![Vibe Coding and AI Agents: The Future of APIs and DevRel [2025]](https://tryrunable.com/blog/vibe-coding-and-ai-agents-the-future-of-apis-and-devrel-2025/image-1-1769355417883.jpg)
Vibe Coding and AI Agents: The Future of APIs and Dev Rel [2025]
You've probably heard the term "vibe coding" thrown around lately. Maybe you dismissed it as another Silicon Valley buzzword destined for the tech graveyard. But here's the thing: vibe coding isn't just a trend. It's a fundamental shift in how developers interact with code, and it's reshaping everything from API design to developer relations strategies.
Six months ago, most developers treated AI code generation as a fun experiment. Today? It's a core part of their workflow. And the implications are far bigger than just writing code faster. We're talking about a complete reimagining of how APIs need to be built, documented, and maintained.
The central challenge isn't technical. It's strategic. Your API might work perfectly for human developers. But what happens when an AI agent tries to integrate with it? What if the agent fails silently? What if it takes ten attempts instead of one? These aren't hypothetical questions anymore. They're the operational reality shaping API platforms right now.
This article dives deep into vibe coding, what it means for your API strategy, and how developer relations teams need to adapt. We're covering the dual audience problem, the metrics that actually matter, and why first-movers in the AI-ready API space will win big.
TL; DR
- Vibe coding is now mainstream: 89% of developers use generative AI in their workflows, but only 24% of organizations design APIs for AI agents.
- APIs need dual optimization: Machine-readable structure and human-friendly documentation are both essential for the AI era.
- Dev Rel metrics are changing: Forum activity and tutorial completions no longer tell the full story of API adoption.
- Schema and metadata matter more: Consistent naming, clear endpoint definitions, and machine-readable schemas directly impact AI agent success rates.
- First-movers gain advantage: APIs optimized for AI agents today will see faster adoption and fewer integration failures tomorrow.
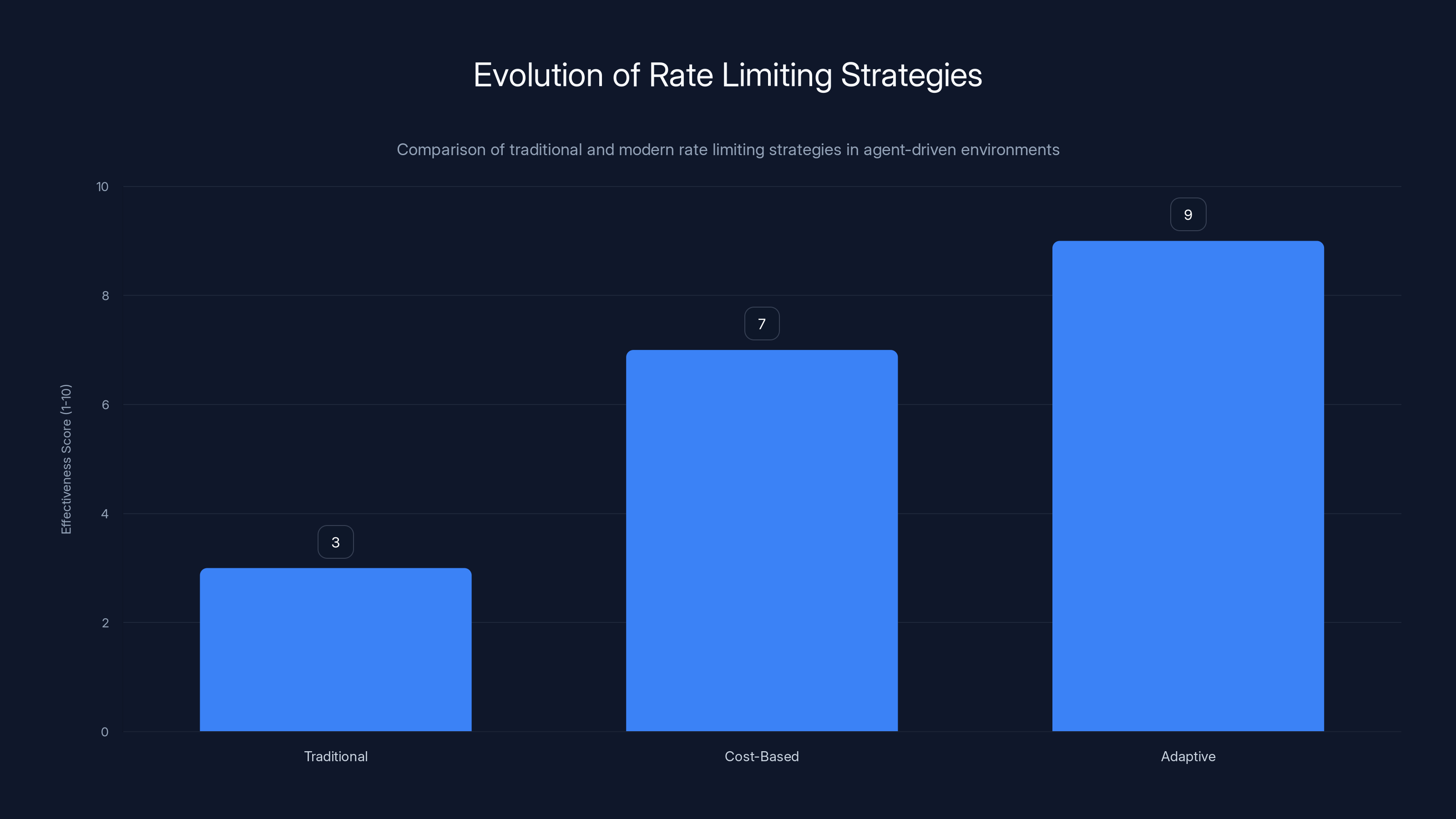
Adaptive rate limiting is the most effective strategy in managing requests in an agent-driven world, scoring higher than traditional methods. Estimated data.
What Actually Is Vibe Coding?
Vibe coding emerged naturally from the collision of two forces: the explosion of generative AI tools and the way developers actually work. It's not structured. It's not methodical. It's exploratory, creative, and yes, a bit chaotic. That's where the name comes from.
When a developer fires up Chat GPT or Copilot to quickly scaffold a database connection, iterate on a regex pattern, or spin up a prototype in thirty minutes, they're vibe coding. No pre-planned architecture. No formal requirements. Just the vibe of "let's try this and see what happens."
The traditional dev workflow looked something like this: plan, design, implement, test, refine. Vibe coding flattens that. You generate code, test it immediately, refine based on output, generate again. It's a feedback loop measured in minutes, not weeks.
What's remarkable is how quickly this became normal. Two years ago, developers worried about being judged for using AI tools. Now, they're worried about being inefficient if they're not using them. The social stigma disappeared almost overnight.
But here's what most people miss: vibe coding isn't just changing how individual developers write code. It's changing who the consumer of your API actually is. Your API documentation isn't just being read by humans anymore. It's being fed to AI models that parse it, understand it, and make integration decisions based on it.
The problem is most APIs weren't designed with this in mind.
The Dual Audience Problem: Humans vs. Machines
Let's say you're an API provider. For years, you've optimized everything for human developers. Your documentation is beautifully written. Your guides are detailed. Your examples are clear. You've got a thriving developer community on your forum. By every traditional metric, you're nailing it.
Then an AI agent tries to integrate with your API.
The agent reads your documentation. But unlike a human developer, it doesn't fuzzy-match ambiguous parameter names. It doesn't infer intent from context. It doesn't get creative with edge cases. It follows what you've written, literally and exactly.
