![From AI Pilots to Real Business Value: A Practical Roadmap [2025]](https://tryrunable.com/blog/from-ai-pilots-to-real-business-value-a-practical-roadmap-20/image-1-1770653702495.jpg)
From AI Pilots to Real Business Value: A Practical Roadmap [2025]
Your AI pilot looked perfect in the demo. The model was accurate, the team was excited, and leadership approved the budget. Then something happened that caught everyone off guard: it didn't scale.
You're not alone. This story plays out at hundreds of organizations every quarter. According to industry forecasts, more than 40% of projects described as agentic AI will be scrapped before they deliver meaningful outcomes by 2027. That's not a technology problem. That's an execution problem.
The gap between impressive pilots and actual business value isn't about AI itself. It's about the systems, governance, and organizational alignment that separate proof-of-concept demos from sustainable, scaled operations. Most companies treat AI like a shiny new feature to bolt onto existing workflows. The best companies treat it like a fundamental shift in how work happens.
Here's what separates the two: successful organizations approach AI with the same rigor they'd apply to any major operational change. They start with a business-first vision. They establish cross-functional teams with clear accountability. They embed governance into workflows from day one, not as an afterthought. And they treat AI as a living system that evolves continuously, not a static tool deployed once and forgotten.
This roadmap covers the five practical steps that high-performing organizations use to move AI from pilots into full-scale programs. These aren't theoretical frameworks. They're battle-tested approaches that reduce common pitfalls, accelerate adoption, and ensure AI delivers measurable business outcomes instead of becoming another sunk cost.
TL; DR
- Successful AI programs start with business outcomes, not technology: Clear KPIs and measurable goals separate real deployments from vanity projects
- Governance isn't optional, it's foundational: Embedding compliance, escalation, and ethical guardrails into workflows from day one prevents chaos at scale
- Cross-functional collaboration drives adoption: Centers of excellence and business-IT alignment transform isolated experiments into enterprise capabilities
- AI is a living system, not a static tool: Continuous monitoring, telemetry, and refinement ensure systems evolve with the business instead of becoming stale
- Process mapping precedes technology: Understanding workflows end-to-end reveals where AI genuinely adds value, not where vendors say it should
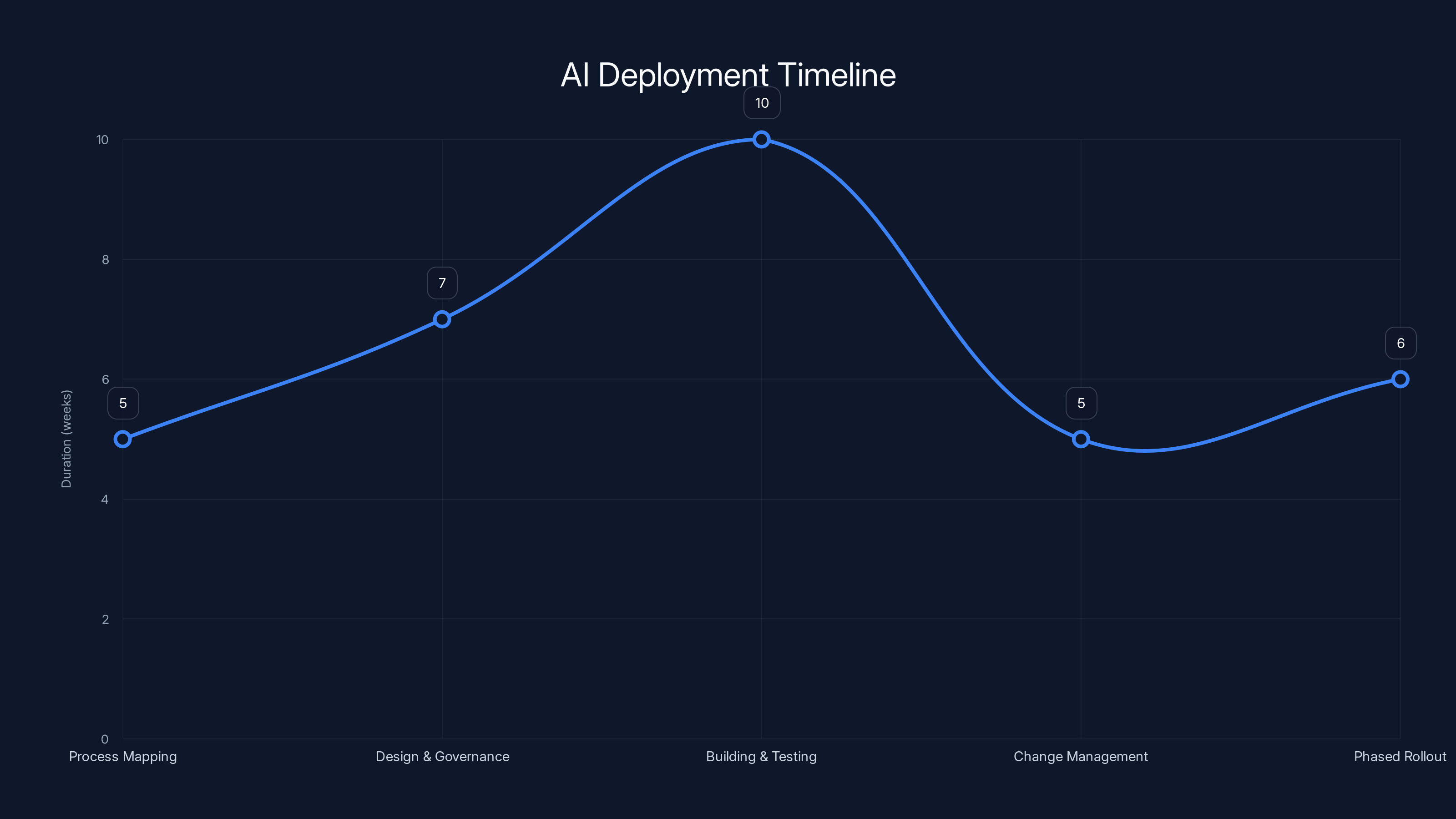
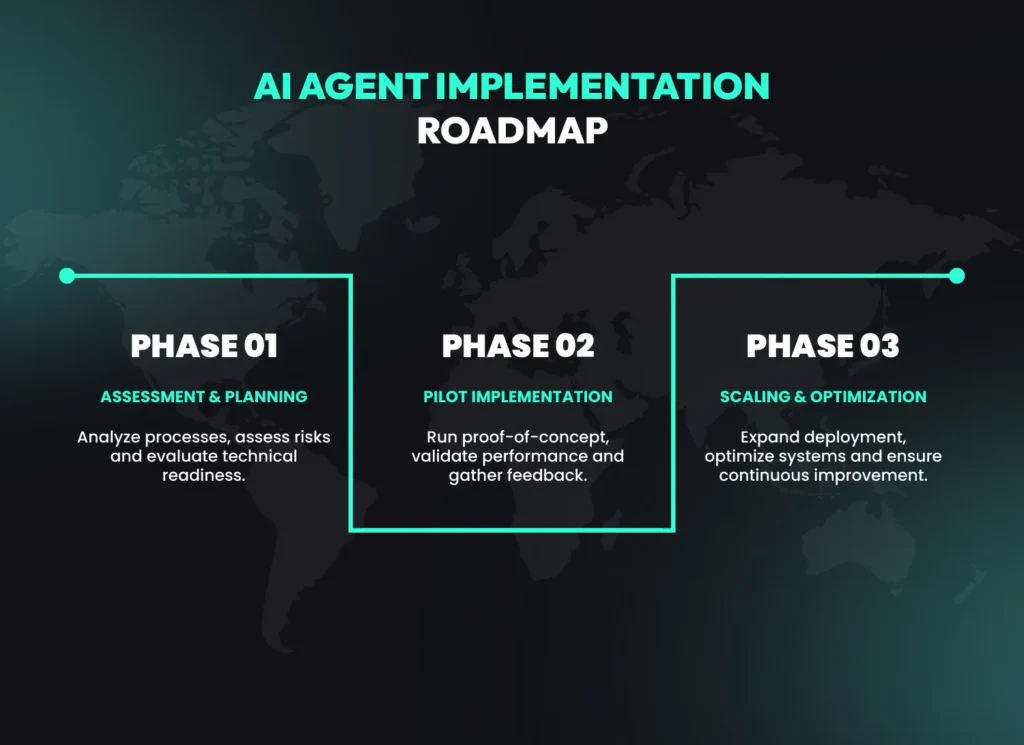
The typical AI deployment timeline spans 6-9 months, with each phase requiring careful planning to avoid issues during scaling. Estimated data based on typical organizational processes.
