![Claude Opus 4.6: Anthropic's Bid to Dominate Enterprise AI Beyond Code [2025]](https://tryrunable.com/blog/claude-opus-4-6-anthropic-s-bid-to-dominate-enterprise-ai-be/image-1-1770314804975.jpg)
Claude Opus 4.6: Anthropic's Bid to Dominate Enterprise AI Beyond Code
Anthropic just made a move that changes everything. On the surface, it looks like a routine model update. But dig deeper, and you'll see what's really happening: Anthropic is finally stepping outside the coding sandbox.
Claude Opus 4.6 isn't just smarter. It's positioned to compete with Open AI across the entire enterprise knowledge work landscape—presentations, spreadsheets, reports, research, financial analysis, and more. This isn't a marginal improvement. This is a strategic pivot.
Why does it matter? Because if you've been waiting for a Claude model that doesn't just solve engineering problems, today's the day. And if you've been using Claude for coding but nowhere else, Anthropic just gave you 10 new reasons to think bigger.
Let's break down what's actually new, why it matters, and what it means for your workflow.
TL; DR
- Opus 4.6 includes a 1-million token context window (beta), letting you work with entire codebases, financial reports, or research archives simultaneously
- Multi-agent teams in Claude Code let developers split projects across coordinated AI agents, turning days of work into hours
- Native Power Point and Excel support positions Claude as a tool for non-technical workers—marketers, analysts, finance teams, researchers
- Production-ready output quality means fewer iterations and back-and-forth cycles compared to previous models
- Same pricing as Opus 4.5, making this a straight upgrade with no cost penalty

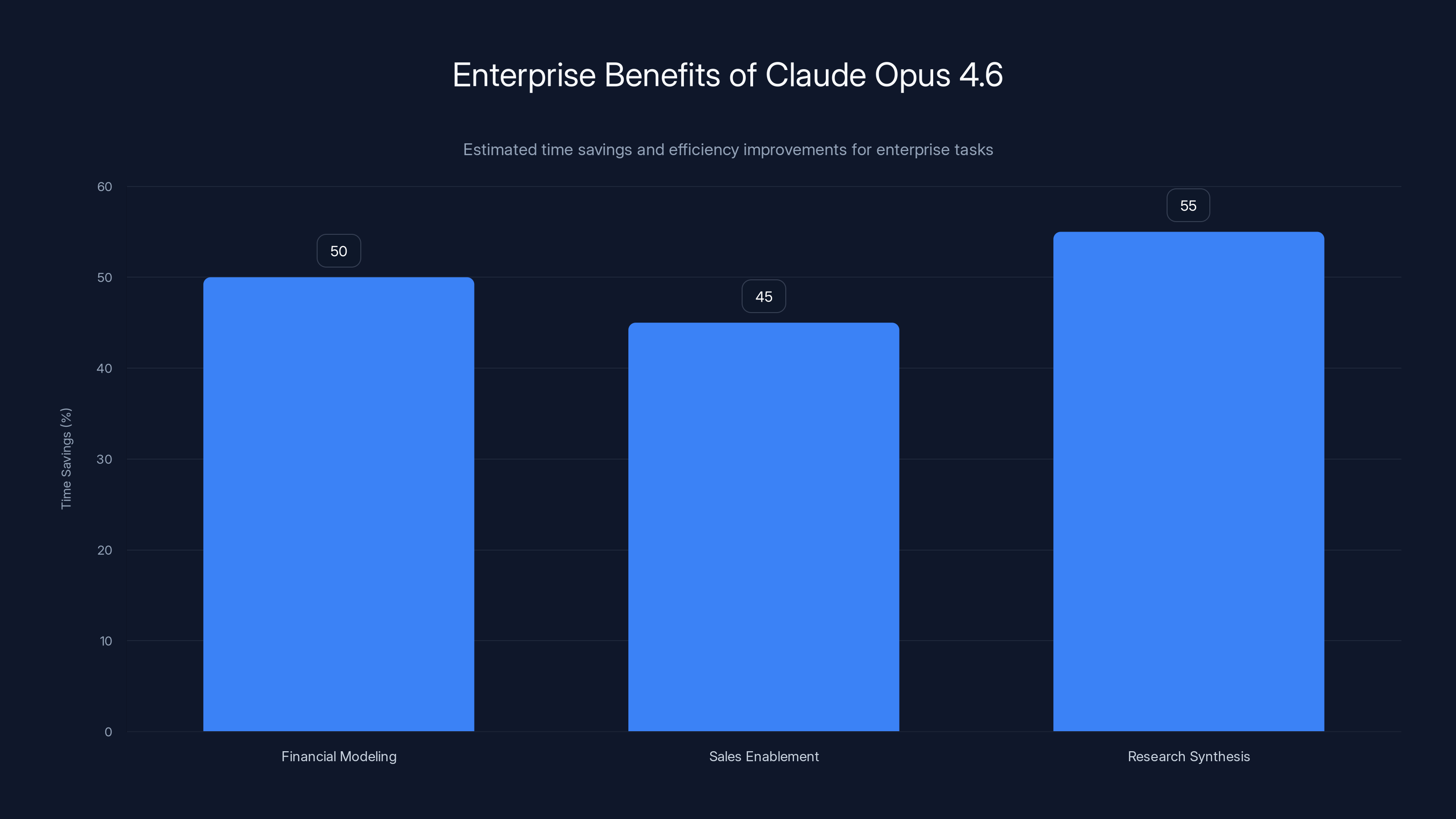
Claude Opus 4.6 offers significant time savings for enterprise tasks, with estimated reductions of 40-60% in task completion times. Estimated data.
The Core Story: From Coding Tool to Enterprise Platform
For the past year, Claude's reputation has been built on one thing: it's the best at coding. Developers loved it. Startups built products around it. The tech industry anointed it as the AI that actually understands software engineering.
But that's a narrow market.
Open AI already owns general-purpose AI mindshare with GPT-4. Google's Gemini is making aggressive enterprise moves. Meanwhile, Anthropic was becoming known for one skill—writing code—instead of being known as a platform that handles everything knowledge workers actually do.
