![The Future of Digital Documents: Moving Beyond PDFs With AI [2025]](https://tryrunable.com/blog/the-future-of-digital-documents-moving-beyond-pdfs-with-ai-2/image-1-1769624003120.png)
The Future of Digital Documents: Moving Beyond PDFs With AI
The PDF has been around longer than the internet itself. Created in 1991, it was designed for one job: making a document look identical on any screen or printer. And it's been doing that job so well that roughly three trillion PDFs are currently floating around in corporate systems, inboxes, and archives worldwide.
But here's the problem. That same rigidity that made PDFs perfect for static documents has become a straightjacket in an era where artificial intelligence, real-time collaboration, and dynamic data are reshaping how businesses actually work.
A Tel Aviv-based startup called Factify just emerged from stealth with a bold premise: the document itself needs an entirely new foundation. Not an incremental upgrade. Not a new feature. A complete reimagining of what a digital file actually is.
The company raised $73 million in seed funding led by Valley Capital Partners and backed by heavy hitters like John Giannandrea, former head of AI at Google. The bet is simple but audacious. The static, rigid nature of most digital files has fundamentally limited their utility. A better, more intelligent document that carries its own identity, permissions, audit logs, and can interface directly with AI systems isn't just possible—it's inevitable. And whoever gets there first could own a multi-billion-dollar market.
This isn't just another document startup. This is about fundamentally rethinking the infrastructure that organizations depend on every single day.
TL; DR
- PDFs and Word documents were designed for static files, not dynamic, collaborative, AI-enabled workflows that modern organizations actually need
- Three trillion PDFs exist globally, representing massive fragmentation, version control problems, and security risks that cost businesses time and money
- Intelligent documents add permanent identity, permissions, and audit trails, making them both more secure and more functional than traditional files
- AI needs structured data to function properly, and current document formats force AI systems to guess at content using image recognition instead of understanding actual structure
- The document format is ripe for disruption because the last major innovation was Google Docs in 2006—nearly 20 years ago

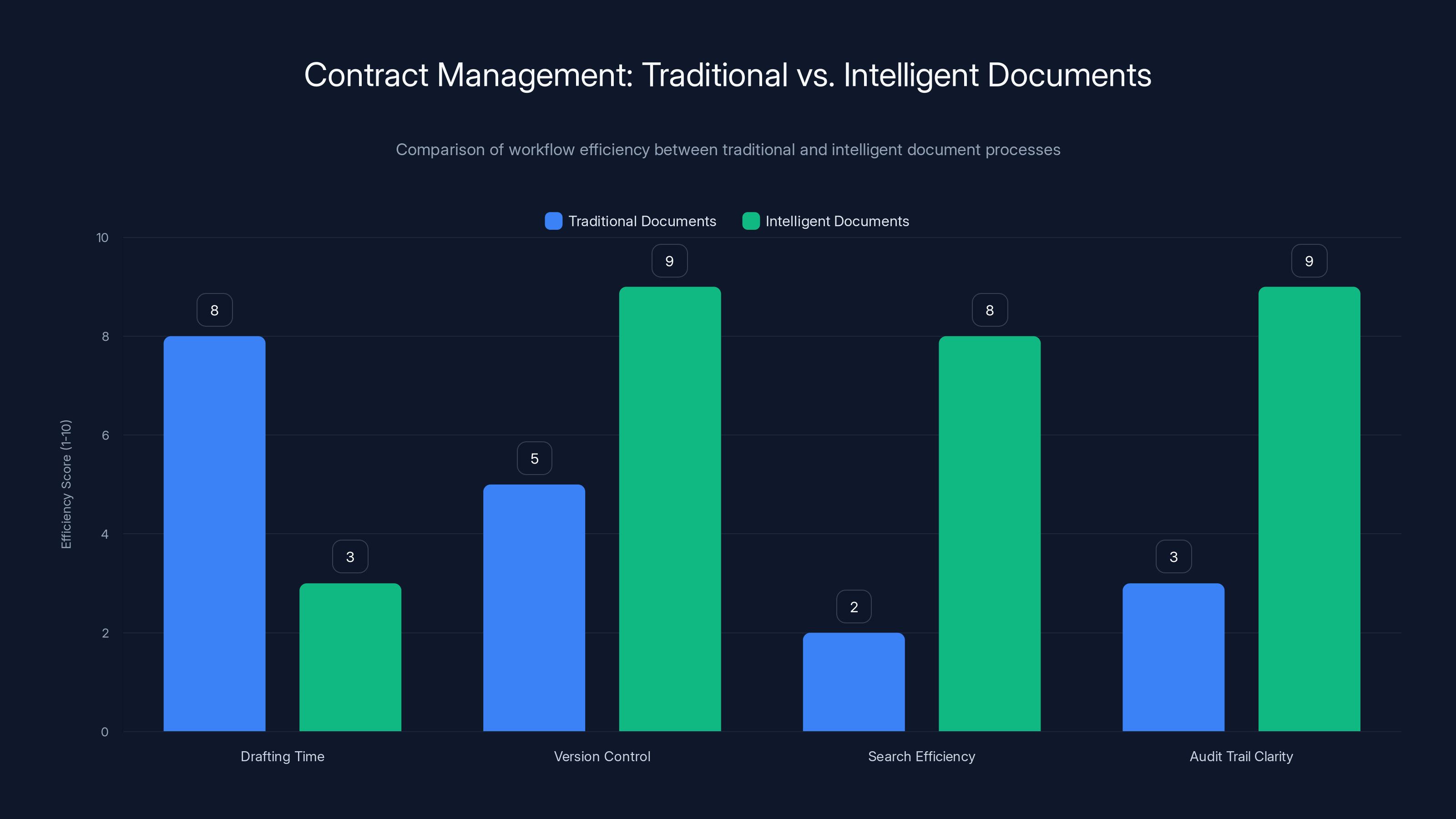
Intelligent documents significantly improve efficiency in contract management by reducing drafting time, enhancing version control, improving search efficiency, and providing a clearer audit trail. Estimated data based on typical process improvements.
Understanding the Digital Document Problem
Before you can appreciate why a $73 million seed round makes sense for a document company, you need to understand just how trapped businesses actually are in the current system.
The fragmentation problem starts the moment a document leaves its birthplace. Let's say you create a contract in Microsoft Word. You send it to a colleague via email. They make changes, save a new version, and send it back. Now you have Word_Final.docx and Word_Final_v 2.docx and Word_Final_REAL.docx—the naming convention nobody admits they use but everyone recognizes.
Then the contract gets converted to PDF for signing. The original Word file stays on someone's hard drive. A copy lives in the company shared drive. Another copy is archived in Box. Someone prints it and files it physically. The audit trail is now scattered across five different locations, and nobody can definitively answer which version is the source of truth.
This isn't just annoying. It's a liability.
Multiply this scenario by millions of documents across thousands of organizations, and you start seeing the real problem. Version control is broken. Access management is opaque. When a PDF leaves your system, you lose all control. Permissions don't travel with the file. Edit history evaporates. If someone leaks a confidential document, you might never know who accessed it or when.
And then there's the AI problem, which is becoming more critical by the day.
The AI Accessibility Problem
When artificial intelligence systems try to read a PDF, they're not actually reading it the way humans do. They're essentially guessing.
PDFs are visual containers. They store information about where text appears on a page, what font is used, what color it is—but not the underlying structure or meaning. When an AI model encounters a PDF, it has to use optical character recognition to convert that visual information into text. This is lossy. Information gets scrambled, tables get misaligned, context gets lost.
Compare this to how AI works with structured data. Give an AI a properly formatted JSON file with clear relationships between data points, and it understands context, hierarchy, and meaning instantly. The AI can reason about the data, extract insights, and even predict what comes next.
Documents in their current form force AI to work with the worst possible input: fuzzy, unstructured, visual approximations of actual information. This isn't just inefficient. It actively degrades AI performance.
For enterprises building AI-driven workflows, this means spending engineering time on workarounds. Build a document intake system that can actually parse forms? That's a custom project. Create an AI that understands contract language across different templates? That's multiple iterations and failures before you get it right.
The document format itself is the bottleneck. And nobody has fixed it in a way that addresses both human usability and AI accessibility.

