![AI Governance & Data Privacy: Why Operational Discipline Matters [2025]](https://tryrunable.com/blog/ai-governance-data-privacy-why-operational-discipline-matter/image-1-1771515551845.jpg)
Introduction: The Hidden Reality Behind AI Governance
There's a conversation happening in boardrooms and security meetings right now. It's about AI governance, data privacy, and how to safely integrate large language models into regulated environments. But it's almost entirely wrong.
Most organizations focus on the flashy stuff: AI policy frameworks, governance models, and sophisticated guardrail implementations. They build committees, establish review processes, and document their "AI strategy." Then they deploy models into production and watch in horror as sensitive data starts leaking through systems nobody realized were exposed.
Here's what nobody wants to admit: AI governance isn't fundamentally a policy problem. It's an operational problem.
When you deploy an AI model into your infrastructure, you're not introducing some mysterious new force that requires invented solutions. You're connecting a tool to systems, databases, and workflows that were already there. And those systems? They probably have governance gaps that existed long before anyone thought about machine learning.
The real question isn't whether your AI model is "safe." It's whether your operational foundations are solid enough to contain and control it. A sophisticated policy document means nothing if your access controls are inconsistent, your data classification is unclear, or your deployment pipelines have blind spots.
This distinction matters because it changes everything about how you should approach AI readiness. Instead of building elaborate new frameworks, you need to fix what's broken in your existing operations. Data masking, access controls, testing procedures, vendor scrutiny, environmental isolation—these aren't "AI-specific" controls. They're the basics of operational security that mature teams have been doing for years.
The catch? They're the basics that most organizations still do poorly.
What separates organizations that safely deploy AI from those that create disasters is usually not intelligence or resources. It's discipline. It's the unglamorous work of understanding what data actually exists, where it moves, who can access it, and whether those boundaries are enforced consistently across production systems.
This article breaks down why AI doesn't create new risks so much as it exposes existing ones. We'll examine why fast-moving platforms amplify governance blind spots, what "AI-ready" actually means in regulated environments, and the specific operational foundations that make trustworthy AI possible. If you're trying to deploy AI responsibly at scale, this is where you start.
TL; DR
- AI governance is an operational problem, not a policy problem: Models inherit risks from underlying systems, access controls, and deployment processes.
- Data exposure happens through operational gaps, not model misbehavior: AI reveals information people didn't realize was accessible due to inconsistent boundaries and controls.
- Fast-moving platforms create hidden exposure risks: SaaS, cloud, and low-code environments shift data paths faster than visibility can follow, leaving gaps in oversight.
- "AI-ready" means understanding your tolerance for exposure and building controls progressively: Start with low-risk use cases, prove reliability, then scale.
- DevOps foundations are essential: Clear access controls, data hygiene, testing procedures, vendor scrutiny, and cultural buy-in determine whether AI deployments succeed or fail.
- Bottom line: Safe AI adoption is built on unglamorous operational discipline, not sophisticated frameworks.
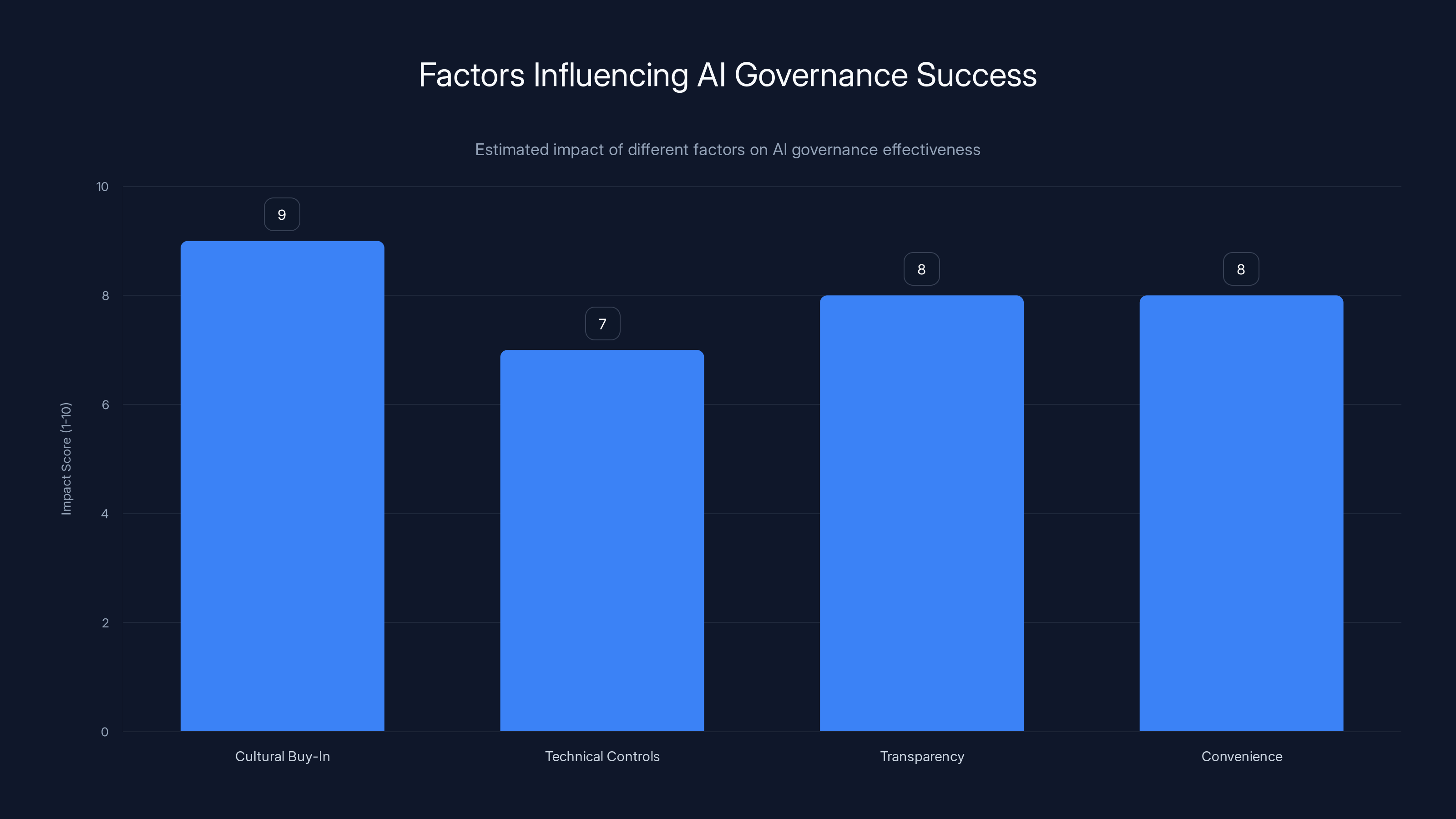
Cultural buy-in is crucial for AI governance success, scoring higher than technical controls. Estimated data.
Why AI Risk Is Fundamentally an Operational Problem, Not a Policy One
How AI Inherits Risk From Surrounding Systems
Let's start with a concrete scenario. You've just deployed a state-of-the-art large language model into your enterprise environment. The model is fine-tuned, tested, and comes with all the right safety considerations. Your policy framework says it's restricted to non-sensitive data.
Then something unexpected happens: the model generates an output that includes a customer's social security number.
The conversation that follows typically goes like this. Security team reviews the model's architecture. They check the fine-tuning data. They verify the training process. Everything looks correct. The model shouldn't have that information.
But it does.
When you dig deeper—and you will eventually—you discover the problem wasn't the model. It was the database connection. Your "test environment" was regularly cloned from production data. Nobody had explicitly masked PII before that clone happened. The model was querying exactly what the architecture allowed: everything the underlying database returned.
This scenario repeats itself constantly in different forms. A data scientist uses a public generative AI service to analyze an internal workflow. An AI agent operates with the same API credentials as the engineer who deployed it, giving it access far beyond its intended scope. A fine-tuning dataset includes sensitive information because the data governance process that should have filtered it out was never actually implemented.
None of these failures are about model behavior. They're about operational discipline.
AI systems don't operate in isolation. They exist inside infrastructure that was built long before anyone thought about machine learning. That infrastructure has databases, access controls, deployment pipelines, testing environments, and workflows. Some of those are well-governed. Many aren't.
When you connect AI to that infrastructure, the model doesn't somehow become smarter about boundaries than the people who built the systems around it. It works within the rules it's given. If the underlying systems have inconsistent access controls, the model inherits that inconsistency. If data classification is unclear, the model can't magically infer what should be protected. If there's no testing framework to catch leakage before production, the model will deploy with whatever blindness the rest of your infrastructure has.
This is why many sophisticated "AI guardrails" fail in real environments. A guardrail in code can say "this model can't access sensitive data." But that guardrail is only as strong as the access control layer beneath it. If your authentication system is weak, your permission boundaries are unclear, or your network isolation is incomplete, the guardrail is theater.
Why AI Reveals Rather Than Creates New Risks
Here's something that catches organizations off guard: AI doesn't introduce fundamentally new types of risk. It exposes existing ones.
