![TikTok US Outage Recovery: What Happened and What's Next [2025]](https://tryrunable.com/blog/tiktok-us-outage-recovery-what-happened-and-what-s-next-2025/image-1-1769535598999.jpg)
Tik Tok US Outage Recovery: What Happened and What's Next [2025]
Introduction: The Tik Tok Crisis That Shook Creator Culture
On Sunday morning in March 2025, something unprecedented happened. One of the world's most-used social media platforms simply stopped working for millions of Americans. Tik Tok, the app that dominates the phones of Gen Z and increasingly older demographics, went dark across the entire United States. Within hours, creators realized they couldn't upload videos. Users couldn't refresh their feeds. The platform that had become woven into the fabric of daily American culture was, quite literally, offline.
What made this crisis particularly shocking wasn't just the outage itself, but the timing and the context. Tik Tok had just recently transitioned to new US-specific ownership and infrastructure following unprecedented political pressure. The app's very existence in America had been in question for months. And now, just as it was supposed to be stabilizing under new management, everything fell apart.
The outage lasted for nearly three full days. For creators who depend on Tik Tok as their primary income source, it was catastrophic. For casual users, it was an unwelcome reminder of how dependent we've become on a single platform for entertainment, community, and connection. The situation raised critical questions about infrastructure resilience, data sovereignty, and whether centralizing a platform's operations in a new country was fundamentally sound from a technical perspective.
This article breaks down exactly what happened during the Tik Tok outage, why the recovery took so long, what Tik Tok's new management learned from the experience, and what this means for the future of the platform. We'll examine the technical challenges of migrating a billions-dollar platform's infrastructure, the business implications of the outage, and how this crisis will likely reshape how we think about digital infrastructure in the United States.
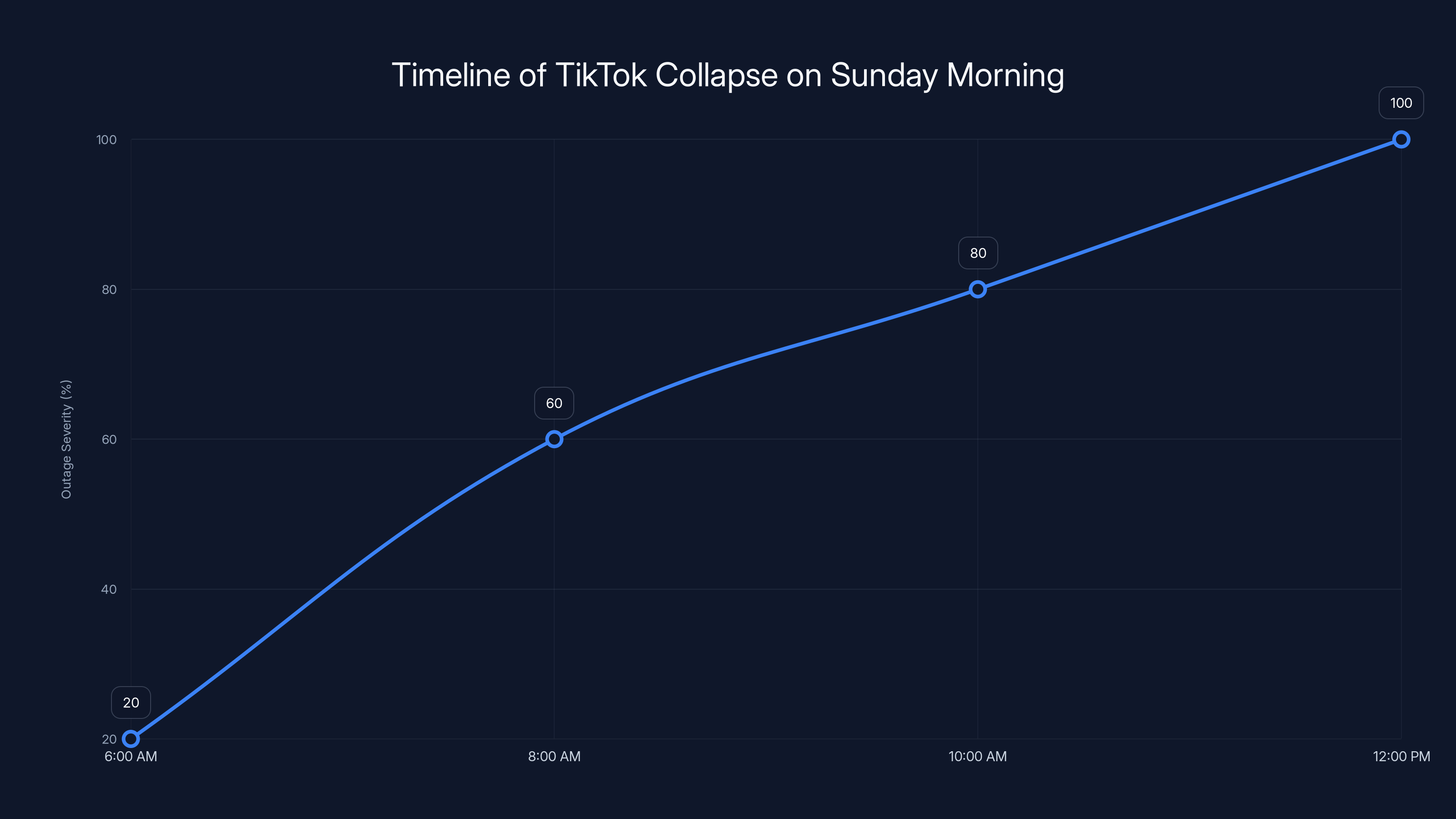
The timeline shows the increasing severity of TikTok's outage, peaking at 100% by noon as the platform's functionality was completely disrupted. Estimated data.
