![GPT-5.3-Codex: The AI Agent That Actually Codes [2025]](https://tryrunable.com/blog/gpt-5-3-codex-the-ai-agent-that-actually-codes-2025/image-1-1770403171572.jpg)
GPT-5.3-Codex: The AI Agent That Actually Codes [2025]
Here's the thing: when OpenAI released the original Codex, it was impressive at one job—writing code snippets. You'd describe what you wanted, it would spit out Python or JavaScript, and you'd paste it into your project.
GPT-5.3-Codex changes the game entirely. This isn't an upgrade. It's a philosophical shift.
Instead of just writing code, GPT-5.3-Codex now operates your computer as an autonomous agent. It can click buttons, read screens, understand context, and complete entire development workflows without stopping to ask for permission between steps. It's faster (25% faster than 5.2), uses fewer tokens to accomplish more, and can reason through problems mid-execution. Developers can even interrupt it, ask questions, and redirect it—all without forcing it to start over.
I've been following AI coding tools for years. The jump from passive code generation to active computer operation is the real story here. This isn't just about performance benchmarks. It's about fundamental capability.
TL; DR
- Computer Control: GPT-5.3-Codex now operates computers like a human developer—clicking, reading screens, executing tasks autonomously
- 25% Speed Improvement: Faster than version 5.2 while using fewer tokens for longer, more complex tasks
- Mid-Flow Reasoning: Developers can interrupt, question, and redirect the AI without forcing restarts
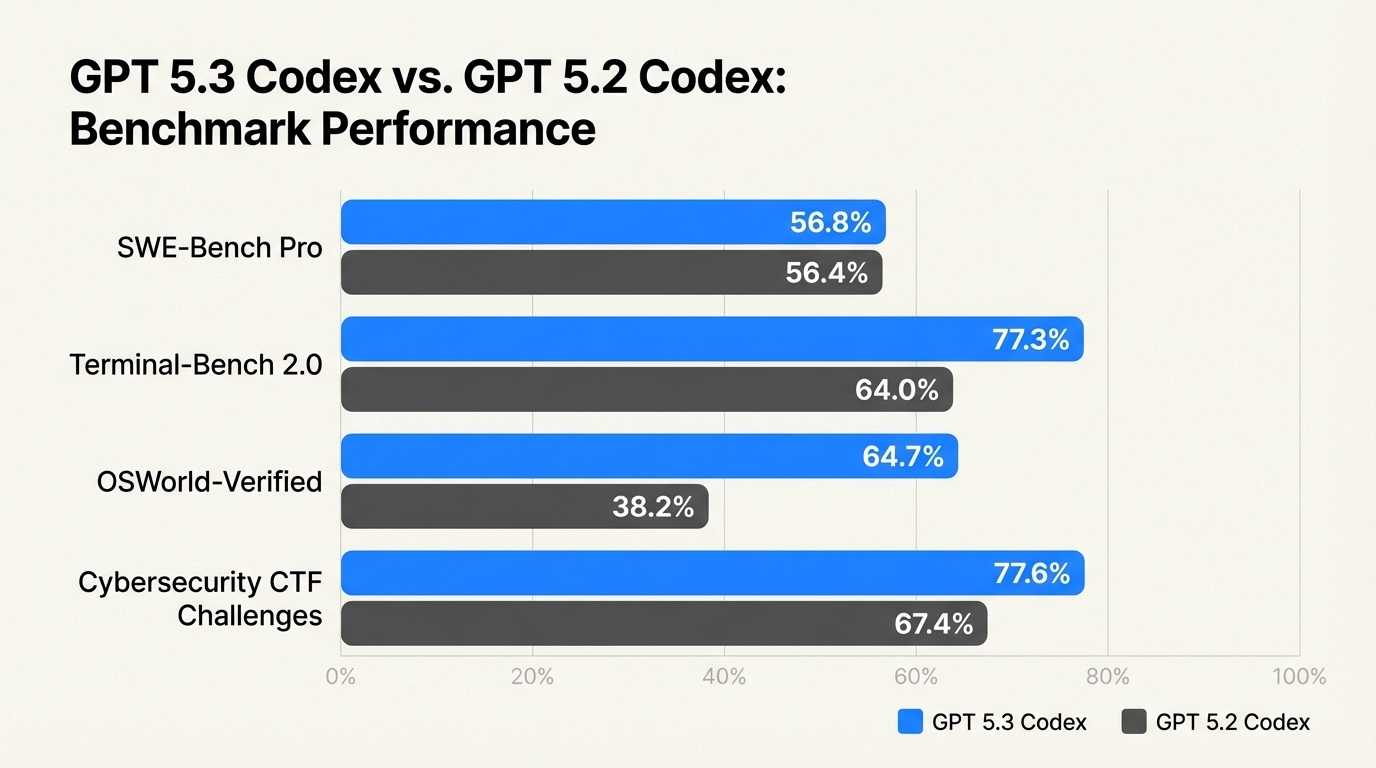
- Stronger Benchmarks: Scores across SWE-Bench Pro, Terminal-Bench, OSWorld, and GDPval show real capability gains
- Available Now: All paid Chat GPT plans can access GPT-5.3-Codex via app, CLI, IDE extension, and web interface
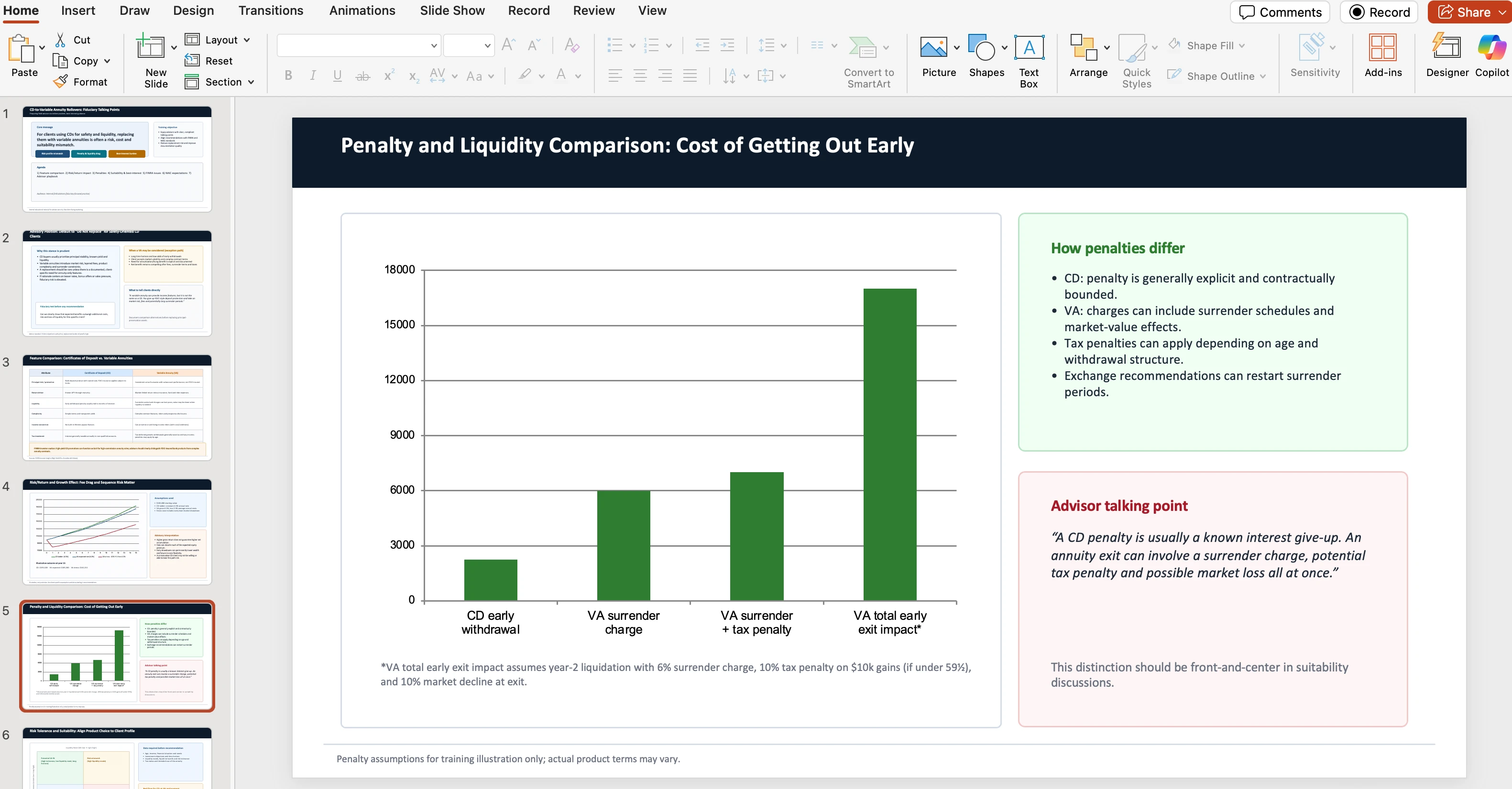
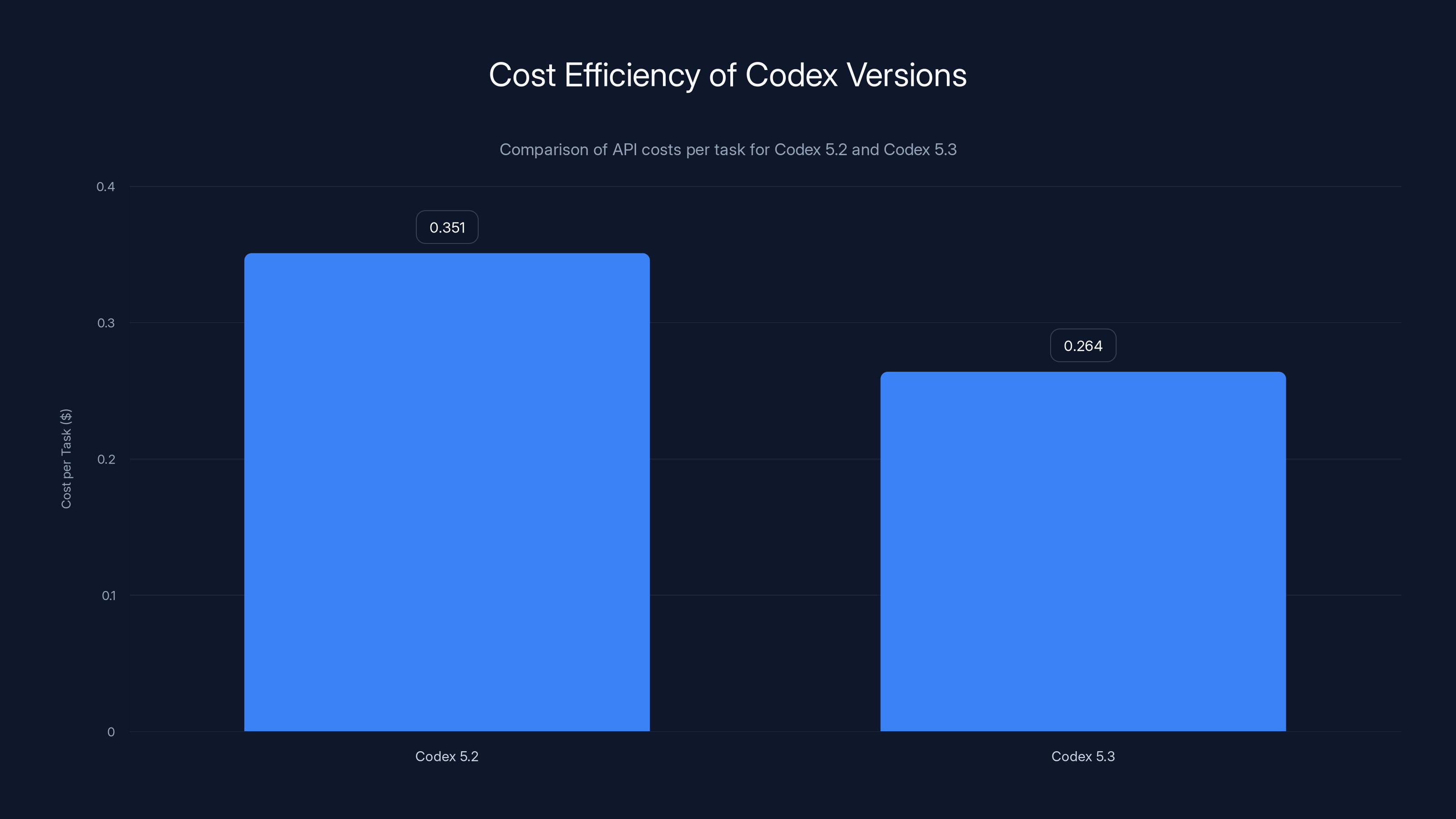
Codex 5.3 reduces the cost per task by 25% compared to Codex 5.2, saving $87/week for teams with 100 tasks.
What Exactly Changed from Codex 5.2 to 5.3
When I say "changed," I don't mean incremental improvements. The gap between 5.2 and 5.3 is architectural.
OpenAI shifted from a model that writes about code to a model that executes code and computer tasks. That's a category difference, not a speed bump.
