![TikTok Power Outage: How Data Center Failures Cause Cascading Bugs [2025]](https://tryrunable.com/blog/tiktok-power-outage-how-data-center-failures-cause-cascading/image-1-1769474237892.jpg)
TikTok Power Outage: How Data Center Failures Cause Cascading Systems Failures [2025]
It started Sunday without warning. Millions of TikTok users in the US woke up to a broken app. Videos showed zero views. Creators couldn't upload content. The "for you" feed turned into a broken record, showing the same videos repeatedly. Some people saw their earnings vanish entirely.
On Monday, TikTok finally broke silence: a data center power outage had triggered what they called a "cascading systems failure." That's corporate speak for "a bunch of stuff broke because one thing broke" as reported by PNJ.
But here's what matters. This wasn't just a TikTok problem. This was a window into how modern internet infrastructure actually works, how fragile it can be, and what happens when a single data center goes dark.
Let me walk you through what happened, why it matters, and what it means for the apps and services you depend on every day.
What Actually Happened During the TikTok Outage
On Sunday, January 26, 2025, one of TikTok's US data centers lost power. Not partially. Completely. The facility went dark, and suddenly millions of requests that should've been handled smoothly had nowhere to go according to KTAL News.
When a data center fails, it's not like flipping a light switch off and back on. The systems running inside those facilities are interconnected in complex ways. One failure touches everything downstream.
TikTok's statement said the power loss triggered a "cascading systems failure." What does that actually mean? Imagine dominoes, but instead of falling in a line, they fall in all directions at once.
Here's the chain of events. The power goes out. Backup generators kick in but fail to stabilize. Critical services trying to handle requests get timeouts. Other services waiting for responses from those failed services also start failing. Load balancers meant to distribute traffic can't figure out where to send requests. The entire system enters a state of confusion as detailed by Engadget.
The visible symptoms for users:
View counts showed as "0" across millions of videos. Creators uploaded content and watched their engagement vanish. The algorithm that powers TikTok's entire recommendation system got confused, serving the same videos repeatedly or showing generic content that hadn't been personalized. Earnings displays broke, showing empty values where actual money should appear. Login issues plagued some users. Upload functionality became unreliable.
What TikTok didn't explicitly say but implied: the damage wasn't limited to display issues. The company called these "display errors caused by server timeouts." But server timeouts affecting data storage and display suggest deeper database synchronization problems.
The company claimed user data was safe, that the actual engagement numbers still existed somewhere in the system. That might be true. But here's the reality: if a system can't reliably serve that data or display it, from the user's perspective, it doesn't exist.
TikTok operates not just TikTok. The parent company runs other apps too. The statement said "a power outage at a U.S. data center impacting TikTok and other apps we operate." That's a clue that this wasn't a TikTok-specific problem. The infrastructure failure affected multiple services running on shared infrastructure as noted by American University.
That pattern matters because it shows how consolidated modern internet infrastructure has become. One facility failure cascades through multiple products.

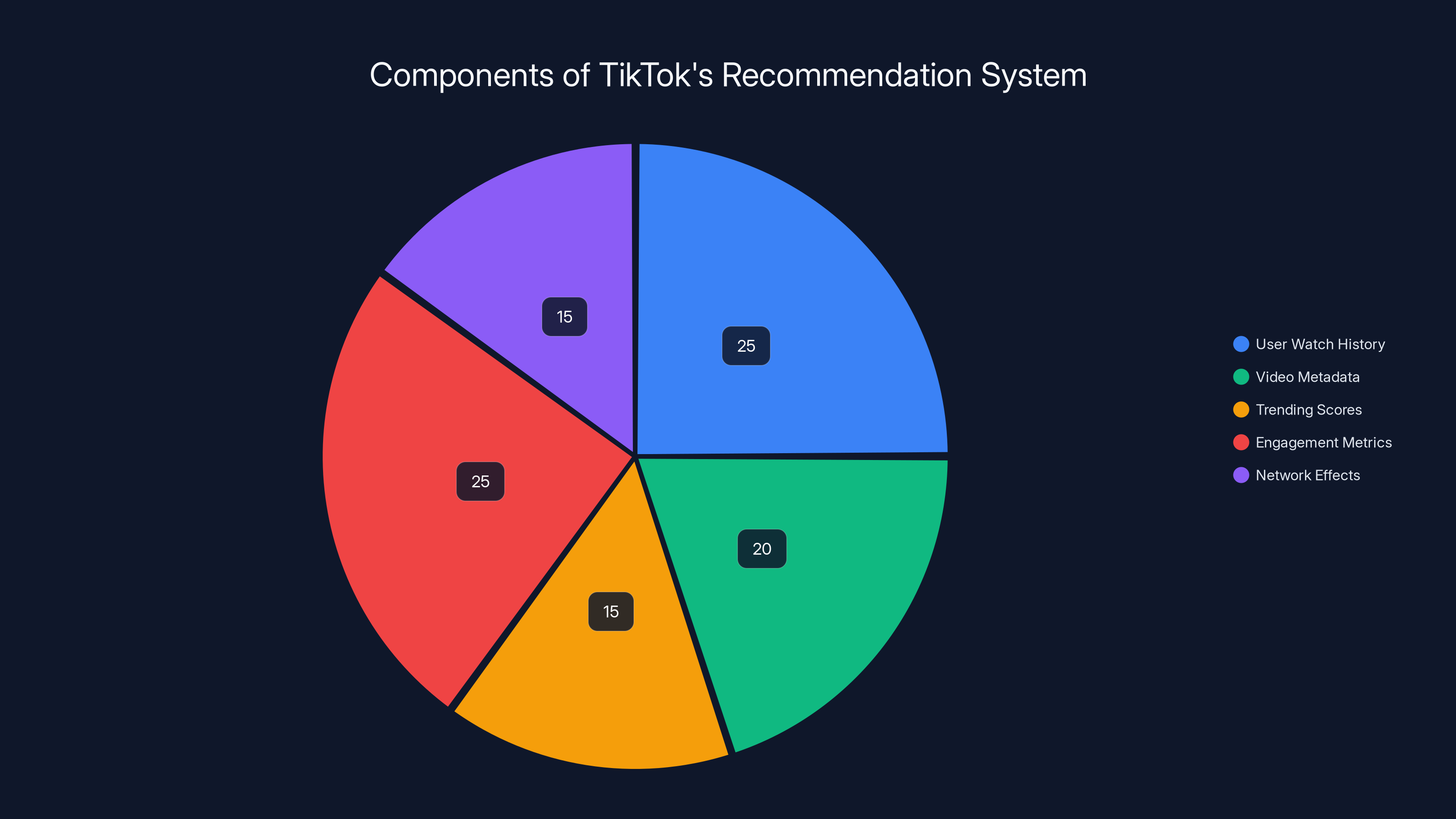
The pie chart illustrates the estimated importance of various components in TikTok's recommendation algorithm. User watch history and engagement metrics are crucial, each contributing significantly to personalized content delivery. (Estimated data)
Understanding Data Center Power Failures and Redundancy
Data centers are designed for redundancy. That's the whole point. Critical facilities should never depend on a single power source. They should have multiple connections to the power grid, backup diesel generators, uninterruptible power supplies (UPS) systems that can bridge the gap while generators start up.