Consider what an AI model does when it operates at scale. It processes data, makes connections, and operates across systems with speed and consistency that humans don't. That speed is valuable—that's why organizations deploy AI. But it also means that any gap in your governance gets exposed faster.
A human analyst doing manual work might encounter sensitive data in the wrong place. They'd probably notice it, recognize it's out of place, and report it. The exposure gets fixed before it causes damage.
An AI system encountering the same situation at scale might process thousands of records before anyone notices. It might generate outputs, move data, or feed results into downstream systems. The exposure doesn't get caught until much later—sometimes after damage has already occurred.
The gap was always there. The AI just revealed it.
This distinction is crucial because it changes how you should think about AI governance. You're not defending against some novel threat that only AI creates. You're fixing the operational weaknesses that already exist in your infrastructure.
Some of those weaknesses are obvious once you look for them. Data isn't consistently classified. Access controls are applied inconsistently across environments. Test systems have production-shaped data. Sensitive information is stored in places it shouldn't be. These aren't sophisticated governance problems that require innovative solutions. They're basic operational discipline problems that mature teams solved years ago.
Other gaps are more subtle. Permissions change frequently, but nobody maintains a clear record of what changed and when. Environments are cloned regularly, but the cloning process doesn't include systematic data cleanup. Teams have good intentions about keeping systems separate, but in practice, integration points create cross-environment access that wasn't explicitly planned.
AI doesn't create these gaps. It just operates within them with mechanical consistency, making their existence undeniable.
The Core Problem: When Processes and Policy Diverge
There's a critical gap between what organizations believe about their systems and how those systems actually work. A policy can state "sensitive data is restricted to authorized users only." But that policy only matters if the operational reality enforces it.
In fast-moving enterprise environments, policy and reality diverge constantly. A project needs to move quickly, so someone grants broader access than the policy technically allows but reasons it's temporary. A new system is implemented with a slightly different access model, and nobody updates documentation. An environment is spun up for testing, and the data governance process that should have cleansed it gets skipped because of deadline pressure.
Each deviation from policy is usually small. But they compound. Over time, the gap between policy and reality becomes substantial.
This is where AI creates a particular problem. An AI system will operate within the operational reality, not the stated policy. If the reality has governance gaps, the AI will exploit them—not maliciously, but mechanically. It will access data because access is technically available, even if policy says it shouldn't be.
When something goes wrong, the response is often to add more policy. More guardrails. More framework layers. But if the underlying operational reality hasn't changed, adding policy won't help. You're just documenting governance gaps instead of fixing them.
The solution is unglamorous: align operational reality with policy by implementing consistent, enforced controls. That means audit trails. That means regular review of who actually has access to what. That means testing whether your stated controls actually work. That means fixing the gap between what you think is happening and what's actually happening.
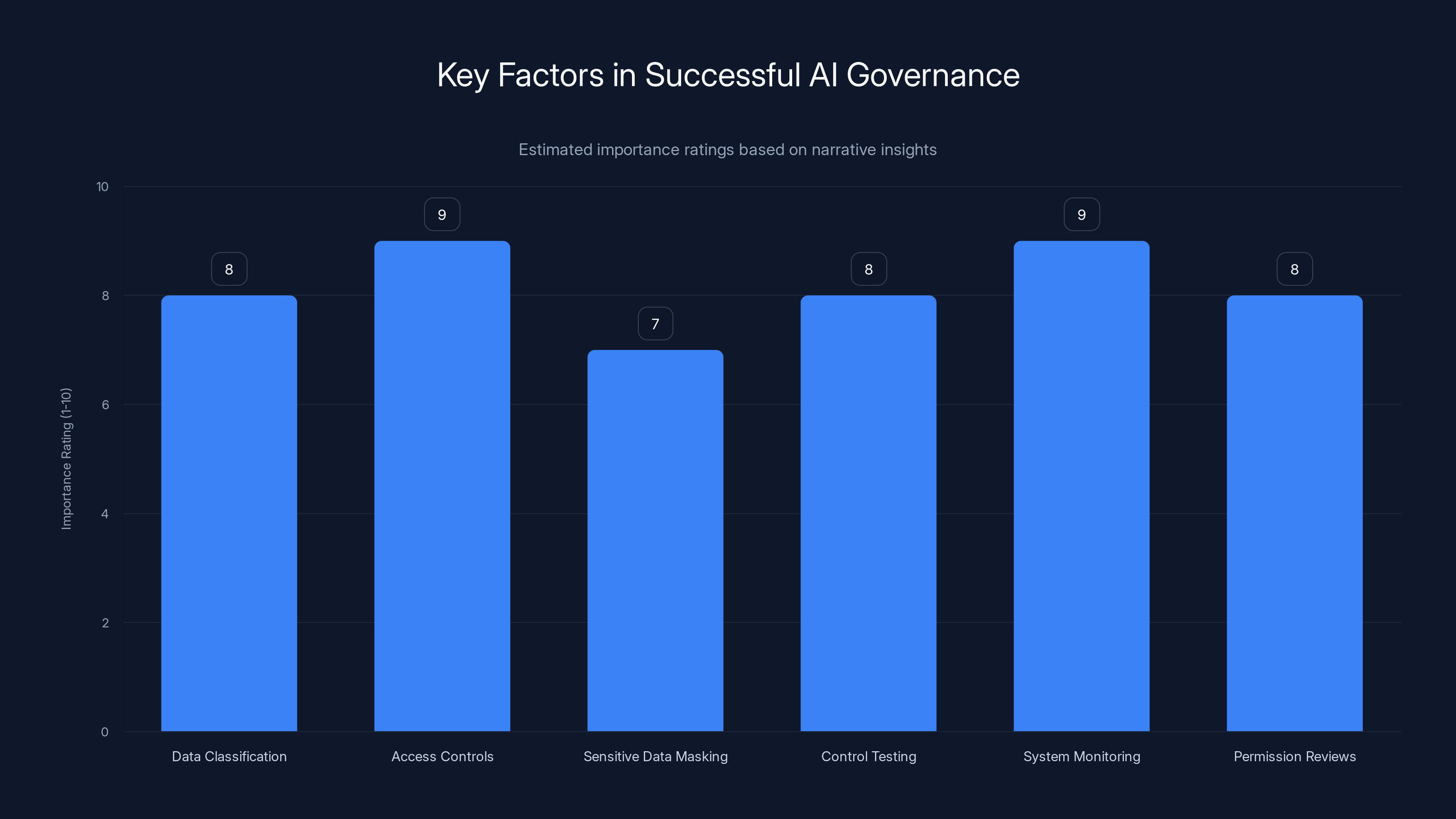
Organizations focusing on operational discipline, such as access controls and system monitoring, are more successful in AI governance. Estimated data based on narrative insights.
How Fast-Moving Platforms Create Hidden Data Exposure
The Velocity Problem: When Systems Change Faster Than Visibility Can Follow
Modern enterprise infrastructure moves fast. Cloud-based platforms spin up resources in minutes. Low-code environments let teams configure systems without traditional development processes. Automation pipelines deploy code continuously. SaaS applications constantly update their APIs and interfaces.
All of this speed is valuable. It lets organizations respond to business needs quickly, iterate on products, and deploy improvements without waiting for quarterly release cycles.
But velocity creates a specific governance problem: data paths and access patterns change faster than visibility can follow.
Consider what happens when a team clones an environment for testing. The process is automated. New database copies are created, new API endpoints are configured, new user accounts are provisioned. This might happen dozens of times per week. Each clone creates temporary pathways for data to move, new access points, new potential exposure surfaces.
If your governance framework assumes that data paths are stable and well-documented, you're already behind. By the time you've documented a path, it's changed.
Or consider a different scenario: a SaaS platform you use updates its API. The update changes which fields are accessible and introduces new integration points. Your governance framework said certain data was protected because the old API didn't expose it. Now the new API does. Nobody intentionally created that exposure—it's just what happens when systems move fast and governance doesn't keep pace.
These aren't theoretical problems. They're what organizations actually experience when they try to understand what data an AI system can actually access. Teams will confidently state that sensitive information is protected. Then an AI system encounters it anyway, not because the team was wrong about their systems, but because their understanding was frozen in time. The systems have evolved since then.
Why Best Intentions Fail at Scale
Most teams genuinely want to govern data properly. The problem is that intention doesn't scale. When you have dozens of systems, hundreds of data sources, and thousands of access pathways, good intentions break down against the complexity.
A team might intend to keep test data separate from production data. That's a reasonable intention. But in practice, maintaining that separation at scale is work. You need processes to refresh test environments, tools to mask sensitive information, automation to prevent accidental copies of production data into non-production systems, and auditing to verify these processes actually work.
Some teams do that work. Many don't—not because they're negligent, but because the work is unglamorous and there's always something that seems more urgent.
So what actually happens? Test environments gradually accumulate production-shaped data. Sometimes it's masked. Often it isn't. Teams tell themselves it's "controlled," but control is more of an aspiration than a reality. Then an AI system gets deployed into that environment, and it encounters sensitive data nobody explicitly intended to be there.
Similar patterns happen with access controls. A developer needs temporary access to a database to debug something. That access is provisioned with the intention that it'll be removed when debugging is done. But the ticket to remove it gets lost. The developer moves to a different team, but their access remains. New team members inherit overly broad permissions because the access review process that should catch that doesn't consistently happen.
