![How AI Models Use Internal Debate to Achieve 73% Better Accuracy [2025]](https://tryrunable.com/blog/how-ai-models-use-internal-debate-to-achieve-73-better-accur/image-1-1769713758491.jpg)
Introduction: Why Your AI Is Failing at Complex Reasoning
You've probably noticed something frustrating. You ask an AI model to solve a complex problem, and it confidently gives you an answer that's completely wrong. Or it nails the technical details but misses the obvious flaw in its own logic. Then you ask it the same question again and get a totally different answer.
There's a reason for this. Most AI models think in straight lines. They process information sequentially, reaching a conclusion and moving on. No second-guessing, no internal debate, no "wait, let me check that again."
Here's what's changed: The latest reasoning models don't work that way anymore. Instead of thinking in monologues, they've learned something remarkable. They simulate what researchers call a "society of thought." Inside a single model, multiple internal voices emerge. A skeptic challenges the optimizer. A cautious verifier questions the planner. A creative thinker proposes alternatives while a fact-checker pushes back.
This isn't multiple models running in parallel. It's one model developing the ability to argue with itself.
Recent research from Google and other labs reveals that this internal debate mechanism is exactly why advanced models like Deep Seek-R1 and Qw Q-32B are so much better at reasoning tasks. When you measure the difference, it's dramatic. Models using internal debate show improvement rates of 30-73% on complex tasks compared to their single-line-of-thought counterparts. For enterprises, this means building AI systems that actually catch their own mistakes, verify their own logic, and deliver more reliable results.
The implications go beyond academic curiosity. If you're building AI applications for mission-critical work—financial analysis, code generation, strategic planning, scientific research—understanding how internal debate works could be the difference between a tool that helps and one that hurts.
Let's break down exactly what's happening, why it matters, and how you can use this to build better AI systems.
TL; DR
- Society of Thought Creates Diverse Perspectives: Advanced reasoning models develop multiple internal personas with different expertise, personality traits, and viewpoints that challenge each other within a single model instance.
- 73% Accuracy Improvements Documented: Empirical research shows reasoning models using internal debate achieve significantly higher accuracy on complex reasoning, planning, and creative tasks compared to standard chain-of-thought approaches.
- Emerges Naturally from Reinforcement Learning: Models trained with RL develop internal debate autonomously without explicit human instruction, suggesting this is a fundamental emergent behavior.
- Enterprise Implementation Is Practical: Teams can prompt-engineer models to trigger debate structures, design systems for scaled test-time compute, and fine-tune on multi-party conversations to unlock these benefits.
- Bottom Line: Internal debate represents a fundamental shift in how AI reasoning works, enabling self-correction and robust decision-making that was impossible in earlier approaches.

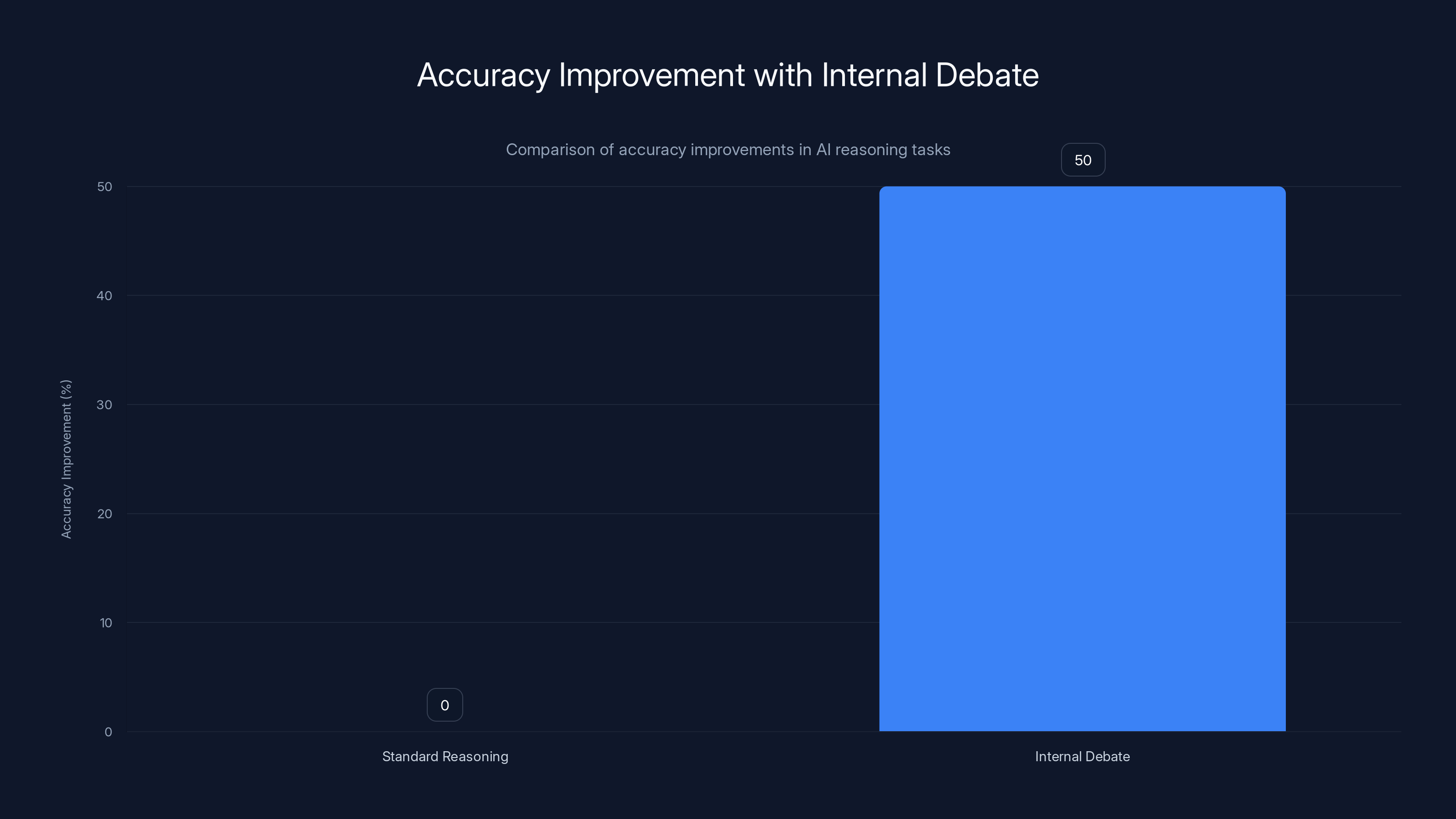
Internal debate improves accuracy by an estimated 50% on complex tasks compared to standard reasoning, highlighting the value of diverse perspectives. Estimated data.
What Is Society of Thought? The Cognitive Science Behind AI Debate
Let's start with the concept itself, because it's not as mystical as it sounds.
Society of thought is based on a deceptively simple idea from cognitive science: human reasoning evolved as a social process. We think better together than we think alone. When you're solving a complex problem, you debate alternatives, challenge assumptions, and consider different perspectives. That friction—those disagreements—actually makes your thinking sharper.
Now here's what's interesting about AI models. They've somehow learned to internalize this process. Instead of needing multiple humans (or multiple models) to generate debate, advanced reasoning models developed the ability to simulate multiple viewpoints within their own reasoning chain.
The research describes it this way: "cognitive diversity, stemming from variation in expertise and personality traits, enhances problem solving, particularly when accompanied by authentic dissent." Translation: different perspectives matter more than having lots of perspectives. What counts is that they actually disagree in productive ways.
Inside a model like Deep Seek-R1, this manifests directly in the chain of thought. You don't need to prompt it explicitly with "now think about this from another angle." The debate emerges autonomously. One internal voice proposes a solution. Another voice immediately questions it. A third voice provides new information. The model synthesizes these competing views into a refined answer.
The key insight here is that you're not running multiple models or multiple passes. You're watching a single model instance develop and resolve internal tensions. It's more like a really intelligent person thinking out loud, catching their own mistakes, and correcting course.
This happens because models trained with reinforcement learning (RL) are optimized for one thing: getting the right answer. If developing internal debate helps them reach better answers, RL will reinforce that behavior. The model learns that diverse reasoning paths lead to correct solutions more often than straightforward paths.
