![Why Accurate AI Still Fails: Graph RAG vs. Standard RAG [2025]](https://tryrunable.com/blog/why-accurate-ai-still-fails-graph-rag-vs-standard-rag-2025/image-1-1771434586267.png)
Introduction: The Accuracy Paradox That's Costing Companies
You'd think accuracy alone would solve AI's problems. Get to 95% accuracy, 99% accuracy, and you're golden. But here's where that logic breaks down: accuracy and completeness aren't the same thing. A lawyer asks an AI system about patent liability in five jurisdictions. The system returns a technically accurate answer—but only covers three of them. That's a disaster waiting to happen.
This isn't theoretical. It's happening right now in legal tech, financial services, healthcare, and anywhere high-stakes decisions depend on exhaustive, bulletproof answers. The traditional retrieval-augmented generation (RAG) approach that most enterprises deployed two years ago? It's starting to show serious cracks.
The problem gets worse when you dig deeper. Standard RAG prioritizes relevance. It pulls content that semantically matches your query. But relevance isn't authority. A citation might be topically correct but legally overruled by a newer precedent. It might be from a lower court that doesn't apply to your jurisdiction. It might sound relevant while pointing to discredited arguments. None of these failures trigger your accuracy metrics, but all of them destroy customer trust.
That's why companies like Lexis Nexis, which have spent decades building authoritative legal knowledge bases, are now engineering a completely different approach. They're layering graph structures on top of semantic search. They're deploying specialized AI agents that break complex questions into sub-questions, then criticize their own outputs before serving them. They're building systems where humans and AI collaborate instead of AI pretending to know everything.
This shift isn't just a minor optimization. It represents a fundamental rethinking of how enterprise AI should work when accuracy alone isn't enough. The stakes are too high. The consequences of incomplete or misleading answers are too severe. And the technical solutions are finally mature enough to implement at scale.
In this article, you'll learn what standard RAG is missing, why graph-based approaches work better, how reflection and planner agents improve outcomes, and most importantly, how to evaluate whether your AI system is actually good enough for your use case. Because "accurate" without "complete" is dangerously incomplete.
TL; DR
- Standard RAG prioritizes relevance over authority: It retrieves semantically similar content without guaranteeing it's legally valid, current, or actually applicable to the user's jurisdiction.
- Completeness is a separate metric from accuracy: A system can be accurate in what it returns while missing critical legal considerations, making answers dangerously incomplete.
- Graph RAG adds authority filtering: By traversing knowledge graphs after initial semantic retrieval, systems can verify that returned documents are authoritative and haven't been overruled.
- Planner and reflection agents handle complexity: These agents break multi-faceted questions into sub-questions and criticize their own drafts before delivery, catching errors humans would catch.
- Human-AI collaboration beats full automation: The future isn't AI replacing lawyers, it's AI handling research, drafting, and analysis while experts review, refine, and make final decisions.
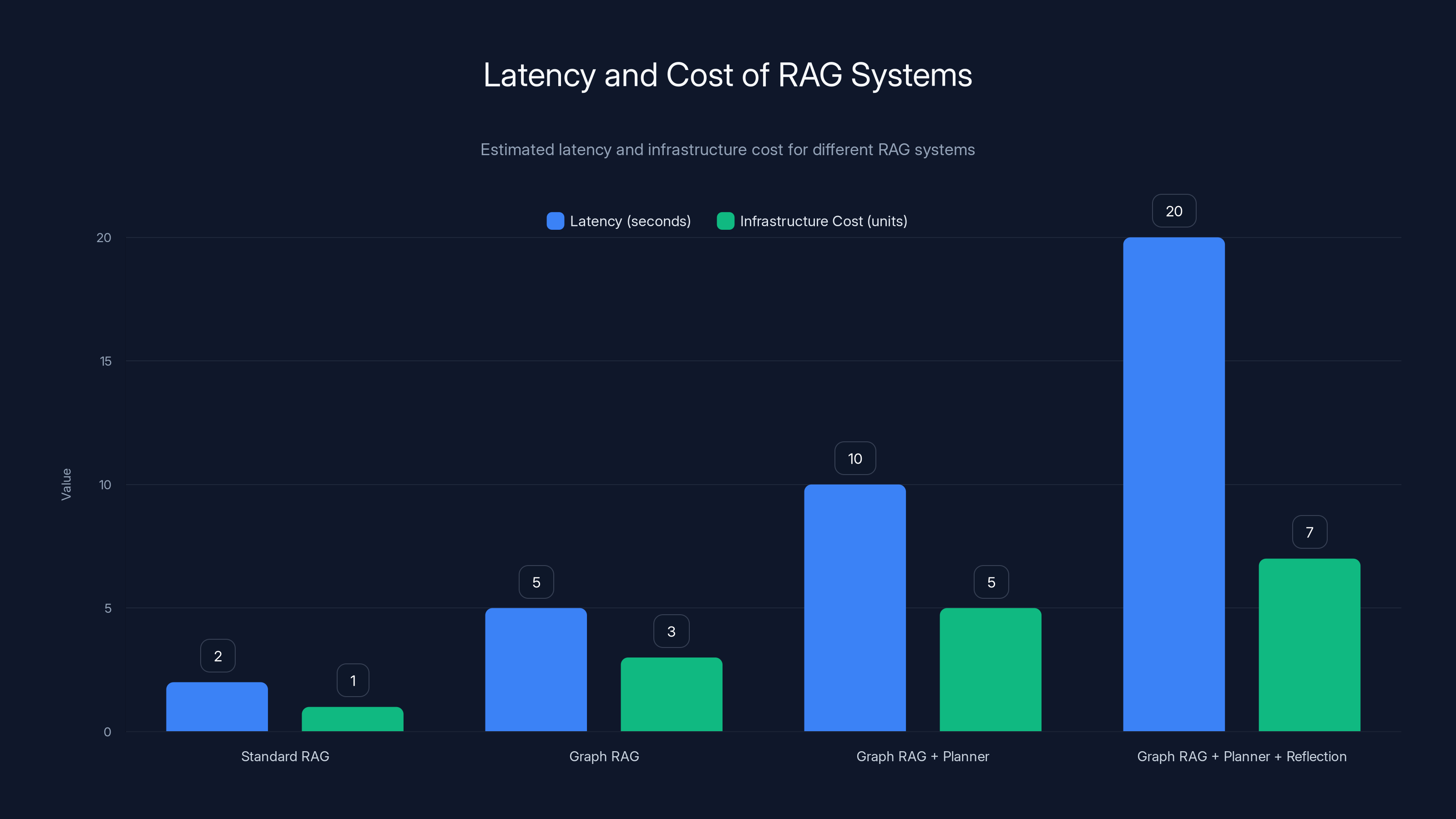
The chart illustrates the trade-offs between latency and infrastructure cost across different RAG systems. As sophistication increases, both latency and cost rise significantly. (Estimated data)
The Core Problem: Accuracy ≠ Completeness
Let's start with the uncomfortable truth that most AI vendors won't tell you. You can have a model with 94% accuracy and still deliver dangerous, incomplete answers.
Accuracy measures whether what the system returns is correct. If it says "Company X was founded in 1987," and the answer is 1987, that's accurate. If it says the Supreme Court ruled 6-3 on a case, and it actually ruled 5-4, that's inaccurate. These metrics are important. They tell you whether the AI is hallucinating or whether it's getting facts right.
But completeness is different. Completeness asks: did the AI answer all the relevant parts of the question? A lawyer asks about liability risks in patent litigation involving software. That's really five separate questions hiding under one umbrella. What's the statutory liability? What's case law liability? What do current precedents say? What about recent changes to patent law? What's different in different jurisdictions?
A standard RAG system might pull great content about statutory liability and case law. That content might be 100% accurate. But if it misses recent changes or jurisdictional variations, the answer is incomplete. From a user perspective, it's not just wrong—it's dangerously incomplete because they might not realize they're missing context.
The stakes here matter. In legal work, an incomplete answer isn't a minor annoyance. It's professional malpractice waiting to happen. A lawyer relies on that research, builds a case on it, and finds out mid-trial that there was a critical precedent they didn't know about. That's career-ending.
Other high-stakes domains have the same problem. In medical AI, completeness means capturing all relevant side effects, contraindications, and drug interactions. In financial advisory, it means not missing tax implications, regulatory changes, or relevant market conditions. In compliance work, it means identifying all applicable regulations, not just the main ones.
Standard RAG systems were built for different kinds of problems. They work great when you're building a customer service chatbot that needs to answer questions about billing or product features. They're adequate when the downside of missing information is minor. But in high-stakes domains, they're fundamentally insufficient.

Understanding Traditional RAG: Why It Worked (And Why It Failed)
Let's back up and understand how standard RAG actually works, because you need to know where it succeeds and where it breaks down.
