![Why Businesses Fail at AI: The Data Gap Behind the Divide [2025]](https://tryrunable.com/blog/why-businesses-fail-at-ai-the-data-gap-behind-the-divide-202/image-1-1769848574622.jpg)
Why Businesses Fail at AI: The Data Gap Behind the Divide
Your company just spent $2 million on AI. Your competitors are spending twice that. Everyone's rushing to deploy machine learning models, chatbots, and automation systems. Yet somehow, nothing's working quite right.
You're not alone. This is the AI divide, and it's getting wider every single day.
TL; DR
- 95% of enterprise AI projects fail because companies prioritize the technology before fixing their data foundations
- The real bottleneck isn't AI capability, it's data fragmentation, siloing, and lack of orchestration
- Data-readiness determines success more than model sophistication, investment size, or team expertise
- Agentic AI can solve the data problem, not just operate on top of it, but few companies understand this yet
- Workflow redesign beats point solutions by 10-20x when it comes to real business impact

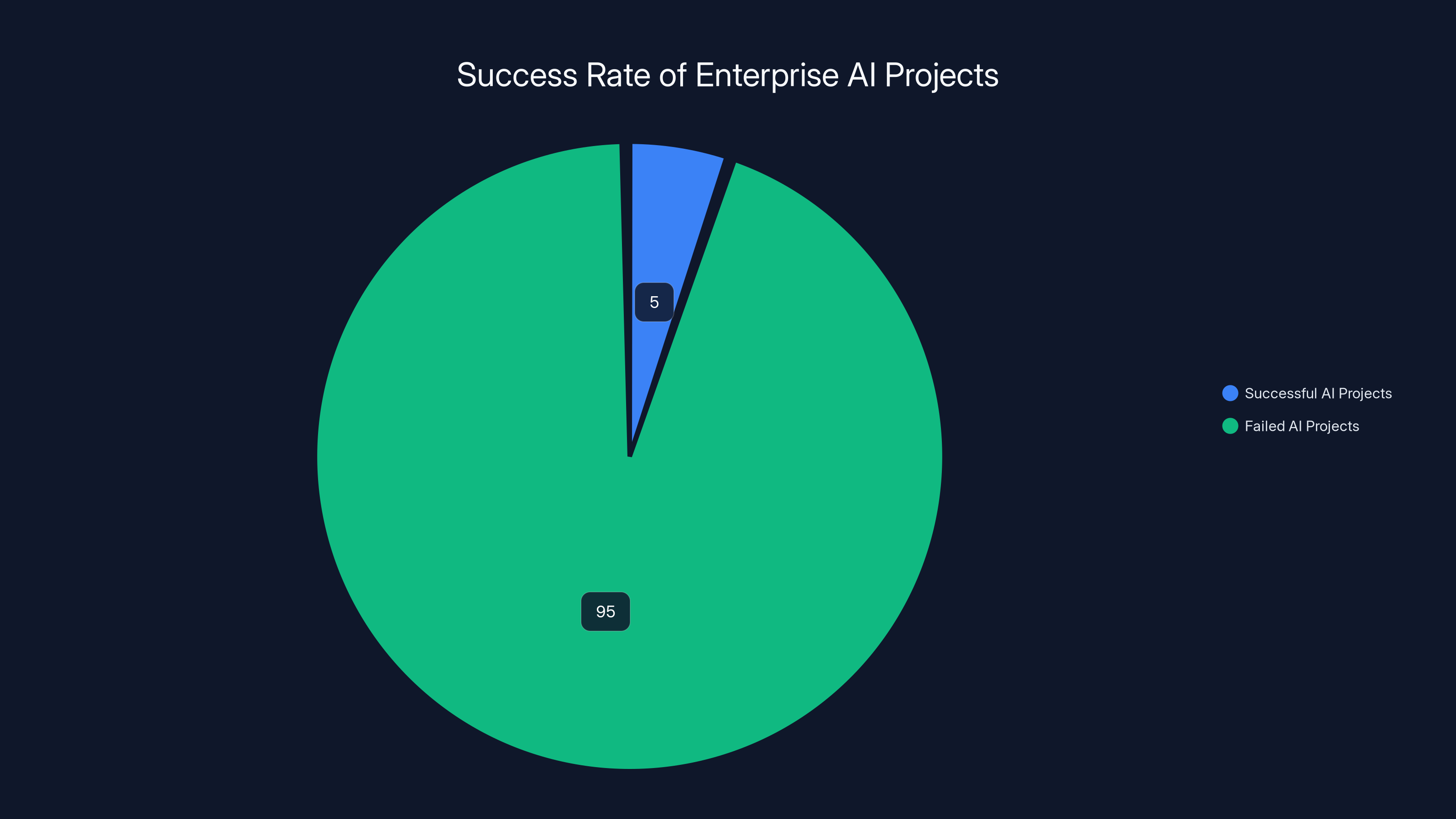
An estimated 95% of enterprise AI projects fail to deliver meaningful value, highlighting the importance of data readiness and strategic implementation.
The AI Paradox: Why Investment Isn't Translating to Value
Here's something that keeps enterprise leaders awake at night. In the first half of 2025 alone, roughly two-thirds of U.S. gross domestic product growth came from business spending on software and equipment designed to fuel AI adoption. That's not a small number. Companies are throwing unprecedented resources at artificial intelligence, automation, and machine learning infrastructure.
So where's the payoff?
Researchers have identified what they're calling the AI paradox. Despite massive investments, despite widespread adoption, despite the hype cycle that just won't quit, the majority of businesses still can't point to concrete, measurable value from their AI spending. The gap between theoretical potential and real-world results has become impossible to ignore.
The numbers tell an uncomfortable story. Roughly 95% of enterprise AI projects fail to deliver meaningful results. That's not a failure rate. That's near-universal struggle. And the kicker? Most companies expected results by now. They didn't. The narrative shifted from "when will AI pay off" to "why isn't AI paying off."
Investors are starting to ask harder questions. Business leaders are getting grilled in earnings calls about their AI ROI. Teams that were promised AI would solve everything are realizing they've just added complexity to their operations without corresponding benefit.
But here's the thing that most analyses miss: the problem isn't AI itself. The technology works. Large language models are genuinely capable. Machine learning frameworks are mature. The infrastructure exists. The problem is what happens before you get to the AI part.