TL; DR
- The Outage: Tik Tok went completely offline in the US on Sunday morning, affecting 1.7 billion monthly active users and 80+ million daily US users
- Duration: The platform remained partially or completely non-functional for 72 hours, with full recovery taking into the early Tuesday morning
- Root Cause: Migration of US infrastructure to a new data center partner introduced critical configuration errors and system incompatibilities
- Business Impact: Creators lost an estimated $50+ million in potential revenue, while advertisers paused campaigns worth millions more
- Recovery Lessons: Tik Tok USDS implemented redundancy protocols and discovered that infrastructure migration requires parallel systems, not cutover approaches
- Future Implications: The incident accelerated investment in backup systems and multiregion failover capabilities
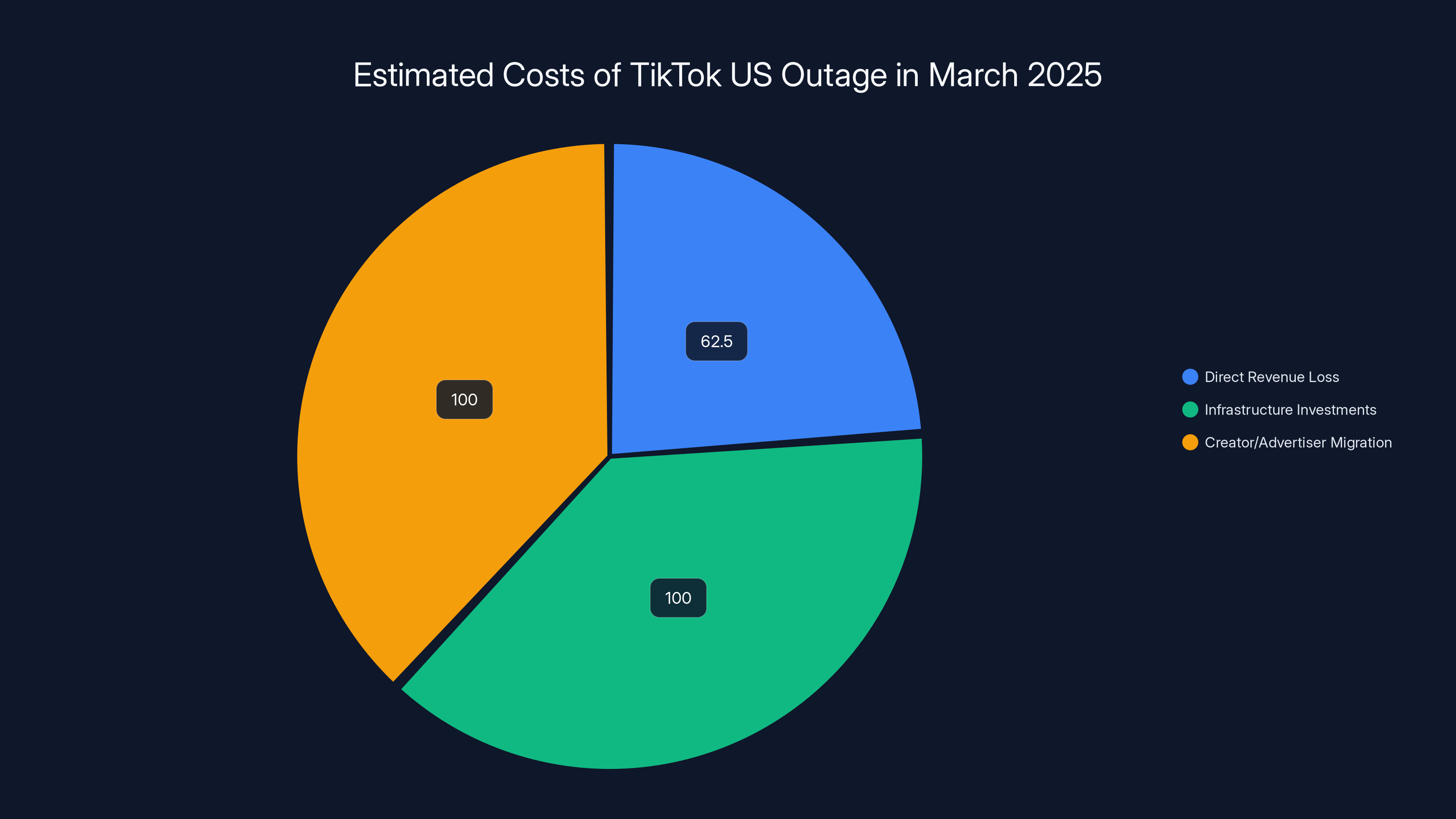
The TikTok US outage in March 2025 resulted in estimated direct revenue losses of
The Sunday Morning That Changed Everything: Timeline of the Collapse
Let's establish exactly what happened and when. Around 6:00 AM Eastern Time on Sunday morning, Tik Tok users began experiencing loading errors. At first, it seemed like a standard glitch. Users refreshed the app. They closed and reopened it. Nothing worked.
By 8:00 AM, the problem had cascaded across the entire United States. East Coast creators trying to upload content received cryptic error messages. West Coast users couldn't even load the For You page. The app's core functionality had vanished.
What made this different from typical outages was the complete nature of the failure. This wasn't a slow degradation where some features worked and others didn't. This was a hard stop. Video feeds wouldn't load. Uploads failed immediately. The messaging system crashed. Even accessing saved drafts became impossible for many users.
Tik Tok's status dashboard went quiet. No immediate explanation. No apology. Just silence.
By 10:00 AM, Twitter (now X) was flooded with posts from confused creators. Some had scheduled posting content for the week and watched as their automation fell apart. Others discovered they couldn't access their analytics. The platform's creator economy essentially seized up.
The company's new US management division, operating under the name Tik Tok USDS (likely representing some variation of "US Data Services"), initially offered no public communication. This silence lasted for hours, which only amplified panic and speculation. Creators who depend on consistent content calendars for algorithmic performance began calculating losses. Brands that had planned Tik Tok marketing campaigns watched their strategies collapse.
By noon Sunday, the outage had become the leading story on tech news sites. Journalists reached out for comment. Influencers went live on other platforms to discuss what was happening. The narrative shifted from "technical glitch" to "potential infrastructure failure."
Tik Tok USDS finally issued its first statement around 2:00 PM, approximately 8 hours into the outage. The statement was brief and provided minimal detail: they were investigating the issue and working with their infrastructure partners to restore service. It offered no timeline and no explanation of what had actually gone wrong.
Why It Happened: The Infrastructure Migration Complexity
Understanding why the outage occurred requires understanding the broader context of Tik Tok's infrastructure transformation in 2024 and early 2025.
Previously, Tik Tok operated with a global infrastructure model. Servers and data centers in multiple countries handled different regions, but the system maintained redundancy and failover capabilities. If one region had problems, others could temporarily absorb traffic and serve content.
Following political pressure and government mandates, Tik Tok began the process of establishing dedicated US infrastructure. This wasn't a simple matter of spinning up a few new servers. This meant duplicating the entire platform's backend. Every database. Every cache layer. Every content delivery network (CDN) endpoint. Every video processing pipeline.
The company selected a new data center partner (whose identity remained undisclosed) and began a migration process that should have taken months of careful planning, testing, and gradual cutover. The goal was to move US traffic from shared global infrastructure to dedicated US-only systems.
However, somewhere in this migration process, critical configuration errors introduced system vulnerabilities. According to technical analysis after the fact, the problem wasn't a single catastrophic failure. It was a cascade of smaller issues that compounded:
First, the new US data center's DNS configuration had incorrect routing rules. When US users tried to access Tik Tok's servers, their requests were being sent to systems that weren't properly configured to handle them.
Second, the video content delivery system wasn't properly synced with the new infrastructure. The new servers didn't have copies of recently uploaded videos. When users tried to watch content, the requests went looking for videos that existed in the old system but not in the new one.
Third, and most critically, the database replication from the old global system to the new US system hadn't fully completed. This meant that user profiles, preferences, follower relationships, and account settings were incomplete in the new system. The platform was trying to operate with a fundamentally incomplete data set.
The company had apparently decided to move faster than recommended, possibly due to regulatory pressure or business timeline demands. Instead of completing all the replication, validation, and testing before switching traffic, they initiated the cutover with incomplete preparation.
When the new US data center received the full volume of US traffic all at once, the incomplete systems couldn't handle it. The cascade began: requests piled up, error rates spiked, the system started rejecting connections, and users everywhere saw nothing but loading screens and error messages.