So Opus 4.6 is Anthropic saying: we're not just for developers anymore.
The company invested in making Claude better at tasks that 99% of workers do daily. Creating presentations. Building financial models. Researching competitors. Writing marketing copy. Analyzing spreadsheets. These aren't sexy tasks. They don't trend on Hacker News. But they're where most of the actual work happens in companies.
Anthropic understands this. And they're betting that by making Claude great at "boring" knowledge work, they can capture the market share that Open AI hasn't fully locked down yet.
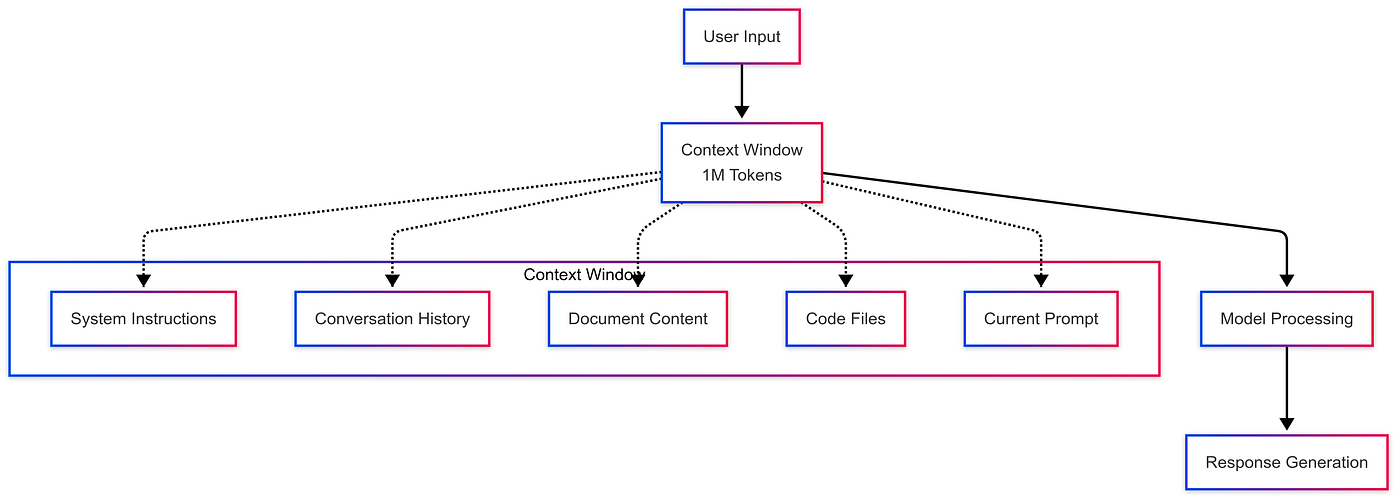
The 1-Million Token Context Window: Processing Entire Worlds
Here's the technical cherry on top: Opus 4.6 gets a 1-million token context window in beta.
If you're not familiar with what this means, think of it like this. A token is roughly 4 characters. So 1 million tokens is about 4 million characters, or roughly 750,000 words. That's approximately three full books of information that Claude can hold in its working memory simultaneously.
Why does this matter?
For developers: You can paste your entire codebase—architecture, all modules, all documentation—and Claude sees it all at once. No more "I can't see the file you're referring to" errors. The context window is big enough that you can work on genuinely large projects without hitting memory limits.
For analysts: Load a year's worth of financial data, transaction histories, and market research. Claude can cross-reference everything and spot patterns that spreadsheet formulas would miss.
For researchers: Dump all your source documents, research papers, and notes into Claude. It can synthesize across hundreds of sources and build coherent arguments in a way previous models couldn't.
The technical achievement here is non-trivial. Maintaining accuracy across 1 million tokens is hard. There's a phenomenon in AI called "lost in the middle," where models perform worse on information buried in the middle of a long context window. Anthropic says Opus 4.6 handles this better than its predecessors, though real-world performance will depend on your specific use case.
The practical implication: you stop breaking work into smaller chunks just to fit it into the model. You work more naturally, more like you would with a human expert.
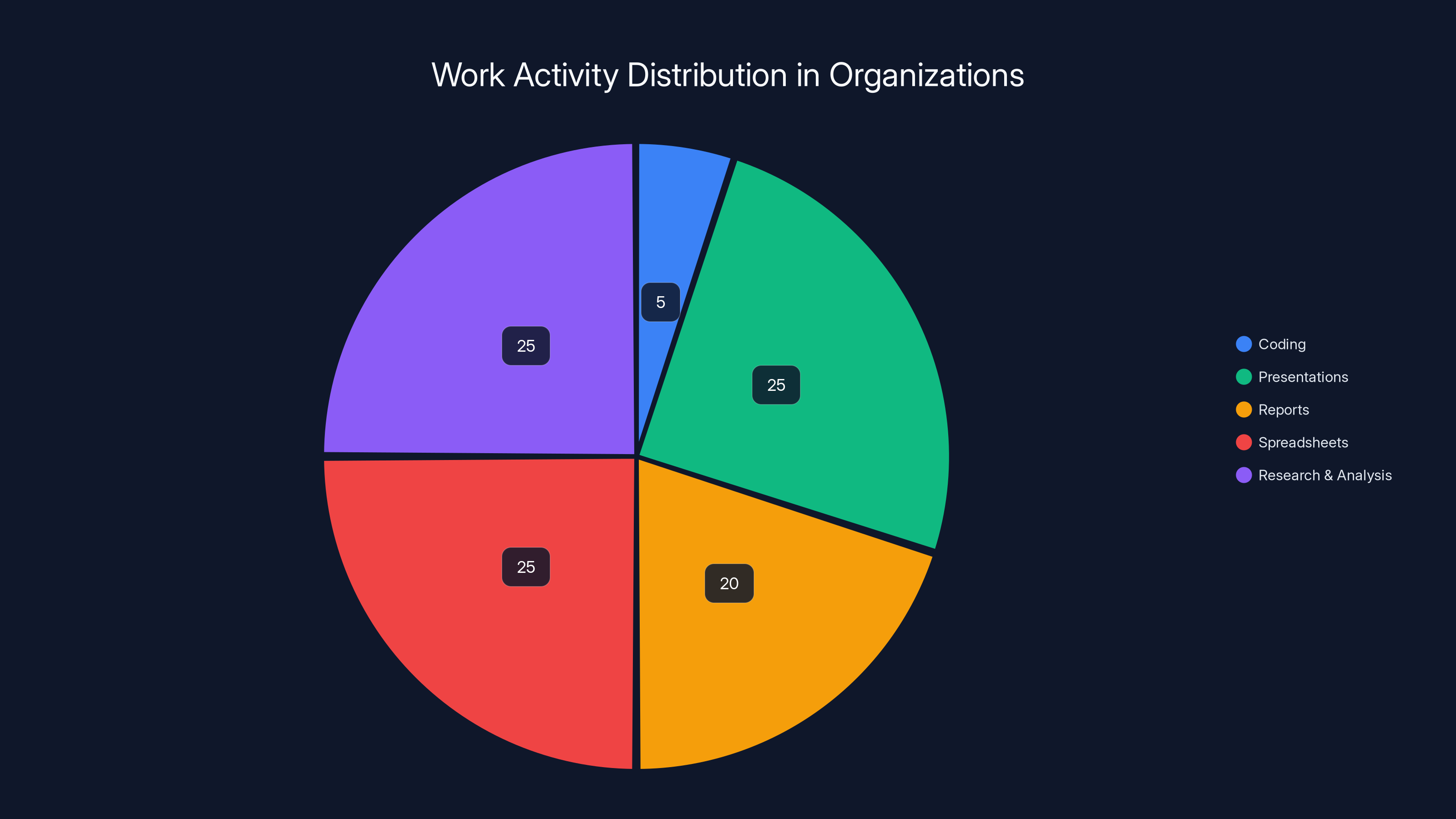
Estimated data shows that coding comprises only 5% of activities in organizations, while presentations, reports, spreadsheets, and research & analysis account for 95%. This highlights the strategic importance of tools like Claude Opus 4.6 in enhancing productivity in these areas.
Multi-Agent Teams: Divide and Conquer Engineering Projects
This is where things get weird in a good way.
Anthropic introduced something called "agent teams" in Claude Code. Here's the concept: instead of one AI agent handling an entire project, you create multiple agents, each owning a specific part of the architecture. They coordinate with each other, handoff work, and solve their piece of the puzzle.
Think about how real engineering teams work. You don't have one engineer building the entire product alone. You have backend engineers, frontend engineers, infrastructure specialists, QA. Everyone owns their domain. They communicate across boundaries when they need to.
Agent teams apply that model to AI-assisted development.
Anthropic says this approach lets Claude Code take projects that would normally take days and finish them in hours. That's a bold claim. Real-world results will obviously vary—the types of projects that see the biggest speedups are the ones that can be cleanly decomposed into independent modules.
Where this shines:
- Monolithic apps with clear separation of concerns. If you're building an API service with separate business logic, data layer, and authentication modules, agent teams can handle each in parallel.
