UK's CMA Takes Action on Google AI Overviews: Here's What Publishers Need to Know [2025]
If you run a news site, publish original research, or create content professionally, you've probably felt the pressure. Your articles get written. Google's AI summarizes them. Traffic tanks. And you didn't get a say in the matter.
That tension just exploded into the regulatory spotlight. The UK's Competition and Markets Authority recently threw its weight behind a proposal that could fundamentally change how Google treats publisher content in its AI Overviews feature. And unlike most tech regulation talk that fades into the background, this one has real teeth as reported by Reuters.
Here's what's happening, why it matters, and what it could mean for the future of digital publishing.
TL; DR
- The CMA wants publishers to opt out: Publishers could refuse to let Google use their content for AI features like Overviews or AI model training according to Press Gazette.
- Attribution requirements: Google would need to properly credit the sources it pulls from in AI-generated summaries as noted by The Guardian.
- Strategic market status: The UK formally designated Google with "strategic market status," giving regulators real enforcement power as detailed by VAR India.
- Google's response: The company says it's exploring opt-out controls but warns against measures that "break Search" as reported by TechCrunch.
- Broader implications: This could reshape how AI companies handle publisher content globally, particularly in the EU and beyond as discussed by BBC.

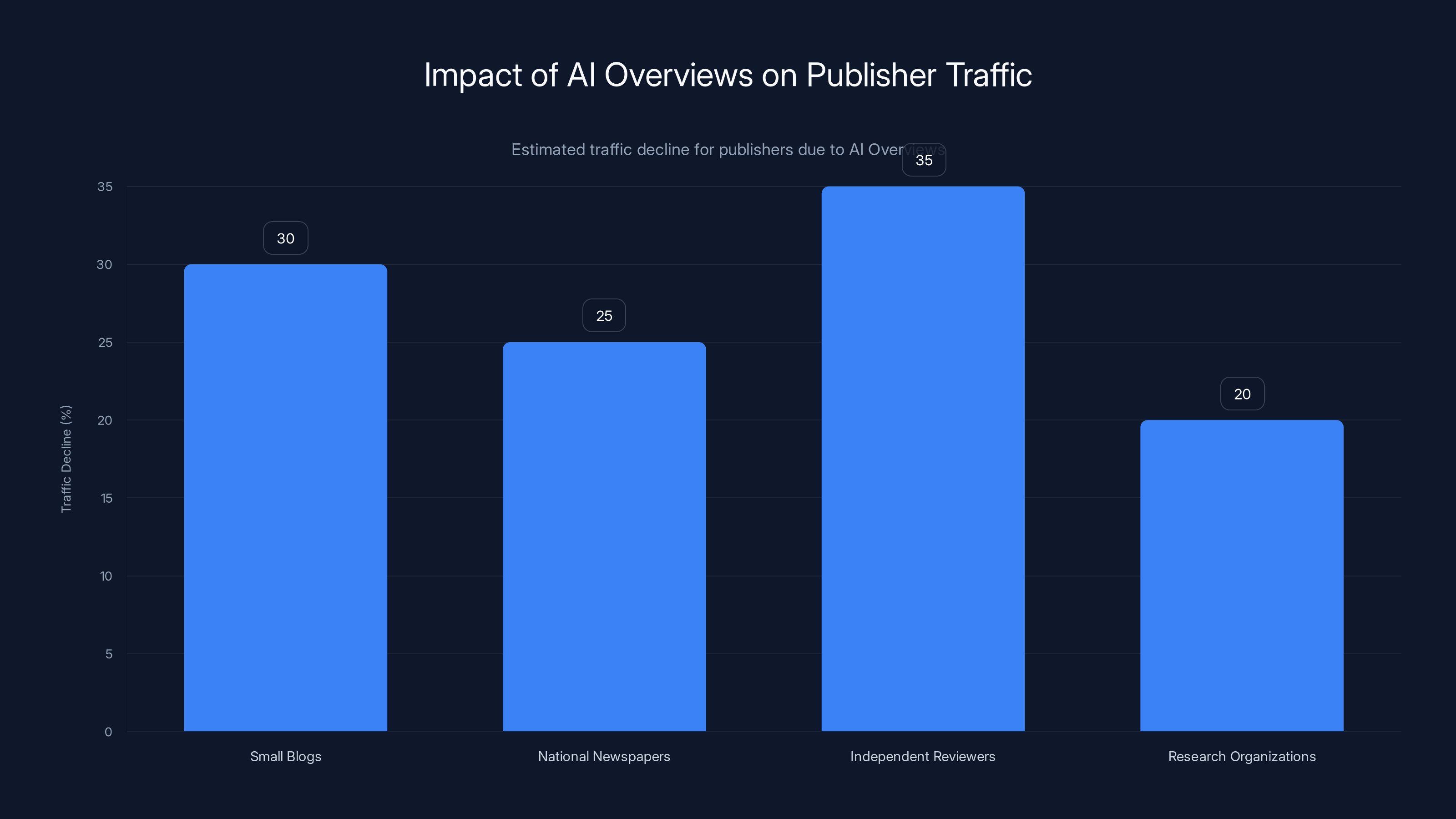
Estimated data shows that AI Overviews have caused significant traffic declines for various types of publishers, with independent reviewers experiencing the highest drop at 35%.
The Problem: Why Publishers Are Furious About AI Overviews
Let's start with the core issue. Google's AI Overviews feature does something simple and devastating: it answers your question before you click on any result.
You search "best wireless earbuds under $100." Instead of showing you a list of articles from tech sites, product review pages, and retailers, Google generates an AI summary. It synthesizes information from multiple sources and presents the answer right there in the search results.
For the user, this is convenient. No clicking required. Information delivered instantly.
For publishers, it's a nightmare.
Consider what happens from a publisher's perspective. A tech journalist spends six hours testing wireless earbuds. They write a 3,000-word review with audio samples, detailed comparisons, battery life measurements, and fit assessments. Google's AI reads that article, extracts key information, and serves it directly to the user. The user gets the answer. The journalist gets zero traffic.
That's not a hypothetical scenario. This has been happening at scale since Google rolled out generative AI features. News outlets report drops in traffic. Independent reviewers see declining clicks. Niche publishers covering specific industries watch their audience shrink as AI summaries steal their core value as highlighted by WebProNews.
The financial impact is real. For a mid-sized publication with advertising-based revenue, this isn't just an inconvenience. It's a business model threat.
Now multiply this across thousands of publishers. Small blogs, national newspapers, independent reviewers, research organizations. All of them suddenly competing not with each other for clicks, but with AI that gives away the answer for free.
That's the context for what the CMA just proposed.
Who Is the CMA and Why Do They Have Power Over Google?
The Competition and Markets Authority is the UK's independent regulator for competition and consumer protection. Think of them as the British equivalent of the FTC or the EU's antitrust division.
For years, the CMA investigated tech platforms but had limited direct power. They could propose changes or file complaints. Enforcement was slow and indirect.
