![Modern Audit Loop: Real-Time AI Governance [2025]](https://tryrunable.com/blog/modern-audit-loop-real-time-ai-governance-2025/image-1-1771781778572.png)
Modern Audit Loop: Real-Time AI Governance [2025]
Traditional software governance feels quaint now. Your compliance team gathers quarterly, reviews spreadsheets, and files reports. Three months pass before anyone notices the problem. But here's the thing: AI systems don't wait for quarterly meetings. A machine learning model drifts. A deployed agent makes decisions that contradict policy. A data pipeline corrupts silently. By the time your audit catches it, the system has already made hundreds or thousands of bad decisions—decisions that might be impossible to untangle or reverse.
This is the fundamental tension of modern AI governance. You need oversight. But you also need speed. Traditional audits kill speed. Real-time audits enable it.
This is where the "audit loop" enters the conversation. Not a yearly checkpoint or quarterly review. An actual loop. A continuous, integrated compliance process that runs alongside your AI systems from development through production. Shadow mode tests. Drift detectors that fire in milliseconds. Audit logs designed for legal defensibility. Guardrails that nudge teams toward compliance without halting innovation.
The organizations winning at this aren't building compliance theater. They're embedding governance directly into the AI lifecycle. Compliance teams aren't gatekeepers anymore—they're partners. They define the rails, monitor the metrics, and alert when something drifts outside acceptable bounds. When done right, this approach actually builds trust with stakeholders instead of creating friction.
Let's walk through how this works in practice.
TL; DR
- Shadow mode deployments let you test new AI systems against production data without affecting real decisions, catching compliance issues before full rollout
- Real-time drift detection monitors input distributions, prediction changes, and confidence scores continuously, alerting teams to problems as they happen
- Audit logs engineered for legal defense capture decision rationale, confidence scores, and human overrides—creating a defensible record of AI behavior
- Governance metrics and guardrails define quantitative bounds for model performance and establish automated escalation when systems exceed thresholds
- Cultural shifts from reactivity to proactive monitoring require compliance and engineering teams to collaborate on defining policy and monitoring live systems together
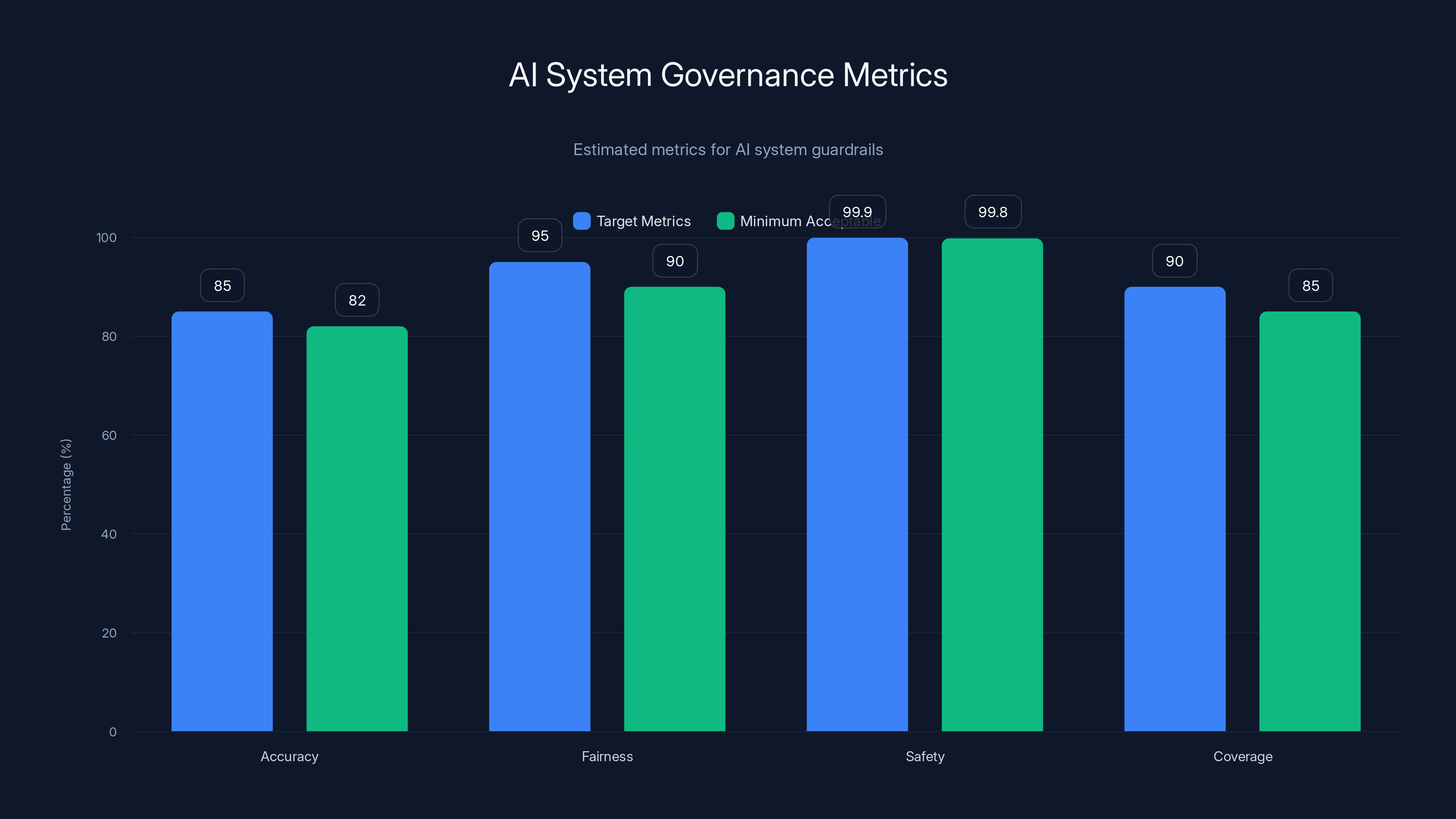
This chart illustrates the target and minimum acceptable metrics for AI governance, highlighting the importance of maintaining high standards in accuracy, fairness, safety, and coverage. Estimated data.
From Reactive Audits to Continuous Compliance
For decades, compliance worked in a straightforward way: Create a checklist. Run through it once a year (or once a quarter if you're diligent). Document the results. Move on. This worked because software moved at human speed. Code deployments took weeks. Policy changes took months. By the time the next audit rolled around, the system looked roughly the same as it did last time.
AI broke this model completely. A model retrains daily. Inference patterns shift with new customer behavior. A bug in the data pipeline propagates in real-time. Governance that waits for quarterly reviews is governance that's already obsolete.
So what's the alternative? Governance that operates continuously. Not instead of periodic reviews, but alongside them. You still want formal audits. But you also need live monitoring. You need alerts. You need a feedback loop that closes in minutes or hours, not months.
This shift changes how compliance teams think about their role. Traditional compliance: We check boxes. We verify that policies were followed. We document everything. That's necessary, but it's backward-looking. Continuous compliance adds forward-looking monitoring. What's happening right now? Is the system behaving as expected? If not, what's the problem and how do we fix it?
The second shift is cultural. Compliance teams can't sit in a separate building anymore. They need to work with engineering teams in real-time. They need to understand the models. They need to define metrics that matter. They need to build dashboards that show what's happening. They become, as some organizations describe it, "AI co-pilots" rather than after-the-fact auditors.
This requires trust in both directions. Engineering teams need to trust that compliance isn't trying to slow them down—it's trying to keep them from making expensive mistakes. Compliance needs to trust that engineers will actually use the monitoring data and respond to alerts. When both sides are aligned on the same goal ("Ship something customers love without breaking regulations"), the tension mostly disappears.