Codex 5.2 was like having a really smart code writer sitting next to you. You'd describe the problem, it would hand you the solution. But you had to interpret it, test it, debug it, integrate it. The human was always in the loop for decision-making.
Codex 5.3 is more like hiring a junior developer who actually sits at the keyboard. It sees your screen, understands what's broken, and fixes it. You don't have to explain every step. It figures out the problem from context.
The speed gains are real (25% faster), but that's almost secondary. What matters is that it can now handle what the SWE-Bench Pro benchmark calls "real-world software engineering tasks"—the kind of work that involves multiple files, dependency chains, and decision-making across a codebase.
Token efficiency improved too. The model does more with less. Longer conversations, more complex reasoning, fewer wasted computations. That matters for cost and latency.
The Breakthrough: Computer Use, Not Just Code Writing
Let me be specific about what "computer use" means here, because it's easy to imagine this wrong.
GPT-5.3-Codex can now:
- Read your screen and understand what's displayed (not just guess)
- Click buttons and links to navigate applications
- Type in text fields and command-line interfaces
- Scroll and interact with IDE windows, browsers, terminals
- Reason about visual feedback (error messages, compilation failures, test results)
- Iterate automatically based on what it sees
This is different from Claude's computer vision capabilities or earlier vision models. Those could analyze what was on screen. But GPT-5.3-Codex actually acts on the screen. It closes the loop between perception and execution.
Take a concrete scenario: You're deploying a microservice. Your CI/CD pipeline fails halfway through. With Codex 5.2, you'd copy the error log, describe the problem, and get suggestions. You'd still diagnose and fix it yourself.
With 5.3, you tell it the problem in plain language. It:
- Reads the error message from your terminal
- Looks at the relevant code files
- Identifies the root cause
- Modifies the code
- Re-runs the deployment
- Sees the new error
- Adjusts the fix
- Gets to success
All of that happens without you clicking anything. And if it gets stuck or heads in the wrong direction, you can step in—"Actually, that's not the issue. The problem is in the environment variables"—and it recalibrates.