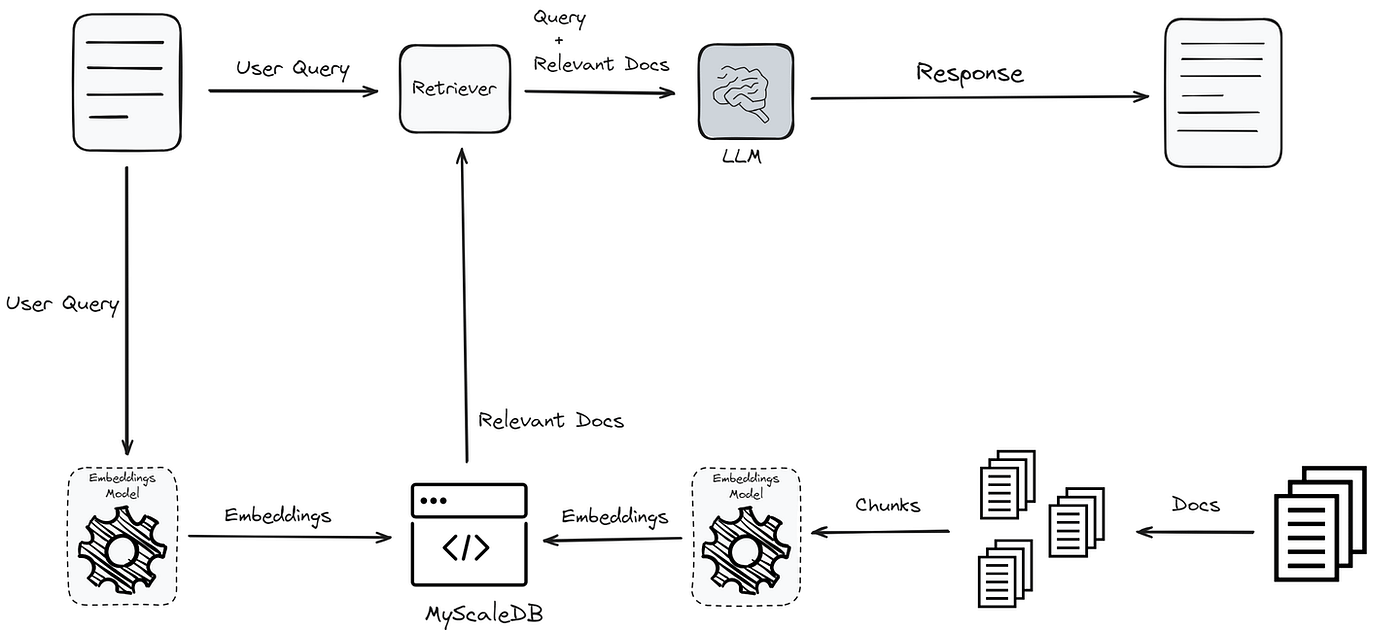
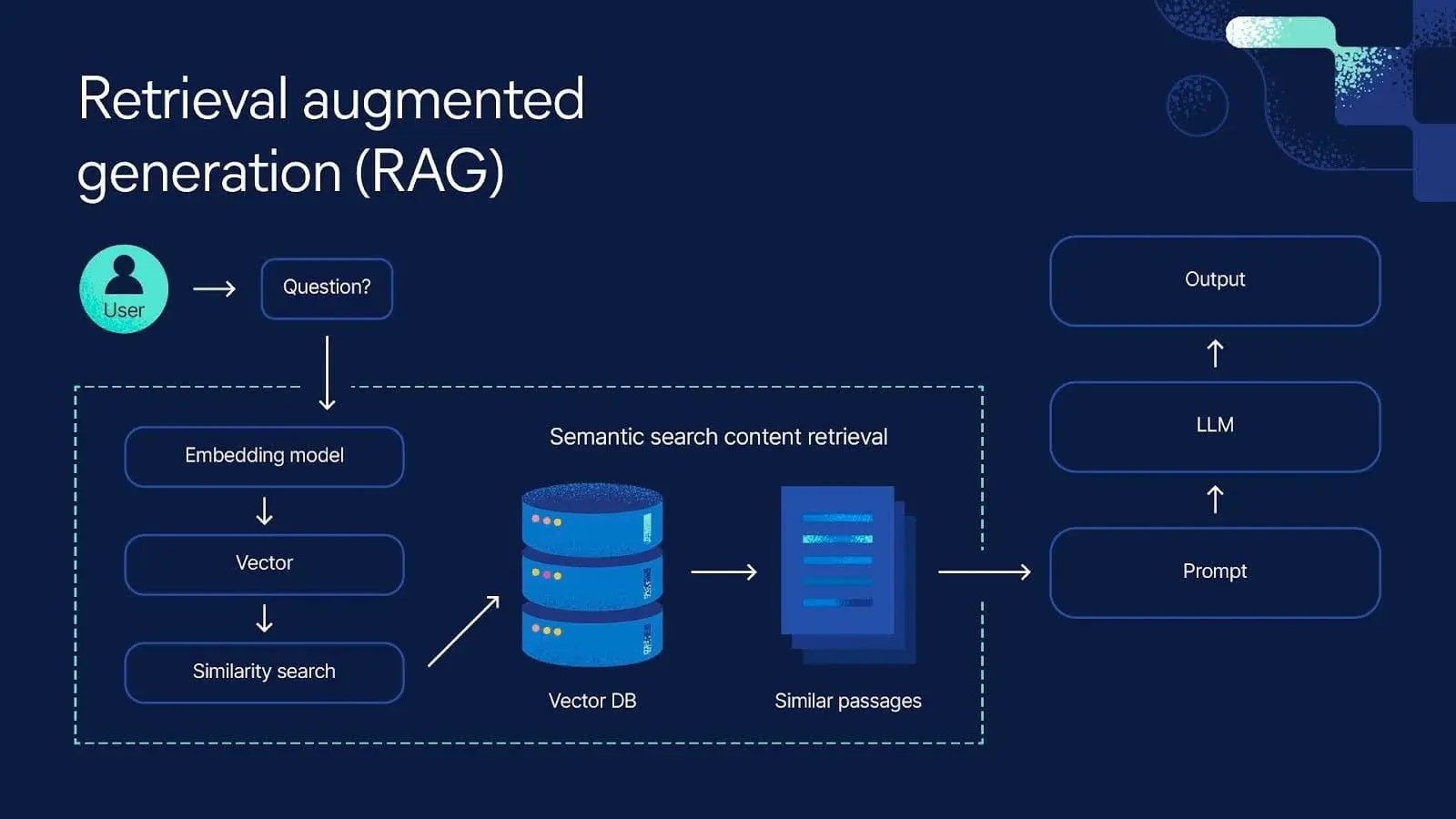
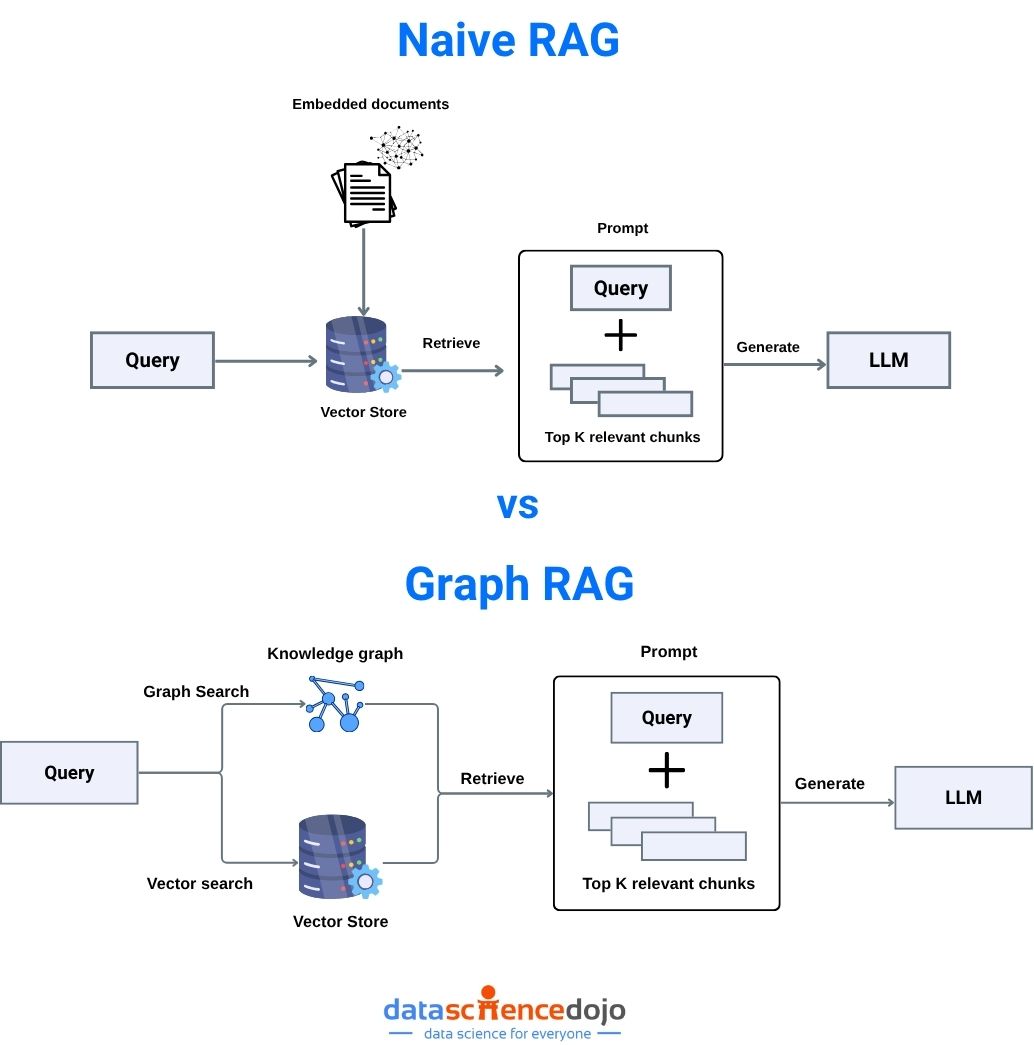
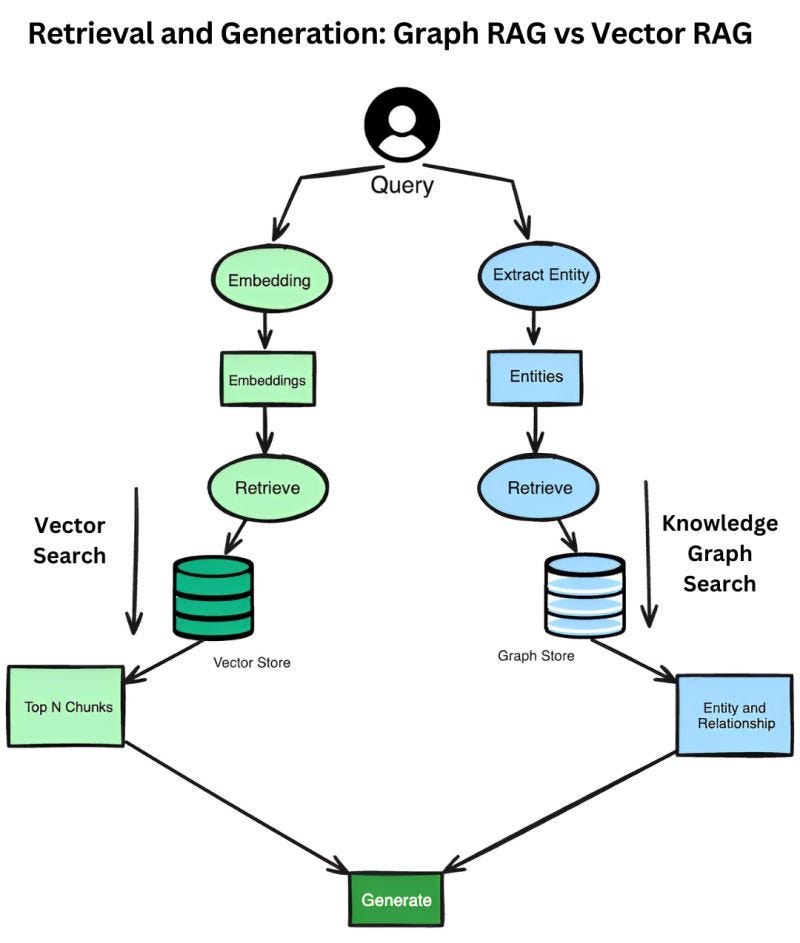
Retrieval-augmented generation starts with a simple idea: instead of letting an AI model generate answers purely from its training data, ground it in actual documents. You have a knowledge base—legal cases, company documents, research papers, whatever. You convert them into vector embeddings (mathematical representations of meaning). When a user asks a question, you convert that question into a vector, search for similar vectors in your knowledge base, and return the matching documents. Then you feed those documents to a language model and ask it to answer the question based on those specific sources.
This approach solved a real problem. Language models trained on internet data have a cutoff date. They hallucinate. They confidently state things that are completely wrong. RAG fixed that by ensuring the model could only work with information you explicitly provided. If the answer isn't in your documents, the model can't invent it.
But RAG made a key assumption: semantic similarity equals relevance. The system assumes that if a document's vector embedding is close to the question's embedding, it's relevant to answering the question. And in many cases, that works fine. If you're asking about product features and the document discusses those features, semantic similarity does indicate relevance.
The problem emerges when semantic similarity doesn't indicate authority, currency, or applicability.
Consider a legal example. A lawyer asks: "Can I be liable for patent infringement if I make software that technically doesn't violate the patent claims but arguably violates the spirit of the patent?"
Semantic search will return documents discussing infringement liability, patent interpretation, and software patents. Many of these will be semantically relevant. But among them might be:
- A case that was overruled by a higher court (semantically relevant but legally superseded)
- A case from a jurisdiction that doesn't apply to you (semantically relevant but not applicable)
- A law review article discussing an older interpretation that's been reversed (semantically relevant but outdated)
- A court decision that's been legislatively overturned (semantically relevant but invalid)
None of these documents make the system "inaccurate" in a traditional sense. The system correctly extracted information from them and accurately conveyed what they say. But the information is useless or worse than useless because it leads to wrong conclusions.
This is why standard RAG breaks down in domains where authority matters. A medical researcher asking about a drug interaction might get semantically relevant papers that report obsolete dosing guidelines. A financial analyst might get information about regulations that have since changed. A lawyer might get citations that no longer represent valid law.
The system's accuracy metrics don't catch this because the system isn't inaccurate about what the documents say—it's just that the documents themselves aren't authoritative anymore.