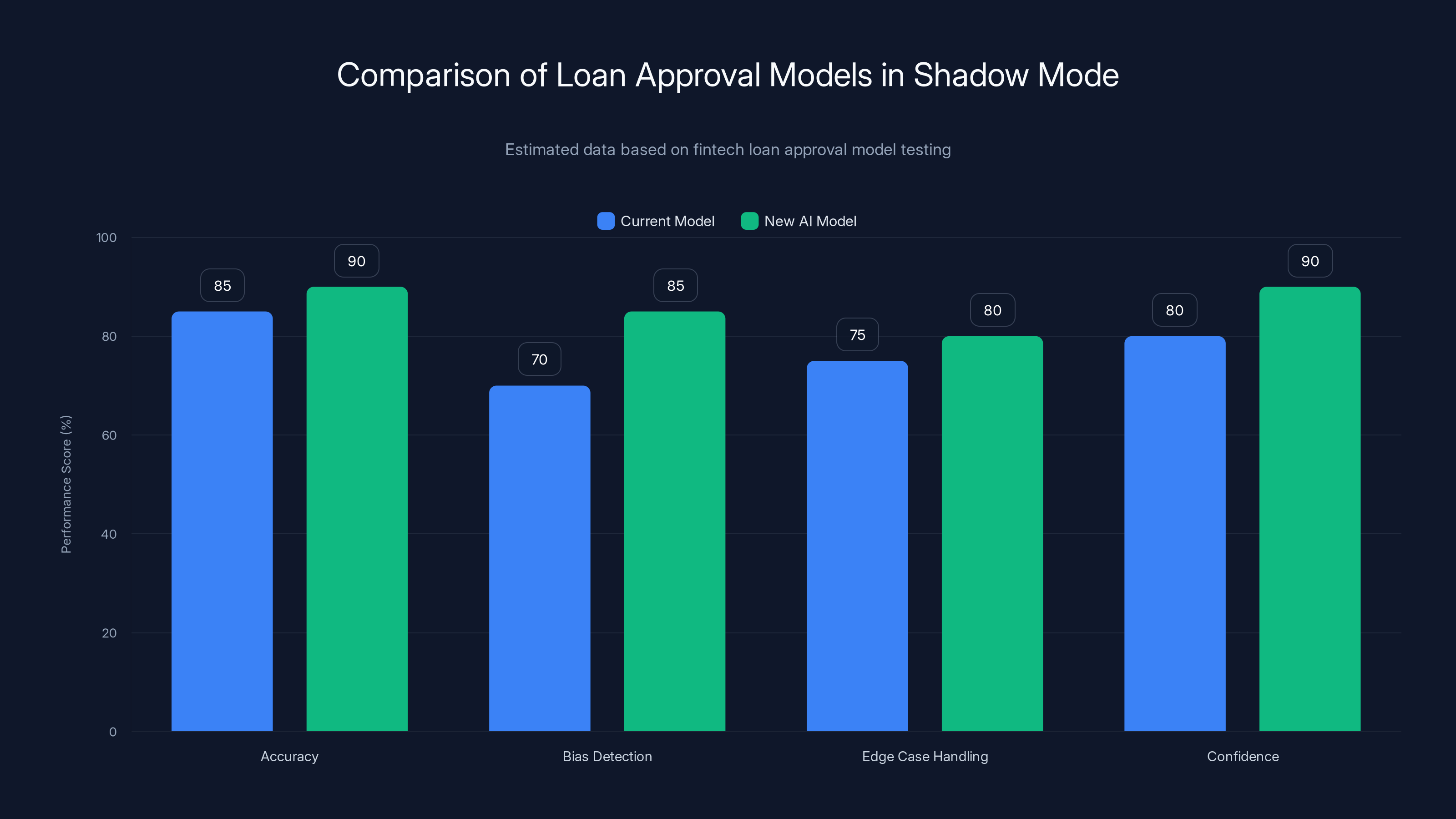
The new AI model shows improved accuracy and bias detection in shadow mode, indicating potential for better loan approval decisions. Estimated data.
Shadow Mode Deployments: Testing Compliance Without Risk
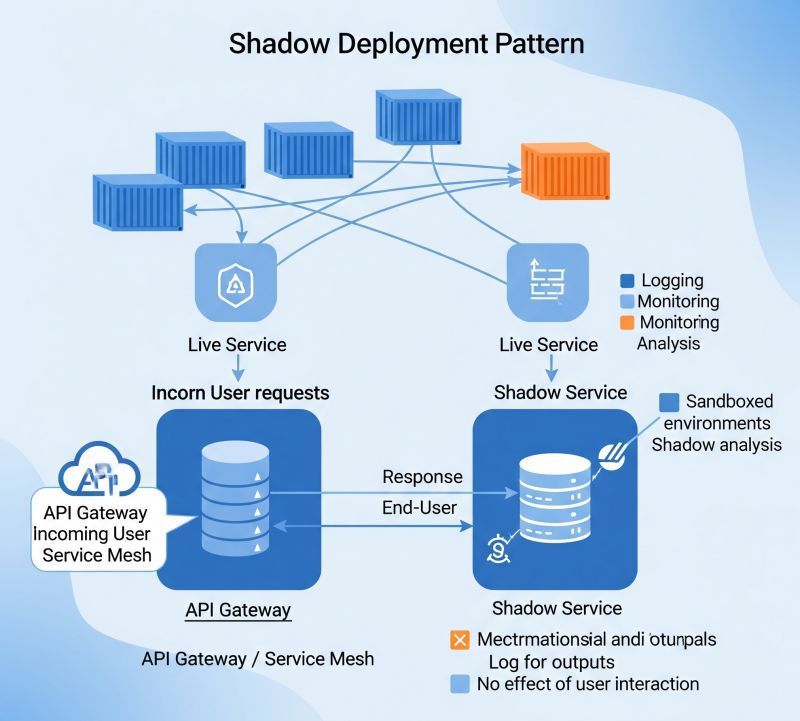
Imagine rolling out a new version of your recommendation engine. You've tested it thoroughly, but production is different. Real data is messier. Edge cases emerge that your test suite missed. You could deploy it to 10% of users and watch carefully. Or you could do something smarter: Run it in shadow mode first.
Shadow mode means your new system processes real production data but doesn't actually make decisions. It runs in parallel. The old system continues to serve users. The new system calculates what it would do, but those calculations go into logs for analysis only. Users never see them.
This is powerful for compliance. You get to test the new system against real-world inputs without any real-world consequences. You can compare its outputs to the current system. You can check whether it meets your accuracy standards. You can look for bias. You can verify that it handles edge cases correctly. All before a single user sees it.
Here's a concrete example. A fintech company builds a new loan approval model. The current model uses 20 features and has strong historical accuracy. The new model uses AI to surface additional signals. Before deploying, the team runs both models on every loan application for two weeks. They compare predictions. They look for divergence. They check whether the new model approves loans that the old model would reject—and if so, whether those loans actually perform better or worse.
This comparison surfaces real issues. Maybe the new model over-indexes on a particular feature that correlates with the applicant's race. Maybe it's overly confident on a subset of applications with limited historical data. Maybe it processes certain types of loan applications correctly but stumbles on others. All these issues show up in shadow mode. You discover them before they affect anyone's loan decision.
The second benefit is psychological. Shadow mode builds confidence. When you flip the switch and your new system starts making real decisions, your team knows it's safe. They've watched it perform against real data for weeks. They've seen the output quality. They've compared it to the baseline. The deployment feels like validation rather than a leap of faith.