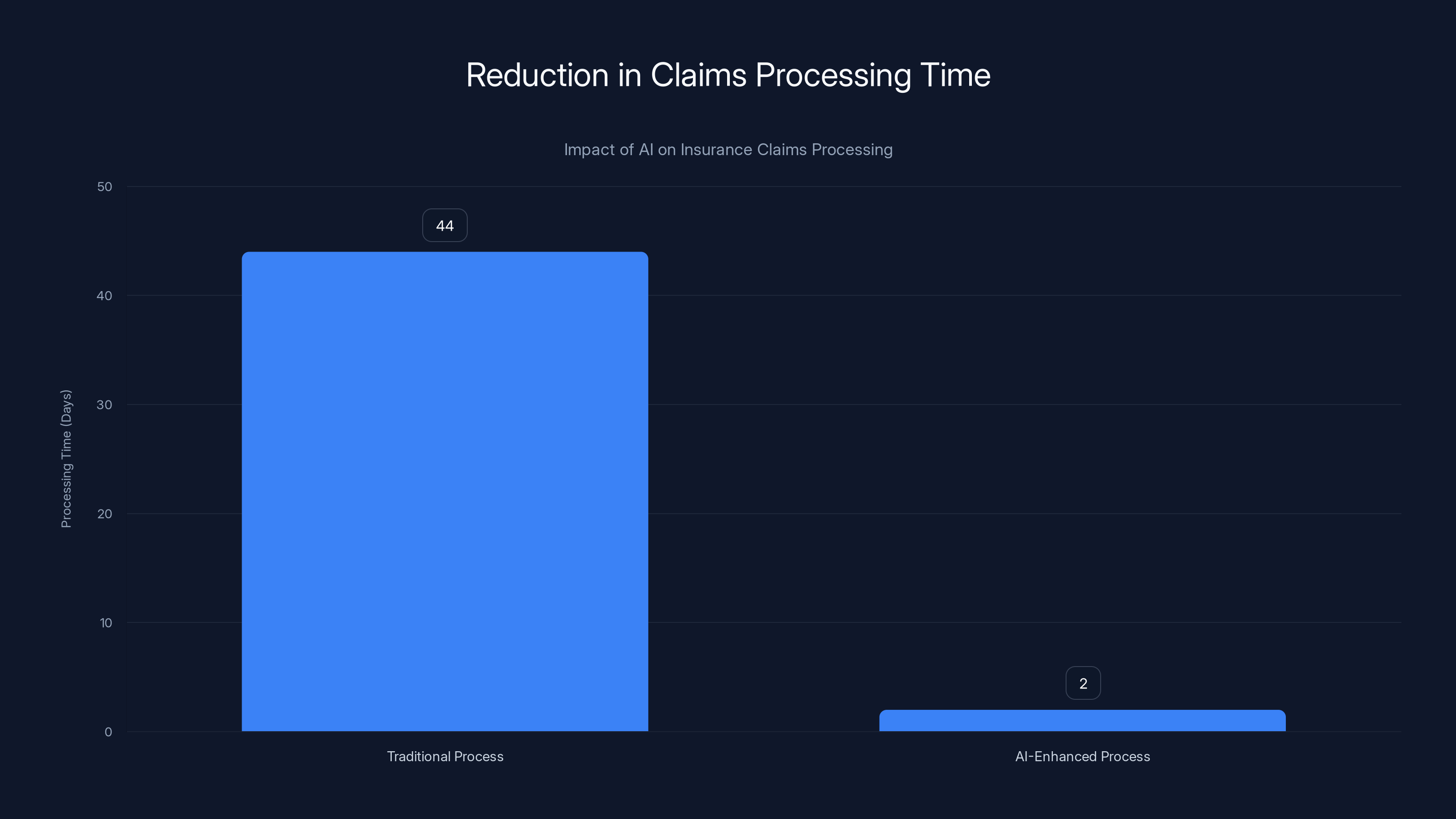
The implementation of AI in the claims process reduced the average processing time from 44 days to just 2 days, demonstrating a significant efficiency improvement.
The Hidden Bottleneck: Data Fragmentation and Siloing
Most business leaders understand the concept by now. You need good data to get good results from AI. Everyone nods along when someone says "data is the new oil." It's become a cliché, and like most clichés, it obscures the actual problem.
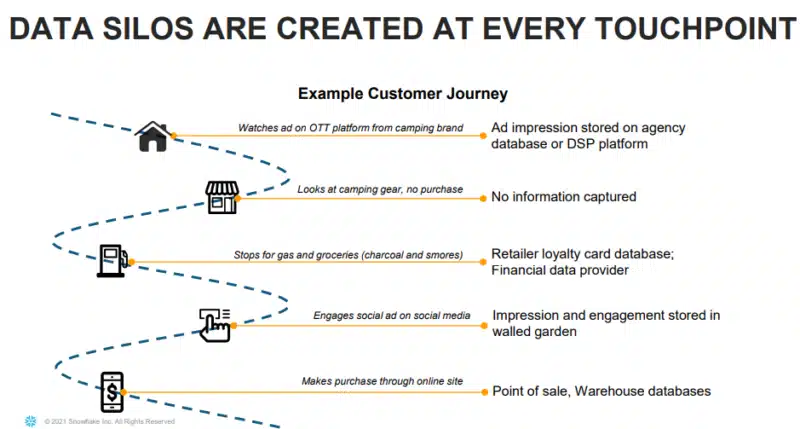
Here's what actually happens in real companies: data sits in dozens of different systems. Your CRM stores customer information one way. Your accounting system stores financial data differently. Your operations team has spreadsheets. Your product team has its own data warehouse. Your marketing automation platform maintains yet another version of the truth. None of these systems talk to each other properly. Some data is structured, some is completely unstructured. Some is recent, some is months or years old. Some is accurate, some is garbage.
This isn't a technical accident. It's how companies naturally grow. You acquire smaller companies, each with their own data architecture. You implement new software because the old system wasn't cutting it anymore. You build custom solutions that work great for one department but don't integrate with anything else. Over time, your data estate becomes a patchwork of incompatible, siloed systems.
Now here's where most AI initiatives fail: companies look at this mess and think "we need to clean this up before we can do AI." So they launch massive data migration projects. They spend months or years trying to move everything to a unified data warehouse. They hire data engineers. They implement ETL pipelines. They try to standardize data formats. It's expensive, it's slow, and it often fails partway through.
But here's what separates the companies actually succeeding with AI from those stuck in perpetual POC mode: instead of treating data harmonization as a prerequisite to AI, they use AI to solve the data problem itself.
Instead of manually mapping data schemas, you use agentic AI to discover relationships between datasets automatically. Instead of building ETL pipelines by hand, you use AI agents to understand data quality issues and fix them in context. Instead of standardizing formats beforehand, you use AI to translate between different data representations on the fly.
In other words, you flip the sequence. Most companies try to clean data first, then apply AI. The winners use AI to make their data AI-ready.
Data-Readiness: The Single Factor That Separates Winners from Losers
I've watched this play out in dozens of companies across different industries. When you cut through all the noise, when you get past the vendor marketing and the consultant recommendations, one pattern emerges with stunning clarity.
Companies that succeed with AI are data-ready. Companies that fail are not. Everything else is downstream from that single fact.
Data-readiness doesn't mean perfect data. It doesn't mean you've eliminated all silos or achieved some mythical state of complete data harmonization. It means your organization can actually access and use data from across different systems, in different formats, at scale, without months of manual preparation.
Specifically, it means:
- Accessibility: Different teams can actually access the data they need without going through a six-week approval process or waiting for a data engineer to query a database
- Discoverability: Your organization understands what data exists, where it lives, and what it actually means (not just the technical definition, but the business context)
- Quality understanding: You know which datasets are reliable and which ones need skepticism, and you can measure quality problems quantitatively
- Orchestration capability: You can pipe data through different systems and processes in sequence, with AI agents handling transitions between incompatible formats
- Feedback loops: The results from AI systems can inform data collection and improve data quality over time
Think about what that means. If your AI system can't access the data it needs, it produces garbage. If your organization doesn't understand what data you have, you miss opportunities. If you can't measure data quality, you don't know whether your AI is making good decisions or just reflecting bad data. If you can't orchestrate data flows, you're stuck with point solutions that don't scale.
Data-readiness is the foundation. Everything else is built on top of it.
I've also seen the flip side: organizations that made data-readiness their real priority from day one. They didn't wait for perfect data. They didn't try to boil the ocean with enterprise-wide initiatives. Instead, they focused relentlessly on making data accessible and usable within their AI systems. Those companies are the ones actually extracting value.
Their AI projects don't just fail less often. They fail dramatically less often. The difference isn't in the models they use or the money they spend. It's in the data foundation.
Estimated data suggests that AI projects with
Why Massive Data Migration Projects Fail
Many companies take the traditional approach: identify the goal state of data infrastructure, then try to move everything there through a centralized migration project. It sounds logical. On a PowerPoint, it looks straightforward.
In practice, it's where AI initiatives go to die.
These projects have predictable failure modes. First, they take far longer than expected. A year becomes two becomes three. Organizations lose momentum. Key team members move on. The original business case becomes outdated. Meanwhile, you're already paying for the migration infrastructure without seeing any benefits.
