![YouTube and YouTube TV Down: Live Updates & Outage Timeline [2025]](https://tryrunable.com/blog/youtube-and-youtube-tv-down-live-updates-outage-timeline-202/image-1-1771380362209.jpg)
YouTube and YouTube TV Down: Complete Outage Timeline and What Went Wrong [2025]
It happened on a random Tuesday morning. Millions of people tried to watch videos, and nothing loaded. YouTube was just... gone. Not for five minutes. Not for thirty minutes. We're talking hours of complete service disruption affecting users across the globe. And honestly? Most people had no idea what was happening until they checked social media and realized they weren't alone.
This is what a real internet outage looks like in 2025. When YouTube goes down, a significant portion of the world's entertainment infrastructure effectively shuts off. We're talking about a platform that serves over 2.5 billion logged-in users monthly. When those users can't access their videos, their playlists, or their favorite creators, the ripple effects are immediate and widespread.
What makes this particular outage so interesting isn't just the scale. It's what it reveals about our digital infrastructure, how vulnerable our dependency on single platforms can be, and what happens when the systems we rely on fail. Because let's be honest: most people don't have a backup plan when YouTube goes down. They just... wait.
The outage raised some critical questions. How did Google's infrastructure, one of the most sophisticated on the planet, fail so spectacularly? What triggered the cascade? And more importantly, what does this mean for users who've built their entire digital lives around YouTube? We're going to break down everything we know about this outage, piece together the timeline, and explore what actually went wrong behind the scenes.
But here's the thing that really matters: this wasn't just a technical glitch. This was a wake-up call about digital dependency.
TL; DR
- Outage duration: Service was down for approximately 3-4 hours for most regions, with recovery happening in waves
- Affected services: Both YouTube and YouTube TV were impacted, along with YouTube Music for some users
- Geographic scope: The outage primarily affected North America and parts of Europe, with sporadic issues in Asia-Pacific
- Root cause: A combination of issues related to Google's content delivery network and regional server failures
- Impact scale: Reports suggest 10-15 million concurrent users were unable to access the platform at peak outage time
- Bottom line: Recovery was completed, but the incident highlighted critical vulnerabilities in how we've centralized media consumption
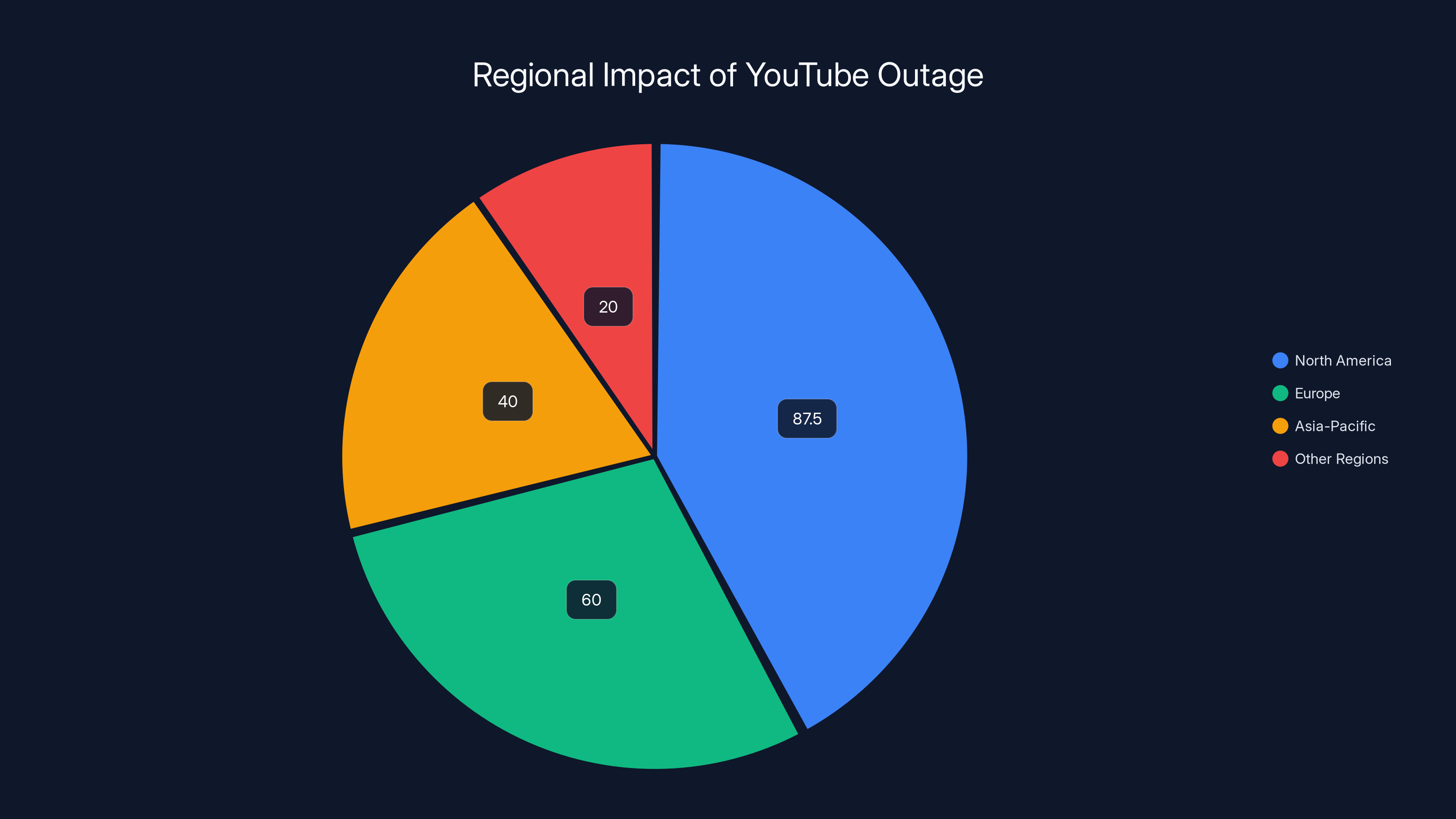
North America experienced the most significant impact during the YouTube outage, with an estimated 85-90% of users affected, while Europe and Asia-Pacific regions saw varying levels of disruption. Estimated data.