Shadow mode also works well for phased rollouts. Start with shadow mode. Then move to a small percentage of decisions (maybe 5%). Monitor carefully. If everything looks good, increase to 10%, then 25%, then 100%. Each phase builds evidence that the system behaves as expected.
Some teams extend this further. They show the shadow system's output to a human reviewer before the human makes a decision. This creates a feedback loop: The human decides, and you log whether the shadow system would have agreed. Over time, you build a dataset showing when the new system is reliable and when it needs human review. This informs both deployment strategy and operational policy.
Real-Time Drift Detection and Monitoring
Your model trained perfectly. You tested it in shadow mode. You deployed it gradually. Everything worked. Then three weeks in, something shifts. The model starts making different kinds of mistakes. Accuracy drops on certain segments. Confidence scores increase while correctness decreases. Something is wrong, but what?
This is drift. It's the problem that haunts AI systems. And it's invisible without active monitoring.
Drift takes several forms. Data drift means the input data distribution changed. Maybe your lending model was trained on 2024 data, but 2025 applicants have different income distributions or credit profiles. The model hasn't changed, but the world has, so its performance diverges from training data. Concept drift is subtler: The relationship between inputs and outputs changes. A feature that was predictive stops being predictive. Or it reverses—now it predicts the opposite. Model drift is when your model retrains on new data and produces different outputs, sometimes without anyone realizing the retraining happened.
Without monitoring, you don't know drift is happening. Users see degraded performance. You notice it eventually from complaints or internal metrics. But that's weeks or months of bad decisions already made.
Real-time drift detection flips this around. You define what "good" looks like for your model. Then you monitor whether it stays in bounds.
What does monitoring actually look like? First, you establish baseline metrics. For your lending model, maybe that's "accuracy of 85% on all segments, with accuracy on minority segments no less than 82%." You pick quantitative bounds that matter for your use case. Second, you stream predictions and ground truth (or your best estimate of ground truth) into a monitoring system. As new data arrives, you calculate whether the model still meets your baselines. Third, you set up alerts. If accuracy on minority segments drops below 82%, someone knows about it within minutes, not weeks.
This requires that you actually have ground truth. For some systems, that's easy: Loan approval prediction can be validated against actual loan outcomes (months later, but still). For others, it's harder. Maybe you're using an AI system for content moderation. You don't have ground truth until a human reviews the decision. So you set up a sampling system: Every 100th decision gets human review. You know within an hour whether the system is drifting.
What else do you monitor? Confidence scores. If your model suddenly starts outputting very high confidence on decisions it should be uncertain about, that's a red flag. Input distributions. Are you seeing inputs you didn't see during training? If 10% of incoming data is outside the training distribution, your model will probably fail. Latency and throughput. If API calls suddenly start taking 10x longer, something is broken. Feature importance shifts. If the model suddenly uses different features to make decisions, it's learning different patterns—possibly because the world changed, or possibly because something is broken.
The key is automation. You can't have humans checking these metrics every five minutes. You build systems that check automatically and alert only when something is actually wrong. This is the difference between noise and signal. A dashboard showing 50 metrics is useless. A single alert saying "accuracy on minority segments dropped from 82% to 78% in the last hour" is actionable.
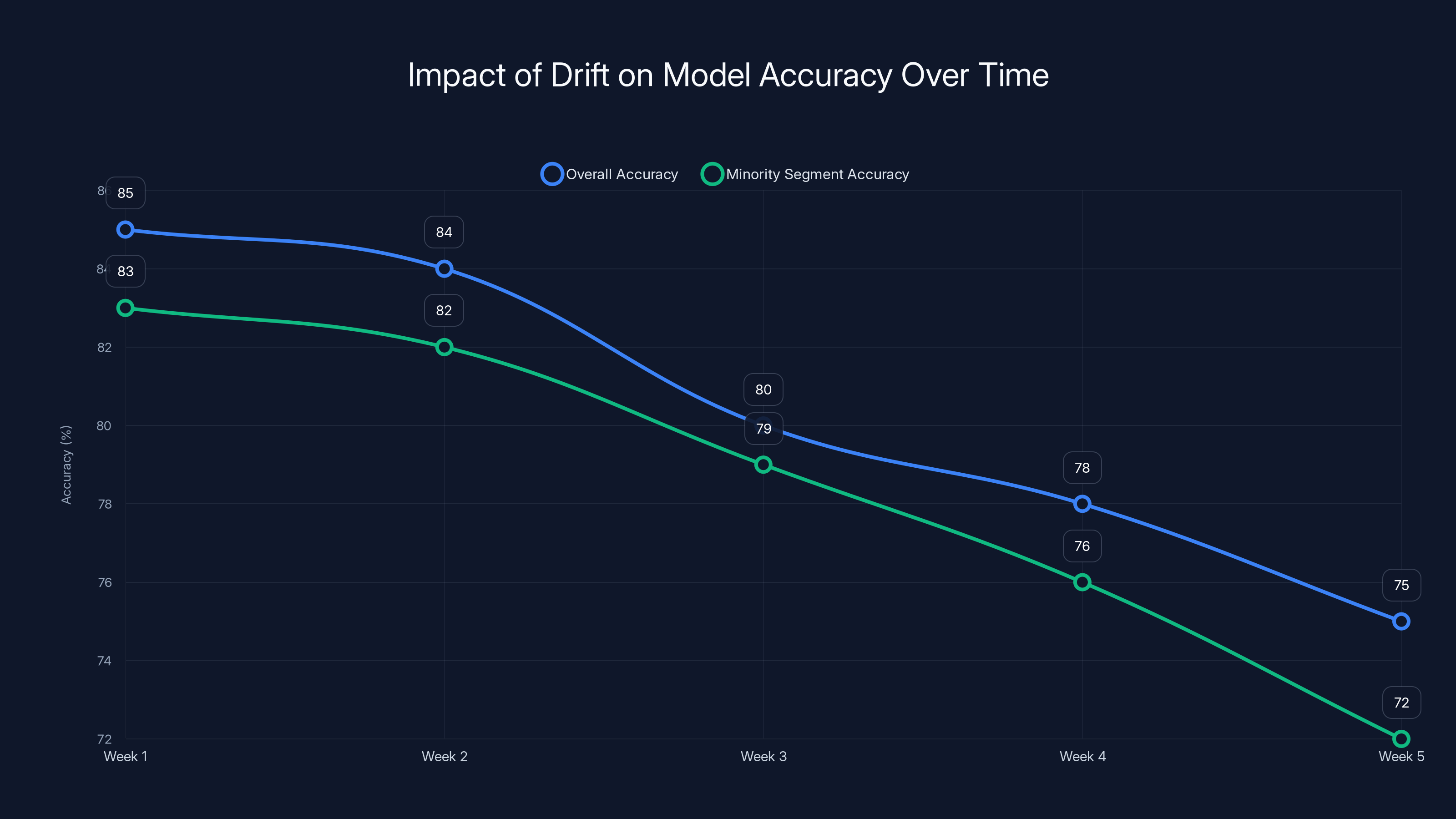
This chart illustrates how model accuracy can degrade over time due to data, concept, or model drift, highlighting the importance of real-time monitoring. Estimated data.
Designing Audit Logs for Legal Defense
Here's something most engineering teams don't think about: Your audit logs are evidence. If your AI system makes a decision that harms someone and they sue, your audit logs will be examined by lawyers and regulators. What you log today becomes your defense (or your liability) tomorrow.