What makes this different from previous AI reasoning approaches is the absence of central control. Earlier systems used prompting tricks to force models to think step-by-step or to consider multiple options. Society of thought emerges naturally. The model discovers it works better and keeps doing it.
This is profound because it suggests that something fundamental changed in how these models process information. They're not just retrieving and synthesizing information anymore. They're evaluating competing claims, testing hypotheses, and refining conclusions through internal dialogue.
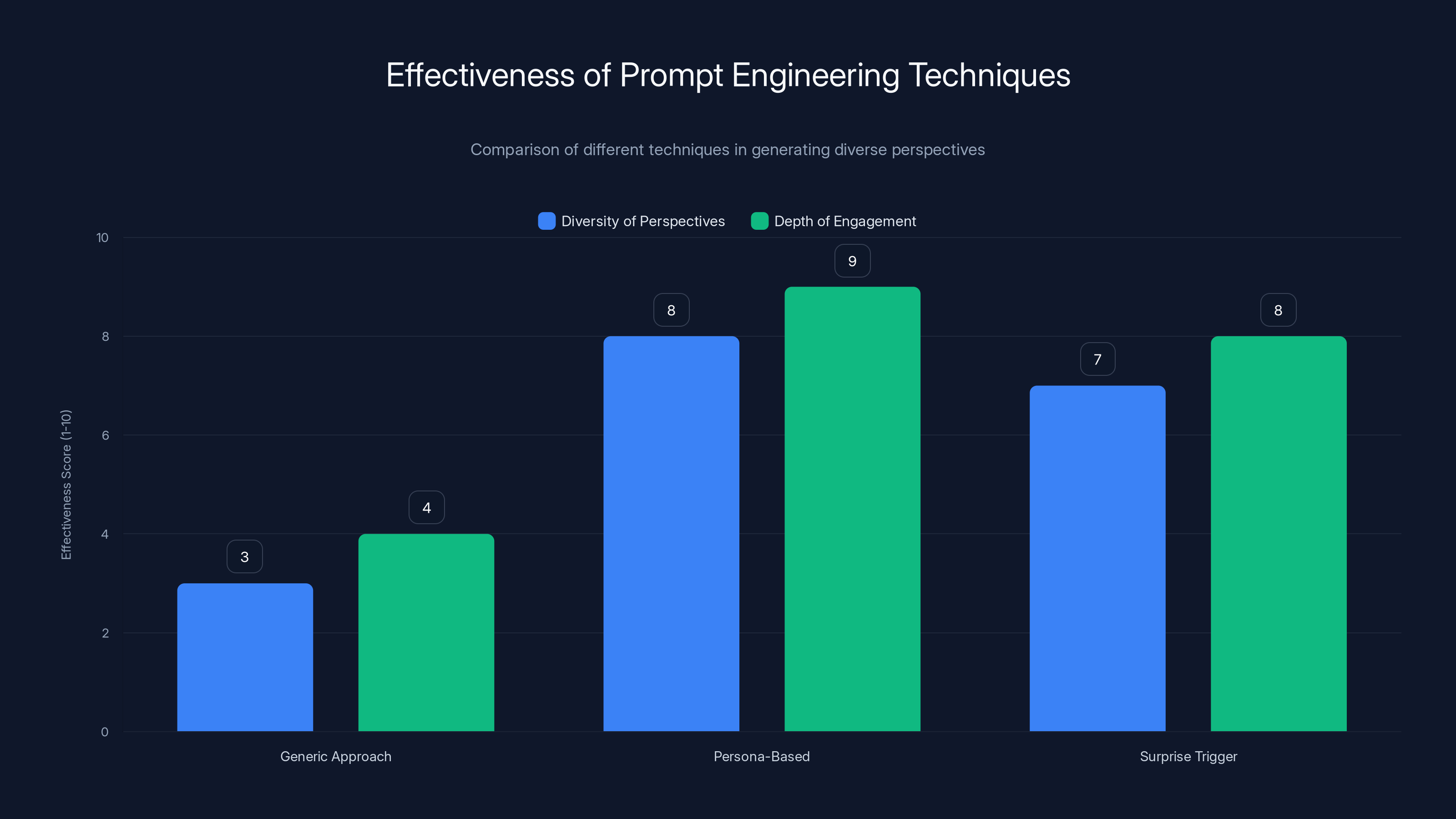
Persona-based prompting and surprise triggers significantly enhance diversity and depth in model-generated debates compared to generic approaches. Estimated data.
How Deep Seek-R1 Thinks: Real Examples of Internal Debate in Action
Theory is useful, but examples make it stick. Let's look at what actually happens inside these models when they're solving real problems.
The Chemistry Problem: Where Critical Verification Saves the Day
Consider a complex organic chemistry synthesis problem. This is exactly the kind of task where most models fail because it requires not just knowledge but verification.
Deep Seek-R1 encounters the problem and immediately spawns what researchers identified as distinct internal personas. There's a "Planner" voice that proposes a synthesis pathway based on chemical knowledge. The pathway looks reasonable. Standard reactions in a logical sequence.
But then another voice emerges: the "Critical Verifier." This persona is characterized as having high conscientiousness (detail-oriented, thorough) and low agreeableness (willing to challenge consensus). The Critical Verifier doesn't just accept the plan. It interrupts with a specific challenge: "Wait, that assumption about the reactivity here is based on standard conditions. What if we're in a different solvent system?"
The Verifier provides counter-evidence from different chemical literature. The Planner reconsiders. Together, they identify that the original pathway would fail under the problem's specific conditions. The model adjusts, proposes an alternative, and the Critical Verifier evaluates that too.
By the time the model reaches its final answer, it's not just proposed a solution. It's tested that solution against critical scrutiny and refined it. The accuracy improvement comes directly from this process.
The Creative Rewrite: Balancing Fidelity and Innovation
Here's where it gets less intuitive. You'd think internal debate would be most useful for technical problems with clear right answers. But models show similar patterns on creative tasks.
Take the sentence: "I flung my hatred into the burning fire."
A user asks the model to rewrite this while improving the style. The task sounds simple, but there's tension embedded in it. Improve style without changing meaning. Add freshness without adding new ideas.
Inside the model, a "Creative Ideator" voice starts suggesting alternatives. It proposes: "I hurled my deep-seated resentment into the blazing flames."
Then the "Semantic Fidelity Checker" voice responds: "But that adds 'deep-seated,' which wasn't in the original. We should avoid adding new ideas that weren't explicitly there."
This is fascinating because the two voices aren't just debating facts. They're debating values and constraints. The Ideator wants to improve elegance. The Checker wants to preserve fidelity. The model works toward a compromise that respects both priorities.
The result? Better rewrites that maintain the original meaning while genuinely improving the prose. Neither voice would have achieved that alone. The Ideator would have overreached. The Checker would have blocked most improvements.
The Countdown Game: Emergent Strategy Switching
Perhaps the most striking example comes from a mathematical puzzle called the Countdown Game. You're given specific numbers and must use them to reach a target value. It's harder than it sounds because you can only use each number once.
Early in training, before RL optimization, the model approached this with a monologue strategy. It would try combinations sequentially, and when they failed, it would just try more combinations. Not very effective.
But as the model trained with RL, something remarkable happened. It spontaneously developed a two-voice structure. A "Methodical Problem-Solver" voice handles the calculations and tracks progress. An "Exploratory Thinker" voice monitors the process and suggests strategy changes.
Here's how it worked: The Problem-Solver would start trying standard approaches—addition, multiplication, working toward the target. When that stalled, the Exploratory Thinker would interrupt: "Again no luck. Maybe we can try using negative numbers. What if we work backward from the target instead of forward?"
The Problem-Solver would switch strategies based on this guidance. The accuracy improvement was dramatic. The model wasn't just thinking harder. It was thinking differently, and it was making those switches at the right moments.
The key observation: the model developed this structure entirely through RL optimization. Nobody wrote explicit prompts forcing this two-voice structure. The model discovered it was more effective and kept using it.