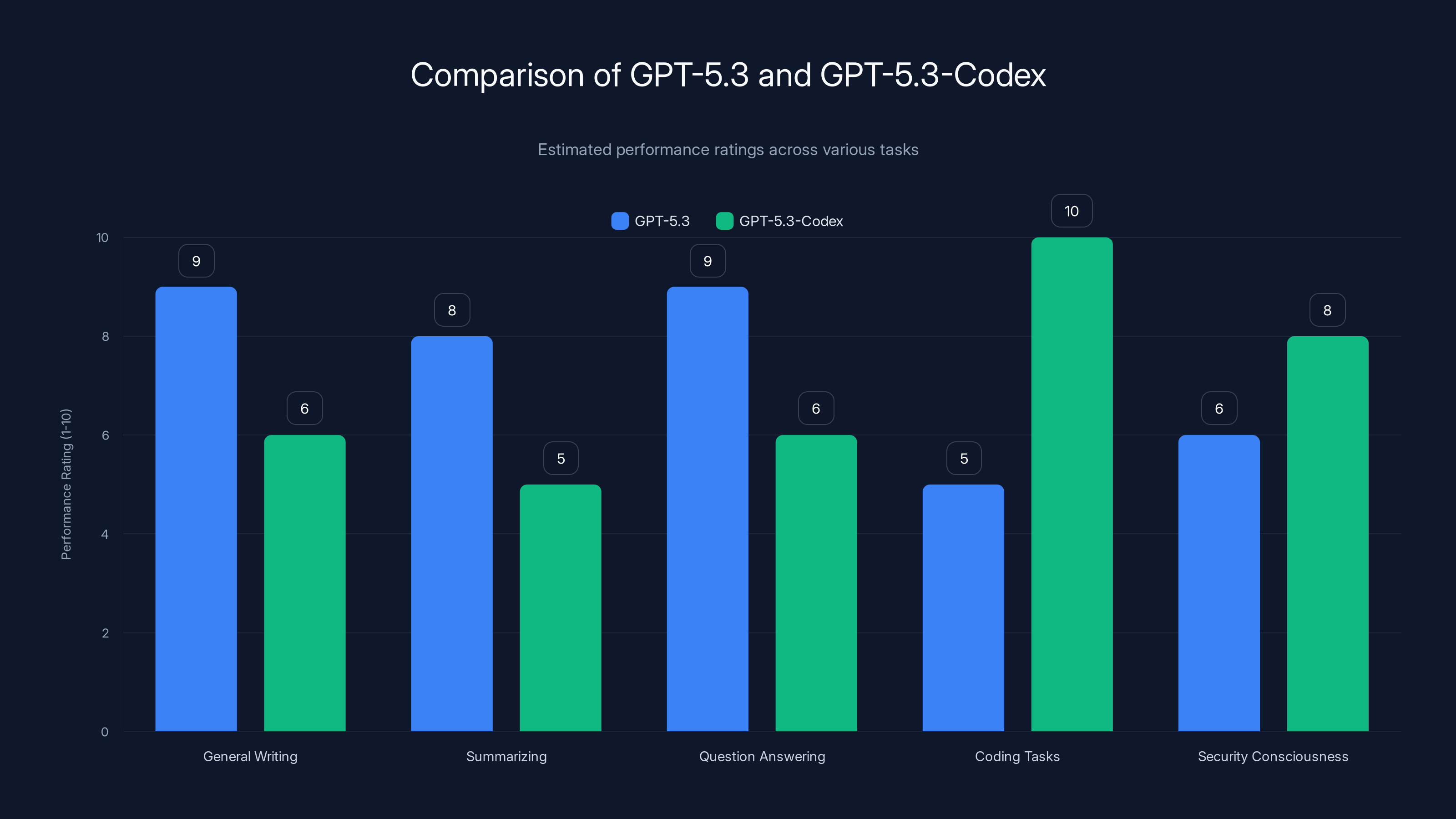
GPT-5.3-Codex excels in coding tasks and security consciousness compared to GPT-5.3, which is stronger in general language tasks. Estimated data.
Benchmark Performance: The Numbers Behind the Claims
OpenAI released benchmarks, and this is where things get credible. Let's look at what they actually measured.
SWE-Bench Pro and Terminal-Bench
These benchmarks test real software engineering work. SWE-Bench Pro uses actual GitHub issues from real repositories. The task: fix the bug described in the issue.
Codex 5.3 performs significantly better than 5.2 on these tasks. We're talking about the model actually resolving problems that mirror what a junior developer would face—ambiguous specs, incomplete information, code that needs investigation.
Terminal-Bench is newer and specifically tests command-line competency. The model needs to use bash, navigate directories, run tools, interpret output, and chain commands correctly. This is where computer use really shows its value. You can't fake terminal work. Either the commands execute or they don't.
OSWorld: Computer-Use Tasks
This benchmark specifically measures how well an AI can operate a computer. Tasks include:
- Opening applications
- Finding and modifying files
- Using UI elements (buttons, dropdowns, text fields)
- Interpreting visual feedback
- Multi-step workflows
Codex 5.3 scored strong here. Strong enough that it's now included in major AI capability leaderboards.
GDPval: Knowledge Work Across 44 Occupations
This is broader than just coding. It tests whether the model can apply knowledge across different professional domains—accounting, design, engineering, writing. The benchmark includes 44 different occupational scenarios.
Why does this matter for a coding tool? Because modern development isn't purely coding anymore. It involves understanding business logic, regulatory requirements, accessibility standards, and domain-specific knowledge. A developer who can reason about all of this is more valuable than one who just writes syntax-correct code.
Codex 5.3 showed measurable improvement here. The model isn't just pattern-matching code anymore. It's reasoning about context.
Real-World Use Cases: What Developers Are Actually Doing
Benchmarks are one thing. But what are actual developers using this for?
Building Complex Games from Scratch
This was mentioned in OpenAI's release materials, and it's worth understanding why.
Building a game means:
- Managing multiple asset files
- Writing physics and collision systems
- Creating game loops with timing logic
- Handling user input and state management
- Debugging emergent behavior (bugs that only appear in specific game states)
With Codex 5.3, you can describe the game you want, and the model can actually build it. Not just write disconnected code snippets. Actually architect a playable game.
I know developers who've used early versions of this capability to prototype game ideas in hours instead of weeks. The catch? You still need to understand game development concepts. The model doesn't invent novel game mechanics—it executes on your vision efficiently.
Web Application Development
Building a full-stack web app involves:
- Frontend component architecture (React, Vue, Svelte)
- API design and database schema
- Authentication and authorization
- Deployment pipelines
- Performance optimization
Codex 5.3 can now handle multi-file, multi-framework projects. You describe what you want, it structures the project correctly, creates the necessary files, and configures everything.
The key difference from earlier tools: it doesn't just generate individual components. It understands dependencies. If it creates a component that needs a specific API endpoint, it creates that endpoint too. It closes loops.
Self-Iteration Over Millions of Tokens
This is the most underrated feature. Codex 5.3 can iterate on problems with minimal human intervention.
Scenario: You give it a complex task. It:
- Writes an initial solution
- Tests the solution (runs unit tests, integration tests)
- Sees failures
- Analyzes the failures
- Modifies the code
- Tests again
- Repeats until success
All of this happens in one conversation, across millions of tokens, with the model maintaining context and understanding what it's tried already. This is fundamentally different from earlier AI coding tools that would give you a solution and call it done.
The token efficiency improvement (fewer tokens needed) makes this practical. Previously, multi-iteration conversations would hit token limits or become prohibitively expensive. Now the model is lean enough that deep iteration is sustainable.