So how does a data center still lose all power?
There are several failure modes. The primary power connection fails. Both backup connections fail simultaneously. Generators fail to start. Generators start but can't supply full load. UPS systems fail or run out of battery. A combination of some or all of these happens at once.
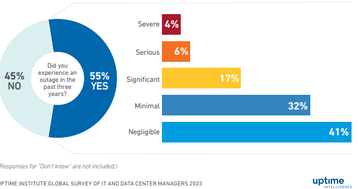
According to industry data from the Uptime Institute, about 70% of data center outages involve human error or procedural failures. Someone sets something up wrong. Someone forgets to test the backup generators. Someone performs maintenance on multiple systems simultaneously, not realizing the interdependency.
The remaining 30% are environmental failures: power grid failures, cooling system failures, equipment failures.
What's interesting about the TikTok outage specifically is that it wasn't just a power failure. It was a cascade. The power failure alone wouldn't cause algorithmic misbehavior or display corruption. The cascade does.
Here's how cascading failures work:
Service A depends on Service B. Service B depends on Service C. When C goes down, B starts timing out waiting for C's responses. When B times out, it stops responding to A. A, not knowing B is having problems, assumes B is overwhelmed or broken, so it might stop sending requests (a defensive mechanism). But that also breaks users trying to reach A.
Meanwhile, A tries to cache responses from B. When B doesn't respond, A serves stale cache. If A's cache doesn't have what the user needs, the user sees empty data or errors.
The algorithm issue is even more complex. TikTok's recommendation system likely relies on real-time or near-real-time data from multiple backend services. If those services start timing out or returning incomplete data, the algorithm makes decisions based on incomplete information. It might return generic content instead of personalized content. It might return the same content repeatedly because it's all that's available or cached.
Database replication is critical here too. If the primary data center goes down, TikTok should fail over to secondary data centers. But that failover isn't instantaneous. There are quorum-based decisions, consistency checks, and synchronization requirements. If the failover happens while data is still being written to the primary, synchronization breaks. That data loss or corruption could explain why view counts and earnings displays were broken.
TikTok apparently uses a data center partner for this infrastructure. That's significant. The company isn't running its own data centers for US service (at least not exclusively). They depend on third-party providers. That adds another layer of potential failure modes as highlighted by Politico.
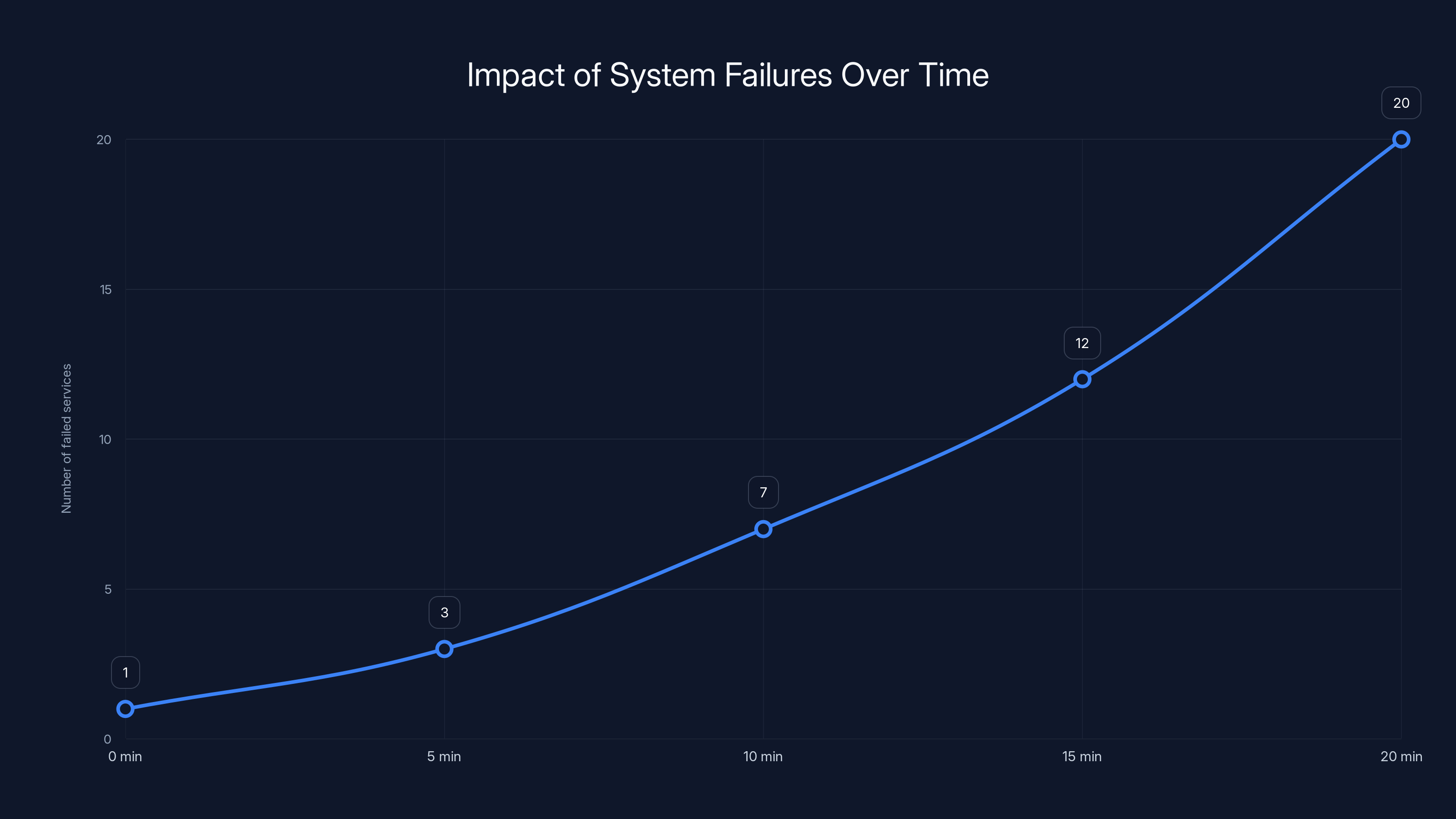
The chart illustrates how a single system failure can lead to a rapid increase in the number of failed services over time, highlighting the accelerating nature of cascading failures. Estimated data.
The Chain Reaction: How One System Failure Breaks Everything
Cascading systems failures are sneaky. They don't break one thing and stop. They break multiple things in sequence, and the breakage accelerates.
Imagine TikTok's architecture. At the highest level, there's probably a service mesh or load balancer that directs user requests to appropriate backend services. Below that, there are services for different functions: authentication, video processing, recommendation engine, earnings calculations, storage, etc.
When the data center loses power, the physical servers hosting these services go down. But here's where it gets weird. Not all servers go down simultaneously in a clean way. Some might still be running, others might be in a crashed state, some might be booting up but not fully initialized.
During this chaotic restart period, services trying to communicate with each other encounter three scenarios. Some services respond normally. Some don't respond at all. Some respond with errors. This inconsistency breaks assumptions in the code.
