geographic advantage (Guildford, UK) provides access to European engineering talent and might position them well for GDPR-conscious enterprises where data residency matters.
The open-source approach creates community momentum. 31,000 GitHub stars indicates genuine interest among developers. Open-source adoption often precedes enterprise adoption.

Security, Compliance, and Enterprise Readiness
Enterprise database adoption requires strong security credentials.
Surreal DB supports authentication, authorization, and encryption at rest and in transit. Role-based access control lets you define permissions at granular levels.
For compliance-heavy industries like finance and healthcare, important questions remain: What audit trails exist? How are backups handled? What disaster recovery guarantees apply? How does the system handle regulatory requirements like CCPA and HIPAA?
Public documentation on these topics isn't extensive yet. This isn't unusual for younger databases, but enterprises will require detailed answers before moving critical workloads.
The self-hosted deployment option helps here. Companies can run Surreal DB on their own infrastructure, maintain complete control over data, and implement their own security policies.
Cloud deployment through Surreal Cloud introduces vendor lock-in considerations. How portable is your data if you decide to move?
Competitive Landscape: How Surreal DB Fits
The competitive matrix is interesting because Surreal DB doesn't directly compete with any single competitor. It competes with combinations of competitors.
PostgreSQL + Pinecone + Neo4j + Redis is the typical competitive set. Surreal DB is positioning as the alternative to that stack.
