![Mirai's On-Device AI Inference Engine: The Future of Edge Computing [2025]](https://tryrunable.com/blog/mirai-s-on-device-ai-inference-engine-the-future-of-edge-com/image-1-1771513751995.jpg)
Mirai's On-Device AI Inference Engine: The Future of Edge Computing [2025]
The cloud has dominated AI conversations for the past three years. Every startup worth its Series A talks about massive data centers, distributed computing, and infinite scaling. But here's the thing nobody wants to admit: sending every inference to the cloud costs money, uses bandwidth, and kills latency. A team of seasoned consumer app founders just raised $10 million to change that.
Mirai isn't trying to compete with Open AI or Anthropic. It's solving a completely different problem. Instead of building bigger models, Mirai is making existing models run better on the devices people already carry in their pockets. That's a subtle but critical distinction. When you're building consumer apps, every millisecond matters. Every API call costs something. Every cloud request is a point of failure.
The founding team brings serious credibility to this mission. Dima Shvets co-founded Reface, the face-swapping app that went viral and caught Andreessen Horowitz's attention. Alexey Moiseenkov built Prisma, which defined the AI filters space and dominated app charts. These aren't academic researchers or infrastructure engineers working in a vacuum. They're builders who've shipped consumer products used by millions. They understand what happens when your infrastructure can't scale, when your costs spiral out of control, and when users demand instant responsiveness.
What makes Mirai's approach genuinely different is the timing. Five years ago, running meaningful AI models on-device was borderline impossible. The hardware couldn't handle it. The models were too large. The tooling didn't exist. Today? Apple Silicon is genuinely powerful. Models are getting more efficient. The economics of cloud inference are forcing companies to look for alternatives. Mirai is stepping into that exact moment.
This article breaks down what Mirai is actually building, why it matters, and what it means for the future of AI infrastructure. We'll explore the technical challenges of on-device inference, the business case for edge computing, and how this fits into the broader AI landscape. By the end, you'll understand not just what Mirai does, but why every developer building consumer AI products should care.
TL; DR
- Mirai raised $10M seed led by Uncork Capital to optimize AI model inference on devices like iPhones and laptops
- Founded by consumer app veterans Dima Shvets (Reface) and Alexey Moiseenkov (Prisma), bringing real-world product experience to infrastructure
- Built inference engine in Rust that claims up to 37% speed improvements while preserving model quality
- Cloud inference economics are broken for consumer apps, making on-device alternatives increasingly essential
- Edge computing solves real problems: lower latency, reduced costs, privacy preservation, and offline capability
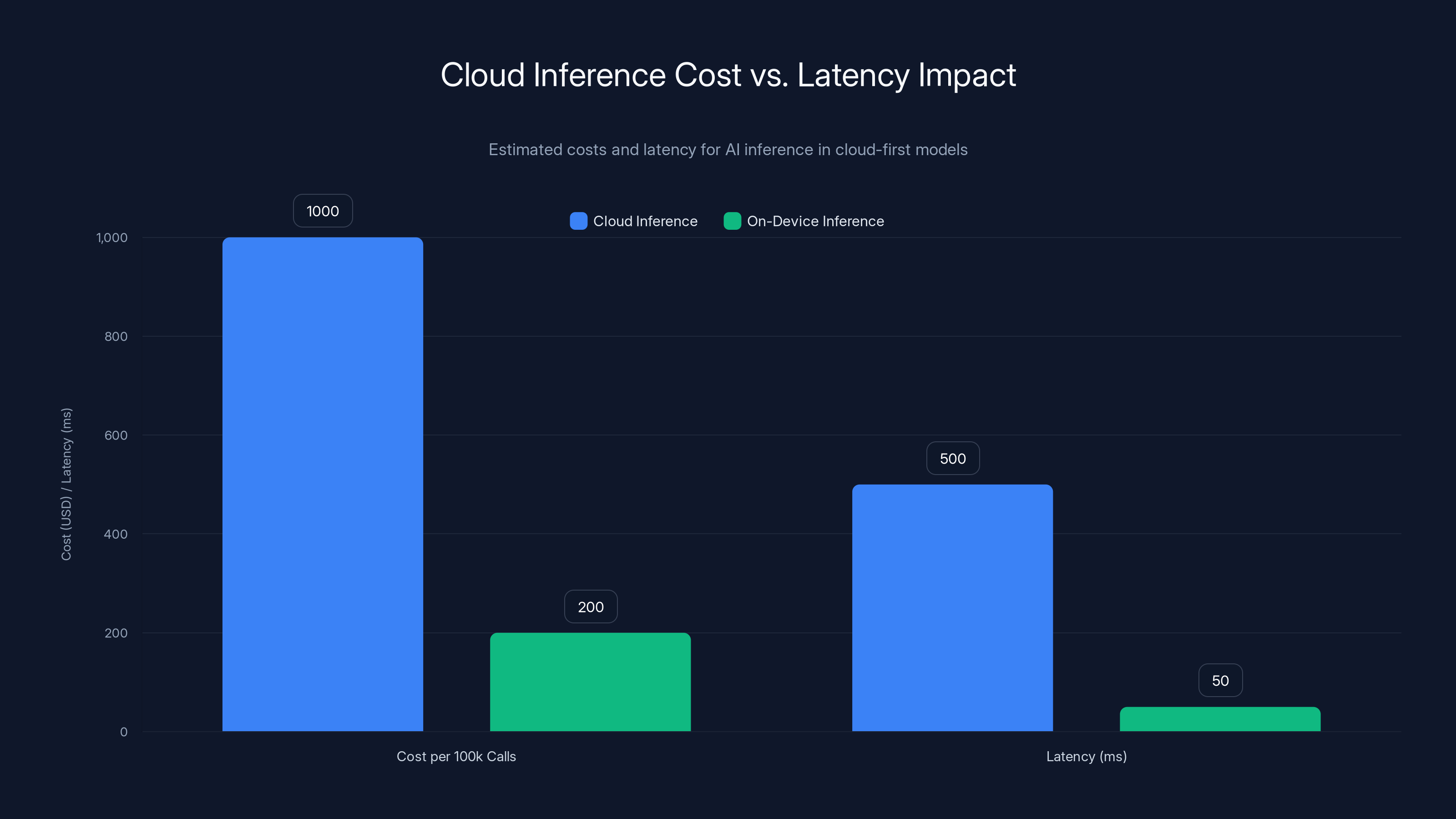
Cloud inference incurs higher costs and latency compared to on-device solutions. Estimated data highlights the economic and performance benefits of on-device AI.
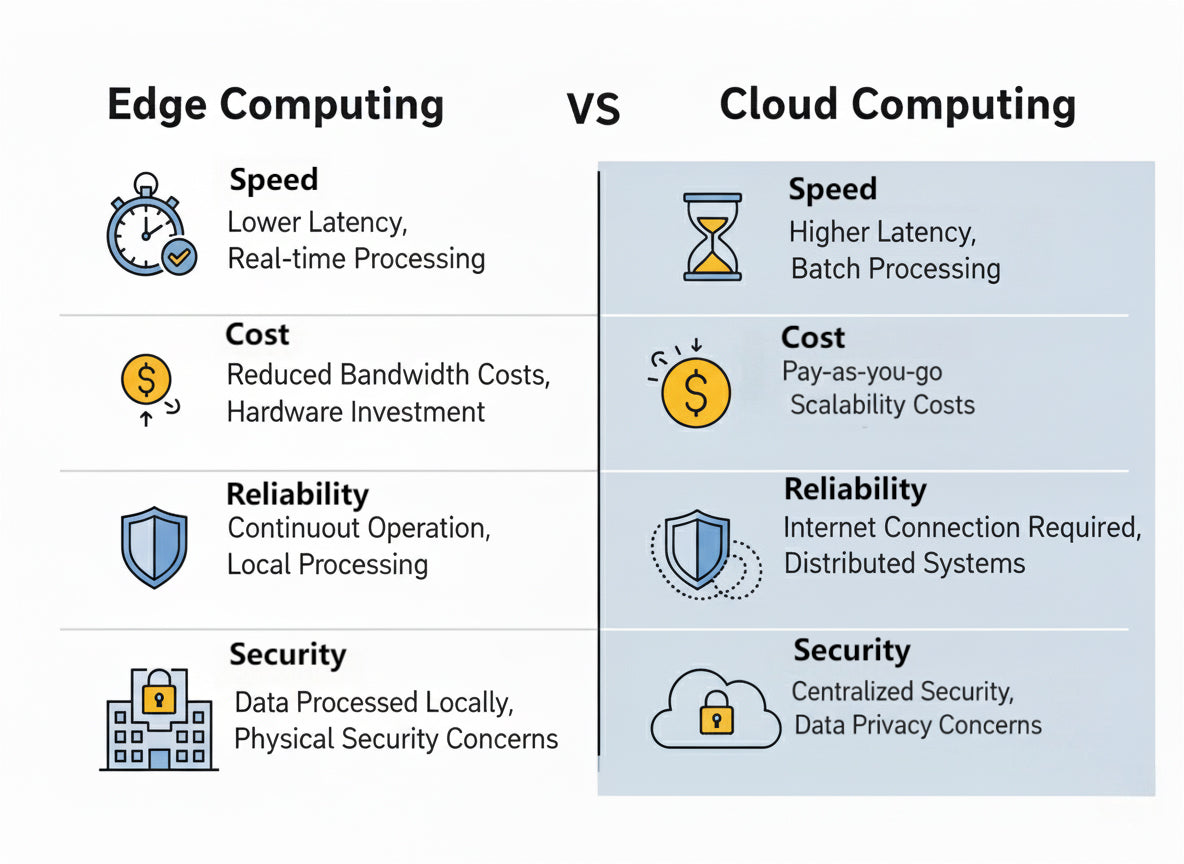
The Problem with Cloud-First AI
Let's talk about the elephant in the room. Building AI products today means one thing: cloud dependency. You train a model, you deploy it on GPUs in a data center, and you route every single user request through your API. It works. It scales. It's also expensive and slow.