Over time, the principle of least privilege becomes the principle of whatever access someone requested last year and nobody cleaned up.
AI systems will operate within those overly permissive boundaries. An AI agent won't know that access was meant to be temporary. It'll just see that the access exists and use it.
The Transparency Gap: What You Think Is Protected vs. What Actually Is
Organizations often have a significant blind spot about what data is actually exposed. Teams believe sensitive information is protected. Security frameworks say it should be. But when you actually trace where data lives and who can access it, the reality often differs from the belief.
This isn't malice. It's usually complexity. Modern data infrastructure is intricate. Data moves through pipelines, gets copied and transformed, gets integrated with other systems, gets cached in multiple places. A single dataset might exist in five different formats across three different systems, each with slightly different access controls.
Understanding what data actually exists, where it lives, and who can access it is hard work. Organizations often skip it, assuming their access controls are sufficient based on principle.
But principle and practice diverge. An API that's "restricted to authorized users" might be accessible from any computer on your network. A database that's "encrypted at rest" might have all its data in plaintext logs. A service that's "sandboxed" might have network access to your internal systems.
AI deployments have a way of colliding with these gaps because they operate systematically across infrastructure. An AI agent might not encounter exposed sensitive data through direct access. It might encounter it through logs, caches, or integration points nobody explicitly considered.
The solution isn't to add more restrictions to AI systems. It's to actually understand and map your data infrastructure. What sensitive information exists? Where does it live? Who should be able to access it? What actually happens if they try?
Until you can answer those questions with specificity and confidence, you don't really know what exposure your systems have.
Understanding What "AI-Ready" Actually Means in Regulated Environments
AI-Ready Is a Progression, Not a Binary State
Organizations often approach AI readiness as if it's a destination. You either are ready or you aren't. You either have governance or you don't. You either can deploy AI or you can't.
This framing causes problems because it encourages organizations to try to reach "readiness" as quickly as possible, often by building frameworks and policies rather than by actually fixing underlying issues.
Better framing: AI readiness is a progression built on evidence and confidence.
You start with projects where the stakes are low. You learn how your organization actually behaves when deploying AI. You discover gaps in your operational controls. You fix them. Then you take on slightly more ambitious projects, continuing this cycle.
This approach sounds slower, but it's actually faster in practice because you're not building theoretical governance frameworks that don't actually constrain behavior. You're building evidence that your operational controls work.
Consider what this looks like in practice. An organization might start with an AI project to help with documentation. Documentation is valuable to generate, but if the AI produces incorrect documentation, the blast radius is limited. Stakes are low. The project teaches the team about how to integrate AI into their development workflow, what governance mechanisms actually matter, what turns out to be unnecessary complexity.
Based on what they learn, they might take on a slightly higher-stakes project: automating routine analysis or testing internal data. Still no customer-facing data. Still contained. But now the team is building genuine confidence in their ability to control the AI system.
Only after multiple successful lower-risk deployments do they move to projects that involve sensitive data or regulated processes. By that point, they have real evidence that their controls work, not just policies that claim they do.
This progression-based approach is more demanding than building a governance framework, because it requires actual sustained discipline. But it's the only way to build genuine readiness rather than the illusion of it.
Starting Low-Risk: The Foundation for Safe Scaling
The pressure to show AI delivering business value is enormous. Executives want to see impact. Teams want to use AI for meaningful problems. There's always a tempting high-value use case just waiting to be solved with AI.
Resist that pressure. Start with something that matters, but where the stakes are genuinely low.
Ideal starting use cases share several characteristics. They involve non-sensitive data or heavily masked sensitive data. They're internal-facing, not customer-facing. They're additive (AI provides suggestions, not final decisions) rather than deterministic. They're part of workflows where humans are already involved and can catch mistakes.
Documentation generation fits these criteria well. Tests often match as well. Content classification for internal routing. Summarizing internal reports. Suggesting code refactoring. These are all valuable, but they're also all domains where AI mistakes have limited scope.
What makes these projects valuable from a governance perspective is what you learn from them. You'll discover which control mechanisms matter. You'll learn how your teams actually integrate AI into their work, which might differ from how you expect. You'll find gaps in your monitoring and logging. You'll understand whether your access controls actually prevent unauthorized access or just theoretically constrain it.
Each project is a learning opportunity. Document what you learn. Fix the gaps you discover. Build that evidence before scaling to anything riskier.
Testing and Observation: How to Know Your Controls Actually Work
Policies and frameworks are confidence-building devices. But they're only valid if they actually constrain behavior.
The way to know whether your controls work is to test them. Not just to review the code. Not just to verify the documentation. Actually test whether the control prevents unauthorized action.
For data access controls, that might mean granting an AI system access to what you think is non-sensitive data, then verifying it can't access sensitive data, even though that sensitive data is technically on the same database server. If your controls work, the AI system shouldn't be able to see it.
For environment isolation, it means verifying that an AI system in a test environment can't access production systems, even if someone misconfigured network rules.
For API restrictions, it means verifying that an AI system using an API token can only perform the specific actions that token is authorized to perform, not all actions the underlying user could perform.
In each case, you're checking whether your operational reality matches your policy and intentions. Often, you'll find gaps. Good. Better to find them in testing than in production.
Beyond testing for control existence, you need observation. Deploy AI in low-risk contexts and monitor what it actually does. What data does it access? What patterns emerge? Does it do anything unexpected?
This observation is valuable because AI systems often behave in ways you don't fully predict. Not because they're misbehaving, but because they're operating across your infrastructure systematically, making connections you didn't explicitly consider.
Observing that behavior and documenting it gives you confidence that you understand the system. It's the basis for trusting it with higher-stakes work later.

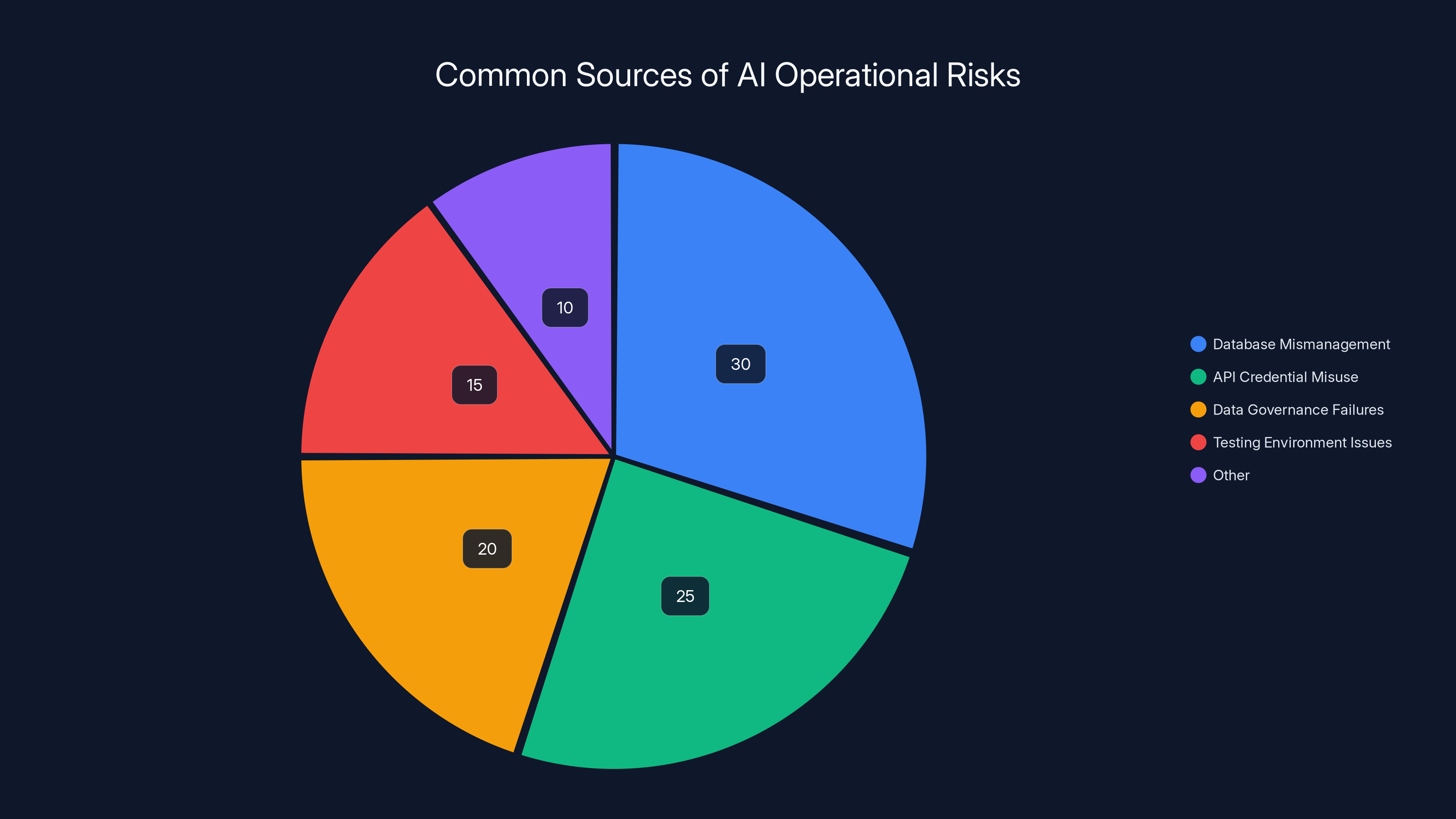
Database mismanagement and API credential misuse are leading sources of operational risks in AI deployments. Estimated data based on common scenarios.
