![Google Gemini 3.1 Pro: The AI Reasoning Breakthrough Reshaping Enterprise AI [2025]](https://tryrunable.com/blog/google-gemini-3-1-pro-the-ai-reasoning-breakthrough-reshapin/image-1-1771524689480.png)
Introduction: The AI Crown Changes Hands Again
The artificial intelligence race isn't just moving fast—it's accelerating exponentially. Every few months, another breakthrough emerges that forces enterprises to reconsider their AI strategy. Last year, Google launched Gemini 3 Pro and held the crown for approximately three weeks before OpenAI and Anthropic released competing models that reclaimed the title.
Now Google is back, and this time they're bringing something different. Instead of just iterating on speed or scale, Gemini 3.1 Pro focuses on reasoning capability that matters far more to serious developers and researchers.
We're talking about a model that can solve logic puzzles it's never encountered before. A model that understands 3D rotations well enough to fix long-standing bugs in animation pipelines. A model that can read atmospheric themes from 19th-century literature and translate them into functional web design.
But here's what makes this announcement different from the usual AI noise cycle. The performance gains aren't just marketing fluff. Third-party evaluations show Gemini 3.1 Pro has objectively leapt to the front of the pack. More importantly, Google isn't charging extra for these gains. The pricing remained identical to the previous version, meaning you're getting double the reasoning performance for the exact same cost.
That efficiency-to-price ratio matters in the real world. It means developers building autonomous agents, researchers running complex simulations, and enterprises automating knowledge work can suddenly do more with their existing budgets.
Let's break down what changed, why it matters, and whether this is actually the breakthrough moment everyone claims it is.
TL; DR
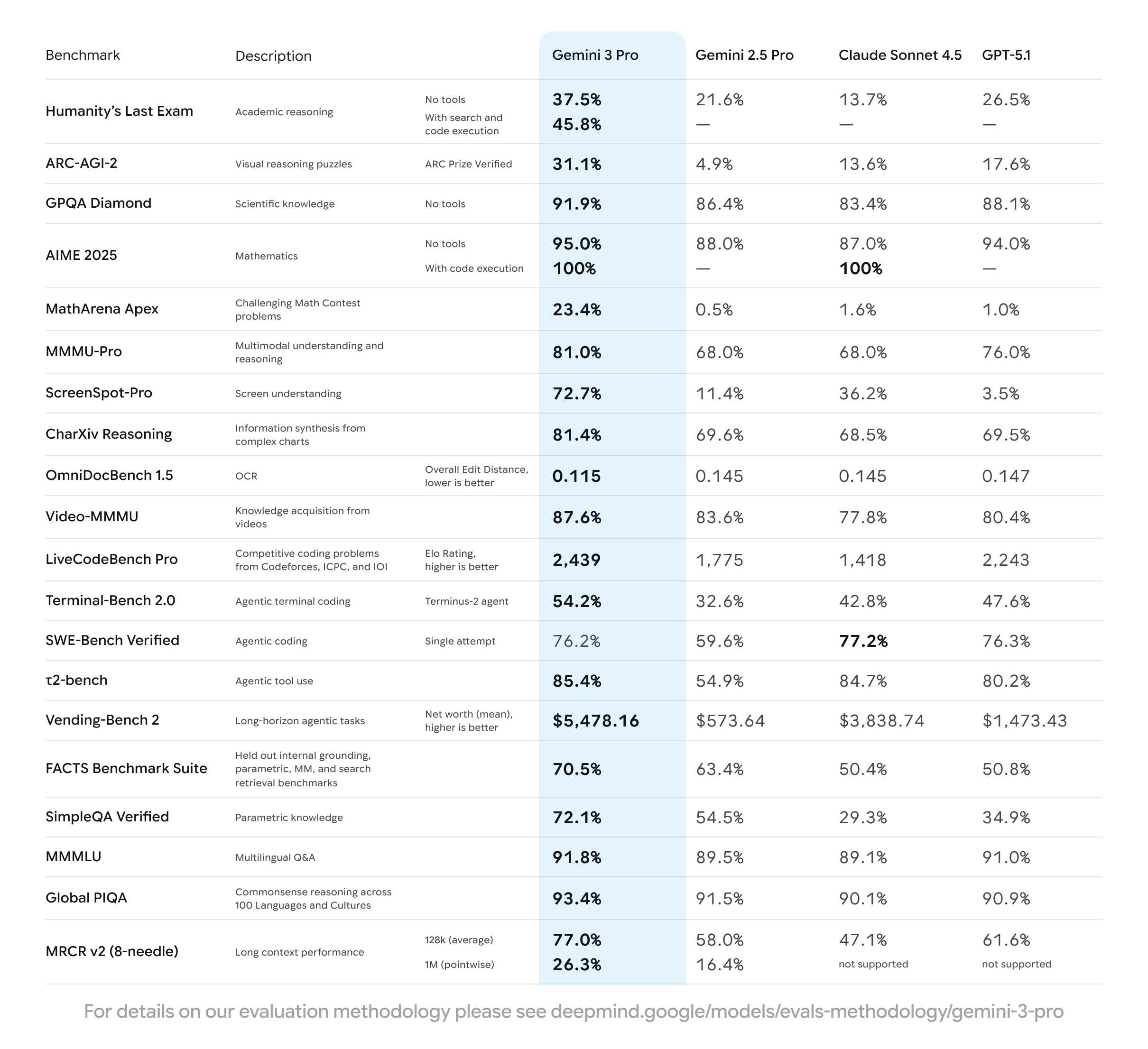
- Reasoning Performance Doubled: Gemini 3.1 Pro achieved 77.1% on ARC-AGI-2, more than double the previous Gemini 3 Pro's performance on abstract logic benchmarks.
- Same Price, Better Performance: Maintained $2.00 per 1M input tokens pricing despite significant capability improvements.
- Specialized Domain Excellence: Scores 94.3% on scientific knowledge (GPQA Diamond), 80.6% on coding benchmarks (SWE-Bench Verified), and 92.6% on multimodal understanding.
- Enterprise-Ready Applications: Enables autonomous agents, complex system synthesis, 3D design, and creative coding that require genuine reasoning.
- Third-Party Verification: Independent evaluations from Artificial Analysis confirm Gemini 3.1 Pro as the most powerful AI model currently available.