A service designed to handle timeouts might get overwhelmed if 50% of its dependencies are timing out simultaneously. It might decide to reject all new requests to protect itself. That rejection spreads to upstream services. Those upstream services now reject requests from users.
Database consistency is another victim. If a service crashes mid-transaction, that transaction might be partially committed. Data might exist in some parts of the database but not others. The view count might be updated, but the earnings record might not be. The recommendation index might be partially updated, causing inconsistencies.
TikTok's recommendation algorithm likely trains on data from multiple sources: user behavior logs, video metadata, engagement metrics, trending information. If these data sources become inconsistent during recovery, the algorithm makes poor predictions. It might not have access to trending information, so it returns generic content. It might not have engagement data, so it repeats what's available.
The display errors (view counts showing as "0") suggest a specific cascade: the service that returns view counts times out, the frontend gets no response, the frontend defaults to showing "0" rather than making multiple retry attempts (a common defensive pattern).
The earnings display issue is similar but more concerning. If the earnings calculation service is down or returning incomplete data, the frontend might show nothing, zero, or stale data from before the outage. Users see their earnings "disappear," which creates panic and support tickets.
What's critical here: none of these symptoms mean the underlying data is lost. It means the system can't retrieve it reliably during recovery. But to users, the data is gone.
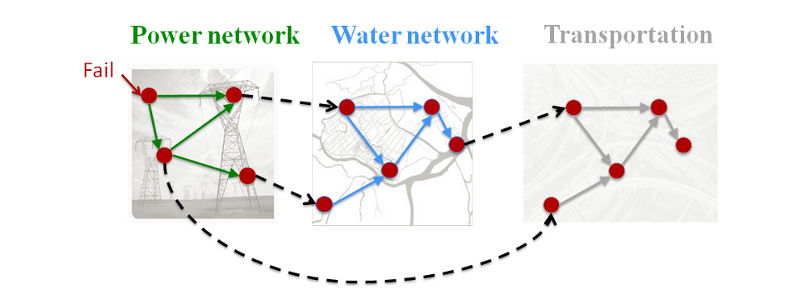
Cascading Failures in Real-World Distributed Systems
TikTok's failure isn't unique. This is a recurring pattern in internet infrastructure.
When Amazon's AWS us-east-1 region had issues in 2016, services across the internet went down, not because they used AWS, but because they depended on services that used AWS. The failure cascaded outward.
When Fastly had a global CDN failure in 2021, major websites (Reddit, GitHub, Spotify, Twitter) went down simultaneously. Why? They all depended on Fastly's edge caching. When Fastly failed, requests that should've been served from cache had to go to origin servers. Those origin servers got overwhelmed, started timing out, became unavailable.
When GitHub experienced an outage, it cascaded through the developer ecosystem. CI/CD pipelines failed because they couldn't pull code from GitHub. Build systems failed. Deployment systems failed.
The pattern is consistent: one failure triggers dependent failures, which trigger their dependent failures, creating exponential impact.
The Uptime Institute tracks these events. They found that 35% of data center outages lasted longer than expected because of cascading failures in recovery. Services that came online at the wrong time in the wrong order caused new problems. Load balancers got confused about which services were healthy. Caches got corrupted because they served stale data from incompletely recovered systems.
The theoretical foundation for understanding this is queuing theory. When a system can't handle incoming requests, queue depth increases. As queue depth increases, response time increases exponentially. At a certain point, requests timeout. Once timeouts start, they become contagious. Services that are working fine start timing out because they depend on services that are timing out.
The formula for queue depth's effect on response time approximates:
Where R is response time, S is service time, and ρ (rho) is utilization. As utilization approaches 1.0 (100% capacity), response time approaches infinity. The system enters an unstable state.
In a cascading failure, utilization of dependent services spikes because they're retrying failed requests. They quickly hit 100% utilization, causing their own response times to spike, causing their dependents to spike, and so on.
The only way to stop the cascade is to break the chain somewhere. Circuit breakers do this. A circuit breaker stops sending requests to a failing service, protecting the services that depend on it. But implementing circuit breakers correctly is hard. Too sensitive, and you lose requests unnecessarily. Too lenient, and the cascade continues.
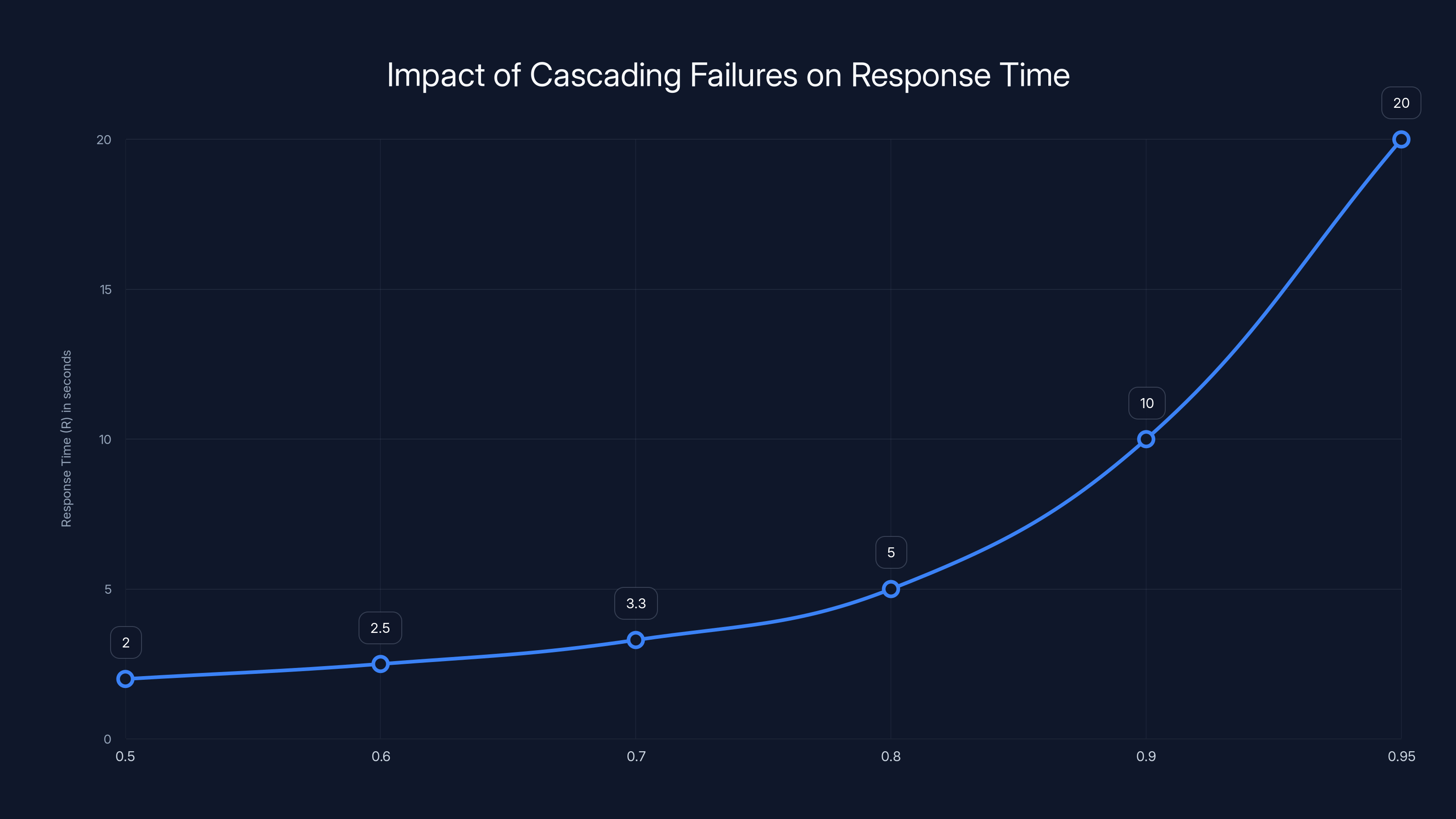
As system utilization (ρ) approaches 1, response time (R) increases exponentially, illustrating the impact of cascading failures. Estimated data based on queuing theory.