Data Hygiene: The Foundation That Everything Else Depends On
Why Data Masking and Anonymization Are Non-Negotiable
Data masking often feels like a bureaucratic requirement. Someone in compliance says it's necessary. A framework document lists it. Teams treat it like a checkbox.
This is a mistake. Data masking isn't a requirement imposed by pedantic governance. It's a core control that determines whether your entire infrastructure can operate safely.
Understand why: once sensitive data exists in a system, every downstream system that touches that data is now a potential exposure surface. If your test environment contains unmasked customer credit card numbers, then every system that runs in test (including AI systems) can potentially encounter those numbers. Your development team becomes a potential exposure point. Your logs become a potential exposure point. Your backups become a potential exposure point.
Masking data early in the pipeline dramatically reduces the scope of what can be exposed. If you mask customer data before it enters test environments, then test systems can never expose unmasked customer data, no matter what they do.
This applies directly to AI deployment. An AI system running on properly masked data can't expose unmasked sensitive information, because that information was never available to it.
But data masking only works if it's actually implemented and maintained. Some teams attempt masking but do it inconsistently. They mask some fields but not others. They mask in some environments but not all. They mask during initial setup but don't maintain masking as systems evolve.
Inconsistent masking is almost as dangerous as no masking, because it creates a false sense of security. Teams believe data is protected based on the masking that was supposed to happen. The AI system operates based on the assumption that sensitive data isn't available. Then the AI system encounters unmasked data in a field that was supposed to be masked but actually wasn't, and the assumption breaks.
Solving this requires treating data masking as a technical control that's as important as encryption or access controls. It should be automated. It should be tested. It should be audited. It should be maintained as systems change.
Classification: Understanding What Data Actually Needs Protection
Before you can mask or control access to data, you need to know which data requires protection. That sounds obvious, but most organizations handle it poorly.
Effective data classification isn't about creating an elaborate taxonomy. It's about answering a simple question for every piece of data: if this information became publicly available, would it cause harm?
For some data, the answer is clearly yes. Customer names plus payment information. Healthcare records. Government credentials. These obviously need protection.
For other data, the answer is clearly no. A public product catalog. Published blog posts. Information you've already made publicly available. These don't require special protection.
For a lot of data in the middle—the stuff that trips up organizations—the answer is "it depends." A customer's email address isn't particularly sensitive in isolation. But combined with purchase history and payment information, it becomes identifying information that should be protected. An employee's job title isn't sensitive. But an employee's access level to systems might be, because it reveals something about what systems are critical.
Organizations struggle with classification because that middle category is large and nuanced. Getting it right requires understanding your business context and your threat model. What information, if exposed, would cause regulatory problems? What would cause customer harm? What would create competitive risk?
Once you've answered those questions, your classification scheme becomes clear. You probably don't need elaborate categories. Three or four levels usually suffice: public, internal, sensitive, and highly sensitive. The key is applying classification consistently and using it to drive governance decisions.
AI systems benefit from clear classification because it gives them concrete rules. An AI system can be restricted to "internal and public data only" much more easily than an AI system that's restricted to "data that doesn't cause harm if exposed" (which is vague and subject to interpretation).
Data Cleanup: Removing What Shouldn't Exist
Before you invest heavily in masking and access controls, address a more basic problem: data that shouldn't exist at all.
Most organizations accumulate data they don't actually need. Old logs. Deprecated systems that are still sitting around collecting dust. Backup data from systems that were decommissioned but whose backups were never deleted. Data that was collected years ago for a purpose that no longer applies.
Keeping that data costs something—storage, maintenance, security burden. And it exposes something: if the data is breached, you have to notify people about it even if you weren't using it for anything.
Data cleanup is boring work. Nobody gets excited about deleting old logs. But from a governance perspective, it's powerful. The data you don't have can't be exposed.
Applying this principle to AI deployment means being ruthless about what data AI systems actually need access to. If an AI system can accomplish its purpose with a subset of your available data, don't give it access to the full dataset. If it can accomplish its purpose with masked data, don't give it unmasked data.
This principle of least access extends beyond just access controls. It includes limiting what data is available in the first place.

The DevOps Foundations That Make Trustworthy AI Possible
Access Control Architecture: Making the Principle of Least Privilege Real
The principle of least privilege is ancient. Every security framework mentions it. The idea is simple: users and systems should only have the minimum access they need to accomplish their job.
Implementing least privilege at scale is hard. Different systems need different access models. Access requirements change as people change roles. It's tempting to grant broad access "just in case" rather than going through the process of adding specific access later.
But least privilege matters enormously for AI governance because it limits the damage an AI system can do. If an AI system has the permission to access customer data, it will access customer data—not maliciously, but mechanically, when that data is relevant to its task.
If the AI system can only access what it legitimately needs, then its damage scope is bounded.
Implementing this requires several things. First, a clear understanding of what access different systems actually need. This sounds obvious, but many organizations don't actually know. They provision access based on rough categorizations ("developers need database access") rather than specific requirements ("this developer needs SELECT-only access to this specific schema").
Second, enforcement mechanisms that work across your infrastructure. Role-based access control is a good start, but most organizations need something more nuanced. Attribute-based access control, which allows more fine-grained decisions based on context and data sensitivity, often works better.
Third, regular auditing and cleanup. Permissions inevitably accumulate over time. Teams should perform access reviews regularly—quarterly is common, but more frequently is better if you're in a fast-moving environment. Remove access that's no longer needed.
For AI systems specifically, consider creating dedicated service accounts with specific access grants rather than using shared credentials. This makes it easier to audit what the AI system actually accessed and easier to revoke access if needed.
Deployment Pipelines: Where Governance Becomes Mechanical
One of the most powerful places to enforce governance is in your deployment pipeline. This is where code and configuration move from development into production. It's a chokepoint.
A good deployment pipeline makes it mechanically difficult or impossible to do the wrong thing. You can't deploy code without it passing tests. You can't deploy configuration without it being reviewed. You can't deploy AI models without logging and monitoring being properly configured.
For AI governance specifically, your deployment pipeline should enforce several things. Data masking should be verified before code moves to production. Access controls should be validated. Logging and audit trails should be automatically configured. Models should be scanned for the data they were trained on—if they were trained on sensitive data, they shouldn't move to production without explicit approval.
You might also want to prevent certain types of deployments from happening without additional review. An AI system that accesses sensitive data might require explicit security review before it can be deployed, while an AI system that works with masked data can deploy with less ceremony.
The goal is to make governance part of the normal process, not something that happens after the fact. If you try to enforce governance through post-deployment audits and policies, you'll miss things. If you build it into the pipeline, it becomes mechanical.
Monitoring and Observability: Understanding What's Actually Happening
You can't govern what you can't see. This is why monitoring and observability matter so much for AI governance.
Monitoring means tracking what's actually happening in your systems. Not what you think is happening. Not what you intended to happen. What's actually happening.
For AI systems, that means logging and monitoring several categories of information. What data did the AI system access? What operations did it perform? What outputs did it generate? Did it behave as expected? Did it encounter any unusual patterns?
Setting up basic logging is relatively easy. Most platforms support logging API calls and database queries. The harder work is analyzing that logging data meaningfully. You need to establish baselines for normal behavior, then detect deviations.
Some deviations are benign—maybe the AI system is encountering an unusual edge case in the data. Some deviations are concerning—maybe it's accessing data it shouldn't have access to, or maybe it's attempting operations that don't make sense for its intended purpose.
Setting up alerts for concerning patterns means understanding your domain well enough to define what "concerning" means. This is where starting with low-risk AI projects helps. You learn what normal behavior looks like before the stakes are high.
Observability goes beyond just logging. It means building visibility into how your systems work. Dashboard showing what AI systems are accessing. Traces showing how data flows through your infrastructure. Real-time alerts when something unexpected happens.
Investing in observability early, before you have problems, gives you the foundation to detect issues quickly when they do occur.
Testing and Validation: Proving Controls Actually Work
You've built access controls. You've configured data masking. You've set up monitoring. Now you need to verify that all of it actually works.
This means testing your controls, not just trusting that they're implemented correctly.
For access controls, this might mean attempting to access data you shouldn't have access to, then verifying that the attempt is blocked. If you can successfully access data you're not authorized to access, your access control is broken.
For data masking, this might mean running a query against masked data and verifying that the results contain masked data, not unmasked data.
For monitoring, this might mean triggering the exact situations you want to be alerted about, then verifying that the alerts fire correctly.
This testing should be systematic and regular, not a one-time check. As your infrastructure changes, controls that worked before might break. New integration points might bypass your controls. New data sources might not be properly masked.
