![AI Video Generation Without Degradation: How Error Recycling Fixes Drift [2025]](https://tryrunable.com/blog/ai-video-generation-without-degradation-how-error-recycling-/image-1-1771015004294.jpg)
Introduction: The Problem Nobody Really Talks About
You've probably watched an AI-generated video that started coherent and then just... fell apart. Objects morphed into impossible shapes. Faces became distorted. Motion logic abandoned all reason. It's like watching reality glitch out in real time.
Here's what's happening under the hood: every frame in a video generation model is built on top of the previous frame. It's like a game of telephone, except played with pixels. A tiny error in frame one gets magnified in frame two, which then throws off frame three, and by frame thirty, your video looks like it was generated by a fever dream algorithm.
The technical term for this degradation is drift. And it's one of the most stubborn problems in generative video today.
Most AI video systems crash hard around the 30-second mark. After that, shapes blur into nonsense, colors shift unexpectedly, and the whole sequence loses any semblance of logical continuity. This time limit isn't some feature, it's a hard wall. You hit it, and generation just... stops making sense.
But what if AI could learn from its own mistakes?
Researchers at EPFL's Visual Intelligence for Transportation lab just published something that changes the game: a method called error recycling. Instead of trying to avoid mistakes, they deliberately feed the model's errors back into itself during training. The AI doesn't fight against its failures, it learns from them.
The implications are staggering. We're talking about potentially removing the time constraints on video generation entirely. Sequences that could run for minutes, hours, or theoretically forever without degrading. But here's the thing: the method isn't perfect, and the questions it raises are more complex than the answers it provides.
Understanding Drift: Why AI Videos Fall Apart
The Accumulation Problem
Let's start with the core issue. When you generate an AI video, you're not rendering a pre-computed animation. You're asking a neural network to predict what the next frame should look like, given the previous frame as input.
Sound simple? It's not.
The model was trained on pristine, perfect video data. High-quality sequences where every frame is crystal clear. But when it starts generating, it's working with its own predictions, which are inherently imperfect. There's a mathematical term for this: distribution shift. The model encounters data it never saw during training: its own mistakes.
Imagine training a chess AI on thousands of expert games. Every move is optimal, every position is ideal. Then you release the AI to play against humans. Suddenly, it faces positions that violate its training data. Messy boards. Suboptimal moves from its opponent. The AI's confidence drops because it's operating outside its training distribution.
Video generation has the exact same problem, except the error accumulation is visual and geometric. A slight blur in frame one becomes a distorted object in frame two. That distortion becomes impossible topology in frame three. By frame thirty, your subject has literally transformed into something that violates the laws of physics.
Why Models Struggle With Imperfect Input
Training data quality is everything in machine learning. Researchers spend enormous resources curating perfect datasets: properly lit scenes, high resolution, consistent motion, logical continuity. The model learns to predict based on these ideal conditions.
But when the model generates a frame with a subtle imperfection, it has no playbook for what to do next. It wasn't trained on what follows imperfect predictions. So it makes its best guess, which is often slightly worse than the previous frame. That worse frame becomes the input for the next prediction, and the degradation cascades.
This is why conventional approaches to video generation are so computationally expensive. Researchers try to avoid errors altogether by using massive models, extensive conditioning, and aggressive quality checks. But you can't completely prevent imperfection. At some point, the model has to handle something slightly off from its training data.
Mathematical Representation of Drift
If we represent the error magnitude in frame
This linear model is oversimplified, but it illustrates the core problem: errors accumulate linearly with sequence length. In reality, errors compound non-linearly, making long sequences exponentially more prone to degradation:
where
This exponential growth is why 30 seconds feels like a cliff edge. The error magnitude doesn't slowly increase; it explodes.

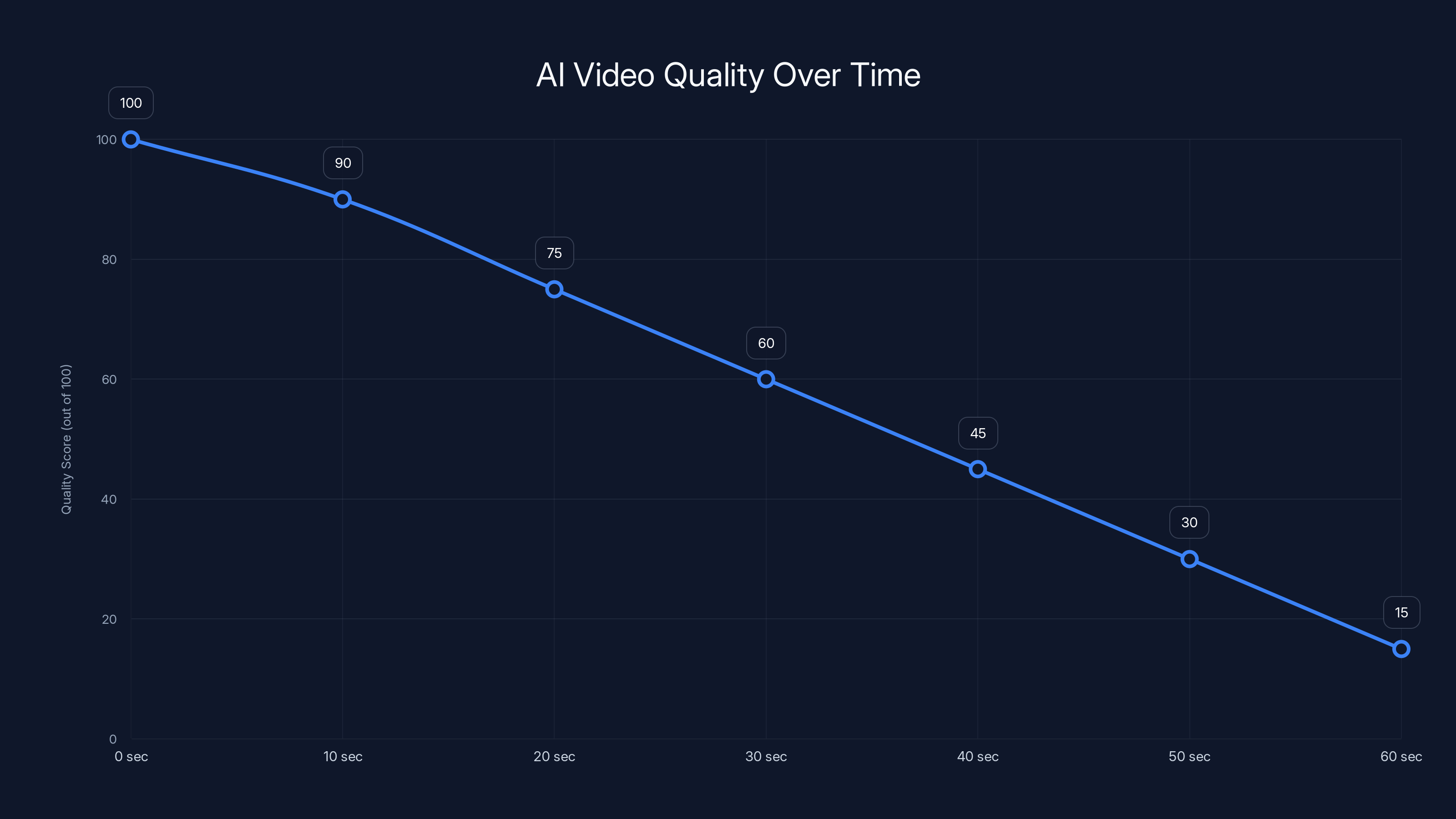
AI video quality degrades significantly after 30 seconds due to drift accumulation, dropping from a perfect score to 15 by 60 seconds. Estimated data.