Second, they often create new problems while solving old ones. You move data from System A to System B, but System B can't handle the volume. Or the data quality issues from System A propagate to System B. Or business rules that were embedded in the original system get lost in translation.
Third, they become single points of failure. Everything depends on the new central system. If there's a problem, nothing works. You've replaced distributed fragmentation with centralized brittleness.
Fourth, they're extraordinarily expensive. You need specialized talent. You need lengthy planning phases. You need infrastructure. You need testing. All of that costs money, and much of it provides no business value on its own.
Worse: by the time the project completes, new systems have been added to your organization. New SaaS tools, new databases, new applications. The problem you were solving is now different from the problem you started with.
Instead, companies that are succeeding are taking a different approach: incremental data integration paired with AI-driven harmonization. Rather than trying to move everything at once, they pick a specific business problem that requires cross-system data. They build an AI-powered integration layer for that specific use case. The AI agents handle the data translation, quality checking, and orchestration automatically.
Once that's working, they move to the next problem. Over time, they've integrated the data that matters for their highest-value business processes, without a massive single project.

The Insurance Industry Case Study: From 44 Days to 2 Days
Let me give you a concrete example of what this looks like in practice. The property and casualty insurance industry is one of the most data-intensive businesses on earth. Every decision depends on data. Every workflow touches data multiple times.
Insurers are also burdened with incredibly complex processes that have grown organically over decades. Underwriting happens one way. Claims processing happens another way. Customer service happens a third way. Each department has its own systems, its own databases, its own data standards.
For the insurance industry as a whole, this fragmentation has a tangible impact on customers. When you file a homeowners claim, from the moment you report the incident to the moment you receive payment takes an average of 44 days. That's not because adjusters are slow. It's because information is stuck in silos.
An adjuster gets a claim report. They manually review the details. They request photos, audio of the incident, additional documentation. All of these arrive in different formats and systems. The adjuster has to manually check coverage rules. They run separate checks for fraud. They review historical data about similar claims. All of these checks happen sequentially, with data being manually transferred between systems.
It's Byzantine, but it's also where the insurance industry has been stuck for years. Automation helped at the margins, but couldn't solve the fundamental problem: data living in different systems with different formats and different quality standards.
Now picture this: a major national insurer decided to redesign this entire workflow from the ground up using agentic AI. But here's the crucial part: they didn't just add AI on top of the existing system. They actually restructured how data flows through the claims process.
When a customer reports a loss, that initial report goes into a standardized format. When photos arrive, AI agents extract relevant information and store it in a structured way. When audio calls come in, AI agents transcribe and summarize them. When adjuster notes are entered, AI agents parse them. When coverage data is needed, AI agents fetch it. When fraud checks run, AI agents execute them. When historical context is needed, AI agents retrieve it.
The key insight: all of this data now flows through the system in a consistent, standardized format that subsequent AI agents can work with reliably. It's not that the AI models are smarter. It's that the data is actually usable.
The result: claims processing time dropped from several weeks to two days. Not weeks. Days.
That's a 95% reduction in cycle time. For customers waiting for payment, that's transformative. For the insurer's operational efficiency and customer satisfaction metrics, that's massive.
But here's what's critical: that transformation wasn't about finding a better language model or throwing more compute at the problem. The secret sauce was orchestration. The insurer choreographed the full spectrum of data sources (incident images, audio calls, adjuster notes, claims data, historical context, vehicle information, data quality checks, coverage reviews, fraud checks) into a harmonized, AI-powered workflow where each component fed reliable data to the next.
Estimated data suggests that speed improvements have the highest impact on ROI from AI investments, followed by quality improvements, cost reductions, and risk reductions.
The Role of Agentic AI in Data Discovery and Transformation
Here's where the technology angle becomes important. Modern agentic AI (which is fundamentally different from just running prompts through a large language model) can automate entire classes of work that previously required manual effort.
Data discovery used to mean hiring a consultant to interview people, then documenting what data exists. Now, AI agents can scan your systems, understand data structures, identify relationships, and build discovery maps automatically. They can find the data you didn't know you had.
Data transformation used to mean writing custom ETL code or using specialized ETL tools. Now, AI agents can understand data in one format, understand requirements in business language, and execute transformations without needing technical specifications. When data arrives in a new format, agents can adapt without new code.
Data quality checks used to be manual spot-checking or threshold alerts. Now, AI agents can run continuous quality monitoring, understand why quality issues exist, and sometimes fix them automatically. They can flag suspicious data patterns and help explain anomalies.
Data governance used to be about rules and policies that people hopefully followed. Now, AI agents can enforce governance automatically by understanding what data different people and systems should be able to access, ensuring compliance without slowing down operations.
The point is this: AI isn't just something you apply at the end of your data pipeline to make predictions. AI is something you can apply throughout your data infrastructure to make data itself more usable and reliable.
When companies understand this, everything changes. Instead of treating data infrastructure as a prerequisite to AI (which is expensive and slow), they treat AI as a tool to improve their data infrastructure (which is fast and economical).

Embedding AI Agents at Critical Decision Points
Once your data is actually usable, the next question is where to apply AI for maximum impact. Here's where most companies still get it wrong.
They think about AI as something you deploy broadly: "Let's put AI across our entire operation." Or they think about it tactically: "Let's automate this one task." Both approaches miss the real opportunity.
The companies succeeding are embedding AI agents at specific, carefully chosen decision points where data-driven decisions have high leverage. In the insurance example, they didn't try to automate every part of claims processing. They identified the critical bottlenecks and decision points where better information flow would have the biggest impact.
That's strategic AI deployment. You're not trying to replace all human work. You're trying to ensure that the humans making critical decisions have access to the right information, properly prepared, at the moment they need it.
An adjuster making a coverage determination needs to instantly see relevant policy language, historical precedent, and regulatory requirements. That's a decision point where embedding an AI agent makes sense. The agent orchestrates information from multiple systems, presents it clearly, and surfaces risks or edge cases the adjuster should consider.
A customer service representative handling an escalated claim needs to understand the full history, the current status, and what options are available. Another decision point. Another opportunity for AI agents to orchestrate complex information into a usable form.
Fraud detection isn't just about automated rules anymore. It's about embedding AI agents that can correlate information across multiple dimensions (claim patterns, customer history, incident characteristics, network analysis) and flag suspicious patterns while providing evidence for why they're suspicious.
The pattern is clear: identify where humans make high-stakes or high-volume decisions. Embed AI agents that improve information quality, speed, and comprehensiveness at those points. Don't try to eliminate the human decision-maker. Amplify their effectiveness.