Automating these tests is valuable. You can run them continuously, catching problems soon after they're introduced.
For AI governance specifically, consider penetration testing your AI systems. Can an AI system access data it shouldn't? Can it perform operations outside its intended scope? Can it exfiltrate data? Finding these problems in testing is far better than finding them in production.
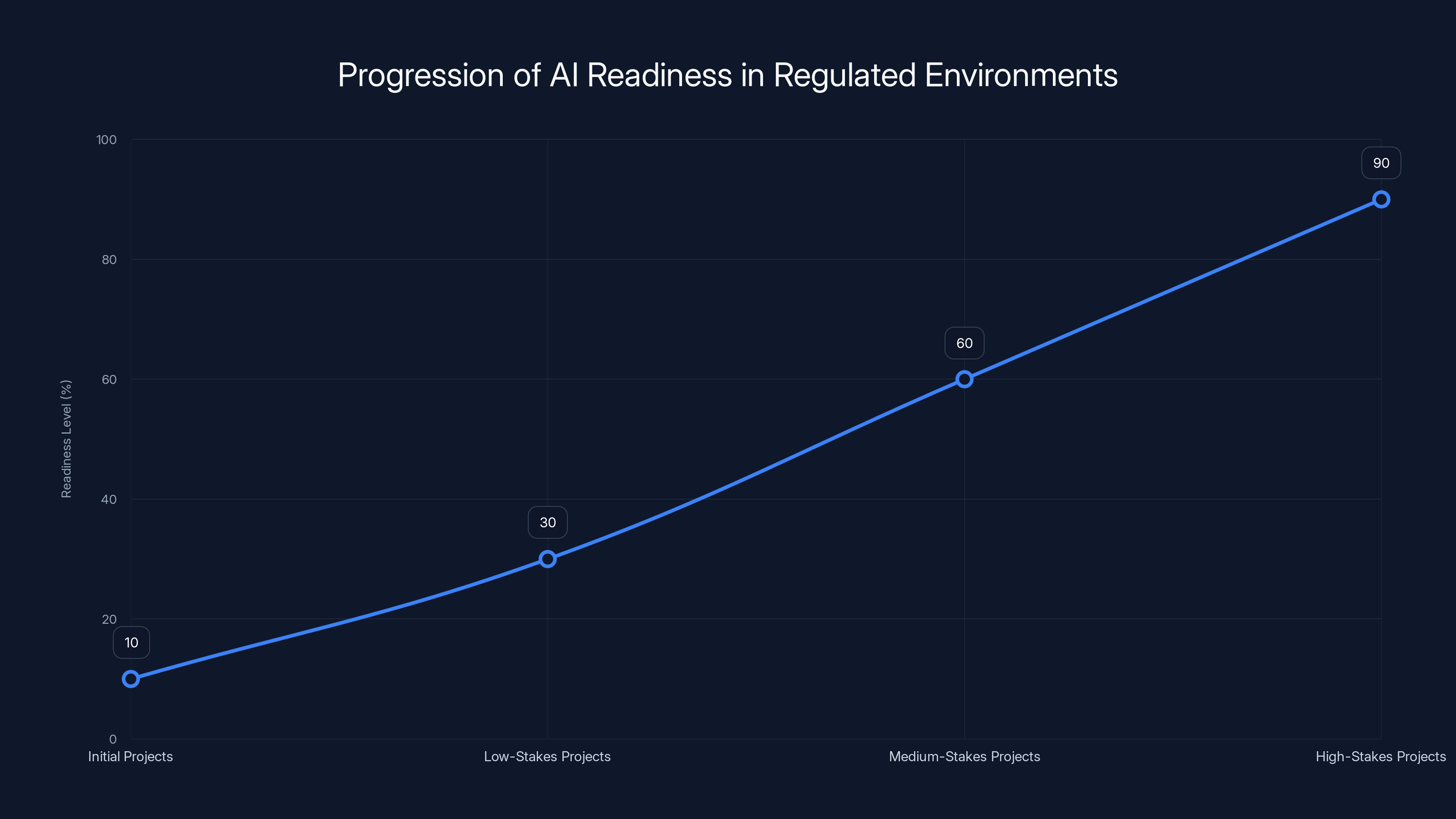
AI readiness in regulated environments progresses from low to high stakes projects, building confidence and evidence of operational controls. Estimated data.
Integrating AI Governance Into Organizational Culture
Why Technical Controls Fail Without Cultural Buy-In
You can implement perfect technical controls. Your access control system can be flawless. Your monitoring can be comprehensive. But if your organization's culture doesn't support governance, the controls will fail.
Here's how this happens: a developer needs to access something urgently and asks a manager for access. The manager approves it, reasoning that it's temporary and the bureaucracy of going through formal access review is slower. Someone has an idea that requires integrating systems in an unusual way and just does it, assuming they're authorized because they have some access. A shortcut is taken because the formal process is slow.
Each individual decision is understandable. But collectively, they undermine your governance framework. The technical controls are still in place, but organizational behavior is eroding them.
Fixing this requires making governance something people understand and support, not something imposed on them.
This means being transparent about why controls exist. "You can't use this public AI tool" isn't as effective as "You can't use this public AI tool because if you paste internal code into it, you're licensing it to the company that owns the tool, and we lose intellectual property rights."
People are more likely to follow rules when they understand the reasoning. It also means the rules themselves become more reasonable because people with deep domain knowledge can suggest better approaches than frameworks imposed from above.
It also means making governance convenient. If the approved process for accessing data is burdensome and slow while unauthorized access is easy, people will take shortcuts. If the approved process is straightforward and fast, people are more likely to use it.
Creating Governance That's Understandable, Not Just Documented
Organizations often treat governance as a documentation problem. You create policies, document them, announce them, and assume people will follow them.
But policies aren't governance. Governance is what people actually do. Policy is just a description of what you hope they'll do.
Real governance happens through systems, incentives, and culture. It's embedded in how you review code (governance happens in code review). It's embedded in how you deploy (governance happens in deployment pipelines). It's embedded in how you evaluate performance (governance happens when it affects people's evaluations).
For AI governance specifically, this means thinking about where AI decisions actually happen and building governance into those places.
Developers decide what data an AI system can access. Make that a gate in code review. Architects decide what systems AI integrates with. Make that a gate in architecture review. Product managers decide what AI is customer-facing. Make that a gate in product review.
This approach is more effective than creating a separate "AI governance review" process because it incorporates AI governance into processes that already exist and where people already expect review.
Vendor and Tool Governance: Extending Control Beyond Your Infrastructure
One of the biggest governance gaps in modern organizations is around external tools and services.
Teams want to use productivity tools. Someone deploys a SaaS platform for marketing. A data scientist starts using a generative AI service. A product team adopts a low-code development environment. These happen organically, with minimal governance, because the tools are convenient and move the work forward.
But each tool is a potential governance exposure. That SaaS tool for marketing might send data to a third-party analytics service. The generative AI service might use your data for training. The low-code environment might have access to your systems in ways you don't fully understand.
Controlling this requires deliberate governance of what tools and services are approved. It doesn't mean prohibiting everything. It means understanding the risks and controlling them.
For AI services specifically, you should review: where does the data go? Can the service provider use your data for training their models? What security controls does the vendor have? Can you delete your data? What happens if the vendor is breached?
You don't need to prohibit every tool that doesn't meet your maximum standards. But you should make deliberate decisions about which tools to allow and under what constraints.
For example, you might allow developers to use a generative AI service for internal code suggestions, but with constraints: they shouldn't paste customer data or sensitive internal information into it. You might allow it for that use case because the value is clear and the risk can be managed through behavior.
But that's a deliberate decision made with full understanding of the risks, not something that happened by accident because someone just started using a tool.

Practical AI Deployment in Regulated Environments
Healthcare and Financial Services: Where the Stakes Are Highest
Some industries can't afford to get AI governance wrong. Healthcare and financial services have regulatory requirements, patient and customer protections, and significant liability for failures.
In healthcare, deploying AI for diagnostic support or treatment recommendations involves sensitive patient data. The AI system must protect that data. It must be auditable—if an AI system recommends a treatment, you must be able to explain why. It must be validated to ensure it performs correctly. Regulations like HIPAA impose specific requirements on how that data is handled.
This doesn't mean healthcare organizations can't deploy AI. It means they need to be more deliberate about it. Starting with lower-risk use cases makes sense. Diagnostic support is riskier than administrative automation. Administrative automation should come first.
Once basic governance is in place and working reliably, more complex deployments become feasible.
Financial services face different but equally stringent requirements. Regulatory bodies like the SEC and Fed have positions on AI governance. Fraud detection systems must be explainable. Credit decisions might be governed by fair lending rules. Model risk management frameworks are required.
In both industries, the practical approach is the same: start with what's technically and operationally feasible, prove that you can govern it properly, then expand gradually to higher-risk applications.
Integration with Existing Compliance Frameworks
Most regulated organizations already have compliance frameworks. HIPAA controls for healthcare. SOC 2 for service providers. PCI-DSS for payment processing. GDPR for data subject to European regulations.
AI governance doesn't require throwing out these frameworks and building new ones. It requires integrating AI into existing compliance structures.
