![Meta, NVIDIA Confidential Computing & WhatsApp AI [2025]](https://tryrunable.com/blog/meta-nvidia-confidential-computing-whatsapp-ai-2025/image-1-1771414644943.jpg)
Meta, NVIDIA Confidential Computing & WhatsApp AI: The Future of Private AI Infrastructure [2025]
Introduction: The Paradox of AI at Scale
There's a problem nobody wanted to admit out loud until recently: the more AI you run, the more data you expose.
Every time you ask Chat GPT a question, every time you generate an image with Midjourney, every time you ask Claude to write code—that data goes somewhere. A server. A database. The cloud. And once it's there, it's vulnerable. Breaches happen. Regulations tighten. Users get nervous.
Meta just made a bet that changes how this works.
In January 2025, Meta announced a massive partnership with NVIDIA to deploy something called "confidential computing" across WhatsApp. The deal involves buying millions of NVIDIA Blackwell and Rubin GPUs—a spend analysts estimate in the tens of billions. But the real story isn't about the hardware. It's about running AI without ever exposing the data.
This is the difference between processing your data securely (encrypting it before sending it to a server) and computing on encrypted data (never decrypting it, even when running AI on it). The second one sounds impossible. It's not. And it's about to reshape how every major tech company builds AI infrastructure.
Meta's commitment to building up to 30 data centers by 2028—including 26 in the US—as part of a $600 billion infrastructure spend signals something bigger than just more computing power. It signals a fundamental shift in how AI companies think about trust, privacy, and regulatory compliance. Companies like OpenAI, Google, and Microsoft are all watching this closely.
So what exactly is confidential computing? How does it actually work? And why is Meta willing to spend tens of billions to make it happen? Let's dig in.

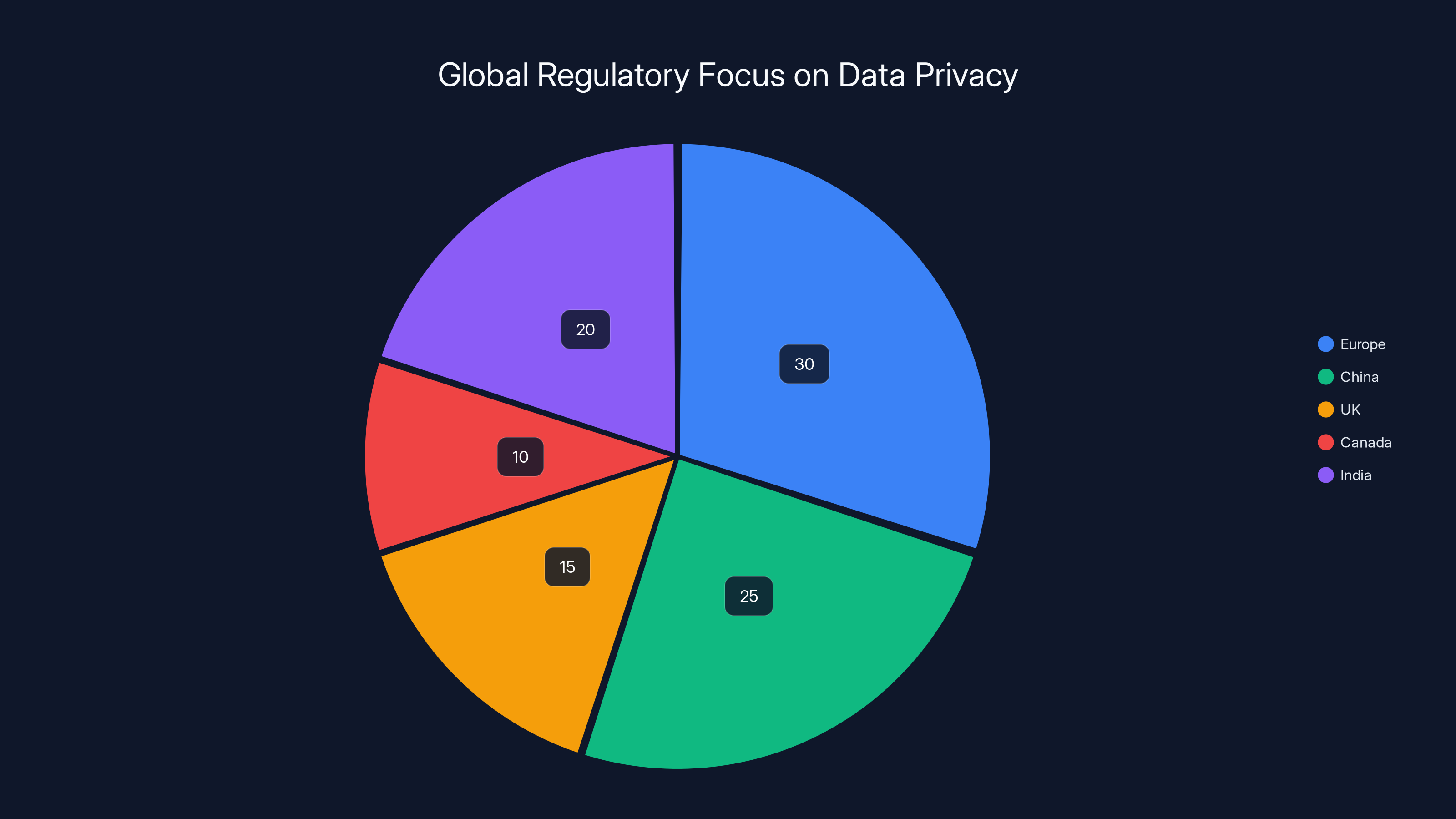
Estimated data shows Europe leading in regulatory focus on data privacy, with significant contributions from China and India. Estimated data.
TL; DR
- Meta is buying millions of NVIDIA GPUs as part of a long-term partnership focused on AI infrastructure
- Confidential computing lets AI run on encrypted data without exposing it, even to Meta itself
- This solves a real regulatory problem: GDPR, data privacy laws, and user trust all push toward this approach
- Grace CPUs will handle inference workloads independently, not just paired with GPUs
- WhatsApp AI features will be the first public deployment of this confidential computing architecture

What Is Confidential Computing, Actually?
Confidential computing sounds like marketing speak. It's not.