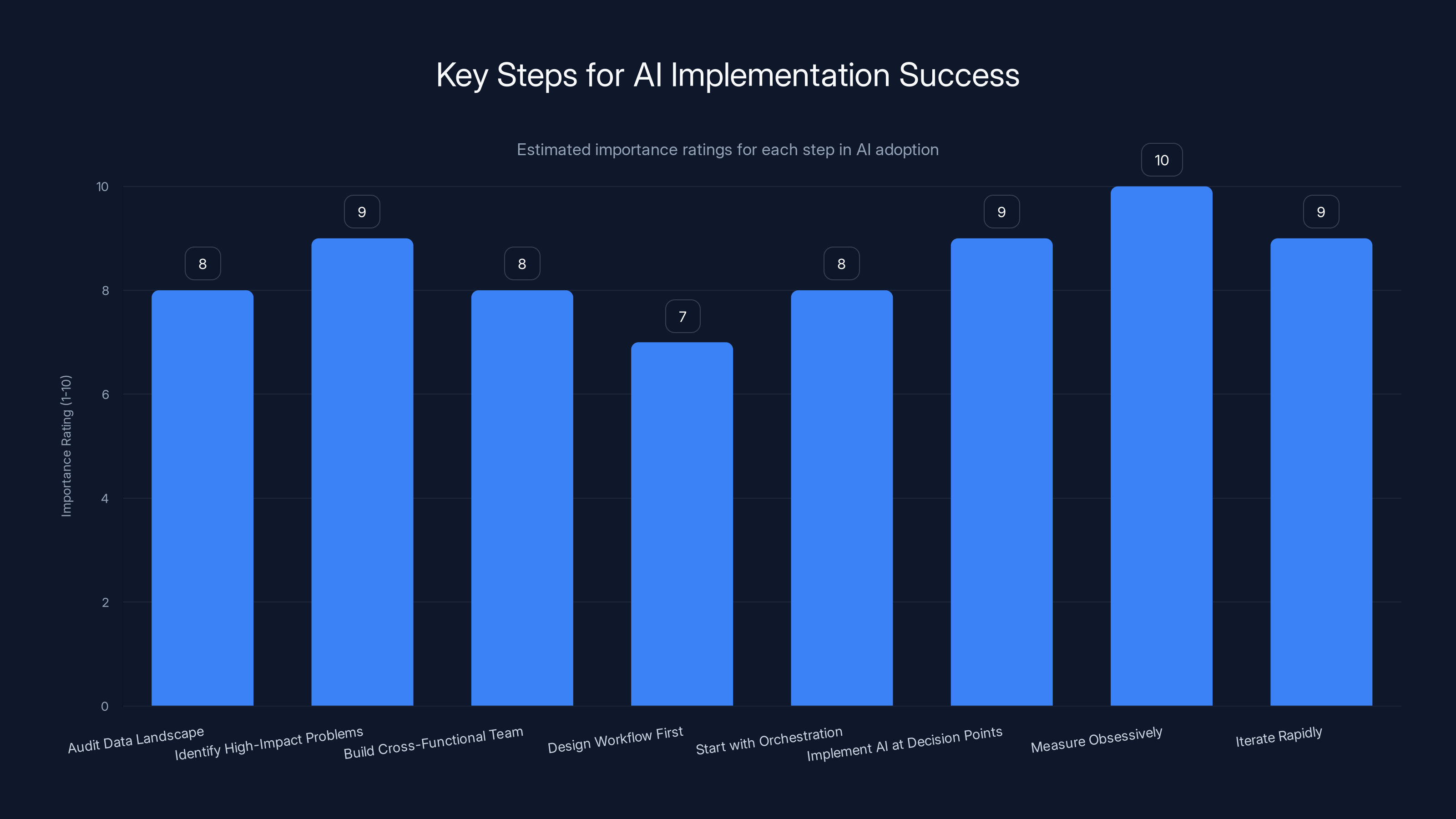
The chart estimates the importance of each step in successfully adopting AI within an organization. Measuring outcomes and iterating rapidly are crucial for success. (Estimated data)
The Orchestration Challenge: Connecting Systems That Weren't Built to Talk
Here's where most enterprises hit the real wall. Your company has dozens of systems. Some are old and inflexible. Some are modern SaaS applications. Some were custom-built for your industry. Some are industry-standard solutions. Getting them to work together is a nightmare.
When you try to implement AI, this problem becomes acute. Your AI system needs data from System A, System B, and System C. But System A stores dates in one format and System C stores them differently. System B doesn't have an API. System A charges per API call. System C has access restrictions.
Traditional solutions involve building custom connectors, maintaining integration code, and hoping nobody changes their system. It's expensive and fragile.
Orchestration solves this differently. Instead of trying to make systems talk to each other directly, you use AI agents as intermediaries. An AI agent understands System A's output format and can translate it to a standardized internal format. Another agent understands the standardized format and can translate it to what System B expects. If System C changes its format, you don't rewrite integration code. You give the agent new examples and it adapts.
This sounds like software abstraction, and in a sense it is. But the intelligence is different. Rather than writing rules for every possible variation, you're teaching AI agents to understand intent and adapt to variations they haven't seen before.
In practice, this means your AI systems become far more robust to system changes, API updates, and business requirement shifts. The AI agents handle variations that would break traditional integrations.
It also means you can add new systems faster. Instead of building connectors for each new tool you add, you teach your agents to work with the new system. The integration curve flattens dramatically.
Domain Expertise: Why AI Alone Isn't Enough
Here's something that often gets overlooked in the AI hype: raw AI capability without domain expertise produces confident mistakes.
A large language model can write code, but it doesn't understand whether that code will actually work for your specific infrastructure. It can draft insurance policy language, but it doesn't understand the regulatory implications. It can analyze financial data, but it doesn't understand your industry's accounting quirks.
This is where domain expertise becomes critical. Your best insurance adjusters, your most experienced engineers, your longest-serving finance people—they have mental models about how your business works, what exceptions matter, when rules should be broken. That knowledge is incredibly valuable.
The companies succeeding at AI aren't replacing domain experts with models. They're augmenting domain experts with AI. An experienced claims adjuster with access to AI agents that handle the data choreography, quality checks, and pattern analysis becomes far more effective than either the adjuster or the AI alone.
This means your organizational structure for AI implementation matters. You can't just hand a problem to data scientists and expect them to solve it. You need domain experts at the table. You need people who understand the business process deeply enough to know what "good" looks like, what exceptions matter, and where the AI might go wrong.
In the insurance example, the project succeeded because it involved deep partnership between insurance domain experts and AI specialists. The domain experts understood claims processing. The AI specialists understood how to orchestrate data and automate decision-making. Together, they could design a system that was both technically sound and operationally coherent.
Without the domain experts, they would have built something technically impressive that didn't actually work for adjusters and customers. Without the AI specialists, the domain experts wouldn't have known what was possible.

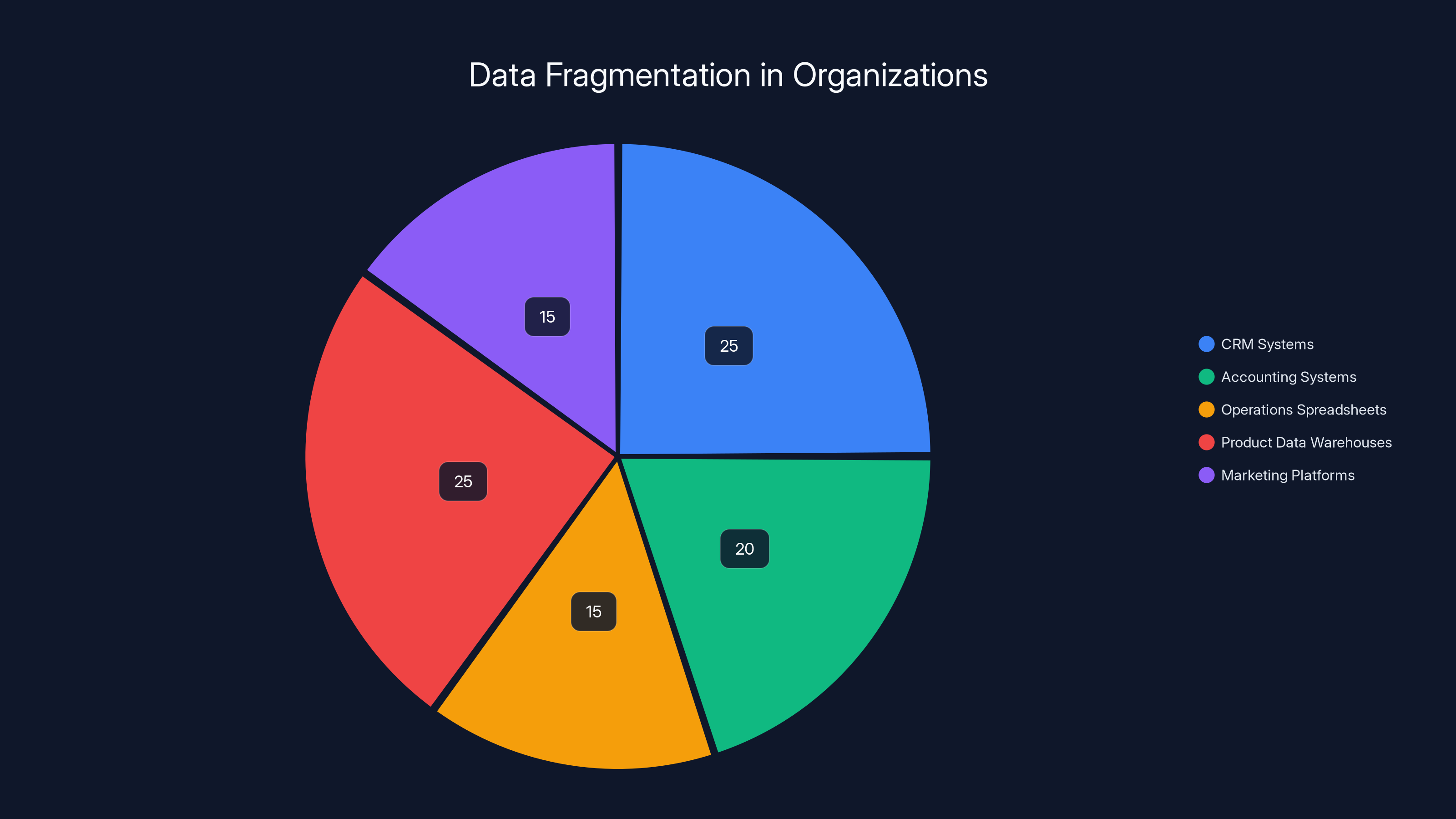
Estimated data shows that CRM and product data warehouses hold the largest share of fragmented data in organizations, highlighting the challenge of integrating diverse systems.