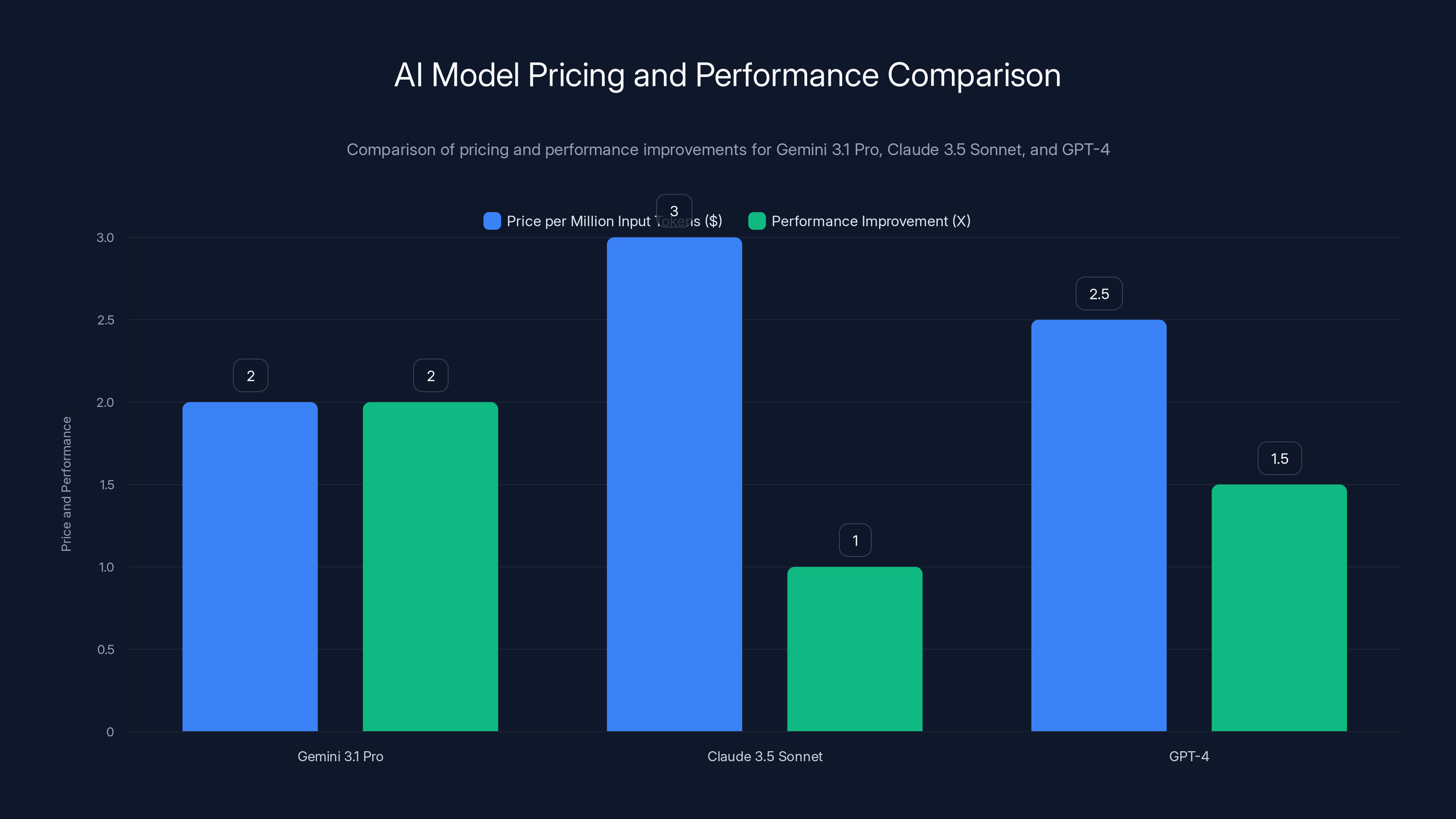
Gemini 3.1 Pro offers double the reasoning performance at a lower price compared to Claude 3.5 Sonnet and similar pricing to GPT-4, making it a cost-effective choice for enterprises.
The Reasoning Revolution: What Changed Under the Hood
When Google announced Gemini 3.1 Pro, the technical headline focused on one metric: performance on the ARC-AGI-2 benchmark. The model achieved 77.1% accuracy on this test, which measures a model's ability to solve novel logic patterns it has never encountered during training.
This isn't like improving your score on a benchmark you've seen examples of. ARC-AGI-2 forces the model to recognize completely new logical relationships, understand underlying patterns, and apply reasoning to unfamiliar problems. Getting this right requires something closer to actual thinking.
For context, the previous Gemini 3 Pro scored significantly lower on this same benchmark. The jump from the earlier version to 3.1 Pro represents a more-than-doubling of performance on abstract reasoning tasks. That's not incremental. That's a fundamental shift in what the model can do.
The improvement comes from how Google refined the model's handling of "thinking tokens." These are internal computational steps the model takes before generating output. Essentially, the model learned to allocate more of its reasoning capacity to working through hard problems step-by-step rather than trying to generate answers immediately.
This approach isn't entirely new in AI. OpenAI has explored similar techniques with their reasoning models. But Google's implementation appears to have reached a new level of efficiency. The model can now tackle long-horizon tasks (problems that require many sequential reasoning steps) with greater reliability.
What does this mean in practical terms? Imagine you're building an autonomous agent that needs to plan a complex workflow. With previous models, the agent might reason correctly through the first five steps but then get lost or backtrack. Gemini 3.1 Pro's improved reasoning maintains coherence through longer planning sequences.
The enhancement extends beyond abstract logic. Google's internal benchmarks show improvements across multiple reasoning domains. These improvements compound when you combine them. A model that reasons better about code also generates better code. A model that understands scientific concepts more deeply can answer more nuanced research questions.
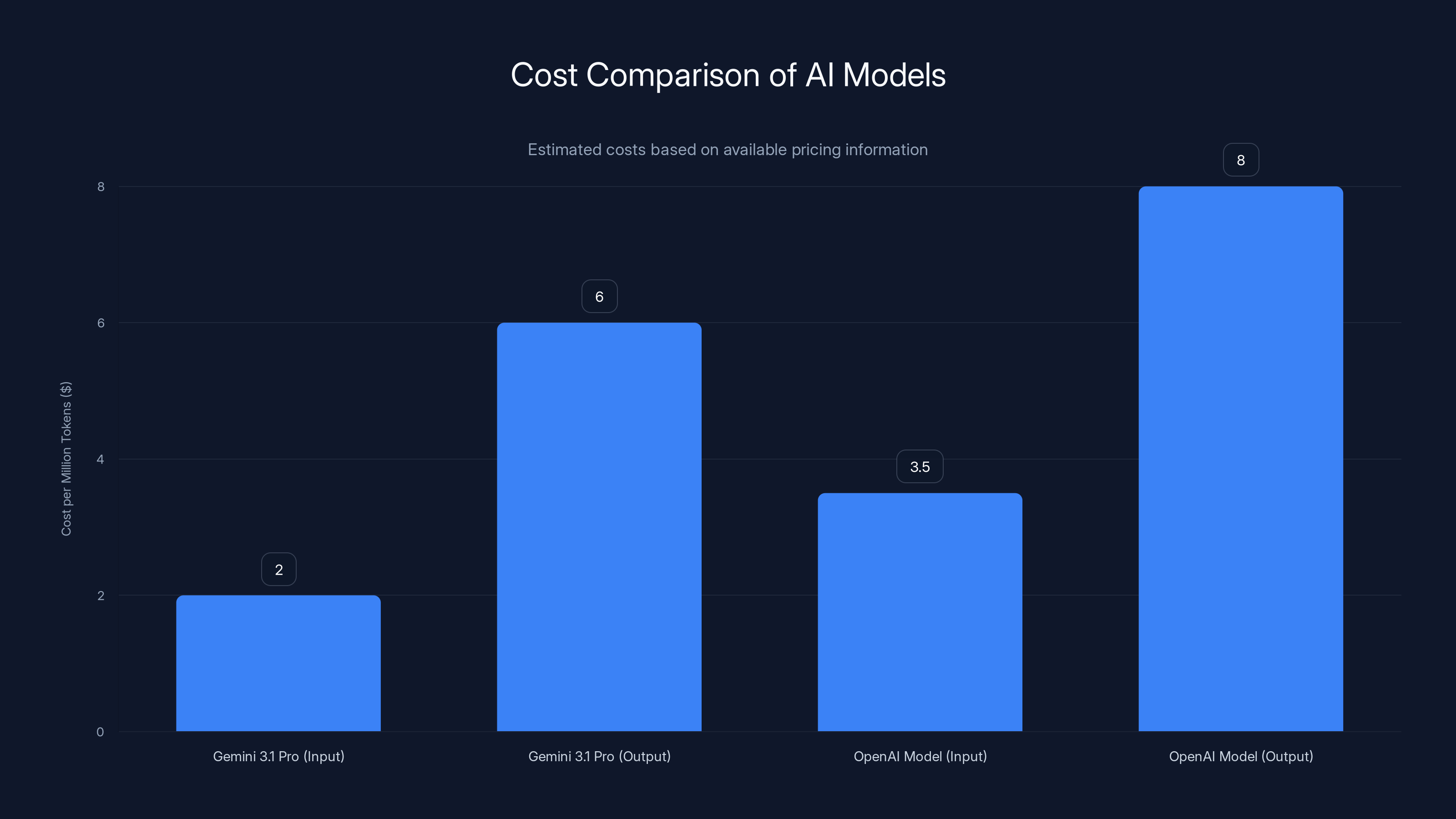
Gemini 3.1 Pro offers competitive pricing with
Specialized Capabilities: Where Gemini 3.1 Pro Dominates
Benchmarks can feel abstract until you see how they translate to real-world performance. Gemini 3.1 Pro doesn't just improve across the board—it dominates in specific domains that matter to different industries.
Scientific Knowledge and Reasoning
The GPQA Diamond benchmark tests graduate-level physics, chemistry, and biology knowledge. Think questions that require understanding quantum mechanics, molecular dynamics, or protein synthesis at a level that would require a Ph.D. to answer correctly.