Why Most AI Pilots Fail at Scale
Let's talk about what actually happens after the successful demo.
You've got a model that works. It's accurate, it's fast, and it solves a real problem. Your team learned something valuable. Leadership is impressed. So you start planning the rollout. This is where the story goes sideways for most organizations.
The first problem: isolated teams. An AI pilot usually lives in one corner of the organization. Data science owns the model. Engineering owns the infrastructure. Business owns the requirements. But nobody owns the process of actually integrating it into daily operations. When pilots succeed in this silo, they're succeeding in a vacuum. Once you try to connect them to real workflows, real data, and real people, complexity explodes.
The second problem: governance comes too late. During pilots, you can manually check important decisions. You can flag edge cases. You can escalate unclear situations to a human. But manual oversight doesn't scale. When you're processing hundreds of transactions per day, that oversight either becomes a bottleneck or disappears entirely. Most organizations discover this the hard way: after deployment, when someone asks, "Who approved this decision and why?"
The third problem: metrics that don't matter. Pilot teams celebrate high accuracy scores. They celebrate fast inference times. They celebrate test set performance. None of that translates to business value. The metric that matters is what business leaders actually care about: Did we cut costs? Did we improve customer satisfaction? Did we free up time for high-value work? Most pilots can't answer those questions because they never defined them.
The fourth problem: static deployments. After months of careful tuning and optimization, the AI system gets deployed. And then it sits there. The business evolves. Customer behavior shifts. Edge cases emerge that weren't in the training data. But the AI system doesn't evolve with it. Six months later, performance has quietly degraded 15%. Nobody noticed because there's no monitoring. Nobody updated the prompts because the team moved on. The system just became another legacy application.
These aren't failures of AI technology. They're failures of organizational structure and planning. The technology works fine. The problem is everything around it.

Architecture and testing patterns are rated highest in importance for AI agent templates, ensuring consistency and reliability. (Estimated data)
What Sets Successful AI Programs Apart
When you look at organizations that actually delivered real value with AI, several patterns emerge immediately.
They start with a business-first vision. Leadership doesn't say, "Let's deploy AI." They say, "We need to accelerate claims processing by 40% and reduce cycle time from 5 days to 2 days." Or: "We're losing customers to poor fraud detection. We need to catch 95% of fraudulent transactions before they impact customers." Or: "Our customer service team is spending 30% of time on repetitive questions. If we automate that, we free up capacity for complex issues."
Notice what's missing: any mention of technology. The business outcome comes first. The AI is the mechanism, not the goal. This clarity changes everything about how the program gets structured and measured.
The second pattern: cross-functional structure from the beginning. Successful programs don't have a single team owning AI. They have centers of excellence. These are structures that pull together data scientists, engineers, business leaders, compliance experts, and operational people. The center establishes standards, shares best practices, and ensures that every new initiative learns from previous ones. This prevents the isolated silo problem.
The third pattern: governance built in from day one, not bolted on later. Mature organizations integrate human-in-the-loop checks, confidence scoring, escalation paths, and fallback logic directly into the workflow. This isn't a compliance checkbox. It's an operational necessity. When you build governance into the process design itself, it becomes part of normal operations instead of a speed bump.
The fourth pattern: metrics that track business impact, not just model performance. Successful programs measure cost savings, operational efficiency, customer satisfaction, and time freed up. They also measure the things that prevent disasters: escalation rates, human override rates, accuracy on edge cases, and time to resolution. These metrics tell you whether the AI is actually delivering value or just creating work for people to clean up.
The fifth pattern: continuous evolution. High-performing organizations treat AI as a living system. They monitor telemetry and performance data constantly. They use that data to refine prompts, retrain models, and optimize processes. They adjust as the business changes. They don't deploy once and consider the job done.

Step 1: Map Your Processes End-to-End Before Touching Technology
This is where it all starts, and most organizations skip it.
Before you even think about where AI fits, you need to understand your process completely. Not theoretically. Not in a conference room. Actually.
Sit with the people doing the work. Watch them handle transactions. See where they pause. See where they check multiple systems. See where they consult with someone else. See where they pause because they're unsure. See where they take 20 minutes on a task that should take 5 minutes. Write it down. Map it. Understand it.
Now, here's the critical insight: some of these steps are great candidates for AI. Some aren't. Most teams get this backwards. They assume AI should handle the complex decisions. Actually, AI often works better on the high-volume, repetitive decisions. The complex decisions often need better tools, clearer processes, or better training.
A good process map for AI deployment includes:
- Current state workflows: What actually happens today, step by step
- Decision points: Where are humans choosing between options
- Data requirements: What information is needed to make each decision
- Bottlenecks: Where does work pile up or take longer than expected
- Error rates: Where do mistakes happen most frequently
- Compliance requirements: What rules or regulations apply to each step
Once you have this map, you can identify high-impact opportunities. These are usually high-volume, rule-based decisions where accuracy matters but judgment is relatively straightforward. Claims triage in insurance. Fraud detection in financial services. Ticket routing in customer service. Content tagging in content management.
The mistake most teams make: they identify the opportunity, then immediately start building. They should instead map how the AI decision flows into the rest of the process. Who approves it? What happens if it's wrong? How does it connect to downstream systems? What's the fallback if the AI can't make a confident decision?
This mapping phase takes time. It's not glamorous. But it prevents building beautiful AI solutions that don't connect to anything useful. It reveals whether you actually need AI or whether you need better process design first. Sometimes the answer is, "We need to simplify our process before AI even makes sense."
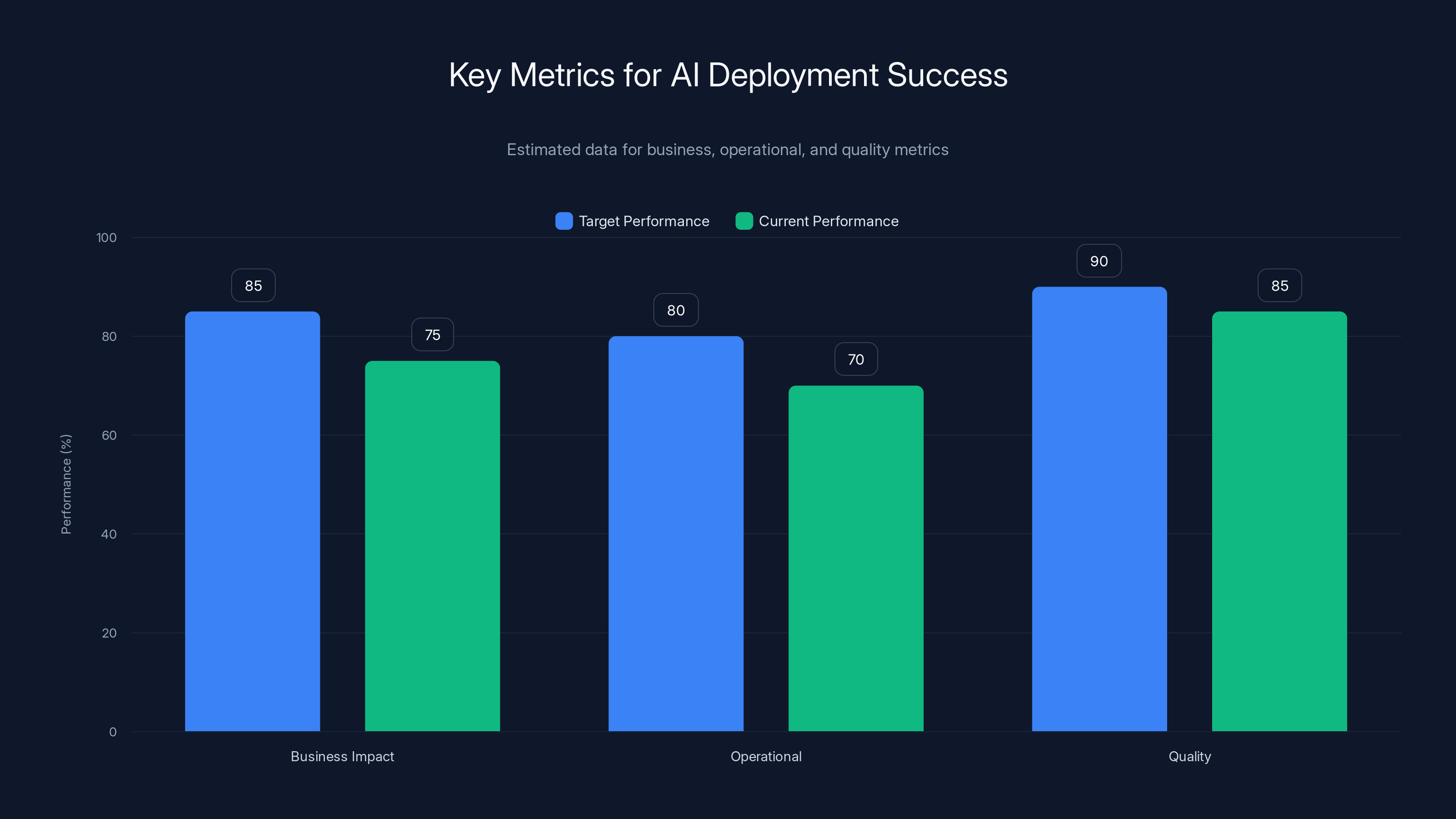
This chart compares target and current performance across business impact, operational, and quality metrics for AI deployment. Estimated data shows room for improvement in all areas.