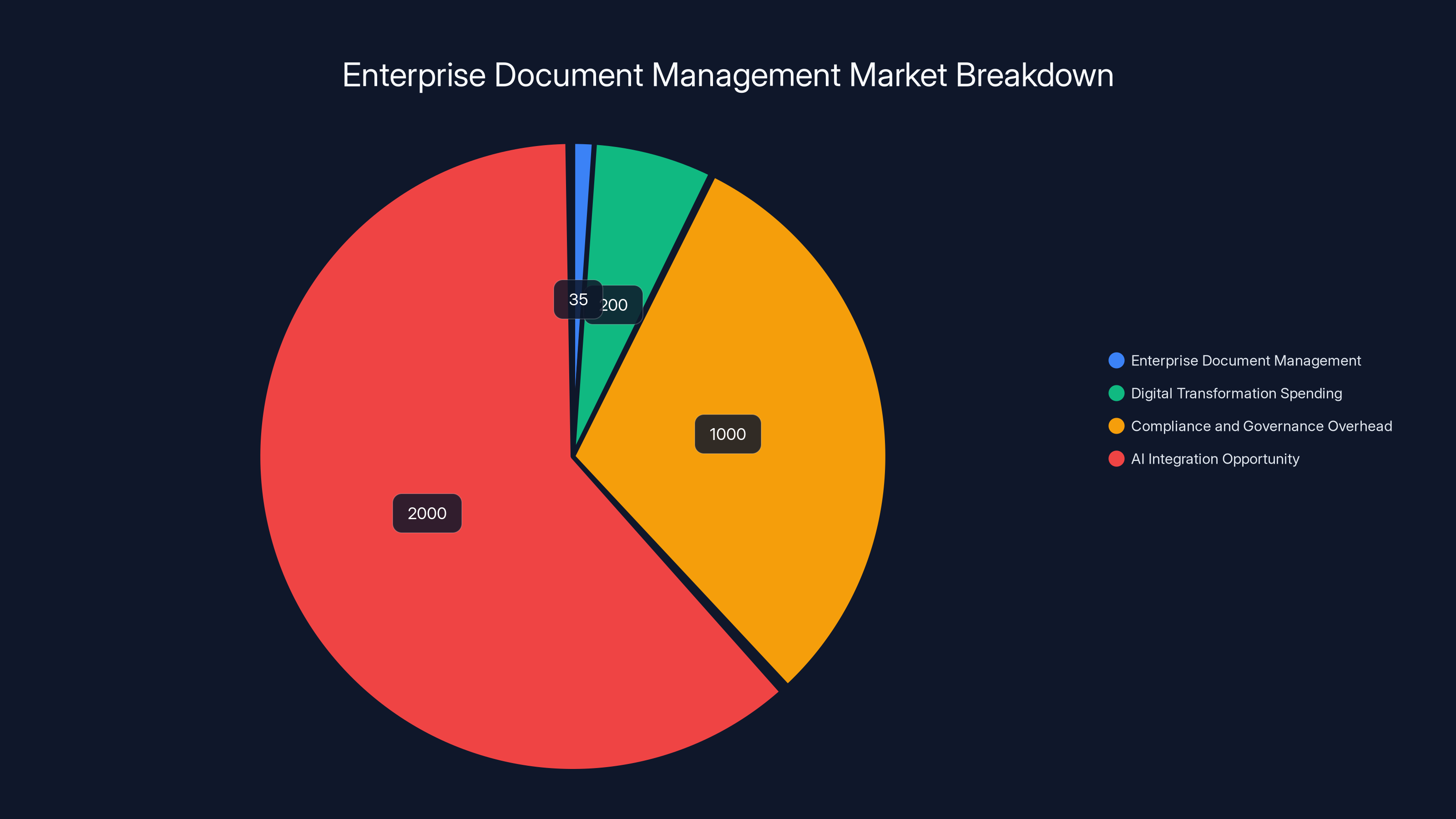
Estimated data shows the vast potential for disruption in document management, with AI integration offering the largest opportunity valued at trillions.
The Evolution of Digital Document Formats
To understand why Factify's vision is compelling, you need to see how we got here. The history of digital documents isn't a straight line where better formats replace worse ones. It's actually a story of evolution where different formats emerged to solve specific problems at specific moments in time.
The Word Era (1980s-1990s): Editable Files
Digital documents started as isolated artifacts bound to specific hardware. In the 1980s, a document created in Word Perfect on a DOS machine was completely unreadable on a Mac. There was no universal format. Each platform had its own word processor, its own file format, its own rules.
Microsoft Word changed that by leveraging something that became enormously powerful: the dominance of Windows. By the early 1990s, .doc format became the default container for editable professional documents. It wasn't the best format. It was just the most ubiquitous.
But here's something most people don't realize: the original .doc format was designed as a "memory dump" of how Word displayed text in memory. This meant the files were often bloated, structurally fragile, and occasionally corrupted. Worse, deleted text sometimes remained hidden in the file's binary data—a privacy nightmare that led to many embarrassing security breaches when organizations realized they were inadvertently sharing confidential information that had been "deleted" but never actually erased.
The format solved the portability problem but created new ones around file stability and security.
The PDF Era (1991-2006): Immutable Distribution
Adobe's PDF didn't start as a tool for writing. It was a tool for viewing. In 1991, Adobe co-founder John Warnock released the "Camelot Project" white paper proposing something radical: a universal document format that would look identical on any device, any operating system, any printer.
Unlike Word files, which were designed to be edited and manipulated, PDFs were designed to be immutable. They use the Post Script imaging model to place characters at precise coordinates on a page, ensuring pixel-perfect fidelity. Once a PDF is created, it stays created.
Adoption was initially slow. Most businesses still preferred Word files because they could be edited. But Adobe made a brilliant strategic move in 1994 by releasing Acrobat Reader for free. Suddenly, anyone could view PDFs without paying for software. The format exploded.
By the 2000s, PDFs had become the standard for anything permanent: contracts, government forms, tax documents, bank statements, medical records, legal filings. When you wanted a document that couldn't be accidentally modified, couldn't be corrupted, and would look the same everywhere, you converted it to PDF.
The format solved the permanence and portability problem but sacrificed editability and lost all structural information in the process.
The Collaborative Cloud Era (2006-Present): Living Documents
Google Docs arrived in 2006 and disrupted the entire model again.
Instead of sending files back and forth, Google Docs let multiple people edit the same document simultaneously from their browsers. This was powered by something called Operational Transformation, an algorithm that could merge concurrent edits from multiple users in real-time without conflicts.
The paradigm shifted from "sending a file" to "sharing a link." A document stopped being a static artifact you downloaded, edited locally, and re-uploaded. It became a living process that existed in the cloud. Everyone accessed the same version. Changes were instantaneous. You could see who edited what and when.
Google Workspace now has over 3 billion users, primarily in consumer and education markets. It fundamentally changed how teams collaborate. But it also revealed a new limitation: these cloud documents are tethered to the platform that created them. You can't easily move a Google Doc to Microsoft Word. You can't download it in a portable format without losing formatting. You're essentially locked into the Google ecosystem.
Each era solved problems from the previous era while introducing new ones.
The Modern Document Crisis: Fragmentation and Loss of Control
The real problem with having three competing paradigms is that most organizations now use all of them simultaneously.
You create documents in Google Docs for collaboration. You convert them to Word for final drafting. You export them as PDFs for distribution and archiving. You send them via email. You upload them to Dropbox. You store them in Microsoft Teams. You maybe print a few and file them physically.
Now you have the same document living in at least six different formats, in at least five different locations, with potentially different versions in each place.
When you need to find the authoritative version, there's no clear answer. When you need to revoke access to a shared document, good luck—once it's been downloaded, it exists in people's devices, email accounts, and backup systems. If the document contains sensitive information and someone leaks it, you might never know who had it or who shared it.
This fragmentation has a hidden cost that most organizations don't fully appreciate.
The Access Control Problem
Traditional file-based documents have essentially no access control mechanism. Once a file is created, you can set permissions in the folder where it lives. You can mark a file as "read-only." But the moment someone downloads the file, those permissions become suggestions rather than enforcements.
Download a PDF that's marked read-only in your shared drive? You can still modify it, print it, and share it with anyone. The original permissions stayed in the folder. They didn't travel with the file.
This is why enterprises end up building complicated file governance systems. You need policies about where documents can live. You need audit trails of who accessed what. You need data loss prevention software that monitors downloads. You need regular audits to find documents that have leaked.
All of this overhead exists because documents themselves have no built-in access control mechanism. The permissions live somewhere else—in the folder, in the cloud storage system, in a separate management tool.
The Version Control Problem
Version control works great for software engineers using Git. Every change is tracked. Every version is preserved. You can see exactly who changed what and when. You can revert to any previous version. You can merge changes from multiple branches.
But version control in most document systems is a joke. Version control in shared drives means you manually save files with different names and hope you remember which one is the latest. Version control in Google Docs means you can look at the revision history, but that history is only preserved as long as the document exists, and it lives entirely in Google's system.
Version control in email means you're relying on people's ability to remember what they sent and when, and hoping nobody loses the attachment in a hard drive crash.
Most organizations have cobbled together a system that works okay for day-to-day documents but breaks down when you need to audit what actually happened. Who requested this change? When did the client approve this version? Were the edits documented? Does our final contract match what the client actually agreed to?
These are questions that are surprisingly hard to answer if your documents are just files scattered across systems with no unified version history.
The AI-Native Problem
Here's the emerging problem that most organizations don't realize yet: if you're building AI workflows that depend on reading and understanding documents, the current file formats are actively hindering your progress.
Let's say you're building an AI system that reads contracts and extracts key terms. You feed it PDFs. The AI has to:
- Convert the visual PDF into text using OCR
- Identify which text represents contract terms
- Disambiguate terms that have similar names but different meanings
- Understand context where a term is referenced multiple times with different meanings
- Extract values and relationships
Most of this work is error-prone. PDFs with scans instead of digital text? The OCR fails more often. PDFs with complex layouts? The text gets extracted in random order. PDFs with embedded images containing important information? Completely lost.
Now imagine if the contract was stored in a format designed for AI interpretation. Metadata tags could identify which sections are terms. Structured data could show relationships between different clauses. Machine-readable fields could contain specific values that don't need to be extracted—they're already present in structured form.
The AI would work 10x faster and 10x more accurately. Because the document format itself would be optimized for being understood, not just for looking good on a screen.