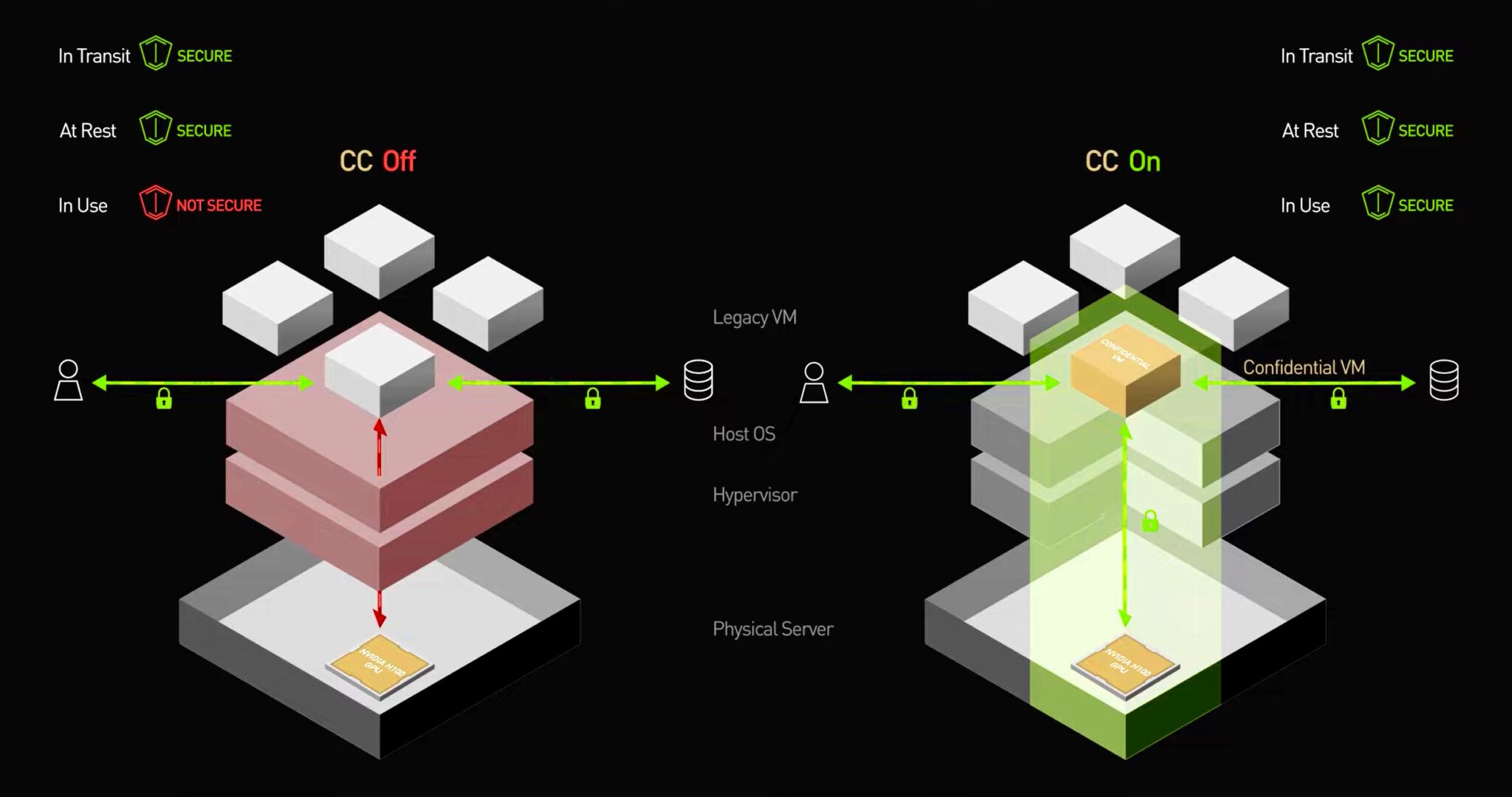
Here's the traditional flow: User sends data to a cloud server. Server decrypts the data. Runs AI on it. Sends results back. The data is encrypted in transit but unencrypted at rest and during computation. That's the vulnerability window.
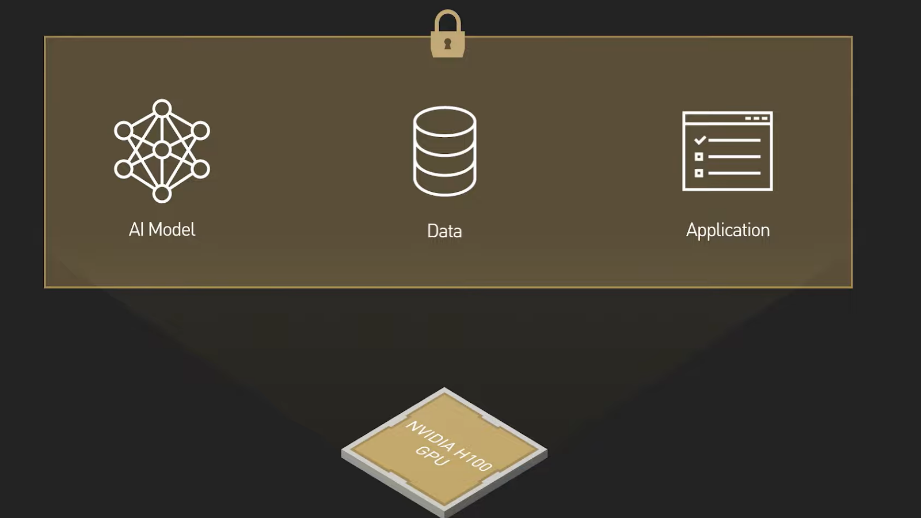
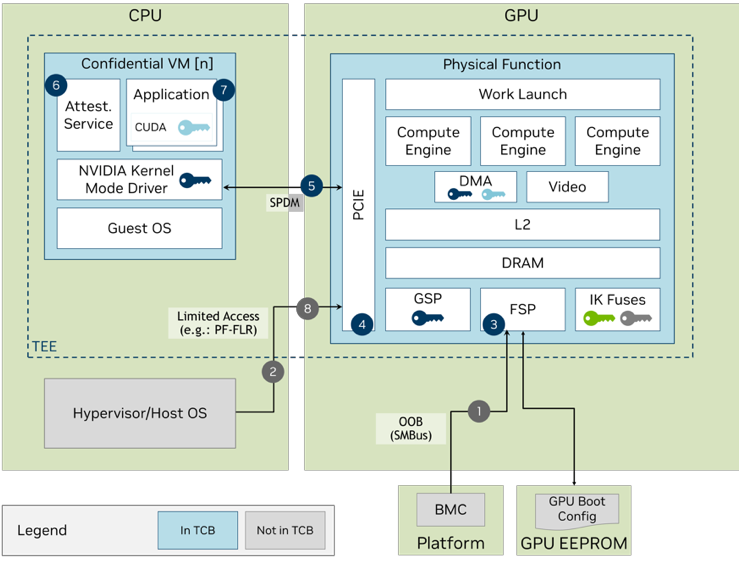
Confidential computing works differently. The data stays encrypted throughout the entire computation process. The AI model runs on ciphertext—the encrypted version—not the plaintext. Special hardware called Trusted Execution Environments (TEEs) make this possible.
NVIDIA's implementation uses something called Hopper and Blackwell architecture processors with built-in encryption acceleration. These chips can perform mathematical operations on encrypted data without ever decrypting it. It's cryptographic magic, and it's real.
The math behind it relies on something called homomorphic encryption. The basic idea: certain encryption schemes preserve mathematical properties so that operations on encrypted data produce encrypted results that, when decrypted, match what you'd get if you'd run the operation on plaintext data.
Here's a simplified formula:
Where E is encryption. You add encrypted numbers without decrypting them first.
In practice, homomorphic encryption is computationally expensive. A simple addition might take microseconds on plaintext but milliseconds on encrypted data. Scale that to a neural network with billions of parameters, and you see why Meta needs millions of GPUs.