Step 2: Design Repeatable Patterns and Templates
Imagine you've successfully deployed one AI agent. It's working. It's delivering value. Now what?
Most teams start building the next one from scratch. Same decisions, same architecture, same governance structures, same tests. This is where scaling falls apart. Every new project becomes a custom build. Every project takes longer. Every project introduces new risks because it hasn't been vetted.
The best organizations create templates. These are proven patterns for how AI agents should be structured, how they should interact with systems, how they should handle uncertainty, how they should escalate to humans, and how they should be monitored.
A good template includes:
Architecture pattern: How the agent connects to data sources, how it processes information, how it outputs decisions. Same structure every time.
Oversight pattern: How humans stay informed. Most successful patterns follow a "recommendation" model: AI recommends, human approves. Or "AI filters, human judges." The specific pattern depends on your risk tolerance, but consistency matters more than perfection.
Escalation logic: When does an issue go to a human? Define it clearly. "When confidence is below 75%." "When the transaction amount exceeds $50K." "When the situation matches these edge cases." This logic becomes part of the code, not a manual process.
Fallback behavior: What happens when the AI can't decide? Does it escalate to a human? Does it apply a conservative default? Does it route through a different process? Define this before deployment.
Testing pattern: What tests must every agent pass before it goes live? Accuracy thresholds? Edge case coverage? Performance benchmarks? Having a standard set means every agent gets the same rigor.
Once you have templates, onboarding new use cases becomes faster and more consistent. A new project doesn't start with a blank page. It starts with a proven pattern. The team can focus on business logic instead of reinventing infrastructure.
Here's a concrete example: financial services. A bank might create a template for AI agents that handle customer decisions. The template includes: authentication, data validation, decision logic, approval workflow, audit logging, and escalation paths. Every new agent (claims assessment, credit decisions, fraud detection, customer service routing) uses this same template. Changes to compliance requirements can be made once in the template, not in fifty different projects.
This approach also creates organizational muscle memory. People understand how AI agents work in their company. They trust them because they're built consistently. They know what to expect.
Step 3: Embed Governance Into Workflows, Not Around Them
This is the difference between organizations that scale AI responsibly and organizations that create AI disasters.
Most teams approach governance like this: we'll build the AI system, and then we'll add compliance checks around it. We'll add monitoring. We'll add approval workflows. We'll add audit logging.
This creates friction. The AI is fast. The governance is slow. Something has to give, and it's usually governance. People start finding workarounds. Approval workflows get bypassed. Monitoring gets ignored because it slows down operations.
The right approach: governance is part of the process design itself. Not an addition. Part of the core logic.
How? Think about the workflow, not the technology.
Example: fraud detection in payment processing. The workflow is:
- Payment request arrives
- AI evaluates risk
- System applies governance
- Decision gets made
- Transaction completes or escalates
Governance isn't a separate step. It's embedded in steps 3 and 4. The AI doesn't just output a decision. It outputs a decision WITH a confidence score. The governance logic says: "If confidence is above 95% and amount is below $5K, approve automatically. If confidence is 80-95%, hold for review. If confidence is below 80%, escalate to a human analyst." This logic is part of the workflow. It's not optional. It's not a separate approval process. It's how decisions get made.
Another example: customer service. The workflow is:
- Customer question arrives
- AI classifies the question
- AI generates a potential response
- System applies governance
- Response gets delivered or escalated
The governance logic: "If this is a standard question (confidence >90%), deliver the response automatically with a 'Was this helpful?' feedback button. If it's less certain or involves sensitive topics, let a human review before sending. If it's completely outside the AI's training, escalate to a specialist." Again, this is baked into the workflow.
Why does this matter? Because when governance is part of the process, it doesn't slow things down. It clarifies how decisions are made. It creates accountability. It allows safe scaling.
For highly regulated sectors like financial services, healthcare, or insurance, this is critical. Regulators don't want to see AI making decisions in a black box. They want to see clear decision logic, human oversight, and audit trails. When governance is part of the workflow, you have all of that.
The practical implementation:
- Confidence scoring: Every decision gets a confidence score. This isn't optional.
- Escalation rules: Define clear thresholds for when humans get involved. Make these rules explicit.
- Audit logging: Every decision gets logged with reasoning. This is part of the code, not a manual process.
- Feedback loops: Humans reviewing escalated decisions need to feed that information back to improve the AI. This closes the loop.
- Ethical checks: Certain decisions require additional scrutiny. Build that into the logic.
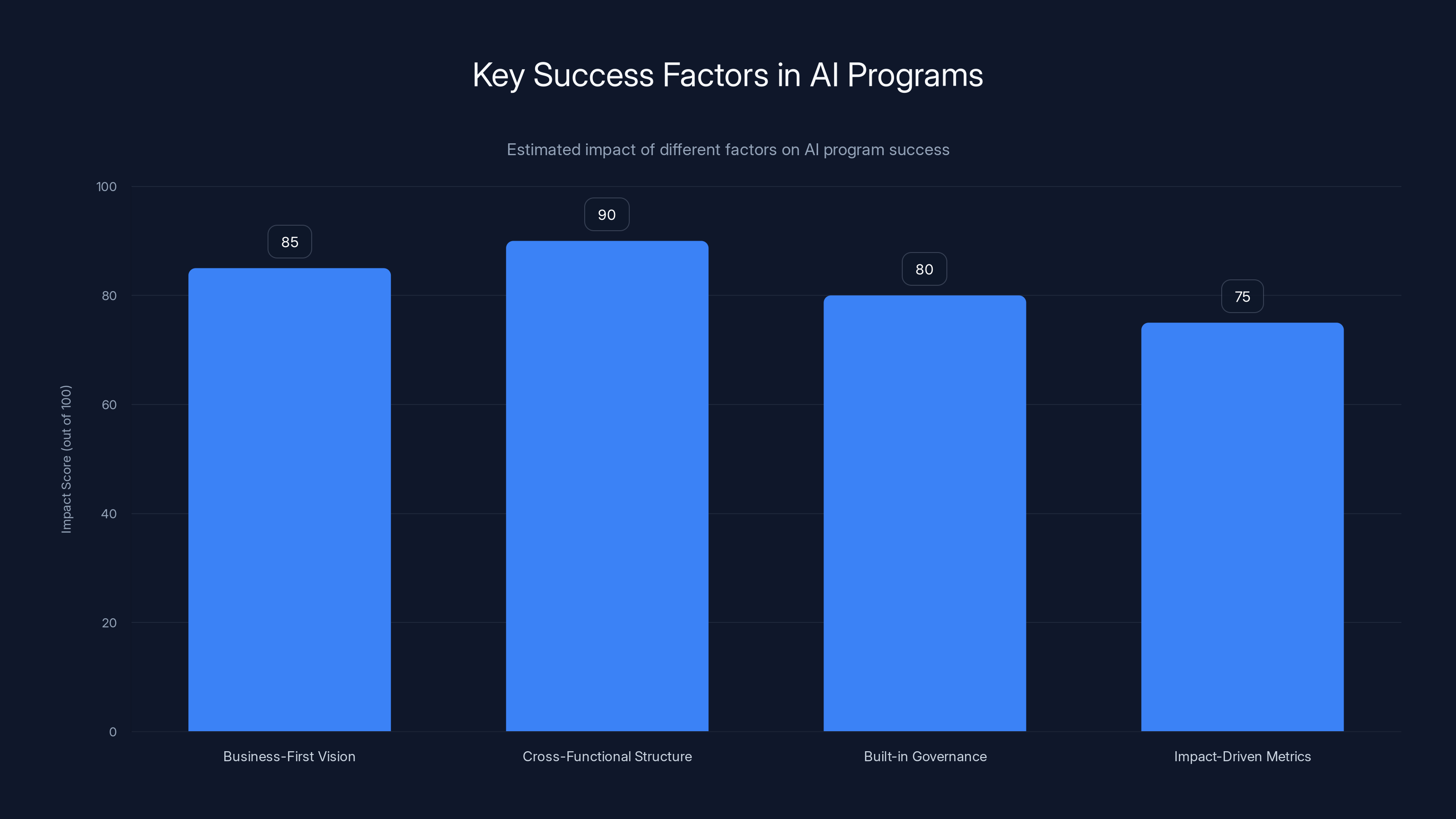
Successful AI programs often have a business-first vision, cross-functional structures, built-in governance, and metrics focused on business impact. Estimated data based on common patterns.