Gemini 3.1 Pro achieved 94.3% accuracy on GPQA Diamond. This score places it alongside the very best language models for scientific reasoning. For researchers, this means the model can serve as a legitimate research assistant for literature synthesis, hypothesis evaluation, and problem-solving in scientific domains.
The practical application here is significant. Academic teams can use Gemini 3.1 Pro to explore literature, generate ideas for experiments, and validate reasoning about complex systems. Biotech companies can leverage it for hypothesis generation in drug discovery workflows. The model understands enough nuance to be genuinely useful rather than a source of confident-sounding but incorrect information.
Software Engineering and Code Generation
On the Live Code Bench Pro benchmark, which evaluates code generation across real-world programming tasks, Gemini 3.1 Pro reached an Elo rating of 2887. For context, Elo ratings in chess are familiar to many people—2800+ in chess indicates world-class mastery.
The model also scored 80.6% on SWE-Bench Verified, which measures the ability to solve real GitHub issues in actual codebases. This is a much tougher test than generating toy code snippets. It requires understanding existing code architecture, identifying bugs, and implementing fixes that don't break other functionality.
What this means: developers can use Gemini 3.1 Pro not just for writing new code from scratch, but for actually improving existing codebases. It can read through a codebase, understand the architecture, identify inefficiencies, and suggest legitimate improvements.
Multimodal Understanding
Multimodal means the model understands images and text together. MMMLU (Massive Multitask Multilingual Language Understanding with Multimodal components) at 92.6% indicates the model handles complex visual reasoning tasks accurately.
In practice, this opens doors for document analysis, diagram interpretation, screenshot analysis, and any task that requires visual context plus text understanding. Engineering teams can feed the model system architecture diagrams and ask clarifying questions. Product teams can analyze user interface screenshots and discuss design improvements.
From Benchmarks to Applications: Vibe Coding and Dynamic Synthesis
Google doesn't just release models and wait for developers to figure out applications. They demonstrated Gemini 3.1 Pro through a series of real-world use cases that showcase capabilities you couldn't accomplish with earlier models.
The most interesting of these is what they're calling "vibe coding." This isn't a new technical term—it's actually a pretty good description of what's happening. You describe the overall "feeling" or aesthetic you want, and the model generates code that captures that vibe.
How Vibe Coding Works in Practice
Traditional code generation works like this: you provide a technical specification ("create a form with three fields: name, email, and message"), and the model generates code that matches the spec. The result works, but it's often generic and uninspired.
Vibe coding flips this. You might say: "I want an interactive experience that feels like watching fireflies in a dark field. Users can click and drag to move around. Everything has soft glowing effects." The model understands the aesthetic intent and generates animated SVGs (Scalable Vector Graphics) that match that description.
Why SVG instead of video or traditional animation? Because SVGs are code-based rather than pixel-based. They remain crisp at any resolution, the file sizes are tiny (kilobytes instead of megabytes), and they're interactive and dynamic.
The practical benefit: you can create highly polished, professional animations for websites and presentations without hiring a specialized animator or spending weeks in animation software. For enterprise applications, this means your dashboards and interface elements can have sophisticated visual polish that previously required specialized design skills.
Complex System Synthesis
Google demonstrated the model successfully configuring a live telemetry stream and building a real-time International Space Station orbit visualization. The model had to understand how to fetch data from an external API, process that data, and render it in a way that clearly communicates ISS position and trajectory.
This isn't a simple code-generation task. It requires understanding data structures, API documentation, visualization best practices, and spatial reasoning about orbital mechanics. The model needed to connect multiple systems together coherently.
For enterprises, this capability matters because it enables rapid prototyping of complex data visualizations without deep technical expertise. Your product team can describe what they want to visualize, and the model can generate the end-to-end integration.
Interactive 3D Design and Hand Tracking
One particularly impressive demonstration showed the model generating a 3D starling murmuration (the coordinated movement of large flocks of birds) that users can manipulate via hand-tracking gestures. The model also generated a generative audio score that accompanies the visual.
What's remarkable here isn't just that it created 3D code. It's that it understood how to coordinate visual and audio elements to create a coherent aesthetic experience. The audio generation was generative (meaning it continuously creates new audio based on parameters), not pre-recorded.
This opens possibilities for immersive applications that combine 3D, interaction, and dynamic audio—capabilities that were previously in the domain of specialized game engines and audio software.
Creative Interpretation and Style Translation
Perhaps the most intellectually interesting demonstration was the model's ability to read Emily Brontë's "Wuthering Heights," identify its atmospheric themes (Gothic, dark, brooding, passionate, tumultuous), and translate those themes into a modern web design.
The model didn't just make dark colors and big fonts. It understood the narrative structure, emotional arc, and thematic elements of the novel, then expressed those themes through interface design principles. This requires genuine semantic understanding, not just pattern matching.
For design teams, this suggests you could use Gemini 3.1 Pro to generate style guides, visual systems, and design direction based on brand narrative or emotional intent rather than just functional requirements.

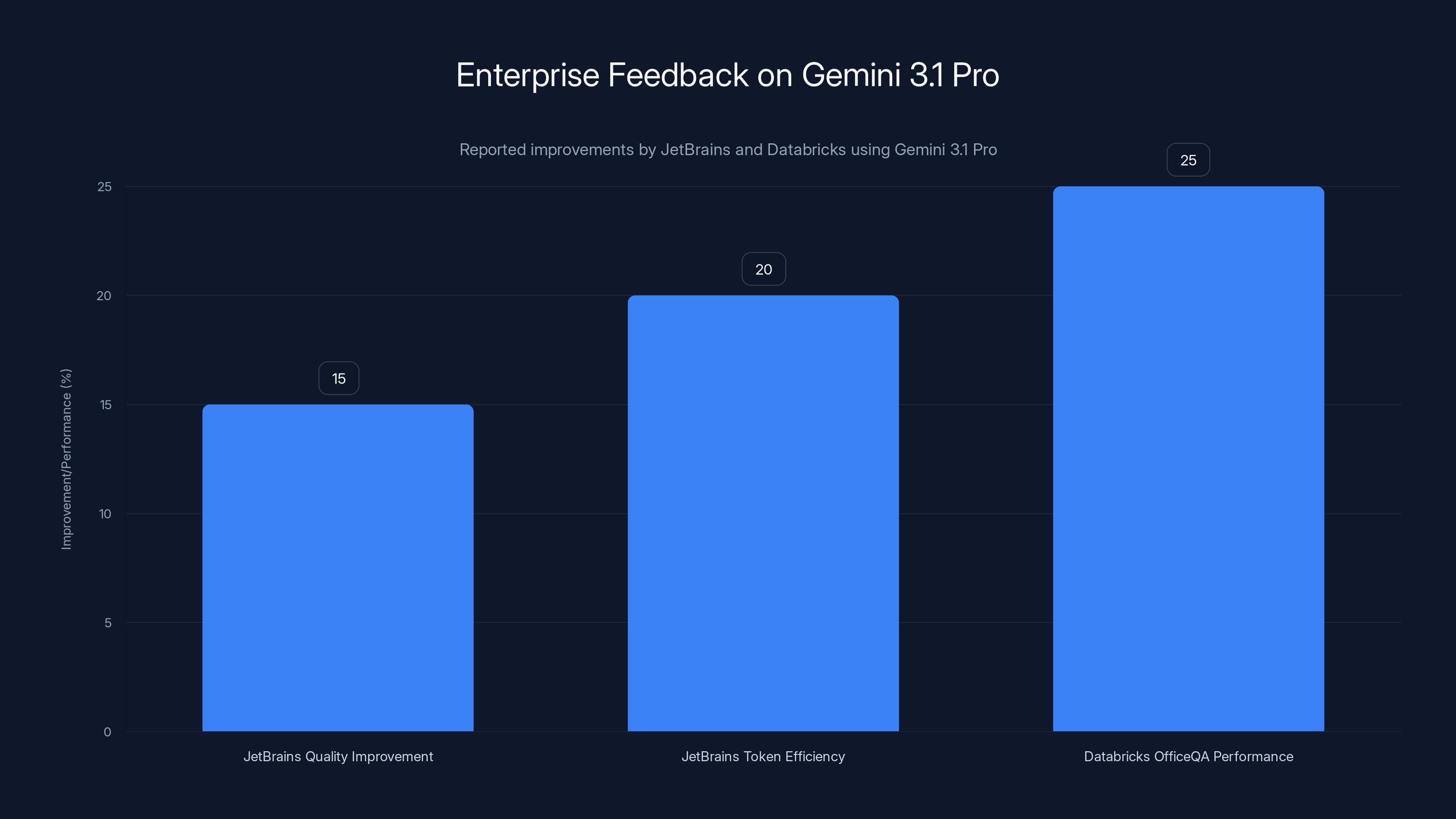
JetBrains reported a 15% improvement in code quality and a 20% reduction in token use, while Databricks highlighted a 25% performance boost on OfficeQA. Estimated data for token efficiency and OfficeQA performance.