Why the Recommendation Algorithm Broke
TikTok's algorithm issue deserves separate analysis because it reveals something specific about how the system is designed.
The recommendation engine is probably the most computationally intensive part of TikTok's backend. It needs to consider thousands of signals in real-time: user watch history, video metadata, trending scores, engagement metrics, network effects, time-decay factors. Generating a personalized feed for 150 million daily active users requires serious horsepower.
When the data center went down, the algorithm didn't just lose compute capacity. It lost access to the data it needs to function.
Recommendation systems typically depend on several data feeds. A feature store containing pre-computed features about users and videos. A real-time events stream of user behavior. A search index for finding relevant content. A metadata database for video information. Scoring services that rank content.
If any of these feeds become unavailable or inconsistent, the algorithm degrades. It might serve content from cache, but caches degrade over time. Content that was trending 2 hours ago might not be trending now. Users you'd normally recommend to might have logged off.
When TikTok users reported seeing the same videos repeatedly, or generic content instead of personalized feeds, it suggests the algorithm fell back to an emergency mode. It probably tried to serve cached feeds first. When cache hit was low, it served trending content as a fallback. When trending data was stale, it served generic content as Wired discusses.
This isn't a bug in the algorithm code itself. It's a cascading failure where the algorithm is working as designed, but it's working with broken inputs.
Recovering from this is hard because the algorithm learned from outdated data. If the cache served data from before the outage, the algorithm might recommend videos that were popular then but aren't anymore. Users click less, engagement drops, feedback loops get worse.
The recovery process probably involved clearing stale caches, recomputing trend scores, rebuilding indices. That takes time. During that time, the algorithm continues to serve suboptimal recommendations, perpetuating the feeling that the app is broken.

The "Display Error" Claim and Data Integrity Concerns
TikTok's statement that view counts showing as "0" were "display errors" caused by "server timeouts" deserves scrutiny.
A "display error" suggests the data exists, but the frontend couldn't fetch it. That's plausible for timeouts. The view count service times out, the frontend returns "0" as a default value.
But consider this scenario: if requests are timing out, what's happening to new engagement? When a user watches a video during the outage, is that view being recorded? If the view-counting service is down, it probably isn't.
So when the system recovers, it has three types of data: views recorded before the outage, views missed during the outage, and views recorded after recovery. If the system can't reconcile these, you get inconsistent view counts.
Users saw views appear again after recovery, but not all views. Some views might be permanently lost. Other views might be counted twice.
The earnings display issue is even more complex. TikTok's creator earnings depend on real-time calculations: view count, watch time, completion rate, audience geography, content type. If any of these metrics are corrupted or incomplete, earnings calculations become wrong.
Earnings are financial data. Getting them wrong has real consequences. Creators might think they're owed money they didn't earn, or won't see money they did earn. The reconciliation process afterward could take weeks.
TikTok's claim that "actual data and engagement are safe" is probably true in the sense that data hasn't been permanently deleted. But "safe" doesn't mean "accurate" or "complete." It likely means "recoverable," which is different.

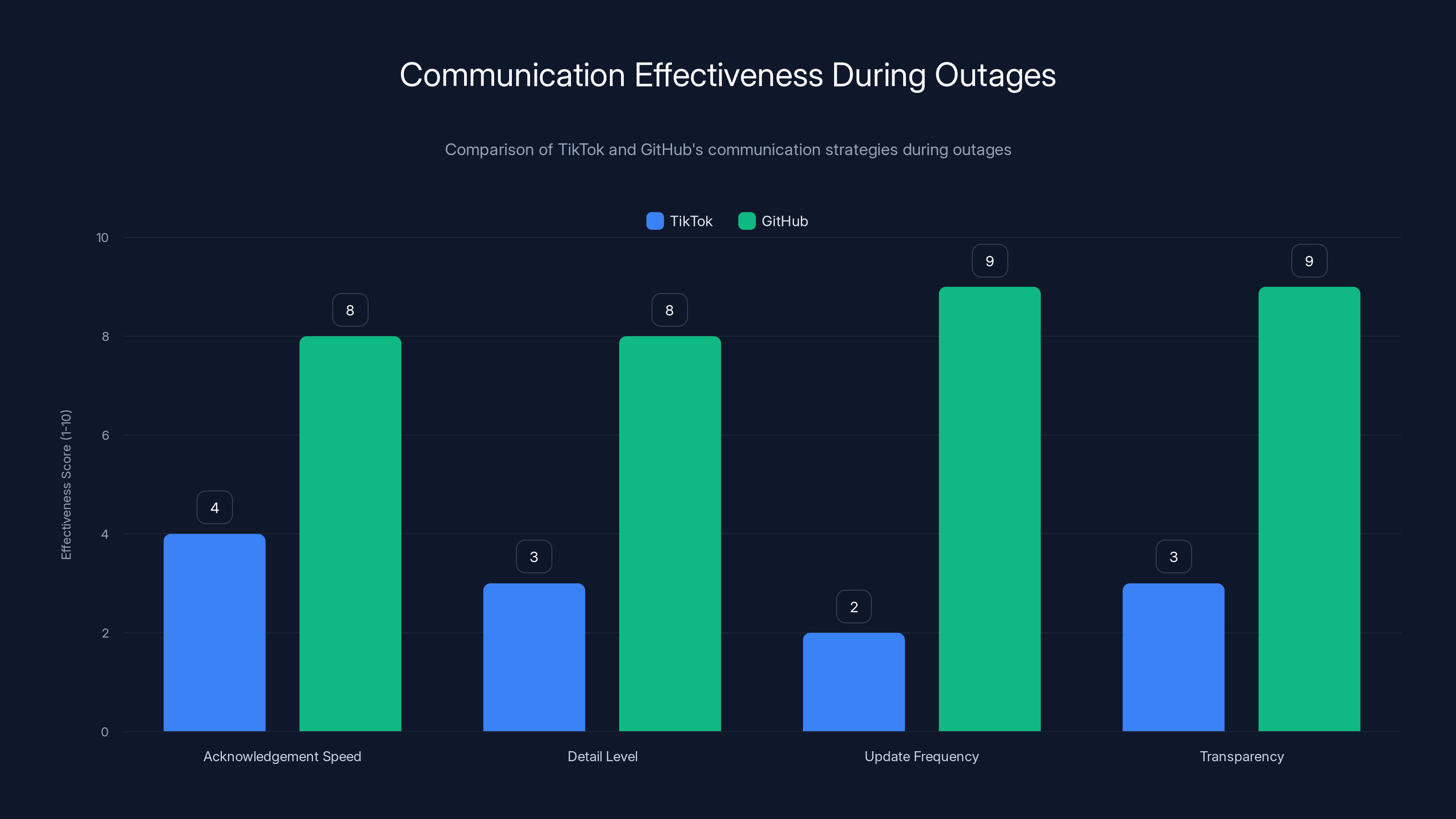
GitHub outperforms TikTok in communication effectiveness during outages, particularly in update frequency and transparency. Estimated data based on typical practices.