That changed in October 2024 when the UK designated Google with "strategic market status" for search activities under the Digital Markets Act framework. This is huge because it means the CMA can now impose binding conduct requirements on Google without waiting for the full formal investigation process as reported by Engadget.
In regulatory terms, this is like upgrading from "we'd really prefer if you..." to "you must implement these changes by this deadline."
Sarah Cardell, the CMA's chief executive, stated that the authority aims to "provide a fairer deal for content publishers, particularly news organizations." This isn't performative language. It's the CMA explicitly saying Google's AI Overviews feature is creating unfair competitive conditions.
Why focus on the UK? Google processes more than 90% of search queries in the UK. In practical terms, this means Google is so dominant in search that they operate with minimal competitive pressure. Users can't switch to alternatives because there effectively are none. That dominance is what triggers regulatory scrutiny as noted by Fallows.
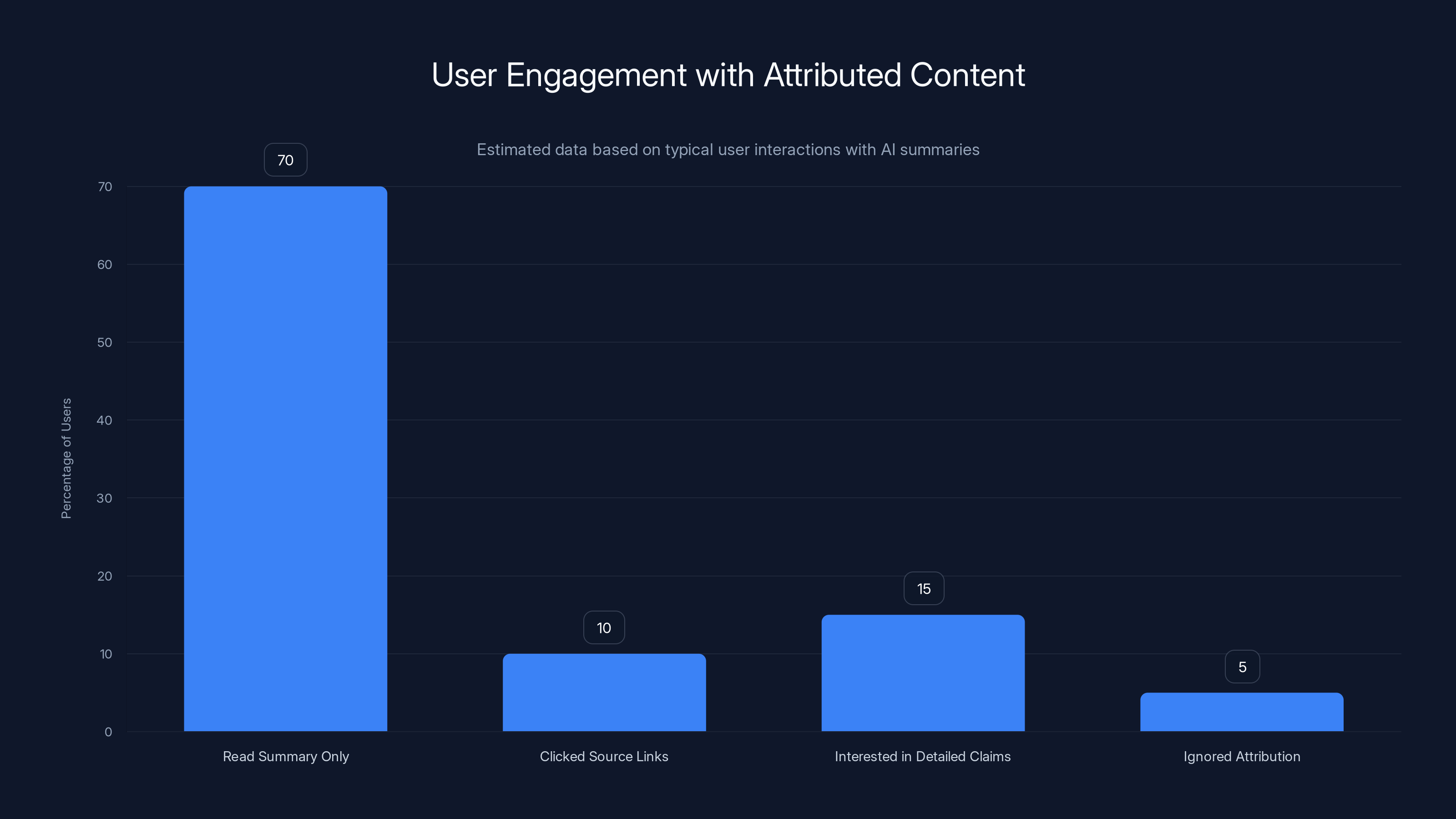
Estimated data shows that most users read summaries without engaging with source links, highlighting the need for more visible attribution.
The CMA's Proposed Measures Explained
The CMA didn't just say "Google should be nicer to publishers." They proposed specific, enforceable measures. Let's break down what each one actually does.
Opt-Out Controls for Content Use
This is the headline-grabbing proposal. Publishers would be able to opt out of having their content used for AI Overviews and AI model training.
Here's what this means in practice: A news organization could go into Google Search Console (or a new settings interface) and indicate "Do not use our content for generative AI features." Google's algorithms would then exclude that site from being summarized in AI Overviews.
The catch is more nuanced than it sounds. Opt-out controls work best when publishers know they exist and actively manage them. But here's the problem: if a publisher doesn't opt out, does Google have implicit permission to use their content? The CMA wants explicit language here.
There's also a question of scope. Would opt-out apply only to AI Overviews, or also to training data for future AI models? The CMA proposal suggests both, which means publishers would effectively control whether Google uses their content for improving Google's AI systems.
Google's response was cautiously positive but hedged. They said they're "exploring updates to let sites specifically opt out of Search generative AI features." Notice the careful language: "exploring" (not committing) and "Search generative AI features" (not mentioning model training) as reported by Mexico Business News.
The company also warned that any controls need to "avoid breaking Search in a way that leads to a fragmented or confusing experience for people." Translation: we're concerned users will get worse results if too many publishers opt out.
Proper Attribution Requirements
The second major proposal: Google must properly attribute content sources when using them in AI Overviews.
This sounds obvious, but it's not how AI Overviews currently work. When you get an AI summary of search results, you might see a few links at the bottom, but there's no clear "this paragraph came from Tech Crunch" or "this information is from The Guardian." The attribution is vague.
The CMA wants attribution to be clear and linked. If Google's AI pulls a fact from Publisher A's article, that fact should be visibly linked back to Publisher A's article.
Why does this matter? Because if attribution is strong and visible, users who want more detail click through to the source. The publisher still gets the traffic. They get the context. They benefit from the search visibility even if their content was condensed into the AI summary.
Without attribution, the answer is self-contained. Users get what they need and move on. Publishers get nothing.
Google's position here is that they already do attribution. But the CMA's proposal is more stringent. It wants consistent, always-visible attribution, not optional or background attribution.
Fair Search Result Rankings for Businesses
This proposal addresses a different but related concern: when a user searches for a product or service, does Google favor its own services in the results?