Enterprise Adoption: Real Feedback from Industry Leaders
Benchmark scores tell one story. Real-world deployment tells another. Google shared feedback from enterprise partners already using the Gemini 3.1 Pro preview, and their observations reveal what actually matters in production environments.
JetBrains: 15% Quality Improvement with Lower Token Consumption
JetBrains, the company behind IntelliJ IDEA and other developer tools, reported a 15% quality improvement in code generation and understanding tasks. More importantly for their business model, the model required fewer output tokens to accomplish the same tasks.
What does "fewer output tokens" mean? If your pricing model charges per token (and most API models do), then lower token consumption directly translates to cost savings. You're getting better results while spending less.
For JetBrains, this matters because they're integrating AI capabilities into their IDEs. Every API call costs them money. If Gemini 3.1 Pro delivers better results with fewer tokens, they can pass those savings to their users or improve their margins.
The 15% quality improvement for code generation is significant. It means the code produced is more likely to work correctly, requires fewer iterations, and has fewer bugs or performance issues that need fixing later.
Databricks: Grounded Reasoning on Structured and Unstructured Data
Databricks reported that Gemini 3.1 Pro achieved "best-in-class results" on OfficeQA, a benchmark that tests reasoning over both tabular (spreadsheet-like) and unstructured (text-like) data.
Why does this matter? Most enterprises don't have perfectly structured databases. They have spreadsheets, email inboxes, documents, and various semi-structured data sources. Being able to reason over mixed-format data is genuinely useful. You can ask the model to find specific information in a spreadsheet, understand context from related documents, and synthesize answers based on both.
For Databricks' customers (data engineers and analysts), this capability means Gemini 3.1 Pro could serve as an intelligent assistant that understands your actual data landscape, not just hypothetical data structures.
Cartwheel: Solving 3D Rotation Bugs
Cartwheel, a platform for 3D animation and design, highlighted the model's substantially improved understanding of 3D transformations. Specifically, they mentioned it resolved long-standing bugs in rotation order—a notoriously tricky problem in 3D graphics.
Why is rotation order complicated? In 3D graphics, the order in which you apply rotations around different axes (X, Y, Z) matters significantly. Apply them in the wrong order and your object rotates incorrectly. This is called "gimbal lock" and has plagued 3D graphics programmers for decades.
That Gemini 3.1 Pro understands this deeply enough to identify and fix rotation order bugs suggests genuine 3D geometric reasoning, not just pattern matching on training data. This is the kind of specialized knowledge that typically requires experienced engineers.
For 3D animation and CAD software companies, this means Gemini 3.1 Pro could assist in debugging complex geometric transformations, generating animation code, and understanding spatial relationships.
Hostinger Horizons: Understanding Intent and Generating Style-Accurate Code
Hostinger Horizons (Hostinger's AI product line) noted that the model understands the "vibe" behind a prompt, translating aesthetic intent into style-accurate code.
For non-developers and small business owners, this is huge. You don't need to know CSS or JavaScript to describe what you want: "I want something that feels modern and minimalist, with a lot of white space and smooth interactions." The model understands that intent and generates code that matches.
This democratizes web design. You no longer need deep technical skills or expensive designers to create polished-looking websites and interfaces.

The Pricing Advantage: Same Price, Doubled Performance
This is where Gemini 3.1 Pro's positioning becomes strategically important. When the previous Gemini 3 Pro launched, Google positioned it in the mid-to-high price tier at $2.00 per million input tokens. This was already competitive, but not the cheapest option available.
When they released Gemini 3.1 Pro with double the reasoning performance, they kept the exact same price: $2.00 per million input tokens for standard prompts. For developers and enterprises using the API, this represents an immediate efficiency gain.
Understanding API Pricing and Token Economics
To understand why this matters, you need to understand how API pricing works for language models. You pay for two things: input tokens (the information you send to the model) and output tokens (the response the model generates).
With Gemini 3.1 Pro's improved efficiency (generating results with fewer output tokens while producing better quality), your cost per useful output decreases. You're not getting 5-10% better results. You're getting 2X better reasoning performance for the same price.
Over a year, if your organization makes thousands of API calls to an AI model, that efficiency difference compounds. Consider a team using an AI API extensively:
- Monthly API spend: $10,000
- Performance improvement: 2X on reasoning tasks
- Token efficiency improvement: ~15-20% (based on JetBrains feedback)
- Annual savings or reallocation potential: $18,000-24,000
That's real money, and it goes straight to the bottom line or enables more extensive AI integration without budget increases.
Competitive Positioning Against Claude and GPT-4
How does Gemini 3.1 Pro's pricing compare to alternatives?
Anthropic's Claude 3.5 Sonnet prices at
For reasoning-focused tasks where Gemini 3.1 Pro excels, the cost difference becomes significant. You're getting equivalent or superior performance at a substantial discount.
This pricing strategy is interesting because it suggests Google's longer-term confidence in their cost structure. They're not pricing for scarcity or premium positioning. They're pricing to capture market share, banking on the fact that lower prices will drive adoption and volume.
Output Token Pricing and Practical Implications
Output tokens (the model's response) cost slightly more than input tokens, as is typical. Google charges $6.00 per million output tokens for Gemini 3.1 Pro standard mode. This is where the token efficiency improvement from JetBrains becomes important.
If the model generates better responses with fewer tokens, your output costs decrease. Imagine the difference between a model that generates 500 tokens to explain a concept versus one that gets the same point across in 400 tokens. Over thousands of API calls, that 20% reduction in output tokens adds up.
Context Window: 1 Million Tokens of Information
Gemini 3.1 Pro's context window—the maximum amount of information you can give the model at once—is 1 million tokens. This is an enormous window. For comparison, GPT-4 Turbo's context window is 128,000 tokens.
What does 1 million tokens mean in practical terms? You could give the model an entire book, multiple long documents, weeks of email conversations, or a large codebase all at once, and it would consider all that context when answering your question.
This capability is particularly powerful for research and analysis tasks. You don't need to break down large documents into smaller chunks or make multiple API calls to build context. Feed it everything at once and ask questions about the whole thing.