Consider the economics. If you're running a consumer app with a million active users, and 10% of them trigger an AI inference per day, that's 100,000 API calls daily. At typical pricing (around $0.01 per 1,000 tokens for inference), that's not trivial. Scale that to a billion-user product, and cloud inference becomes your largest cost center. Open AI, Anthropic, and other frontier model providers know this. They're optimizing their pricing models accordingly, which means costs for end consumers keep climbing.
But here's the subtle part: cost isn't even the main problem for many use cases. Latency is. A user opens your app, types a message, and expects a response in under 500 milliseconds. If that request has to round-trip to a cloud API, you're already pushing it. Network latency alone can eat 200-300ms. Add processing time, and you're well past the threshold where the experience feels instant.
Then there's reliability. Every cloud API adds a single point of failure. Your product works perfectly until AWS goes down, or your API rate limits get hit, or a DDoS attack targets your inference infrastructure. On-device inference doesn't have that problem. If it runs on the user's hardware, it's as reliable as their device.
Privacy adds another dimension. Sending sensitive user data to the cloud for processing creates liability, regulatory complexity, and user trust issues. Healthcare apps, financial software, and communication tools all have strong incentives to keep data local. On-device inference solves that naturally.
This is where Mirai enters. The timing is perfect because the constraints have shifted. Five years ago, on-device AI was theoretical. Now it's practical but nobody's built the right tools yet.
Who Mirai Is and Why They're Credible
Mirai's founding story matters more than most startups because infrastructure is about trust and execution. You're not buying software; you're buying a team's ability to optimize your most critical path.
Dima Shvets' background is instructive. Reface wasn't just another filter app. It used face-swapping technology to let users create deepfakes of themselves in movie scenes and celebrity videos. The technical challenges were genuinely hard: real-time face detection, alignment, and synthesis on consumer hardware. Shvets didn't just hire people to build it; he shipped it himself. The app hit 100 million downloads. He caught the attention of a16z (who invested) and eventually became a scout for the firm. That's not a typical resume for a 30-something entrepreneur. That's someone who genuinely understands how to build consumer products that work at scale.
Alexey Moiseenkov's track record is even more impressive in some ways. Prisma wasn't just popular; it defined a category. For most of the 2010s, Prisma owned the AI filters space on mobile. The product was elegant, fast, and had genuine aesthetic value. More importantly, Prisma survived. It's still around, still used, still generating revenue. In a space where most viral apps die in six months, longevity matters. Moiseenkov knows how to maintain and evolve products that depend on machine learning.
Together, they bring something rare: deep technical expertise combined with real product intuition. They're not researchers who've decided to commercialize their academic work. They're builders who've shipped products to hundreds of millions of users and watched what works and what breaks.
The founding story also tells us something about market timing. Both founders were thinking about on-device ML before it became trendy. Shvets explicitly stated they were considering this problem even before generative AI blew up. They weren't chasing hype; they were solving a problem they'd lived with as product builders. That's the best kind of startup founder.

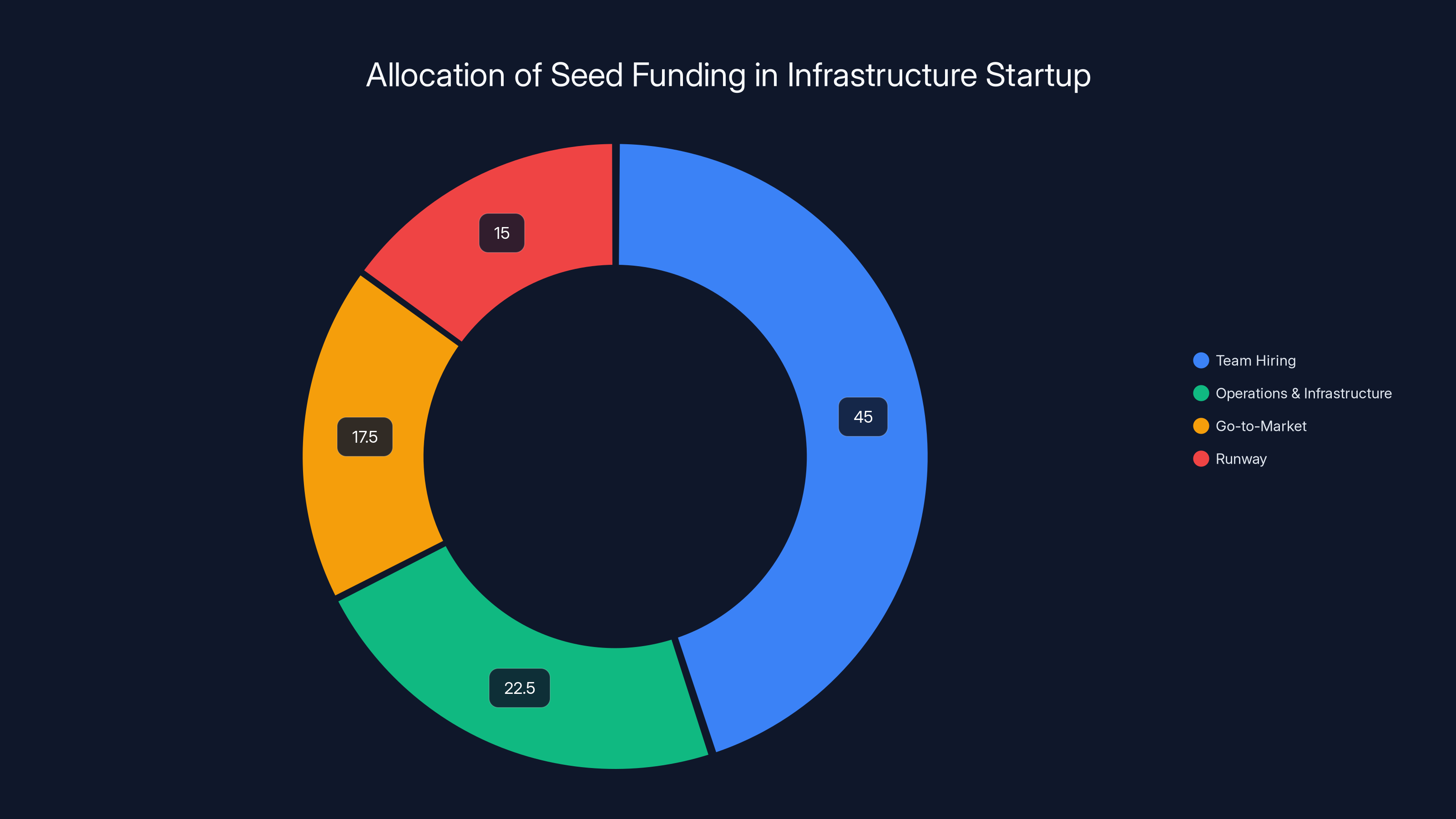
Estimated data shows that the largest portion of seed funding (45%) is allocated to team hiring, followed by operations (22.5%), go-to-market strategies (17.5%), and maintaining a runway (15%).