If your API has inconsistent naming conventions across endpoints, the agent will stumble. If you've omitted edge-case behaviors from your schema, the agent will fail. If your error messages are poetic but vague, the agent won't know how to recover.
This is the fundamental dual audience challenge: you now have two users who want very different things from the same API.
Humans want narrative. Context. Personality. "Here's why we named it this way." "Be careful with this parameter in high-traffic scenarios." "This endpoint was deprecated in favor of that one." They can read between the lines. They can ask follow-up questions. They can adapt when something's unclear.
Machines want structure. Predictability. Unambiguity. Machines need the schema to match the behavior exactly. They need consistent naming patterns. They need complete parameter documentation. They need error handling that's explicit enough to learn from.
The worst part? You can't just build for the machine and hope humans figure it out. You also can't build for humans and expect machines to adapt. You need to do both, simultaneously.
This is where machine-readability becomes a first-class design goal. Not optional. Not a nice-to-have. A core requirement from the very first API design meeting.
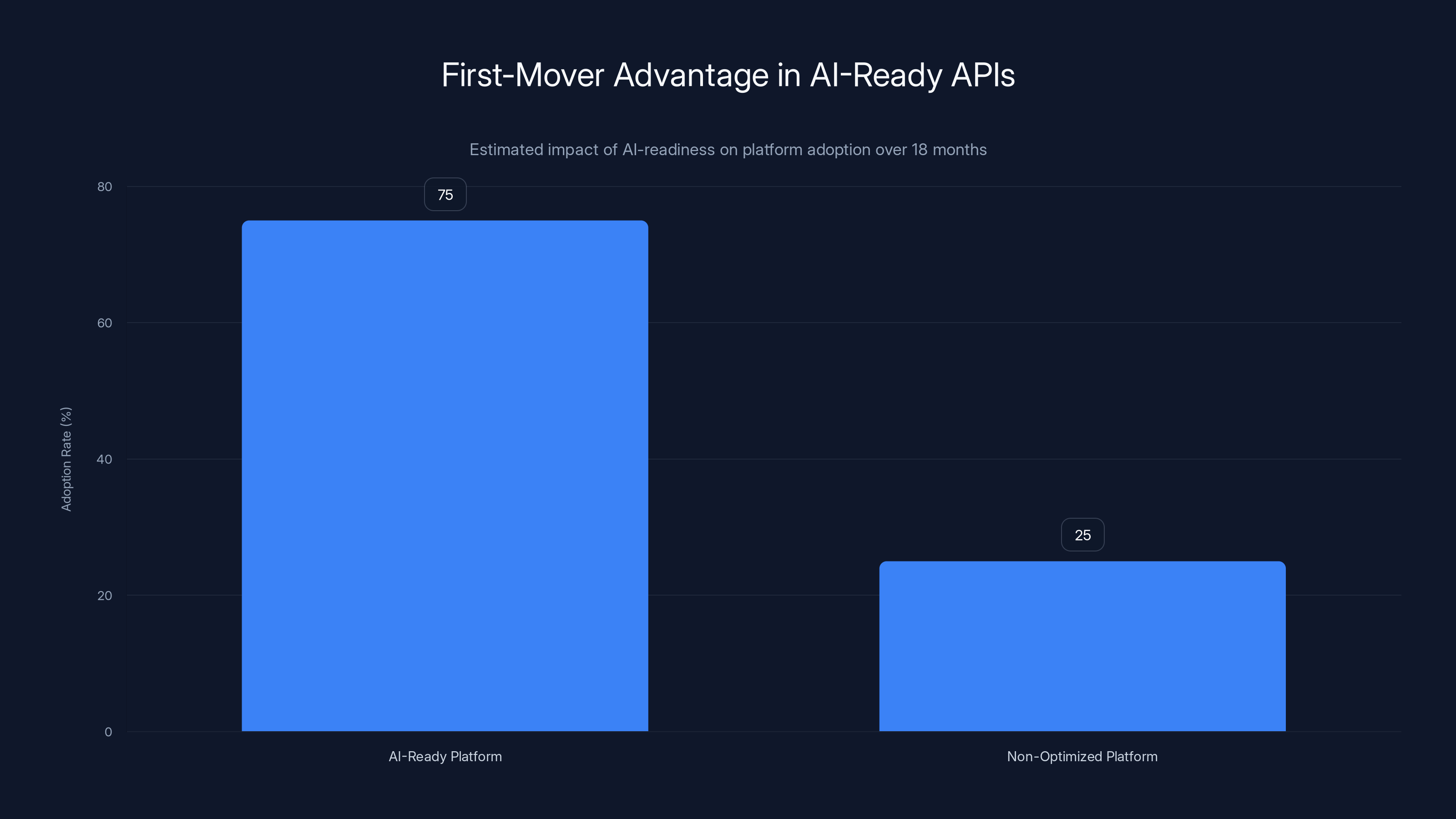
AI-ready platforms are estimated to capture 75% of new developer integrations due to ease of use and network effects, compared to only 25% for non-optimized platforms. Estimated data.
Machine-Readability as a Core Design Principle
Machine-readability means your API structure, naming, and metadata can be automatically parsed, understood, and acted upon by software. It's the difference between an API that an AI agent can integrate with on the first attempt and one that requires ten retries and human intervention.
Here's what machine-readable looks like in practice:
Consistent naming conventions. Every endpoint that creates a resource uses POST. Every endpoint that retrieves a resource uses GET. The response structure is identical across similar operations. Parameter names follow the same pattern throughout.
Human developers adapt to inconsistency. An AI agent treats it as ambiguity and fails.
Clear, complete schemas. Every parameter has a description. Every type is explicit (not "string or number," but one or the other). Every possible value is documented. Deprecations are marked clearly.
Machine-readable metadata. Open API specs aren't just documentation. They're actionable instructions for AI systems. When an AI agent reads your schema, it understands exactly what your endpoint does, what parameters it accepts, what it returns, and what can go wrong.
Explicit error handling. Different error codes mean different things. A 400 Bad Request means something different from a 429 Too Many Requests. Your error responses include structured information about what went wrong and how to recover.
The best part? All of this also makes your API better for humans. Consistency is easier to understand. Complete documentation is more helpful. Clear error messages matter whether you're a person or an algorithm.
Think about discovery surfaces. When a human developer wants to integrate with your API, they read your docs. When an AI agent wants to integrate, it reads your schema. If those two things disagree, something's going to break.
The industry research backs this up. The same organizations seeing the fastest AI adoption are the ones that rebuilt their APIs to be machine-first. Their integration times are shorter. Their error rates are lower. Their developers can focus on business logic instead of debugging integration issues.
How AI Agents Are Changing the Integration Landscape
Five years ago, API adoption looked like this: developer discovers API, reads documentation, builds integration, iterates based on errors, finally deploys.
Today? Developers are handing the early part of that process to AI.
Developer says: "Integrate with the Stripe API to process payments." AI agent spins up, reads the schema, examines your SDK, generates integration code, runs basic tests, and drops a working implementation in the codebase. Developer reviews it, tweaks it, ships it.
But here's where it gets interesting: the agent's first impression of your API determines whether it even attempts deep integration or quickly defaults to something simpler.
Imagine an AI agent trying three different payment processors. It hits Stripe's API, gets a clean response on its first attempt, understands the schema perfectly, and generates working code immediately. It tries the second option, encounters ambiguous documentation, gets a 400 error it doesn't understand, retries three times, eventually gives up. It tries the third option and has similar issues.
Guess which one gets integrated into production?
First impressions matter now in ways they never did before. The moment an AI agent makes its first successful request determines whether it continues deeper or turns elsewhere.