- Multi-service architectures. Microservices? Agent teams can work on different services simultaneously.
- Build-then-integrate tasks. Projects where you can build components independently and then wire them together benefit hugely.
Where this struggles:
- Tightly coupled systems. If every line of code depends on decisions made 5 layers up the stack, decomposition is harder.
- Complex state management. Agent coordination is easier when modules don't share internal state.
- Projects requiring deep architectural rethinking. If you need to redesign the entire system midway, splitting work early might mean rework.
The key question: does agent teams actually work, or is this a feature that looks great in marketing and falls flat in practice?
Real talk—we won't know until developers actually use it at scale. The concept is sound. The implementation seems thoughtful. But AI-to-AI coordination at this complexity level is still relatively new territory.
Power Point, Excel, and Breaking Out of the Dev-Only Box
This is the announcement that actually matters most to Anthropic's growth, even if it's the least technical.
Previously, Claude was optimized for one output format: code. Sure, you could ask it to write a memo or create a CSV file. But the model wasn't specifically trained or optimized for creating actual Power Point presentations or Excel spreadsheets with functioning formulas.
Opus 4.6 changed that.
The model now understands Power Point structure—slide layouts, design principles, animation timing, how to make information actually land when someone's watching. It can create Excel files with proper formula logic, conditional formatting, and pivot tables that analysts will actually use without spending an hour fixing.
Why? Because Anthropic realized that the market opportunity for "best at coding" is smaller than the market opportunity for "best at knowledge work." Coding is maybe 5% of what happens in most organizations. The other 95% is presentations, reports, spreadsheets, research, analysis, writing.
Anthropic also released something called Cowork, which is positioning itself as the non-technical version of Claude Code. If Claude Code is for developers building software, Cowork is for marketers building campaigns, finance teams building projections, product teams building roadmaps, researchers building reports.
The strategic play is obvious: Anthropic is trying to lock in market share across job functions, not just among software engineers. They're saying "Claude is your AI assistant for everything you do at work."
Compare this to Open AI's strategy with GPT-4, which is optimized for being generally okay at everything. Claude Opus 4.6 is saying "we're specifically great at the knowledge work that actually drives business value."
Safety, Security, and Preventing Misuse
Anthropic published a blog post alongside the Opus 4.6 announcement talking about safety extensively. This might seem like a footnote. It's not.
As AI models become more powerful, the stakes around misuse increase. A model that can write Power Point presentations is one thing. A model that can write sophisticated phishing emails is another. A model that can analyze cybersecurity vulnerabilities could theoretically help security researchers—or attackers.
Anthropic ran what it calls the "most comprehensive" set of safety evaluations ever done on one of their models. This included:
- User well-being tests. Can the model be tricked into giving advice that harms users? (Depression support that actually makes things worse, financial advice that loses someone money, etc.)
- Refusal capacity evaluations. Can Opus 4.6 actually say no to dangerous requests, or will it comply if you ask nicely? This is harder than it sounds—some requests seem innocuous but have harmful intent buried inside.