Estimated data shows that document versions are evenly distributed across multiple locations, highlighting the fragmentation problem in document management.
What an Intelligent Document Actually Is
Factify's core insight is deceptively simple: a document should be more like an API than a file.
A traditional file is a container. You create it, you edit it, you save it, and it sits there. It has no inherent intelligence. It doesn't know who created it, who should be able to access it, what changes were made, or what it means.
An intelligent document, by contrast, is a first-class citizen in your digital infrastructure. It has built-in properties that travel with it everywhere:
Persistent Identity: Every intelligent document has a unique, immutable identifier that stays with it forever. This means you can track a document across systems, know exactly which version someone is accessing, and ensure that references to "that contract from 2023" always point to the same specific document.
Live Permissions: Access control is built into the document itself, not stored separately in some folder. When you revoke access, the document itself stops responding to that user's requests. When you share it, the permissions travel with the document. A leaked copy doesn't get independent permissions—the revocation applies everywhere.
Immutable Audit Trail: Every change is logged. Who made it. When they made it. What they changed. This log is cryptographically signed and impossible to forge. You have a complete, verifiable history of how the document evolved.
Structured Data Layer: Instead of storing information purely as visual formatting, the document has an underlying data structure that AI systems can read directly. The difference between a PDF that says "Contract Value: $500,000" and a document that actually stores contract Value: 500000 in a machine-readable format.
Semantic Understanding: The document format includes metadata about what things mean. This isn't just markdown formatting. It's explicit semantic information that systems can query. "What are all the payment terms in this document?" isn't a question for a human to answer by reading. It's a query an AI can answer by reading the structured metadata.
API-First Design: Instead of being a static file you download, an intelligent document is accessed through an API. The document lives on a server. Applications request the information they need. Permissions are enforced at request time. Changes sync in real-time.
The combination of these properties creates something that current documents fundamentally lack: trustworthiness and accessibility.
With a traditional file, if I send you a Word document, you have no way to know if it's been modified since I sent it. You don't know who else has access to it. You don't know if someone deleted content. You're trusting me to tell the truth about what I sent.
With an intelligent document, the document proves its own integrity. The audit trail is cryptographic. The permissions are enforced by the system itself, not by policies or folders.
This is the shift from "trust me about what this document is" to "the document proves what it is."