The CMA wants to require an "effective process for raising and investigating issues" if a business believes Google is ranking results unfairly. This creates accountability and a formal complaint mechanism.
In practical terms, this means if a small hotel booking site believes Google is unfairly ranking Google Hotels above their site, they have a formal channel to raise the issue and get it investigated.
Google operates under different incentive structures in different countries, so fair ranking practices in the UK would need to be enforced with clear criteria.
Choice Screen for Alternative Search Options
Finally, the CMA proposed that Google provide a "choice screen" on Android and Chrome browsers in the UK. This would let users easily select alternative search engines.
This is similar to what the EU required Apple to do with app stores. When you install iOS in the EU, Apple shows you options for alternative app stores before locking you into the Apple App Store.
The CMA wants something similar for search. Open Chrome or Android in the UK, and users would see a choice screen with alternatives to Google Search before defaulting to Google.
The goal is straightforward: reduce Google's lock-in effect and make it easier for users to switch search engines.
Why the Timing Matters: The Global AI Regulation Race
The CMA's proposal arrives at a critical moment. Governments worldwide are scrambling to figure out how to regulate AI. The EU already passed the Digital Markets Act and AI Act. The US is debating frameworks. China is implementing restrictions.
The UK, post-Brexit, is trying to position itself as a tech-friendly regulator that gets the balance right: you can innovate, but you can't abuse market dominance.
This proposal sends a signal: the UK will enforce rules with real teeth when dominant tech companies harm publishers and competition as noted by Marketing Dive.
But here's the interesting part. The CMA's approach is narrower and more practical than the EU's approach. Rather than sweeping requirements about how AI should work generally, the CMA targeted specific harms: unfair content extraction, lack of attribution, anticompetitive behavior.
This narrower approach might actually be more effective. It doesn't try to regulate AI as a technology. It regulates Google's conduct as a dominant player.
Google's Pushback: The Business Case Against Regulation
Google's response to the CMA wasn't just acceptance. The company mounted a business-case argument against some proposals.
When the CMA first designated Google with strategic market status in October 2024, Google complained that similar EU measures "produced 'negative results' that have cost businesses $114 billion." The company cited a study (presumably internal or commissioned research) suggesting that EU digital regulation hampers innovation and growth.
Google's argument has some legitimate components. If you optimize Search for attribution to every possible source, the user experience might suffer. If opt-out becomes widespread, AI features might become less useful because fewer sources are available.
But there's a fundamental tension here. Google's core argument is "regulation hurts innovation and growth." Yet Google itself has become the regulated company, precisely because their innovation and growth came at the expense of publishers and competition.
This tension reveals the actual core issue: who bears the cost of innovation?
When Google developed AI Overviews, they optimized for their own user experience and their own AI capability improvements. Publishers bore the cost through lost traffic. Google's argument is now "if you regulate how we extract content, we can't innovate as fast."
But publishers' argument is "you've already extracted value from our content without permission or compensation. Now you want us to accept worse AI features as the cost of fairness?"
The CMA's position is essentially: "you can innovate, but not at the expense of unfair market harm." That's a regulatory middle ground.
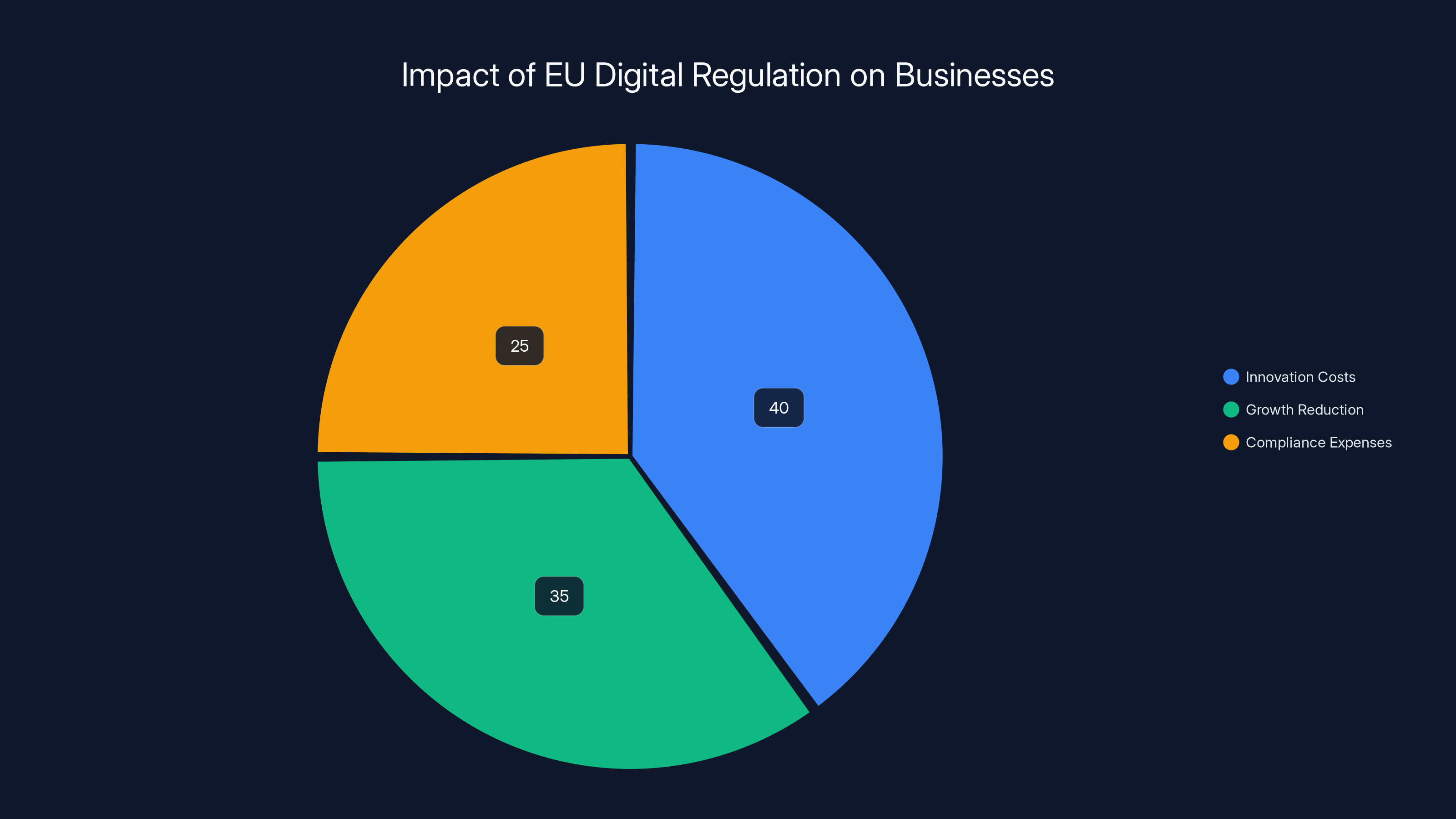
Estimated data shows that innovation costs constitute the largest portion of the $114 billion impact, followed by growth reduction and compliance expenses.