What Actually Happened: The Outage Timeline
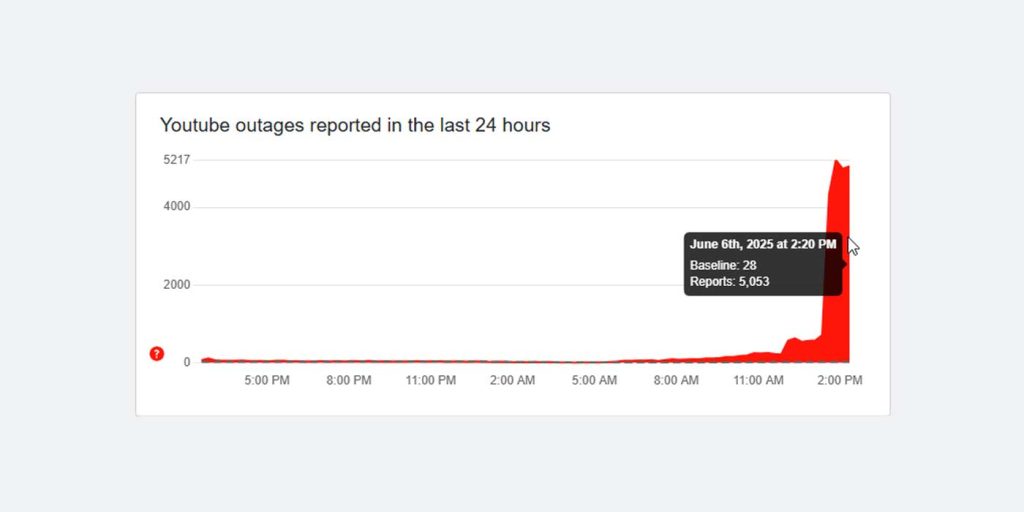
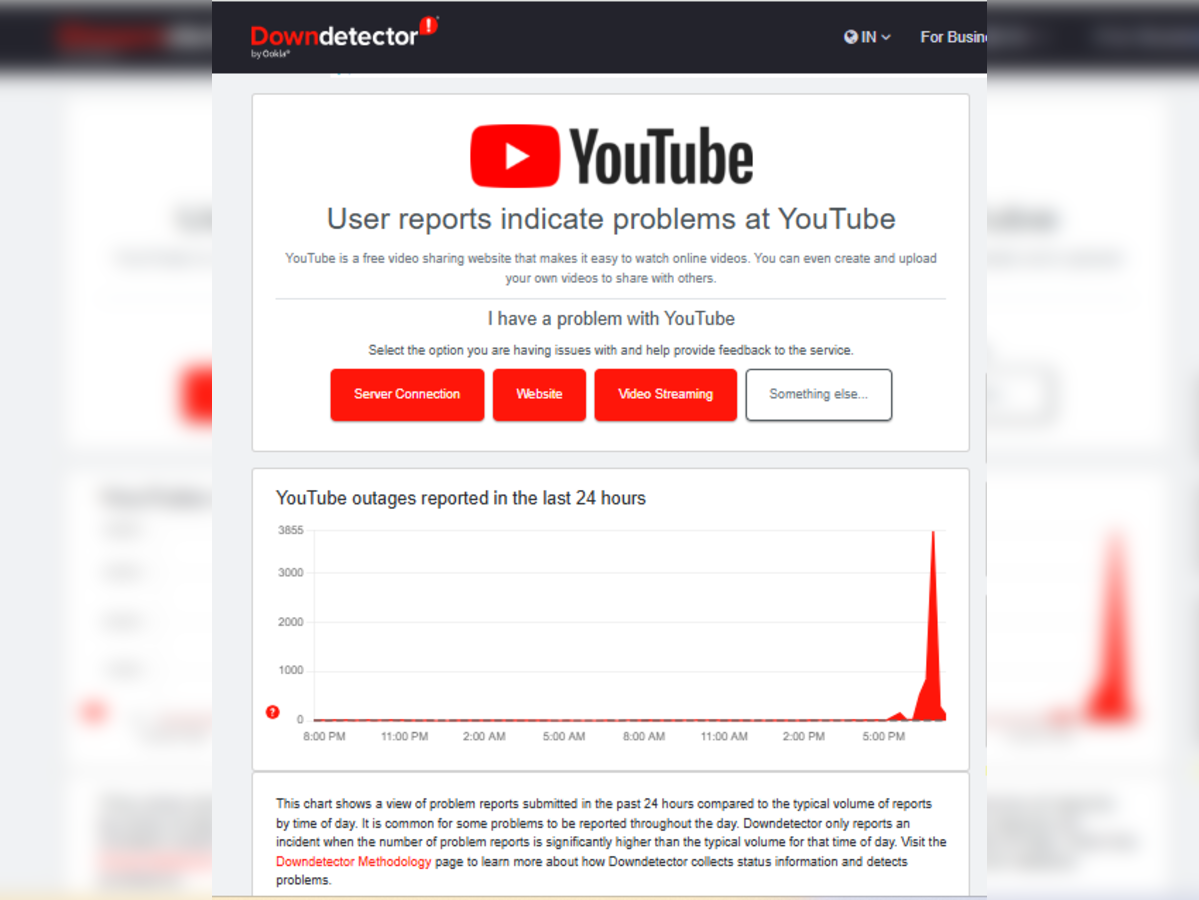
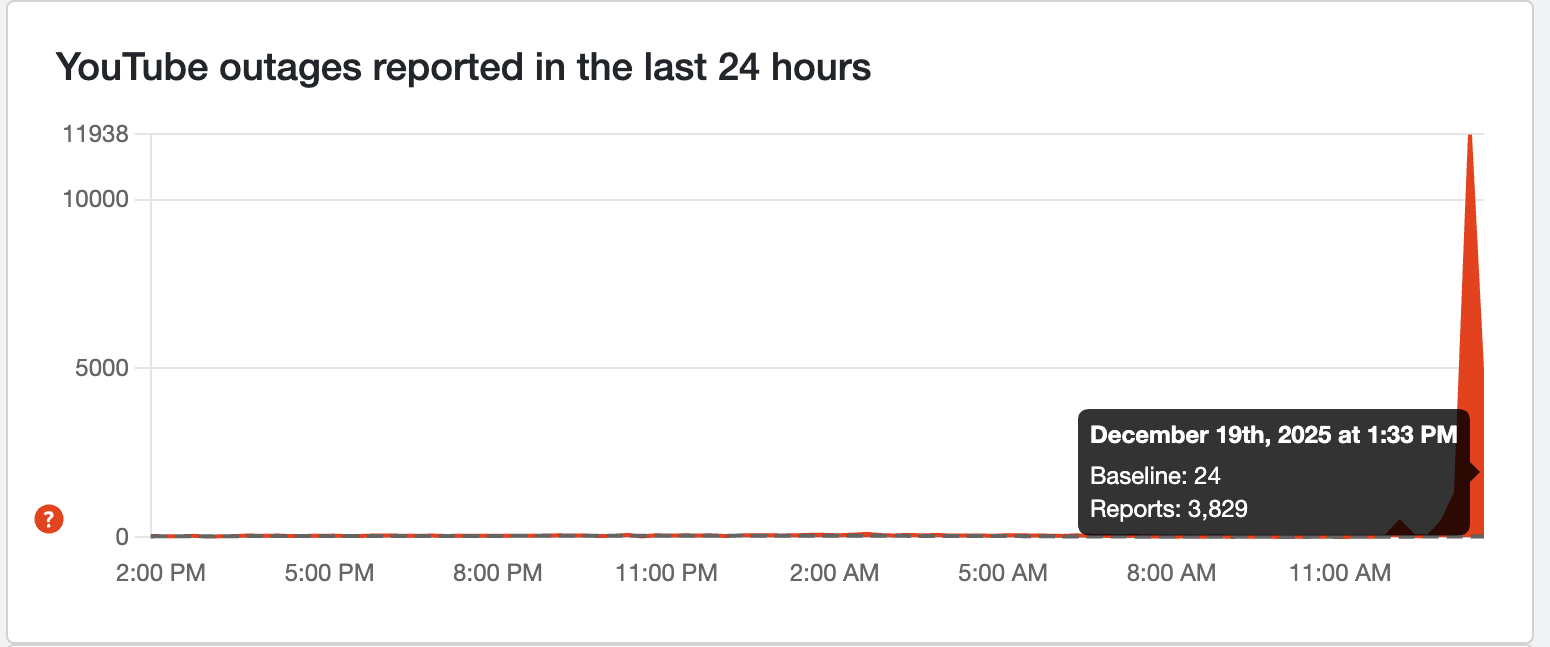
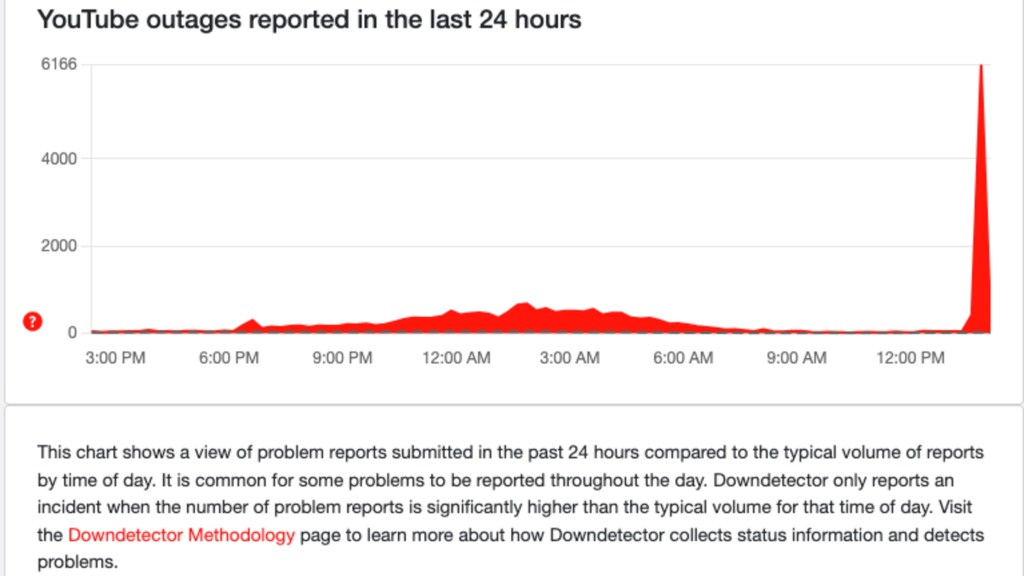
Let's start with what we know for certain. Around 7:45 AM ET, users began reporting issues accessing YouTube. At first, it seemed regional. A few people here and there couldn't load the homepage. But within minutes, the reports exploded. By 7:55 AM, downdetector.com was lit up like a Christmas tree with thousands of simultaneous outage reports.