The Technical Architecture Behind Intelligent Documents
Building intelligent documents requires rethinking several core assumptions about how documents work.
Traditional documents are file-based. You create a file, you save it to disk or to cloud storage, and it sits there. If someone else wants to edit it, you either share the file location or send them a copy. The document is the file.
Intelligent documents are service-based. The document exists on a server and is accessed through an API. Applications don't download the document and edit it locally. They request the information they need, make changes through the API, and the server handles consistency, permissions, and logging.
This architectural shift has several implications:
Centralized State Management: Because all access goes through the server, there's a single source of truth. Two people can't both be editing different versions of the document. Permissions are enforced at request time, not at download time. If someone's access is revoked, they lose access immediately—not when they close and reopen the document.
Real-Time Synchronization: Changes propagate instantly to everyone viewing the document. This is similar to Google Docs, but with additional guarantees. Every change is timestamped. Every user is authenticated. Every change is immutable once committed.
Cryptographic Verification: The audit trail isn't just a log. It's a cryptographic chain where each entry references the previous entry. This makes it impossible to modify history without detecting the tampering. This is the same technology used in blockchain, but applied to documents.
Structured Query Capability: Because the document has a data layer separate from its presentation, you can query the document. "What are all values greater than $100,000?" isn't a question for a human to answer by reading. The document can answer it directly.
Schema Validation: The document format includes a schema that defines what fields are required, what data types they should be, what values are valid. This prevents corruption and ensures consistency.
Multilayer Rendering: The same underlying document can be rendered different ways for different purposes. Render it as a PDF for printing. Render it as HTML for web viewing. Render it as a structured API response for AI systems. The underlying data is the same; the presentation changes based on need.
Implementing this requires a new document format from scratch. The Post Script imaging model that PDF uses isn't designed for this. The streaming format that Word uses isn't designed for this. They need something completely new.