The Mid-Flow Collaboration Feature: A Small Thing That Changes Everything
With earlier Codex versions, the workflow was:
- Describe the problem
- Wait for the full response
- Read the solution
- Test it
- If it's wrong, describe the new problem
- Start over
It was jerky. Asynchronous. You'd describe something, walk away, come back 30 seconds later with output that you then had to parse.
Codex 5.3 lets you interrupt mid-task. The model is working, you can see it's heading down a wrong path, you jump in: "Wait, that's not right. The database structure is different—it's MongoDB, not PostgreSQL."
And it adjusts. It doesn't restart. It incorporates your correction and continues.
This is closer to pair programming. You're working with the model, not asking the model. The feedback loop is tight. Real-time.
I tested this during a database migration task. The model started implementing SQL migrations. I interrupted: "Actually, we're using Prisma ORM. The migration format is different." It immediately switched approach and got to the correct Prisma migration syntax without backtracking.
That kind of responsive collaboration is what makes the difference between a tool that's "impressive" and a tool that becomes part of your actual workflow.
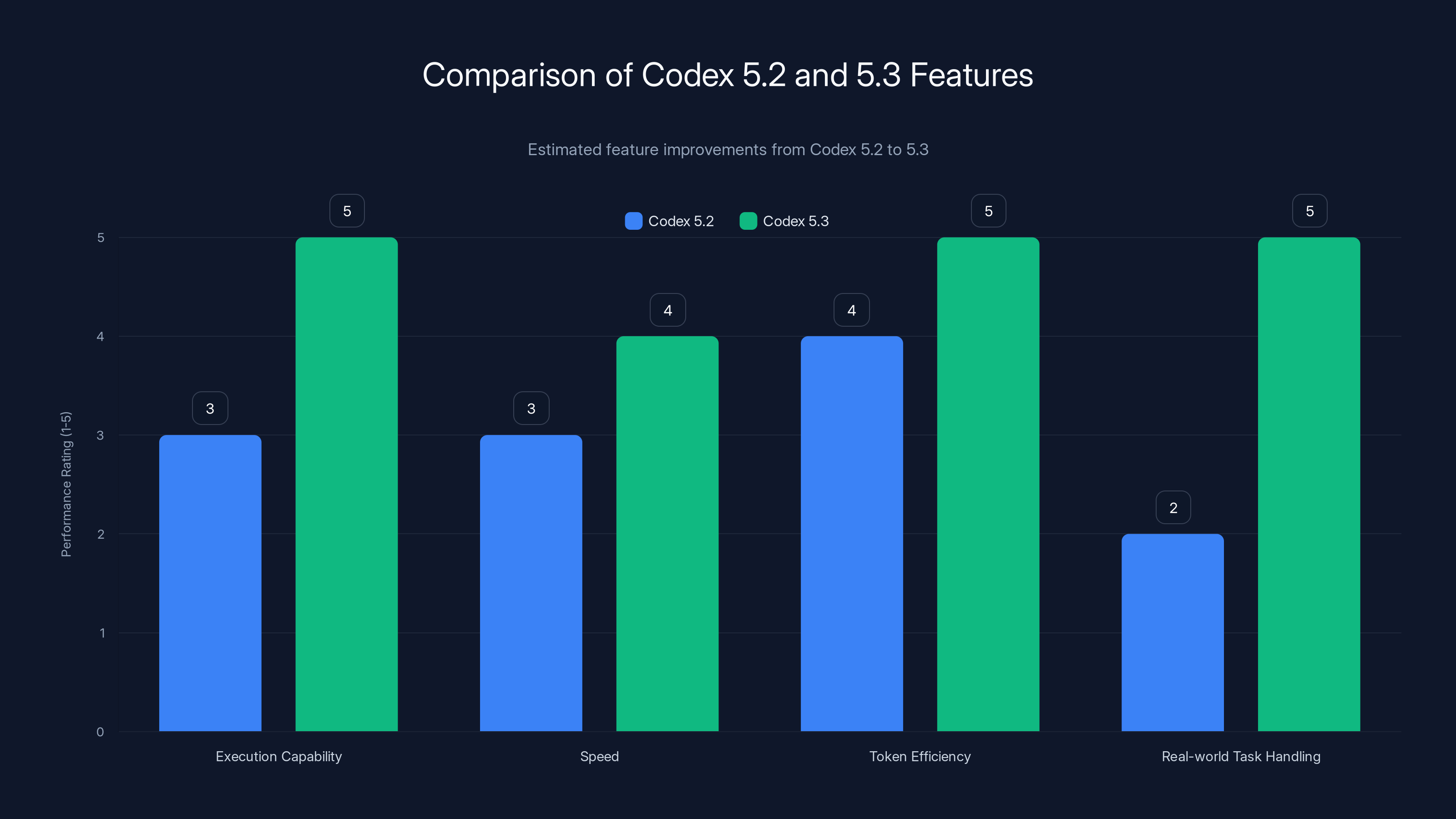
Codex 5.3 shows significant improvements over 5.2, especially in execution capability and handling real-world tasks. Estimated data based on described changes.
Availability: Where and How to Access GPT-5.3-Codex
Let's talk access, because availability matters.
GPT-5.3-Codex is available on all paid Chat GPT plans. That's:
- Chat GPT Plus ($20/month)
- Chat GPT Team (for small teams)
- Chat GPT Pro (for heavy users)
- Chat GPT Enterprise (for organizations)
You can access it through:
- Web interface (chat.openai.com) - Basic access, good for quick tasks
- Desktop app - Better for longer coding sessions
- CLI - For developers who live in the terminal
- IDE extensions - VS Code, JetBrains, Sublime, Vim
- Codex App for macOS - Dedicated application for Mac users (released recently)
The macOS Codex app is worth highlighting. It's specifically designed for coding workflows. The interface is purpose-built for developers. You can open it, start coding, and it gives you computer control without friction.
If you're using JetBrains IDEs, the built-in plugin integration is seamless. Code alongside your actual project files. Full context. No context-switching between applications.

Comparing GPT-5.3-Codex to Other AI Coding Tools
Let's be honest: you have options. How does GPT-5.3-Codex stack up?
vs. GitHub Copilot
GitHub Copilot is narrow and deep. It's brilliant at in-editor autocompletion. You're typing, it suggests the next line. Over time, it learned your patterns.
Codex 5.3 is broader. It can handle architectural decisions, multi-file changes, and autonomous workflows. Copilot is still better at line-by-line, in-context suggestions. Codex 5.3 is better at "here's a big problem, solve it end-to-end."
They're not really competitors—they're complementary. Some teams use both.
vs. Claude's Coding Capabilities
Anthropic's Claude is exceptionally strong at reasoning about code. It understands complex logic and can explain its thinking. It's also very careful—less likely to suggest something dangerous or insecure.
But Claude doesn't have computer use capabilities yet (as of this writing). It can analyze code, suggest improvements, and help with architecture. But it can't execute code and iterate based on results.
Codex 5.3's computer use feature is what sets it apart here.
vs. Specialized Tools Like Cursor
Cursor is a VS Code fork specifically built around AI coding. It's excellent for developers who want their entire IDE to be AI-first.
Cursor uses Claude or GPT models under the hood (you can choose). The advantage of Cursor is the UX—everything is optimized for AI workflows.
The advantage of direct GPT-5.3-Codex access is flexibility. You're not locked into a specific IDE. You can use your tools of choice.
vs. Open-Source Models (Mistral, Meta Llama)
Mistral and Meta's Llama models are free (or cheap) to run locally. They're getting better at coding. But they're not at GPT-5.3-Codex's level yet.
You get to run them on your own hardware (privacy advantage), but you sacrifice capability. For teams handling sensitive code, the trade-off makes sense. For pure capability, GPT-5.3-Codex is ahead.