This is changing how platform teams think about onboarding. Traditional onboarding for humans involves a tutorial, maybe a guide, eventually a full integration. Onboarding for AI agents starts with: does your schema parse correctly? Can we extract the available operations? Do the examples work?
The agents are also more honest about API quality than humans are. A human developer might work around an inconsistency and just document it internally. An agent will try the same inconsistent parameter name twelve times, fail each time, and try a different approach.
From an API provider's perspective, this is incredibly valuable feedback. Your agents are basically running automatic audits of your API quality.
The Impact on API Design and Documentation Strategy
The old playbook for API success went something like this: ship an API, write good documentation, engage the community, iterate based on feedback.
That still works. But now you need a parallel playbook: ship an API that's machine-parseable, ensure your schema is the source of truth, structure your metadata for agent consumption, and monitor how AI systems interact with your platform.
Let's talk about documentation. You still need beautiful, narrative documentation for humans. But now you also need machine-readable reference documentation. These aren't the same thing.
Narrative documentation tells a story. Here's what this endpoint does. Here's why you'd use it. Here's what happens if you pass an invalid parameter. Here's how to build on this foundation.
Machine-readable reference documentation is structured data. Every endpoint. Every parameter. Every possible response. Every error condition. Organized in a way that software can parse and act on.
The best API platforms now have both. They have the polished guides and tutorials for humans who are learning the platform. They also have the Open API specs and machine-friendly metadata for agents who are building integration code.
Here's where it gets really interesting: SDKs. Human developers love SDKs. They abstract away the complexity of HTTP, serialization, error handling. They make integration fast.
AI agents care about SDKs too, but for different reasons. A well-structured SDK gives agents clear examples of how to invoke operations, what data types to use, what errors to handle. A poorly structured SDK is just noise.
Some of the leading platforms are now generating SDKs specifically for agent consumption. Not for humans. For the AI systems that are building integration code. These SDKs are minimal, focused, explicit about types and errors.
Discovery surfaces matter more now too. When a human developer wants to find an endpoint, they browse your API reference. When an AI agent wants to find an endpoint, it queries your discovery models and metadata endpoints.
If your platform can't tell an agent "here are all the operations available," "here's what each one does," and "here's how they relate to each other," you're forcing the agent to figure it out through trial and error.
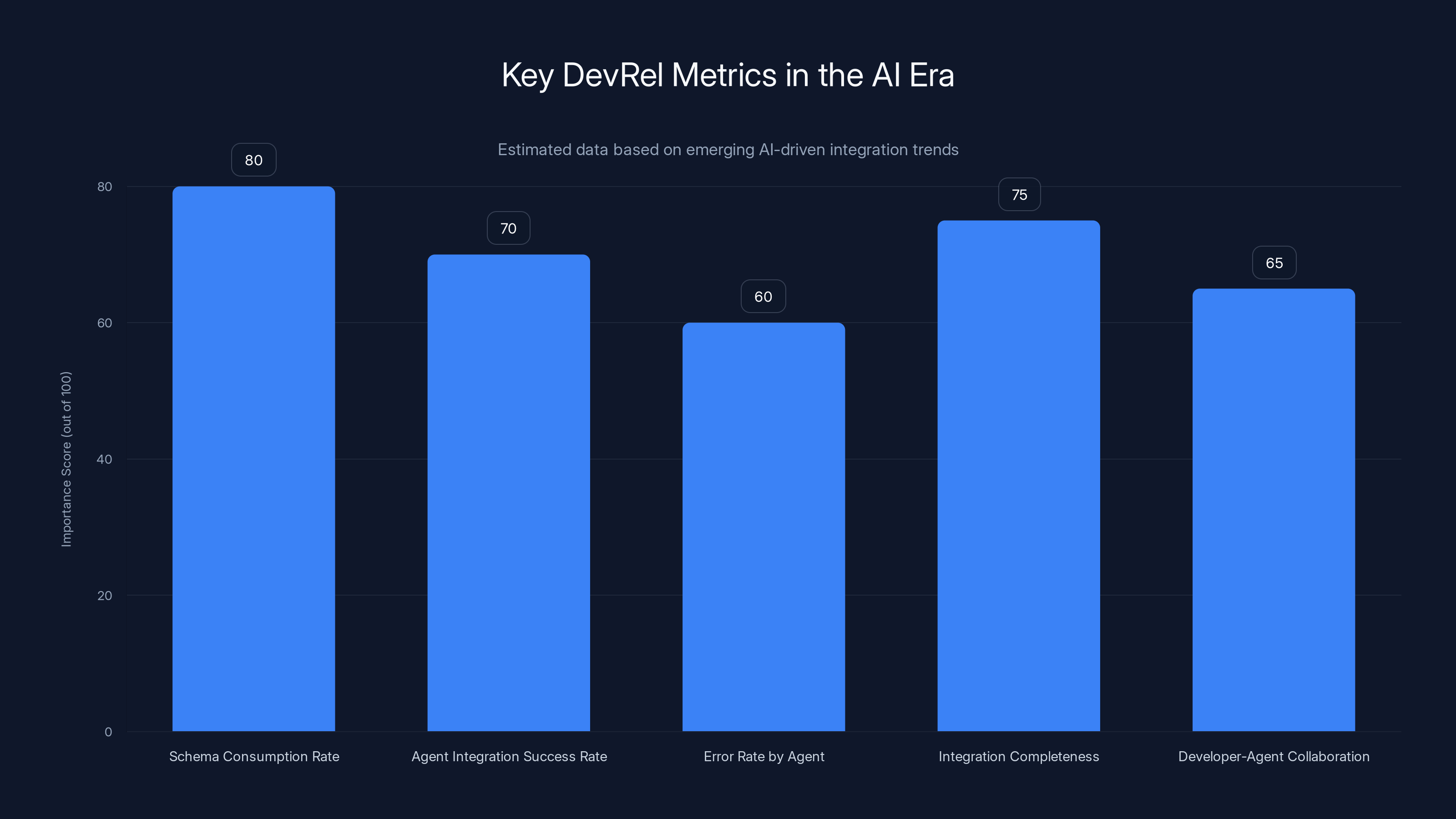
In the AI era, schema consumption and integration success rates are crucial metrics for DevRel teams, reflecting the shift towards AI-driven development. Estimated data.
Real-World Implications: The First-Mover Advantage
We're at an inflection point. Most API platforms haven't optimized for AI agents yet. But that won't last.
In the next 18 months, expect rapid consolidation around AI-ready APIs. Developers (and their AI copilots) will migrate to platforms that provide clean, predictable, machine-readable interfaces. The migration will be quiet and quick.
Platforms that haven't optimized will wake up one day and realize their adoption rates are falling. The reason won't be customer complaints. It'll be that developers stopped trying to integrate, not because they didn't want to, but because their AI systems couldn't figure out how.
Here's the advantage for first-movers: network effects. When you're the easiest API for AI agents to integrate with, you get more integrations. More integrations mean more use cases. More use cases mean more developers discover your platform. More developers means more community. More community means stronger network effects.
Think about it from an AI agent's perspective. It's building integrations for a customer. The customer wants Stripe, Twilio, and a third-party analytics platform. Stripe has a clean schema, clear error handling, and fast response times. The third-party service has inconsistent naming, vague documentation, and unclear error messages.
The agent tries Stripe first. Success. It tries the third-party service. Multiple failures. The agent reports back: Stripe integrated fine, but the other service is problematic.
Guess which platform just lost a potential customer.
Competitive advantage in the API space has traditionally come from features, pricing, or community. Now it's coming from machine-readability. That's a massive shift.