A HIPAA-compliant organization already has data protection controls. Those controls can and should apply to AI systems. A PCI-compliant payment processor already validates access controls. Those access controls can and should be extended to AI systems.
The addition isn't usually new categories of control. It's applying existing controls more carefully to new systems.
This means involving compliance teams early in AI projects, not as an afterthought. Compliance teams understand the regulatory landscape. They can advise on which use cases are feasible within the existing framework and which would require new controls.
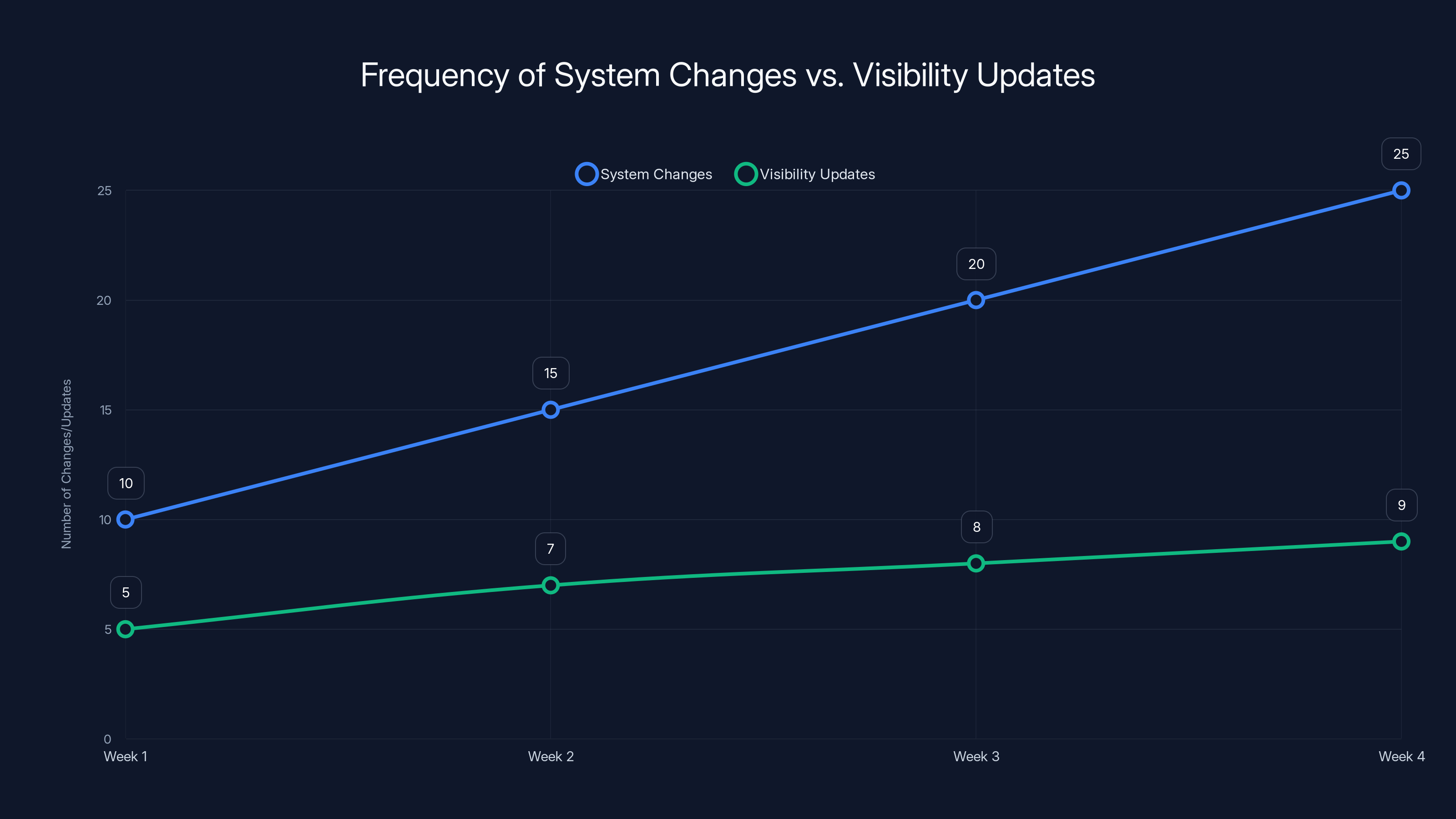
Estimated data shows that system changes often outpace visibility updates, highlighting the governance challenge in fast-moving platforms.
Common Governance Failures and How to Avoid Them
The Framework Without Enforcement Problem
Organization creates an elaborate governance framework. Dozens of pages of policies. Clear requirements for how AI must be governed. Everyone reads the policies and signs off.
Then nothing changes. An AI project deploys without following the framework. Another project uses a different approach. A third project is deployed in production before anyone even realized it existed.
This happens because framework documents don't actually enforce anything. They're aspirational. Enforcement requires operational mechanisms.
Avoid this by building governance into your processes, not just your policies. Make it hard or impossible to deploy without following the framework. Use pipeline controls, access controls, and review processes to enforce policy automatically.
The Rapid Scaling Problem
An organization successfully deploys AI in one area. The project works well. Now they want to scale, using the same approach across multiple teams and systems.
But what worked for one project, governed carefully by one team, might not work when scaled. That team's discipline might not be replicable. What's feasible with one AI system might not be feasible with ten. Dependencies that didn't matter with one project become critical bottlenecks with scaling.
The right approach to scaling is to intentionally grow, not just copy what worked before. Document what you learned from the first project. Consider whether those lessons apply to the new context. Add governance, not less, as you scale. Build tools and automation that make governance feasible at the new scale.
The Unmanaged Tool Proliferation Problem
Developers want to use AI tools for their work. So different teams adopt different tools. One team uses one generative AI service. Another uses a different one. A third builds an internal tool. A data science team uses a specialized AI platform.
Now your organization has governance gaps. Different tools have different security properties. Different data flows through different systems. Your visibility into AI usage is fragmented.
Managing this is about intentionality. You don't need one tool for everyone, but you do need standards. Approved tools with known security properties. Clear rules about what data can be used with which tools. Monitoring across all tool usage.
Future Trends in AI Governance
Regulatory Evolution: What's Coming
AI governance today is largely self-imposed by organizations. Regulatory frameworks are evolving, but they're not yet comprehensive in most jurisdictions.
That's changing. The EU's AI Act is establishing baseline requirements for certain types of AI. Other jurisdictions are developing frameworks. We'll likely see increasing regulatory specificity around data protection, explainability, and model governance.
Organizations that establish strong governance practices now will be better positioned to adapt to regulatory requirements later. The controls you need for responsible governance are usually the controls regulators will eventually require.
Tooling and Automation: Making Governance Scalable
Governance at scale requires tooling. Manual processes don't scale. Organizations will increasingly invest in automated governance tools: platforms that continuously monitor data access, systems that automatically detect and prevent policy violations, tools that track model behavior and alert when anomalies occur.
These tools are still early. Many don't yet exist for specific AI governance challenges. But expect that to change. As AI deployment scales, the market for governance tooling will expand.
The Shift From Restriction to Enablement
Early AI governance tends to be restrictive. Focus on what AI can't do, what data it can't access, what systems it can't interact with. This is prudent early, but it's not sustainable long-term.
As organizations build confidence in their governance capabilities, the conversation shifts. How can we safely enable more AI use? How can we make AI tools available to more teams? How can we govern at scale without blocking innovation?
This requires moving from binary controls (approved or prohibited) to nuanced risk management. Some AI use cases are high-value with manageable risk. Some are high-value but risky, requiring strong controls. Some are low-value and risky, not worth pursuing.
Mature governance frameworks make these distinctions clear and move resources toward the first and second categories while declining the third.