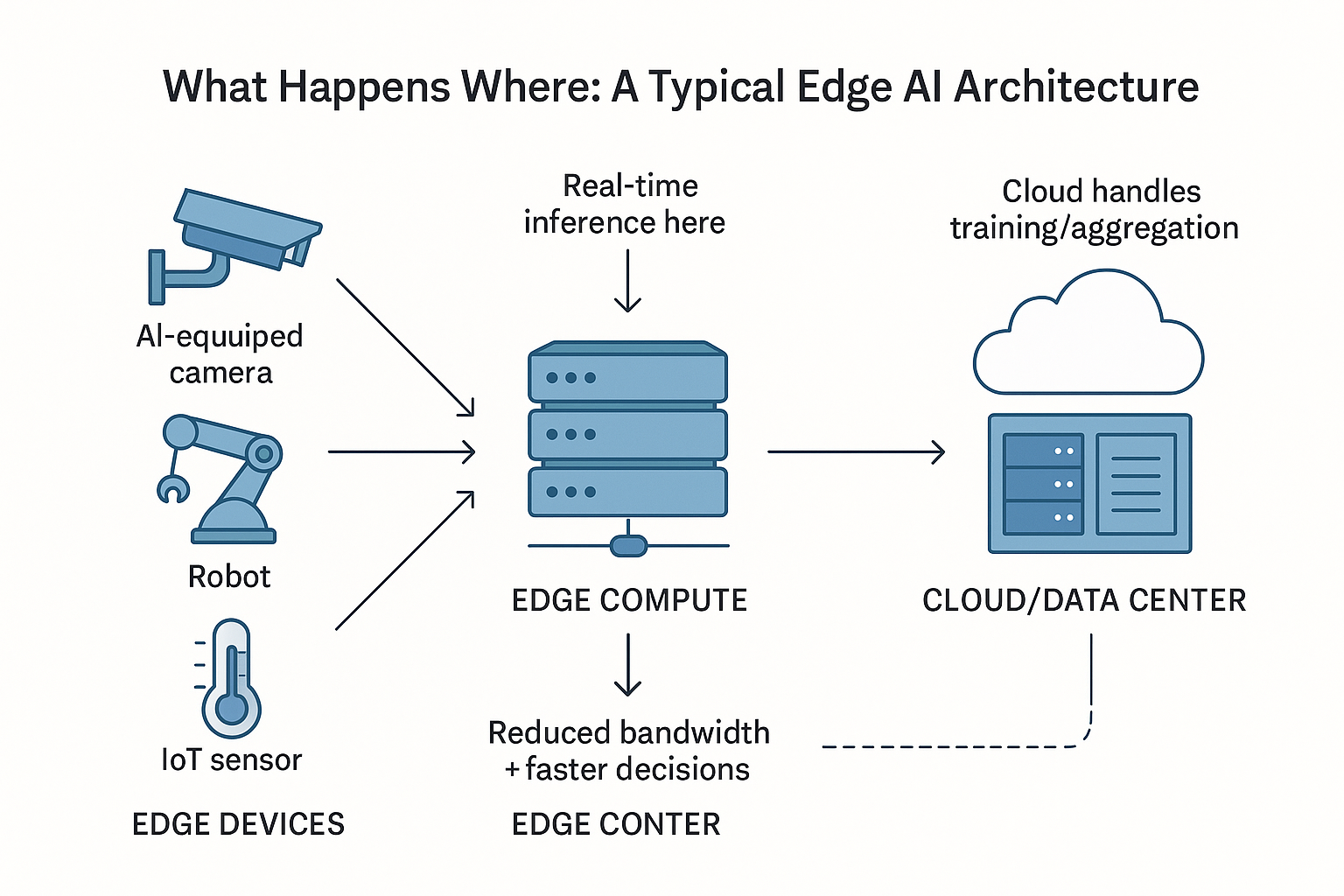
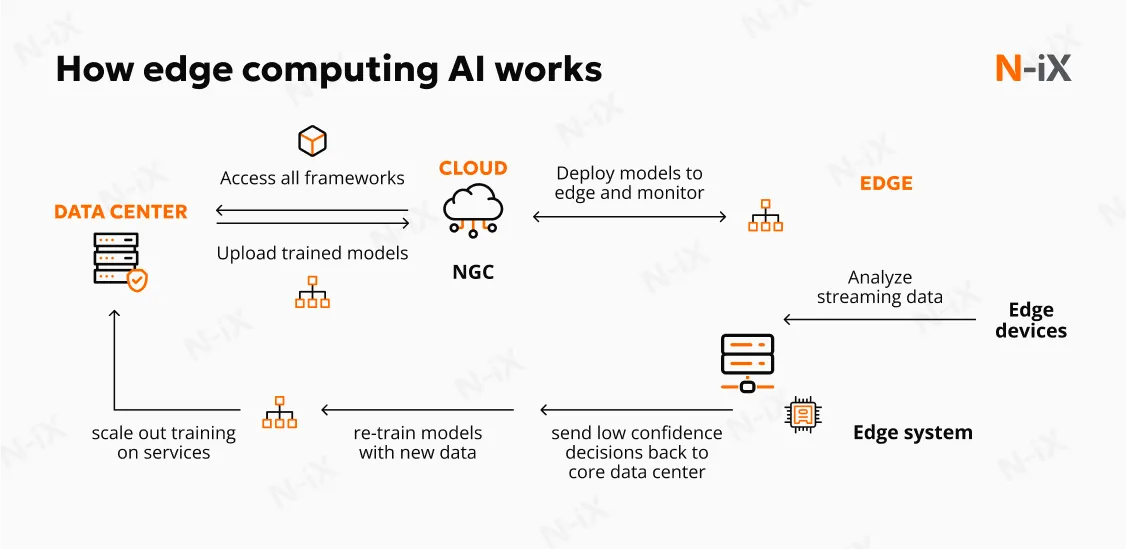
How On-Device Inference Works
Before understanding what Mirai does, you need to understand the fundamental difference between training and inference, and why inference on consumer devices is so hard.
When you train a model, you feed it massive amounts of data and let it learn patterns. That's computationally intensive but happens once. Inference is what happens when you use the trained model to make predictions on new data. Show it a photo, get back labels. Send it text, get back completions. Inference is what users actually experience.
Traditionally, inference happens like this: user makes a request to your server. Your server loads the model into memory. The model processes the input. The results come back to the user. Simple, reliable, but slow and expensive.
On-device inference changes the architecture entirely. The model lives on the user's phone or laptop. When they make a request, the model runs locally. Results come back instantly. No cloud round-trip needed.
The challenge is that models are heavy. A typical language model might be 7 billion parameters. Each parameter is a number that needs to be stored and computed. Modern phones have maybe 6-8GB of RAM. Even after compression, many models don't fit. They're too slow to load. Too memory-intensive to run. The math doesn't work.
This is where optimization comes in. There are several techniques for making models smaller and faster:
Quantization reduces the precision of the numbers in the model. Instead of storing weights as 32-bit floats, you use 8-bit integers. That's a 75% reduction in size with minimal quality loss. Your model goes from 50GB to 12GB. Still too large for most phones, but moving in the right direction.
Pruning removes parts of the model that don't contribute much to predictions. If a neuron has minimal impact on the output, you can just delete it. This reduces computation and memory needs.
Distillation trains a smaller model to mimic a larger one's behavior. This is slower than quantization or pruning but often produces better results. You take a 70-billion-parameter model, have it label a bunch of data, then train a 3-billion-parameter model to predict the same labels. The small model learns a compressed version of the large one's knowledge.
Hardware-specific optimization is where Mirai comes in. The same model can be compiled differently for different hardware. Apple Silicon has specific capabilities. Qualcomm chips have different strengths. Optimizing for specific hardware can give you another 20-40% speed improvement without changing the model itself.
Mirai built their inference engine in Rust, which is significant. Rust is designed for maximum performance with minimal overhead. A typical inference library might be written in Python or C++. Python is slow. C++ is fast but verbose. Rust is fast and lets you write clean, safe code. According to the company's claims, this optimization approach yields up to 37% speed improvements on Apple Silicon.
What makes Mirai's approach different from general inference optimization is the claim that they don't tinker with model weights. They keep the model architecture intact and purely optimize how it executes on specific hardware. This is important because it means you get the speed benefits without sacrificing accuracy. The model's outputs remain identical to cloud versions.
The Technical Architecture Behind Mirai
Mirai's stack is layered, which makes sense for a company targeting developers. You need low-level optimization, but also developer-friendly abstractions.
At the bottom sits the inference engine itself, compiled for specific hardware. This is where all the optimization work lives. Hand-tuned kernels for matrix operations, memory management optimized for mobile constraints, and hardware-specific code paths. It's the kind of work that takes deep expertise and months of iteration.
On top of that sits an SDK that developers actually interact with. The company claims you can integrate it with just a few lines of code. This matters more than it sounds. If you make developers jump through hoops, even amazing infrastructure won't get adopted. If you make it dead simple, adoption accelerates.
The third layer is orchestration. Not all inference can happen on-device. Sometimes models are too large. Sometimes the device doesn't have the right hardware. Sometimes you need real-time data that only lives in the cloud. Mirai's orchestration layer handles this gracefully. If a request can't be fulfilled locally, it automatically sends it to the cloud. The developer doesn't need to handle that logic; it's transparent.
Currently, the stack focuses on text and voice. That's intentional. These modalities are the most economically important for consumer apps. Text generation is where the big inference costs live. Voice transcription is where low-latency really matters. Vision is coming, but text and voice first makes strategic sense.
The company is also building benchmarks for on-device performance. This is underrated in importance. Model makers need to know how their models perform on different devices. Mirai's benchmarks will give frontier model providers concrete data about on-device inference speeds. That feeds back into better models, better optimization, and better tools. It's a virtuous cycle.