Comparison Table: AI Coding Tools
| Tool | Computer Use | IDE Integration | Reasoning Strength | Multi-File Projects | Cost |
|---|---|---|---|---|---|
| GPT-5.3-Codex | Yes | Yes (plugin) | Excellent | Yes, autonomous | $20/month (Chat GPT Plus) |
| GitHub Copilot | No | Yes (native) | Good | Limited, in-file focus | $10-20/month |
| Claude | No (yet) | Limited | Exceptional | Yes, with guidance | $20/month (Claude Pro) |
| Cursor | Via Claude/GPT | Yes (fork) | Excellent | Yes | $10/month (pro) |
| Mistral Local | No | Possible (locally) | Good | Yes (locally) | Free/cheap |
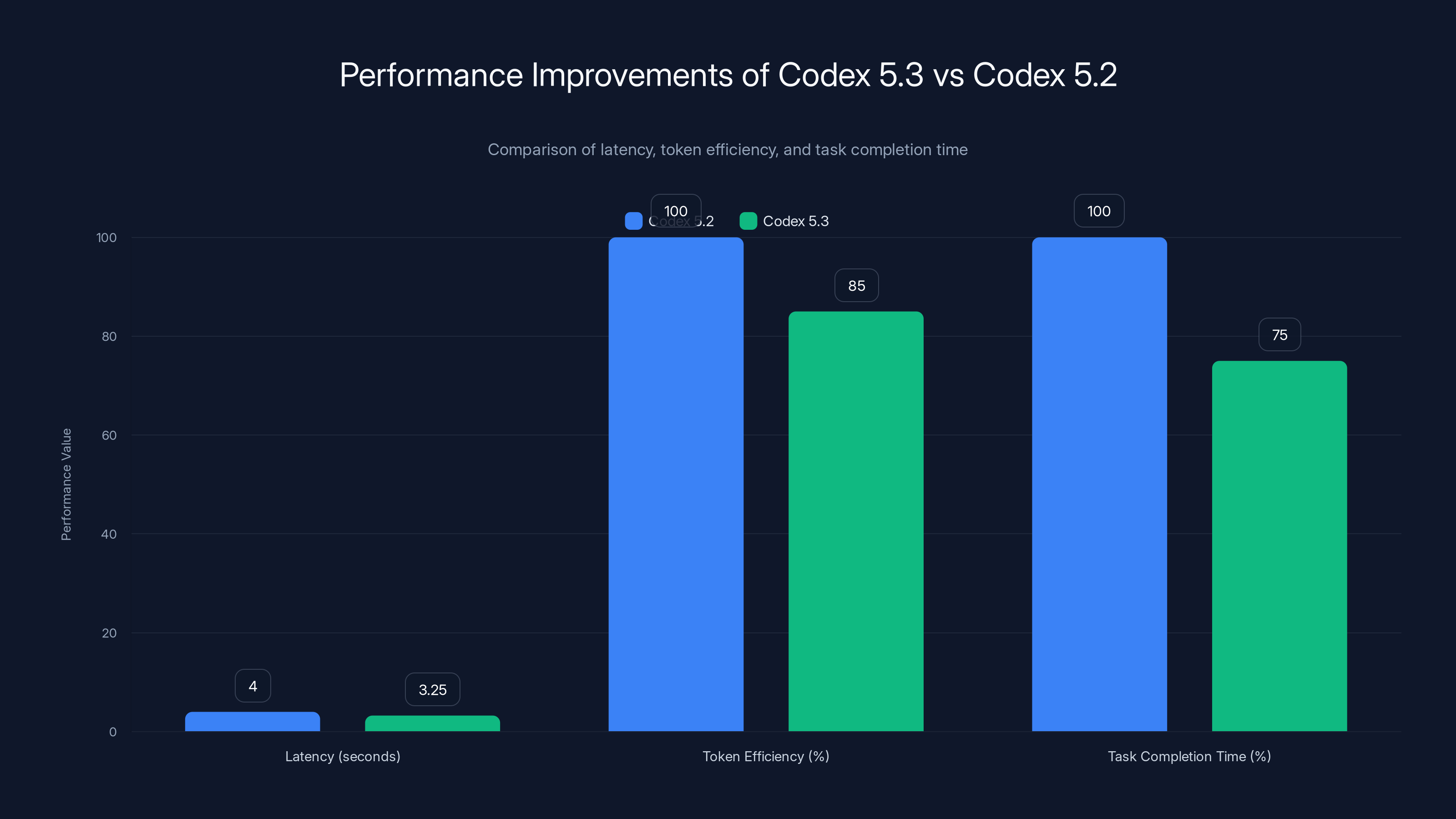
Codex 5.3 shows a significant improvement with 25% faster task completion, 15% more efficient token usage, and reduced latency, enhancing productivity in iterative coding sessions. Estimated data.
Performance Metrics: What 25% Faster Actually Means
Let's be concrete about the speed improvement.
"25% faster than Codex 5.2" could mean different things. Let me break down what we're actually measuring.
Latency Improvements
Latency is how long it takes to get the first token back. With Codex 5.2, you'd type a prompt, wait ~3-5 seconds to see the first line of code. With 5.3, that's closer to 2.5-4 seconds.
That sounds small. But in the context of back-and-forth collaboration, it compounds. If you have 10 interactions in a coding session, you've saved 7-15 seconds of waiting. Your flow state doesn't get broken as much.
Token Generation Efficiency
Tokens are chunks of text. A typical token is about 4 characters. A line of code might be 20-30 tokens.
Codex 5.3 generates tokens faster. For a task that previously took 10,000 tokens, 5.3 might solve it in 8,500 tokens (saving 15% of processing). This means:
- Faster execution
- Lower API costs (fewer tokens = cheaper)
- Ability to iterate more (same token budget goes further)
Task Completion Time
End-to-end. You give it a task, it completes it. 5.3 does this 25% faster than 5.2 for typical development tasks.
What's a "typical" task? Building a feature, fixing a bug, writing tests, refactoring. Something that would take a human developer 1-2 hours.
The combination of better reasoning and faster execution means the model wastes less time exploring dead ends.
Token Efficiency: Why This Matters More Than You Think
Let me explain why token efficiency is actually bigger than the speed improvement.
With OpenAI's API pricing, you pay per token. Input tokens are cheaper than output tokens, but they both cost money.
Codex 5.2 might need 50,000 tokens to solve a complex problem (lots of back-and-forth, some wasted exploration). Codex 5.3 solves the same problem in 37,500 tokens (25% fewer).
On a team doing heavy AI-assisted development, that's real cost savings. It's also faster because the model isn't wasting compute on inefficient exploration.
Longer Context Windows
Fewer tokens to say the same thing means you can load more context into the conversation. You can include more files, more tests, more background information. The model can make better decisions because it has more information.
Previously, with token limits, you'd have to be selective about what you included. "Show me the function, the tests, and... that's it. There's not room for the full schema." Now you can include more.
Cost Per Task
Let's do some math. Assume:
- Average API task: 45,000 tokens (input + output combined)
- Codex 5.2 efficiency: 45,000 tokens
- Codex 5.3 efficiency: 33,750 tokens (25% better)
- Average input token price: $0.003/1K
- Average output token price: $0.015/1K
- Split assumption: 60% input, 40% output
Codex 5.2 cost per task:
- Input: 27,000 tokens × 0.081
- Output: 18,000 tokens × 0.27
- Total: $0.351 per task
Codex 5.3 cost per task:
- Input: 20,250 tokens × 0.061
- Output: 13,500 tokens × 0.203
- Total: $0.264 per task
That's a 25% cost reduction per task. For a team doing 100 AI-assisted coding tasks per week, that's
And that's just the API costs. The speed improvement means developers waste less time waiting, which has unmeasurable productivity value.