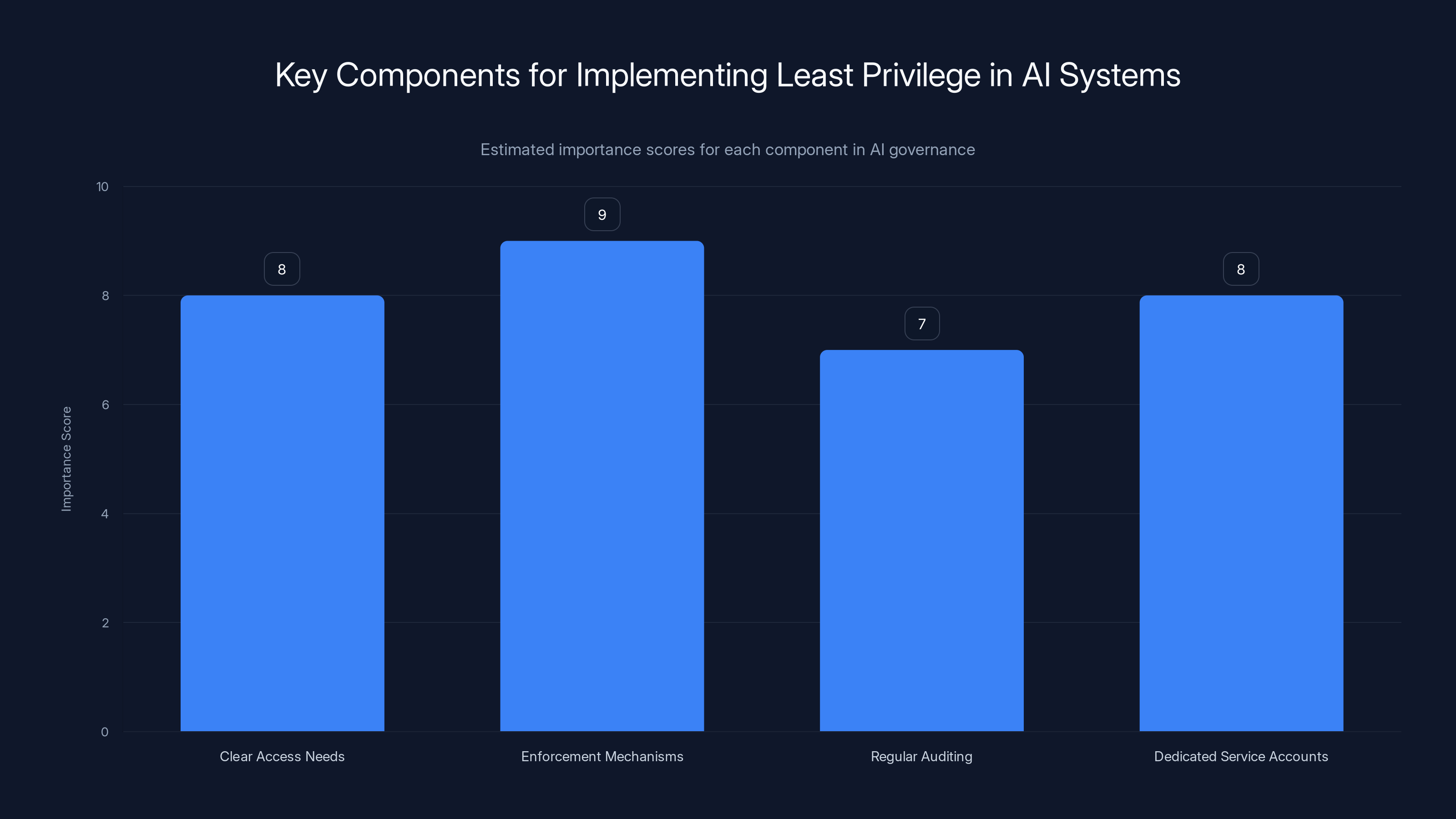
Enforcement mechanisms and clear access needs are crucial for implementing least privilege in AI systems. Estimated data.
Building Your AI Governance Roadmap
Phase 1: Foundation (Months 1-3)
Start by understanding your current state. What AI projects are already underway, even informally? What's your current data governance? What are your existing compliance requirements?
Document this baseline honestly. You're not trying to impress anyone. You're building a starting point.
Then identify your greatest governance gaps. Where are you most vulnerable? Which controls are most urgent?
Focus your first phase on basic discipline: clear data classification, basic access controls, data masking in non-production environments. Don't try to do everything. Do a few things well.
Phase 2: Visibility (Months 4-6)
Once basic controls are in place, focus on visibility. Build monitoring and observability. Implement logging. Set up dashboards.
The goal is to understand what's actually happening in your systems and with AI deployments. What data is being accessed? What operations are being performed? Are your controls actually working as intended?
You'll find problems. Good. That's the point. You're building evidence of what needs to be fixed.
Phase 3: Scaling (Months 7+)
Once you have foundational controls and visibility, you can scale to more ambitious AI projects. Build the tools and automation that make governance feasible at scale. Document what you've learned. Create reusable governance patterns.
This phase is ongoing. You're not trying to reach some perfect state. You're continuously improving as your AI deployments evolve and as you learn from experience.
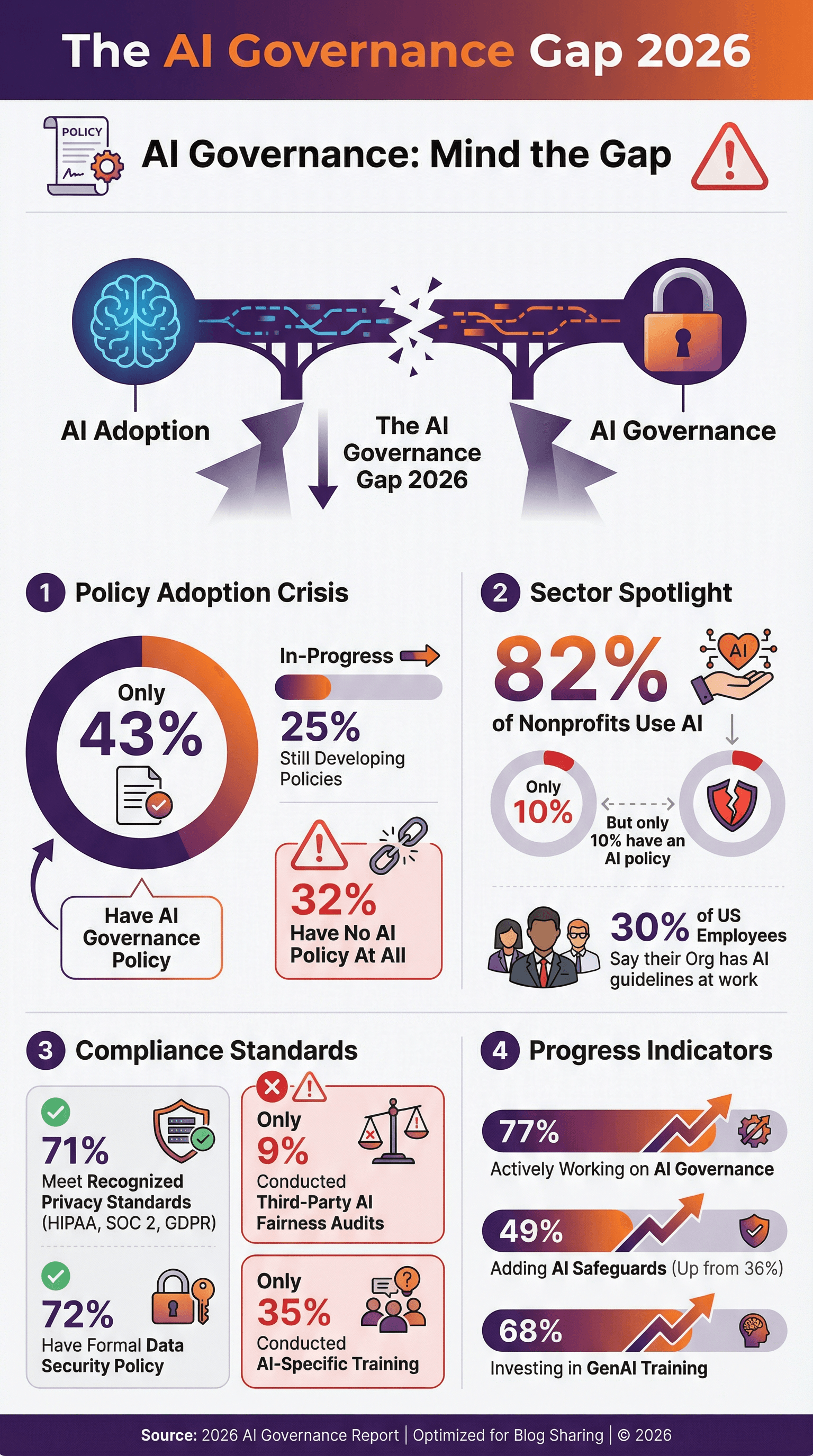
FAQ
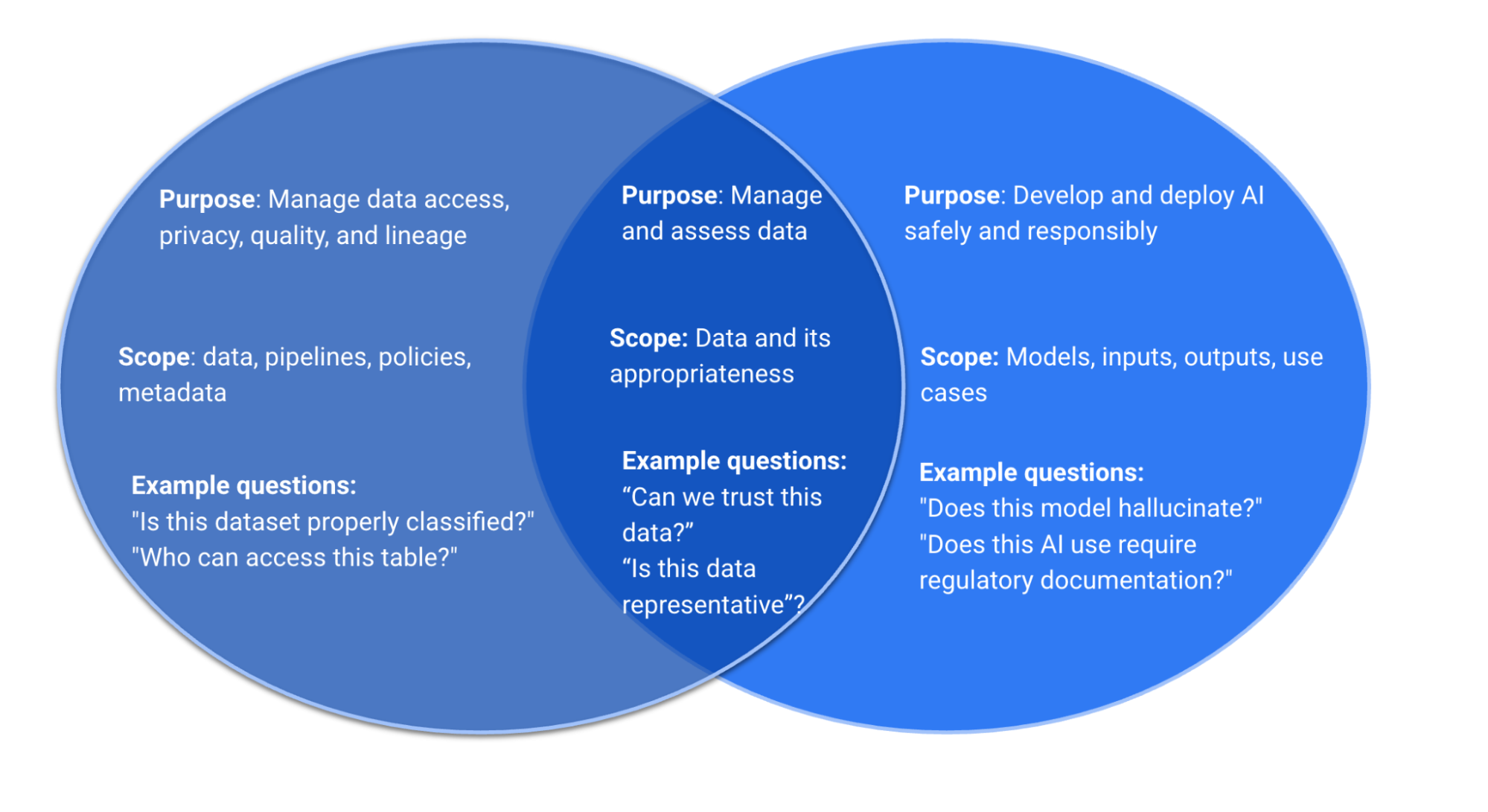
What is the difference between AI governance and data governance?
