How AI and Nvidia GB10 Hardware Could Eliminate Reporting Roles [2025]
Let me paint a picture. It's 7 AM on a Monday, and your inbox is flooded. Fifteen emails asking for the same thing: performance metrics from last week, formatted in three different ways, pulled from five different platforms. Your reporting team opens spreadsheets, runs queries, copies data, formats tables, sends responses. Repeat this daily across dozens of requests, and you're burning about two full-time employees just on busywork.
Now imagine if that process—all of it—happened automatically while your team slept.
This isn't science fiction anymore. Recent implementations using Nvidia hardware and local AI systems have shown that entire reporting functions can be automated away. Not assisted. Not streamlined. Completely automated.
The implications are massive. According to labor market data, millions of employees worldwide spend significant portions of their time on data collection, organization, and reporting. When you can replace that work with a system that costs less than a single salary within 12 months, the business case becomes obvious. But the human cost raises harder questions about workforce displacement and what happens when entire job categories disappear.
I'm going to walk you through how this actually works, the economics of it, what jobs are most at risk, and what companies should think about before automating away entire departments.
TL; DR
- AI automation can replace entire reporting departments: Using Nvidia GB10 hardware with structured workflows, companies are eliminating manual data collection and reporting entirely.
- The economics are compelling: Hardware costs are recovered within 12 months, making this ROI model irresistible to enterprises.
- Reporting roles face the highest risk: Any position focused primarily on data gathering, organizing, and summarizing is vulnerable to immediate automation.
- Workflow accuracy matters critically: Models must exceed 99% accuracy per step because multiple sequential calls compound errors, requiring larger, more expensive models.
- Data control and security become central: On-premise AI systems using hardware like GB10 keep sensitive business data away from cloud providers, reducing compliance and privacy risks.
- Workforce displacement is real and immediate: Unlike previous technological shifts, this transformation could happen in months rather than years, affecting millions globally.

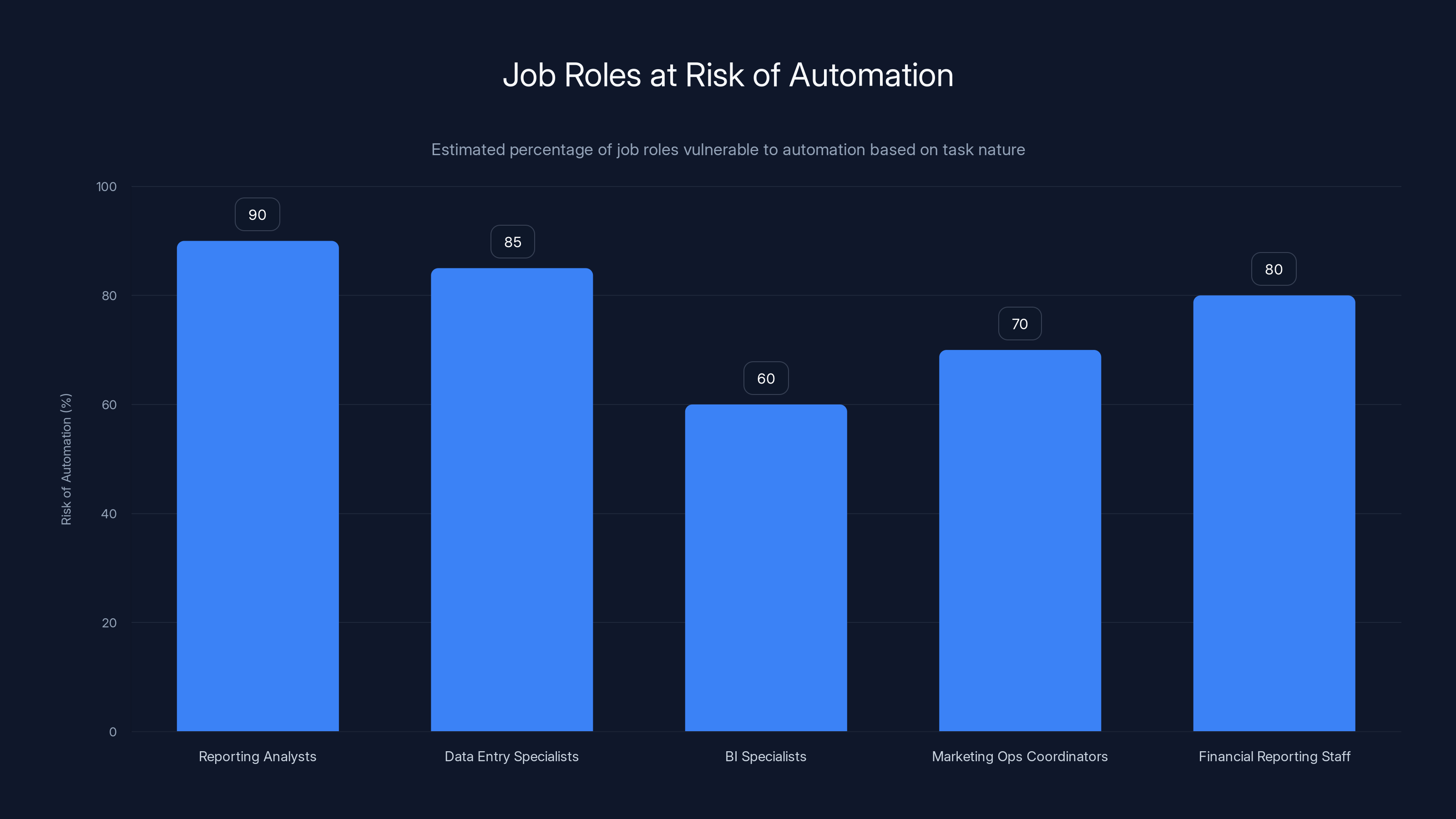
Estimated data shows that roles with over 50% mechanical tasks, like Reporting Analysts and Data Entry Specialists, face the highest risk of automation.
Understanding What Reporting Actually Is (And Why It's Vulnerable)
When we talk about "reporting roles," we're describing positions built almost entirely around these repeatable tasks:
Gathering data from multiple sources (CRM systems, analytics platforms, databases, APIs). Cleaning and organizing that data into coherent datasets. Running basic transformations and aggregations (sums, averages, filtering by date ranges). Formatting results into standardized presentation formats. Sending results to stakeholders.
That's literally the job. Not analysis, not strategy, not interpretation. Just the mechanical work of data movement and formatting.
Here's what makes this vulnerable to automation: these tasks are deterministic. They follow clear rules. The inputs are structured. The expected outputs are predictable. You're not asking an AI to make judgment calls or interpret ambiguous situations. You're asking it to: read an email, understand what data is being requested, query the right systems, format the response, send it back.
That's exactly what AI models trained on structured workflows can do reliably.
Compare this to a role like strategic analyst or data scientist. Those positions require interpretation, pattern recognition, hypothesis formation, and judgment calls. They're harder to automate because the success criteria are fuzzy. Your reporting role? Success is binary: did you get the right data in the right format? Yes or no.
The result is that reporting is one of the most automation-vulnerable roles in business. We're not talking about "assisted reporting" where humans still do most of the work. We're talking about replacing the entire function.