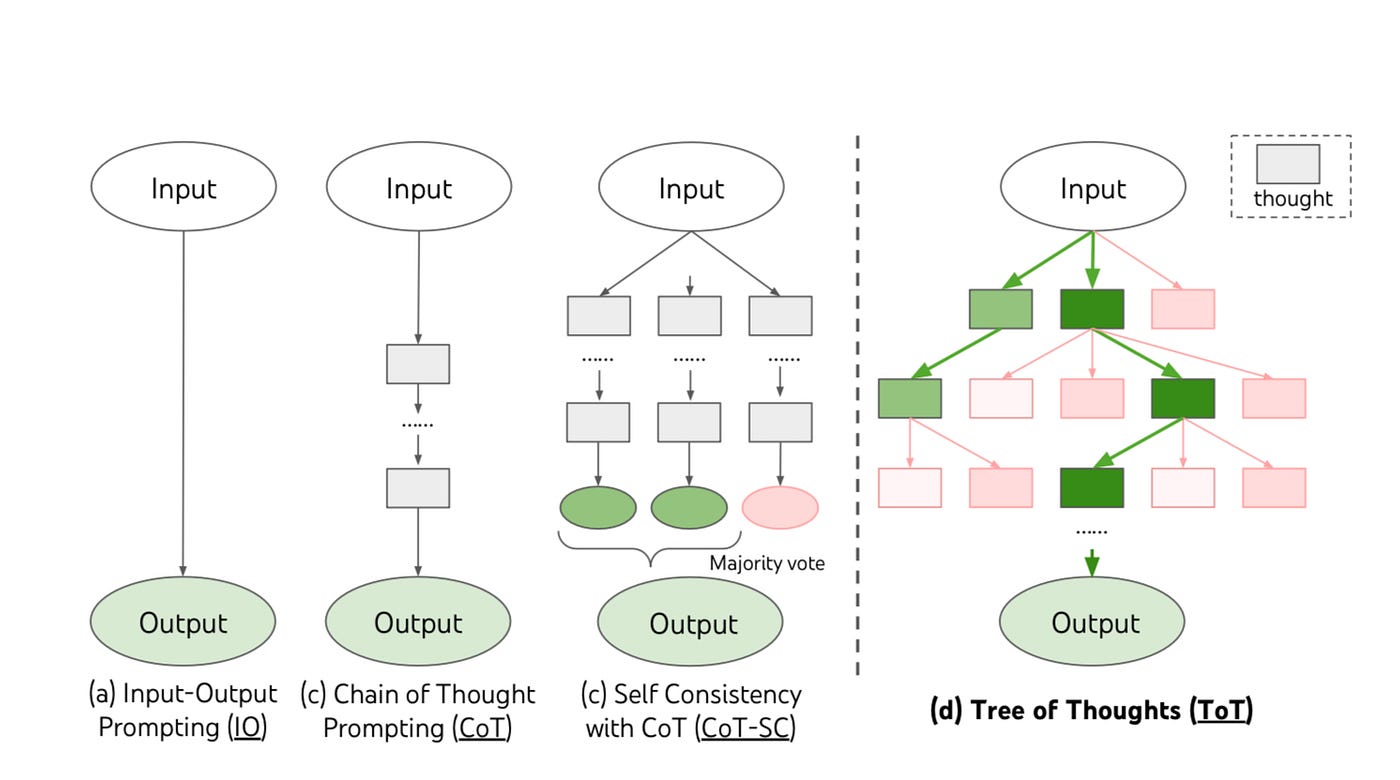
Why Monologues Fail and Debate Succeeds: The Mechanics of Better Reasoning
Let's dig into why this matters mechanically. Why is internal debate fundamentally better for reasoning than longer chains of thought?
The core problem with monologue reasoning is a psychological one, even in AI. When you commit to a path and start explaining it, you get invested in that explanation. You unconsciously seek information that supports your initial direction and rationalize around contradictions. This is confirmation bias, and models have their own version of it.
A longer monologue doesn't fix this. It amplifies it. The model just generates more sophisticated-sounding justifications for the same flawed initial assumption.
Internal debate breaks this pattern. When a different voice challenges the first answer, the model must genuinely reconsider. It's not an option to just double down. The debate forces evaluation of alternatives.
Research measured this empirically. When models use only monologue chains of thought, they plateau at certain accuracy levels. Adding debate doesn't just extend the plateau. It shifts the entire curve upward. And crucially, longer monologues don't get you there. You need the diversity.
One experiment made this explicit: researchers artificially manipulated the model's activation space to suppress "conversational surprise" and suppress personality-related features. What happened? Accuracy dropped by roughly 50% on complex tasks. The moment you remove the diversity of perspectives, you lose the benefits.
Conversely, when models are fine-tuned on multi-party conversation datasets (actual debates between voices), they outperform models fine-tuned on standard chains of thought by substantial margins. The data encoding these debates is more useful than longer individual reasoning chains.
Another finding challenges conventional wisdom directly: Supervised fine-tuning (SFT) on monologue data actually underperforms raw RL that naturally develops multi-agent conversations. This suggests that the dialogue structure itself is part of what gets learned, and you lose something if you filter it out.
This has huge implications. It means that test-time compute (giving models more time and resources to reason) is most useful when that compute is spent on diverse reasoning paths, not just longer paths. A model that debates for 10 steps will often outperform a model that monologues for 100 steps.
The mechanisms that enable this superiority are concrete:
Verification and backtracking: When a critic voice challenges an assumption, the model backtracks to check it. This catches logical errors early.
Alternative exploration: Different voices naturally explore different solution paths. The model discovers approaches it wouldn't have considered in a monologue.
Bias detection: A skeptical voice catches overconfidence and unsupported leaps. A risk-averse voice flags dangerous assumptions.
Synthesis: The model learns to combine insights from different voices rather than just picking one winner. The final answer often incorporates wisdom from multiple perspectives.
None of this requires explicit prompting, though it can be enhanced with thoughtful prompting. It emerges because models optimize for accuracy through RL, and these debate structures improve accuracy.
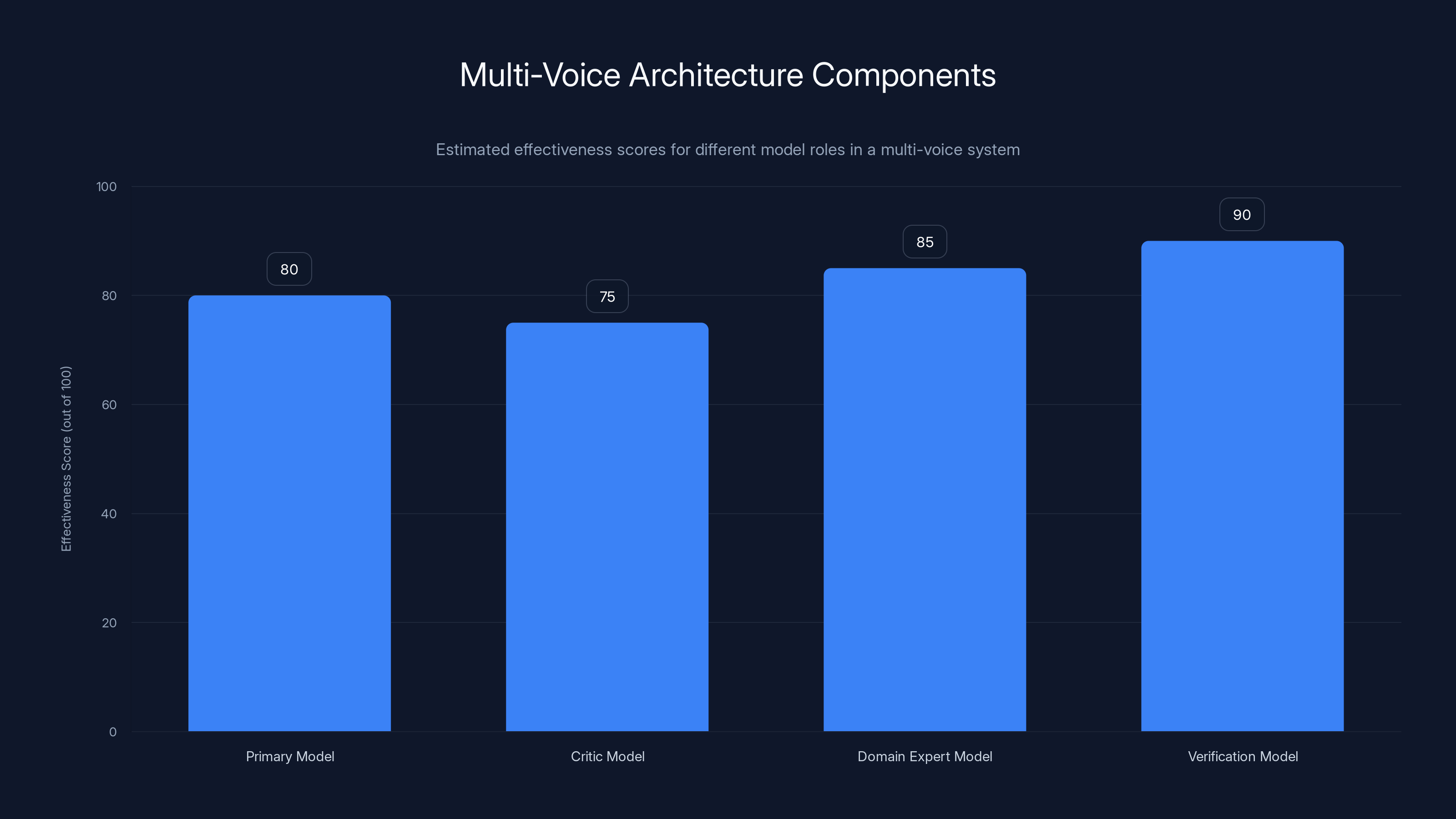
Estimated data shows that verification models tend to have the highest effectiveness in multi-voice architectures, ensuring consistency and accuracy.