The Error Recycling Breakthrough: Training on Mistakes
What Error Recycling Actually Does
The EPFL team flipped the conventional approach on its head. Instead of trying to avoid errors, they made error correction part of the training process itself.
Here's the basic methodology: generate a video sequence, identify where the model's predictions diverged from perfect ground truth, then retrain the model specifically on those error cases. The model learns to recognize imperfect input and correct it in the next frame.
In essence, you're teaching the AI to handle the exact scenarios it struggles with: its own mistakes.
The process looks like this:
- Generate a video sequence frame by frame
- Compare each generated frame to the ideal ground truth
- Identify discrepancies (objects in wrong positions, color shifts, blur artifacts)
- Collect these error cases as new training data
- Retrain the model to correct these specific discrepancies
- Generate new sequences using the updated model
- Repeat the process iteratively
After multiple cycles, the model gets dramatically better at self-correction. It doesn't eliminate errors, but it learns to prevent those errors from cascading into catastrophic degradation.
Why This Works Better Than Previous Approaches
Traditional methods tried to brute-force their way out of the problem: use bigger models, more parameters, higher resolution training data. These approaches have diminishing returns because they don't address the fundamental issue: the model hasn't seen its own mistakes during training.
Error recycling directly attacks this distribution shift problem. By showing the model examples of imperfect input and training it to correct those specific errors, you're expanding its training distribution to include the scenarios it actually encounters during generation.
It's like the difference between a doctor who studied textbook cases versus a doctor who's treated thousands of complex, messy real-world cases. The latter has experience with edge cases and knows how to handle them.
The Iterative Improvement Process
What makes error recycling particularly elegant is that it compounds. After the first round of retraining, the model is slightly better at handling errors. This means when you generate new sequences, those errors are smaller. Smaller errors mean the retraining process captures subtler correction patterns. After several iterations, you get exponential improvement in stability.
EPFL's preliminary results showed that videos trained with error recycling could maintain coherence for significantly longer than baseline models. We're talking about doubling or even tripling the duration before visible degradation.
But here's where it gets interesting: the method isn't about perfect error correction. It's about slowing down the rate of degradation. Instead of errors exploding exponentially, they grow more linearly. That's a fundamental shift in the problem's behavior.
Mathematically, error recycling transforms the error function from exponential growth to something closer to linear, giving you far more frames before things fall apart:
where

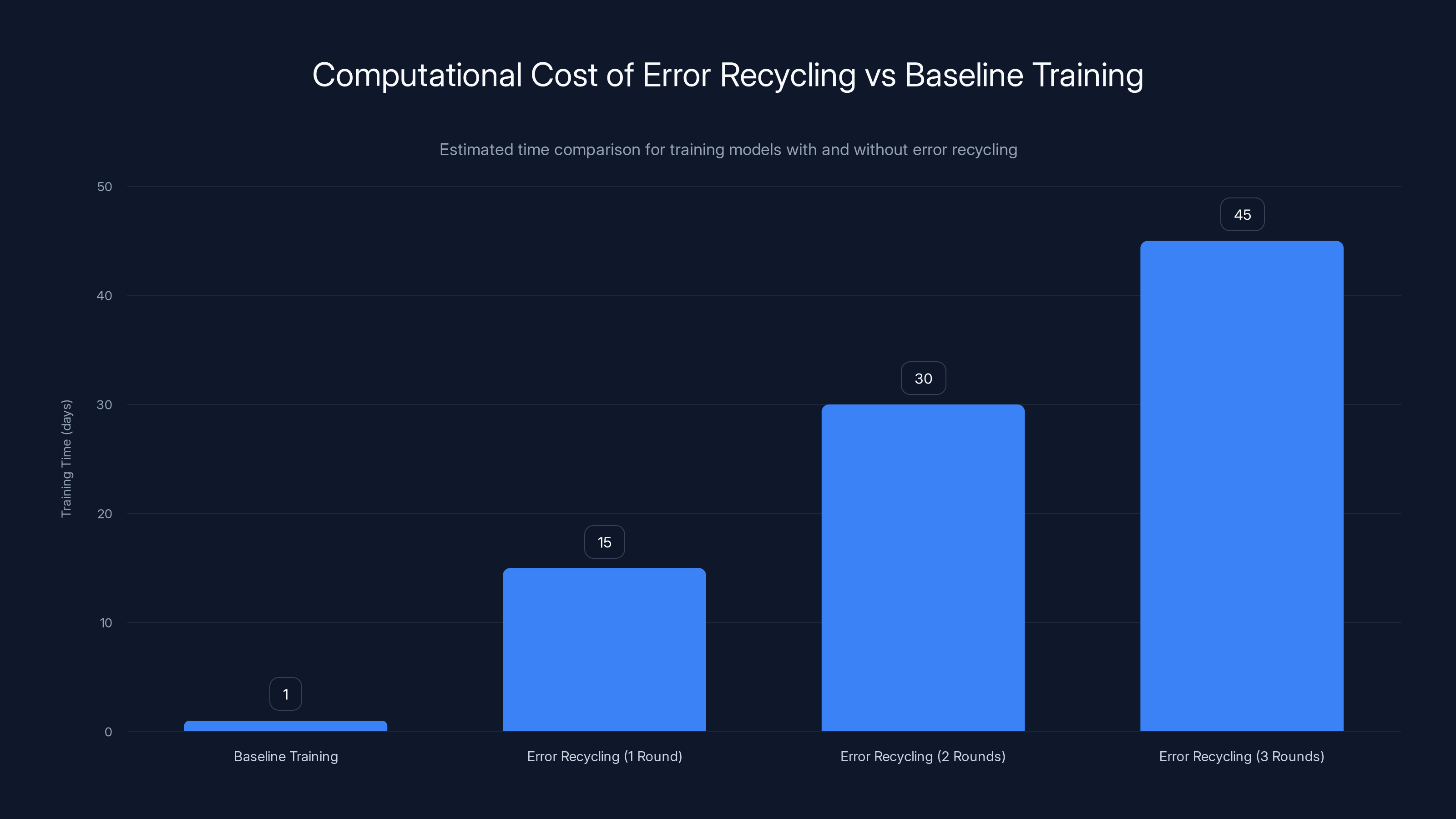
Error recycling significantly increases training time, with each round taking 10-20 times longer than baseline training. Estimated data suggests substantial computational costs.