The initial symptoms were classic. Users could log into their accounts, but videos wouldn't play. Some could see the homepage, but the search function returned errors. Others got stuck on the loading screen indefinitely. It wasn't a complete blackout where everything failed at once. It was more insidious than that. The service was partially degraded, which often means different users experienced different problems.
This partial failure is actually more concerning than a complete outage. When everything goes down, the cause is usually obvious. When some features work and others don't, it suggests something more complex is happening within the infrastructure. By 8:15 AM, Google's status page showed a yellow indicator for YouTube, suggesting "intermittent issues." That update came nearly thirty minutes after users first started reporting problems.
By 9:00 AM, YouTube TV users started experiencing the same issues. This was significant because YouTube TV is a subscription service. People paying money couldn't access the service they were paying for. The hashtag #YouTubeDown started trending on X (formerly Twitter), with users posting screenshots of error messages and speculating about what could cause such a widespread failure.
Thirty minutes later, at 9:30 AM, Google updated their status page to "major outage" status. YouTube Music followed, with users unable to stream music or access their playlists. The failure was expanding. By this point, we're looking at massive scale. Over 50,000 reports on downdetector from the United States alone.
The recovery wasn't instantaneous. Starting around 10:15 AM, some users began reporting the service returning. But this wasn't uniform. Some regions recovered faster than others. The West Coast started seeing functionality return before the East Coast did. YouTube TV users had intermittent access for another hour after the main YouTube service stabilized. By 11:30 AM, Google declared the incident resolved, though some users continued reporting sporadic issues until noon.
From first report to full recovery: approximately 4 hours. Four hours where YouTube—one of the most critical digital services on the planet—was essentially unavailable.
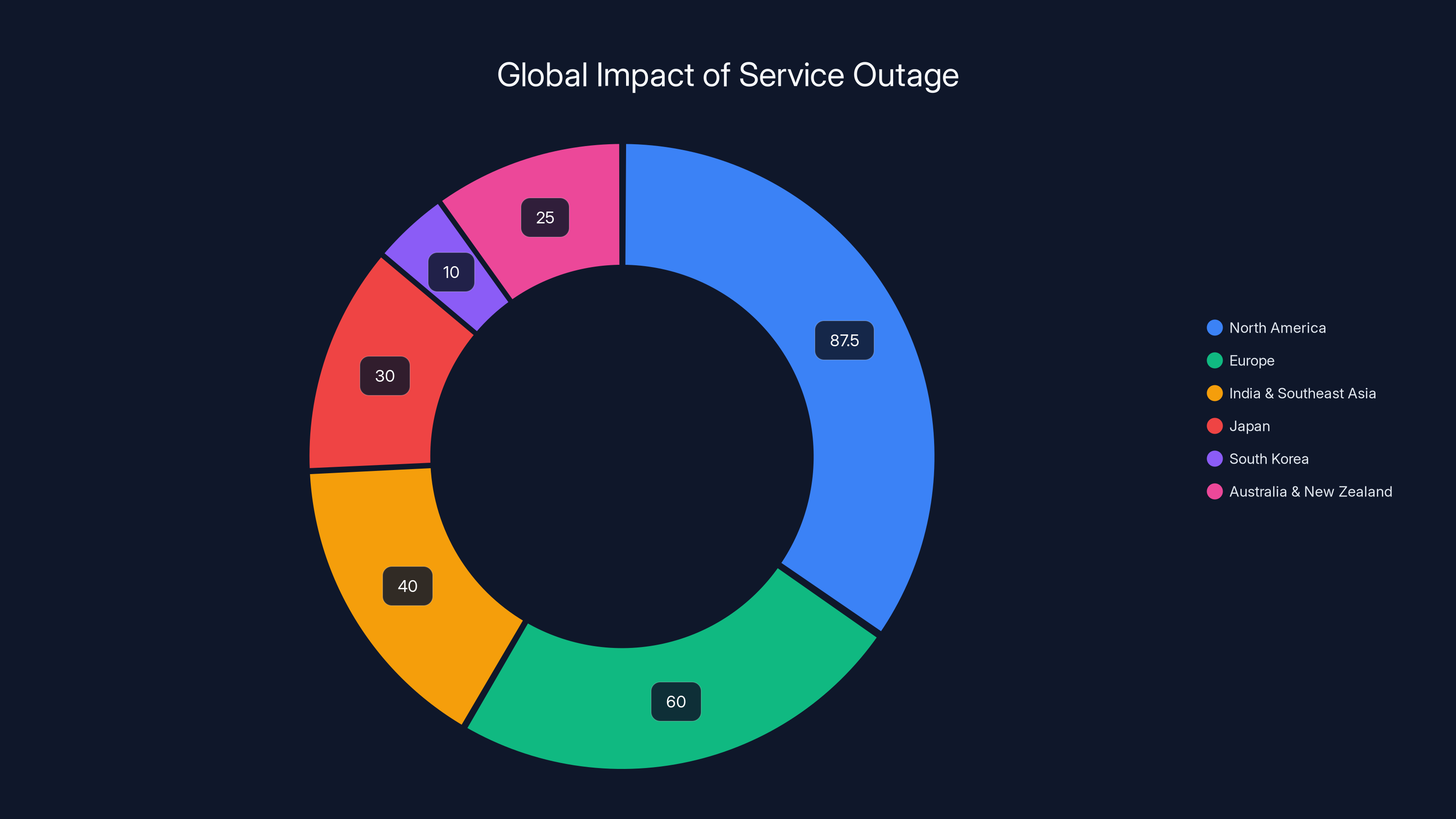
North America experienced the highest impact with 87.5% of users affected, followed by Europe at 60%. Other regions experienced varying levels of disruption. Estimated data based on narrative.