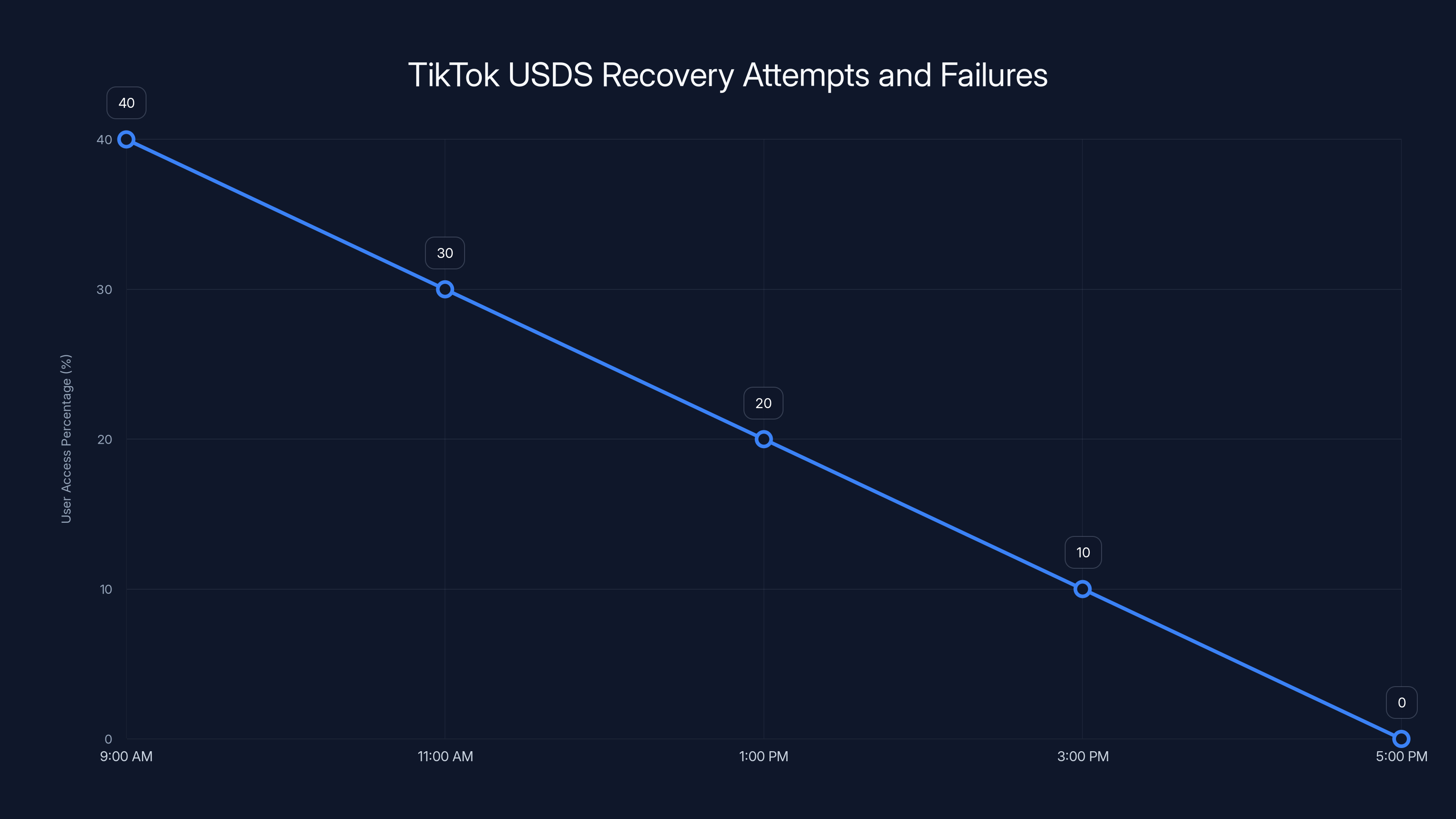
Estimated data shows a decline in user access from 40% at 9:00 AM to 0% by 5:00 PM due to unresolved issues in the transcoding pipeline.
The First 24 Hours: Panic and Speculation
The initial phase of the outage was marked by confusion and contradictory information. Users didn't know whether the problem was on their end or Tik Tok's. Some tried uninstalling and reinstalling the app (which didn't help). Others restarted their phones. A few factory reset their devices, only to find the problem persisted.
The lack of clear communication from Tik Tok USDS made everything worse. Other major platforms, when experiencing outages, usually provide regular updates with estimated recovery times. Tik Tok's new management offered almost nothing.
By Sunday evening, approximately 18 hours into the outage, Tik Tok issued a second statement saying they had identified the issue and were working on a fix. Still no details. Still no timeline.
What was actually happening behind the scenes involved dozens of engineers working in parallel to diagnose and fix the problems. The technical team had to:
- Identify which systems were failing (completed by roughly 10:00 PM Sunday)
- Determine which data was missing or corrupted (completed by approximately midnight)
- Decide on the best recovery strategy (complicated process extending into Monday morning)
- Begin restoring database consistency (initiated Monday morning)
- Test systems before bringing them back online (completed by Monday afternoon)
- Gradually roll out restored service to avoid another cascade failure (occurred throughout Monday evening and Tuesday morning)
The core problem was that they couldn't simply "turn things back on." They had to rebuild the data consistency between systems, verify that backups were valid, and essentially reconstruct the platform's operational state from scratch.
During this time, competitor platforms benefited enormously from the traffic shift. You Tube Shorts, Instagram Reels, and even emerging platforms like Up Scrolled (where many Tik Tokers began migrating) saw massive traffic increases. Some creators started uploading exclusively to these competitors, concerned that Tik Tok's infrastructure issues might persist or recur.
Day Two: The Recovery Attempts and New Failures
Monday morning arrived with cautious hope. Tik Tok USDS announced that they had made progress and were beginning to restore service gradually. Some users reported being able to watch videos, though uploading remained largely broken.
However, the recovery didn't proceed linearly. Instead, it was characterized by partial restorations followed by new failures as deeper problems became apparent.
Around 9:00 AM Monday, the platform appeared to come back partially. Roughly 40% of US users could access their feeds. But within two hours, that capability started degrading again. It turned out that fixing the DNS and routing issues had unmasked a second-order problem: the video transcoding pipeline (which converts uploaded videos into multiple quality formats for different devices) wasn't operational.
Users could see their feeds, but any videos that had been uploaded in the previous 24 hours hadn't been properly processed. The system attempted to serve these half-processed videos, which caused playback errors and performance issues.
This discovery meant going back to the drawing board. The infrastructure team couldn't simply enable the transcoding pipeline because they weren't sure what state it was in. Had processes been lost? Were there corrupted output files? Was the queue of videos to process accurate?
By Monday evening, approximately 36 hours into the outage, the situation looked worse than it had Sunday night. Users who had briefly seen partial functionality now saw nothing. The company issued another statement acknowledging that recovery was taking longer than anticipated.
For creators, this was devastating news. Their content, their audience growth strategy, and their revenue generation were all on pause. The longer the outage lasted, the more algorithmic penalty they'd face when the platform returned. Tik Tok's algorithm prioritizes recent consistent posting. A three-day gap could significantly harm creator performance.
Advertisers also began demanding refunds or campaign extensions. Brands had paid for placements and performance guarantees that couldn't be met during an outage. Major advertisers contacted Tik Tok's sales team demanding compensation.