Impact on Creators and Businesses
For casual users, a few hours of broken recommendations is annoying. For creators, it's business impact.
TikTok creators depend on consistent visibility. The algorithm is their primary distribution channel. When the algorithm breaks, visibility drops. When visibility drops for a few hours, that's lost reach, lost engagement, lost potential earnings.
Moreover, the timing matters. If you upload a video during an outage, it enters a broken queue. It might not get properly indexed. Its metadata might not get processed. When the system recovers, your video might be behind thousands of other videos in the processing queue. By the time it's ready for recommendations, the initial engagement window has closed.
First-hour engagement is crucial for TikTok's algorithm. Videos that get high engagement in the first hour get shown to more people. Videos uploaded during an outage miss that window. They start with zero engagement. The algorithm sees them as unengaging and stops recommending them.
Creators report that they saw zero new views after uploading during the outage, even hours after the system recovered. That's not a display error. That's a real consequence of the cascading failure.
For businesses running ads on TikTok, the outage creates different problems. Campaigns couldn't be launched or modified during the outage. Real-time bidding systems might've made suboptimal decisions based on incomplete data. Analytics became unreliable, making it hard to know what actually happened.
Advertisers typically have SLAs with platforms around uptime and data accuracy. Extended outages can trigger SLA penalties. TikTok might've owed refunds or credits for the period when ads couldn't run properly as noted by Vital Law.
Timing: Days After the US Spinoff Deal
Here's context that matters. This outage happened days after TikTok finalized a deal to spin off its US business.
Political pressure in the US led to demands for TikTok to separate from its Chinese parent company or face a ban. The spinoff deal was meant to satisfy those demands as reported by CNN.
The timing of this outage raises questions. Was infrastructure being migrated? Were systems being reconfigured to operate independently? Were new data centers being brought online?
Any of those transitions could increase the risk of cascading failures. When you're moving critical services between data centers, or reconfiguring how services communicate with each other, you introduce new failure modes. Old assumptions about data consistency might not hold. New integrations might have bugs.
TikTok didn't disclose whether the outage was related to spinoff activities. But the proximity is notable. Infrastructure transitions are when major failures happen.
This could also explain why the cascade was so severe. If systems were in transition, redundancy might've been compromised. If they were testing new configurations, monitoring might've been incomplete. If they were migrating data, synchronization might've been fragile.
The statement said the power outage was at "a data center partner," implying TikTok uses third-party infrastructure. Third-party data centers have their own operational challenges. TikTok might have less visibility or control over failover procedures. Communication delays between TikTok's engineers and the data center operator's engineers could've slowed response times.
We don't know the full story. But the context suggests this might've been more complicated than a simple power failure as discussed by Dawan Africa.
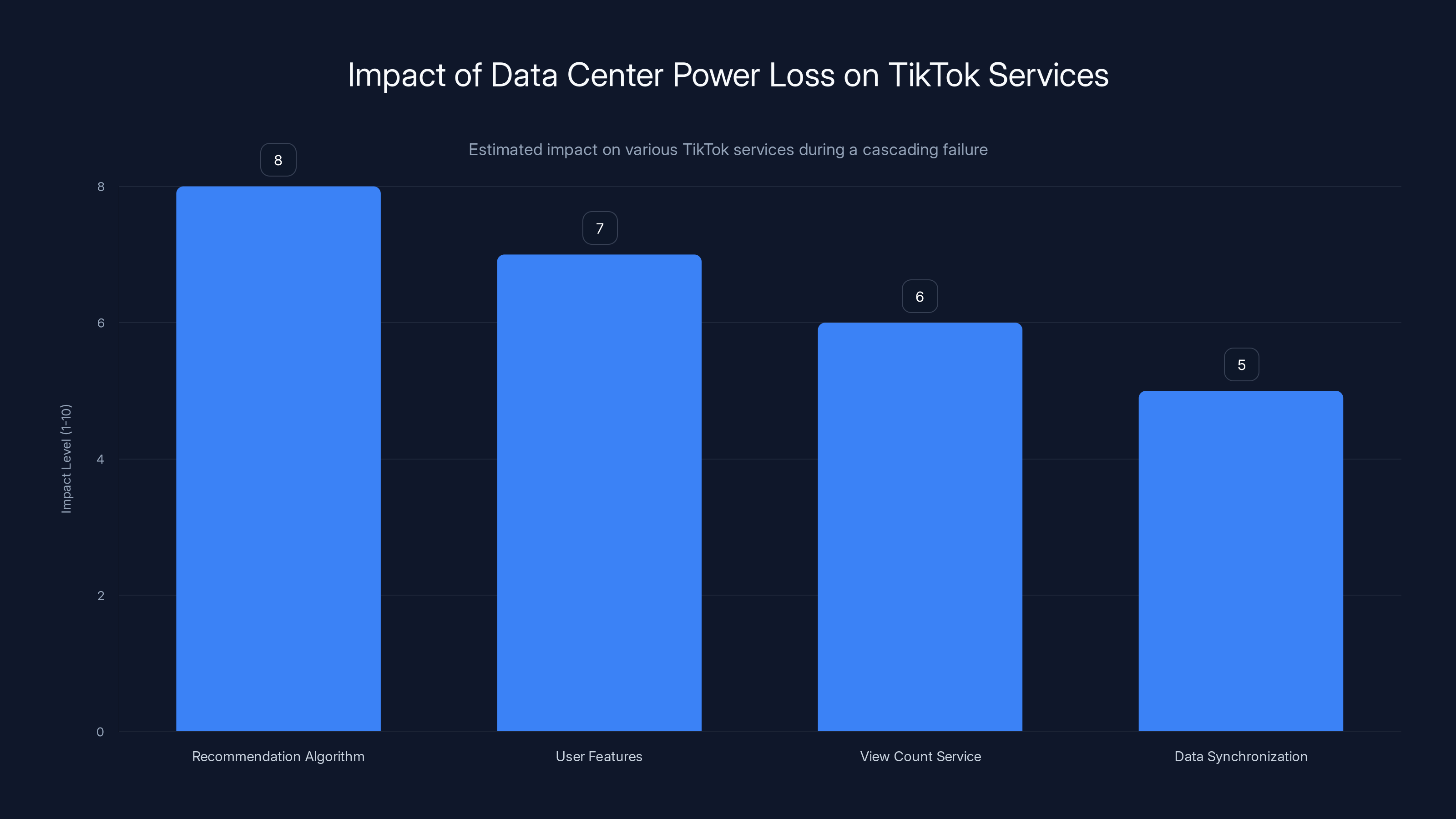
The recommendation algorithm was most affected by the power loss, leading to poor user experience. Estimated data.