This changes what you log and how. Traditional application logs answer operational questions: Did the request succeed? How long did it take? What error occurred? Those logs are useful for debugging. They're not useful for legal defense.
Defensive audit logs answer different questions: Why did the system make this decision? What was the system thinking? How confident was it? Who was involved in building the system? When did it change? What evidence informed the decision?
Let's get specific. When your AI system makes a consequential decision, your log should capture:
Decision context. Who requested the decision? What were the inputs? What was the exact timestamp? This establishes a clear record that the decision actually happened and exactly when.
Model information. Which version of the model made the decision? When was that model deployed? Who trained it? Who approved the deployment? This matters because regulators will ask why you were running this particular model at this particular time.
Confidence and reasoning. What was the model's confidence score for this decision? If the model outputs top-N predictions, log all of them. If you can extract feature importance, log which inputs most influenced the decision. This shows that the system was working as designed and that you understand what it's doing.
Human involvement. Did a human review this decision before it was executed? If so, log what the human decided and how long they took. If the human disagreed with the model, log that explicitly. This shows that you have human oversight.
Policy enforcement. Did the decision violate any guardrails? For example, maybe your policy says "don't approve loans for applicants with obvious fraud signals." If the model tried to approve one anyway, log that the guardrail fired and the decision was blocked. This shows that you have safety mechanisms.
Outcomes. If possible, log what happened after the decision. Loan approved? Did it default? Applicant hired? Did they succeed in the role? Recommendation accepted? Did the user engage? This ground truth is valuable for auditing and retraining.
All of this gets stored in a tamper-proof log. Not just a database table that someone could accidentally overwrite. A real audit trail that survives indefinitely. You want these logs to still be readable and intact in five years when a regulatory inquiry arrives.
The volume of logs can be enormous. If you're making millions of decisions per day, logging everything is expensive. So you make thoughtful choices about sampling. Maybe you log every decision for consequential systems (lending, hiring, healthcare). Maybe you log 10% of decisions for less risky systems (recommendations, content moderation). Maybe you log 1% of decisions for very low-risk systems (search results, autocomplete). The key is that the sampling is random and documented—you can always defend your sampling strategy.
This matters more than most teams realize. Several AI systems have been successfully challenged in court or regulatory proceedings largely because the companies couldn't explain why the system made a specific decision. They had no logs. They had no reasoning. They couldn't prove the system was fair or unbiased. Good audit logs prevent that problem. They prove that you were thinking about fairness, that you were monitoring for problems, and that you can explain what happened.
Defining Guardrails and Governance Metrics
What does "good" look like for your AI system? Be specific. Not "good accuracy" but "accuracy of 85% on all segments, with accuracy on minority segments no less than 82%." Not "fair" but "no more than 5 percentage point difference in approval rates between demographic groups." Not "safe" but "harmful content moderation errors no more than 0.1% of decisions."
These quantitative bounds are your guardrails. They're the boundaries that define acceptable behavior. And they need to be defined before you deploy the system. Define them with input from compliance, legal, product, and engineering. Make sure everyone agrees on what success looks like.
Once you have guardrails, you need metrics that measure against them. Some metrics are straightforward: accuracy, precision, recall. Others are more subtle. You need to measure fairness, which might mean demographic parity or equalized odds or individual fairness—choose the right definition for your context. You need to measure coverage: what percentage of requests can your system actually handle, versus how many require human review? You need to measure drift and instability: is the system's performance consistent, or is it jumping around?
Then you need to know what you'll do when a guardrail is violated. Do you alert someone? Do you automatically trigger human review? Do you disable the feature? Do you roll back to the previous model? Do you pause the system while investigating? Your policy should say. And it should be automated. If guardrails are violated, the response should be automatic unless someone explicitly overrides it.
This requires real-time metrics. Not a report you run every week. Not a dashboard you check every morning. Metrics that update second by second. Systems that alert you within minutes of a problem. This is the difference between reactive governance (you discover a problem, you investigate) and proactive governance (you detect a problem automatically, it alerts, your team can respond before it causes damage).
How do you build this? Three pieces. First, a metrics engine that calculates these metrics continuously. For some metrics, this is simple: count successes over the last hour, divide by total requests, that's your accuracy. For others, it's harder: fairness metrics require you to group by protected attributes and compare outcomes, which requires careful engineering to avoid accidentally building a system that's aware of protected attributes in a way that itself is discriminatory. Second, a monitoring system that stores these metrics and detects when they violate thresholds. Third, an alerting system that tells the right people the right information at the right time. Not a fire hose of alerts. Targeted, actionable alerts that tell you what broke and what you probably need to do about it.
Here's a concrete architecture. Your model API logs every request: input, output, confidence, timestamp. Every hour, your metrics engine queries these logs and calculates fairness metrics, accuracy on slices (gender, age, income level, geography), drift scores, and latency percentiles. These metrics flow into a time-series database. Your alerting system watches for anomalies: Has accuracy dropped? Has drift increased? Have we seen a 5x latency increase? If so, it routes an alert to the Slack channel that your ML team monitors. The alert includes the metric, the threshold, the actual value, and a link to a dashboard showing more detail. Your team sees it within five minutes and can investigate.

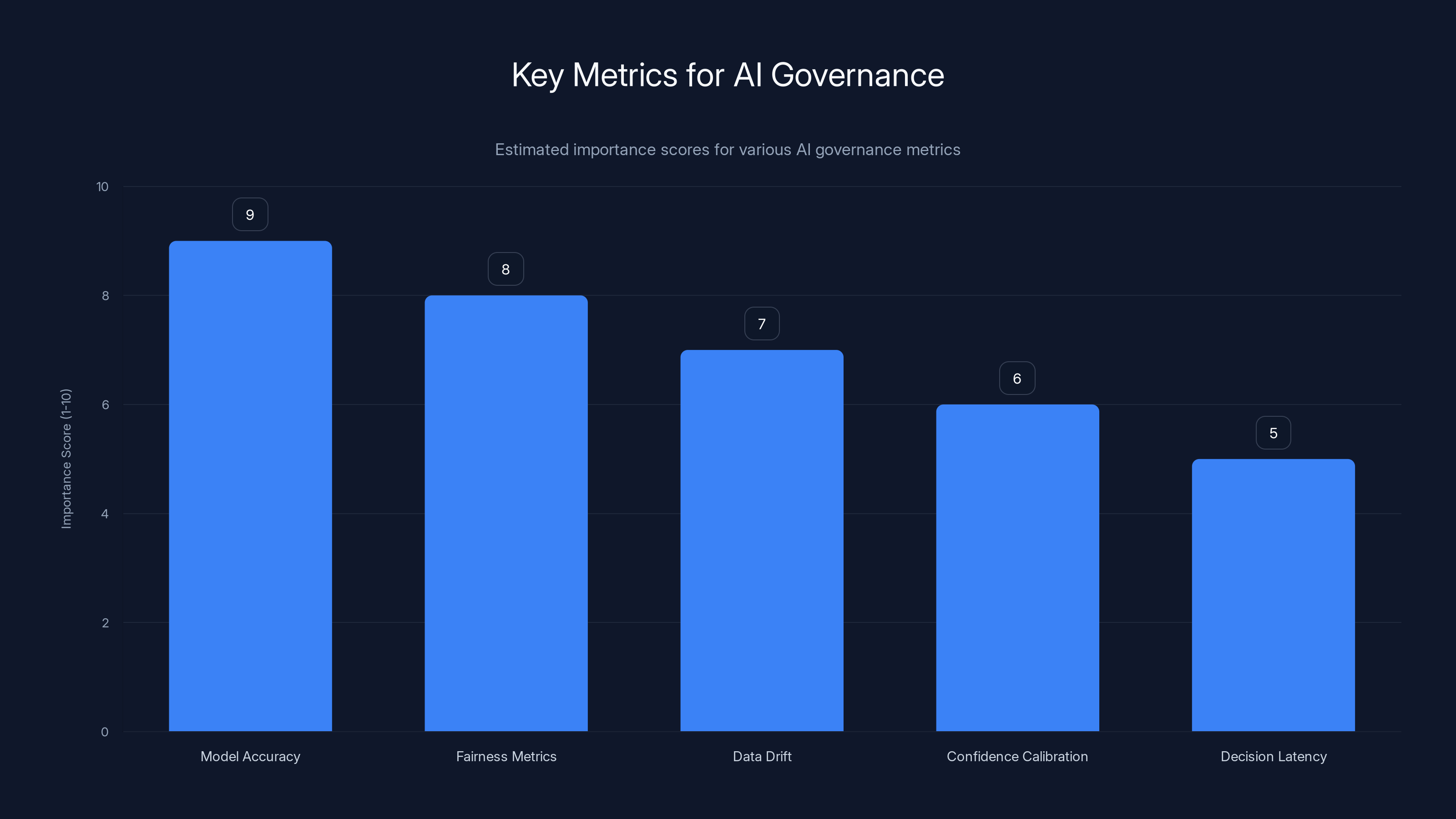
Model accuracy and fairness metrics are critical for AI governance, followed by data drift and confidence calibration. Estimated data.