Other unified database attempts exist. MongoDB with vector search capabilities moves in this direction. Elasticsearch with native vector support. Even traditional relational databases adding vector capabilities.
What distinguishes Surreal DB: it's purpose-built from the ground up as unified, not adding vectors as an afterthought. The transactional consistency model across all data types is genuinely different.
The question for the market: are developers willing to adopt a newer database (and thus less battle-hardened) for the architectural benefits, or do they prefer assembling best-of-breed components even if it's more complex?
History suggests both approaches coexist. Some teams will standardize on Surreal DB. Others will stick with the familiar stack. The market outcome depends on whether the development velocity gains and consistency improvements translate into real ROI at scale.

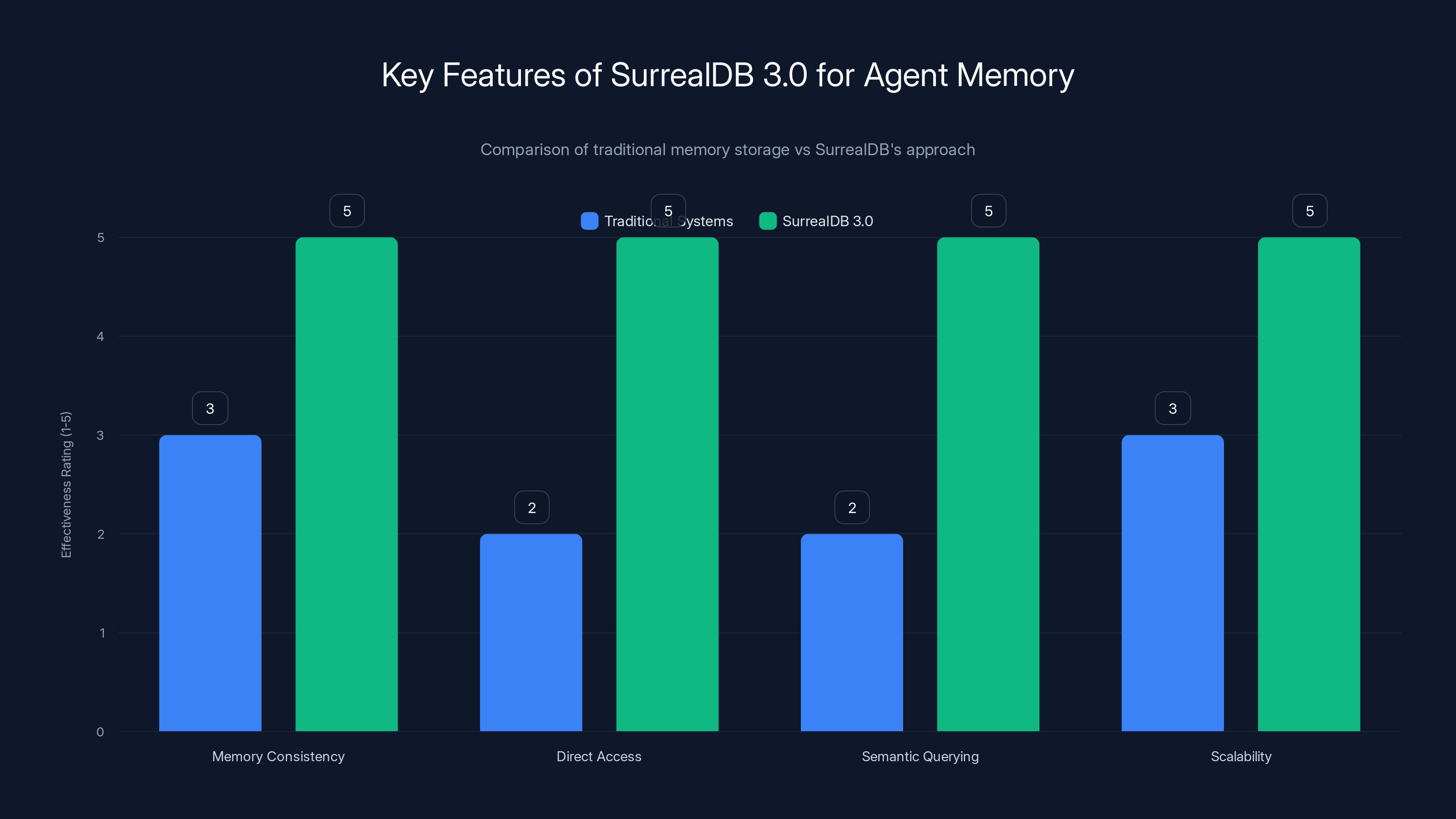
SurrealDB 3.0 offers superior memory consistency, direct access, semantic querying, and scalability compared to traditional systems. Estimated data based on described capabilities.
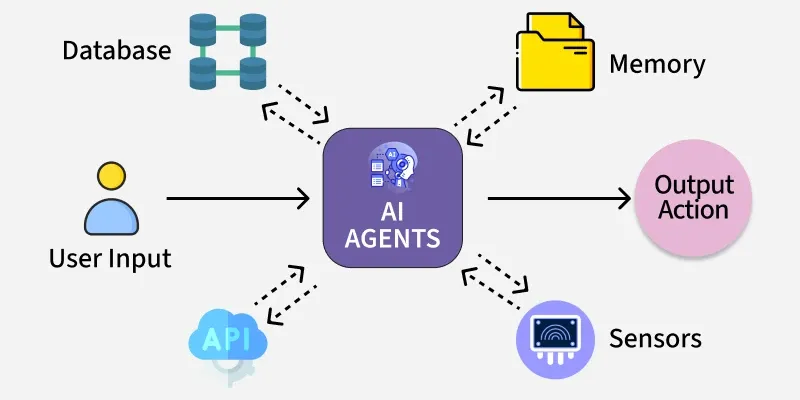
Building AI Agents on Surreal DB: Practical Architecture
Let's think through what actually building an AI agent on Surreal DB looks like.
Architecture consists of three layers:
Data Layer: Your business data (customers, products, orders) lives in Surreal DB along with their relationships. Embeddings for semantic search are stored natively.
Memory Layer: Agent-specific memory—decisions made, patterns learned, context—lives as graph relationships and metadata inside Surreal DB. The Surrealism plugin system lets you define custom logic for how this memory updates.
Reasoning Layer: Your LLM integration layer that actually runs the inference. Tools call into Surreal DB to fetch context, update memory, execute business logic.