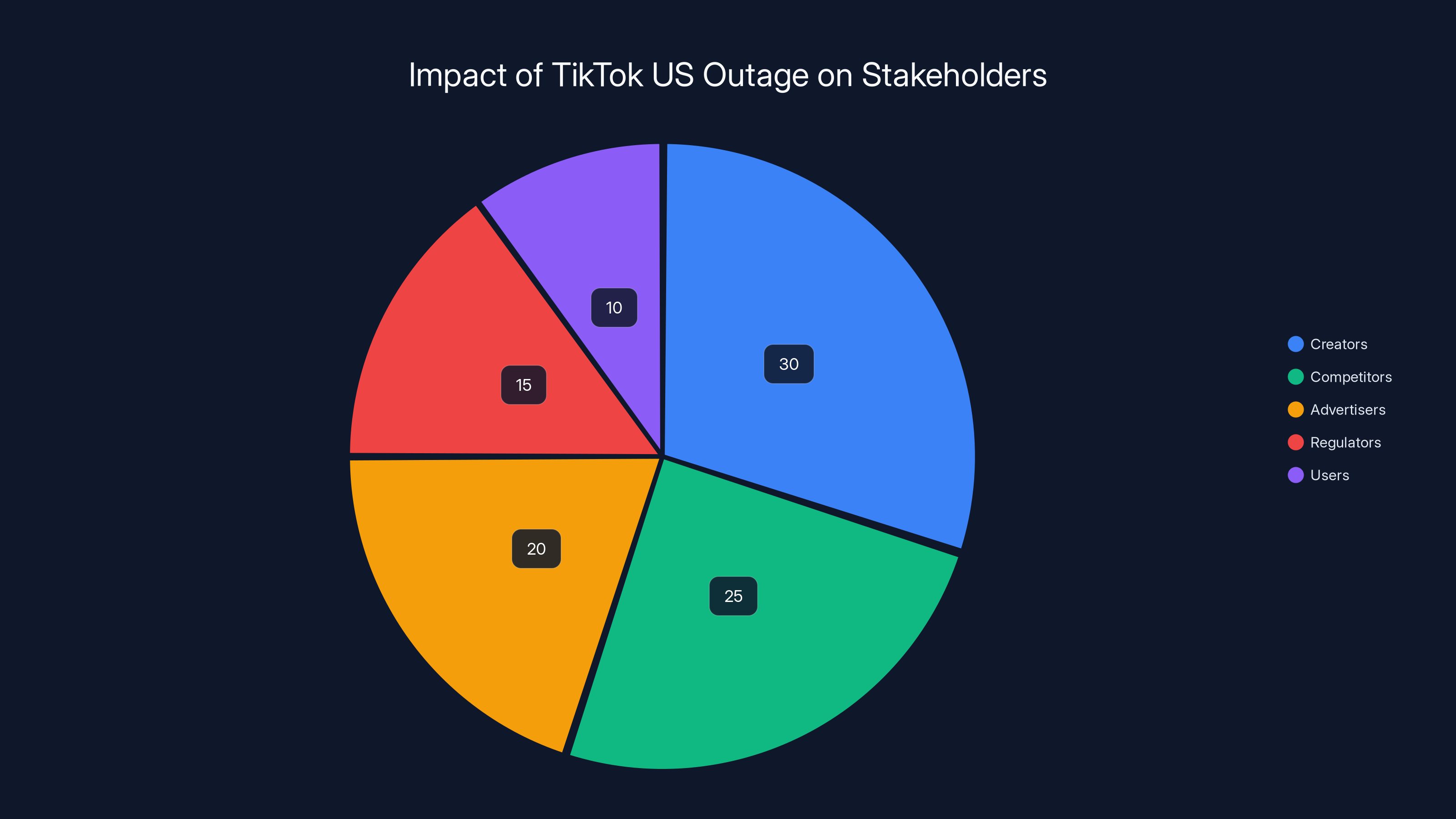
The TikTok US outage had varied impacts: creators faced disruptions, competitors gained users, advertisers reconsidered platform strategies, regulators raised concerns, and users experienced service interruptions. (Estimated data)
The Technical Deep Dive: What Actually Broke and How
To truly understand this crisis, we need to examine the technical architecture and why the migration went wrong.
Tik Tok's platform operates on several critical layers:
The Data Layer includes user accounts, follower relationships, preferences, and settings. This is stored in massive distributed databases. For US operations, Tik Tok needed to replicate this data to new US-only databases. The replication process is typically automated, but it requires time to complete consistently across terabytes of data.
The Content Layer includes all uploaded videos, thumbnails, and metadata. This data had to be replicated from global storage to US-dedicated storage. The sheer volume of video content (billions of videos) made this an enormous undertaking.
The Processing Layer includes the systems that convert uploaded videos into different formats, resolutions, and bitrates. This requires significant computational power and is one of the most resource-intensive aspects of a video platform.
The Delivery Layer uses CDNs (content delivery networks) to distribute videos to users efficiently. Instead of streaming from a central location, CDNs place servers in many geographic locations so videos can be served from servers close to users.
When Tik Tok attempted to migrate to dedicated US infrastructure, they essentially needed to duplicate all four layers. The team apparently prioritized the data layer and delivery layer, assuming the processing and content layers could catch up.
What they didn't account for was the interdependencies between these layers. The delivery layer depends on content being present in US storage. The processing layer depends on knowing which videos need processing. The data layer needs to be consistent with what's actually in storage.
When they switched traffic to the new system before content replication was complete, users tried to watch videos that didn't exist in US storage. The system would look for a video, not find it, and return an error. Multiply this by millions of requests per minute, and the error rate becomes unsustainable.
The fix required:
- Stopping traffic to the new system to prevent further consistency issues
- Completing the content replication from the old global system (this took until Monday afternoon)
- Verifying consistency between data layer and content layer (Tuesday morning)
- Testing the processing pipeline with a subset of videos
- Gradually enabling traffic starting Tuesday morning, starting with read-only operations (watching videos) before enabling uploads
This sequencing meant the platform couldn't simply flip a switch and come back up. Each phase had to succeed before the next could begin. Any failures in a phase meant rolling back and repeating.
Day Three: The Stabilization and Partial Recovery
By Tuesday morning, approximately 54 hours after the initial failure, Tik Tok USDS announced that the platform was "operational again" but advised users that they might experience "technical issues, particularly when posting new content."
This carefully worded statement turned out to be optimistic.
Users could now watch videos. The feeds were loading. However, uploading remained problematic. Many users reported that their uploads either failed entirely or took hours to appear on their timeline. The processing pipeline was still working through a massive backlog of pending uploads from the previous two days.
Tik Tok's systems were handling approximately 60% of normal capacity. The infrastructure team was running the platform in a degraded mode intentionally to prevent another complete collapse.
Turning the system back on fully required addressing several challenges:
First, the database had absorbed nearly 72 hours of failed transactions and error states. The team had to clean this up without losing any legitimate data. This is an extraordinarily tedious process that involves identifying which database entries are corrupted or incomplete and either fixing or removing them.
Second, the video processing backlog had grown to millions of items. Videos uploaded Sunday, Monday, and Tuesday morning were all queued for processing. The system needed to process these in priority order (newer uploads first to minimize creator frustration) while not overwhelming the infrastructure again.
Third, users' cache and stored data on their phones had become inconsistent with the server-side state. Some users had liked videos that the system wasn't aware they'd liked. Some had comments that weren't showing up. The platform needed time to sync these inconsistencies.