How Other Platforms Handle Similar Failures
The architecture choices large platforms make determine their resilience to cascading failures.
Netflix is often cited as the gold standard for outage resilience. They use a system called Hystrix (open-sourced) that implements circuit breakers across all service boundaries. When a service starts failing, Hystrix stops sending requests to it, preventing cascades. Netflix can lose entire AWS regions and continue operating because they designed for regional failure from the start.
Google uses a different approach: canary deployments and staged rollouts. They make frequent small changes to production. If a change causes problems, they roll it back quickly, affecting a small number of users instead of everyone. Their system is designed to fail gracefully by affecting a subset of users.
Amazon (AWS) uses multiple availability zones in each region. Services run across zones, so a single zone failure doesn't cause a complete outage. But this requires services to handle partition tolerance, a harder problem than it sounds.
TikTok's architecture is less documented, but from what we can infer from this outage, it might not have the same level of cascade prevention that Netflix has. The cascading failures suggest that many services depended on the data center that went down, and when it failed, those dependencies weren't broken properly.
Implementing proper cascade prevention is expensive. You need circuit breakers at every service boundary. You need fallback strategies. You need to design services that can work with degraded inputs. You need sophisticated monitoring to detect cascades early.
Smaller companies often skip these investments until they have a catastrophic failure. Then they prioritize them.

Recovery Process and Root Cause Analysis
After a cascading failure like TikTok experienced, recovery has two phases: immediate stabilization and medium-term recovery.
Immediate stabilization means getting the system back to a state where critical functionality works, even if degraded. For TikTok, this meant:
- Restoring power to the data center
- Booting services in the correct order (dependencies first)
- Checking data consistency
- Activating fallback caches
- Gradually increasing load to avoid overloading services that just came back online
Medium-term recovery means fixing the damage:
- Fixing corrupted data
- Reprocessing videos stuck in the queue
- Recalculating trending scores and recommendations
- Reconciling view counts and engagement metrics
- Recalculating creator earnings
This can take days. View counts might be inconsistent for hours. Creator earnings might need manual reconciliation for some accounts.
Root cause analysis would determine why the cascade was so severe. Was it a lack of circuit breakers? Was it data center redundancy being compromised due to spinoff activities? Was it monitoring failing so the team couldn't see the problem early? Was it a runbook (disaster recovery procedure) that didn't work as expected?
Ideal outcome: TikTok publishes a post-mortem explaining what happened, what failed, and what they're doing to prevent recurrence. Most platforms don't do this publicly, but Netflix and some others have set a good example.
Likely outcome: TikTok addresses the issue internally, improves some specific failure mode that caused this particular cascade, but doesn't address the fundamental architecture issues that made the cascade so severe.
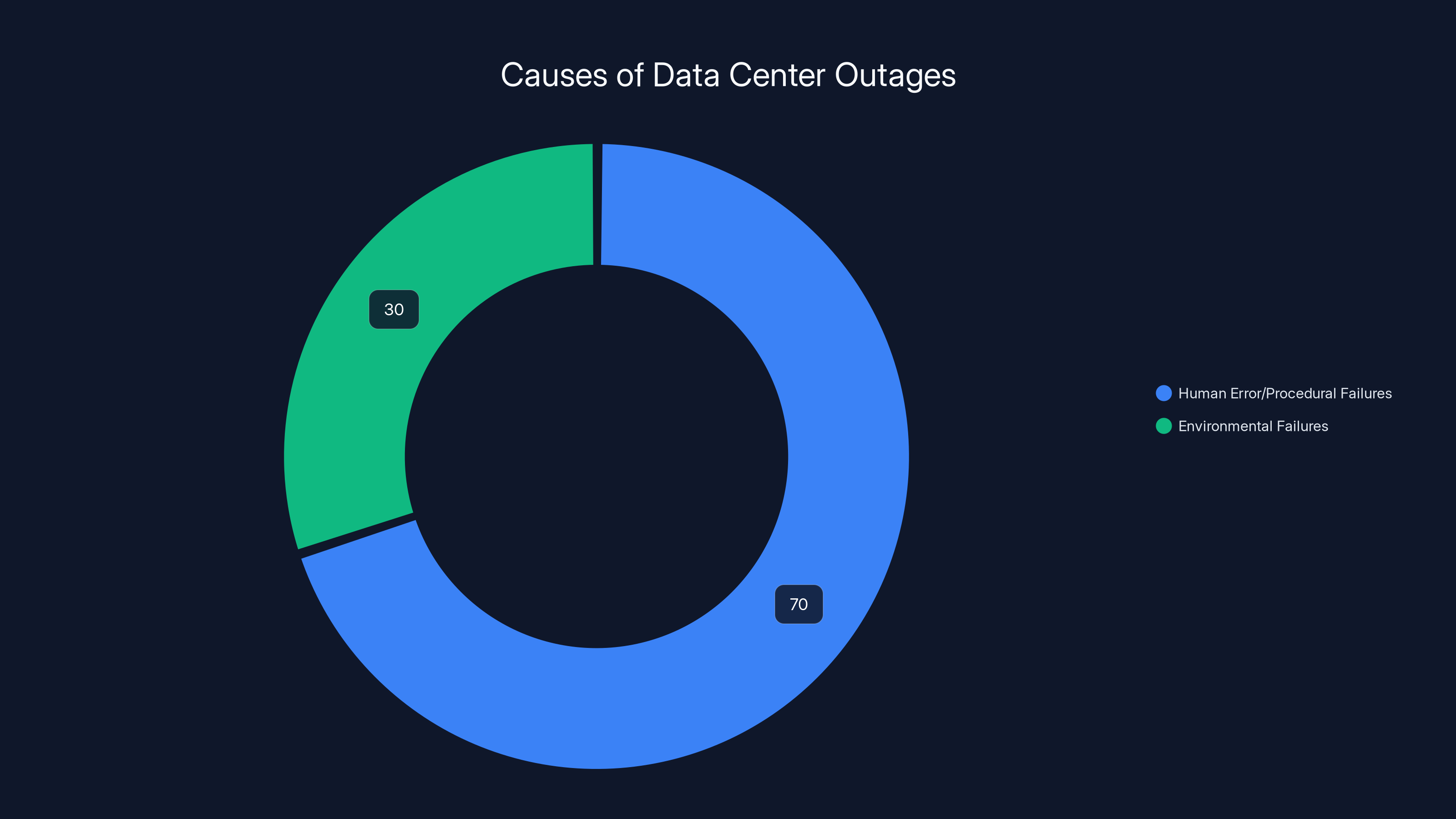
Human error and procedural failures account for 70% of data center outages, while environmental failures make up the remaining 30%.
Database Replication and Consistency During Outages
One aspect of the TikTok outage that deserves deeper analysis is database consistency.
Modern platforms use multi-region database replication. Data is written to a primary database, then replicated to secondary databases in other regions. If the primary region fails, one of the secondaries is promoted to primary.