Training Dynamics: How Internal Debate Emerges Through Reinforcement Learning
Understanding how internal debate develops during training is crucial for building systems that leverage it effectively.
When models train with standard supervised learning on curated examples, they tend to mimic the training data. If training data is mostly monologues with occasional diversity, the model learns to output mostly monologues.
But reinforcement learning works differently. The model gets a reward signal: "this answer was correct" or "this answer was wrong." The model then tries to figure out what reasoning patterns lead to correct answers.
Over many iterations, something interesting emerges. Models discover that internal debates—generating multiple perspectives and evaluating them—lead to more correct answers. Not sometimes. Significantly more often.
The models aren't being told to debate. They're being incentivized to be correct. Debate happens to be an effective strategy for correctness.
This is where it gets sophisticated. Different models, trained with different architectures and RL procedures, independently converged on similar debate structures. Deep Seek-R1 and Qw Q-32B both developed this society of thought behavior without being explicitly prompted to. This suggests it's a fundamental solution that models discover when optimizing for accuracy.
The implications are important: you can't engineer this by just writing better prompts on top of non-reasoning models. The model needs to be trained with RL on tasks where accuracy matters. That training process shapes the internal structure.
But here's the practical insight: once a model has developed these capabilities through RL training, you can enhance them further with smart prompting. You're not creating debate from scratch. You're amplifying something that already exists in the model's learned structure.
Research on this showed something counterintuitive: Supervised fine-tuning models on monologue chains of thought actually erases some of this emergent debate capability. When you filter training data to only show the final reasoning path, you remove the signals about how disagreement and alternative consideration actually work.
Conversely, fine-tuning on multi-party conversation datasets (where you preserve the debate structure) significantly enhances performance. You're not teaching the model to debate. You're showing it examples of what successful debates look like, and it generalizes that pattern.
This has a direct implication for how enterprises should think about fine-tuning. If you're fine-tuning reasoning models on your own domain-specific data, preserve the debate structure in your training examples. Don't oversimplify to single reasoning paths.

Practical Implementation: Prompt Engineering for Internal Debate
Alright, so these capabilities exist in modern reasoning models. How do you actually use them?
The naive approach is asking for a debate directly: "Now think about this from a different perspective." This sometimes works, but it's weak. The model often just generates the same idea again with different wording.
What actually works is role-specific prompting with genuine conflicting incentives. Instead of generic roles, you assign personas with opposing dispositions.
Consider this approach for a business decision: Instead of "think about risks," you create two explicit personas:
Persona 1 (Growth-Focused Product Manager): "Focused on market opportunity and competitive advantage. Tends toward optimism about execution timelines and market response. Values speed to market and first-mover advantage."
Persona 2 (Risk-Averse Compliance Officer): "Focused on regulatory requirements, data security, and legal liability. Naturally skeptical of timelines. Wants to validate assumptions thoroughly before commitment."
Then you structure the prompt so these personas must genuinely debate the decision. Not "consider both views." Actually engage in disagreement and resolution.
The magic is the opposing incentives. A growth-focused persona and a risk-averse persona won't accidentally agree. They'll naturally find tension points. The model then has to work through those tensions to reach a conclusion.
Compare this to a generic "pros and cons" list approach. A generic approach can feel balanced while actually being shallow. The persona approach forces deeper engagement because the personas have real stakes in different outcomes.
Another technique that works well: trigger surprise. Research showed that prompting models to express uncertainty or surprise activates a broader range of personality and expertise features. A simple cue like "This is unexpected because..." can trigger better debate.
Or structure prompts around verification: "Before finalizing, list three ways this could be wrong." This explicitly invokes the critical verifier voice.
These techniques work because they're not fighting the model's learned structure. They're activating patterns the model already knows how to use.
Here's a concrete example for technical planning:
Instead of: "What are potential issues with this architecture?"
Use: "An experienced architect optimizing for performance disagrees with a reliability engineer optimizing for fault tolerance on this design. What's their argument? How do they resolve it?"
The second version forces genuine tension because performance optimization and fault tolerance optimization actually have tradeoffs. The model can't just agree with both. It has to work through the conflict.
This is replicable across any domain. Financial decisions (growth vs. caution), product decisions (speed vs. quality), technical decisions (optimization vs. maintainability). Assign personas with genuinely conflicting optimization criteria, and debate emerges naturally.
One caution: this works best with reasoning models that have been trained with RL. General-purpose models like GPT-4 can approximate it through prompting, but they don't have the same internal structure that reasoning models developed. The debate feels a bit more forced.
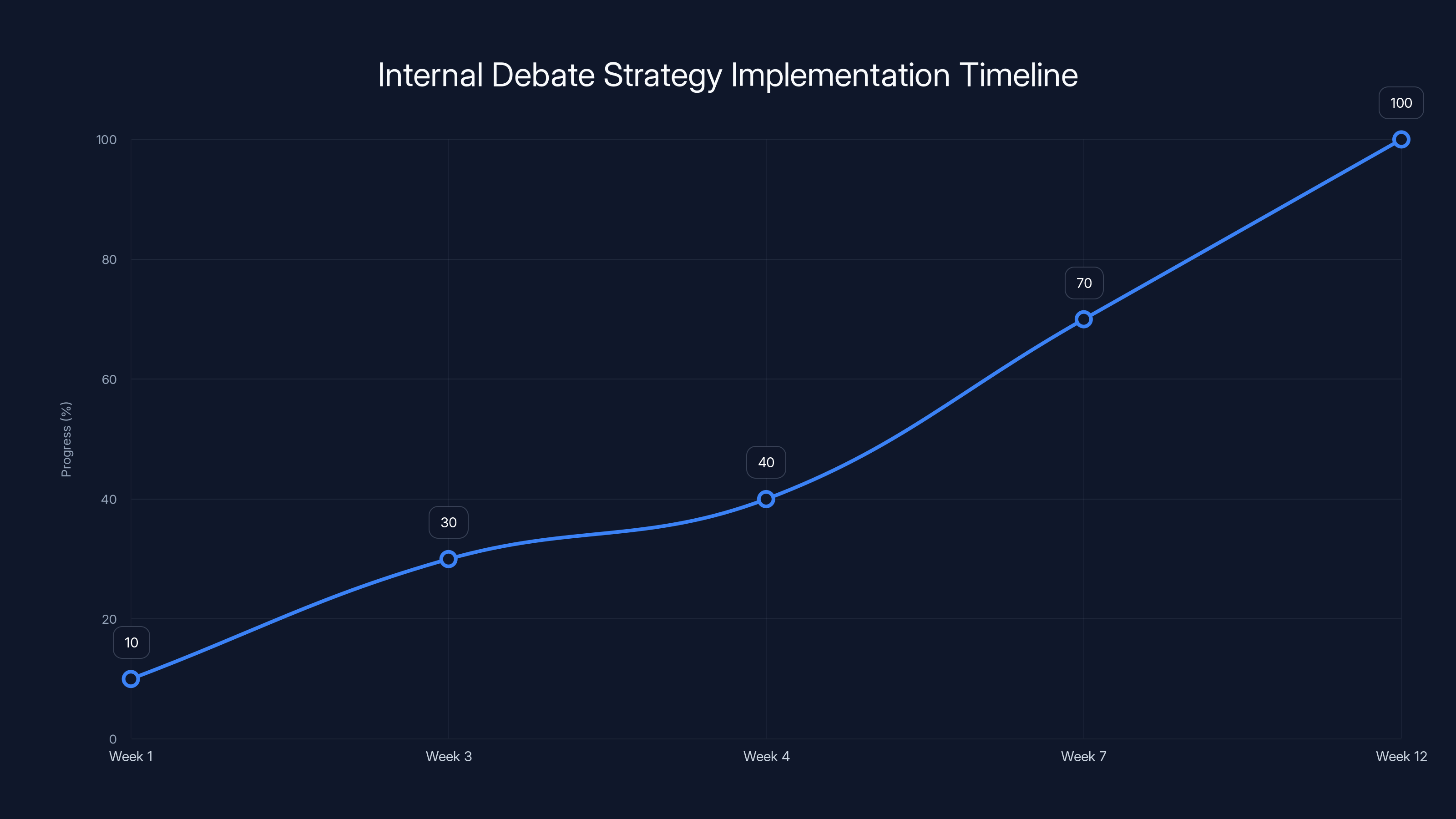
The roadmap for building an internal debate strategy spans approximately 12 weeks, with key phases including evaluation, use case identification, debate structure design, proof of concept, and iteration. Estimated data.