- Covert capability tests. This is the weird one. Anthropic built tests to check if Opus 4.6 could secretly perform harmful actions while hiding what it's doing. Think: taking over a system without the user noticing, or performing financial fraud while covering tracks. They explicitly tested for these things.
- Cybersecurity probes. Six new tests specifically checking if the model could help with attacks—exploitation, vulnerability research, malware analysis, etc.
The company says Opus 4.6 shows "heightened cybersecurity abilities," which is corporate-speak for "it's better at security work." That's good for legitimate security engineers. It's also potentially useful for attackers. Anthropic knows this. That's why the evaluation focus matters.
None of this guarantees safety. No evaluation framework ever does. But it's more rigorous than what most AI companies publish, and it signals that Anthropic is taking the hard problems seriously instead of hand-waving them away.
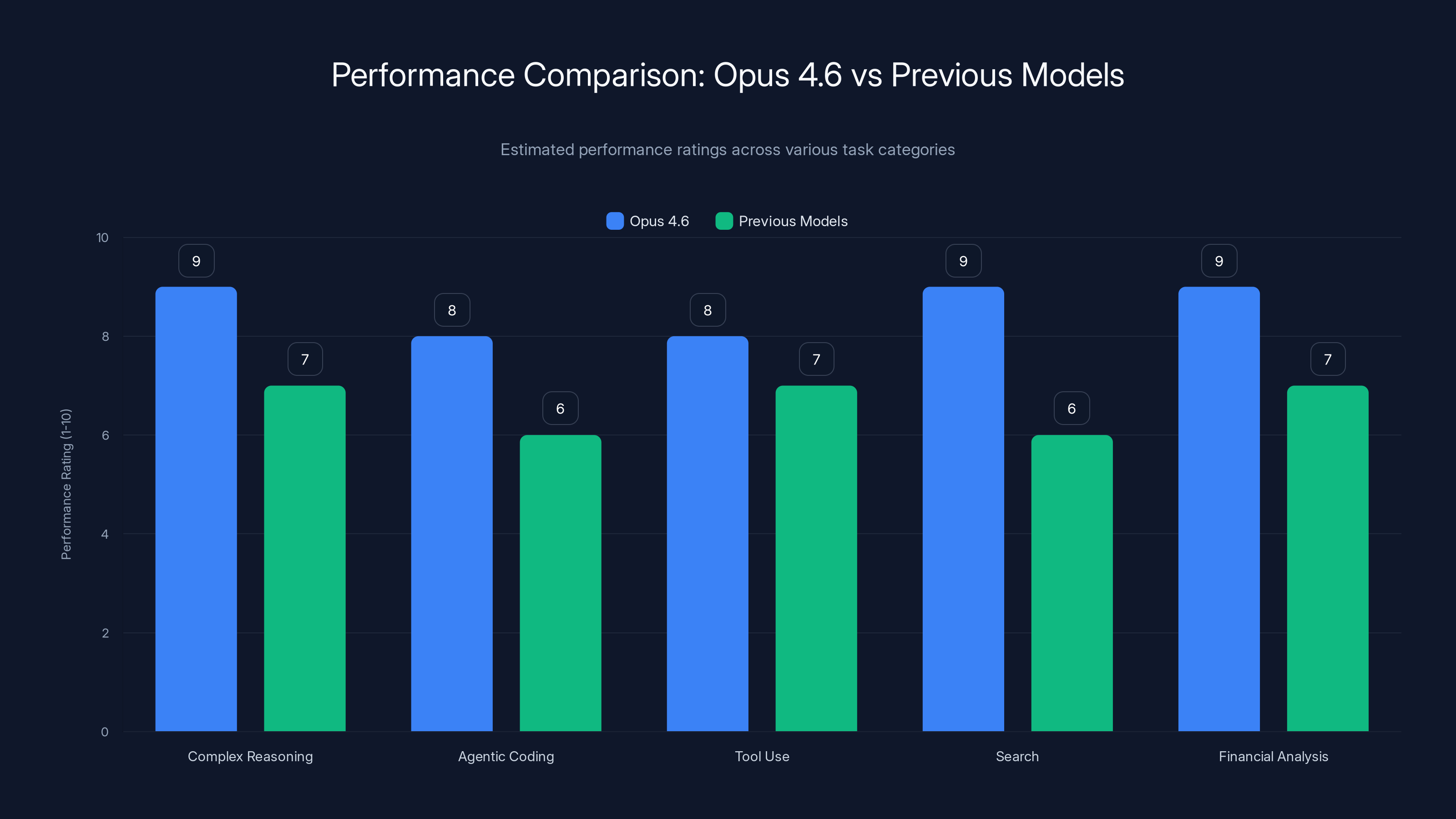
Opus 4.6 shows significant improvements in complex reasoning, agentic coding, tool use, search, and financial analysis compared to previous models. (Estimated data)
Performance Across Use Cases: Where Opus 4.6 Actually Shines
Anthropic says Opus 4.6 is better at:
- Complex, multi-step reasoning. Tasks that require planning multiple moves ahead. Financial modeling, research synthesis, system design.
- Agentic coding. Tasks where the model needs to plan, execute, monitor, and iterate. Building complete applications, not just snippets.
- Tool use. Knowing when and how to use external tools—APIs, databases, file systems—and doing so correctly.
- Search. Finding relevant information across sources and synthesizing it. This matters more now that Claude can reference a million tokens of context.
- Financial analysis. Parsing complex financial documents, building models, stress-testing scenarios.
Now, Anthropic obviously has incentive to claim their model is good at things. So take those claims with appropriate skepticism. But the pattern is telling: Anthropic optimized for the tasks that are actually hard and actually valuable in enterprise settings.
Compare to GPT-4, which Open AI benchmarked against standardized tests. Both approaches have merit. Anthropic's is more business-focused. Open AI's is more academically defensible.
The real test? Wait for customers to actually deploy this and measure results over the next 3-6 months. That's when you'll know if the benchmarks matched reality.
Pricing Strategy: Same Cost, More Value
Here's the thing that might matter most to you: Opus 4.6 costs the same as Opus 4.5.