Real-World Applications: Where Error Recycling Changes Everything
Simulation and Physics Modeling
Simulations are where long-duration video generation becomes genuinely useful. Think about training a self-driving car on driving scenarios. You need realistic, physically coherent video sequences that can run for minutes. A single 10-minute drive simulation requires 18,000 frames of perfect coherence.
With error recycling, you could generate these long training sequences without the current constraint of constant degradation. The model learns to maintain physical consistency over extended periods. Objects don't suddenly teleport. Vehicles maintain momentum. Weather patterns evolve logically.
This directly impacts how autonomous vehicles learn. More realistic training data means better real-world performance. Currently, most simulation-based training uses hand-crafted graphics because AI video is too unstable for long sequences. Error recycling bridges that gap.
Animated Content and Visual Storytelling
Animators currently use AI for specific segments, not full sequences. A shot might be AI-generated, but entire scenes are still hand-crafted or stitched together from multiple short AI sequences.
With longer coherent generation, you could generate entire scenes automatically. A filmmaker describes a scene, the AI generates five minutes of footage that actually maintains continuity. No sudden character morphing mid-scene. No unexplained changes in environment logic.
The economic implications are significant. Professional animation studios spend millions on labor for inbetweening frames. If an AI could generate stable sequences for 10 minutes at a time, that cost drops dramatically.
Medical and Scientific Visualization
Scientific visualization often requires showing complex processes over time. How blood flows through the heart for an entire cardiac cycle. How molecules interact over an extended simulation. How planets move through orbital mechanics.
Current AI video generation can't handle these because they require perfect logical consistency. Error recycling opens the door for AI-generated scientific visualizations that maintain accuracy throughout long sequences. That's genuinely useful for research and education.

The Computational Cost: Why Error Recycling Isn't Free
Training Overhead
Here's where the practical limitations start showing. Error recycling requires multiple rounds of retraining. Each round involves:
- Generating full-length video sequences (computationally expensive)
- Computing error maps (comparing predictions to ground truth)
- Retraining the model on error data
- Validating improvements
A single round of error recycling could take 10-20 times longer than training the baseline model. For large models, this means days or weeks of GPU time. Multiple rounds multiply this cost.
There's a mathematical trade-off at play. If we represent the computational cost per recycling iteration as
Memory and Storage Requirements
Error recycling requires storing:
- Original generated sequences
- Ground truth reference data
- Error maps for each frame
- Multiple versions of the model during retraining
For a video generation system running at scale (generating millions of frames for training data), storage becomes a non-trivial constraint. Some implementations require terabytes of intermediate data.
This is manageable for well-funded research labs like EPFL. For startups or smaller organizations, it becomes a serious bottleneck. The infrastructure cost of implementing error recycling at production scale is substantial.
Real-Time Generation Trade-Offs
Error recycling requires offline training. You can't do it in real time. This means the performance improvements apply to pre-recorded generation, not live streaming or interactive applications.
If you want to use AI to generate video in response to user input (like an interactive storytelling app), error recycling doesn't help. The model has to be frozen after training. Any errors made during live generation can't be corrected; they just cascade forward.
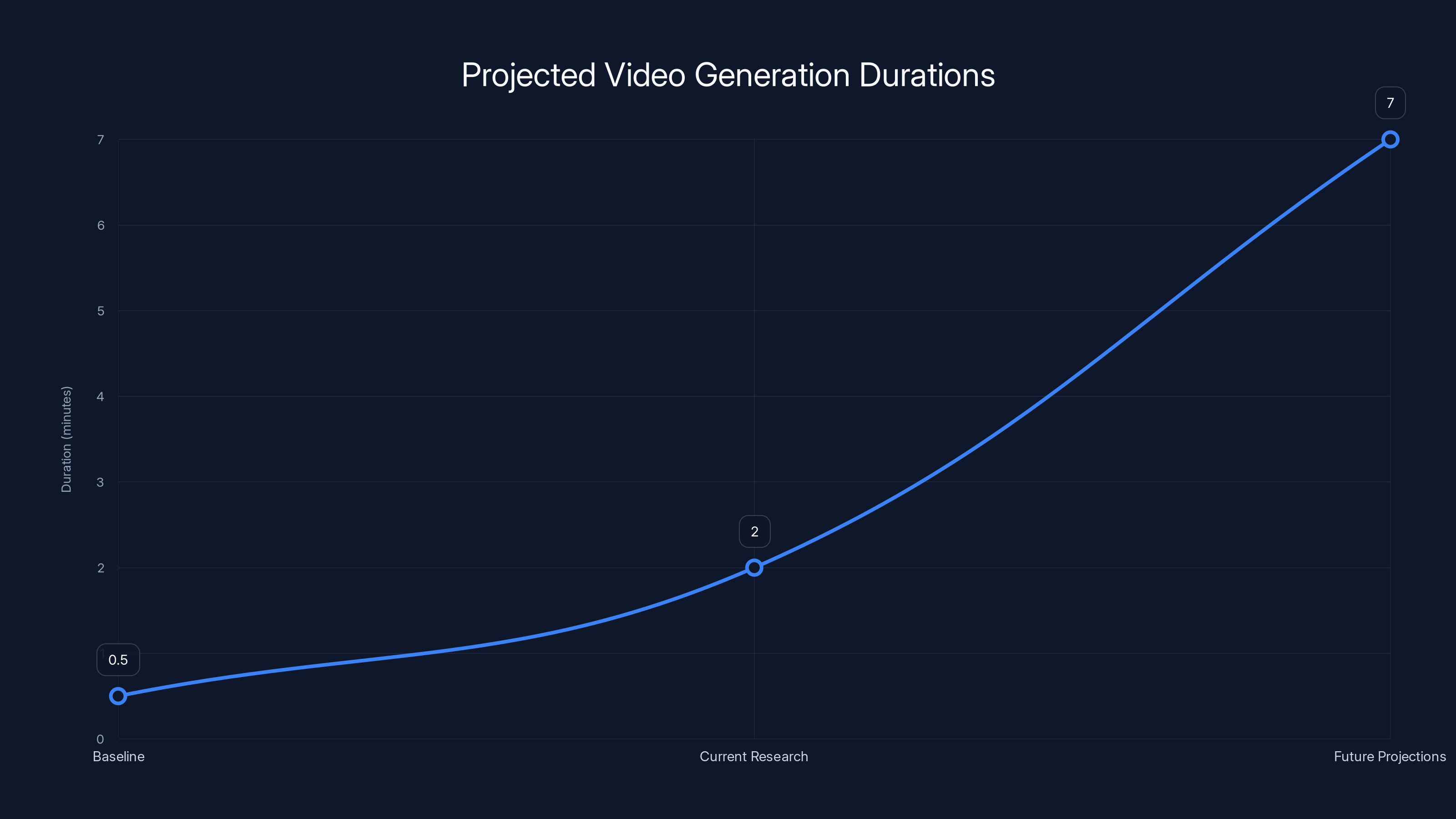
Estimated data shows that while current research extends video generation from 30 seconds to 2 minutes, future projections could reach 5-10 minutes. However, infinite generation remains unrealistic.