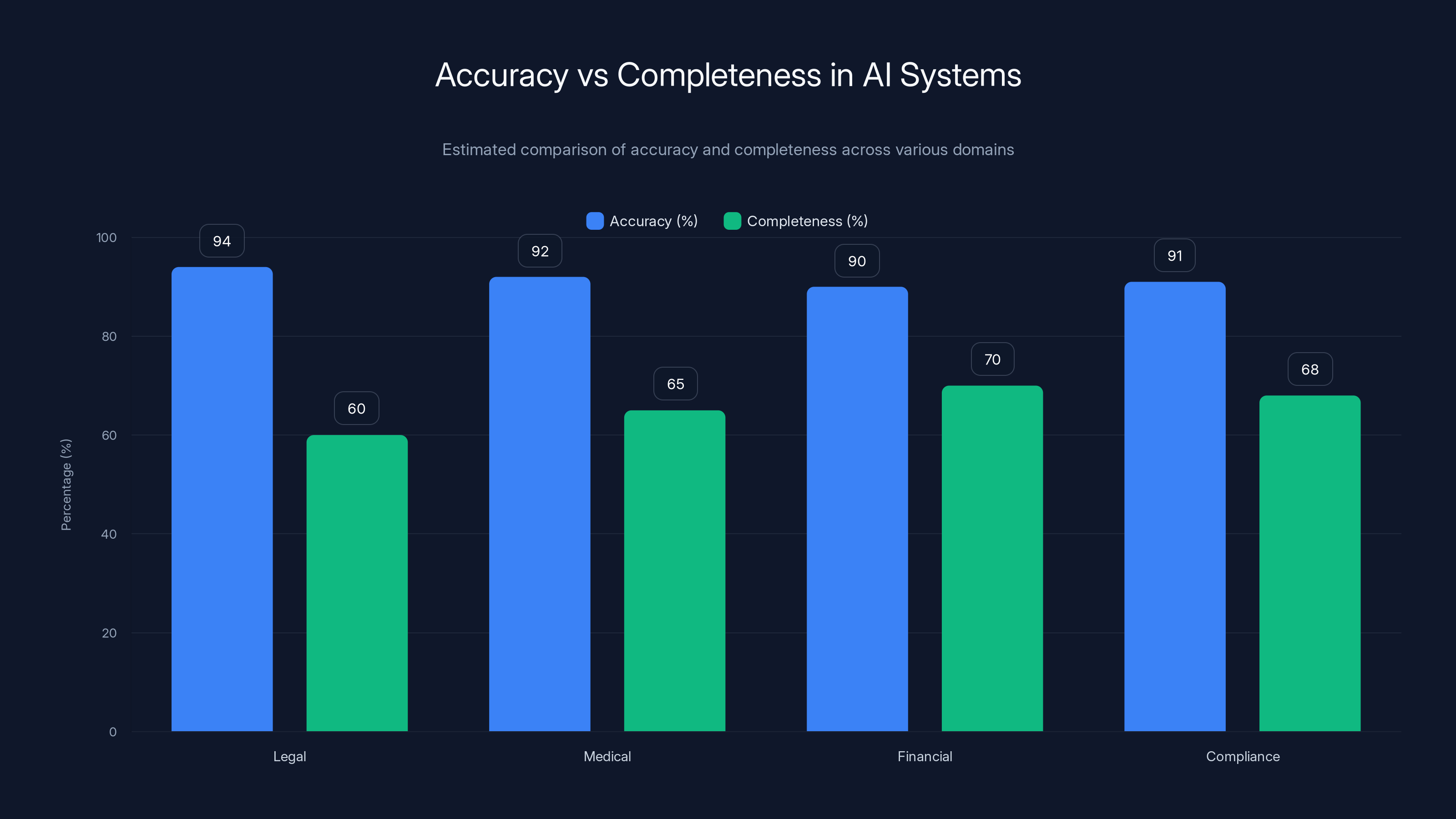
Estimated data shows that while AI systems may achieve high accuracy, completeness often lags significantly, especially in high-stakes domains like legal and medical fields.
The Citation Crisis: When Relevance Becomes Liability
Here's a specific problem that keeps enterprise teams up at night: bad citations.
When your AI system returns an answer, it needs to cite sources. The user needs to know where information came from so they can verify it, dive deeper, or use it as evidence. This seems straightforward, but it's where many systems completely fall apart.
Let's say an AI system is helping a lawyer research patent law. The lawyer asks: "What's the current standard for willful infringement damages?"
The system returns something like: "Courts now award willful infringement damages of up to three times the actual damages. See Case v. Manufacturer (2015)."
That citation is semantically relevant. It's about willful infringement damages. It mentions the topic. But here's the catch: the 2015 case is discussing damages under the old standard. In 2017, a Supreme Court decision changed how willful infringement damages work. The 2015 case isn't legally invalid—courts still cite it—but it's discussing a standard that no longer applies. A lawyer relying on that citation without reading the full case law might base their strategy on an outdated framework.
The system isn't hallucinating. It's not making up cases. It's accurately reporting what the source document says. But the citation is misleading because it's outdated.
This happens constantly in domains with evolving standards. Medical protocols change. Regulations get updated. Court precedents evolve. A semantically relevant source isn't necessarily an authoritative current source.
Worse, some systems return citations that are actively wrong even though the semantic matching worked perfectly. The system returned a document that discussed topic X. The document is real, it does discuss topic X, and the system extracted a fact correctly. But the document argues against the position the system just recommended. A medical AI might cite a paper and then recommend something the paper argues against.
These problems don't show up in traditional accuracy metrics. The system isn't "inaccurate" in a narrow sense. But the citations are useless or misleading, which is arguably worse because it creates false confidence.
Enter Graph RAG: Adding Authority to Retrieval
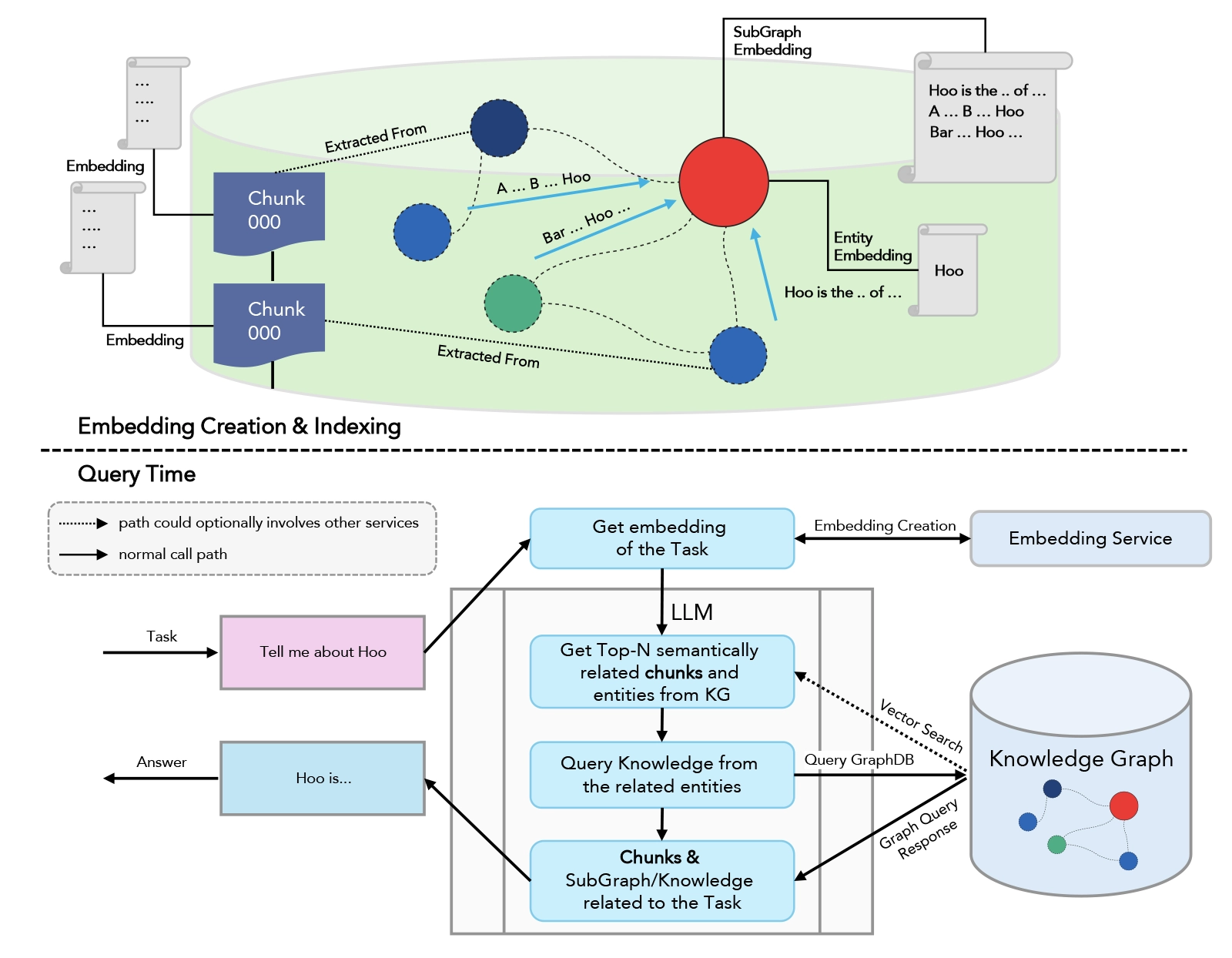
This is where graph-based retrieval changes the game.
Instead of just using semantic search to find relevant documents, graph RAG adds a layer of structure. After retrieving semantically relevant documents, the system traverses a knowledge graph—a structured representation of relationships between concepts, documents, and authority levels—to filter for the most authoritative results.
In a legal context, this works something like this: semantic search retrieves documents about patent infringement liability. But instead of stopping there, the system then traverses the "point of law" graph. This graph knows which cases cite other cases, which laws override other laws, which rules are superseded by newer rules. It knows the authority hierarchy. A Supreme Court decision is more authoritative than a district court decision. A current law is more authoritative than a repealed law.
By filtering through this graph layer, the system can return not just semantically relevant documents, but semantically relevant documents that are actually authoritative and current in the domain.
The difference is profound. Semantic search alone answers the question: "Which documents are most similar to what the user asked?" Graph RAG answers: "Which documents are most similar AND most authoritative in the current legal/medical/financial landscape?"
Let's make this concrete. Suppose you search for "liability in software patent cases." Semantic search might return:
- A 2015 case on willful damages (highly semantically relevant)
- A 2022 court ruling on software patent scope (semantically relevant, more current)
- A law review article from 2019 discussing trends (semantically relevant)
- A 2018 case that was later overruled (semantically relevant)
Graph RAG would reorder these based on a knowledge graph that knows:
- The 2022 ruling supersedes the 2015 case on damages
- The 2018 case was overruled and shouldn't be weighted equally
- The 2019 article is outdated given the 2022 ruling
- Recent court decisions are more authoritative than older ones
The result: you get a smarter ranking that actually reflects authority and currency, not just semantic similarity.
This requires building and maintaining a knowledge graph, which is expensive and requires domain expertise. You need to know the relationships between documents. You need to know which ones supersede others. You need to understand the authority structure of your domain. For a legal knowledge base with millions of cases, this is a significant engineering project.
But the payoff is real. Systems using graph RAG report dramatically better citation quality, fewer misleading answers, and higher user trust. Because they're not just finding semantically relevant documents—they're finding semantically relevant documents that actually represent current, authoritative knowledge.
The Agentic Layer: Planner Agents Break Down Complex Questions
But here's the thing about graph RAG: it still assumes the question is simple enough that one retrieval pass will find what you need.
Many real-world questions aren't like that. They're multi-faceted. A lawyer doesn't ask "What is patent infringement?" They ask: "If I make software that doesn't literally infringe the patent claims but accomplishes the same result, could I be sued, what are the damages, and how does this differ between software patents and hardware patents?"