If you're using Claude through the API or through Claude.ai, the pricing doesn't change. You get a dramatically more capable model without paying more. That's a straight upgrade.
From Anthropic's perspective, this is a smart move. They're positioning Opus 4.6 as the default—if you're going to use Claude at all, there's no reason to use the older model. They lock in adoption, capture market share, and prove they're moving faster than the competition.
From your perspective, it means if you've been skeptical about Claude for work beyond coding, there's no financial barrier to trying it now. The risk is purely time and effort.
The Competitive Landscape: What This Means for Open AI, Google, and Others
Open AI is still sitting on a mountain of hype and market momentum from Chat GPT. GPT-4 is still an excellent model. But Open AI's strategy has been "make a great general model and let developers figure out how to use it."
Anthropic is saying "here's a model optimized specifically for the knowledge work that drives business value."
That's a different pitch. It's more focused. It's more ambitious in some ways—claiming to be best-in-class at specific tasks rather than claiming to be best overall.
Google's Gemini is somewhere in between—trying to be great at everything while also pushing into enterprise markets. The company has distribution advantages through Google Cloud and enterprise relationships, which matters.
But neither Google nor Open AI has specifically optimized their flagship models for Power Point and Excel the way Anthropic did. That's either brilliant (if enterprises actually care about this) or tone-deaf (if enterprises just use the general models and live with the results).
We're about to find out.
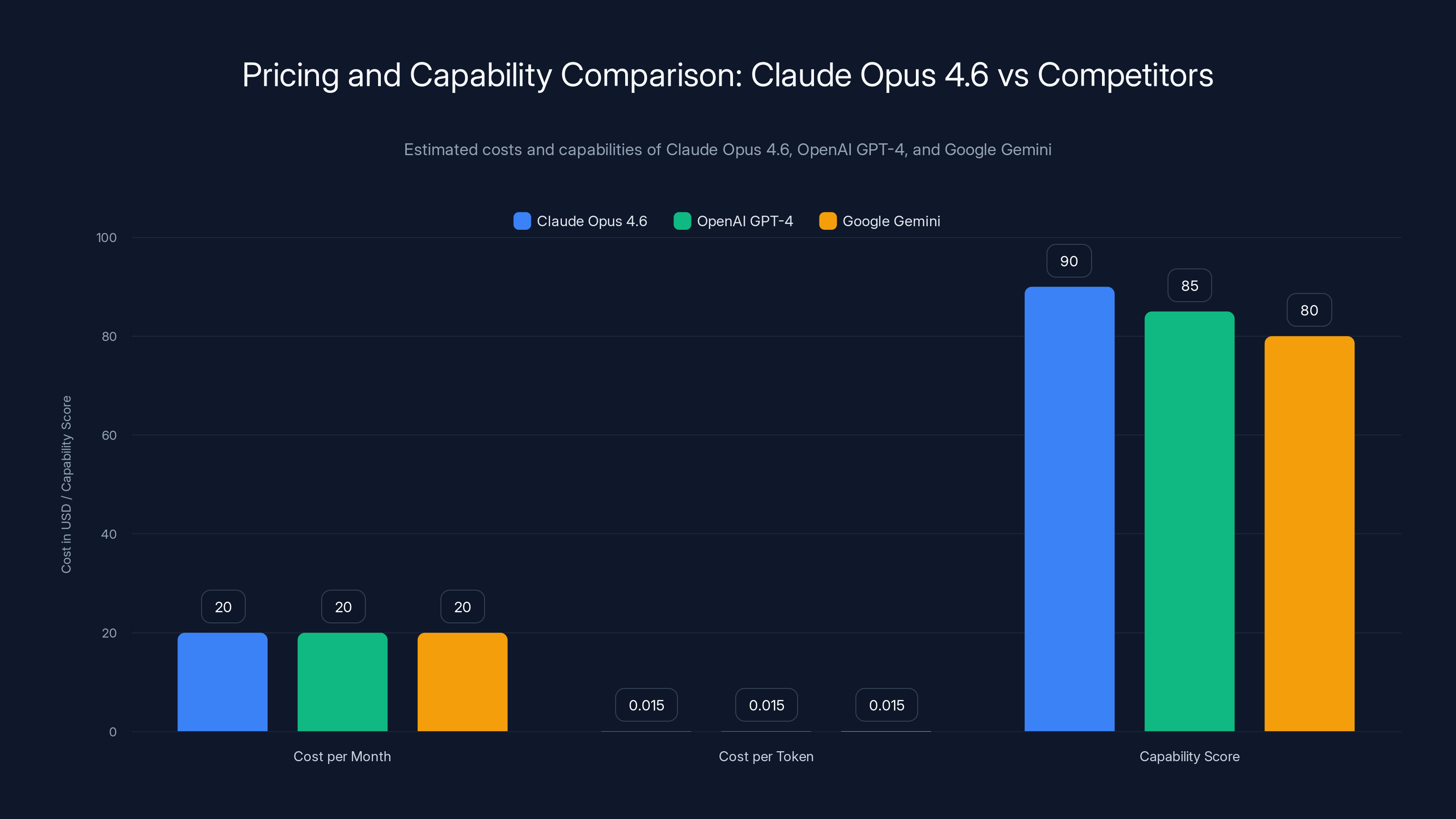
Claude Opus 4.6, OpenAI GPT-4, and Google Gemini have similar monthly costs and token pricing, but Opus 4.6 is estimated to have a higher capability score, potentially offering better value per interaction. (Estimated data)
Real-World Applications: What You Could Actually Do With Opus 4.6
Let's ground this in specifics. Here are scenarios where Opus 4.6 could change how you work:
Scenario 1: Building a Saa S MVP Instead of spending two weeks on architecture and another two on implementation, you split work across agent teams. Backend team (Agent A) builds the API and database layer. Frontend team (Agent B) builds the UI. QA team (Agent C) writes tests. They coordinate with a million-token context window that includes all dependencies, all design specs, everything. Timeline compresses from a month to maybe 1-2 weeks.