The Practical Implementation Question: How Would Opt-Out Actually Work?
Here's where the proposal gets technically interesting and potentially messy.
Opt-out systems sound simple but have real implementation challenges. Let's think through how this would work:
Scenario 1: Robots.txt-Based Opt-Out
Google could extend the robots.txt standard (a file that controls how search engines crawl sites) to include AI-specific directives. Publishers could add:
User-agent: Google Bot-AI
Disallow: /
This would tell Google's AI systems not to use the site for generative features. The advantage: publishers already understand robots.txt. Implementation is straightforward. The disadvantage: it requires publishers to take action. Google would need to educate millions of publishers about this new directive.
Scenario 2: Search Console Control Panel
Google could add a toggle in Google Search Console: "Allow my site's content in AI Overviews: Yes / No."
This is more user-friendly because it's in an interface publishers already use. Disadvantage: it's another control panel feature for Google to maintain and monitor. Publishers might not discover it.
Scenario 3: Industry-Standard Metadata Tags
Google could use HTML metadata standards, like the existing rel="nofollow" attribute, but create a new rel="noai" or similar tag. Publishers could add to their pages:
html<meta name="AI-Training" content="no">
This would signal "do not use for AI training." It's technically clean and follows existing web standards.
The Real Challenge: Verification
Regardless of which method the CMA and Google settle on, there's a verification problem. How does the CMA verify that Google is actually respecting opt-outs?
Google processes trillions of search queries. Auditing compliance would be difficult. Google would need to submit evidence that they're respecting opt-out directives. The CMA would need independent verification.
This is why most tech regulation includes regular audits and reporting requirements. The CMA would likely require Google to submit quarterly or annual compliance reports showing how many publishers opted out and how thoroughly Google respected those opt-outs.
The Attribution Problem: Making It Visible and Meaningful
The attribution requirement sounds straightforward but has subtleties.
Current AI Overviews show sources at the bottom of the summary, but the attribution is background noise. Users read the summary. Most don't click the source links.
For attribution to meaningfully help publishers, it needs to be prominent and integrated. Imagine if each sentence or paragraph in the AI summary was visibly tagged with its source:
The RTX 4080 features 16 GB of GDDR6X memory and supports DLSS 3. (Tech Crunch)
It delivers approximately 80% better performance than the RTX 3090 Ti in ray-traced gaming. (Tom's Hardware)
The card costs $1,199, positioning it as the high-end option for 4K gaming. (Gamers Nexus)
This approach makes attribution visible and functional. Users who want more detail about a specific claim can click the source.
But here's the challenge: if every claim is attributed, the UI gets cluttered. If attribution is consolidated at the end, publishers still don't benefit much.
Google's engineering team would need to solve this design problem. The CMA might need to specify minimum attribution standards: what counts as proper attribution? How visible must it be?
Impact on News Organizations: Who Benefits Most?
The CMA's proposal targets "content publishers, particularly news organizations." But not all publishers benefit equally.
Winners:
- National news organizations (BBC, The Guardian, The Financial Times): These sites already have strong brand recognition. If they opt out of AI Overviews, users will still come to them directly. They lose the traffic that was already marginal.
- Specialist publishers (medical journals, legal databases, academic publishers): These serve professional audiences who need primary sources. Users wouldn't accept AI summaries of medical literature. These publishers might opt out without losing meaningful traffic.
- Premium subscription publishers: If you have a paywall and users find you through direct search or brand recognition (not AI Overviews), opt-out is purely strategic. You prevent free summarization of your premium content.
Losers (paradoxically):
- SEO-dependent publishers (tech blogs, listicles, budget comparison sites): These sites depend entirely on Google referral traffic. Opting out means zero traffic from that query type. Staying in means zero traffic because the AI summary is the answer. They lose either way.
- Small independent publishers: These lack brand recognition. They rely on being discovered through search. If they opt out, they become invisible. If they stay in, they're summarized and never clicked.
This reveals a hard truth: opt-out only helps publishers who have alternatives to search traffic. For publishers entirely dependent on search discovery, the problem isn't solvable through opt-out controls alone.
They'd need other protections: mandatory traffic sharing agreements, licensing fees for content use, or contractual partnerships with Google. The CMA proposal doesn't address these mechanisms.

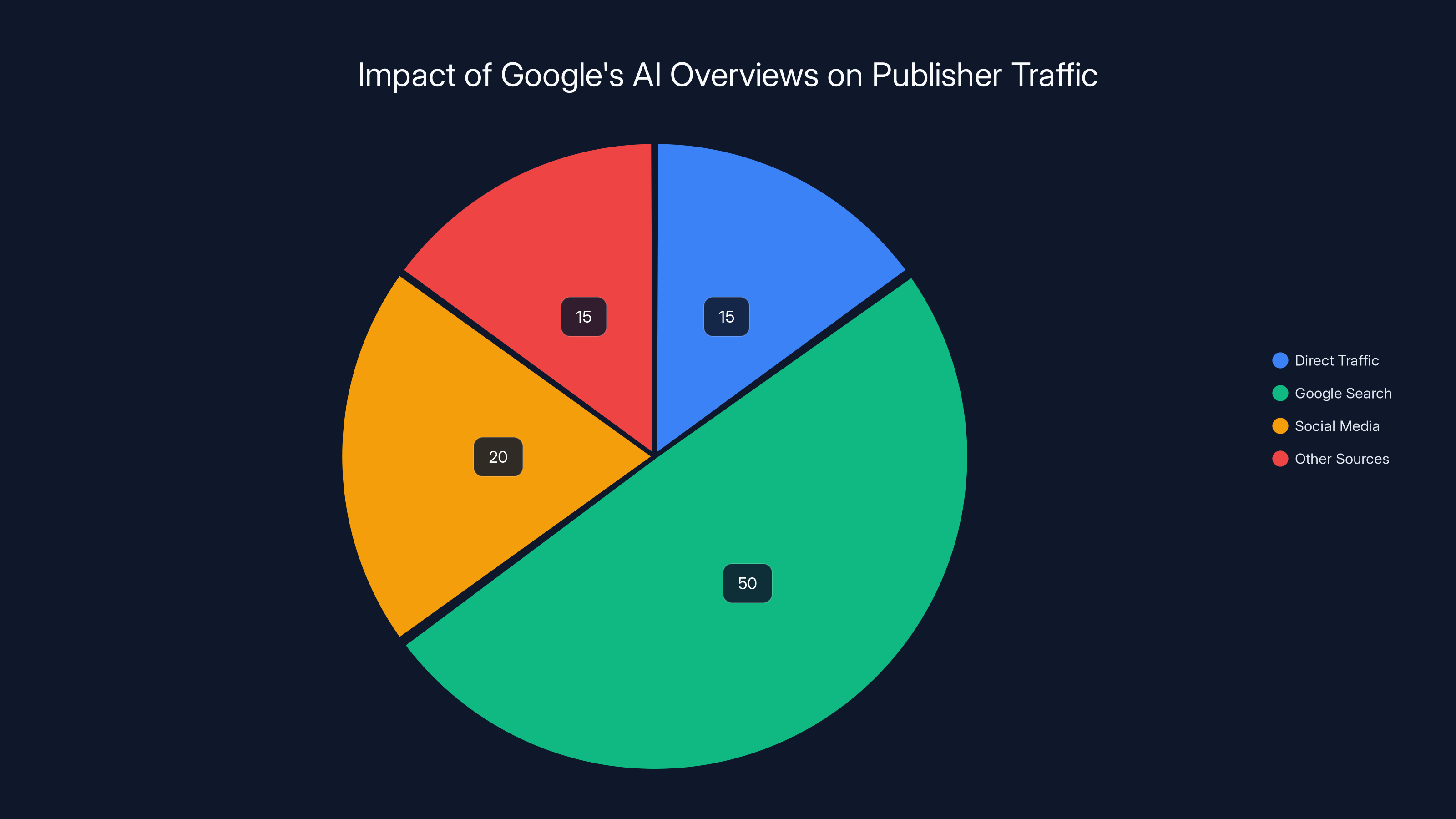
Estimated data shows a significant portion of traffic (50%) now comes directly from Google Search, impacting publisher traffic from other sources.