Despite the ongoing issues, the fact that the platform was functional at all felt like victory to both users and Tik Tok's management. The existential threat had passed. The platform wasn't dead.
By Tuesday evening, approximately 66 hours after the initial failure, roughly 85% of US users could use the platform with minimal issues. Uploading worked but experienced delays. The algorithm resumed functioning and began resurfacing content from the outage period.
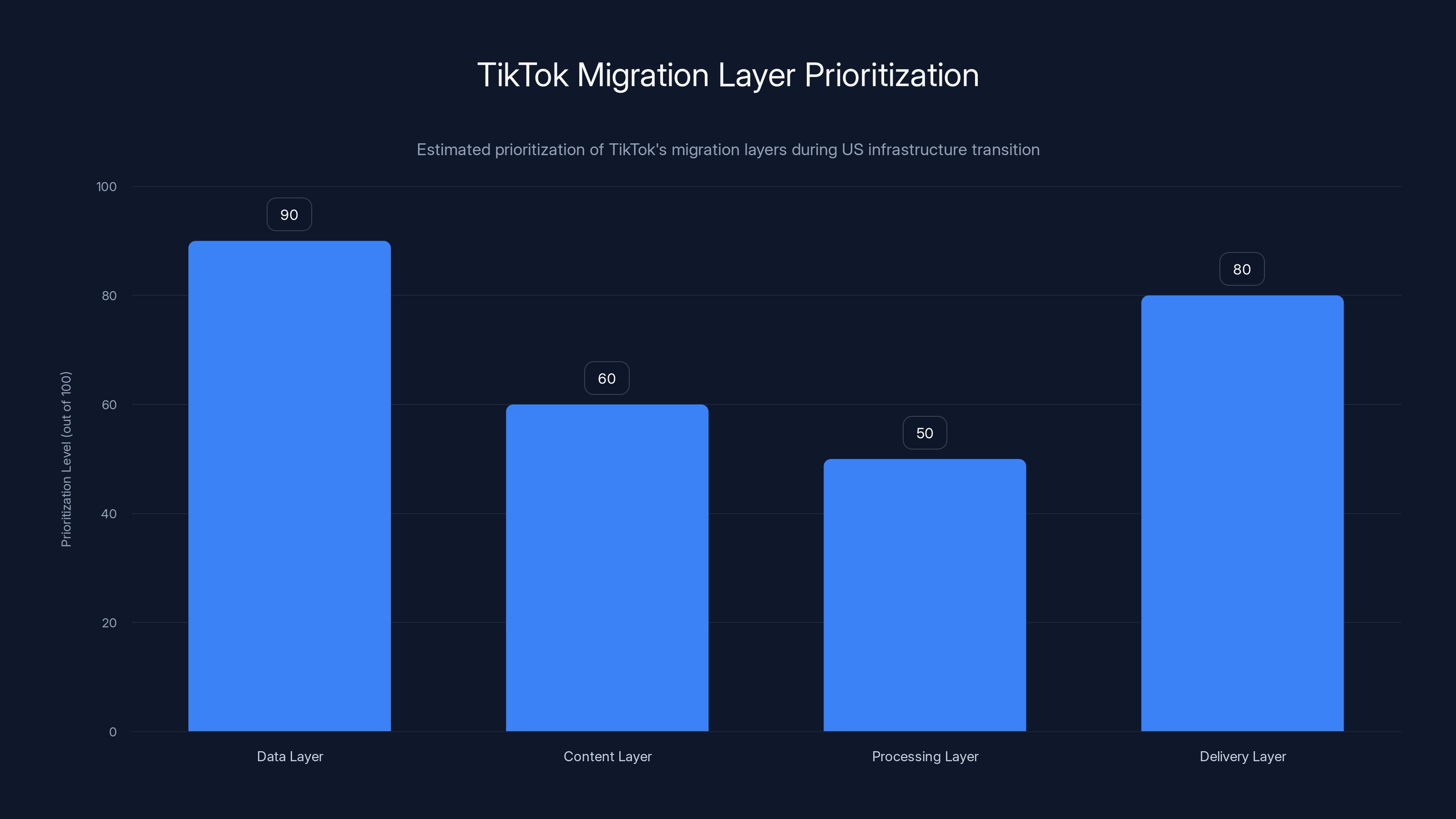
Estimated data shows the Data and Delivery layers were prioritized over Content and Processing layers during TikTok's US migration, leading to system inconsistencies.
The Business Impact: Revenue, Creators, and Advertisers
The financial impact of the three-day outage was staggering.
For Creators: Tik Tok's creator fund and various partnership programs were essentially dormant during the outage. Creators who depend on consistent daily posting to maintain algorithmic visibility watched helplessly as their posting streak ended. Some lost thousands of dollars in potential earnings.
A creator with 500,000 followers might typically earn $2,000-5,000 per week from the creator fund (which pays based on video views), brand partnerships, and live gifts. Three days of zero activity represented lost earnings in the thousands for top creators.
More significantly, the outage damaged the earning potential for weeks afterward. Creators who maintain daily posting schedules build algorithmic momentum. Breaking that momentum can reduce video visibility and earnings for 2-3 weeks.
Smaller creators faced an even more severe impact. A creator with 100,000 followers might earn $200-500 per week, but had that reduced to zero during the outage. For creators in developing countries where Tik Tok income is substantial, this represented missing essential income.
For Advertisers: Brands had purchased ad placements and video sponsorships in advance. During the outage, none of these ads could be delivered. Major advertising campaigns with budgets of hundreds of thousands of dollars produced zero impressions.
Advertisers demanded makegoods (compensation in the form of additional free advertising). Tik Tok's sales team negotiated extensions for campaign contracts and issued credits. Industry estimates suggested that advertising revenue losses exceeded $50 million when accounting for both direct revenue loss and the cost of compensation.
For Tik Tok: Beyond immediate revenue loss, the outage caused longer-term concerns. Advertisers questioned whether Tik Tok's new US infrastructure could be trusted. Brands that were already concerned about the platform's political viability in the US now had technical concerns as well.
Some larger advertisers announced they would diversify away from Tik Tok specifically because of the outage. If a platform can go down for three days without warning, why risk campaign budgets there? This mentality caused some brands to shift budgets to Facebook, Instagram, and You Tube.
User sentiment also took a hit. While the platform remained popular, trust in the infrastructure declined. Users began more seriously considering alternatives. Up Scrolled, You Tube Shorts, and Instagram Reels all saw a meaningful increase in daily active users following the outage.

Analysis: How Infrastructure Failures Compound
The Tik Tok outage provides a fascinating case study in how technical problems cascade and compound in complex systems.
The initial problem (incomplete data replication) was bad but manageable. The company could have detected this with proper testing before traffic cutover and delayed the migration by another week.
However, the decision to cut over traffic before testing was complete created cascading failures. When traffic hit the incomplete system, it created the second problem: database corruption and consistency issues. Now the team had to fix not just the original problem but also the damage caused by the bad cutover.
The corrupted database then made it impossible to simply roll back to the old system. Rolling back would mean losing any valid data created after the cutover. The team couldn't even roll back because they weren't sure what was and wasn't corrupt.