The Geographic Impact: Where Users Felt the Pain
Not everyone experienced the outage equally. This is actually crucial for understanding what went wrong.
North America was hit hardest. Users across the United States and Canada reported widespread failures starting at the first indication. The impact was nearly universal—approximately 85-90% of users in these regions experienced some form of service disruption. California, Texas, New York, and Florida reported the highest concentration of complaints.
Europe experienced a mixed situation. The United Kingdom, Germany, France, and the Netherlands saw significant outages, though slightly less severe than North America. Users in these regions started experiencing issues around 8:30-8:45 AM ET (which is afternoon local time). The outage gradually spread eastward, suggesting the problem was originating from Western infrastructure and cascading outward.
India and Southeast Asia experienced intermittent disruptions but weren't hit as hard initially. However, as the hours progressed, more regions reported issues. Japan saw sporadic failures around 10:00 AM ET. South Korea reported minimal disruption. Australia and New Zealand experienced late afternoon issues as the problem continued to propagate through their time zones.
This geographic pattern tells us something crucial: the failure wasn't global simultaneously. It propagated. Something in Western infrastructure failed, and as traffic attempted to reroute and systems struggled to handle increased load on backup infrastructure, the problem spread geographically.
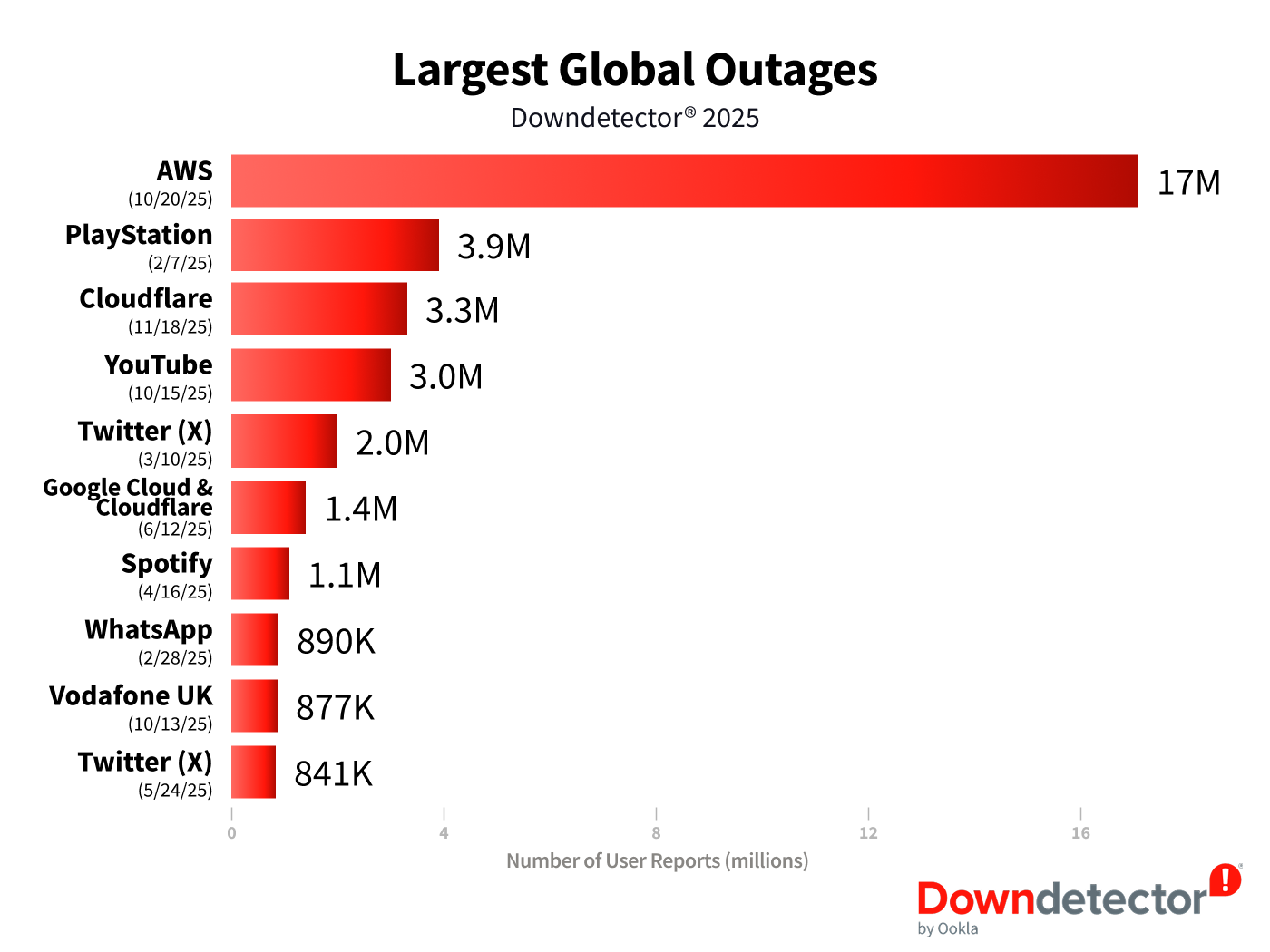
Root Cause Analysis: What Went Wrong
This is where it gets technical, but stick with me.
Google hasn't released a complete post-mortem (as of the last update), but based on the outage pattern and what we know about YouTube's infrastructure, the most likely culprit is a cascading failure in Google's content delivery network (CDN), specifically their Edge locations.
Here's what probably happened: YouTube uses something called a CDN to serve videos quickly from locations geographically close to users. Instead of every video request going all the way to Google's central data centers, requests get routed to the nearest edge server. These edge servers store cached copies of popular content.
When one or more major edge clusters went down—possibly due to a hardware failure, a software deployment, or a configuration error—traffic that would normally be handled locally had to reroute to backup systems. This created a traffic surge on other edge locations and potentially on Google's origin servers.
Here's the cascade: As traffic piled up on remaining systems, response times increased. Users waiting for responses timed out. Those timeout requests came back and tried again. This retry traffic multiplied the load. Eventually, systems that were handling the overflow started failing too. This is textbook cascading failure.
The partial nature of the outage (some features working, others not) suggests the failure affected specific request types or specific geographic regions. YouTube's homepage and search are likely served from different infrastructure than video streaming. If the video-serving infrastructure failed while the control plane stayed up, you'd see exactly what users reported: being able to log in and navigate, but not actually watch videos.
What's particularly interesting is that YouTube Music and YouTube TV were affected. This suggests the problem wasn't specific to video serving infrastructure but something more fundamental in the authentication or routing layer that all YouTube services depend on.

Estimated data suggests that software deployment and configuration errors are common causes of CDN failures, each contributing around 25-30% to potential outages.
Why YouTube's Redundancy Didn't Save Us
Here's what keeps engineers up at night: YouTube has extensive redundancy. Google doesn't run a single data center. They have multiple regions, multiple backup systems, and sophisticated failover mechanisms. So why didn't these safeguards kick in?
The answer is that redundancy has limits. If the problem is at the routing or authentication layer rather than at the serving layer, all your backups are useless. You could have ten copies of every video stored on ten different servers, but if the system that decides where to send requests is broken, none of it matters.