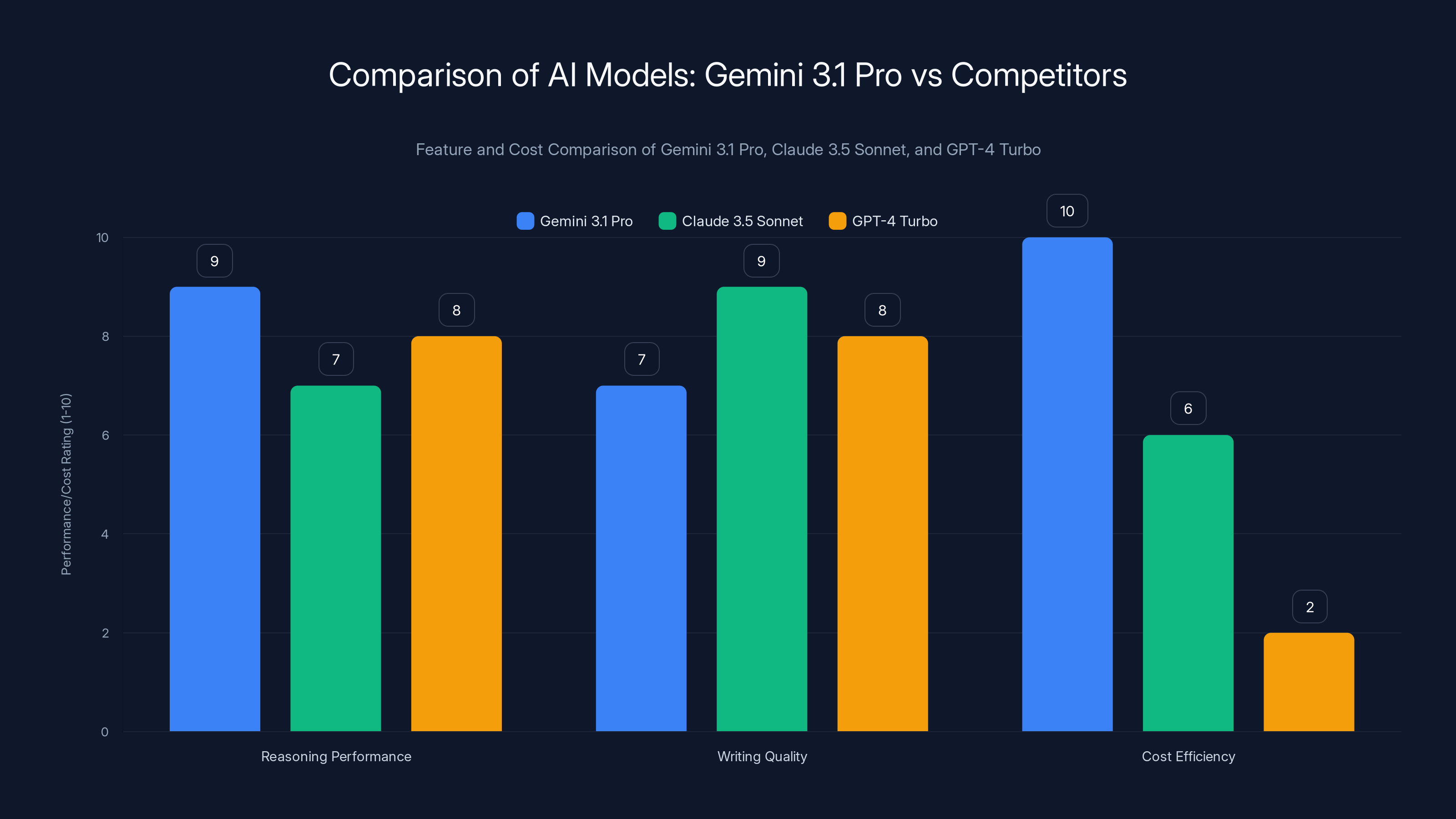
Gemini 3.1 Pro excels in reasoning performance and cost efficiency, while Claude 3.5 Sonnet leads in writing quality. GPT-4 Turbo is strong in general performance but less cost-effective.
Autonomous Agents: The Real Long-Term Application
Benchmark scores and vibe coding are impressive demonstrations, but the real strategic importance of Gemini 3.1 Pro lies in its ability to power autonomous agents—AI systems that can plan, reason through multi-step problems, and take actions without constant human oversight.
What Autonomous Agents Actually Need
Building an AI system that can autonomously accomplish complex tasks requires several capabilities that aren't equally distributed across all AI models. You need:
- Long-horizon reasoning: Planning through 10, 20, or 50 sequential steps
- Error recovery: Recognizing when a step failed and adjusting the plan
- Uncertainty handling: Proceeding effectively when information is incomplete
- Tool use: Calling external systems (APIs, databases, code execution environments)
- Context awareness: Maintaining understanding across many steps
Traditional language models struggle with long-horizon reasoning. After many steps, they lose track of the original goal or introduce contradictions. Gemini 3.1 Pro's improved reasoning capability directly addresses this limitation.
Practical Autonomous Agent Use Cases
Software Development Agents: An agent that understands a codebase, can identify bugs, create tests, and implement fixes with minimal human intervention. The improved 3D geometry understanding and code reasoning capability in Gemini 3.1 Pro makes this more feasible.
Research Agents: An agent that can search literature, synthesize findings, identify gaps in research, and even suggest new hypotheses. The 94.3% GPQA Diamond score suggests genuine scientific understanding.
Data Analysis Agents: An agent that can query databases, perform statistical analysis, generate visualizations, and produce reports. The improved multimodal reasoning helps when combining structured data with documents and charts.
System Administration Agents: An agent that can manage cloud infrastructure, identify performance issues, and implement optimizations. The 2887 Elo code reasoning score enables understanding complex infrastructure-as-code.
The common theme: all these tasks require genuine reasoning, not just pattern matching. They require the agent to think through problems step-by-step, which is exactly what Gemini 3.1 Pro's improved thinking token allocation enables.
The Challenge of Staying "On-Task"
One problem with autonomous agents is goal drift. The agent starts trying to accomplish X, gets distracted by a subtask, and never returns to the original goal. Or it becomes confused about whether it's already completed a step.
Gemini 3.1 Pro's improved reasoning should help here. The model can maintain a clearer understanding of the overall goal and subgoals, less likely to lose track.
Will it be perfect? No. Autonomous agents are still prone to confusion and error. But the improvement is meaningful enough that agents built on Gemini 3.1 Pro should accomplish more complex tasks than agents built on previous models.

Technical Architecture: Thinking Tokens and Efficient Inference
Google hasn't released extensive technical details about Gemini 3.1 Pro's architecture, but the performance improvements suggest specific technical innovations worth understanding.
Improved Thinking Token Allocation
The core innovation appears to involve how the model allocates its computational effort (thinking tokens) before generating output. Rather than immediately jumping to an answer, the model spends more effort thinking through hard problems.
This is similar to how humans approach difficult problems. For simple questions, you know the answer immediately. For complex questions, you work through them step-by-step mentally before speaking.
Google's implementation appears to have optimized this "mental workspace" to be more efficient. The model wastes less effort on irrelevant reasoning paths and more effectively explores relevant ones.
The technical challenge Google solved: making this thinking process efficient enough that it doesn't dramatically increase latency or cost. If you have to spend 10X more computation to improve reasoning 2X, it's not worth it. But if you can improve reasoning 2X with 20-30% more computation, it becomes economically viable.
Long-Context Handling and Coherence
With 1 million tokens of context window, maintaining coherence across that entire context is non-trivial. The model needs to effectively reference information from earlier in the context, not just focus on the most recent information.
Gemini 3.1 Pro appears to handle this more effectively than previous versions. This is important for the autonomous agent use case, where the agent might be working with large context windows containing code, documentation, and previous conversation history.
Efficiency Improvements in Inference
JetBrains' observation about fewer output tokens needed to accomplish the same task suggests Google optimized not just the reasoning capability but also how the model presents its reasoning.
A model might know the right answer but explain it inefficiently. "The answer is X because reasons A, B, C, D, E, F, and G." A better-optimized model says, "The answer is X because of reason A (which implies B and C)." Same reasoning, more concise communication.
This might seem like a small point, but at scale across millions of API calls, more concise communication with fewer tokens translates to direct cost savings.