The Economics of Edge AI vs. Cloud AI
Let's do some math because numbers tell the real story.
Assume you're building a consumer AI app with 1 million monthly active users. On average, each user triggers one AI inference per day. That's 1 million inferences per month, or about 33,000 per day.
Cloud-based inference cost:
Most modern models generate about 100 tokens per inference (a mix of input and output tokens). Cost is typically
On-device inference cost:
Download the model once (included in app install or a small OTA update). Run everything locally. Inference cost: basically zero. The compute happens on the user's device using their battery.
The difference is massive: $10,000 per month down to zero. Now multiply that across a company's whole product, and you're looking at potential savings in the hundreds of thousands monthly.
But there are trade-offs:
Bandwidth: Every user needs to download the model. If it's 500MB, that's bandwidth cost. But that's one-time per user. Cloud APIs hit that data transfer cost on every inference.
Storage: The model needs to live on every device. That's app size cost. Users don't like huge apps. But modern compression and smart caching mitigate this.
Maintenance: Cloud models can be updated instantly. On-device models require app updates. That's friction. But for models that change slowly, it's not a big deal.
Accuracy: On-device models are often slightly quantized or pruned versions. But as Mirai claims, this can be done without accuracy loss.
The net math is clear: for use cases where latency, cost, and privacy matter (which is most consumer AI), on-device wins. The only blocker is developer friction. If building on-device inference requires PhD-level knowledge, most developers won't bother. If it requires a few lines of code, adoption explodes.
That's the game Mirai is playing. They're removing the friction.
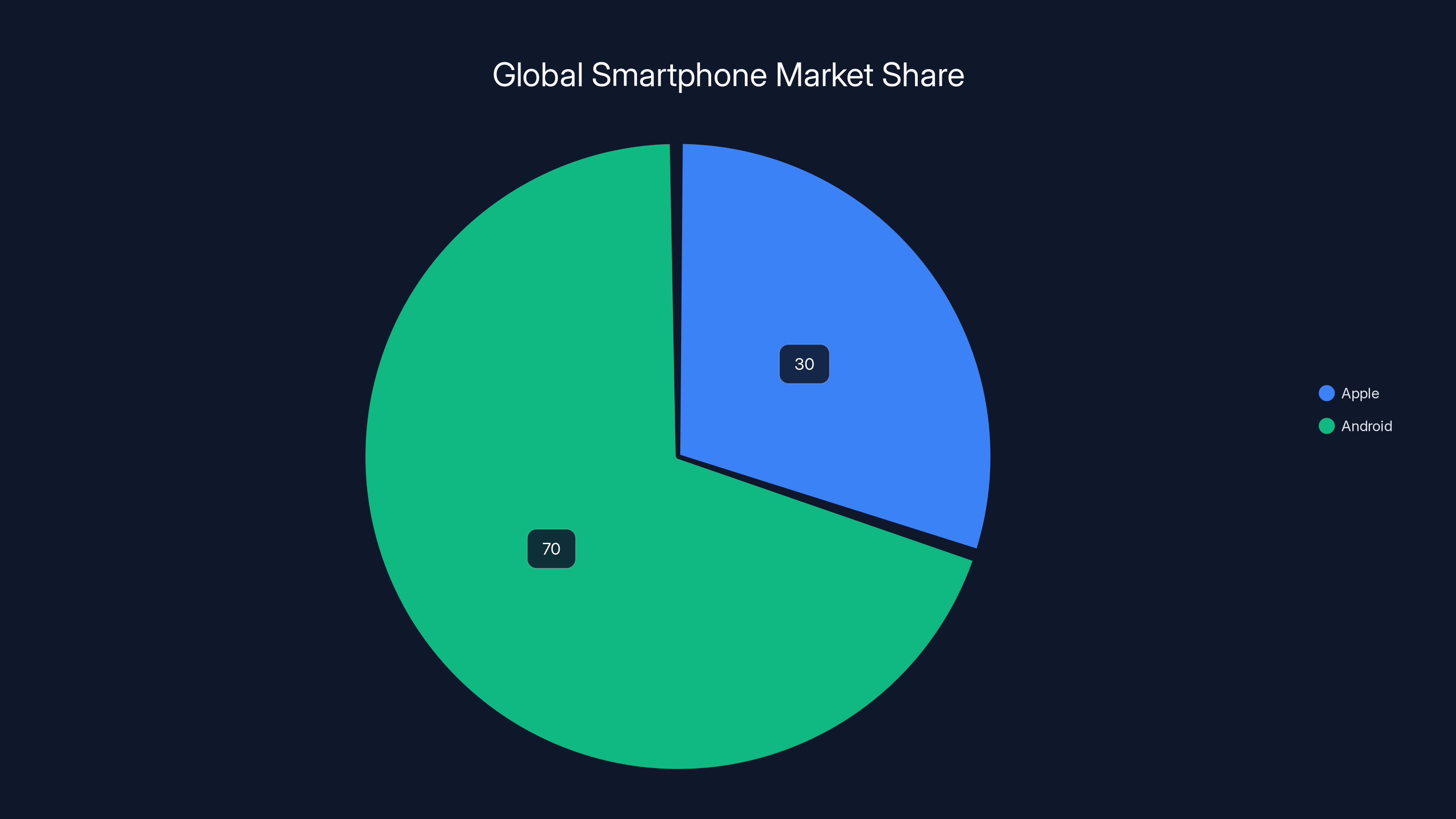
Android holds a significant 70% of the global smartphone market share, making it a crucial platform for Mirai's future expansion strategy. Estimated data.
Why Now? The Perfect Storm of Conditions
On-device AI isn't new. It's been possible for years. So why is Mirai launching now with $10 million in funding? Because conditions have shifted.
Hardware capability: Apple Silicon (M-series) and modern Qualcomm chips have genuine AI accelerators. The Neural Engine in Apple's chips can do matrix operations that used to require GPUs. These chips are shipping in millions of devices already.
Model efficiency: Frontier labs have been publishing smaller, more efficient models. They're realizing that you don't need 70 billion parameters for most tasks. A 3-billion-parameter model, properly trained and optimized, can handle 80% of use cases. That changes everything for on-device viability.
Infrastructure cost explosion: Cloud inference costs have become untenable. As more companies use AI, cloud providers are raising prices or capping usage. Developers are actively looking for alternatives.
Developer familiarity: Three years ago, most developers had never used transformers or inference. Now they have. Building on-device inference might still be hard, but it's no longer completely foreign.
Consumer app maturation: Companies like Apple and Qualcomm are publicly committing to on-device AI. Apple announced on-device Apple Intelligence. Qualcomm is pushing Snapdragon for AI. The industry is aligning around this direction.
Mirai is timing the wave perfectly. They're launching infrastructure that developers actually need, at the moment when developers are actively looking for solutions. That's the difference between a startup that struggles for years and one that gains traction quickly.
The $10 million seed round from Uncork Capital reflects this timing. Uncork's managing partner noted he invested in edge ML years ago, and it was premature. The company eventually sold to Spotify. But he sees this moment as different. The foundation is there now. The tools are there. The need is urgent.
Mirai's Go-to-Market Strategy and Product Positioning
Mirai isn't building a consumer product. They're building infrastructure. That means their go-to-market is fundamentally different from a consumer app company.
Their target customers are developers building AI-powered consumer applications. Think chat apps, transcription services, content creation tools, translation services, anything where inference is on the critical path. These developers have a problem: cloud inference is too slow or too expensive or both.
Mirai's positioning is elegant: we make your existing models run better on devices. You don't need to rebuild anything. You don't need to retrain. You take your existing model, run it through our optimization, and deploy. That's incredibly appealing to developers with existing products.
The SDK approach is key to adoption. If Mirai made developers dive into C++ and hand-optimize kernels, only experts would use them. Instead, they're building abstractions. You call a function, pass a model, and the optimization happens automatically. That's a completely different story.
The fact that they're targeting text and voice first is strategic. These are highest-impact for consumer apps and highest-impact for cost. Get wins in these modalities, build credibility, then expand to vision and other modalities.
The orchestration layer is also brilliant from a positioning perspective. Developers get on-device performance when possible, cloud fallback when necessary. They don't have to redesign their architecture. They can use Mirai as a drop-in optimization layer.
Benchmarks are their long-game move. If Mirai becomes the standard way to measure on-device performance, they become central to how models are evaluated. Model providers start optimizing for Mirai's platform. Developers use Mirai because models are optimized for it. That's a network effect.
The Investor Thesis and Strategic Positioning
The seed round is interesting because it tells you what sophisticated investors believe about the future of AI.
Uncork Capital's thesis is explicit: cloud inference economics are unsustainable. Every model maker will eventually need to run part of their inference workload at the edge. Mirai is positioned to capture that demand.
Look at the other investors. David Singleton (Dreamer) understands creator tools. Francois Chaubard from Y Combinator has seen thousands of startups and knows what fails and succeeds. Marcin Żukowski from Snowflake understands data infrastructure. Scooter Braun, despite his entertainment background, invests in infrastructure and has supported companies like Groq.