But replication isn't instantaneous. There's always a replication lag. If the primary database fails while data is still being written, that data might not have reached the secondaries yet. That data is lost.
TikTok probably uses eventual consistency, where the system acknowledges writes before replication completes. This is faster than strong consistency (waiting for replication), but riskier. If failures happen, data can be lost.
The alternative is strong consistency, where writes don't complete until data is replicated. This is safer but slower. It's not practical for systems with millions of concurrent writes.
The view count and engagement display issues suggest data consistency problems during failover. The system probably chose to:
- Promote a secondary database to primary
- Discover that the secondary was missing some data (the replication lag)
- Attempt to reconcile the missing data with the primary (now offline)
- Since the primary was offline, they couldn't reconcile
- Serve the incomplete secondary data, showing incorrect view counts
Realizing view counts are wrong after serving them to users creates a different problem: how do you fix it? You could rebuild the counts from logs, but that's slow. You could show "data unavailable" instead of "0," but that's a worse user experience. You could serve the incorrect data and let users see when it recovers (which is what happened).
Optimal systems use event sourcing and immutable logs. Every view is logged to an immutable log. View counts are computed on-demand from the log. If consistency issues arise, you recompute from the log. This is slower but more correct.
TikTok likely doesn't use full event sourcing for view counts (too expensive), but uses it for some systems and regular databases for others. The inconsistency between systems during cascade recovery created the reported issues.

Lessons for Developers and Platform Teams
If you build or maintain production systems, the TikTok outage offers several lessons.
Design for graceful degradation. Systems should have fallback modes when dependencies fail. Serve cached data, serve reduced functionality, serve generic content. Don't fail completely.
Implement circuit breakers. Break dependency chains so failures don't cascade. Open-source libraries like Hystrix, Resilience 4j, and others implement this. Use them.
Monitor cascade indicators. Track metrics like average response time, error rate, and queue depth. When these spike simultaneously across multiple services, you might have a cascade. Alert on it.
Design recovery carefully. Booting services in the wrong order can cause new cascades. Have a tested recovery plan and practice it regularly.
Use bulkheads. Isolate critical services from each other so a failure in one doesn't affect the other. This is harder than it sounds but worth it.
Build observability. When failures happen, you need dashboards and logs that show what's actually happening. If your monitoring is also affected by the failure, you're blind during the crisis.
Test assumptions. Distributed systems work under normal conditions but fail under stress. Load test. Failure test. Chaos test. Find problems in controlled environments before users find them in production.
When building on platforms like TikTok, understand that outages happen. Plan for them. Don't depend on real-time TikTok data for critical business decisions. Cache what you can. Degrade gracefully when TikTok is unavailable.
For creators, backup your content. TikTok probably isn't going to lose your videos permanently, but their upload system can fail. Having a backup on YouTube, Loom, or another platform ensures you're not dependent on TikTok's infrastructure.

Future Infrastructure Resilience
The TikTok outage is a reminder that modern internet infrastructure is fragile in specific ways.
We've built systems that are resilient to random hardware failures (bit flips, disk corruption) through redundancy and error correction. But we're fragile to coordinated failures (entire data centers going dark, network partitions) because we haven't invested in the right architectural patterns.
Things are improving. Kubernetes and container orchestration have made it easier to implement resilience patterns. Service meshes like Istio handle circuit breakers and retry logic transparently. Observability tools have gotten better.
But progress is uneven. Not every platform uses these tools. Many platforms are built on legacy architectures designed before these patterns were mature.
The future probably involves:
- More distributed deployments. Services spread across more regions, fewer single points of failure.
- Better failure isolation. Using techniques like chaos engineering to find and fix failure modes before they reach users.
- Smarter cascading prevention. Machine learning to detect cascade patterns and respond automatically.
- Improved data consistency. Better protocols for multi-region data replication.
- Standardized resilience patterns. Like how cryptography libraries are now standardized, we'll have standardized cascading prevention libraries.
Larger companies are already moving in this direction. Smaller companies and startups are behind. The gap creates opportunities for infrastructure companies building better tools.

What We Can Learn About Distributed Systems
The TikTok outage illustrates fundamental principles of distributed systems that appear in textbooks but are easy to forget.
The first is synchronization. When systems need to coordinate across multiple nodes, synchronization becomes expensive. This is why TikTok's recommendation algorithm broke during failover. Coordinating data between the primary data center and secondaries requires synchronization. When synchronization fails, data becomes inconsistent.
The second is the CAP theorem. Data systems can guarantee consistency (all nodes agree on data) or availability (system keeps working), but not both during network partitions. TikTok chose availability (keep serving data) over consistency (ensure data is correct). This is the right choice for a social media platform, but it means accepting data inconsistencies.
The third is cascading failures. Systems have dependencies. When one dependency fails, dependent systems fail. The more dependencies, the more likely a failure cascades. This is inevitable in complex systems.
The fourth is observability vs. availability trade-offs. Detailed monitoring and logging come with overhead. Some platforms skip it to optimize performance. This makes failures harder to detect and debug.
The fifth is the value of testing. Failures that testing would've caught don't happen if testing is thorough. TikTok probably tested individual services extensively but didn't test what happens when an entire data center goes dark while the spinoff transition is happening.
These principles apply to any platform at scale: Google, Amazon, Netflix, Meta, Discord, Slack. Understanding them helps you design better systems.

The Broader Implications for Dependent Creators
The outage revealed something important about creator economics on platforms you don't own.
Creators build their businesses on platforms. TikTok's algorithm drives their audience. Their earnings depend on TikTok's systems. When TikTok fails, creators can't control the impact.
This is different from owning your own website or platform. A website hosted on reliable infrastructure can have 99.99% uptime. You control the infrastructure.
On third-party platforms, you depend on the platform's infrastructure decisions. If the platform hasn't invested in resilience, you suffer outages. If the platform is doing a spinoff transition, you risk outages from changes you can't see.
Smart creators maintain a multi-platform presence. Primary content goes to TikTok (where the audience is), but it's also syndicated to YouTube, Instagram, LinkedIn. This hedges against platform-specific failures.
It also creates leverage. If TikTok knows creators can easily move to other platforms, they'll invest more in reliability. But if creators are locked in with no alternatives, TikTok has less incentive to spend on redundancy.
Long-term, this pattern will probably lead to platform consolidation (creators go where the audience is) or to inter-platform syndication tools that reduce lock-in.

TikTok's Response and Communication
How TikTok communicated during the outage is worth analyzing.
They took several hours to acknowledge the problem. Users reported issues on Sunday. Monday morning, TikTok finally posted on X (Twitter) explaining the outage. That delay is problematic when millions of users are affected.
Their initial statement said they were "working with our data center partner to stabilize our service." This suggests they don't operate the data center themselves. A third-party data center operator is involved. This adds a layer of communication delays.
Their second statement provided more detail: "cascading systems failure." This is specific enough to tell experienced engineers what probably happened, but vague enough to avoid admitting specific problems.
They stated "your actual data and engagement are safe" and claimed view counts were "display errors." This is reassuring, but incomplete. It doesn't address whether all data from the period is recovered, or if some data is missing.
Good communication during outages acknowledges what's happening, sets expectations for recovery time, updates frequently, and explains the root cause afterward.