Detecting and Responding to Model Misuse
Drift is one problem. Misuse is another. Your system might be performing correctly but being used incorrectly. Maybe someone is automating decisions with the system in a way you never intended. Maybe the system is being used on a population it wasn't trained for. Maybe someone is gaming the system intentionally.
Example: You build a credit scoring model. It's trained on consumer lending data and tested thoroughly. But then your retail team wants to use it for merchant financing. Different population, different risk profile, and your model probably won't generalize. Or your sales team starts asking the model what the absolute minimum credit score is that would get approved, and they use that to farm leads to submit. The system isn't broken, but it's being used in a way you didn't anticipate.
Detecting misuse requires monitoring usage patterns. Are you seeing the same requesters over and over? Are requests coming from unexpected systems? Are you seeing an unusual volume of requests near the decision boundaries (just-barely-approved or just-barely-rejected)? Are the features in incoming requests different from what you saw during development? Any of these could indicate misuse.
The response needs to be rapid. If you detect that someone is using your system incorrectly, you need to alert them and potentially block the usage quickly. This requires clear ownership: Who owns the model? Who can disable it or restrict usage? What's your process for investigating potential misuse?
This gets thorny when the misuse isn't malicious. Maybe a product manager genuinely thought using the model in a new context was fine. Maybe an engineer integrated it into a system without fully understanding the implications. You need processes that handle this gracefully. Educate when possible. Alert when necessary. Block only as a last resort.
Building a Culture of Continuous Compliance
The hardest part isn't technical. It's cultural. You need your engineering teams and compliance teams working together instead of working at odds. You need engineers who actually believe in monitoring instead of seeing it as overhead. You need compliance teams who move fast instead of acting as blockers.
This starts at the top. The leadership message needs to be clear: We ship fast because we're confident. We're confident because we monitor. We monitor because we care about users and regulations. This isn't bureaucracy. It's the opposite. It's what allows us to move faster without blowing up.
Second, you need shared ownership. Not "compliance owns governance" and "engineering owns features." These teams own the outcome together. When a model launches, they're jointly responsible for it working correctly. When something breaks, they investigate together. When a monitoring system fires, the first slack message goes to a shared channel, not just one team.
Third, you need the right tooling. Monitoring should be easy. Accessing audit logs should be easy. Checking whether a model meets guardrails should be easy. If compliance teams have to jump through hoops to do their job, they'll do it less often. And if engineers have to ask permission to get monitoring data, they'll do it less often too. Build systems that make compliance frictionless.
Fourth, you need regular training. Not a once-a-year compliance training where everyone tunes out. Ongoing conversations about what good looks like. Case studies of what went wrong at other companies. Discussion of edge cases and how to handle them. This can be done in 30-minute weekly syncs. The goal is shared understanding: Everyone on the team understands why monitoring matters, what they should be watching for, and what to do when an alert fires.
Fifth, you need to reward good behavior. When someone catches a problem early because they were monitoring, celebrate them. When someone suggests a better metric, make sure it gets used. When an engineer and a compliance person collaborate on defining a guardrail, highlight that as an example of how the team should work. Culture shifts are reinforced by how you celebrate behaviors.
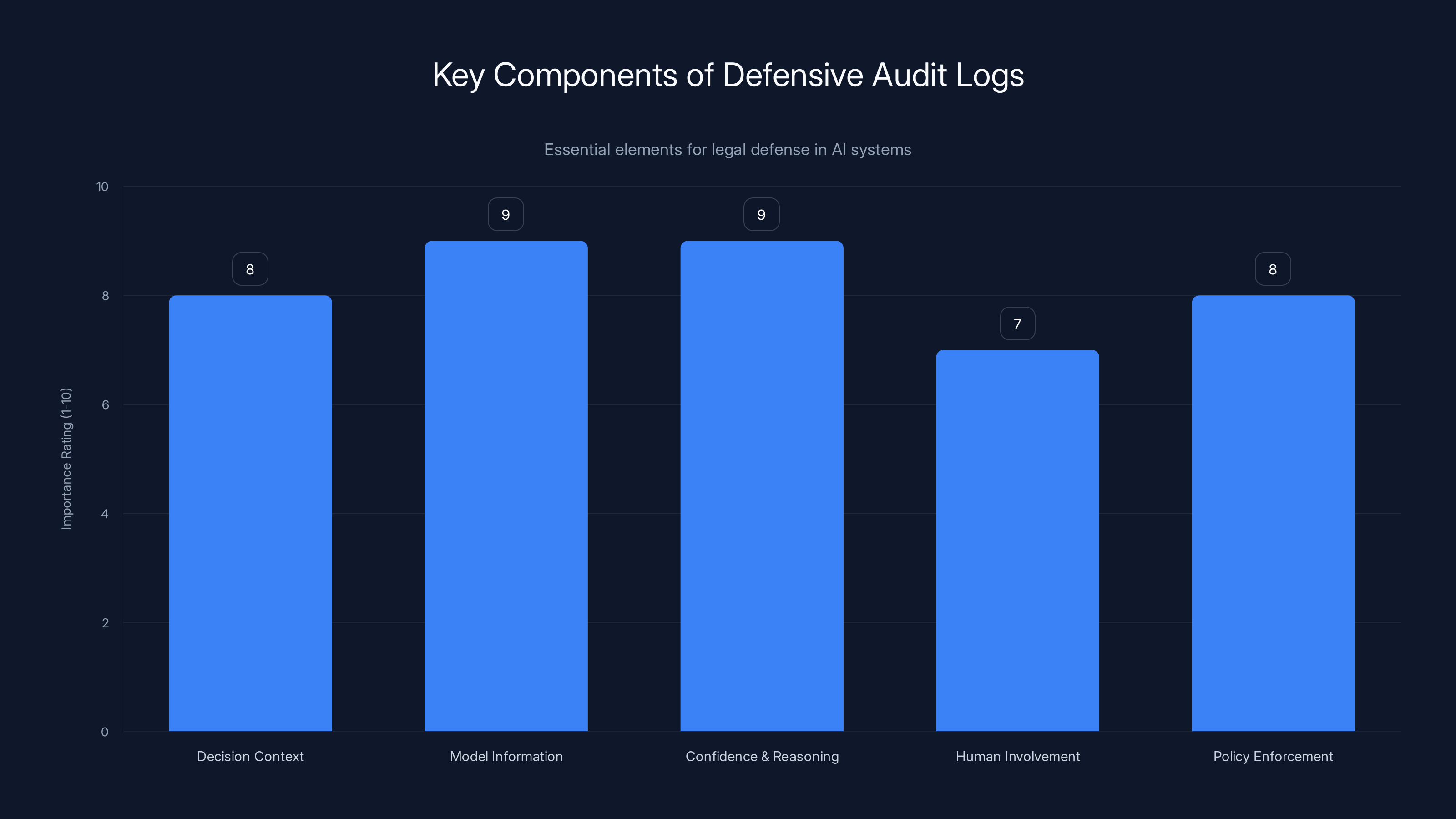
This chart highlights the importance of various components in defensive audit logs, crucial for legal defense in AI systems. Estimated data based on typical priorities in audit logging.