This investor pool isn't looking for a quick flip. They're backing the infrastructure layer they think will become essential. That's how you get $10 million from individuals and funds who know better than to jump at every AI startup pitch.
The positioning relative to other infrastructure companies is important. Hugging Face is primarily about model sharing and fine-tuning. Together AI focuses on distributed training and serving. Replicate handles serverless inference. Mirai is specifically about optimizing existing models for edge devices. It's a narrower niche, but within that niche, it's more focused.
This also explains why Mirai hired a 14-person technical team. That's small enough to be lean but large enough to tackle real infrastructure complexity. You need systems engineers, CUDA/Metal optimization experts, and SDK developers. You can't do this with five people.
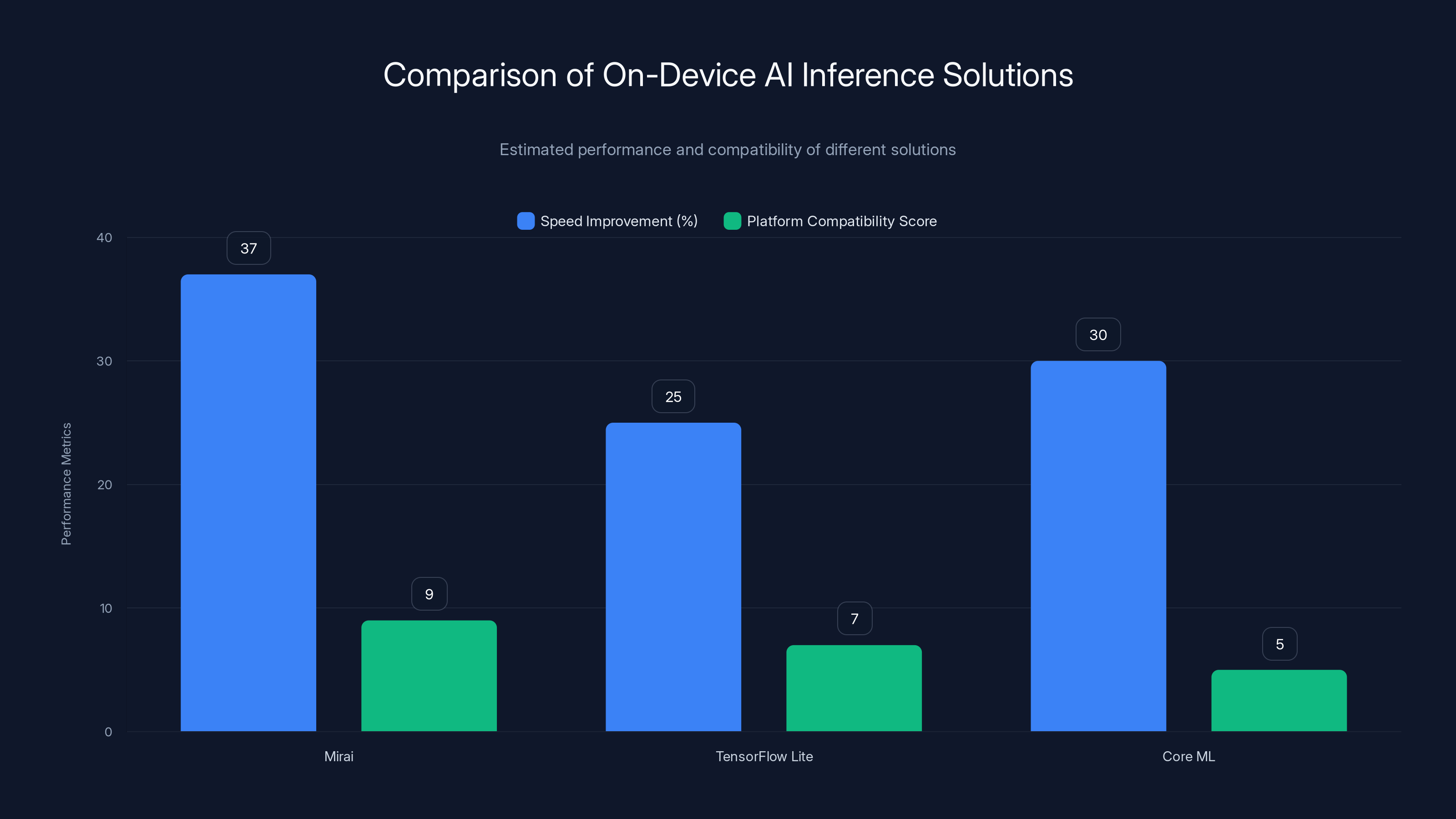
Mirai offers the highest speed improvement and platform compatibility among the compared on-device AI inference solutions. Estimated data.
Use Cases Where On-Device Inference Wins
Not every AI use case benefits from on-device inference. But many do, and they're increasingly important in the consumer space.
Real-time transcription is a killer use case. Imagine a note-taking app that transcribes as you speak. Round-tripping to a cloud API introduces latency that breaks the experience. On-device transcription is instant. Users can see captions appearing in real-time as they speak. That's a completely different product experience.
Content summarization works well on-device. A news app could automatically summarize articles. Reading list app could abstract key points. This doesn't require internet connectivity and happens instantly. Users expect it to be fast. Cloud APIs make it slow.
Personalization and search within an app is another win. A messaging app could use on-device models to rank which conversations appear first, based on the user's actual behavior. Without exposing anything to the cloud. Without privacy concerns. Without latency.
Offline-first applications are unlocked by on-device inference. A travel app could work completely offline, summarizing and translating content without internet. That's not possible with cloud inference.
Privacy-sensitive applications see huge benefits. Healthcare apps analyzing patient records. Financial apps analyzing transactions. Legal apps analyzing documents. All of this can happen locally without sending sensitive data to the cloud. HIPAA compliance and SOC 2 compliance become easier.
Language translation is compelling on-device. A messaging app could translate messages as you read them. No latency. No cloud dependency. Works offline. Same experience regardless of internet quality.
Classification and tagging of content is efficient on-device. Automatically tag emails as promotional or personal. Tag photos by content. Filter spam. All of this can happen locally, instantly.
The unifying theme is low latency, privacy, offline capability, or cost sensitivity. For those use cases, on-device inference is better than cloud. For pure capability cases (complex reasoning, massive context), cloud inference is still better.
The Technical Challenges Mirai is Solving
Building a successful on-device inference platform requires solving multiple hard problems simultaneously.
Model compilation is non-trivial. You take a model trained in PyTorch or TensorFlow and need to convert it to run efficiently on different hardware. Apple Silicon needs one format. Qualcomm needs another. Android needs yet another. Each conversion is a compilation problem, and getting each one right requires expertise.
Memory management is brutal on devices. A cloud GPU has 40GB of VRAM. An iPhone has 6GB of RAM shared with the operating system and the rest of your app. You need to page weights in and out of memory, manage tensor allocation carefully, and batch operations to avoid fragmentation. This is solved on data centers. It's not solved on mobile.
Numerical precision is tricky. You want quantized models (8-bit or 4-bit) because they're smaller and faster. But you need to do that without losing accuracy. Different layers might need different precision levels. Some layers are more sensitive to quantization than others. You need tools to analyze that automatically.
Hardware heterogeneity is endless. Different phone models have different chips. Different OSes have different constraints. Your optimization needs to target multiple hardware profiles, or your solution only works on premium phones.
Battery and thermal constraints matter on devices. Cloud servers can use unlimited power and cooling. Phones have batteries and thermal budgets. Running a model can drain battery visibly or cause the phone to thermally throttle. You need to balance speed against power consumption.
Versioning and updates are different on devices. Cloud inference can change instantly. On-device models need app updates. You need systems for managing model versions, ensuring compatibility, and allowing gradual rollouts.
Mirai's 14-person team is presumably deep in these problems. They've built solutions that other companies can use without solving them themselves. That's the value proposition.
)
Platform Strategy and Future Expansion
Mirai's current focus is Apple Silicon and text/voice. But their long-term vision is broader.
Android expansion is inevitable and important. Apple has about 30% of the smartphone market globally. Android has 70%. For on-device inference to be broadly relevant, it needs to support Android. The company has this in their roadmap.
Vision models are the next modality. Text and voice are important, but image understanding is increasingly critical for consumer apps. Photo editing, object recognition, visual search, and content moderation all benefit from on-device vision. As they expand vision support, their addressable market expands significantly.
Model provider partnerships are crucial. The company is already in talks with frontier model providers. The goal is to have models pre-optimized for Mirai's platform. If you download Llama 2 or Mistral from Hugging Face, it "just works" optimally on Mirai. That changes adoption dramatically.
Chipmaker partnerships are also underway. Working with Qualcomm, Apple, and others to ensure the runtime takes full advantage of specialized hardware. As new chips are released with better AI accelerators, Mirai's runtime can leverage them immediately.