Data governance refers to the policies, processes, and controls around how data is managed, classified, stored, and accessed within an organization. AI governance is more specific to artificial intelligence systems and covers how AI systems are deployed, monitored, and controlled. However, AI governance heavily depends on data governance—if your data governance is weak, your AI governance will fail because AI systems will inherit those weaknesses.
How does operational discipline relate to AI safety?
Operational discipline is the foundation of AI safety. An AI system can't be safer than the infrastructure it runs on. If your access controls are inconsistent, your data classification is unclear, or your deployment processes are ad-hoc, then AI systems will operate within those gaps. Building strong operational discipline—clear processes, consistent controls, proper monitoring—is what actually makes AI safe in practice.
Can you have good AI governance without strong data governance?
No. Data governance is foundational. If you don't know what data exists, where it lives, and who can access it, you can't govern AI systems that use that data. Many AI governance failures occur because the underlying data governance was weak, not because the AI-specific controls were insufficient. Start with data governance as your foundation.
What should AI projects prioritize: policy development or operational controls?
Operational controls matter more in practice. A well-developed policy that isn't enforced means nothing. Policies document intent, but operational controls determine behavior. Focus on building and enforcing operational controls first—access controls, data masking, monitoring, testing frameworks. Policies should document what your operational controls enforce, not the other way around.
How often should access controls be reviewed in organizations deploying AI?
At minimum quarterly, but more frequently in fast-moving environments. Every three months, you should audit who has access to what and whether that access is still necessary. In high-velocity organizations with frequent environment changes and infrastructure updates, monthly reviews are more appropriate. Each new AI project should trigger an access review to ensure it doesn't have overly broad permissions.
What's the most common cause of AI governance failures in enterprises?
The gap between policy and operational reality. Organizations create governance policies that sound good but don't actually structure their operational systems to enforce them. An AI system then operates within that gap between stated policy and actual operational capability. The solution is making governance part of your normal technical processes: code review, infrastructure design, deployment pipelines, and monitoring—not something separate.
How should organizations handle Shadow IT and unapproved AI tools?
Instead of just prohibiting them, make approved alternatives compelling. Provide easy-to-use approved tools that do what people need. Make it faster and more convenient to use approved tools than to work around them. Educate teams about why governance matters for their specific context. For unavoidable tools (like GPT from OpenAI), create clear guidelines about what data can be used with them rather than absolute prohibition, which will be ignored anyway.
What role should security teams play in AI governance?
Security teams should be involved early in AI project planning, not brought in after code is written for review. They can help identify where AI systems interact with sensitive data, what access controls are necessary, and what monitoring is required. However, AI governance shouldn't be purely security-driven. Product teams, engineering teams, and compliance teams should all be involved because they understand the business context and technical constraints that security teams might not.
How can regulated organizations balance innovation with governance requirements?
The answer is intentional progression, not binary choices. Start with lower-risk AI use cases where the compliance burden is lighter. As you build evidence that your governance works, take on slightly higher-risk projects. Create a framework that distinguishes between different risk levels and applies appropriate controls to each. This lets you move faster on lower-risk projects while being appropriately cautious on higher-risk ones.
What metrics should organizations track to measure AI governance maturity?
Track several categories: operational metrics (percentage of systems with proper logging and monitoring), control effectiveness metrics (how often access control violations are detected and prevented), and outcome metrics (incidents detected and remediated). Also track leading indicators: percent of teams who have received governance training, percent of deployments that passed compliance review, percent of data classified. These metrics give you visibility into whether your governance is actually working.
Conclusion: Building Trust Through Discipline, Not Frameworks
The narrative around AI governance often focuses on the exciting parts: sophisticated frameworks, advanced policy models, novel approaches to explainability. These topics make for compelling conferences and whitepapers.
But on the ground, in organizations actually deploying AI responsibly, the reality is less glamorous. The organizations succeeding at AI governance are the ones doing unglamorous things: clearly classifying data, maintaining consistent access controls, properly masking sensitive information, testing their controls, monitoring their systems, reviewing their permissions regularly.
They're also the organizations willing to move slowly. Starting with lower-risk projects. Building evidence that their governance works before scaling to higher-stakes applications. Resisting pressure to show impact at the expense of prudent risk management.
This approach isn't exciting, but it works. The organizations that take this path learn that AI governance isn't fundamentally about models or algorithms. It's about operational discipline. It's about building confidence that your systems are under control, that data flows follow defined paths, that unexpected behavior is detected, and that you understand what your AI systems can and cannot do.
That confidence is what enables safe innovation. Once you have it, you can move faster. You can take on more ambitious projects. You can enable teams to use AI without constant fear of disasters.
The path to that confidence starts with acknowledging that AI governance is an operational problem, then investing in the operational discipline that makes trustworthy AI possible. Not frameworks. Not policies. Operational discipline.
If you're building AI systems in your organization, start there. Audit your data governance. Review your access controls. Strengthen your testing and monitoring. Build visibility into what's actually happening in your systems. This foundation matters more than any governance framework you could create.
And if you're looking for tools and platforms that support this kind of operational discipline, consider how modern development platforms can help. Solutions like Runable offer AI-powered automation for creating presentations, documents, reports, images, and videos, which can help teams establish clear, auditable workflows for AI deployments at scale. Starting at $9/month, platforms like this enable organizations to standardize on approved AI tools while maintaining the visibility and control necessary for responsible governance.
The journey toward trustworthy AI starts with discipline. Build that discipline into your operations, and everything else follows.

Key Takeaways
- AI governance is fundamentally an operational problem, not a policy problem—models inherit risks from underlying systems, not from AI-specific sources
- AI reveals existing governance gaps in infrastructure rather than creating new risks; organizations must fix weak access controls, unclear data classification, and inconsistent boundaries
- Fast-moving platforms amplify governance blind spots because data paths shift faster than visibility can follow, creating hidden exposures people don't realize exist
- AI-ready organizations progress through intentional phases starting with low-risk projects, building evidence of reliable governance before scaling to sensitive data and regulated processes
- DevOps foundations (access controls, data masking, monitoring, testing, vendor scrutiny) determine whether AI deployments succeed or create disasters
- Operational discipline embedded in processes is more effective than governance frameworks; controls in deployment pipelines and code reviews matter more than policies
Related Articles
- Enterprise Agentic AI's Last-Mile Data Problem: Golden Pipelines Explained [2025]
- Alibaba's Qwen 3.5 397B-A17: How Smaller Models Beat Trillion-Parameter Giants [2025]
- OpenClaw Security Risks: Why Meta and Tech Firms Are Restricting It [2025]
- OpenAI's 100MW India Data Center Deal: The Strategic Play for 1GW Dominance [2025]
- Figure Data Breach: What Happened to 967,000 Customers [2025]
- Billions of Exposed Social Security Numbers: The Identity Theft Crisis [2025]