Real-Time Intervention and Course Correction
Monitoring and alerting aren't enough if you can't actually do something about problems. What does rapid response look like?
For lower-risk systems, maybe that's a Slack alert and someone checking the dashboard within an hour. For higher-risk systems, you want faster response. Maybe guardrails trigger automatic human review. Maybe detected drift automatically rolls back to the previous model version. Maybe drift in fairness metrics automatically reduces the volume of decisions the AI system makes (shifting back to human review) until you investigate.
This requires clear decision rights. Who decides to roll back? Who decides to disable a system? Who decides to increase human review? You want these to be automated decisions, not things that require a committee meeting. "If accuracy drops below 80%, automatically route all decisions to human review until investigation is complete." That's a clear rule that can be automated.
You also want to make it easy to reverse automated responses. If a system automatically rolled back to the previous model because drift was detected, and you investigate and find it was a false alarm, you should be able to re-deploy the new model with one click. Don't make the process of fixing overreactive guardrails so painful that people disable monitoring.
The speed of response matters. Studies on system reliability show that the cost of an incident isn't proportional to its duration—it's proportional to how long you spent not knowing about it. If your system drifts and you don't notice for a week, the damage is done. If you notice in five minutes but take two hours to decide what to do, most of the damage is already done. The key is minimizing time-to-detection and time-to-decision. Everything else is secondary.
Handling Edge Cases and Uncertainty
Real systems are messier than textbook examples. Your model sometimes outputs confidence scores that don't match its actual accuracy. Your new model sometimes beats your old model on some segments and loses on others. Your fairness metric sometimes conflicts with your accuracy metric. How do you handle this?
The answer is: You define rules for these situations ahead of time. "If confidence score and accuracy diverge by more than 10 points, human review is required." "If the new model wins on one segment but loses on another, we run shadow mode for two weeks before deploying." "If fairness and accuracy conflict, fairness wins." These rules turn ambiguous situations into clear decisions.
You also need to log uncertainty. If you're not sure whether something is a problem or not, log that you're not sure. Your audit trail should include decision quality, not just decisions. "This decision had high confidence, but the model hasn't seen similar inputs before, so we flagged it for human review anyway." That kind of annotation is valuable for auditing and for learning.
Finally, you need to be comfortable with being wrong sometimes. Your guardrails will sometimes trigger false alarms. Your monitoring will sometimes detect problems that don't actually exist. The response isn't to disable monitoring. It's to learn from false alarms and refine your guardrails. "The fairness metric flagged a potential bias, but investigation showed it was a statistical artifact. We adjusted the metric to avoid future false alarms in this situation." That's how you build more sophisticated systems over time.

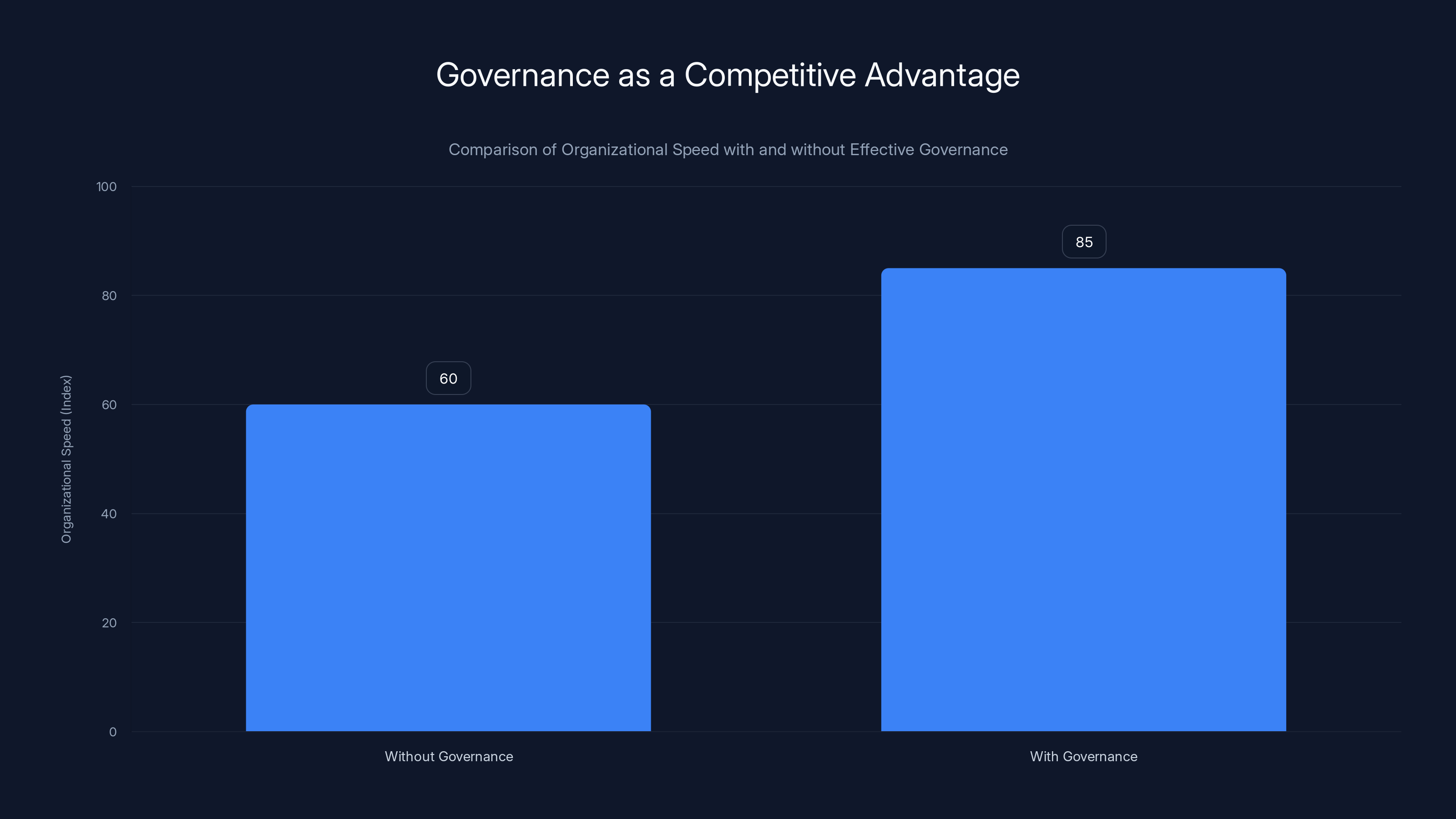
Organizations with effective governance move 25% faster due to increased confidence and trust. Estimated data.