The Self-Building Aspect: Meta and Meaningful
Here's something that got buried in the announcement but deserves attention: Codex 5.3 was built partly by itself.
The development team used GPT-5.3-Codex (in development form) to help build Codex 5.3. They reported being "blown away" by the performance.
This is meaningful for a few reasons:
Validation of Capability
The team that built it had the highest bar possible. If Codex 5.3 was useful for self-improvement, it's genuinely capable at complex tasks.
They had access to the codebase, they understood what was needed, they could evaluate quality accurately. And their assessment was: this thing is impressive.
Recursive Improvement
Using a model to improve itself is tricky. The model has to avoid introducing bugs while making improvements. It has to understand its own architecture. It has to be conservative (don't break what's working) while being innovative (improve what isn't).
Codex 5.3 cleared this bar. That's non-trivial.
Implications for Future Versions
If version 5.3 can help build 5.4, and 5.4 can help build 5.5... there's a compounding effect. Each generation becomes easier to improve because the tools get better.
This doesn't mean singularity or unbounded improvement (there are still hardware limits and fundamental constraints). But it does mean OpenAI's ability to iterate on these models might accelerate.

Estimated data shows SQL Injection and hardcoded secrets as common pitfalls in AI-generated code. Regular reviews are crucial.
Reasoning Capability: The Underrated Improvement
The announcement mentions "stronger reasoning." That's vague. Let me be specific.
Chain-of-Thought Improvements
Codex 5.3 is better at explaining why it's doing something. When it refactors code, it can articulate why the refactored version is better. When it chooses an algorithm, it can explain the trade-offs.
This isn't just nice. It's educational. Your team learns better approaches by seeing the model's reasoning.
Multi-Step Problem Decomposition
Complex problems break down into steps. "Build a user authentication system" decomposes into:
- Design the schema
- Write the database layer
- Create the auth endpoints
- Add middleware
- Write tests
Codex 5.3 is better at recognizing these steps and executing them in order without getting lost. Codex 5.2 would sometimes jump ahead, or miss dependencies.
Edge Case Handling
Reasoning includes thinking about what can go wrong. Codex 5.3 is better at catching edge cases without explicit prompts.
Example: You ask it to build an API endpoint. Codex 5.2 might write the happy path. Codex 5.3 also thinks about: What if the input is invalid? What if the user doesn't have permission? What if there's a race condition? And it handles those cases.
This is what you want in production code.

Security and Code Quality Considerations
Faster and better-reasoning AI code generation raises a real concern: are we lowering quality standards?
Technically, no. The benchmarks measure code that actually works. But there are practical concerns.
When AI Writes Security-Critical Code
If Codex 5.3 writes code that handles passwords, encryption keys, or authentication, you need to be extra careful. The model can make subtle mistakes that look correct.
Best practice: Have security-sensitive code reviewed by a human, always. Don't assume the AI got it right just because it's more capable now.
Common Pitfalls
SQL Injection Prevention: The model knows about parameterized queries. It usually uses them. But not always. Test it.
API Keys and Secrets: The model shouldn't hardcode secrets. It usually knows this. But in a complex task, it might slip one in. Review it.
Dependency Vulnerabilities: The model uses popular packages. Sometimes those packages have known vulnerabilities. The model doesn't always check the version number.
Mitigation Strategies
- Security Review: Treat AI-generated code the same as junior developer code—review everything
- Automated Scanning: Run static analysis tools (SonarQube, Semgrep, etc.) on all AI-generated code
- Testing: Write tests that specifically target security concerns
- Code Owners: Have security-minded developers own security-critical components
Codex 5.3 makes developers more productive. It doesn't eliminate the need for code review. If anything, the speed of generation means you need to review more code total.
Implementation Best Practices
If you're adopting GPT-5.3-Codex for your team, here's what actually works.
Start with Non-Critical Work
Test the model on:
- Utility functions
- Tests
- Documentation
- Admin tools
- Sample code
Not on:
- Payment processing
- Authentication
- Core business logic (initially)
Once you understand how the model works and what quality to expect, expand to more critical areas.
Establish Review Processes
Before: Developer writes code → Peer review → Merge
With AI: Developer prompts AI → AI writes code → Developer reviews → Peer review → Merge
You've added a step. That's actually good—it forces intentionality. You're not just taking the code. You're reviewing what the AI generated.
Some teams add an automated step: Generate code → Run linters, type checkers, tests → Show results to developer → Developer reviews → Peer review.
Automation catches obvious mistakes early.
Document Prompts
When the model generates code, save the prompt in a comment:
javascript// Generated by GPT-5.3-Codex with prompt:
// "Write a function that validates email addresses, handling edge cases like subdomains"
function validateEmail(email) {
// implementation
}
This helps with:
- Reproduction (if there's a bug, you can prompt the model again)
- Understanding (future developers know what the code is supposed to do)
- Debugging (you can trace the prompt's intent)
Monitor and Measure
Track:
- How much code is AI-generated vs. human-written
- Code review turnaround time (faster or slower?)
- Bug rates in AI-generated code vs. human-written code
- Developer time spent coding vs. reviewing
After a month, you'll have data. Use it to adjust your process.
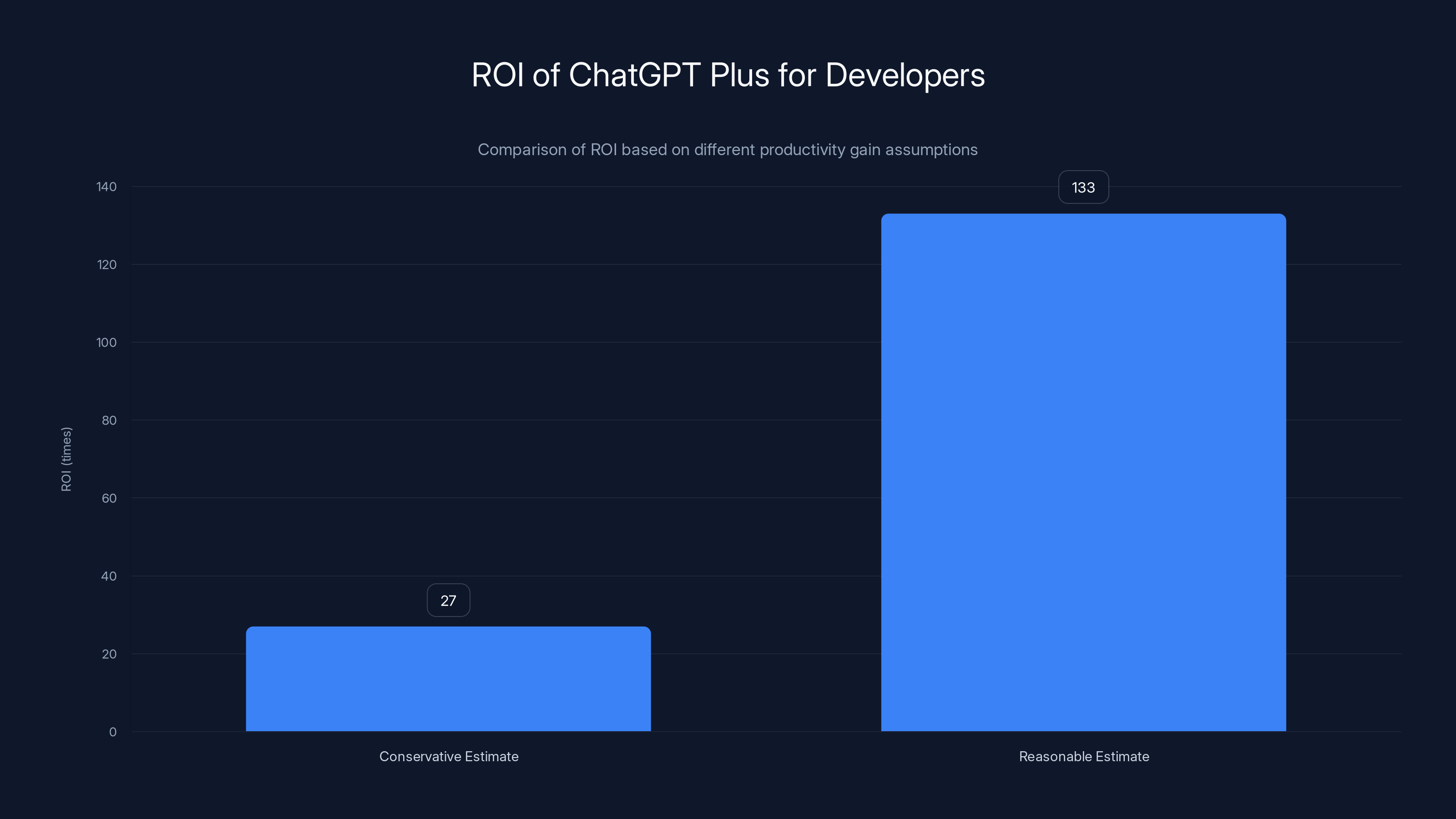
The ROI for using ChatGPT Plus ranges from 27x to 133x depending on productivity gains, making it a highly worthwhile investment for developers.