Platforms that move fast will own their category. Platforms that wait will spend the next three years playing catch-up, trying to explain to customers why their APIs are harder to integrate than the competition.
Dev Rel Metrics That Actually Matter in the AI Era
Here's where things get uncomfortable for Dev Rel teams.
For years, developer relations has measured success through human-centric metrics: forum activity, tutorial completions, SDK downloads, community events, engagement scores. These were good proxies for adoption because human developers drove adoption.
Now those metrics lie.
You can have zero forum activity and massive adoption. You can have thousands of SDK downloads that never actually get used in production because the AI agents replacing them are using your schema directly. You can have beautiful tutorials nobody reads because developers are just asking their copilot to build the integration.
You need new metrics.
Schema consumption rate. How often is your Open API spec being requested? By how many unique clients? What patterns are they querying?
Agent integration success rate. Of all the AI-driven integration attempts against your API, what percentage succeed on the first try? What percentage require human intervention?
Error rate by agent. Which agents struggle with your API? What are the common failure points? Is it your schema, your naming, your error messages?
Integration completeness. Are agents building full integrations or giving up halfway through? What's the median number of endpoints per integration?
Developer-agent collaboration patterns. What's the ratio of AI-generated code to human-written code in integrations? Are developers mostly reviewing and approving, or are they rewriting large portions?
These metrics tell you things the old metrics never could. They tell you exactly where your API is confusing, exactly where agents struggle, and exactly which improvements would have the biggest impact.
This creates an interesting shift in how Dev Rel teams operate. Instead of focusing on developer education and community engagement, they're increasingly focused on schema quality, metadata accuracy, and agent success rates.
It's not that the old stuff doesn't matter anymore. It does. But the new stuff is becoming the primary driver of adoption.
The teams adapting fastest are treating their Dev Rel function like a product. What's the product? An API that's easy for both humans and agents to use. What are the metrics? Success rates, error rates, time-to-integration. What's the roadmap? Improvements to schema, metadata, and error handling.
This is a fundamental reframing. Dev Rel isn't about marketing anymore. It's about building the best technical experience for the broadest audience.
Schema Design and Standardization: The New Foundation
You want to know the single biggest factor in whether an AI agent can successfully integrate with your API? Schema quality.
I'm not talking about a perfectly comprehensive schema that documents every quirk and edge case. I'm talking about a schema that's correct, complete, and consistent.
Correct means the schema matches the actual behavior of the API. If your schema says a parameter is required, it's required. If the schema says an endpoint returns an object with these fields, it returns exactly those fields. No surprises.
Complete means nothing is missing. Every endpoint. Every parameter. Every possible response. Every error condition. There's no "oh, that's not documented, but it's available in the schema."
Consistent means the same patterns repeat throughout. All create operations use POST. All list operations use GET. All responses follow the same structure. Parameter naming is predictable.
AI agents can work with any two of these. Missing one? Integration fails.
Here's the challenge: maintaining a correct, complete, and consistent schema is work. Real work. It requires discipline in code review. It requires someone owning the schema as a product, not treating it as a side effect of engineering.
The platforms doing this best have appointed a schema owner. Someone whose job is to ensure the Open API spec stays in sync with reality. Someone who reviews API changes through the lens of "does this break the schema? Does this create inconsistency? Does this add the right documentation?"
It's not glamorous work. But it's incredibly high-leverage.
Some platforms are going further. They're standardizing their schema language. Not everyone's using Open API yet. Some are stuck with older standards. Some have proprietary formats. But the clear winner is Open API, and the momentum is only increasing.
Why? Because it's the lingua franca that AI agents understand. GPT-4 understands Open API specs out of the box. When you hand it an Open API spec, it knows exactly what it's looking at.
If you're still maintaining custom schema formats, you're making it harder for agents to integrate with you. Migration to Open API is now a competitive issue, not a technical nicety.
The standardization is also enabling tooling. Once everyone's using Open API, the ecosystem builds around it. Code generators. Testing frameworks. Documentation tools. Schema validators. All of this tooling benefits your API.

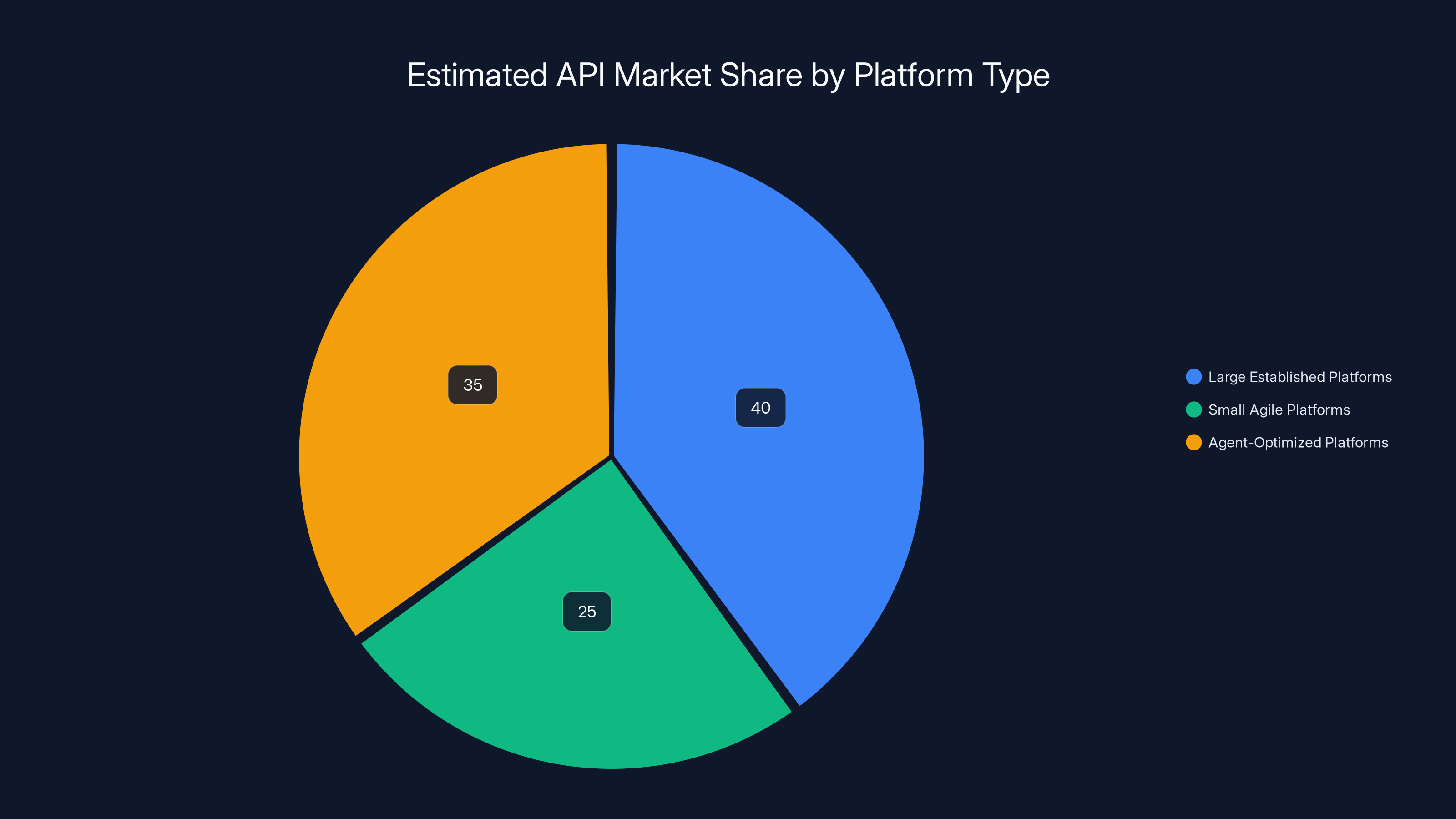
Agent-optimized platforms are projected to capture a significant portion of the API market, challenging large established platforms. Estimated data.