Governance Through the Full ML Lifecycle
Governance isn't just about monitoring production systems. It starts in development and continues through retirement. Here's what a complete lifecycle looks like.
Development phase. Define what you're trying to build. What's the use case? What's the success metric? What could go wrong? What regulations apply? Who are the stakeholders? You're not building systems first and asking these questions later. You're asking them first, then building systems that answer them.
Testing phase. You test for accuracy, but also for fairness, robustness, and alignment with requirements. Do you have adequate test coverage for edge cases? Have you tested on data from different geographic regions? Different demographic groups? Have you tried adversarial inputs to see if the model breaks? Have you tested what happens when the model gets inputs it's never seen?
Approval phase. Before deployment, someone approves that the system is ready. Not just "it's technically correct," but "it meets our compliance requirements, it's fair, it's explainable, we've got monitoring in place, and we've got a plan for what to do if something goes wrong." This is a gate. Systems that don't meet the bar don't ship.
Deployment phase. You start with shadow mode (if it's a major change). Then phased rollout. Then full deployment. At each phase, you're collecting evidence that the system is safe.
Production phase. Continuous monitoring. Metrics dashboards. Alerting. Human review. Periodic audits. This is where most organizations focus, but it's only one piece.
Retirement phase. When you decide to shut down a system, what do you do with the data? How long do you keep audit logs? How do you notify users? This might sound trivial, but it's part of governance too.
Integration With Product and Business Goals
Governance that fights against your business goals will lose. You can't build systems that are completely fair but never ship because you're too conservative. You also can't ship systems that are profitable but cause harm because you ignored compliance.
The solution is integration. Governance isn't separate from product strategy. It's part of the product strategy. "We're building a lending system. Our success metric is loan volume. Our guardrail is that we never have more than a 3-point fairness gap between demographic groups. Both constraints are equally important. How do we build a system that optimizes loan volume subject to the fairness constraint?"
This reframes the problem. You're not asking "How do we make governance not slow us down?" You're asking "What does excellent look like, both in terms of business metrics and governance metrics?" And you're building systems to achieve both.
This requires that product leaders understand governance and governance leaders understand product. It requires shared language. When your product leader talks about "user acquisition," and your compliance leader talks about "regulatory risk," you're both talking about business impact. They just use different metrics. The goal is to optimize overall business impact, not to maximize one metric at the expense of others.

Tools and Infrastructure for Modern Governance
You can't build a modern audit loop without the right tools. You need a few pieces.
Monitoring and observability. Real-time dashboards showing model performance, drift, and compliance metrics. Tools like Runable help automate governance workflows and documentation, while specialized ML monitoring platforms track model health.
Audit logging. A tamper-proof system that captures every decision your AI system makes, along with context and reasoning. This needs to be scalable (millions of decisions per day) and queryable (you need to be able to search for specific decisions).
Policy enforcement. Tools that let you define guardrails and automatically enforce them. If accuracy drops below 80%, do X. If drift is detected, do Y. These need to be programmable, not manual checks.
Alerting and escalation. Slack integration, email, Pager Duty, whatever gets the right information to the right person at the right time.
Versioning and rollback. You need to know exactly which model version is running in production. You need the ability to roll back to a previous version with one click. This needs to be fast and safe.
Explainability. Tools that help you understand why your model made a specific decision. Feature importance, SHAP values, attention visualizations, whatever format makes sense for your model.
Building all of this in-house is possible but expensive. Many organizations start with open-source tools (MLflow, Evidently, Great Expectations) and custom infrastructure. As they grow, they often move to commercial platforms that integrate all these pieces.
Regulatory Landscape and Compliance Requirements
Governance isn't just best practice. It's increasingly required by law. The regulatory landscape around AI is rapidly evolving, and most jurisdictions now require some form of AI governance and monitoring.
The EU AI Act requires detailed documentation and governance for high-risk AI systems. You need to be able to demonstrate that you understood the risks and put controls in place. The SEC has issued guidance suggesting that companies using AI should have adequate controls and disclosure. The FTC has increased focus on AI bias and deceptive practices. Most countries are either passing or considering AI-specific regulations.
The common theme: You need to be able to demonstrate that you were thinking about problems, that you monitored for them, and that you addressed them when they occurred. Good governance does this. Bad governance leaves you defenseless.
This is where the "defensible audit logs" piece becomes critical. If a regulator asks "How do you ensure your AI systems are fair?", you want to be able to show them a 12-month audit trail showing that you measured fairness daily, that you set thresholds, that you alerted when thresholds were violated, and that you investigated and fixed problems. That's proof of good governance. If you can't show them that, you've got a problem.

Scaling Governance Across Multiple Models and Teams
Starting with one model is manageable. But most organizations end up with dozens or hundreds of AI systems in production. Scaling governance is hard.
The key is standardization. Define a standard format for audit logs. Define standard metrics. Define standard guardrails. Create templates that new models should follow. This lets you build tooling that works across all models, instead of building custom solutions for each one.
You also need to standardize the process. How does a new model get approved? What documentation is required? What tests must pass? Who makes the decision? Document this as a clear process that every model goes through. This seems bureaucratic, but it actually moves faster than ad hoc decisions. Everyone knows what's expected. There's no ambiguity about whether you've done enough.
Finally, you need to scale your monitoring infrastructure. One monitoring dashboard for one model is fine. One dashboard for 100 models is overwhelming. You need dashboards that aggregate metrics across models. You need alerts that route to the right team based on which model has a problem. You need to be able to quickly find the status of any model in your organization.
Future Trends: Automated Governance and Collaborative Auditing
Governance is evolving. We're moving from manual monitoring to automated monitoring. We're moving from once-a-year audits to continuous audits. What's next?
Automated policy enforcement. Today, you define a guardrail and set up an alert. In the future, guardrails will automatically enforce themselves. Drift is detected, the system automatically rolls back. Fairness metrics drop, the system automatically shifts decisions to human review. No human decision required unless explicitly configured otherwise.
Collaborative auditing. Regulators have started requiring audits by third parties. This is expensive and creates friction. The future might involve regulators and companies sharing monitoring data in real-time, reducing the need for traditional audits. Google and Facebook already share ad data with regulators in some jurisdictions. That model might expand.
Explainability at scale. Today, explaining AI decisions is hard. You often need specialized tools and expertise. In the future, explanations might be generated automatically. The system explains why it made a decision in clear language that a layperson can understand.
Continuous learning loops. Right now, you monitor, you find problems, you fix them offline. In the future, systems might automatically incorporate feedback. Your monitoring system detects that a model is drifting in a particular way, and it automatically retrains on more recent data to fix it. Humans still oversee this, but the cycle is faster.

Common Pitfalls and How to Avoid Them
Organizations often stumble on governance in predictable ways. Here's how to avoid the biggest traps.
Pitfall 1: Treating governance as separate from product. This creates friction and slow decision-making. Solution: Integrate governance into product strategy from day one. Define guardrails alongside success metrics.
Pitfall 2: Monitoring everything, acting on nothing. You end up with dashboards no one looks at and alerts everyone ignores. Solution: Ruthlessly prioritize. Monitor only what matters. Alert only when action is needed.
Pitfall 3: Assuming audit logs aren't important. Someone will get sued or regulated. Audit logs become critical then. Solution: Start logging defensibly from the beginning. It's easy to improve logging. It's hard to recreate logs after the fact.
Pitfall 4: Leaving governance to compliance teams alone. They move too slow and don't understand the technical details. Solution: Make it a shared responsibility. Compliance defines policy. Engineering implements and monitors.
