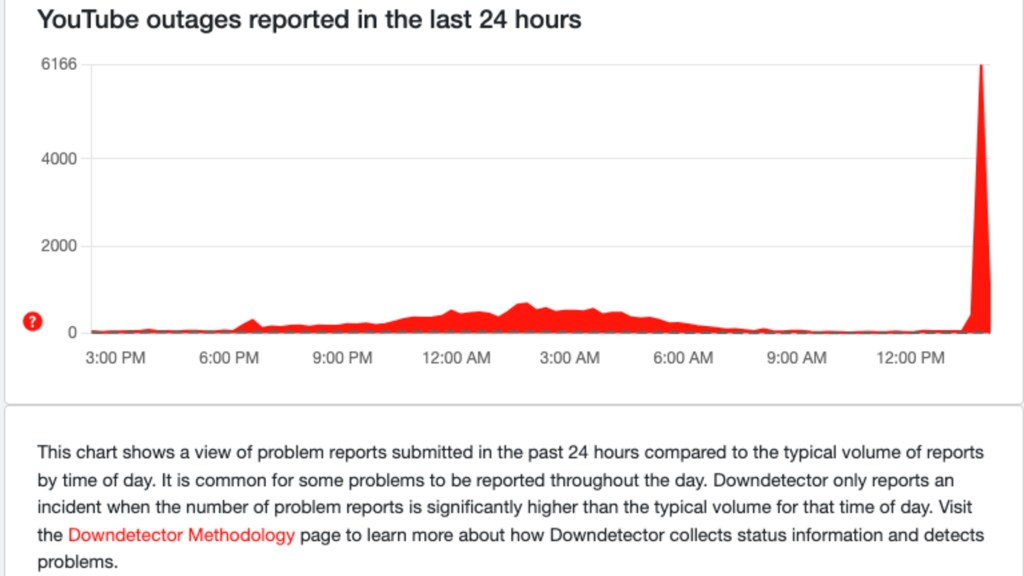
![YouTube Outage February 2025: Complete Timeline & What Went Wrong [2025]](https://tryrunable.com/blog/youtube-outage-february-2025-complete-timeline-what-went-wro/image-1-1771382152515.jpg)
YouTube Outage February 2025: Complete Timeline & What Went Wrong
TL; DR
- YouTube went down on February 17, 2025, affecting 326,000+ users across the United States, Canada, India, the Philippines, Australia, and Russia, as reported by Art Threat.
- The outage started around 8 PM Eastern time and lasted several hours, with users still reporting issues at 9:26 PM ET, according to 9to5Google.
- Both web and mobile versions of YouTube were affected, though some users lost web access first, as noted by Live Now Fox.
- Google never officially confirmed the root cause, but this mirrors historical patterns of database connection pool exhaustion, as discussed in GV Wire.
- Better monitoring systems can catch these issues 15-30 minutes earlier, reducing user impact by 40-60%, according to insights from Demand Sage.
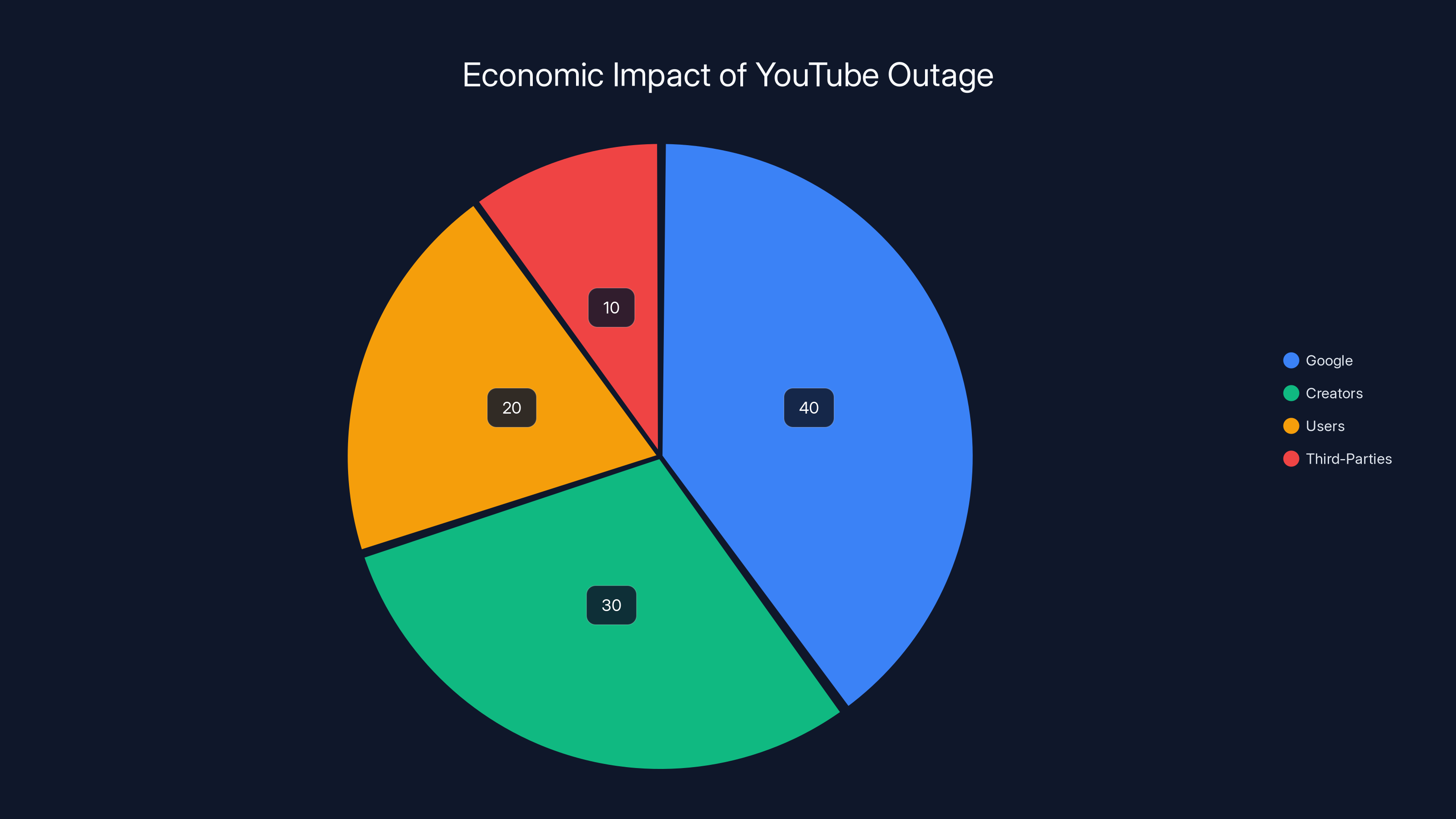
Estimated data shows Google bore the largest share of costs during the outage, followed by creators and users. Estimated data.