Technical Challenges: The Things That Could Go Wrong
Overfitting to Error Patterns
When you train a model specifically on its own mistakes, there's a serious risk of overfitting to those specific error types. The model learns to correct errors that occurred during generation, but encounters different errors in new scenarios.
Imagine a model that was error-recycled on summer footage. It learns to correct certain color shifts and lighting artifacts specific to bright sunlight. Then you use it to generate nighttime scenes. The error patterns are completely different, but the model is optimized for summer errors. It might perform worse, not better.
This is especially problematic because error patterns can be highly dependent on scene content, lighting conditions, camera movement, and object types. A single recycling process can't capture all possible error scenarios.
Bias Toward Specific Failure Modes
Error recycling naturally biases the model toward whatever errors were most prominent during its generation and retraining. If the training data had mostly outdoor scenes, the model learns to correct outdoor errors. Indoor scenes become neglected.
Over multiple recycling iterations, this bias can become pronounced. The model becomes a specialist in correcting specific error types at the expense of generalization.
Loss of Generalization Capability
As a model gets more specialized through error recycling, its ability to handle truly novel scenarios decreases. Machine learning models have a fundamental trade-off between specialization and generalization.
If you recycle errors on urban driving scenarios, the model might become great at correcting errors in those scenarios but worse at rural driving. This creates a brittle system that works well in narrow conditions but fails unexpectedly outside those conditions.
This is a critical concern for any safety-critical application. A self-driving car trained on error-recycled data that's specialized to urban conditions might catastrophically fail on rural highways.
Detecting and Handling Unknown Error Types
What happens when the model encounters an error it wasn't specifically trained to correct? The model has no strategy. It might amplify the error or produce strange artifacts.
Error recycling doesn't create a model that's robust to all errors. It creates a model that's good at correcting specific errors it's learned about. Unknown errors fall through the cracks.
The Generalization Question: Does This Scale to Real Video?
Testing on Controlled vs. Wild Data
EPFL's initial results were impressive, but they came from testing on controlled scenarios. High-quality source video, consistent lighting, relatively simple scenes.
This is standard practice in research. You test on the clean data first, show the improvement, then gradually move toward messier real-world scenarios. But there's a massive gap between "stable generation on curated test sequences" and "stable generation on arbitrary user input."
Real-world video is wildly unpredictable. Sudden lighting changes, complex occlusions, unusual camera movements, objects entering and leaving frame, dramatic changes in scene composition. Error recycling trained on clean data might not handle these edge cases.
The Diversity Problem
A single error recycling process can't cover all possible video content types. You'd need separate recycling for:
- Different camera movements
- Different lighting conditions
- Different object types
- Different scene complexities
- Different temporal dynamics
Either you run error recycling separately for each category (expensive and fragmented), or you run it on diverse data and accept that some categories won't be optimized.
This is a fundamental scaling problem. The broader the training distribution, the weaker the specialization. The stronger the specialization, the narrower the applicable domain.
Transfer Learning Limitations
Could error recycling trained on one domain transfer to another? That's an open question. Machine learning research suggests that transfer works when domains are similar but degrades as domains diverge.
Error patterns in photorealistic video generation are quite different from error patterns in artistic animation, which differ from error patterns in scientific visualization. Transfer learning between these domains might yield minimal improvement.