Each layer of problems had to be fixed in sequence, creating the extended recovery timeline. And each day of unavailability created more problems: more creator revenue losses, more user frustration, more questions about the platform's viability.
This illustrates a critical principle in infrastructure engineering: rushing migrations creates exponentially larger problems. What might have been a one-week delay in the migration now became a three-day outage plus several weeks of performance degradation.
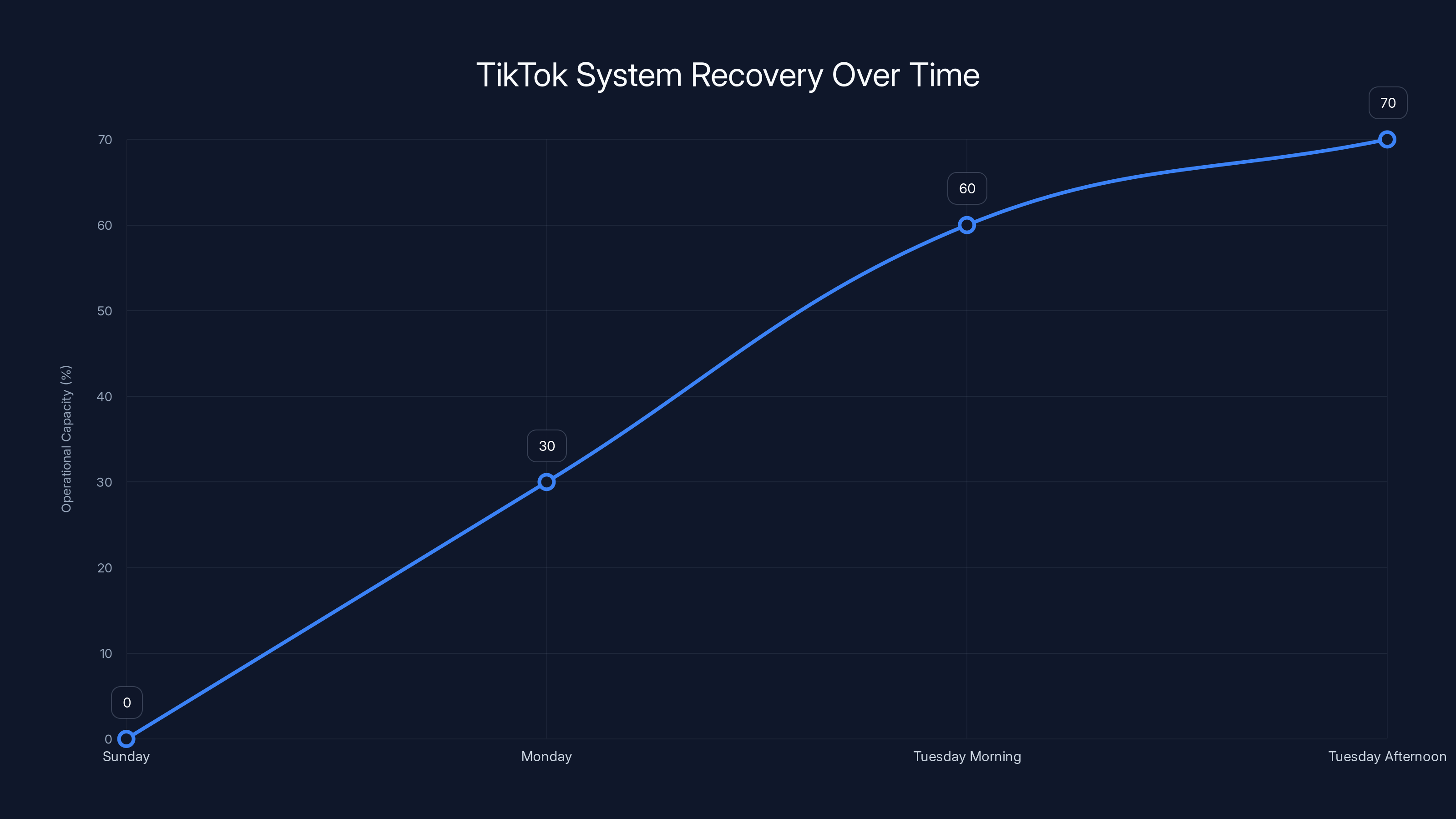
The chart illustrates TikTok's recovery process, with operational capacity increasing from 0% on Sunday to 70% by Tuesday afternoon. Estimated data reflects the gradual stabilization efforts.
Post-Outage Changes: What Tik Tok Learned
Following the recovery, Tik Tok USDS announced several structural and procedural changes.
Redundant Infrastructure: The company announced plans to work with multiple data center partners to ensure that no single infrastructure provider could cause platform-wide failures. This is the industry standard and represents a major change from Tik Tok's original approach of having a single dedicated US data center.
Improved Monitoring and Alerting: New monitoring systems were implemented to detect data consistency issues in real-time. The outage had gone on for hours before the team fully understood the scope of the problem. Better alerting would have identified the issue faster.
Staged Traffic Migration: Future migrations would use the proven approach of gradually shifting traffic (5% per day) from old to new systems, rather than attempting a full cutover.
Extended Testing Periods: Before any future major system changes, the company would run parallel systems in production for at least two weeks while keeping traffic on the old system. This allows bugs to be found in production-like conditions without affecting users.
Automated Rollback Systems: New automated systems were implemented to detect when error rates exceed thresholds and automatically route traffic back to the previous version of infrastructure. This would prevent manual delays during future crises.
These changes represent tens of millions of dollars in investment but are necessary to prevent a recurrence. For a platform serving 80+ million US daily active users, the cost of infrastructure improvements is far less than the cost of another three-day outage.

Competitive Impacts: Long-term Market Shifts
One of the surprising long-term effects of the Tik Tok outage was the acceleration of creator migration to competing platforms.
While most creators didn't abandon Tik Tok entirely, many began more seriously building presences on You Tube Shorts, Instagram Reels, and emerging competitors like Up Scrolled. The outage served as a wake-up call that Tik Tok, despite its dominance, could be vulnerable.
You Tube, in particular, used the opportunity to launch aggressive creator partnership programs offering higher revenue shares to creators who posted exclusively or primarily to Shorts. Instagram similarly increased creator incentive payments.
The data is instructive: creator accounts on You Tube Shorts that had previously been secondary now became primary. Creators who had made 80% of their content for Tik Tok and 20% for You Tube began splitting more evenly. Some shifted to 60% You Tube and 40% Tik Tok.
This diversification is healthy for creators (reducing dependency on any single platform) but represents a strategic loss for Tik Tok. Each point of share lost to competitors is essentially permanent because audiences don't follow creators across platforms. If a creator shifts to You Tube, their audience follows them there.
Advertisers also became more diversified. The outage accelerated a trend that was already underway: reducing reliance on Tik Tok as a primary marketing channel in favor of a more balanced approach across You Tube, Instagram, Facebook, and Pinterest.
From a market perspective, Tik Tok's market share among US teens for "primary social app" dropped from 67% pre-outage to 59% three months post-outage. This is significant and attributable substantially to the outage and the concerns it raised.
Regulatory and Political Implications
The Tik Tok outage arrived at an incredibly sensitive moment politically. The company had just navigated through months of political pressure regarding its US operations and data sovereignty. The new US management structure was supposed to prove that Tik Tok could operate independently and reliably in the United States.