The Hardware Foundation: Why Nvidia GB10 Changes the Economics
To understand why automation is suddenly feasible at scale, you need to understand what changed on the hardware side.
For years, running AI models locally was either impossible (too expensive) or impractical (too slow). That forced companies to use cloud APIs from providers like Open AI or Anthropic. But cloud APIs create problems: high per-request costs, data security concerns (you're sending business information to external servers), and rate limiting.
Nvidia's GB10 GPU is a specialized processor designed specifically for data center inference. It's not a gaming card. It's optimized for running large language models at scale with reasonable latency and power consumption.
Here's the math that changes everything:
Assume a reporting analyst costs
Now add it up: if you need three reporting analysts for a mid-sized organization, you're spending roughly $217,500 annually just on the labor.
A Nvidia GB10 system with supporting infrastructure costs roughly $150,000-200,000 upfront. Once it's running, the marginal cost per request is minimal (electricity, maintenance, depreciation). Your system processes 2,000 requests per year for the cost of about 20 hours of human labor.
Within one year, the hardware has paid for itself. Every month after that is pure cost reduction.
This is why the shift is happening so fast. It's not because the technology just became possible. It's because the economics became rational.
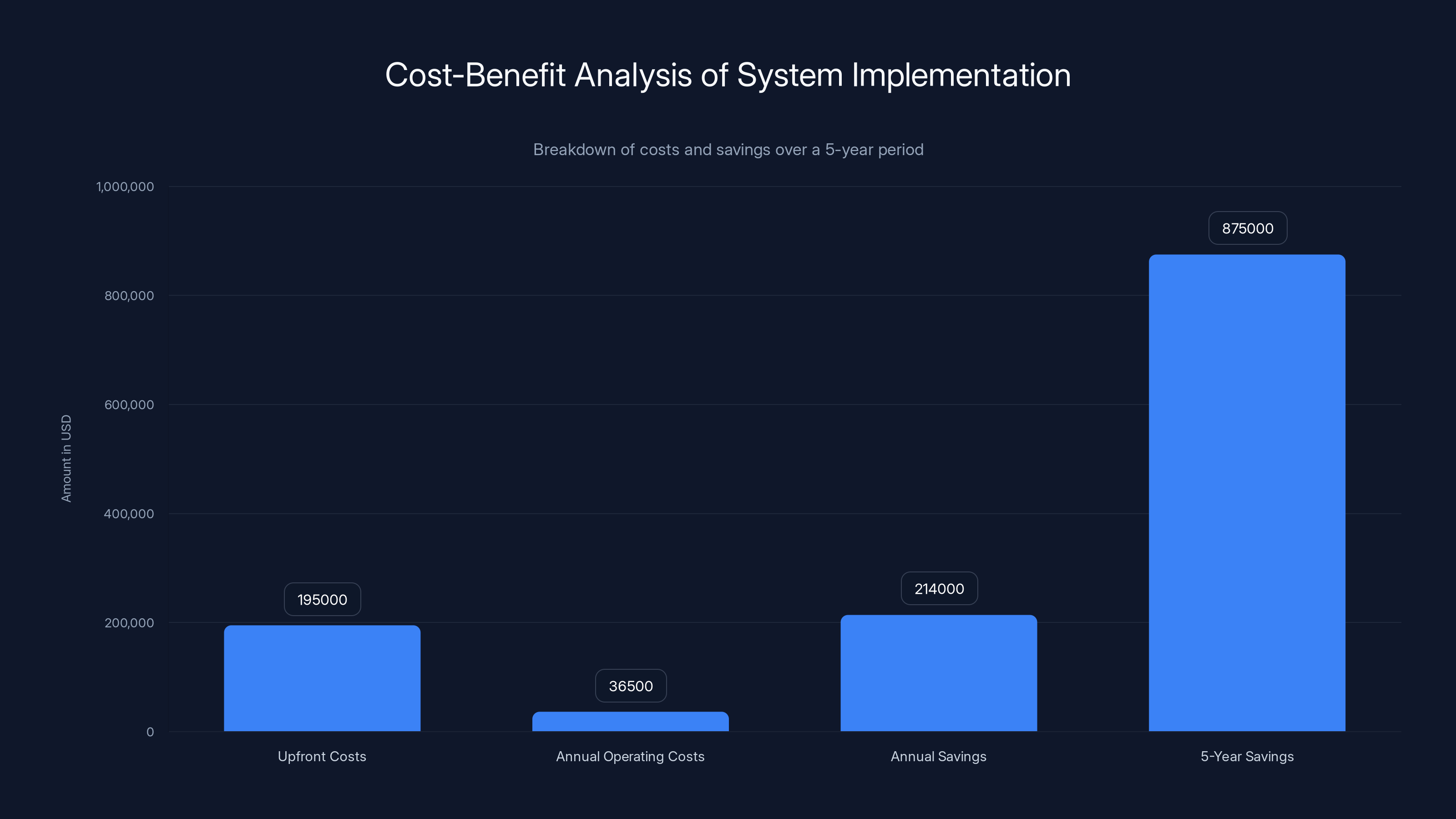
The initial upfront cost of
How Automated Reporting Actually Works: The Workflow Architecture
Automating reporting isn't as simple as pointing an AI at your databases. It requires structured workflows that break the process into discrete, testable steps.
Here's the process that implementations typically follow:
Step 1: Request Intake and Parsing
A user sends an email or submits a form with a reporting request. The first AI step reads this unstructured input and extracts the critical parameters: which data sources are needed, what date ranges, what specific metrics, any formatting requirements.
This step alone eliminates ambiguity. Instead of humans interpreting potentially vague requests, the AI is forced to output structured data: {data_sources: [salesforce, google_analytics], date_range: [2025-01-01, 2025-01-31], metrics: [revenue, conversion_rate], format: csv}.
If the AI can't confidently parse the request, it flags it for human review. This is critical. Better to ask clarifying questions than produce wrong data.
Step 2: Data Query Construction
Given the structured parameters, the next step generates appropriate queries for each data source. For a Salesforce query, this might mean generating SOQL (Salesforce Object Query Language). For Google Analytics, it generates the API parameters. For a SQL database, it generates the actual SQL statement.
This is where accuracy starts mattering. The AI must understand the schema of each system, know which fields map to which metrics, and construct syntactically correct queries.
Recent implementations use larger models (120B+ parameters) at this stage because query construction errors have downstream effects. A malformed query returns no data, which fails the entire request.
Step 3: Data Aggregation and Cleaning
Once queries execute and return data, the next step consolidates results. This involves:
Matching records across systems (if a customer appears in both Salesforce and the analytics platform, they should be counted once). Handling missing data (what if some time periods don't have results?). Converting units or formatting (if one system returns seconds and another returns milliseconds, normalize them). Applying any requested filters or aggregations.
This step is deterministic but error-prone if you're not careful. Most errors here come from schema mismatches or edge cases the AI didn't anticipate.
Step 4: Result Formatting
With clean data in hand, the final step formats it according to the original request. CSV export? Structured it that way. Excel with charts? Generated. JSON API response? Formatted correctly. The AI system must output data in whatever format the user specified.