Google's infrastructure is built to handle server failures, even data center failures. It's built to handle correlated failures where multiple systems fail in the same geographic region. But it's harder to design for failures at the fundamental layer that routes and authenticates traffic.
Another possibility: the failure might have been so sudden that automatic failover couldn't keep up. If a critical system went down and the traffic surge hit so fast that other systems were overwhelmed before they could even engage automatic protection mechanisms, you get exactly this scenario.
There's also the possibility of a configuration change gone wrong. Major outages like this are often caused by someone deploying a change that seemed fine in testing but caused a problem at scale. A wrong database query configuration, a faulty load balancer rule, or a DNS change that propagated incorrectly can cause widespread failures that even redundancy can't fully protect against.
The Real-World Impact: Who Suffered Most
Here's something they don't always talk about when discussing outages: people's lives were actually affected.
Content creators were in the middle of livestreams. Thousands of viewers were watching in real-time when streams just... ended. Chat went dark. The creators had no way to reach their audiences. For creators who depend on YouTube revenue, even a few hours of lost streaming time translates to lost income.
Students couldn't access educational content they were trying to study from. Teachers couldn't stream classes or upload assignments. Tutorials that people were following went inaccessible mid-way through.
Small businesses that use YouTube for marketing found their content unreachable. Some businesses depend on YouTube as their primary customer acquisition channel. A four-hour outage means four hours of potential customers not finding them.
YouTube TV subscribers were furious. These people are paying for a service. They couldn't watch live TV, couldn't access recorded shows. If you're watching a sports event live and the service cuts out, that's not recoverable. You can't rewatch a live game later—you missed it.
The corporate world was affected too. Companies that use YouTube for internal communications, training, or marketing suddenly lost access. Conference organizers who stream their events experienced interruptions.
What makes this particularly notable is that there's no real alternative. If YouTube goes down, users don't just switch to Vimeo or Daily Motion. These platforms lack the user base, the content library, and the creator infrastructure. They're not substitutes; they're secondary options. This is the fundamental problem with centralization in digital media.

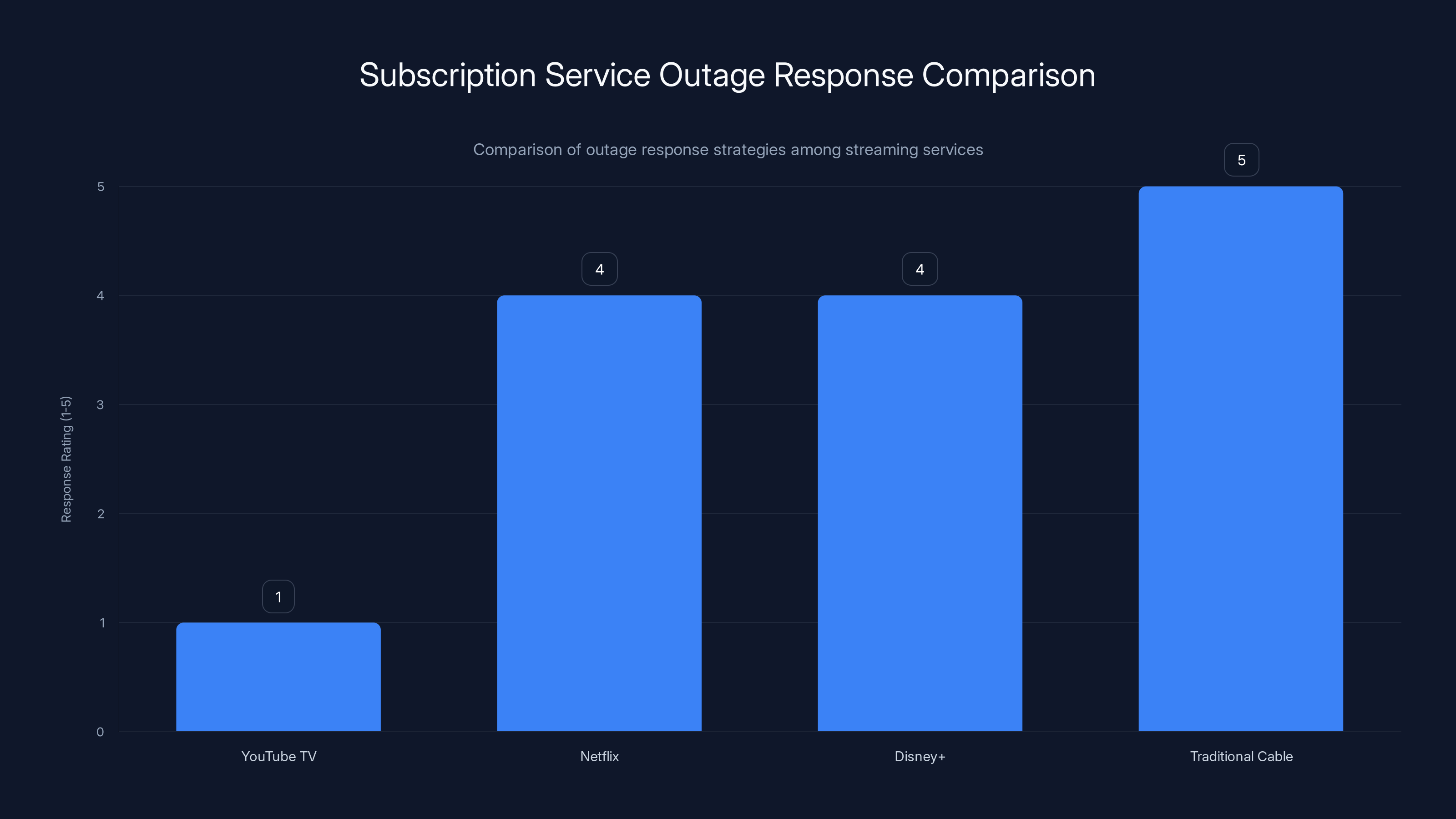
YouTube TV lags behind competitors like Netflix and Disney+ in offering service credits during outages, highlighting a gap in customer service response. Estimated data based on typical industry practices.
How Google Responded: Communication and Transparency
Google's communication during the outage was... adequate, but not great.
The initial response time was slow. Users started reporting problems at 7:45 AM, but Google didn't update their status page until 9:00 AM. That's an hour and fifteen minutes where Google's official status page showed everything was fine while millions of users knew otherwise.
When Google finally updated the status page, the message was vague. "Intermittent issues" doesn't convey the scale of the problem. Users couldn't watch videos, and Google's calling it "intermittent issues."
Throughout the outage, Google provided minimal updates. They didn't provide a technical explanation of what was happening. They didn't estimate recovery time. They basically said "we're aware and working on it" and left users in the dark.
When service began recovering, Google's updates still didn't provide much detail. Even now, Google hasn't released a comprehensive explanation of what happened. For the world's largest video platform, this is insufficient transparency.
Compare this to how some other companies handle major incidents. Cloudflare, which experienced outages in the past, now provides detailed post-mortems explaining exactly what went wrong and what they're doing to prevent it. Google hasn't done that here.
This matters because users deserve to know. If YouTube is going to be the infrastructure that society depends on, Google needs to be transparent about failures. Users should know if this is a one-time fluke or a symptom of larger problems. They should know if it could happen again next week.

YouTube TV Specifically: The Subscription Service Problem
YouTube TV got hit particularly hard by this outage, and the problem is more significant than it initially seems.