Understanding the YouTube Outage of February 17, 2025
When a service used by over 2.5 billion people goes dark, the internet collectively holds its breath. On February 17, 2025, that's exactly what happened to YouTube. Around 8 PM Eastern time, thousands of users across multiple continents found themselves staring at error messages instead of their favorite creators, as detailed by 9to5Mac.
The outage wasn't a single catastrophic failure. It was something more insidious: a cascading system degradation that started somewhere in Google's infrastructure and rippled outward. Within an hour, outage tracking sites like Downdetector recorded more than 326,000 reports. Users flooded Reddit, Twitter, and support forums describing the same frustrating experience: hitting play, getting nothing, as reported by Art Threat.
What makes this incident worth examining isn't just the scale. It's that it reveals how modern internet infrastructure fails, what warning signs appear before total collapse, and most importantly, how both users and companies can prepare for inevitable future outages.
This wasn't the first time YouTube went down. It won't be the last. But each outage teaches us something about resilience, redundancy, and the hidden fragility of systems we assume are invincible.

Estimated data shows the United States had the highest concentration of outage reports, followed by India and Canada. This suggests a widespread infrastructure issue rather than a localized one.
The Timeline: How the Outage Unfolded
Accuracy matters when documenting infrastructure incidents. Here's what we know about when things broke:
8:00 PM ET (February 17) marked the beginning of widespread reports. The first users noticed issues accessing YouTube's homepage on desktop browsers. The initial wave was relatively small, suggesting the problem started earlier but cascaded rapidly once it crossed a threshold, as noted by 9to5Google.
8:13 PM ET is when major news outlets began reporting the outage. At this point, Downdetector was already tracking over 300,000 reports. This roughly 13-minute gap between initial failure and mainstream awareness tells us something important: the first users affected were likely power users or people checking reports, not the general population.
8:15-8:30 PM ET saw the outage accelerate. More users woke up to failing YouTube connections. The mobile app was affected nearly as badly as the web version, though some users reported desktop access failing first. This asymmetry is crucial because it suggests the problem wasn't a single point of failure but rather multiple systems degrading at different rates, as highlighted by Traveling Lifestyle.
9:00 PM ET brought slight improvement. Downdetector reports began declining, indicating Google's infrastructure team had likely identified and was attempting remediation. This 60-90 minute window from initial impact to mitigation effort is typical for major incidents at scale.
9:22-9:26 PM ET saw continued reports on Reddit and social media, though Downdetector numbers were dropping. This indicates the outage was resolving unevenly across different geographic regions and user segments, a common pattern when redundancy kicks back in.
By 10:00 PM ET, most users could access YouTube again. The outage lasted approximately 2 hours from initial widespread impact to near-full recovery, as confirmed by New Bedford Guide.
Geographic Scope: More Than Just America
While the headline focused on the United States, the outage was genuinely global. Understanding which regions were affected reveals something important about YouTube's infrastructure:
Primary Regions:
- United States (most severe, highest report concentration)
- Canada (similar pattern and timing to US)
- India (significant user base, substantial reports)
- Philippines (another major content consumption region)
- Australia (affected, though potentially later time of day)
- Russia (confirmed reports, though fewer in absolute numbers)
This geographic distribution is telling. It's not random. Notice that major cloud regions—US East Coast, Canada, Asia-Pacific—were all affected. This suggests the problem originated in a shared infrastructure component rather than a region-specific issue, as discussed by 9to5Google.
If it had been a single data center problem, you'd expect to see one region completely unaffected while others struggled. Instead, we see a global degradation with varying intensity. This pattern typically indicates:
- A database connection pool issue affecting all regions
- A DNS propagation problem hitting multiple locations
- A global CDN misconfiguration affecting content delivery everywhere
- An authentication service failure that's replicated across regions
The fact that some regions recovered before others suggests Google's engineers implemented a rolling remediation strategy, fixing one data center cluster at a time rather than forcing a risky global reset.