The Broader Context: Where AI Coding Is Headed
GPT-5.3-Codex is a step. It's not the final form.
The Trajectory
We started with:
- Model: Can't code. (GPT-2)
- Model: Can write snippets. (GPT-3 + Codex)
- Model: Can write functions. (GPT-3.5, early GPT-4)
- Model: Can write features. (GPT-4, Claude)
- Model: Can architect and build projects. (GPT-5, GPT-5.3-Codex)
- Next: Can architect, build, test, deploy, and maintain projects?
The trajectory is clear. Each step makes the model less of a "tool" and more of a "collaborator."
What's Still Hard
GPT-5.3-Codex is powerful, but it's not a replacement for developers. It still struggles with:
- Novel domains: If you're doing something nobody's written code for before, the model has less pattern to work from
- Long-term consistency: Very long projects where decisions made early affect choices late
- Business logic nuance: Understanding why a specific business decision was made and not breaking that logic
- Performance optimization: The code works, but it might not be optimal for your specific constraints
- Legacy system integration: Code written decades ago with weird quirks
These are solvable problems. The models will get better. But right now, these are where humans add value.
The Job Transformation
This is the real question: What does a developer do when the AI can code?
The answer is: More valuable work.
Developers spend less time typing code and more time:
- Understanding business problems
- Designing systems
- Making architectural decisions
- Reviewing and improving code
- Testing and debugging
- Mentoring other developers
Code writing is becoming a smaller percentage of a developer's job. The work that requires judgment, creativity, and deep domain knowledge is becoming more important.
This is actually good. Most developers don't love typing code—they love solving problems. AI handles the typing. Developers handle the thinking.

Potential Limitations and Honest Assessment
Let me be direct: Codex 5.3 is very capable, but it's not perfect.
Still Requires Direction
You still need to tell it what to build. "Make my app faster" is too vague. "The database queries for the user profile page are returning data 2 seconds slower than they should. Optimize them" is clear enough.
The model is good at execution, not at discovering what needs to be built. That's still human work.
Context Limitations
Even with fewer tokens needed, there are practical limits to how much context you can give the model. A 100,000-line codebase? The model can't see all of it at once. You have to guide it to the relevant parts.
Deployment and Infrastructure
The model can write code, but it can't deploy it. It can't negotiate with your DevOps team. It can't handle the reality of your specific infrastructure. You still need engineers who understand your deployment pipeline.
Maintenance Over Time
Code that works today might break next year when dependencies update. The model can help fix it, but it doesn't have responsibility. Developers do.
The Testing Reality
The model writes tests. But unit tests aren't enough. You still need integration tests, end-to-end tests, load tests, security tests. The model helps, but testing is still hard.
Cost Analysis: Is It Worth It?
Let's be practical.
Chat GPT Plus (GPT-5.3-Codex access): $20/month per developer
Productivity gain: Estimates vary, but a reasonable assumption is 20-30% faster coding for tasks where the AI can help (which is maybe 40-50% of tasks).
ROI calculation:
Assume a developer costs $100/hour (loaded cost including benefits, taxes, etc.).
A developer works ~1,600 hours/year (40 hours/week × 40 weeks).
20% productivity gain = 320 hours/year saved.
320 hours ×
ROI:
Even if you're more conservative—assume only 10% productivity gain on 40% of tasks:
10% × 40% = 4% overall productivity improvement = 64 hours/year.
64 hours ×
ROI:
This is conservative. The actual value is probably higher because:
- Time saved on debugging (the model catches mistakes)
- Knowledge transfer (developers learn from the model's code)
- Ability to tackle more ambitious projects
- Reduced context-switching
So yes, it's worth it. By a lot.
Integration Patterns: How to Actually Use This
People often ask: "How do I incorporate Codex into my workflow?"
Here are patterns that actually work:
Pattern 1: The Pair Programmer
You and Codex sit at the keyboard together.
- You describe what you want to build
- Codex writes a first draft
- You review and test it
- You ask for changes or improvements
- Codex iterates
- You sign off
This works for features, bug fixes, refactoring. You maintain control while letting the model handle execution.
Pattern 2: The Code Reviewer
Codex generates code, you review it like you'd review a junior developer's PR.
- Codex writes the code (you provide a detailed spec)
- Code gets merged to a branch
- You review the code
- You request changes if needed (Codex implements them)
- Tests pass
- Code goes to production
This works for routine coding tasks. The model's speed means you can review more code.
Pattern 3: The Explorer
You use Codex to explore solutions quickly.
- Describe a problem
- Get three different approaches
- Test them mentally (or literally)
- Pick the best one
- Have Codex implement it properly
This is good for architecture decisions. Codex can generate alternatives faster than you can think of them.
Pattern 4: The Debugger
You have broken code, Codex helps fix it.
- Describe the bug and symptoms
- Show Codex the error message
- Codex identifies the likely cause
- Codex suggests fixes
- You try them
- Once it's fixed, have Codex write tests to prevent recurrence
Many developers are finding this is where they save the most time.

Industry Impact and Competitive Dynamics
Codex 5.3's release has ripple effects.
Pressure on Competitors
Anthropic and other AI labs are now racing to add computer use capabilities. Mistral announced computer use capabilities recently. The feature wars are heating up.
This is good for users. Competition drives innovation.
Enterprise Adoption
Large companies with existing Microsoft relationships (which includes Copilot Pro) are watching. They're comparing Copilot's trajectory to Codex's capabilities.
Expect more companies to negotiate enterprise licenses for AI coding tools.
Skill Shifts
The demand for developers who can use AI tools effectively is rising. The demand for developers who just type code is... adjusting.
Investment in upskilling is smart. Junior developers especially should get fluent with AI tools—it's table stakes going forward.
Getting Started: A Practical Walkthrough
Ready to try it?
Step 1: Get Access
Subscribe to Chat GPT Plus ($20/month). You instantly have Codex 5.3 access.
Step 2: Choose Your Interface
Start simple: web interface (chat.openai.com). Once you're comfortable, try the IDE plugin.
Step 3: Pick a Small Task
Not your critical project. Something low-stakes. A utility function, tests for existing code, or a small feature.
Step 4: Prompt Clearly
Bad prompt: "Write a function"
Good prompt: "Write a function that takes an array of objects with 'name' and 'age' properties, and returns a new array with only objects where age is greater than 21, sorted by name alphabetically."