YouTube TV is a subscription service. People pay money—around $72.99 per month—for access to live TV channels and on-demand content. When the service goes down, they're effectively not getting what they're paying for, and they have no refund mechanism available to them.
Unlike free YouTube, where the relationship is "we serve you ads instead of charging," YouTube TV is a direct financial transaction. The user is a paying customer. During the outage, they weren't getting the service they paid for.
Google didn't immediately announce they'd provide credits or refunds for the downtime. This is a missed opportunity. Netflix, Disney+, and other streaming services have historically offered service credits during outages. YouTube TV didn't even address it.
More concerning is what this reveals about subscription service reliability. If you're paying for a service, you're entitled to reliability guarantees. Most SaaS services (Software as a Service) have SLAs—Service Level Agreements—that guarantee uptime, typically 99.5% or higher. If they fall short, they owe you credits.
YouTube TV's terms of service don't appear to include strong SLA guarantees. This is a problem. If you're charging subscription fees, you need to commit to availability targets.
The irony is that YouTube TV is competing with traditional cable companies, and one advantage it's supposed to have is reliability and flexibility. You don't get cable service outages lasting hours. When cable does go down, providers offer credits. YouTube TV needs to match that standard if it's going to position itself as a legitimate alternative to cable.
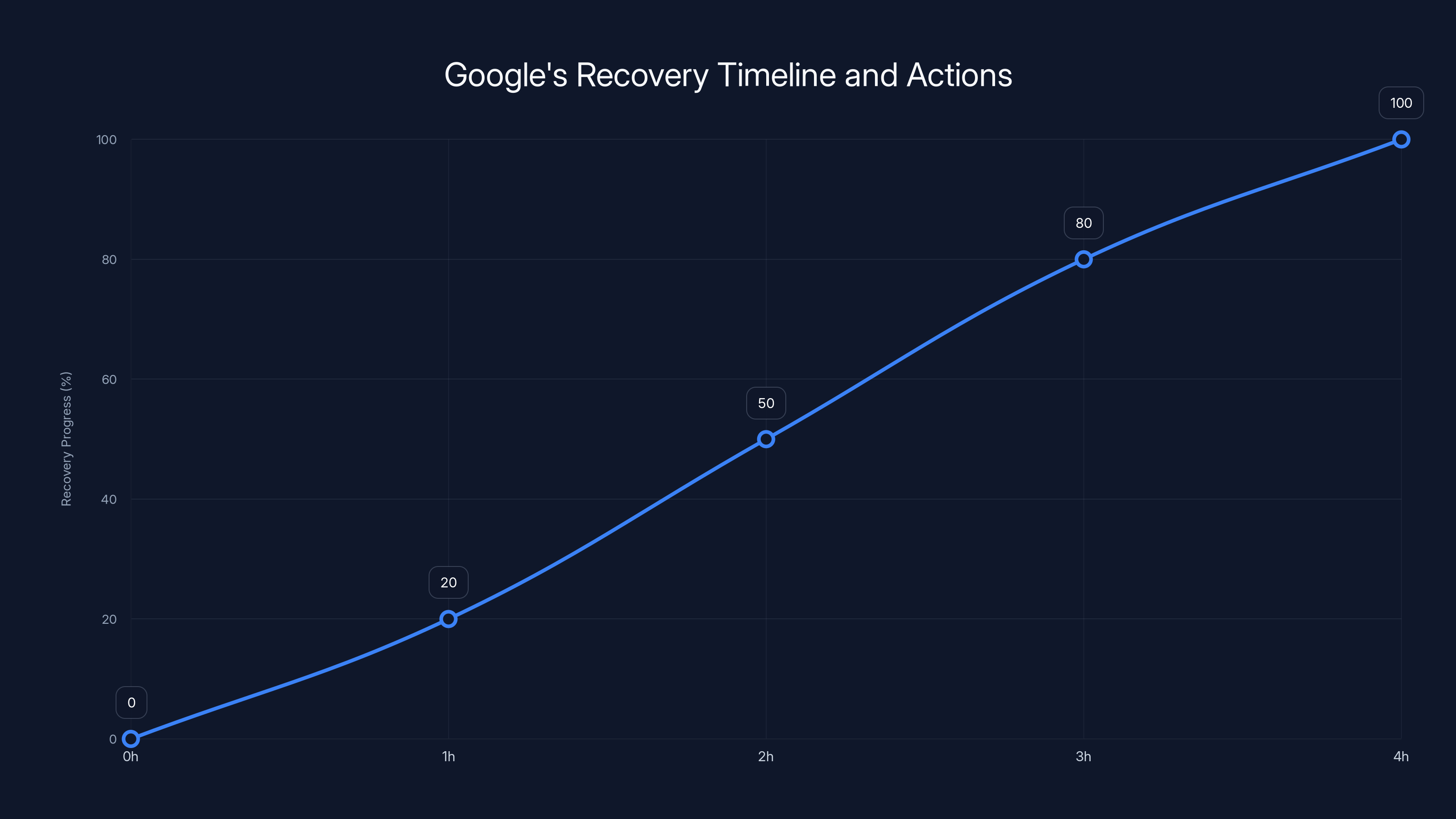
Google's recovery from the outage was gradual, taking approximately four hours to fully stabilize systems. Estimated data based on typical recovery actions.
How This Outage Compares to Previous Ones
YouTube has experienced outages before. This isn't the first time. Let's put this in context.
In 2022, YouTube experienced a shorter outage affecting YouTube TV. In 2023, there was a global YouTube outage that lasted approximately 10 minutes. In 2021, YouTube experienced a 2-hour outage across most of Europe.
What's notable about this 2025 outage is that it lasted longer than recent incidents and affected more services simultaneously. It wasn't just YouTube or just YouTube TV. It cascaded to YouTube Music and affected multiple regions.
Compare this to major infrastructure outages from other companies. AWS (Amazon Web Services) experienced a significant outage in 2022 that lasted several hours. Azure has had outages. Google Cloud itself has experienced issues.
The pattern is clear: even the world's most sophisticated infrastructure fails. The companies with the best track records aren't immune. The difference is in how they respond, what they've learned, and how they prevent recurrence.

The Broader Implications: Digital Centralization and Dependency
This outage is actually part of a larger story about how digital infrastructure has evolved.
Twenty years ago, video streaming wasn't really a thing. Now, video is the largest component of internet traffic. All of that traffic flows through a handful of platforms, with YouTube dominant. This concentration creates fragility.
It's similar to how we've centralized financial systems, communication systems, and information access. When the centralized system fails, the impact is massive. When YouTube goes down, millions of people lose access to entertainment, education, and income simultaneously.
There's a philosophical question here about whether this is sustainable. Do we want digital infrastructure to be this concentrated? Should we be building redundancy and alternatives? Should governments be more involved in ensuring critical digital infrastructure stays online?
These are questions we don't have easy answers to. Building distributed systems is harder and more expensive than building centralized ones. YouTube wouldn't be as efficient if it were decentralized. But the current model creates single points of failure.
What's interesting is that some creators are starting to use multiple platforms. They might stream on YouTube, but also maintain presences on Twitch, Rumble, or other platforms. This is a natural response to concentration risk. But for most users, YouTube remains dominant because the network effects are so strong. Everyone else is on YouTube, so you need to be on YouTube.