The ROI Question: How to Measure Value from AI Investments
Maybe the most important question is the one that keeps leaders up at night: Is this actually making money?
With traditional software, ROI is relatively straightforward. You automate a task, count how much labor it saves, multiply by the labor cost, subtract software cost, and you have a simple metric. With AI, it's messier.
Partially that's because AI improvements often don't come from labor elimination. They come from speed improvement. They come from better decision quality. They come from enabling people to take on more complex work. They come from reducing errors. All of those are real business value, but they're harder to quantify.
The companies that are actually succeeding at AI are also succeeding at measuring it. They're not looking for a single ROI metric. They're tracking multiple dimensions:
Speed improvements: How much faster do processes complete? In the insurance example, 44 days to 2 days is a 95% cycle time reduction. That's quantifiable and valuable. Faster claims processing means customers are happier, which means fewer cancellations and better retention. It also means capital isn't tied up waiting for payouts.
Quality improvements: How much better are decisions? Are claims approvals more accurate? Are fraud detections catching real problems? This is trickier to measure but can be quantified by comparing approval rates pre-AI and post-AI, measuring customer satisfaction with decisions, or analyzing fraud catch rates.
Cost reductions: Where is AI actually eliminating work? Not all work. But specific, repetitive, high-volume work that AI agents can do entirely is fair game for cost reduction measurement.
Risk reduction: Are there errors, regulatory violations, or exposures that AI is preventing? This is harder to measure (how do you quantify something that didn't happen?) but can be estimated through comparative analysis.
Enablement: Are people able to handle more volume or complexity? If an adjuster can process more claims with AI support, that's value even if the role isn't eliminated.
The key is measuring against a clear baseline. What was the process before? What metrics mattered? Now that AI is involved, how have those metrics moved? That's how you actually know whether your AI investment is working.
Most of the 95% of AI projects that fail never get to this measurement phase. They're still stuck trying to prove the concept works, years after deployment started.
Organizational Change: The Underestimated Challenge
Every major AI implementation I've seen has underestimated one factor: organizational change.
You can have perfect data. You can have the best models. You can have flawless engineering. And if your organization isn't actually ready to use AI differently, it still won't work.
There's a reason insurance adjusters were slow to adopt AI-powered claims processing. It's not because the technology didn't work. It's because adjusters had mental models about how to do their jobs that didn't include AI agents. They didn't trust the data. They didn't understand how to work with AI systems. They were worried about being replaced. They preferred the devil they knew to the uncertain new system.
Successful implementations handle this head-on. They start with training. They involve end-users early in design. They show adjusters (or doctors, or engineers, or whoever is using the system) how AI actually works, what it can and can't do, and where they should trust it versus where they should be skeptical. They give people time to adapt.
They also change incentives. If your compensation system rewards people for doing things the old way, nobody's going to change. If your performance metrics measure volume without quality, people won't care whether AI is helping them make better decisions. If your culture punishes failure, people won't experiment with new tools.
Change management isn't an afterthought in successful AI implementations. It's part of the core strategy.
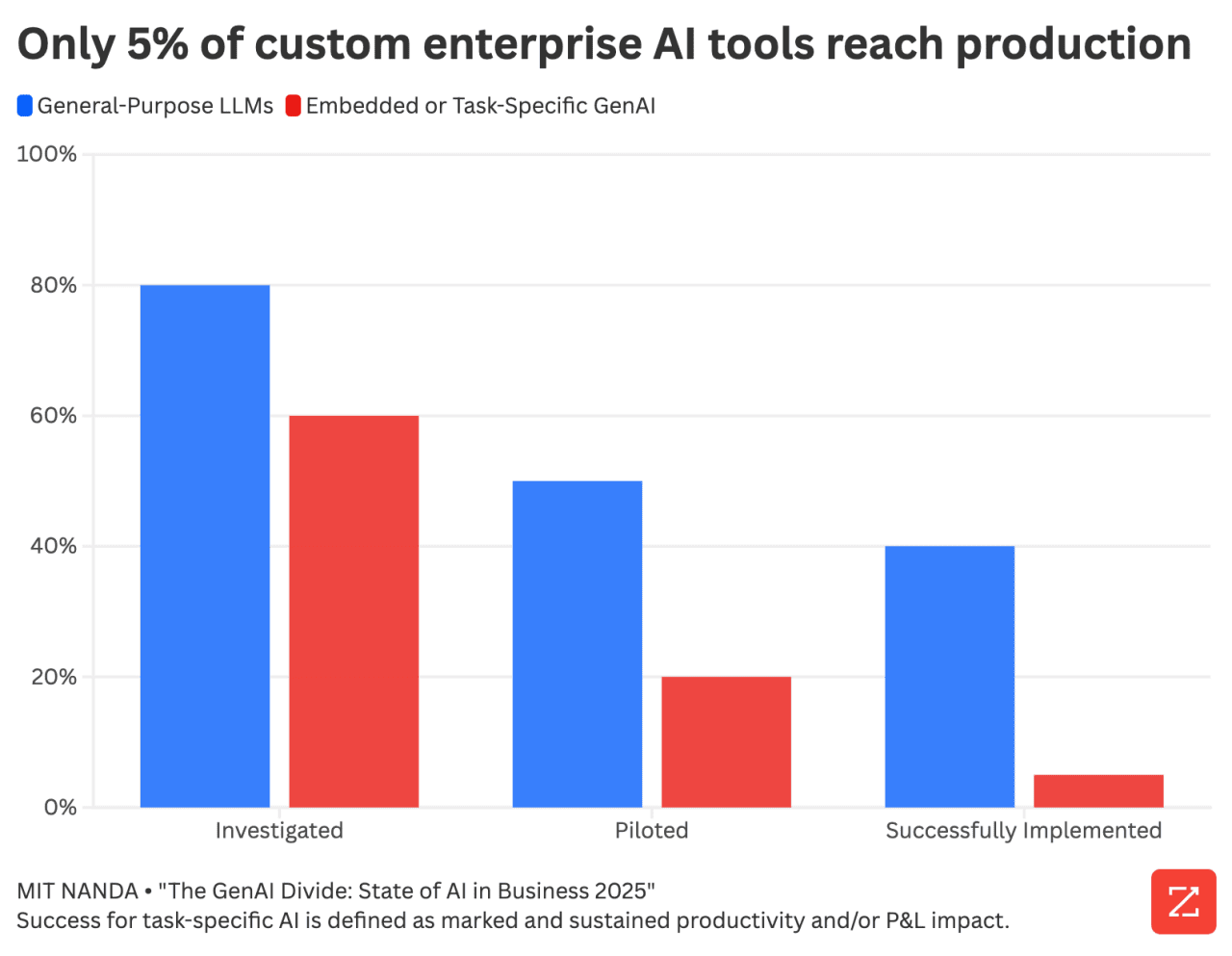
What Distinguishes AI Winners from AI Losers
If you strip away all the complexity, the companies actually winning at AI share certain characteristics:
First, they understand the data problem before they pick the model. They don't say "let's use GPT-4" and then figure out what data to feed it. They start by understanding what data they have, what data is actually usable, and what gaps exist. Only then do they design an AI system that works with the data they have.