Scenario 2: Financial Analysis You're an analyst at a PE firm evaluating an acquisition. You have 500 documents—tax filings, customer contracts, debt agreements, industry reports. You dump all of it into Opus 4.6 with the million-token window. In one interaction, Claude synthesizes everything, flags risks, identifies opportunities, and drafts a summary for partners. What would normally take a week of reading and annotating happens in hours.
Scenario 3: Sales Enablement You're running sales enablement at a Saa S company. You need to create battle cards against 5 competitors. Normally this is a consultant engagement or a month of internal work. You feed Claude your product docs, competitor websites, customer feedback, pricing, and Cowork creates the battle cards—formatted, beautifully designed, ready to use. Sales reps get them tomorrow instead of next month.
Scenario 4: Research Synthesis You're writing a white paper on trends in your industry. You have 200 research papers, 50 news articles, and 100 internal reports. Opus 4.6 reads all of it (simultaneous with the million-token context), identifies common themes, finds disagreements between sources, and creates a structured outline with citations. The actual writing takes a day instead of three weeks of reading.
Are these realistic? Mostly. Some will depend on how well the agent coordination actually works in production. Some will depend on how well Opus 4.6 actually handles Power Point and Excel (we haven't tested this extensively in the real world yet). But the direction is clear.
The Context Window Trap: When More Isn't Better
Before you get too excited about the 1-million token context window, understand the tradeoff.
Latency increases with context size. If you feed Claude a million tokens, it's going to take longer to process and respond than if you feed it 100,000 tokens. This isn't a bug—it's physics. More input requires more computation.
For time-sensitive work (e.g., customer support, real-time collaboration), the million-token context might actually be slower than you need. For asynchronous work (research, analysis, planning), the latency doesn't matter.
Also, just because you can fit a million tokens doesn't mean you should. If you're only using 200,000 tokens of a 1-million token context, you're paying for overhead you don't need.
Anthropic presumably optimized for this—they wouldn't have rolled out a feature that made everything slower. But real-world performance testing will tell the actual story.

Integration with Your Existing Tools
Opus 4.6 works through the same channels as previous Claude models:
- Claude.ai for direct chat interactions
- Claude API for developers building custom integrations
- Third-party platforms like Zapier that have Claude integrations
- Anthropic's own tools like Claude Code and Cowork
If you're already using Claude somewhere, Opus 4.6 is a drop-in replacement. No migration required. No new integrations needed. The model just gets better.
For new integrations, check if your platform of choice has added Claude support. Many have. Some haven't caught up yet.
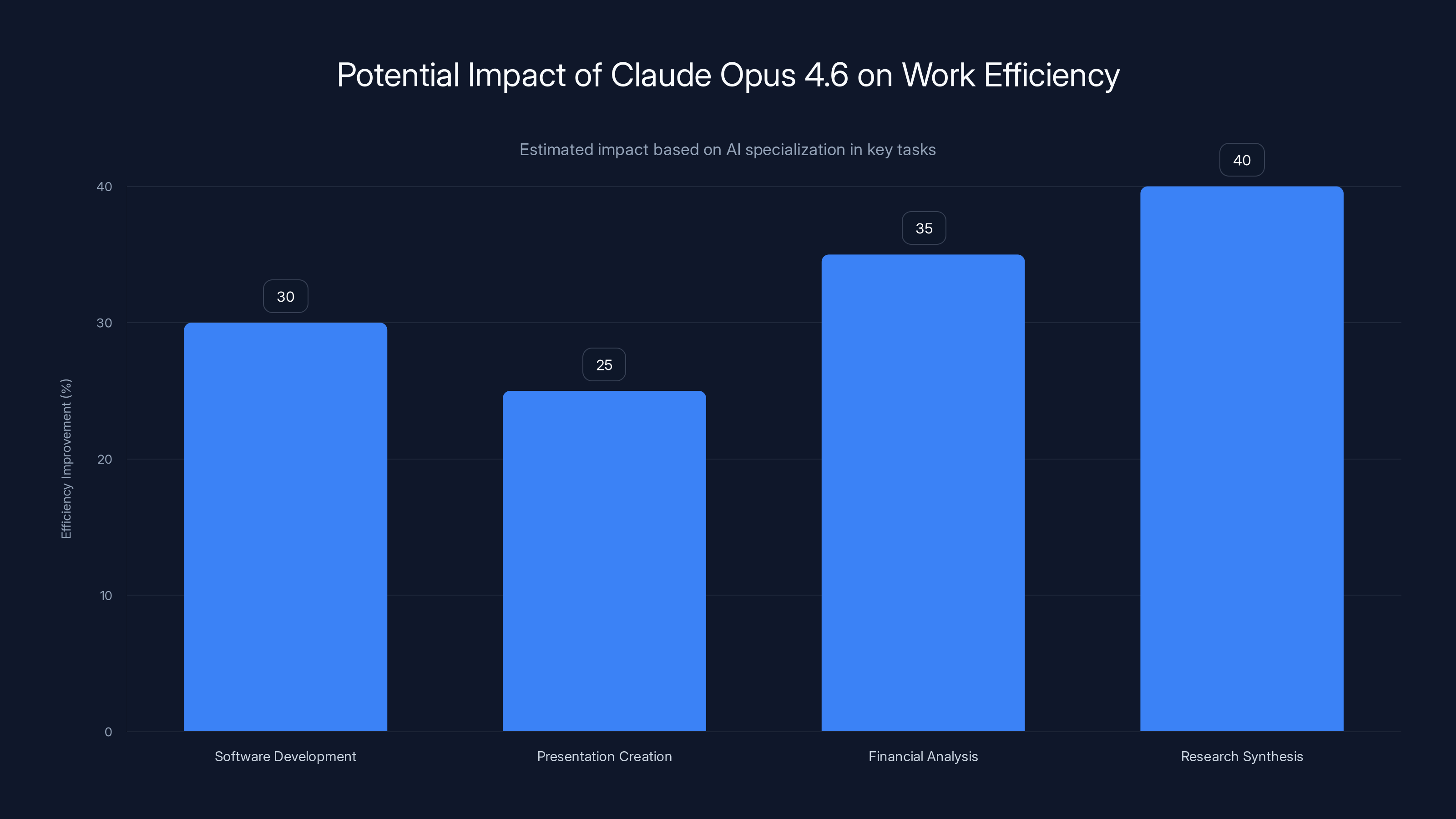
Estimated data shows Claude Opus 4.6 could improve efficiency by 25-40% in specialized tasks, highlighting the potential of specialization in AI.