Scaling Test-Time Compute: When to Let Your Model Think
Here's another practical insight that flows from understanding internal debate: how you allocate compute during inference matters.
Traditional models optimize for fast inference. You get one forward pass, you get one answer, done. But reasoning models benefit from test-time compute. The model gets more time (or more samples) to develop its reasoning.
The question is: what's the optimal way to use that compute?
Naive approach: longer chains of thought. Just give the model more tokens to output.
Better approach: budget for debate. Allocate compute toward generating diverse reasoning paths and evaluating them.
This might mean:
Multiple samples with synthesis: Run the model several times with temperature > 0 to get diverse reasoning chains. Then have the model synthesize across them. This creates natural debate between the different samples.
Explicit verification passes: After a first reasoning attempt, allocate compute to a verification phase where a different voice (or a second model) critiques the first answer. The system then synthesizes feedback.
Iterative refinement: Start with a rough answer, then have different voices refine it based on different criteria. This is cheaper than longer monologues and often more effective.
The key metric is not total tokens generated but diversity of reasoning paths. A model that explores 5 different approaches and synthesizes them will usually outperform a model that generates a 5x longer single approach.
For enterprises, this has cost implications. If you're paying per token (like with API-based models), you might assume longer reasoning is more expensive and is only worth it on the hardest problems.
Actually, strategic debate-focused reasoning at moderate lengths often yields better cost-to-accuracy ratio than longer monologues. You're spending tokens more efficiently.
For fine-tuned models running on your own infrastructure, you have even more control. You could:
- Generate multiple reasoning chains and use a separate critic model to evaluate them
- Route complex queries to deeper debate structures (more personas, more iterations)
- Cache verified knowledge so debate doesn't waste compute re-verifying obvious facts
- Use specialized voices for different domains (a code reviewer voice, a domain expert voice, etc.)
The architecture becomes more like a system that thinks together rather than a single model that monologues.

Building Robust Systems: Beyond Single Models to Multi-Voice Architectures
Okay, so individual models can debate internally. What about building actual systems?
This is where things get interesting for enterprise applications. You don't have to wait for all models to develop perfect internal debate. You can architect systems that create productive debate between different components.
One approach: use different models as different voices. You might have:
- A primary model generating initial solutions
- A specialized critic model trained to identify flaws
- A domain expert model trained on specific knowledge
- A verification model that checks consistency
These run sequentially or in parallel, and the system synthesizes their perspectives. This is more expensive than single-model debate, but it gives you fine-grained control over what kinds of debate happen.
For example, a financial analysis system might structure it as:
Analyst voice (GPT-4 or Claude): Generates initial analysis and recommendations
Risk voice (fine-tuned model optimized for risk identification): Reviews the analysis for hidden risks
Regulatory voice (fine-tuned model trained on compliance frameworks): Checks regulatory implications
Synthesis (reasoning model): Integrates feedback and produces final recommendation
Each voice brings genuine expertise (or simulated expertise through training). The debates between them are productive because they have different optimization criteria.
Another approach for enterprises: debate templates. You define common debate structures for your most important decision types. For technical architecture decisions, you always run: optimization voice vs. reliability voice. For product decisions: growth voice vs. quality voice.
You can even score the quality of debate. Did each voice actually make a substantive point? Did the synthesis genuinely address concerns from minority voices? These metrics help you catch when systems are just going through the motions.
The architecture question becomes: what trade-off do you want? Speed vs. robustness? Cost vs. accuracy?
Internal debate within a single model is fastest and cheapest. Multi-model debate is more robust but slower. Hybrid approaches (internal debate within models + verification via specialist models) balance these concerns.
For mission-critical applications, the answer is often: don't optimize for speed. Optimize for correctness. Let the system debate. The computational cost is usually small compared to the cost of wrong decisions.
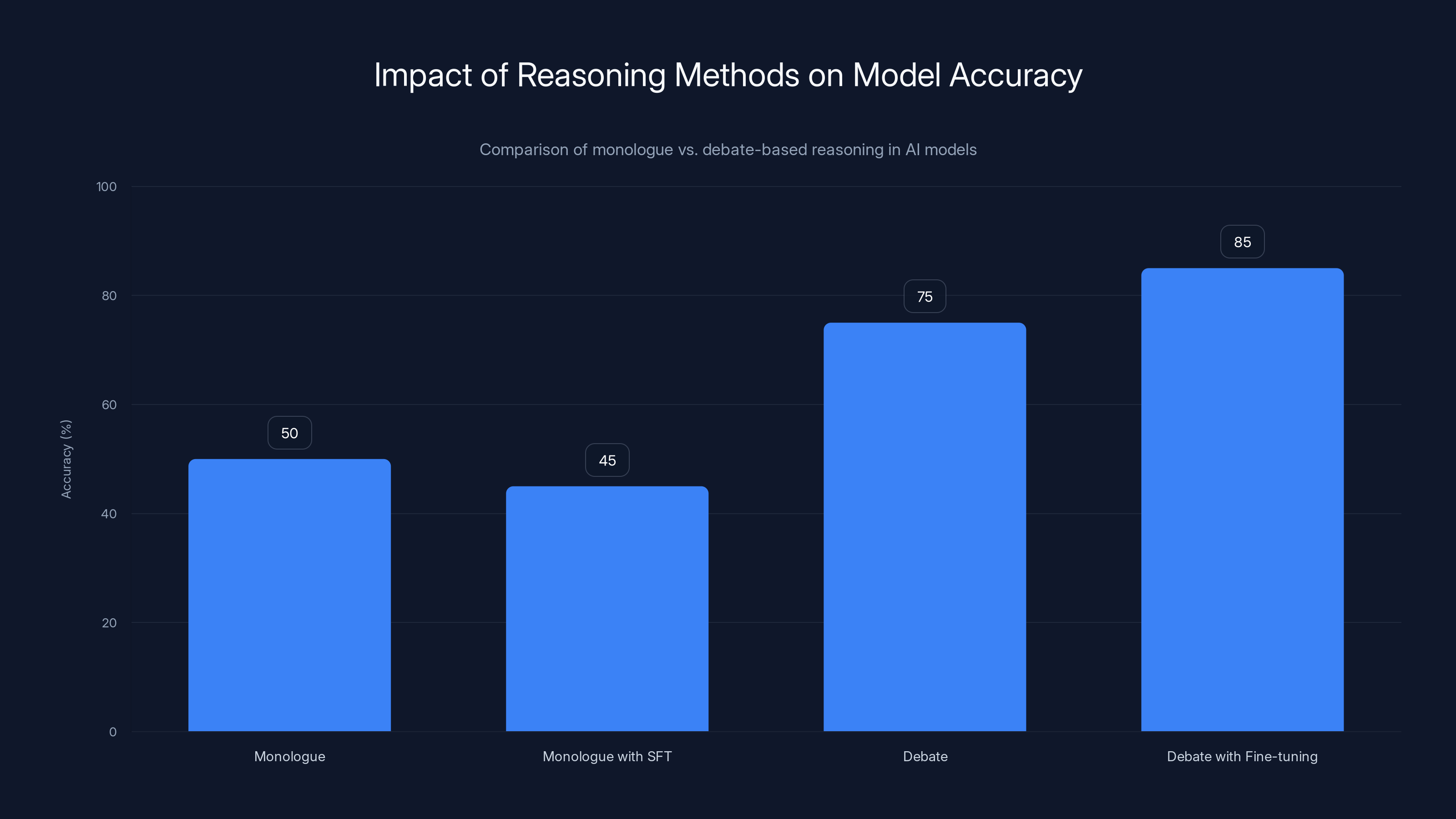
Debate-based reasoning significantly improves model accuracy compared to monologue methods, especially when fine-tuned on debate datasets. Estimated data based on typical findings.