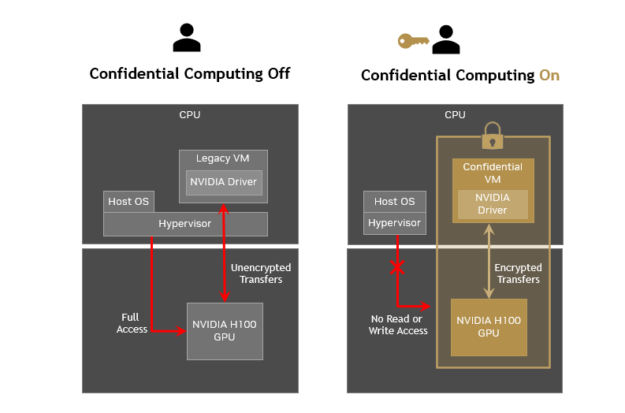
But NVIDIA's approach doesn't rely solely on full homomorphic encryption. Instead, it uses a hybrid model: TEEs provide secure enclaves where computation happens in an isolated hardware environment. The CPU encrypts the data, loads it into the enclave, runs the computation inside (still encrypted), then outputs the result (still encrypted). No unencrypted data ever escapes the secure boundary.
This is different from traditional cloud computing where a database administrator could theoretically read your data if they had the right access. With confidential computing, nobody can—not even Meta's own engineers.
The implications are staggering. GDPR compliance becomes easier. Regulatory audits become simpler—you can literally prove that data was never accessed in unencrypted form. Users can verify their data privacy without trusting Meta's word.

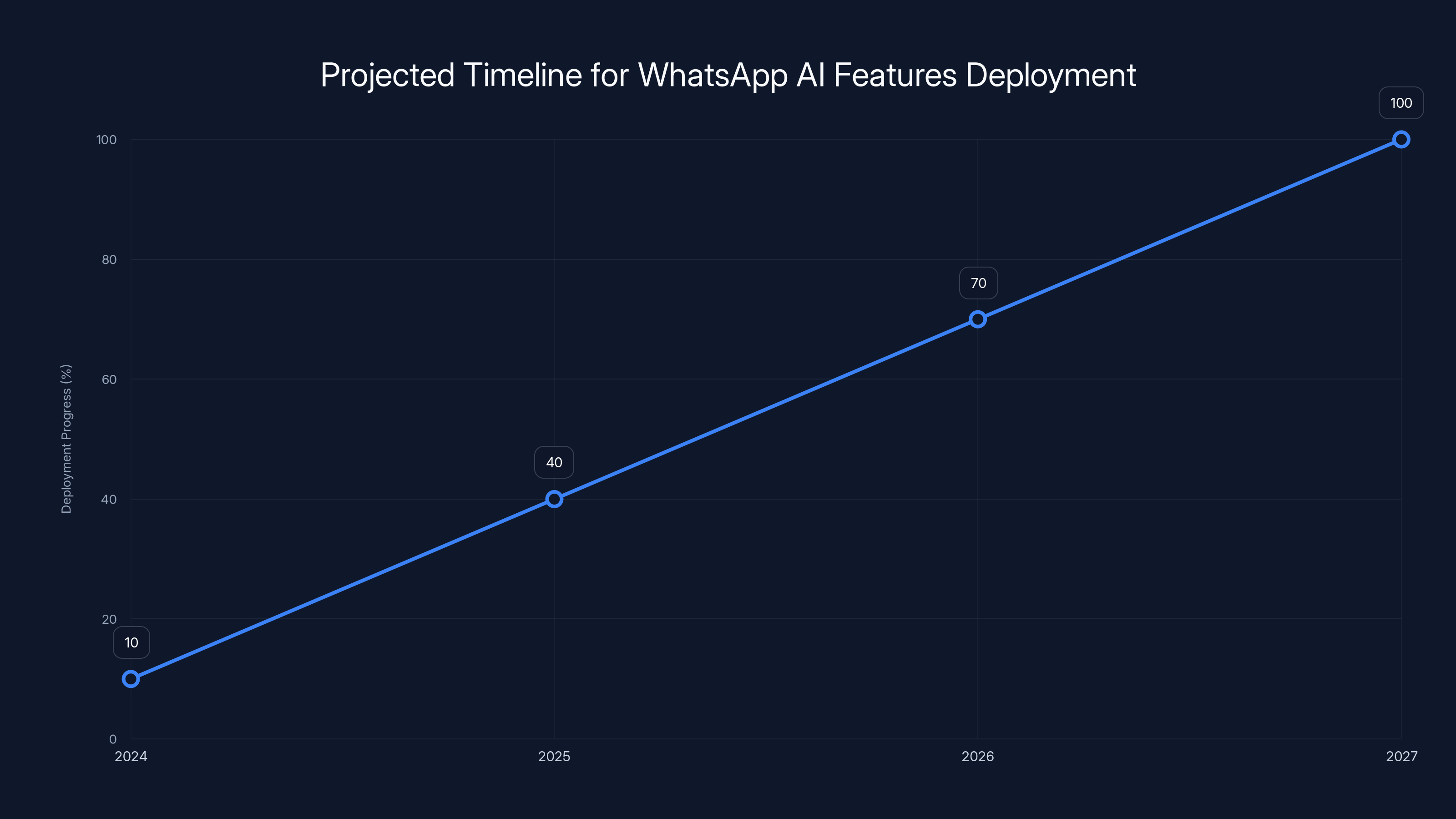
WhatsApp users can expect gradual AI feature rollouts starting in 2026, with full deployment anticipated by 2027. Estimated data based on typical infrastructure timelines.
Why Meta Needs This Now: The Regulatory Squeeze
Meta isn't doing this out of altruism. They're doing it because they have to.
Europe's Digital Markets Act (DMA) and General Data Protection Regulation (GDPR) have made it increasingly difficult to run AI on user data without explicit consent and ironclad privacy guarantees. The European Union is actively investigating whether Meta's current data practices comply. Fines can reach 4% of annual global revenue. For Meta, that's billions.
China, the UK, and Canada are all tightening data privacy regulations. India is drafting new digital privacy laws. The pattern is clear: regulators worldwide don't trust companies to self-regulate on data access.
Confidential computing solves this at the infrastructure level. You can run AI on user data, extract value, and genuinely guarantee that the data was never exposed—not even to human access. It's regulatory armor.
But there's another reason: user trust. WhatsApp's core promise has always been end-to-end encryption. Adding AI features without compromising that promise is a marketing advantage. Every competitor—from Signal to Telegram—has the same pressure. If WhatsApp can offer AI-powered smart replies, better search, real-time translation, and language understanding while guaranteeing that your messages never leave encrypted form, that's a meaningful differentiator.
The math is also favorable. Meta's infrastructure spend is massive—$135 billion in 2026 alone. Adding confidential computing doesn't require a parallel infrastructure. It's a software and firmware layer on top of existing hardware. The marginal cost is real but manageable.
Compare this to the cost of data breaches, regulatory fines, and lost user trust. Confidential computing looks cheap.

The NVIDIA Hardware Stack: Blackwell, Rubin, and Grace
Meta's commitment to buy "millions" of GPUs sounds vague until you understand the components.
The main workhorses are Blackwell and Rubin. Blackwell is NVIDIA's current flagship, released in 2024. It's designed for both training and inference, with massive improvements in memory bandwidth and arithmetic throughput. Rubin, coming in 2026, pushes those improvements further. Think of Blackwell as the 2024 generation and Rubin as the 2025-2026 generation—a natural evolution.
But the real story is Grace CPUs.
Meta announced it would be the first to deploy Grace CPUs in a standalone configuration, not paired with GPUs. This is significant. Grace CPUs are ARM-based processors designed for inference and "agentic workloads." Agentic workloads mean AI agents—systems that perform multi-step tasks, call external APIs, make decisions, and loop until they solve a problem.