Pitfall 5: Overshooting the guardrails. You set fairness thresholds so strict that your model can't operate. Then you gradually loosen them without telling anyone. Solution: Set realistic guardrails with input from all stakeholders. Revisit them quarterly, not constantly.
Pitfall 6: Ignoring the human in the loop. You set up guardrails that trigger human review, but then the humans rubber-stamp everything. Solution: Make sure humans have time and resources to actually review. Don't ask them to review 1,000 things per day.

Conclusion: Governance as Competitive Advantage
Traditional thinking treats governance as a cost center. Compliance is overhead. Monitoring slows you down. Audit logs are bureaucracy. This thinking is backwards.
Organizations that do governance well move faster than organizations that don't. Why? Because they move with confidence. They launch features knowing they'll be monitored. They make decisions understanding the risks. When problems occur, they catch them fast and fix them fast. They're not constantly second-guessing themselves or building features they're afraid to deploy.
The audit loop is how you achieve this. You define what success looks like. You monitor continuously. You catch problems before they cause harm. You fix them quickly. You prove to regulators and customers that you're thinking about their interests. That builds trust. Trust lets you move faster.
This isn't rocket science. It's the same approach successful companies have used for decades in physical systems. Planes have continuous monitoring systems. Bridges have structural health monitoring. Medical devices have post-market surveillance. These industries move fast because they monitor carefully. AI is no different.
The organizations that will win in the next five years aren't the ones that ship fastest without thinking about consequences. They're the ones that ship fast while maintaining control. They'll have real-time governance. They'll have audit trails that prove they were thinking about fairness and safety. They'll have the trust of regulators and customers. And that trust will let them move even faster.
Start building your audit loop today. Define your metrics. Set up monitoring. Deploy shadow mode systems. Create audit logs. Build the culture where compliance and engineering work together. This is how you build AI systems that people trust.
FAQ
What exactly is the "audit loop" in AI governance?
The audit loop is a continuous, integrated compliance process that runs alongside your AI systems from development through production, rather than relying on traditional after-the-fact audits. It involves real-time monitoring of model performance, drift detection, compliance metrics, and automated alerts when systems diverge from expected behavior. Shadow mode testing, drift detection, and defensible audit logging create feedback loops where teams identify and fix problems in hours, not months.
How does shadow mode deployment actually reduce compliance risk?
Shadow mode lets you run a new AI system on real production data without affecting actual decisions. The new system processes every request but its outputs go to logs only. You can compare the new system's decisions to your current system for weeks, measuring accuracy, fairness, and compliance against your guardrails before any user sees the new system's output. This gives you proof that the system meets your standards before deployment, significantly reducing the risk of deploying problematic models.
What specific metrics should we monitor for AI governance?
Key metrics include model accuracy (overall and on protected groups), fairness metrics like demographic parity or equalized odds, input distribution divergence (data drift), confidence calibration, decision latency, human review rates, feature importance shifts, and outcome quality (when ground truth is available). Start with 3-5 metrics that matter most for your use case, automate their calculation, and trigger alerts only when genuine problems appear. Additional metrics like coverage (percentage of decisions the AI can make vs. requiring human review) and audit trail completeness help ensure you're capturing sufficient evidence.
How long should we retain audit logs, and what legal risks apply?
Retain audit logs indefinitely for consequential decisions (lending, hiring, healthcare). For lower-risk decisions, consider 1-3 years depending on your jurisdiction's requirements. Audit logs become critical evidence in legal disputes and regulatory inquiries, so they must be tamper-proof and queryable. Several jurisdictions now require companies to retain and produce decision logs for AI systems—check your local regulations. The cost of storing logs is trivial compared to the liability of having no record of how a decision was made.
Can drift detection work if we don't have ground truth for all decisions?
Yes, but you need to implement sampling. For example, randomly sample 1% of decisions for human review to establish ground truth, then use those validated outcomes to calculate drift metrics on the broader population. You can also detect data drift without outcome labels by monitoring input distributions and prediction distributions. A sudden shift in what inputs you're seeing, even without knowing if predictions were correct, is a warning signal worth investigating.
How do we balance speed of development with governance requirements?
Governance shouldn't slow you down; it should enable you to move faster with confidence. Define clear guardrails and metrics upfront. Use shadow mode to validate new versions before deployment. Set up automated monitoring and alerts instead of manual reviews. Make rollback easy so you can fix problems without lengthy approval processes. When governance is built into the development process (not added after), it's fast. The overhead comes from adding governance retroactively.
What's the connection between our audit logs and regulatory compliance?
Audit logs are your primary evidence to regulators that you understood AI risks and took them seriously. When regulators ask "How do you ensure your systems are fair?" you can show a 12-month trail of fairness measurements, alerts triggered when thresholds were breached, and investigations of every alert. Systems without such logs look careless or deceptive. That's the legal exposure. Defensible logs that prove you were monitoring—even if you caught some problems—are much better than no logs.
How should governance teams interact with engineering teams?
They should partner, not govern separately. Compliance teams should help define metrics and guardrails that matter for legal and ethical reasons. Engineering teams should implement the monitoring infrastructure and respond to alerts. Both teams should review incidents together and adjust guardrails based on what's learned. Make shared responsibility clear: The product and its governance are both everyone's job.
What's the minimum viable governance system to start with?
Start with three things: (1) Define 3-5 key metrics that could cause harm if wrong, (2) Set up automated calculation of those metrics on production data, (3) Configure alerts when metrics diverge from baselines. Add audit logging (log the decision, inputs, model version, and outcome when available) for higher-risk systems. Add shadow mode for major model updates. Expand gradually as you see what works. You don't need to build everything at once.
The Modern Audit Loop at a Glance
The transition from reactive auditing to continuous governance represents a fundamental shift in how organizations manage AI risk. Shadow mode deployments provide safe testing grounds. Real-time drift detection catches problems in hours instead of months. Audit logs engineered for legal defense protect your organization and inform regulators about your controls. Governance metrics and guardrails turn abstract concerns ("is this fair?") into measurable thresholds ("demographic accuracy gap < 3%"). And crucially, this system only works if compliance and engineering teams trust each other and collaborate on shared goals.
The organizations leading in this space aren't moving more slowly than competitors. They're moving faster with less risk. They deploy features knowing they'll be monitored. They catch problems early. They fix them quickly. That confidence accelerates development, not slows it. The audit loop is how you win.

Key Takeaways
- Modern AI governance requires continuous, real-time monitoring rather than traditional quarterly audits that detect problems weeks or months after they occur
- Shadow mode deployments safely test new AI systems on production data without affecting actual decisions, catching compliance issues before full rollout
- Real-time drift detection monitoring input distributions, accuracy on protected groups, and confidence calibration prevents silent model degradation
- Audit logs engineered for legal defense capture decision context, confidence scores, human oversight, and guardrail enforcement to create defensible decision records
- Governance teams and engineering teams must partner as equals, with compliance defining metrics and engineers implementing monitoring—treating governance as enabler, not obstacle
Related Articles
- AI Governance & Data Privacy: Why Operational Discipline Matters [2025]
- Complyance Raises $20M Series A: How AI Is Reshaping Enterprise Compliance [2025]
- API Management & Agentic AI Security: Closing Blind Spots [2025]
- Stellantis Crisis: How a $26.5B EV Bet Went Wrong [2025]
- Enterprise Agentic AI's Last-Mile Data Problem: Golden Pipelines Explained [2025]
- Figure Data Breach: What Happened to 967,000 Customers [2025]