Fine-Tuning on Your Own Data: Creating Domain-Specific Debate
If you have specialized data and want to build models for specific domains, how do you preserve and enhance internal debate?
The research on training dynamics points to a clear approach: fine-tune on multi-party conversations, not single reasoning chains.
This sounds like an extra burden, but it might actually be lower friction. Instead of curating perfect single reasoning paths, you collect examples where domain experts debate or where reasoning naturally explores alternatives.
For a legal domain example: Instead of training on "here's the right legal analysis," train on "lawyer A argues the contract means X, lawyer B argues it means Y, here's how they resolve it."
The debate examples encode more useful information. The model learns not just facts but how to handle conflicting interpretations. When you deploy it, it has these patterns internalized.
Another practical approach: synthetic debate generation. You can use stronger models to generate multi-party debate examples, then use those to fine-tune weaker models. An expert model generates "here's how a senior architect and junior architect would discuss this design decision," and you fine-tune on that.
This works better than you'd expect because the patterns are often reusable across similar problems.
For implementing this:
Step 1: Collect base domain examples - Gather representative problems or decisions in your domain
Step 2: Generate debate examples - Use a strong model to generate multi-perspective debate on those examples
Step 3: Curate and augment - Have domain experts refine the debates, add their own perspectives
Step 4: Fine-tune - Train your target model on this debate-rich dataset
Step 5: Test and iterate - Benchmark against baseline. Adjust persona definitions if debate is too shallow.
The key is maintaining diversity in the training data. If all debates converge to the same conclusions, you're not really training debate. You're training consensus. The value comes from examples where perspectives differ and have to be resolved.
For enterprises, this also creates an interesting feedback loop. As your deployed system generates debates and makes decisions, you can capture those debates (the good ones and the mistakes) as training data. Your model improves over time as it learns from its own debate patterns.
Common Failure Modes: When Internal Debate Doesn't Work
Inside every useful technique is a set of failure cases. Understanding when internal debate fails is as important as knowing when it works.
Failure Mode 1: Fake Diversity
The model generates multiple perspectives that are actually the same underlying idea dressed in different language. The "debate" is a monologue wearing different hats. This happens when you don't have genuine conflicting incentives in your prompts.
Solution: Make sure personas have opposite optimization criteria, not just different starting points.
Failure Mode 2: False Consensus
The model generates disagreement early but then rushes to agreement that ignores one perspective's genuine concerns. The debate is performative, not substantive.
You see this when prompts pressure the model toward a final answer too quickly. The model cuts off the debate before it's productive.
Solution: Explicitly ask for resolution of disagreements. "How do these perspectives reconcile their different concerns?" rather than "come to a final answer."
Failure Mode 3: Paralysis Through Too Much Debate
The model generates endless debate without reaching useful conclusions. Compute is wasted on circular arguments.
This happens with too many voices or voices with irreconcilable differences. Some debates won't resolve because they're genuinely about different values, not facts.
Solution: Limit the number of voices to 2-3 for efficiency. Add a clear resolution criterion.
Failure Mode 4: Debate That Doesn't Leverage Domain Knowledge
The model debates at an abstract level without bringing specific domain expertise into the disagreement. Generic debate is less useful than debate that's informed by specific knowledge.
Solution: Structure personas with specific domain expertise assignments. "The financial perspective" is vague. "The treasury manager perspective focused on cash flow" is concrete.
Failure Mode 5: Debate That Privileges Confidence Over Accuracy
Both sides of the debate sound confident, so the model picks the one that sounds more confident, which might actually be wrong. Debate without verification is just opinion polling.
Solution: Include verification steps that check claims, not just accept confident-sounding assertions. A verifier voice that demands evidence.
The pattern here: debate is powerful when it's structured and specific. Unstructured or overly generic debate is often worse than no debate. The system wastes compute on circular discussions without gaining useful output.
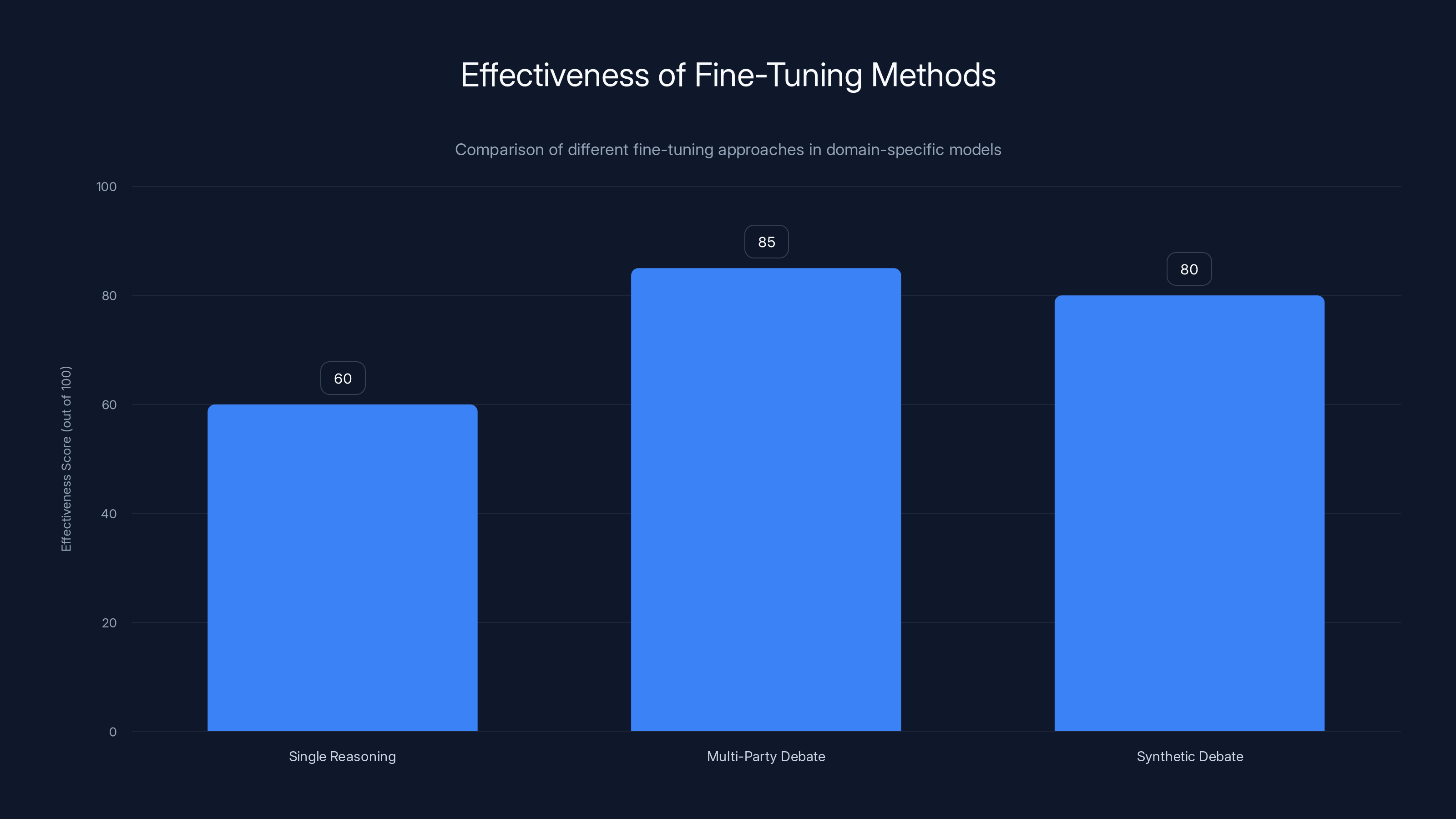
Multi-party debate fine-tuning shows higher effectiveness in domain-specific models compared to single reasoning chains. Synthetic debates also perform well, offering reusable patterns. Estimated data.