Benchmarking infrastructure they're building is a long-game move. If Mirai becomes the standard way to measure on-device inference performance, they become central to how models are evaluated and compared. That's a soft moat against competition.
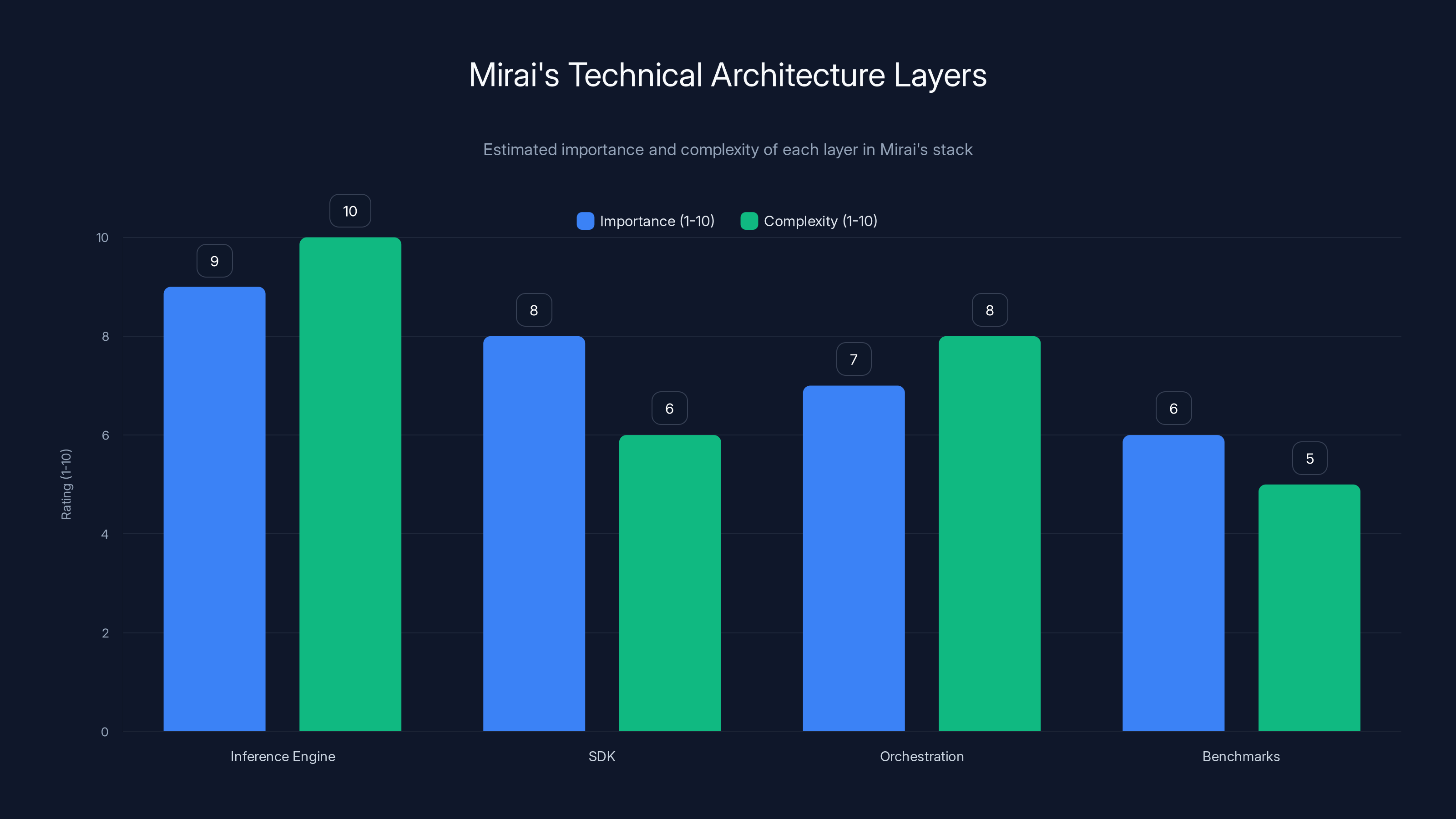
The inference engine is the most complex and important layer, crucial for optimization. The SDK and orchestration layers are vital for ease of use and flexibility. Benchmarks, while less complex, are essential for performance insights. (Estimated data)
Competitive Landscape and Differentiation
Mirai isn't entering an empty market. There are existing solutions for on-device inference. But none of them have the specific combination of optimization, developer experience, and founder credibility that Mirai brings.
TensorFlow Lite is Google's on-device inference framework. It's mature, well-documented, and free. But it requires developers to handle most optimization themselves. You quantize, you prune, you test. Mirai automates much of that.
Core ML is Apple's framework. It's native to iOS but limited to Apple devices. Doesn't solve the cross-platform problem.
ONNX Runtime is another open-source option. Good but requires developers to understand optimization deeply.
What Mirai offers that these don't is ease of use combined with aggressive optimization. You don't need to understand quantization or pruning. You upload a model, get back an optimized version, integrate it in five lines of code. That's a different product.
They're also not competing primarily on price. Infrastructure tools rarely do. They're competing on reducing developer friction. If integrating Mirai takes hours but saves your company $100,000 per month, you integrate Mirai.
The founder credibility also matters for differentiation. When Dima Shvets talks about on-device ML, he's speaking from experience. He's built consumer apps that needed this. He's not pitching theory; he's shipping solutions.
The Broader Implications for AI Infrastructure
Mirai's existence and funding signal something important about where AI infrastructure is heading.
For the past three years, the focus has been on building bigger, more capable models. GPT-4, Claude, Gemini. These are cloud-native products that require massive compute. That's not changing. But the infrastructure around using those models is shifting.
Some inference will always happen in the cloud. But increasingly, inference happens on the edge. Users want privacy. Developers want economics that work. Users want speed. The cloud is the tool for complex reasoning and processing. The edge is the tool for user-facing responsiveness and privacy.
This has implications for multiple industries:
Mobile app development gets fundamentally better UX. Faster, more responsive, works offline.
Privacy-sensitive industries (healthcare, finance, legal) can actually implement AI without massive regulatory complexity.
Emerging markets where internet connectivity is unreliable get real value from offline-capable AI.
Edge hardware manufacturers have stronger value propositions. If your phone can run advanced AI, it's more valuable.
Model providers need to think about on-device performance as a first-class concern, not an afterthought.
Mirai is building the infrastructure layer that enables this shift. That's why serious investors backed them. Not because on-device AI is novel, but because making it developer-friendly at scale is genuinely hard. Mirai is solving that hard problem.
Organizational Structure and Team Dynamics
A 14-person team at this stage is lean but focused. Let's think about what roles you need to actually ship on-device inference optimization.
Compiler and runtime engineers are essential. These are experts in taking models from frameworks like PyTorch and compiling them to run on specific hardware. This isn't build-another-inference-engine work. This is deep knowledge of LLVM, MLIR, and hardware-specific optimization.
Optimization specialists understand quantization, pruning, and knowledge distillation deeply. They can analyze a model, identify where accuracy loss will happen, and engineer solutions.
SDK developers build the interface developers actually use. They handle all the complexity of different hardware versions, different OS versions, edge cases, and error handling.
DevOps and infrastructure engineers manage benchmarking infrastructure, CI/CD for different platforms, and developer tooling.
That's a tough team to assemble. You need people who understand deep learning intimately, combined with people who understand systems programming and hardware. Those skill sets don't overlap much. Shvets and Moiseenkov brought capital and domain experience; they presumably attracted strong technical talent by offering equity and a real problem to solve.
The founder combination also suggests good organizational dynamics. Shvets brings the infrastructure vision and venture credibility. Moiseenkov brings product intuition and understanding of consumer apps. They complement each other.