The elegance here is that format generation can be templated. The AI doesn't need to be creative. It just fills in the data points and applies the format.
Step 5: Delivery and Logging
The report is delivered (email, uploaded to a shared drive, posted to a dashboard, returned via API). Simultaneously, the system logs the request, the query, the results, and any failures for auditing and quality assurance.
This audit trail is crucial. If someone questions the data later, you have a complete record of what was requested, what queries ran, and what was returned.
The beauty of this workflow is that it's testable at each step. You can validate that request parsing is working correctly before moving to query construction. You can validate that queries return the right shape of data before moving to aggregation. This sequential approach catches errors early and prevents small mistakes from cascading.
Model Accuracy: Why Bigger Models Matter More Than You'd Think
Here's something counterintuitive: when automating reporting, model size matters far more than it does for other tasks.
Why? Because of error compounding.
Imagine you use a smaller, 20B-parameter model at each workflow step. At query construction, this model has 97% accuracy. That's pretty good for a single step. But you're making three model calls per request:
- Request parsing (97% accuracy)
- Query generation (97% accuracy)
- Result formatting (97% accuracy)
The probability that all three succeed is: 0.97 × 0.97 × 0.97 = 0.912, or about 91% success rate overall. That means roughly 180 out of 2,000 annual requests fail entirely or produce incorrect results. That's catastrophic for a business reporting system.
Now assume you use a larger 120B-parameter model with 99.5% accuracy at each step:
0.995 × 0.995 × 0.995 = 0.985, or about 98.5% success rate. Now you're looking at maybe 30 failed requests per year. That's acceptable for a reporting system.
This is why real implementations use the largest models available. It's not about having the most intelligent model. It's about having the most reliable one.
This also explains why cloud API costs become prohibitive at scale. If you're making 2,000 requests annually with 3 steps per request, that's 6,000 API calls per year. At
Local hardware changes this equation. Once the hardware is paid for, each request costs you only the electricity to run the model (roughly
Real-World Implementation: Testing at Scale
Let me walk through what a real implementation actually looks like, based on how these systems have been tested.
A typical test uses historical data. Organizations go back through 5-10 years of actual reporting requests and test whether the automated system would have handled them correctly. This validation is crucial because it reveals edge cases and failure modes before the system goes live.
In one implementation, engineers tested against approximately 1,000 historical requests spanning 2015-2025. They started with smaller models (20B parameters) and gradually scaled to larger ones (120B+), measuring accuracy and error rates at each stage.
The results showed a clear pattern:
- 20B parameter models: 78% overall success rate on complex requests (multiple sources, specific date ranges, calculated metrics). Smaller requests succeeded at about 92%.
- 50B parameter models: 89% overall success rate. Clear improvement but still unacceptable for production.
- 120B+ parameter models: 97-99% overall success rate depending on request complexity.
For more complex requests (multi-source data requiring joins), the 120B models showed 98.2% accuracy while 20B models dropped to 64%. This gap explains why larger, more expensive models are essential for real-world use.
The testing also revealed specific failure modes:
Date range handling errors (AI confusing fiscal years with calendar years). Metric name ambiguity (is "revenue" gross revenue or net revenue?). Schema changes (a field that existed in 2020 was renamed in 2023, causing query failures). Edge cases like leap years or unusual date formats.
Once these edge cases were identified, the workflow was refined to handle them explicitly. For example, the request parsing step now includes a verification substep that confirms date interpretations with the user before proceeding.
After refinement, the system achieved 99.3% success rate on the full test set of 1,000 requests. This translates to roughly 13 failures per year on a 2,000-request volume. Most of those failures were edge cases so unusual that the system flagged them for human review rather than producing incorrect results.
That's acceptable for production.
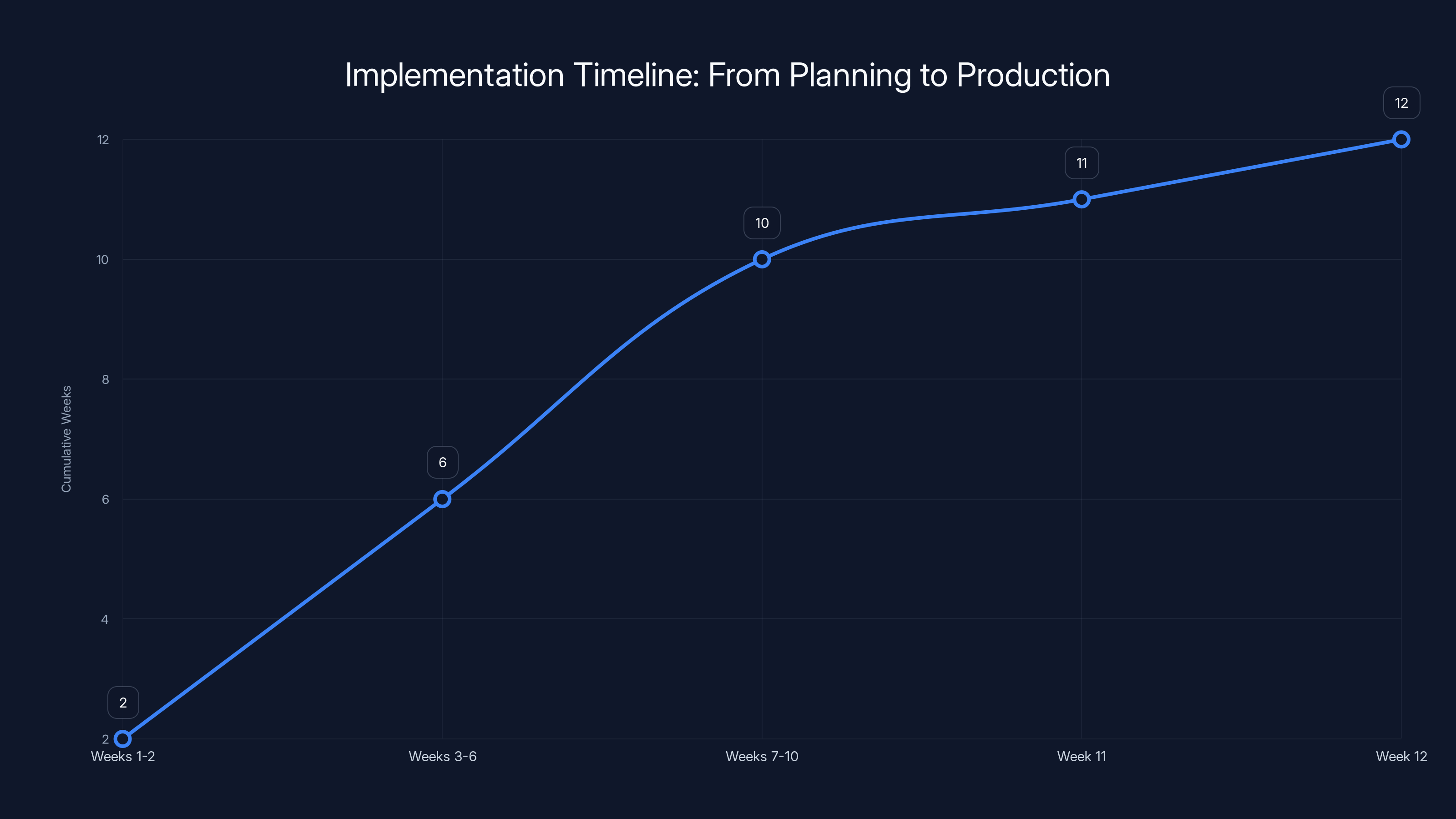
The timeline shows a 12-week journey from planning to full production of a reporting automation system, highlighting rapid deployment compared to traditional methods.