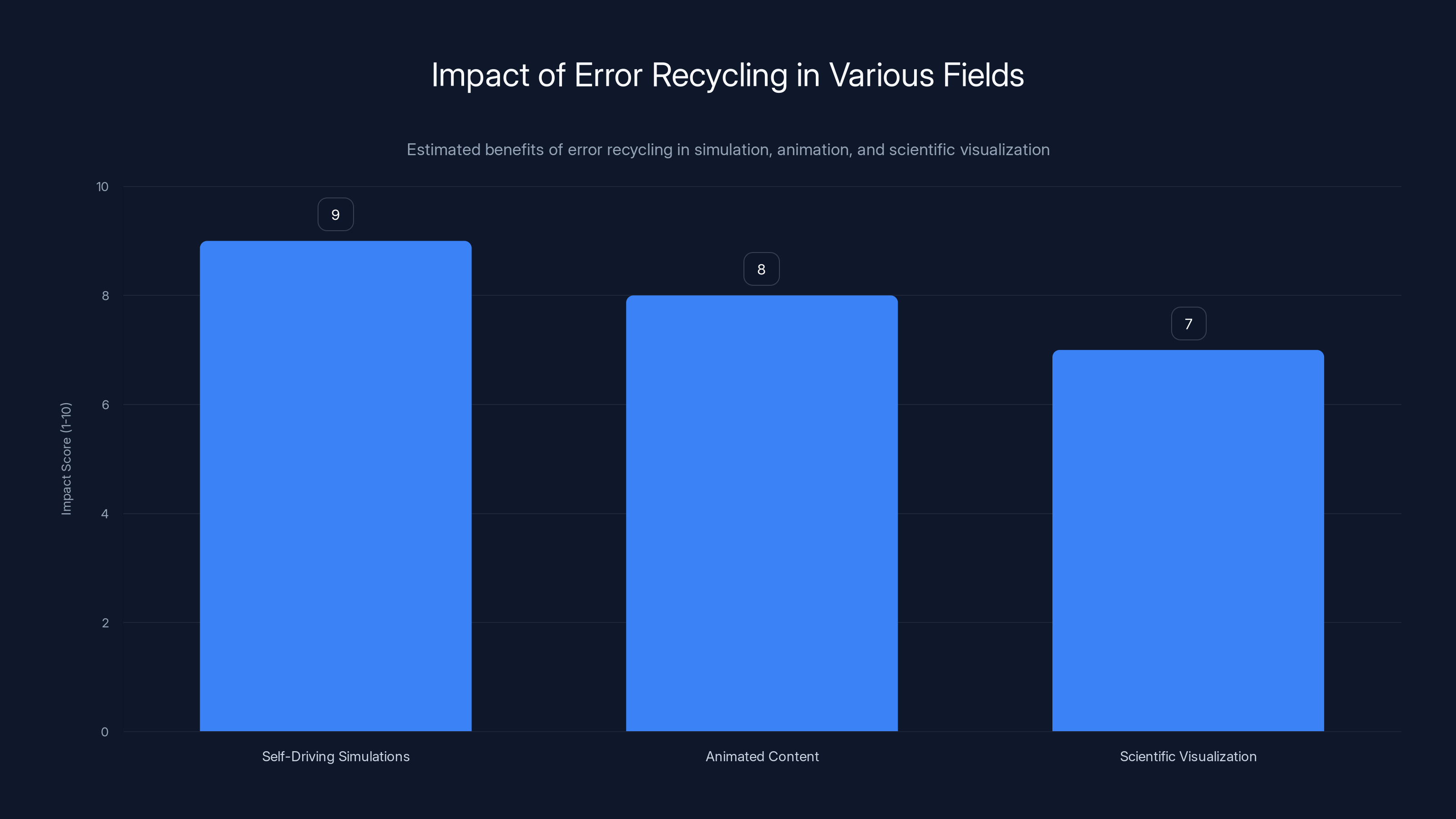
Error recycling significantly enhances the realism and efficiency of simulations, animations, and scientific visualizations, with self-driving simulations benefiting the most. Estimated data.
Long-Duration Video Generation: Is the Dream Realistic?
The Theoretical Maximum
There's a fundamental question: how long can you push error recycling before diminishing returns become severe?
Mathematically, even with linear error growth (
To push this higher, you need either better error control (smaller
At some point, you're constrained by the fundamental quality of your model and training data. Error recycling can push the boundary, but it doesn't eliminate it.
Practical Duration Expectations
EPFL's research showed significant improvements, but the absolute numbers matter. If baseline generates stable video for 30 seconds and error recycling extends that to 2 minutes, that's a 4x improvement. Impressive, but not infinite.
The research community is still learning what realistic maximums look like. Some predictions suggest error recycling could push stable generation to 5-10 minutes for well-controlled scenarios, but that's still not "infinite generation."
The marketing around this technology sometimes suggests we're on the verge of unlimited generation. The reality is more modest: we're solving the 30-second cliff edge and extending to minutes. That's transformative but not unlimited.
Practical vs. Theoretical Limits
Even if you solve the technical drift problem, there are other constraints:
Memory constraints: Generating a 10-minute 4K video requires storing massive amounts of intermediate data. GPU memory limits how long you can generate in a single pass.
Computational cost: Each additional frame requires computation. A 10-minute sequence costs hundreds of times more compute than a 30-second sequence.
User expectations: Quality expectations grow with duration. A 30-second sequence can hide minor imperfections. A 10-minute sequence gets scrutinized frame by frame.
These practical constraints might matter more than the technical drift problem.
The Broader AI Video Landscape: Where Error Recycling Fits
Current State of AI Video Models
As of 2025, the field is moving rapidly. Open AI's Sora, Google's Gemini Video, Runway ML, and others are pushing boundaries on what's possible. Error recycling is one technique among many for improving quality and duration.
But it's not the only approach. Some researchers are exploring:
- Better training data curation: Using only the highest quality, longest-duration source videos
- Different architectures: Models designed from the ground up for long sequence generation
- Hierarchical generation: Generating multiple timescales simultaneously
- User-guided correction: Having humans provide corrections that inform training
Error recycling is promising, but it's not a silver bullet.
Competitive Landscape
EPFL isn't the only organization working on drift reduction. Academic labs and companies are exploring various solutions:
- Some are focusing on better encoder-decoder architectures
- Others are investigating temporal attention mechanisms
- Still others are exploring world models that maintain internal consistency
Error recycling might be one of several techniques that eventually combine into more robust systems.
Integration With Existing Workflows
For error recycling to have real impact, it needs to integrate with existing video generation platforms. That means:
- Compatible APIs and interfaces
- Integration with popular tools like Da Vinci Resolve or Adobe Premiere
- Reasonable computational requirements
- Clear documentation and tutorials
Right now, error recycling is a research technique. Productizing it for mainstream use requires significant engineering work.