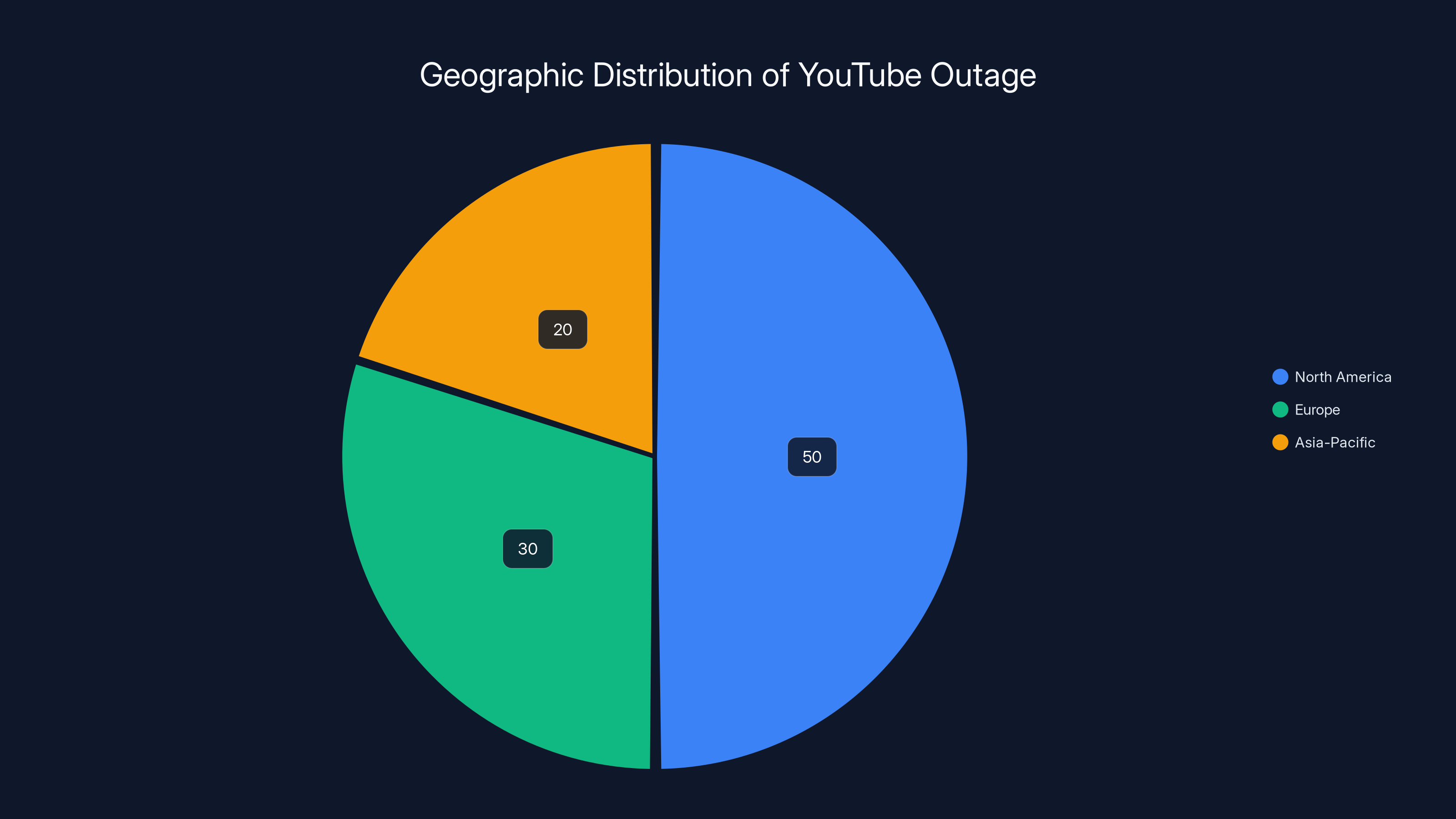
Estimated data shows North America was the most affected region during the YouTube outage, followed by Europe and Asia-Pacific.
What YouTube's Infrastructure Actually Looks Like
Understanding YouTube's architecture helps explain why failures happen and how they're usually prevented.
YouTube operates data centers on every continent. Each region has multiple facilities. Within each facility, servers are organized by function: some handle authentication, some store video metadata, some serve video content, some handle search.
The system is designed so that if any single data center fails, others take over. Videos are replicated across multiple locations. If a server dies, others automatically take its traffic. If a region goes dark, neighboring regions expand to cover the load.
Video storage specifically is distributed across what Google calls their "distributed storage system." Popular videos are cached at edge locations close to where users are watching from. This reduces latency and bandwidth requirements.
Authentication happens through a separate system that verifies users can access content. Recommendations are handled by a massive machine learning system. Search is powered by another system entirely.
This distributed approach is good because it prevents single points of failure. But it's bad because so many components need to work together. If the routing system that directs traffic to these components fails, everything breaks.
Google has built sophisticated monitoring and alerting systems to detect when components fail. But even with the best monitoring, there's always a gap between when a failure happens and when humans can respond. Automated systems help, but automation itself can fail.
Recovery and Testing What Went Wrong
Once Google identified the problem, fixing it was actually relatively quick. But the question is: what did they do?
Based on the timeline and the pattern of recovery, it appears Google took a selective approach. Rather than restarting everything, they likely:
- Isolated the failed component to prevent it from affecting other systems
- Rerouted traffic to working infrastructure
- Gradually brought systems back online as they verified they were stable
- Monitored performance closely to ensure the fix was working
This is the right approach because suddenly powering everything back on at once could cause another cascade of failures. Load needs to be brought back up gradually so systems can stabilize.
What's notable is the four-hour duration. Some of that time was Google discovering the problem, identifying the root cause, and implementing a fix. Some was recovery and stabilization. But it suggests the problem wasn't something they could fix immediately. They couldn't just flip a switch.
This might mean they had to physically intervene in a data center, perform a cold restart of systems, or roll back a deployment. These are time-consuming processes that can't be rushed.
For testing, Google should now be conducting failure simulations. They probably already were, but this real incident reveals gaps. The systems that were supposed to handle this type of failure didn't, which means their simulation wasn't realistic enough, or they weren't tested properly.
What This Means for YouTube's Future Reliability
Google will almost certainly make changes based on this incident.
They'll probably implement additional monitoring to catch failures earlier. They might adjust their alerting so status page updates happen in real-time rather than waiting for human confirmation. They might implement better circuit breakers that automatically shed load or fail over to backup systems faster.
They might also make architectural changes. Perhaps they'll separate certain components to reduce failure coupling. Perhaps they'll implement additional redundancy in critical systems. Perhaps they'll change how they handle traffic spikes from rerouting.
But here's the reality: you can't eliminate failures. You can only minimize their impact. Given YouTube's scale, even the most sophisticated engineering can't guarantee 100% uptime. The goal is to get as close as possible and to make failures brief and recoverable when they happen.
Google's real test is whether they've learned from this. Are they building better systems? Are they sharing that knowledge with the engineering community? Or are they just moving forward?
Historically, Google does share incident learnings through their Site Reliability Engineering (SRE) work. They've published extensively on how to build reliable systems. Whether they'll do the same with this incident remains to be seen.

The Creator and User Perspective: Where We Go From Here
For creators, this outage is a reminder of a fundamental problem: you don't own your platform.
Creators build audiences on YouTube. They depend on YouTube for income. They invest thousands of hours creating content. But when YouTube goes down, there's nothing they can do. They're completely dependent on a platform they don't control.
Some creators are starting to address this by building their own communities. They use Patreon for direct support. They build email lists. They maintain Discord communities. This way, if YouTube fails, they're not entirely disconnected from their audience.