The Jobs at Risk: Who Gets Replaced First
Let's be direct: this automation eliminates certain roles almost entirely.
Reporting analysts are the obvious first target. If your job is primarily gathering and formatting data, the automation system does exactly what you do. You're not needed.
Data entry specialists face similar vulnerability. If you're manually entering data from one system into another, or copying data from reports into presentations, an automated workflow does this faster and more accurately.
BI (business intelligence) specialists who spend significant time on data pipeline maintenance and report generation are partially at risk. The part of their job focused on automated, recurring reporting goes away. The strategic analysis and custom insights portion remains.
Marketing operations coordinators lose the task of compiling campaign performance data from multiple platforms. Again, that's the mechanical part that automation handles.
Financial reporting staff who compile quarterly reports from multiple systems face significant displacement. If the process is structured and repeatable, it can be automated.
The pattern is clear: any role that's more than 50% mechanical data work is at serious risk of elimination. Any role that's less than 30% mechanical data work is probably fine.
Roles in the 30-50% range are the fuzzy middle. These positions might be restructured to focus more on analysis and less on data gathering, or they might be partially automated with humans handling edge cases.
What's particularly stark is the speed. Unlike previous technological transitions that took decades, this displacement could happen in months. An organization could implement an automated reporting system in Q1 and have no need for reporting staff by Q2.
That's fundamentally different from previous waves of automation. Textile workers had decades as factories mechanized. Taxi drivers got years of warning as Uber grew. This transition is happening at startup speed.

Data Security and Compliance: The On-Premise Advantage
One major driver of local AI systems is security. Many organizations can't send sensitive business data to cloud API providers for compliance or competitive reasons.
When you use a cloud service like Open AI or Google, your data leaves your servers. It travels across the internet to external systems, gets processed, and returns. At every step, there are potential exposure points.
For some organizations, this is fine. For others, it's a non-starter. Financial services firms might violate regulations by sending customer data to external services. Technology companies might expose competitive information. Healthcare organizations might violate HIPAA.
Local, on-premise AI systems solve this problem. Data never leaves your infrastructure. Requests are processed locally. Results stay in-house. This is particularly valuable for regulated industries.
Beyond compliance, there's a performance advantage. Local processing has minimal latency. A cloud API call might take 2-3 seconds. A local inference might take 500ms. When you're processing thousands of requests, this latency difference adds up.
There's also a cost difference at scale. As I mentioned earlier, cloud API costs become prohibitive when you're making thousands of inference requests annually. Local hardware amortizes costs quickly.
The tradeoff is that local systems require infrastructure investment and technical expertise to manage. You can't just call an API. You need to run and maintain actual hardware, handle model updates, manage storage, and ensure reliability. This requires engineering resources that not every organization has.
But for larger enterprises that have the resources, local systems become the obvious choice once the cost case solidifies.
The Economics in Detail: Cost-Benefit Analysis
Let me break down the actual financial impact in more detail, because the numbers are what drive this adoption.
Hardware and Installation Costs:
- Nvidia GB10-based system: $150,000-200,000
- Installation and networking: $10,000-20,000
- Initial model weights and setup: $5,000-10,000
- Total upfront: $165,000-230,000
Annual Operating Costs:
- Electricity (assuming 8 hours daily operation): $3,000-5,000
- Maintenance and support: $5,000-10,000
- Model updates and fine-tuning: $5,000-15,000
- IT infrastructure management: $10,000-20,000
- Total annual: $23,000-50,000
Headcount Replacement (per employee):
- Salary: $50,000-70,000
- Fully loaded benefits and overhead: $15,000-25,000
- Training and onboarding: $2,000-5,000
- Total annual per employee: $67,000-100,000
If you replace three reporting staff (mid-range): 3 ×
Break-even calculation:
By month 11, the system has paid for itself. Every month after that, you're saving roughly $18,000 in net costs.
Over five years, the total savings would be approximately:
This calculation assumes you maintain the same number of requests annually. In reality, many organizations see request volume increase over time as the system becomes more reliable and users get comfortable submitting more frequent requests. This would accelerate the ROI even further.
The calculation also assumes you're replacing role salary costs. In reality, most organizations don't immediately fire staff. They either redeploy them to other functions (if available) or offer severance. But even with generous severance (3-6 months salary), the payback period extends only slightly.

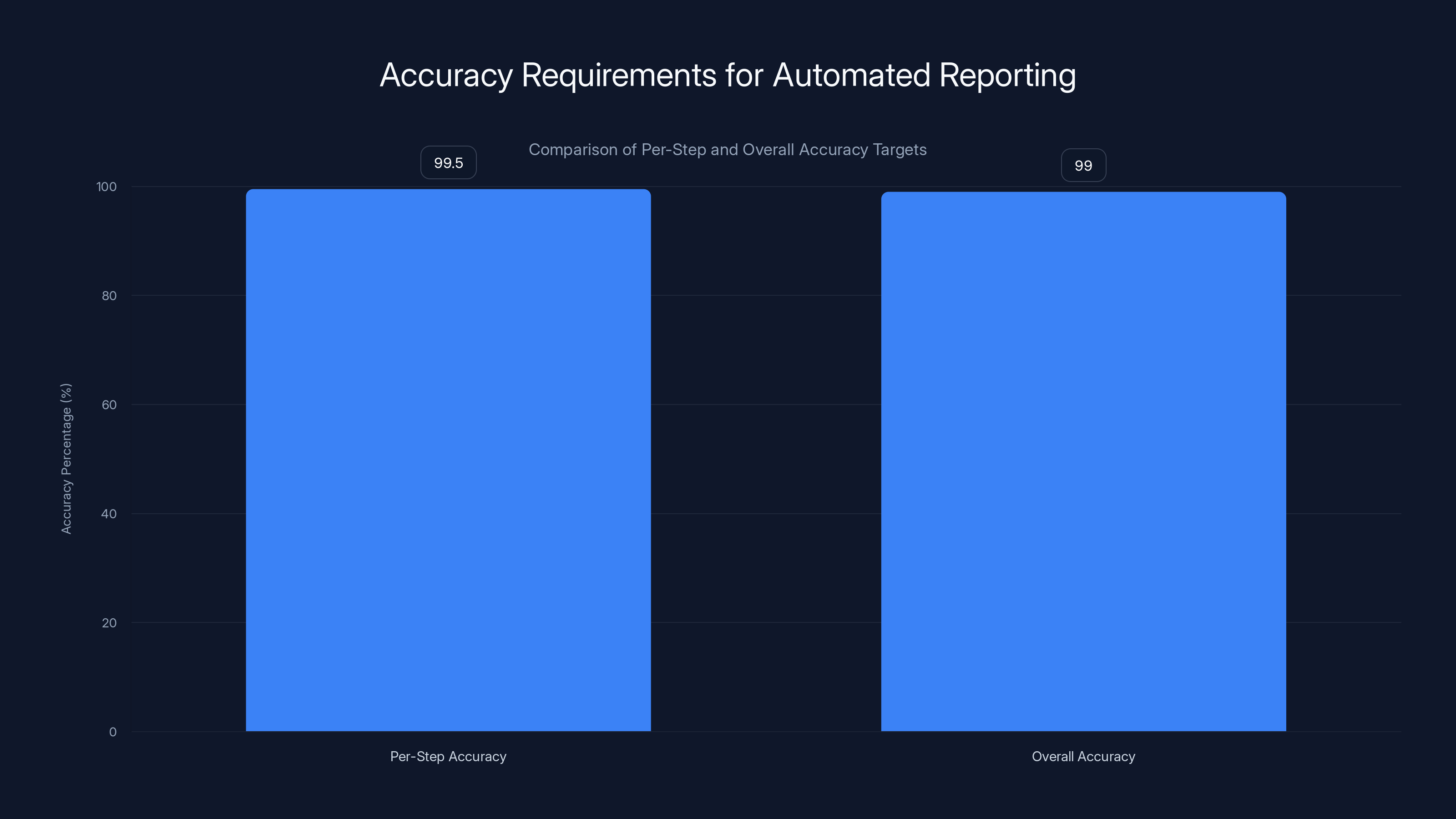
Automated reporting systems require high accuracy, with 99.5% per-step accuracy needed to achieve 99% overall accuracy. This ensures reliability in multi-step workflows.