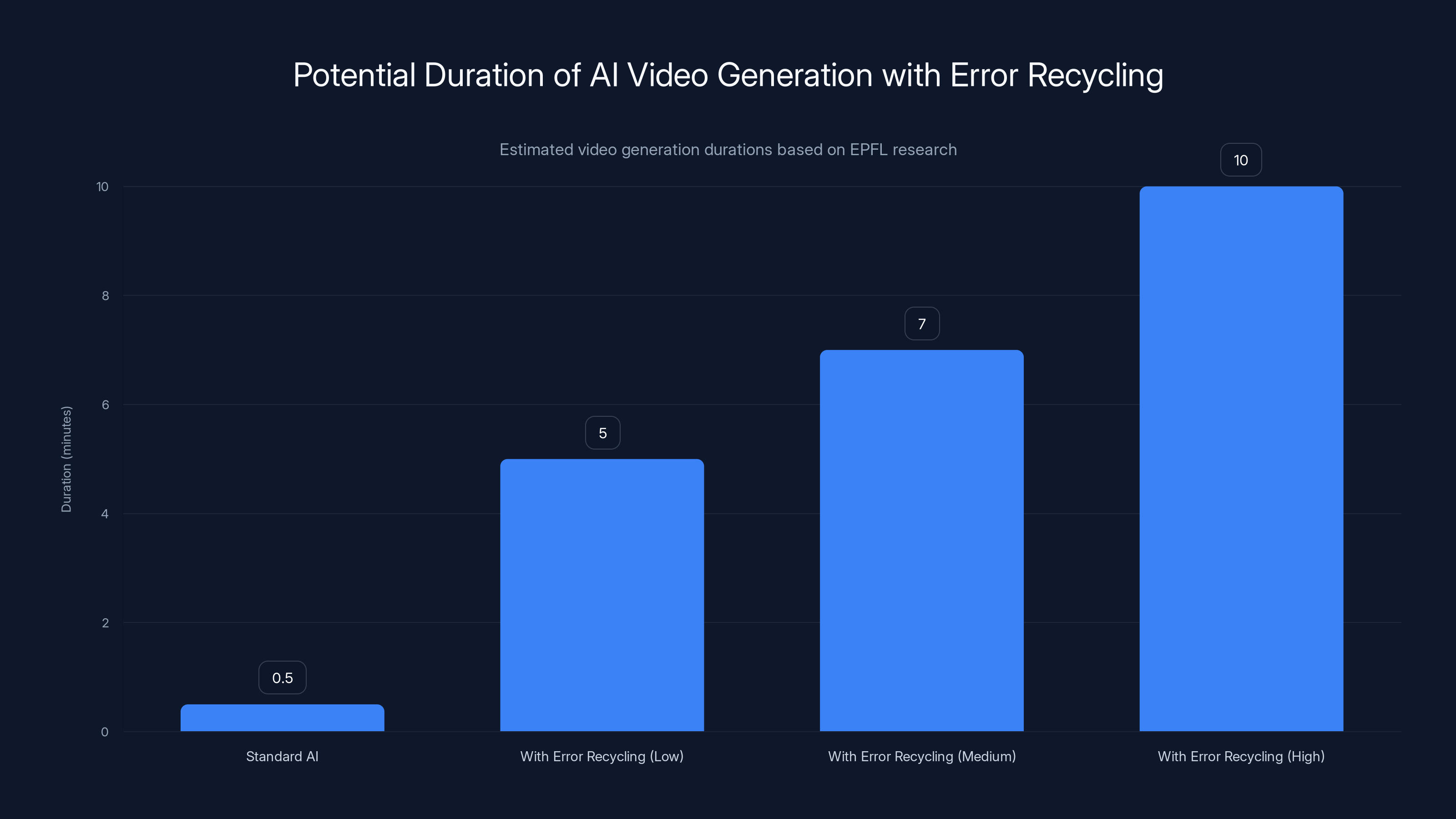
Error recycling can significantly extend AI video generation duration from 30 seconds to potentially 5-10 minutes, depending on implementation quality. Estimated data.
Potential Risks and Ethical Considerations
Creating Infinitely Long Deepfakes
The ability to generate arbitrarily long, coherent AI video has obvious implications for synthetic media and deepfakes. If error recycling enables 30-minute coherent video generation, it becomes dramatically easier to create convincing false footage.
This isn't an argument against the technology (fundamental research shouldn't be suppressed). But it is an argument for thinking carefully about detection methods and verification systems.
We'll need better tools for:
- Detecting synthetic video regardless of duration
- Cryptographic verification of authentic footage
- Watermarking systems that survive editing
Bias Amplification in Training Data
Error recycling learns from its mistakes. But if the source training data contained biases, error recycling might amplify them. If a model was trained to generate people primarily from certain demographics, error recycling might reinforce those biases.
This requires careful attention to training data composition and explicit bias testing during the recycling process.
Environmental Cost
Error recycling is computationally expensive. Multiple rounds of retraining multiply energy consumption. Large-scale deployment could have significant environmental impact.
This isn't unique to error recycling, but it's a consideration for any scaling effort in AI.
Displacement of Creative Professionals
Longer, more coherent AI-generated video means fewer human-created frames and sequences. Professional animators, visual effects artists, and video editors could see reduced demand for their work.
This is a broader AI challenge, not specific to error recycling. But it's worth acknowledging as the technology matures.
Future Directions: Where This Technology Could Go
Hybrid Human-AI Workflows
Instead of fully automated generation, future workflows might involve:
- AI generates a rough 10-minute sequence
- Human artists identify issues and mark correction points
- Error recycling trains specifically on those marked issues
- AI re-generates with learned corrections
- Repeat until satisfactory
This combines human creativity and quality control with AI efficiency. Error recycling becomes a tool for interactive refinement rather than fully automated generation.
Multi-Modal Error Correction
What if error recycling could learn from multiple modalities? Not just comparing generated frames to ground truth, but also:
- Audio-visual consistency checks (does the motion match the audio?)
- Physics-based error detection (are objects violating gravity?)
- Semantic consistency (does this object still make sense in this context?)
Multi-modal error detection could catch errors that simple pixel-level comparison misses.
Adaptive Error Thresholds
Future systems might dynamically adjust what counts as an error based on context. In artistic animation, small deviations might be acceptable. In scientific visualization, they're unacceptable. An adaptive system could adjust its error tolerance based on the application.
Foundation Models for Error Correction
What if error correction itself became a learned task? A separate foundation model trained on massive amounts of degraded video data, learning to spot and correct errors across any video domain?
This would be a meta-model: a model that learns to improve other models' outputs. It's an interesting direction for future research.