Second, they think in terms of workflows, not point solutions. They don't try to automate individual tasks in isolation. They redesign entire processes to leverage AI at multiple points, with data flowing cleanly between stages. This is harder than building a single AI system, but dramatically more effective.
Third, they treat data orchestration as a core competency. They invest in infrastructure, tools, and talent that lets them connect systems and pipe data reliably. They understand that this is the foundation everything else is built on.
Fourth, they measure relentlessly. They establish clear baselines. They track what changes when AI is introduced. They're willing to kill projects that aren't delivering. They celebrate wins publicly and learn from failures quickly.
Fifth, they involve domain experts in everything. They don't let data scientists and engineers build systems in isolation. They have insurance adjusters, financial analysts, product managers, operational leaders helping design how AI should work.
Sixth, they accept that it's a journey, not a destination. They don't expect to solve everything at once. They pick one important problem, solve it well, then move to the next. Over time, they've transformed their entire operation. But they did it incrementally, learning as they went.
Companies that ignore any of these factors are part of the 95% that struggle.

The AI Maturity Curve: Where Are You Today?
Most organizations can map themselves onto a maturity curve for AI:
Stage 1: Exploration. "We need to understand what AI can do." Lots of pilots. Lots of vendors pitching solutions. Lots of team members learning. Not much operational impact yet.
Stage 2: Data Foundation Realization. "We need to get our data in order first." This is where many companies stall out. They launch massive data projects. They spend money. They don't see results on the AI side yet. Some projects fail at this stage.
Stage 3: Targeted Implementation. "We're going to solve one important problem really well." This is where the trajectory changes. Companies pick a specific, high-impact use case and dedicate resources to solving it. They involve domain experts. They measure obsessively. They're willing to iterate.
Stage 4: Process Transformation. "AI is now part of how we work." The first success creates momentum. The team has learned what works. Domain expertise is embedded in how AI systems are built. New implementations move faster because you understand the playbook.
Stage 5: Continuous Evolution. "AI is how we improve operations." New tools and models are integrated as they become available. The organization has the muscle memory to adapt quickly. AI isn't a project anymore. It's how the company works.
Most large enterprises are somewhere between Stage 1 and Stage 2. The ones getting real value are at Stage 3 or beyond. The gap isn't in intelligence or resources. It's in understanding that data foundation and workflow redesign come before model sophistication.
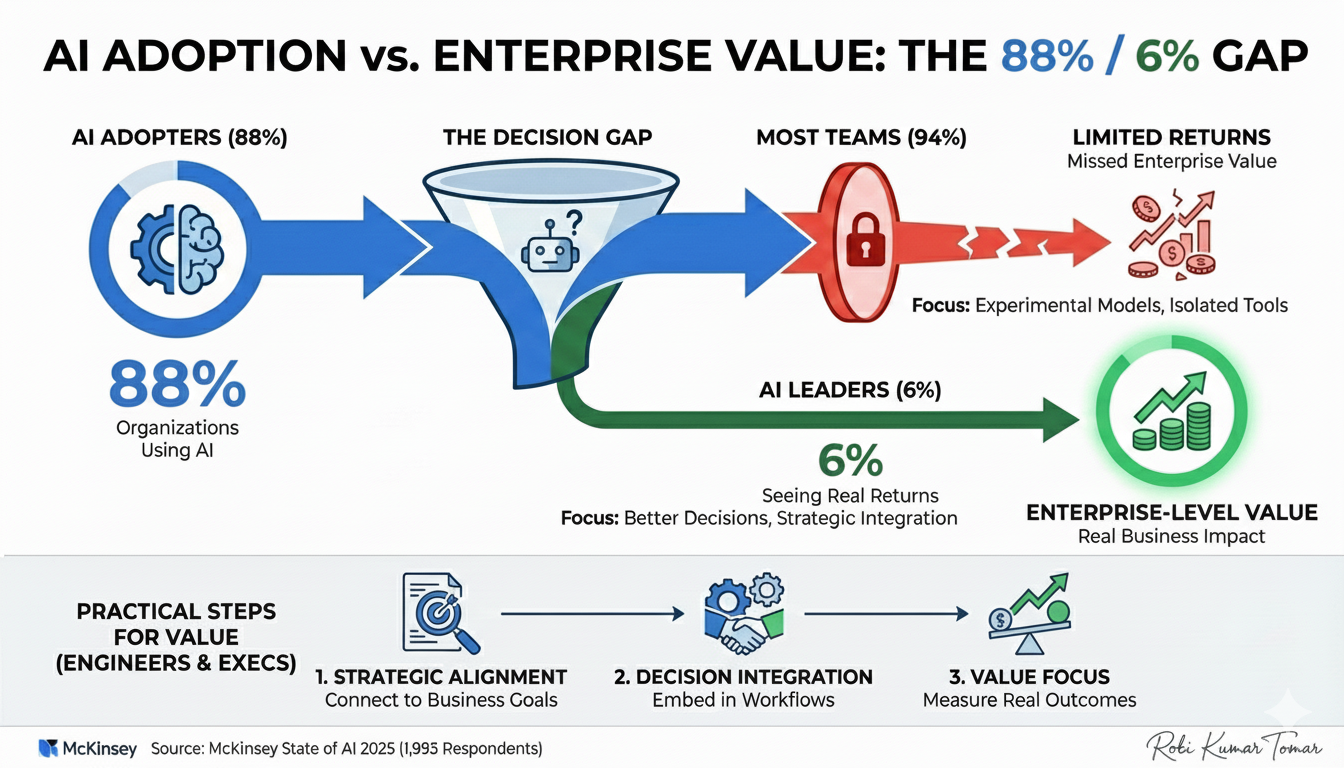
Common Pitfalls and How to Avoid Them
I've watched companies make the same mistakes over and over. Here are the ones that hurt the most:
Pitfall 1: Leading with the model. "We're going to use GPT-5 for this." Wrong order. Start with the problem and the data. The model is a detail.
Pitfall 2: Expecting AI to fix bad data. "Our data is messy, but the AI will figure it out." No it won't. Garbage in, garbage out. Bad data stays bad. You need to improve data quality first.
Pitfall 3: Building AI in isolation. Data scientists develop the model in a vacuum. Then they throw it over the wall to operations. Operations doesn't understand how it works or why it's making the decisions it makes. Adoption fails.
Pitfall 4: Ignoring the human side. You automate a task, but you don't help the human who used to do that task transition to a new role. They feel threatened. They actively work to undermine the system. Sabotage often looks like "the AI isn't working."
Pitfall 5: Pursuing perfection. "We'll deploy AI once we've solved all the edge cases." You'll never deploy. Edge cases are infinite. Deploy at 70% quality, learn what matters, improve. Perfection is the enemy of value.