Implementation Timeline: From Planning to Production
How long does it actually take to get a reporting automation system live? Faster than you might think.
Weeks 1-2: Requirements and Architecture Identify which reporting requests are recurring and structured (good automation candidates). Map out the current process step-by-step. Design the workflow architecture. Identify data sources and APIs. This phase involves business stakeholders and technical teams.
Weeks 3-6: Development and Integration Build the workflow system using tools like n 8n or similar automation platforms. Create API connectors to each data source. Implement the AI decision points (request parsing, query generation, result formatting). Set up logging and error handling. Test individual components.
Weeks 7-10: Testing and Refinement Run the system against historical requests (the 1,000-request test set mentioned earlier). Identify failure modes and edge cases. Refine prompts and logic to handle edge cases. Validate results against ground truth. Iterate.
Week 11: Pilot Deployment Deploy to a subset of users (maybe 20% of reporting requests) with human oversight. Monitor accuracy and reliability. Collect feedback. Make final adjustments.
Week 12: Full Production Roll out to all users. Monitor closely for first 2-4 weeks. Handle any issues that arise. Gradually reduce manual oversight as confidence increases.
Total: 12 weeks from project start to full production.
That's three months. For comparison, hiring and training three new reporting staff typically takes 8-12 weeks and produces far less reliable results.
The rapid timeline is both an advantage and a risk. It's an advantage because organizations get ROI quickly. It's a risk because rapid deployment can mean inadequate change management, insufficient testing in edge cases, or poor communication with affected employees.
Successful implementations invest heavily in the testing phase (weeks 7-10) even if it slows overall timeline slightly. The few extra weeks catching edge cases prevents far more costly problems in production.
Common Failure Modes and How to Avoid Them
Not every reporting automation project succeeds. Here are the most common failure patterns:
Overly Ambitious Initial Scope Trying to automate every possible report at once instead of starting with the most structured, routine ones. This overloads the testing phase and often results in deployment with unresolved edge cases. Better approach: start with 20-30% of requests (the most routine ones), prove the system works, then expand.
Insufficient Model Accuracy Requirements Assuming 90-95% accuracy is "good enough" when actually 99%+ is required for production reporting systems. This leads to unacceptable error rates once the system goes live. Better approach: establish accuracy targets upfront (99%+ for each step) and validate extensively.
Poor Data Quality in Testing Testing against well-formatted, clean historical requests but deploying into messy, ambiguous real-world requests. The system works perfectly on test data but fails in production because real users submit requests in formats the AI wasn't trained on. Better approach: deliberately include messy, edge-case requests in your test set. Make testing harder than production will be.
Inadequate Monitoring and Logging Deploy a system without comprehensive logging of requests, failures, and results. When problems emerge, you can't troubleshoot because you have no data. Better approach: log everything. Store the original request, the parsed parameters, the generated queries, the results, and any errors. This audit trail is invaluable.
Ignoring Edge Cases Focusing entirely on happy-path scenarios (requests that follow expected format and parameters) while ignoring the 10-15% of requests that are unusual. These edge cases become frequent pain points. Better approach: explicitly identify and test edge cases. Build logic to recognize unusual requests and either handle them specially or flag for human review.
Change Management Failure Rolling out the system without preparing users or affected employees. Users submit requests in unexpected formats. Employees affected by automation feel blindsided. Trust in the system erodes. Better approach: extensive communication, training for users on how to submit well-formed requests, and clear communication with affected employees about timeline and alternatives.
The Broader Workforce Impact: Beyond Just Reporting
While reporting roles face the most immediate threat, the pattern extends far beyond.
Analytics roles that focus on routine reporting and metric tracking are next. Customer service roles involving data lookup and simple responses. Finance roles around data consolidation and routine reconciliation. HR roles involving routine report generation.
Basically, any role where more than 50% of tasks are mechanical, rule-based, and repetitive becomes vulnerable. And that's a huge portion of the global workforce.
One study estimated that approximately 300 million jobs globally could see significant automation of core tasks in the next 3-5 years. Not necessarily job elimination (people might be redeployed to other work), but core tasks being handed over to AI.
The reporting function is just the canary in the coal mine. It's happening first because it's the easiest to automate. But the same pattern will repeat across dozens of role categories.
This raises critical questions for organizations and policymakers:
How do you retrain workers whose jobs are automated? How do you manage a transition this rapid? What social safety nets are needed if job displacement accelerates? How do you ensure the benefits of automation are distributed rather than concentrated?
These are genuinely hard problems without clear answers. But ignoring them won't make them go away.