Here's why this matters: not every AI workload needs a GPU. Training a large language model? Absolutely, you need GPUs. Running inference on a language model? GPUs help, but CPUs can be more efficient depending on batch size and latency requirements. Running an AI agent that spends 80% of its time waiting for API calls, database queries, or network I/O? A CPU is often enough.
By separating inference and agentic workloads onto Grace CPUs, Meta can allocate Blackwell/Rubin GPUs to higher-throughput training and batch inference tasks. This is pure infrastructure optimization.
NVIDIA's Spectrum-X Ethernet switches complete the picture. These switches are optimized for GPU communication, reducing latency and increasing throughput for the massive data transfers required between compute nodes. In a data center with thousands of GPUs, network bandwidth becomes the bottleneck. Spectrum-X alleviates that.
Let's do the math on what "millions" of GPUs might cost. A single Blackwell GPU costs roughly
Then add CPUs, networking gear, memory, storage, cooling, and real estate. The $600 billion infrastructure spend Meta announced suddenly makes sense.
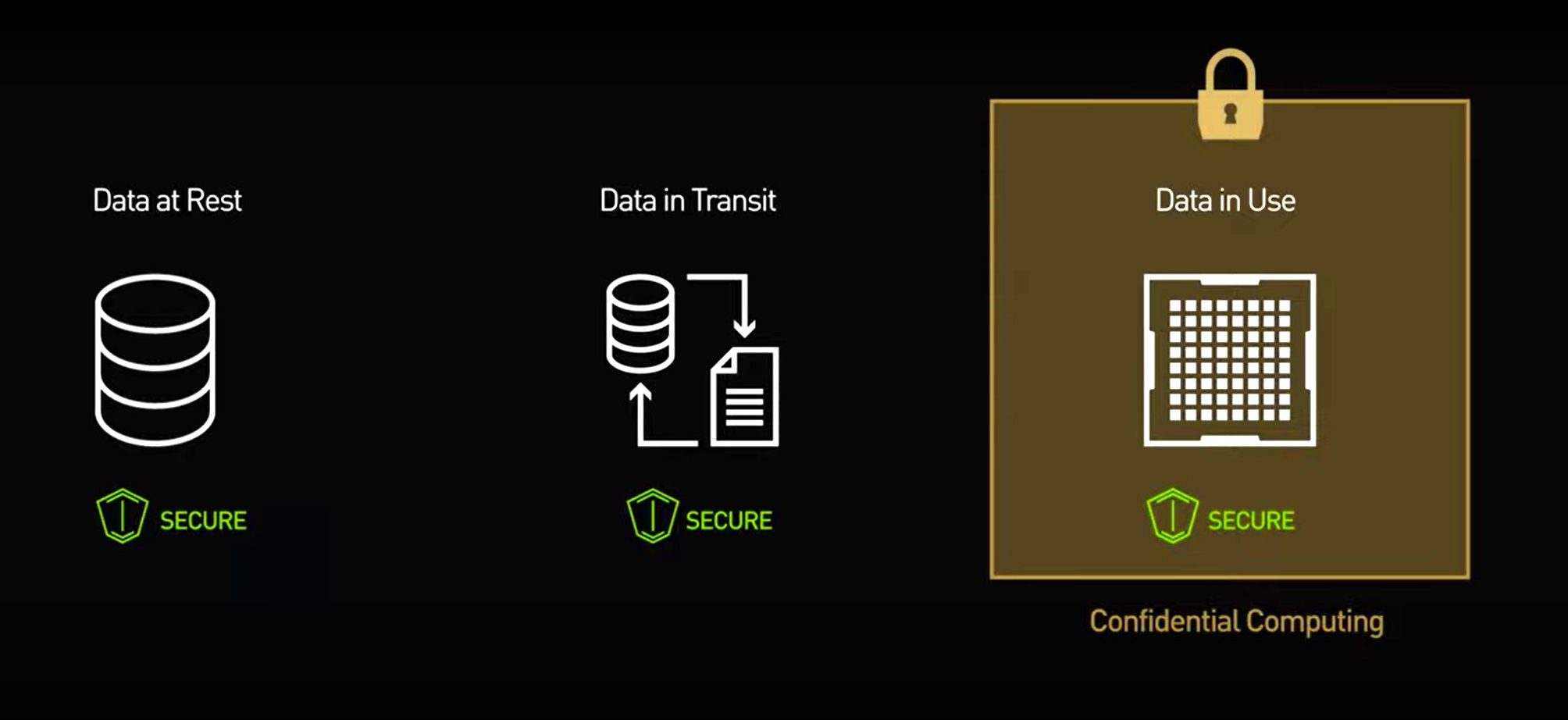
How WhatsApp AI Will Actually Work (The Architecture)
When you open WhatsApp in 2026 and ask the AI to "summarize this conversation," what happens behind the scenes?
Your message request stays encrypted with WhatsApp's end-to-end encryption key. It never gets sent to Meta's servers in plaintext. Instead, it goes to an edge server (probably geographically close to you) that still sees only the encrypted message. This server routes the encrypted request to a confidential computing data center.
Inside the data center, the request lands in a Trusted Execution Environment. This is a hardware boundary—part of the CPU/GPU memory that's isolated and encrypted. Nobody, not even the operating system kernel or system administrators, can read what's inside.
Your encrypted message enters the TEE. Inside, it's decrypted using your encryption key. The AI model (running within the TEE) processes your request. The results are encrypted again. Everything—the decryption, the AI computation, and the re-encryption—happens in isolated hardware.
The encrypted results go back to your phone. WhatsApp decrypts them using your key. You see the summary.
Meta's infrastructure team never sees your message. Neither does any human. The only entity that decrypts your data is your phone, using your key.
This is fundamentally different from how current AI services work. When you ask Chat GPT to summarize something, OpenAI can access your prompt. They claim it's anonymized and deleted. But technically, they can. With confidential computing on WhatsApp, they literally cannot—the architecture prevents it.
For feature-rich AI, Meta will use Grace CPUs running inference workloads. Features like smart reply suggestions, language detection, and basic chat analysis don't require GPU throughput. A CPU can handle these with lower latency and better energy efficiency.
For more complex tasks—like if WhatsApp ever does advanced language understanding or image analysis—those workloads might spin up on Blackwell GPUs, still within the TEE boundary.
The result: AI features that feel native to WhatsApp without compromising privacy architecture.