Error Handling and Debugging for AI Agents
Error handling is another area where human and machine expectations diverge.
When a human developer gets a 500 error, they might read the error message, check the logs, see that there was a database timeout, and retry. They can infer that the service is temporarily overloaded and come back in a minute.
When an AI agent gets a 500 error, it sees one thing: the operation failed. Unless you're explicit about what it means and what to do, the agent won't recover gracefully.
The best APIs now have error responses that machines can understand and act on.
Structured error responses. Not just a message string, but a structured object. Error code. Error message. Retry-ability. Rate limit information. Suggestions for recovery.
Example:
json{
"error": {
"code": "RATE_LIMIT_EXCEEDED",
"message": "You have exceeded your rate limit of 100 requests per minute",
"retry After": 45,
"retry After Unit": "seconds",
"documentation": "https://api.example.com/docs/rate-limiting"
}
}
An AI agent can read this and understand: wait 45 seconds and retry. It doesn't need to parse the message string or guess. The structure tells it exactly what to do.
Compare that to:
json{
"error": "Too many requests. Please try again later."
}
An agent receives this, has no idea when to retry, and might give up or retry immediately.
Some platforms are going even further. They're providing error recovery suggestions. "This operation failed because of X. You could try Y instead." They're providing context about the error. "This endpoint is deprecated as of 2025-Q1. Use this endpoint instead."
They're monitoring which errors agents encounter most frequently and treating those as design flaws to fix, not as expected failure modes.
This is a huge opportunity for platforms that embrace it. Agents that have clear error recovery paths will succeed more often. That drives adoption. That drives more integrations. That drives growth.
Platforms that ignore it will see agents fail silently and move on to competitors.
The Evolution of API Documentation for Dual Audiences
Documentation used to be one thing: a comprehensive guide for developers to understand and use your API.
Now it's at least three things.
Narrative documentation. For humans learning the platform. This is your "getting started" guide. This is your tutorial. This is the part that tells a story about what you're building and why. This is timeless work. Humans need this as much as ever.
Reference documentation. Also for humans, but more systematized. Here's every endpoint. Here are the parameters. Here are the responses. This is reference material, not narrative. Humans browse this when they need to look something up.
Machine-readable documentation. For agents. This is your Open API spec. This is your schema. This is structured metadata. This is what agents parse and act on.
The challenge is keeping all three in sync. If your narrative guide says you can do X, but your schema says you can't, something's broken. If your reference documentation lists a parameter that doesn't actually exist, agents will fail.
The platforms handling this best are making their Open API spec the source of truth. Everything else derives from it. Reference documentation can be auto-generated from the spec. Examples can be generated from the spec. Even parts of narrative documentation can be templated and auto-populated.
This isn't new in software. Internal API documentation has worked this way for years. But it's relatively new in the public API space, and it's spreading fast.
Some platforms are also providing prompt templates. "Here's how to ask an AI agent to integrate with our API." This sounds trivial, but it's not. It's the difference between an agent trying random approaches and an agent with explicit instructions on how to get the best results.
Example prompt template:
"Integrate with our API to fetch the user's account balance. Use the GET /accounts/{account Id} endpoint. First, call GET /me to get the current user's account ID. Then use that to call GET /accounts/{account Id}. Handle rate limiting errors by waiting the number of seconds specified in the retry-after header."
Versus no template, where the agent has to figure all of this out from the schema.
The template saves the agent time and reduces failure modes.

Building for Autonomous Agents: Long-Running Operations and State Management
Here's where things get really interesting. Traditional APIs were designed for single requests. Developer makes a request, gets a response, moves on.
Autonomous agents work differently. They might initiate an operation that takes hours. They might retry when things fail. They might need to check status. They might need to orchestrate multiple operations in sequence.
API design is already starting to shift to accommodate this.
Async operations and webhooks. Instead of waiting for a response, agents initiate an operation and get back a job ID. They can check the status of the job. When it completes, your platform sends a webhook notification.
Idempotency keys. Agents might retry the same operation multiple times. You need a way to guarantee that the operation only happens once, regardless of how many times the agent retries.
State machines. Complex operations have clear states. Pending, processing, complete, failed. Agents need to understand these states and be able to query them.
Transaction handling. Agents might be orchestrating multiple operations that need to succeed or fail together. Your API needs to support this.
These patterns aren't new, but they're becoming table stakes for modern APIs. Agents depend on them.
Platforms that designed for synchronous, request-response operations are now retrofitting async capabilities. It's painful. Platforms that are designing from scratch are starting with async as the foundation.
Agents don't care about the underlying implementation. But they do care about the interface. A clean async interface is easy for agents to work with. A messy retrofitted async system is not.
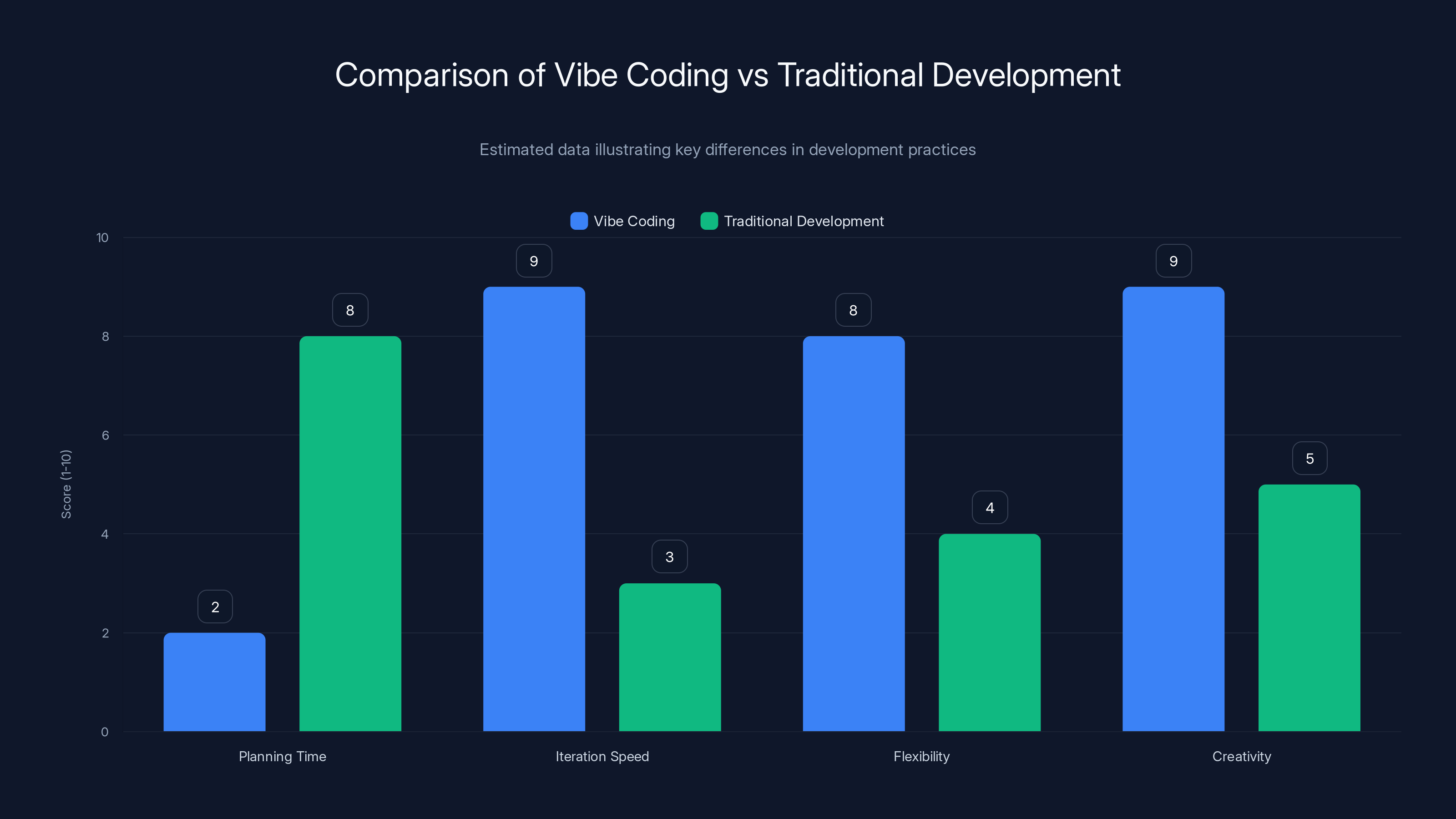
Vibe coding significantly reduces planning time and increases iteration speed, flexibility, and creativity compared to traditional development. (Estimated data)
Rate Limiting, Quotas, and Fair Usage in an Agent-Driven World
When most of your traffic was human developers, rate limiting was relatively simple. Humans made requests at human speeds. You needed to prevent abuse and enforce your business model.