That's not one question. It's five questions nested together. Traditional RAG retrieves documents similar to that whole question, but different sub-questions need different documents. One sub-question is about infringement definitions. Another is about damages calculations. Another is about jurisdictional differences. Another is about patent type variations. A single semantic search can't optimize for all of them.
This is where planner agents come in.
A planner agent takes a complex question and breaks it into sub-questions automatically. The user asks the five-part question above. The planner agent responds with something like:
- What are the standards for patent infringement (literal vs. doctrine of equivalents)?
- What damages are available for patent infringement?
- How do software patents differ from hardware patents in infringement analysis?
- How do jurisdictional differences affect infringement liability?
- What's the current state of willful infringement standards?
The user can review these sub-questions, edit them, add context, or clarify intent. Then the system retrieves documents for each sub-question separately, potentially using different retrieval strategies for each.
This matters because different questions need different retrieval approaches. A question about current standards needs recent sources. A question about foundational concepts can use older, well-established sources. A question about controversial issues needs sources that represent multiple perspectives. A single retrieval pass can't optimize for all these needs.
Planner agents also surface assumptions. When the system breaks down a question into sub-questions, it's making clear what assumptions it's making about what you're asking. If those assumptions are wrong, you catch them before the system wastes time retrieving and analyzing documents. You say "Actually, I don't care about hardware patents, only software patents" and the system adjusts.
This also makes the system more auditable. You can see exactly what questions the system is trying to answer. You can evaluate whether it's asking the right questions before you trust the answers. You can spot where the system might have misunderstood your intent.
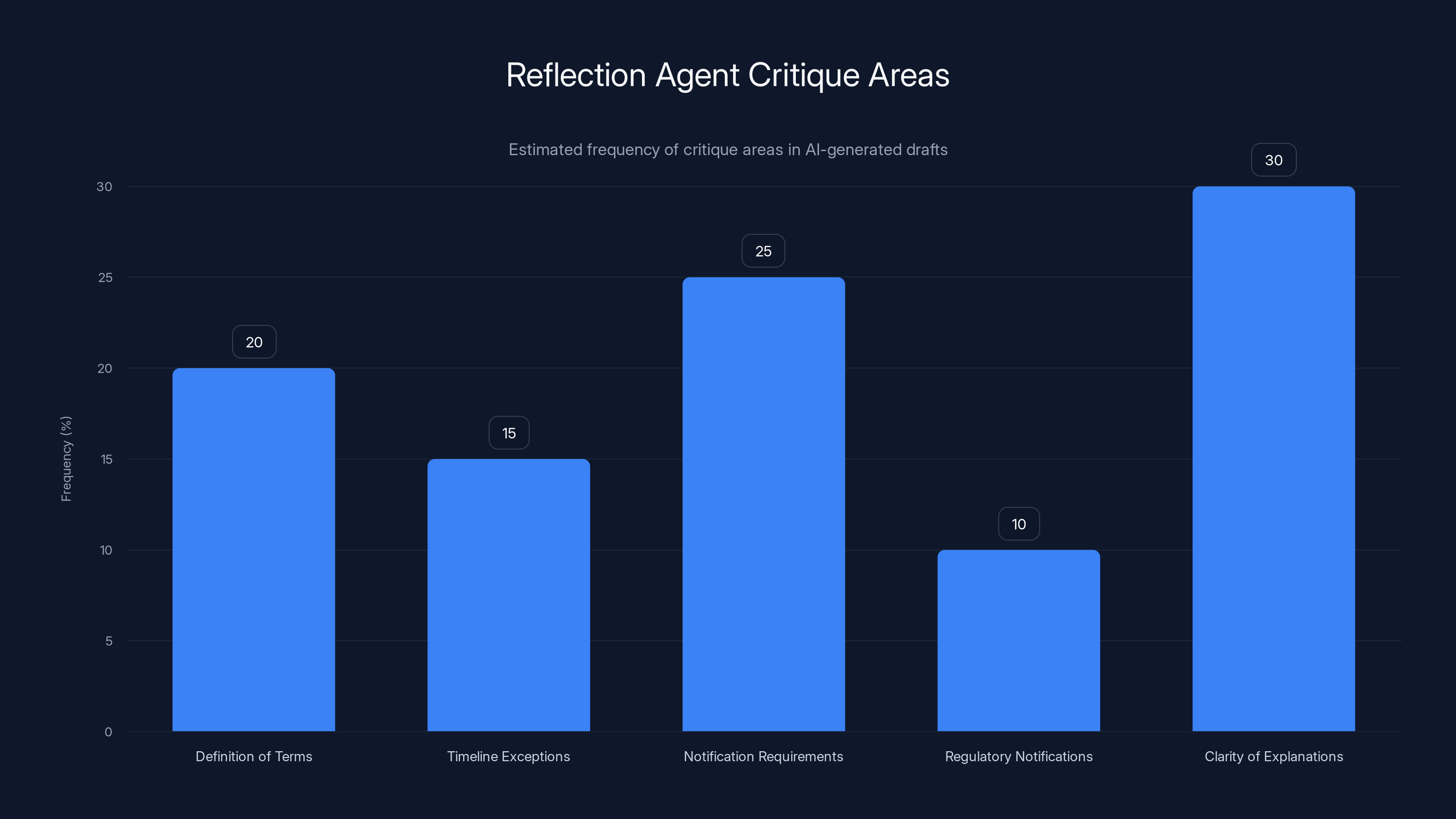
Estimated data shows that clarity of explanations and notification requirements are the most frequently critiqued areas by reflection agents in AI-generated drafts.
Reflection Agents: Self-Criticism Before Delivery
Now we're getting to the really interesting stuff. What if you could have an AI system that doesn't just generate an answer and serve it, but generates an answer, critiques it, and refines it before giving it to you?
This is what reflection agents do.
A reflection agent works for generative tasks like document drafting. You ask the system to draft a legal memo, a patent application, a compliance report, or anything that requires sustained writing. Instead of generating once and delivering, the system:
- Generates the initial draft
- Steps back and critiques the draft
- Incorporates the criticism and refines the output
- Delivers the refined version
This sounds simple but it's transformative because it mimics what expert humans do. When a lawyer drafts a memo, they write, they re-read, they think "wait, this logic doesn't follow," they revise. They notice gaps. They catch overstatements. They refine the argument. Reflection agents do something similar.
The difference is the reflection is happening in the model's "reasoning" space, not in real time. The system generates text, evaluates that text, and produces a better version. All of this happens before you see it.
Let's get concrete. Suppose you ask a system to draft a compliance memo for a healthcare provider about HIPAA notification requirements. The system generates an initial draft that covers the basic requirements, timelines, and notice procedures.
Now the reflection step kicks in. The agent critiques the draft:
- This draft doesn't address what constitutes "personal data" under HIPAA
- It mentions timelines but doesn't address the exception for law enforcement delays
- It doesn't explain the difference between individual notification and credit monitoring requirements
- It doesn't mention the Secretary of HHS notification requirement
- The explanation of "unreasonable delay" is vague and could be more precise
The system then revises, addressing each of these gaps. The result is a more comprehensive, more accurate memo.
The kicker: all of this happens automatically. You didn't have to ask for a second draft. You didn't have to review and send back comments. The system caught its own gaps and fixed them.
This doesn't make the system perfect. But it makes it dramatically better than a single-pass generation. Studies in AI reasoning show that models generate better outputs when they're forced to explain or critique their own work. Reflection agents operationalize this insight.
One important caveat: reflection agents still need human review. The "criticism" the agent generates is model-generated criticism, not human domain expertise. The system might miss things a human expert would catch. The refinement might introduce new errors while fixing old ones. But as a quality improvement layer before human review, it's powerful.