The EU's Approach: Learning from the Digital Markets Act
The EU already went further in some respects. The Digital Markets Act imposes conduct requirements on large digital platforms, and the AI Act is coming.
But the EU's approach has been broader and more complex. Rather than specific fixes for AI Overviews, the EU is trying to regulate large platforms' behavior generally.
The UK's narrower approach might actually be more effective for this specific problem. By targeting AI Overviews directly, the CMA can write clear requirements that are easier to enforce.
However, there's a risk: if different countries implement different requirements, Google might maintain multiple versions of AI Overviews. In the UK version, opt-out and attribution. In the US version, more permissive. In the EU, stricter rules.
This fragmentation has costs, both for Google (multiple systems to maintain) and for publishers (different protections in different regions).
The Licensing Alternative: Why Not Just Pay Publishers?
Here's the question nobody's asking loudly enough: why doesn't Google just pay publishers for content used in AI Overviews?
Open AI is negotiating licensing deals with news organizations. Google has the financial capacity to license content. Why not take that path instead of regulations?
Several reasons:
Google's perspective: Licensing would set a precedent that all content is monetizable. This would increase costs significantly. Google would also need to renegotiate constantly as new publishers appear.
Publishers' perspective: They'd love payment, but licensing negotiations often result in pennies-on-the-dollar payouts. The AP (Associated Press) has negotiated with various AI companies and reports low offers.
Regulatory perspective: The CMA could argue that licensing is an insufficient remedy if the underlying problem is unfair content extraction. Even paid extraction could be unfair if rates are too low or terms are too restrictive.
The CMA's approach is saying: "First, make it fair. Then you can negotiate licensing if you want." In that framing, opt-out and attribution are prerequisites, not alternatives to licensing.
That said, there's room for a hybrid approach: opt-out controls + attribution requirements + optional licensing partnerships. Google could negotiate voluntary licensing deals with willing partners while respecting opt-outs from those who don't want to negotiate.

Technical Feasibility: Can Google Actually Implement This?
The short answer: yes, but not without engineering effort.
Google has built far more complex systems than content opt-out tracking. The company already:
- Manages robots.txt exclusions for billions of URLs
- Respects copyright takedown notices at scale
- Implements regional compliance requirements (GDPR, COPPA, etc.)
- Tracks publisher preferences in Search Console
Adding a new opt-out system for AI features isn't technically infeasible. It would require:
- Database expansion: Storing opt-out preferences for publishers
- Crawl-time checking: Before indexing content or using it for AI training, check opt-out status
- Serving-time checking: When generating an AI Overview, exclude sources that opted out
- Audit logging: Record which sources are used, for compliance verification
All of this is within Google's engineering capabilities. The cost is real but not prohibitive.
The tougher challenge is scope creep. If the CMA gets opt-out and attribution requirements right, how long until publishers demand more? Removal rights? Traffic sharing agreements? That's where the real friction would build.
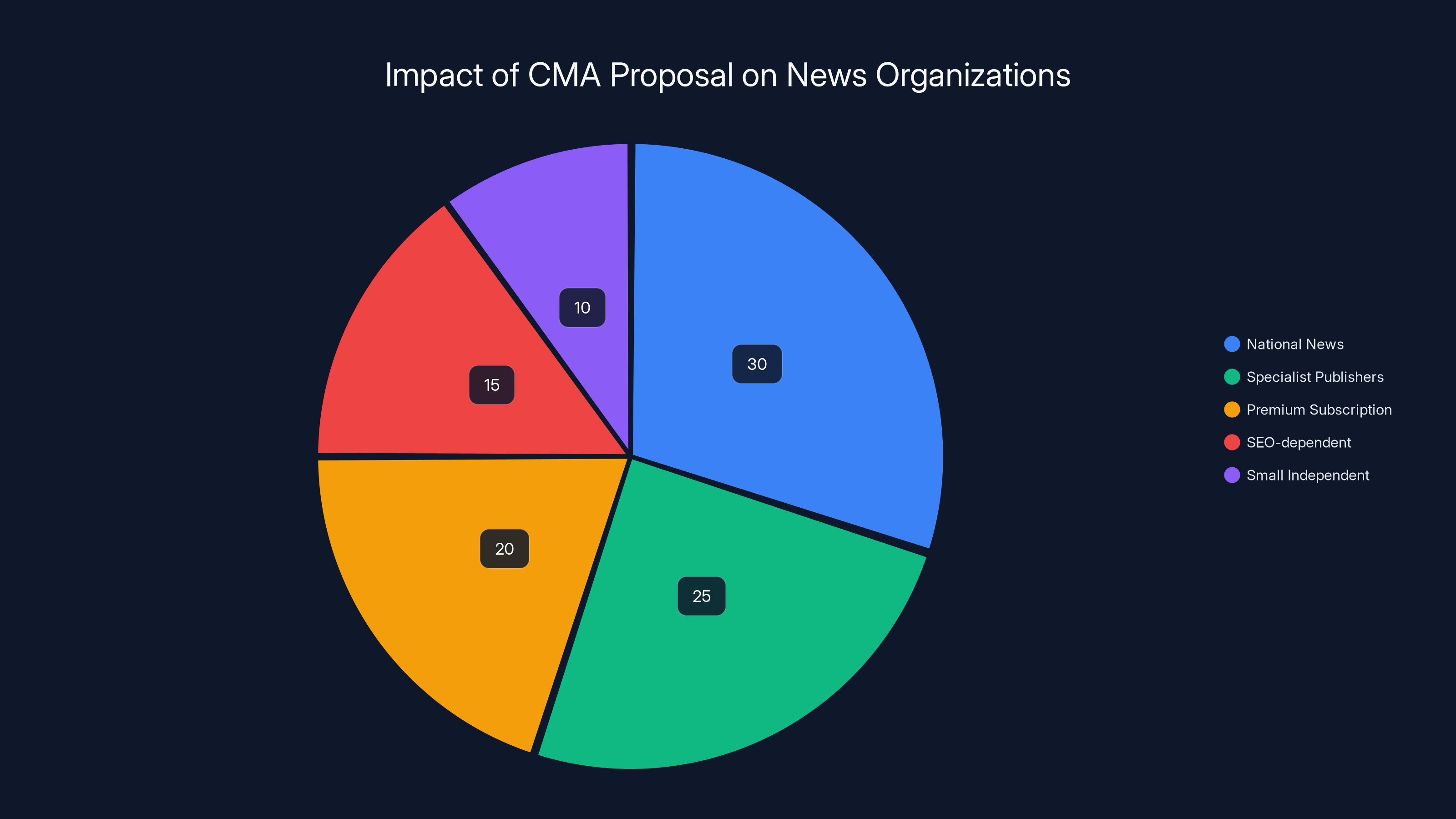
Estimated data shows national news and specialist publishers benefit most from the CMA proposal, while SEO-dependent and small independent publishers are disadvantaged.