When the agent needs to make a decision:
- It formulates a query expressing what context it needs
- Surreal DB executes that query transactionally, combining all data types
- The result feeds into the LLM as context
- The LLM generates a response
- The agent updates memory in Surreal DB
Each step is isolated and consistent. The agent never operates on stale data or inconsistent views across multiple databases.
For complex agents managing state across multiple conversations and users, this architecture simplifies everything.
Future Roadmap and Evolution
What comes next for Surreal DB matters for long-term viability.
The company has indicated focus on:
Performance improvements across all query types to narrow the gap with specialized systems.
Enterprise features like more sophisticated access control, audit logging, and compliance-specific capabilities.
Ecosystem expansion including more official integrations with tools developers actually use.
Distributed improvements enabling larger clusters and better scalability characteristics.
Operational tooling for monitoring, debugging, and optimizing Surreal DB deployments.
The roadmap suggests they understand the market. They're not trying to out-compete Pinecone at vector search. They're building the best platform for unified, transactional queries.
Open-source development transparency matters here. You can see the roadmap, watch progress, contribute. This builds trust among skeptical developers.

Cost Analysis: Surreal DB vs. Multi-Database Stack
Cost calculations seem straightforward but aren't.
Surreal DB approach: One database service. Whether cloud-hosted or self-hosted, you have one bill and one operational surface to maintain.
Multi-database approach: Separate bills for PostgreSQL (usually cheap), Pinecone (can be expensive at scale), Neo4j (moderately expensive), Redis (cheap), plus infrastructure overhead.
Raw compute cost might favor the multi-database stack if you use managed services carefully. But total cost of ownership includes:
- Engineering time architecting and maintaining integrations
- Debugging consistency issues across systems
- Operations overhead scaling each system independently
- Training new team members on five different query languages
These soft costs often exceed hardware costs. A unified database reduces these dramatically.
For a team of four engineers, the time saved by not maintaining integration logic might be worth six figures annually. Multiply that across a company of 50 engineers, and the math shifts significantly.
Cost analysis requires plugging your specific numbers in, but the direction of benefit is clear for teams currently managing multi-database complexity.
Risk Assessment and Adoption Considerations
Adopting a newer database involves risks worth articulating.
Maturity risk: Surreal DB is newer than PostgreSQL or Neo4j. You'll encounter edge cases those databases have solved. The community is smaller, so answers to unusual problems might not exist.
Vendor lock-in risk: If the company fails, you're maintaining open-source code yourself. This is solvable but requires engineering resources.
Performance risk: In specific query scenarios, Surreal DB might not match specialized systems. You won't know until you benchmark your specific workloads.
Scaling uncertainty: How Surreal DB behaves at massive scale (terabytes, zettabytes) is less proven than traditional databases.
These risks aren't disqualifying. Every technology adoption involves trade-offs. But acknowledging them explicitly helps with decision-making.
Mitigation strategies include: start with non-critical workloads, build expertise gradually, maintain escape hatches if migration back to traditional stacks becomes necessary, and invest in team training early.