Now agents are making requests at machine speeds. A single AI assistant might trigger hundreds of requests in a second. Multiply that by thousands of developers using different AI assistants, and you've got a very different traffic pattern.
Rate limiting strategies need to evolve.
Traditional rate limiting (requests per minute) is becoming less useful. It worked when you were protecting against human abuse. It doesn't work when agents are legitimately making thousands of requests.
Cost-based rate limiting is becoming more important. Different operations have different computational costs. A simple read is cheap. A complex computation is expensive. Rate limiting based on computational cost is fairer and more efficient.
Adaptive rate limiting is the frontier. Your system observes agent behavior and adjusts limits dynamically. If an agent is consistently staying within limits and succeeding, maybe you increase its limits. If an agent is behaving erratically, maybe you decrease them.
Quotas are also becoming more granular. Instead of "100 requests per day," you might have "10,000 compute units per day." Or "1,000 write operations per day." These give agents more flexibility while still protecting your resources.
Fair usage policies are also evolving. Traditional fair use was about preventing one customer from hogging resources. Now it's also about preventing one poorly-written agent from initiating millions of requests.
The platforms handling this best are being explicit about what's fair and what's not. They're providing agents with clear feedback when they're approaching limits. They're offering higher tiers for power users. They're being transparent about billing.
This is becoming a competitive differentiator. Agents choose platforms with clear, fair pricing models over platforms with opaque quotas and surprise overages.

Integration Ecosystems and Marketplace Dynamics
API platforms are evolving beyond just "here's an API, integrate with it." They're becoming ecosystems.
Consider Zapier. It's an integration platform that connects thousands of APIs. Humans create Zaps (integrations). Now imagine AI agents creating Zaps, or agents creating integrations directly between APIs.
This is happening. And it's reshaping how integration marketplaces work.
Third-party developers are building tools specifically to help AI agents integrate with APIs. Schema enrichment tools. Integration generators. Testing frameworks. These are all new categories that didn't exist before.
Platforms are also starting to integrate directly with popular AI models. "Here's how to integrate with our API using Chat GPT." Not just documentation, but direct integration.
Some platforms are providing specialized versions of their APIs for agents. Stripped-down, optimized for machine consumption. Not for all operations, but for the ones agents use most frequently.
The marketplace dynamics are also changing. Previously, successful integrations were determined by demand from developers. Now they're also determined by how easy they are for AI agents to create.
Some integrations that were previously difficult for humans to build are becoming trivial for agents, because agents can read the schema and generate code without needing human-friendly documentation.
Other integrations that were previously easy for humans are becoming harder for agents, because they require workarounds that aren't documented in the schema.
Security, Permissions, and Governance in an Agent-Driven World
When a human developer integrates with your API, there's a person responsible. You can trace back to an individual if something goes wrong.
When an AI agent integrates with your API, who's responsible? The developer who created the agent? The AI vendor? The customer using the agent?
Security and governance models need to evolve to handle this ambiguity.
API keys and authentication are becoming more granular. Instead of a single API key that gives access to everything, you might have multiple keys with different permissions. One key for reading data, another for writing data, another for admin operations.
Scoped permissions are becoming necessary. An agent might have permission to read customer data but not permission to delete it. Or permission to initiate operations but not permission to cancel them.
Audit logs are becoming more detailed. Not just "someone called this endpoint," but "an agent created by [developer] called this endpoint on behalf of [customer] and this is what it did."
Rate limiting and quotas are also security controls now. They're protecting your system from runaway agents, whether those runaway conditions are due to bugs or malice.
Consent and transparency are becoming critical. When an agent is acting on a customer's behalf, the customer needs to know what it can and can't do. This is both a security and a compliance issue.
Some platforms are implementing agent-specific security policies. "This agent is only allowed to make read requests." "This agent's operations must be approved by a human before execution." "This agent can operate in sandbox mode only."
Compliance is also becoming more complex. When an AI agent processes personal data, who's responsible for compliance? If an agent deletes data it shouldn't have access to, who's liable?
These questions don't have clear answers yet. But platforms that get ahead of them will have a competitive advantage.