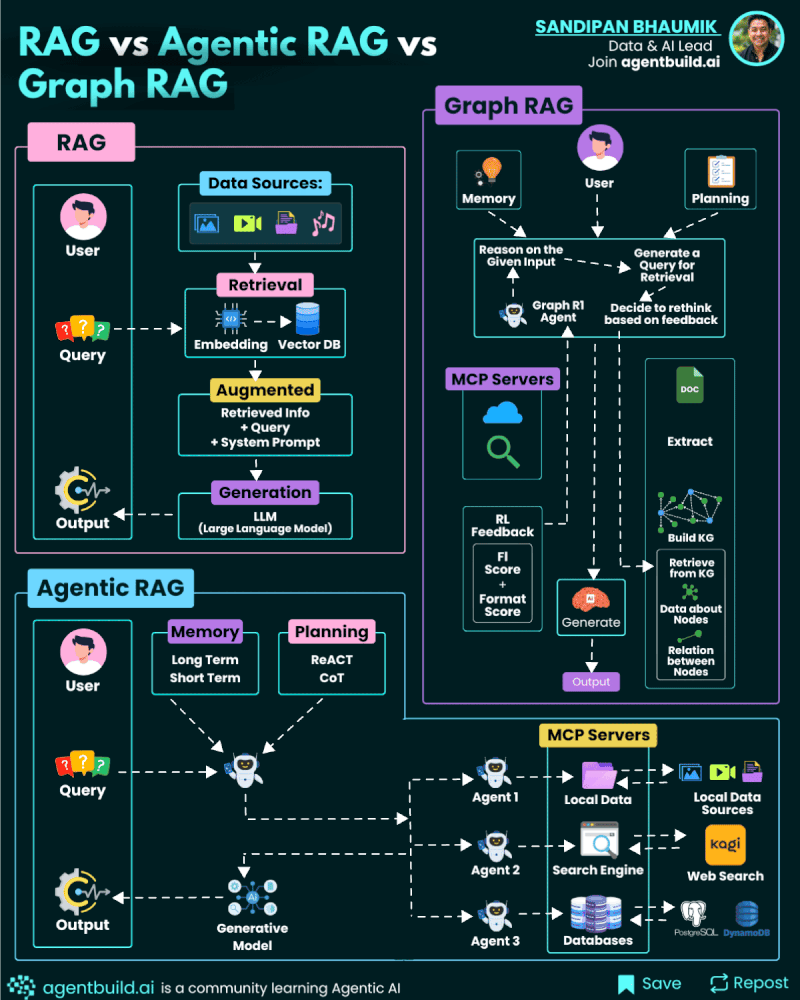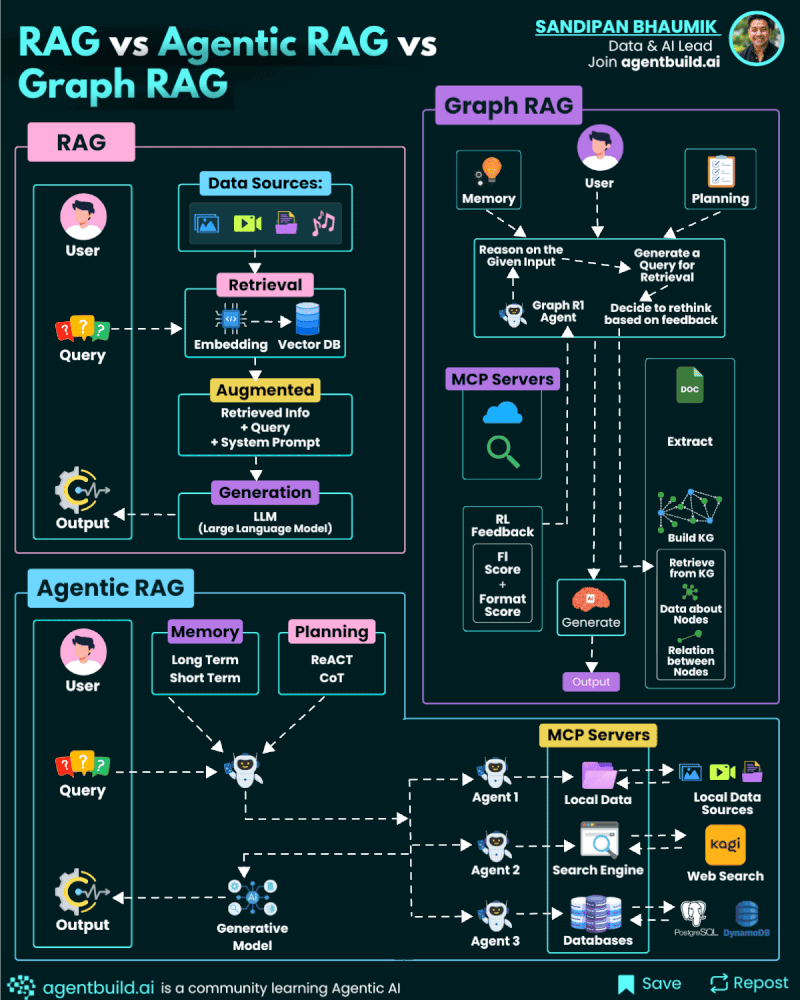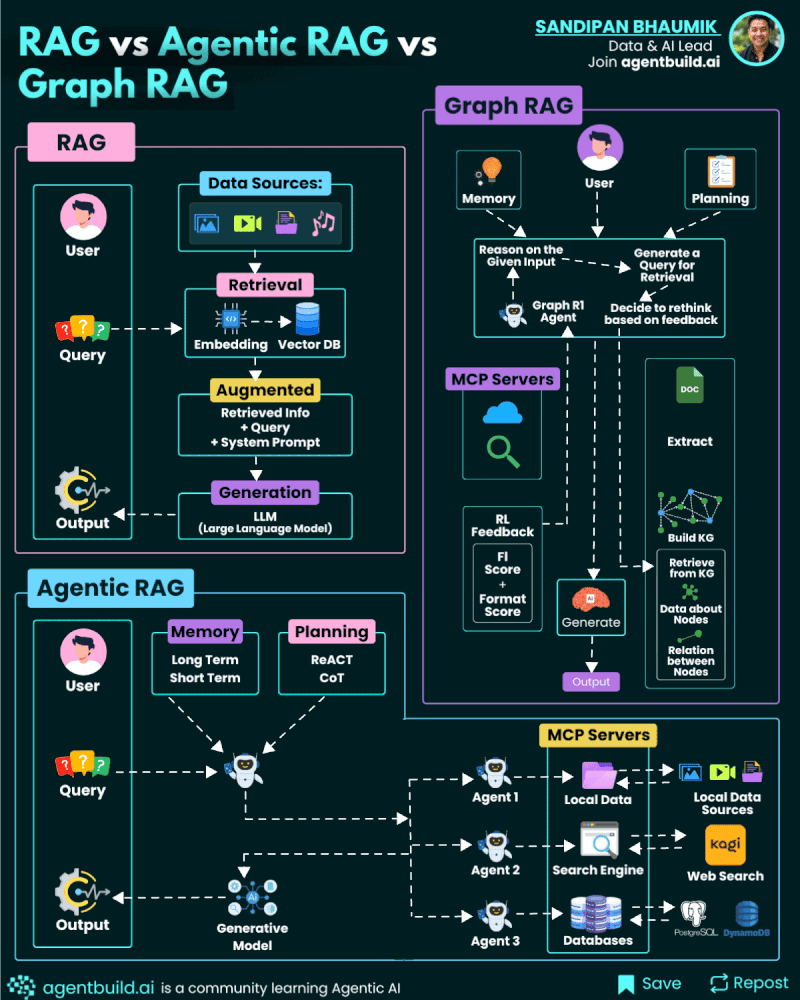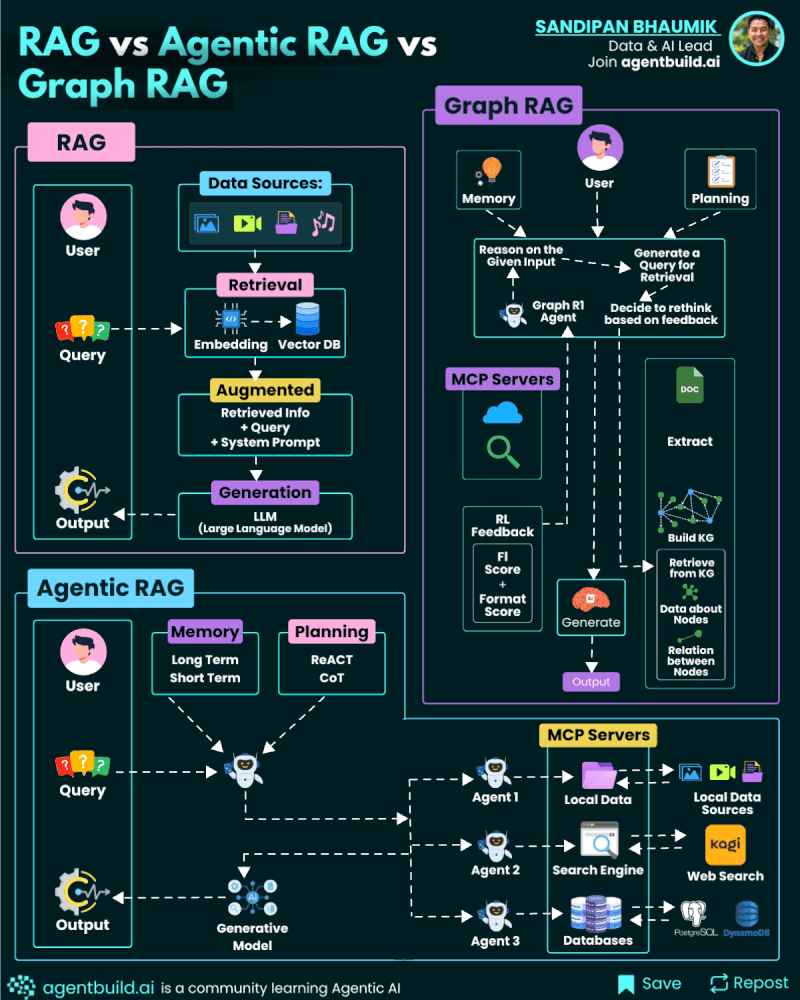
Combining Forces: The Agentic Graph Ecosystem
The real power emerges when you combine these approaches.
You have graph RAG handling retrieval with authority-aware filtering. You have planner agents breaking complex questions into manageable sub-questions. You have reflection agents refining generated outputs. You have human experts who can review, critique, and make final decisions.
When these work together, you get something genuinely different from standard RAG.
The workflow might look like:
- User asks a complex question
- Planner agent breaks it into sub-questions and shows them to the user for approval
- For each sub-question, graph RAG retrieves semantically relevant, authoritative documents
- Language models generate answers to each sub-question based on those documents
- Reflection agents critique each answer and refine it
- The system combines the refined sub-answers into a comprehensive response
- A human expert reviews the combined response before it's delivered
Each layer adds something. The planner ensures you're asking the right questions. Graph RAG ensures you're finding authoritative sources. The language model generates coherent answers. Reflection agents catch obvious gaps and errors. The human expert catches subtle issues and makes final calls.
This is much more expensive and slower than standard RAG. It requires more infrastructure, more domain expertise, more human involvement. But for high-stakes domains, it's worth it. Because what you get is not just accurate outputs—you get complete, authoritative, well-reasoned outputs that someone can actually rely on.
The key insight here is that none of these technologies replace humans. They don't make legal work fully automated or medical diagnosis fully algorithmic. Instead, they handle the parts of the work that are amenable to automation—research, analysis, documentation, initial drafting—while leaving judgment calls, risk assessment, and final decision-making to humans.
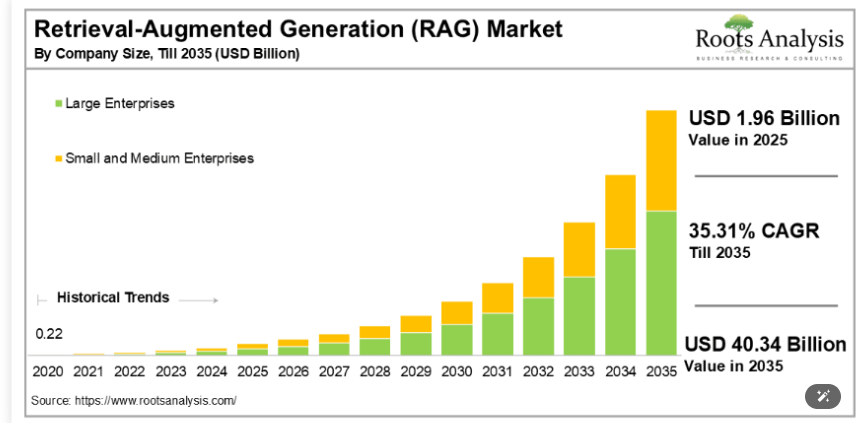
The Metrics That Actually Matter: Beyond Standard Accuracy
If you're building or evaluating a high-stakes AI system, you need better metrics than just accuracy.
Accuracy tells you whether the AI gets facts right. It's important. But on its own, it's insufficient. You need what sophisticated enterprises now call "sub-metrics" that measure different dimensions of quality.
Authority metrics measure whether returned sources are authoritative in the domain. This is particularly important in legal work, medical research, and financial advisory where some sources are more authoritative than others. A system might correctly extract information from a source, but if the source isn't authoritative, the information is misleading. Authority metrics catch this.
Citation accuracy measures whether sources actually support the claims made about them. A system might cite a source correctly (the source exists, is accurate about what it says) but misrepresent what the source concludes. Citation accuracy metrics try to catch this by checking whether cited sources actually justify the claims.
Hallucination rates measure how often the system invents information. This is the traditional focus of RAG systems. But hallucination is just one failure mode. A system can have low hallucination rates and still be unreliable if it misinterprets sources or pulls from non-authoritative sources.
Completeness measures whether the system addressed all relevant aspects of the question. This is where many systems fail. The system might give an accurate, well-cited answer that's incomplete. Completeness metrics try to quantify whether you got a comprehensive response or a partial one.
Relevance measures whether the system actually addressed the question asked, not a related question or a simplified version. A system might return an accurate, complete answer to a different question than the one you asked.
Legibility measures whether humans can actually understand the answer. This sounds obvious, but it matters. An AI system might generate technically correct but incomprehensibly complex answers. Some high-stakes domains require not just accuracy but clarity.
Measuring these sub-metrics requires domain expertise. You can't measure citation accuracy or authority without someone who understands the domain well enough to know which sources are authoritative and which are outdated. You can't measure completeness without understanding what a complete answer to that particular question would include.
This is why enterprises moving to graph RAG and agentic systems are investing in evaluation infrastructure. They're hiring domain experts to manually evaluate a sample of AI outputs across these dimensions. They're building datasets of test questions with "correct" comprehensive answers and measuring how close AI output comes to those answers. They're treating evaluation as a serious engineering discipline, not an afterthought.