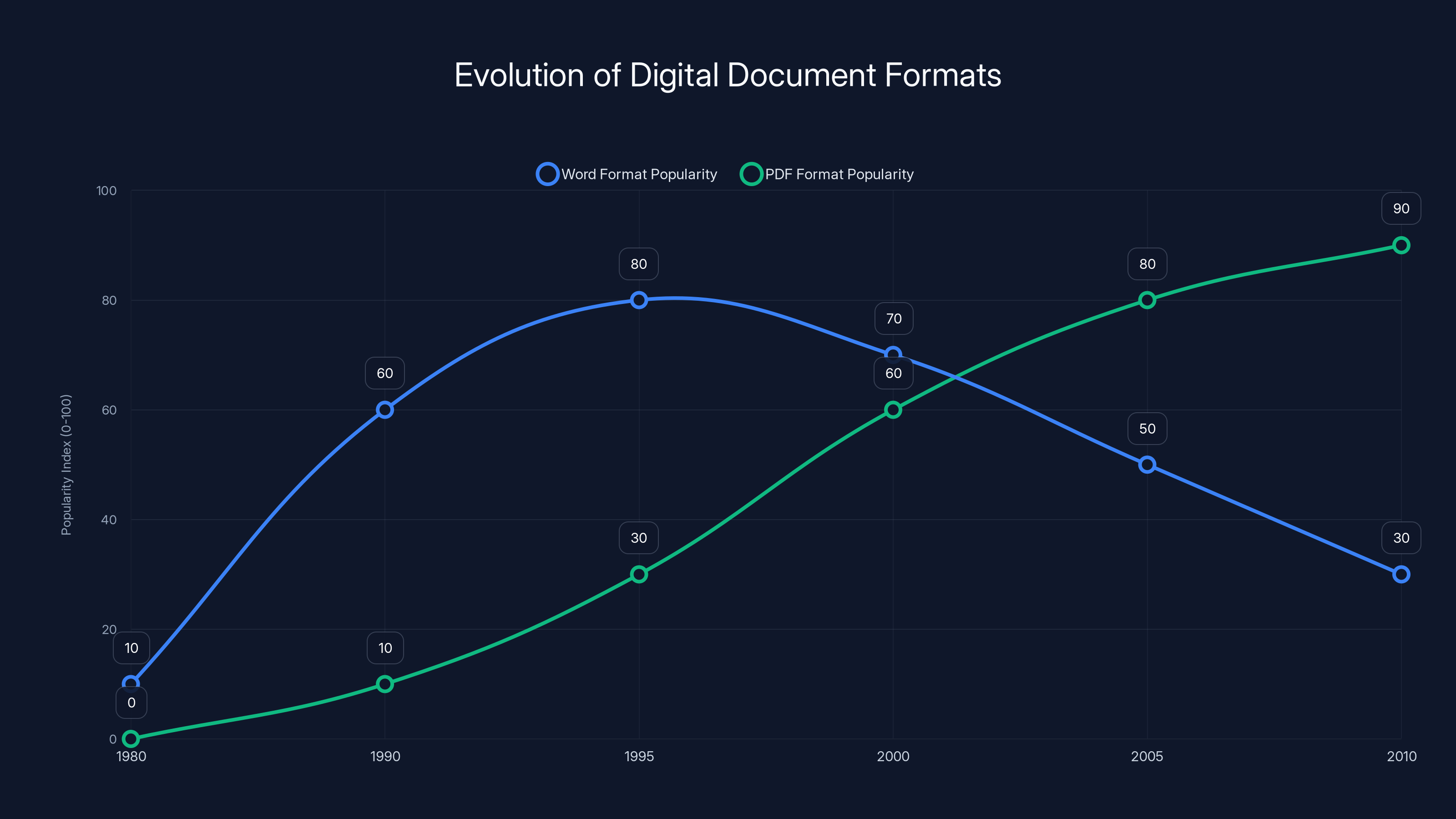
The chart illustrates the rise of Word and PDF formats over time. Word peaked in the 1990s, while PDF gained prominence in the 2000s. (Estimated data)
How Intelligent Documents Transform Business Processes
Understanding the technical architecture is interesting, but the real value of intelligent documents comes from how they transform actual business workflows.
Let's trace through what happens when a company switches from traditional documents to intelligent documents.
Contract Management: Before and After
The Traditional Way: A legal department drafts a contract in Word. They email it to the client. The client makes comments, sends it back. Legal reconciles the comments, creates a new version, sends it back for approval. This goes back and forth five to ten times. Each version is manually named and tracked. The final contract gets signed via Docu Sign, which creates a separate document. The signed contract gets stored in a file system alongside all the draft versions.
Now the contract is active. But the company has no clear record of what was actually agreed to. Was it the version from March 15th? The version from March 18th? Someone needs to manually audit the file system to determine which version was actually executed.
Six months later, someone needs to find all contracts with a specific payment term. They have to either manually read through every contract or use text search, which is error-prone. "Payment due within 30 days" might be phrased as "net 30" or "due no later than 30 calendar days" in different contracts.
Two years later, a dispute arises about what was agreed. The company needs to prove who said what, when. The file system has versions, but no clear chain of custody. Email messages might be deleted. Slack conversations weren't captured. The audit trail is fragmented across multiple systems.
The Intelligent Document Way: A legal department creates a contract using an intelligent document template. The template has structured fields: parties involved, payment amount, payment terms, liability limits, termination clauses, etc.
They share the document with the client via a link. The client can see the document with their permissions. They make changes using tracked edits. Every edit is logged with their identity, timestamp, and what they changed.
Legal reviews the changes. If they disagree, they can propose an alternative. The document's API tracks both versions, allowing real-time comparison.
Once both parties agree, the client digitally signs the contract within the same document system. The signature is cryptographically bound to that specific version. You can't argue about what was signed because the document proves it.
Now the contract is active. The company wants to find all contracts where payment is due within 30 days. They query the document system: "Give me all contracts where payment Terms.days To Payment <= 30." The system returns a list because it's querying structured data, not searching text.
Two years later, a dispute arises. The company pulls up the contract's audit trail. It shows exactly what was in the final executed version. It shows when the client agreed to it. It shows when they signed it. It shows any subsequent changes. It's irrefutable.
The contract is effectively self-defending. It proves what was agreed to because the entire history is cryptographically sealed.
Compliance and Audit: The Hidden Leverage
Intelligent documents create a massive efficiency win in areas that don't initially seem like they need documents.
Corporate compliance means maintaining documentation that proves the company followed required procedures. Did we review this contract with legal? We need documentation. Did we get appropriate approvals? We need documentation. Did we follow the change management process? We need documentation.
With traditional documents, proving compliance means manually collecting evidence. "Can you show me the email where legal reviewed this?" Or "Can you find the approval from the CFO?" These pieces of evidence are scattered across systems, email inboxes, and filing cabinets.
With intelligent documents, compliance is automatic. Every contract has a built-in audit trail showing who reviewed it, who approved it, and when. Auditors don't need to search for documentation—the document itself contains the proof.
Regulatory audits that currently take weeks because they require manually gathering evidence become automated. Pull the document. Show the audit trail. Prove compliance. Done.
For organizations in regulated industries (financial services, healthcare, pharmaceuticals), this translates into millions of dollars in operational savings just from audit efficiency.
AI Integration: Making AI Actually Work with Documents
The biggest leverage of intelligent documents comes from how they interact with AI systems.
Companies are investing billions in AI to improve business processes. But much of that investment is wasted on problems that shouldn't exist: parsing documents, extracting information, handling format inconsistencies, dealing with corrupted data.
With intelligent documents, much of this overhead disappears. An AI system doesn't need custom parsers for each document type. It doesn't need to guess at what information means. It can query the document's structured data layer directly.
This creates a massive productivity multiplier. The same AI system that requires 10 engineers to build on top of traditional documents might be buildable by one engineer on top of intelligent documents.
Consider a bank building an AI system to identify loan applicants at risk of default. With traditional documents, the AI needs to:
- Read loan applications (which come in different formats)
- Extract income, debt, employment history, credit score
- Handle inconsistent formatting and data entry errors
- Deal with scanned documents where OCR fails
- Verify extracted data against multiple sources
With intelligent documents, the loan application already has structured fields. Income is already validated and stored as a number. Employment history is already in a standard format. There's no OCR step. The AI gets clean, structured data and can focus on the actual prediction problem.
Intelligent documents don't just make AI applications faster to build. They make them more accurate, more auditable, and more maintainable.

The Competitive Advantage of Intelligent Documents
For organizations that adopt intelligent documents early, the advantages compound over time.
Speed to Market for AI Products: Companies that build AI products on top of intelligent documents move faster than competitors using traditional documents. Less engineering time spent on data parsing means more time spent on actual model development.
Superior Compliance and Risk Management: Automated audit trails and enforced permissions reduce compliance risk. Organizations move faster through audits, require fewer document management tools, and have stronger evidence of proper procedures.
Better Data Quality for Decision-Making: Structured documents with schema validation mean higher data quality. Better data means better analytics, better insights, better decisions.
Reduced Operational Overhead: Fewer document management tools needed. Simpler access control. Faster search and retrieval. Less time spent on document governance and compliance reporting.
Competitive Moat: Once an organization standardizes on intelligent documents, switching costs increase. Documents with 10 years of audit trail history have significant value. Rebuilding that history in a different system is difficult and risky.
These advantages are most pronounced in organizations that are document-heavy: financial services, legal firms, insurance companies, healthcare, pharmaceuticals, and government agencies.


Intelligent documents significantly enhance traditional documents by integrating persistent identity, live permissions, immutable audit trails, structured data layers, and semantic understanding.
The Path to Adoption: How Intelligent Documents Will Take Over
Given how revolutionary intelligent documents are, you might wonder: why isn't everyone using them already?
The answer is classic technology adoption dynamics. Network effects matter. If nobody else uses intelligent documents, their value decreases. You can't share documents across organization boundaries if the recipient doesn't have the software.
Adoption will likely follow this pattern:
Phase 1: Early Adopters in High-Value Use Cases: Organizations that handle the most sensitive documents or have the strictest compliance requirements will adopt first. Financial services firms, law firms, and pharmaceutical companies will be early movers because the ROI is clearest in their environments.
Phase 2: Ecosystem Building: As early adopters gain advantages, competitors in those industries will follow. Document formats will improve. Integrations with existing systems will become available. Tools will improve.
Phase 3: Mainstream Enterprise: Once intelligent documents are integrated with major productivity platforms (Microsoft, Google, Salesforce), adoption will accelerate rapidly. Not because every user understands the technical benefits, but because they're already available in the tools everyone uses.
Phase 4: Consumer and Small Business: Eventually, the benefits will trickle down to small businesses and consumers. But this will take the longest because the current formats work "well enough" for less complex use cases.
The transition won't happen overnight. PDF and Word documents will exist alongside intelligent documents for 10+ years, creating a hybrid world where organizations use both.
But the direction is clear. The static document format is reaching obsolescence. Something better is coming.