Global Implications: Domino Effect or Isolated Decision?
Here's the question that keeps tech policy analysts up at night: does this UK requirement cascade globally?
Historically, there are two patterns:
Pattern 1: Regulatory Fragmentation
Companies end up maintaining different systems for different regions. Apple's app store works differently in the EU than the US. Google's data handling in GDPR-compliant countries is stricter. Content platforms have different moderation in different countries.
If this pattern holds, Google might implement UK-compliant AI Overviews just for UK users. Users in the US wouldn't get those protections.
Pattern 2: Regulatory Gravity
Alternatively, large enough markets pull global behavior. When California passes privacy laws, many companies implement them globally rather than maintaining California-specific versions. GDPR had worldwide impact beyond the EU.
The UK is significant (about 70 million people, substantial digital economy), but it's not China, the US, or the entire EU. Will it have regulatory gravity?
Most likely scenario: partial convergence. Google implements core requirements (opt-out, attribution) globally because it's easier than maintaining versions. But it adapts implementation details to regional laws.
When or if the CMA's proposal becomes binding (it's currently recommended, not finalized), we'll learn more about Google's actual flexibility on this issue.
Timeline and Enforcement: How Long Will This Take?
Here's where regulatory processes get frustrating: they take forever.
The CMA's current proposal is based on its October 2024 "strategic market status" designation. That designation itself came from investigation. Now Google has time to respond, negotiate, and challenge.
Typical timeline for such processes:
- Month 1-3: Parties submit formal responses to proposals
- Month 4-6: CMA may issue updated proposals or conduct further investigation
- Month 7-12: Final decision and enforcement order issuance
- Month 13-18: Google implements and CMA monitors compliance
- Ongoing: Regular audits and potential penalties for non-compliance
So we're looking at potentially 18-24 months before real enforcement happens, assuming the proposal moves forward without major complications.
During that time, AI Overviews continue as they are. Publishers continue losing traffic. The underlying problem persists while process unfolds.
This is one reason why regulatory intervention can feel inadequate to affected parties. By the time rules are enforced, the market may have evolved or the problem may have worsened.
What This Means for Publishers: A Practical Assessment
If you run a publisher, you're probably wondering: should I expect relief soon?
Honest answer: not immediately, and not as much as you might hope.
Here's what to expect:
Best Case (12-18 months):
- CMA issues binding enforcement order
- Google implements opt-out controls
- Publishers opt out of AI Overviews
- Attribution improves
- Traffic recovers somewhat for affected publishers
Realistic Case (18-24 months):
- CMA issues order with some provisions
- Google implements with caveats and negotiations
- Opt-out exists but is complex or poorly publicized
- Attribution improvements are marginal
- Traffic recovery is modest
Worst Case (ongoing):
- Google and CMA litigate over specific provisions
- Implementation is delayed
- Publishers see no relief
- Tech companies find workarounds
Publishers shouldn't sit around waiting for regulation to save them. They should:
- Diversify traffic sources: Reduce dependence on Google search
- Build direct audiences: Email lists, subscriptions, social media, newsletters
- Engage with this process: Submit comments to regulators, participate in consultations
- Explore partnerships: Work with platforms on licensing or alternative models
- Protect your content: Implement robots.txt controls proactively
Regulation can create conditions for fairness, but it can't substitute for business adaptation.

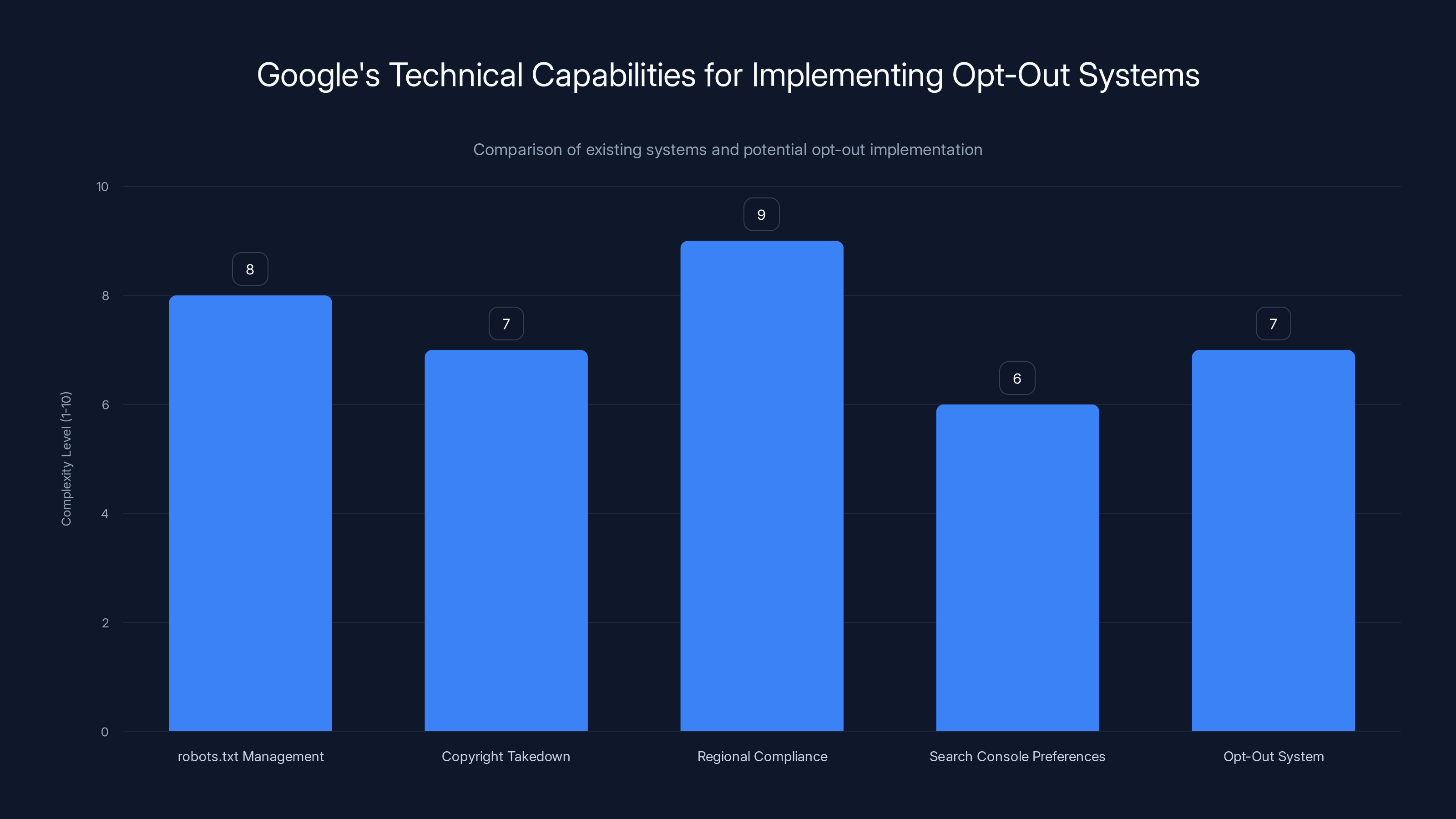
Google's existing systems, like managing robots.txt and regional compliance, demonstrate its capability to implement an opt-out system with similar complexity. Estimated data.