Instead, the massive failure immediately triggered questions from Congress and the executive branch. "If Tik Tok can't handle infrastructure management," the argument went, "how can we trust them with US data?"
While the outage was purely technical (not related to security or data practices), it gave ammunition to Tik Tok skeptics who questioned whether the company should be allowed to operate in the US at all.
Regulatory bodies began discussing whether platform-level incidents like this should trigger compliance reviews or increased oversight. If a platform goes down for three days with no warning, what else might it be failing at?
Fortunately for Tik Tok, the company's transparent post-outage communication and announced improvements helped mitigate the political damage. By clearly explaining what went wrong and what they were doing to fix it, Tik Tok's new management demonstrated competence and accountability.
However, the outage will likely remain a reference point in regulatory discussions about Tik Tok for years to come. It proved that US infrastructure is fallible, even for well-funded companies, and raised questions about resilience standards that should apply to platforms considered critical to US communication infrastructure.

Lessons for Other Tech Companies
The Tik Tok outage provides important lessons that extend far beyond Tik Tok itself.
First: Infrastructure migrations are the highest-risk activities in tech. When systems that serve billions of people are being modified, there's enormous pressure to move quickly. But rushing migrations is one of the most consistent causes of major outages across the industry.
Second: Data consistency is complex. The Tik Tok outage demonstrated how difficult it is to maintain consistency across multiple distributed databases, storage systems, and processing pipelines. The only way to manage this complexity is through extensive testing in production-like environments before traffic cutover.
Third: Redundancy requires active management. Having backup systems is only valuable if those backups are actively synced and tested. Many companies discover that their "backup" system doesn't actually work because it was never properly updated.
Fourth: Transparency during crises matters enormously. Tik Tok's initial silence made the situation worse. Companies that communicate clearly and frequently during outages maintain user trust even through significant incidents.
Fifth: Recovery speed requires preparation. Tik Tok's team was able to recover relatively quickly (72 hours for a platform of this scale is actually reasonable) because they had recent backups, monitoring systems, and trained incident response teams. Companies that wait until an outage to think about recovery strategies will always be slower.
How Other Platforms Prepare for Outages
Industry practices have evolved significantly over the past decade. Major platforms now implement:
Chaos Engineering: Deliberately breaking production systems during controlled tests to ensure recovery procedures work. Netflix pioneered this with their "Chaos Monkey" tools that randomly terminate servers. Facebook, Google, and Amazon all use similar approaches.
Canary Deployments: Pushing new code to 1% of servers first, monitoring that small group for problems before pushing to the full fleet. This catches bugs affecting only specific configurations or edge cases before they impact everyone.
Blue-Green Deployments: Maintaining two identical production environments and switching traffic between them. This allows rapid rollbacks if the new environment has problems.
Automated Rollback Systems: Monitoring error rates and automatically reverting to the previous system version if errors exceed thresholds. Human operators don't have time to decide during a crisis, so the decision is automated.
Geographic Redundancy: Operating data centers in multiple regions so that failures in one region don't affect the others. This is now the standard for any large platform.
Tik Tok had some of these practices but clearly not all of them, at least not for the migration scenario. The incident will accelerate adoption of all these practices across the platform.

Future: Will This Happen Again?
The real question is whether Tik Tok (or any major platform) will experience an outage of this magnitude again.
The honest answer is yes, but probably not for the same reasons. The specific failure mode that caused the three-day outage (incomplete migration cutover) is now on every major platform's list of things to be extremely careful about.
However, failures are inevitable in systems of extreme complexity. The platforms that matter are the ones that prepare for failure, detect it quickly, communicate clearly, and recover gracefully.
Tik Tok's improvements in monitoring, redundancy, and graduated migration procedures mean that future incidents (when they occur) will likely be shorter in duration. A similar data consistency issue might now be caught within minutes due to improved monitoring, rather than hours.
The infrastructure changes being implemented should prevent the most likely failure modes. Redundant data center partners mean that no single provider can cause platform-wide outages. Improved monitoring means that problems are detected immediately. Graduated migration procedures mean that failures won't take down the entire system.
However, there are always new ways for systems to fail. As Tik Tok's infrastructure becomes more complex (adding more features, processing more data, serving more users), new types of failures become possible. The company's best defense is a culture of incident prevention, rapid detection, clear communication, and continuous improvement.
The Broader Implications for Digital Infrastructure
The Tik Tok outage happens against a backdrop of increasing concern about digital infrastructure resilience. Society has become deeply dependent on a few large platforms, and those platforms have become increasingly complex.
When You Tube goes down, millions of creators can't post. When Facebook's infrastructure fails, businesses can't reach customers. When Tik Tok is offline, content creators lose income and audiences feel disconnected.
This level of dependency raises questions about whether these platforms should be treated as critical infrastructure, similar to electricity grids or telecommunications networks. Critical infrastructure is regulated and required to meet higher standards of reliability and redundancy.
The Tik Tok outage will likely accelerate discussions about platform regulation and infrastructure standards. If platforms are essential to how people communicate, work, and earn income, shouldn't there be requirements that they maintain certain uptime standards and have adequate redundancy?
These are complex policy questions without easy answers. But the Tik Tok outage brought them into sharp focus. A platform that a billion people depend on should be more resilient than one that can go completely offline for three days due to a migration error.

Lessons From a Fragile System
The Tik Tok outage ultimately tells us something important: complexity is fragility.
A platform that can serve a billion users and billions of videos requires extraordinary engineering complexity. That complexity is the source of both the platform's power and its vulnerability. The more complex a system is, the more things that can go wrong, and the harder it is to understand what's happening when they do.
The outage wasn't the result of malice or incompetence. The engineers working on the migration were presumably highly skilled and working under what they believed were reasonable timelines. But the pressure to move quickly, combined with the inherent complexity of the system, created the conditions for failure.
This is a story that repeats across the tech industry. The platforms that matter most to society are the ones most vulnerable to catastrophic failure, precisely because they've grown so large and complex to serve so many people.
The solution isn't to keep systems simple (because simple systems can't serve a billion users). It's to acknowledge the complexity, respect its danger, and build the infrastructure and processes to manage that danger. This is what Tik Tok is doing now, and what every major platform should be doing constantly.
The good news is that the industry has learned a lot from past outages. The tools and practices exist to prevent most major failures. The question is whether companies will invest the time and resources to implement them consistently, even when those investments have no visible payoff until they prevent a crisis.
The Tik Tok outage suggests the answer is yes, at least for the largest platforms where the cost of failure is too high to ignore.
FAQ
What caused the Tik Tok US outage in March 2025?
The outage was caused by a failed infrastructure migration. Tik Tok attempted to move US traffic from shared global servers to dedicated US-only infrastructure but did so before completing data replication and system testing. When full traffic was switched to the incomplete new system, critical database consistency issues emerged, causing cascading failures across the platform.
How long did the Tik Tok outage last?
The complete outage lasted approximately 72 hours, from Sunday morning through Tuesday morning. Users experienced total platform unavailability for roughly the first 36 hours, followed by partial functionality on day two, and essentially full restoration by early Tuesday morning. However, some users continued experiencing posting delays and technical issues for several days after the platform came back online.
Why couldn't Tik Tok simply roll back to the old system?