Intelligent Documents and Enterprise Software Integration
For intelligent documents to truly displace PDFs and Word documents, they need to work seamlessly with the enterprise software ecosystem that organizations already depend on.
This means integrations with:
ERP Systems: Accounting software, supply chain management, financial reporting. Intelligent documents need to feed data into ERPs automatically and pull structured data from ERPs to populate documents.
CRM Systems: Customer contracts, communication history, agreements. Customer records should be able to reference the documents that define the relationship.
Workflow Automation: When a document is executed, it should trigger workflows automatically. A signed contract triggers order fulfillment. A change order triggers accounting entry.
AI and Analytics Platforms: Documents should feed data into business intelligence systems and machine learning pipelines without custom extraction work.
e-Signature Solutions: Documents should be signable within the intelligent document system or via integrations with existing e-signature tools.
Collaboration Tools: Slack, Teams, Slack notifications should include document status updates. Comments should flow to the document system.
Building all these integrations is non-trivial. This is why early-stage document companies often fail—they underestimate how much ecosystem work is required before the technology becomes valuable.
Companies that get adopted by large organizations first (enterprises, government agencies) have advantages because:
- They can afford to build integrations with many enterprise systems
- They have IT departments who can maintain those integrations
- They have the leverage to push vendors to support standards
This creates a bootstrapping problem: intelligent documents are most valuable in large organizations with complex ecosystems, but they're expensive to sell to because integrations are required.
The companies that solve this problem successfully will be the ones that own the intelligent document standard and make it economically viable for the ecosystem to build integrations.

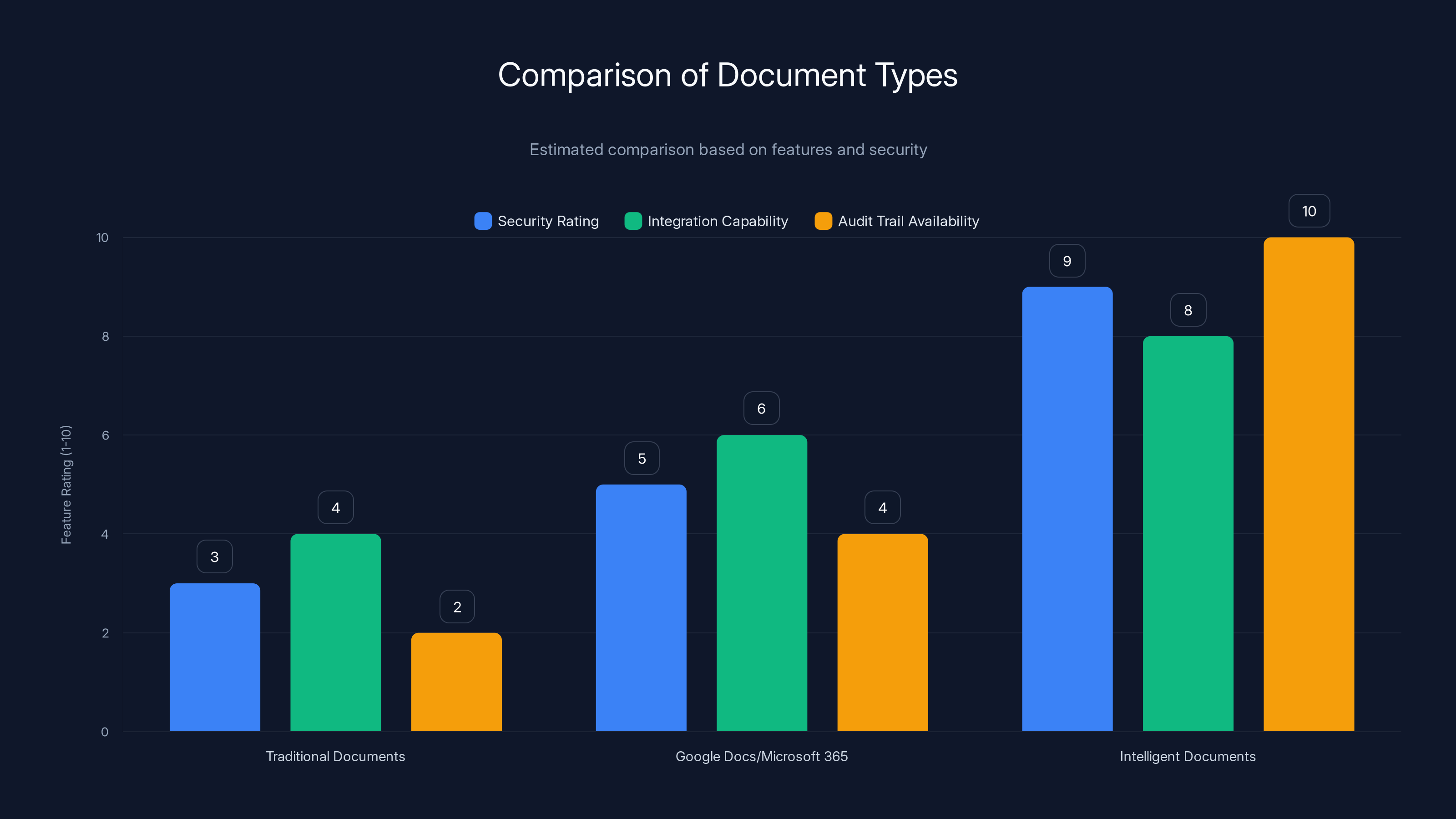
Intelligent documents outperform traditional and cloud-based documents in security, integration, and audit trail features. Estimated data based on typical capabilities.
Security and Privacy in Intelligent Documents
Given that intelligent documents carry sensitive information and audit trails, security is paramount.
The security model for intelligent documents needs to address several challenges:
Data at Rest: Documents stored on servers need to be encrypted using strong encryption standards. This protects against data breaches from external attackers and malicious insiders.
Data in Transit: Documents transmitted over networks need to use TLS encryption. This prevents interception and man-in-the-middle attacks.
Access Control: Permission enforcement needs to be foolproof. A revoked user cannot access a document, even if they previously had access. Permissions can't be bypassed by downloading the document.
Audit Trail Integrity: The audit trail itself is a high-value target. An attacker who could modify the audit trail could hide their actions. This is why cryptographic signing of audit trails is essential. Each entry signs the previous entry, making modification detectable.
Insider Threats: Employees with system access might try to access documents they shouldn't. The system needs role-based access control, separation of duties, and monitoring for suspicious access patterns.
Data Residency and Compliance: Organizations in regulated jurisdictions need documents stored in specific geographic regions. The system needs to support this.
Key Management: Encryption keys need to be managed securely. This is the hardest part of security and often the weakest link. If an attacker gets the encryption keys, all encryption is worthless.
Intelligent document systems need security to be better than traditional document storage because they're more valuable targets. The audit trail alone is often worth more to an attacker than the document content, because it shows what someone accessed and when.
This means building security in from the ground up, not adding it later. It means regular security audits, penetration testing, and continuous monitoring.