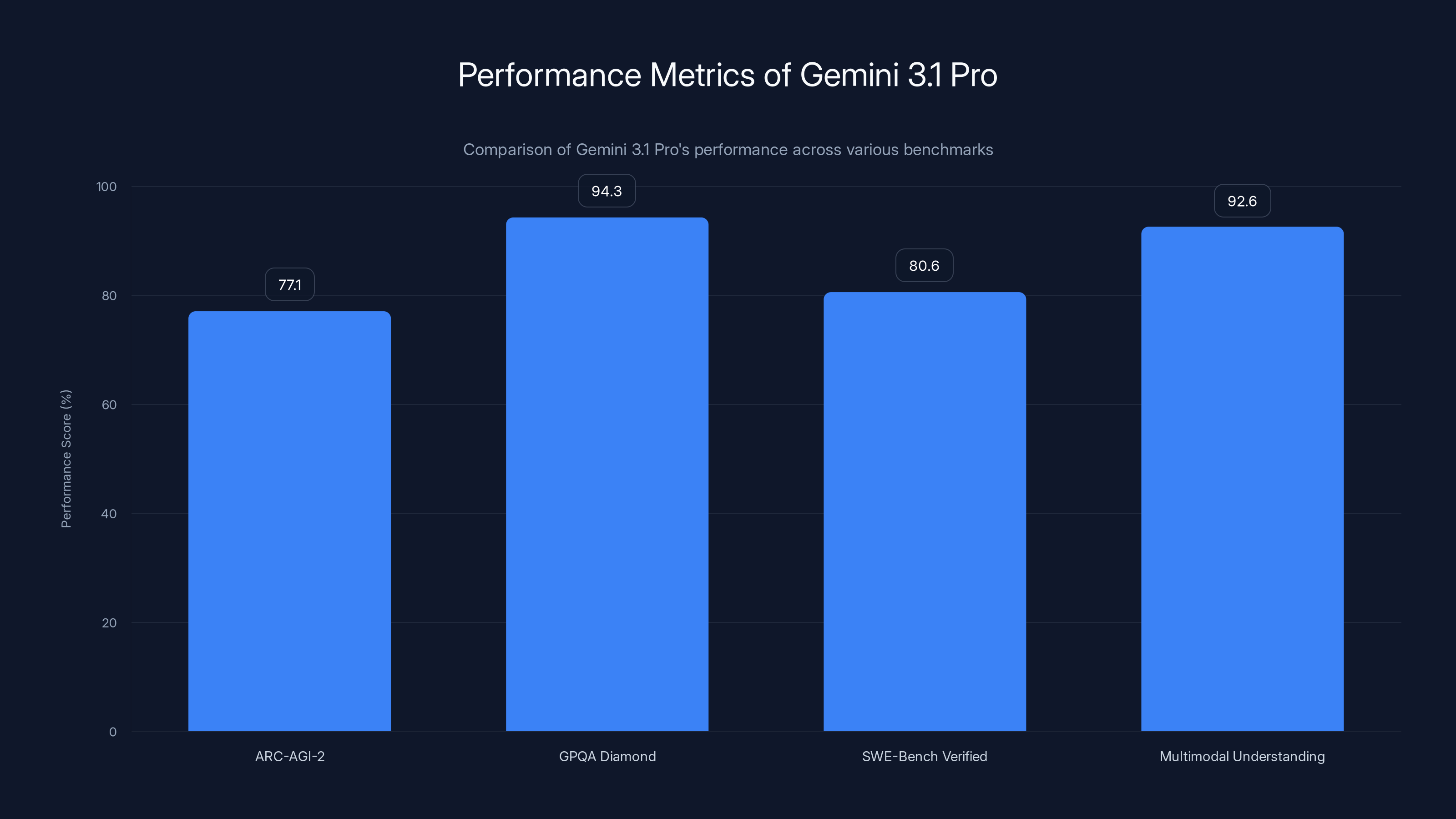
Gemini 3.1 Pro excels in specialized domains with a notable 94.3% in scientific knowledge and 77.1% in abstract logic, showcasing its enhanced reasoning capabilities.
Limitations and Honest Assessment
No model is perfect, and it's worth being honest about what Gemini 3.1 Pro still struggles with, even after these improvements.
Real-Time Information and Current Events
Gemini 3.1 Pro's knowledge cutoff (the point in time when its training data ends) means it doesn't know about events after its training date. If you need current information about stock prices, recent news, or today's weather, you need to provide that information to the model.
This is a limitation of all large language models, not specific to Gemini 3.1 Pro, but it's important to understand. The model reasons well about what it knows, but it can't know things it hasn't been trained on.
Perfect Code Generation is Still Impossible
Even with 80.6% accuracy on SWE-Bench Verified, that means roughly 1 in 5 coding problems still result in incorrect solutions. For some applications, you need 100% correctness, which requires human review.
The improvement is significant—you're not spending time on obviously broken code anymore—but you still need quality assurance processes.
Hallucination Reduction, Not Elimination
Hallucinations (confident-sounding but factually incorrect information) have plagued language models. Gemini 3.1 Pro appears to reduce hallucinations through better reasoning, but they don't disappear entirely.
For critical applications (medical advice, legal interpretation, financial recommendations), you need human expertise in the loop, not just AI assistance.
Specialized Domain Depth Has Limits
The GPQA Diamond score of 94.3% is impressive, but 94.3% still means 5.7% of graduate-level physics/chemistry/biology questions get answered incorrectly. For Ph.D.-level research, that error rate matters.
The model is genuinely knowledgeable, but it's not a replacement for domain expert review. It's an accelerant for domain experts.
Multimodal Understanding Still Imperfect
At 92.6% on MMMLU, the model understands most images and diagrams correctly. But there's a 7.4% error rate. For critical applications like medical imaging analysis, that's not quite acceptable without expert review.
Comparison with Competitor Models
How does Gemini 3.1 Pro actually stack up against the alternatives your organization might consider?
Gemini 3.1 Pro vs. Claude 3.5 Sonnet
Anthropic's Claude models, particularly the 3.5 Sonnet variant, are known for writing quality and thoughtful responses. Claude excels at nuanced tasks like editing, analysis, and creative writing.
On reasoning benchmarks, Gemini 3.1 Pro appears to have the advantage. Claude 3.5 Sonnet doesn't publicly disclose its ARC-AGI-2 score, but Anthropic focuses more on safety and interpretability than raw reasoning performance.
For your organization: Choose Claude if you prioritize writing quality and nuanced analysis. Choose Gemini 3.1 Pro if you need reasoning performance and specialized domain knowledge (coding, science).
Price: Claude 3.5 Sonnet (
Gemini 3.1 Pro vs. GPT-4 Turbo
OpenAI's GPT-4 Turbo was the previous industry standard for multi-domain reasoning and capability. It excels at writing, analysis, and general knowledge tasks.
On specialized reasoning benchmarks (ARC-AGI, code generation, scientific knowledge), Gemini 3.1 Pro appears to have the edge. GPT-4 Turbo remains excellent for writing and general-knowledge tasks.
Price: GPT-4 Turbo (
For your organization: If you're currently using GPT-4 Turbo for reasoning and coding tasks, Gemini 3.1 Pro should deliver better results at a fraction of the cost. If you're primarily using it for writing, the benefit is less clear.
Gemini 3.1 Pro vs. Specialized Models
Beyond general-purpose models, specialized models exist for specific domains. Open-source models like Llama (from Meta) can be fine-tuned for specific tasks and offer cost advantages for high-volume inference.
Gemini 3.1 Pro's advantage is breadth. One model handles reasoning, coding, images, science, and creative tasks. With specialized models, you need different models for different tasks, increasing complexity.

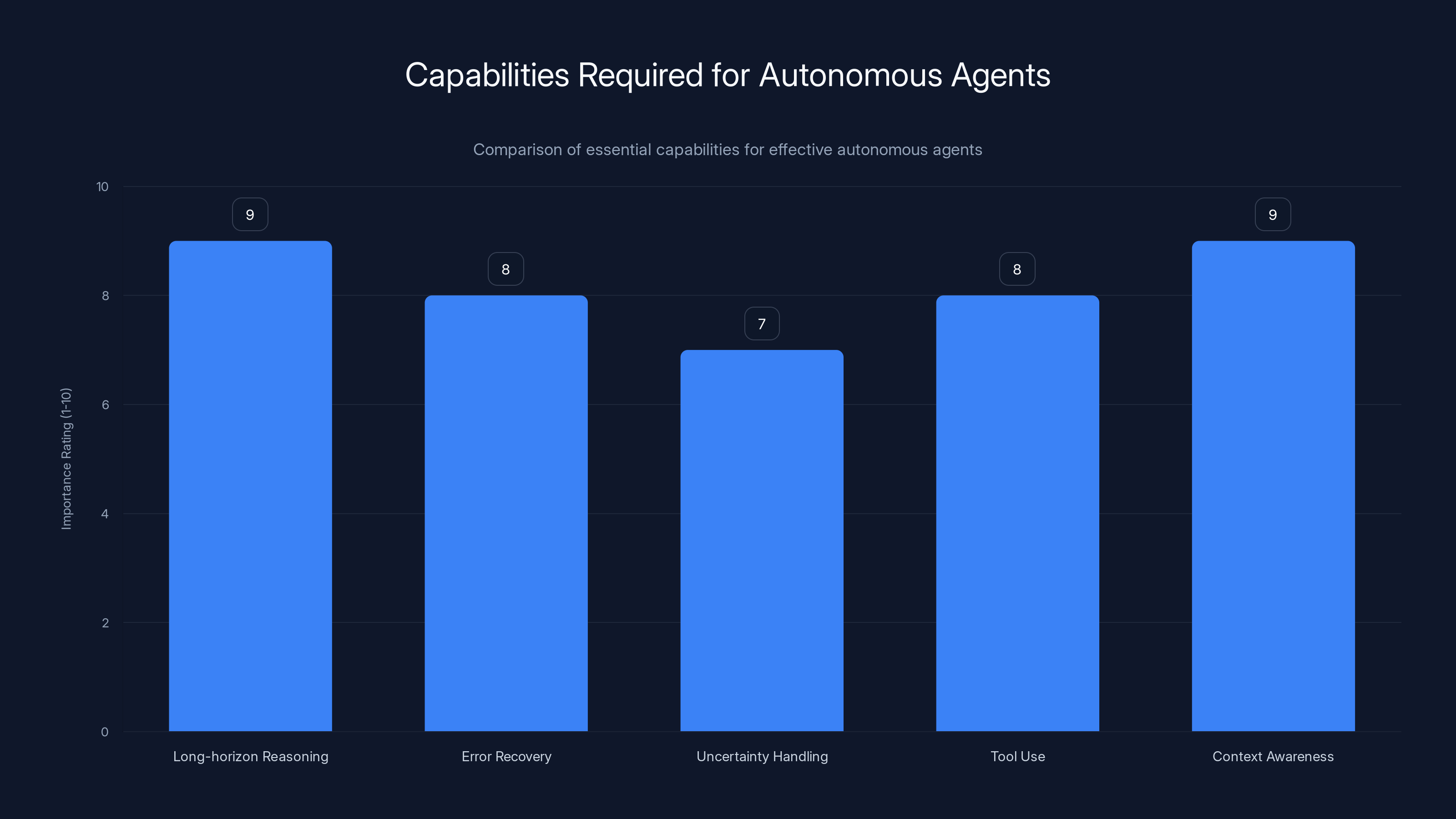
Long-horizon reasoning and context awareness are crucial for autonomous agents, with high importance ratings. Estimated data.