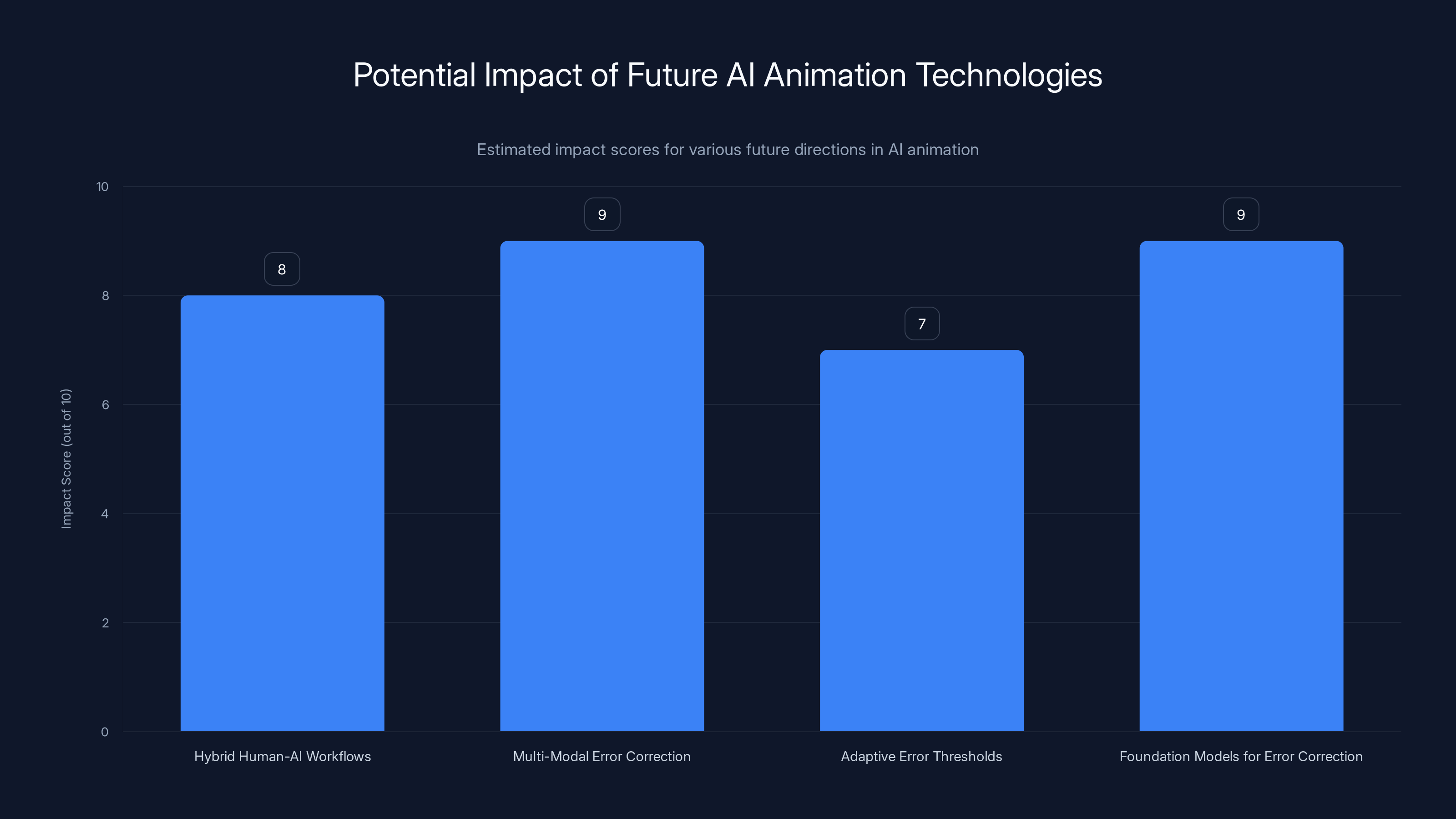
Estimated data suggests that multi-modal error correction and foundation models for error correction could have the highest impact on future AI animation technologies.
Practical Implementation: What You Need to Know
Who Should Care About This
Error recycling is relevant if you're working in:
- Research institutions building new video generation models
- Animation studios exploring AI-assisted production
- Simulation companies creating synthetic training data
- Visual effects companies looking to extend AI video capabilities
- Autonomous vehicle platforms needing realistic extended video sequences
If you're a casual user of AI video tools, this is a behind-the-scenes advancement that will trickle into consumer products over the next 1-2 years.
Implementation Considerations
If you're considering implementing error recycling:
-
Start with your specific use case: Don't assume results transfer. Test on your exact content types.
-
Budget for computational overhead: Plan for 10-20x longer training times.
-
Curate error data carefully: The quality and diversity of error cases determines effectiveness.
-
Monitor for overfitting: Track performance on held-out test data that's different from recycling training data.
-
Consider hybrid approaches: Error recycling might work better combined with other techniques.
-
Plan for iteration: This isn't a one-shot improvement. Multiple cycles of refinement yield better results.
Timeline for Mainstream Adoption
Based on research-to-product timelines in AI:
- 2025: Research techniques published, academic implementations
- 2026-2027: Integration into commercial platforms (Runway, Da Vinci, etc.)
- 2027-2028: Widespread availability in consumer tools
- 2028+: Optimization and refinement based on real-world usage
We're currently at the beginning of this timeline.

Comparing to Alternative Approaches
Error Recycling vs. Better Training Data
You could improve video generation by just using better training data. Longer sequences, higher quality, more diverse content.
Error Recycling Advantage: Works with existing training data, improves iteratively.
Better Training Data Advantage: Simpler conceptually, doesn't require multiple training rounds.
Best approach: Combine both. Better training data + error recycling yields the best results.
Error Recycling vs. Larger Models
More parameters generally mean better quality. Scaling up model size could solve drift problems through brute force.
Error Recycling Advantage: Works with existing model sizes, computationally lighter.
Larger Models Advantage: Eventually, raw capacity might solve more problems.
The reality: Larger models still need error recycling. They solve different problems.
Error Recycling vs. Architectural Innovation
Completely new model architectures designed for long-sequence generation might be better than recycling errors.
Error Recycling Advantage: Works with existing architectures, proven technique.
New Architectures Advantage: Potentially solve the problem at its root.
Neither approach has definitively won yet. Both are promising research directions.
The Honest Assessment: What We Don't Know
Unknowns in the Research
- Scale limits: How long can error recycling really push stable generation? No one knows yet.
- Generalization bounds: How well do models trained with error recycling transfer to new domains?
- Optimal recycling strategy: How many rounds? What data selection? What training procedures? Still being explored.
- Interaction with other techniques: How does error recycling interact with other drift-reduction methods?
Marketing vs. Reality
The research papers are exciting. The media coverage is sometimes overenthusiastic. The reality is:
- Error recycling is a genuine advancement, not hype
- It solves real problems, not imaginary ones
- But it's not infinite generation, not perfect, not a complete solution
- It's one piece of a larger puzzle
What's Actually Achievable
Realistic expectations:
- Doubling or tripling stable video duration: Very likely achievable with error recycling
- 10x improvements: Possible with optimization, but requires careful implementation
- Removing time constraints entirely: Unlikely in the near term
- Perfect long-duration generation: Not achievable, not even theoretically

FAQ
What exactly is error recycling in AI video generation?