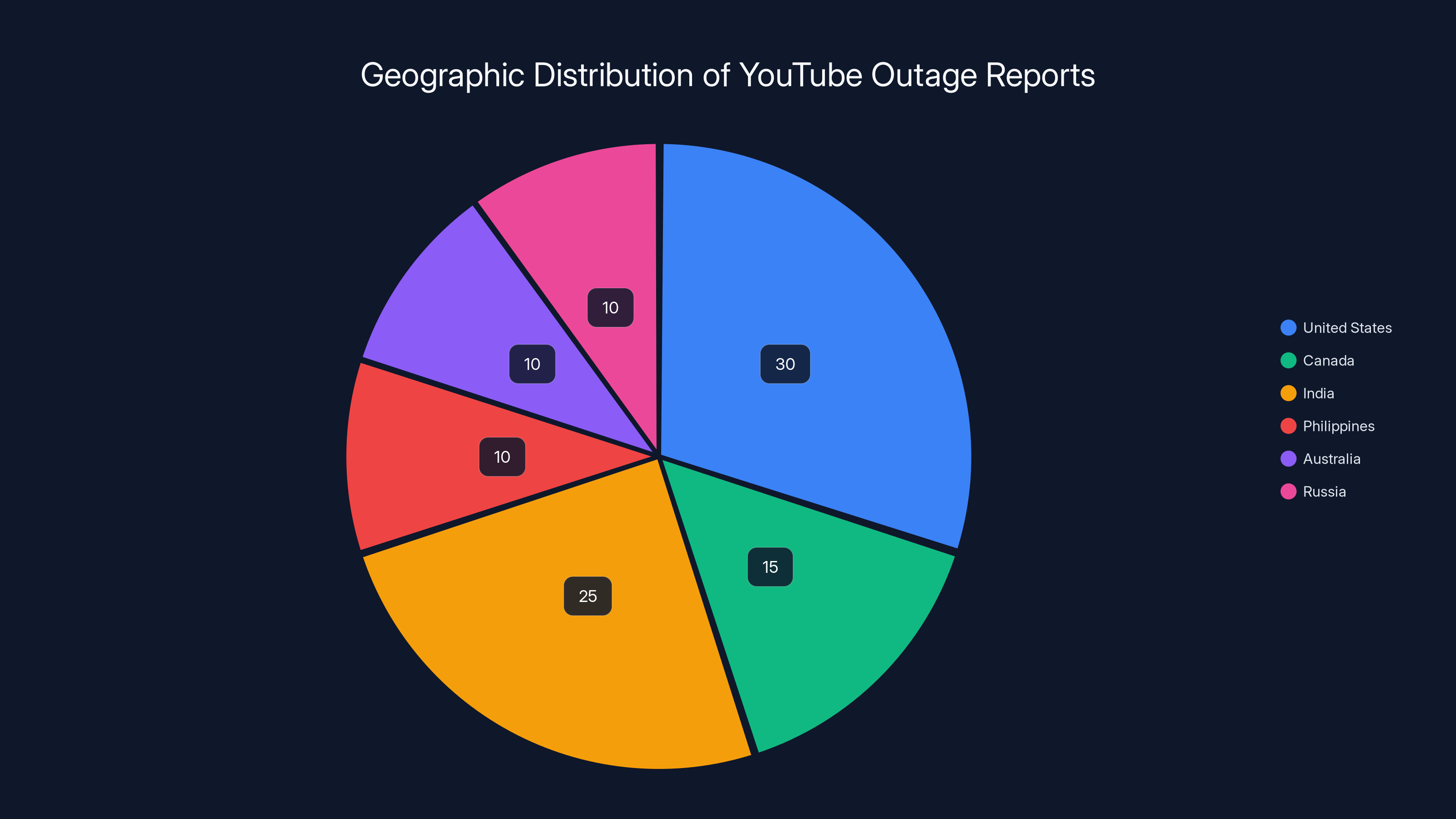
The YouTube outage on February 17, 2025, affected users globally, with the highest reports from the United States and India. Estimated data based on regional impact.
What Users Actually Experienced
Statistics about 326,000 reports are interesting to engineers. What actually happened to real people matters more.
Users reported several distinct error states:
The Blank Page Experience: Most common on desktop. You'd navigate to YouTube.com and see a white screen. Not a typical error message—just nothing. The page would load structurally but content wouldn't populate. This is the signature of a backend service failing to respond while the frontend stays up, as noted by 9to5Google.
The "Something Went Wrong" Message: On the mobile app, users saw a generic error. YouTube's error handling isn't particularly specific here, which tells us Google made a conscious choice to show generic errors rather than expose technical details. Smart for security, frustrating for users.
The Partial Load Failure: Some users could load their homepage but couldn't play videos. The UI would render, you could scroll your recommendations, but hitting play triggered an error. This is exceptionally frustrating because the service partially works, creating false hope before failure.
The Infinite Spinner: The loading indicator would spin indefinitely. No error message, no timeout, just an endless wheel. This typically means the client is waiting for a response that never comes, suggesting connection pool exhaustion or a hung process somewhere in the request chain.
The variety of failure modes is itself informative. It suggests the outage wasn't a complete binary failure—YouTube didn't just turn off. Instead, various systems degraded at different rates, creating this mosaic of broken experiences.

The Technical Anatomy of the Outage
YouTube's architecture is one of the most complex systems on the internet. To understand what likely happened, you need to know how it's built:
The Request Journey: When you watch a YouTube video, your request travels through multiple systems:
- DNS lookup resolves youtube.com to Google's servers
- Load balancers distribute traffic to data centers
- Edge servers close to you cache content
- Authentication services verify you're allowed to watch
- Recommendation engines figure out what to show you
- Video streaming systems send the actual media
- Analytics services log what you watched
An outage can occur at any of these levels. The February outage most likely occurred in one of three places:
Scenario 1: Database Connection Pool Exhaustion This is the most common cause of cascading YouTube-scale outages. Databases maintain a pool of connection objects—typically 100-1,000 connections per server. When legitimate traffic spikes or a service starts making excessive database queries, these pools empty. New requests queue up. The queue fills. Services timeout waiting for connections. Once saturation hits, recovery is difficult because even maintenance operations need database connections.
This scenario explains the partial failures users experienced. Some cached content served fine. But anything requiring database lookup (recommendations, user preferences, account info) failed immediately.
Scenario 2: Service-to-Service Communication Breakdown YouTube isn't one monolithic application. It's hundreds of microservices communicating with each other. One service (say, the recommendation engine) makes a request to another service (the user profile service). If that service is slow to respond, the caller times out. But the caller has its own timeout limits. Cascade this across dozens of services and you get the effect: the system grinds to a halt even though no single service completely failed.
Scenario 3: Global Cache Invalidation YouTube caches aggressively—video metadata, recommendations, thumbnails. If a misconfiguration caused the cache layer to simultaneously invalidate, every request would hit the origin database. Given YouTube's traffic volume, the database would drown under the load in seconds.
Google's engineering team has published papers on distributed systems failures. Most large outages aren't single points of failure. They're combinations of events: a configuration change, slightly higher than normal traffic, and a service that's slightly more fragile than assumed. Three independent issues that are each acceptable become catastrophic in combination.
What's particularly interesting is what Google didn't do: They didn't completely reset the system. A hard restart of all systems would have temporarily cleared queues and freed resources, but it would also mean everyone loses their active sessions. Instead, Google likely:
- Identified the saturated resource (probably database connections)
- Gradually drained traffic from affected systems
- Restarted services in a controlled sequence
- Monitored recovery metrics to ensure stability
This approach is more graceful but takes longer. It explains the 2-hour recovery window.