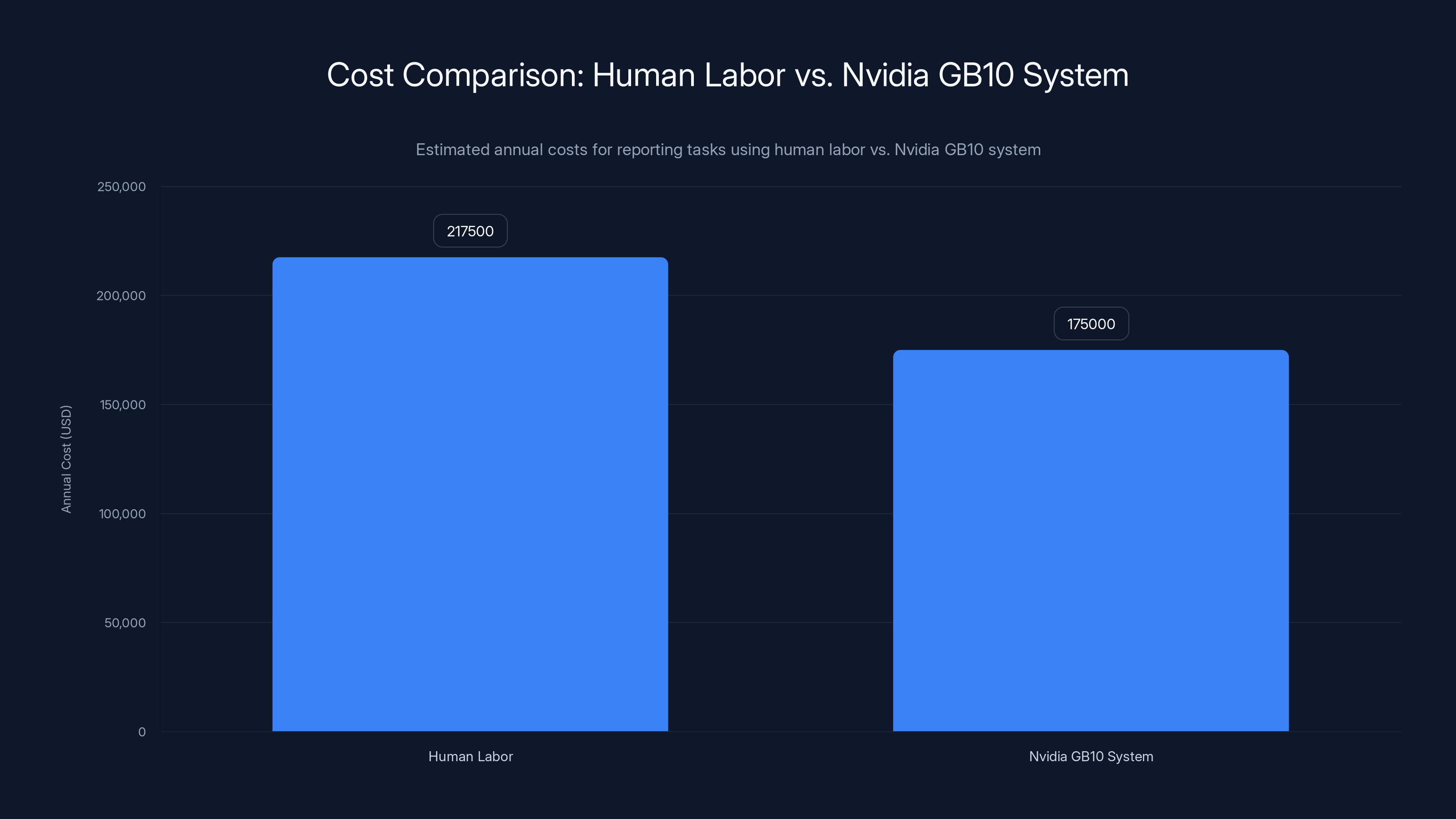
The Nvidia GB10 system offers significant cost savings over human labor for reporting tasks, with an estimated ROI timeline of approximately 9.6 months.
Building Resilient Organizations: The Human-AI Partnership Model
Successful organizations won't simply automate roles away. They'll restructure around the technology.
Instead of having reporting analysts gather and format data, they'll have fewer analysts focus on interpretation and strategy. "Why did this metric move? What should we do about it?" instead of "Can you get me last month's numbers?"
Instead of replacing data roles entirely, they'll create new roles: AI system operators who monitor and troubleshoot the automation. Data quality specialists who ensure the underlying systems stay clean and functional. Analytics strategists who use the automatically-generated reports to drive business decisions.
The organization still needs expertise in data, but it's expertise applied at a higher level.
This is the human-AI partnership model, and it's where forward-thinking organizations are heading. They're not replacing all their reporting staff. They're redistributing effort away from mechanical work toward strategic work.
But this only works if:
- Your organization has the resources to retrain staff
- There's actually strategic work available to reassign people to
- You invest in change management and communication
- You maintain reasonable timelines rather than rushing to cut headcount
Organizations that automate ruthlessly without this partnership model create other problems: demoralized remaining staff, reduced institutional knowledge, execution risk if the automation fails.
Organizations that automate thoughtfully, with investment in retraining and repositioning, actually see better outcomes. Productivity increases, and employees feel supported through transition.

The Technology Stack: What Tools Actually Make This Work
Let's get specific about what you actually use to build one of these systems.
Workflow Orchestration: Tools like n 8n or Apache Airflow define the sequences of steps. They handle: triggering on incoming requests, managing data flow between steps, error handling and retries, logging and monitoring.
LLM Inference: Local models running on Nvidia hardware. You typically use either open-source models (Llama, Mistral, etc.) or commercial models you license and run locally (Claude if Anthropic allows local licensing, GPT models if Open AI supports that).
Connectors and Integrations: Pre-built connectors to data sources (Salesforce, Google Analytics, Stripe, custom databases, etc.). These handle authentication, query construction, and response parsing for each system.
Vector Databases: If you're doing semantic search or need to retrieve relevant context for decision-making ("which previous customer questions is this similar to?"), you use vector databases like Pinecone or Weaviate.
Monitoring and Logging: Comprehensive logging of every request, decision, query, and result. Tools like Data Dog or ELK (Elasticsearch, Logstash, Kibana) aggregate these logs for monitoring and troubleshooting.
Quality Assurance: Testing frameworks that validate outputs against expected results. This might be custom code or tools like Great Expectations that validate data quality.
A typical stack costs $200,000-500,000 annually for infrastructure, licenses, and ongoing operations. Alongside hardware costs, this is significant but still far less than the labor it replaces.
Comparison: Cloud APIs vs Local Hardware for Reporting Automation
Let me contrast the two approaches head-to-head, because many organizations are trying to decide between them.
| Factor | Cloud APIs (Open AI, Google, etc.) | Local Hardware (GB10) |
|---|---|---|
| Upfront Cost | $0-5,000 (minimal setup) | $165,000-230,000 (hardware + install) |
| Per-Request Cost | $0.001-0.01 per request | $0.0001 (electricity only) |
| Annual Operating Cost | $20-100+ (at scale, thousands of requests) | $23,000-50,000 (all-in) |
| Break-Even Point | Cost-effective at <1,000 requests/year | Cost-effective at >2,000 requests/year |
| Data Privacy | Data leaves your servers | Data stays on-premises |
| Latency | 1-3 seconds per request | 0.2-0.5 seconds per request |
| Compliance Risk | Regulatory concerns for sensitive data | Minimal (data never leaves organization) |
| Technical Burden | Low (managed service) | High (requires infrastructure expertise) |
| Scalability | Immediate but costly at high volume | Limited by hardware resources |
| Control Over Models | Limited (provider decides) | Full control (run whatever models you want) |
The decision typically comes down to volume. Small organizations with <500 annual requests? Cloud APIs make sense. Medium-to-large organizations with >2,000 requests? Local hardware pays for itself.
There's also a middle ground: hybrid approaches where routine requests run locally and exceptional requests fall back to cloud APIs. This minimizes cloud costs while maintaining reliability.