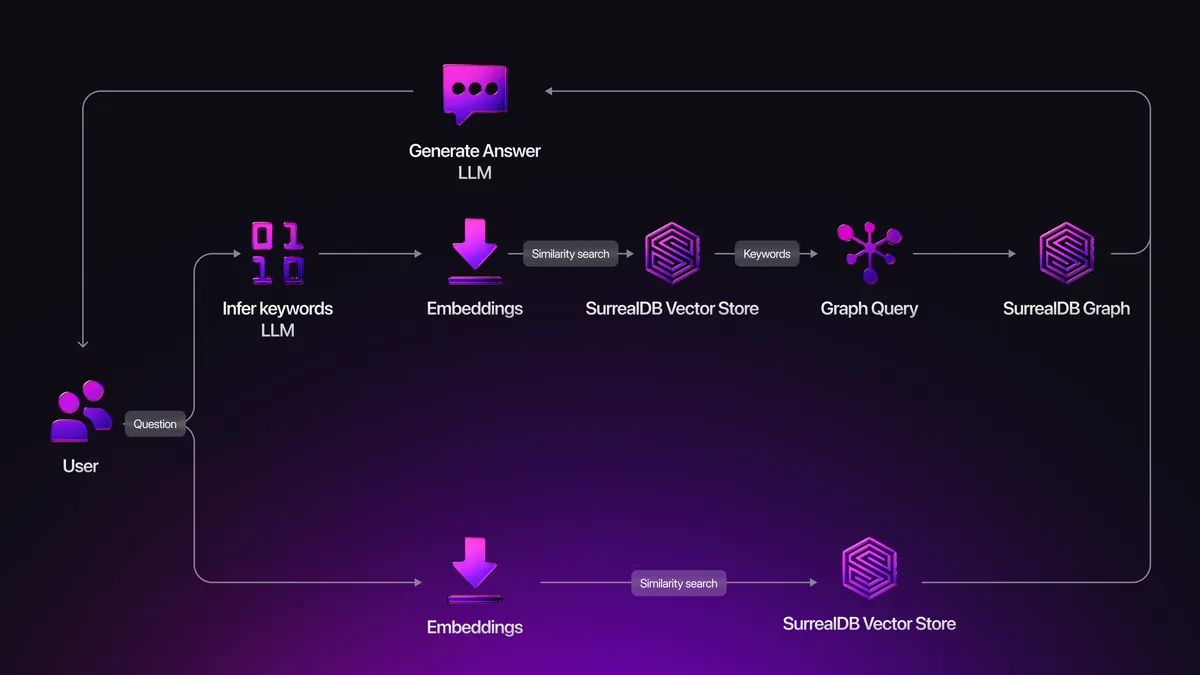
Developer Sentiment and Community Growth
What are actual developers saying about Surreal DB?
On GitHub and social platforms, sentiment leans positive. Developers appreciate the architectural coherence of having vectors, graphs, and structured data in one system. They like that Surreal QL is approachable. They value the open-source transparency.
Common complaints center on documentation gaps (documentation improves constantly but always trails behind developer needs) and wanting to see more official integrations.
Adoption trajectories suggest early adopters tend toward startups building new applications or teams actively frustrated with multi-database orchestration. Enterprises remain cautious, which is typical for database adoption.
The 2.3 million downloads metric is significant, though context matters. Not every download converts to active usage. But it suggests sufficient interest to make the project viable.
Community growth appears to track with AI agent trends. As more companies build production AI systems, Surreal DB's value proposition becomes more relevant.
Industry Implications and Market Impact
If Surreal DB succeeds at scale, what changes in how companies build systems?
The short term: More teams consolidate their database stacks. Development velocity for AI applications increases. Complexity management becomes simpler.
The medium term: Specialized databases might be forced to offer better integration points or accept becoming specialist tools for very specific scenarios rather than general solutions.
The long term: Database architecture might shift away from polyglot persistence (using many databases) toward more unified approaches for operational systems.
This isn't guaranteed. Market history shows both trends can coexist. Companies using polyglot persistence don't disappear when unified solutions arrive. They coexist.
What does change: the decision criteria shifts. Choosing polyglot persistence becomes an explicit choice rather than the default. You choose it because you need the specific strengths of each system, not because the alternative is immature.

Practical Next Steps for Evaluation
If you're considering Surreal DB, here's how to evaluate thoughtfully:
Step 1: Audit your current database architecture. List every database you use. Calculate the engineering overhead. Estimate how much time is spent on integration logic.
Step 2: Download Surreal DB and run it locally. Define a small subset of your schema. Write some queries combining data types.
Step 3: Benchmark on realistic queries. Compare against your current stack. Include not just query time but development time to express the query.
Step 4: Identify a non-critical application or feature. Migrate it to Surreal DB. Run it for 30 days in production. Monitor performance and stability.
Step 5: Based on real operational experience, make a decision about broader adoption.
This evaluation path is safer than either blind adoption or dismissal based on architectural theorizing.