Step 4: Define the Right Metrics and Monitor Obsessively
Here's a question: how do you know if your AI deployment is actually working?
Most teams measure model accuracy. They celebrate an 89% accuracy rate. But does 89% accuracy translate to business value? Only if you defined what value means in the first place.
The right metrics track three things:
Business impact metrics: Cost saved per transaction. Time freed up per customer interaction. Customer satisfaction improvement. Revenue impact. These are the numbers that matter to leadership and customers.
Operational metrics: How many decisions is the AI making? How many decisions require human escalation? What's the average time from decision to outcome? What's the error rate on decisions that go live? These tell you if the system is actually working at operational scale.
Quality metrics: What percentage of automatically approved decisions are correct? What percentage of human-reviewed escalations result in overriding the AI recommendation? What's the performance on edge cases? These tell you if the AI is degrading over time.
Let's make this concrete. Say you deploy an AI system for accounts payable. The business wanted to reduce payment processing time from 3 days to 1 day and free up accounting staff for strategic work.
Your metrics should track:
-
Business impact: Average days from invoice receipt to payment (target: 1 day). Percentage of invoices processed without human intervention (target: 85%). Accounting staff time allocated to strategic projects (target: 60% of time). Cost per transaction (target:
2.50). -
Operations: Invoices processed per day. Escalation rate (% requiring human review). Time from escalation to resolution. System uptime and response time.
-
Quality: Accuracy on invoices processed automatically. Agreement rate when humans review escalated decisions. Performance on unusual invoice types. Fraud detection rate if that's in scope.
Now here's the critical part: you need to actually monitor these metrics continuously. Not quarterly. Not when someone asks. Continuously.
Why? Because AI systems degrade. The data distribution shifts. The business processes change. Edge cases emerge. Customer behavior evolves. If you're not actively monitoring, you won't notice until the problem is serious.
Implement a monitoring stack:
- Real-time dashboards: Key metrics visible every day. Set up alerts for anomalies.
- Weekly reviews: Look at trends. Is accuracy stable or drifting? Are escalation rates increasing? Are cycle times still improving?
- Monthly deep dives: Analyze specific failure cases. Why did the AI miss that one? What pattern should it have caught?
- Quarterly business reviews: How are we doing against original goals? What's changed in the business that we need to adapt to?
The teams that do this well often find they can improve performance 15-30% in the first year just by refining based on operational data. They also catch problems early instead of discovering them when customers start complaining.
Step 5: Commit to Continuous Improvement and Evolution
This is where most AI deployments become legacy systems.
After months of development, testing, and careful optimization, the AI system gets deployed. The team celebrates. Then everyone moves on to the next project. The AI system sits there, processing transactions, making decisions, running happily. But the business changes. Customer expectations evolve. New competitor behaviors emerge. Edge cases appear that weren't in the training data.
Six months later, the system is still working. Performance metrics look fine. But they're not as good as they used to be. Nobody notices immediately because degradation is gradual. But if you compare day one to day 180, performance is down 12%. Confidence is lower. Escalation rates are creeping up. The system is silently failing.
The organizations that prevent this treat AI as a living system. They invest in continuous improvement.
What does this look like in practice?
Monthly prompt refinement: For large language models, the prompts matter enormously. As you learn how the system behaves in production, you can write better prompts. One organization we've seen improved accuracy from 78% to 91% just by refining prompts based on production data. No model retraining. Just better prompts.
Quarterly retraining: Gather new data from production. Retrain with it. Test the new model. Deploy if it's better. This keeps the model aligned with how the business has evolved.
Constant edge case discovery: Every escalation is a data point. If humans are escalating a pattern of decisions, that's a signal that the AI needs to improve in that area. Document these patterns. Use them to improve the model.
Regular failover testing: What happens when the AI is unavailable? Can the process continue manually? Is the fallback process reasonable? Test this regularly.
Customer feedback loops: Is the AI making decisions that customers hate? Are they approving things customers expected to be rejected? Set up mechanisms to understand how customers perceive the decisions. Use that feedback.
Competitor monitoring: If competitors are using AI in similar ways, how is their approach different? Can you learn from what they're doing? Are there new AI techniques that have emerged since you built your system?
Here's a practical framework for this:
Week 1-2 of each month: Review operational data. Are there patterns in escalations? Did accuracy drop? Are there new edge cases?
Week 3: Implement improvements. This might be prompt changes, configuration updates, or simple logic improvements.
Week 4: Test changes. Make sure they don't break anything.
Monthly retrospective: What did we learn? What should we prioritize for next month?
Quarterly deep dive: Is the system still meeting business objectives? What's changed that we need to adapt to? Should we retrain the model?
The organizations that do this report that their AI systems improve by 5-15% every quarter. Not because the technology improves, but because they're actively optimizing based on production data.
The investment required is modest. You're usually talking about one person spending 20-30% of their time on continuous improvement. The payoff is enormous. You get compounding improvements. You catch problems early. You keep the system relevant as the business changes.