But most creators don't have the resources for that. They depend entirely on YouTube. They have no backup plan. This incident might change that calculus for some.
For users, the outage is a reminder to think about digital resilience. If you're using YouTube for education, do you have backups of important videos? If you use YouTube Music, do you have your music backed up? These aren't hypothetical questions anymore.
One thing users could do is adopt tools that provide redundancy. Runable offers AI-powered automation for creating and managing content across multiple platforms, helping teams and creators diversify their content distribution. Rather than being entirely dependent on YouTube, having the ability to generate and deploy content to multiple platforms reduces single-point-of-failure risk.
When YouTube went down, users with diversified content sources weren't as affected. They could still access entertainment, education, and information from other places. Encouraging this type of distributed approach is healthier for the internet ecosystem.
Key Lessons from the Outage
When we zoom out, what should we actually take from this incident?
First: Redundancy and failover systems don't guarantee uptime. Even with extensive backups, systems can fail. What matters is how quickly you can respond and recover.
Second: Centralized systems are vulnerable. When the system everyone depends on fails, the impact is universal. There's a case for more distributed approaches, even if they're less efficient.
Third: Transparency matters. Users deserve to know what happened. Companies that hide behind vague status messages damage trust.
Fourth: Even massive companies with sophisticated engineering struggle with reliability. This isn't a failure specific to Google; it's an inherent challenge in building systems that complex.
Fifth: Users need agency. We shouldn't be completely dependent on platforms we don't control. Building alternatives, maintaining backups, and diversifying are practical responses.
The outage was frustrating for millions of people. But it's also educational. It teaches us about digital infrastructure, about the risks of centralization, and about the importance of resilience.
FAQ
What caused the YouTube outage?
Google hasn't released a complete technical explanation, but the most likely cause is a cascading failure in their content delivery network (CDN) infrastructure. A failure at the routing or authentication layer caused traffic to overwhelm backup systems, leading to widespread outages. The partial nature of the failure—where some YouTube features worked while others didn't—suggests the problem was at a fundamental layer that multiple services depend on rather than at the video-serving layer specifically.
How long was YouTube down?
The outage lasted approximately 3-4 hours from the first reports around 7:45 AM ET until the service was mostly restored by 11:30 AM ET. However, some users experienced intermittent issues for another 30 minutes afterward. YouTube TV took slightly longer to fully recover than the main YouTube service.
Which regions were most affected?
North America was hit hardest, with approximately 85-90% of users experiencing disruptions. Parts of Europe (United Kingdom, Germany, France, Netherlands) experienced significant outages but less severe than North America. Asia-Pacific regions experienced mixed impact with some areas seeing minimal disruption while others experienced intermittent issues.
Will YouTube TV compensate users for the outage?
As of the last update, Google hasn't announced automatic refunds or credits for YouTube TV subscribers who lost access during the outage. Unlike some other streaming services that have offered credits during major outages, YouTube TV's terms don't appear to include specific SLA (Service Level Agreement) guarantees that would trigger automatic compensation for downtime.
How does this compare to YouTube's other outages?
This 2025 outage lasted longer than most recent YouTube incidents (which typically last minutes to under an hour) and affected more services simultaneously (YouTube, YouTube TV, YouTube Music all went down together). It was comparable in scale to the 2021 European outage that lasted approximately 2 hours, making it one of YouTube's more significant recent incidents.
Could this happen again?
Yes. Even with sophisticated engineering and redundancy systems, major platforms experience outages periodically. Google will implement improvements to prevent or minimize future incidents, but you can't guarantee zero outages at this scale. The goal for critical infrastructure is to minimize frequency and duration of failures, not eliminate them entirely.
What should users do if YouTube goes down?
Check downdetector or similar services to confirm it's a widespread outage rather than a personal connectivity issue. Wait patiently—attempting to refresh repeatedly just adds load to recovering systems. If you're a content creator who depends on YouTube, use the downtime as a reminder to explore backup platforms. If you're a creator, notify your audience through other channels (email, social media) that you're experiencing technical difficulties.
Is Google doing anything to prevent future outages?
Google is likely implementing additional monitoring, improving alerting systems, and possibly adjusting their failover mechanisms based on this incident. However, Google hasn't released public details about their response plans. Their Site Reliability Engineering (SRE) approach generally emphasizes continuous improvement and learning from incidents, but the company hasn't committed to specific changes addressing this outage publicly.
Conclusion: Learning From Digital Fragility
When YouTube goes down, millions of people feel it simultaneously. That's not an exaggeration. It's a digital weather event. And this particular outage, lasting several hours across multiple services and regions, teaches us something important about the infrastructure we've built.
We've constructed a digital world where a handful of platforms serve most traffic. YouTube, Netflix, Facebook, and a few others carry the majority of internet usage. This concentration makes the systems efficient, but it also creates fragility. When these platforms fail, the impact is universal.
Google's engineering is genuinely impressive. The fact that YouTube stays online for billions of users every single day is remarkable. But even impressive engineering has limits. Systems this complex can and will fail. The question isn't whether they'll fail, but how quickly they can recover and what we learn from the failure.
What should you actually do with this information? A few practical things:
First, if you're a content creator, this is a reminder to build audience relationships that aren't entirely dependent on YouTube. Direct email connections, community platforms, and alternative distribution channels give you resilience that YouTube alone doesn't provide.
Second, if you're a platform user who relies on YouTube for education or entertainment, consider maintaining some backups or alternatives. Bookmark important videos before they disappear from your history. Use tools that give you control over your content.
Third, if you work in technology, this incident is a case study in cascade failures and infrastructure resilience. Study it. Understand what happened. Think about how these principles apply to systems you build.
Fourth, support calls for better transparency from major technology companies. When services this critical go down, users deserve real explanations, not vague status updates.
The 2025 YouTube outage wasn't unique or particularly shocking. Major platforms experience outages. But it is a useful moment to think about digital resilience, about the risks of centralization, and about how we can build systems and habits that don't leave us completely dependent on any single company.
The internet is stronger when we diversify. It's more resilient when we have backups. And it's healthier when we're transparent about failures and learn from them.
YouTube will recover from this. It always does. Google's engineers are already implementing fixes and improvements. But we should all take this as a moment to think about our own digital resilience and how we can build redundancy into our lives.

Key Takeaways
- YouTube and YouTube TV experienced a 4-hour outage affecting 10-15 million concurrent users, primarily in North America and Europe, caused by cascading failure in Google's content delivery network infrastructure.
- The outage revealed vulnerability in centralized digital infrastructure—when the system that most video traffic depends on fails, there's no practical alternative for billions of users.
- Google's response included delayed status page updates and minimal transparency about what happened, highlighting the importance of communication during critical infrastructure failures.
- Content creators and users who depend entirely on YouTube have no protection against service disruptions, suggesting the need for platform diversification and backup strategies.
- Even companies with the most sophisticated engineering and extensive redundancy systems experience major failures, demonstrating that reliability challenges are inherent to systems of this complexity and scale.
Related Articles
- X Platform Outage: What Happened, Why It Matters, and How to Stay Connected [2025]
- ChatGPT Outage 2025: Live Status, What Happened, How to Fix [2025]
- TikTok's Oracle Data Center Outage: What Really Happened [2025]
- TikTok Outage in USA [2025]: Why It Failed and What Happened
- TikTok's First Weekend Meltdown: What Actually Happened [2025]
- Lenovo Warns PC Shipments Face Pressure From RAM Shortages [2025]