TikTok's communication was mediocre. It could've been faster, more detailed, and more frequent.
Comparison: When GitHub has outages, they provide frequent updates (every 30 minutes minimum), explain what they know and don't know, update status pages with specific metrics, and publish a detailed post-mortem afterward. That's the gold standard.
TikTok seems to be following the pattern of many large platforms: acknowledge minimally, avoid detailed explanations, move on. Users are left uncertain about whether the problem is fully resolved.
FAQ
What is a cascading systems failure?
A cascading systems failure occurs when one system or component breaks, causing dependent systems to break, which causes their dependencies to break, creating an expanding wave of failures. In TikTok's case, the data center power loss caused critical services to fail, which caused other services depending on them to fail, which caused user-facing features to fail. The "cascade" metaphor refers to how failures propagate outward, similar to dominoes falling.
How does a data center power loss cause algorithm problems?
When the data center went dark, TikTok's recommendation algorithm lost access to real-time data feeds it needs to function: user behavior logs, trending information, engagement metrics. The system fell back to serving cached content, which was stale. The algorithm couldn't compute personalized recommendations, so it served generic or repeated content. During recovery, the algorithm continued to work with incomplete data, causing poor recommendations for hours after power was restored.
Why did view counts show as zero if data wasn't actually lost?
When the view count service crashed and came back online, it needed to synchronize with the database. During the synchronization process, it likely couldn't retrieve view count data reliably, so the frontend application defaulted to showing "0" rather than making repeated failed requests. The data existed in the database, but the service retrieving it was timing out or returning errors. This is a display error, not data loss, but users couldn't distinguish between the two.
What is eventual consistency and why does it matter for platforms like TikTok?
Eventual consistency means that when you write data (like a new view count), the system acknowledges the write immediately but doesn't guarantee that all copies of the data are updated yet. This is faster than strong consistency (waiting for all copies to update), but riskier if failures happen before replication completes. TikTok probably uses eventual consistency to handle millions of concurrent writes, but this meant data could be lost during the power outage and failover.
How do circuit breakers prevent cascading failures?
A circuit breaker monitors calls to a failing service. When failures exceed a threshold, the circuit breaker "opens" and stops sending requests to the failing service, returning errors immediately instead. This prevents dependent services from wasting time and resources trying to reach a service that's not working. By breaking the chain of dependencies, circuit breakers prevent cascades from spreading. Netflix uses this pattern extensively and can survive major regional failures because of it.
What should TikTok have done differently?
TikTok could've prevented the severity of this cascade by implementing circuit breakers at all service boundaries, using bulkheads to isolate critical systems from each other, designing for graceful degradation where the system continues functioning with reduced capability when parts fail, and conducting chaos engineering tests regularly to find failure modes before they affect users. Additionally, faster detection and response during the initial failure could've reduced duration.
Why does the timing of the spinoff matter?
TikTok's spinoff from Chinese ownership to US-based ownership likely involved infrastructure reconfiguration, data migration, and system changes. During such transitions, redundancy is often temporarily reduced and new failure modes are introduced. If the outage occurred during or shortly after such work, the infrastructure might've been in a fragile state with fewer safeguards than normal. The proximity suggests the outage might not be a simple random failure but could be related to the transition itself.
How long does recovery from a cascading failure typically take?
Immediate recovery (getting the system back online) can take 30 minutes to 2 hours. However, full recovery including data reconciliation, cache rebuilding, and verification can take 24-48 hours. Users might see partial degradation for days after the system is technically online. Underlying data inconsistencies can take weeks to fully resolve if manual reconciliation is needed.
Should creators worry about TikTok outages affecting their livelihood?
Creators should understand that platform-dependent livelihoods carry infrastructure risk. When TikTok has outages, creators lose visibility and earnings during the outage period. The outage can also affect content posted during the outage, preventing it from reaching audiences. Diversifying across multiple platforms and maintaining backup copies of content reduces this risk. Additionally, having savings to cover 1-2 months of reduced earnings helps weather platform-related issues.

Conclusion: Why This Matters Beyond TikTok
The TikTok data center outage is significant not because it's unique, but because it's common. Major platforms experience cascading failures regularly. Most are smaller in scope and recover quickly. TikTok's was notable for its severity and visibility.
What happened is instructive for anyone building or depending on online systems. Infrastructure is fragile in specific ways. A single failure point can cascade through multiple systems. Recovery is slow because systems need to carefully rebuild consistency.
For developers, the lesson is clear: design for failure. Assume services will fail. Assume data will be inconsistent. Build systems that gracefully degrade when parts break. Implement circuit breakers, bulkheads, and other resilience patterns. Test failure scenarios regularly.
For creators and businesses depending on platforms, understand that outages happen. They're not preventable, only manageable. Diversify your presence across platforms. Maintain backups. Don't depend on real-time data from a single platform for critical business decisions.
For users, recognize that the reliability you see is built into infrastructure decisions you can't see. Platforms that invest heavily in resilience are less likely to fail. Platforms that skip this investment fail more often. You can't know which is which without experiencing failures.
TikTok will likely improve its infrastructure resilience from this incident. They'll add better circuit breakers, improve their disaster recovery procedures, and invest in better observability. Their engineering team is talented, and they have the resources to learn from failures.
But the fundamental challenge remains: distributed systems are hard. Failures will happen again. The goal is not to prevent all failures, but to detect them early, contain them to small areas, and recover quickly.
The next time a major platform has an outage, remember TikTok's cascade. Understand that what you're seeing is not a bug, but a system trying to recover from failures in interconnected parts. Patience helps. Yelling at the platform doesn't. But demanding they invest in resilience and publish post-mortems explaining what happened and how they'll prevent recurrence? That does help.
Platforms respond to user pressure. If creators and users demand reliability and transparency, platforms will invest in them. TikTok's ability to invest is massive. They should use it to build infrastructure that rarely fails and recovers quickly when it does.

Key Takeaways
- A single data center power failure caused cascading failures across multiple TikTok services simultaneously, not just display issues
- Cascading failures are exponential: one service failure causes dependent services to fail, causing their dependencies to fail, creating waves of failures
- TikTok's recommendation algorithm broke because real-time data feeds became unavailable, forcing the system to serve stale cached content
- View count and earnings data weren't lost, but the systems that retrieve and display them failed, creating the appearance of data loss
- Recovery from cascading failures requires careful sequencing of service restarts and data consistency verification, taking 24-48 hours minimum
- Netflix's circuit breaker architecture and Google's canary deployments are proven methods for preventing cascades that TikTok appears not to use comprehensively
- Creators and businesses depending on platforms carry infrastructure risk; diversification across multiple platforms hedges against platform-specific failures
Related Articles
- TikTok's First Weekend Meltdown: What Actually Happened [2025]
- TikTok Power Outage: What Happened & Why Data Centers Matter [2025]
- TikTok's US Data Center Outage: What Really Happened [2025]
- Meta's Premium Subscriptions Strategy: What It Means for You [2025]
- Shipping Code 180 Times Daily: The Science of Safe Velocity [2025]
- TikTok Data Center Outage Sparks Censorship Fears: What Really Happened [2025]