Error recycling is a technique where researchers deliberately feed an AI model's mistakes back into its training process. Instead of trying to avoid errors, they collect the model's prediction errors during video generation and retrain the model specifically on these error cases. This teaches the model to recognize and correct its own mistakes in future generations. It's essentially learning from failure in a structured, iterative way.
How does error recycling prevent video drift?
Video drift occurs because errors accumulate across frames in a cascading effect. Error recycling slows this accumulation by teaching the model to correct imperfections before they compound. When the model encounters input that's slightly different from its training data (its own mistakes), it now has learned strategies to handle that situation. Instead of errors growing exponentially, they grow more linearly, giving you significantly longer before visible degradation occurs. The model essentially learns to be its own error-correction system.
How long can AI videos be generated with error recycling?
Results are still preliminary, but EPFL's research suggests error recycling can extend stable video generation from the current 30-second standard to several minutes. Some predictions suggest 5-10 minutes is achievable with well-optimized implementations on controlled content. However, this isn't infinite generation. Errors still accumulate, just at a slower rate. The exact duration depends heavily on content type, model quality, and how aggressively error recycling is applied.
What are the computational costs of implementing error recycling?
Error recycling is computationally expensive because it requires multiple training rounds. Each round involves generating full-length video sequences, computing error maps, and retraining the model. Implementation research suggests that a complete error recycling process takes 10-20 times longer than training the baseline model. For large-scale models, this means weeks of GPU processing rather than days. This makes error recycling most practical for batch processing rather than real-time applications.
Could error recycling make it easier to create deepfakes?
Yes, potentially. Longer, more coherent AI-generated video does create risks for synthetic media. However, this is a general AI advancement question rather than something specific to error recycling. The counterbalance is that we need better detection methods, verification systems, and watermarking technology. The research community is aware of these implications and is working on detection and authenticity verification tools in parallel.
Does error recycling work equally well for all types of video content?
No. Error recycling is most effective when trained on specific content types. A model trained with error recycling on outdoor scenarios might not perform as well on indoor scenes. This creates a generalization problem where models become highly specialized but potentially brittle outside their trained domains. For maximum effectiveness, error recycling would need to be applied separately to different content categories or trained on extremely diverse data, which reduces specialization benefits.
When will error recycling be available in commercial video tools?
Based on typical research-to-product timelines, error recycling techniques developed in 2024-2025 should start appearing in commercial tools like Runway and Da Vinci Resolve by 2026-2027. Consumer tools will likely follow 1-2 years later. The technology is promising but requires significant engineering work to integrate into existing platforms and optimize for production use. Educational adoption will likely precede commercial adoption.
Could AI eventually generate truly infinite video sequences?
Unlikely, at least not with current approaches. Even with error recycling, mathematical models suggest that errors will eventually exceed acceptable thresholds given enough frames. However, "infinite" might not be necessary. If error recycling enables 30-minute coherent video (compared to current 30-second limit), that's transformative for most applications. The question isn't really "infinite or not" but "how long is long enough," and error recycling pushes that boundary significantly.
What makes error recycling different from just using more training data?
Error recycling specifically targets errors the model actually makes during generation. You could improve video generation by collecting better source footage, but that doesn't address the fundamental distribution shift problem: the model has never seen its own mistakes during training. Error recycling deliberately exposes the model to its failure modes and teaches it to handle them. It's targeted improvement rather than brute-force scaling. The two approaches are complementary, not competing.
Is error recycling a complete solution to the video drift problem?
No. It's a significant improvement but not a complete solution. Error recycling slows drift but doesn't eliminate it. Other research directions (new architectures, different training approaches, better conditioning) might eventually solve drift more completely. Error recycling is best thought of as one technique among many for improving video generation. The real solution will likely involve combining error recycling with other approaches and ongoing research into fundamental model design.

Conclusion: The Realistic Future of AI Video
Error recycling represents a genuine breakthrough in video generation research. The EPFL team identified a real problem, proposed an elegant solution, and demonstrated that it works. That deserves recognition.
But it's important to keep perspective. We're not on the verge of infinite, perfect AI video. We're moving from "collapses after 30 seconds" to "stable for several minutes." That's transformative but bounded.
The technology matters most for specific applications: simulation, animation training, scientific visualization, long-form storytelling. For casual AI video use, the improvements are nice but not essential.
The broader lesson from error recycling is important: sometimes you solve problems not by avoiding them but by facing them directly. By deliberately introducing errors during training, the model learns resilience. That's a principle that extends beyond video generation.
For the next 1-2 years, error recycling will remain primarily a research technique. You'll see it in academic papers, in experimental tools, in specialized implementations. By 2027, you'll likely see it in mainstream video tools. By 2029, you might not even notice it's there because it'll be built into the default workflows.
What should you do now? If you're building video generation tools, watch this research closely. If you're using AI video, enjoy the current capabilities and look forward to longer, more stable generation in the coming years. If you're in research, this is an exciting direction that's still wide open for improvement.
The future of AI video isn't about infinite generation. It's about practical generation long enough to be genuinely useful. Error recycling is moving that needle. Not all the way, but meaningfully in the right direction.
And in machine learning research, that's often enough to change everything.
Key Takeaways
- Error recycling teaches AI models to correct their own mistakes by deliberately feeding prediction errors back into training, solving the 30-second video degradation limit
- Video drift occurs because errors accumulate exponentially across frames; error recycling converts exponential degradation to linear, extending stable generation from 30 seconds to potentially minutes
- Computational costs are substantial: error recycling requires 10-20x more GPU time than baseline model training due to multiple retraining cycles
- Generalization remains uncertain: models trained with error recycling on specific content may not transfer well to different domains like indoor vs outdoor video
- Real-world applications like autonomous vehicle simulation and scientific visualization benefit most, while real-time interactive applications remain impractical due to offline training requirements
Related Articles
- Runway's $315M Funding Round and the Future of AI World Models [2025]
- India's New Deepfake Rules: What Platforms Must Know [2026]
- How Spotify's Top Developers Stopped Coding: The AI Revolution [2025]
- Deepfake Detection Deadline: Instagram and X Face Impossible Challenge [2025]
- AI-Generated Music at Olympics: When AI Plagiarism Meets Elite Sport [2025]
- Will Smith Eating Spaghetti: How AI Video Went From Chaos to Craft [2025]