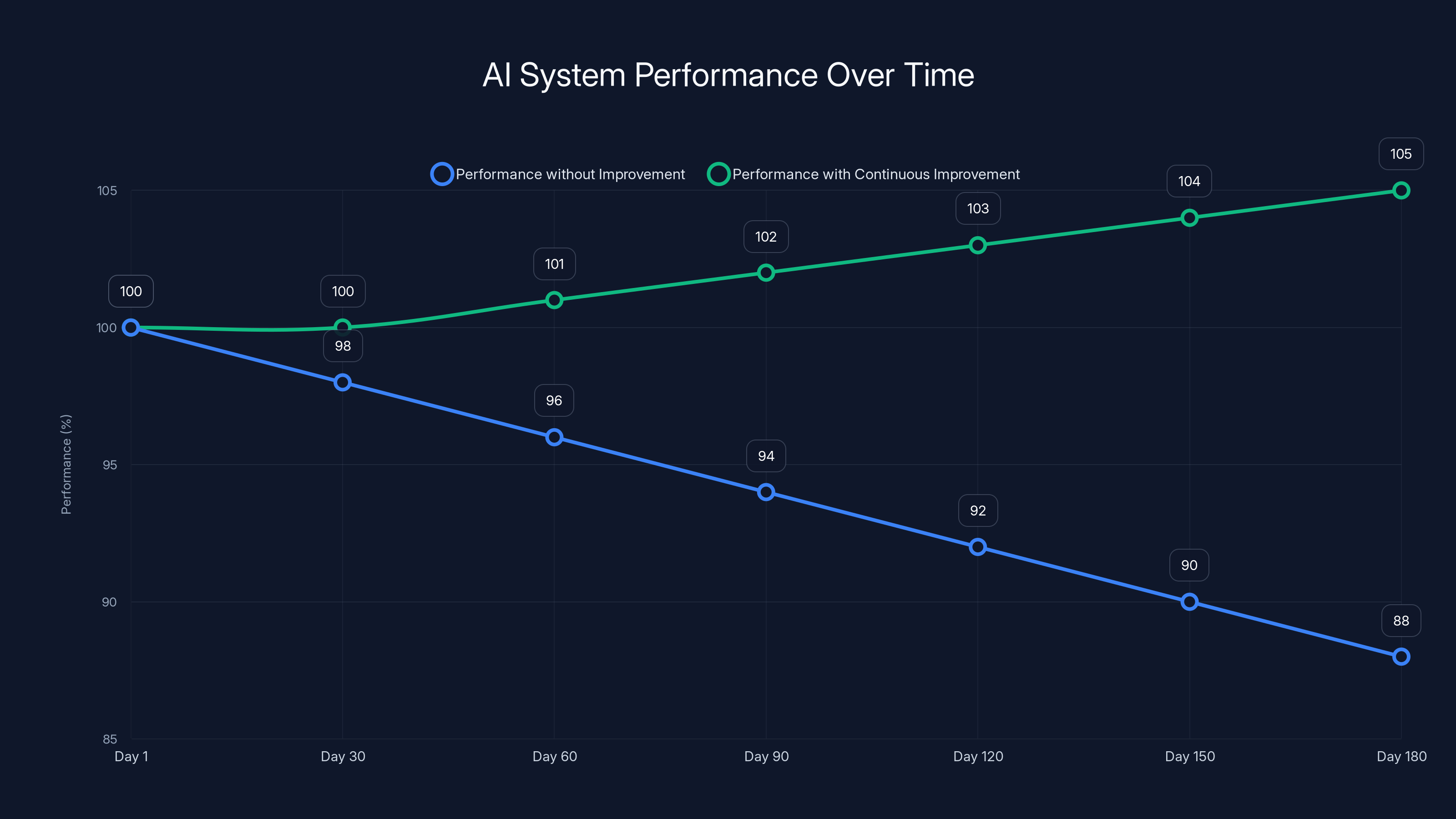
Without continuous improvement, AI system performance can degrade by 12% over six months. Implementing strategies like prompt refinement and retraining can enhance performance by 5% over the same period. Estimated data.
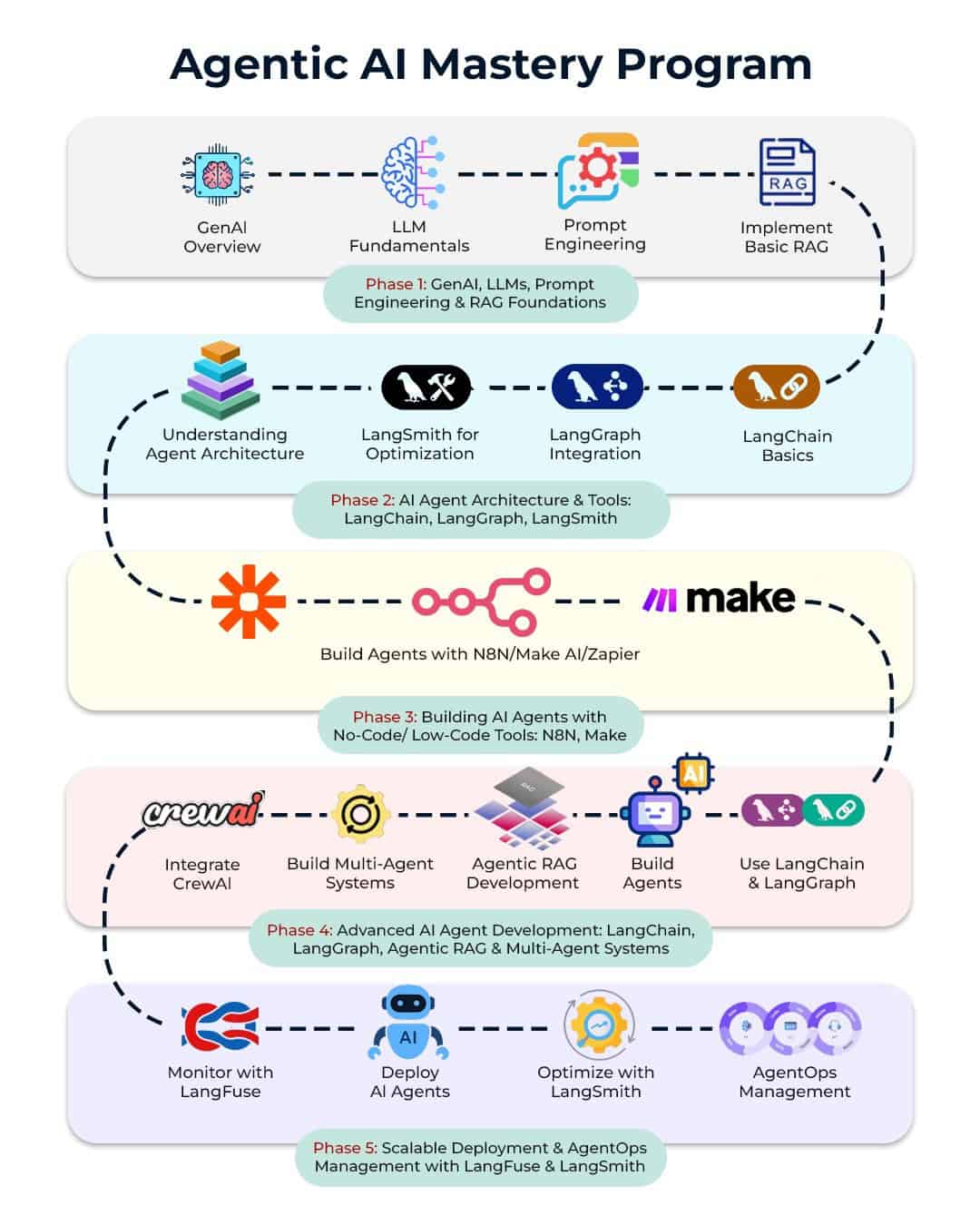
Building a Center of Excellence for AI at Scale
Once you've proven AI works in one area, the question becomes: how do we scale this across the organization without losing consistency, quality, or governance?
The answer is a center of excellence. This is a structure that most successful organizations eventually create, either formally or informally.
A center of excellence typically includes:
Leadership layer: Executive sponsor with authority to set standards and allocate resources. This person answers questions like, "Should we use this AI vendor or build in-house?" and "Should this project be approved?" Without authority, standards get bypassed.
Architecture and standards team: These folks define how AI agents should be built, how they should connect to systems, what governance they need, how they should be tested. They're creating the templates we discussed earlier.
Delivery teams: Cross-functional teams with data scientists, engineers, business leads, and operators. They're responsible for specific implementations.
Governance and risk team: Compliance experts, risk managers, and auditors who understand regulatory requirements and help design appropriate controls.
Knowledge sharing: Regular meetings where teams share what's working, what's not, and what they've learned.
Why does this matter? Because without this structure, every team is solving the same problems independently. Team A spends 3 months figuring out how to properly escalate decisions. Then Team B reinvents the same thing. Team C does it differently and creates inconsistency. You waste resources and create problems.
With a center of excellence, you solve each problem once. You share solutions. You move faster. You have consistent governance and quality across all AI initiatives.
The structure doesn't have to be formal. Some organizations call it a task force. Some call it a working group. The important thing is that it exists, meets regularly, has authority to set standards, and actively helps teams implement those standards.
Organizational Change and Getting Buy-In
Here's something that surprises people: the biggest barrier to successful AI deployments isn't technical. It's organizational.
People are comfortable with how work happens today. They know the processes. They know who to talk to when something breaks. AI changes that. The job might look different. Decisions might get made differently. Trust might feel like it's gone because a system is making decisions instead of a person.
Getting people on board requires:
Transparency about what's changing and why: Don't surprise people. Tell them about the changes before they happen. Explain why the change is happening. "We're deploying this to free you up from repetitive work so you can focus on complex customer issues." Not: "We're automating your job." Frame matters.
Involving people in design: The people doing the work today are experts in the work. Ask them where AI would actually help. Ask them what they're worried about. Incorporate their feedback into the design. This creates ownership instead of resistance.
Starting small: Don't deploy AI across 10 departments simultaneously. Start with one. Build confidence. Let success spread to other departments.