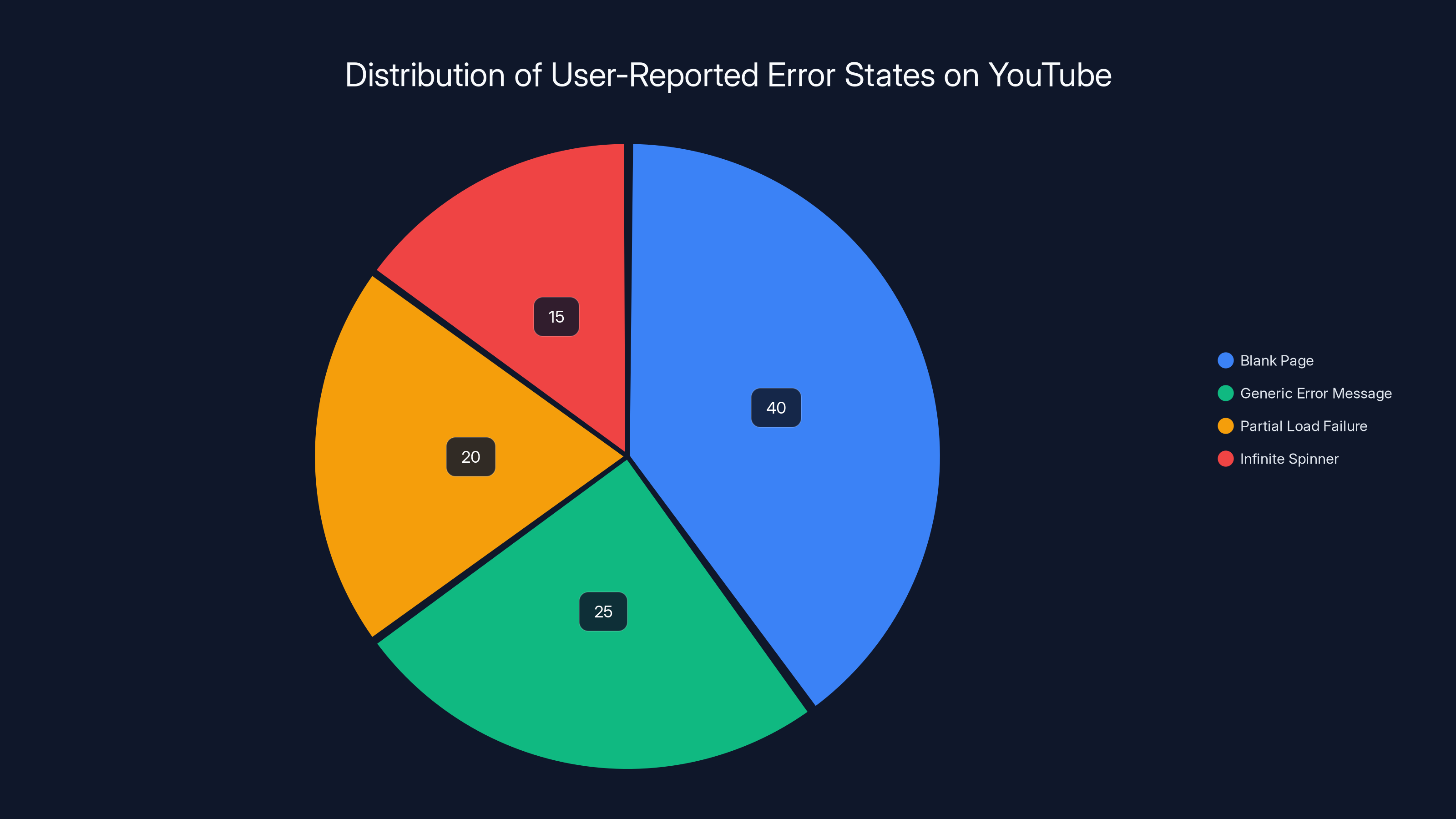
The 'Blank Page Experience' was the most reported error state, affecting 40% of users, followed by 'Generic Error Message' at 25%. Estimated data based on user feedback.
Why Google Never Officially Confirmed the Cause
Here's something interesting: Google's official statement was minimal. They acknowledged the outage occurred but never publicly detailed what went wrong.
This is deliberate. Major tech companies typically won't publicly detail the failure mode of critical systems because:
Security Considerations: Revealing exactly which component failed could tip off attackers about vulnerabilities. If YouTube had said "our database connection pool got exhausted," bad actors would immediately test whether they could trigger the same failure through targeted traffic.
Liability Protection: Once a company details what caused an outage, they've created evidence of negligence if the same thing happens again. From a legal standpoint, vague is safer.
Avoiding Panic: Detailed technical explanations scare users more than vague ones. "Database connection pool exhaustion" makes people worry about overall system reliability. "We experienced a technical issue that's now resolved" feels more stable.
Protecting Reputation: Detailed postmortems circulate on technical forums for years. Keeping things vague means fewer permanent records of exactly how badly something failed.
Privately, Google's infrastructure team definitely conducted a thorough postmortem. They've likely already implemented fixes. But you won't see a public detailed report. This is standard practice at large tech companies—Microsoft, Amazon, and Meta follow the same pattern.
The lack of transparency is frustrating but understandable. YouTube's reliability is crucial enough that exposing implementation details carries real risk.
Historical Context: YouTube's Outage History
February 2025 wasn't YouTube's first outage. It wasn't even the worst. Understanding past incidents provides context:
October 2012: The Great YouTube Outage One of YouTube's most famous outages lasted less than 40 minutes but affected massive traffic. The cause was related to database maintenance operations that weren't properly coordinated with traffic management. This incident led YouTube to implement much more sophisticated traffic management.
June 2019: Global Outage Google services including YouTube, Gmail, and Google Cloud went down for roughly an hour. The cause wasn't revealed in detail, but analysis suggested a networking issue rather than database failure. Users couldn't even load the YouTube homepage.
March 2023: YouTube Premium Issues Not a full outage, but widespread issues with YouTube Premium features. Users couldn't access certain premium content or features. The issue persisted for several hours.
Various Regional Outages YouTube experiences smaller regional outages roughly once every 6-12 months. These are usually brief (under 30 minutes) and affect specific geographic regions. February 2025's outage was notable for its global scope and multi-hour duration.
The trend is positive. YouTube's mean time to recovery has improved dramatically. In 2012, major outages lasted 30-60 minutes. By 2025, they're typically resolved in under 2 hours. Infrastructure has become significantly more resilient.