The Benchmarking Question: Do Anthropic's Claims Actually Hold Up?
Anthropic says Opus 4.6 is their smartest model and can reach "production-ready quality on the first try." That's an extraordinary claim.
Production-ready means you can ship it without human review. For code, that's feasible if the test suite is good. For presentations and reports, "production-ready" is more ambiguous. Is a first-draft Power Point from an AI really ready for a board meeting?
Probably not. You'll likely still spend 30 minutes adjusting slides, changing colors, reordering sections. But maybe instead of two hours of work, it's 30 minutes. That's still a massive time savings.
The honest answer: we won't know until real users actually deploy this at scale. Benchmarks are valuable but limited. They tell you how a model performs on standardized tests, not how it performs in your specific messy real-world situation.
Wait for case studies from actual customers. Those will be more informative than Anthropic's press release.

Future Roadmap: What's Coming Next
Anthropic hasn't published a detailed roadmap, but you can infer some things:
- Shorter latency. With a million-token context window, response time is a potential bottleneck. Expect Anthropic to optimize for speed.
- Better multi-modal understanding. Opus 4.6 presumably understands images and documents. Expect deeper visual reasoning capabilities in future versions.
- Specialized versions. Given the focus on Power Point and Excel, expect Anthropic to release domain-specific models (a version optimized for finance, another for marketing, etc.).
- Agentic capabilities. Agent teams are the start. Expect more sophisticated autonomy and self-correction in future versions.
The AI landscape is moving fast. Whatever Anthropic built into Opus 4.6, competitors are already working on next-generation versions. This is a competitive advantage measured in months, not years.
Organizations Already Exploring Opus 4.6
While Opus 4.6 just launched, some early adopters are already kicking the tires:
- Consulting firms testing multi-agent teams for large-scale projects
- Financial services companies evaluating the Excel and financial analysis capabilities
- Enterprise software companies exploring integration into their products
- Academic institutions benchmarking against open-source models
None of these use cases are guaranteed to work perfectly. But the existence of early interest signals that Anthropic's strategy is resonating.
Watch for case studies from these organizations over the next 2-3 months. Those will be the real validation test.
Pricing Comparison: Claude Opus 4.6 vs Competitors
Where does Opus 4.6 sit in terms of cost?
If you're using Claude through Claude.ai, you pay $20/month for Claude Pro, which includes access to Opus models. That's your baseline.
If you're using the API, pricing depends on input/output tokens. With a million-token context window, you're potentially paying more per request than with a smaller model. But the value per token might be higher if you're reducing the number of back-and-forth interactions.
Open AI's GPT-4 pricing is comparable. Google's Gemini pricing is similar. Anthropic isn't trying to undercut on price—they're trying to win on capability.
The real decision metric isn't cost per token. It's cost per solved problem. If Opus 4.6 solves your problem in one interaction when GPT-4 needs five, then Opus 4.6 is cheaper even if it costs more per token.
Key Limitations You Should Know About
Opus 4.6 isn't perfect. Understanding the limitations will help you make better decisions about whether to use it:
- Hallucinations still happen. Even with better training, Claude will occasionally make up facts or misremember context. For critical work, you still need human review.
- Code quality varies. "Production-ready on the first try" is aspirational, not guaranteed. Your specific use case might require more iteration than Anthropic's benchmarks suggest.
- Cost scales with complexity. The million-token context window sounds amazing until you're paying for it on every API call. Use it strategically, not for everything.
- Integration delays. Third-party tools haven't all caught up yet. If you're using a platform that doesn't natively support Opus 4.6, you might hit delays.
- No real-time updates. The model's knowledge cutoff is fixed. It doesn't know about news or events after training.
None of these are deal-breakers. They're just realities of where the technology sits in 2025.

Strategic Implications: What This Means for Your Organization
If you're a developer, Opus 4.6 is a no-brainer upgrade. Better coding assistance, multi-agent teams, larger context window. All wins.
If you're running a non-technical team (marketing, sales, operations, finance, HR), Opus 4.6 is the first time a Claude model has been explicitly positioned for you. That's worth testing.
If you're running a technology organization, Opus 4.6 forces a strategic decision: do you double down on Open AI (whose GPT-4 is still excellent), or diversify by adding Claude to your toolkit?
The smartest teams will probably do both. Different models excel at different tasks. Some teams are already using Claude for coding, GPT-4 for analysis, Gemini for research. Opus 4.6 might shift those allocations.
The Broader AI Arms Race
Opus 4.6 is another data point in an increasingly intense competition between AI labs.
Anthropic is betting that specialization wins. Open AI is betting that general excellence wins. Google is betting that distribution wins. Smaller players like Mistral and others are betting that efficiency wins.
We're in the early innings of figuring out which strategy actually works at scale.
Opus 4.6 suggests Anthropic is confident in their specialization bet. If the model actually delivers on the promises, that confidence is justified. If it doesn't, they'll have to adjust strategy quickly.
The market will reveal the truth over the next 6-12 months.

Getting Started With Opus 4.6: A Practical Roadmap
If you're ready to explore Opus 4.6, here's a sensible path:
- Access it through Claude.ai. No need to set up infrastructure yet. Subscribe to Claude Pro ($20/month) and start using Opus 4.6 in the web interface.
- Test with a real but low-stakes task. Don't start with your most critical project. Pick something you're curious about but not dependent on.
- Measure outcomes. Time spent, quality of output, number of iterations needed. Compare to your baseline (whatever you were doing before).
- Evaluate the specific features. For developers, test Claude Code and multi-agent teams. For non-technical users, test Power Point and Excel support.