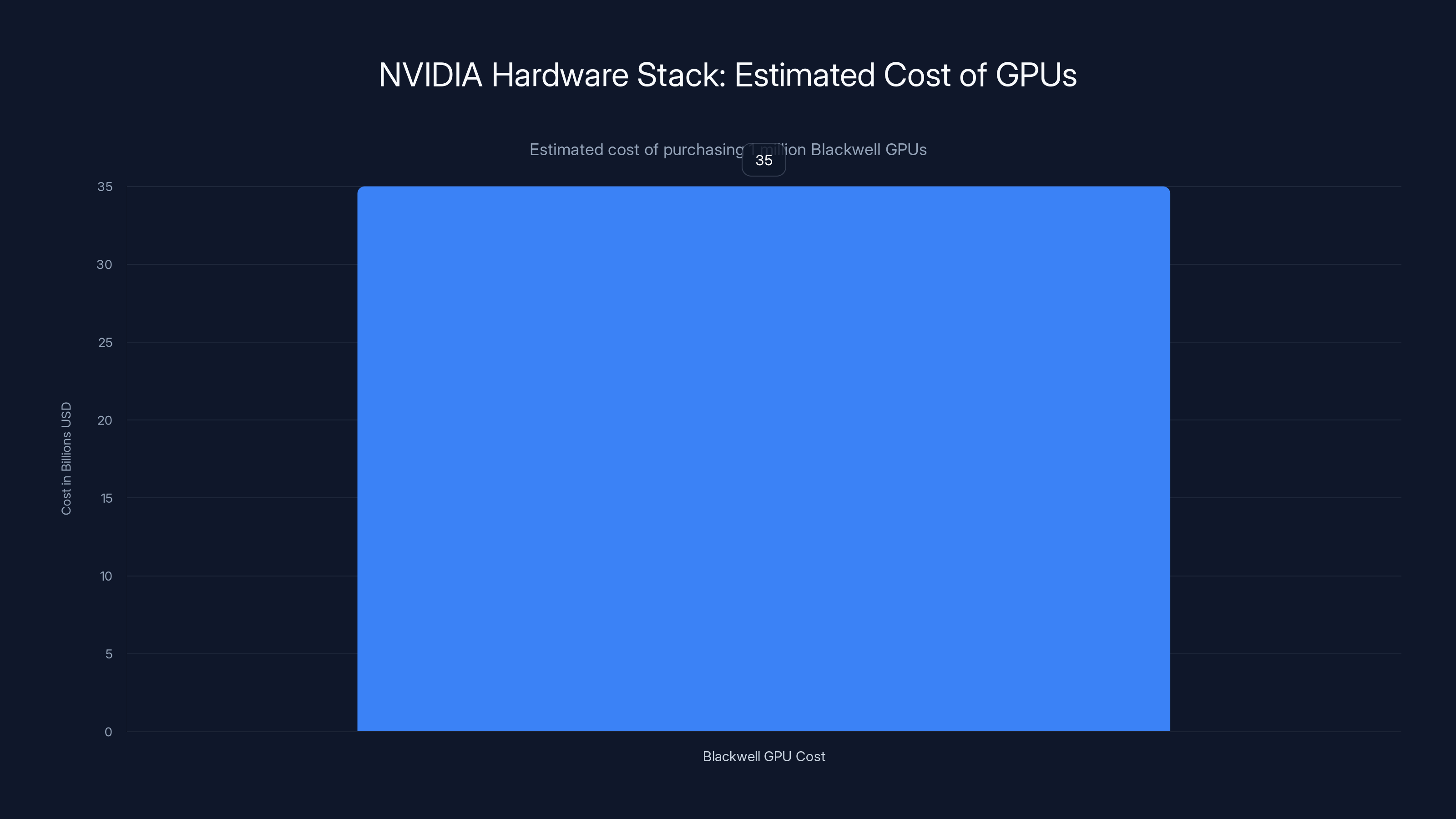
Purchasing one million Blackwell GPUs at an average cost of
The Inference Challenge: Why Grace CPUs Matter
People often think of AI as a training problem. It's not—training is hard, but inference is the real operational challenge.
When Meta trains a model, it's a one-time cost. When Meta runs inference—answering user requests—that's recurring, billions of times per day. The economics of inference determine whether an AI feature is profitable or not.
Take smart reply on WhatsApp. When a user receives a message, WhatsApp needs to compute reply suggestions in under 200 milliseconds. Latency matters. Users notice delays. The infrastructure must be fast and cheap.
A GPU is powerful but expensive to run at idle. When inference requests come in bursts (someone gets a flurry of messages, asks for a summary, then nothing for 5 minutes), GPU utilization crashes. You're burning money on idle hardware.
A CPU is lower power, cheaper to run, and can handle non-GPU workloads efficiently. Grace CPUs are specifically designed for this: ARM architecture (power efficient), large caches, and optimized for AI inference serving.
Meta's strategy: use CPUs for the bulk of inference (smart reply, language detection, basic analysis) and reserve expensive GPU capacity for high-throughput training and batch inference jobs.
This is economically sound. A single Grace CPU might serve 100,000 chat queries per day. A single Blackwell GPU might generate $10,000 of value per day in training throughput. Different tools for different jobs.
When agentic workloads enter the picture—AI agents that loop multiple times per request, call external APIs, and make complex decisions—the economics shift. These workloads have variable compute requirements. Sometimes they need heavy computation; sometimes they're waiting for API responses. Grace CPUs handle the decision-making and API orchestration. When heavy computation is needed, the agent can delegate to a GPU.
This hybrid approach is why Meta invested heavily in having Grace as a standalone option.

Confidential Computing vs. Federated Learning: Different Tools
When people talk about privacy-preserving AI, they often conflate different approaches. Let's clear that up.
Confidential computing (what Meta is doing) means: centralized computation on encrypted data, guaranteed by hardware.
Federated learning means: distributed computation where the model trains on-device, and only model updates (not raw data) go to the server.
They're complementary, not competing.
Federated learning is great for smartphones. Your phone trains a model on your local data. Only the parameter updates get sent to Meta's servers. The raw data never leaves your device.
But federated learning has limitations. It's slower than centralized training. It's hard to do cross-user analytics. Some features require global context.
Confidential computing solves these problems differently. You can do centralized training and inference (fast, powerful) while guaranteeing data privacy through hardware.
Meta will likely use both. On-device federated learning for personalization. Confidential computing for features that need server-side understanding.
The tradeoff: confidential computing requires specialized hardware. Not every data center has it. Federated learning runs anywhere. But confidential computing offers cryptographic proofs of privacy. Federated learning requires trusting your updates aren't revealing information indirectly.
As hardware becomes more standardized, confidential computing will likely become the default for sensitive workloads.

The Competitive Response: What Google, Microsoft, and OpenAI Are Doing
Meta isn't alone in recognizing this shift. Every major AI company is experimenting with confidential computing.
Google has been investing in TEE technology for years. Their Confidential Computing offerings on Google Cloud use AMD SEV or Intel TDX to isolate workloads. But Google hasn't yet announced deployment at Meta's scale.
Microsoft is running Azure Confidential Computing using Intel TDX. They're marketing it to healthcare and financial services. But again, nothing as ambitious as Meta's WhatsApp integration.
OpenAI has been quiet on confidential computing. They offer data privacy controls (don't train on user data), but not TEE-backed guarantees. This is a competitive vulnerability. If Meta proves that confidential computing works at scale on WhatsApp, OpenAI might face pressure to implement similar guarantees.
Amazon is investing in custom silicon (Trainium, Inferentia) but hasn't emphasized confidential computing as heavily as NVIDIA's partnership with Meta.
What's happening: Meta is moving first and moving boldly. By deploying confidential computing at scale through WhatsApp, they're essentially forcing every competitor to follow. Users will see that private AI is possible. They'll expect it everywhere.
The competitive advantage won't last long. Once the technology matures, it becomes table stakes. But Meta gets 12-18 months of marketing advantage, plus regulatory goodwill for taking privacy seriously.