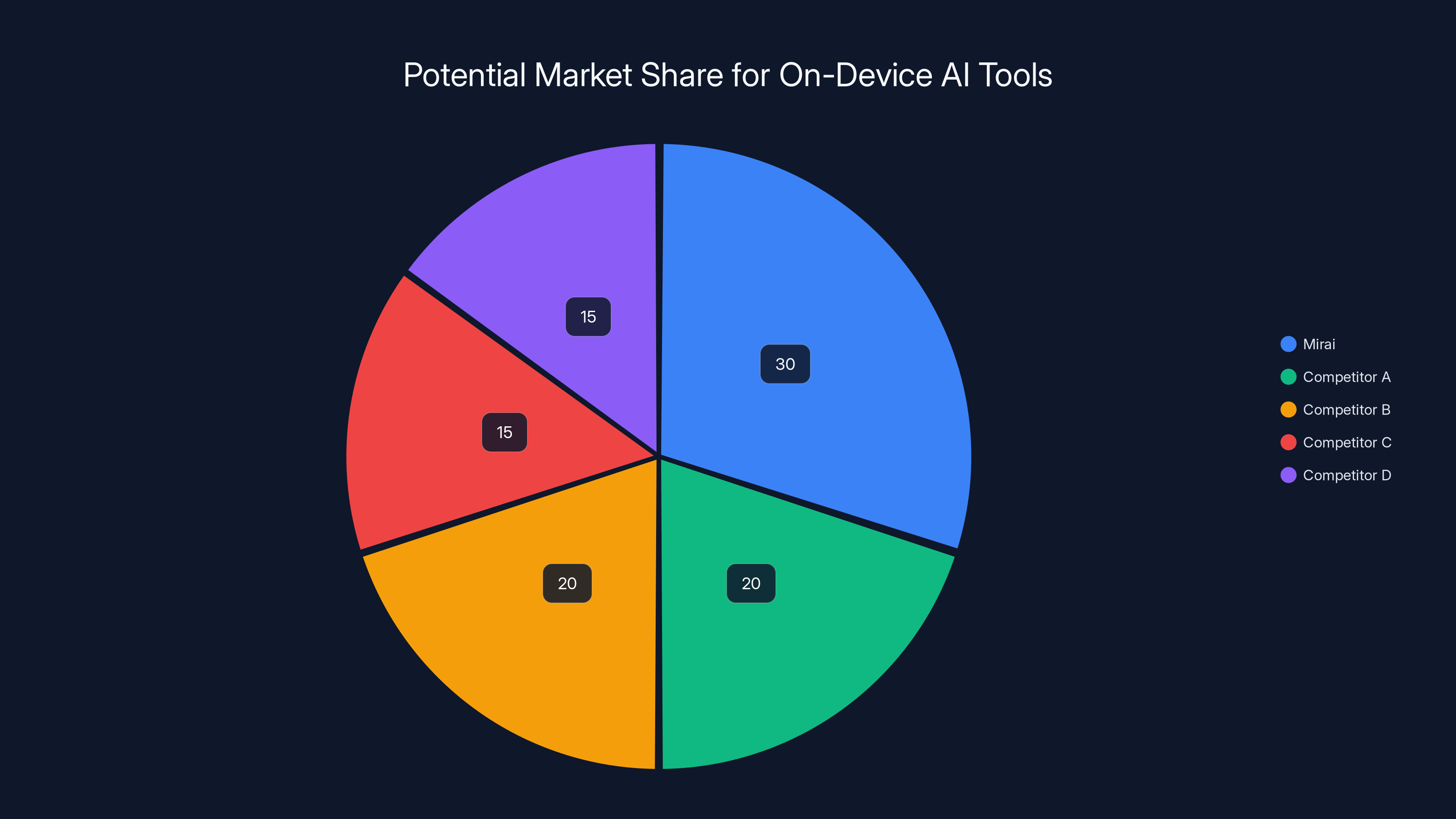
Estimated data: Mirai could capture 30% of the on-device AI market by becoming a standard or expanding services, while competitors share the remaining market.
Funding and Financial Sustainability
$10 million in seed funding is substantial but not unlimited. It signals investor confidence but also means they're on a specific timeline.
Typical use for seed funding at an infrastructure startup:
Team hiring (40-50% of budget): The founders can hire 5-6 experienced engineers over 18 months. That's probably where we get from 14 to maybe 20-25 people by Series A.
Operations and infrastructure (20-25% of budget): Developing benchmarking infrastructure, maintaining CI/CD pipelines, cloud costs for testing different hardware configurations.
Go-to-market (15-20% of budget): Developer relations, documentation, conferences, community building. For infrastructure, this is less about advertising and more about being where developers hang out.
Runway (10-15% of budget): Just cash reserves to survive if fundraising takes longer than expected.
At typical burn rate for a small infrastructure team in London (salaries, rent, cloud costs), $10 million is probably 18-24 months of runway. They need to hit meaningful traction and product-market fit before Series A.
For Mirai, traction probably looks like: developers adopting the SDK, measurable speed improvements demonstrated, partnerships with model providers, and ideally some public use cases or customers. By the time they raise Series A, they should have proof that their optimization actually works and that developers will use it.
The investor composition also suggests a path to Series A. Uncork Capital will likely lead or participate in Series A. The individual investors (many with infrastructure experience) will likely advise and potentially participate. They're building relationships that make the next round easier.
Regulatory and Compliance Considerations
On-device inference has some regulatory advantages over cloud inference, which could be a long-term moat.
Data protection regulations like GDPR are easier to comply with when data never leaves the device. CCPA, PIPEDA, and other privacy laws favor on-device processing.
Medical device regulations for healthcare apps are complex but simplified if the app can work offline without sending data to a cloud backend.
Export controls on AI technology are less relevant if models run on consumer devices rather than being accessed via APIs controlled by US companies.
Financial services regulations for banking apps similarly favor on-device processing.
These aren't massive competitive moats, but they're advantages. Companies will choose Mirai partly for infrastructure reasons and partly because it helps with compliance.
The flip side is that Mirai as a company needs to be careful about compliance. If they're in London and working with developers globally, they need to consider their own regulatory obligations around exporting optimization technology.

Long-Term Vision and Market Potential
The on-device AI market is growing, but how large can it actually be?
Estimate total TAM (total addressable market) for on-device inference tools: probably
Mirai's path to $1B+ valuation probably requires one of the following:
-
Becoming the standard for on-device inference. If 80% of consumer AI apps use Mirai, they capture massive value.
-
Expanding beyond developer tools into model optimization as a service. Instead of just providing SDK, they become the company that optimizes any model for any device.
-
Acquisition by a major company. Apple, Qualcomm, or a major cloud provider buying Mirai to own the edge inference stack.
-
Enterprise expansion. Beyond consumer developers, enterprise applications (medical, financial, industrial) have even higher willingness to pay for reliable on-device inference.
Shvets and Moiseenkov probably see one of these paths. They're not building a sustainable local business; they're building infrastructure they believe will become essential.
The Macro Trend: Edge AI Adoption
Mirai exists because the market is moving toward edge AI. This isn't just a Mirai opportunity; it's an industry shift.
Apple explicitly positioning on-device ML as a competitive advantage. Qualcomm investing in AI accelerators on chips. Google bringing TFLite improvements to every release. This is industry-wide momentum.
The economics drive this. Cloud inference doesn't scale to billions of inferences daily. The marginal cost is too high. The latency is problematic. The privacy implications are growing more serious.
The hardware enables this. Phone chips now have neural accelerators that can run models at reasonable speed. Battery efficiency is improving. Storage is cheap enough that gigabyte-sized models fit on devices.
Mirai is a bet that this trend becomes dominant. Not exclusive, but increasingly important. For consumer developers, edge will be the default, cloud the exception.
If that macro trend is correct, Mirai wins. If cloud inference remains dominant, Mirai is stuck in a niche. But the visible trend strongly suggests edge is winning.
Key Challenges and Risks
Mirai faces real challenges despite strong fundamentals.
Developer adoption is not automatic. Developers are creatures of habit. If they're used to cloud inference, switching requires motivation. Mirai needs to make the motivation so strong (easy integration, massive cost savings) that developers have no excuse not to adopt.
Model fragmentation is a problem. Every major lab releases models in different formats with different optimization challenges. Supporting Llama, Mistral, Gemma, and other models means engineering work for each one. This could become a scaling problem.
Hardware fragmentation on Android is brutal. Thousands of device models, different chipsets, different OS versions. Optimizing for this matrix is endless work. Apple's simplicity is a gift to developers. Android's diversity is a curse.
Accuracy degradation from optimization is real even if Mirai claims they avoid it. As models get more aggressive about on-device optimization, someone will optimize away actual capability. Managing this story is tricky.
Competitive response from major companies. If Mirai gains traction, Qualcomm, Apple, or Google could build equivalent tools natively into their platforms. Smaller company gets crushed by incumbents with larger teams and distribution.
Market saturation. If the on-device inference market becomes obvious, 20 companies will launch competing solutions. Differentiation becomes harder. Prices compress.
These are real risks. But founders who've built billion-user apps know how to navigate risk. Shvets and Moiseenkov have shipped products at scale. They're not naive about execution difficulty.
The Developer Experience Question
Infrastructure adoption ultimately hinges on developer experience. Mirai's success depends on this more than anything else.
A developer considering Mirai asks themselves:
- How many lines of code to integrate? (Mirai claims "a few")
- How much does it improve my product? (Latency drops, costs drop, works offline)
- What's the maintenance burden? (Model updates, version compatibility)
- What if something breaks? (Support, documentation, community)
On these dimensions:
Integration difficulty: Mirai seems to be winning. Zero-to-hero in minutes if they deliver on this promise.
Actual improvement: Real, measurable benefits from the 37% speed claim. That's meaningful.
Maintenance: TBD. This is where many infrastructure projects fail. Easy to integrate, hard to maintain.
Support: Early startup, so support will initially be founders and small team. As they grow, this gets better.
The fact that Shvets and Moiseenkov are technical founders is crucial here. They'll prioritize developer experience because they've lived as developers. They know what sucks about infrastructure tools.