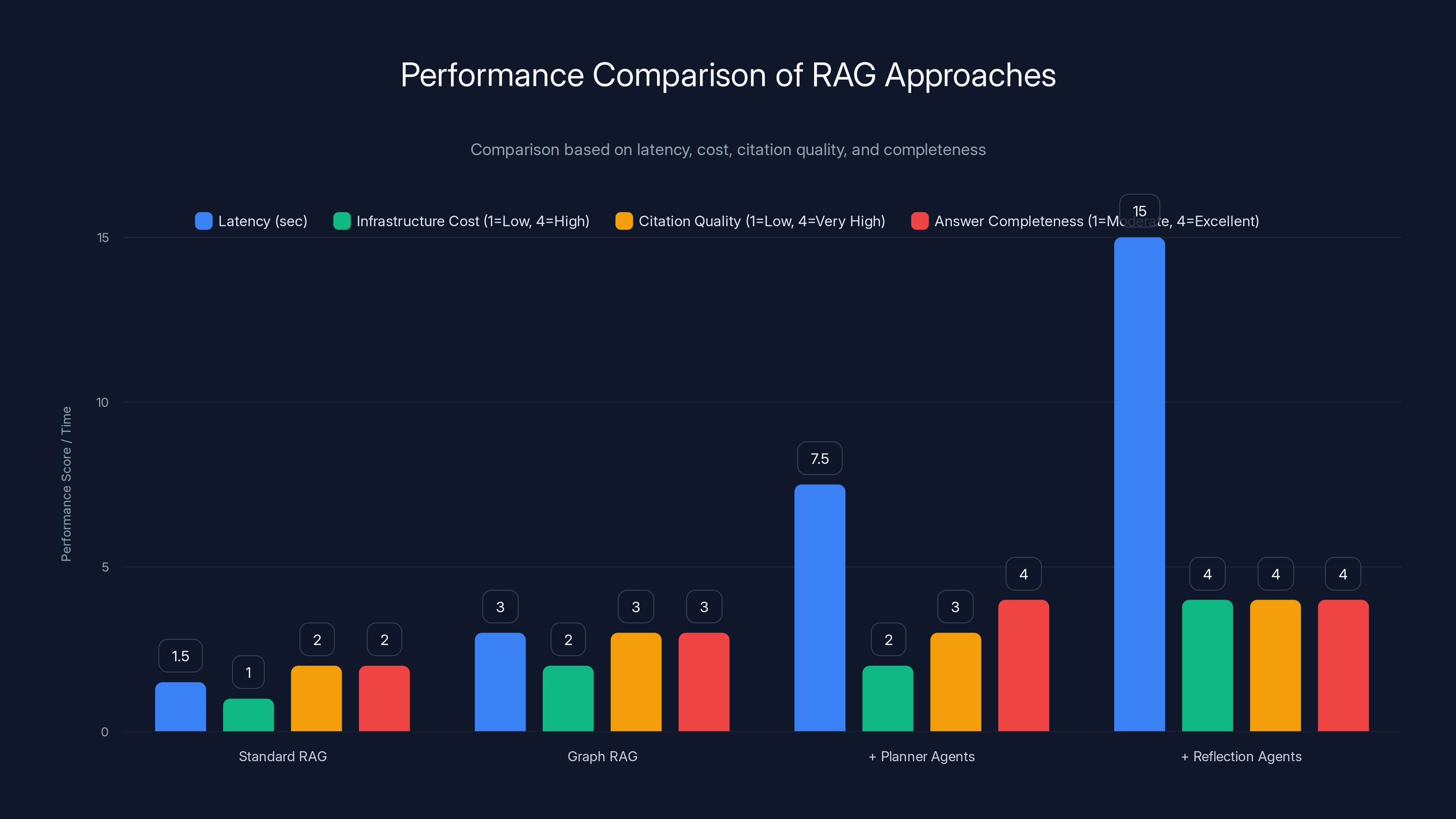
The chart illustrates that while all RAG approaches maintain high accuracy, enhancements like graph and agent additions improve citation quality and completeness at the cost of increased latency and infrastructure expenses.
The Cost-Speed-Quality Triangle: Hard Trade-offs
Here's where things get real. All of this sophistication costs something. Nothing is free.
Standard RAG is fast and cheap. One semantic search, one model inference, done in seconds. Infrastructure requirements are modest. Graph RAG is slower and more expensive. You need a knowledge graph (which requires building and maintaining it), semantic search, graph traversal, model inference. That's more computation, more latency.
Adding planner agents adds more latency. Instead of one inference to answer the question, you now have multiple inferences—one to plan the sub-questions, multiple inferences to answer each sub-question, one more to synthesize. This takes longer. It also takes more tokens if you're paying per-token pricing.
Adding reflection agents adds even more. Each answer gets generated twice (initial + refined), which doubles the model inference. Graph RAG plus planner agents plus reflection agents means your system might take 10-20 seconds to answer a question that standard RAG answered in 2 seconds.
For some use cases, that's fine. A lawyer waiting for comprehensive legal research might happily wait 15 seconds if the answer is thorough and reliable. An AI system helping with compliance analysis might run overnight, so speed is irrelevant.
For other use cases, it's a deal-breaker. A customer support chatbot can't take 15 seconds to answer simple questions. Real-time applications might have strict latency requirements. Some applications might need to handle hundreds of concurrent users where the infrastructure cost of sophisticated analysis becomes prohibitive.
This is why the most sophisticated enterprises don't use one-size-fits-all approaches. They use a tiered system. Simple questions that need simple answers use standard RAG. Complex questions that require comprehensive research use graph RAG plus planner agents. Critical decisions that need maximum reliability use everything including reflection agents and human review.
They also don't run everything through the full system. A lawyer using an AI assistant might start with a fast standard RAG search to get initial information, then run a more sophisticated analysis if they need deeper research. The user controls the trade-off.
The lesson: understand the trade-offs. Standard RAG is fast and cheap. Sophisticated agentic systems are slow and expensive. Matching your infrastructure to your actual needs matters. Running reflection agents on every query when 90% of your queries are simple is wasteful. Running only standard RAG on complex questions where errors are costly is reckless.
Human-AI Collaboration: The Actual Future
Let's talk about the elephant in the room that everyone's afraid to say: full automation of high-stakes work isn't coming, and we shouldn't want it to.
When this technology works best, it's not replacing humans. It's changing what humans do. A lawyer using AI still needs to review the research, validate the citations, and make judgment calls. A doctor using AI still makes diagnoses and treatment decisions. A compliance officer using AI still makes final calls on regulatory interpretation.
But those humans are no longer doing the grunt work. They're not spending eight hours manually researching case law or searching medical literature or tracking regulatory changes. An AI system does that work, surfaces the findings, and the human applies expertise and judgment.
This division of labor works because AI systems are good at things humans are bad at: reading hundreds of documents, maintaining consistent logical rules, catching errors in structured data, generating drafts quickly. Humans are good at things AI is bad at: understanding context and nuance, applying judgment to edge cases, recognizing when general rules don't apply, taking responsibility for decisions.
The best systems lean into these strengths. The AI does retrieval, synthesis, and drafting. The human does interpretation, judgment, and final decision-making. Neither fully automates the other away.
This also means the AI system needs to be designed for collaboration, not just autonomous performance. When a planner agent breaks down your question into sub-questions, you need to see those sub-questions and be able to modify them. When a reflection agent refines a draft, you need to see what it changed and why. When graph RAG retrieves sources, you need to see which sources and understand why they were selected.
This transparency is critical. In some sense, it makes the AI slower and more cumbersome, because you're not just getting an answer, you're getting an interactive process you can examine and guide. But that examination is where the value lives. It's where you catch errors, inject domain knowledge, and ensure the AI is actually solving your problem.

Industry Applications Beyond Legal: Where Graph RAG Is Going
The original discussion focused on legal tech, which makes sense. Legal work is high-stakes, depends on authoritative sources, and requires comprehensive answers. Graph RAG solved a real problem for legal AI.
But the approach is spreading to other domains where similar problems exist.
In medical research and clinical decision support, graph RAG helps distinguish between current clinical guidelines and outdated ones. A medical AI system that cites best practices from 2019 when current guidelines are from 2024 is dangerous. Graph RAG can weight recent guidelines more heavily and flag outdated information.
In financial advisory, graph RAG helps distinguish between current regulations and superseded ones. Tax law changes frequently. Investment regulations evolve. A system that returns accurate information about outdated rules is misleading. Graph RAG can ensure that retrieved information reflects the current regulatory landscape.
In compliance and regulatory work, graph RAG helps manage complex hierarchies of regulations. Federal regulations, state regulations, local ordinances, and industry standards all interact. A semantic search might return all relevant regulations, but graph RAG can help identify which ones supersede others and which are actually binding in your jurisdiction.
In academic research, graph RAG helps distinguish between retracted papers, papers from unreliable sources, and papers from authoritative sources. The academic literature is enormous and includes everything from peer-reviewed articles to preprints to misleading papers. Graph RAG can help filter for actual trustworthy sources.
The common thread: any domain where authority matters, where standards evolve, and where completeness is critical benefits from graph-based retrieval. These are domains where semantic similarity to a question doesn't guarantee that the answer is good.
As these technologies mature, we'll likely see graph RAG become standard in high-stakes domains, not exotic. Just as we now expect medical AI systems to cite their sources, we'll expect them to distinguish between current and outdated information, authoritative and questionable sources.
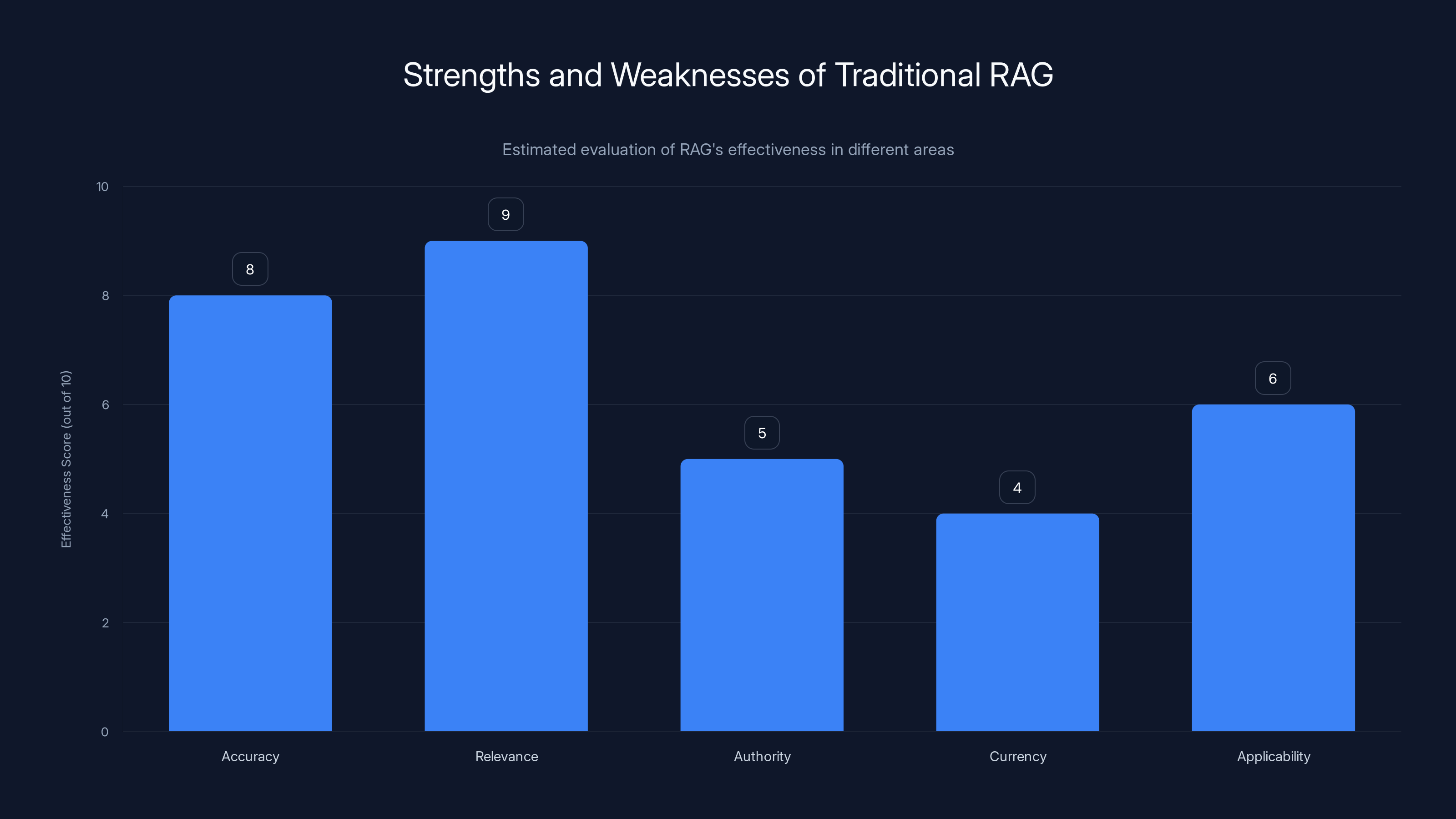
Traditional RAG excels in ensuring relevance and accuracy but struggles with authority, currency, and applicability. Estimated data based on typical RAG challenges.