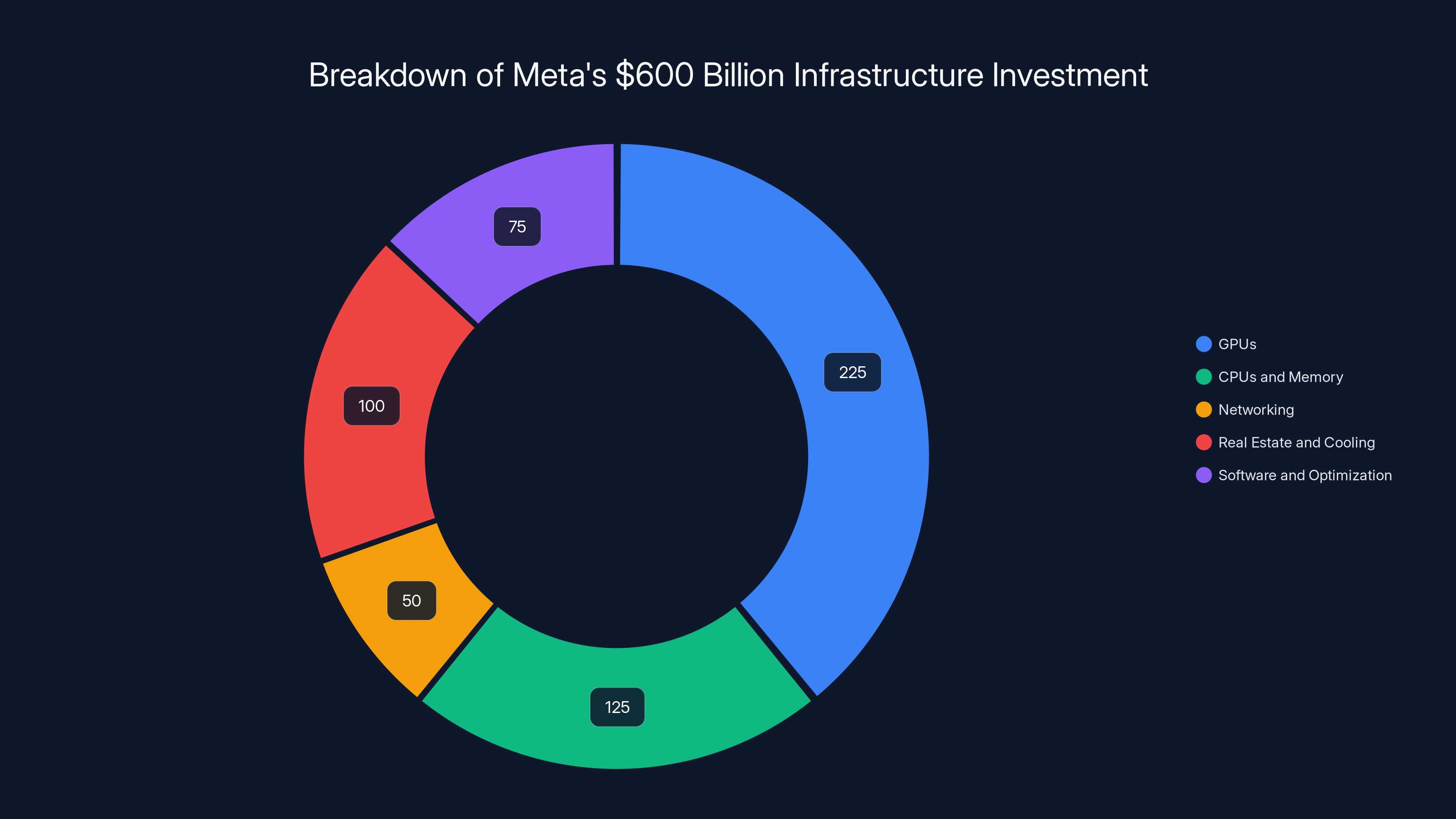
Meta's $600 billion infrastructure investment is heavily weighted towards GPUs, with significant allocations for CPUs, memory, and real estate. Estimated data based on projected spending.
Regulatory Advantages: Why This Is a Compliance Superpower
GDPR compliance is expensive and complicated. Data Processing Agreements, Data Protection Impact Assessments, consent management, audit trails—it's a whole department.
Confidential computing simplifies this dramatically.
Under GDPR, Meta is responsible for ensuring that personal data is processed securely and that processing is limited to stated purposes. Currently, Meta must implement "pseudonymization and encryption" as technical measures. But encryption in transit and at rest isn't enough—the data must be decrypted for processing, creating vulnerability windows.
With confidential computing, Meta can demonstrate something stronger: "We have cryptographic and hardware-based guarantees that user data cannot be accessed in unencrypted form, even by our own administrators."
This is a defense multiplier in regulatory investigations. If a regulator asks, "How can you guarantee WhatsApp messages weren't accessed for training purposes?" Meta can point to the hardware isolation. The architecture makes unauthorized access technically impossible.
For users in jurisdictions with strict data laws—the UK, Canada, Australia—this is trust infrastructure.
The same applies to industry-specific regulations. HIPAA (healthcare), FINRA (finance), PCI-DSS (payment cards)—all of these have audit and access control requirements. Confidential computing satisfies them natively.
Longer term, this becomes regulatory leverage. If Meta's approach proves reliable, regulators might trust Meta more than competitors who don't invest in similar infrastructure. This could translate to lighter compliance burdens, faster feature approvals, and less scrutiny.
It's a long game, but the stakes justify it.

The Economics of Scale: $600 Billion and What It Gets You
Meta's $600 billion infrastructure commitment through 2028 is staggering. Let's break it down:
- GPUs: ~$200-250 billion (millions of Blackwell/Rubin chips)
- CPUs and memory: ~$100-150 billion (Grace, RAM, SSD storage)
- Networking: ~$50 billion (Spectrum-X, custom switching fabric)
- Real estate and cooling: ~$100 billion (30 data centers, land, construction, power infrastructure)
- Software and optimization: ~$50-100 billion (R&D, model training, optimization)
Why the massive spend? Because AI is compute-bound. To power 3 billion WhatsApp users with AI features, you need infrastructure that can handle:
- 1 billion requests per day at peak (rough estimate for smart reply, language detection, etc.)
- Sub-200ms latency (users notice anything slower)
- 99.99% uptime (messaging is critical)
- Redundancy and geo-distribution (data centers worldwide)
The compute required to hit these targets is enormous. A single inference request on a large language model might require 100-1,000 floating-point operations. At 1 billion requests per day, you're looking at 100 quintillion operations daily. That's not hyperbole.
But here's the important part: confidential computing adds overhead. Homomorphic encryption, TEE context switching, and secure enclaves all reduce throughput. Meta needs extra hardware to compensate.
If confidential computing adds 20% overhead (a conservative estimate), Meta needs 20% more hardware. At a
This spend also signals commitment to AI competition. Google is investing heavily. Microsoft is bundling AI with enterprise products. Amazon is pushing Bedrock. Meta is saying: we're not ceding AI infrastructure to anyone.
The Supply Chain Reality: Can NVIDIA Keep Up?
There's a practical question: can NVIDIA manufacture millions of GPUs per year?
Short answer: barely.
NVIDIA's Blackwell production is ramping through 2025-2026. Industry estimates suggest NVIDIA can produce 10-20 million GPUs annually at peak capacity. Meta's deal for "millions" of units is a substantial percentage of global capacity.
This creates supply chain risk. If NVIDIA has production issues, Meta's timeline slips. If other AI companies (OpenAI's Microsoft partnership, Google, Amazon, Apple) also buy heavily, prices rise or allocation constraints tighten.
Meta mitigates this by signing a long-term exclusive partnership. It's probably a multi-year commitment with volume guarantees in exchange for price discounts and priority allocation.
But there's still supply constraint risk. If a major NVIDIA customer—say, Microsoft—faces unexpected demand spikes, that could cascade. Supply is finite.