Clear escalation paths: People need to know that if something goes wrong, they can get help. Make sure there are clear escalation processes. Make sure they're actually used.
Retraining and reskilling: Some jobs will change. Be upfront about that. Help people understand what the new job looks like. Retrain them if needed. Some people will become AI oversight specialists. Some will focus on edge cases. Some will move to different departments. Help them navigate that.
Celebrating early wins: When the AI system delivers value, make it visible. Show how much time was freed up. Show cost savings. Show quality improvements. This builds confidence.
The organizations that handle this well report much higher adoption rates and faster time to value. The organizations that don't handle it well see resistance, workarounds, and eventually abandoned projects.
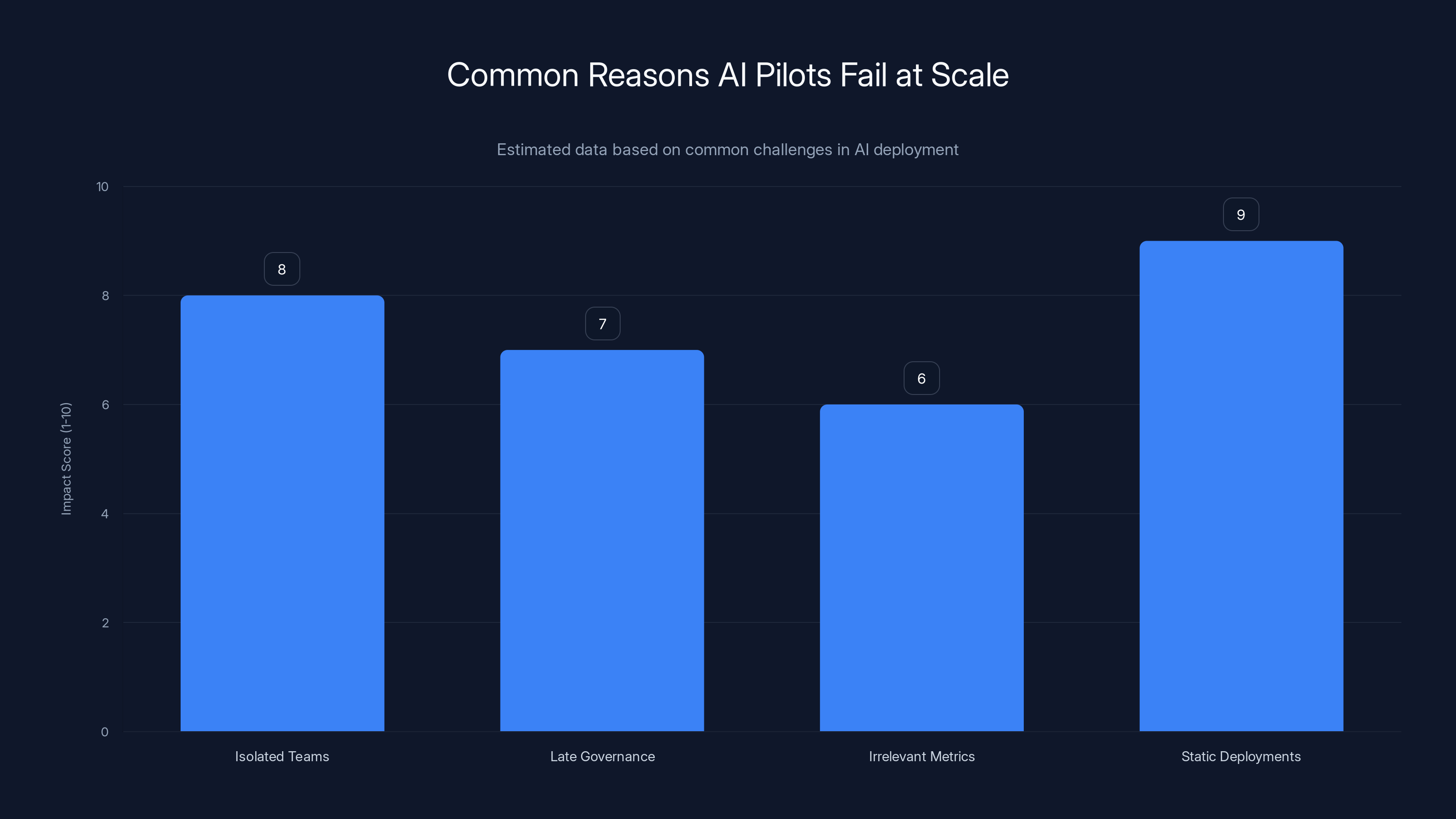
AI pilots often fail at scale due to isolated teams, late governance, irrelevant metrics, and static deployments. Estimated data reflects common impact scores of these challenges.
Risk Management and What Can Go Wrong
Let's talk about the things that keep CIOs awake at night.
Data quality issues: Garbage in, garbage out. If your training data is biased, incomplete, or outdated, the AI will reflect those problems. Spend time understanding your data before building AI on top of it.
Regulatory compliance: Depending on your industry, AI decisions might be heavily regulated. Financial services, healthcare, insurance, employment all have specific regulations about decision-making. Make sure you understand what applies to you before you deploy.
Model drift: As we discussed, models degrade over time. The data distribution changes. Performance drops. You need monitoring to catch this.
Security vulnerabilities: AI systems can be attacked. Adversarial examples can fool models. Training data can be compromised. Think about security from the beginning.
Explainability: Some decisions need to be explainable. "Why did you deny my loan application?" If you can't answer that question clearly, regulators will have a problem. Build explainability into your system design.
Bias and fairness: If your training data reflects historical biases, your AI will perpetuate those biases. Be intentional about testing for fairness. Some organizations have dedicated teams focused on this.
Over-reliance: Once AI starts making decisions, teams stop scrutinizing them. They trust the system too much. When the system makes a mistake, the impact is bigger because nobody was paying attention. Design for appropriate skepticism.
Vendor lock-in: If you build everything on one vendor's platform, you're locked in. Switching later becomes expensive and painful. Consider portability from the beginning.
The best organizations manage these risks by addressing them early. Not as afterthoughts. Not during a late-stage compliance review. During design.

Technology Stack Decisions
Eventually, you need to decide what tools to use. This is a practical decision that deserves clear thinking.
Build vs. buy vs. partner: Do you build AI capabilities in-house? Buy a solution from a vendor? Use an AI-as-a-service platform? Each has tradeoffs. In-house gives you control but requires expertise. Vendors give you a product but less flexibility. Platforms are fast but have constraints.
Model choices: Are you using large language models? Smaller specialized models? Ensemble approaches? Different approaches have different performance, cost, and complexity tradeoffs.
Infrastructure: Are you running on-premises? Cloud-based? Hybrid? This affects cost, security, latency, and scalability.
Integration points: How does the AI system connect to your existing systems? Are you building custom integrations? Using APIs? This affects complexity and maintenance burden.
Frank advice: don't get too caught up in the technology decision. The technology matters, but organizational factors matter more. A well-executed implementation using okay technology beats a poorly executed implementation using excellent technology every time.
Prioritize:
- Organizational readiness
- Process clarity
- Governance structure
- Skill availability
- Technology fit
In that order.
Measuring Success: Real Business Outcomes
Let's be specific about what success looks like. Not in theory. In practice.
A successful AI deployment has measurable outcomes:
Cost metrics: Cost per transaction reduced by X%. Total staff hours allocated to the process reduced by X%. Cost of errors reduced by X%.
Efficiency metrics: Cycle time reduced from X days to Y days. Volume processed increased by X%. Throughput per staff member increased by X%.
Quality metrics: Error rate reduced from X% to Y%. Customer satisfaction on this process improved from X to Y. Compliance violations dropped from X to Y.
Customer impact: Customer satisfaction score improved. Customer effort to resolve the issue reduced. Customer acquisition or retention improved.
Here's what success doesn't look like:
- High model accuracy with no business impact
- Impressive demos with poor operational reality
- Busy activity without measurable outcomes
- Technology implemented but not used
- Cost spent but value not delivered
When you measure success, track both leading indicators (things that predict success) and lagging indicators (actual outcomes).
Leading indicators might be: number of edge cases addressed, percentage of stakeholders trained, governance compliance rate, escalation resolution time.
Lagging indicators are the actual business metrics: cost saved, time freed up, quality improved, customer satisfaction increased.