Building Your Own Evaluation Framework
If you're considering implementing sophisticated AI systems, you need evaluation before deployment.
Start by defining your success metrics explicitly. Don't start with "We want accurate AI." Start with "What does good look like in our domain?" For legal work, is it completeness? Citation quality? Speed? Cost? For medical work, is it catching all relevant factors? Distinguishing between current and outdated information? For compliance work, is it identifying all applicable rules? Managing complexity?
Different domains care about different things. Pick your top 3-5 metrics. Weight them. Articulate what you'll measure to evaluate each metric.
Second, build a test set. Identify 20-50 representative questions in your domain—questions that are complex enough to be interesting, important enough to matter if they're answered wrong. Get domain experts to provide comprehensive answers to these questions. These become your ground truth.
Third, run your AI system on each test question. Evaluate its output against each of your metrics. How complete was the answer? How authoritative were the sources? How accurate were the citations? How many relevant factors did it miss?
Fourth, compare approaches. Run your test set through standard RAG, graph RAG, agentic systems. See which performs better on which metrics. See what the trade-offs are in speed and cost.
Fifth, pilot with real users. Don't launch system-wide. Have a subset of your team use it and give feedback. Have domain experts evaluate its outputs. Iterate based on what you learn.
This sounds like a lot of work, and it is. But it's necessary work. Deploying an AI system without understanding how it performs on your actual use cases is how you end up with confident but incomplete answers that lead to bad decisions.

The Evolution of Enterprise AI: Where This Heads
We're at an inflection point in enterprise AI. The first wave was just deploying LLMs and hoping for the best. The second wave was adding retrieval. We're now entering the third wave: adding structure, domain knowledge, and reasoning to make AI systems actually reliable in high-stakes domains.
What's coming next? Probably deeper integration of domain knowledge. Instead of generic knowledge graphs, expect specialized graphs for different domains. Legal knowledge graphs that understand case law hierarchy. Medical knowledge graphs that understand clinical guidelines and evidence hierarchies. Financial knowledge graphs that understand regulatory hierarchies.
Expect better agent orchestration. Instead of planner agents and reflection agents working independently, expect more sophisticated multi-agent systems where different agents specialize in different aspects of a problem and coordinate.
Expect better human-AI collaboration interfaces. As AI systems become more sophisticated, the interfaces between humans and AI will become more sophisticated. You won't just get answers—you'll get interactive processes where you can steer the AI's reasoning.
Expect verification to become a first-class concern. Not all enterprises have the resources to build knowledge graphs and maintain them. We'll see verification services emerge—companies that maintain authoritative knowledge graphs for specific domains and let other companies use them.
Most importantly, expect the bar to keep rising. As these systems improve, expectations will exceed their capabilities. What counts as "good enough" will keep changing. The AI systems that are impressive today will be table-stakes in two years and outdated in five.
Practical Implementation: Starting Your Journey
If you're responsible for deploying AI in a high-stakes domain, here's a practical roadmap.
Start where you are. If you're already using standard RAG, understand its limitations. What kinds of errors are you seeing? Are you getting incomplete answers? Are your citations outdated? Are you missing relevant factors? Understanding your specific failure modes guides what to improve.
Identify quick wins. Before you build a knowledge graph, are there simpler improvements you can make? Can you filter your source documents to exclude outdated information? Can you weight more recent sources more heavily? Can you add human review to catch obvious errors?
Pilot graph RAG on specific use cases. Don't convert your entire system at once. Start with one domain or one type of question. Build a knowledge graph for that domain. Run comparative tests against your standard RAG system. Measure the improvements and the costs. Use what you learn to decide whether to expand.
Add agents incrementally. Start with planner agents for complex questions. See if breaking questions into sub-questions improves your answers. Then add reflection agents for critical outputs. See if self-criticism improves quality. Build based on what you learn, not on a theoretical roadmap.
Invest in evaluation. You can't improve what you don't measure. Invest in building evaluation infrastructure—test sets, metrics, comparison tools. Make evaluation a routine part of your development process.
Hire domain expertise. You can't build graph RAG without people who understand your domain deeply. You can't evaluate outputs without domain experts. Hiring might be your most important investment.
Start with the assumption that you'll need humans in the loop for a while. Maybe forever. Design your system assuming humans will review and refine outputs. This changes how you build everything—your interfaces, your error handling, your quality targets.
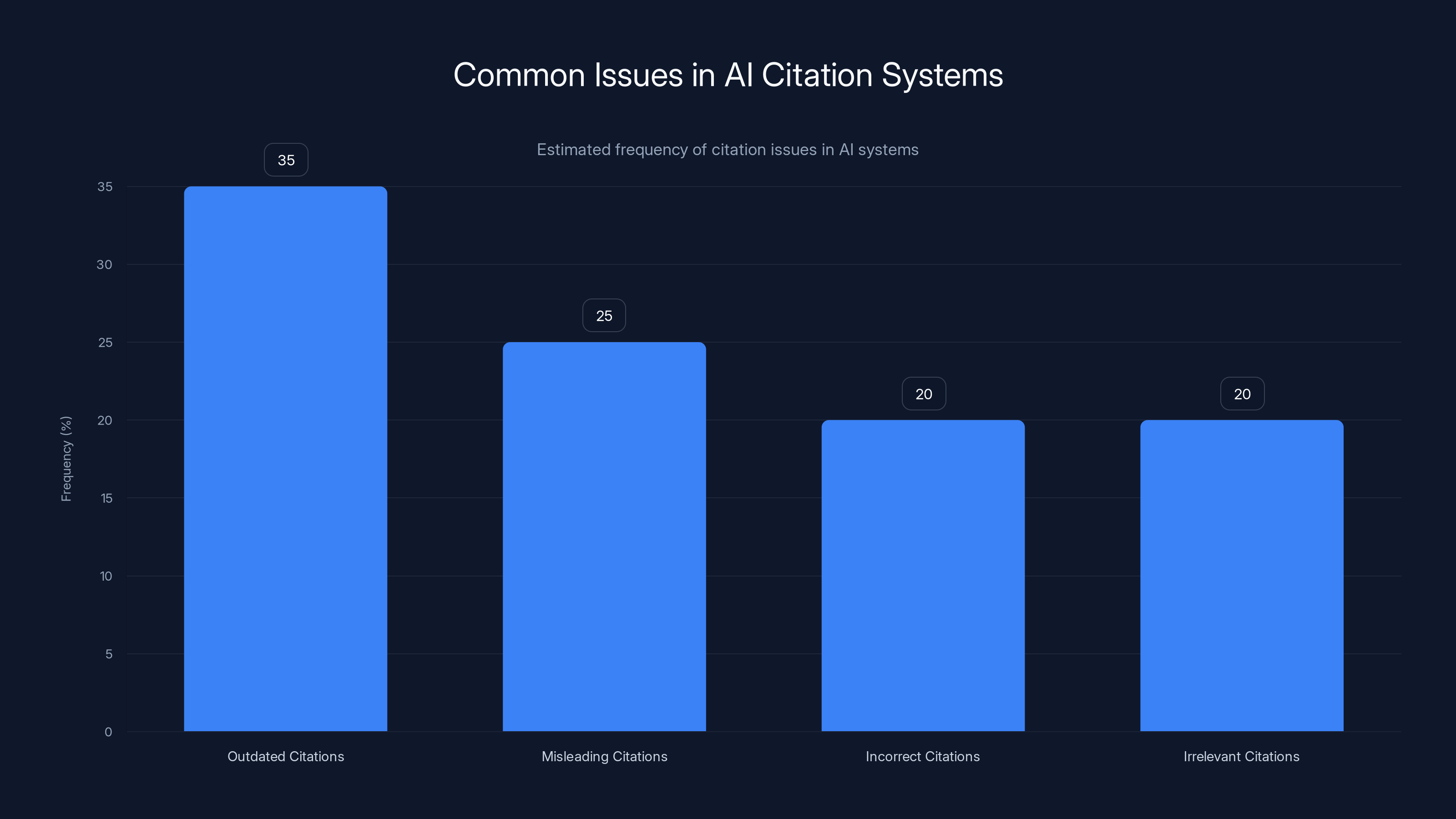
Outdated citations are the most common issue in AI systems, representing 35% of citation problems. Estimated data based on typical issues in evolving domains.
The Hard Limits: What These Systems Still Can't Do
Let's be honest about what sophisticated AI systems still struggle with, because understanding limitations matters as much as understanding capabilities.
They still struggle with genuinely novel questions that don't have clear precedent. If you're asking "How do I handle a situation no one has faced before?", the system can retrieve all relevant context, but it can't tell you what to do because no one knows what to do. That requires human judgment in fundamentally uncertain territory.
They struggle with questions that require understanding context across multiple domains. A question about regulating AI in healthcare requires understanding both AI technology and healthcare regulation. A system strong in one domain might not be strong in integrating across both.
They struggle with questions where the right answer depends on values or priorities. "Should we prioritize cost or quality?" isn't a question with a factual answer. It's a judgment call based on values. An AI system can explain the trade-offs, but it can't make the choice.
They struggle with questions where expertise itself is contested. In emerging fields where experts disagree fundamentally, no knowledge graph captures the "right" answer because there is no right answer yet. The best the system can do is represent multiple perspectives.
They struggle with truly black swan events. If something is genuinely unprecedented, there's no historical data to learn from. An AI system trained on historical data can't predict novel crises well.
Understanding these limitations is important because it helps you use these systems well. They're great for research, analysis, and handling established problems. They're poor for judgment calls, novel situations, and value-based decisions. Use them where they're strong, get human judgment where they're weak.
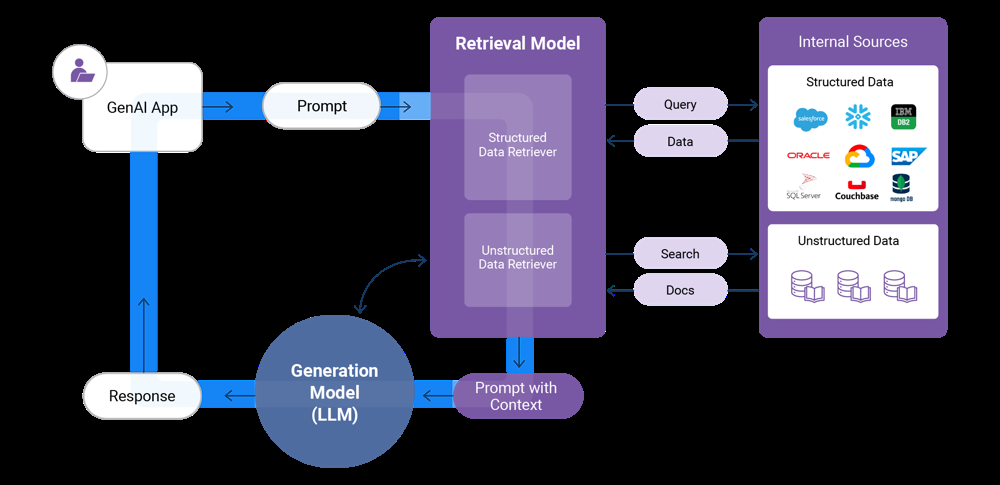
Comparing RAG Approaches: A Performance Matrix
Let's cut through the complexity and give you a simple comparison. How do these different approaches actually stack up?