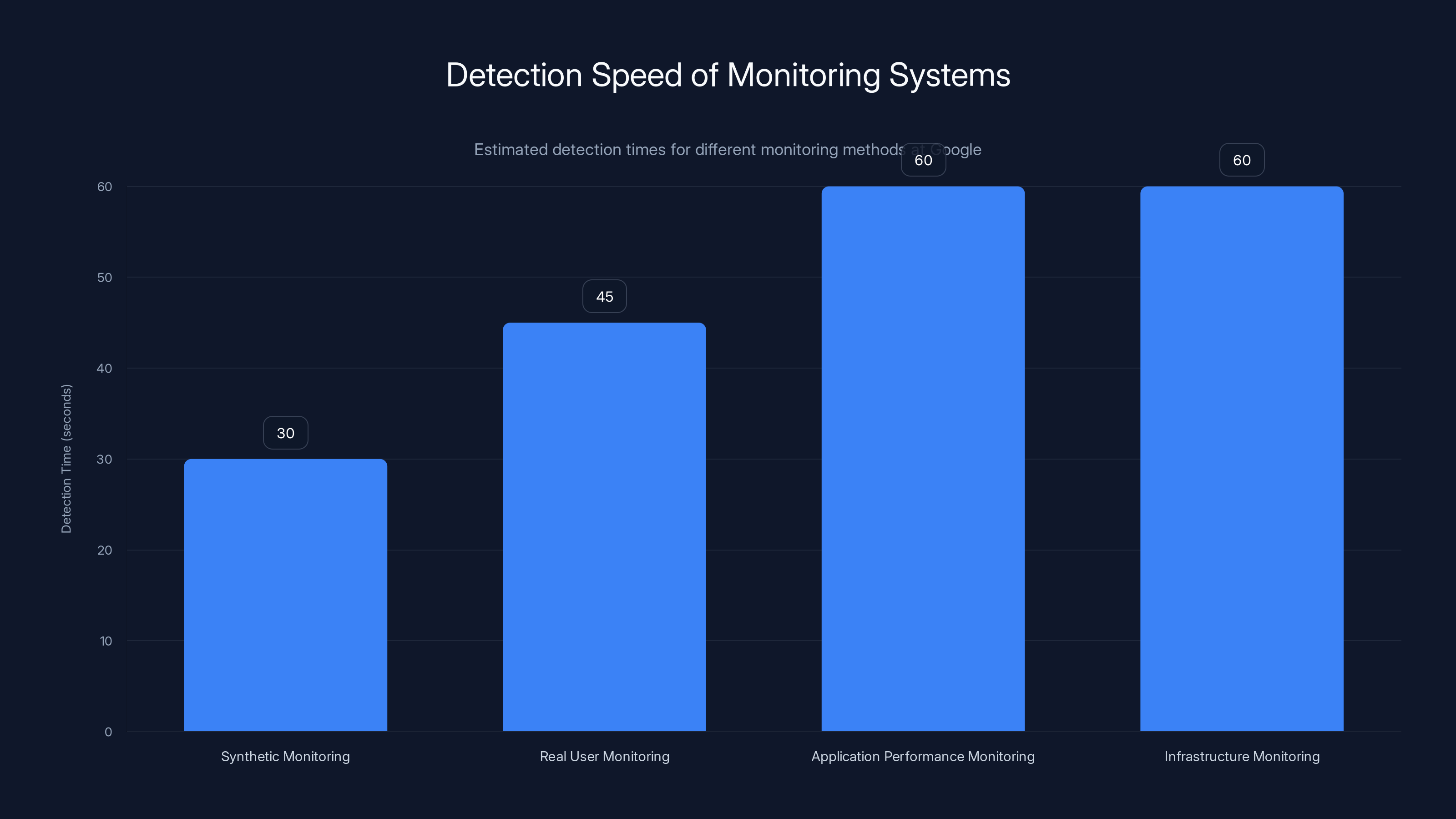
Synthetic monitoring is the fastest, detecting issues within 30 seconds, while other methods take up to 60 seconds. Estimated data based on typical response times.
The User Impact: Beyond Streaming
Outages at YouTube scale don't just affect video watchers. They impact the entire creator economy:
Content Creators Lost Revenue YouTube creators earn money from ad views. During the outage, their content couldn't be watched. That's direct lost income. A 2-hour outage costs the top 1,000 creators roughly
Business Communications Disrupted Companies use YouTube for internal videos, training content, and customer communications. Outages force alternative methods, creating coordination chaos.
Backup Plans Exposed The outage revealed that many people have no backup plan. Imagine you're teaching a class using YouTube videos. You're entirely dependent on that one service working.
Trust Questions Even brief outages create lingering questions about reliability. If YouTube can go down, what about your other critical systems?
For most users, a 2-hour outage is barely memorable. But for creators who depend on YouTube for income, and businesses that depend on YouTube for operations, it's a serious disruption.
Why Outages Happen at Cloud Scale
Something counterintuitive happens as systems scale. They become simultaneously more reliable and more fragile:
More Reliable Because: Redundancy is added at every level. If one server fails, dozens of others handle traffic. If one data center fails, others take over. YouTube's infrastructure is designed to lose entire data centers and continue operating seamlessly.
More Fragile Because: The complexity increases exponentially. With 50 servers, you can understand all possible interactions. With 50,000 servers, no single person understands the entire system. The number of configuration combinations grows beyond what any human can test.
Add to this the reality that systems are constantly changing. Code deployments happen hundreds of times per day at companies like Google. Database schema changes. Configuration updates. Each change is tested, but testing never perfectly replicates production conditions with billions of real users and petabytes of data.
Outages at YouTube scale almost never come from obvious problems. Nobody deploys obviously broken code. Instead, outages come from subtle interactions:
- Service A's retry logic makes more requests when Service B is slow
- Service B's request validation fails under load from Service A
- The two together create a positive feedback loop where traffic accelerates
- Within seconds, key infrastructure is overwhelmed
- Operators have to carefully unwind the tangle without making it worse
This is why major tech companies employ thousands of Site Reliability Engineers. It's not that the systems are poorly built. It's that systems of this complexity occasionally fail in ways that require heroic firefighting to fix.