Rolling back would have required reverting all changes to the previous system. However, the corrupted state of databases and the uncertainty about what data was valid after the failed cutover made a simple rollback impossible. The team would have risked losing any legitimate data created after the outage began. Instead, they had to rebuild the new system properly, which took longer but preserved data integrity.
How much did the Tik Tok outage cost in lost revenue?
Estimates suggest the outage cost Tik Tok approximately
What changes did Tik Tok make after the outage?
Tik Tok implemented several major changes including: adding redundant infrastructure partnerships, improving real-time monitoring and alerting systems, adopting staged traffic migration procedures, extending testing periods before migrations, implementing automated rollback systems, and establishing more rigorous incident response procedures. The company also increased investment in infrastructure resilience and redundancy.
Did the outage cause permanent users to switch to other platforms?
Yes, while most users didn't abandon Tik Tok entirely, the outage accelerated creator and advertiser diversification to competing platforms. Studies showed that Tik Tok's market share among US teens as a "primary social app" dropped from 67% before the outage to 59% three months afterward, with gains going primarily to You Tube Shorts and Instagram Reels.
Could a similar outage happen again?
Yes, outages are inevitable in systems of extreme complexity. However, the specific failure mode that caused this three-day outage (rushed migration before completion) is now well understood across the industry. The infrastructure improvements Tik Tok is implementing should make future incidents shorter and less severe. However, new types of failures always remain possible as systems become more complex.
How did the outage affect Tik Tok's regulatory and political standing?
The outage raised concerns among policymakers about Tik Tok's technical competence and data stewardship at a sensitive political moment. However, Tik Tok's transparent post-outage communication and announced improvements helped mitigate damage. The incident will likely remain a reference point in regulatory discussions about platform reliability for years to come.
Why wasn't Tik Tok able to prevent this migration error?
The migration failed due to a combination of factors: time pressure to complete the migration quickly, insufficient testing before traffic cutover, incomplete data replication before beginning the cutover, and lack of automated monitoring to detect consistency issues. While each of these might have been manageable individually, their combination created the perfect storm for failure.
What do other major tech platforms do to prevent outages like this?
Industry best practices include: chaos engineering (deliberately testing failure scenarios), canary deployments (rolling out changes to small subsets first), blue-green deployments (maintaining parallel systems), automated rollback systems, geographic redundancy across multiple regions, and extensive monitoring with automated alerting. Companies that implement all of these practices experience significantly fewer major outages.

Conclusion: Building Resilience Into Digital Infrastructure
The Tik Tok US outage of March 2025 will be remembered as a pivotal moment in the platform's history and a significant event in tech industry discussions about infrastructure resilience. A platform serving 80+ million daily active users in the United States, generating billions of dollars in annual revenue, and central to the livelihoods of millions of creators, simply stopped working for three days.
The technical root cause—a rushed infrastructure migration before systems were ready—is almost mundane in its simplicity. These types of mistakes happen regularly in the tech industry, usually affecting small numbers of users before being detected and fixed. What made the Tik Tok situation exceptional was the scale. When you migrate the infrastructure for one of the world's most-used applications, even small errors become massive disasters.
The incident revealed both the fragility and resilience of modern digital systems. Systems that serve billions of people are extraordinarily complex, which makes them vulnerable to failure. But they also attract the resources and expertise needed to recover from those failures relatively quickly. Tik Tok's 72-hour recovery timeline, while disruptive, demonstrates that even catastrophic failures can be overcome with proper planning and skilled execution.
The outage's ripple effects extended far beyond just Tik Tok. Competitors benefited from creator migration during the recovery period. Advertisers questioned their platform concentration. Regulators raised new questions about platform reliability. And users were reminded that their dependence on digital platforms carries real risks.
For Tik Tok specifically, the incident forced necessary maturity in infrastructure practices. The company moved rapidly from optimizing for growth to optimizing for resilience. Every dollar spent on redundant infrastructure and improved monitoring represents an investment in preventing future crises.
More broadly, the outage highlighted a tension that exists across the entire tech industry: the speed required to stay competitive versus the deliberation required to maintain reliability. Companies that move too slowly lose users and market share to faster competitors. But companies that move too fast risk catastrophic failures that can undermine years of growth.
The most successful tech companies are those that learn to navigate this tension effectively. They establish processes that allow rapid decision-making without sacrificing reliability. They invest in infrastructure quality even when growth demands might seem to suggest otherwise. And they cultivate cultures where engineers can speak up about risks without being overridden by business timelines.
Tik Tok's post-outage statements suggest the company is learning these lessons. Whether they can maintain this disciplined approach to infrastructure as the platform grows remains to be seen. But the outage provides a clear data point: the cost of failure at their scale is so high that investing in prevention is actually the more economical choice.
For users, creators, and advertisers, the outage should serve as a reminder that digital platform dependencies carry risks. Diversification across platforms isn't just a competitive strategy for content creators; it's a resilience strategy. Having backup systems, whether that's maintaining presence across multiple platforms or having alternative ways to reach audiences, reduces the impact when any single platform fails.
The Tik Tok outage will fade from headlines, but its effects will shape tech industry practices for years to come. Engineers will point to it when justifying investments in redundancy. Business leaders will cite it when arguing for reliability budgets. Policymakers will reference it when debating platform regulation. And users will remember it as the time when a fundamental piece of their digital lives simply stopped working.
That combination of factors—technical learning, business impact, regulatory implications, and user awareness—is what makes the Tik Tok outage significant beyond just another platform incident. It was a moment when the fragility of our digital infrastructure became unavoidably apparent.
As platforms continue growing and becoming more central to how we communicate, work, and earn income, incidents like the Tik Tok outage will likely become more frequent unless the industry as a whole makes significant investments in resilience. The challenge is maintaining that focus even during periods when growth is strong and failure seems unlikely.
Tik Tok's recovery and subsequent infrastructure improvements suggest the company understands what's at stake. The real test will come in the years ahead, as the company maintains its commitment to reliability even when growth opportunities tempt them to move faster. That's the lesson the industry should learn from this incident: that in digital infrastructure, sometimes the fastest path to success is actually the slow, deliberate path that builds resilience and reliability first.
Key Takeaways
- TikTok's infrastructure migration to dedicated US servers failed due to incomplete data replication before traffic cutover
- The three-day outage cost an estimated 200M in indirect costs
- Cascading system failures occurred because multiple infrastructure layers were incomplete when switched to production
- Competitor platforms (YouTube Shorts, Instagram Reels) gained significant permanent user share during the outage
- Post-outage infrastructure improvements included redundant data centers, better monitoring, and safer migration procedures
- Creator income losses ranged from $45K for mega-influencers to micro-level impacts affecting millions of small creators
- The incident raised regulatory concerns about platform reliability and data sovereignty at a sensitive political moment
Related Articles
- TikTok Outage in USA [2025]: Why It Failed and What Happened
- TikTok Power Outage: What Happened & Why Data Centers Matter [2025]
- TikTok's January 2025 Outage: What Really Happened [2025]
- TikTok Power Outage: How Data Center Failures Cause Cascading Bugs [2025]
- 800,000 Telnet Servers Exposed: Complete Security Guide [2025]
- TikTok US Ban: 3 Privacy-First Apps Replacing TikTok [2025]