Broader Questions: Is Opt-Out the Right Model?
Underlying the entire CMA proposal is an assumption: opt-out is the right default.
But is it?
Opt-out assumes you need Google's permission to not be used. You have to go to their system, find the setting, and disable the feature.
Opt-in is the opposite: Google asks permission first. You have to affirmatively allow your content to be used for AI training.
EU regulation tends to prefer opt-in (GDPR cookie consent). The CMA's proposal leans toward opt-out.
Why does this matter?
Opt-in advantages:
- Respects creator agency: your default is protected
- Creates higher standards for use
- Forces Google to justify why they need the content
Opt-in disadvantages:
- Requires publishers to take action
- Most won't opt in (default inertia)
- Could make AI features less useful
Opt-out advantages:
- Preserves innovation by default
- Easier user experience
- Balances flexibility with control
Opt-out disadvantages:
- Requires publishers to be aware and active
- Defaults favor extraction
- Creators might not know opt-out exists
The CMA chose opt-out, probably because they don't want to cripple Google's AI development completely. Requiring opt-in for all content might make AI Overviews significantly worse.
But this choice reflects a value judgment: innovation is important, but so is fairness. Opt-out tries to balance both.
Some argue opt-out isn't strong enough. Others argue it's already too restrictive. The CMA essentially split the difference.
The Precedent: What Other Regulators Are Watching
Every regulator evaluating AI and publishers is watching this process. Here's what they're noting:
- Can the CMA actually enforce? If CMA successfully compels Google to implement changes, it validates the strategic market status approach. Other regulators might adopt similar tactics.
- Does opt-out work? If implementation is messy or adoption is low, it might discourage other regulators from pursuing opt-out models.
- Does this solve the underlying problem? If publishers still lose traffic despite opt-out and attribution, it suggests the real issue is more fundamental (user behavior, not platform policy).
Regulators in Canada, Australia, and other countries are developing their own approaches. Some are considering licensing mandates (like Australia's News Media Bargaining Code). Others are exploring AI-specific rules.
The UK's approach is somewhat unique: using existing competition law (strategic market status) to address AI-specific harms, rather than creating new AI regulation.
If this works, it becomes a template. If it fails, it discredits the approach.
Industry Reactions: What Publishers, Tech Companies, and Users Say
The CMA's proposal hasn't generated universal celebration or universal opposition. Different stakeholders have different views.
News Organizations: Mostly supportive. The UK News Media Association has been vocal about unfair content extraction. Seeing concrete regulatory action validates their concerns.
Specialist Publishers: More cautious. Some academic and professional publishers worry that opt-out controls might affect discoverability. They'd prefer licensing deals that compensate fairly.
Small Independent Publishers: Skeptical. They understand that opting out doesn't solve the fundamental problem: users now prefer AI summaries to articles. Regulation that just gives you a choice to opt out doesn't rebuild that reader relationship.
Tech Companies: Generally critical, though diplomatically. Google's official position is supportive of publisher protections while warning about unintended consequences. Smaller AI companies using web data worry about downstream impacts.
Users: Mostly unaware the issue exists. Users like AI Overviews. They provide quick answers without clicking. Whether sources are attributed properly doesn't affect the user experience they care about.
This misalignment between user preferences (fast summaries) and publisher interests (traffic and revenue) is the core tension. No regulatory fix can fully resolve it because it's not actually a market failure. Users prefer summaries. Publishers prefer clicks. Those preferences conflict.
The Licensing Model: Why Open AI's Approach Differs
Open AI has taken a different path than Google. Rather than relying on fair use arguments, Open AI is negotiating direct licensing deals with news organizations and publishers.
This approach has advantages and disadvantages:
Advantages:
- It's transparent: both parties know there's a commercial relationship
- It provides revenue: publishers get paid for content
- It respects publisher agency: they choose whether to license
- It sidesteps regulatory complexity
Disadvantages:
- Licensing is expensive at scale: Open AI can't license every source
- Power imbalances remain: Open AI sets the price, publishers take it or leave it
- It leaves many publishers without recourse: small sites won't negotiate licenses
- It could create pay-to-play dynamics where only publishers with negotiating power benefit
Google hasn't seriously pursued licensing partly because licensing everything would be prohibitively expensive. Google's business model is built on free indexing of content. Moving to a licensing model would fundamentally change their economics.
Regulation forces that change. If opting out becomes widespread, Google loses training data and content sources. They might decide licensing becomes cost-effective by comparison.
So the CMA's opt-out proposal might indirectly push Google toward licensing deals. The threat of opt-outs makes licensing economically rational.

Mathematical Framework: Modeling the Trade-offs
Let's think about this mathematically. Define the value exchange:
For Google:
- Benefit (B_g): Improved AI models, user engagement, search quality
- Cost (C_g): Implementation, compliance, lost training data if opt-out is widespread
- Net Value:
For Publishers:
- Benefit (B_p): Traffic from search results, improved discoverability
- Cost (C_p): Lost traffic to AI summaries, attribution effort
- Net Value:
Before regulation:
- (Google benefits)
- (publishers lose)
After regulation with opt-out:
- Some publishers opt out: training data (B_g) decreases
- decreases but might still be positive
- Publishers who opt out: traffic returns, improves
- Publishers who stay in: might be compensated or attributed better, slightly improves
The regulation works if the resulting equilibrium is:
- threshold (Google still benefits enough to keep features)
- closer to zero or positive (publishers aren't catastrophically harmed)
This is essentially the CMA's goal: a rebalancing where both parties have positive value.
The challenge: Google might decide
FAQ
What is Google's AI Overviews feature and how does it affect publishers?
Google's AI Overviews is a feature that generates an AI-written summary of search results directly on the search results page, providing users with immediate answers without clicking through to websites. For publishers, this reduces traffic significantly because users get the information they need directly from Google rather than visiting the source articles, impacting advertising revenue and engagement for news sites, review sites, and content publishers.