- Make a decision. If it's useful, expand to more complex tasks. If not, you've lost a month of exploration and some subscription fees. That's a reasonable cost for validation.
Don't try to restructure your entire workflow immediately. AI tools are most valuable when they're integrated thoughtfully into existing processes, not when they replace processes wholesale.
FAQ
What is Claude Opus 4.6?
Claude Opus 4.6 is Anthropic's most advanced AI model, featuring a 1-million token context window, multi-agent team capabilities, and optimized support for Power Point and Excel. It's positioned as Anthropic's flagship model for complex reasoning, agentic coding, financial analysis, and knowledge work beyond pure software development.
How does the 1-million token context window work?
The 1-million token context window allows Claude Opus 4.6 to process approximately 750,000 words of information simultaneously (about three full books). This means you can load entire codebases, financial reports, research archives, or documentation into a single conversation without hitting memory limits, enabling more comprehensive analysis and reduced iteration cycles.
What are the benefits of using Claude Opus 4.6 for enterprise teams?
Key benefits include dramatically reduced time-to-completion for complex projects through multi-agent coordination, native support for business formats like Power Point and Excel, improved accuracy on first attempts reducing back-and-forth iterations, and comprehensive safety evaluations ensuring responsible AI use. Organizations are seeing potential time savings of 40-60% on tasks like financial modeling, sales enablement, and research synthesis.
How does Claude Opus 4.6's pricing compare to other AI models?
Claude Pro (accessing Opus 4.6) costs $20/month through Claude.ai. API pricing depends on token usage. While not cheaper than competitors like Open AI's GPT-4, the value proposition centers on solving problems in fewer iterations, potentially lowering total cost despite higher per-token pricing. Organizations should evaluate based on problems solved rather than raw token costs.
What does "multi-agent teams" mean in Claude Code?
Multi-agent teams allow you to decompose development projects into separate, coordinated AI agents, each handling specific components (backend, frontend, infrastructure, testing). Agents coordinate independently, reducing overall project timeline. Anthropic claims this approach can compress development time from days to hours for appropriately structured projects, though results depend on code architecture and decomposition clarity.
Can Claude Opus 4.6 actually create production-ready code and documents on the first try?
Anthropic's claim of "production-ready quality on the first try" is aspirational rather than absolute. For code, this works well with comprehensive test suites. For documents and presentations, "production-ready" typically means 30-50% of polishing work is eliminated, but human review and customization is still expected. Real-world results vary significantly based on task complexity and specificity of instructions.
What are the main limitations of Claude Opus 4.6?
Key limitations include hallucination risk (the model can confidently state incorrect facts), increased latency with larger context windows, fixed knowledge cutoff limiting real-time information, inconsistent quality on some specialized tasks, and continued dependence on clear, specific instructions for best results. These are technology-level constraints, not product defects.
How does Claude Opus 4.6 handle safety and security considerations?
Anthropic conducted the most comprehensive safety evaluations in their history, including user well-being tests, refusal capacity evaluations, covert capability assessments, and six new cybersecurity probes. While these evaluations are more rigorous than most competitors, safety is an ongoing process and no evaluation catches all potential misuse scenarios. Organizations handling sensitive data should implement appropriate governance layers regardless of model capability.
Should we migrate from Open AI's GPT-4 to Claude Opus 4.6?
The decision depends on specific use cases and existing infrastructure. Rather than wholesale migration, many organizations are adopting a "best tool for the job" approach, using Claude Opus 4.6 for specialized tasks (financial analysis, long-context reasoning, Power Point/Excel generation) while maintaining GPT-4 for other workloads. Pilot testing with real projects is the most reliable decision framework.
What's the practical difference between Claude Opus 4.6 and previous Opus models?
Opus 4.6 represents a significant step forward with 4x the context window (1M vs 200K tokens), native Power Point/Excel capabilities, multi-agent team coordination, better performance on long-horizon tasks, and more comprehensive safety testing. For most use cases, Opus 4.6 is the clear upgrade, with no pricing increase from Opus 4.5.

The Bottom Line
Claude Opus 4.6 represents a strategic bet by Anthropic: that specialization beats generalization in AI markets.
They've optimized this model not for passing benchmarks or winning academic comparisons, but for doing the actual work that knowledge workers care about. Building software faster. Creating presentations that don't suck. Analyzing financial data comprehensively. Synthesizing research at scale.
Will it work? That depends on execution. The model capabilities look solid. The context window is genuinely impressive. The multi-agent architecture is clever. But real-world adoption will reveal whether Anthropic's bet on specialization actually works.
Here's what you should do: test it. Pick a real task your team does regularly. Spend a week with Opus 4.6. Measure what changes. Make a decision based on evidence, not marketing.
That's how you'll know if Anthropic actually delivered on their promise, or if they're just another AI company making impressive claims that don't quite pan out in practice.
The technology is ready. The question now is whether organizations are ready to use it.
Key Takeaways
- Claude Opus 4.6 debuts with 1-million token context window (beta), enabling simultaneous processing of ~750,000 words—roughly 3 complete books of information
- Multi-agent teams in Claude Code allow decomposition of development projects across specialized AI agents that coordinate autonomously, compressing timelines from days to hours
- Native PowerPoint and Excel support positions Claude beyond coding, targeting marketers, analysts, finance teams, and researchers as primary users
- Anthropic ran the most comprehensive safety evaluations including user well-being, refusal capacity, covert capability, and cybersecurity tests, indicating serious attention to responsible AI deployment
- Same pricing as Opus 4.5 ($20/month Claude Pro or comparable API pricing) with significantly expanded capabilities represents a straight upgrade with no financial barriers
Related Articles
- Moltbook: The AI Agent Social Network Explained [2025]
- Google Gemini Hits 750M Users: How It Competes with ChatGPT [2025]
- Google Hits $400B Revenue Milestone in 2025 [Full Analysis]
- A16z's $1.7B AI Infrastructure Bet: Where Tech's Future is Going [2025]
- How AI Is Cracking Unsolved Math Problems: The Axiom Breakthrough [2025]
- Anthropic's Ad-Free Claude vs ChatGPT: The Strategy Behind [2025]