Longer term, this accelerates diversification. Meta might develop custom AI chips (like they've done with inference processors). Google has TPUs. Amazon has custom silicon. As volumes grow and margins compress, custom hardware becomes attractive.
But for the next 3-5 years, NVIDIA dominates. Their TEE technology and confidential computing support give them advantage over AMD or Intel alternatives.

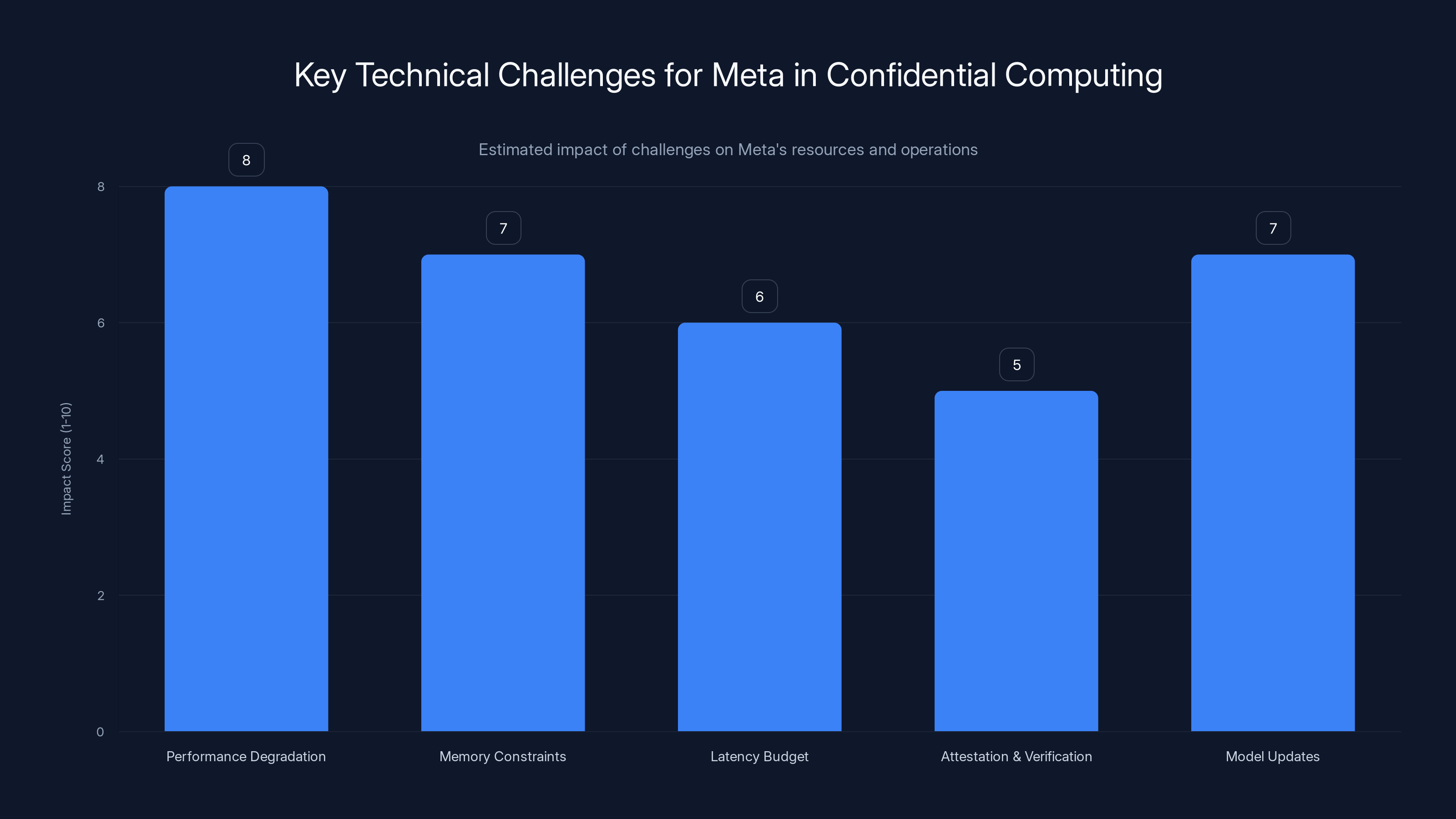
Performance degradation and memory constraints are the most significant challenges for Meta, with high impact scores. Estimated data based on described challenges.
What This Means for WhatsApp Users: When Will You See This?
The honest answer: 2026-2027, probably.
Meta announced the partnership in January 2025. Building 30 data centers takes years. Deploying confidential computing infrastructure takes additional time. Testing, security audits, regulatory approvals—all of this adds latency.
When it does launch, don't expect dramatic user-facing changes. The infrastructure is invisible.
Where you'll notice it:
Smart replies will get more sophisticated. Instead of simple pattern-matching, WhatsApp AI can understand context, tone, and conversation history.
Search will be faster and smarter. Finding a message from 6 months ago will work even if it's in group chats or encrypted conversations.
Language features will improve. Real-time translation, spell-check, tone detection—all become possible.
AI agents might emerge. Imagine an AI assistant that can schedule meetings, look up contacts, and compose messages automatically, all within WhatsApp's privacy guarantees.
The key difference: these features exist today on other platforms (Gmail, Slack, Teams). But those platforms require trusting Google or Microsoft with your data. WhatsApp's version will offer genuine privacy guarantees through hardware.
That's the real product innovation.

The Broader Implications: Privacy as Infrastructure
Where does this lead in 5-10 years?
If Meta proves that confidential computing works at WhatsApp's scale, the precedent is set. Other companies will follow. Not because of altruism, but because users will demand it and regulators will enforce it.
Imaging Microsoft deploying confidential computing on Outlook. Google on Gmail. Slack on its workspace platform. Every company offering the same guarantee: "Your data is processed in secure enclaves. We cannot access it unencrypted."
This becomes a trust multiplier. Users aren't choosing between privacy and features anymore. You get both.
For businesses, this changes procurement. Healthcare providers, financial firms, government agencies—they'll demand confidential computing from vendors. It becomes a table stakes requirement.
For innovators, this creates opportunities. Companies building AI tools for sensitive domains (legal, medical, financial) can compete with Big Tech by offering privacy guarantees. The playing field levels.
For regulators, this simplifies oversight. You can verify privacy through hardware instead of trusting audits and policies. Compliance becomes objective.
Longer term, this might reshape the entire cloud computing model. Instead of trusting cloud providers' access controls, you trust hardware. Security shifts from policy to physics.
Meta's bet isn't just on WhatsApp AI. It's on privacy as a core infrastructure layer that eventually becomes universal.
Key Technical Challenges Meta Must Solve
For all the promise, confidential computing faces real technical hurdles:
Performance degradation: Encryption overhead means slower inference. Meta needs 20-50% more hardware than traditional setups. That's expensive and needs optimization.
Memory constraints: TEEs have limited memory. A large language model might not fit inside a secure enclave. Meta will need to use memory encryption (entire GPU memory, not just the enclave) or partition workloads across TEEs.
Latency budget: WhatsApp users expect sub-200ms response times. Adding cryptographic operations (encryption/decryption) to each request adds milliseconds. Pipelining and optimization are crucial.
Attestation and verification: Users need proof that their data stayed encrypted. This requires attestation mechanisms where TEE hardware cryptographically signs computations. Implementing this at scale is non-trivial.