Enterprise Applications: Where Internal Debate Delivers Real Value
Let's get concrete about where this is actually useful in business contexts.
Financial Analysis and Decision Support
A finance team uses AI to evaluate potential acquisitions. The analysis needs to be robust because wrong decisions are expensive.
With internal debate architecture: an analyst voice proposes valuation and synergy analysis. A risk voice scrutinizes assumptions about market conditions. A legal voice flags regulatory concerns. A realistic voice questions overly optimistic timelines.
The synthesis integrates these perspectives into a recommendation that explicitly acknowledges trade-offs and uncertainties. Decision-makers see the reasoning, including the points of disagreement.
Compare to a single model output: one number, one recommendation, no visibility into where experts would disagree.
The debate version catches risks the individual analysis might miss because different experts naturally focus on different concerns.
Product Requirements and Technical Design
A product team is deciding on architecture for a new system. Should they build monolithic or microservices? Should they prioritize rapid development or long-term maintainability?
Traditional approaches: either decision-makers argue until someone's decision wins, or they rely on a single architect's recommendation.
With debate: structure it as "growth-focused architect vs. reliability-focused architect." Let the system explore the tradeoffs. Surfaces which assumptions are load-bearing and which are negotiable.
The output isn't "do X" but "doing X requires accepting risks in these areas." Much better for actual decision-making.
Code Review and Quality Assurance
A system reviews code before deployment. A code quality voice looks for maintainability and style. A security voice looks for vulnerabilities. A performance voice looks for efficiency issues.
The debate surfaces where tradeoffs exist (maximum safety might hurt performance) and helps developers understand the reasoning.
This is starting to happen in real systems. Rather than having automated linters that say "fix this," imagine systems that explain "this approach is secure but slow; here are faster approaches with different tradeoff profiles."
Scientific Research and Hypothesis Generation
Researchers use AI to help formulate hypotheses and evaluate experimental designs. A theorist voice generates novel ideas. A skeptical voice questions whether ideas are actually testable. An empiricist voice asks what data would be needed.
The debate often surfaces weaknesses in proposed experiments before resources are spent. Different perspectives catch design flaws.
Content Generation and Creative Work
A writing system helps produce documentation or marketing content. A clarity voice prioritizes making content understandable. A persuasion voice tries to motivate action. An accuracy voice ensures claims are supported.
The internal debate often produces better content than any single optimization criterion.
Across all these applications, the pattern is the same: internal debate uncovers hidden tradeoffs, surfaces assumptions, and improves robustness.
The ROI usually isn't about speed. It's about accuracy, robustness, and catching expensive mistakes.

The Future: Advanced Debate Architectures
We're still early in this curve. Current implementations are relatively straightforward: one model with multiple voices, or a few models in sequence.
What's likely coming?
Hierarchical Debate: Some perspectives matter more for some domains. Future systems might weight voices by relevance. A security perspective matters more for some decisions, less for others. Dynamic weighting improves efficiency.
Meta-Debate: Debate about how to debate. Different decision types might need different debate structures. Financial decisions might benefit from more voices. Time-sensitive decisions might need faster debate. Systems that choose their own debate structure.
Cross-Domain Synthesis: Expert models trained on narrow domains debating at scale. Imagine systems where a materials science specialist, a manufacturing engineer, and an economist all debate design tradeoffs for a new product.
Debate With Humans in the Loop: Humans injecting perspective mid-debate. A system debates, shows intermediate conclusions, humans provide insight or correction, debate continues. Much more collaborative than current "human asks question, AI answers" patterns.
Certified Debate: Systems that prove their debate was thorough. Not just "we considered multiple perspectives" but provably having engaged with strongest versions of competing arguments.
These aren't far-fetched. Most require engineering more than fundamental innovation. The research foundation (internal debate improves reasoning) is solid. The engineering challenge is scaling and directing that debate effectively.
For enterprises, the key insight is that this is a solvable problem. You don't need perfect models. You need well-structured debate.
The limiting factor is usually not technology but understanding how to prompt and structure debate in your specific domain. That requires domain expertise, iteration, and testing.
Comparing Approaches: Society of Thought vs. Traditional Chain of Thought
Let's compare side by side how these different reasoning approaches actually perform.
| Dimension | Standard Co T | Long Co T | Society of Thought | Multi-Model Debate |
|---|---|---|---|---|
| Accuracy on complex tasks | Baseline | +15-20% | +30-73% | +40-80% |
| Inference speed | Fast | Slow | Moderate | Slow |
| Cost per inference | Low | High | Moderate | Highest |
| Robustness to adversarial input | Low | Moderate | High | Very High |
| Explanation quality | Good | Good | Excellent | Excellent |
| Detectability of errors | Low | Moderate | High | Very High |
| Infrastructure complexity | Simple | Simple | Moderate | Complex |
| Capability on reasoning tasks | Moderate | Moderate-High | High | Very High |
| Capability on creative tasks | Moderate | Moderate | High | High |
| Fine-tuning data efficiency | High | Moderate | Moderate | Low |
The pattern: Society of Thought gives you much better accuracy than longer monologues while using less total compute. That's the core finding.
Multi-model debate beats everything on accuracy but requires the most infrastructure and complexity.
For most enterprise applications, Society of Thought (internal debate within reasoning models) hits the sweet spot. Much better than baselines, reasonable computational cost, implementable with existing infrastructure.

Building Your Internal Debate Strategy: Practical Roadmap
If you want to implement this in your organization, here's a practical sequence.
Phase 1: Evaluate and Test (Weeks 1-3)
Get hands-on with reasoning models that support internal debate. Deep Seek-R1, Qw Q-32B, Claude's reasoning features. Try them on problems you care about.
Specifically: take a complex decision your organization makes regularly. Try it with standard prompting. Try it with society of thought prompting (competing personas). Measure quality and accuracy.
Budget: Minimal. Just API usage.
Phase 2: Identify High-Value Use Cases (Week 4)
Where does debate add most value? Usually:
- High-consequence decisions
- Complex decisions with hidden tradeoffs
- Decisions where speed is less critical than accuracy
- Decisions where your team currently debates anyway
Pick 1-2 use cases to pilot.
Phase 3: Design Debate Structure (Weeks 5-7)
For your chosen use case, design the personas and debate structure.
What conflicting incentives exist in this decision? Implement those as personas.
Write initial prompts. Test with your models. Refine based on results.
Key: make sure personas have genuine disagreement. Generic "pro and con" personas are weak.
Phase 4: Build Proof of Concept (Weeks 8-12)
Integrate into a workflow. Ideally: take actual decisions from your organization, run them through the debate system, compare quality and decisions.
Metrics: accuracy on decisions where you can verify the right answer later, quality of reasoning shown to decision-makers, speed of decision process.
Phase 5: Iterate and Expand (Ongoing)
Learn from Phase 4. What worked? What failed? Refine debate structures.
Expand to additional use cases or domains.
Consider: fine-tuning on your own data if you see strong potential.
Budget estimate for a mid-size organization: initial evaluation, low cost. POC and Phase 4, moderate cost (maybe $50-100K depending on scale and models). Phase 5 expansion, depends on scope.
ROI often comes from better decisions on high-consequence problems. A small number of better acquisitions, better technical decisions, or caught risks can easily justify the investment.
Key Insights and Actionable Takeaways
Let's synthesize the key points:
Internal debate is fundamental to reasoning quality. Models trained with RL spontaneously develop it because it works. Not a trick. A core mechanism.
Debate beats length. A shorter reasoning chain with diverse perspectives outperforms a longer monologue. If you're budgeting compute, optimize for diversity, not depth.