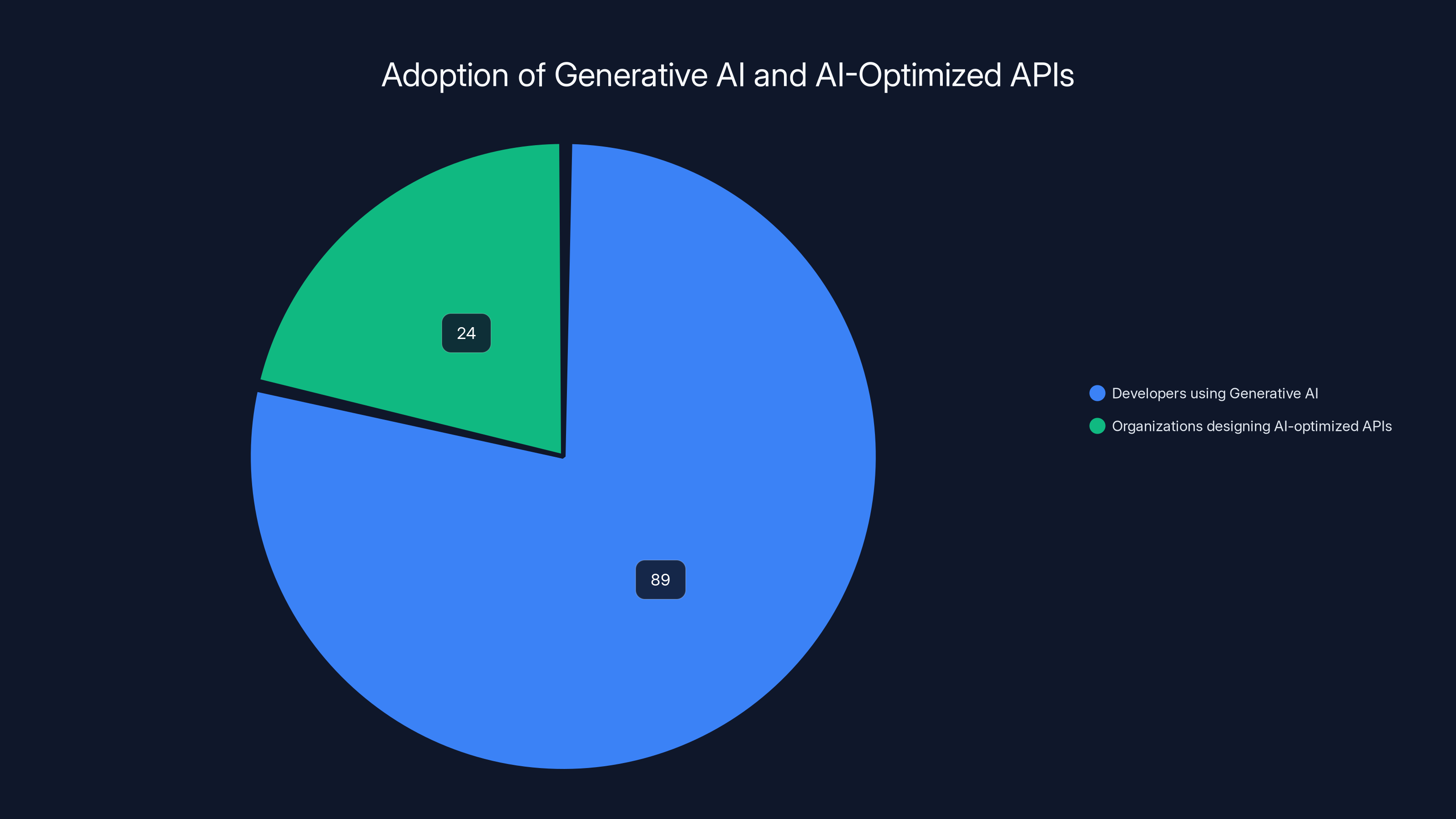
While 89% of developers integrate generative AI into their workflows, only 24% of organizations have designed APIs specifically for AI agents. Estimated data.
Organizational Changes: How Teams Are Restructuring for the AI Era
Technical changes to APIs are just the beginning. The real transformation is organizational.
Six months ago, a typical API platform team looked like this: engineers building the API, Dev Rel folks doing community outreach, product managers setting roadmap, maybe a documentation specialist.
Today's top platforms are adding new roles:
Schema owner. Someone whose job is to ensure the Open API spec is correct, complete, and consistent. This is a full-time job at scale.
Agent integration specialist. Someone focused specifically on making it easy for AI systems to integrate with your platform. They're testing integrations with popular AI models. They're gathering feedback from agents and using it to improve the API.
Developer experience engineer focused on automation. Not just traditional Dev X engineering, but specifically optimizing for automated integration and agent-driven adoption.
Other teams are reorganizing around this shift. Instead of "human Dev Rel" and "agent Dev Rel," they're unified under "platform experience," with the understanding that both audiences matter equally.
Product roadmaps are also shifting. Features are being evaluated not just on human developer demand, but on whether they make the platform more accessible to agents.
Training is becoming important too. Not every engineer understands the requirements of agent integration. They need to learn how to design for machine-readability. How to think about error handling for agents. How to optimize for fast agent iteration.
Culture is shifting as well. The best performers aren't just good at building APIs anymore. They're good at building APIs that work for both humans and agents. That's a different skillset.
Competitive Dynamics and Market Consolidation
We're at an inflection point in the API market. Platforms that adapt quickly to the agent-driven world will consolidate market share. Platforms that don't will lose relevance.
Here's why consolidation is happening faster than you might expect:
Agents make decisions based on metrics, not brand loyalty. A developer might stick with an API because of inertia, community, or existing integrations. An agent will switch to whichever API it can successfully integrate with faster.
Network effects are amplifying this. Once an API becomes the obvious choice for agents, more agents integrate with it, which improves its schema and metadata, which makes it even easier for the next agent, which drives more adoption.
This creates a "winner-take-most" dynamic in categories where a clear leader emerges in agent-readiness.
Smaller platforms have an advantage here. They can move faster, experiment more freely, and adapt their APIs more quickly than large, established players.
Large platforms have advantage in resources and customer relationships. But if they can't move fast enough, they'll lose share to more agile competitors.
M&A activity is also heating up. Large platforms are acquiring smaller, agent-optimized platforms to fill gaps in their portfolios. Integration platforms are acquiring domain-specific APIs. This consolidation is reshaping the landscape.
Pricing is also shifting. Platforms that charge per request are facing pressure from agent-driven platforms that consume a lot of requests but drive high volume. Some are moving to consumption-based pricing with compute units instead of request counts. Others are moving to tier-based pricing optimized for high-volume scenarios.

Future Predictions: Where APIs Are Heading
Let me paint a picture of what the API landscape looks like in three years.
Agent-native design is the norm. APIs are designed from the ground up to be consumed by agents. Human documentation is generated from the schema, not the other way around.
Multimodal APIs are everywhere. Your API doesn't just have a REST endpoint. It has a GraphQL endpoint for complex queries. It has a gRPC endpoint for performance-critical operations. It has webhooks for async operations. It has an AI-optimized endpoint for agent consumption.
Verification and trust are critical. As agents become more autonomous, verifying what they can and can't do becomes crucial. Provenance of integrations, audit trails, and consent mechanisms are built into every platform.
Observability shifts toward agents. Instead of monitoring human developer adoption, you're monitoring which agents are integrating, how successfully, and what they're doing. Your observability tooling is optimized for agent behavior, not human behavior.
Specialized AI interfaces emerge. Just like mobile forced platforms to create mobile-specific interfaces, agents will force platforms to create agent-specific interfaces. Not just schemas, but interfaces optimized for how agents actually consume APIs.
Integration becomes a UX problem, not a technical problem. The technical aspects of integration are solved. Every agent can read a schema. The competitive differentiation is in making integration so frictionless that agents choose your platform.
Compliance and governance become centerpieces. Regulations are coming that require agents to be auditable. Platforms that bake this in from the start will have an advantage.
Open standards dominate. Proprietary schema formats and custom authentication mechanisms are phased out. Open API, OAuth, and other standards become non-negotiable.
The Dev Rel Playbook for an AI-Driven World
If you're on a Dev Rel team, here's what you need to do right now.
Audit your API from an agent perspective. Have an AI try to integrate with your platform without human help. Document where it succeeds and where it fails. Treat failures as bugs.
Establish schema ownership. Appoint someone to be responsible for the quality and accuracy of your Open API spec. Make this a formal role.
Publish your agent integration results. "Here's how our API performs with Chat GPT, Claude, and other popular models." Transparency builds trust and attracts agent users.
Invest in error handling. Make sure your error responses are structured and actionable. Agents will judge your API based on how well they can recover from errors.
Create agent-specific documentation. Not everything you document for humans is useful for agents. Create documentation specifically optimized for agent consumption.
Monitor agent behavior. Track how agents are integrating with your platform. What endpoints do they use most? Where do they fail? Use this data to improve your API.
Engage with AI vendors. If Chat GPT, Claude, or other major AI models are important to your business, work with those vendors to optimize your schema and metadata for their systems.
Join community standards efforts. Contribute to Open API, Async API, and other open standards. Shape the future of how APIs are described and consumed.
The platforms that are winning right now are doing all of this. It's not about marketing anymore. It's about technical excellence and Dev X.