Conclusion: The Unified Database Question
Surreal DB 3.0 addresses a real problem: managing multiple databases for AI applications is complex, error-prone, and expensive.
The solution is architecturally coherent. Storing vectors, graphs, structured data, and relationships in one transactional engine with a unified query language genuinely simplifies development. For teams building AI agents where consistency matters and multiple data types are essential, this architecture has real merit.
The question isn't whether Surreal DB could replace your five-database RAG stack. It probably could. The question is whether doing so makes sense for your specific situation.
For new applications, especially those heavily involving AI agents, the answer leans yes. You get simplicity, consistency, and development velocity benefits without the risk of maintaining legacy infrastructure.
For existing systems with years of PostgreSQL and other databases, the answer is more nuanced. You gain long-term architectural benefits but face near-term migration costs.
The market will validate whether this approach resonates. The funding, development activity, and community interest suggest the company is positioned to find out.
What matters now: real production deployments at scale. Not just the automotive and defense examples but visible success stories with mainstream companies building mainstream applications on Surreal DB. When you see a Fortune 500 company run critical systems on Surreal DB, you'll know adoption has achieved escape velocity.
Until then, Surreal DB remains a promising alternative for teams actively seeking to simplify their data architecture. For most organizations, running a pilot project to evaluate the fit makes sense.
The dream of a single database handling all data types transactionally isn't new. But the execution in Surreal DB is genuinely worth your attention if you're building or maintaining complex AI systems where consistency and unified context matter.

FAQ
What exactly is Surreal DB and how does it differ from traditional databases?
Surreal DB is a unified database engine that combines capabilities of relational databases, vector databases, graph databases, and in-memory caching into a single transactional system. Traditional databases focus on specific data types: PostgreSQL handles structured data excellently, Pinecone specializes in vector search, Neo4j excels at graphs. Surreal DB handles all three natively in one engine, executing queries transactionally across all data types simultaneously. This eliminates the need to query multiple databases and merge results in application code.
How does Surreal DB maintain consistency across vectors, graphs, and structured data?
Surreal DB uses a unified query engine built in Rust that executes all operations transactionally within a single process. When you execute a query combining vector similarity search, graph traversal, and relational joins, they all execute against the same in-memory state. Every node in a distributed cluster maintains transactional consistency, not eventual consistency like read replicas. This means when one agent writes memory to the database, all other agents immediately see that update, eliminating the stale data problems that plague traditional multi-database architectures.
What are the main benefits of using Surreal DB for AI agent applications?
The primary benefits for AI agents include unified context (all data types accessible in one query), transactional memory (agent learning stored and retrieved consistently), reduced development time (no orchestration logic between multiple databases), eliminated consistency bugs (no stale data between systems), and operational simplicity (one database to monitor and maintain instead of five). AI agents requiring decision-making based on complete, current context find these benefits particularly valuable since fragmented data across multiple systems leads to degraded reasoning quality.
When should I use Surreal DB versus specialized databases like Pinecone or Neo4j?
Use Surreal DB when you need multiple data types together and consistency is critical, such as building AI agents, real-time recommendation systems, or edge applications. Use specialized databases when you have a single dominant access pattern: pure vector search only (Pinecone), pure graph traversal (Neo4j), or massive analytical queries (columnar data warehouses like Snowflake). Surreal DB's architectural trade-off involves slight performance compromises on specialized tasks for gains in unified complexity management and consistency guarantees.
What deployment options does Surreal DB offer and how do they work?
Surreal DB offers three deployment models: cloud deployment through Surreal Cloud (managed infrastructure with automatic scaling), self-hosted deployment (run on your own servers for data residency and compliance control), and edge deployment (run on embedded systems or mobile devices with sync to cloud). The edge deployment capability is particularly unique, enabling offline-first architectures where local decisions happen instantly without waiting for network round-trips, then syncing to central instances later.
How long does it typically take to migrate from a multi-database stack to Surreal DB?