What regulatory power does the UK's CMA have over Google?
The CMA designated Google with "strategic market status" for search activities under the Digital Markets Act framework, which gives the CMA authority to impose binding conduct requirements on Google without waiting for a full formal investigation. Since Google processes more than 90% of search queries in the UK, this designation reflects Google's overwhelming market dominance and triggers regulatory oversight that prevents abuse of that dominance.
What does the opt-out control proposal mean for publishers?
Publishers would be able to opt out of having their content used in Google's AI Overviews and AI model training through a mechanism (likely in Google Search Console or via robots.txt directives). Publishers who opt out would no longer have their articles summarized in AI Overviews, theoretically preserving their traffic, though users might simply search a different way or get the answer from another source that didn't opt out.
How would attribution requirements work practically?
Attribution requirements would mandate that when Google's AI uses content from a publisher's article in an AI Overview, that specific information must be visibly and clearly linked back to the source article. Instead of vague source links at the bottom, each fact or paragraph in the AI summary would be tied to its original source, encouraging users to click through for more context and giving publishers traffic credit even when their content is summarized.
Why hasn't Google just paid publishers for using their content in AI Overviews?
Google could pursue licensing deals with publishers, similar to partnerships that other AI companies like Open AI have negotiated. However, licensing all published content at scale would be financially prohibitive and would set a precedent requiring payment for all content use. The CMA's regulatory approach sidesteps this by requiring opt-out and attribution controls first, which might eventually make licensing financially rational for Google if enough publishers opt out and reduce training data availability.
What happens if the CMA's proposal becomes binding on Google?
If the CMA's recommendations become binding (through a formal enforcement order), Google would be legally required to implement opt-out controls, improve attribution, ensure fair search rankings, and provide choice screens for alternative search engines in the UK. Non-compliance would result in fines (potentially calculated as a percentage of revenue) and additional regulatory action. Google would likely implement these features, potentially adapting them for other markets as well to avoid maintaining multiple versions of their search system.
Who benefits most from these proposed regulations?
National news organizations, subscription-based publishers, and specialist publishers (medical journals, academic publishers) benefit most because they have brand recognition and alternative traffic sources. They can opt out of AI Overviews without catastrophic impact. Publishers entirely dependent on search traffic benefit less because opting out means invisibility while staying in still results in lost traffic as AI summaries replace click-throughs. The regulations help high-authority publishers more than small independent creators.
Could these regulations harm Google's ability to improve AI features?
It's possible. If widespread opt-outs occur, Google would have less training data and fewer sources for AI Overviews, potentially making the feature less useful. Google argues that regulation could "break Search" by creating a fragmented or inferior experience. However, the CMA's position is that innovation achieved through unfair content extraction shouldn't be protected, and that fair competition requires some trade-offs in feature capability.
How does the UK's approach differ from EU regulation of similar issues?
The UK's approach is narrower and more specific, targeting direct harms from AI Overviews (opt-out controls, attribution) rather than broad platform regulation. The EU has implemented broader Digital Markets Act requirements and the AI Act framework. The UK's targeted approach might be easier to enforce but less comprehensive. Both aim to balance innovation with fairness, but take different regulatory paths.
When will these rules actually go into effect?
The CMA's proposal is currently in the recommendation stage, not yet binding. The process typically involves 12-24 months of formal responses, negotiations, and final enforcement order issuance before Google would be legally required to comply. Publishers shouldn't expect immediate changes, though Google may implement some provisions voluntarily while the CMA's formal process continues.

Conclusion: The Bigger Picture Behind the Regulatory Battle
The CMA's proposal isn't really about Google. It's about a fundamental question: who owns the value created by content on the internet?
For decades, that answer was clear. Publishers created content. Google indexed it, directed traffic to it, and benefited from the search ecosystem that content enabled. Both sides won: publishers got traffic, Google got data and user engagement.
AI changes the equation. Now Google can extract value from content without directing traffic to it. The summary is the answer. The publisher is unnecessary.
This isn't a technological inevitability. It's a choice about how to design AI systems. Google chose to extract value directly rather than create traffic-driving summaries. That choice maximizes Google's own benefit.
Regulation is saying: okay, but that's not fair. If you're extracting value from publisher content, they should benefit too. Either through traffic (attribution) or through optionality (opt-out) or through compensation (licensing).
Google's response is essentially: but that makes our service worse and innovation slower. We're optimizing for the user experience, not for publisher compensation.
Both sides have legitimate points. The CMA is essentially saying: your job is to compete fairly, not to optimize yourself into dominance.
That's the real debate. Not about AI Overviews specifically, but about the terms on which dominant platforms can use other people's content and effort.
The proposed rules try to rebalance that relationship. Whether they succeed depends partly on implementation (are opt-out controls actually usable?), partly on adoption (will publishers and users use them?), and partly on economics (can Google's business model survive with these constraints?).
What's certain is that this won't be the last time a regulator addresses this issue. AI companies will keep pushing to extract value directly. Publishers and creators will keep pushing back. Regulators will keep trying to establish fair-ish compromises.
The UK's CMA just moved first. Other regulators will learn from what happens here—what works, what gets gamed, what unintended consequences emerge.
For now, publishers in the UK should pay close attention to this process. It might be the difference between a viable publishing business and an increasingly marginal one. For the rest of the world, it's a signal about what's coming. AI companies that ignore these questions will find regulators increasingly willing to answer them for you.
The fair deal the CMA is seeking probably won't fully solve the underlying tension between what users want (fast answers) and what publishers need (traffic and revenue). But it might make the tension less one-sided. And in regulation, that's often the best you can achieve: a more level playing field, not a permanently perfect solution.
The next 18-24 months will tell us whether opt-out, attribution, and choice screens are enough. My guess? They're a start, but they're not the end of this particular regulatory story. There's more to come.
Key Takeaways
- The UK CMA designated Google with strategic market status, giving regulators binding enforcement power to protect publishers from unfair AI content extraction
- Proposed measures include opt-out controls for AI Overviews, mandatory source attribution, fair search rankings, and choice screens for alternative search engines
- Opt-out controls only help publishers with alternative traffic sources; search-dependent publishers face losing traffic either way
- Implementation and enforcement could take 12-24 months before rules become binding, during which AI Overviews continue impacting publishers
- This regulatory approach targets specific harms rather than regulating AI broadly, potentially creating a template for other regulators worldwide
Related Articles
- UK AI Copyright Law: Why 97% of Public Wants Opt-In Over Government's Opt-Out Plan [2025]
- Pornhub UK Ban: Why Millions Lost Access in 2025 [Guide]
- State Crackdown on Grok and xAI: What You Need to Know [2025]
- TikTok's U.S. Infrastructure Crisis: What Happened and Why It Matters [2025]
- Pornhub's UK Shutdown: Age Verification Laws, Tech Giants, and Digital Censorship [2025]
- Where Tech Leaders & Students Really Think AI Is Going [2025]