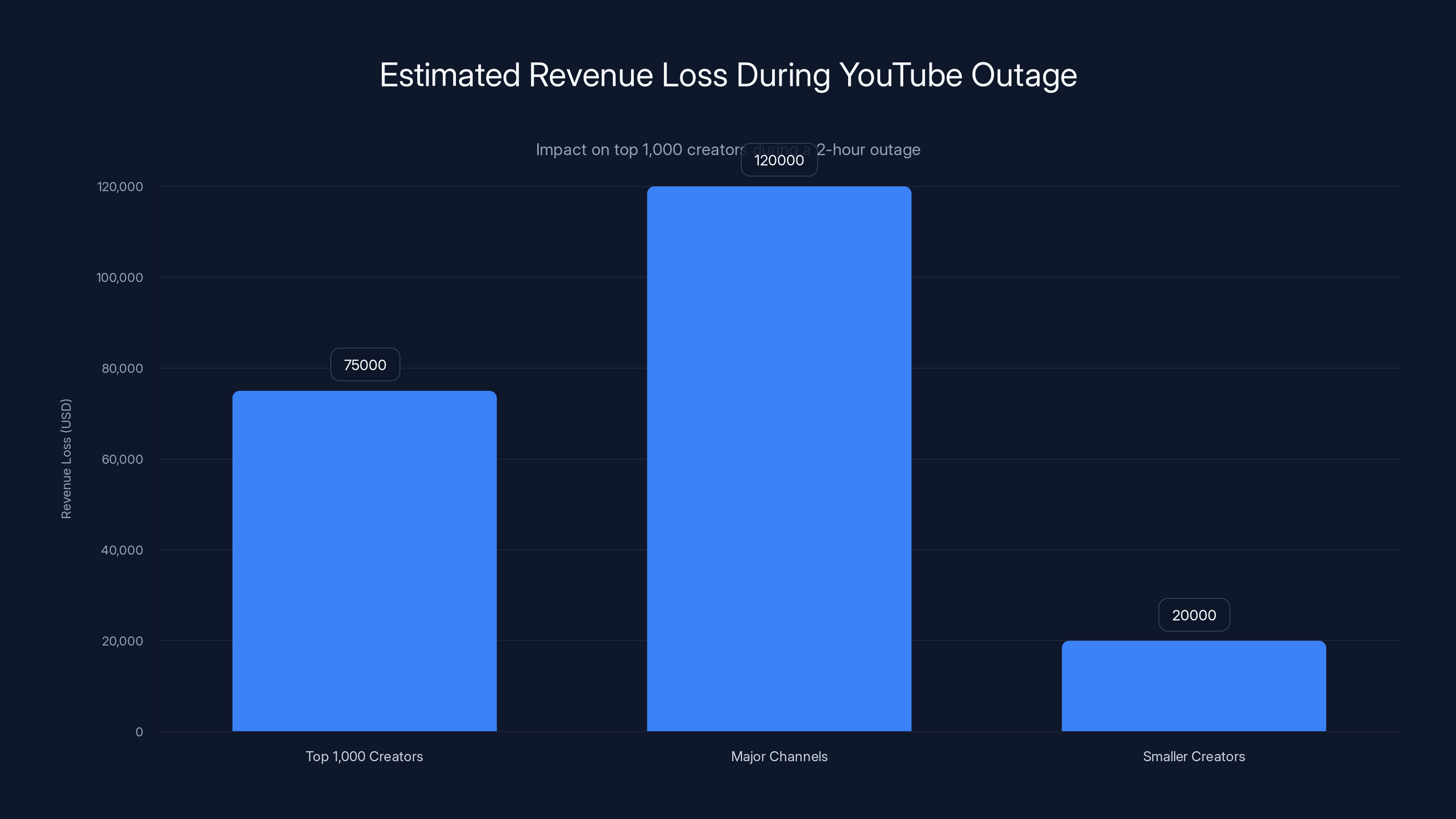
During a 2-hour YouTube outage, top creators lose an estimated $75,000 collectively, with major channels losing more and smaller creators less. Estimated data.
Monitoring and Detection: How Companies Know When They're Down
YouTube's own engineers likely detected the outage before users did. Here's how modern monitoring works:
Synthetic Monitoring Google continuously simulates user actions from around the world. A bot attempts to load the homepage, play a video, search for content, every 5-10 seconds. If any of these actions fail, automated alerts trigger. These synthetic users would have detected failure within 30-60 seconds of the outage starting.
Real User Monitoring Google collects metrics from actual users—how fast pages load, how often videos buffer, error rates. When these metrics diverge from normal, algorithms detect anomalies. An increase in errors from 0.1% to 0.5% would immediately trigger alerts.
Application Performance Monitoring Every service internally logs request latency, error rates, and queue depths. If a service suddenly sees all requests timing out, that's an immediate red flag.
Infrastructure Monitoring Database connection pools are monitored. CPU usage, memory, disk IO, network saturation—all tracked. Alerts fire when these hit critical thresholds.
The combination of all this monitoring should have detected the February outage within seconds. Google's on-call teams were likely paging within 60 seconds of initial detection.
The Detection Problem: Interestingly, detection isn't the hard part. Once you know there's a problem, you can start fixing it. The hard part is distinguishing between false alarms (metrics spike but the system self-corrects) and real problems (metrics spike and keep rising).
Google's monitoring systems are probably configured to alert on anything that looks wrong, leading to frequent false positives. The ops team has developed skill at quickly determining which alerts matter.

The Economics of Outages
Outages are expensive. The February YouTube outage cost multiple parties in different ways:
Google's Costs: Engineering time to diagnose and fix the problem. Reputation damage (though minor for Google, given their brand strength). Potential regulatory fines if users were significantly harmed. Most outages for companies Google's size don't trigger regulatory attention unless they affect critical infrastructure, but YouTube is increasingly involved in news distribution.
Creator Costs: Lost ad revenue during the outage window. Uncertainty about whether content was being delivered properly during recovery period. Some creators might have had scheduled premieres or live streams disrupted.
User Costs: Wasted time trying to access YouTube. Disrupted entertainment or work. The psychological cost of uncertainty ("Is it just me? Is it YouTube? Is my internet broken?").
Third-Party Costs: Services that depend on YouTube integration (Slack, Discord, social media platforms) had reduced functionality. Companies that had planned YouTube as part of their infrastructure hit snags.