Clear prompts get clear results.
Step 5: Review Carefully
Don't assume correctness. Run it. Test it. Read it. Is it what you wanted?
Step 6: Iterate
If something's off: "Actually, I need it sorted by age, not name." The model adjusts.
Step 7: Ship It
Once you're confident, merge it. You've shipped AI-generated code. Welcome to the future.
Future Outlook: What's Next
If Codex 5.3 is where we are now, where are we going?
Multimodal Integration
Right now, Codex works with text and code. Soon, it'll work with:
- Screenshots and designs ("Build this UI")
- Videos ("Implement what you see in this demo")
- Audio ("Here's what the user wants, build it")
Deeper IDE Integration
The IDE extension will become smarter. It won't just be about code generation. It'll be about:
- Understanding your entire codebase architecture
- Suggesting refactors without being asked
- Predicting what you're about to type
- Catching bugs before you run the code
Specialized Models
General Codex is useful. But specialized models ("Codex for React," "Codex for DevOps") could be even more powerful. They'd be trained specifically on domain knowledge.
Autonomous Agents
The line between "tool you use" and "agent that works for you" will blur. You might describe a project, and an AI agent:
- Breaks it into tasks
- Writes all the code
- Tests everything
- Deploys to production
- Monitors for issues
We're not there yet. But the trajectory is clear.

The Developer's Perspective: Why This Matters
Here's the thing: before Codex, AI coding was cool tech but not practically useful. The code quality wasn't good enough. The reasoning was superficial. It was faster to type it yourself.
Codex 5.3 crosses a threshold. It's now actually useful. Not for everything, but for enough tasks that it changes how you work.
For developers who've been skeptical about AI tools, 5.3 is the inflection point. You test it on a real task, you see that it works, and suddenly you're thinking: "What else can I delegate to this?"
That's the shift. From "AI is interesting" to "AI is part of my toolkit."
The developers who recognize this early have an advantage. They develop fluency with the tool. They understand its strengths and limitations. They build better products faster.
FAQ
What exactly is the difference between GPT-5.3-Codex and GPT-5.3?
GPT-5.3 is OpenAI's latest general-purpose language model. It's good at writing, summarizing, answering questions, and many tasks. GPT-5.3-Codex is a specialized version fine-tuned specifically for coding tasks. It can operate computers, understands code architecture, and excels at multi-file projects. Think of it like the difference between a general contractor and a carpenter—both capable, but one specializes in what you need.
Do I need coding experience to use GPT-5.3-Codex?
Yes and no. You should understand programming concepts and the language you're targeting. Codex won't teach you JavaScript if you've never seen it. But if you understand the fundamentals, Codex can write code for you in ways you couldn't have imagined before. It's a tool for developers, not a substitute for learning development.
Is AI-generated code secure?
AI-generated code has the same security risks as code written by junior developers: it can have bugs, vulnerabilities, and architectural flaws. The model doesn't inherently understand your security requirements. You need to review it, test it, and validate it. Security-critical code absolutely needs human review. That said, GPT-5.3-Codex is better at security-conscious code than earlier versions, and it improves over time as OpenAI tunes it.
How much does GPT-5.3-Codex cost?
Can I use GPT-5.3-Codex for enterprise/production code?
Yes, many enterprise companies use OpenAI's models for production code. There are considerations: your code goes to OpenAI's servers (though they have privacy terms), you depend on their API availability, and you need to review the generated code carefully. For sensitive code, some enterprises run open-source models locally instead. But GPT-5.3-Codex is absolutely used in production at major companies.
How does GPT-5.3-Codex handle legacy code and unusual architectures?
Legacy code is tough for any AI. Codex can usually understand it if you show it enough context, but older code with weird patterns might confuse it. If your codebase is 20 years old and full of technical debt, Codex will struggle. But for reasonably modern code, even if it's unconventional, Codex adapts well. You might need to guide it: "The codebase uses a custom router, not Express. Here's the pattern..." Then it gets it.
Will AI coding make junior developers obsolete?
No, but it will change their role. Junior developers who can leverage AI tools effectively become more productive and learn faster. Junior developers who ignore AI tools fall behind. The demand for good developers isn't going away—it's increasing. But the skills that matter are shifting: less "can you implement this algorithm" and more "can you design systems and make good architectural decisions."
What happens if I'm using GitHub Copilot—should I switch to Codex 5.3?
Not necessarily. They're complementary. Copilot is great for line-by-line suggestions. Codex 5.3 is great for feature-level generation and autonomous work. Some teams use both. If you're happy with Copilot, there's no urgent reason to switch. But if you're doing complex multi-file projects, Codex 5.3 might be more powerful.
How accurate is GPT-5.3-Codex at generating code that actually works?
Better than you'd expect, but not 100%. The model produces syntactically correct code most of the time. Logically correct code is more variable. It depends on how clearly you specify the requirements and how well the model understands your domain. For straightforward tasks: 70-85% of generated code works first try. For complex tasks: 40-60%. You always need to test and verify.
Can GPT-5.3-Codex generate code in any programming language?
It's better at popular languages (JavaScript, Python, Java, C++) because those are well-represented in training data. Less common languages (Rust, Go, Kotlin) work but with lower quality. Niche languages might struggle. The rule: the more code exists on the internet in that language, the better Codex handles it.
What's the difference between GPT-5.3-Codex and open-source alternatives like Meta Llama?
Llama and Mistral models are free to run locally. They're improving. But they're not at GPT-5.3-Codex's level yet in capability and reasoning. However, if you need privacy (code stays on your servers), open-source might be the choice. If you want the best capability, commercial models lead right now.
Wrapping Up
GPT-5.3-Codex represents a meaningful step forward in AI coding capability. It's not perfect, but it's genuinely useful in ways that earlier versions weren't.
The computer-use capability is the real breakthrough. The model can now understand your screen, reason about what it sees, and act on it. That's not incremental improvement—that's a new capability class.
The speed and efficiency gains matter, but they're secondary to the reasoning and autonomy improvements. A developer who can delegate multi-step tasks to an AI and get them done correctly has fundamentally changed their productivity.
If you haven't tried it yet, you should. Start with something small and low-stakes. Get comfortable with it. Then you'll start thinking about bigger applications.
The developers and teams that adopt this tooling early will have a clear advantage. Not because the tool is magic, but because they'll develop expertise in using it effectively.
Welcome to the new era of development. It's not about writing code faster. It's about thinking bigger, delegating execution, and focusing on the problems that actually require human judgment.
That's where Codex 5.3 takes you.
Use Case: Speed up your AI-assisted development workflow by automating code documentation and test generation with Runable's AI agents.
Try Runable For Free
Key Takeaways
- GPT-5.3-Codex transitions from writing code to operating computers autonomously, fundamentally changing AI coding capability
- 25% speed improvement and token efficiency gains reduce costs and enable longer, more complex task handling
- Computer use capability enables the model to read screens, click buttons, and iterate based on visual feedback without human intervention
- Strong benchmark performance across SWE-Bench Pro, Terminal-Bench, OSWorld, and GDPval validates real-world capability
- Available through all paid ChatGPT plans, with ROI typically positive within weeks at team level ($240/year for 27-133x return)
Related Articles
- OpenAI GPT-5.3 Codex vs Anthropic: Agentic Coding Models [2025]
- GPT-5.3-Codex vs Claude Opus: The AI Coding Wars Escalate [2025]
- ChatGPT Caricature Trend: How Well Does AI Really Know You? [2025]
- Claude Opus 4.6: Anthropic's Bid to Dominate Enterprise AI Beyond Code [2025]
- From Chat to Control: How AI Agents Are Replacing Conversations [2025]
- Why Loyalty Is Dead in Silicon Valley's AI Wars [2025]