The Economics of Document Disruption
Why did Factify raise $73 million in seed funding? Because the opportunity is genuinely enormous.
Consider the TAM (Total Addressable Market):
Enterprise Document Management Market: Estimated at $30-40 billion annually including software, services, and overhead costs.
Digital Transformation Spending: Enterprises are spending hundreds of billions annually on digital transformation, much of which involves figuring out how to handle documents better.
Compliance and Governance Overhead: Organizations spend trillions cumulatively on compliance, auditing, and document management. Even a 10% improvement in efficiency is worth hundreds of billions.
AI Integration Opportunity: As organizations build AI into their workflows, better document formats will become essential. The value could be worth trillions if it unlocks AI use cases that are currently economically unfeasible.
The bet Factify is making is that they can capture a fraction of this market. Even a 1% market share in document management would be a multi-billion-dollar business.
But the $73 million seed round also reflects the risks:
Technology Risk: Building a document format that actually works at scale is hard. The engineering is complex. Bugs could be catastrophic if they affect audit trails or security.
Adoption Risk: Even if the technology is excellent, getting organizations to switch from PDFs and Word documents is difficult. Network effects and installed base inertia are powerful.
Regulatory Risk: If documents are used for compliance, regulators might slow adoption until they understand the new format and trust the security model.
Competition Risk: Microsoft and Google could add intelligent document features to their platforms, making standalone intelligent document companies less relevant.
The company is betting that the benefits of intelligent documents are so compelling that adoption will overcome these risks. And they're betting that being early—getting the standard right before competitors do—gives them an insurmountable advantage.

What Enterprise Organizations Should Know About Intelligent Documents
If you're an executive or technologist in an enterprise organization, intelligent documents will likely affect your organization within the next 3-5 years.
Here's what you should think about:
Start with High-Value Use Cases: Don't try to switch your entire document infrastructure overnight. Start with documents where the value of audit trails, access control, and AI integration is highest. Contracts, compliance documents, financial records.
Evaluate Vendor Stability: The intelligent document market is emerging. Companies will fail. Evaluate whether vendors have enough funding and customers to survive. Look for companies with clear paths to profitability.
Understand Integration Requirements: Assess how deeply intelligent documents will need to integrate with your existing systems. This is often where the real work happens. Factor in integration costs when evaluating ROI.
Plan for Hybrid Environments: You won't switch everything at once. Plan for environments where intelligent documents coexist with traditional formats. This requires good export/import tooling.
Invest in Training: Your teams will need to understand how intelligent documents work. What seems obvious to engineers won't be obvious to legal or compliance teams. Build training into your implementation plan.
Monitor Standards Development: Intelligent document formats will evolve. Standards will emerge. Organizations that embrace open standards will have more flexibility than those locked into proprietary formats.

The Broader Implications for Digital Infrastructure
Intelligent documents are interesting not just as a standalone technology but as part of a broader trend in digital infrastructure.
For decades, we've separated:
- Data (stored in databases and data lakes)
- Presentation (displayed in applications)
- Logic (computed in application servers)
This separation made sense when computers were expensive and networks were slow. You stored data efficiently, computed results on the server, and sent the presentation to clients.
But in an era of cheap storage, fast networks, and ubiquitous AI, this separation creates overhead. Data needs to be extracted from documents, processed by AI systems, stored in databases, and presented back to users. Each transformation loses information.
Intelligent documents blur this separation. The document itself is data, presentation, and logic combined. The document knows what it means, who can access it, and how it's changed over time.
This is part of a broader architectural shift toward data systems that are self-describing, self-managing, and first-class citizens in the cloud.
Other examples include:
Self-Healing Infrastructure: Systems that automatically repair themselves when failures are detected.
Autonomous Databases: Database systems that tune themselves and manage their own resources.
Edge Intelligence: AI models that run locally rather than requiring cloud calls.
Decentralized Systems: Infrastructure that doesn't depend on a central point of failure.
Intelligent documents fit into this broader movement toward systems that are more autonomous, more resilient, and more efficient.

Looking Forward: The Next Decade of Document Evolution
If intelligent documents do achieve mainstream adoption, what happens next?
Over the next 10 years, we'll likely see:
Vertical-Specific Document Standards: Healthcare will develop document standards optimized for medical records. Finance will develop standards for contracts and transactions. Legal will develop standards for case documents. General-purpose document formats will coexist with specialized ones.
AI-Native Authoring: Instead of writing documents manually, AI systems will help generate documents. You describe what you want, and AI drafts the document. You refine it. The process becomes conversation rather than blank page.
Real-Time Document Intelligence: Instead of analyzing documents after they're created, systems will provide real-time feedback while documents are being created. "This contract term conflicts with your existing policy. Do you want to change it?"
Automatic Document Evolution: As your business changes, documents should automatically update if they reference policies or procedures. Old contracts should remain unchanged, but new versions should reflect current practices.
Cross-Organizational Document Networks: Today, organizations work with external partners using email and file sharing. Tomorrow, partners might share intelligent documents directly, with permissions and audit trails that cross organizational boundaries.
AI-Generated Contracts: Legal terms might become standardized to the point where contracts are generated algorithmically rather than written by humans. Negotiation becomes parameter adjustment rather than lengthy document revisions.
These are speculative, but they're natural extensions of intelligent documents properly implemented.

The Reality Check: Why PDFs Aren't Going Anywhere
Before you get too excited about intelligent documents replacing PDFs, consider why PDFs have survived for 30+ years despite many attempts to dethrone them.
PDFs have one crucial advantage: they're a dead format. They don't evolve. They don't require updates. A PDF you created in 1995 looks the same today. You can open it with any number of tools. Nobody can push updates that break your ability to view old documents.
Intelligent documents require active infrastructure. They need servers. They need updates. They need security patches. An intelligent document system that goes out of business means those documents become inaccessible.
For documents that need to be preserved for decades or centuries (legal contracts, government records, historical documents), this is terrifying. PDFs can be preserved through simple bit-by-bit copying. Intelligent documents depend on software systems that need to be maintained.
So the realistic future isn't "intelligent documents replace PDFs." It's "organizations use intelligent documents for active workflows, and PDF is used for archival and long-term preservation."
Intelligent documents enable new capabilities. But they don't eliminate the need for static, permanent formats. They coexist.