Structure matters. Unstructured debate is often worse than no debate. Personas need genuine conflicting incentives. Debates need to result in synthesis, not just disagreement.
Implementation is practical. You don't need perfect multi-agent systems. Good prompting + reasoning models gets you most of the way. Multi-model debate adds complexity but marginal returns.
It scales to domain-specific applications. Fine-tune on multi-party conversations from your domain. The patterns stick.
Timing matters in enterprise deployment. Debate is most valuable for high-consequence, complex decisions. Less valuable when decisions need to be made in seconds.
The overarching insight: AI systems are ready to move beyond single-line reasoning to more collaborative, debate-based reasoning. The technology works. The challenge is engineering it well for your specific needs.

FAQ
What exactly is society of thought in AI reasoning?
Society of thought is a reasoning pattern where a single AI model develops multiple internal perspectives with different personalities, expertise levels, and viewpoints that debate and challenge each other within the chain of thought. Rather than linearly proposing a single solution, the model generates conversations between these internal voices—a Planner might propose an approach while a Critical Verifier questions it, leading to refinement and more robust conclusions. This emerges naturally in models trained with reinforcement learning optimized for accuracy.
How does internal debate improve accuracy compared to standard reasoning?
Internal debate improves accuracy through several mechanisms: it forces verification of assumptions by having a skeptical voice challenge claims, it enables exploration of alternative solution paths through different perspectives, it catches biases and logical errors through diversity of viewpoints, and it naturally synthesizes different concerns rather than picking a single approach. Empirical testing shows improvements of 30-73% on complex reasoning tasks compared to standard approaches, with the key factor being perspective diversity rather than reasoning length.
Can I use internal debate with general-purpose models like GPT-4 or Claude?
Yes, but less effectively than with reasoning models like Deep Seek-R1 or Qw Q-32B. General-purpose models can simulate debate through prompting and role assignment, but they don't have the same internal structures that reasoning models developed during RL training. You can still use persona-based prompting to trigger debate-like behavior, but the naturalness and effectiveness will be lower than with models that evolved this capability through training.
What are the best use cases for implementing internal debate?
Internal debate delivers the most value for high-consequence decisions with complex tradeoffs, where accuracy matters more than speed, and where your organization already debates these decisions among team members. Practical examples include acquisition analysis, technical architecture decisions, product strategy, compliance review, scientific hypothesis evaluation, and financial planning. Less valuable for routine operational decisions or time-sensitive choices that require immediate answers.
How do I design personas that actually create productive debate?
The key is genuine conflicting incentives rather than just different perspectives. Instead of "analyst perspective" and "critical perspective," define personas with opposite optimization criteria: "growth-focused product manager" vs. "risk-averse compliance officer," or "performance-optimized architect" vs. "reliability-focused architect." These personas naturally disagree because they're optimizing for different outcomes. Include specific expertise assignments and decision criteria so the debate is concrete rather than abstract.
Is multi-model debate better than internal debate in a single model?
Multi-model debate is more robust and can achieve higher accuracy (potentially 40-80% improvement), but it requires more infrastructure, is slower, and costs more to run. Internal debate within reasoning models typically achieves 30-73% accuracy improvement with simpler infrastructure and lower cost. For most enterprise applications, internal debate provides the best cost-to-accuracy ratio. Multi-model debate makes sense for mission-critical applications where accuracy is paramount and computational cost is secondary.
Can I fine-tune models to improve internal debate capabilities?
Yes, specifically by fine-tuning on multi-party conversation data rather than single reasoning chains. Training data that preserves debate structures, where competing perspectives are shown working through disagreements, naturally improves the model's ability to engage in internal debate. Training on simplified single-path reasoning actually reduces internal debate capability. For domain-specific applications, you can generate or curate debate examples in your domain and use those for fine-tuning.
How much test-time compute should I allocate to debate versus depth?
Allocate for diversity over pure depth. A model exploring 3-5 different reasoning approaches and synthesizing them is usually more effective than a model generating a single approach with 5x more tokens. Budget compute for generating multiple perspectives, evaluating alternatives, and synthesis rather than extending single reasoning chains. This typically provides better cost-to-accuracy ratios and is easier to implement.
What are the main failure modes when implementing internal debate?
Common failures include: generating fake diversity where different perspectives are actually the same idea in different words (fix by assigning genuinely conflicting incentives), rushing to false consensus before disagreements are genuinely resolved (fix by explicitly requiring reconciliation), excessive debate that wastes compute without reaching conclusions (fix by limiting voices to 2-3 and adding resolution criteria), and generic debate lacking domain expertise (fix by making personas domain-specific with concrete expertise assignments).
How do I measure whether internal debate is actually improving my system's quality?
Test on problems where you already know the right answer. Compare output quality and accuracy between standard prompting and debate-structured prompting. Measure not just final answers but quality of reasoning—does the system catch its own errors? Do the explanations surface relevant tradeoffs? For deployment, track accuracy metrics on real decisions, gather feedback from decision-makers on whether the reasoning is more useful, and monitor whether the system catches errors that would have been missed with simpler approaches.
Conclusion: The Future of AI Reasoning Isn't Soliloquy, It's Dialogue
For years, we've optimized AI reasoning in a particular direction: longer chains of thought, bigger models, more parameters. The assumption was that depth of thinking came from scale and extension.
What the latest research reveals is that we had the model backwards. Better reasoning comes from diverse perspectives engaging in productive conflict. A smaller model that argues with itself outperforms a larger model that monologues.
This changes how we think about building AI systems. It's not about finding bigger compute or more sophisticated individual models. It's about creating structures where different viewpoints naturally emerge and refine each other.
For enterprises, this is genuinely useful. The decisions your organization struggles with are usually struggles because different legitimate perspectives compete. Financial stability vs. growth. Speed to market vs. quality. Innovation vs. compliance. These aren't problems with bad data or insufficient processing. They're problems that benefit from diverse intelligent perspectives.
AI systems that simulate internal debate on these tradeoffs don't make the decisions for you. They surface the tradeoffs more clearly. They catch hidden assumptions. They verify logic. They explore alternatives.
That's not intelligence replacing human judgment. That's tools that genuinely support better judgment.
The technical foundation is solid. Reasoning models naturally develop internal debate when trained for accuracy. The debate mechanisms work—documented accuracy improvements of 30-73% on complex tasks. Implementation is practical with current tools.
The remaining questions are deployment questions, not technology questions. How do you structure debate in your specific domains? How do you integrate debate-based systems into your workflows? How do you measure whether they're actually improving decisions?
These are solvable problems. Organizations that figure them out first will have a significant edge. Not because their AI is smarter. Because their systems surface uncertainty, encourage genuine consideration of alternatives, and catch mistakes before they're expensive.
If you're building with AI today, especially on complex reasoning tasks, internal debate should be part of your toolkit. Start with reasoning models. Design personas with genuinely conflicting incentives. Let the debate emerge. Measure the improvement.
The future of AI reasoning isn't a single voice thinking longer. It's multiple voices thinking together. That's how humans evolved to reason. That's how the best AI models are learning to think too.

Key Takeaways
- Internal debate improves reasoning accuracy by 30-73% compared to standard chain-of-thought approaches by forcing evaluation of multiple perspectives.
- Society of Thought emerges naturally in models trained with reinforcement learning optimized for accuracy, not from explicit human prompting.
- Productive debate requires genuinely conflicting incentives in persona design, not just different perspectives on the same viewpoint.
- Allocating test-time compute to diverse reasoning paths outperforms extending single reasoning paths for better cost-to-accuracy ratios.
- Enterprise implementation works best for high-consequence decisions where accuracy matters more than speed and tradeoffs genuinely exist.
Related Articles
- Microsoft's $7.6B OpenAI Windfall: Inside the AI Partnership [2025]
- AI Pro Tools & Platforms: Complete Guide to Enterprise AI [2025]
- ChatGPT 5.2 Writing Quality Problem: What Sam Altman Said [2025]
- Is AI Adoption at Work Actually Flatlining? What the Data Really Shows [2025]
- Enterprise AI Agents & RAG Systems: From Prototype to Production [2025]
- Uber's AV Labs: How Data Collection Shapes Autonomous Vehicles [2025]