Migration timeline varies significantly based on complexity and team size. New greenfield applications might deploy to Surreal DB within weeks. Existing systems typically follow a phased approach: running Surreal DB alongside existing systems for new features (weeks to months), gradually migrating domains (months to years), retiring legacy systems last. The key advantage of phased migration is risk reduction—you learn the system incrementally before betting critical workloads on it.
What about performance? Will Surreal DB be slower than my optimized PostgreSQL and Pinecone stack?
Performance varies by query type. Pure relational queries on Surreal DB might be 10-15% slower than optimized PostgreSQL. Pure vector search might lag specialized Pinecone by a similar margin. However, queries combining multiple data types should be faster in Surreal DB because you avoid network overhead and application-level merging. The real performance gain appears in queries that would be complex and slow in a multi-database stack. Surreal DB eliminates the latency of sequential queries across systems.
Does Surreal DB have mature security and compliance features for enterprise use?
Surreal DB supports authentication, authorization, encryption at rest and in transit, and role-based access control. However, enterprise-specific features like sophisticated audit logging, compliance-specific tools, and detailed regulatory documentation (HIPAA, GDPR, CCPA) are still maturing. The self-hosted deployment option helps with compliance since you maintain complete data control. Before adopting for regulated industries, thoroughly evaluate specific compliance requirements against current Surreal DB capabilities or work with the team to implement necessary features.
What's the cost comparison between Surreal DB and maintaining multiple databases?
Raw compute costs might favor a multi-database stack if managed carefully, but total cost of ownership heavily favors Surreal DB. The soft costs of managing integration logic, debugging consistency issues, scaling each system independently, training engineers on five query languages, and maintaining operational oversight typically exceed hardware costs. For organizations with teams actively managing multi-database orchestration, switching to unified infrastructure often pays for itself within 6-12 months through reduced engineering overhead and faster development velocity.
What risks should I consider before adopting Surreal DB in production?
Key risks include maturity (Surreal DB is younger than PostgreSQL or Neo4j, so edge cases may exist), vendor lock-in (though open-source mitigates this), performance uncertainty (specialized systems may outperform on specific queries), and scaling at massive scale (less proven at exabyte scales). Mitigation strategies include starting with non-critical workloads, running a 30-day production pilot before major adoption, maintaining technical expertise to manage open-source deployment if needed, and planning potential fallback paths to traditional databases if adoption doesn't meet expectations.
How does the development experience with Surreal QL compare to SQL, GraphQL, or other query languages?
Surreal QL borrows syntax from SQL (familiar for relational developers), adds graph traversal notation similar to GraphQL, and extends with native vector operations. Developers with SQL experience typically find Surreal QL approachable, though the learning curve for unified queries across multiple data types is shallower than learning each system's query language independently. The real advantage emerges when expressing complex queries: what requires orchestration logic in application code becomes a single Surreal QL statement. Training new team members on Surreal QL takes less time than training them on five different systems.
Key Takeaways
- SurrealDB consolidates five separate database systems (PostgreSQL, Pinecone, Neo4j, Redis, others) into one transactional engine
- Transactional consistency across all nodes eliminates stale data problems plaguing multi-database AI agent systems
- Agent memory stores as graph relationships inside the database, enabling queries that maintain perfect context consistency
- Development timelines compress from 6-12 months to days for basic implementations by eliminating orchestration complexity
- Real deployments span automotive edge devices, retail recommendations, and Android ad serving with 2.3M downloads
Related Articles
- OpenAI Hires OpenClaw Developer Peter Steinberger: The Future of Personal AI Agents [2025]
- OpenClaw Founder Joins OpenAI: The Future of Multi-Agent AI [2025]
- Adani's $100B AI Data Center Bet: India's Infrastructure Play [2025]
- Infosys and Anthropic Partner to Build Enterprise AI Agents [2025]
- Peter Steinberger Joins OpenAI: The Future of Personal AI Agents [2025]
- India AI Impact Summit 2025: Key News, Investments, and Industry Shifts [2025]