Implementation Considerations for Your Organization
If you're considering adopting intelligent documents in your organization, here are practical considerations:
Cost Analysis: Calculate the total cost of ownership including software licensing, integration work, training, and support. Compare against your current document management costs. The ROI timeline is typically 2-3 years for organizations with high document volumes or strict compliance requirements.
Change Management: Organizational change is often the bottleneck, not the technology. Plan for resistance from teams who are comfortable with current processes. Identify champions who can advocate for the new system.
Pilot Program: Don't implement across the entire organization. Start with a single department or business unit. Use the pilot to work out integration issues and build organizational support.
Vendor Evaluation: Evaluate multiple vendors, not just the largest ones. Look for companies with deep expertise in your industry. Check references with similar organizations.
Data Migration: Plan for how you'll handle your existing document library. Migrating every document is expensive. Often, you leave old documents in their existing format and only use intelligent documents going forward.
Governance: Establish policies around how documents can be created, shared, and archived. Without governance, intelligent documents won't provide the benefits you expect.
Security Baseline: Conduct a security assessment of proposed vendors before committing. Document security requirements and verify they're met. Security can't be added after deployment.
FAQ
What exactly is an intelligent document?
An intelligent document is a digital file format that combines content, structure, permissions, and audit history in a single unified system. Unlike traditional PDFs or Word documents, intelligent documents carry metadata about who created them, who can access them, what's changed over time, and what the content means. They function more like a cloud service with an API rather than a static file you download and store locally.
How are intelligent documents different from Google Docs or Microsoft 365?
Google Docs and Microsoft 365 are cloud-based collaboration tools, but they're still fundamentally document-oriented rather than infrastructure-oriented. You can't easily query their data, permissions don't travel with documents when exported, and they don't provide the cryptographic audit trails that intelligent documents offer. Intelligent documents are designed as infrastructure that other applications build on top of, rather than standalone productivity tools.
What are the main security advantages of intelligent documents?
Intelligent documents enforce permissions at the system level rather than the file level, so revoking access means the document stops responding to that user immediately rather than just removing their folder access. They provide cryptographically signed audit trails that prove who accessed documents and when, making tampering detectable. They can encrypt data at rest and enforce role-based access control. These features make them significantly more secure for sensitive documents than traditional formats.
Can intelligent documents integrate with existing enterprise systems?
Yes, but integration is typically not automatic and requires development work. Intelligent document systems need to be built with APIs that allow integration with ERPs, CRMs, e-signature solutions, and workflow automation tools. This integration work is one of the largest implementation costs for organizations. Modern intelligent document platforms like Factify are being designed with API-first architecture specifically to make integrations easier.
How long will it take for intelligent documents to replace PDFs?
Realistically, it will take 10-15 years for intelligent documents to become as ubiquitous as PDFs. Early adoption will be concentrated in regulated industries and large enterprises where the ROI is clearest. Small businesses and consumers will adopt much more slowly. PDFs will likely continue to exist as an archive and long-term preservation format even as intelligent documents become the primary format for active documents.
What happens to intelligent documents if the vendor goes out of business?
This is a legitimate concern with intelligent documents since they depend on active infrastructure. The best mitigation is to require that vendors provide export capabilities and that the document format itself is based on open standards rather than proprietary formats. This allows you to migrate to another vendor or manage documents yourself if necessary. It's one reason why vendor stability and format openness should be key criteria when evaluating intelligent document systems.
How do intelligent documents handle version history and collaboration?
Intelligent documents maintain complete, immutable version history where every change is timestamped and attributed to a specific user. This allows real-time collaboration similar to Google Docs, but with stronger guarantees about integrity and a permanent audit trail. Multiple users can edit simultaneously with real-time synchronization, and you can see exactly what each person changed and when.
What's the learning curve for using intelligent documents?
For basic usage, the learning curve is minimal—they work similarly to familiar tools like Google Docs or Word. The bigger learning curve is for understanding how to leverage the more advanced features like structured queries, AI integration, and audit trail analysis. Organizations will need training for IT teams, compliance teams, and power users who want to use these advanced capabilities.
How do intelligent documents impact data privacy and compliance like GDPR?
Intelligent documents can actually improve GDPR compliance by providing clear audit trails of who accessed data and when, making it easier to demonstrate compliance. They can enforce the "right to be forgotten" at the system level by securely deleting data. However, this depends on vendors implementing privacy-by-design principles. When evaluating vendors, you should specifically assess their GDPR, HIPAA, or other relevant compliance certifications.
Why haven't intelligent documents already replaced PDFs if they're so much better?
Intelligent documents require active infrastructure and vendor support, while PDFs work with simple tools and are future-proof as long as the PDF format specification remains publicly available. Network effects matter too—if nobody you work with uses intelligent documents, their benefits decrease significantly. Adoption also depends on solving the integration problem with existing enterprise systems, which is complex and expensive. It's a classic case where the better technology needs to overcome significant adoption friction.

The Bigger Picture: Digital Infrastructure Evolution
Factify's emergence and $73 million seed funding aren't just about one company's product. They're a signal that the document format itself—something we've largely taken for granted—is becoming a platform that will shape how organizations handle information for the next decade.
The transition won't happen overnight. Organizations with existing document infrastructure won't abandon it immediately. PDFs will exist alongside intelligent documents for a decade or more. But the direction is clear.
The static document format was designed for a world where information flowed in one direction: from author to reader. Intelligent documents are designed for a world where information flows multi-directionally, where AI systems need to understand and interact with documents, and where audit trails and permissions are as important as content.
This isn't just an upgrade. It's a fundamental architectural shift.
For your organization, the question isn't whether intelligent documents will matter. It's when you'll need to understand them enough to make smart decisions about if and how to adopt them. That time is closer than you think.

Key Takeaways
- PDFs and traditional documents were designed for static viewing and distribution, not for AI-enabled, collaborative, auditable workflows that modern organizations need
- Three trillion PDFs globally create fragmentation, version control problems, and security vulnerabilities that cost enterprises billions in operational overhead
- Intelligent documents embed permissions, audit trails, and structured data directly into the file format, making them simultaneously more secure and more useful than traditional formats
- AI systems gain 10x efficiency improvements when working with structured intelligent documents versus struggling with OCR and text extraction from PDFs
- Adoption will follow predictable patterns with early movers in regulated industries (finance, legal, healthcare) capturing significant competitive advantages within 3-5 years
Related Articles
- Enterprise AI Agents & RAG Systems: From Prototype to Production [2025]
- Claude Cowork: Enterprise AI Infrastructure Beyond Chat [2025]
- OpenAI Prism: AI-Powered Scientific Research Platform [2025]
- Is AI Adoption at Work Actually Flatlining? What the Data Really Shows [2025]
- Pinterest Layoffs 15% Staff Redirect Resources AI [2025]
- Gemini 3 Becomes Google's Default AI Overviews Model [2025]