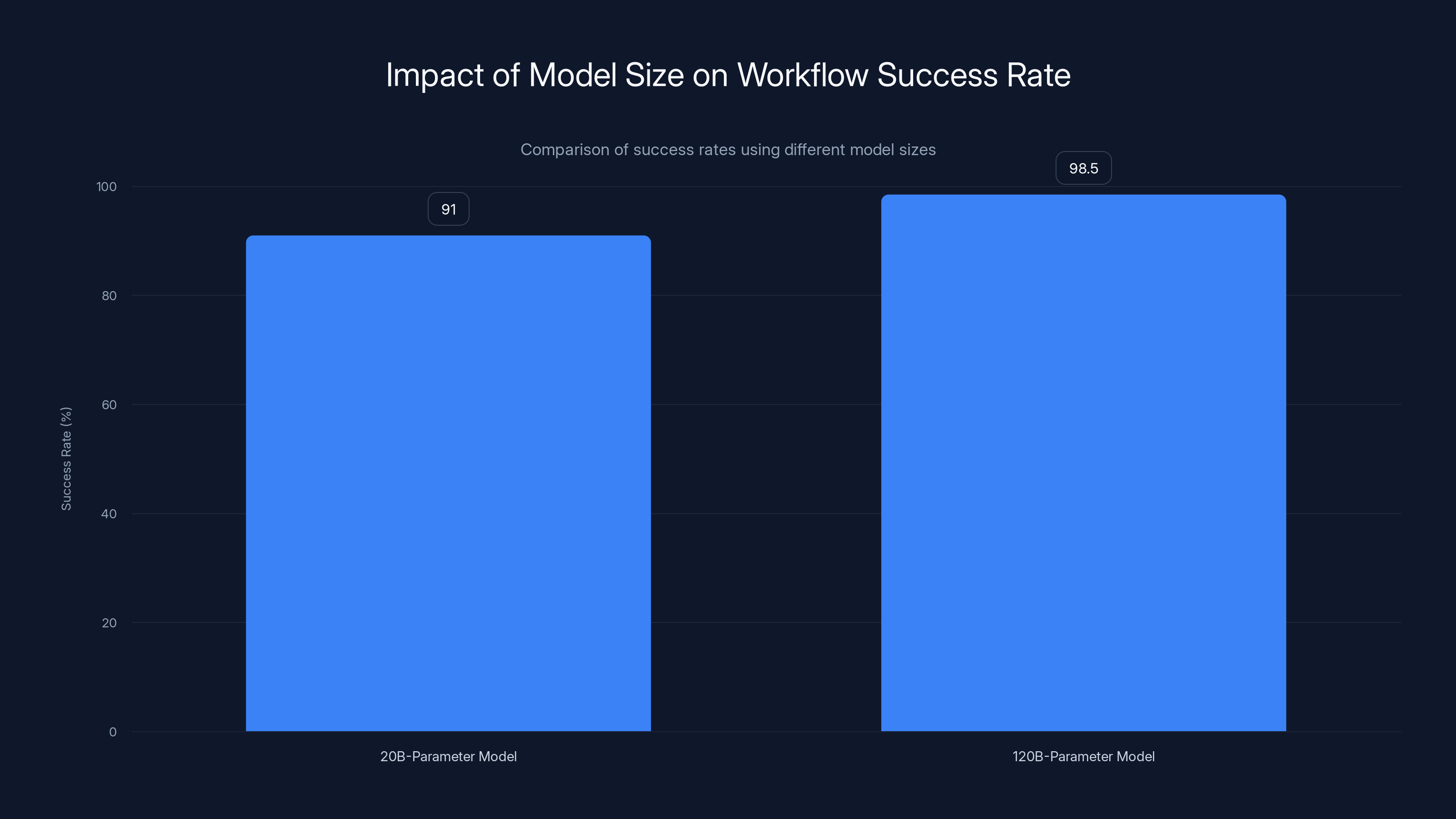
Larger models significantly increase the overall success rate in multi-step workflows, reducing the number of failed requests from 180 to 30 annually. Estimated data based on typical model accuracy.
Preparing Your Organization: A Practical Roadmap
If you're seriously considering reporting automation, here's a practical roadmap:
Phase 1: Assessment (2-4 weeks)
- Document current reporting processes in detail
- Count annual reporting requests by type and complexity
- Calculate time spent on reporting by role and function
- Identify structured vs unstructured requests
- Estimate labor costs being spent on reporting
Phase 2: Business Case (1-2 weeks)
- Compare cloud API costs vs local hardware at your volume
- Calculate payback period and 5-year ROI
- Identify which roles might be affected by automation
- Create workforce transition plan
- Get executive alignment and budget approval
Phase 3: Pilot (8-12 weeks)
- Select 20-30% of requests (routine ones)
- Build automation system for these requests
- Extensive testing against historical data
- Deploy with human oversight
- Measure accuracy, uptime, user satisfaction
Phase 4: Expansion (ongoing)
- Gradually expand to additional request types
- Improve system based on learnings
- Automate additional processes beyond reporting
Throughout, invest in change management. Communicate clearly with employees about what's happening, why, and what it means for them. People who understand the "why" and see themselves in the future state are far more supportive than people who feel blindsided.
The Inevitable Questions: What About Quality, Errors, and Responsibility?
One persistent concern with automated reporting: what happens when the system gets something wrong?
A human analyst might occasionally misread a metric or send results from the wrong date range. But they're also reasoning about what they're doing. An AI system might confidently return completely wrong results because it misunderstood the request or the query was malformed.
For this reason, mature implementations implement multiple safeguards:
Output Validation: Automated checks that the results make sense. "Is this metric value within expected ranges? Does the data shape match what was requested?" If validation fails, the request gets flagged for human review.
Sanity Checks: Comparing results to previous periods and flagging unusual variations. "Last month was
Audit Trails: Complete logging of what was requested, what queries ran, what results were returned. This allows investigation if someone questions the data later.
Human Escalation: Clear rules for when to flag requests for human review. Ambiguous requests. Unusual data. System errors. These go to humans, not directly to requesters.
Gradual Rollout: Starting with limited scope (low-risk requests) before expanding. This means errors affect fewer people.
These safeguards add complexity and cost but are essential for maintaining trust.
There's also a liability question: if the automated system produces incorrect data and a business decision is made based on it, who's responsible? The organization using the system? The AI provider? The automation vendor? This is genuinely unsettled territory legally. Most organizations handle it through clear disclaimers and audit trails that show the data was AI-generated.

The Path Forward: What's Changing in 2025 and Beyond
The technology isn't slowing down. Here's what's likely coming:
Better, Cheaper Hardware: Nvidia GB10s represent current-gen inference hardware. The next generation will be faster and more efficient. This accelerates the cost-benefit crossover point for local hardware.
Cheaper, More Capable Models: Open-source models are improving rapidly. Soon, open-source models might match or exceed proprietary offerings, reducing licensing costs even further.
Plug-and-Play Automation: Platforms are emerging that let non-technical people build automation without custom code. This accelerates adoption by smaller organizations.