Model updates: If Meta updates an AI model, it needs to re-encrypt it for the TEE. Model swapping during inference is complex.
Meta has resources to solve these. But they're not trivial engineering problems. Expect the first year of deployment to be rough, with iterative improvements.

Competitive Positioning: Is Meta Ahead or Behind?
On AI infrastructure, Meta has always been strong. Their custom ASIC work, data center optimization, and networking expertise are world-class.
Confidential computing deployment at WhatsApp scale is new competitive territory. Neither Google nor Microsoft has announced comparable infrastructure investments for consumer messaging. That's an advantage.
But there's a caveat: privacy-focused competitors like Signal and Telegram offer similar end-to-end encryption without requiring new infrastructure. The question is whether users care about AI features with privacy or just privacy without AI.
Meta is betting users want both. Based on WhatsApp's adoption trajectory (100+ million daily active users for status updates alone), they're probably right.
For OpenAI and other API-based AI companies, Meta's move is a long-term threat. If WhatsApp users get AI features natively with privacy guarantees, why pay for Chat GPT Plus? Meta's integration advantage is powerful.
But OpenAI has brand trust and capabilities that WhatsApp doesn't. This isn't zero-sum. It's just a different positioning.
FAQ
What exactly is confidential computing and how does it differ from regular encryption?
Confidential computing uses hardware-based Trusted Execution Environments (TEEs) to process encrypted data without ever decrypting it into unencrypted memory. Regular encryption encrypts data in transit and at rest, but must decrypt it for processing, creating vulnerability windows. With confidential computing, the CPU/GPU performs operations directly on encrypted data using cryptographic techniques. This means even Meta's own administrators cannot access unencrypted data—it's cryptographically impossible, not just policy-based.
Why is Meta spending $600 billion on infrastructure if they already have data centers?
Meta's $600 billion commitment through 2028 funds the massive buildout required to support AI features across billions of users while maintaining confidential computing guarantees. The infrastructure includes millions of GPUs, CPUs, memory, networking equipment, real estate for 30 new data centers, cooling systems, and power infrastructure. Confidential computing adds 20-50% computational overhead compared to standard setups, requiring extra hardware. Additionally, serving AI requests to 1+ billion WhatsApp users daily demands unprecedented scale and geographic redundancy.
When will WhatsApp users see AI features powered by this confidential computing infrastructure?
Based on typical data center deployment timelines, expect AI features on WhatsApp to launch in 2026-2027. Building 30 data centers, deploying confidential computing stacks, security audits, regulatory approvals, and beta testing all require significant time. Initial rollouts will likely be gradual—starting with smart reply suggestions and language detection, expanding to more complex features like real-time translation and AI agents over months.
How does confidential computing impact latency and performance for end users?
Confidential computing adds computational overhead through encryption operations, potentially degrading performance by 20-50% compared to standard processing. However, Meta mitigates this through hardware optimization (GPUs with built-in encryption acceleration), strategic use of efficient CPUs for lightweight workloads, and infrastructure at scale that absorbs latency overhead through parallel processing. WhatsApp users should notice minimal latency impact—smart replies should still appear in under 200 milliseconds—but the infrastructure handling requires significantly more hardware investment.
Will other messaging platforms adopt similar confidential computing approaches?
Yes, likely within 2-3 years. Signal and Telegram compete on privacy, while Google (Messages), Apple (iMessage), and Microsoft (Teams) all offer messaging with AI potential. Once Meta demonstrates that confidential computing works reliably at scale, regulatory pressure and user expectations will push competitors to follow. Additionally, GDPR and emerging digital privacy laws may eventually make such guarantees mandatory for any platform processing user communications with AI.
How much does confidential computing cost compared to traditional cloud AI infrastructure?
Confidential computing adds 20-50% to infrastructure costs due to computational overhead and the need for specialized hardware (TEEs, encryption-enabled GPUs, Spectrum-X networking). However, when factoring in compliance costs, regulatory risk, and brand value from privacy guarantees, confidential computing often becomes economically justified. Meta's additional hardware investment from this overhead is estimated at
Can confidential computing be used for model training or only inference?
Confidential computing is primarily optimized for inference (running trained models) due to performance overhead. Model training remains computationally intensive and typically runs on standard GPU infrastructure. However, future implementations may support training on encrypted data using advanced homomorphic encryption or hybrid approaches. Meta's deployment will focus on inference for WhatsApp features, while training remains on standard hardware with policy-based privacy controls.
What happens if Meta or NVIDIA experiences a security vulnerability in their confidential computing implementation?
This is a real risk. TEEs and confidential computing stacks are complex, and vulnerabilities have been discovered before (e.g., Spectre, Meltdown affecting Intel TEEs). However, the architecture provides defense-in-depth: even if one layer is breached, encrypted data remains protected. Additionally, vulnerabilities in TEE hardware would affect all industry players, creating incentive for rapid patching. Users also benefit from independent security audits that can verify privacy claims—a transparency advantage over traditional cloud architectures.
The Bottom Line
Meta's partnership with NVIDIA to deploy confidential computing on WhatsApp represents a watershed moment in AI infrastructure. For the first time, a major platform is betting that privacy-preserving AI at scale is not just possible but essential.
The economics are brutal (billions in extra hardware investment). The technical challenges are real (performance overhead, latency management, memory constraints). The regulatory winds are favorable (GDPR, data privacy laws, user skepticism).
But the bigger story is cultural: Meta is signaling that AI doesn't require compromising privacy. Other companies will follow because users will demand it and regulators will enforce it.
In 5 years, confidential computing won't be a differentiator. It'll be table stakes. Every platform offering AI features will need privacy guarantees. The race isn't to be first—it's to be good enough before users and regulators demand it.
Meta is moving aggressively because they understand this trajectory. The company that pioneers privacy-preserving AI infrastructure at scale earns trust capital that pays dividends for years.
Whether WhatsApp's specific implementation succeeds is an open question. But the direction is inevitable. Privacy, AI, and infrastructure are converging. Companies that don't converge them will find themselves on the wrong side of both user expectations and regulatory requirements.
Meta's $600 billion bet is expensive. But it might be cheap compared to the alternative: trying to catch up when privacy becomes mandatory.
Key Takeaways
- Confidential computing uses Trusted Execution Environments to process encrypted data without ever decrypting it, protecting privacy through hardware not just policy
- Meta's $600B infrastructure investment through 2028 funds 30 new data centers and millions of NVIDIA GPUs specifically to support confidential computing at WhatsApp's scale
- Grace CPUs will handle lightweight AI inference (smart replies, language detection) while Blackwell GPUs manage intensive training workloads, optimizing cost and latency
- WhatsApp AI features arriving 2026-2027 with genuine privacy guarantees will pressure Google, Apple, and Microsoft to deploy similar infrastructure or lose user trust
- Confidential computing adds 20-50% computational overhead but provides regulatory armor against GDPR violations and future data privacy laws that may mandate this protection
Related Articles
- Humanoid Robots & Privacy: Redefining Trust in 2025
- Network Modernization for AI & Quantum Success [2025]
- Mesh Optical Technologies $50M Series A: AI Data Center Interconnect Revolution [2025]
- AI Data Centers Hit Power Limits: How C2i is Solving the Energy Crisis [2025]
- Nvidia's Dynamic Memory Sparsification Cuts LLM Costs 8x [2025]
- StreamFast SSD Technology: The Future of Storage Without FTL [2025]