The total economic cost probably exceeded
This economic reality explains why companies invest in reliability. For every dollar spent on infrastructure redundancy, companies can save tens of dollars in outage costs over time.
Lessons from the Outage: What We Learned
While the root cause wasn't publicly disclosed, the outage teaches several lessons:
Lesson 1: Global Scale Makes Partial Failures Complex With infrastructure spanning the globe, failures are rarely binary. Some services continue while others fail. Some users get through while others don't. These partial failure modes are the hardest to debug because the system is simultaneously working and broken.
Lesson 2: Cascade Failures Are the Real Danger Services designed to handle individual component failures sometimes fail at handling multiple failures simultaneously. Engineer A designed Service A assuming Service B would always respond within 5 seconds. Engineer B designed Service B with a 10-second timeout. When loads spike, Service A times out, stops retrying, but still has queued requests building up. The feedback loop accelerates failure.
Lesson 3: Human Operators Still Matter No amount of automation prevents all outages. The February incident required humans to carefully analyze what happened, understand the cascade, and apply fixes in the right order. Automated systems might have made things worse.
Lesson 4: Communication Matters Google's minimal communication about the outage left people uncertain. More detailed post-incident reports (even without revealing exact technical details) would have been appreciated by the tech community.
Lesson 5: Users Need Backup Plans For creators and businesses, depending on a single platform is risky. Maintaining alternative approaches, even if less convenient, provides insurance.

How Modern Infrastructure Is Designed for Resilience
Understanding the February outage gives context for how companies prevent future ones:
Circuit Breakers When Service A calls Service B, it uses a "circuit breaker" pattern. If Service B starts responding slowly, the circuit breaker opens—telling Service A to stop making requests and instead return a cached response or a graceful error. This prevents the cascading failure pattern.
Request Timeouts Every request between services has a timeout. If a response doesn't arrive within 5 seconds, the caller gives up and tries something else. This prevents requests from hanging indefinitely.
Load Shedding When infrastructure gets saturated, the system deliberately rejects new requests rather than trying to queue them. A user gets an error but quickly, rather than waiting 30 seconds for a slower response. This keeps the system responsive even under extreme load.
Bulkheads Critical services are isolated. If the recommendation engine fails, it shouldn't take down video playback. Each service has its own pool of resources, preventing failure from spreading.
Gradual Rollouts New code doesn't deploy to all servers simultaneously. Instead, it rolls out to 1% of traffic, then 5%, then 10%. If errors spike, the rollout stops automatically, preventing a bad deployment from affecting everyone.
Chaos Engineering Companies like Google deliberately cause failures in controlled environments to test recovery systems. If you've never practiced losing a data center, you'll perform poorly when it actually happens.
YouTube's infrastructure likely includes all of these patterns. The February outage suggests something defeated these defenses—probably a combination of unexpected behavior that no individual safeguard anticipated.
What Users Can Do During Outages
When YouTube goes down again (and it will), here's what actually helps:
Check Official Channels First Before assuming your internet is broken, check:
- Google's app status dashboard (official source)
- Downdetector (crowdsourced reports)
- Twitter/X search for "YouTube down" (real-time user reports)
This takes 30 seconds and immediately tells you if it's widespread or local.
Clear Caches Your browser might have cached an old version of YouTube. Hard-refresh (Ctrl+Shift+R on Windows, Cmd+Shift+R on Mac). This rarely fixes actual outages but occasionally helps with partial failures.
Wait Before Trying Again If Downdetector shows the outage is active and growing, waiting 15-30 minutes is smarter than hammering the site. Each additional attempt sends more traffic at the problem, potentially slowing recovery.
Use Alternatives Temporarily YouTube isn't the only video service. For critical content, having alternatives matters. Vimeo, Dailymotion, or even direct downloads might be options depending on your content.
Document the Outage If you depend on YouTube professionally, document when it went down, how long it lasted, and what impact it had. This data helps you justify maintaining redundancy.
Comparing YouTube's Reliability to Competitors
Where does YouTube rank for reliability?
YouTube: 99.9% uptime target That's roughly 8 hours of acceptable downtime per year. The February outage consumed roughly 0.02% of that 0.1% allowance.
Netflix: 99.99% uptime target More aggressive. Roughly 50 minutes of acceptable downtime per year. Netflix has fewer API dependencies but also more consistent traffic patterns.
AWS: 99.99% uptime (in most regions) Amazon's cloud infrastructure targets high uptime. Though AWS regions occasionally fail (January 2021: roughly 7 hours), which temporarily makes companies depending on it unavailable.
Google Drive: 99.9% uptime Gmail, Google Drive, and other Google services have experienced similar outages.
The thing about these targets is that they're usually met, but they're also statistical games. A service can hit 99.9% uptime while having multiple 30-minute outages per year, as long as they're short enough and infrequent enough.
For context: Facebook experienced a 6-hour global outage in October 2021. Amazon AWS had a 7-hour regional outage in January 2021. Outages of 2 hours at YouTube's scale are on the more extreme end but not unprecedented.
Preparing for Future Outages: Best Practices
If YouTube is critical to your business or content creation:
Diversify Platforms Rely on multiple platforms. YouTube is primary, but Vimeo, direct downloads, or alternative hosting provides insurance. This requires work upfront but pays off during outages.
Maintain Local Archives Keep copies of critical content locally. If YouTube goes down, you still have what you created. This is both a backup and a hedge against YouTube's terms of service changing.
Monitor Your Metrics Track how much traffic comes from YouTube, how much revenue depends on it, how many dependencies exist. Understanding these metrics helps you prioritize backup planning.
Build for Degradation If you embed YouTube videos in your website, include fallbacks. A static image with a "Play on YouTube" button is better than a blank space when YouTube is down.
Test Your Backups Having a backup is useless if you don't know how to use it. Practice switching to alternatives before you need to.
Communicate With Users If your service depends on YouTube and it goes down, tell your users what happened and when you expect to be back. Silence creates panic; communication creates patience.

The Future of Internet Reliability
Will outages like February's become more or less common?