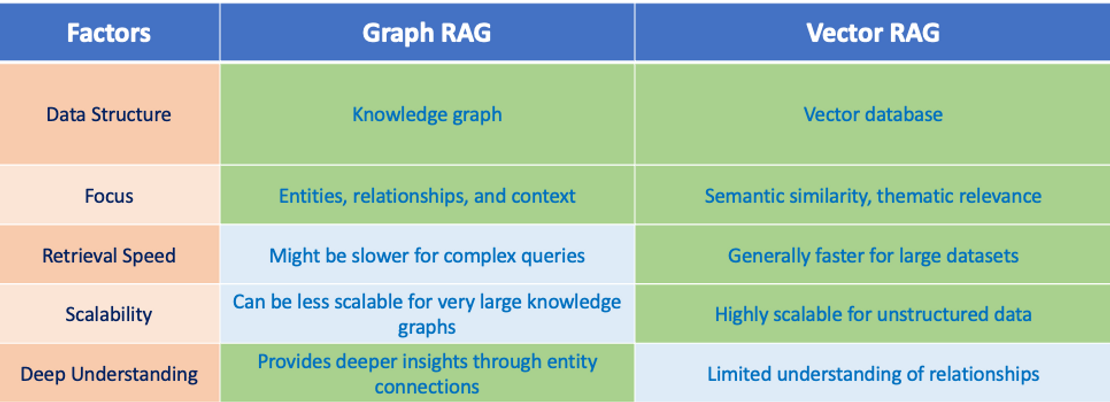
| Dimension | Standard RAG | Graph RAG | + Planner Agents | + Reflection Agents |
|---|---|---|---|---|
| Latency | 1-2 sec | 2-4 sec | 5-10 sec | 10-20 sec |
| Infrastructure Cost | Low | Medium | Medium | High |
| Citation Quality | Moderate | High | High | Very High |
| Answer Completeness | Moderate | Good | Very Good | Excellent |
| Accuracy | High | High | High | High |
| Domain Expertise Required | Low | High | Medium | Medium |
| Human Review Still Needed | Yes | Yes | Yes | Yes |
| Implementation Time | Weeks | Months | Months | Months |
The table reveals something important: you don't get accuracy gains by going sophisticated. Standard RAG already has high accuracy. What you get is better completeness, better citation quality, and better handling of complex questions. You trade speed and cost for those improvements.
This is why different approaches make sense for different use cases. If you need speed and reasonable accuracy, standard RAG is fine. If you need completeness and authority, graph RAG is worth the cost. If you need to handle genuinely complex questions, add agents. If you need maximum reliability for critical decisions, use the full stack.
Future-Proofing Your AI Investment
AI infrastructure is changing rapidly. How do you build systems that won't be obsolete in two years?
First, focus on the problem, not the technology. Define what you're trying to achieve (complete, authoritative answers) rather than betting on specific tech (graph RAG). As technologies evolve, you can swap components while keeping the same objectives.
Second, build modular systems. Instead of monolithic "AI solutions," build systems where components can be swapped or updated. Maybe you start with standard RAG and upgrade to graph RAG later. Maybe you upgrade your embedding model without rebuilding everything. Modularity lets you evolve.
Third, invest in evaluation infrastructure, not just in the model itself. Evaluation infrastructure tells you what's working and what's not. Model-specific investments can become obsolete, but good evaluation systems remain valuable.
Fourth, focus on data quality and domain expertise. These are more stable than any specific technology. A system with excellent source data and deep domain expertise can adapt to new technologies. A system with poor data and weak domain expertise will fail regardless of the technology.
Fifth, plan for continuous improvement. Don't treat deployment as the end goal. Plan for ongoing evaluation, iteration, and refinement. Technology will improve. Your understanding of your problem will improve. Your system should evolve accordingly.
Conclusion: Accuracy Isn't Enough, But it's Table Stakes
We started with a simple question: why isn't accuracy enough? After working through the details, the answer is clear. Accuracy is necessary but insufficient. You can be accurate about each individual fact and still deliver dangerous answers because you're missing context, citing outdated information, or answering incomplete questions.
In high-stakes domains, you need accuracy plus completeness, plus citation quality, plus authority. You need systems that don't just generate answers but reason about what they're saying, break down complex questions, and verify their own work.
Standard RAG moved us forward by grounding AI in actual documents instead of letting models hallucinate. Graph RAG moved us further by adding authority filtering to retrieval. Agentic systems with planner and reflection agents moved us further still by handling complexity and self-criticism.
But none of these approaches eliminate the need for human judgment. They change what humans do—replacing grunt work with higher-level oversight—but they don't replace humans entirely. For good reason. The most reliable systems are human-AI partnerships, not fully autonomous AI.
If you're building or evaluating AI systems for high-stakes work, remember: accuracy is table stakes, completeness is competitive advantage, and human expertise is irreplaceable. Build accordingly.
The future of enterprise AI isn't fully autonomous systems. It's systems that are sophisticated enough to handle complex work, transparent enough that humans can understand and verify their outputs, and humble enough to know what they don't know.
That's the direction the best systems are heading. That's where the real value is being created. And that's what separates systems that are just accurate from systems that are actually trustworthy.
FAQ
What is the difference between accuracy and completeness in AI systems?
Accuracy measures whether the information the system returns is factually correct. A system is accurate if it correctly reports what sources say and extracts facts correctly. Completeness measures whether the system addressed all relevant aspects of the question. A system can be highly accurate but incomplete if it answers 3 out of 5 relevant sub-questions. In high-stakes domains, both matter, but they're measuring different things and both are required for reliable outputs.
How does graph RAG improve upon standard retrieval-augmented generation?
Standard RAG retrieves documents based on semantic similarity to the question, assuming that similarity indicates relevance. Graph RAG adds a second layer that filters retrieved documents through a knowledge graph, which understands authority relationships, supersession relationships, and domain structure. This allows graph RAG to return documents that are both semantically relevant and authoritative in the domain, eliminating outdated or superseded information that standard RAG might surface.
What are planner agents and how do they help with complex questions?
Planner agents take complex multi-faceted questions and break them down into simpler sub-questions. Instead of trying to answer "What's my liability for patent infringement in software, what damages might I face, and how does this differ by jurisdiction?" as one question, a planner agent breaks it into five separate sub-questions. Users can review and edit these sub-questions, and the system retrieves and answers each sub-question separately, leading to more comprehensive and better-targeted responses.
How do reflection agents improve output quality?
Reflection agents generate an initial output, then critique that output by identifying gaps, logical errors, or incomplete reasoning. The agent incorporates this self-criticism and refines the output before delivering it. This process, which mimics how experts revise their own work, typically produces higher-quality outputs than single-pass generation because the model catches and corrects obvious errors before a human sees the output.
Why do enterprise AI systems still require human review if they have planner and reflection agents?
Because planner agents might still be asking the wrong questions, reflection agents might miss subtle domain-specific issues that only experts understand, and AI systems don't take responsibility for their outputs. Human experts bring domain knowledge, judgment, and accountability that AI systems can't replicate. The most reliable systems have AI handling analysis and drafting while humans handle review, judgment, and final decision-making.
What metrics should I use to evaluate AI systems for high-stakes domains beyond just accuracy?
Beyond accuracy, measure citation quality (whether cited sources actually support the claims), authority (whether sources are from authoritative current sources rather than outdated or weak ones), completeness (whether all relevant aspects of the question were addressed), hallucination rates (whether the system invents information), relevance (whether the system actually answered the question asked), and legibility (whether experts can understand the answer). Different domains weight these differently, but high-stakes domains need multiple metrics beyond just accuracy.
How long does it take to implement graph RAG compared to standard RAG?
Standard RAG can be implemented in weeks with existing tools and embedding models. Graph RAG implementation typically takes months because you need to build or integrate a knowledge graph that understands domain-specific relationships and authority structures. The additional complexity comes from needing deep domain expertise to correctly model relationships between documents and entities in your knowledge base.
Is graph RAG necessary for all AI applications or only high-stakes domains?
Graph RAG is most valuable in domains where authority matters—legal, medical, financial, regulatory—where standards evolve over time, and where incomplete answers are risky. For customer service chatbots, general knowledge systems, or internal documentation retrieval, standard RAG is often sufficient. The sophistication should match the stakes. Low-stakes applications benefit from speed and simplicity. High-stakes applications benefit from sophistication and rigor.
How should organizations balance the cost-quality trade-off when implementing sophisticated AI systems?
Start by defining what success looks like in your specific domain, then measure which components actually improve those metrics. Don't implement graph RAG, planner agents, and reflection agents all at once. Implement incrementally, measure the improvement from each addition, and continue only if the improvement justifies the cost. Some questions might use simple RAG, while complex questions use sophisticated approaches. Tiered systems often provide the best balance.
What's the relationship between knowledge graphs and domain-specific training data for enterprise AI?
They're complementary. Domain-specific training data or fine-tuned models improve the language model's understanding of domain concepts. Knowledge graphs improve the retrieval system's understanding of relationships and authority in the domain. A system with poor training data but excellent knowledge graphs will still struggle. A system with excellent training data but no knowledge graph will struggle with citation quality and authority. Both matter for high-stakes applications.
Final Thoughts: Where We Go From Here
The AI systems being built today for high-stakes domains represent a genuine shift in how we think about artificial intelligence. We've moved past the "just make it accurate" phase into a more nuanced understanding that accuracy is necessary but not sufficient.
This shift matters because it changes what we should expect from AI systems. We should stop asking "Is this accurate?" and start asking "Is this complete, authoritative, well-cited, and understandable to domain experts?"
We should stop expecting AI to replace expertise and start expecting AI to augment it, handling the parts of the work that humans find tedious while leaving judgment and responsibility to humans.
We should stop treating AI deployment as a one-time project and start treating it as ongoing operational work requiring continuous evaluation, iteration, and improvement.
These changes sound small but they're actually profound. They mean enterprises serious about AI are investing in evaluation infrastructure, hiring domain experts, and taking responsibility for outcomes instead of just deploying models.
They mean the competitive advantage isn't going to companies with the fanciest models—it's going to companies with the best evaluation processes, the deepest domain expertise, and the most thoughtful approach to human-AI collaboration.
The future of enterprise AI isn't hype cycles and flashy demos. It's the unglamorous work of building systems that actually solve real problems reliably. That's where the real value is being created, and that's where smart enterprises are focused.
If you're building or evaluating AI systems, focus on that unglamorous work. Define success clearly. Invest in evaluation. Hire domain experts. Assume humans will be involved. Iterate continuously. That's not sexy, but it works.
Key Takeaways
- Accuracy alone is insufficient for high-stakes AI—completeness, citation quality, and authority matter equally in legal, medical, and financial domains
- Graph RAG adds authority-aware filtering to standard retrieval, preventing systems from surfacing outdated or superseded information
- Planner agents break complex multi-faceted questions into sub-questions for more comprehensive retrieval and targeted answers
- Reflection agents improve output quality by self-critiquing initial drafts and incorporating refinements before delivery
- The most reliable enterprise AI systems combine sophisticated retrieval with human-expert review, replacing grunt work while preserving judgment and responsibility
Related Articles
- Reinforcement Learning Plateaus Without Depth: NeurIPS 2025 [2025]
- Infosys and Anthropic Partner to Build Enterprise AI Agents [2025]
- How AI Transforms Startup Economics: Enterprise Agents & Cost Reduction [2025]
- Harvey's $11B Valuation: How Legal AI Became Silicon Valley's Hottest Startup [2025]
- Context-Aware Agents & Open Protocols in Enterprise AI [2025]
- AI Judges and Arbitration: The Future of Legal Decisions [2025]