Implementation Strategy: How to Actually Use Gemini 3.1 Pro
If you've decided Gemini 3.1 Pro makes sense for your organization, here's how to implement it effectively.
Phase 1: Evaluation and Proof of Concept
Start small. Identify one concrete problem your organization has that might be solved or accelerated by an AI model. Don't try to solve everything at once.
Examples:
- A team spending 10 hours/week on code review. Can Gemini 3.1 Pro automate the initial code review pass?
- A research team spending time on literature synthesis. Can the model accelerate literature review?
- A product team creating documentation. Can the model draft documentation from code?
Build a prototype that addresses this one problem. Measure the outcome:
- Time saved
- Quality improvement
- Error rates
- User satisfaction
Phase 2: Integration with Your Systems
Once you've validated the approach, integrate Gemini 3.1 Pro into your actual workflows. This might mean:
- Building a Slack bot that answers questions about your documentation
- Creating a VS Code extension that suggests code improvements
- Developing a dashboard that generates automated reports from data
- Building an analysis tool that helps with customer support
The integration point matters. Some organizations benefit most from AI integrated into tools developers already use. Others prefer dedicated AI chat interfaces.
Phase 3: Optimization for Your Use Case
Once integrated, you'll learn what actually works for your specific situation. This is where you optimize:
- Prompt engineering: Exactly how you phrase questions affects results
- Context provision: What information should you give the model upfront?
- Output processing: How should the model's response be formatted for your users?
- Error handling: How do you handle cases where the model gets things wrong?
This optimization phase determines whether you get a useful tool or just a fun toy. Invest time here.
Phase 4: Team Training and Adoption
Don't expect your team to instantly figure out how to use an AI model effectively. Training matters:
- Show specific examples of how the model helps with their work
- Explain the limitations so they don't over-rely on it
- Create templates or prompts that work well for common tasks
- Share successful use cases from other teams

The Broader Competitive Landscape: What This Means for AI in 2025
Gemini 3.1 Pro doesn't exist in isolation. It's part of a broader competitive landscape where multiple organizations are pushing hard on AI reasoning and capability.
The Pattern: Reasoning as the New Differentiator
For years, the AI competition focused on scale (bigger models, more training data). The conversation has shifted. Now it's about reasoning quality. Can the model think through problems effectively?
This shift matters because it's harder to commoditize. You can add more computers and more data, but improving reasoning requires genuine algorithmic innovation.
Gemini 3.1 Pro's focus on ARC-AGI-2 performance signals that Google sees reasoning as the battleground. OpenAI is making similar bets with their reasoning models. Anthropic is focusing on interpretability (understanding how the model reasons).
We'll likely see continued competition on reasoning performance through 2025-2026.
Cost Reduction as a Strategic Weapon
Google's decision to price Gemini 3.1 Pro identically to the previous version while doubling reasoning performance is strategically aggressive. They're prioritizing market share and usage over revenue per API call.
This could trigger a price war. If customers start switching to Gemini 3.1 Pro because it's cheaper and better, competing model providers will face pressure to lower prices or improve quality.
For organizations, this is good news. Prices will likely decline across the board as competition intensifies.
The Integration Play: AI Everywhere
Both Google and OpenAI are racing to integrate AI into consumer products. Google's embedding Gemini into Search, Workspace, and Android. OpenAI is embedding ChatGPT into iOS, Windows, and various enterprise tools.
For organizations choosing models now, integration with your existing tools matters. If you're a Google Workspace shop, Gemini 3.1 Pro might integrate more seamlessly.
The Open-Source Challenge
While Gemini 3.1 Pro and GPT-4 are closed-source, open-source models continue improving. Meta's Llama models, Mistral, and others are viable for many applications.
The calculus: closed-source models like Gemini 3.1 Pro are more capable but more expensive and less flexible. Open-source models are cheaper and customizable but require more infrastructure and technical expertise.
For 2025, we'll likely see organizations using a mix: closed-source models for cutting-edge capabilities and tasks requiring specialized expertise, open-source models for high-volume inference where cost matters most.
Security, Privacy, and Ethical Considerations
Before adopting any AI model in your organization, you need to understand the security and privacy implications.
Data Privacy: What Happens to Your Data?
When you send a prompt to Gemini 3.1 Pro via the API, Google's privacy policy governs what happens to that data. Generally, API data isn't used to train future models (unlike ChatGPT in its default mode), but you should review the specifics.
If you're in a regulated industry (finance, healthcare, legal), data privacy requirements might restrict which AI models you can use. Some organizations run models locally to avoid sending data to external APIs.
Bias and Fairness
AI models learn patterns from training data. If training data contains biases, the model might perpetuate those biases. Gemini 3.1 Pro isn't immune to this.
Before using any AI model to make consequential decisions (hiring, lending, content moderation), audit for bias. Don't assume the model is fair just because it's new and from a reputable company.
Transparency and Explainability
Gemini 3.1 Pro improved reasoning, but the model can't easily explain why it reached a conclusion. It might give correct answers for somewhat opaque reasons.
For high-stakes applications, you need explanation. How did the model reach this conclusion? What evidence did it consider?
Responsible Use
AI models can be misused. Gemini 3.1 Pro could potentially be used to generate misinformation, automate harassment, or assist in fraud.
Organizations using AI models should establish clear policies about acceptable use, train employees appropriately, and monitor for misuse.
The Future of AI Reasoning: What's Next?
Where does AI development go from here? Based on Gemini 3.1 Pro and industry trends, a few directions seem likely.
Multi-Step Reasoning Becomes Standard
The improved thinking token allocation in Gemini 3.1 Pro will likely become a standard technique across models. Future models will probably allocate computation for reasoning before generating output.
This might extend further: models that can explicitly plan out multi-step solutions, backtrack when reasoning goes wrong, and verify their own conclusions.
Specialization Within General Models
Rather than one-size-fits-all models, we'll likely see models that specialize in reasoning, writing, coding, or image understanding, with different versions for different use cases.
Gemini 3.1 Pro is already moving in this direction with variants for different purposes. This specialization should continue.
Efficient Inference and On-Device Deployment
As AI models improve, the challenge shifts from training to deployment. Running large models requires significant computational resources, limiting who can use them.
Research into more efficient models (smaller, faster, requiring less computation) will likely accelerate. This could enable AI capabilities on phones, edge devices, and within organizations without massive cloud infrastructure.