Why Leadership Matters More Than Technology
Here's something that might surprise you: the most successful AI deployments are led by people focused on business outcomes, not people obsessed with AI technology.
This isn't anti-technology. It's pro-execution.
Leaders who understand the business know what matters. They can make decisions quickly. They can resolve conflicts between departments. They can explain to the organization why this matters. They can navigate the politics of change.
Leaders obsessed with technology often get sidetracked. They want to use the latest model. They want to add features that sound cool. They want to solve problems that don't actually exist. They get frustrated when people don't immediately adopt their brilliant system.
The best leaders:
Start with strategy, not technology: What business problems are we trying to solve? What would success look like? What needs to happen for this to matter? Only then, what technology makes sense?
Build organizational commitment: This isn't something the AI team does alone. This is an organizational shift. Leaders need to commit resources. Leaders need to model the behavior they expect. Leaders need to celebrate progress and address obstacles.
Prioritize simplicity over sophistication: Start with simple approaches. Get them working. Refine them. Often the difference between a successful deployment and a failed one is deciding to keep it simple instead of trying to build the perfect system.
Invest in people, not just technology: The technology is the easy part. Building organizational capability is hard. It takes investment in training, change management, governance structures, and time.
Stay focused on execution: Don't get distracted by what competitors are doing. Don't chase the latest AI trend. Stay focused on the specific outcomes you committed to. Deliver them. Then move to the next thing.
Common Pitfalls and How to Avoid Them
Let's look at patterns that consistently derail AI deployments.
Pitfall: Starting with technology instead of process: Teams get excited about an AI vendor and try to use it. Then they look for problems it can solve. This is backwards. Understand your problems first. Then find technology.
How to avoid: Start with process mapping. Understand your business deeply. Only then evaluate technology.
Pitfall: Under-investing in data preparation: People assume their data is clean and ready for AI. It's not. Bad data in. Bad results out. Then they blame the AI.
How to avoid: Budget 40-60% of your time on data preparation. Seriously. Quality data is more important than sophisticated models.
Pitfall: Skipping change management: Technical deployment is the easy part. Getting people to actually use the system and trust it is hard. Teams often skip this because it's not sexy.
How to avoid: Plan change management from day one. Involve frontline people. Address their concerns. Give them time to adjust.
Pitfall: Deploying without sufficient governance: Teams want to move fast and break things. That works for software features. It doesn't work for AI making business-critical decisions. You need governance from the start.
How to avoid: Build governance into the process design. Make it part of how work gets done, not a compliance burden.
Pitfall: Not monitoring performance: Systems degrade. Drift happens. If you're not watching, problems surprise you when they become serious.
How to avoid: Set up monitoring on day one. Make it automatic. Alert on anomalies.
Pitfall: Expecting immediate ROI: AI deployments take time. You're changing how work happens. People need to learn. Systems need to be refined. If you expect payback in 30 days, you'll kill the project when results take 90 days.
How to avoid: Plan for a 6-9 month timeline to full value. Celebrate small wins along the way. Be patient with the process.
Looking Forward: AI Evolution in Enterprise
The AI landscape is evolving rapidly. What's true today might shift next year.
We're seeing several trends:
Specialized models replacing general models: The large general-purpose models are useful for some things, but the trend is toward specialized models for specific domains. Financial services models. Healthcare models. Insurance models. These are trained on relevant data and understand domain-specific nuances.
Agentic AI becoming more sophisticated: We're moving beyond single-step AI decisions to multi-step workflows where AI coordinates multiple decisions and takes actions across systems. This requires better governance and orchestration.
Better tools for observability and control: As AI becomes more critical, we're getting better tools for monitoring, understanding, and controlling AI behavior. This matters for safety and compliance.
Regulatory frameworks solidifying: We're seeing clearer regulations around AI decision-making, especially in regulated industries. Organizations need to design for compliance from the start.
Focus on business value: The hype around AI is decreasing. The focus on actual measurable business value is increasing. This is healthy. It means organizations will invest based on realistic ROI, not excitement.
If you're planning AI deployments, keep these trends in mind. Build for the future. Use today's tools but assume they'll evolve. Invest in flexibility and learning capability.
The Reality of AI in Enterprise: What Happens After the Hype
Here's honest talk: AI is powerful, but it's not magic.
AI excels at specific tasks. Recognizing patterns in data. Making decisions in narrowly defined scenarios. Automating high-volume, repetitive work. It struggles with novel situations, nuanced judgment, and work that requires deep human insight.
The organizations that win with AI are the ones that are realistic about what AI can and can't do. They use AI to amplify human capability, not replace it. They design for humans to stay in control. They treat AI as a tool in a broader workflow, not the entire solution.
They're also patient. They understand that organizational change takes time. That building trust takes time. That refining systems takes time.
They measure what matters. Not benchmarks. Not research papers. Actual business outcomes. Cost saved. Time freed. Quality improved. Customers happier.
They invest in the unsexy stuff that matters: process design, change management, governance, continuous monitoring, team development.
They treat AI as a journey, not a destination. The journey starts with pilots. It continues with scaling. It never really ends because the business keeps changing and AI keeps evolving.
If you approach AI with this mindset, your chances of success multiply significantly. You'll avoid the 40% of projects that get scrapped. You'll be in the group that actually delivers business value. You'll build organizational capability that compounds over time.
That's not flashy. It's not exciting. But it's how you move from AI pilots to real, sustained business value.
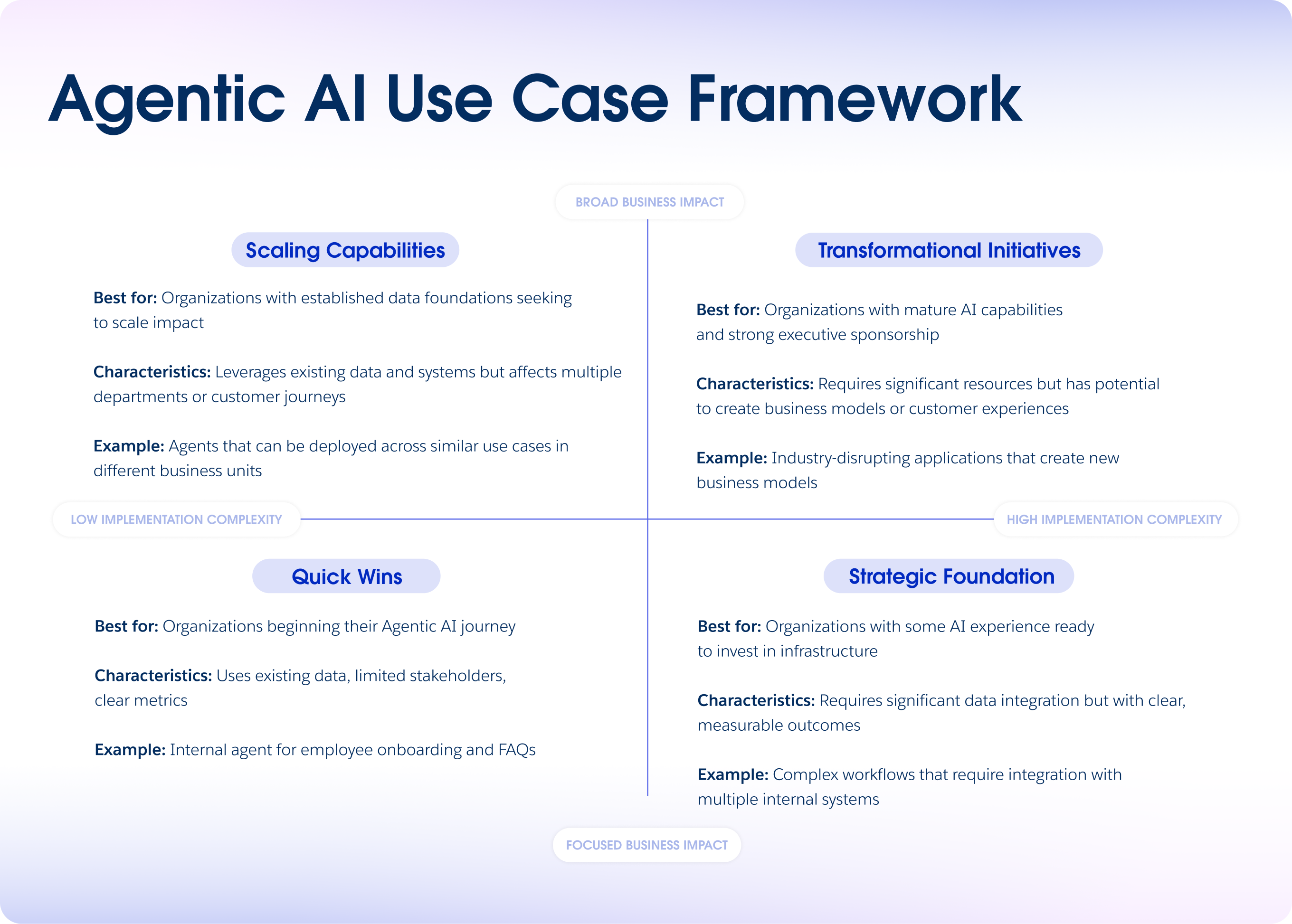
Key Takeaways for Your Organization
Let's distill this to the essentials.