Avoiding Common Pitfalls and Anti-Patterns
Platforms are making mistakes as they adapt to the agent-driven world. Here's what to avoid.
Don't create separate APIs for agents. You'll end up maintaining two APIs and they'll drift. One source of truth is always better.
Don't optimize only for agents and forget humans. You still need great documentation and developer experience for human developers. Just because agents can parse your schema doesn't mean humans will understand it.
Don't treat schema as a side effect. It's a core product. Invest in schema quality like you'd invest in code quality.
Don't ignore agent feedback. When agents fail against your API, you'll see patterns. These patterns are gold. Treat them as design flaws, not as expected failures.
Don't maintain multiple versions of documentation. Keep it DRY. Generate documentation from schema. Keep the schema as the single source of truth.
Don't create custom authentication for agents. Use standard OAuth, API keys, or other standard mechanisms. Agents understand standards. They don't understand custom schemes.
Don't surprise agents with breaking changes. Version your API. Deprecate gradually. Give agents (and humans) clear timelines for breaking changes.
Don't limit third-party agents. Some platforms are restricting which AI models can access their APIs. This is shortsighted. The more agents that can integrate, the more adoption you'll get.
Getting Started: A Concrete Action Plan
If you want to start optimizing your API for agents, here's where to begin.
Week 1: Audit and assess. Generate an Open API spec if you don't have one. Use a tool like Swagger Editor to validate it. Test it with an AI model (Claude, GPT-4, whatever). Document what works and what doesn't.
Week 2-3: Priority improvements. Focus on the highest-impact issues from your audit. Usually this is schema accuracy, naming consistency, and error handling. Fix these first.
Week 4: Testing and validation. Re-run your agent integration tests. Measure improvement. Document the delta.
Month 2: Communication. Publish your findings. Tell developers (and agents) about improvements you've made. Be transparent about where you are on the journey.
Month 3+: Ongoing refinement. Establish monitoring for how agents interact with your API. Make schema quality a standing agenda item in engineering reviews.
This isn't a one-time project. It's an ongoing evolution of your platform. But the first four weeks will give you massive gains.

Conclusion: The Shift Is Inevitable, Your Choice Is Timing
Vibe coding isn't going away. It's getting stronger. More developers are using AI in their workflows. More AI agents are becoming autonomous. More platforms are depending on integration.
The question isn't whether your API needs to support agents. It's when. And right now, most platforms aren't ready.
That's an opportunity.
Platforms that move fast will win. They'll get to market with agent-optimized APIs while competitors are still in the early stages of adaptation. They'll build network effects around agent integrations. They'll attract developers (and agents) who want the path of least resistance.
The technical work is straightforward. Schema quality, naming consistency, error handling, metadata optimization. These aren't rocket science. They're just discipline.
The hard part is organizational change. It's convincing your team that this matters. It's redefining what success looks like. It's investing in tooling and processes that enforce quality. It's measuring different metrics. It's changing how you think about your API.
But this transformation is coming. Every platform will eventually need to do this work. The only question is whether you do it proactively or reactively.
Proactive is better. Start now. Audit your API. Improve your schema. Measure agent success. Iterate. In twelve months, you'll have an API that's optimized for the future. In eighteen months, you'll have market advantage. In twenty-four months, if your competitors haven't caught up, you'll have category leadership.
Vibe coding is the present and future of software development. The platforms that understand this will thrive. The ones that don't will fade.
Which will you be?
FAQ
What exactly is vibe coding?
Vibe coding is the informal, exploratory use of AI-powered code generation tools to quickly build, test, and iterate on software solutions. Rather than following a rigid, pre-planned development process, developers use AI tools like Chat GPT or Copilot to generate code, test it immediately, refine based on output, and generate again in a rapid feedback loop. It's exploratory rather than structured, creative rather than methodical.
How does vibe coding differ from traditional development practices?
Traditional development follows a linear progression: plan, design, implement, test, refine. Vibe coding flattens this process into immediate iteration cycles. Developers ask AI to generate code, see the output in seconds, refine their request based on what they see, and iterate again. Instead of weeks of planning before writing a line of code, vibe coding developers might have a working prototype in thirty minutes.
Why do AI agents struggle with poorly-designed APIs?
AI agents don't understand context, infer intent, or adapt creatively the way humans do. When an API has inconsistent naming conventions, missing schema documentation, ambiguous parameter types, or unclear error messages, agents can't adapt. They follow the schema literally. If the schema disagrees with the actual API behavior, the agent fails. If error messages are poetic but vague, the agent won't know how to recover.
What is machine-readability and why does it matter?
Machine-readability means your API structure, naming, and metadata can be automatically parsed and understood by software. A machine-readable API has consistent naming conventions, complete and accurate schemas, explicit error handling, and machine-friendly metadata like Open API specs. This matters because AI agents consume APIs through their structure and metadata first, not through human documentation. An API might be perfect for human developers but nearly impossible for AI agents to work with.
How should Dev Rel teams adapt their metrics in the AI era?
Traditional Dev Rel metrics like forum activity, tutorial completions, and SDK downloads no longer tell the full story of API adoption. Teams should now track schema consumption rates, agent integration success rates (percentage of first-try successes), error patterns by agent, integration completeness, and developer-agent collaboration patterns. These metrics reveal where agents struggle with your API and provide actionable data for improvements.
What are the first steps for making an API agent-ready?
Start by auditing your API from an agent perspective. Generate an Open API spec if you don't have one, validate it, and have an AI attempt to build a basic integration without human help. Document where it succeeds and fails. Prioritize fixing schema accuracy, naming consistency, and error handling. Establish schema ownership and make sure someone is responsible for keeping it in sync with reality. Monitor how agents interact with your API and iterate based on what you learn.
Should platforms create separate APIs optimized for agents?
No. Creating separate APIs leads to maintenance burden and feature drift. Instead, design a single API that works well for both humans and machines. This means investing in schema quality, naming consistency, clear error handling, and comprehensive metadata. When done right, the same API serves both audiences effectively. Auto-generate human documentation from your schema rather than maintaining separate documentation and APIs.
How will agent-driven development change competitive dynamics in the API market?
Agents make integration decisions based on metrics like success rate and speed, not on brand loyalty or community. This creates "winner-take-most" dynamics in API categories where a clear leader emerges in agent-readiness. Platforms that optimize for agents early will consolidate market share quickly. Network effects amplify this as more successful agent integrations drive more adoption, which improves the API, which attracts more agents. Platforms that wait risk losing category leadership to more agile competitors.
Use Case: Automating API documentation generation and integration testing with AI agents
Try Runable For Free
Key Takeaways
- 89% of developers use generative AI in their workflows, but only 24% of organizations design APIs with AI agents in mind.
- Machine-readable APIs with consistent naming, clear schemas, and structured error handling are becoming competitive necessity.
- DevRel metrics must evolve from human-centric (forum activity, tutorial completions) to agent-centric (integration success rates, schema consumption).
- First-mover advantage is massive: platforms optimizing for agents now will consolidate market share through network effects.
- Organizational changes required include appointing schema owners and agent integration specialists as dedicated roles.
Related Articles
- Claude Code Is Reshaping Software Development [2025]
- AI Coding Agents and Developer Burnout: 10 Lessons [2025]
- Managing 20+ AI Agents: The Real Debug & Observability Challenge [2025]
- Google's Internal RL: Unlocking Long-Horizon AI Agents [2025]
- Vivun's Ava: The AI Sales Engineer Automating Complex Technical Sales [2025]
- Why AI Agents Keep Failing: The Math Problem Nobody Wants to Discuss [2025]