Comparison: Mirai vs. Existing Solutions
Let's be concrete about how Mirai stacks up against alternatives.
| Factor | Mirai | TensorFlow Lite | Core ML | ONNX Runtime |
|---|---|---|---|---|
| Setup complexity | Easy | Medium | Easy (iOS only) | Hard |
| Automatic optimization | Yes | Manual | Partial | No |
| Cross-platform | Yes | Yes | No | Yes |
| Founded/Focused | 2024/On-device | 2017/General | 2016/Apple only | 2019/General |
| Commercial support | Yes | No | No | No |
| Speed optimization | 37% claimed | 10-20% typical | 15-25% typical | Varies |
This is oversimplified, but it shows Mirai's positioning. They're not the only option, but they're optimized for a specific use case: making inference easy and fast across devices.
Industry Partnerships and Ecosystem
Mirai's success depends partially on becoming part of the broader AI infrastructure ecosystem.
Partnership with model providers (Meta, Mistral, Together) puts Mirai models in their optimization pipeline. Developer downloads pre-optimized models. Win-win.
Partnership with chipmakers (Qualcomm, Apple) ensures Mirai can take full advantage of new hardware capabilities. As chips improve, Mirai's optimizer gets smarter automatically.
Partnership with app frameworks (Flutter, React Native) or development platforms could make integration even easier. Developers already using these platforms can add Mirai with a plugin.
These partnerships aren't guaranteed. But they're the natural evolution if Mirai succeeds initially. Once the pattern is clear (on-device inference matters), partnerships align incentives naturally.

Lessons for Other AI Infrastructure Startups
Mirai's approach offers lessons beyond just on-device inference.
Start with real problems: The founders built consumer apps and felt pain directly. They're not solving theoretical problems. That focus leads to better prioritization.
Founder credibility matters: In infrastructure, people bet on founders' ability to execute at scale. Shvets and Moiseenkov have shipped products used by hundreds of millions. That credential is worth $5+ million of the funding.
Focus is powerful: Mirai isn't trying to solve all inference problems. They're solving on-device inference for consumer apps. Deep focus enables deeper optimization than generalist solutions.
Developer experience is competitive advantage: TensorFlow is more mature. Core ML is native. But Mirai can win on ease of use. That's a competitive advantage that compounds.
Timing matters: Mirai exists now because hardware, models, and market conditions are right. Five years too early, they're irrelevant. Five years too late, the market is commodified. They nailed the timing.
What's Next for Mirai
If Mirai executes well, here's the likely trajectory:
Next 12 months: SDK availability, integration by early adopters, partnerships announced, benchmarks published. Goal is proof that the optimization works and developers adopt.
12-24 months: Series A fundraising on back of adoption metrics, scaling team, Android support, vision model optimization, developer community growth.
2-3 years: Becoming standard in on-device inference ecosystem, $50M+ ARR, enterprise customers, potential acquisition targets.
The company is at a stage where execution now determines whether they become essential infrastructure or one of many failed attempts. The fundamentals are right. The team is right. The timing is right. Execution is everything.
FAQ
What is on-device AI inference and why does it matter?
On-device inference means running AI models directly on phones, laptops, or edge devices rather than sending data to cloud servers for processing. It matters because it enables faster response times, reduces costs, works offline, and preserves user privacy by keeping sensitive data local. For consumer applications, on-device inference often provides better user experience than cloud-dependent alternatives.
How does Mirai's approach differ from other on-device inference solutions?
Mirai focuses on making existing models run faster on consumer hardware without modifying the model itself. Unlike TensorFlow Lite (which requires manual optimization) or Core ML (which only works on Apple devices), Mirai claims to optimize models automatically across multiple platforms with just a few lines of code. Their Rust-based engine reportedly achieves up to 37% speed improvements while preserving model accuracy.
What are the main benefits of on-device AI inference for app developers?
Key benefits include dramatically reduced infrastructure costs (from $10,000+ monthly for cloud inference to near-zero), significantly lower latency (50-200ms versus 200-500ms for cloud), offline capability, improved user privacy, and reduced dependency on external APIs. For a million-user app doing daily inferences, on-device inference can save hundreds of thousands of dollars annually in cloud costs.
What types of AI models can run effectively on devices?
Smaller language models (3-13 billion parameters), voice recognition models, vision models, and specialized models for classification or summarization work well on devices. Frontier models (70+ billion parameters) require too much memory currently, but as hardware improves and quantization techniques advance, larger models become feasible. Text and voice models are most practical today; vision is improving.
What are the technical limitations of on-device inference?
Key limitations include storage constraints (models must fit on devices), memory constraints (limited RAM shared with other apps), slower execution compared to cloud GPUs, battery consumption considerations, and the need for model updates through app updates rather than instant cloud deployment. Additionally, not all inference tasks can be completed locally; very large models or complex queries still need cloud fallback.
How does on-device inference affect user privacy?
On-device inference significantly improves privacy because user data never leaves the device and never reaches company servers. Sensitive information like medical records, financial data, or personal communications stays local. This is especially important for healthcare, finance, and legal applications where privacy regulations (HIPAA, CCPA, GDPR) create compliance complexity with cloud-dependent solutions.
What is quantization and why does it matter for on-device models?
Quantization reduces the precision of numbers stored in models, typically converting 32-bit floating point numbers to 8-bit integers. This reduces model size by 75% while maintaining similar accuracy. For on-device use, quantization is essential because it allows models to fit in limited storage and execute faster with lower memory requirements. Mirai's approach claims to apply quantization without accuracy loss.
How much does on-device inference typically cost compared to cloud inference?
Cloud inference typically costs
When should developers use on-device inference versus cloud inference?
Use on-device inference when: latency matters (chat, transcription, real-time translation), costs are significant (high-volume apps), privacy is critical (healthcare, finance), offline capability is needed, or user experience is sensitive to network conditions. Use cloud inference when: you need maximum capability (complex reasoning), models are too large to optimize for devices, or you need real-time model updates. Most modern apps benefit from hybrid approaches with on-device for fast operations and cloud fallback for complex tasks.
What is Mirai's orchestration layer and how does it help developers?
Mirai's orchestration layer automatically routes inference requests that can't be completed locally to cloud APIs transparently. If a model doesn't fit on the device or a request requires more computation than available, the system sends it to the cloud automatically. This means developers can build once and the system handles optimization automatically, switching between on-device and cloud as needed without code changes.
Conclusion
Mirai represents something important: the maturation of on-device AI from interesting experiment to practical necessity. The timing, team, and approach all align perfectly.
The founders aren't academics theorizing about edge computing. They're builders who've shipped consumer products at massive scale and felt the pain of infrastructure that doesn't work for their needs. That lived experience shows in how they're positioning the company.
The $10 million seed funding isn't about believing on-device AI is possible. It's about believing that Mirai specifically has solved the developer experience problem in a way other solutions haven't. That's a higher bar and better validation.
What's genuinely interesting is that Mirai isn't revolutionary. On-device inference exists. Optimization techniques are known. The problem they're solving is mundane: making it easy for developers to use. But solving mundane problems at scale is how you build $1 billion companies.
For developers, the immediate takeaway is simple: if you're building consumer AI applications, on-device inference should be part of your architecture conversation. The economics probably justify it. The UX will be better. The privacy story will be stronger. Mirai makes implementing it dramatically easier than alternatives.
For the broader AI infrastructure landscape, Mirai signals a shift that's already visible but accelerating. Cloud will remain important for frontier inference. But increasingly, the default will flip: on-device for most things, cloud when you need maximum capability. Infrastructure companies that enable that shift efficiently will become essential.
Mirai is betting on that shift. Their $10 million seed validates that serious investors agree. The question now is execution. Can they ship an SDK that developers actually love? Can they build partnerships with model providers? Can they expand to Android without losing focus? Can they maintain their technical advantage as competition inevitably arrives?
Those are execution questions, not strategy questions. And based on the founding team's track record, execution is exactly where they'll focus.
The on-device AI wave is real. Mirai is one of the companies trying to capture it. But they're potentially the best positioned to do so.

Key Takeaways
- Mirai raised $10M to make on-device AI inference practical for consumer developers, solving real latency and cost problems
- Founded by Dima Shvets (Reface) and Alexey Moiseenkov (Prisma), bringing proven product-building credibility to infrastructure
- On-device inference costs drop from $10,000+ monthly (cloud) to near-zero while achieving 2-5x faster latency
- Hardware maturity, efficient models, and economics now make edge AI viable; the challenge is developer experience, which Mirai targets
- Broader market shift toward hybrid architectures: on-device for user-facing responsiveness, cloud for complex reasoning
Related Articles
- Sarvam AI's Open-Source Models Challenge US Dominance [2025]
- Meta, NVIDIA Confidential Computing & WhatsApp AI [2025]
- Rapidata's Real-Time RLHF: Transforming AI Model Development [2025]
- Reliance's $110B AI Investment: India's Tech Ambition Explained [2025]
- Nvidia and Meta's AI Chip Deal: What It Means for the Future [2025]
- MSI Vector 16 HX AI Laptop: Local AI Computing Beast [2025]