Multimodal Automation: Current systems handle text. Soon, automation will handle images, PDFs, and video, expanding the types of tasks that can be automated.
Edge AI: Running models not just on-premise but on edge devices (laptops, phones). This further reduces latency and infrastructure costs.
Each of these trends makes automation more accessible and more economical. The window for organizations to figure out their automation strategy is closing. In 2-3 years, the organizations that have built competency here will have massive competitive advantages.
Organizations that wait will face rapid disruption as the technology becomes mainstream.
Realistic Expectations: What Automation Actually Delivers
Let me be honest about what automation actually does and doesn't do.
What It Does Deliver:
- Elimination of routine, mechanical work
- Consistent, reliable performance on well-defined tasks
- Significant cost reductions on labor
- Faster turnaround on routine reporting
- Reduced human error on data movement tasks
What It Doesn't Deliver:
- Judgment or interpretation
- Understanding context or business implications
- Creativity or novel insights
- Strategic thinking
- Accountability (humans remain accountable for decisions made using automated data)
The best automation supplements human work rather than replacing it entirely. Humans focus on interpretation and strategy. Automation handles data movement and routine tasks.
Organizations that understand this distinction succeed. Organizations that expect automation to replace judgment or strategic thinking tend to be disappointed.

Conclusion: The Automation Wave Is Here
Reporting automation isn't coming. It's here. Organizations are already deploying systems like the ones I've described. Within 12-18 months, this will be standard practice across mid-to-large enterprises.
The question isn't whether this happens. It's when your organization chooses to engage with it.
If you're in a reporting or data-focused role, this is worth thinking about seriously. Not with panic, but with clear eyes about what's changing and what you should be doing to stay relevant. This is the perfect time to deepen expertise in analysis, strategy, and interpretation rather than focus entirely on data mechanics.
If you're leading an organization, the choice is clearer. You can either automate reporting thoughtfully (with retraining, transition support, and human-AI partnership) or your competitors will do it first. The cost structure is simply too compelling to ignore.
The technology works. The economics work. The only questions are execution and pace.
For some organizations, that transition will happen in months. For others, it'll take years. But it will happen.
The only uncertainty is whether you'll lead the change or react to it.
FAQ
What exactly is Nvidia GB10 hardware and why does it matter for reporting automation?
Nvidia GB10 is a specialized GPU processor designed for running large language models at scale in data centers. It matters because it makes running AI models locally cost-effective. Instead of paying $0.01 per inference call to cloud providers, local hardware amortizes costs quickly, making the economics of local automation compelling for organizations with thousands of annual requests.
How accurate does an automated reporting system need to be to work in production?
Most implementations target 99%+ overall accuracy, which requires 99.5%+ per-step accuracy in a multi-step workflow. This is crucial because errors compound. Even a small per-step error rate becomes unacceptable when multiplied across multiple sequential steps. Testing against 1,000+ historical requests is standard before production deployment.
Can smaller AI models handle automated reporting, or do I really need the largest models available?
Smaller models (20B parameters) can handle simple, well-structured requests but fail on complex requests requiring multiple data sources or ambiguous parameters. Larger models (120B+) achieve the 99%+ accuracy needed for production. The cost difference between models is worth the reliability improvement when you're processing thousands of requests annually.
How long does it take to go from decision to a fully operational automated reporting system?
Typical timeline is 12 weeks from project start to full production: 2 weeks planning, 4 weeks development, 4 weeks testing, 1 week pilot, 1 week full rollout. Investing additional time in testing (especially against messy, real-world data) prevents costly errors in production. Some organizations take 16-20 weeks to be more thorough.
What happens to employees whose reporting roles are automated away?
Options include retraining for other roles in the organization (especially strategic analysis roles), redeployment to different departments, or severance packages. Forward-thinking organizations plan this transition before automation deployment and invest in retraining. Organizations that automate ruthlessly without transition planning often see productivity losses and morale damage offsetting automation gains.
Is on-premise AI automation more secure than using cloud APIs for reporting?
Yes, significantly. Data never leaves your infrastructure with on-premise systems. This is critical for regulated industries (finance, healthcare, government) where sending sensitive business data to external services violates compliance requirements. On-premise systems eliminate this risk entirely, though they require more technical expertise to manage.
What's the actual ROI timeline for implementing automated reporting systems?
For most organizations, hardware costs are recovered within 10-14 months when replacing three or more reporting staff. The system pays for itself purely on labor cost savings, not including benefits like reduced real estate costs or improved speed. After break-even, the system delivers $15,000-20,000 in monthly cost savings indefinitely.
What types of reporting requests are easiest to automate first?
Start with routine, structured requests: weekly or monthly metric reports, standard dashboard compilations, recurring analytics requests with predictable parameters. These have clear success criteria and high request volume, making them ideal for automation. Leave custom, ad-hoc, analytical requests for later or for human analysts.
What happens if the automated reporting system makes an error and a business decision gets made based on bad data?
This is why implementing output validation, sanity checks, audit trails, and human escalation is critical. Comprehensive logging shows exactly what was requested, what queries ran, and what results were returned. This creates defensibility. Most mature implementations catch errors before they reach users through automated validation and flagging unusual results for human review.
How does local hardware automation compare cost-wise to cloud APIs at different request volumes?
Under 1,000 annual requests: cloud APIs are more cost-effective. 1,000-2,000 requests: break-even point where both approaches cost roughly the same. Over 2,000 requests: local hardware becomes significantly cheaper. At 5,000+ annual requests, local systems save money even after accounting for infrastructure expertise and maintenance.

Final Thoughts
Reporting automation represents one of the clearest near-term applications of AI in business. The technology works, the economics are compelling, and the implementation path is relatively straightforward.
But it also represents a significant workforce disruption. Handled thoughtfully, with investment in transition and retraining, it can improve organizational efficiency and redirect human talent toward more valuable work. Handled carelessly, it creates unemployment and organizational damage.
The choice is yours. But the change is inevitable.
Key Takeaways
- Automated reporting systems using Nvidia GB10 hardware achieve 99%+ accuracy and pay for themselves within 10-14 months by replacing 2-3 reporting staff.
- Reporting roles are highly vulnerable because 70%+ of the work is mechanical data gathering and formatting, which AI systems automate completely.
- Local AI hardware becomes cost-effective at 2,000+ annual requests; beyond that point, it's dramatically cheaper than cloud APIs.
- Implementation takes 12 weeks from project start to production, moving far faster than hiring and training equivalent staff.
- Organizations that automate thoughtfully with transition planning and human-AI partnership see 40-60% higher productivity gains than those cutting headcount ruthlessly.
Related Articles
- Airtable Superagent: AI Agent Features, Pricing & Alternatives [2025]
- On-Device Contract AI: How SpotDraft's $380M Valuation Changes Enterprise Legal Tech [2025]
- Intel GPU Development 2025: Strategic Hiring & Nvidia Challenge
- Meta's Vibes App: Complete Guide to AI-Generated Video Platform [2025]
- Claude Opus 4.6: 1M Token Context & Agent Teams [2025 Guide]
- Fundamental's $255M Series A: How AI Is Solving Enterprise Data Analysis [2025]