Pitfall 6: Forgetting the business case. You build something technically impressive that doesn't actually solve a business problem that matters. It looks great in demos. It produces nothing of value.
Pitfall 7: Treating AI as a cost center. You ask IT to manage AI. You apply the same cost-cutting mentality you use with other infrastructure. You end up with an undersized team that can't deliver. AI needs to be treated as a capability, not a cost.
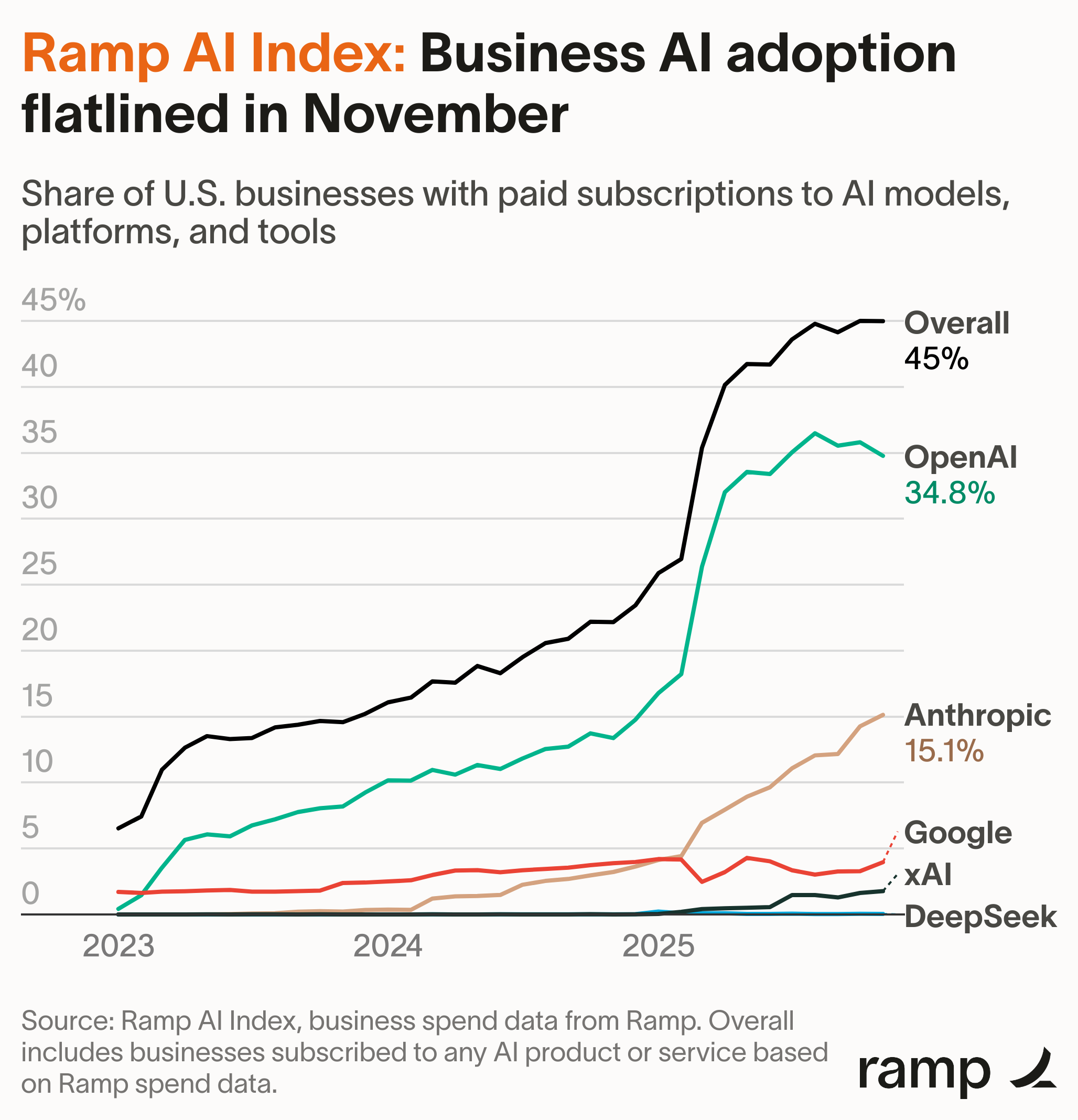
Practical Steps to Shift Your Organization Toward AI Success
If your organization is stuck in Stage 1 or 2, here's what actually works:
Step 1: Audit your data landscape. Don't hire consultants. Have your teams document what data actually exists, where it lives, what quality it's in. You're looking for understanding, not a perfect inventory. This takes weeks, not months.
Step 2: Identify high-impact, narrow problems. Don't try to fix everything. Look for a process that's genuinely broken, genuinely important, and genuinely solvable with data and AI. In the insurance example, it was claims processing. What's your claims processing?
Step 3: Build a cross-functional team. Data scientists, engineers, domain experts, operations people, whoever understands the process deeply. Make this team responsible for success or failure. Don't let them hand off their work to someone else.
Step 4: Design the workflow first, technology second. Draw out how the process should work with AI helping at critical points. How does data flow? Where are the decision points? What information does someone need to make good decisions? Only then do you pick tools and models.
Step 5: Start with orchestration, not models. Get your data flowing reliably between systems. Get it in formats your AI system can work with. Test this before you add the AI. You're half done once data orchestration is working.
Step 6: Implement AI at decision points. Once data is flowing, add AI agents at the places where they'll have the most impact. Not everywhere. Not at first. Just at the critical decision points.
Step 7: Measure obsessively. You should have baseline metrics from before AI. You should track what changes. You should be able to show exactly what value the system is creating. If you can't measure it, you haven't actually solved the problem.
Step 8: Iterate rapidly. Get 70% of the way there and release. Learn what matters. Improve. Release again. Don't try to ship perfection.
The Future of AI in Enterprise: Where This is Heading
If the last year has taught us anything, it's that the companies dominating AI aren't the ones with the biggest models. They're the ones with the best data infrastructure and the deepest understanding of their business problems.
Looking ahead, I expect to see a few clear trends:
Trend 1: Data infrastructure becomes a competitive advantage. Companies that can move data reliably, quickly, and at scale will be able to implement AI faster and more effectively than competitors. Data infrastructure investments that seem boring will drive competitive differentiation.
Trend 2: Agentic AI moves from hype to routine. Within a few years, the question won't be "should we use agentic AI?" It will be "how should we orchestrate our AI agents?" The technology is moving fast. Adoption will follow.
Trend 3: Workflow redesign becomes the real source of value. Point solutions will continue to disappoint. The companies creating value will be the ones redesigning entire workflows around what AI makes possible. That's harder work, but it's where the real ROI lives.
Trend 4: Domain expertise becomes more valuable, not less. As AI capabilities become commodified, the differentiator is understanding your business so deeply that you know where AI can actually help. Domain experts will be the bottleneck, not engineers.
Trend 5: The AI divide widens. Companies that figured out the data problem early will be years ahead of those still trying. The gap between AI leaders and AI laggards will become massive. This could affect entire industries.

How to Accelerate Your Path to AI Success
If you're the person responsible for getting your organization to the other side of the AI divide, here's my honest assessment:
You probably can't do it with your current approach. If you're still in "exploration" mode, if you're still thinking about AI as something you bolt onto existing processes, if your data strategy is still "we'll figure that out later," you're going to end up in the 95% that struggles.
But the path forward is clear. It's not mysterious. It's not even that complicated. Dozens of companies have already done it.
Focus on data foundation first. Understand your data landscape. Don't try to migrate everything at once. Use AI to make your data usable. Then pick one important problem and solve it comprehensively. Involve domain experts. Design workflows, not point solutions. Measure what matters. Iterate.
Do those things consistently, and you'll be in the 5% that's actually creating value from AI.