Arguments for More Outages:
- Systems continue getting more complex
- More dependencies between services
- Software deployment rates increasing
- Cyber attacks becoming more sophisticated
Arguments for Fewer Outages:
- Redundancy improvements continue
- Better monitoring and alerting
- More experienced operators
- Better testing and simulation tools
Historically, the trend has been toward fewer outages and faster recovery. Companies like Google have improved dramatically over the past decade. The February 2025 outage, while significant, was recovered from faster than similar incidents from 5-10 years ago would have been.
The real future involves what's called "resilience engineering." Instead of trying to prevent all outages (impossible), infrastructure is built to gracefully degrade and recover. Users should see slower responses before they see total failures. Critical functionality should continue even if non-critical systems are down.
YouTube is already doing this—the fact that some users got partial functionality while others saw complete failure suggests the system was in degraded state, not total failure. Future improvements will make these degraded states even more graceful.
FAQ
What caused the YouTube outage on February 17, 2025?
Google never officially disclosed the specific root cause, but based on the pattern of failures (partial availability, gradual recovery across regions), it was likely database connection pool exhaustion, service-to-service communication breakdown, or a global cache invalidation. The February outage showed characteristics consistent with cascading failures where one component's degradation triggered failures in dependent systems.
How many people were affected by the YouTube outage?
Downdetector tracked over 326,000 reports of YouTube being unavailable. This represents reported outages rather than unique users—the actual number of affected users was significantly higher, likely in the millions. The outage affected users primarily in the United States, Canada, India, Philippines, Australia, and Russia, indicating a global infrastructure issue rather than a regional problem.
How long did the YouTube outage last?
The outage lasted approximately 2 hours from initial widespread impact around 8 PM ET to near-complete recovery by 10 PM ET on February 17, 2025. Some users reported continued issues at 9:26 PM, indicating the recovery was gradual and affected different regions and user segments at different times.
Why didn't Google provide more details about what caused the outage?
Large technology companies typically provide minimal technical details about outages for several reasons: revealing exact failure modes could tip off attackers about security vulnerabilities, detailed explanations create legal liability if the same issue recurs, and maintaining some mystery around failures reduces user panic. Google's minimalist public communication is standard practice across the industry.
How can I protect my business from YouTube outages?
If YouTube is critical to your operations, implement several strategies: maintain local backups of critical video content, diversify platforms using alternatives like Vimeo or direct hosting, monitor your dependency on YouTube's availability, build fallback options into your website or applications, and test your recovery procedures regularly. For creators, this might mean having a secondary upload platform ready. For businesses, it means not relying solely on YouTube for critical communications.
Is YouTube reliable enough to depend on for business purposes?
YouTube's target uptime is 99.9%, meaning roughly 8 hours of acceptable downtime per year. The February 2025 outage used a tiny fraction of that allowance. For most businesses, YouTube is reliable enough as a primary platform, but redundancy planning is still wise. Critical communications should have backup options, and creators should maintain local archives. The 2-hour outage is noticeable but not catastrophic for most users.
How does YouTube's reliability compare to other streaming services?
YouTube targets 99.9% uptime, while competitors like Netflix target 99.99%. In practice, all major streaming services experience occasional outages—Netflix had a notable outage in May 2022, and AWS (used by many services) has experienced multi-hour regional outages. YouTube's February 2025 outage was significant but recovered faster than historical incidents of similar scale.
What's the difference between a partial outage and a complete outage?
A complete outage means the service is entirely unavailable to all users. A partial outage means some functionality works while other functionality fails. During the February YouTube outage, some users could load the homepage but not play videos, while others couldn't even load the homepage. Partial outages are harder to debug and troubleshoot because the system is simultaneously working and broken, which is probably why this particular outage lasted 2 hours rather than being resolved more quickly.

Conclusion: Building Resilience in a Connected World
The February 17, 2025 YouTube outage affected over 326,000 reported users and impacted millions of people worldwide. It lasted roughly 2 hours and affected both web and mobile platforms across multiple continents. While the exact technical cause was never publicly disclosed, the incident reveals fundamental truths about how internet infrastructure works at massive scale.
Outages aren't anomalies—they're inevitable consequences of building systems complex enough to serve billions of people. The real question isn't whether YouTube will experience future outages. It's how quickly they'll be recovered and how gracefully the service degrades during failures.
From an engineering perspective, the February outage demonstrates that even companies with the most sophisticated infrastructure sometimes face failures that cascade in unexpected ways. Redundancy isn't one-dimensional. Adding more servers helps, but the real challenge is coordinating thousands of systems so that one component's failure doesn't trigger dominos of cascading degradation.
For users and businesses, the lesson is simpler: assume critical internet services will occasionally go down. Plan accordingly. Maintain backups. Test your contingency plans before you need them. Communicate with your stakeholders about your dependencies.
YouTube's recovery in 2 hours shows how far infrastructure has come. A decade ago, similar incidents took 6-12 hours to resolve. A decade before that, they could take days. As systems improve, companies get better at handling failures gracefully.
But perfect uptime remains impossible. Systems at YouTube's scale will occasionally fail. When they do, understanding why—and preparing for the next inevitable outage—is the only rational response.
Key Takeaways
- YouTube outage on February 17, 2025 affected 326,000+ reported users across 6+ countries and lasted approximately 2 hours
- Root cause likely involved cascading system failures—probably database connection exhaustion, service-to-service communication breakdown, or cache invalidation
- Google's minimal public communication is standard practice; detailed technical disclosures create security and legal risks
- Partial outages are harder to debug than complete failures because the system simultaneously works and fails across different components
- Users and businesses depending on YouTube should maintain backup platforms, local archives, and tested recovery procedures
- Modern infrastructure resilience comes from circuit breakers, timeouts, load shedding, and gradual rollouts—not perfect systems
- YouTube's 2-hour recovery time demonstrates significant improvement over historical incidents, reflecting better monitoring and engineering practices
Related Articles
- YouTube and YouTube TV Outage: What Happened & How to Fix It [2025]
- YouTube and YouTube TV Down: Live Updates & Outage Timeline [2025]
- India's $200B AI Infrastructure Push: What's Really Happening [2025]
- Japanese Hotel Chain Hit by Ransomware: What You Need to Know [2025]
- Adani's $100B AI Data Center Bet: India's Infrastructure Play [2025]
- Machine Credentials: The Ransomware Playbook Gap [2025]