Real-Time Integration with External Systems
Current models can call APIs and read data, but the integration is often slow and limited. Future models will likely have tighter, faster integration with external systems, enabling true autonomous agents that act in real-time.
Better Uncertainty Quantification
Models that can explicitly state their confidence level ("I'm 95% confident in this answer" vs. "I'm 40% confident") would be more useful. Research in this area is active and could yield significant improvements.

Conclusion: Assessing the Real Impact of Gemini 3.1 Pro
So, is Gemini 3.1 Pro the breakthrough Google claims? Yes, but with important caveats.
The Genuine Breakthroughs
The doubling of reasoning performance on abstract logic tasks (ARC-AGI-2 from ~35% to 77.1%) is real and significant. This translates to genuine improvements in the model's ability to solve novel problems.
The maintained pricing despite performance improvements is a smart strategic move that benefits customers. You're getting more capability for the same cost.
The applications Google demonstrated (vibe coding, complex system synthesis, 3D design) suggest the reasoning improvements enable genuinely new capabilities, not just incremental improvements.
Third-party verification from Artificial Analysis adds credibility. This isn't just Google marketing; independent evaluators confirm Gemini 3.1 Pro's leadership position.
The Realistic Limitations
Reasoning improvements don't solve all problems. The model still hallucinates, makes mistakes, and has knowledge gaps. For many applications, it's an accelerant for human expertise, not a replacement.
The comparison with other top models (Claude, GPT-4) is more nuanced than headlines suggest. Gemini 3.1 Pro excels at reasoning and coding. For writing and nuanced analysis, other models might remain competitive.
The Implementation Reality
Getting value from Gemini 3.1 Pro requires genuine thought about how to integrate it into your workflows. It's not a plug-and-play magic bullet. Organizations that invest in proper implementation, training, and optimization will see significant benefits. Those expecting immediate results from minimal effort will be disappointed.
The Strategic Takeaway
If your organization relies on AI models and hasn't evaluated Gemini 3.1 Pro, you should. The combination of improved reasoning, lower price than many competitors, and proven real-world applications makes it compelling for many use cases.
If you're currently using GPT-4 Turbo or other models primarily for reasoning, coding, or specialized domain tasks, Gemini 3.1 Pro warrants serious evaluation. The performance improvement and cost reduction could translate to significant savings and capability gains.
The AI landscape continues evolving rapidly. Gemini 3.1 Pro represents a meaningful step forward, but it won't be the last. Organizations that understand how to effectively integrate AI tools will continue gaining competitive advantage through 2025 and beyond.
The reasoning revolution in AI is just beginning. Gemini 3.1 Pro marks a notable milestone, but the race is far from over.

FAQ
What is Gemini 3.1 Pro exactly?
Gemini 3.1 Pro is Google's latest flagship AI model that doubles the reasoning capability of its predecessor while maintaining the same pricing. The model is designed for complex tasks requiring deep planning, scientific reasoning, software engineering, and creative synthesis. Unlike a general-purpose chatbot, Gemini 3.1 Pro specializes in thinking through difficult problems step-by-step and understanding complex patterns it hasn't encountered during training.
How does Gemini 3.1 Pro achieve 2X reasoning improvement?
The model improved through better allocation of "thinking tokens"—internal computational steps the model takes before generating output. Rather than immediately jumping to answers, the model now spends more computational effort working through complex problems methodically, similar to how humans mentally work through difficult questions. This improved thinking process, combined with enhanced handling of long-context information and better planning capabilities, enables the doubling of abstract reasoning performance on benchmarks like ARC-AGI-2.
What are thinking tokens and why do they matter?
Thinking tokens are the internal reasoning steps an AI model takes before providing output to users. A model with effective thinking token allocation can work through complex multi-step problems more reliably. For Gemini 3.1 Pro, optimized thinking token usage means the model wastes less effort on irrelevant reasoning paths and focuses more on solving the actual problem. For your organization, this translates to better solutions for complex problems without proportional increases in API costs.
How much does Gemini 3.1 Pro cost compared to other models?
Gemini 3.1 Pro costs
Is Gemini 3.1 Pro suitable for autonomous AI agents?
Yes, Gemini 3.1 Pro is particularly well-suited for autonomous agents that need to plan multi-step solutions and reason through complex problems. The improved reasoning capability enables agents to maintain coherence across longer planning sequences, recover from errors more effectively, and tackle problems requiring genuine thinking rather than pattern matching. Enterprise partners have already reported using Gemini 3.1 Pro preview for agent development with promising results.
What happens if Gemini 3.1 Pro makes a mistake?
Like all AI models, Gemini 3.1 Pro can hallucinate (confidently state incorrect information), make reasoning errors, or produce suboptimal code despite its improvements. The 77.1% score on ARC-AGI-2 means 22.9% of novel logic problems still result in incorrect solutions. For critical applications (medical, legal, financial decisions), you need human expertise in the loop to verify the model's work rather than accepting all output as correct.
Should we switch to Gemini 3.1 Pro from our current AI model?
That depends on your current model and primary use cases. If you're using GPT-4 Turbo mainly for coding or reasoning tasks, switching to Gemini 3.1 Pro should improve results at substantially lower cost. If you're using other models primarily for creative writing or general analysis, the benefits are less clear and might require testing. The best approach is to pilot Gemini 3.1 Pro on your most important AI-intensive tasks and measure the results directly.
What's the context window size and why does it matter?
Gemini 3.1 Pro supports a 1 million token context window, enabling you to provide enormous amounts of information to the model at once. For perspective, that's equivalent to a 500+ page book in a single prompt. This matters because you can analyze entire codebases, synthesize research across many papers, or ask questions about your complete documentation without splitting work across multiple API calls, saving time and improving context understanding.
Can Gemini 3.1 Pro access real-time information?
No, Gemini 3.1 Pro has a knowledge cutoff (a point in time after which it doesn't know about events). For current information like today's stock prices, recent news, or real-time data, you need to provide that information in your prompt. The model reasons brilliantly about what you give it, but cannot independently access the internet or know about recent events not in its training data.
What specialized domains does Gemini 3.1 Pro excel in?
Gemini 3.1 Pro demonstrates exceptional performance in scientific knowledge (94.3% on GPQA Diamond graduate-level science questions), software engineering (80.6% on real GitHub issues), and multimodal understanding (92.6% on image and text combined reasoning). The model also shows strong capabilities in 3D geometric reasoning, understanding code architecture, and interpreting visual designs. For research, engineering, and coding-heavy organizations, these specializations provide genuine advantages.

Additional Resources and Implementation Support
If you're considering Gemini 3.1 Pro for your organization, Runable offers an AI-powered automation platform starting at $9/month that can help accelerate your AI integration workflow. Runable enables teams to automate document generation, create presentations, build reports, and design visualizations using AI agents—all capabilities that complement advanced reasoning models like Gemini 3.1 Pro.
Use Case: Automate your technical documentation and report generation, freeing your team to focus on reasoning and analysis with Gemini 3.1 Pro.
Try Runable For Free
Key Takeaways
- Gemini 3.1 Pro achieved 77.1% on ARC-AGI-2, more than doubling reasoning performance for novel logic problems.
- Maintained $2.00 per million input tokens pricing despite 2X performance improvement, offering superior cost-efficiency.
- Scores 94.3% on GPQA Diamond (scientific knowledge), 80.6% on SWE-Bench (real code tasks), and 92.6% on MMMLU (multimodal).
- Enables vibe coding (aesthetic-driven code generation), complex system synthesis, and autonomous agent development.
- Enterprise partners report 15% quality improvements with fewer output tokens, resulting in both better results and lower costs.
- 1 million token context window enables analysis of entire codebases and research without splitting across multiple API calls.
- Best choice for reasoning-intensive and coding-heavy tasks; competitive advantage over GPT-4 Turbo at 20% of the price.
Related Articles
- Google I/O 2026: 5 Game-Changing Announcements to Expect [2025]
- OpenAI's 850B Valuation Explained [2025]
- Alibaba's Qwen 3.5 397B-A17: How Smaller Models Beat Trillion-Parameter Giants [2025]
- Sarvam AI's Open-Source Models Challenge US Dominance [2025]
- OpenClaw AI Ban: Why Tech Giants Fear This Agentic Tool [2025]
- Jikipedia: AI-Generated Epstein Encyclopedia [2025]