The companies on the wrong side of the AI divide aren't there because they lack intelligence or resources. They're there because they're trying to do things in the wrong order. Fix the sequence, and everything else becomes possible.

FAQ
What is the AI divide and why is it growing?
The AI divide is the expanding gap between companies that are successfully extracting business value from artificial intelligence investments and those that are spending money on AI without seeing real results. Despite massive investment in AI technology and adoption, roughly 95% of enterprise AI projects fail to deliver meaningful value, while a small percentage of companies are seeing transformative results from AI implementations. This gap exists because successful companies understand that data foundation and workflow redesign are prerequisites to AI success, while struggling companies are trying to implement sophisticated AI models on top of fragmented, siloed data infrastructure.
Why do 95% of enterprise AI projects fail?
Most AI projects fail because companies prioritize technology implementation before addressing their underlying data problems. Specifically, they attempt to deploy advanced AI models and automation on data that lives in siloed systems, lacks consistent formatting, has quality issues, and isn't accessible across the organization. Rather than treating data fragmentation as something to solve with AI itself, companies try to fix the data problem through expensive, slow migrations before attempting AI. By the time data infrastructure is ready (if it ever is), the original business case has become outdated. The 5% of companies that succeed flip this sequence: they use AI to make their data usable, then apply AI to business problems.
How does data-readiness differ from data quality, and why does it matter for AI success?
Data quality is about individual records being accurate and complete. Data-readiness is about your organization's ability to discover, access, orchestrate, and use data across siloed systems at scale. You can have excellent data quality in one system and still fail at AI because data from that system can't talk to data from other systems. Data-readiness requires that data is discoverable (people know it exists), accessible (people can actually reach it), orchestrated (data flows reliably between systems), and quality-checked (you understand reliability issues). It's data-readiness that determines whether your AI systems will actually work with real business data at scale.
What is workflow orchestration and how does it relate to AI success?
Workflow orchestration is the automated coordination of multiple systems, processes, and data sources to execute complex business workflows where AI agents handle translation, quality assurance, and decision-making between incompatible components. Rather than building custom connectors to make each system talk to other systems (expensive, fragile, doesn't scale), orchestration uses intelligent agents as intermediaries. An AI agent understands what one system outputs, translates it to a standardized format, and passes it to the next system. When systems change or new ones are added, agents adapt rather than requiring new integration code. Orchestration is how you get AI systems to work reliably in complex enterprise environments with many incompatible data sources.
Can agentic AI actually solve the data discovery and transformation problem?
Yes, and this is where the real innovation is happening. Rather than treating data discovery and transformation as prerequisites to AI (which requires expensive consulting, months of planning, and custom ETL code), companies are using agentic AI to solve the data problem itself. AI agents can automatically scan systems to discover relationships between datasets, understand data quality issues, translate data between incompatible formats, and identify data that's missing or unreliable. This approach is faster, cheaper, and more flexible than traditional data infrastructure projects, because AI agents can adapt to new systems and new data formats without requiring new code.
How should we measure ROI from AI investments?
Rather than looking for a single ROI metric, successful companies track multiple dimensions: speed improvements (how much faster do critical processes complete?), quality improvements (are decisions more accurate or effective?), cost reductions (where is repetitive work actually being eliminated?), risk reduction (what errors or exposures is AI preventing?), and enablement (can people handle more volume or complexity?). The key is measuring against clear baselines: what was the process before AI? What metrics mattered? Now that AI is involved, how have those metrics moved? If you can't measure changes in business outcomes, your AI implementation isn't actually delivering value. Most companies that struggle with AI never get to this measurement phase because they're still trying to prove the concept works years after deployment started.
What's the relationship between domain expertise and AI implementation success?
Domain expertise is crucial to AI success because AI models can produce confident mistakes without it. A language model can write insurance policy language, but it doesn't understand regulatory implications. It can analyze financial data, but it doesn't understand your industry's accounting quirks. The companies succeeding at AI aren't replacing domain experts with models. They're augmenting domain experts with AI. An experienced claims adjuster with access to AI agents that handle data orchestration and pattern analysis becomes far more effective than either the adjuster or the AI working alone. This means domain experts need to be at the table during AI system design, not just during rollout. They inform what the AI should do, where it might go wrong, and what exceptions matter.
What is the typical path from AI exploration to AI success?
Most organizations follow a maturity curve: Stage 1 (Exploration with many pilots), Stage 2 (Data Foundation Realization where projects often stall), Stage 3 (Targeted Implementation solving one important problem comprehensively), Stage 4 (Process Transformation where AI is embedded in how work gets done), and Stage 5 (Continuous Evolution where AI becomes routine). The critical transition is between Stage 2 and Stage 3, which is where organizational competency actually develops. Organizations that successfully make this transition reduce their AI project failure rate from 95% to below 30%. The path forward involves auditing your data landscape, identifying high-impact narrow problems, building cross-functional teams, designing workflows before technology, implementing data orchestration first, and measuring obsessively.
How can we avoid the most common AI implementation mistakes?
The most damaging mistakes are: leading with the model instead of the problem and data (pick your model last, not first); expecting AI to fix bad data (data quality must come first); building AI in isolation without domain expert input; ignoring the organizational change and human adoption challenge; pursuing perfection instead of releasing at 70% quality then iterating; building things technically impressive that don't solve actual business problems; and treating AI as a cost center instead of a strategic capability. Each of these is preventable if you're aware of them. The common thread is that successful AI implementations involve deep collaboration between technologists and domain experts, ruthless focus on business outcomes rather than technical sophistication, and acceptance that it's a learning journey rather than a final destination.
Why do companies still fail at AI despite having more resources and better models than ever before?
Technology is not the constraint. The constraint is organizational understanding of the proper sequence for AI implementation. Companies that fail typically start with technology ("we're deploying a GPT model") instead of starting with problems ("this process is too slow") and data ("here's what data we have access to"). They also treat data infrastructure as a prerequisite that takes too long and costs too much, rather than as something AI can help solve. Even with unlimited budget and access to the best models, if you're working with fragmented, siloed data and trying to automate isolated tasks without redesigning workflows, you'll be part of the 95% that struggles. The companies succeeding aren't smarter or better resourced. They're just sequencing their work differently.
If your organization is still on the wrong side of the AI divide, the issue isn't a lack of talent or resources. It's that you're approaching the problem in the wrong order. Start with understanding your data landscape and the business problems you're actually trying to solve. Use AI to make your data more usable. Then redesign workflows to leverage AI at critical decision points. Measure what matters. Iterate. That's the path to the 5% that's actually creating value.
The companies dominating AI three years from now won't be the ones with the biggest models. They'll be the ones with the best data foundations and the deepest understanding of their business. Get those right, and everything else follows.

Key Takeaways
- 95% of enterprise AI projects fail because companies prioritize technology before fixing their data foundation and business workflows
- Data-readiness (accessibility, discoverability, orchestration, quality understanding) is the single factor separating AI winners from losers
- Agentic AI can solve data discovery and transformation problems instead of treating data harmonization as a prerequisite to AI
- One major insurer reduced claims processing from 44 days to 2 days by embedding AI agents at decision points and standardizing data formats
- Successful AI implementations think in terms of entire workflow redesign, not point solutions, and measure impact across speed, quality, cost, risk, and enablement dimensions
- Companies transition from 95% failure rate to 30% success rate when they move from general exploration to targeted implementation of one high-impact problem
Related Articles
- The AI Deployment Gap: Why Surface-Level Integration Is Costing You [2025]
- SME AI Adoption: US-UK Gap & Global Trends 2025
- The AI Trust Paradox: Why Your Business Is Failing at AI [2025]
- Agentic AI Security Risk: What Enterprise Teams Must Know [2025]
- Windows 11 Hits 1 Billion Users: What This Milestone Means [2025]
- How AI Models Use Internal Debate to Achieve 73% Better Accuracy [2025]