Business outcomes come first: Define what success looks like before you build anything. Make sure everyone agrees on the target. Measure progress against it.
Process understanding precedes technology: You can't make good decisions about where AI fits if you don't understand your current processes deeply. Map them. Understand them. Optimize them if needed. Then add AI strategically.
Governance is part of the design, not a constraint: Build it in from day one. Make it part of how decisions get made. This allows safe scaling instead of creating friction.
Organizational structure matters as much as technology: Centers of excellence. Cross-functional teams. Clear ownership. Change management. All of this is as important as the AI models.
Continuous improvement is mandatory: Deploy once and monitor obsessively. Refine based on what you learn. Adapt as the business changes. Static deployments degrade.
Measure business impact, not just technical metrics: Accuracy scores are nice. Cost savings are better. Time freed up is better still. Focus on metrics that matter to business leaders and customers.
Start small, learn fast, scale deliberately: Don't boil the ocean with your first deployment. Prove the concept with one use case. Learn from it. Apply those lessons to the next one. Build from success.
Invest in people and culture: The technology is the easy part. Building an organization that can effectively deploy and manage AI is the hard part. That's where the investment belongs.
Use Case: Automating customer reports and data-driven documents with AI-powered templates that save your team 8-10 hours per week while maintaining consistency and quality.
Try Runable For Free
FAQ
What is agentic AI and how does it differ from traditional AI?
Agentic AI refers to artificial intelligence systems that can operate autonomously, making decisions and taking actions with minimal human intervention. Unlike traditional AI, which typically performs single tasks or outputs recommendations that require human approval, agentic AI can handle multi-step workflows, manage complex decision-making, and execute actions across multiple systems. Traditional AI might score a risk or classify a transaction. Agentic AI might assess risk, route decisions to appropriate teams, update systems, and monitor outcomes, all within a defined set of rules and guardrails. The key difference is autonomy within defined boundaries.
How long does it typically take to move from an AI pilot to full-scale deployment?
Most organizations find that moving from pilot to full-scale deployment takes 6-9 months, though this varies significantly based on process complexity, governance requirements, and organizational readiness. The timeline includes process mapping (4-6 weeks), design and governance setup (6-8 weeks), building and testing (8-12 weeks), change management and training (4-6 weeks), and phased rollout (4-8 weeks). Starting with an overly aggressive timeline often leads to skipped steps that cause problems later. It's better to move deliberately than to rush and have to rework fundamental elements. Organizations that try to do it in 8-10 weeks typically underinvest in governance and change management, creating problems during scaling.
What specific metrics should we track to measure AI deployment success?
Successful AI programs track three categories of metrics: business impact (cost per transaction, processing time, quality improvements), operational metrics (volume processed, escalation rates, system uptime), and quality metrics (accuracy on automated decisions, accuracy on edge cases, error rates on escalations). Rather than chasing high accuracy scores on your test set, focus on whether the system is actually delivering the business outcomes you committed to. If you said the AI would reduce payment processing time from 3 days to 1 day, that's what you should measure. If you said you'd free up 15 accounting staff members for strategic work, measure that. Business metrics matter more than technical metrics.
What's the biggest mistake organizations make when scaling AI?
The most common mistake is deploying without sufficient governance or treating governance as an afterthought. Teams build impressive AI systems, then struggle when they try to add compliance, escalation workflows, and approval processes around them. This creates friction and often leads to governance being bypassed. The solution is to embed governance into the process design from day one. Make it part of how decisions get made, not a separate approval layer. This actually speeds up deployment because governance happens naturally, not as a bottleneck.
How do we handle edge cases that the AI can't confidently make decisions about?
Edge cases are addressed through escalation logic built directly into the workflow. Define clear thresholds: if confidence is below 75%, escalate to a human. If the situation matches certain patterns that the AI struggles with, escalate. If the stakes are high (large dollar amount, sensitive customer), escalate. The key is making these rules explicit and part of the code, not manual decisions. This prevents the "gray area" problem where nobody knows when something should go to a human. Track escalations carefully because they're data points for improving the AI. If a pattern of similar decisions keeps getting escalated, that's a signal the AI needs to improve in that area.
What organizational structure works best for scaling AI across multiple departments?
A center of excellence is the most effective structure. This pulls together data scientists, engineers, business leads, compliance experts, and operators. The center establishes standards, creates templates, shares best practices, and helps individual departments implement AI successfully. It prevents every team from solving the same problems independently and ensures consistency across the organization. The center doesn't need to be large (often 5-8 people), but it needs authority to set standards and be directly involved in major implementations. Without this structure, you often see duplication, inconsistent approaches, and slower time to value across departments.
How do we get buy-in from frontline employees who might be worried about their jobs?
Transparency and involvement are critical. Explain what's changing and why. Explain how it affects their jobs. Be honest about it. If the AI will automate part of their current work, say that. Then explain what the new job looks like. Usually, it involves more complex judgment, better quality decisions, and more customer interaction. Involve them in the design process. Ask them where AI would actually help. Ask them what concerns them. Show them early and often. Start with volunteers who are curious. Let their positive experience spread to others. Celebrate when the AI frees them up to do work they actually find more valuable. Most resistance comes from surprise and misunderstanding. Transparency removes both.
What should we do if our AI system starts underperforming after deployment?
First, determine whether it's a problem with the model, the data, or the business context. Monitor performance metrics constantly, so you catch degradation early (within weeks, not months). If accuracy is dropping, it usually means the data distribution has shifted. You might need to retrain with new data. If confidence scores are unreliable, you might need to recalibrate the model. If the AI is being overridden frequently, it might be solving the wrong problem. Investigate the override patterns. Whatever the problem, use production data to improve. Every override and escalation is information. Use it. Most organizations find they can improve performance 15-30% in the first year just by actively monitoring and refining based on operational data.
How do we ensure our AI system doesn't perpetuate bias from historical data?
Start by understanding your historical data. Is it representative of all customer segments? Does it reflect biases from past decision-making? Document what you find. When you build the AI, actively test for fairness across demographic groups. Some organizations have dedicated teams that specifically look for bias. Don't just test overall accuracy. Test accuracy for each demographic group. If Asian customers have 87% approval rates and Black customers have 73%, that's a problem. During operation, monitor fairness metrics. If you see disparate impact, investigate why and fix it. This is regulatory requirement in many industries and ethical imperative in all of them. Building for fairness from day one is much easier than trying to fix bias after deployment.
The path from AI pilot to real business value isn't mysterious. It's methodical. It requires clear thinking about business outcomes. It requires rigorous process discipline. It requires investment in organizational capability, not just technology. It requires patience with how long change takes.
But when you execute it well, the results are remarkable. Cost structures shift. Employee productivity increases. Customer experiences improve. Competitive advantage compounds over time.
Start with business outcomes. Start with process understanding. Build governance in from day one. Measure what matters. Commit to continuous improvement. Scale deliberately.
That's how you move from impressive pilots to business value that actually matters.
Related Articles
- New York's AI Regulation Bills: What They Mean for Tech [2025]
- Larry Ellison's 1987 AI Warning: Why 'The Height of Nonsense' Still Matters [2025]
- Network Modernization for AI & Quantum Success [2025]
- Agentic AI and Unified Commerce in Ecommerce [2026]
- Claude's Constitution: Can AI Wisdom Save Humanity? [2025]
- Data Center Services in 2025: How Complexity Is Reshaping Infrastructure [2025]

